

数据蒸馏
任务简介
- 基于ERNIE预训练模型效果已达到业界领先,但在ERNIE强大的语义理解能力背后,需要同样强大的算力才能支撑起如此大规模的训练和预测。
- 部分工业应用场景对性能要求较高,针对上述场景,若不能对ERNIE模型进行有效的压缩则会导致无法实际应用的情况。
- 为此,文心提供数据蒸馏技术,其原理为通过数据作为桥梁,将ERNIE模型的知识迁移至小模型,以较小的效果牺牲达到上千倍的预测速度的提升。
适用场景
数据蒸馏的适用场景:由于预测性能的限制导致只能采用规模较小模型的场景,可通过数据蒸馏方案提升小模型效果。
数据蒸馏步骤
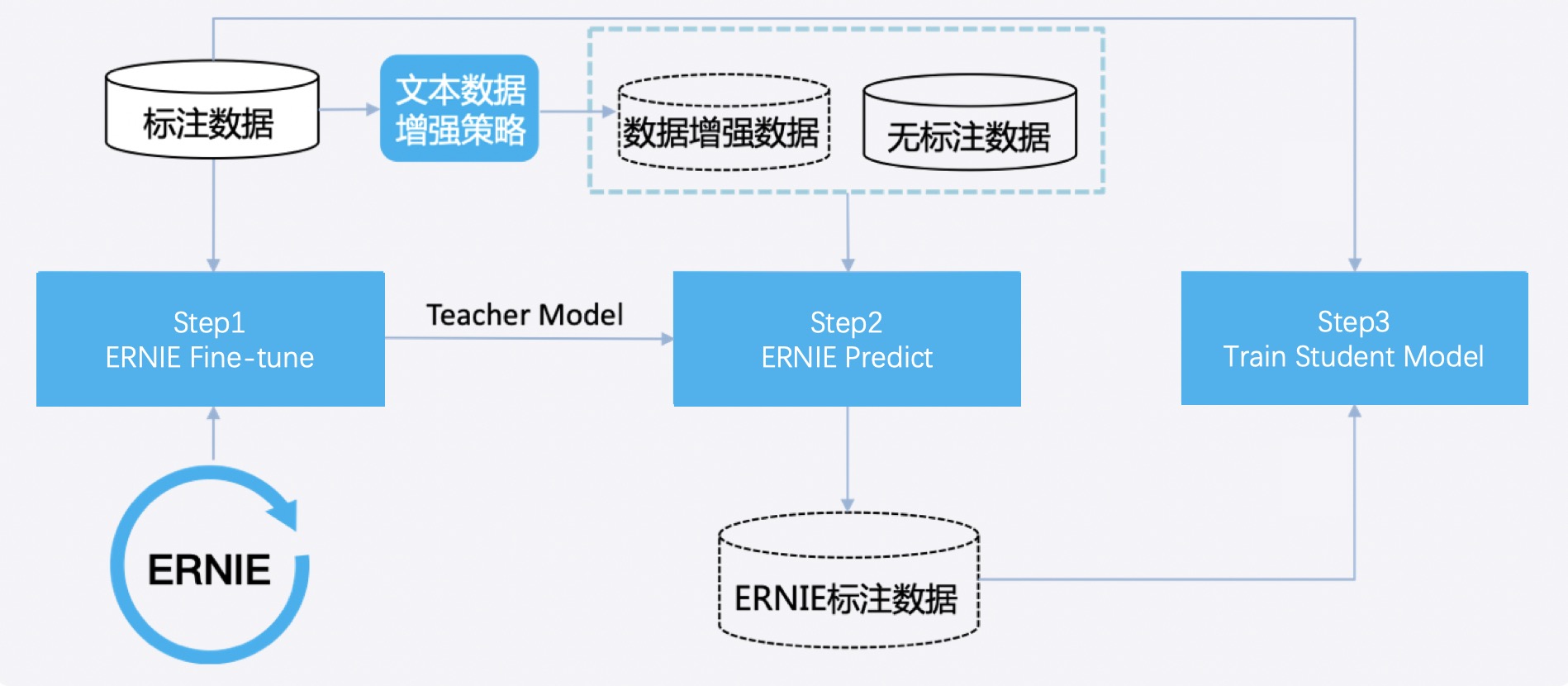
数据蒸馏的步骤如下图所示,具体包括以下三个步骤:
- Step1: 使用ERNIE模型对标注数据进行Fine-tune,得到教师模型(Teacher Model);
-
Step2: 该步骤的目标为获取更多的数据,可采取的方式有:
- 可将已有的标注数据采取文心提供的数据增强工具得到增强后的数据;目前专业版开发套件中暂不提供数据增强服务,如有需要,可前往文心官网申请文心NLP开发套件旗舰版试用。
- 用户可提供大规模无标注数据,需与标注数据同源;
采用Step1得到的Teacher Model对上述无监督数据进行预测,将预测结果作为数据的标签;
- Step3: 将已有的标注数据和Step2中得到的预测数据进行汇总,使用汇总后的数据训练得到学生模型(Student Model)。
准备工作
数据准备
- 采用的数据集、词表文件等都必须为UTF-8格式,如果您的数据为其他格式可使用文心提供的数据预处理小工具进行格式转换。
- 在文心中,基于ERNIE的模型可不需要用户分词和提供词表文件,非ERNIE模型需要用户提前分好词,词之间以空格分割并提供词表文件。关于分词和词表生成可使用文心提供的数据预处理小工具获得。
- 为满足学生模型的预测性能要求,通常情况下,教师模型采用ERNIE模型,学生模型采用非ERNIE模型,为此提供给教师模型的数据可不需要分词,但提供给学生模型训练的数据需用户提前分词。
- 文心提供文本分类任务(Chnsenticorp数据集)作为数据蒸馏使用的Demo,以供用户参考,其他任务的数据格式可参考任务详解对应任务中的准备工作章节。
教师模型数据集(文本分类任务)
训练集/验证集/测试集
训练集、测试集和验证集的数据格式相同,下面将提供具体示例:
-
ERNIE模型数据
-
数据集 数据分为两列,列与列之间用\t进行分隔。第一列为文本,第二列为标签。
房间太小。其他的都一般。。。。。。。。。 0 LED屏就是爽,基本硬件配置都很均衡,镜面考漆不错,小黑,我喜欢。 1 差得要命,很大股霉味,勉强住了一晚,第二天大早赶紧溜 0-
词表 词表文件示例:词表分为两列,第一列为词,第二列为id(从0开始),列与列之间用\t进行分隔,ERNIE词表由文心提供,wenxin/tasks/model_files/dict路径下有各ERNIE模型的词表文件,用户可根据需要进行选择。
[PAD] 0 [CLS] 1 [SEP] 2 [MASK] 3 , 4 的 5 、 6 一 7 人 8
-
-
-
非ERNIE模型数据
-
数据集
通常情况下教师模型为ERNIE模型,为此无需分词操作,但若用户的教师模型采用非ERNIE模型,需对文本进行分词操作,非ERNIE数据集与ERNIE数据集格式一致,不同之处在于需要分词,如下所示:
房间 太 小 。 其他 的 都 一般 。 。 。 。 。 。 。 。 。 0 LED屏 就是 爽 , 基本 硬件 配置 都 很 均衡 , 镜面 考 漆 不错 , 小黑 , 我喜欢 。 1 差 得 要命 , 很大 股霉味 , 勉强 住 了 一晚 , 第二天 大早 赶紧 溜。 0-
词表
非ERNIE词表文件内容格式与ERNIE的一致,需注意的是,在文心的词表中,[PAD]、[CLS]、[SEP]、[MASK]、[UNK]这5个词是必须要有的,若用户自备词表,需保证这5个词是存在的。部分词表示例如下所示:
[PAD] 0 [CLS] 1 [SEP] 2 [MASK] 3 [UNK] 4 郑重 5 天空 6 工地 7 神圣 8
-
-
学生模型数据集
无监督数据集
用户需提供无标注数据集供教师模型进行预测以获取教师模型的知识,数据格式为一列文本,如下所示(注意:若教师模型采用的为非ERNIE模型,该文本需进行分词操作):
房间太小。其他的都一般。。。。。。。。。
LED屏就是爽,基本硬件配置都很均衡,镜面考漆不错,小黑,我喜欢。
差得要命,很大股霉味,勉强住了一晚,第二天大早赶紧溜文心提供了未标注的增强数据示例,增强后的数据为原训练数据的10倍(96000行),可运行下面的命令进行下载。
cd ./wenxin/tasks/ernie_slim
# 运行数据下载脚本,下载的数据在wenxin/tasks/ernie_slim/distill目录
sh download_data.sh下载后的数据目录结构如下所示:
.
└── chnsenticorp
├── student ## 学生模型数据集
│ ├── dev
│ │ └── part.0
│ ├── teacher_vocab.txt
│ ├── train
│ │ └── part.0
│ ├── unsup_train_aug ## 未标注增强训练数据
│ │ └── part.0
│ └── vocab.txt
└── teacher ## 教师模型数据集
├── dev
│ └── part.0
├── train
│ └── part.0
└── vocab.txt该数据集对chnsenticorp训练集采取了三种增强策略,分别为:
- 添加噪声:对原始样本中的词,以一定的概率(如0.1)替换为”UNK”标签;
- 同词性词替换:对原始样本中的所有词,以一定的概率(如0.1)替换为本数据集中随机一个同词性的词;
- N-sampling:从原始样本中,随机选取位置截取长度为m的片段作为新的样本,其中片段的长度m为0到原始样本长度之间的随机值。
预测集
训练好的学生模型作为数据蒸馏的产物,该学生模型可满足性能的限制条件且效果损失较小。分类任务下,预测集的示例如下:
-
学生模型为非ERNIE模型
仅一列为文本,需对文本进行分词操作,不需要标签列
房间 太 小 。 其他 的 都 一般 。 。 。 。 。 。 。 。 。 0 LED屏 就是 爽 , 基本 硬件 配置 都 很 均衡 , 镜面 考 漆 不错 , 小黑 , 我喜欢 。 1 差 得 要命 , 很大 股霉味 , 勉强 住 了 一晚 , 第二天 大早 赶紧 溜。 0 -
学生模型为ERNIE模型
数据格式和非ERNIE一致,不同之处在于不需要分词,如下所示:
房间太小。其他的都一般。。。。。。。。。 0 LED屏就是爽,基本硬件配置都很均衡,镜面考漆不错,小黑,我喜欢。 1 差得要命,很大股霉味,勉强住了一晚,第二天大早赶紧溜 0
快速开始
环境安装
准备数据
详情请查看"准备工作-数据准备"章节
训练我的第一个数据蒸馏模型
-
目录结构
数据蒸馏任务位于/wenxin/tasks/ernie_slim
. ├── __init__.py ├── env.sh ## 环境变量配置脚本 ├── run_with_json.py ## 只依靠json进行模型训练的入口脚本 ├── run_infer.py ## 只依靠json进行模型预测的入口脚本 ├── run_distill.sh ## 数据蒸馏的入口脚本 ├── download_data.sh ## chnsenticorp的增强数据下载脚本 ├── examples ## 各典型网络的json配置脚本 │ ├── model_cnn.json │ ├── ernie_2.0_base_ch_config.json │ ├── model_ernie2.0.json │ └── model_ernie2.0_infer.json └── dict ## 示例词表文件夹 ├── vocab_cnn.txt └── vocab_ernie2.0.txt -
ERNIE预训练模型下载;
以ERNIE_2.0_base模型为例,使用以下命令在../model_files/中通过对应脚本下载ernie_2.0_base模型参数文件,其对应配置文件ernie_2.0_base_ch_config.json和词表vocab_ernie_2.0_base_ch.txt分别位于../model_files/目录下的config/和dict/文件夹,用户无需更改;
# ernie_2.0_base 模型下载 # 进入model_files目录 cd ../model_files/ # 运行下载脚本 sh download_ernie_2.0_base_ch.sh -
配置环境变量;
请在../ernie_slim/env.sh中根据提示配置相应环境变量的路径,如需了解更多详情,请参考环境配置详细说明;
# 进入数据蒸馏任务目录 cd ../ernie_slim source ./env.sh -
一键数据蒸馏
-
为方便用户使用,文心提供了一键蒸馏脚本:
# 基于ernie_2.0_base的数据蒸馏。 sh ./run_distill.sh训练运行的日志会自动保存在./log/test.log文件中。
- 数据蒸馏过程说明:
-
| 步骤 | 配置文件 | |
|---|---|---|
| Step1 | 在标注数据上Fine-tune得到教师模型 | ./examples/model_ernie2.0.json |
| Step2 | 加载训练好的教师模型,预测无监督数据的标签(Hard-label) | ./examples/model_ernie2.0_infer.json |
| Step3 | 使用人工标注数据集+教师模型标注的无监督数据集训练学生模型 | ./examples/model_cnn.json |
注:关于json配置文件具体字段说明可参考文本分类-开始训练与预测参数配置章节
-
数据细节说明
- Step2中,事先构造好的增强数据放在distill/chnsenticorp/student/unsup_train_aug目录下,若用户已经拥有了无监督数据,将其放入上述目录即可;
- Step2中,基于配置文件./examples/model_ernie2.0_infer.json对无监督数据进行预测,最终的标注文件为distill/chnsenticorp/student/train/part.1。标注结果包含两列, 第一列为明文,第二列为标注label。
- Step3中,学生模型的训练数据于./distill/chnsenticorp/student/train/目录下,part.0为原监督数据,part.1为教师模型标注数据。
模型预测
-
在./env.sh中配置对应的环境变量,并执行source env.sh ,如需了解更多详情,请参考环境安装与配置。
source ./env.sh - 选定配置好的json文件,把你将要预测的模型对应的inference_model文件路径填入json文件的“inference_model_path”变量中。具体json文件配置可参考文本分类-开始训练与预测参数配置章节。
-
模型训练的入口脚本为./run_infer.py , 通过--param_path参数来传入./examples/目录下的json配置文件。
python run_infer.py --param_path ./examples/model_cnn_infer.json预测运行的日志会自动保存在./output/predict_result_cnn_student.txt中。
效果验证
我们将实际应用场景分类为两种:用户提供“无标注数据”和用户未提供“无标注数据”(通过数据增强生成数据)。
Case#1 用户提供"无标注数据"
| 模型 | 评论低质识别【分类 ACC】 | 中文情感【分类 ACC】 | 问题识别【分类 ACC】 | 搜索问答匹配【匹配 正逆序】 |
|---|---|---|---|---|
| ERNIE-Finetune | 90.6% | 96.2% | 97.5% | 4.25 |
| 非ERNIE基线(BOW) | 80.8% | 94.7% | 93.0% | 1.83 |
| + 数据蒸馏 | 87.2% | 95.8% | 96.3% | 3.30 |
Case#2 用户未提供"无标注数据"(通过数据增强生成数据)
| 模型 | ChnSentiCorp |
|---|---|
| ERNIE-Finetune | 95.4% |
| 非ERNIE基线(BOW) | 90.1% |
| + 数据蒸馏 | 91.4% |
| 非ERNIE基线(CNN) | 91.6% |
| + 数据蒸馏 | 92.4% |
| 非ERNIE基线(LSTM) | 91.2% |
| + 数据蒸馏 | 93.9% |