

EasyDL语音自训练平台
简介
HI,您好,欢迎使用EasyDL语音识别。
原语音自训练平台即日已结束公测正式上线,品牌升级更名为“EasyDL语音识别”,平台和语音识别通用接口全面打通,语音技术下任一接口开通付费即可免费训练语音识别模型,无需额外费用。
——————————————————————
如果您在调用通用语音识别模型时遇到如下困难:
1、在垂直业务领域下通用语音识别模型准确率不满足需求,语音识别应用的场景专业词汇较集中,如医疗词汇、金融词汇、教育用语、交通地名、人名等,识别结果存在“同音不同字”的情况。例如“虹桥机场”识别为“红桥机场”;“债券”识别为“在劝”。
2、语音识别结果不准带来更高的后处理成本,并且语音识别模型针对性优化训练存在技术门槛、成本高、训练周期长。
欢迎使用EasyDL语音识别,可以通过自助训练语言模型的方式有效提升您业务场景下的识别准确率。
使用流程概述
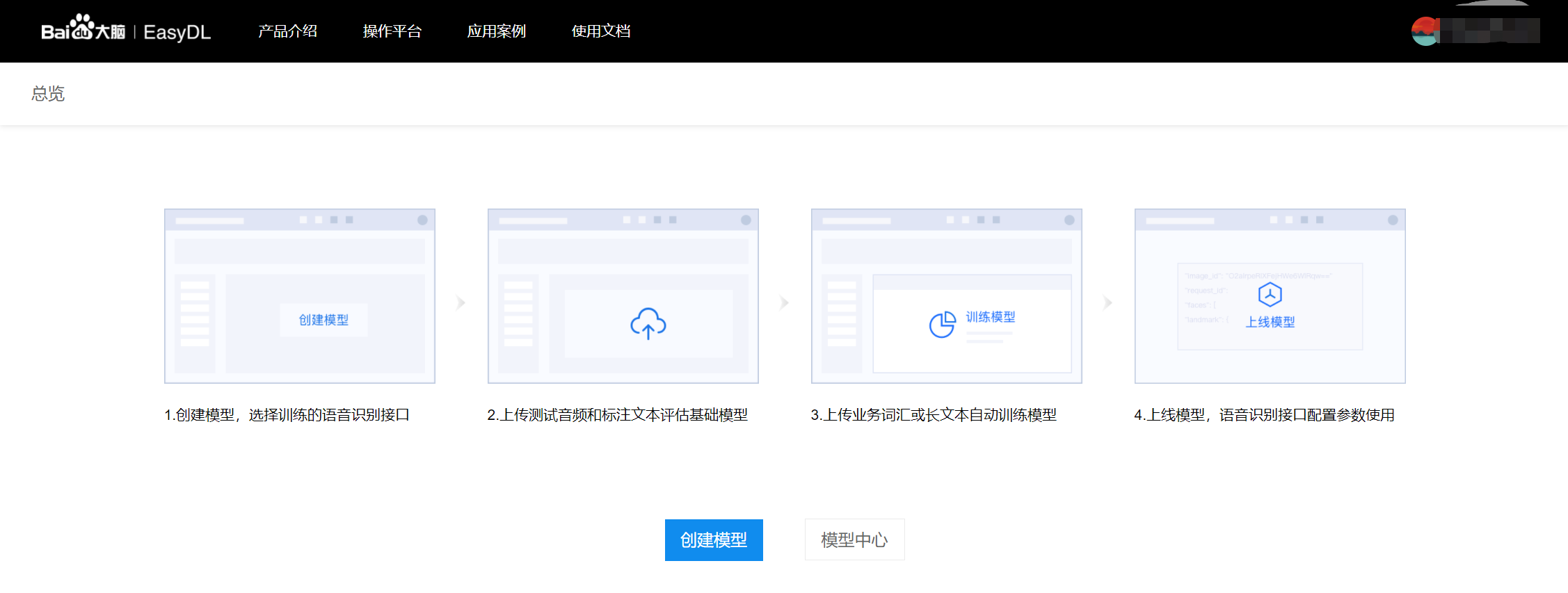
平台使用的基本流程如下图所示,全程可视化简易操作,在数据已经准备好的情况下,最快一天内即可获得专属模型。

1、创建模型:选择您需要训练的语音识别接口,目前支持训练短语音识别-中文普通话、短语音识别极速版、实时语音识别-中文、呼叫中心语音解决方案接口。填写基础信息为您的模型进行命名和功能描述,并留下您的联系方式以便于我们和您联系。
2、系统评估:上传您业务场景中的真实音频和对应的正确标注文本(尽可能覆盖全部的场景),客观科学地评估基础模型的识别率。根据评估结果,系统自动推荐最佳的基础模型,您可以选择任一基础模型进行训练。
3、训练模型:上传您业务场景中出现的高频词汇或者是长句文本,可以有效提升业务用语的识别率;并可以迭代训练,持续优化。
5、上线模型:得到满意的训练模型即可申请上线,审批通过自动上线模型。模型上线后,在语音识别的接口中配置模型参数即可使用训练后的效果。
开始使用平台前,先了解一下您需要提前准备的物料及准备建议:
1、【测试集(包括业务音频+准确100%的标注文本)】,用于评估基础模型识别率和训练后模型识别率,相当于准备一份“标准答案”。如果模型使用业务范围较广(例如某行业领域模型),建议测试集在1000-3000条左右评估会相对客观;如果是针对某些特定场景训练,可只提供该场景的音频测试集几十条-几百条均可,包含希望评估的业务内容即可。
2、【训练集(投入平台进行训练的文本)】,用于语言模型训练,建议文本要和测试集的内容强相关。训练文本可以放置希望提升识别效果的词汇,如业务上的固定搭配和业务关键词等,或者可以将某个词汇放在不同句式的句子中,高频出现。**影响训练效果的关键因素为“文本出现的频率”和“上下文的句意理解”等**。无需重复提交大量文本,少量关键文本即可有训练效果。输入用户名及密码,点击“登录”,进入EasyDL语音识别。可以看到整体训练流程,点击创建模型可以直接进行模型创建,点击模型中心可以进入到模型列表页面。
整体训练流程将按照目录栏的顺序依次操作即可。
下面将详细介绍每一步的操作方式和注意事项。若遇到的问题在此文档没有找到答案,可以提交工单进行咨询。
STEP1 创建模型
在导航栏【模型中心】-【我的模型】页中可以点击【创建模型】按钮;也可以直接点击左侧导航菜单中的【创建模型】进入创建模型步骤。目前一个账号下支持创建10个模型,模型可删除。
在创建模型步骤中,需要进行“基础信息填写”“上传测试集”“选择基础模型”三个环节完成创建。
测试集的作用为通过上传音频和正确的标注文本评估基础模型的识别率,根据基础模型识别率选择最合适的基础模型进行训练。等模型训练后系统自动使用该测试集评估得到训练后模型的识别率,可以直观的查看训练提升效果。
1、 基础信息:包括场景类型、模型名称、公司/个人、所属行业、应用场景、应用设备、功能描述、邮箱地址、联系方式
A、 产品类型:包括短语音识别(支持16K采样率音频)、实时语音识别(支持16K采样率音频)和呼叫中心场景(支持8K采样率音频)3种,用户可以基于应用场景和音频采样率来进行选择。 
B、 模型名称:用户可自行填写模型名称,可支持中文、英文、数字、下划线.+#*()^-
C、 公司/个人:模型归属企业则需要填写企业名称,归属个人则不需填写
D、 所属行业:企业业务或个人应用所属的行业信息
E、 应用场景:语音识别模型应用落地的业务场景
F、 应用设备:业务中使用语音技术的录音设备终端
G、 功能描述:描述模型应用的场景,有助于上线审核哦
H、 邮箱地址:填写联系人的邮箱地址,用于模型上线等信息的通知
I、 联系方式:第一个模型需要用户填写联系方式,后面的模型系统自动复制第一个模型的联系方式(可修改) 其中,公司/个人、所属行业、应用场景、应用设备、功能描述、邮箱地址、联系方式在第一个模型中的填写信息会重复使用,后面创建的模型不用重复填写,但可修改信息
填写完毕后点击【下一步】,会在导航栏【我的模型】列表中生成一条记录保存信息,并跳转至“2、上传测试集”
2、上传测试集:包括填写测试集名称、上传音频文件、上传标注文件
A、 上传测试集:用户可自行填写测试集名称,可支持中文、英文、数字、下划线.+#*()^-
B、 上传语音文件:上传音频压缩zip文件(请将所有音频文件直接压缩,请勿将音频存放在文件夹内再压缩),格式要求:
16k 16bit单声道pcm/wav文件 8k 16bit 单声道pcm/wav文件(客服场景); 音频文件名请不要包含中文、特殊符号、空格等字符; 所有音频需直接打包压缩为zip文件格式后上传,zip大小不超过100M,解压后单个音频大小不超过150M
C、 上传标注文件:上传音频的标注文本txt文件,格式要求:
标注文件内容应与音频文件相对应的内容一致(单条音频对应文本长度不超过5000字); 标注文件格式应为txt格式,GBK编码; 标注txt文本中,由音频名称、标注内容两部分构成,用"tab"区隔,带后缀或不带后缀均可,以下为格式示例:
01.pcm(tab换列)今天天气真不错。
上传完语音文件及标注文件,点击【开始评估】,后台进入评估状态,此时弹窗提示评估完毕时间,并自动跳转回【我的模型】。一个账号只能同时评估一个模型。待模型评估完毕后通过【我的模型】可以点击进入“选择基础模型”
3、 选择基础模型:系统根据基础模型的识别率自动推荐适合训练的基础模型,基础模型识别率超过50%才可选择进行训练。
若基础模型识别率未达到50%,请检查语音文件和标注文件内容是否匹配,若不匹配,训练结果无意义。若检查标注文件无误后识别率仍旧过低,可以加入官方QQ群进行咨询:686267521
短语音识别产品类型中目前支持对短语音识别极速版进行训练;
实时语音识别产品类型中目前支持对实时语音识别的中文普通话模型进行训练
呼叫中心产品类型中目前支持对呼叫中心语音解决方案进行训练。
选择基础模型后点击【开始训练】即可在该模型上进行模型训练。
点击“查看评估详情”可以查看测试集在基础模型上的具体识别结果,评估详情包括:字准率,句准率,插入错误,删除错误,替换错误5个指标,以及在该测试集上的具体识别结果与标注结果的对比,根据识别错误信息可以更加精准地准备训练文本。
在“查看评估详情”页点击“返回上一步”或“创建模型”可返回选择基础模型
STEP2 训练模型
可以在【创建模型】-“选择基础模型“页点击【开始训练】按钮进入【训练模型】
也可以在【我的模型】列表页选择已创建完成的模型点击操作栏中的“开始训练”进入【训练模型】;
也可以直接在左侧导航栏中点击【训练模型】,进入【训练模型】
在训练模型步骤中,选择需要训练的模型,并上传训练文本。目前有两种训练方式可以选择,可以上传热词,或者是长段文本,也可以两种均上传进行训练。
热词文本格式要求:热词训练支持上传热词txt文件进行训练,每个词之间需要换行,txt格式要求gbk编码,大小不超过5M
句篇文本格式要求:句篇训练支持上传多行单句或一整段篇章(一段文字且需要符号)txt文件进行训练,txt格式要求gbk编码,大小不超过5M
建议您上传与您所需模型内容相关度较高的文本或关键词, 以便最大程度提高您的模型识别率
上传训练文本成功之后点击【开始训练】,后台进入模型训练状态,此时弹窗提示评估完毕时间,并自动跳转回【我的模型】。一个账号下同时只能训练一个模型。待模型训练完毕后生成新的模型版本,在【我的模型】列表页可以查看模型训练结果。
在【我的模型】列表,
可以查看基础模型的识别率,和当前版本的识别率,了解训练提升效果
1、训练结果详情:可以查看训练后模型在测试集上的识别详情,包括:字准率,句准率,插入错误,删除错误,替换错误5个指标,以及在测试集上的具体识别详情。
可以进行操作
2、历史版本:可以查看历史训练的所有记录并进行操作
3、申请上线:对当前模型训练结果较为满意,可以点击申请上线,跳转至上线模型步骤
4、迭代训练:当前模型训练结果不满意,可以在当前版本基础上或者基础模型上继续添加新的训练语料,进行迭代训练获得新的模型版本
5、下载:可以下载评估模型上传的测试集和训练模型的训练集
6、删除:可以删除整个模型(包括所有历史版本),删除后不能恢复
STEP3 上线模型
可以在【我的模型】选择要上线的模型,在操作栏点击“申请上线”
或者在左侧导航栏中点击【上线模型】,选择要上线的模型和版本进行上线(只有模型训练成功生成版本号才可上线)
一个账号下最多只能上线3个模型。申请上线后需要后台管理员进行审核,1-3天内会有审核结果,可在【我的模型】中查看审核状态。若对审核过程有任何问题可以加入官方QQ群(群号: 686267521)咨询群管。
- 审核中:可以查看历史版本训练情况;可以取消申请,取消后方可继续训练
- 审核失败:问号可查看审核失败原因;可以查看历史版本训练情况;可以迭代训练或重新训练;可以重新申请上线
- 审核通过:审核通过则后台自动上线,上线时间需要1-3天,上线过程中模型不可以做任何操作
-
上线完成:上线完成的模型可以正式调用
STEP4 模型使用
上线通过的模型,在【我的模型】可以点击“模型调用”,查看如何使用模型
也可以在左侧导航栏中点击【模型调用】
选择您需要上线的模型(训练完成的模型才可申请上线)
——如果您选择的产品类型为短语音识别,则按如下操作
第一步:创建语音技术应用(若已创建可直接使用),获取鉴权参数AppID,API Key,Secret Key。立即创建
第二步:获取专属模型参数 模型ID: xxxx 基础模型pid: xxxx
第三步:配置鉴权参数和专属模型参数即可使用
短语音识别极速版支持API方式调用 具体使用方法详见技术文档
——如果您选择的产品类型为实时语音识别,则按如下操作
第一步:创建语音技术应用(若已创建可直接使用),获取鉴权参数AppID,API Key,Secret Key。立即创建
第二步:获取专属模型参数 模型ID: xxxx 基础模型pid: xxxx
第三步:根据业务情况,选择合适的调用方式,配置鉴权参数和专属模型参数即可使用
实时语音识别支持Websocket API,Android、iOS、Linux SDK方式调用。
呼叫中心模型支持MRCP server调用方式,具体使用方法详见技术文档