

Windows-SDK
Windows-SDK
简介
本文介绍Windows版飞桨开源模型SDK的使用方法
快速开始
文件结构说明
EasyEdge-win-m29730-x86
└── EasyEdge-win-x86
├── bin # demo二进制程序
│ ├── easyedge_image_inference.exe
│ ├── easyedge_serving.exe
│ └── easyedge_video_inference.exe
├── data
│ ├── model # 模型文件资源文件夹
│ │ ├── conf.json
│ │ ├── label_list.txt
│ │ ├── model
│ │ ├── params
│ │ └── infer_cfg.json
│ └── config # 配置文件
├── dll
├── include
├── lib
├── python # python相关
│ ├── BaiduAI_EasyEdge_SDK-${version}-cp37-cp37m-win_amd64.whl
│ ├── requirements.txt
│ ├── infer_demo
│ │ ├── demo_x86_cpu.py
│ │ ├── demo_nvidia_gpu.py
│ │ └── demo_serving.py
│ └── tensor_demo
│ │ ├── demo_x86_cpu.py
│ │ └── demo_nvidia_gpu.py
├── src # c++/c# demo源码
├── EasyEdge.exe # 主程序
└── README.md # 环境说明安装依赖
c++及c#
- 运行依赖请参考SDK内附的README.md中的说明
-
编译依赖 + cmake: 3.0 以上
- Microsoft Visual Studio 2015及以上
python
CPU 预测时安装:
python3 -m pip install paddlepaddle==2.2.2 -i https://mirror.baidu.com/pypi/simple NVIDIA GPU 预测时安装:
python3 -m pip install paddlepaddle-gpu==2.2.2.post101 -f https://www.paddlepaddle.org.cn/whl/windows/mkl/avx/stable.html # CUDA10.1的PaddlePaddle
python3 -m pip install paddlepaddle-gpu==2.2.2 -i https://mirror.baidu.com/pypi/simple # CUDA10.2的PaddlePaddle
python3 -m pip install paddlepaddle-gpu==2.2.2.post110 -f https://www.paddlepaddle.org.cn/whl/windows/mkl/avx/stable.html # CUDA11.0的PaddlePaddle
python3 -m pip install paddlepaddle-gpu==2.2.2.post111 -f https://www.paddlepaddle.org.cn/whl/windows/mkl/avx/stable.html # CUDA11.1的PaddlePaddle
python3 -m pip install paddlepaddle-gpu==2.2.2.post112 -f https://www.paddlepaddle.org.cn/whl/windows/mkl/avx/stable.html # CUDA11.2的PaddlePaddle使用 NVIDIA GPU 预测时,必须满足:
- 机器已安装 cuda, cudnn
- 已正确安装对应 cuda 版本的paddle 版本
- 通过设置环境变量
FLAGS_fraction_of_gpu_memory_to_use设置合理的初始内存使用比例
EasyEdge Python Wheel安装:
python3 -m pip install -U BaiduAI_EasyEdge_SDK-{version}-cp37-cp37m-win_amd64.whl测试Demo
模型资源文件默认已经打包在开发者下载的SDK包中,请先将zip包整体拷贝到具体运行的设备中,再解压缩使用。
EasyEdge.exe
打开EasyEdge.exe,输入要绑定的Host及Port并启动
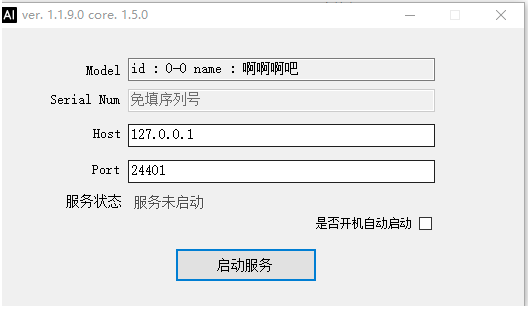
服务启动后可以打开浏览器,http://{host}:{port},选择图片来进行测试。
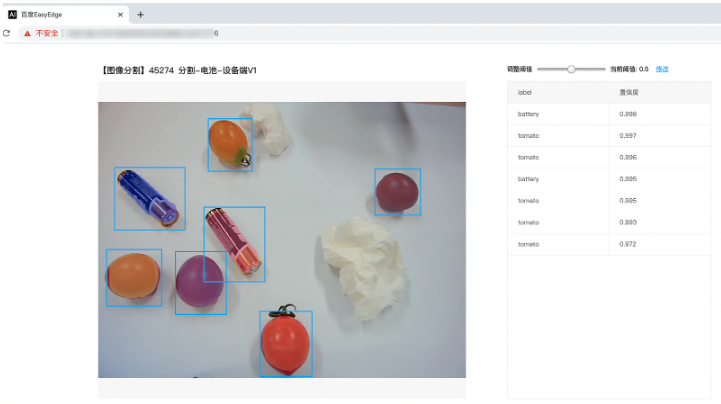
同时,可以调用HTTP接口来访问服务,具体参考下文接口说明。
bin\easyedge_image_inference:预测图像
.\easyedge_image_inference {模型model文件夹} {测试图片路径}bin\easyedge_video_inference:预测视频流
.\easyedge_video_inference {模型model文件夹} {video_type} {video_src}其中video_type支持三种:
/**
* @brief 输入源类型
*/
enum class SourceType {
kVideoFile = 1, // 本地视频文件
kCameraId = 2, // 摄像头的index
kNetworkStream = 3, // 网络视频流
};video_src 即为文件路径(1) 或者本地摄像头id(2)或网络视频流地址(3)
bin\easyedge_serving:启动HTTP预测服务
.\easyedge_serving {模型model文件夹路径} 启动后,日志中会显示
HTTP is now serving at 0.0.0.0:24401字样,此时,开发者可以打开浏览器,http://{设备ip}:24401,选择图片来进行测试。
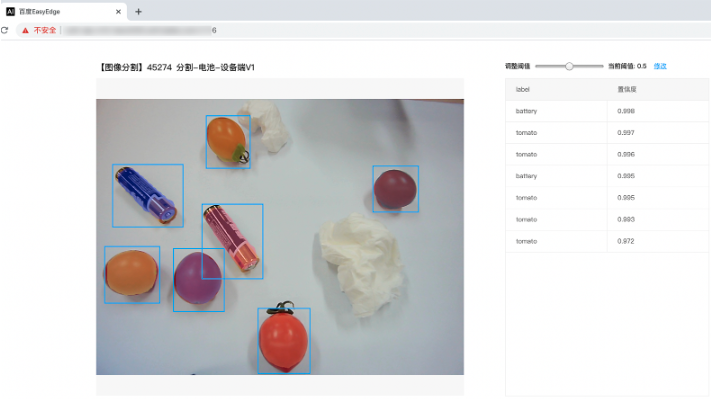
同时,可以调用HTTP接口来访问服务,具体参考下文接口说明。
python\infer_demo\demo_x86_cpu.py:预测图像
python3 demo_x86_cpu.py {模型model文件夹} {测试图片路径}python\infer_demo\demo_serving.py:启动HTTP预测服务
python3 demo_serving.py {模型model文件夹} "" {host, default 0.0.0.0} {port, default 24401}c++ SDK二次开发使用说明
使用该方式,将运行库嵌入到开发者的程序当中。
基础流程
src文件夹中包含完整可编译的cmake工程实例,建议开发者先行了解cmake工程基本知识
❗注意,请优先参考SDK中自带的Demo工程的使用流程和说明。遇到错误,请优先参考文件中的注释、解释、日志说明。
// step 1: 配置运行参数
EdgePredictorConfig config;
config.model_dir = {模型文件目录};
// step 2: 创建并初始化Predictor;这这里选择合适的引擎
auto predictor = global_controller()->CreateEdgePredictor(config);
// step 3-1: 预测图像
auto img = cv::imread({图片路径});
std::vector<EdgeResultData> results;
predictor->infer(img, results);
// step 3-2: 预测视频
std::vector<EdgeResultData> results;
FrameTensor frame_tensor;
VideoConfig video_config;
video_config.source_type = static_cast<SourceType>(video_type); // source_type 定义参考头文件 easyedge_video.h
video_config.source_value = video_src;
/*
... more video_configs, 根据需要配置video_config的各选项
*/
auto video_decoding = CreateVideoDecoding(video_config);
while (video_decoding->next(frame_tensor) == EDGE_OK) {
results.clear();
if (frame_tensor.is_needed) {
predictor->infer(frame_tensor.frame, results);
render(frame_tensor.frame, results, predictor->model_info().kind);
}
//video_decoding->display(frame_tensor); // 显示当前frame,需在video_config中开启配置
//video_decoding->save(frame_tensor); // 存储当前frame到视频,需在video_config中开启配置
}若需自定义library search path或者编译器路径,修改CMakeList.txt即可。
SDK参数配置
SDK的参数通过EdgePredictorConfig::set_config和global_controller()->set_config配置。set_config的所有key在easyedge_xxxx_config.h中。其中
PREDICTOR前缀的key是不同模型相关的配置,通过EdgePredictorConfig::set_config设置CONTROLLER前缀的key是整个SDK的全局配置,通过global_controller()->set_config设置
以CPU线程数为例,KEY的说明如下:
/**
* @brief 指定使用的CPU线程数。 一般来说,线程数越接近物理核数,速度越快。
* 该参数表示在一次识别过程中,同时使用多少CPU线程。
* 若期望同时使用多个线程来同时识别多张图片,可自行创建多个predictor来使用。
* 值类型: int
* 默认值:4 (维持默认值时,ARM CPU上会自动根据大小核的情况自动调整)
*/
static constexpr auto PREDICTOR_KEY_CPU_THREADS_NUM = "PREDICTOR_KEY_CPU_THREADS_NUM";使用方法如下:
EdgePredictorConfig config;
config.model_dir = ...;
config.set_config(params::PREDICTOR_KEY_CPU_THREADS_NUM, 8);具体支持的运行参数可以参考开发工具包中的头文件的详细说明。
初始化
- 接口
auto predictor = global_controller()->CreateEdgePredictor(config);
predictor->init();若返回非0,请查看输出日志排查错误原因。
预测图像
infer接口有超过11个重载函数,可以根据实际情况、参数说明自行传入需要的内容做推理
- 接口
/**
* @brief
* 通用接口
* @param image: must be BGR , HWC format (opencv default)
* @param result
* @return
*/
virtual int infer(
cv::Mat& image, std::vector<EdgeResultData>& result
) = 0;
/**
* @brief see:
* @related infer(cv::Mat & image, EdgeColorFormat origin_color_format, std::vector<EdgeResultData> &result, float threshold)
*/
virtual int infer(
std::vector<cv::Mat> &images,
EdgeColorFormat origin_color_format,
std::vector<std::vector<EdgeResultData>> &results
);图片的格式务必为opencv默认的BGR, HWC格式。
- 返回格式
EdgeResultData中可以获取对应的分类信息、位置信息。
struct EdgeResultData {
int index; // 分类结果的index
std::string label; // 分类结果的label
float prob; // 置信度
// 物体检测活图像分割时才有
float x1, y1, x2, y2; // (x1, y1): 左上角, (x2, y2): 右下角; 均为0~1的长宽比例值。
// 图像分割时才有
cv::Mat mask; // 0, 1 的mask
std::string mask_rle; // Run Length Encoding,游程编码的mask
};关于矩形坐标
x1 * 图片宽度 = 检测框的左上角的横坐标
y1 * 图片高度 = 检测框的左上角的纵坐标
x2 * 图片宽度 = 检测框的右下角的横坐标
y2 * 图片高度 = 检测框的右下角的纵坐标
关于图像分割mask
cv::Mat mask为图像掩码的二维数组
{
{0, 0, 0, 0, 0, 0, 0, 0, 0, 0},
{0, 0, 0, 1, 1, 1, 0, 0, 0, 0},
{0, 0, 0, 1, 1, 1, 0, 0, 0, 0},
{0, 0, 0, 1, 1, 1, 0, 0, 0, 0},
{0, 0, 0, 1, 1, 1, 0, 0, 0, 0},
{0, 0, 0, 0, 0, 0, 0, 0, 0, 0},
}
其中1代表为目标区域,0代表非目标区域关于图像分割mask_rle
该字段返回了mask的游程编码,解析方式可参考 http demo
以上字段可以参考demo文件中使用opencv绘制的逻辑进行解析
预测视频
SDK 提供了支持摄像头读取、视频文件和网络视频流的解析工具类VideoDecoding,此类提供了获取视频帧数据的便利函数。通过VideoConfig结构体可以控制视频/摄像头的解析策略、抽帧策略、分辨率调整、结果视频存储等功能。对于抽取到的视频帧可以直接作为SDK infer 接口的参数进行预测。
- 接口
classVideoDecoding:
/**
* @brief 获取输入源的下一帧
* @param frame_tensor
* @return
*/
virtual int next(FrameTensor &frame_tensor) = 0;
/**
* @brief 显示当前frame_tensor中的视频帧
* @param frame_tensor
* @return
*/
virtual int display(const FrameTensor &frame_tensor) = 0;
/**
* @brief 将当前frame_tensor中的视频帧写为本地视频文件
* @param frame_tensor
* @return
*/
virtual int save(FrameTensor &frame_tensor) = 0;
/**
* @brief 获取视频的fps属性
* @return
*/
virtual int get_fps() = 0;
/**
* @brief 获取视频的width属性
* @return
*/
virtual int get_width() = 0;
/**
* @brief 获取视频的height属性
* @return
*/
virtual int get_height() = 0;struct VideoConfig
/**
* @brief 视频源、抽帧策略、存储策略的设置选项
*/
struct VideoConfig {
SourceType source_type; // 输入源类型
std::string source_value; // 输入源地址,如视频文件路径、摄像头index、网络流地址
int skip_frames{0}; // 设置跳帧,每隔skip_frames帧抽取一帧,并把该抽取帧的is_needed置为true
int retrieve_all{false}; // 是否抽取所有frame以便于作为显示和存储,对于不满足skip_frames策略的frame,把所抽取帧的is_needed置为false
int input_fps{0}; // 在采取抽帧之前设置视频的fps
Resolution resolution{Resolution::kAuto}; // 采样分辨率,只对camera有效
bool enable_display{false};
std::string window_name{"EasyEdge"};
bool display_all{false}; // 是否显示所有frame,若为false,仅显示根据skip_frames抽取的frame
bool enable_save{false};
std::string save_path; // frame存储为视频文件的路径
bool save_all{false}; // 是否存储所有frame,若为false,仅存储根据skip_frames抽取的frame
std::map<std::string, std::string> conf;
};source_type:输入源类型,支持视频文件、摄像头、网络视频流三种,值分别为1、2、3。
source_value: 若source_type为视频文件,该值为指向视频文件的完整路径;若source_type为摄像头,该值为摄像头的index,如对于/dev/video0的摄像头,则index为0;若source_type为网络视频流,则为该视频流的完整地址。
skip_frames:设置跳帧,每隔skip_frames帧抽取一帧,并把该抽取帧的is_needed置为true,标记为is_needed的帧是用来做预测的帧。反之,直接跳过该帧,不经过预测。
retrieve_all:若置该项为true,则无论是否设置跳帧,所有的帧都会被抽取返回,以作为显示或存储用。
input_fps:用于抽帧前设置fps。
resolution:设置摄像头采样的分辨率,其值请参考easyedge_video.h中的定义,注意该分辨率调整仅对输入源为摄像头时有效。
conf:高级选项。部分配置会通过该map来设置。
注意:
1.如果使用VideoConfig的display功能,需要自行编译带有GTK选项的opencv,默认打包的opencv不包含此项。
2.使用摄像头抽帧时,如果通过resolution设置了分辨率调整,但是不起作用,请添加如下选项:
video_config.conf["backend"] = "2";3.部分设备上的CSI摄像头尚未兼容,如遇到问题,可以通过工单、QQ交流群或微信交流群反馈。
具体接口调用流程,可以参考SDK中的demo_video_inference。
TensorIn/Out 推理
TensorIn/Out 推理不会对输入数据做预处理、后处理,开发者一般使用普通推理接口即可。
/**
* @brief 不负责模型前后处理,只进行模型推理,输入Tensor序列,输出Tensor序列
* @param [in] 输入Edge Tensor序列
* @param [out] 输出Edge Tensor序列
* @experimental The api may change in the next release version
*/
virtual int forward(
const std::vector<ETensor> &feed, std::vector<ETensor> &fetch
);日志配置
设置 EdgeLogConfig 的相关参数。具体含义参考文件中的注释说明。
EdgeLogConfig log_config;
log_config.enable_debug = true;
global_controller()->set_log_config(log_config);python SDK二次开发使用说明
使用该方式,将运行库嵌入到开发者的程序当中。
基础流程
❗注意,请优先参考SDK中自带demo的使用流程和说明。遇到错误,请优先参考文件中的注释、解释、日志说明。
infer_demo\demo_xx_xx.py
# 引入EasyEdge运行库
import BaiduAI.EasyEdge as edge
# 创建并初始化一个预测Progam;选择合适的引擎
pred = edge.Program()
pred.init(model_dir={model文件夹路径}, device=edge.Device.CPU, engine=edge.Engine.PADDLE_FLUID) # x86_64 CPU
# pred.init(model_dir=_model_dir, device=edge.Device.GPU, engine=edge.Engine.PADDLE_FLUID) # x86_64 Nvidia GPU
# pred.init(model_dir=_model_dir, device=edge.Device.CPU, engine=edge.Engine.PADDLE_LITE) # armv8 CPU
# 预测图像
res = pred.infer_image({numpy.ndarray的图片})
# 关闭结束预测Progam
pred.close()infer_demo\demo_serving.py
import BaiduAI.EasyEdge as edge
from BaiduAI.EasyEdge.serving import Serving
# 创建并初始化Http服务
server = Serving(model_dir={model文件夹路径}, license=serial_key)
# 运行Http服务
# 请参考同级目录下demo_xx_xx.py里:
# pred.init(model_dir=xx, device=xx, engine=xx, device_id=xx)
# 对以下参数device\device_id和engine进行修改
server.run(host=host, port=port, device=edge.Device.CPU, engine=edge.Engine.PADDLE_FLUID) # x86_64 CPU
# server.run(host=host, port=port, device=edge.Device.GPU, engine=edge.Engine.PADDLE_FLUID) # x86_64 Nvidia GPU
# server.run(host=host, port=port, device=edge.Device.CPU, engine=edge.Engine.PADDLE_LITE) # armv8 CPU初始化
- 接口
def init(self,
model_dir,
device=Device.CPU,
engine=Engine.PADDLE_FLUID,
config_file='conf.json',
preprocess_file='preprocess_args.json',
model_file='model',
params_file='params',
label_file='label_list.txt',
infer_cfg_file='infer_cfg.json',
device_id=0,
thread_num=1
):
"""
Args:
model_dir: str
device: BaiduAI.EasyEdge.Device,比如:Device.CPU
engine: BaiduAI.EasyEdge.Engine, 比如: Engine.PADDLE_FLUID
config_file: str
preprocess_file: str
model_file: str
params_file: str
label_file: str 标签文件
infer_cfg_file: 包含预处理、后处理信息的文件
device_id: int 设备ID
thread_num: int CPU的线程数
Raises:
RuntimeError, IOError
Returns:
bool: True if success
"""若返回不是True,请查看输出日志排查错误原因。
SDK参数配置
使用 CPU 预测时,可以通过在 init 中设置 thread_num 使用多线程预测。如:
pred.init(model_dir=_model_dir, device=edge.Device.CPU, engine=edge.Engine.PADDLE_FLUID, thread_num=4)使用 NVIDIA GPU 预测时,可以通过在 init 中设置 device_id 指定需要的GPU device id。如:
pred.init(model_dir=_model_dir, device=edge.Device.GPU, engine=edge.Engine.PADDLE_FLUID, device_id=0)预测图像
- 接口
def infer_image(self, img,
threshold=0.3,
channel_order='HWC',
color_format='BGR',
data_type='numpy'):
"""
Args:
img: np.ndarray or bytes
threshold: float
only return result with confidence larger than threshold
channel_order: string
channel order HWC or CHW
color_format: string
color format order RGB or BGR
data_type: string
仅在图像分割时有意义。 'numpy' or 'string'
'numpy': 返回已解析的mask
'string': 返回未解析的mask游程编码
Returns:
list
"""- 返回格式:
[dict1, dict2, ...]
| 字段 | 类型 | 取值 | 说明 |
|---|---|---|---|
| confidence | float | 0~1 | 分类或检测的置信度 |
| label | string | 分类或检测的类别 | |
| index | number | 分类或检测的类别 | |
| x1, y1 | float | 0~1 | 物体检测,矩形的左上角坐标 (相对长宽的比例值) |
| x2, y2 | float | 0~1 | 物体检测,矩形的右下角坐标(相对长宽的比例值) |
| mask | string/numpy.ndarray | 图像分割的mask |
关于矩形坐标
x1 * 图片宽度 = 检测框的左上角的横坐标
y1 * 图片高度 = 检测框的左上角的纵坐标
x2 * 图片宽度 = 检测框的右下角的横坐标
y2 * 图片高度 = 检测框的右下角的纵坐标
可以参考 demo 文件中使用 opencv 绘制矩形的逻辑。
结果示例
i) 图像分类
{
"index": 736,
"label": "table",
"confidence": 0.9
}ii) 物体检测
{
"index": 8,
"label": "cat",
"confidence": 1.0,
"x1": 0.21289,
"y1": 0.12671,
"x2": 0.91504,
"y2": 0.91211,
}iii) 图像分割
{
"name": "cat",
"score": 1.0,
"location": {
"left": ...,
"top": ...,
"width": ...,
"height": ...,
},
"mask": ...
}mask字段中,data_type为numpy时,返回图像掩码的二维数组
{
{0, 0, 0, 0, 0, 0, 0, 0, 0, 0},
{0, 0, 0, 1, 1, 1, 0, 0, 0, 0},
{0, 0, 0, 1, 1, 1, 0, 0, 0, 0},
{0, 0, 0, 1, 1, 1, 0, 0, 0, 0},
{0, 0, 0, 1, 1, 1, 0, 0, 0, 0},
{0, 0, 0, 0, 0, 0, 0, 0, 0, 0},
}
其中1代表为目标区域,0代表非目标区域data_type为string时,mask的游程编码,解析方式可参考 demo
TensorIn/Out 推理
TensorIn/Out 推理不会对输入数据做预处理、后处理,开发者一般使用普通推理接口即可。
流程参考:使用tensor_demo\demo_xx_xx.py
fetch_tensors = pred.forward(feed_tensors)日志配置
设置 EasyEdge Log。
import BaiduAI.EasyEdge as edge
import logging
edge.Log.set_level(logging.INFO)
# edge.Log.set_level(logging.DEBUG)基于http服务二次开发使用说明
使用该方式,将运行库嵌入到开发者的程序当中。
1. 开启http服务
- 直接使用
EasyEdge.exe - 直接使用
bin\easyedge_serving - 直接使用
python\infer_demo\demo_serving.py - 参考
src\demo_serving\demo_serving.cpp文件修改相关逻辑
/**
* @brief 开启一个简单的demo http服务。
* 该方法会block直到收到sigint/sigterm。
* http服务里,图片的解码运行在cpu之上,可能会降低推理速度。
* @tparam ConfigT
* @param config
* @param host
* @param port
* @param service_id service_id user parameter, uri '/get/service_id' will respond this value with 'text/plain'
* @param instance_num 实例数量,根据内存/显存/时延要求调整
* @return
*/
template<typename ConfigT>
int start_http_server(
const ConfigT &config,
const std::string &host,
int port,
const std::string &service_id,
int instance_num = 1);2. 请求http服务
开发者可以打开浏览器,
http://{设备ip}:24401,选择图片来进行测试。
http 请求方式一:不使用图片base64格式
URL中的get参数:
| 参数 | 说明 | 默认值 |
|---|---|---|
| threshold | 阈值过滤, 0~1 | 如不提供,则会使用模型的推荐阈值 |
HTTP POST Body即为图片的二进制内容(无需base64, 无需json)
Python请求示例
import requests
with open('./1.jpg', 'rb') as f:
img = f.read()
result = requests.post(
'http://127.0.0.1:24401/',
params={'threshold': 0.1},
data=img).json()Java请求示例
import java.io.*;
import java.net.HttpURLConnection;
import java.net.URL;
/**
* 适用于百度EasyDL 离线SDK服务请求
* @author 小帅丶
* @date 2019/5/8
* @param reqUrl 接口地址
* @param fileUrl 本地图片路径
* @return java.lang.String
**/
private static String doPostFile(String reqUrl, String fileUrl) {
HttpURLConnection url_con = null;
String responseContent = null;
try {
URL url = new URL(reqUrl);
url_con = (HttpURLConnection) url.openConnection();
url_con.setRequestMethod("POST");
url_con.setDoOutput(true);
url_con.setRequestProperty("Content-type", "application/x-java-serialized-object");
byte[] data = Util.readFileByBytes(fileUrl);
url_con.getOutputStream().write(data, 0, data.length);
url_con.getOutputStream().flush();
url_con.getOutputStream().close();
InputStream in = url_con.getInputStream();
BufferedReader rd = new BufferedReader(new InputStreamReader(in, "UTF-8"));
String tempLine = rd.readLine();
StringBuffer tempStr = new StringBuffer();
String crlf = System.getProperty("line.separator");
while (tempLine != null) {
tempStr.append(tempLine);
tempStr.append(crlf);
tempLine = rd.readLine();
}
responseContent = tempStr.toString();
rd.close();
in.close();
} catch (IOException e) {
System.out.println("请求错信息:"+e.getMessage());
} finally {
if (url_con != null) {
url_con.disconnect();
}
}
return responseContent;
}http 请求方法二:使用图片base64格式
HTTP方法:POST Header如下:
| 参数 | 值 |
|---|---|
| Content-Type | application/json |
Body请求填写:
- 分类网络: body 中请求示例
{
"image": "<base64数据>"
"top_num": 5
}body中参数详情
| 参数 | 是否必选 | 类型 | 可选值范围 | 说明 |
|---|---|---|---|---|
| image | 是 | string | - | 图像数据,base64编码,要求base64图片编码后大小不超过4M,最短边至少15px,最长边最大4096px,支持jpg/png/bmp格式 注意去掉头部 |
| top_num | 否 | number | - | 返回分类数量,不填该参数,则默认返回全部分类结果 |
- 检测和分割网络: Body请求示例:
{
"image": "<base64数据>"
}body中参数详情:
| 参数 | 是否必选 | 类型 | 可选值范围 | 说明 |
|---|---|---|---|---|
| image | 是 | string | - | 图像数据,base64编码,要求base64图片编码后大小不超过4M,最短边至少15px,最长边最大4096px,支持jpg/png/bmp格式 注意去掉头部 |
| threshold | 否 | number | - | 默认为推荐阈值,也可自行根据需要进行设置 |
http 返回数据
| 字段 | 类型说明 | 其他 |
|---|---|---|
| error_code | Number | 0为成功,非0参考message获得具体错误信息 |
| results | Array | 内容为具体的识别结果。其中字段的具体含义请参考预测图像-返回格式一节 |
| cost_ms | Number | 预测耗时ms,不含网络交互时间 |
返回示例
{
"cost_ms": 52,
"error_code": 0,
"results": [
{
"confidence": 0.94482421875,
"index": 1,
"label": "IronMan",
"x1": 0.059185408055782318,
"x2": 0.18795496225357056,
"y1": 0.14762254059314728,
"y2": 0.52510076761245728,
"mask": "...", // 图像分割模型字段
"trackId": 0, // 目标追踪模型字段
},
]
}关于矩形坐标
x1 * 图片宽度 = 检测框的左上角的横坐标
y1 * 图片高度 = 检测框的左上角的纵坐标
x2 * 图片宽度 = 检测框的右下角的横坐标
y2 * 图片高度 = 检测框的右下角的纵坐标
关于分割模型
其中,mask为分割模型的游程编码,解析方式可参考 http demo
模型替换说明
SDK中data\model文件夹为模型文件夹,开发者可以按要求整理自定义模型的data\model文件,运行时指定新的data\model即可。
- model: 模型网络结构文件,对应Paddle1.x的
__model__,Paddle2.x的model.pdmodel - params: 模型网络参数文件,对应Paddle1.x的
__params__,Paddle2.x的model.pdiparams - label_list.txt: label文件
- infer_cfg.json:模型推理的预处理、后处理配置文件,具体说明如下
其中,非标记【必须】的可不填
{
"version": 1,
"model_info": {
"best_threshold": 0.3, // 默认0.3
"model_kind": 1, // 【必须】 1-分类,2-检测,6-实例分割,12-追踪,14-语义分割,401-人脸,402-姿态,10001-决策
},
"pre_process": { // 【必须】
// 归一化, 预处理会把图像 (origin_img - mean) * scale
"skip_norm": false, // 默认为false, 如果设置为true,不做mean scale处理
"mean": [123, 123, 123], // 【必须】
"scale": [0.017, 0.017, 0.017], // 【必须】
"color_format": "RGB", // BGR 【必须】
"channel_order": "CHW", // HWC
// 大小相关
"resize": [300, 300], // w, h 【必须】
"rescale_mode": "keep_size", // 默认keep_size, keep_ratio, keep_ratio2, keep_raw_size, warp_affine
"max_size": 1366, // keep_ratio 用。如果没有提供,则用 resize[0]
"target_size": 800, // keep_ratio 用。如果没有提供,则用 resize[1]
"raw_size_range": [100, 10000], // keep_raw_size 用
"warp_affine_keep_res": // warp_affine模式使用,默认为false
"center_crop_size": [224, 224], // w, h, 如果需要做center_crop,则提供,否则,无需提供该字段
"padding": false,
"padding_mode": "padding_align32", // 【非必须】默认padding_align32, 其他可指定:padding_fill_size
"padding_fill_size": [416, 416], // 【非必须】仅padding_fill_size模式下需要提供, [fill_size_w, fill_size_h], 这里padding fill对齐paddle detection实现,在bottom和right方向实现补齐
"padding_fill_value": [114, 114, 114] // 【非必须】仅padding_fill_size模式下需要提供
// 其他
"letterbox": true,
},
"post_process": {
"box_normed": true, // 默认为true, 如果为false 则表示该模型的box坐标输出不是归一化的
}
}预处理的顺序如下:(没有的流程自动略过)
- 灰度图 -> rgb图变换
- resize 尺寸变换
- center_crop
- rgb/bgr变换
- padding_fill_size
- letterbox(画个厚边框,填上黑色)
- chw/hwc变换
- 归一化:mean, scale
- padding_align32
rescale_mode说明:
- keep_size: 将图片缩放到resize指定的大小
- keep_ratio:将图片按比例缩放,长边不超过max_size,短边不超过target_size
- keep_raw_size:保持原图尺寸,但必须在raw_size_range之间
- warp_affine: 仿射变换,可以设置warp_affine_keep_res指定是否keep_res,在keep_res为false场景下,宽高通过resize字段指定