

9.Trainer
简介
在文心中,我们把模型训练过程中常用的操作进行了统一封装、统一调度,形成一套标准流程,这套标准流程的调度就是Trainer(训练器)。一个Trainer实例中的标准操作有初始化运行环境、初始化各项参数、构造神经网络(通过调用Model实现)、数据读取(通过调用Reader实现)、模型训练、模型效果评估、模型保存等。
基本结构
一个Trainer实例中包含一个Reader和Model的实例,Reader实例负责读取明文数据集并将其处理为飞桨可用的Tensor结构;Model实例负责构建神经网络、确定模型指标计算。Trainer实例在train方法(模型训练)中启动一个循环,不断的调用Reader获取数据、然后将数据传递到Model的网络结构中进行计算,并根据用户对模型评估频率和保存频率参数的设置,在指定的时机进行模型评估和模型保存,直到整个训练任务结束。其结构如下所示:
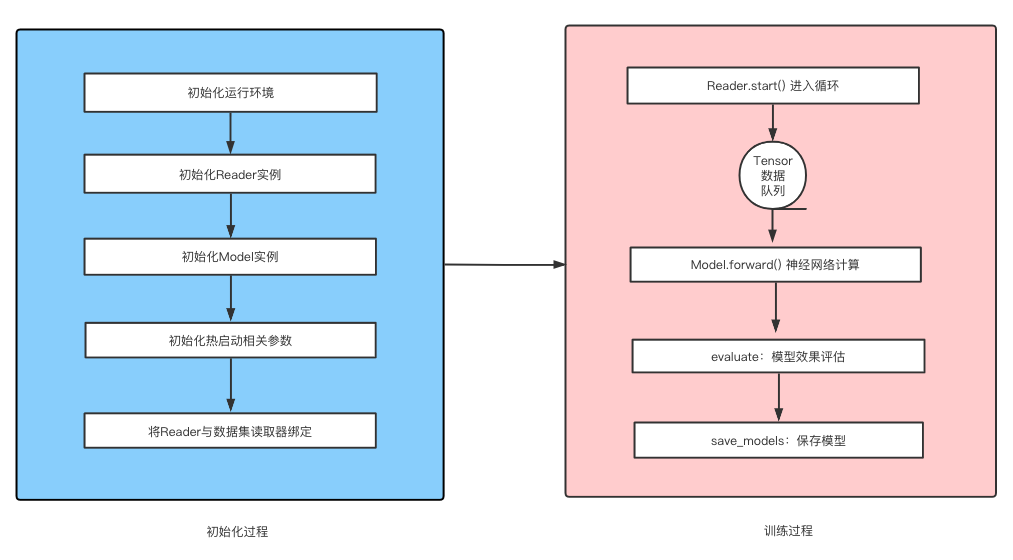
基础操作
Trainer的基类为BaseTrainer,定义在 ./wenxin/common/controler.pyc 中,其主要的方法和能力为:
- 运行环境初始化:根据当前用户的安装环境,初始化飞桨的运行时环境。这部分的代码在基类中已经实现,用户无需自己编码实现,仅需要配置好对应的参数即可,参数定义详见实战演练:使用文心进行模型训练。
-
构造神经网络:调用Model实例的forward和optimizer完成神经网络的构造,这部分的代码在基类中已经实现,部分代码如下所示。用户无需自定义编码实现。关于Model介绍请移步Model。
def init_net(self): """ 初始化神经网络 """ .... self.data_set_reader.train_reader.create_reader() fields_dict = self.data_set_reader.train_reader.instance_fields_dict() ## 构造神经网络 self.forward_train_output = self.model_class.forward(fields_dict, phase=InstanceName.TRAINING) .... -
模型训练:启动训练任务,不断通过Reader读取数据集,送入Model中进行计算,并得到评估结果,直到循环结束。这部分的代码在基类中只是定义了虚方法,需要用户继承来自定义实现。文心目前提供了通用的CustomTrainer类(wenxin/training/custom_trainer.py),能够覆盖大部分训练评估流程,用户如果对自定义训练评估要求不高,可以直接继承该类,部分代码如下所示:
def train_and_eval(self): """ :param fetch_list_value: :param fetch_list_key: :param steps: :param phase: :return: """ ## 启动Reader循环,读取数据到内存队列 self.data_set_reader.train_reader.run() while True: ..... ## 从内存队列读取数据,进到model的前向组网结构中进行计算,并获取当前step的计算结果。 metrics_tensor_value = self.run(InstanceName.TRAINING, need_fetch=True, return_numpy=self.return_numpy) ## 调用model中的get_metrics方法进行效果评估计算。 metrics_output = self.model_class.get_metrics(fetch_output_dict, meta_info, InstanceName.TRAINING) .... -
模型评估:启动待测试数据集对应的Reader,从Reader中读取数据集,送入Model中进行计算,得到每个batch的计算结果并保存,直到循环结束。将所有batch的计算结果汇总起来传入Model的get_metrics方法进行整个评估数据集上的指标计算。这部分的代码在基类中只是定义了虚方法,需要用户继承来自定义实现。文心目前提供了通用的CustomTrainer类(wenxin/training/custom_trainer.py),能够覆盖大部分训练评估流程,用户如果对自定义训练评估要求不高,可以直接继承该类,部分代码如下所示:
def evaluate(self, reader, phase, step): """ :param reader: :param phase: :param step: :return: loss """ reader.run() all_metrics_tensor_value = [] i = 0 time_begin = time.time() while True: try: metrics_tensor_value = self.run(phase=phase, return_numpy=self.return_numpy) if i == 0: all_metrics_tensor_value = [[tensor] for tensor in metrics_tensor_value] else: for j in range(len(metrics_tensor_value)): one_tensor_value = all_metrics_tensor_value[j] all_metrics_tensor_value[j] = one_tensor_value + [metrics_tensor_value[j]] i += 1 except fluid.core.EOFException: reader.stop() break fetch_output_dict = collections.OrderedDict() for key, value in zip(self.fetch_list_evaluate_key, all_metrics_tensor_value): if key == InstanceName.LOSS and not self.return_numpy: value = [np.array(item) for item in value] fetch_output_dict[key] = value time_end = time.time() used_time = time_end - time_begin meta_info = collections.OrderedDict() meta_info[InstanceName.STEP] = step meta_info[InstanceName.GPU_ID] = self.gpu_id meta_info[InstanceName.TIME_COST] = used_time metrics_output = self.model_class.get_metrics(fetch_output_dict, meta_info, phase) -
模型保存:可分为checkpoints和inference model两种形式。这部分代码由基类实现,用户无需自定义实现,直接调用save_models方法即可,其基类中的部分代码实现如下所示:
def save_models(self, steps, save_checkpoint=True, save_inference=True): """ :param steps: :param save_checkpoint: :param save_inference: :return: """ .... if save_checkpoint: self.save_checkpoint(self.executor, steps) if save_inference: self.save_inference(self.executor, self.feed_target_names, self.inference_output, steps, self.infer_dict) ....
文心中的预置Trainer
文心目前提供了2个通用的Trainer,覆盖了一些比较常见的NLP领域的经典任务,包括文本分类、文本匹配、序列标注、信息抽取、阅读理解等,所有的预置Trainer文件位于./wenxin/training/目录下,如下所示:
├── __init__.py
├── custom_trainer.py ## 通用trainer,支持文本分类、匹配、序列标注、信息抽取等常见任务。
├── mrc_trainer.py ## 阅读理解任务使用的trainer
├── trainer_config.py ## 定义trainer所需参数的类进阶使用
文心中提供了通用的Trainer流程,如果用户需要针对自己的业务场景进行自定义优化使用的话,请参考详细的接口设计与自定义Trainer。