

端到端语音语言大模型Android SDK
1. 文档简介
1.1 文档说明
| 文档名称 | 端到端语音语言大模型集成文档 |
|---|---|
| 所属平台 | Android |
| 提交日期 | 2025-05-15 |
| 概述 | 本文档是百度语音开放平台Android SDK的用户指南,描述了端到端语音语言大模型相关接口的使用说明。 |
获取安装包 |
端到端语音语言大模型Android SDK |
本接口处于公测阶段,免费调用额度在进入控制台时自动获取。
2 开发准备工作
2.1 环境准备
- 系统支持:Android 6.0+
- 架构支持:armeabi-v7a,arm64-v8a
- 硬件要求:要求设备上有麦克风
- 网络:支持移动网络(不包括2G、3G)、WIFI等网络环境
- 开发环境:建议使用最新版本Android Studio 进行开发
- 环境要求:gradle 3.0+ , Java jdk 1.8+
2.2 SDK目录结构
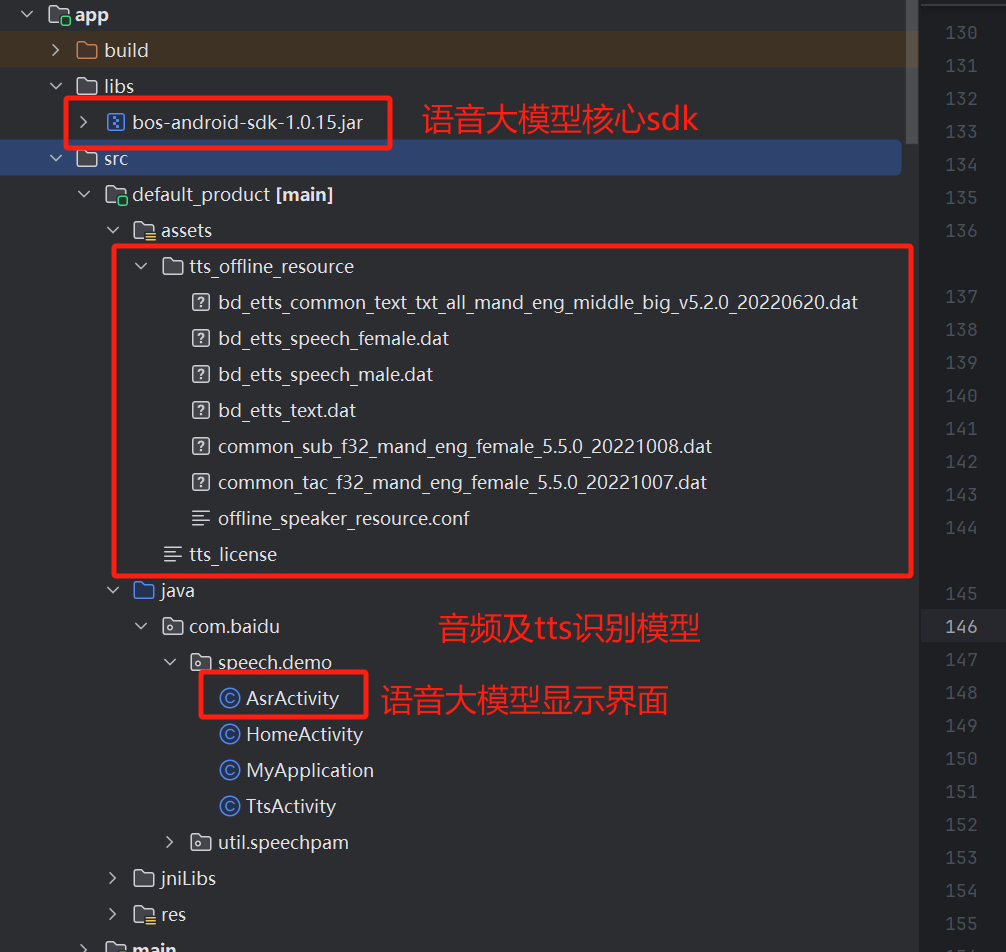
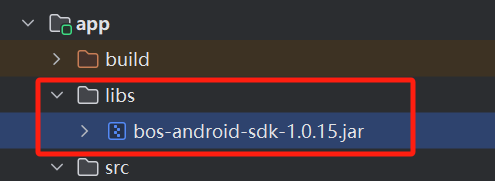
2.3 SDK安装
- 将libs/bos-android-sdk-xxx.jar复制到您的项目的同名目录中
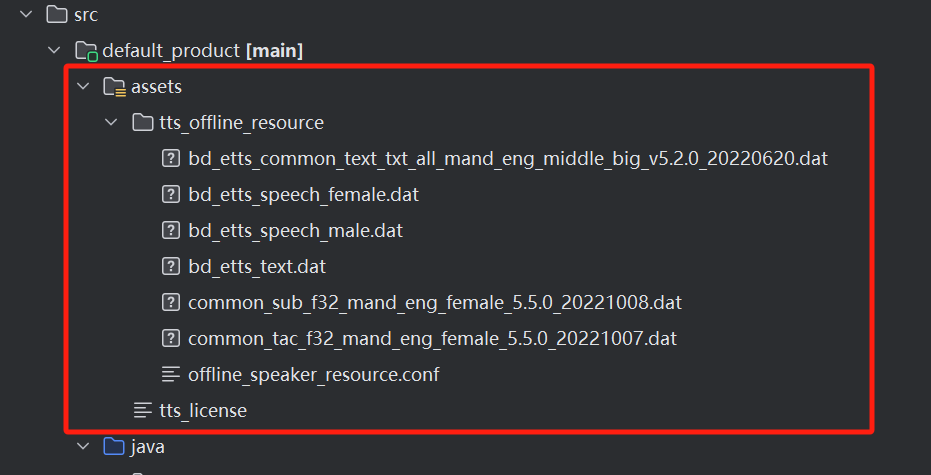
- 添加模型文件
- 在build.gradle中添加依赖
implementation fileTree(dir: 'libs', include: ['*.jar', '*.aar'])
implementation 'com.baidu.speech.asr_tts:bdspeech:1.0.0.3a98445'2.4 鉴权方式
2.4.1 access_token鉴权机制
* 获取AK/SK
请参考 通用参考 - 鉴权认证机制 | 百度AI开放平台中的access_token鉴权机制获取AK/SK, 并得到AppID、API Key、Secret Key三个信息
- 在START开始语音识别时,传入认证信息。详细参数参考"开始识别"
// ... 其他参数已忽略
map.put(SpeechConstant.APP_ID, APP_ID); // 添加appId
map.put(SpeechConstant.APP_API_KEY, APP_KEY); // 添加apiKey
SpeechEventManager.startAsr(this, new JSONObject(map), this);2.4.2 API Key鉴权机制
注意: 邀测阶段暂时仅支持access_token鉴权机制
3. SDK集成
3.1 功能接口
SDK中主要的类和接口如下:
- SpeechEventManager:语音事件管理类,用于管理语音识别、语音合成等事件。
- SpeechSynthesizer: 语音合成类,用于管理语音合成和播放
- JsonUtil:json工具类,帮助组装json请求参数
- SpeechConstant: 包含语音识别、语音合成等参数的key常量
- TtsAudioInfoEntity:用于播放音频的类
- IEventListener: 事件监听器接口,用于处理语音识别过程中产生的各种事件。
- SpeechSynthesizerListener: 语音合成监听器接口,用于处理语音合成过程中产生的各种事件
- SynthesizerResponse:语音合成的响应结构,SpeechSynthesizerListener回调函数中接收到的输入参数
3.1.1 SpeechEventManager:语音识别操作类
-
方法列表
-
initSDK: 初始化SDK
- 功能说明:在应用启动后执行一次,不可重复调用。
-
输入参数
- context: Context, 上下文信息
-
sdkConfig: SpeechEventManager.SDKConfig, SDK配置信息, 包括3部分:
- asr参数:通过setAsrParamMap设置, 可用参数见下表:
-
| 参数名 | 类型 | 是否必须 | 说明 |
|---|---|---|---|
| SpeechConstant.PID | String | 是 | 识别环境ID,1843 |
| SpeechConstant.DEVICE_ID | String | 是 | 设备唯一id,通过getSpeechDeviceId获取 |
- 其他透传参数:通过setExternalMap设置, 可用参数见下表:
| 参数名 | 类型 | 是否必须 | 说明 |
|---|---|---|---|
| SpeechConstant.LOCATION | string | 是 | 位置信息 |
| SpeechConstant.APP_VERSION | string | 是 | 版本号 |
| SpeechConstant.DEVICE_ID | string | 是 | 设备唯一id,通过getSpeechDeviceId获取 |
startAsr: 启动识别
- 功能说明:开启一次识别,注意不要多次调用,下次调用需要在CALLBACK_EVENT_ASR_EXIT回调 或 调用停止接口后调用
输入参数
context:
Context, 上下文信息 * jsonObject:JSONObject, 通过json传递的参数, 具体参数请参考下表
| 参数名 | 类型 | 是否必须 | 说明 |
|---|---|---|---|
| PID | string | 是 | 识别环境 id,1843 |
| URL | string | 是 | 识别环境 url, 默认值https://vop.baidu.com/v2 |
| APP_ID | string | 是 | 开放平台创建应用后分配的鉴权信息,上线后请使用此参数填写鉴权信息。参考 "2.4 鉴权方式" |
| APP_API_KEY | string | 是 | 开放平台创建应用后分配的鉴权信息,上线后请使用此参数填写鉴权信息。参考 "2.4 鉴权方式" |
| ASR_AUDIO_COMPRESSION_TYPE | string | 是 | 必传,音频压缩类型, 默认值:OPUS.(暂不支持其他类型) |
| ASR_MUTIPLY_MODE | string | 否 | json字符串,格式为:scene_id:识别类型(1: 点按识别; 2: 唤醒后识别;4:长按识别,参考"4.2 开发场景" 配置 默认为1) |
| ASR_ENABLE_MUTIPLY_SPEECH | string | 否 | 是否启动全双工 0:单⼯,1:全双⼯ , 默认为0 |
| ASR_VAD_RES_PATH | string | 否 | vad 资源路径,"初始化环境"时拷贝的资源路径 |
| NET_TYPE | string | 否 | 网络类型;1:有turbonet的http(场内网络库);3:无turbonet的http. 默认值:1 |
| LOG_LEVEL | string | 否 | 设置日志等级,可选值:LogUtil.VERBOSE , LogUtil.DEBUG,LogUtil.INFO,LogUtil.WARN,LogUtil.ERROR,LogUtil.OFF |
- listener: IEventListener, 事件监听器, 需要实现
IEventListener接口, 详情请参考IEventListener
stopASR: 停止语音识别
- 功能说明:停止当前语音识别,并保留当前的识别结果,已经发送的音频会被正常处理。
- 输入参数:无
- 返回值: 无
exitASR: 退出语音识别
- 功能说明:退出语音识别,并停止后续处理,已经发送未处理的音频不会继续处理。
- 输入参数:无
- 返回值: 无
pauseAsr: 暂停语音识别
- 功能说明:暂停语音识别 双工长语音功能可以用到,目前只会停止语音识别功能,需记录语音识别最后一条sn,该sn后面的语音都会进行暂停
- 输入参数:无
- 返回值: 无
resumeAsr: 恢复语音识别
- 功能说明:恢复语音识别
- 输入参数:无
- 返回值: 无
getSpeechDeviceId: 获取设备ID
- 输入参数:无
- 返回值:String, 设备唯一ID
3.1.2 IEventListener:语音识别事件监听
用户需要实现此接口,并在启动识别时传入,以监听语音识别过程中产生的事件。
-
方法列表
-
onEvent: 接收识别过程中产生的回调事件
-
输入参数
- name:
string, 事件名称, 具体事件请参考下表 - params:
string, 事件参数。根据事件名称的不同,参数内容不同。详细请参考下表 - data:
byte[], 事件中携带的二进制数据,例如语音合成产生的音频数据。 - offset:
int, 暂未使用 - length:
int, data中数据的长度
- name:
-
返回值
- 无
-
-
| 事件名称 | 事件参数(params) | 说明 |
|---|---|---|
| CALLBACK_EVENT_ASR_READY | 无 | 准备就绪,可以说话,一般在收到此事件后通过UI通知用户可以说话了 |
| CALLBACK_EVENT_ASR_BEGIN | 无 | 检测到开始说话。 |
| CALLBACK_EVENT_ASR_PARTIAL | 返回json字符串,格式为:result_type: 结果类型,可选值: partial_result: asr识别中间结果;final_result: asr识别最终结果;third_result:第三方数据,例如联网搜索结果,暂不支持。best_result: 识别结果。sn: 本次会话的sn | 语音识别中间结果返回 |
| CALLBACK_EVENT_ASR_EXIT | 退出识别 | |
| CALLBACK_EVENT_ASR_END | 说话结束等待识别结果 | |
| CALLBACK_EVENT_ASR_FINISH | 识别完成(这里指的是用户的语音识别完成) | |
| CALLBACK_EVENT_ASR_CANCEL | 用户取消识别 | |
| CALLBACK_EVENT_ASR_PAUSE | 识别暂停 | |
| CALLBACK_EVENT_ASR_RESUME | 识别恢复 | |
| CALLBACK_ASR_TTS_RESULT | 返回json字符串,格式为:result_type: 结果类型,可选值:tts_result:tts合成结果origin_result:合成结果,内容是一个json,包含以下字段: aue: 音频格式。idx:当前片段在整个音频中的索引percent: 当前合成进度百分比samplerate:采样率tex: 音频对应的文本sn: 本次会话的sn | |
| TTS 数据返回 | ||
| CALLBACK_EVENT_TTS_FIRST_PLAYED | tts开始播放 (使用SpeechSynthesizer不会调用这个事件) | |
| CALLBACK_EVENT_TTS_END_PLAYED | tts播放完成(使用SpeechSynthesizer不会调用这个事件) | |
| CALLBACK_EVENT_ASR_VOLUME | 音量回调 |
3.1.3 SpeechSynthesizer:语音合成操作类
方法列表 setSpeechSynthesizerListener:设置回调函数
- 功能说明:设置语音合成回调函数
- 输入参数:listener:
SpeechSynthesizerListener, 语音合成监听器, 需要实现SpeechSynthesizerListener接口, 详情请参考SpeechSynthesizerListener - 返回值: 无 loadAudioPlayer: 加载音频播放器
- 功能说明:加载音频播放器
- 输入参数:无
- 返回值: 无
3.1.4 SpeechSynthesizerListener:语音合成事件监听
用户需要实现此接口,以监听音频播放器的播放事件 方法列表 onSynthesizeResponse
- 功能说明:语音合成的回调函数
- 输入参数:synthesizerResponse:
SynthesizerResponse, 语音合成响应. - 返回值: 无
3.1.5 SynthesizerResponse
SpeechSynthesizerListener.onSynthesizeResponse的输入参数类型 方法列表 getSynthesizeType:当前时间类型
-
返回值:
SynthesizeType, 枚举值,可选值包括:- PLAY_START:开始播放
- PLAY_FINISH:播放结束
- PLAY_PROGRESS: 播放进度上报
getSynthesizerData:获取语音合成数据
-
返回值:
SynthesizerData, 语音合成数据, 有以下方法可用:- getAudioProgress:获取播放进度, 返回值类型:
int - getEngineType:获取引擎类型, 返回值类型:
int - getAudioSampleRate:获取音频采样率, 返回值类型:
int - getAudioData:获取音频数据, 返回值类型:
byte[]
- getAudioProgress:获取播放进度, 返回值类型:
3.2 集成步骤
3.2.1 初始化环境
包括几个步骤:
- 将VAD模型文件和AEC_ALGO模型文件拷贝到设备的目录下
private void initialEnv() {
if (mSampleDirPath == null) {
String sdcardPath = this.getFilesDir().getPath();
mSampleDirPath = sdcardPath + "/" + SAMPLE_DIR_NAME;
}
makeDir(mSampleDirPath);
pathVadRes = mSampleDirPath + File.separator + VAD_MODEL;
copyFromAssets(this, true, VAD_MODEL, pathVadRes);
pathAecRes = mSampleDirPath + File.separator + SpeechConstant.AEC_ALGO_MODEL;
copyFromAssets(this, true, SpeechConstant.AEC_ALGO_MODEL, pathAecRes);
ConfigUtil.setAecModelFile(pathAecRes);
}-
申请需要的权限
- 需要的权限列表:
| 权限 | 说明 | 是否必须 |
|---|---|---|
| android.permission.INTERNET | 允许访问网络 | 是 |
| android.permission.RECORD_AUDIO | 允许程序录制声音通过手机或耳机的麦克 | 是 |
| android.permission.WRITE_EXTERNAL_STORAGE | 外置卡读写权限 | 是 |
| android.permission.READ_PHONE_STATE | 允许获取设备信息权限 | 否 |
- 示例代码
/**
* 请求权限
*
* @return 需要请求的权限数
*/
protected int requestPermissions() {
String[] permissionArray = checkPermissions();
if (permissionArray != null && permissionArray.length > 0) {
ActivityCompat.requestPermissions(this, permissionArray, CODE_REQUEST_PERMISSION);
return permissionArray.length;
}
return 0;
}
protected String[] checkPermissions() {
String[] noGrantedArr = {};
List<String> noGrantedList = new ArrayList<>();
for (String item : sPermissions) {
int hasWriteStoragePermission = ContextCompat.checkSelfPermission(getApplication(), item);
if (hasWriteStoragePermission != PackageManager.PERMISSION_GRANTED) { // 未拥有权限
noGrantedList.add(item);
}
}
return noGrantedList.toArray(noGrantedArr);3.2.2 实现事件回调函数
- 语音识别回调:即实现IEventListener接口, 示例代码如下:详细参数说明参考IEventListener
@Override
public void onEvent(String name, String params, byte[] data, int offset, int length) {
String msg = "name: " + name + ", params: " + params;
switch (name) {
case SpeechConstant.CALLBACK_EVENT_ASR_READY: //准备就绪,可以说话,⼀般在收到此事件后通过UI通知⽤户可以说话了
case SpeechConstant.CALLBACK_EVENT_ASR_BEGIN: //检测到开始说话
appendToView(mTvLog, msg);
break;
case SpeechConstant.CALLBACK_EVENT_ASR_PARTIAL: //中间结果返回
logD(TAG, "SpeechConstant.CALLBACK_EVENT_ASR_PARTIAL" +params);
JSONObject partialJson = JsonUtil.toJSON(params);
String resultType = partialJson.optString("result_type");
String bestResult = "";
String showAsr = "中间识别结果";
if ("partial_result".equals(resultType)) {
bestResult = partialJson.optString("best_result");
} else if ("final_result".equals(resultType)) {
bestResult = partialJson.optString("best_result");
logD(TAG, "------" + params + ", " + mLastFinalSn);
JSONObject json = JsonUtil.toJSON(params);
mLastFinalSn = json.optString("sn");
showAsr = "最终识别结果";
} else if ("third_result".equals(resultType)) {
Log.d(TAG, "third_result: " + resultType);
}
if (!TextUtils.isEmpty(bestResult)) {
String resultInfo = showAsr + ": " + bestResult;
printToView(mTvResult, resultInfo);
}
break;
case SpeechConstant.CALLBACK_EVENT_ASR_EXIT: //退出
appendToView(mTvLog, msg);
handleAsrExit();
break;
case SpeechConstant.CALLBACK_EVENT_ASR_END: //说话结束等待识别结果
case SpeechConstant.CALLBACK_EVENT_ASR_FINISH: //识别完成
case SpeechConstant.CALLBACK_EVENT_ASR_CANCEL: //识别已取消
case SpeechConstant.CALLBACK_EVENT_ASR_PAUSE:
case SpeechConstant.CALLBACK_EVENT_ASR_RESUME:
break;
case SpeechConstant.CALLBACK_ASR_TTS_RESULT: //TTS 数据返回
logD(TAG, "CALLBACK_ASR_TTS_RESULT" + params);
JSONObject ttsJson = JsonUtil.toJSON(params);
String origin_result =ttsJson.optString("origin_result");
JSONObject tts_origin_result =JsonUtil.toJSON(origin_result);
String text = tts_origin_result.optString("tex");
int idx = tts_origin_result.optInt("idx", 0);
break;
case SpeechConstant.CALLBACK_EVENT_TTS_FIRST_PLAYED: // tts 开始播放
appendToView(mTvLog, msg);
Log.d(TAG, "CALLBACK_EVENT_TTS_FIRST_PLAYED: " + msg);
break;
case SpeechConstant.CALLBACK_EVENT_TTS_END_PLAYED: // tts 播放完成
Log.d(TAG, "CALLBACK_EVENT_TTS_END_PLAYED: " + msg);
break;
case SpeechConstant.CALLBACK_EVENT_UPLOAD_FINISH: //上传完成
case SpeechConstant.CALLBACK_EVENT_ASR_AUDIO:
case SpeechConstant.CALLBACK_EVENT_ASR_VOLUME: //⾳量回调
break;
}
}- 语音合成回调:即实现SpeechSynthesizerListener接口, 示例代码如下:详细参数说明参考SpeechSynthesizerListener
@Override
public void onSynthesizeResponse(SynthesizerResponse synthesizerResponse) {
SynthesizerResponse.SynthesizeType synthesizeType = synthesizerResponse.getSynthesizeType();
String sn = synthesizerResponse.getSn();
String utteranceId = synthesizerResponse.getUtteranceId();
String instanceId = synthesizerResponse.getInstanceId();
switch (synthesizeType) {
case PLAY_START:
case PLAY_FINISH:
LoggerProxy.d(TAG, "onSynthesizeResult type = " + synthesizeType.name());
break;
case PLAY_PROGRESS:
SynthesizerResponse.SynthesizerData synthesizerData =
synthesizerResponse.getSynthesizerData();
int progress = synthesizerData.getAudioProgress();
int engineType = synthesizerData.getEngineType();
int sampleRate = synthesizerData.getAudioSampleRate();
byte[] audioData = synthesizerData.getAudioData();
LoggerProxy.d(TAG, "onSynthesizeResult type = " + synthesizeType.name()
+ " sn = " + sn
+ " , instanceId = " + instanceId
+ " , progress = " + progress
+ " , engineType = " + engineType + " , sampleRate = " + sampleRate);
break;
}
}3.2.3 初始化SDK
- 仅保留日志等级设置,其他在Builder中设置默认值
- PID和IOS一样在startAsr中设置
- 示例代码
SpeechEventManager.SDKConfig.Builder builder = new
SpeechEventManager.SDKConfig.Builder();
HashMap<String, String> asrParamMap = new HashMap<>();
asrParamMap.put(SpeechConstant.PID, "8533");
asrParamMap.put(SpeechConstant.DEVICE_ID, mCuid);
asrParamMap.put(SpeechConstant.LOG_LEVEL,
String.valueOf(LogUtil.VERBOSE));
HashMap<String, String> externalMap = new HashMap<>();
externalMap.put(SpeechConstant.LOCATION, "Beijing");
externalMap.put(SpeechConstant.APP_VERSION, "1.0.0");
externalMap.put(SpeechConstant.DEVICE_ID, mCuid);
SpeechEventManager.SDKConfig sdkConfig = builder
.setAsrParamMap(asrParamMap)
.setExternalMap(externalMap)
.build();
int ret = SpeechEventManager.initSDK(this, sdkConfig);
Log.d(TAG, "initSDK: ret = " + ret);3.2.4 启动识别
- 示例代码
HashMap<String, Object> asrParams = new HashMap<>();
// 环境信息设置:
// 识别环境 - pid. 邀测环境PID统一为4144779,仅供体验使用。生产环境使用请联系技术支持获取专属PID
asrParams.put(SpeechConstant.PID, 1860);
// 识别环境 - url
asrParams.put(SpeechConstant.URL, "https://vse.baidu.com/v2");
// 必选参数设置
// 设置VAD/TriggerMode/双工,请参考**开发场景**根据您的业务需求设置。下面示例为双工识别场景。
// 开启VAD
asrParams.put(SpeechConstant.VAD, SpeechConstant.VAD_DOAVAD);
// 是否启动双工
asrParams.put(SpeechConstant.ASR_ENABLE_MUTIPLY_SPEECH, 1);
asrParams.put(SpeechConstant.TRIGGER_MODE, triggerMode); // trigger 1: 点按识别; 2: 唤醒后识别,4:长按识别
// 必选:设置音频压缩类型,
asrParams.put(SpeechConstant.ASR_AUDIO_COMPRESSION_TYPE, SpeechConstant.OPUS);
// 是否返回识别中间结果
asrParams.put(SpeechConstant.ENABLE_EARLY_RETURN, true);
asrParams.put(SpeechConstant.ASR_VAD_RES_PATH, pathVadRes); // vad资源路径,上⽂拷⻉资源的路径
asrParams.put(SpeechConstant.NET_TYPE, 1); // ⽹络类型;1:有turbonet的http;3:⽆turbonet的http
asrParams.put(SpeechConstant.LOG_LEVEL, LogUtil.VERBOSE); // 设置⽇志等级,Debug 使⽤
asrParams.put(SpeechConstant.PAM,
// 第一个参数为DEVICE_ID, 第二个参数为BDVS_ID.
JsonUtil.genAsrPam("75CEB7CF757E522BAEA2E94BCBC676E5|VUGJPCGTI",
"68b509484f249601628e7c1b547a003c", null)); // bdvs 协议参数
SpeechEventManager.startAsr(this, new JSONObject(asrParams), this);3.2.5 停止识别
停止识别,但保留当前识别结果。已经发送的音频会正常识别并生成响应音频
- 示例代码
SpeechEventManager.stopASR();3.2.6 取消识别
取消识别,并停止后续处理。已经发送但是还没有识别和响应的数据将会丢弃。
- 示例代码
SpeechEventManager.exitASR();3.2.7 暂停识别
Map<String, Object> params = new HashMap<>();
LogUtil.d(TAG, "pauseAsr lastSn: " + lastSn); // 该 sn 之后的识别都会被取消
params.put(SpeechConstant.KEY_LAST_FINAL_RESULT_SN, lastSn);
SpeechEventManager.pauseASR(new JSONObject(params));3.2.8 恢复识别
- 示例代码
SpeechEventManager.resumeASR();3.3 开发场景
SDK支持三种开发场景:
- 双工识别:启动后可以多次进行语音对话,直到用户主动停止识别
- 点按短语音识别:启动后进行60s内语音识别,识别到的第一个短句进行语音对话。
- 长按识别:启动后按住按钮不松开会持续识别,且不会进行断句
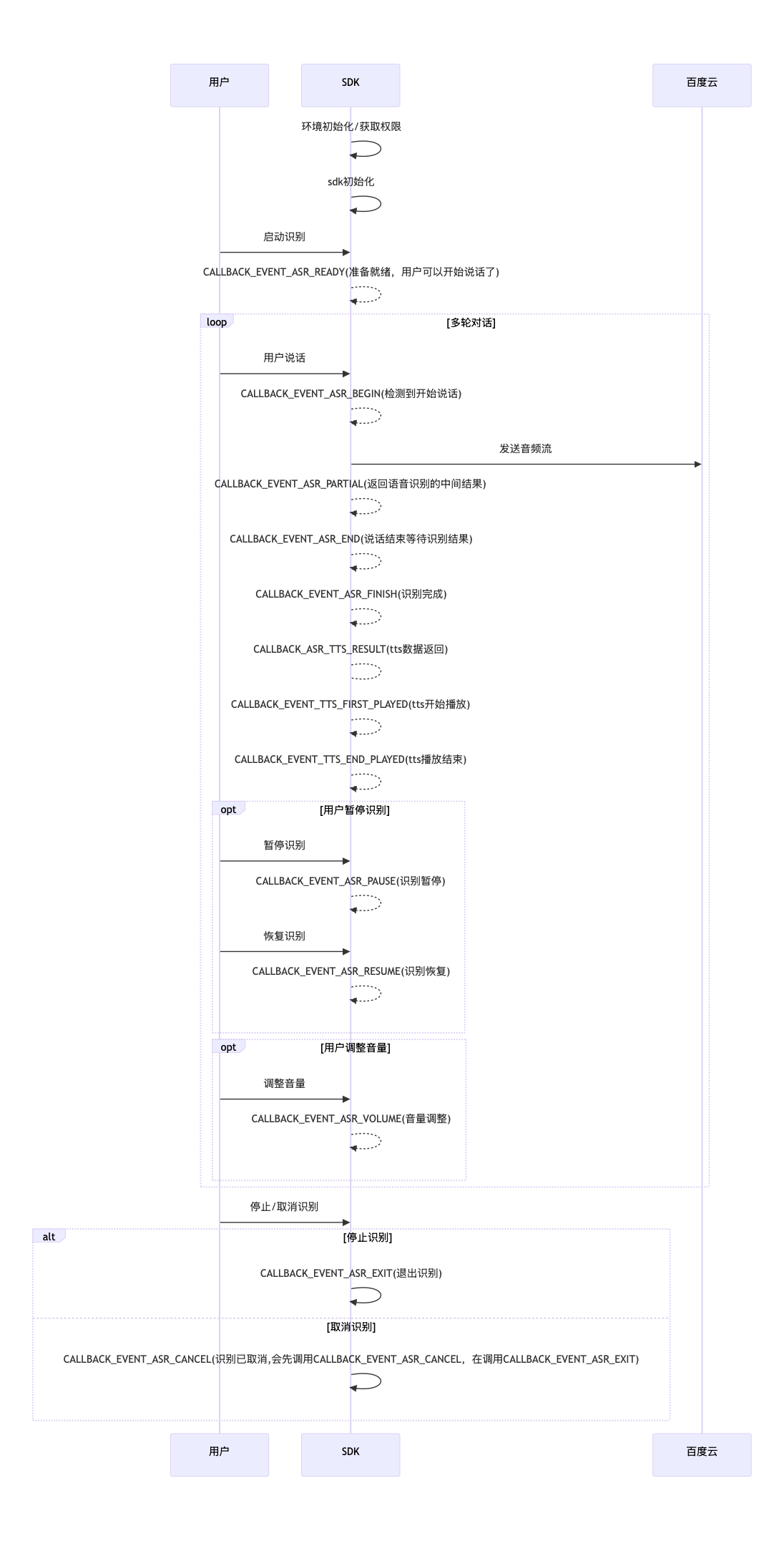
3.3.1 双工识别
- 设置方法
// .... 其他参数已省略
map.put(SpeechConstant.VAD, SpeechConstant.VAD_DOAVAD);
// 双工识别
map.put(SpeechConstant.ASR_ENABLE_MUTIPLY_SPEECH, 1);
// TRIGGER_MODE:2, 唤醒后识别
map.put(SpeechConstant.TRIGGER_MODE, 2);
JSONObject jsonObject;
jsonObject = new JSONObject(map);
SpeechEventManager.startAsr(this.getApplicationContext(), jsonObject, this);- 交互流程
3.3.2 点按短语音识别
- 设置方法
// .... 其他参数已省略
map.put(SpeechConstant.VAD, SpeechConstant.VAD_DOAVAD);
// TRIGGER_MODE:1 短按识别
map.put(SpeechConstant.TRIGGER_MODE, 1)
JSONObject jsonObject;
jsonObject = new JSONObject(map);
SpeechEventManager.startAsr(this.getApplicationContext(), jsonObject, this);- 交互流程

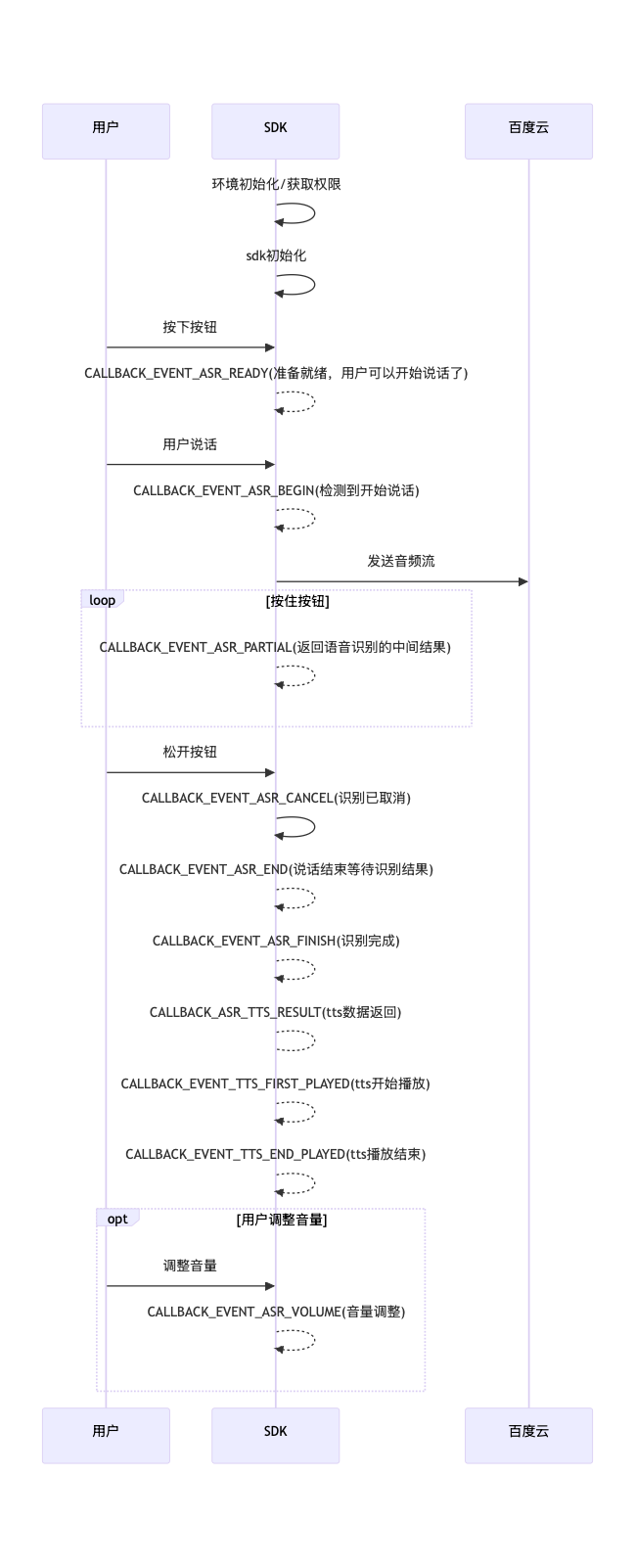
3.3.3 长按识别
- 设置方法
// .... 其他参数已省略
// 在按下时startAsr
asrParams.put(SpeechConstant.VAD, SpeechConstant.VAD_TOUCH);
// TRIGGER_MODE:4 长按识别模式
asrParams.put(SpeechConstant.TRIGGER_MODE, 4)
JSONObject jsonObject;
jsonObject = new JSONObject(asrParams);
SpeechEventManager.startAsr(this.getApplicationContext(), jsonObject, this);
// 在松开时stopAsr
SpeechEventManager.stopAsr();- 交互流程
3.4 错误码
| 错误领域 | 描述 | 错误码 | 错误描述及可能原因 |
|---|---|---|---|
| 1 | 网络超时 | 出现原因可能为网络已经连接但质量比较差,建议检测网络状态 | |
| 1000 | DNS连接超时 | ||
| 1001 | 网络连接超时(用于非chunk模式) | ||
| 1002 | 网络读取结果超时(用于非chunk模式) | ||
| 1003 | 上行网络连接超时(用于chunk模式) | ||
| 1004 | 上行网络读取结果超时(用于chunk模式) | ||
| 1005 | 下行网络连接超时(用于chunk模式) | ||
| 1006 | 下行网络读取结果超时(用于chunk模式) | ||
| 2 | 其他网络错误(网络连接失败 | 出现原因可能是网络权限被禁用,或网络确实未连接,需要开启网络或检测无法联网的原因 | |
| 2000 | 网络连接失败 | ||
| 2001 | 网络读取结果失败 | ||
| 2002 | 上行网络连接失败 | ||
| 2003 | 上行网络读取失败 | ||
| 2004 | 下行网络连接失败 | ||
| 2005 | 下行网络读取失败 | ||
| 2006 | 下行数据异常 | ||
| 2100 | 本地网络不可用 | ||
| 2101 | 本地网络不可用 | ||
| 2102 | 上行网络读取结果失败(代理模式) | ||
| 2103 | 下行网络连接失败(代理模式) | ||
| 2104 | 下行网络读取识别(代理模式) | ||
| 2105 | 下行数据异常(代理模式) | ||
| 2106 | 上行网络连接错误(代理模式) | ||
| 2107 | 请求未创建 | ||
| 3 | 音频错误 | 出现原因可能为:未声明录音权限,或 被安全软件限制,或 录音设备被占用,需要开发者检测权限声明。 | |
| 3000 | 音频异常 | ||
| 3001 | 录音机打开失败 | ||
| 3002 | 录音机参数错误 | ||
| 3003 | 录音机不可用 | ||
| 3006 | 录音机读取失败 | ||
| 3007 | 录音机关闭失败 | ||
| 3008 | 文件打开失败 | ||
| 3009 | 文件读取失败 | ||
| 3010 | 文件关闭失败 | ||
| 3011 | 采样率错误 | ||
| 3013 | 文件读完 | ||
| 3100 | VAD异常,通常是VAD资源设置不正确 | ||
| 3101 | 长时间未检测到人说话,请重新识别 | ||
| 3102 | 检测到人说话,但语音过短 | ||
| 4 | 服务端错误 | 出现原因可能是appid和appkey的鉴权失败 | |
| 4001 | 服务端参数错误(-3001) | ||
| 4002 | 服务端协议错误(-3002) | ||
| 4003 | 服务端识别错误(-3003) | ||
| 4004 | 服务端鉴权错误(-3004) | ||
| 5 | 客户端错误 | 一般是开发阶段的调用错误,需要开发者检测调用逻辑或对照文档和demo进行修复。 | |
| 5001 | 客户端无法加载动态库 | ||
| 5002 | 客户端识别参数有误 | ||
| 5003 | 客户端获取token失败 | ||
| 5004 | 客户端解析URL失败 | ||
| 5005 | 客户端检测到非https URL | ||
| 6 | 超时 | 语音过长,请配合语音识别的使用场景,如避开嘈杂的环境等 | |
| 6001 | 语音过长 | ||
| 7 | 没有匹配的识别结果 | 信噪比差,请配合语音识别的使用场景,如避开嘈杂的环境等 | |
| 7001 | 没有匹配的识别结果 | ||
| 7002 | 识别结果为空 | ||
| 8 | 识别引擎繁忙 | 一般是开发阶段的调用错误,出现原因是上一个会话尚未结束,就让SDK开始下一次识别。SDK目前只支持单任务运行,即便创建多个实例,也只能有一个实例处于工作状态 | |
| 8001 | 识别引擎繁忙 | ||
| 9 | 缺少权限 | 参见demo中的权限设置 | |
| 9001 | 缺少权限 | ||
| 10 | 其他权限 | ||
| 10001 | 离线引擎异常 | ||
| 10002 | 没有授权文件 | ||
| 10003 | 授权文件不可用 | ||
| 10004 | 参数设置错误 | ||
| 10005 | 引擎没有被初始化 | ||
| 10006 | 模型文件不可用 | ||
| 10007 | 语法文件不可用 | ||
| 10008 | 引擎重置失败 | ||
| 10009 | 引擎初始化失败 | ||
| 10010 | 引擎释放失败 | ||
| 10011 | 引擎不支持 | ||
| 10012 | 识别失败 | ||
| 10013 | 引擎loading超时 | ||
| 100013 | 异常统计 | ||
| 11001 | 唤醒引擎异常 | ||
| 11002 | 无授权文件 | ||
| 11003 | 授权文件异常 | ||
| 11004 | 唤醒异常 | ||
| 11005 | 模型文件异常 | ||
| 11006 | 引擎初始化失败 | ||
| 11007 | 内存分配失败 | ||
| 11008 | 引擎重置失败 | ||
| 11009 | 引擎释放失败 | ||
| 11010 | 引擎不支持该架构 | ||
| 11011 | 无识别数据 |