物体检测模型效果评估
可通过模型评估报告或模型校验了解模型效果:
- 模型评估报告:训练完成后,可以在【我的模型】列表中看到模型效果,以及详细的模型评估报告。
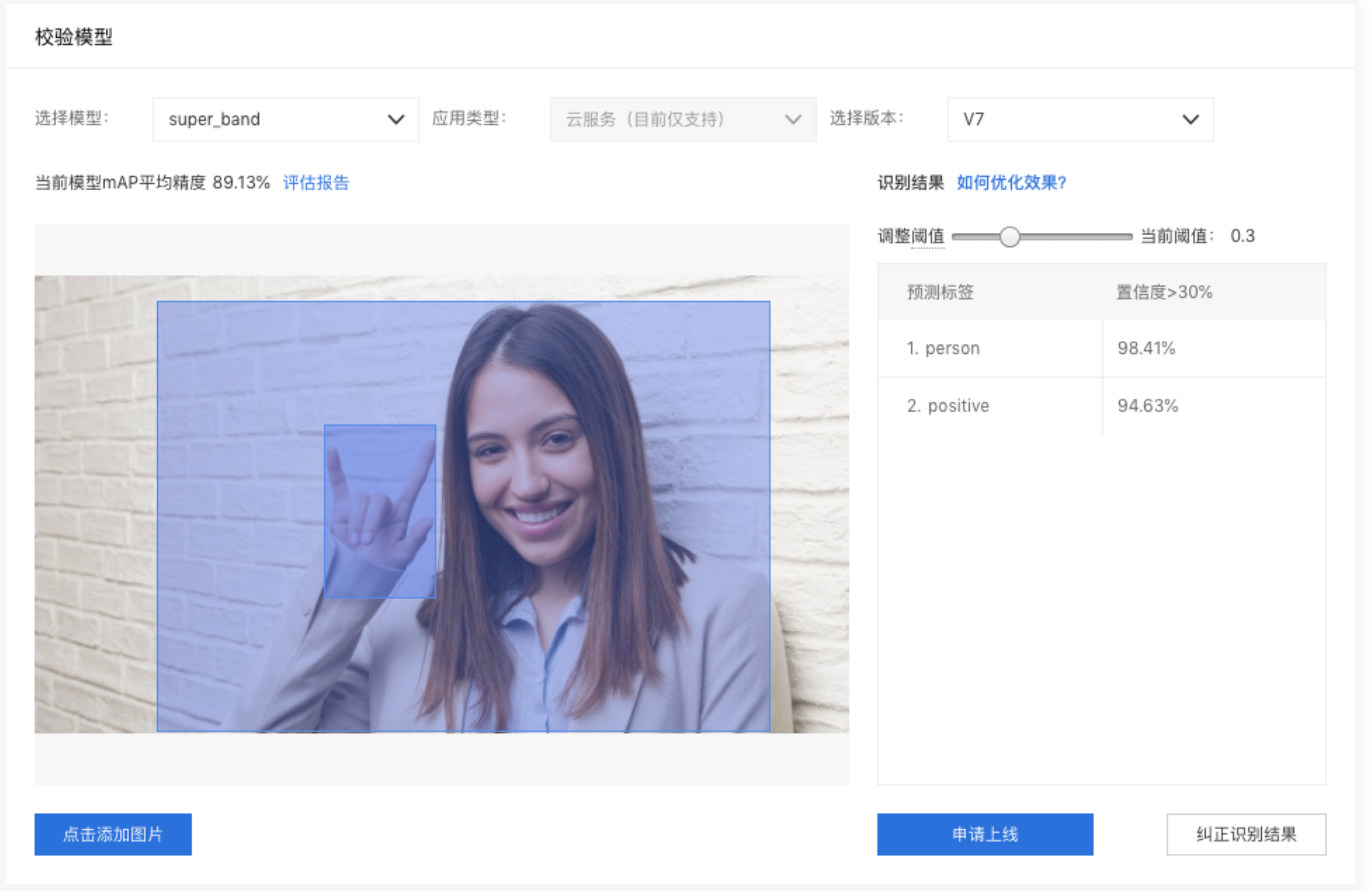
- 模型在线校验:可以在左侧导航中找到【校验模型】,在线校验模型效果。校验功能示意图:
模型评估报告
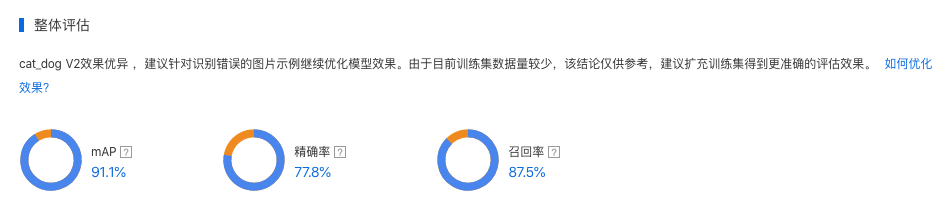
整体评估
在这个部分可以看到模型训练整体的情况说明,包括基本结论、mAP、精确率、召回率。这部分模型效果的指标是基于训练数据集,随机抽出部分数据不参与训练,仅参与模型效果评估计算得来。所以当数据量较少时(如图片数量低于100个),参与评估的数据可能不超过30个,这样得出的模型评估报告效果仅供参考,无法完全准确体现模型效果。
注意:若想要更充分了解模型效果情况,建议发布模型为API后,通过调用接口批量测试,获取更准确的模型效果。
查看模型评估结果时,需要思考在当前业务场景,更关注精确率与召回率哪个指标。是更希望减少误识别,还是更希望减少漏识别。前者更需要关注精确率的指标,后者更需要关注召回率的指标。同时F1-score可以有效关注精确率和召回率的平衡情况,对于希望准确率与召回率兼具的场景,F1-score越接近1效果越好。评估指标说明如下
F1-score: 对某类别而言为精确率和召回率的调和平均数,评估报告中指各类别F1-score的平均数
mAP: mAP(mean average precision)是物体检测(Object Detection)算法中衡量算法效果的指标。对于物体检测任务,每一类object都可以计算出其精确率(Precision)和召回率(Recall),在不同阈值下多次计算/试验,每个类都可以得到一条P-R曲线,曲线下的面积就是average
精确率: 正确预测的物体数与预测物体总数之比。评估报告中具体指经比较F1-score最高的阈值下的结果
召回率: 正确预测的物体数与真实物体数之比。评估报告中具体指经比较F1-score最高的阈值下的结果
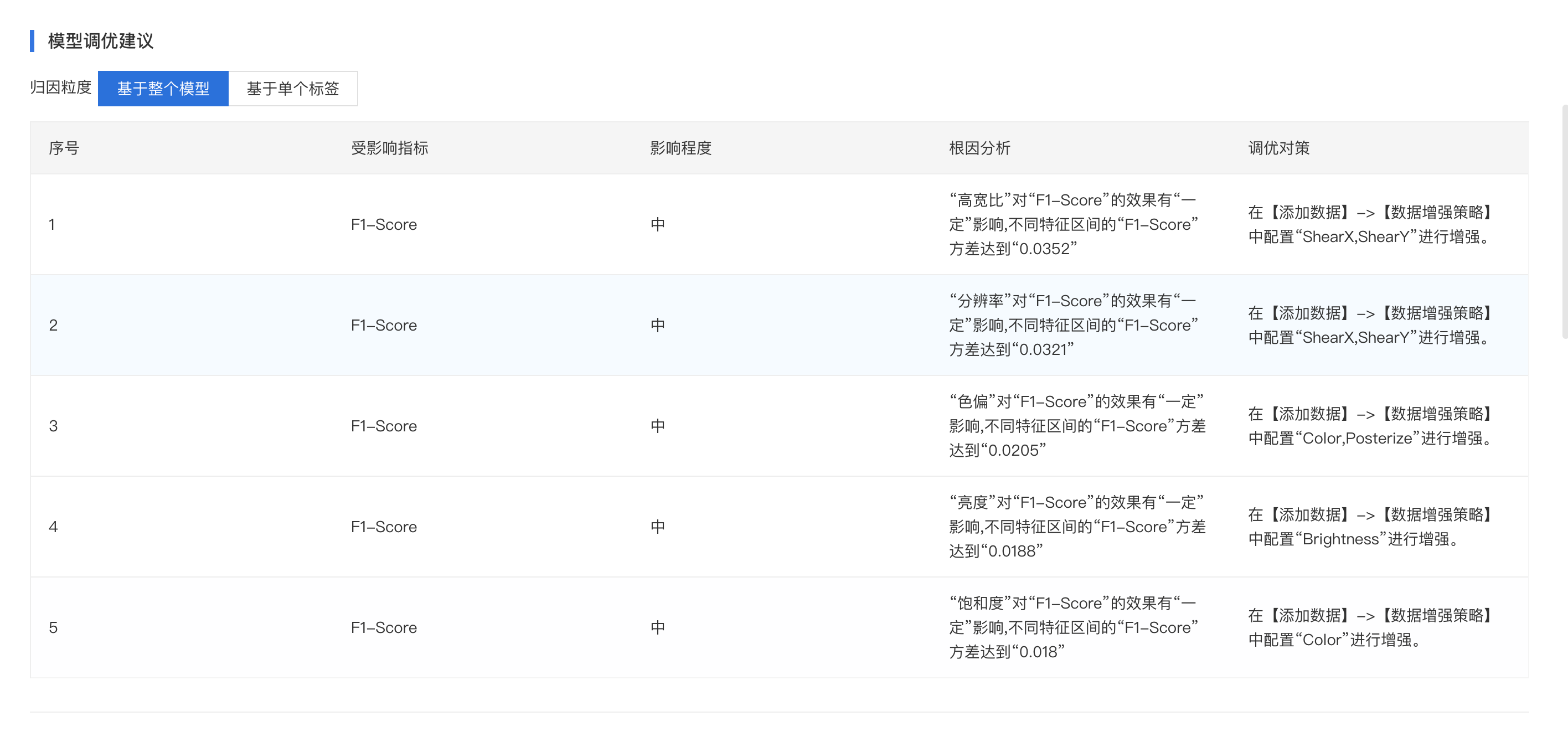
模型调优建议
在模型评估中,EasyDL将会通过智能算法对误识别的样本进行归因分析,可推断出误识别的样本对某个模型评估指标的具体影响以及影响程度,并提供对应优化的方案。同时还可针对某个具体表现不好的标签进行归因分析,针对性优化识别效果
详细评估
在这个部分可以看到不同阈值下的F1-score、模型识别错误的图片示例,以及使用混淆矩阵定位易混淆的标签。
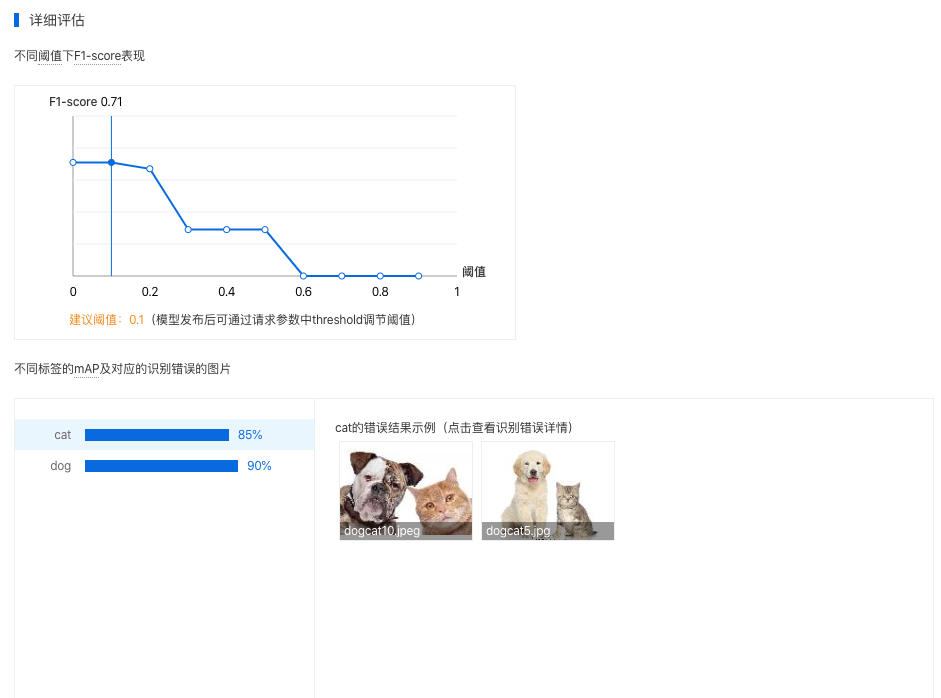
识别错误图片示例
通过分标签查看模型识别错误的图片,直寻找其中的共性,进而有针对性的扩充训练数据;或发现是标注错误,从而直接点击修改标注来将标注修正
如下图所示,可以通过勾选「误识别」、「漏识别」来分别查看两种错误识别的情况:

- 误识别:红框内没有目标物体(准备训练数据时没有标注),但模型识别到了目标物体
观察误识别的目标有什么共性:例如,一个检测电动车的模型,把很多自行车误识别成了电动车(因为电动车和自行车外观上比较相似)。这时,就需要在训练集中为自行车特别建立一个标签,并且在所有训练集图片中,将自行车标注出来。
可以把模型想象成一个在认识世界的孩童,当你告诉他电动车和自行车分别是什么样时,他就能认出来;当你没有告诉他的时候,他就有可能把自行车认成电动车。
- 漏识别:橙框内应该有目标物体(准备训练数据时标注了),但模型没能识别出目标物体
观察漏识别的目标有什么共性:例如,一个检测会议室参会人数的模型,会漏识别图片中出现的白色人种。这大概率是因为训练集中缺少白色人种的标注数据造成的。因此,需要在训练集中添加包含白色人种的图片,并将白色人种标注出来。
黄色人种和白色人种在外貌的差别上是比较明显的,由于几乎所有的训练数据都标注的是黄色人种,所以模型很可能认不出白色人种。需要增加白色人种的标注数据,让模型学习到黄色人种和白色人种都属于「参会人员」这个标签。
以上例子中,我们找到的是识别错误的图片中,目标特征上的共性。除此之外,还可以观察识别错误的图片在以下维度是否有共性,比如:图片的拍摄设备、拍摄角度,图片的亮度、背景等等。
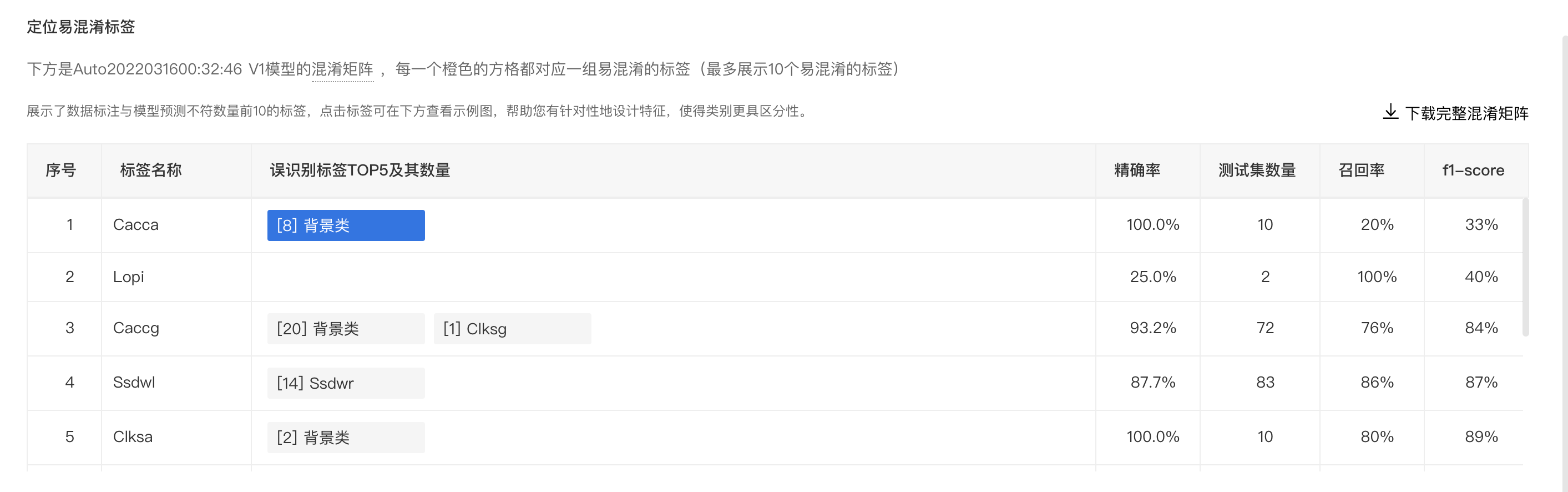
定位易混淆标签
支持按识别错误样本量的绝对数值/相对数值查看混淆矩阵,同时支持下载完整的混淆矩阵进行更深入的分析。