

数据模块使用说明
模块综述
Data模块主要作用是对明文数据进行处理,处理成paddle框架可以使用的tensor类型数据。处理过程的主要步骤为:
(1)按样本格式和任务类型定义好py_reader OP需要的shape、level、type。
(2)从文件(文件夹)中按行读取明文数据,每行数据按列切分各个域,一行数据为一个样本,多个样本组成一个batch,用迭代器方式输出为一个个batch。
(3)对每个batch中的明文数据进行切词、按词表转成id序列。
(4)转成id序列的数据按(1)中定义好的shape、type 输入到 py_reader,生成tensor类型的数据。
(5)以样本中各个域的名称为key(如单句分类样本为text 、label ),以步骤(4)中生成的对应列的tensor数据为value,按dict形式输出给组网部分,组网部分就可以按域名称获取到对应的tensor数据,进而开始后续的组网操作。
概念解释
Vocabulary
词表的封装对象,读入一个词表文件,生成两个dict对象:vocab_dict和id_dict ,vocab_dict中key为明文词汇(token),value为词id,id从0开始编号,不可重复。id_dict中key为id,value为名为词汇。主要方法为convert_ids_to_tokens(id转明文token),convert_tokens_to_ids(明文token转id)。
...
class Vocabulary(object):
"""Vocabulary"""
def __init__(self, vocab_path, unk_token):
"""
:param vocab_path: 词表地址,必填
:param unk_token: unk默认的token,必填
"""
if not vocab_path:
raise ValueError("vocab_path can't be None")
self.vocab_path = vocab_path
self.unk_token = unk_token
self.vocab_dict, self.id_dict = self.load_vocab()
self.vocab_size = len(self.id_dict)
def load_vocab(self):
"""
:return:
"""
vocab_dict = collections.OrderedDict()
id_dict = collections.OrderedDict()
file_vocab = open(self.vocab_path)
for num, line in enumerate(file_vocab):
items = convert_to_unicode(line.strip()).split("\t")
if len(items) > 2:
break
token = items[0]
if len(items) == 2:
index = items[1]
else:
index = num
token = token.strip()
vocab_dict[token] = int(index)
id_dict[index] = token
return vocab_dict, id_dict
def add_reserve_id(self):
"""添加预留的一些id
:return:
"""
pass
def convert_tokens_to_ids(self, tokens):
"""
:param tokens:
:return:
"""
output = []
UNK = self.vocab_dict[self.unk_token]
for item in tokens:
output.append(self.vocab_dict.get(item, UNK))
return output
def convert_ids_to_tokens(self, ids):
"""
:param ids:
:return:
"""
output = []
for item in ids:
output.append(self.id_dict.get(item, self.unk_token))
return output
def get_vocab_size(self):
"""获取词表大小
:return:
"""
return len(self.id_dict)
def covert_id_to_token(self, id):
"""
:param id:
:return: token
"""
return self.id_dict.get(id, self.unk_token)
def covert_token_to_id(self, token):
"""
:param token:
:return: id
"""
UNK = self.vocab_dict[self.unk_token]
return self.vocab_dict.get(token, UNK)
...Tokenizer
分词工具的封装,主要成员变量为一个Vocabulary对象,输入一串明文,输出一个token数组。同时提供token转id,和id转token的功能。备注:一个Tokenizer对象只能有一个Vocabulary成员。
...
@RegisterSet.tokenizer.register
class Tokenizer(object):
"""Tokenizer"""
def __init__(self, vocab_file, split_char=" ", unk_token="[UNK]", params=None):
"""
:param vocab_file: 词表文件路径
:param split_char: 明文分隔符,默认是空格
:param unk_token: unk 对应的token,默认是[UNK]
:param params: 个别tokenizer自己用到的额外参数,dict类型
"""
self.vocabulary = Vocabulary(vocab_file, unk_token)
self.split_char = split_char
self.unk_token = unk_token
self.params = params
def tokenize(self, text):
"""
:param text:
:return: tokens, list类型
"""
raise NotImplementedError
def convert_tokens_to_ids(self, tokens):
"""
:param tokens:
:return:
"""
raise NotImplementedError
def convert_ids_to_tokens(self, ids):
"""
:param ids:
:return:
"""
raise NotImplementedError
def covert_id_to_token(self, id):
"""
:param id:
:return: token
"""
return self.vocabulary.covert_id_to_token(id)
def covert_token_to_id(self, token):
"""
:param token:
:return: id
"""
return self.vocabulary.covert_token_to_id(token)
...FieldReader
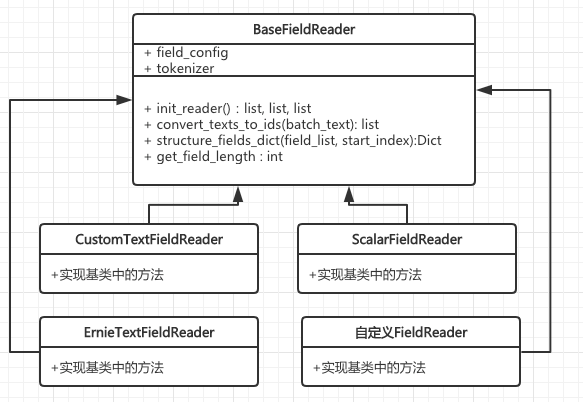
针对于一个样本中的某个列(也称作域,或者field)的封装,主要成员变量是一个Tokenizer对象和一个config对象。 config对象定义这个field的名称、数据类型、字符串最大长度、词表路径等一些配置。 Tokenizer对象用来对field对应的明文进行切词、转id。 FieldReader的主要功能有:定义这个field对应的数据转成py_reader之后的格式,明文转id序列(通过tokenizer对象实现),明文id序列转成dict形式输出。 注:一个FieldReader只能有一个Tokenzier成员。若文本域为离散型,即不需要tokenizer的文本域,则可以参考categorical_field_reader.py来实现。
...
@RegisterSet.field_reader.register
class BaseFieldReader(object):
"""BaseFieldReader: 作用于field的reader,主要是定义py_reader的格式,完成id序列化和embedding的操作
"""
def __init__(self, field_config):
self.field_config = field_config
self.tokenizer = None # 用来分词,需要各个子类实现
self.token_embedding = None # 用来生成embedding向量,需要各个子类实现
def init_reader(self):
""" 初始化reader格式
:return: reader的shape[]、type[]、level[]
"""
raise NotImplementedError
def convert_texts_to_ids(self, batch_text):
""" 明文序列化
:param:batch_text
:return: id_list
"""
raise NotImplementedError
def get_field_length(self):
"""获取当前这个field在进行了序列化之后,在field_id_list中占多少长度
:return:
"""
raise NotImplementedError
def structure_fields_dict(self, fields_id, start_index, need_emb=True):
"""静态图调用的方法,生成一个dict, dict有两个key:id , emb. id对应的是pyreader读出来的各个field产出的id,emb对应的是各个
field对应的embedding
:param fields_id: pyreader输出的完整的id序列
:param start_index:当前需要处理的field在field_id_list中的起始位置
:param need_emb:是否需要embedding(预测过程中是不需要embedding的)
:return:
"""
raise NotImplementedError
...DataSetReader
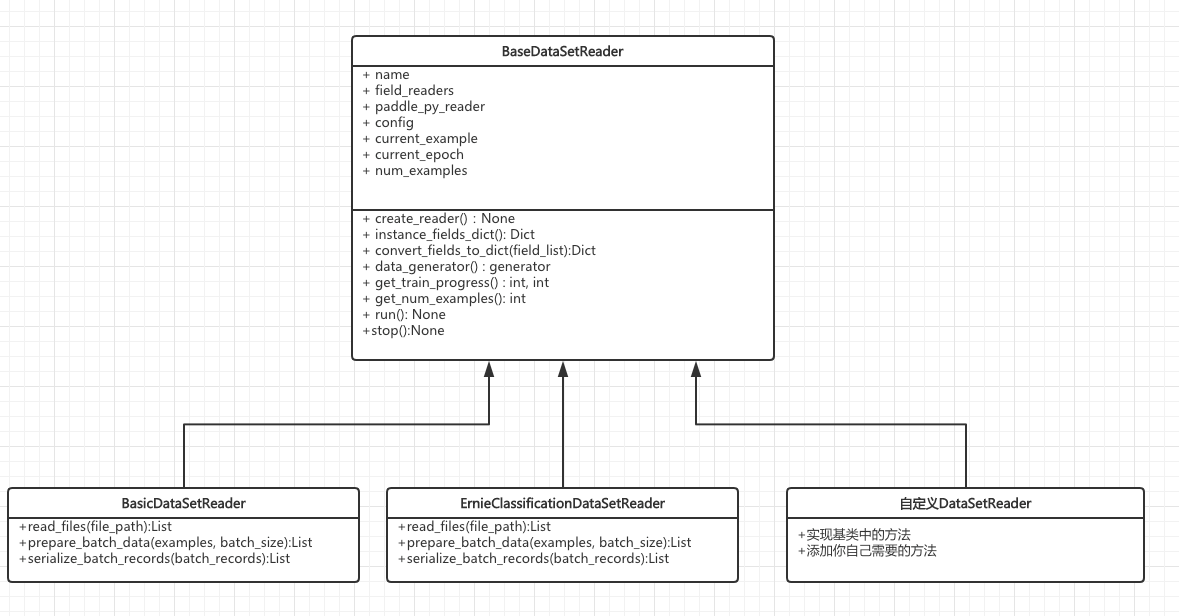
针对一个数据集(文件/文件夹)中的数据,将数据读取、shuffle、组batch等操作统一封装起来,组装成一个py_reader,向外提供一个统一的接口。核心内容是读取明文数据集,通过迭代器将数据组成多个batch,然后转成id序列,灌给py_reader,通过fluid.layers.read_file(py_reader) 接口来获取出对应的tensor数据, 最后将这些tensor以各个field的name为key,转成一个dict类型输出给model(神经网络组网)模块。备注:一个DataSetReader可以有多个FieldReader,对于那种没有域的概念或者各个域之间不相互独立的情况,像阅读理解任务,就不需要使用field_reader, 按BaseDataSetReader接口自定义自己的DatasetReader即可。
...
@RegisterSet.data_set_reader.register
class BaseDataSetReader(object):
"""BaseDataSetReader:将样本中数据组装成一个py_reader, 向外提供一个统一的接口。
核心内容是读取明文文件,转换成id,按py_reader需要的tensor格式灌进去,然后通过调用run方法让整个循环跑起来。
py_reader拿出的来的是lod-tensor形式的id,这些id可以用来做后面的embedding等计算。
"""
def __init__(self, name, fields, config):
self.name = name
self.fields = fields
self.config = config # 常用参数,batch_size等,ReaderConfig类型变量
self.paddle_py_reader = None
self.current_example = 0
self.current_epoch = 0
self.num_examples = 0
def create_reader(self):
"""
必须选项,否则会抛出异常。
用于初始化self.paddle_py_reader。
``self.paddle_py_reader = fluid.layers.py_reader(
capacity=capacity,
shapes=shapes,
name=self.name,
dtypes=types,
lod_levels=levels,
use_double_buffer=True)
``
:return:None
"""
raise NotImplementedError
def instance_fields_dict(self):
"""
必须选项,否则会抛出异常。
实例化fields_dict, 调用pyreader,得到fields_id, 视情况构造embedding,然后结构化成dict类型返回给组网部分。
:return:dict
{"field_name":
{"RECORD_ID":
{"SRC_IDS": [ids],
"MASK_IDS": [ids],
"SEQ_LENS": [ids]
}
}
}
实例化的dict,保存了各个field的id和embedding(可以没有,是情况而定), 给trainer用.
"""
raise NotImplementedError
def data_generator(self):
"""
必须选项,否则会抛出异常。
数据生成器:读取明文文件,生成batch化的id数据,绑定到py_reader中
:return:list
[[src_ids],
[mask_ids],
[seq_lens]
]
"""
raise NotImplementedError
def convert_fields_to_dict(self, field_list, need_emb=False):
"""instance_fields_dict一般调用本方法实例化fields_dict,保存各个field的id和embedding(可以没有,是情况而定),
当need_emb=False的时候,可以直接给predictor调用
:param field_list:
:param need_emb:
:return: dict
"""
raise NotImplementedError
def run(self):
"""
配置py_reader对应的数据生成器,并启动
:return:
"""
if self.paddle_py_reader:
self.paddle_py_reader.decorate_tensor_provider(self.data_generator())
self.paddle_py_reader.start()
logging.info("set data_generator and start.......")
else:
raise ValueError("paddle_py_reader is None")
def stop(self):
"""
:return:
"""
if self.paddle_py_reader:
self.paddle_py_reader.reset()
else:
raise ValueError("paddle_py_reader is None")
def get_train_progress(self):
"""Gets progress for training phase."""
return self.current_example, self.current_epoch
def get_num_examples(self):
"""get number of example"""
return self.num_examples
...DataSet
一个NLP任务,可以在训练过程中对评估集、测试集进行效果验证,那也就意味着有多个数据集,一个DataSetReader可以对一个数据集进行操作,那么DataSet就是将多个DataSetReader集中管理起来。目前的DataSet的主要操作是根据Json配置进行多个DataSetReader的初始化,主要包含以下几个成员变量:训练集DataSetReader(train_reader)、测试集DataSetReader(test_reader)、评估集DataSetReader(dev_reader)、预测集DataSetReader(predict_reader).
...
class DataSet(object):
"""DataSet"""
def __init__(self, params_dict):
""""""
self.train_reader = None
self.test_reader = None
self.dev_reader = None
self.predict_reader = None
self.params_dict = params_dict
def build(self):
""" init readers
:return:
"""
...设计思路
整体设计
Data模块的功能是将明文数据集处理成组网可用的tensor类型数据,并以dict形式传入给组网模块供其后续op使用。具体的处理步骤由DataSetReader控制,对用户透明。
输入:明文数据集
输出:以dict形式迭代出一个个batch,数据类型为tensor。
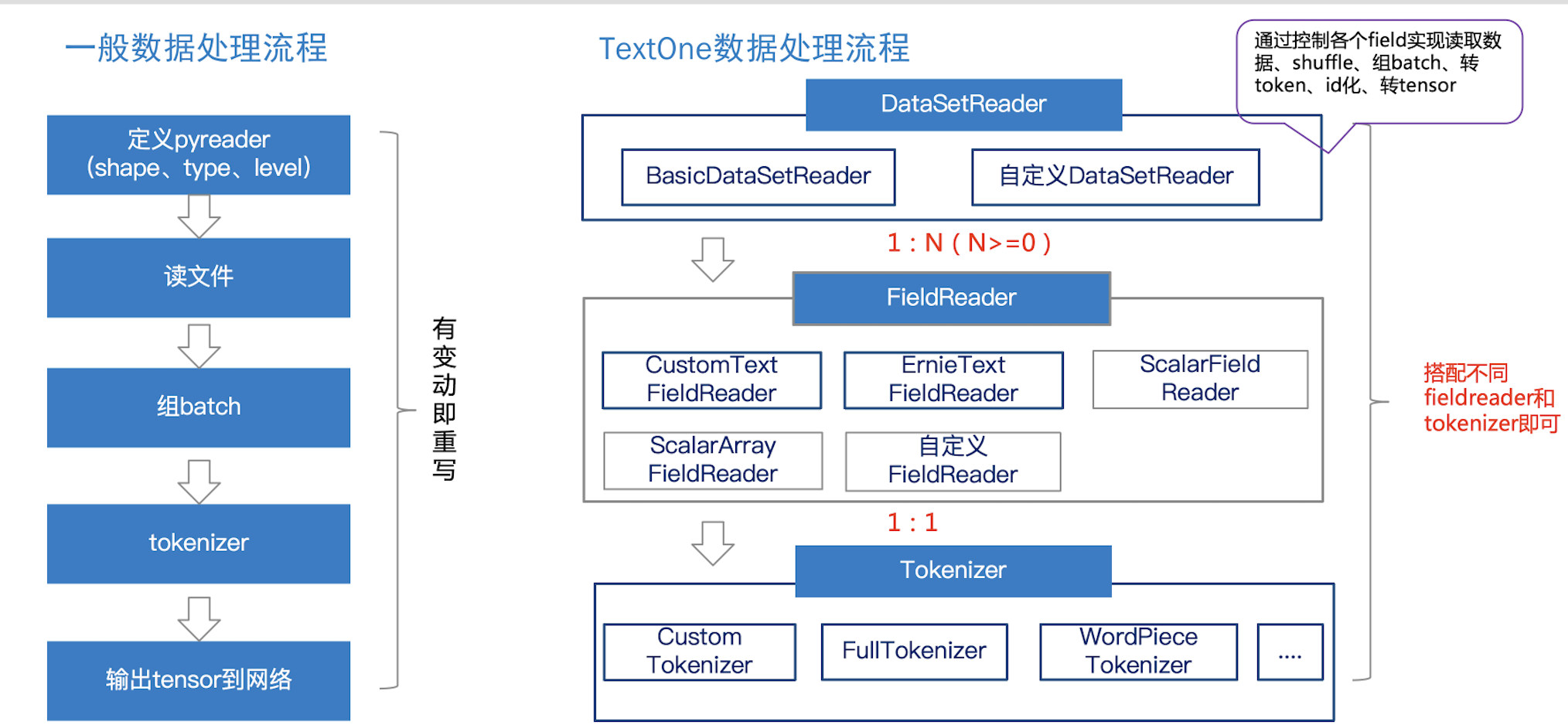
文心平台空间 > 「公共版」文心v1.6.0 Data模块使用说明 > image2020-3-17_19-18-21.png
主要类图

预置内容
预置FieldReader:
TextFieldReader:最基本的文本(String)类型的field_reader,只返回原始src_id(添加了padding)和length。在py_reader中对应的shape=[[batch_size, max_lens, 1], [batch_size,1]]。 其中第一个元素为src_ids, 第二个元素为length
CustomTextFieldReader:通用文本(String)类型的field_reader,文本处理规则是:文本类型的数据会自动添加padding和mask,并返回length。在py_reader中对应的shape=[[batch_size, max_lens, 1], [batch_size, max_lens, 1],[batch_size,1]]。 其中第一个元素为src_ids, 第二个元素为mask_ids,第三个元素为length
ErnieTextFieldReader:使用ernie的文本类型的field_reader,用户不需要自己分词(搭配FullTokenizer使用),处理规则是:自动添加padding,mask,position,task,sentence,并返回length。在py_reader中对应的shape=[[batch_size, max_lens, 1], [batch_size, max_lens, 1], [batch_size, max_lens, 1], [batch_size, max_lens, 1], [batch_size, max_lens, 1],[batch_size,1]]。 其中第一个元素为src_ids, 第二个元素为sentence_ids,第三个元素为position_ids,第四个元素为mask_ids,第五个元素为task_ids, 第六个元素为length。
ErnieClassificationFieldReader:使用ernie的文本类型的field_reader,用户不需要自己分词(搭配FullTokenizer使用),处理规则是:自动添加padding,mask,position,task,sentence,并返回length。shape和ErnieTextFieldReader规则一样。
与ErnieTextFieldReader的区别是如果输入的明文是句对(text_a, text_b),会将两个text拼接成一个text处理,为CLS + text_a + SEP + text_b + SEP
ErnieSeqlabelLabelFieldReader:基于ernie的序列标注专用field_reader,处理规则和custom_text_field一样,自动添加padding和mask,并返回length。不同的地方在于ErnieSeqlabelLabelFieldReader会在序列首尾分别添加UNK_ID来占位,以保证和ernie序列化过程中的[CLS]和[SEP]对应
GenerateLabelFieldReader:seq2seq (文本生成)任务中 label域的专用field_reader,会用label对应的明文先生成src_id , start_id + src_id 来生成train_src _id, src_id + end_id来生成infer_src_id ,接着对train_src _id, infer_src_id分别进行padding和mask,并返回length。
ScalarFieldReader:单个标量的field_reader,直接返回数据本身(数据可以是单个数字,也可以是单个的明文字符,明文通过json文件中配置的vocab_path去进行转换),支持int64和float32两种类型,shape= [batch_size,1]
ScalarArrayFieldReader:标量数组的field_reader,直接返回数据本身(数据可以是明文字符串,但必须是已经分词之后的,且以空格分隔,明文通过json文件中配置的vocab_path去进行转换)和数据长度,支持int64和float32两种类型。备注:数据是加了padding的。
CategoricalField:通用文本(string)类型的field_reader, 不进行分词,直接通过词表将明文转成id,文本处理规则是,文本类型的数据会自动添加padding和mask,并返回length. 比较特殊的一点是,这个field_reader中的length全是1。
预置DataSetReader:
BasicDataSetReader:一个最基础的DataSetReader,实现了文件读取,id序列化,token embedding化等基本操作。
ErnieClassificationDataSetReader:基于Ernie的、拼接方式的句对匹配任务使用的DataSetReader ,需要配合ErnieClassificationFieldReader使用,实现了文件读取,id序列化,token embedding化等基本操作。
预置Tokenizer:
CustomTokenizer:非Ernie任务使用的Tokenizer,将用户输入的明文数据按配置的分割符分隔成多个tokens,然后按配置的词表路径构造Vocabulary,将tokens转成ids。CustomTokenizer不提供分词功能,
需要用户自己先分好词再输入。词表文件也需要用户自己提供。
FullTokenizer:基于Ernie任务的Tokenizer,输入为明文数据(不需要切词),输出为切字之后的ids。Ernie词表是内置好的,不需要用户提供。
WSSPTokenizer:Ernie-Tiny任务专用的Tokenizer,输入为明文数据(不需要切词),输出为切词(SentencePiece方式)之后的ids。Ernie词表是内置好的,不需要用户提供。
目录结构
.
├── data ## 数据读取、嵌入部分
│ ├── __init__.py
│ ├── data_set.py ## 区分训练与评估的与不同域的reader
│ ├── data_set_reader
│ │ ├── __init__.py
│ │ ├── base_dataset_reader.py ## 基类,读文件、组batch
│ │ ├── basic_dataset_reader.py
│ │ └── ...
│ ├── field.py ## 域对象的定义
│ ├── field_reader
│ │ ├── __init__.py
│ │ ├── base_field_reader.py ## 基类
│ │ ├── custom_text_field_reader.py ## 通用文本reader basic + mask(用于区分padding), 非ernie网络通用
│ │ ├── ernie_classification_field_reader.py ## ernie句对分类reader
│ │ ├── ernie_seqlabel_label_field_reader.py ## ernie序列标注标签域reader
│ │ ├── ernie_text_field_reader.py ## ernie双塔文本域reader
│ │ ├── generate_label_field_reader.py ## 文本生成标签域reader
│ │ ├── scalar_array_field_reader.py ## 数值类型数组reader,需要指定整型还是浮点型,支持转为id的文本数据
│ │ ├── scalar_field_reader.py ## 数值类型标量reader,需要指定整型还是浮点型
│ │ └── text_field_reader.py ## 文本reader 只输出padding后的id length(区分非padding)
│ ├── reader_config.py ## 一些配置参数,如batch-size、epoch、shuffle等
│ ├── tokenizer
│ │ ├── __init__.py
│ │ ├── tokenizer.py ## 基类
│ │ ├── custom_tokenizer.py ## 分词用tokenizer, 对于已用空格分好词的文本
│ │ ├── tokenization_spm.py ## 针对英文数据集的ernie pre-train任务的tokenizer, 用户不需要分词
│ │ ├── tokenization_utils.py ## tokenizer过程中会用到的工具方法,如unicode转换、空格清理等
│ │ └── tokenization_wp.py ## 针对中文数据集的ernie任务用到的tokenizer,包括FullTokenzier、WordPiece、SentencePiece等
│ ├── util_helper.py ## 数据处理过程中的一些工具方法,比如添加padding、添加mask。
│ ├── vocabulary.py ## 词表模块
├──举个例子
句对匹配任务(非Ernie任务)

从数据来看,一条样本有三个域 : text_a , text_b, label ,域之间相互独立,各自生成对应的tensor, 那么就应该选择BasicDataSetReader。 text_a , text_b是文本(String)类型,且是分过词的,词之间以空格分隔,那么应该使用CustomTextFieldReader和CustomTokenizer 。label是数字(int)类型, 那么应该使用ScalarFieldReader,对应的类型为int64。详细任务配置可参考「公共版」文心v1.6.0 文本匹配(Text Matching)
基于Ernie的单句分类任务
 从数据来看,一条样本有两个域 : text_a , label ,域之间相互独立,各自生成对应的tensor, 那么就应该选择BasicDataSetReader。text_a 是文本(String)类型,没有分词(Ernie任务不需要分词),那么应该使用ErnieTextFieldReader。
从数据来看,一条样本有两个域 : text_a , label ,域之间相互独立,各自生成对应的tensor, 那么就应该选择BasicDataSetReader。text_a 是文本(String)类型,没有分词(Ernie任务不需要分词),那么应该使用ErnieTextFieldReader。
label是数字(int)类型, 那么应该使用ScalarFieldReader,对应的类型为int64。详细任务配置可参考「公共版」文心v1.6.0 文本分类(Text Classification)
其余任务的reader配置请参考 reader配置说明