

文心核心接口概览
更新时间:2022-01-25
简介
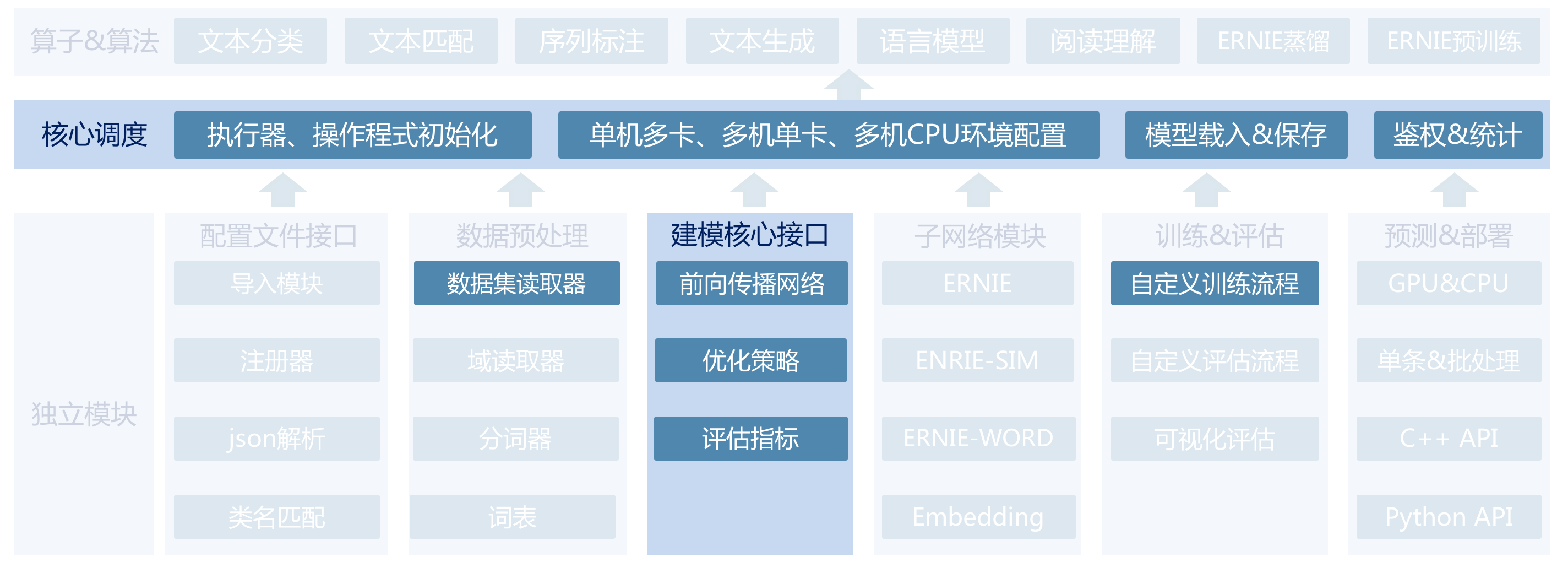
- 为了最灵活地基于文心开发,我们特别整理了文心核心接口部分。用户可以不考虑域框架、json注册机制等封装,直接采用最少的文心接口,完成自由度最高的基于文心和预训练模型的开发,或迁移已有策略到文心。
- 基于文心套件的核心接口如下图所示,用户只需要对齐数据集读取器(data_set_reader)、建模核心接口(model)、核心调度模块(base_trainer)三个代码接口即可。
入口函数
- 本文以文本分类为例进行介绍。其入口脚本在文本分类任务下: ./tasks/text_classification/run_without_register.py
- 主函数作为其入口函数,进行了以下几个工作:构造数据集读取器(data_set_reader)、构造建模核心操作类(model)和构造训练流程(trainer),并进行模型的训练与评估。
- 其中构造训练流程(trainer)需要依赖数据集读取器(data_set_reader)和建模核心操作类(model)。
...
if __name__ == "__main__":
args = args.build_common_arguments()
log.init_log("./log/test", level=logging.DEBUG)
# step1:构造自己的data_set_reader(训练、评估、模型保存需要用到的几个reader的集合,对应的reader的作用是把所有的field组织起来,明文数据转换成tensor)
# dataset_reader_params_dict = _params.get("dataset_reader")
dataset_reader = dataset_reader_from_params()
# step2:构造自己的model(组网部分)
# model_params_dict = _params.get("model")
model_params_dict = {"optimization": {"learning_rate": 2e-05}}
model = model_from_params(model_params_dict)
# step3:构造trainer:trainer中会进行模型训练,主要的成员变量是data_set_reader和model
# trainer_params_dict = _params.get("trainer")
# 基本配置如下所示,用户可根据需要进行配置
# "PADDLE_USE_GPU": 0, 是否采用GPU训练。
# "PADDLE_IS_LOCAL": 1, 是否单机训练
# "train_log_step": 20, 训练时打印训练日志的间隔步数
# "is_eval_dev": 0, 是否在训练的时候评估开发集,如果取值为1一定需要配置dev_reader及其数据路径。
# "is_eval_test": 1, 是否在训练的时候评估测试集,如果取值为1一定需要配置test_reader及其数据路径。
# "eval_step": 100, 进行测试集或验证集评估的间隔步数
# "save_model_step": 10000, 保存模型时的间隔步数,建议设置为eval_step的整数倍
# "load_parameters": 0, 加载包含各op参数值的训练好的模型,用于预测。
# "load_checkpoint": 0, 加载包含学习率等所有参数的训练模型,用于热启动。
# "pre_train_model": [] 加载预训练模型,例如ernie。使用时需要填写预训练模型的名称name和预训练模型的目录params_path
trainer_params_dict = {"PADDLE_USE_GPU": 0, "PADDLE_IS_LOCAL": 1, "train_log_step": 20, "is_eval_dev": 0, "is_eval_test": 0,
"eval_step": 100, "save_model_step": 500, "load_parameters": 0, "load_checkpoint": 0,
"pre_train_model": []}
trainer = build_trainer(trainer_params_dict, dataset_reader, model)
trainer.train_and_eval()数据集读取器
- 由于训练与预测过程中的数据格式可能不一样,数据集读取器(data_set_reader)储存了训练、预测不同情形下的数据集读取器。
- 构造自定义数据集读取器时,可以根据需要采用以下两种方式:
(1)不使用json,不使用field_reader,完全自定义方式
(2)不使用json,但使用预置的field_reader;
完全自定义数据集读取器
- 在复杂任务中(如阅读理解任务,可参考../../textone/data/data_set_reader/basic_dataset_reader_without_fields.py),分域的方式很可能无法满足数据读取的需求,我们提供了在文心套件范围内的自定义方式。
- 这里我们提供了一份用于实现文本分类数据处理的示例文件demo_classify_data_set_reader.py,使用方式如下所示:
def dataset_reader_from_params():
"""构造train_reader, predict_reader, test_reader, dev_reader
每个reader的作用是将原始数据转换成tensor
:return:
"""
## DataSet能够支持依据不同的名字生成不同的reader。
dataset_reader = DataSet(params_dict=None)
## example: 不使用json,不使用field_reader,完全自定义方式
train_config = ReaderConfig()
train_config.data_path = "./data/train_data"
train_config.batch_size = 8
train_config.epoch = 10
## tips:这里是一个完全自定义的DataSetReader
train_reader = DemoClassifyDataSetReader(name="train_reader", fields=None, config=train_config)
dataset_reader.train_reader = train_reader
predictor_reader = DemoClassifyDataSetReader(name="predict_reader", fields=None, config=train_config)
dataset_reader.predict_reader = predictor_reader
return dataset_reader- 我们提供了数据集读取器的接口类:base_dataset_reader (./textone/data/data_set_reader/base_dataset_reader.py),用户可通过继承该基类来实现接口对齐。base_dataset_reader将样本中的数据组装成一个py_reader, 向外提供一个统一的接口。其核心内容是读取明文文件后转换成id,并按照py_reader需要的tensor格式进行输入,最后通过调用run方法让整个循环运行起来。
- 注:py_reader输出的是lod-tensor形式的id,这些id可以用来做embedding等计算。
- 该接口类主要由create_reader()、instance_fields_dict()、data_generator()和run()四个必要方法接口构成。其功能和参数如下所示。
...
def create_reader(self):
"""
必须选项,否则会抛出异常。
用于初始化self.paddle_py_reader。
``self.paddle_py_reader = fluid.layers.py_reader(
capacity=capacity,
shapes=shapes,
name=self.name,
dtypes=types,
lod_levels=levels,
use_double_buffer=True)
``
:return:None
"""
raise NotImplementedError
def instance_fields_dict(self):
"""
必须选项,否则会抛出异常。
实例化fields_dict, 调用pyreader,得到fields_id, 视情况构造embedding,然后结构化成dict类型返回给组网部分。
:return:dict
{"field_name":
{"RECORD_ID":
{"InstanceName.SRC_IDS": [ids],
"InstanceName.MASK_IDS": [ids],
"InstanceName.SEQ_LENS": [ids]
}
}
}
实例化的dict,保存了各个field的id和embedding(可以没有,是情况而定), 给trainer用。
"""
raise NotImplementedError
def data_generator(self):
"""
必须选项,否则会抛出异常。
数据生成器:读取明文文件,生成batch化的id数据,绑定到py_reader中
:return:list
[[src_ids],
[mask_ids],
[seq_lens]
]
"""
raise NotImplementedError
def run(self):
"""
配置py_reader对应的数据生成器,并启动
:return:
"""
if self.paddle_py_reader:
self.paddle_py_reader.decorate_tensor_provider(self.data_generator())
self.paddle_py_reader.start()
logging.info("set data_generator and start.......")
else:
raise ValueError("paddle_py_reader is None")
...- 除此之外,demo_classify_data_set_reader还根据分类任务的需求,实现了convert_fields_to_dict()、read_files()、prepare_batch_data()和pad_batch_records()四个方法,其功能和参数如下所示:
...
def convert_fields_to_dict(self, field_list, need_emb=False):
"""实例化fields_dict,将序列化好的每个field的id和embedding按field名称存在词典中,外部调用的时候可以根据field名称直接获取。
:param field_list:
:param need_emb: 是否需要embedding,默认不需要
:return: dict
{
record_dict_text_a:{
InstanceName.RECORD_ID
...
}
...
}
"""
return fields_instance
def read_files(self, file_path, quotechar=None):
"""读取明文文件
:param file_path
:return: 以namedtuple数组形式输出明文样本对应的实例
"""
return examples
def prepare_batch_data(self, examples, batch_size):
"""将明文样本按照py_reader需要的格式序列化成一个个batch输出
:param examples:
:param batch_size:
:return:
"""
def pad_batch_records(self, batch_records):
"""
:param batch_records:
:return:
"""使用预置field_reader但不使用json
- 域(field)是文心的高阶封装,对于同一个样本存在不同域的时候,不同域有单独的数据类型(文本、数值、整型、浮点型)、开源有单独的词表(vocabulary)等,可以根据不同域进行语义表示,如文本转id等操作。
- field_reader是实现上述操作的类,用于处理样本中各个域相互独立的场景,可以通过data_set_reader管理、整合不同的field_reader。
- 这里我们以文本分类为例,文本域采用预置的CustomTextFieldReader,标签域采用预置的ScalarFieldReader,其使用方式如下所示:
def dataset_reader_from_params():
"""构造train_reader, predict_reader, test_reader, dev_reader
每个reader的作用是将原始数据转换成tensor
:return:
"""
dataset_reader = DataSet(params_dict=None) # DataSet能够支持依据不同的名字生成不同的reader。
text_a_field = Field()
text_a_field.name = "text_a"
text_a_field.data_type = "string"
text_a_field.need_convert = True # 是否需要进行文本转id的操作,比如已经数值化了的文本就不需要再转了
text_a_field.vocab_path = "./dict/vocab.txt"
text_a_field.max_seq_len = 512
text_a_field.padding_id = 0
reader_1 = CustomTextFieldReader(text_a_field)
reader_1.tokenizer = CustomTokenizer(vocab_file=text_a_field.vocab_path)
text_a_field.field_reader = reader_1
label_field = Field()
label_field.name = "label"
label_field.data_type = "int"
label_field.need_convert = False
label_field.max_seq_len = 1
reader_2 = ScalarFieldReader(label_field)
label_field.field_reader = reader_2
train_fields = [text_a_field, label_field]
train_config = ReaderConfig()
train_config.data_path = "./train_data"
train_config.batch_size = 8
train_config.epoch = 10
train_reader = BasicDataSetReader(name="train_reader", fields=train_fields, config=train_config)
dataset_reader.train_reader = train_reader
predictor_reader = BasicDataSetReader(name="predict_reader", fields=train_fields, config=train_config)
dataset_reader.predict_reader = predictor_reader
return dataset_reader建模核心接口
- 我们提供了建模核心接口类:model(./textone/models/model.py),用户可通过继承该基类来实现接口对齐。
- 建模核心接口类model主要由前向计算组网forward()、优化器optimizer()、预测结果解析器parse_predict_result()和指标评估get_metrics()四个主要方法构成,其功能和参数如下所示。
...
def forward(self, fields_dict, phase):
"""
必须选项,否则会抛出异常。
核心内容是模型的前向计算组网部分,包括loss值的计算,必须由子类实现。输出即为对输入数据执行变换计算后的结果。
:param: fields_dict
{"field_name":
{"RECORD_ID":
{"InstanceName.SRC_IDS": [ids],
"InstanceName.MASK_IDS": [ids],
"InstanceName.SEQ_LENS": [ids]
}
}
}
序列化好的id,供网络计算使用。
:param: phase: 当前调用的阶段,包含训练、评估和预测,不同的阶段组网可以不一样。
训练:InstanceName.TRAINING
测试集评估:InstanceName.TEST
验证集评估:InstanceName.EVALUATE
预测:InstanceName.SAVE_INFERENCE
:return: 训练:forward_return_dict
{
"InstanceName.PREDICT_RESULT": [predictions],
"InstanceName.LABEL": [label],
"InstanceName.LOSS": [avg_cost]
"自定义变量名": [用户需获取的其余变量]
}
预测:forward_return_dict
{
# 保存预测模型时需要的入参:模型预测时所需的输入变量
"InstanceName.TARGET_FEED_NAMES": [ids, id_lens],
# 保存预测模型时需要的入参:模型预测时输出的结果
"InstanceName.TARGET_PREDICTS": [predictions]
}
实例化的dict,存放TARGET_FEED_NAMES, TARGET_PREDICTS, PREDICT_RESULT,LABEL,LOSS等希望从前向网络中获取的数据。
"""
raise NotImplementedError
def optimizer(self, loss, is_fleet=False):
"""
必须选项,否则会抛出异常。
设置优化器,如Adam,Adagrad,SGD等。
:param loss:前向计算得到的损失值。
:param is_fleet:是否为多机。
:return:OrderedDict: 该dict中存放的是需要在运行过程中fetch出来的tensor,大多数情况下为空,可以按需求添加内容。
"""
raise NotImplementedError
def parse_predict_result(self, predict_result):
"""按需解析模型预测出来的结果
:param predict_result: 模型预测出来的结果
:return:None
"""
raise NotImplementedError
def get_metrics(self, fetch_output_dict, meta_info, phase):
"""指标评估部分的动态计算和打印
:param fetch_output_dict: executor.run过程中fetch出来的forward中定义的tensor
:param meta_info:常用的meta信息,如step, used_time, gpu_id等
:param phase: 当前调用的阶段,包含训练和评估
:return:metrics_return_dict:该dict中存放的是各个指标的结果,以文本分类为例,该dict内容如下所示:
{
"acc": acc,
"precision": precision
}
"""
raise NotImplementedError
... - 这里我们提供了一份自定义model实现CNN网络的示例./tasks/text_classification/run_cnn.py中的MyModel()供用户参考。
变量设置规则
- 变量设置规则在common.rule.InstanceName中,该部分囊括了数据集读取器(data_set_reader)、建模核心接口(model)的全局变量,实现了数据部分与组网部分的衔接,前向传播loss与优化器反向传播loss、计算metric的loss的衔接。部分示例如下所示:
...
class InstanceName(object):
"""InstanceName:一些常用的命名
"""
RECORD_ID = "id"
RECORD_EMB = "emb"
SRC_IDS = "src_ids"
MASK_IDS = "mask_ids"
SEQ_LENS = "seq_lens"
SENTENCE_IDS = "sent_ids"
POS_IDS = "pos_ids"
TASK_IDS = "task_ids"
# seq2seq的label域相关key
TRAIN_LABEL_SRC_IDS = "train_label_src_ids"
TRAIN_LABEL_MASK_IDS = "train_label_mask_ids"
TRAIN_LABEL_SEQ_LENS = "train_label_seq_lens"
INFER_LABEL_SRC_IDS = "infer_label_src_ids"
INFER_LABEL_MASK_IDS = "infer_label_mask_ids"
INFER_LABEL_SEQ_LENS = "infer_label_seq_lens"
...训练流程与核心调度模块
- 训练流程(trainer)继承了核心调度模块(base_trainer),实现了整个训练评估流程。
- 文心实现了custom_trainer类(textone/training/custom_trainer.py),能够覆盖大部分训练评估流程,用户如果对自定义训练评估要求不高,可以直接继承该类。
- 用过如果对训练评估流程有更强的自定义需求,可参考custom_trainer的编写过程进行自定义操作,其代码如下。由于该类继承了核心调度模块(base_trainer),用户可参考textone/training/base_trainer_demo.py了解其接口封装逻辑。
@RegisterSet.trainer.register
class CustomTrainer(BaseTrainer):
"""CustomTrainer:通用textone任务的trainer"""
def __init__(self, params, data_set_reader, model_class):
"""
:param params:
:param data_set_reader:
:param model_class:
"""
BaseTrainer.__init__(self, params, data_set_reader, model_class)
def train_and_eval(self):
"""
:return:
"""
if self.is_fleet and fleet.is_server():
logging.debug("is fleet.server, over")
return
if self.is_fleet:
logging.debug("worker_index%d start train...." % fleet.worker_index())
num_train_examples = self.params.get("num_train_examples", 0)
if num_train_examples == 0:
num_train_examples = self.data_set_reader.train_reader.get_num_examples()
self.data_set_reader.train_reader.run()
steps = 1
time_begin = time.time()
if 'output_path' in self.params.keys() and self.params["output_path"]:
save_checkpoints_path = os.path.join(self.params["output_path"], "save_checkpoints")
save_inference_model_path = os.path.join(self.params["output_path"], "save_inference_model")
else:
save_checkpoints_path = "./output/save_checkpoints/"
save_inference_model_path = "./output/save_inference_model/"
try:
while True:
try:
if steps % self.params["train_log_step"] != 0:
self.run(InstanceName.TRAINING, need_fetch=False)
else:
metrics_tensor_value = self.run(InstanceName.TRAINING, need_fetch=True)
current_example, current_epoch = self.data_set_reader.train_reader.get_train_progress()
logging.info("epoch {0} progress {1}/{2} pyreader queue size {3}".
format(current_epoch, current_example, num_train_examples,
self.data_set_reader.train_reader.paddle_py_reader.queue.size()))
fetch_output_dict = collections.OrderedDict()
for key, value in zip(self.fetch_list_train_key, metrics_tensor_value):
fetch_output_dict[key] = value
time_end = time.time()
used_time = time_end - time_begin
meta_info = collections.OrderedDict()
meta_info[InstanceName.STEP] = steps
meta_info[InstanceName.GPU_ID] = self.gpu_id
meta_info[InstanceName.TIME_COST] = used_time
metrics_output = self.model_class.get_metrics(fetch_output_dict, meta_info,
InstanceName.TRAINING)
if self.params.get("visualdl_log", False):
assert isinstance(metrics_output, OrderedDict), "metrics_output is must be OrderedDict"
self.visualdl_log(metrics_output, np.mean(fetch_output_dict[InstanceName.LOSS]), steps,
phase=InstanceName.TRAINING)
time_begin = time.time()
if steps % self.params["eval_step"] == 0:
if self.params["is_eval_dev"]:
self.evaluate(self.data_set_reader.dev_reader, InstanceName.EVALUATE, steps)
if self.params["is_eval_test"]:
self.evaluate(self.data_set_reader.test_reader, InstanceName.TEST, steps)
if self.trainer_id == 0:
if steps % self.params["save_model_step"] == 0:
self.save_models(save_checkpoints_path, save_inference_model_path, steps)
steps += 1
if "steps_for_test" in self.params and steps >= self.params["steps_for_test"]:
self.data_set_reader.train_reader.stop()
logging.debug("steps_for_test stop!")
break
except fluid.core.EOFException:
self.data_set_reader.train_reader.stop()
break
if self.params["is_eval_dev"]:
logging.info("Final evaluate result: ")
self.evaluate(self.data_set_reader.dev_reader, InstanceName.EVALUATE, steps)
if self.params["is_eval_test"]:
logging.info("Final test result: ")
self.evaluate(self.data_set_reader.test_reader, InstanceName.TEST, steps)
except Exception as e:
logging.error('traceback.format_exc():%s' % traceback.format_exc())
self.save_models(save_checkpoints_path, save_inference_model_path, steps)
raise e
self.save_models(save_checkpoints_path, save_inference_model_path, steps)
def evaluate(self, reader, phase, step):
"""
:param reader:
:param phase:
:param step:
:return:
"""
if not reader:
raise ValueError("{0} reader is none".format(phase))
reader.run()
all_metrics_tensor_value = []
i = 0
time_begin = time.time()
while True:
try:
metrics_tensor_value = self.run(phase=phase)
if i == 0:
all_metrics_tensor_value = [[tensor] for tensor in metrics_tensor_value]
else:
for j in range(len(metrics_tensor_value)):
one_tensor_value = all_metrics_tensor_value[j]
all_metrics_tensor_value[j] = one_tensor_value + [metrics_tensor_value[j]]
i += 1
except fluid.core.EOFException:
reader.stop()
break
fetch_output_dict = collections.OrderedDict()
for key, value in zip(self.fetch_list_evaluate_key, all_metrics_tensor_value):
fetch_output_dict[key] = value
time_end = time.time()
used_time = time_end - time_begin
meta_info = collections.OrderedDict()
meta_info[InstanceName.STEP] = step
meta_info[InstanceName.GPU_ID] = self.gpu_id
meta_info[InstanceName.TIME_COST] = used_time
metrics_output = self.model_class.get_metrics(fetch_output_dict, meta_info, phase)
if self.params.get("visualdl_log", False):
assert isinstance(metrics_output, OrderedDict), "the metrics_output must be OrderedDict"
eval_loss = np.mean(fetch_output_dict[InstanceName.LOSS])
self.visualdl_log(metrics_output, eval_loss, step, phase=phase)- custom_trainer的基本配置如下所示:
"PADDLE_USE_GPU": 0, # 是否采用GPU训练。
"PADDLE_IS_LOCAL: 1, # 是否单机训练
"train_log_step": 20, # 训练时打印训练日志的间隔步数
"is_eval_dev": 0, # 是否在训练的时候评估开发集,如果取值为1一定需要配置dev_reader及其数据路径。
"is_eval_test": 1, # 是否在训练的时候评估测试集,如果取值为1一定需要配置test_reader及其数据路径。
"eval_step": 100, # 进行测试集或验证集评估的间隔步数
"save_model_step": 10000, # 保存模型时的间隔步数,建议设置为eval_step的整数倍
"load_parameters": 0, # 加载包含各op参数值的训练好的模型,用于预测。
"load_checkpoint": 0, # 加载包含学习率等所有参数的训练模型,用于热启动。
"pre_train_model": [] # 加载预训练模型,例如ernie。使用时需要填写预训练模型的名称name和预训练模型的目录params_path