

平台重点升级介绍
近期 BML 平台针对大模型训练加速和模型监控方面有了较大的功能升级,将逐渐在私有化和公有云的平台解决方案中提供给客户。
大模型训练加速服务
BML 平台针对大模型和主流的深度学习模型的训练都提供了加速服务:
- 在大模型训练场景中,支持了大模型参数下的混合并行加速,支持主流大模型,如ERNIE, GPT, VIT, SWIN-TRANSFORMER等的并行训练加速。
- 在主流深度学习模型的训练场景中,支持了在大规模数据量下的数据并行加速需求。
其核心的技术优化点为:
- 基础网络优化。提供高吞吐,低时延的、低负载的RDMA网络,显著提升云服务之间的通信效率。
- 基础单机性能优化。 提供GPU高性能定制算子,配合混合精度训练机制显著提升单机性能吞吐。
- 分布式梯度通信优化。 提供高压缩比的梯度通信优化技术,可以显著降低节点间(卡间)通信量,在节点间(卡间)通信量成为瓶颈的情况下有显著收益 。
- 并行策略自动调优。通过对并行策略及参数进行自动化调优,可以无需人工调优介入,在较短时间内找到与专家调优持平甚至更优的并行策略组合。
- 自动网络结构搜索。 通过网络结构参数的自动化搜索,可以搜索到精度基本无损、训练吞吐上能有大幅提升的最佳性能子网。
下面围绕自动网络结构搜索和并行策略自动调优,介绍整体的效果提升。
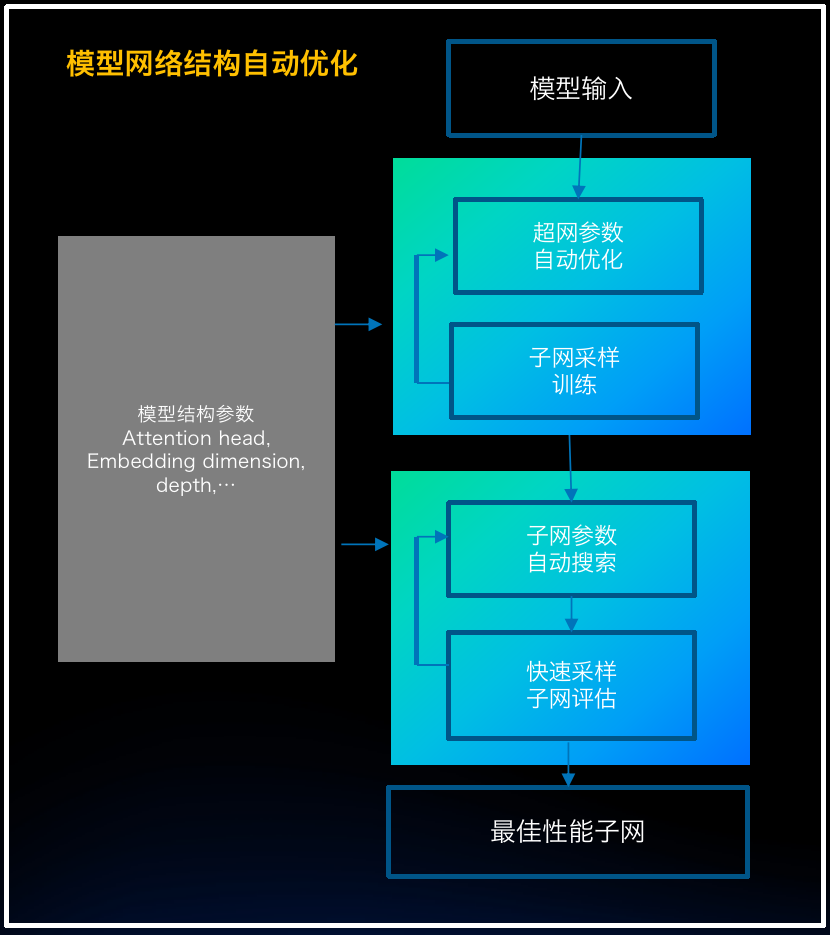
优势项1:自动网络结构搜索
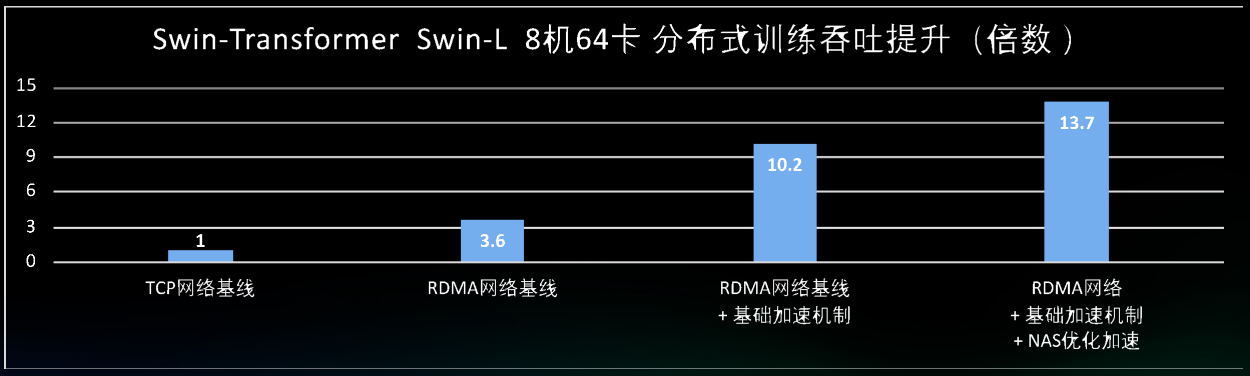
通过网络结构参数的自动化搜索,搜索到精度基本无损、训练吞吐上能有大幅提升的最佳性能子网。例如在swin transformer swin-large的的吞吐提升优化中,自动网络结构搜索后可以将训练吞吐从原来的10.2倍提升到13.7倍。
自动网络结构搜索示意图:
效果提升明显,训练吞吐提升13.7倍,算力成本可节省90%:
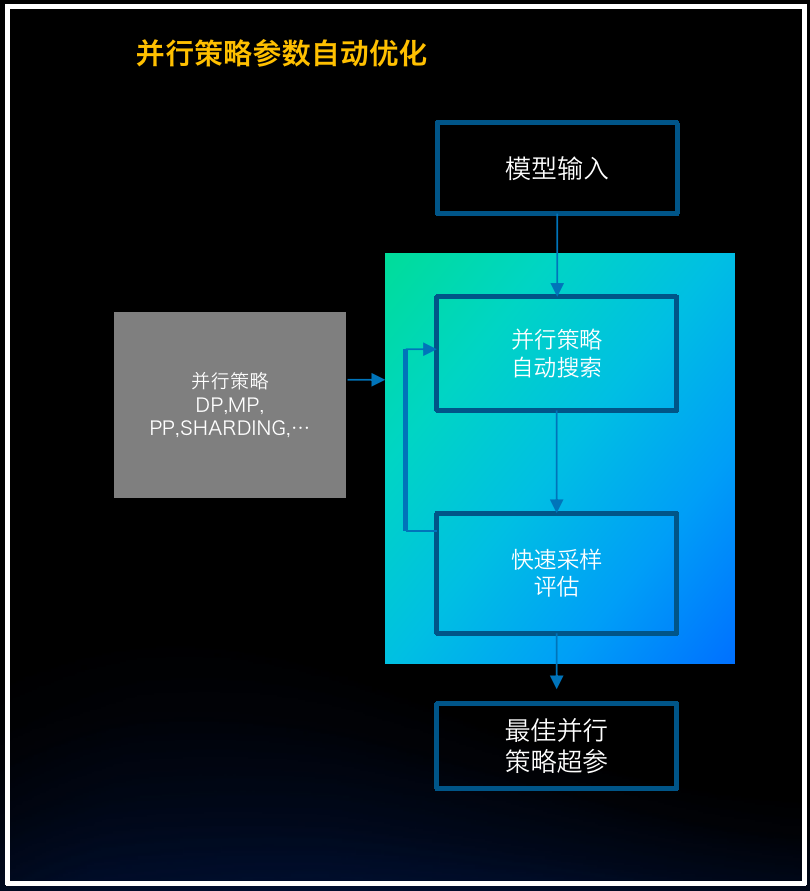
优势项2:并行策略自动调优
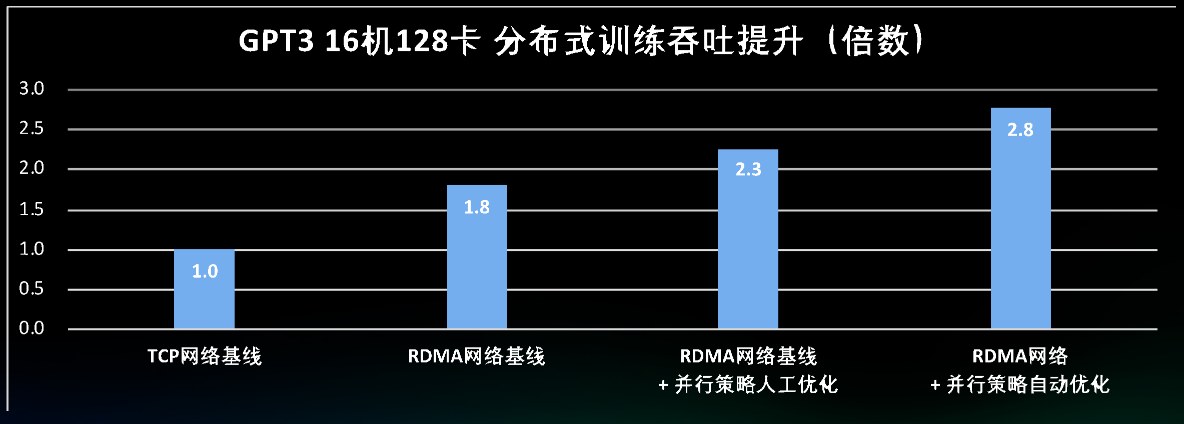
通过对并行策略进行自动化调优,可以无需人工调优介入,在较短时间内找到与专家调优持平甚至更优的并行策略组合。例如在GPT3 16机128卡分布式训练吞吐提升优化中,并行策略自动优化可以将人工优化的2.3倍提升到2.8倍。
并行策略自动调优示意图:
效果提升明显,训练性能提升2.8倍,训练算力成本可节省60%+:
生产环境的模型在线监控
生产环境的模型在线监控旨在使用数据科学和统计技术来持续评估生产中数据的质量、模型的质量,从而在早期发现模型不稳定,了解模型指标下降的方式和原因,对模型衰减做出提前预警,并推动模型的重训。
在经历开发阶段一系列调试、验证之后,模型被正式部署到生产环境中,此时模型研发人员面临的挑战才刚刚开始。在开发阶段研发人员使用静态样例集进行训练,但在生产环境中模型需要应对来自真实世界的动态数据。当模型部署在生产环境之后,它可能会在毫无预兆的情况下,业务指标快速下降,开发中的静态训练数据与生产中的动态数据之间的差异,或是特征与输出数据之间变量关系的变化是导致指标下降的主要可能因素。
在生产中主要通过以下两种方法监控模型性能的下降:模型质量评估和漂移检测。
模型质量评估
针对模型评价指标或业务指标开展的评估作业,旨在反映模型在生产中的实际表现,例如欺诈检测模型是否准确标记某条特定交易是欺诈交易。
- 评价指标:通用,与领域无关,如准确度、AUC等。由于模型设计者可能基于其中一个指标筛选的最佳模型,因此它是重要的监控项。
- 业务指标:基于特定领域定义的指标,如信用评分业务制定的A/B卡。
模型质量评估功能已可以在私有化平台解决方案上进行使用。
漂移检测
- 数据漂移检测
基于输入数据的特征值进行监控,时效性更高,无需等待预测数据标签。它利用模型的认知局限性来预判模型衰减的可能,即预测数据和训练数据的分布表现出明显差异时,模型的预测能力可能会下降。
- 概念漂移检测
基于输入数据的标签值进行监控,旨在观测输入数据和目标变量之间的关系随时间的变化。它可以用于在线学习系统,为分析学习准确率下降提供思路。