
文本匹配任务在自然语言处理领域中是非常重要的基础任务,一般用于研究两段文本之间的关系。文本匹配任务存在很多应用场景,如信息检索、问答系统、智能对话、文本鉴别、智能推荐、文本数据去重、文本相似度计算、自然语言推理、问答系统、信息检索等,这些自然语言处理任务在很大程度上都可以抽象成文本匹配问题,比如信息检索可以归结为搜索词和文档资源的匹配,问答系统可以归结为问题和候选答案的匹配,复述问题可以归结为两个同义句的匹配。
而在知识融合过程中的关键技术是实体对齐,又被称为实体匹配,其旨在推断来自不同数据集合中的不同实体是否映射到物理世界中同一对象的处理过程。实体对齐的终极目标是将多源知识库中的实体建立映射关系,也正因如此,文本匹配算法可以在知识融合过程中针对非结构化文本进行较好的语义对齐,建立映射关系,具体方案如下图所示。
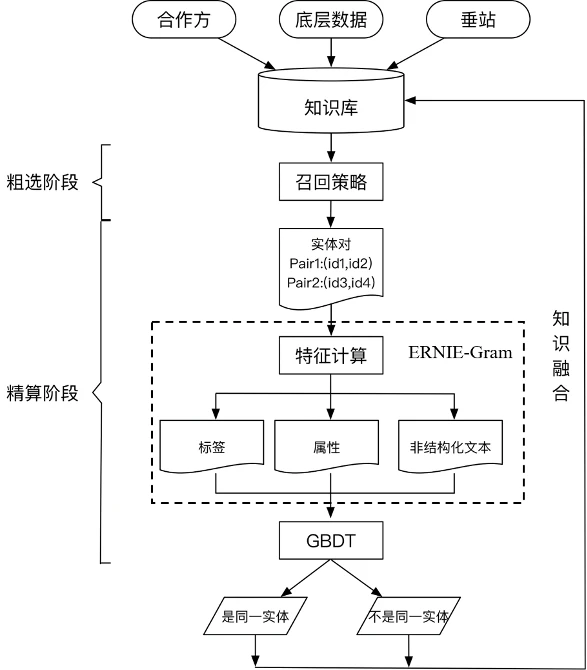
在粗选阶段,我们需要根据知识库寻找相似实体对,通过精准匹配和部分匹配的方式进行实体簇的粗选。其中,精准匹配主要采用同名召回、同音召回、别名召回三类策略。部分匹配主要采用jaccard距离等方法构建倒排,根据阈值进行挑选。
在精排阶段,我们根据粗选出来的实体对,构建Pair-wise类特征,进行精细算分。根据特征的种类,可以划分为标签、属性、非结构化文本三类特征。在实际对齐任务中,头尾部的实体经常缺失各种关键属性,难以判断实体是否可以对齐,此时就利用非结构化文本提供关键信息,这里就可以通过使用飞桨ERNIE-Gram模型将根据计算的三类特征进行实体对齐。由于各领域的schema不同,涉及到的属性类特征也不尽相同。故根据对数据的分析,为schema相差较大的领域设计不同的GBDT模型,最终完成对齐。本文主要讲解精排阶段的文本匹配算法,更多方案和技术细节请参考下述项目。
-
项目链接:https://aistudio.baidu.com/aistudio/projectdetail/5456683?channelType=0&channel=0
-
项目合集:https://aistudio.baidu.com/aistudio/projectdetail/5427356?contributionType=1
01 融合方案操作步骤
PART1 环境版本要求
环境安装需根据Python和飞桨框架的版本要求进行选择。
-
Python3版本要求:python3.7及以上版本,参考https://www.python.org/
-
飞桨框架版本要求:飞桨框架2.0+版本,参考https://www.paddlepaddle.org.cn/documentation/docs/zh/install/pip/macos-pip.html
-
飞桨环境的安装:需首先保证Python和pip是64bit,且处理器架构为x86_64(或称作x64、Intel 64、AMD64)。目前飞桨暂不支持arm64架构(mac M1除外,飞桨已支持Mac M1 芯片)。
PART2 数据集简介
LCQMC[1]是百度知道领域的中文问题匹配数据集,以解决中文领域大规模问题匹配。该数据集从百度知道的不同领域用户问题中抽取构建数据。部分数据集展示如下:
西安下雪了?是不是很冷啊? 西安的天气怎么样啊?还在下雪吗? 0
第一次去见女朋友父母该如何表现? 第一次去见家长该怎么做 0
猪的护心肉怎么切 猪的护心肉怎么吃 0
显卡驱动安装不了,为什么? 显卡驱动安装不了怎么回事 1
一只蜜蜂落在日历上(打一成语) 一只蜜蜂停在日历上(猜一成语) 1
PART3 模型情况
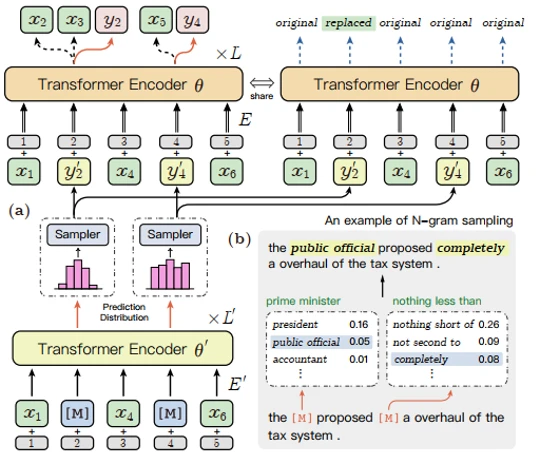
在ERNIE-Gram模型[2]发布以前,学界工作主要集中在将BERT的掩码语言建模(MLM)的目标从Mask单个标记扩展到N个标记的连续序列,但这种连续屏蔽方法忽略了对粗粒度语言信息的内部依赖性和相互关系的建模。作为一种改进方法ERNIE-Gram采用了一种显式n-gram掩码方法,以加强对预训练中粗粒度信息的整合。在ERNIE-Gram中,n-grams被Mask并直接使用明确的n-gram序列号而不是n个标记的连续序列进行预测。此外,ERNIE-Gram采用了一个生成器模型,对可信的n-gram序列号进行采样,作为可选的n-gram掩码,并以粗粒度和细粒度的方式进行预测,以实现全面的n-gram预测和关系建模。在论文中实验表明,ERNIE-Gram在很大程度上优于XLNet和RoBERTa等预训练模型。其中掩码的流程见下图所示。
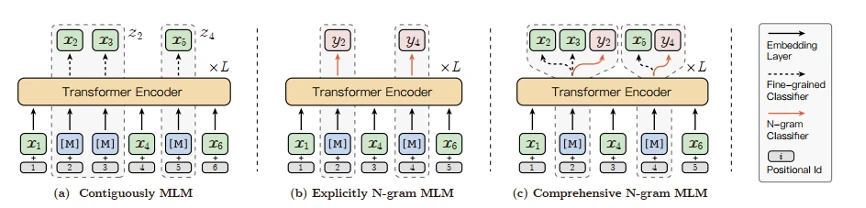
ERNIE-Gram模型充分地将粗粒度语言信息纳入预训练,进行了全面的n-gram预测和关系建模,消除之前连续掩蔽策略的局限性,进一步增强了语义n-gram的学习。n-gram关系建模的详细架构如下图所示,子图(b)中是一个n-gram抽样的例子,其中虚线框代表抽样模块,绿色的文本是原始n-gram,蓝色的斜体文本是抽样的n-gram。本文不一一展开,更多算法原理和技术细节请参考原论文。
为让同学们快速上手,本项目使用语义匹配数据集LCQMC作为训练集,基于ERNIE-Gram预训练模型训练了单塔Point-wise语义匹配模型,用户可以直接基于这个模型对文本对进行语义匹配的二分类任务。(在文本匹配任务数据的每一个样本通常由两个文本组成query和title。类别形式为0或1,0表示query与title不匹配,1表示匹配。)同时考虑到在不同应用场景下的需求,下面也将简单讲解一下不同类型的语义匹配模型和应用场景。
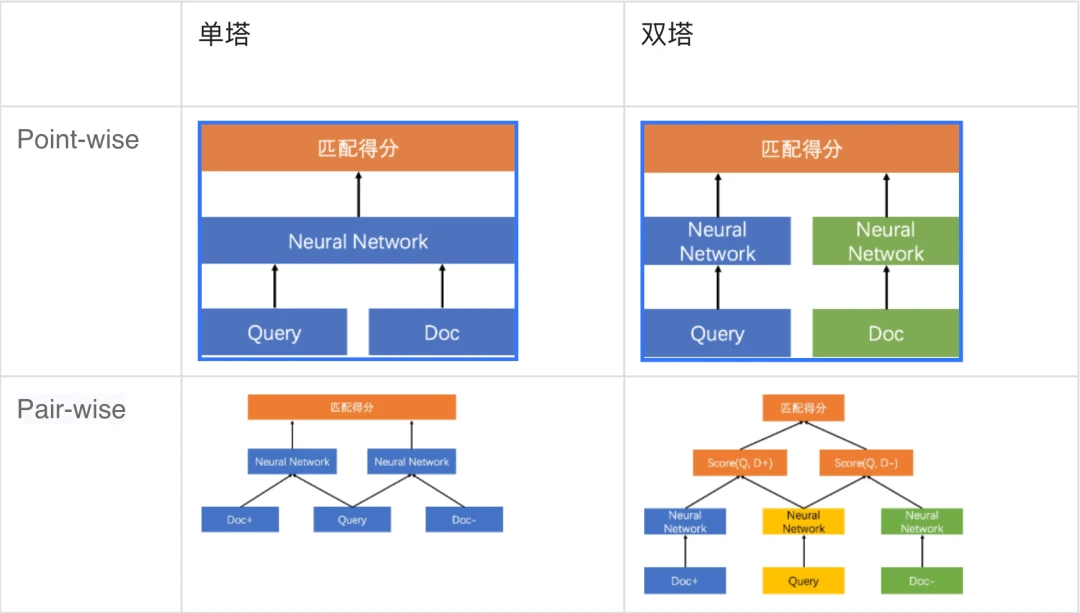
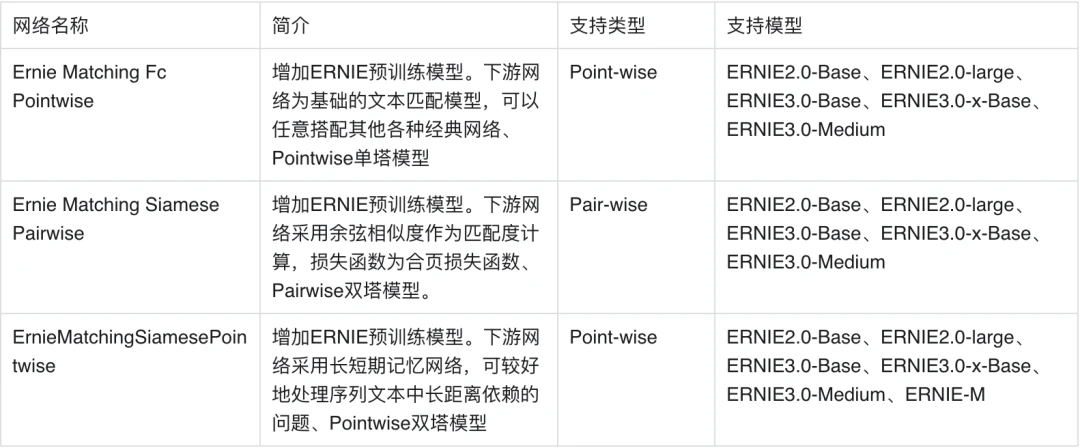
基于单塔Point-wise范式的语义匹配模型Ernie_Matching模型精度高、计算复杂度高, 适合直接进行语义匹配二分类的应用场景。基于单塔Pair-wise范式的语义匹配模型Ernie_Matching模型精度高、计算复杂度高,对文本相似度大小的序关系建模能力更强,适合将相似度特征作为上层排序模块输入特征的应用场景。基于双塔Point-Wise范式的语义匹配模型计算效率更高,适合对延时要求高、根据语义相似度进行粗排的应用场景。
PART4 模型训练与预测
以中文文本匹配公开数据集LCQMC为示例数据集,可在训练集(train.tsv)上进行单塔 Point-wise 模型训练,并在开发集(dev.tsv)验证。
模型训练
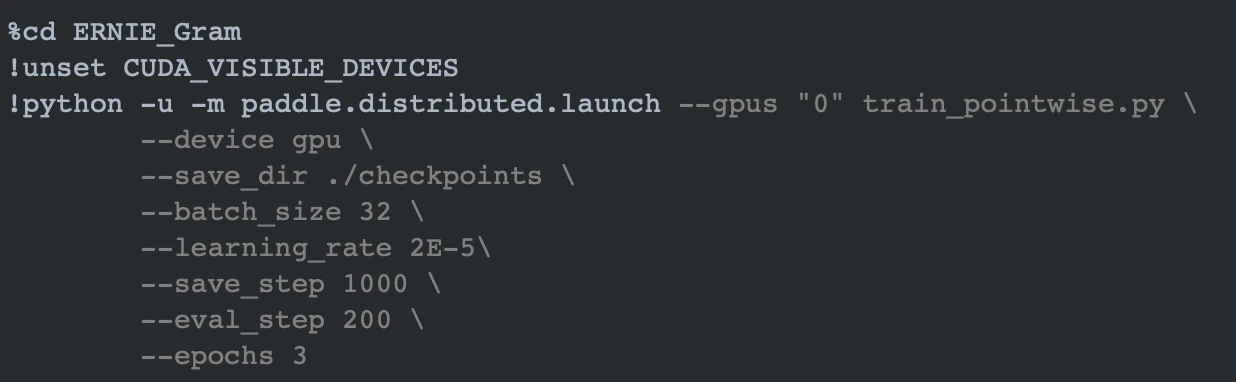

预测结果部分展示。
如果想要使用其他预训练模型如ERNIE、BERT、RoBERTa等,只需更换model和tokenizer即可。
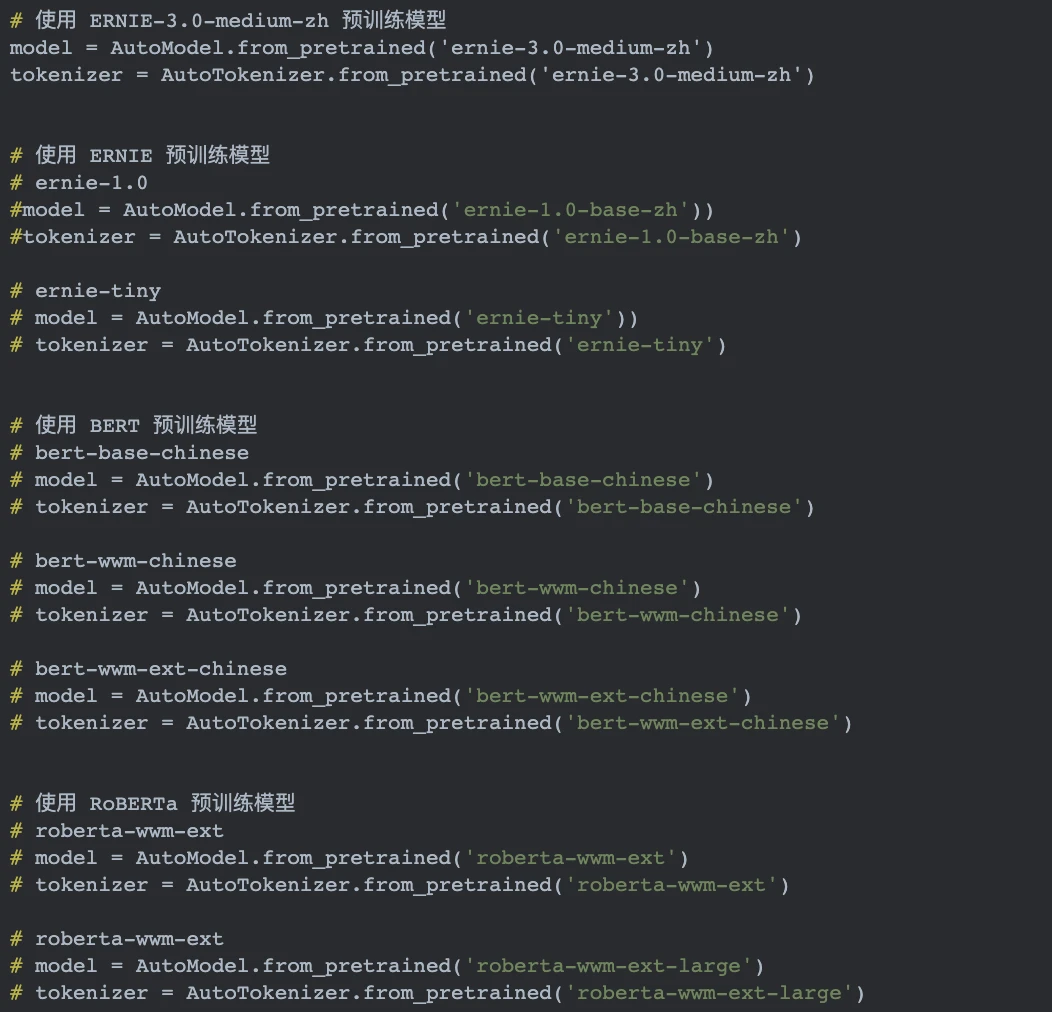
NOTE:如需恢复模型训练,则可以设置init_from_ckpt,如
init_from_ckpt=checkpoints/model_100/model_state.pdparams。如需使用ernie-tiny模型,则需提前先安装sentencepiece依赖,如pip install sentencepiece。
模型预测

在深度学习模型构建上,飞桨框架支持动态图编程和静态图编程两种方式,两种方式下代码编写和执行方式均存在差异。动态图编程体验更佳、更易调试,但是因为采用Python实时执行的方式,开销较大,在性能方面与 C++ 有一定差距。静态图调试难度大,但是将前端Python编写的神经网络预定义为Program描述,转到C++端重新解析执行,从而脱离了对Python的依赖,往往执行性能更佳,并且预先拥有完整网络结构也更利于全局优化。
同时,你可以进行基于静态图的部署预测和模型导出。使用动态图训练结束之后,可以使用静态图导出工具export_model.py将动态图参数导出成静态图参数。实现方式可参考如下指令:


02 结论
PART 1项目小结
该项目中还涉及部分对无监督模型以及有监督模型的对比内容,如下图所示。
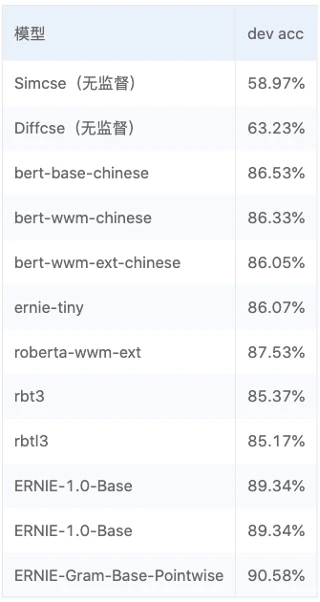
结论如下:
-
SimCSE模型适合缺乏监督数据,但是又有大量无监督数据的匹配和检索场景。
-
相比于SimCSE模型,DiffCSE模型会更关注语句之间的差异性,具有精确的向量表示能力。DiffCSE模型同样适合缺乏监督数据又有大量无监督数据的匹配和检索场景。
-
明显看到有监督模型中ERNIE-Gram比之前所有模型性能的优秀。
受篇幅限制影响,这里不详细展开模型的对比详情,感兴趣的同学可以点击下方链接详细了解。同时欢迎同学们在飞桨AI Studio平台发挥自己的创造力和想象力。
-
项目链接:https://aistudio.baidu.com/aistudio/projectdetail/5456683?channelType=0&channel=0
-
项目合集:https://aistudio.baidu.com/aistudio/projectdetail/5427356?contributionType=1
PART2 未来展望
本项目主要围绕着特定领域知识图谱(Domain-specific Knowledge Graph,DKG)融合方案中的一环讲解了基于ERNIE-Garm的文本匹配算法。希望看到这篇项目的开发者们,能够在此基础上共同努力共建知识图谱领域,走通知识抽取、知识融合、知识推理和质量评估的完整流程。
参考文献
[1] Xin Liu, Qingcai Chen, Chong Deng, Huajun Zeng, Jing Chen, Dongfang Li, Buzhou Tang, LCQMC: A Large-scale Chinese Question Matching Corpus,COLING2018.
[2] Xiao, Dongling, Yu-Kun Li, Han Zhang, Yu Sun, Hao Tian, Hua Wu, and Haifeng Wang. “ERNIE-Gram: Pre-Training with Explicitly N-Gram Masked Language Modeling for Natural Language Understanding.”ArXiv:2010.12148 [Cs].