

term重要性任务
简介
- term重要性任务是指:给出一个明文文本中每个短语的重要程度。
- 样例:

- 在上述例子中,文本被分为4个短语(后文用term代替),其中白居易这个term重要程度最高,边塞诗人次之,数字相同的term表示重要程度一致。
环境安装
目录结构
term重要性任务位于/wenxin/tasks/term_rank
├── __init__.py
├── run_with_json.py ## 依靠json配置文件进行模型训练的入口脚本
├── run_infer.py ## 依靠json配置文件进行模型预测的入口脚本
├── examples ## 各典型网络的json配置文件
│ ├── termrank_ernie_2.0_base_fc_ch.json ## 对ERNIE-2.0-base进行fine tune训练的配置文件
│ ├── termrank_ernie_2.0_base_fc_ch_infer.json ## 对fine tune之后的模型进行预测的配置文件
├── data ## 示例数据文件夹,包括各任务所需训练集、测试集、验证集和预测集
├── train_data
│ └── train.tsv
├── test_data
│ └── test.tsv
├── dev_data
│ └── dev.tsv
├── predict_data
└── infer.tsv准备工作
-
下载ERNIE-2.0-Base预训练模型
# 在wenxin/tasks/model_files/目录下下载管理ERNIE-2.0-Base预训练模型,下载成功会看到名为ernie_2.0_base_ch_dir的目录,里面存放了ERNIE-2.0-Base预训练模型对应的参数文件。 # 进入到 model_files目录 cd wenxin/tasks/model_files/ # 执行下载脚本 sh download_ernie_2.0_base_ch.sh -
准备数据:由于使用ERNIE系列模型进行fine tune,所以不需要用户自己切词和提供词表文件。
-
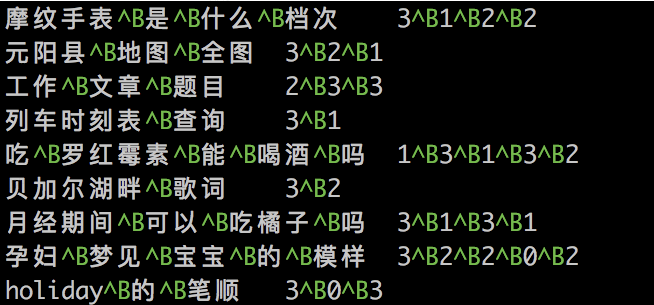
训练集、测试集和验证集的数据格式相同,每个样本占一行,一行两列(两个key),列之间用\t分隔。第一列为切分好term之后的明文文本,term之间以字符^B(0x02)分隔;第二列为第一列中每个term的重要等级,由int类型数字表示,数字越大表示重要程度越高,数字间同样以字符^B(0x02)分隔。如下所示:
- 预测集数据:每个样本占一行,一行一列(只有一个text)

-
开始训练
-
参数配置:demo配置文件为./examples/termrank_ernie_2.0_base_fc_ch.json,用户需要自己配置的参数为:trainer_reader、test_reader、dev_reader这三个reader对应的数据集路径、batch-size、trainer_reader的epoch;trainer中的PADDLE_USE_GPU、PADDLE_IS_LOCAL、output_path、几个step设置等,如下图中的json注释所示:
{ "dataset_reader": { "train_reader": { "name": "train_reader", "type": "BasicDataSetReader", "fields": [ { "name": "text_a", "data_type": "string", "reader": { "type": "ErnieTermRankTextFieldReader" }, "tokenizer": { "type": "FullTokenizer", "split_char": " ", "unk_token": "[UNK]" }, "need_convert": true, "vocab_path": "../model_files/dict/vocab_ernie_2.0_base_ch.txt", "max_seq_len": 512, "truncation_type": 0, "padding_id": 0, "embedding": null }, { "name": "label", "data_type": "float", "reader": { "type": "ErnieTermRankLabelFieldReader" }, "tokenizer": null, "need_convert": false, "vocab_path": "", "max_seq_len": 512, "truncation_type": 0, "padding_id": 0, "embedding": null } ], "config": { "data_path": "./data/train_data", ## 填写自己的训练集路径即可,写到文件夹目录。 "shuffle": true, ## 训练过程中是否要打乱数据顺序 "batch_size": 8, ## 可以根据自己的硬件显存或者内存大小进行调整 "epoch": 10, ## 根据需要自己调整 "sampling_rate": 1.0 } }, "test_reader": { "name": "test_reader", "type": "BasicDataSetReader", .... "config": { "data_path": "./data/test_data", ## 填写自己的测试集路径即可,写到文件夹目录。 "shuffle": false, ## 不需要打乱数据顺序 "batch_size": 8, ## 可以根据自己的硬件显存或者内存大小进行调整 "epoch": 1, "sampling_rate": 1.0 } }, "dev_reader": { "name": "dev_reader", "type": "BasicDataSetReader", .... "config": { "data_path": "./data/dev_data", ## 填写自己的测试集路径即可,写到文件夹目录。 "shuffle": false, ## 不需要打乱数据顺序 "batch_size": 8, ## 可以根据自己的硬件显存或者内存大小进行调整 "epoch": 1, "sampling_rate": 1.0 } } }, "model": { "type": "ErnieTermRank", "optimization": { "learning_rate": 2e-05, "lr_scheduler": "linear_warmup_decay", "warmup_steps": 0, "warmup_proportion": 0.1, "weight_decay": 0.01, "use_dynamic_loss_scaling": false, "init_loss_scaling": 128, "incr_every_n_steps": 100, "decr_every_n_nan_or_inf": 2, "incr_ratio": 2.0, "decr_ratio": 0.8 }, "embedding": { "type": "ErnieTokenEmbedding", "emb_dim": 768, "use_fp16": false, "config_path": "../model_files/config/ernie_2.0_base_ch_config.json", "other": "" }, "margin": 0.15, "temperature": 0.5 }, "trainer": { "PADDLE_USE_GPU": 1, ## 是否使用GPU,1表示使用GPU "PADDLE_IS_LOCAL": 1, ## 是否进行单机训练,1表示单机训练,0表示分布式训练 "train_log_step": 10, ## 训练时打印训练日志的间隔步数。 "is_eval_dev": 1, ## 是否在训练的时候评估验证集,1为需评估,此时必须配置dev_reader。 "is_eval_test": 1, ## 是否在训练的时候评估测试集,1为需评估,此时必须配置test_reader。 "eval_step": 100, ## 进行测试集或验证集评估的间隔步数。 "save_model_step": 500, ## 保存模型时的间隔步数,建议设置为eval_step的整数倍。 "load_parameters": "", ## 加载已训练好的模型的op参数值,不会加载训练步数、学习率等训练参数,可用于加载预训练模型。如需使用填写具体文件夹路径即可。 "load_checkpoint": "", ## 加载已训练好的模型的所有参数,包括学习率等,可用于热启动。如需使用填写具体文件夹路径即可。 "use_fp16": 0, "pre_train_model": [ { "name": "ernie_2.0_base_ch", ## ernie-2.0-base 预训练模型加载时使用的名称,不要修改 "params_path": "../model_files/ernie_2.0_base_ch_dir/params" ## ernie-2.0-base预训练模型的参数目录 } ], "output_path": "./output/term_rank_ernie_2.0_base_fc_ch", ## 保存模型的输出路径,若为空则默认。为"./output" "extra_param": { "meta":{ "job_type": "term_rank" } } } } -
启动训练
如您使用镜像开发套件,您可直接进入下一步骤。如您将文心开发套件与本地已有的开发环境相结合,您需要在./env.sh中配置对应的环境变量,并执行source env.sh ,如需了解更多详情,请参考环境配置。
python run_with_json.py --param_path=./examples/termrank_ernie_2.0_base_fc_ch.json训练运行的日志会自动保存在./log/test.log文件中;
训练中以及结束后产生的模型文件会默认保存在./output/目录下,其中save_inference_model/文件夹会保存用于预测的模型文件,save_checkpoint/文件夹会保存用于热启动的模型文件。
开始预测
-
参数配置:demo配置文件为./examples/termrank_ernie_2.0_base_fc_ch_infer.json,用户需要自己配置的参数为:predict_reader对应的数据集路径、batch-size;inference中的PADDLE_USE_GPU、output_path、inference_model_path,如下图中的json注释所示:
{ "dataset_reader": { "predict_reader": { "name": "predict_reader", "type": "BasicDataSetReader", "fields": [ { "name": "text_a", "data_type": "string", "reader": { "type": "ErnieTermRankTextFieldReader" }, "tokenizer": { "type": "FullTokenizer", "split_char": " ", "unk_token": "[UNK]" }, "need_convert": true, "vocab_path": "../model_files/dict/vocab_ernie_2.0_base_ch.txt", "max_seq_len": 512, "truncation_type": 0, "padding_id": 0, "embedding": null } ], "config": { "data_path": "./data/predict_data", ## 填写你自己的预测数据集路径即可,写到文件夹目录 "shuffle": false, "batch_size": 8, ## 可以根据自己的硬件显存或者内存大小进行调整 "epoch": 1, "sampling_rate": 1.0 } } }, "inference": { "output_path": "./output/predict_result.txt", ## 预测结果存放路径 "PADDLE_USE_GPU": 1, ## 是否使用GPU,1表示使用GPU "PADDLE_IS_LOCAL": 1, ## 不要修改,目前文心不支持多机预测 "inference_model_path": "./output/term_rank_ernie_2.0_base_fc_ch/save_inference_model/inference_step_251_enc", ## 待预测的模型路径。 "extra_param": { "meta":{ "job_type": "term_rank" } } } } -
启动预测
如您使用镜像开发套件,您可直接进入下一步骤。如您将文心开发套件与本地已有的开发环境相结合,您需要在./env.sh中配置对应的环境变量,并执行source env.sh ,如需了解更多详情,请参考环境安装。
python run_infer.py --param_path=./examples/termrank_ernie_2.0_base_fc_ch_infer.json预测运行的日志会自动保存在./output/predict_result.txt文件中。预测结果如下所示,对每个term计算出一个得分,得分越高表示越重要,所有term的得分之和为1。
