009-Python算法组件
Python算法组件
注意:Python算法组件,需连接Python预测组件。
AP聚类
AP 算法的基本思想是将全部样本看作网络的节点,通过网络中各条边的消息传递计算出各样本的聚类中心。聚类过程中,共有两种消息在各节点间传递,分别是吸引度(responsibility)和归属度(availability)。AP 算法通过迭代过程不断更新每一个点的吸引度和归属度值,直到产生m个高质量的 Exemplar(类似于质心),同时将其余的数据点分配到相应的聚类中。
输入
- 输入一个数据集,数据集的特征列必须是数值类型;数据点的参考度列(可选)用于刻画每个点的偏好,需要是数值类型。
输出
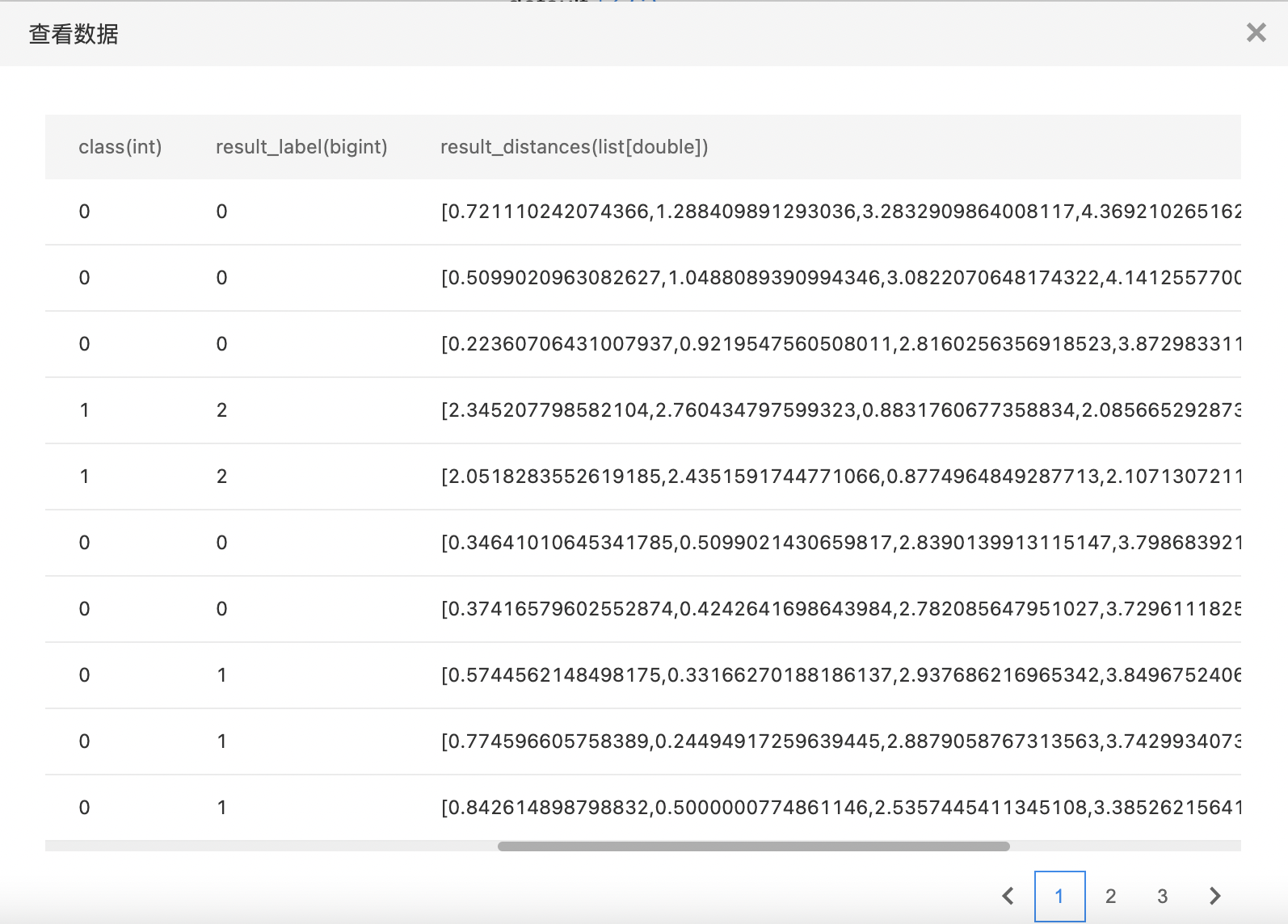
- 输出AP聚类模型。聚类模型预测结果为在原始列上加上两列:result_label,代表聚类index,从0开始;result_distances,代表样本到各个cluster的距离。
算子参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 阻尼系数 | 是 | 为了避免在更新时出现数值振荡,默认值:0.5 范围:[0.5, 0.99] | 0.5 |
| 最大迭代次数 | 是 | 控制算法的迭代次数,默认值:50。此算法时间复杂度较高,为O(NNlogN),其中N为样本数,不适合用于大数据(N>5000)聚类 范围:[1, inf) | 50 |
| 收敛迭代次数 | 是 | 迭代次数,估计簇的数量没有变化,停止收敛,默认值:3 范围:[1, inf) | 3 |
字段参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 特征列 | 是 | 支持数值或数值数组类型 | 无 |
| 数据点的参考度列 | 否 | 每个点的偏好-具有较大偏好值的点更有可能被选择为聚类中心。 聚类中心的个数(即簇的数量)受输入偏好值的影响。 如果偏好值未作为参数传递,则将其设置为输入相似度的中位数 | 无 |
使用示例
- 构建算子结构,配置参数,完成训练。
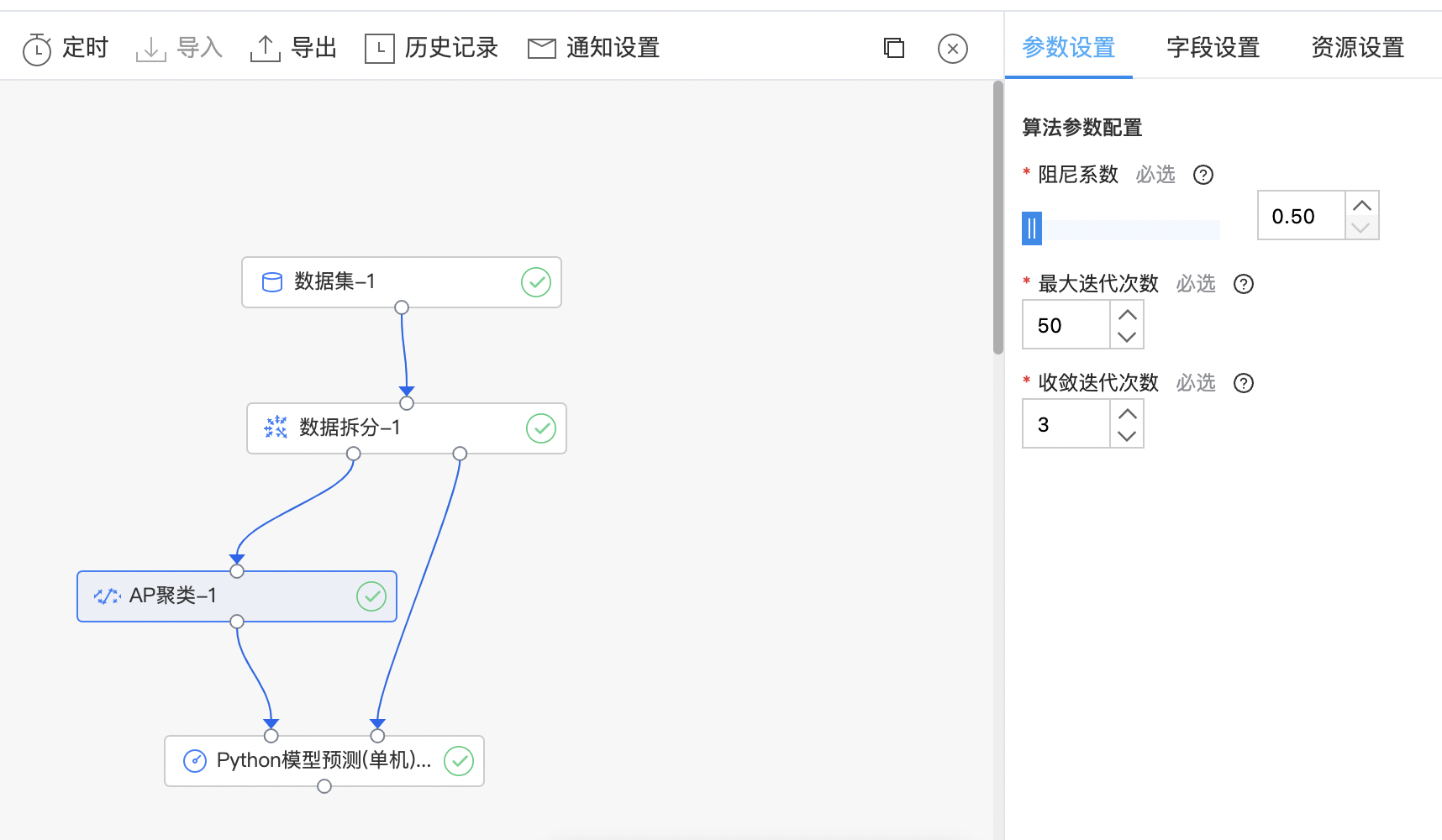
- 查看训练结果。
BML Neural Network
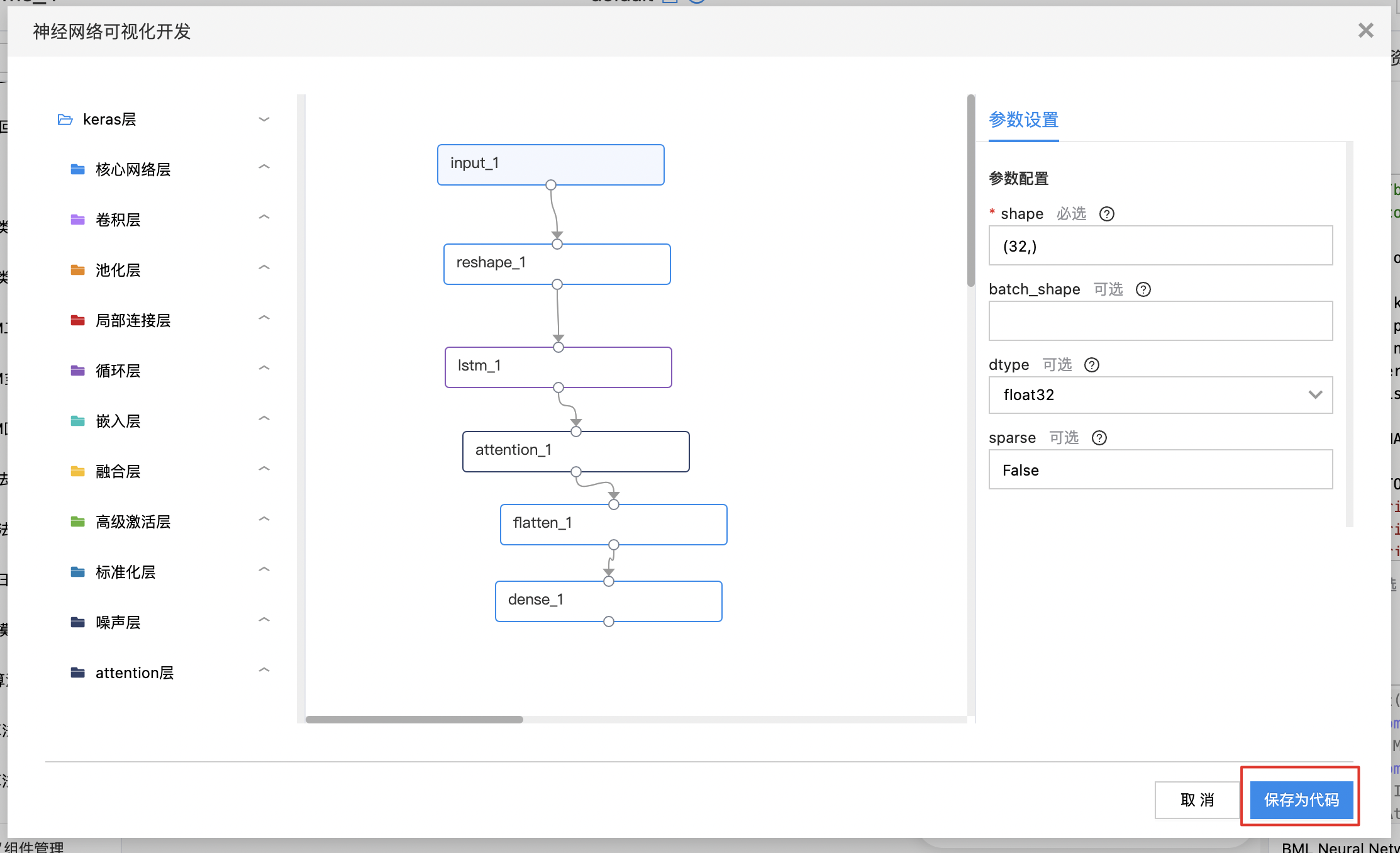
BML Neural Network组件可以进行可视化的神经网络开发,搭建网络方式与可视化建模一致,同时需要编辑代码自定义算子的fit、save、 load、transform 方法。
输入
- 输入一个数据集,需要搭建网络结构并且编写算子的fit、save、 load、transform 方法。
输出
- 输出神经网络模型。
算子参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| Python代码编辑窗口 | 是 | 使用Python开发神经网络 | |
| 网络定义 | 是 | 可在可视化神经网络编辑界面进行编辑 |
使用示例
选中“BML Neural Network”组件后,点击右侧“可视化开发”按钮,进入神经网络可视化开发界面。神经网络可视化开发同可视化建模操作体验类似,选择相应的组件进行串联后,点击组件可进行参数设置。待全部设置完毕后,可点击“保存为代码”。
Catboost二分类(单机)
CatBoost是一种基于对称决策树(oblivious trees)为基学习器实现的参数较少、支持类别型变量和高准确性的GBDT框架,主要解决的痛点是高效合理地处理类别型特征,这一点从它的名字中可以看出来,CatBoost是由Categorical和Boosting组成。此外,CatBoost还解决了梯度偏差(Gradient Bias)以及预测偏移(Prediction shift)的问题,从而减少过拟合的发生,进而提高算法的准确性和泛化能力。
输入
- 输入一个数据集,特征列是数值或数值数组类型,或者类别类型(字符串类型),二分类任务标签列需要是整数或字符串类型,标签唯一值为2。
输出
- 输出Catboost二分类(单机)模型。
算子参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 缺失值的预处理方法 | 否 | 三种缺失值处理方法,Forbidden: 不支持缺失值、Min: 缺失值赋值为最小值、Max: 缺失值赋值为最大值,默认用最小值补缺失值,类别特征不支持空值和填充 | Min |
| 特征分箱的最大箱数 | 否 | 特征值分箱的最大箱数,较少的分箱数可能会降低训练的准确性,但可能会提高总体训练效果(处理过拟合) 范围:[1, 65535] | 254 |
| 学习目标 | 是 | 二分类任务的学习目标 | Logloss |
| 迭代次数 | 是 | 提升迭代次数,也是可以建立的最大树数 范围:[1, inf) | 1000 |
| 学习率 | 是 | 步长收缩率 范围:[0.01, 1.0] | 0.03 |
| 树最大深度 | 是 | 一个树的最大深度,建议在4-10之间,如出现不明原因的失败,请尝试调小该值或调大内存 范围:[1, 16]。 | 6 |
| L2正则化系数 | 是 | 代价函数的L2正则化项的系数,允许任何正值 范围:[0.0, inf)。 | 3 |
| 样本采样随机种子 | 否 | 样本采样随机种子 范围:[0, inf)。 | 0 |
| 采样类型 | 否 | 目前三种类型:Bayesian、Bernoulli、MVS。 | MVS |
| 特征列子采样比例 | 否 | 特征列子采样比例 范围:[0.01, 1.0]。 | 1.00 |
| Bagging强度 | 否 | Bagging强度,范围:[0.01, 1.0]。 | 1.00 |
| 提升模式 | 否 | 提升模式,目前两种类型:Ordered、Plain | Plain |
| 计算叶子节点值的方法 | 否 | 计算叶子节点值的方法,目前支持Gradient和Newton。 | Gradient |
| 是否采用输入数据的顺序 | 否 | 是否采用输入数据的顺序 | 关闭 |
| 随机子空间 | 否 | 随机子空间 | 1.00 |
| 线程数 | 否 | 默认-1表示按CPU核数。要获得最佳速度,请将其设置为实际CPU内核数,而不是线程数(大多数CPU使用超线程为每个CPU内核生成2个线程)。如果数据集很小,请不要将其设置得太大 范围:[0, inf) | 0 |
字段参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 特征列 | 是 | 训练和预测使用的特征列,可以是数值、数值数组、类别类型;当包含类别特征时,需要对类别特征进行标识,且类别特征不能包含空值。 | 无 |
| 标签列 | 是 | 预测目标列,要求是整数或字符串类型,唯一值是2。 | 无 |
| 正样本标签值 | 否 | 二分类的正样本的标签值,应在标签列中存在。 | 无 |
| 类别特征标示 | 否 | 当特征列(不包括Label列)包含【类别】特征时,需要将类别特征单独标示出来,仅支持int或者string类型,不支持空值,选择的列需要是特征列的子集。 | 无 |
使用示例
- 构建算子结构,配置参数,完成训练。
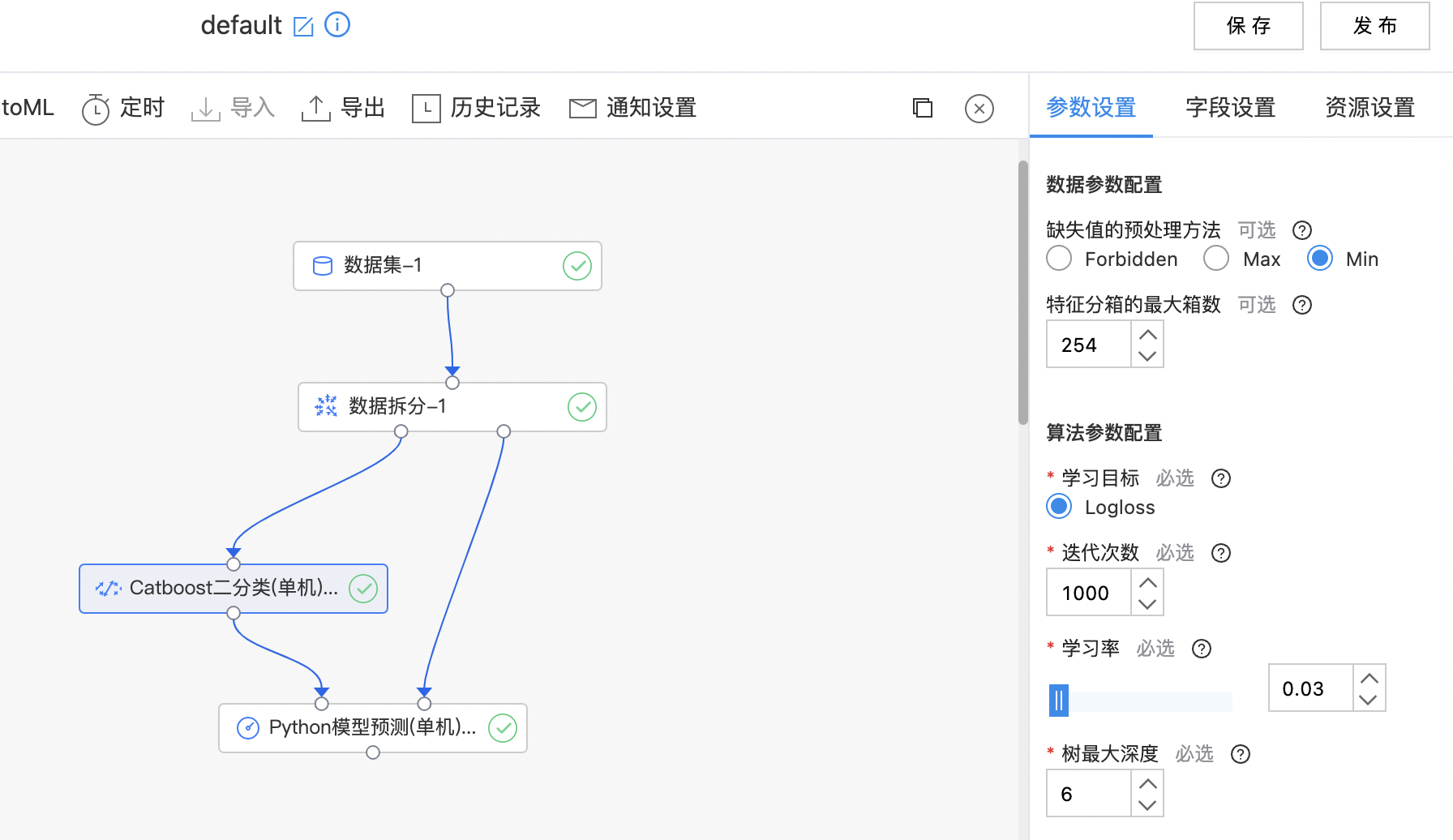
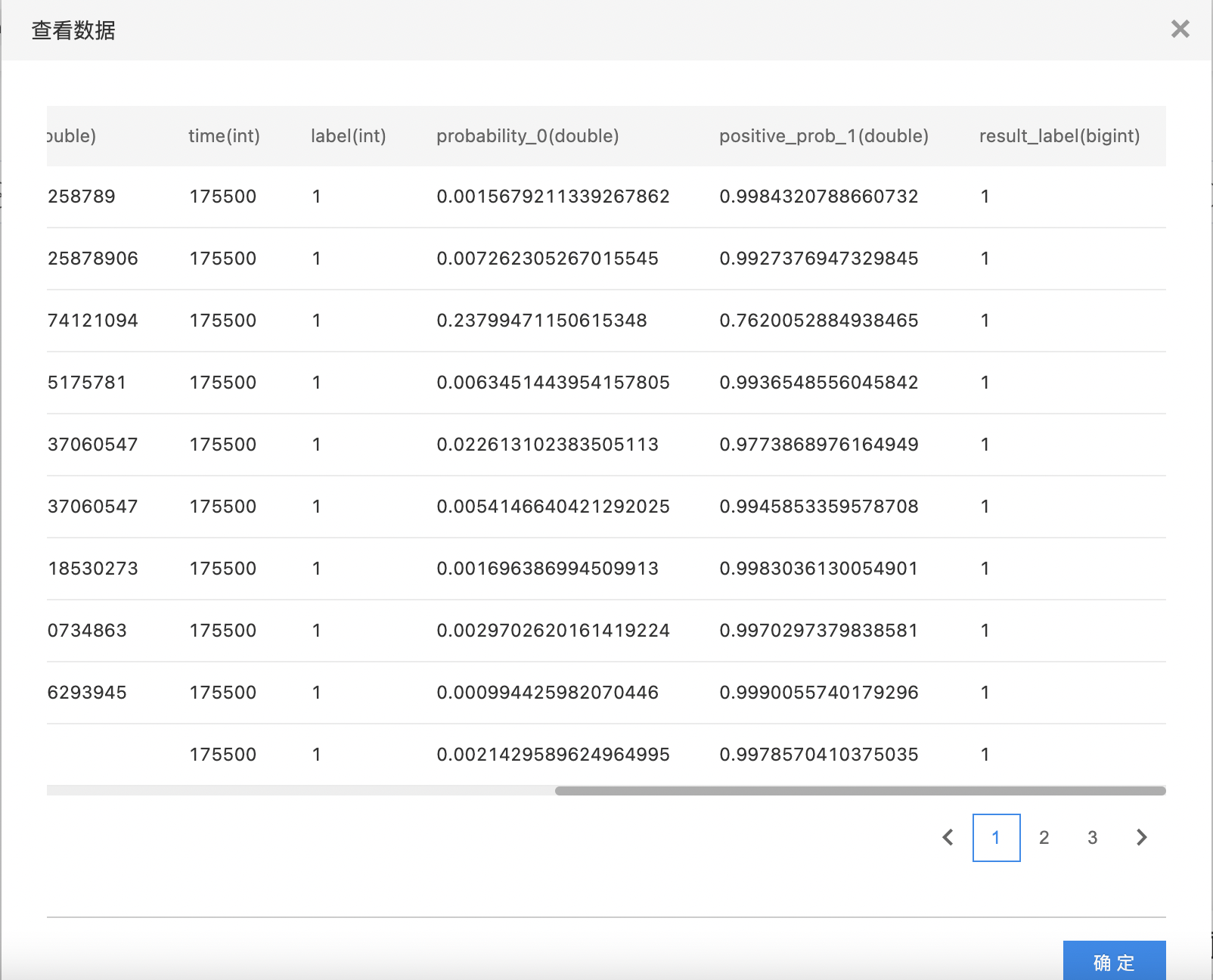
- 查看训练结果。
Catboost多分类(单机)
Catboost多分类与二分类算法原理一致,运用sotfmax和ova(一对多)的方式实现多分类。
输入
- 输入一个数据集,特征列是数值或数值数组类型,或者类别类型(字符串类型),多分类任务标签列需要是整数或字符串类型,标签唯一值大于2。
输出
- 输出Catboost多分类(单机)模型,支持查看Top10分类的概率。
算子参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 缺失值的预处理方法 | 否 | 三种缺失值处理方法,Forbidden: 不支持缺失值、Min: 缺失值赋值为最小值、Max: 缺失值赋值为最大值,默认用最小值补缺失值,类别特征不支持空值和填充 | Min |
| 特征分箱的最大箱数 | 否 | 特征值分箱的最大箱数,较少的分箱数可能会降低训练的准确性,但可能会提高总体训练效果(处理过拟合) 范围:[1, 65535] | 254 |
| 学习目标 | 是 | 多分类任务的学习目标, 如果出现内存溢出或不明原因的失败,请尝试调大内存或者减少树的深度。目前支持MultiClassoftmax)和MultiClassOneVsALL(ova)。 | MultiClass(softmax) |
| 迭代次数 | 是 | 提升迭代次数,也是可以建立的最大树数 范围:[1, inf) | 1000 |
| 学习率 | 是 | 步长收缩率 范围:[0.01, 1.0] | 0.03 |
| 树最大深度 | 是 | 一个树的最大深度,建议在4-10之间,如出现不明原因的失败,请尝试调小该值或调大内存 范围:[1, 16]。 | 6 |
| L2正则化系数 | 是 | 代价函数的L2正则化项的系数,允许任何正值 范围:[0.0, inf)。 | 3 |
| 样本采样随机种子 | 否 | 样本采样随机种子 范围:[0, inf)。 | 0 |
| 采样类型 | 否 | 目前三种类型:Bayesian、Bernoulli、MVS。 | MVS |
| 特征列子采样比例 | 否 | 特征列子采样比例 范围:[0.01, 1.0]。 | 1.00 |
| Bagging强度 | 否 | Bagging强度,范围:[0.01, 1.0]。 | 1.00 |
| 提升模式 | 否 | 提升模式,目前两种类型:Ordered、Plain | Plain |
| 计算叶子节点值的方法 | 否 | 计算叶子节点值的方法,目前支持Gradient和Newton。 | Gradient |
| 是否采用输入数据的顺序 | 否 | 是否采用输入数据的顺序 | 关闭 |
| 随机子空间 | 否 | 随机子空间 | 1.00 |
| 线程数 | 否 | 默认-1表示按CPU核数。要获得最佳速度,请将其设置为实际CPU内核数,而不是线程数(大多数CPU使用超线程为每个CPU内核生成2个线程)。如果数据集很小,请不要将其设置得太大 范围:[0, inf) | 0 |
字段参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 特征列 | 是 | 训练和预测使用的特征列,可以是数值、数值数组、类别类型;当包含类别特征时,需要对类别特征进行标识,且类别特征不能包含空值。 | 无 |
| 标签列 | 是 | 预测目标列,要求是整数或字符串类型。 | 无 |
| 类别特征标示 | 否 | 当特征列(不包括Label列)包含【类别】特征时,需要将类别特征单独标示出来,仅支持int或者string类型,不支持空值,选择的列需要是特征列的子集。 | 无 |
使用示例
- 构建算子结构,配置参数,完成训练。
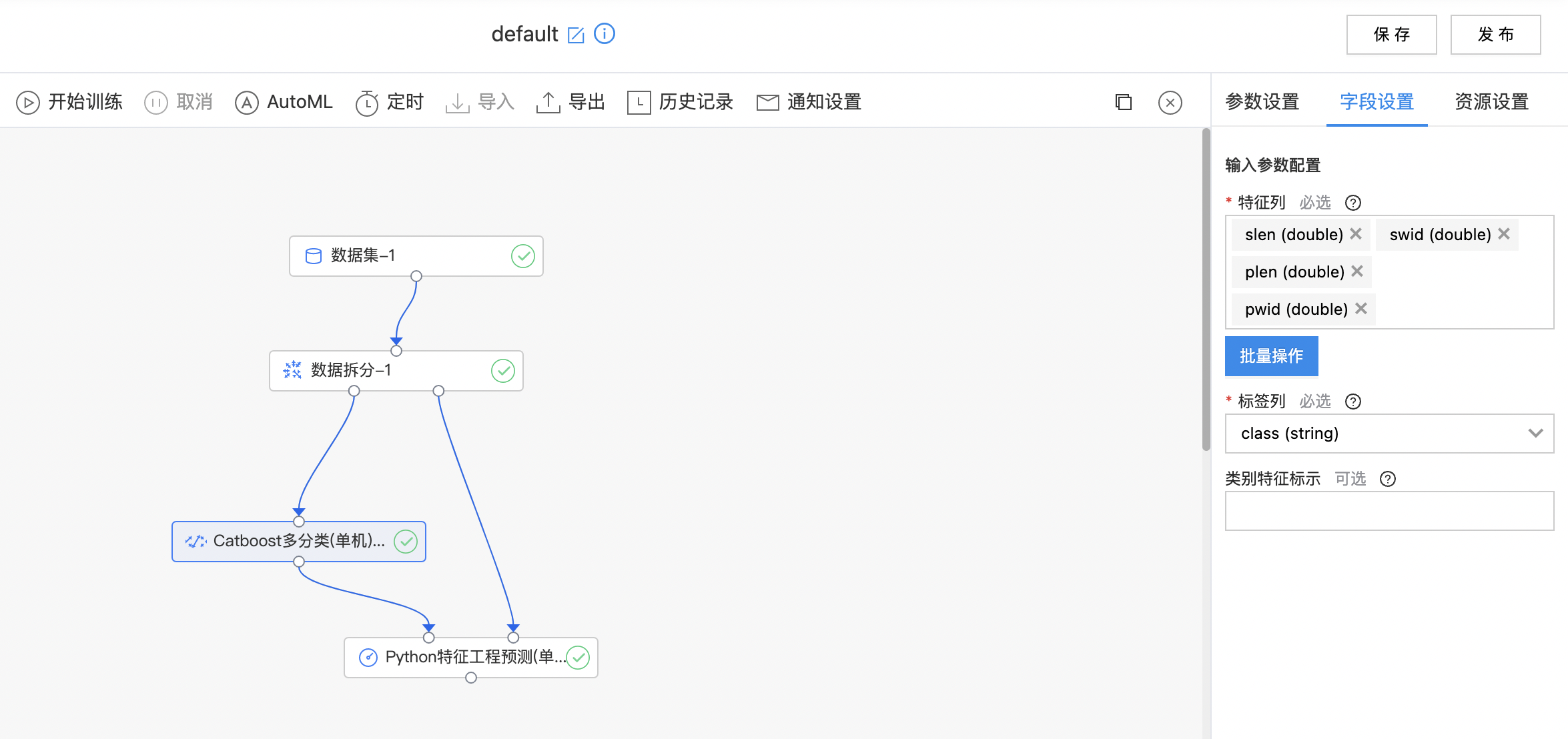
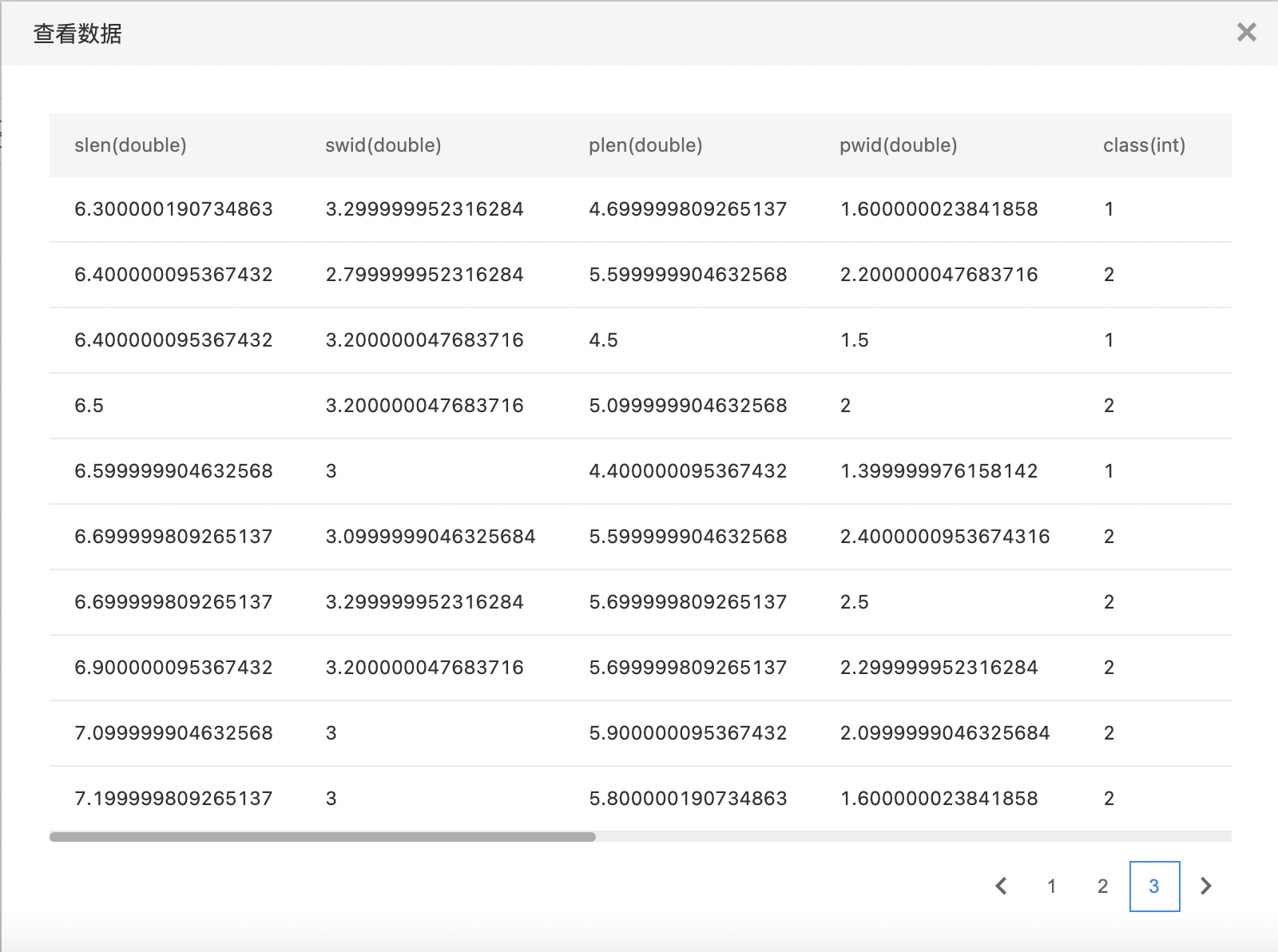
- 查看训练结果。
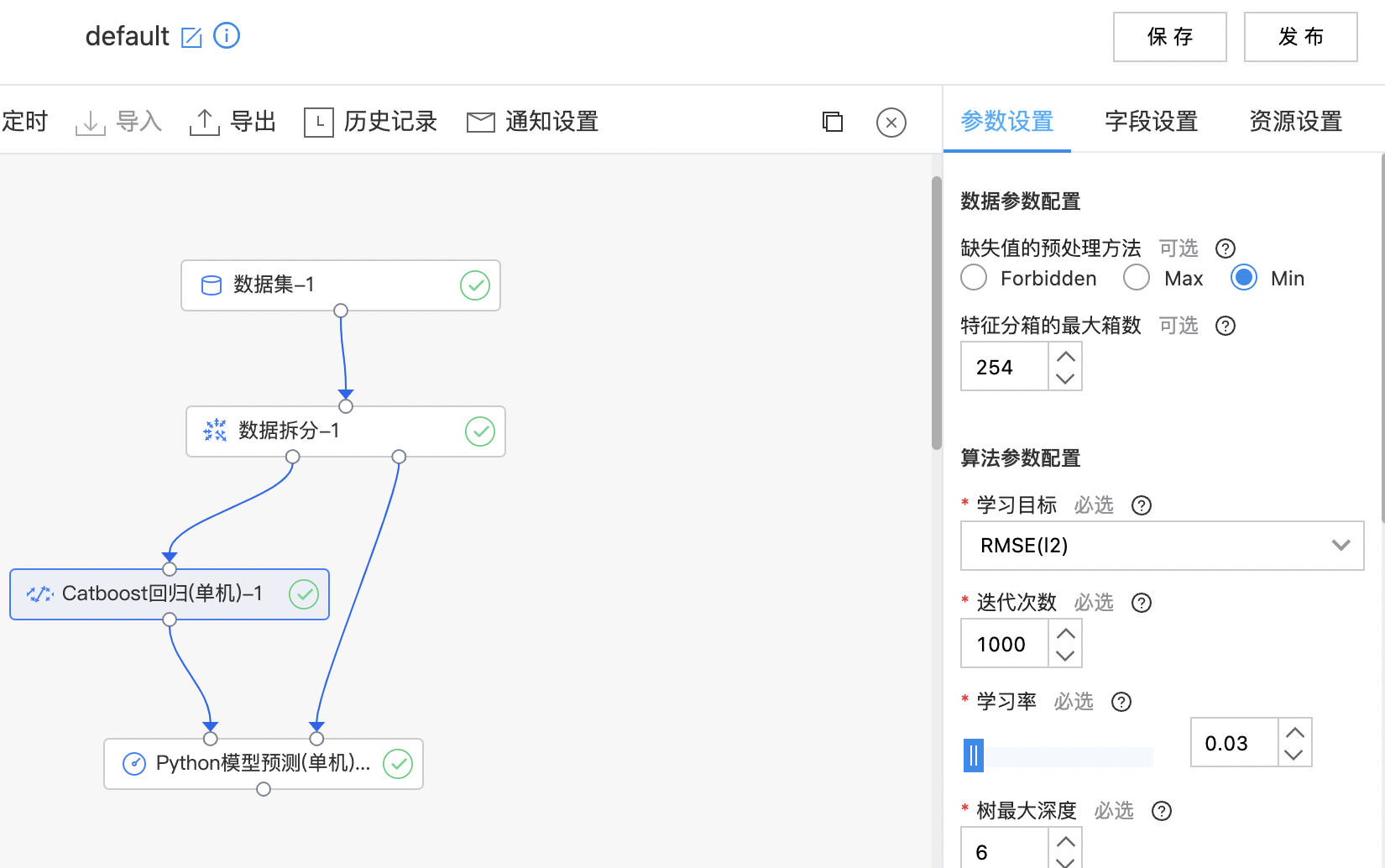
Catboost回归(单机)
Catboost支持回归任务,不同于分类任务,回归任务的学习目标使用RMSE、MAE、Poisson、Tweedie等。
输入
- 输入一个数据集,特征列是数值或数值数组类型,或者类别类型(字符串类型),标签列需要是数值类型,对于回归任务目标函数gamma,要求标签列是正的,对于回归任务目标函数tweedie,要求标签列是非负的。
输出
- 输出Catboost回归(单机)模型。
算子参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 缺失值的预处理方法 | 否 | 三种缺失值处理方法,Forbidden: 不支持缺失值、Min: 缺失值赋值为最小值、Max: 缺失值赋值为最大值,默认用最小值补缺失值,类别特征不支持空值和填充 | Min |
| 特征分箱的最大箱数 | 否 | 特征值分箱的最大箱数,较少的分箱数可能会降低训练的准确性,但可能会提高总体训练效果(处理过拟合) 范围:[1, 65535] | 254 |
| 学习目标 | 是 | 回归任务的学习目标: RMSE(l2) MAE(l1) Poisson Tweedie |
RMSE(l2) |
| 迭代次数 | 是 | 提升迭代次数,也是可以建立的最大树数 范围:[1, inf) | 1000 |
| 学习率 | 是 | 步长收缩率 范围:[0.01, 1.0] | 0.03 |
| 树最大深度 | 是 | 一个树的最大深度,建议在4-10之间,如出现不明原因的失败,请尝试调小该值或调大内存 范围:[1, 16]。 | 6 |
| L2正则化系数 | 是 | 代价函数的L2正则化项的系数,允许任何正值 范围:[0.0, inf)。 | 3 |
| 样本采样随机种子 | 否 | 样本采样随机种子 范围:[0, inf)。 | 0 |
| 采样类型 | 否 | 目前三种类型:Bayesian、Bernoulli、MVS。 | MVS |
| 特征列子采样比例 | 否 | 特征列子采样比例 范围:[0.01, 1.0]。 | 1.00 |
| Bagging强度 | 否 | Bagging强度,范围:[0.01, 1.0]。 | 1.00 |
| 提升模式 | 否 | 提升模式,目前两种类型:Ordered、Plain | Plain |
| 计算叶子节点值的方法 | 否 | 计算叶子节点值的方法,目前支持Gradient和Newton。 | Gradient |
| 是否采用输入数据的顺序 | 否 | 是否采用输入数据的顺序 | 关闭 |
| 随机子空间 | 否 | 随机子空间 | 1.00 |
| 线程数 | 否 | 默认-1表示按CPU核数。要获得最佳速度,请将其设置为实际CPU内核数,而不是线程数(大多数CPU使用超线程为每个CPU内核生成2个线程)。如果数据集很小,请不要将其设置得太大 范围:[0, inf) | 0 |
字段参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 特征列 | 是 | 训练和预测使用的特征列,可以是数值、数值数组、类别类型;当包含类别特征时,需要对类别特征进行标识,且类别特征不能包含空值。 | 无 |
| 标签列 | 是 | 预测目标列,要求是数值类型。 | 无 |
| 类别特征标示 | 否 | 当特征列(不包括Label列)包含【类别】特征时,需要将类别特征单独标示出来,仅支持int或者string类型,不支持空值,选择的列需要是特征列的子集。 | 无 |
使用示例
构建算子结构,配置参数,完成训练。
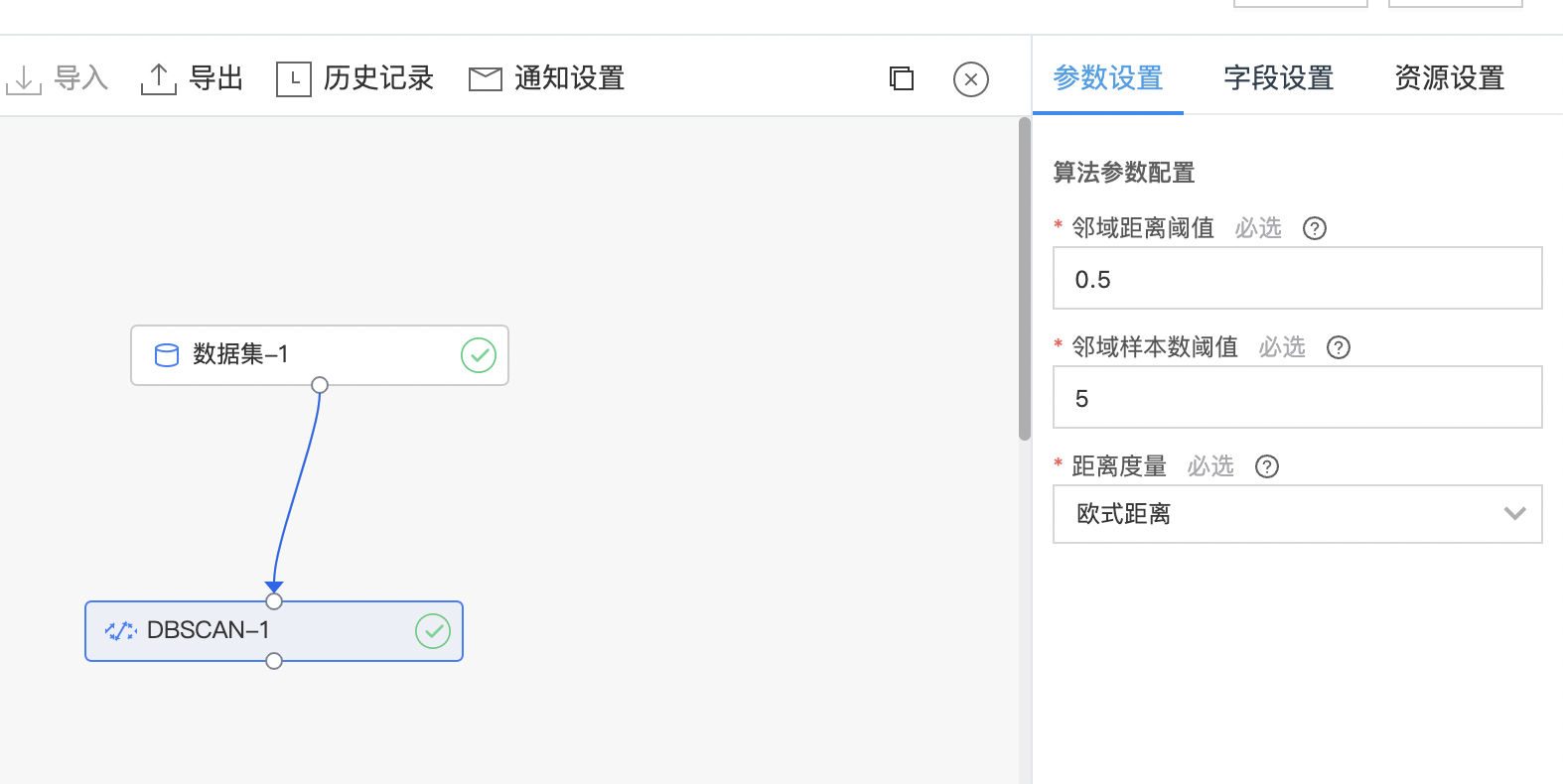
DBSCAN
DBSCAN(Density-Based Spatial Clustering of Applications with Noise,具有噪声的基于密度的聚类方法)是一种很典型的密度聚类算法,和 K-Means,BIRCH 这些一般只适用于凸样本集的聚类相比,DBSCAN 既可以适用于凸样本集,也可以适用于非凸样本集。这类密度聚类算法一般假定类别可以通过样本分布的紧密程度决定。同一类别的样本,他们之间的紧密相连的,也就是说,在该类别任意样本周围不远处一定有同类别的样本存在。通过将紧密相连的样本划为一类,这样就得到了一个聚类类别。通过将所有各组紧密相连的样本划为各个不同的类别,则我们就得到了最终的所有聚类类别结果。
输入
- 输入一个数据集,数据集的特征列必须是数值或数值数组类型。
输出
- 输出DBSCAN模型。
算子参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 邻域距离阈值 | 是 | 一个样本在另一个样本的邻域内的最大距离。这不是簇中点之间距离的最大界限。这是最重要的DBSCAN参数,可以根据数据集和距离函数进行适当选择。 范围:[0.01, inf) | 0.5 |
| 邻域样本数阈值 | 是 | 将某个点视为核心点的邻域中的样本数(包括点本身)。 范围:[2, inf) | 5 |
| 距离度量 | 是 | 提供两种距离度量方式:欧式距离(euclidean)和曼哈顿距离(manhattan)。 | 欧式距离 |
字段参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 特征列 | 是 | 支持数值或数值数组类型。 | 无 |
计算逻辑

使用示例
- 构建算子结构,配置参数,完成训练。
- 查看输出结果。
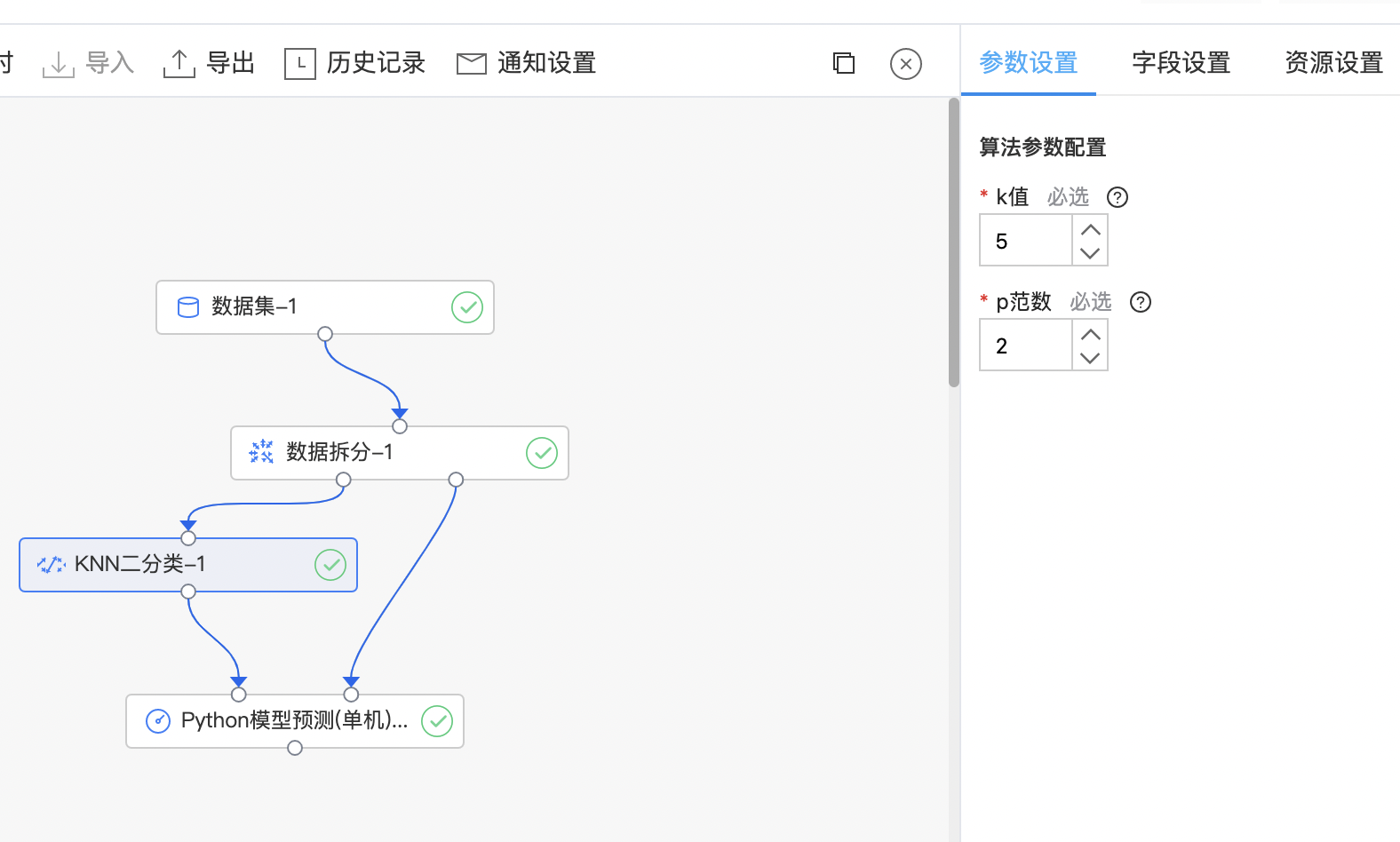
KNN二分类
k 近邻(KNN)是一种常用的监督学习方法,其工作机制非常简单:给定测试样本,基于某种距离度量找出训练集中与其最靠近的 k 个训练样本,然后基于这 k 个“邻居”的信息来进行预测。通常,在分类任务中可使用“投票法”,即选择这 k 个样本中出现最多的类别标记作为预测结果。 k 近邻没有显式的学习过程。事实上,它是懒惰学习(lazy learning)的著名代表,此类学习技术在训练阶段仅仅是把样本保存起来,训练时间开销为零,待收到测试样本后再进行处理。 KNN 二分类:利用 k 近邻学习方法完成二分类任务。
输入
- 输入一个数据集,数据集的特征列必须是数值或数值数组类型,标签列必须是整数类型或字符串类型(如果列中的unique值超过了两种,运行算子时会报错)。
输出
- 输出KNN二分类模型。
算子参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| k值 | 是 | k值选择,要求不大于样本个数 范围:[1, 100] | 5 |
| p范数 | 是 | Lp距离度量,常用p=1,2 范围:[1, 10] | 2 |
字段参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 特征列 | 是 | 预测使用的特征列,要求必须是数值或数值数组类型。 | 无 |
| 标签列 | 是 | 预测目标列,要求是整数或字符串类型,唯一值是2。 | 无 |
| 正样本标签值 | 否 | 二分类的正样本的标签值,应在标签列中存在。 | 无 |
使用示例
- 构建算子结构,配置参数,完成训练。
- 查看训练结果。
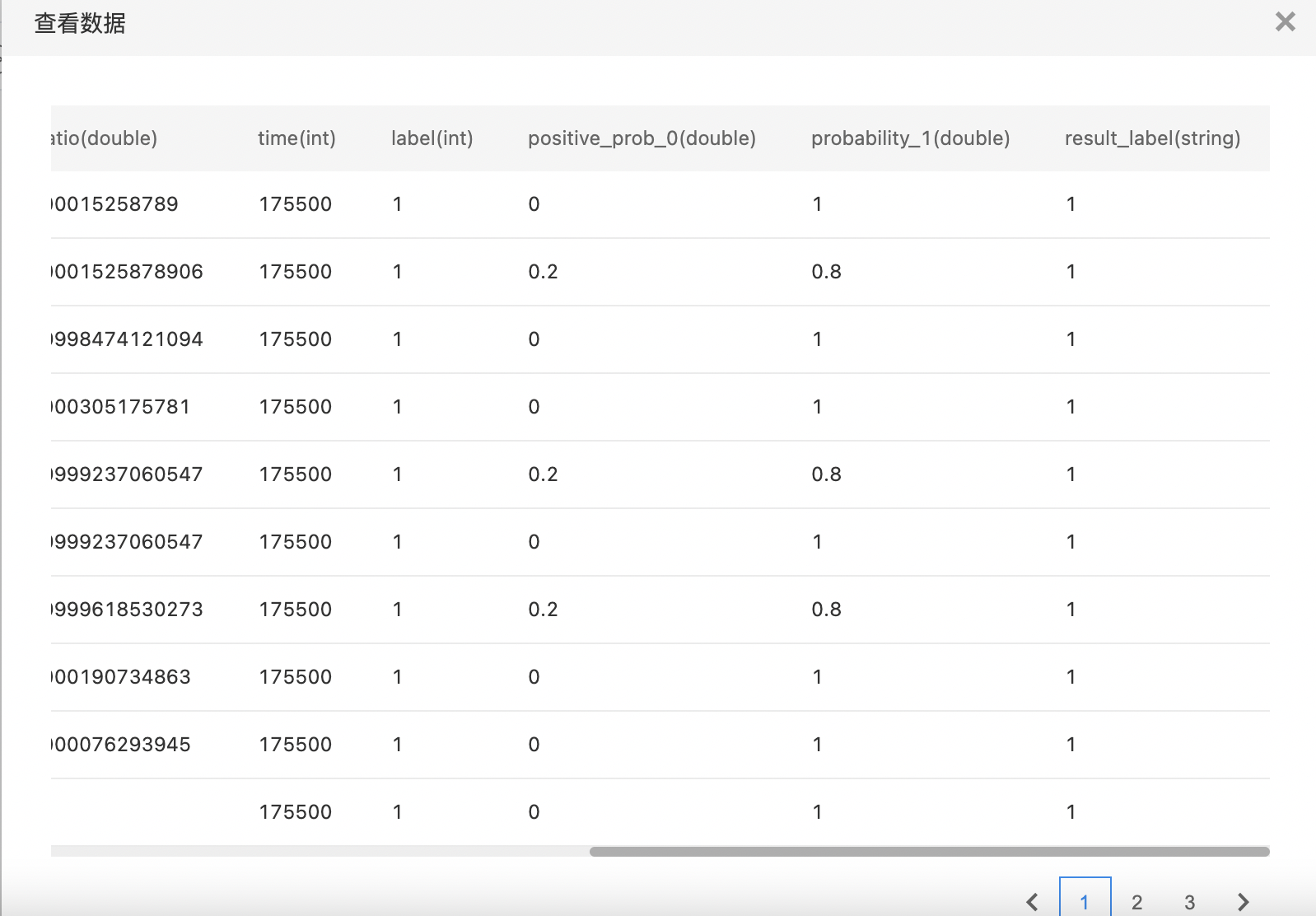
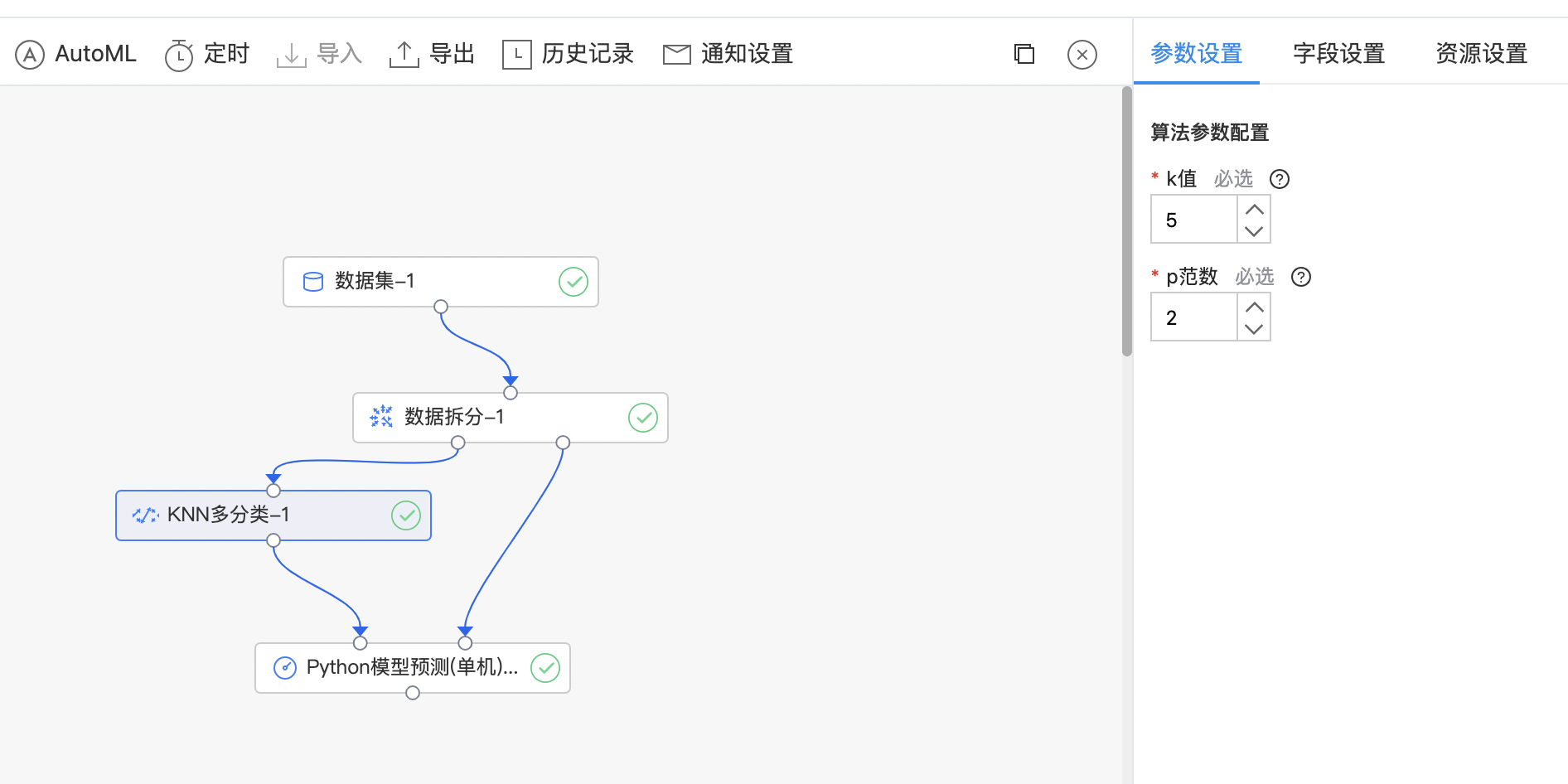
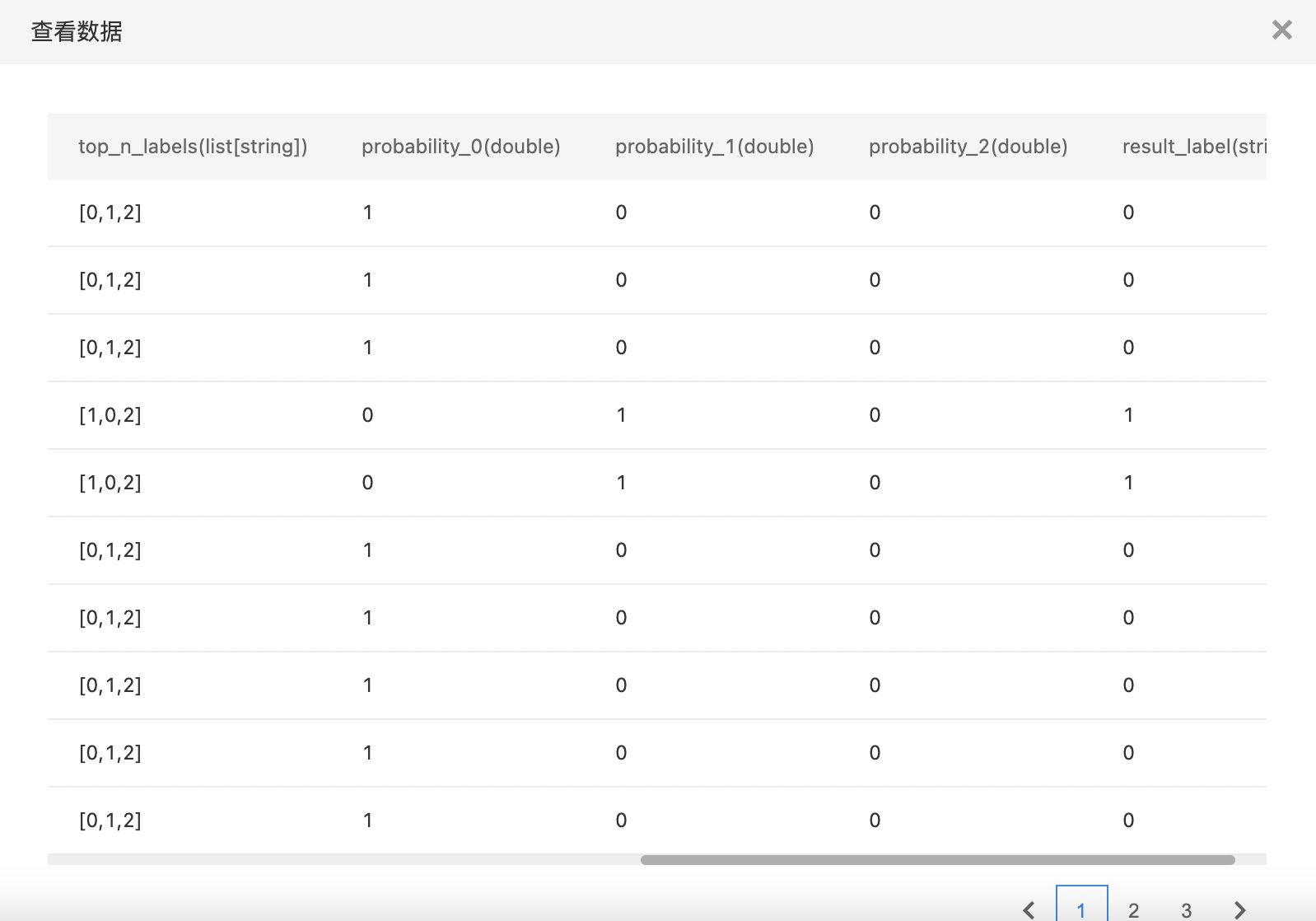
KNN多分类
KNN多分类任务即已分类样本中含两个以上的类别,待分类样本计算距离最近的K个样本,根据"投票法"确定样本分类。
输入
- 输入一个数据集,数据集的特征列必须是数值或数值数组类型,标签列必须是整数类型或字符串类型(如果列中的unique值不足三种,运行算子时会报错)。
输出
- 输出KNN多分类模型,支持查看Top10分类的概率。
算子参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| k值 | 是 | k值选择,要求不大于样本个数 范围:[1, 100] | 5 |
| p范数 | 是 | Lp距离度量,常用p=1,2 范围:[1, 10] | 2 |
字段参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 特征列 | 是 | 预测使用的特征列,要求必须是数值或数值数组类型。 | 无 |
| 标签列 | 是 | 预测目标列,要求是整数或字符串类型。 | 无 |
- 构建算子结构,配置参数,完成训练。
- 查看训练结果。
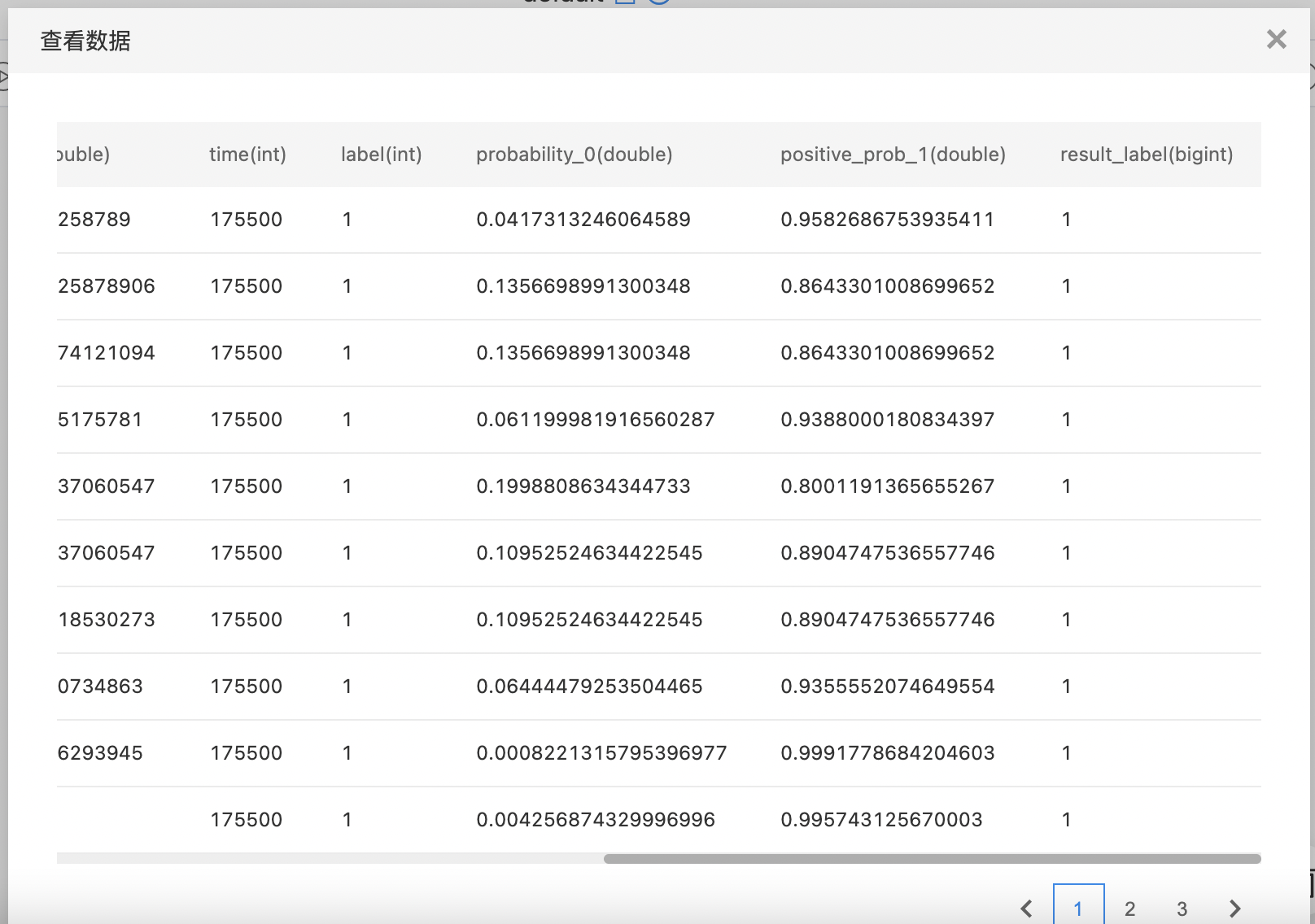
LightGBM二分类(单机)
提升树是利用加模型与前向分布算法实现学习的优化过程,它有一些高效实现,如XGBoost,GBDT等。其中GBDT采用负梯度作为划分的指标(信息增益),XGBoost则利用到二阶导数。他们共同的不足是,计算信息增益需要扫描所有样本,从而找到最优划分点。在面对大量数据或者特征维度很高时,他们的效率和扩展性很难使人满意。微软开源的LightGBM(基于GBDT的)则很好的解决这些问题,它主要包含两个算法:
GOSS(从减少样本角度):排除大部分小梯度的样本,仅用剩下的样本计算信息增益。
EFB(从减少特征角度):捆绑互斥特征,也就是他们很少同时取非零值(也就是用一个合成特征代替)。
输入
- 输入一个数据集,特征列需要是数值或数值数组类型,标签列需要是整数或字符串类型,标签唯一值为2。
输出
- 输出LightGBM二分类(单机)模型。
算子参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 两轮加载 | 是 | 如果数据文件太大而无法放入内存,可以设置两轮加载。 | 关闭 |
| 0作为缺失值 | 是 | 将加载数据中的所有0值作为缺失值,否则np.nan表示缺失值。 | 关闭 |
| 特征最大分箱数 | 是 | 特征值分箱的最大箱数。较少的分箱数可能会降低训练的准确性,但可能会提高总体训练效果(处理过拟合) 范围:[2, inf)。 | 255 |
| 学习目标 | 是 | 二分类任务的学习目标。 | logistic |
| 迭代次数 | 是 | 提升迭代次数 范围:[1, 200]。 | 100 |
| 学习率 | 是 | 步长收缩率 范围:[0.01, 1.0]。 | 0.10 |
| 树最大叶子数 | 是 | 每棵树的最大叶子数 范围:[2, 131072]。 | 31 |
| 划分最小信息增益 | 是 | 划分树(叶子)节点所需的最小信息增益 范围:[0.0, inf) | 0.0 |
| 叶子节点最小样本数 | 是 | 每个叶子节点的最小样本数。可用于处理过拟合 范围:[0, inf)。 | 20 |
| 叶子节点最小样本权重和 | 是 | 每个叶子节点的最小样本权重和。可用于处理过拟合 范围:[0.0, inf)。 | 0.001 |
| 样本采样频率 | 是 | 0表示禁用样本采样;k表示每k次迭代执行一次样本采样。要启用样本采样,[样本采样比例]的值也应设置为小于1.0 范围:[0, inf)。 | 0 |
| 样本采样比例 | 是 | 随机选择部分样本。可用于加快训练。可用于处理过拟合 范围:[0.01, 1.0]。 | 1.00 |
| 正样本采样比例 | 是 | 用于不平衡的二分类问题,将随机采样[正样本数*正样本采样比例]个正样本。应该与[负样本采样比例]一起使用。将此设置为1.0以禁用。如果启用了平衡采样(值设置为小于1.0),则将忽略[样本采样比例] 范围:[0.01, 1.0] | 1.00 |
| 负样本采样比例 | 是 | 用于不平衡的二分类问题,将随机采样[负样本数*负样本采样比例]个负样本。应该与[正样本采样比例]一起使用。将此设置为1.0以禁用。如果启用了平衡采样(值设置为小于1.0),则将忽略[样本采样比例] 范围:[0.01, 1.0] | 1.00 |
| 样本采样随机种子 | 是 | 样本采样随机种子 | 3 |
| 树特征采样比例 | 是 | 如果值小于1.0,将在每次迭代(树)上随机选择部分特征。可用于加快训练。可用于处理过拟合 范围:[0.01, 1.0]。 | 1.00 |
| 树节点特征采样比例 | 是 | 如果值小于1.0,将在每个树节点上随机选择部分特征。可用于处理过拟合。与树特征采样比例不同,这无法加快训练速度。每个树节点最终的特征采样比例为[树特征采样比例*树节点特征采样比例] 范围:[0.01, 1.0] | 1.00 |
| 特征采样随机种子 | 是 | 特征采样随机种子 | 2 |
| L1正则化系数 | 是 | 权重的L1正则化项 范围:[0.0, inf)。 | 0.0 |
| L2正则化系数 | 是 | 权重的L2正则化项 范围:[0.0, inf)。 | 0.0 |
| 提升算法 | 是 | 目前支持两种提升算法:gbdt(梯度提升决策树)、rf(随机森林);如果选择rf,需要设置「样本采样频率」大于0、「样本采样比例」大于0且小于1,这是rf算法本身隐含约束。 | gbdt |
| 线程数 | 是 | 0表示OpenMP中的默认线程数。要获得最佳速度,请将其设置为实际CPU内核数,而不是线程数(大多数CPU使用超线程为每个CPU内核生成2个线程)。如果数据集很小,请不要将其设置得太大 范围:[0, 16] | 0 |
字段参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 特征列 | 是 | 预测使用的特征列,要求必须是数值或数值数组类型。 | 无 |
| 标签列 | 是 | 预测目标列,要求是整数或字符串类型,唯一值是2。 | 无 |
| 正样本标签值 | 否 | 二分类的正样本的标签值,应在标签列中存在。 | 无 |
使用示例
- 构建算子结构,配置参数,完成训练。

- 查看训练结果。
LightGBM多分类(单机)
LightGBM多分类与二分类算法原理一致,运用sotfmax和ova(一对多)的方式实现多分类。
输入
- 输入一个数据集,特征列需要是数值或数值数组类型,标签列需要是整数或字符串类型,标签唯一值大于2。
输出
- 输出LightGBM多分类(单机)模型,支持查看Top10分类的概率。
算子参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 两轮加载 | 是 | 如果数据文件太大而无法放入内存,可以设置两轮加载。 | 关闭 |
| 0作为缺失值 | 是 | 将加载数据中的所有0值作为缺失值,否则np.nan表示缺失值。 | 关闭 |
| 特征最大分箱数 | 是 | 特征值分箱的最大箱数。较少的分箱数可能会降低训练的准确性,但可能会提高总体训练效果(处理过拟合) 范围:[2, inf)。 | 255 |
| 学习目标 | 是 | 多分类任务的学习目标,目前支持:softmax和ova。 | softmax |
| 迭代次数 | 是 | 提升迭代次数 范围:[1, 200]。 | 100 |
| 学习率 | 是 | 步长收缩率 范围:[0.01, 1.0]。 | 0.10 |
| 树最大叶子数 | 是 | 每棵树的最大叶子数 范围:[2, 131072]。 | 31 |
| 划分最小信息增益 | 是 | 划分树(叶子)节点所需的最小信息增益 范围:[0.0, inf) | 0.0 |
| 叶子节点最小样本数 | 是 | 每个叶子节点的最小样本数。可用于处理过拟合 范围:[0, inf)。 | 20 |
| 叶子节点最小样本权重和 | 是 | 每个叶子节点的最小样本权重和。可用于处理过拟合 范围:[0.0, inf)。 | 0.001 |
| 样本采样频率 | 是 | 0表示禁用样本采样;k表示每k次迭代执行一次样本采样。要启用样本采样,[样本采样比例]的值也应设置为小于1.0 范围:[0, inf)。 | 0 |
| 样本采样比例 | 是 | 随机选择部分样本。可用于加快训练。可用于处理过拟合 范围:[0.01, 1.0]。 | 1.00 |
| 样本采样随机种子 | 是 | 样本采样随机种子 | 3 |
| 树特征采样比例 | 是 | 如果值小于1.0,将在每次迭代(树)上随机选择部分特征。可用于加快训练。可用于处理过拟合 范围:[0.01, 1.0]。 | 1.00 |
| 树节点特征采样比例 | 是 | 如果值小于1.0,将在每个树节点上随机选择部分特征。可用于处理过拟合。与树特征采样比例不同,这无法加快训练速度。每个树节点最终的特征采样比例为[树特征采样比例*树节点特征采样比例] 范围:[0.01, 1.0] | 1.00 |
| 特征采样随机种子 | 是 | 特征采样随机种子 | 2 |
| L1正则化系数 | 是 | 权重的L1正则化项 范围:[0.0, inf)。 | 0.0 |
| L2正则化系数 | 是 | 权重的L2正则化项 范围:[0.0, inf)。 | 0.0 |
| 提升算法 | 是 | 目前支持两种提升算法:gbdt(梯度提升决策树)、rf(随机森林);如果选择rf,需要设置「样本采样频率」大于0、「样本采样比例」大于0且小于1,这是rf算法本身隐含约束。 | gbdt |
| 线程数 | 是 | 0表示OpenMP中的默认线程数。要获得最佳速度,请将其设置为实际CPU内核数,而不是线程数(大多数CPU使用超线程为每个CPU内核生成2个线程)。如果数据集很小,请不要将其设置得太大 范围:[0, 16] | 0 |
字段参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 特征列 | 是 | 预测使用的特征列,要求必须是数值或数值数组类型。 | 无 |
| 标签列 | 是 | 预测目标列,要求是整数或字符串类型。 | 无 |
使用示例
- 构建算子结构,配置参数,完成训练。
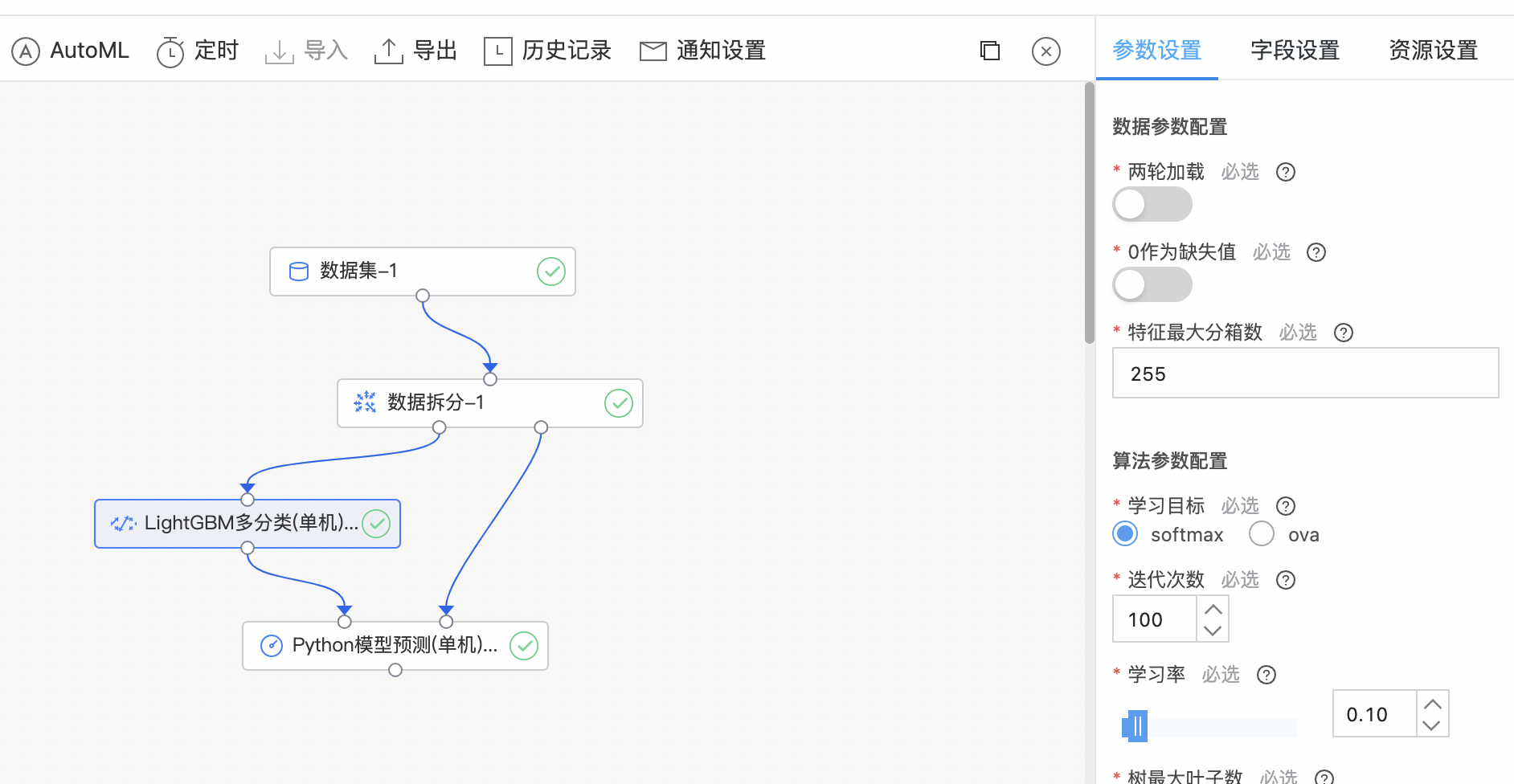
- 查看训练结果。
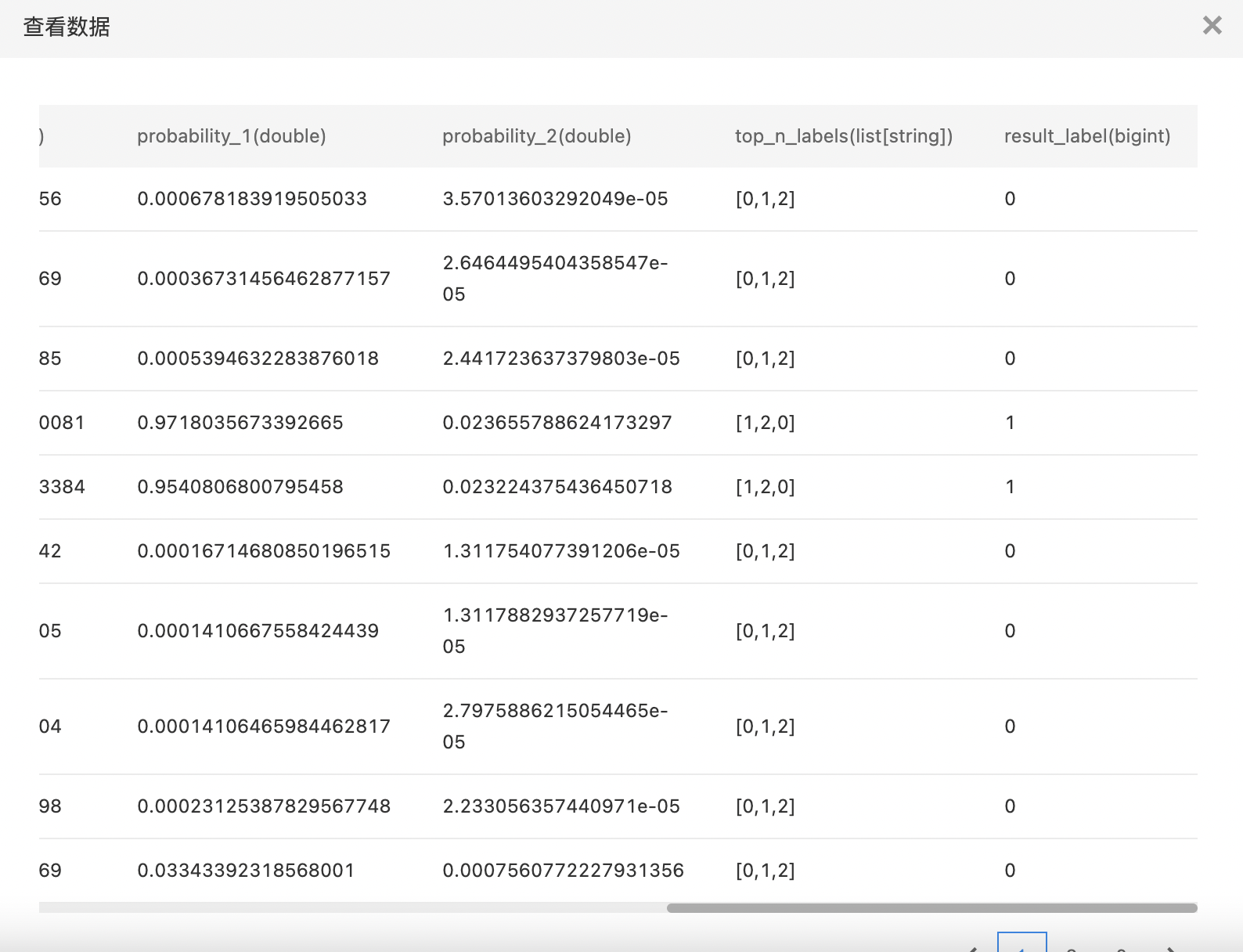
LightGBM回归(单机)
LightGBM支持回归任务,不同于分类任务,回归任务的学习目标使用gamma、tweedie、l1、l2等。
输入
- 输入一个数据集,特征列需要是数值或数值数组类型,回归任务标签列需要是数值类型,对于回归任务目标函数gamma,要求标签列是正的,对于回归任务目标函数tweedie,要求标签列是非负的。
输出
- 输出LightGBM回归(单机)模型。
算子参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 两轮加载 | 是 | 如果数据文件太大而无法放入内存,可以设置两轮加载。 | 关闭 |
| 0作为缺失值 | 是 | 将加载数据中的所有0值作为缺失值,否则np.nan表示缺失值。 | 关闭 |
| 特征最大分箱数 | 是 | 特征值分箱的最大箱数。较少的分箱数可能会降低训练的准确性,但可能会提高总体训练效果(处理过拟合) 范围:[2, inf)。 | 255 |
| 学习目标 | 是 | 回归任务的学习目标,目前支持: gamma tweedie l1 l2 |
L2 |
| 迭代次数 | 是 | 提升迭代次数 范围:[1, 200]。 | 100 |
| 学习率 | 是 | 步长收缩率 范围:[0.01, 1.0]。 | 0.10 |
| 树最大叶子数 | 是 | 每棵树的最大叶子数 范围:[2, 131072]。 | 31 |
| 划分最小信息增益 | 是 | 划分树(叶子)节点所需的最小信息增益 范围:[0.0, inf) | 0.0 |
| 叶子节点最小样本数 | 是 | 每个叶子节点的最小样本数。可用于处理过拟合 范围:[0, inf)。 | 20 |
| 叶子节点最小样本权重和 | 是 | 每个叶子节点的最小样本权重和。可用于处理过拟合 范围:[0.0, inf)。 | 0.001 |
| 样本采样频率 | 是 | 0表示禁用样本采样;k表示每k次迭代执行一次样本采样。要启用样本采样,[样本采样比例]的值也应设置为小于1.0 范围:[0, inf)。 | 0 |
| 样本采样比例 | 是 | 随机选择部分样本。可用于加快训练。可用于处理过拟合 范围:[0.01, 1.0]。 | 1.00 |
| 样本采样随机种子 | 是 | 样本采样随机种子 | 3 |
| 树特征采样比例 | 是 | 如果值小于1.0,将在每次迭代(树)上随机选择部分特征。可用于加快训练。可用于处理过拟合 范围:[0.01, 1.0]。 | 1.00 |
| 树节点特征采样比例 | 是 | 如果值小于1.0,将在每个树节点上随机选择部分特征。可用于处理过拟合。与树特征采样比例不同,这无法加快训练速度。每个树节点最终的特征采样比例为[树特征采样比例*树节点特征采样比例] 范围:[0.01, 1.0] | 1.00 |
| 特征采样随机种子 | 是 | 特征采样随机种子 | 2 |
| L1正则化系数 | 是 | 权重的L1正则化项 范围:[0.0, inf)。 | 0.0 |
| L2正则化系数 | 是 | 权重的L2正则化项 范围:[0.0, inf)。 | 0.0 |
| 提升算法 | 是 | 目前支持两种提升算法:gbdt(梯度提升决策树)、rf(随机森林);如果选择rf,需要设置「样本采样频率」大于0、「样本采样比例」大于0且小于1,这是rf算法本身隐含约束。 | gbdt |
| 线程数 | 是 | 0表示OpenMP中的默认线程数。要获得最佳速度,请将其设置为实际CPU内核数,而不是线程数(大多数CPU使用超线程为每个CPU内核生成2个线程)。如果数据集很小,请不要将其设置得太大 范围:[0, 16] | 0 |
字段参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 特征列 | 是 | 预测使用的特征列,要求必须是数值或数值数组类型。 | 无 |
| 标签列 | 是 | 预测目标列,要求是数值类型。 | 无 |
使用示例
构建算子结构,配置参数,完成训练。
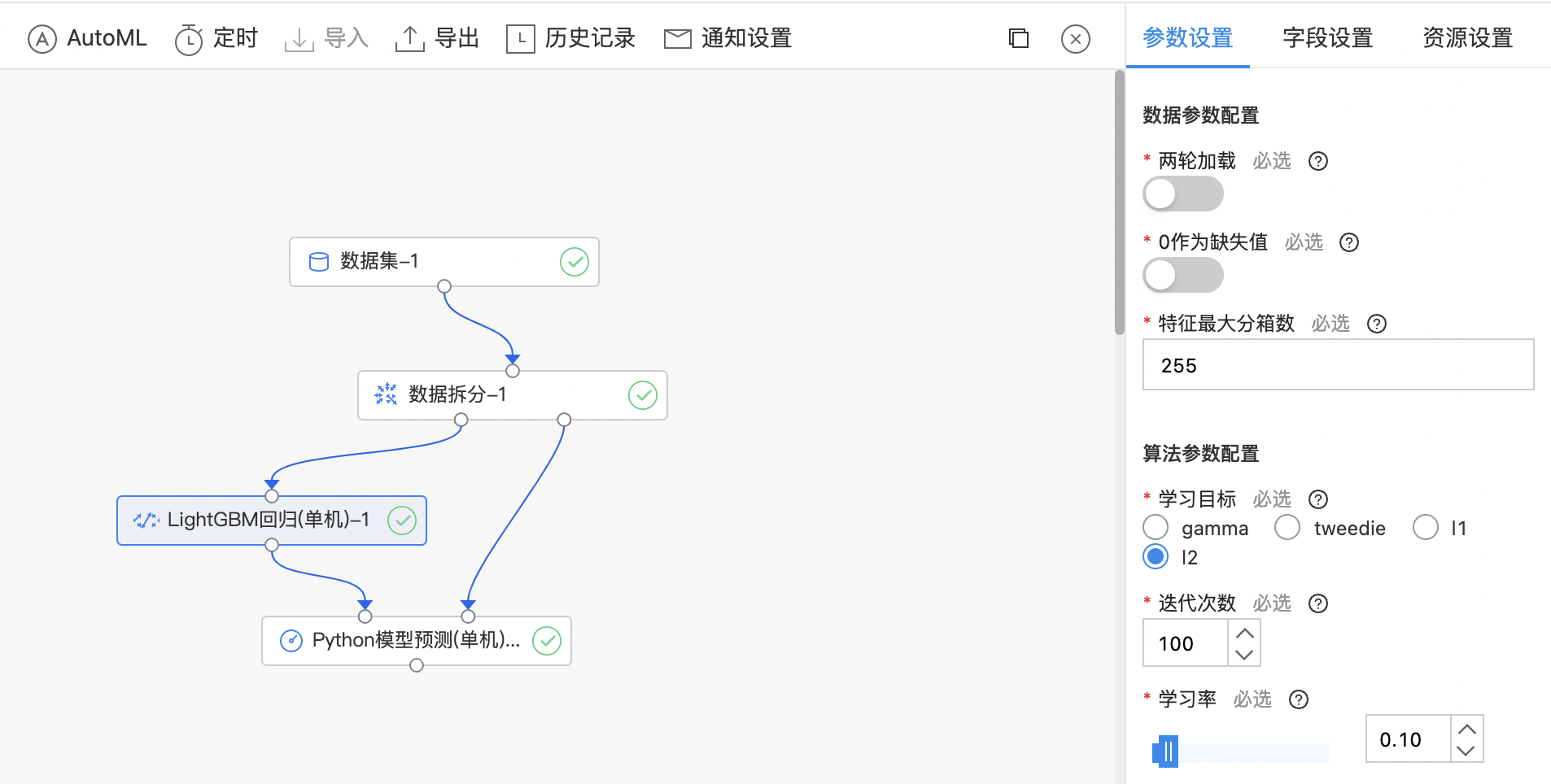
MxNet算法
MxNet 是一个深度学习框架,旨在提高效率和灵活性,允许混合符号和命令式编程,以最大限度地提高效率和生产力。 MxNet 算法组件:利用MxNet库编写自定义python代码,完成各类深度学习任务。该组件仅提供单机运行的模式。
输入
- 输入一个数据集作为训练集,编写Python代码。
输出
- 输出MxNet算法模型。
算子参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| Python 代码编辑窗口 | 是 | 输入Python 代码 |
函数说明
fit:模型训练方法,有且仅有dataset参数
transform:模型预测方法,有且仅有dataset参数,返回的预测结果为pandas.DataFrame
save:模型保存方法,有且仅有model_path参数
load:模型加载方法,有且仅有model_path参数使用示例
- 构建算子结构,编写python代码,完成训练。
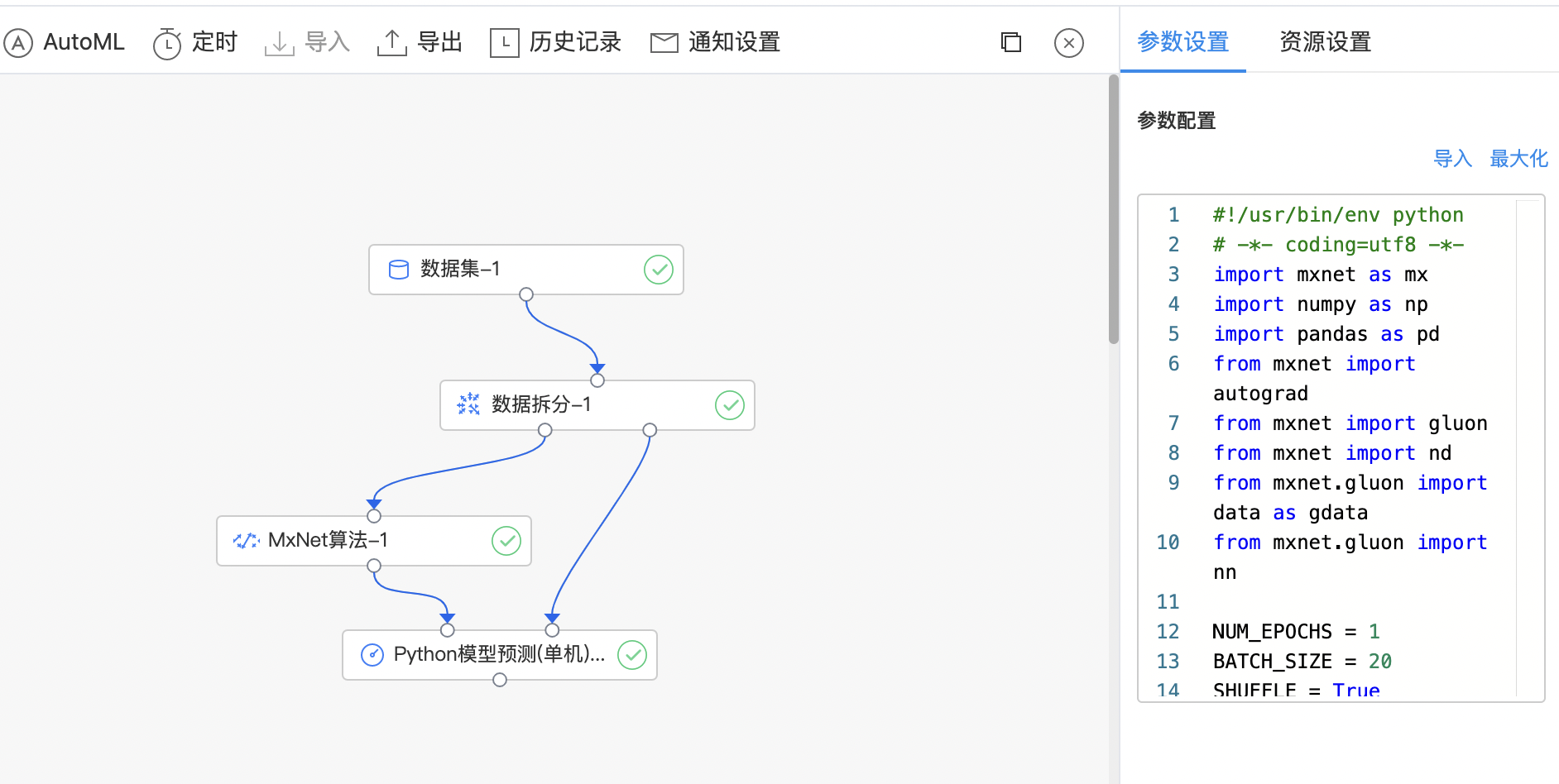
- 查看代码,本例中特征列为slen、swid、plen、pwid,标签列为class。
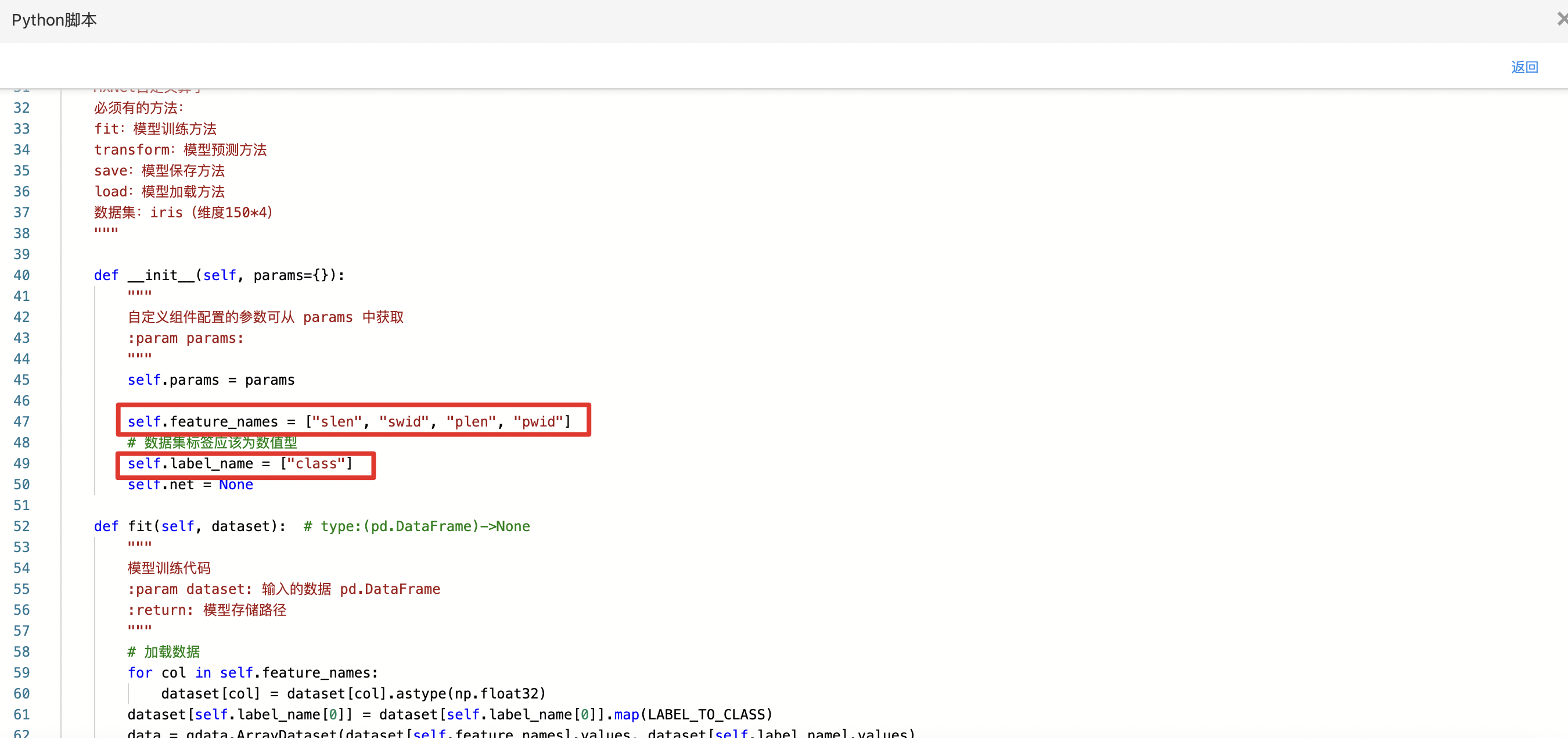
- 查看训练结果。
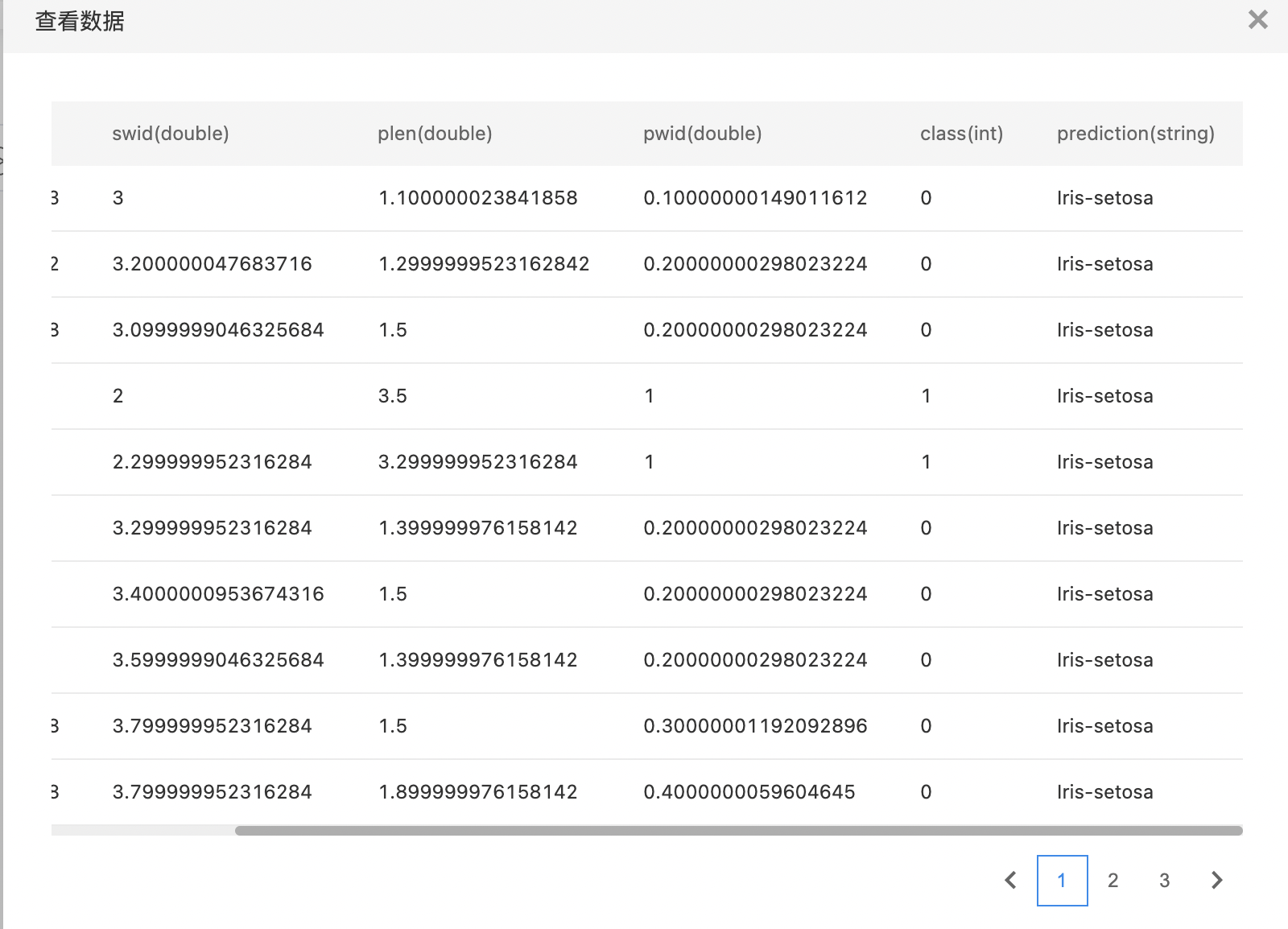
Paddle算法
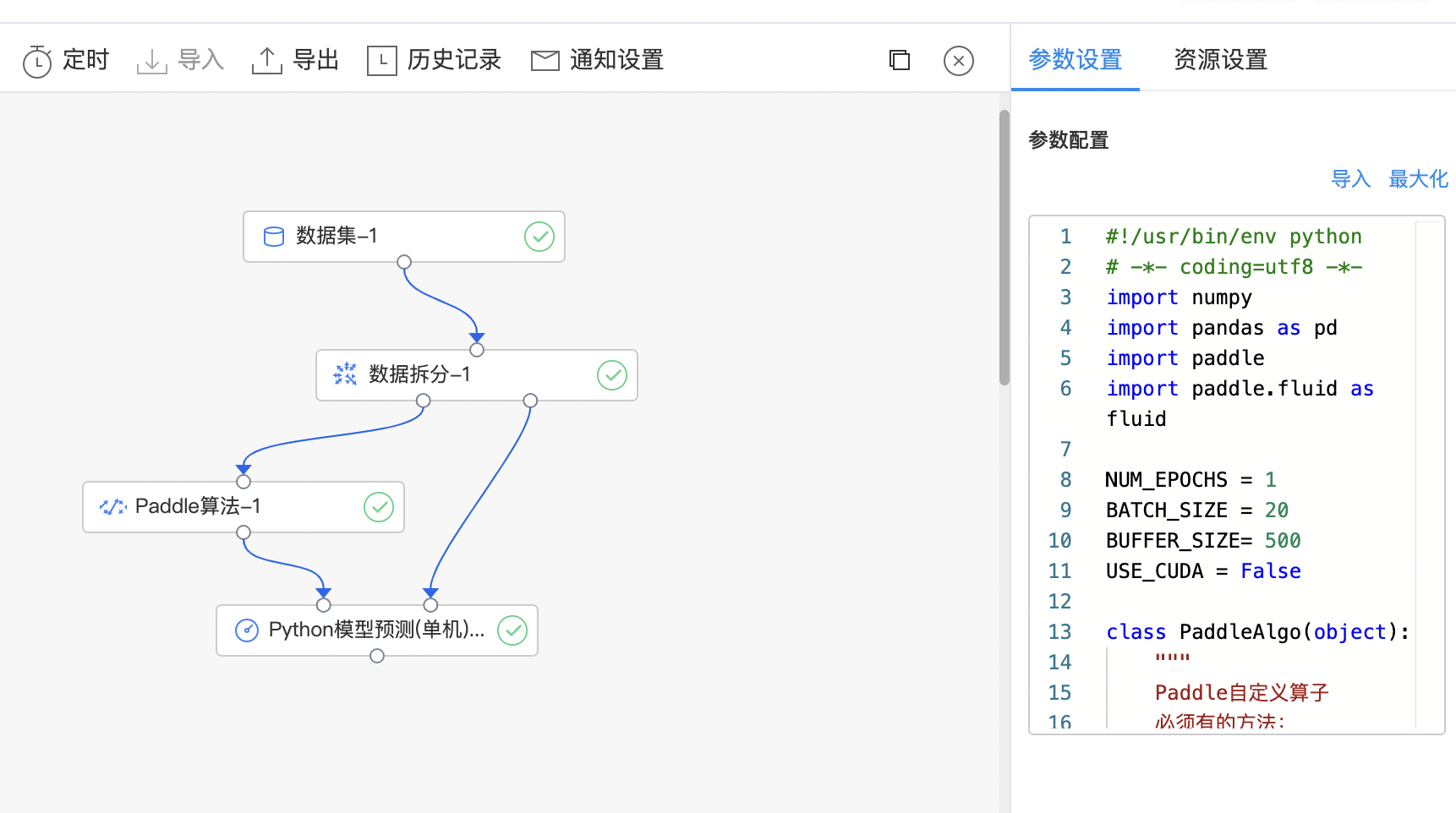
PaddlePaddle(PArallel Distributed Deep LEarning)是一个易用、高效、灵活、可扩展的深度学习框架。 Paddle 算法组件:利用 PaddlePaddle 库写自定义 python 代码,完成各类深度学习任务。
输入
- 输入训练数据集:paddle.reader,每行数据为pandas.core.series.Series格式数据;预测dataset:pandas.DataFrame,每行数据为pandas.core.series.Series格式数据。
输出
- 输出Paddle算法模型。
算子参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| Python 代码编辑窗口 | 是 | 输入Python 代码 |
函数说明
fit:模型训练方法,有且仅有dataset参数
transform:模型预测方法,有且仅有dataset参数,返回的预测结果为pandas.DataFrame
save:模型保存方法,有且仅有model_path参数
load:模型加载方法,有且仅有model_path参数使用示例
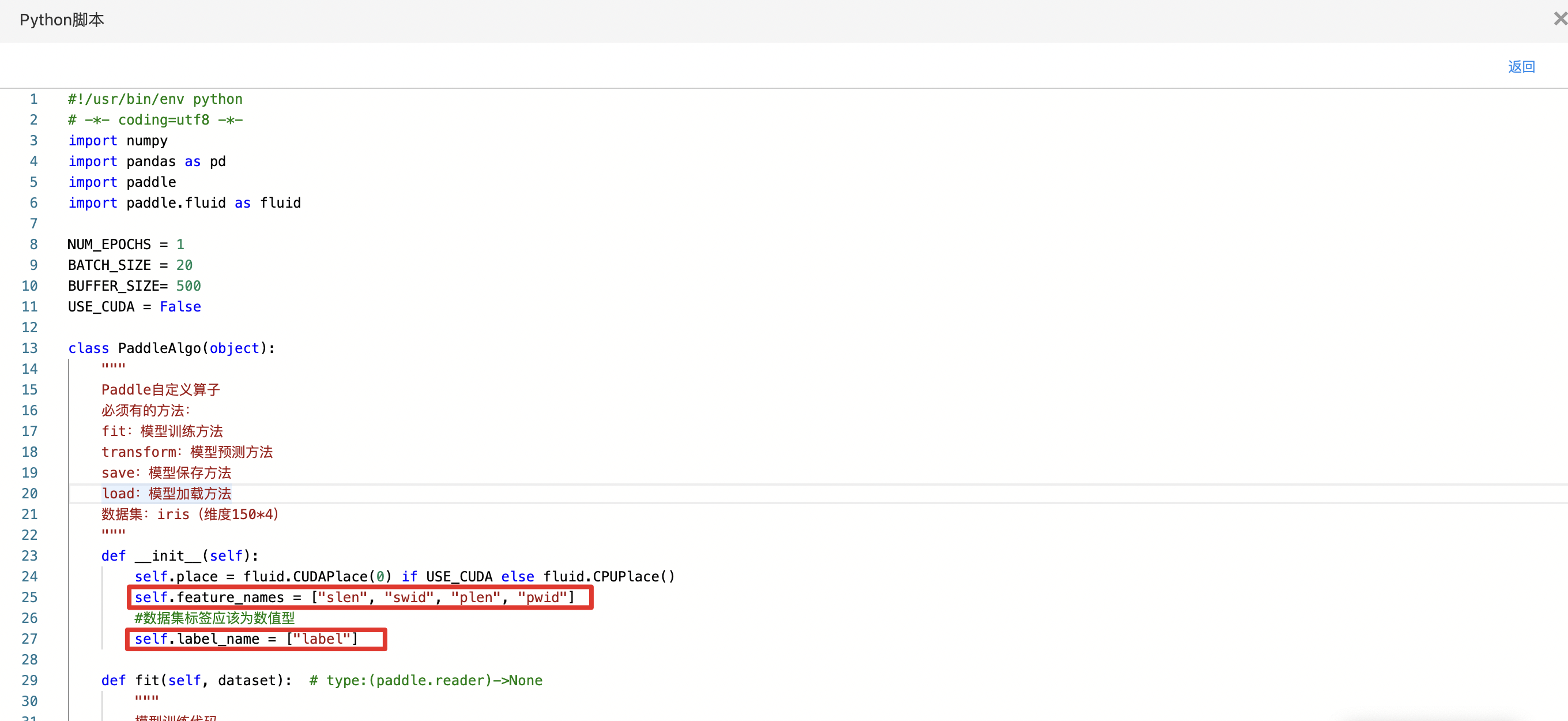
- 构建算子结构,编写python代码,完成训练。
- 查看代码,本例中特征列为slen、swid、plen、pwid,标签列为label。
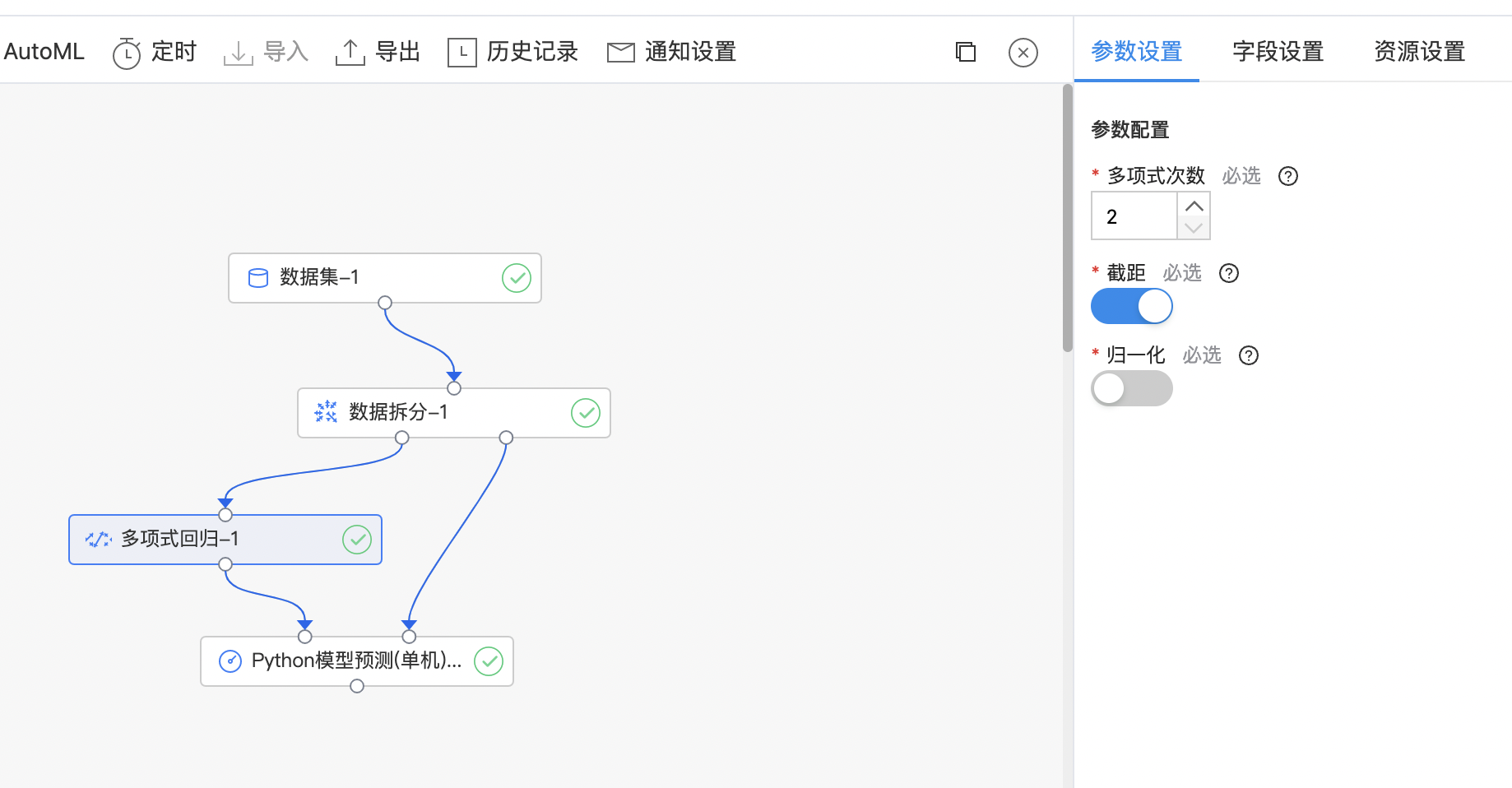
多项式回归
多项式回归,回归函数是回归变量多项式的回归。多项式回归模型是线性回归模型的一种,此时回归函数关于回归系数是线性的。由于任一函数都可以用多项式逼近,因此多项式回归有着广泛应用。 多项式回归模型通常使用最小二乘法来拟合。 实现原理:多项式扩展 + 线性回归。
输入
- 输入一个数据集,数据集的特征列double/int,标记列是Double或Int类型。
输出
- 输出多项式回归模型。
算子参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 多项式次数 | 是 | 多项式回归中选择的多项式次数 范围:[2, 8]。 | 2 |
| 截距 | 是 | 多项式回归中是否使用截距。 | 开启 |
| 归一化 | 是 | 多项式回归中是否使用归一化。 | 关闭 |
字段参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 特征列 | 是 | 预测使用的特征列,要求必须是数值或数值数组类型。 | 无 |
| 标签列 | 是 | 预测目标列,要求是数值类型。 | 无 |
使用示例
构建算子结构,配置参数,完成训练。
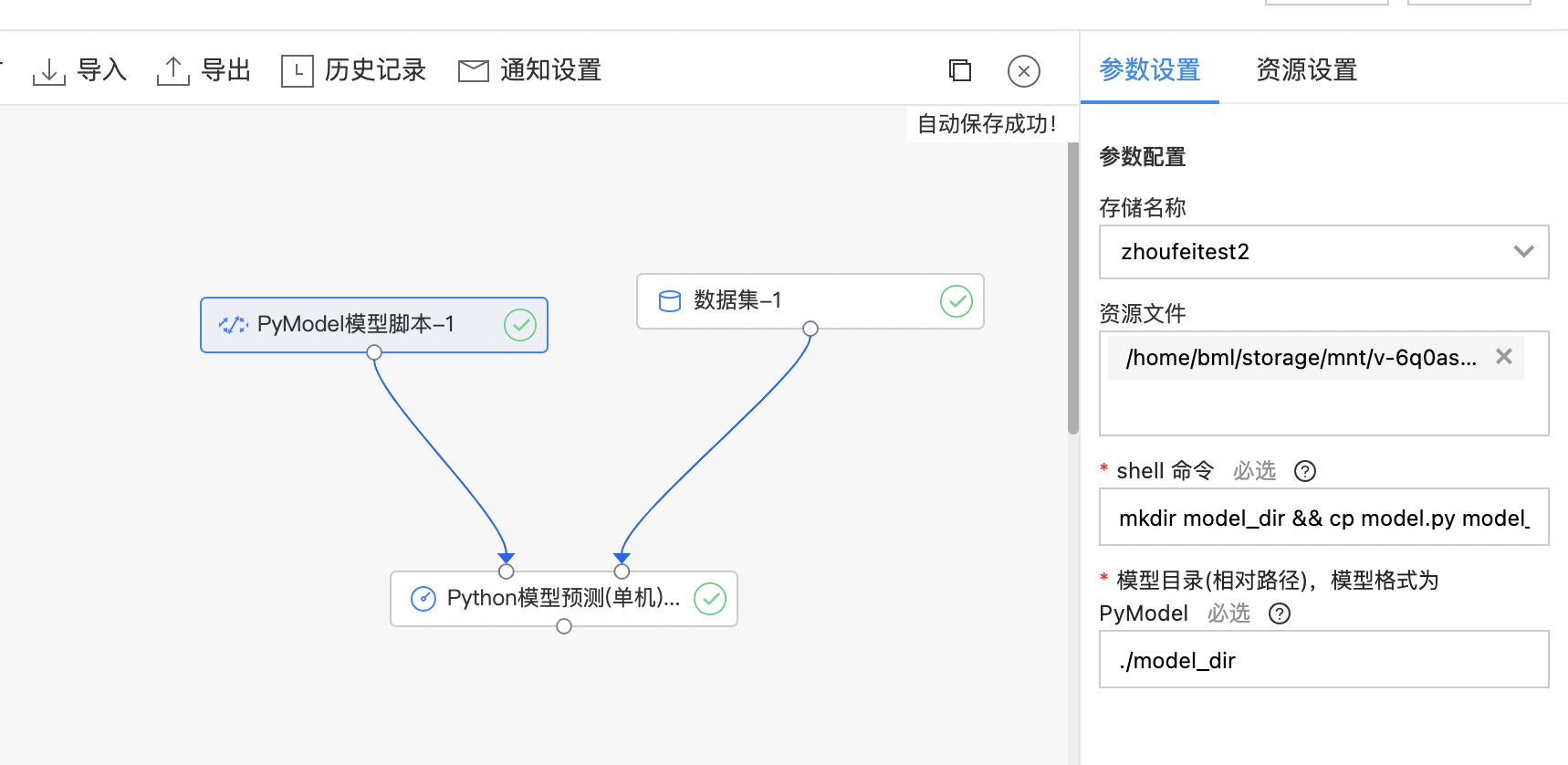
PyModel模型脚本
PyModel支持将上传的代码文件存放到用户填写的目录里面,同时还支持在算子里面用存储里的代码和数据集训练出模型,放到用户填写的目录里。
输入
- 输入选择存储中的文件,需要填写PyModel模型文件的存放路径。
输出
- 输出PyModel格式的模型。
算子参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 存储名称 | 是 | 选择存储名称 | 无 |
| 资源文件 | 是 | 选择上传的资源文件 | 无 |
| shell命令 | 是 | 算子执行的时候,会运行用户输入的shell命令,预期这个shell命令会在用户填写的模型目录产出一个PyModel格式的模型。 | sh man.sh |
| 模型目录(相对路径),模型格式为PyModel | 是 | 模型目录(相对路径),模型格式为 PyModel | ./model_dir |
使用示例
- 上传的示例文件如下,命名为model.py
#!/usr/bin/env python
# -*- coding=utf8 -*-
"""
python script
"""
import pandas as pd
class PyModel(object):
"""
运行环境为 Python 3
"""
def transform(self, dataset): # type:(pd.DataFrame)->pd.DataFrame
"""
:param dataset:
:return:
"""
return pd.DataFrame([{'prediction': 0}])
def load(self):
"""
:return:
"""
pass- 选择存储名称、资源文件(model.py),shell脚本输入框填写"mkdir model_dir && cp model.py model_dir",完成训练。
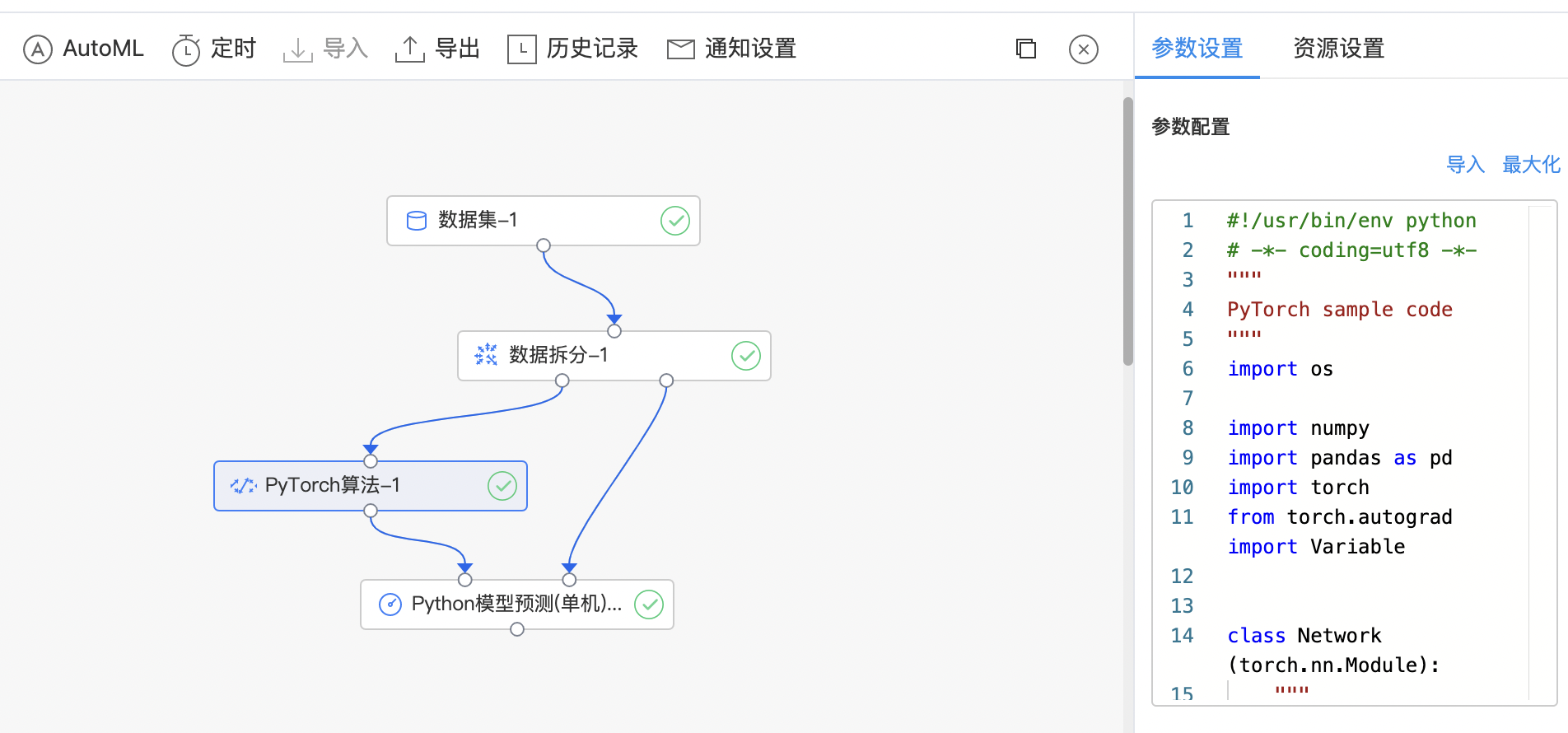
PyTorch算法
PyTorch 是使用 GPU 和 CPU 优化的深度学习张量库。 自定义 PyTorch 代码组件:利用 PyTorch 库写自定义 python 代码,完成各类深度学习任务。
输入
- 输入一个数据集作为训练集,编写Python代码。
输出
- 输出PyTorch算法模型。
算子参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| Python 代码编辑窗口 | 是 | 输入Python 代码 |
函数说明
fit:模型训练方法,有且仅有dataset参数
transform:模型预测方法,有且仅有dataset参数,返回的预测结果为pandas.DataFrame
save:模型保存方法,有且仅有model_path参数
load:模型加载方法,有且仅有model_path参数使用示例
- 构建算子结构,编写python代码,完成训练。
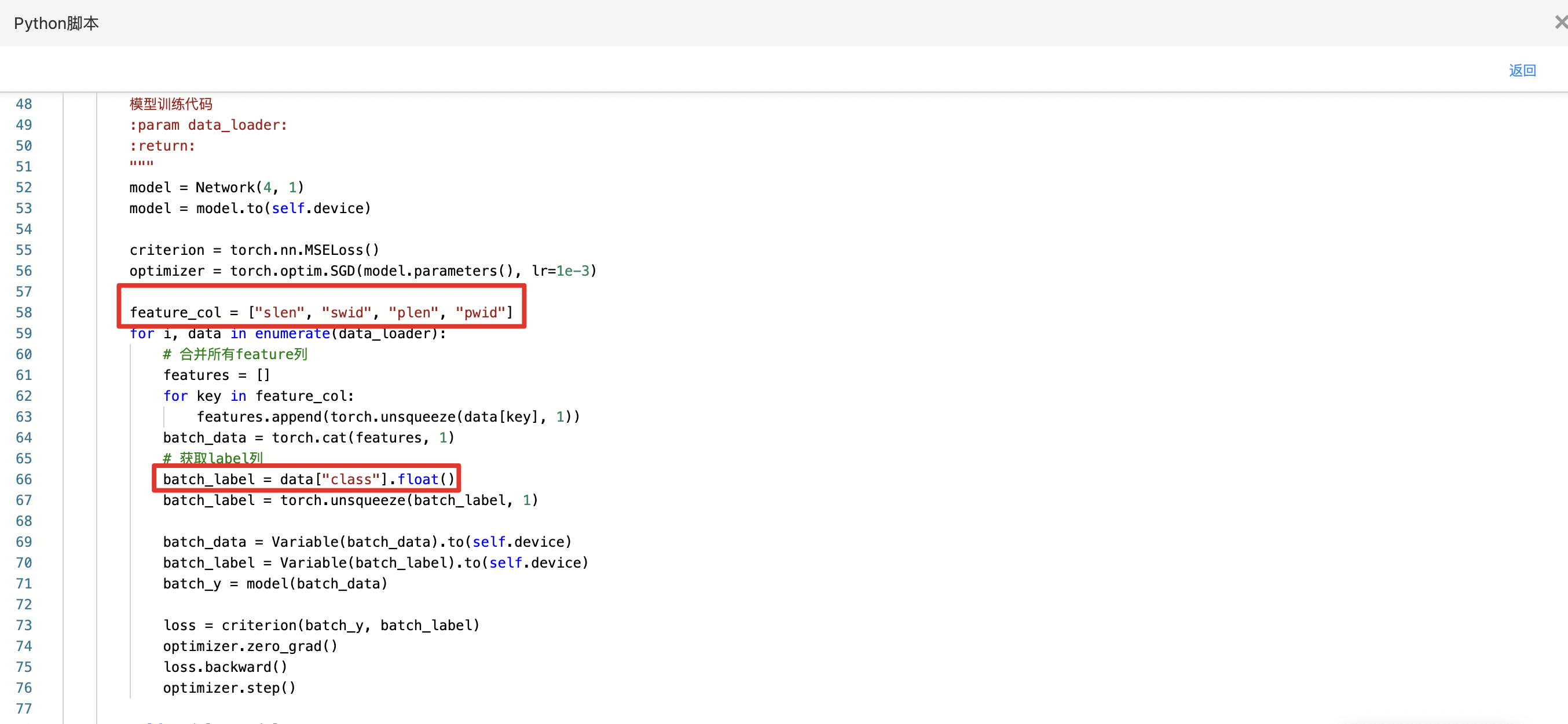
- 查看代码,本例中特征列为slen、swid、plen、pwid,标签列为class。
Sklearn算法
scikit-learn 是基于 Python 语言的机器学习工具。它是建立在 NumPy ,SciPy 和 matplotlib 上的简单高效的数据挖掘和数据分析工具。 自定义 Sklearn 代码组件:利用 scikit-learn 库写自定义 python 代码,完成各类机器学习任务。
输入
- 输入一个数据集作为训练集,编写Python代码。
输出
- 输出Sklearn算法模型。
算子参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| Python 代码编辑窗口 | 是 | 输入Python 代码 |
函数说明
fit:模型训练方法,有且仅有dataset参数
transform:模型预测方法,有且仅有dataset参数,返回的预测结果为pandas.DataFrame
save:模型保存方法,有且仅有model_path参数
load:模型加载方法,有且仅有model_path参数使用示例
- 构建算子结构,编写python代码,完成训练。
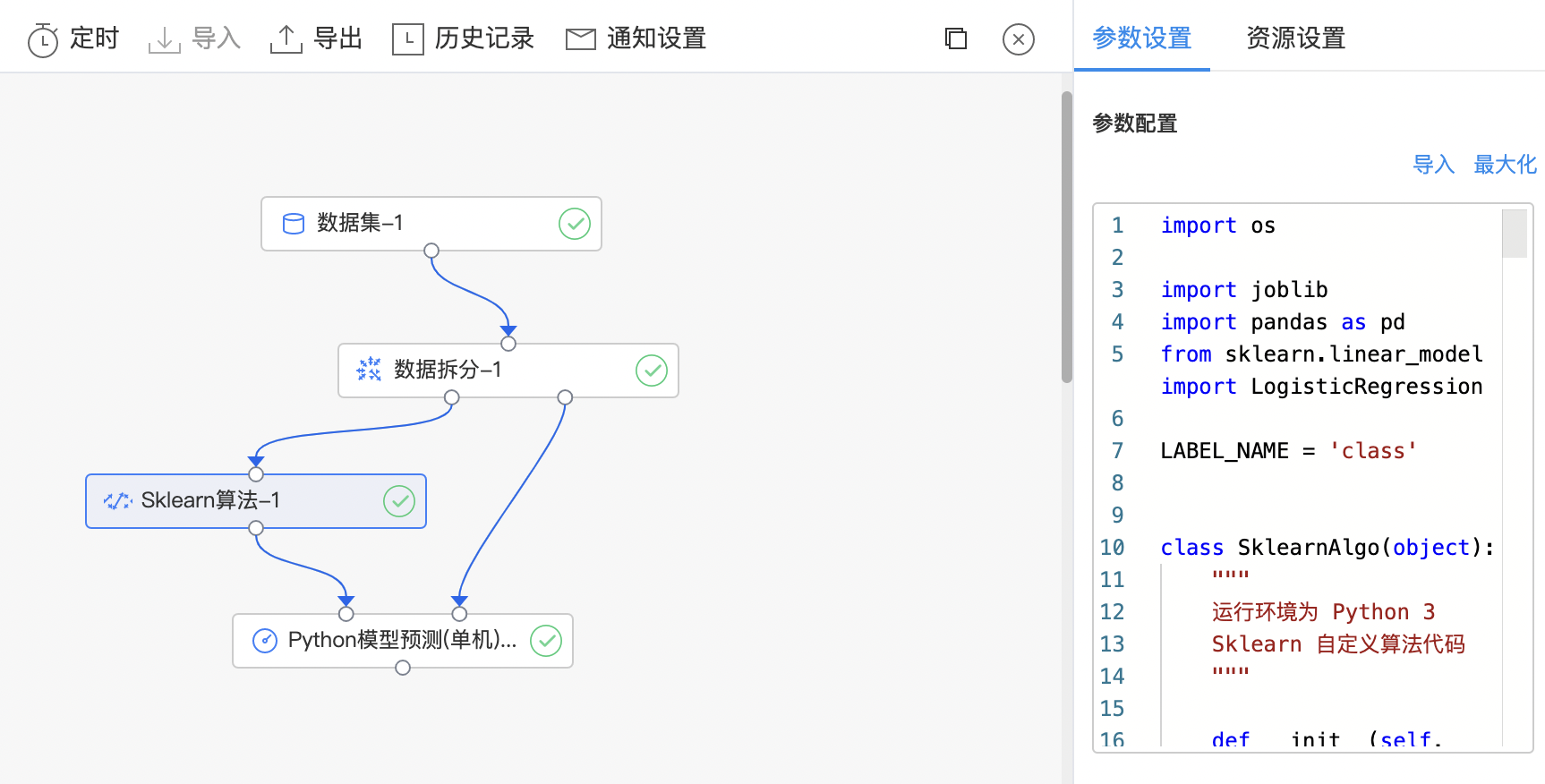
- 查看代码,本例中特征列为slen、swid、plen、pwid,标签列为class。
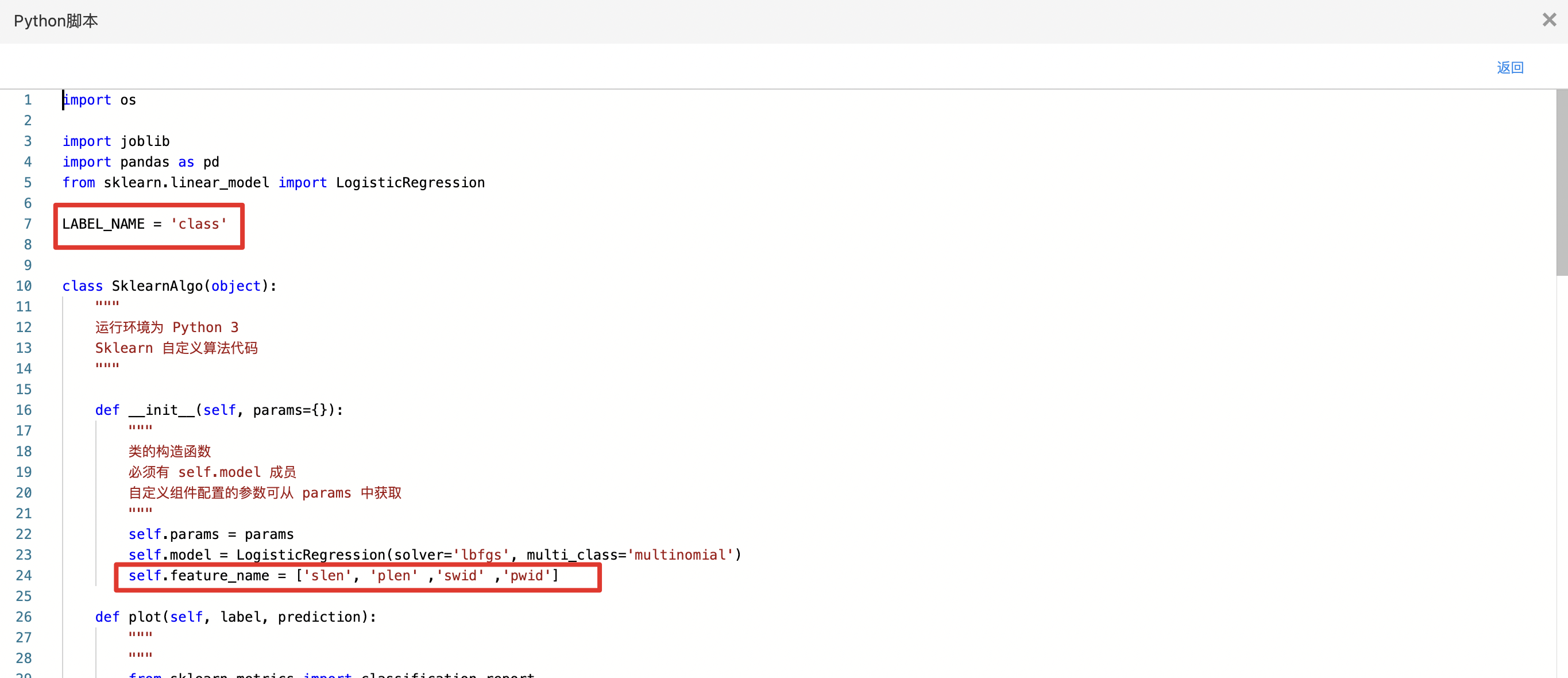
- 查看训练结果。
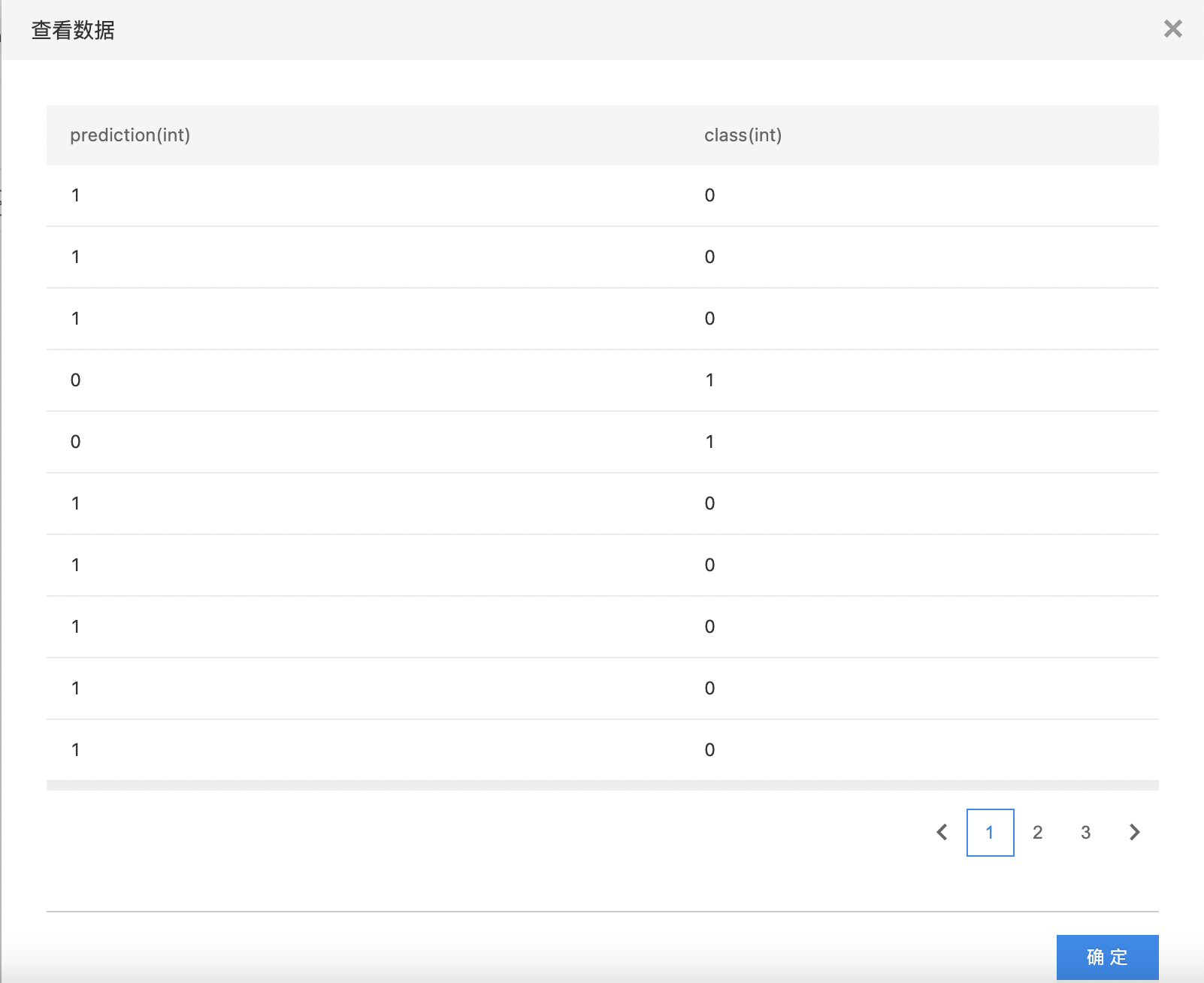
Sklearn算法(Pmml模型)
Sklearn算法(Pmml模型)组件与Sklearn算法组件的使用方法一致,不同的是Sklearn算法(Pmml模型)组件中用户可以自定义load和save 防范,并且训练完成后支持导出Pmml格式的模型。
输入
输入数据:一个数据集作为训练集,编写Python代码。
输出
输出数据:Sklearn算法(Pmml模型)。
算子参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| Python 代码编辑窗口 | 是 | 输入Python 代码 |
使用示例
- 构建算子结构,编写python代码,完成训练。
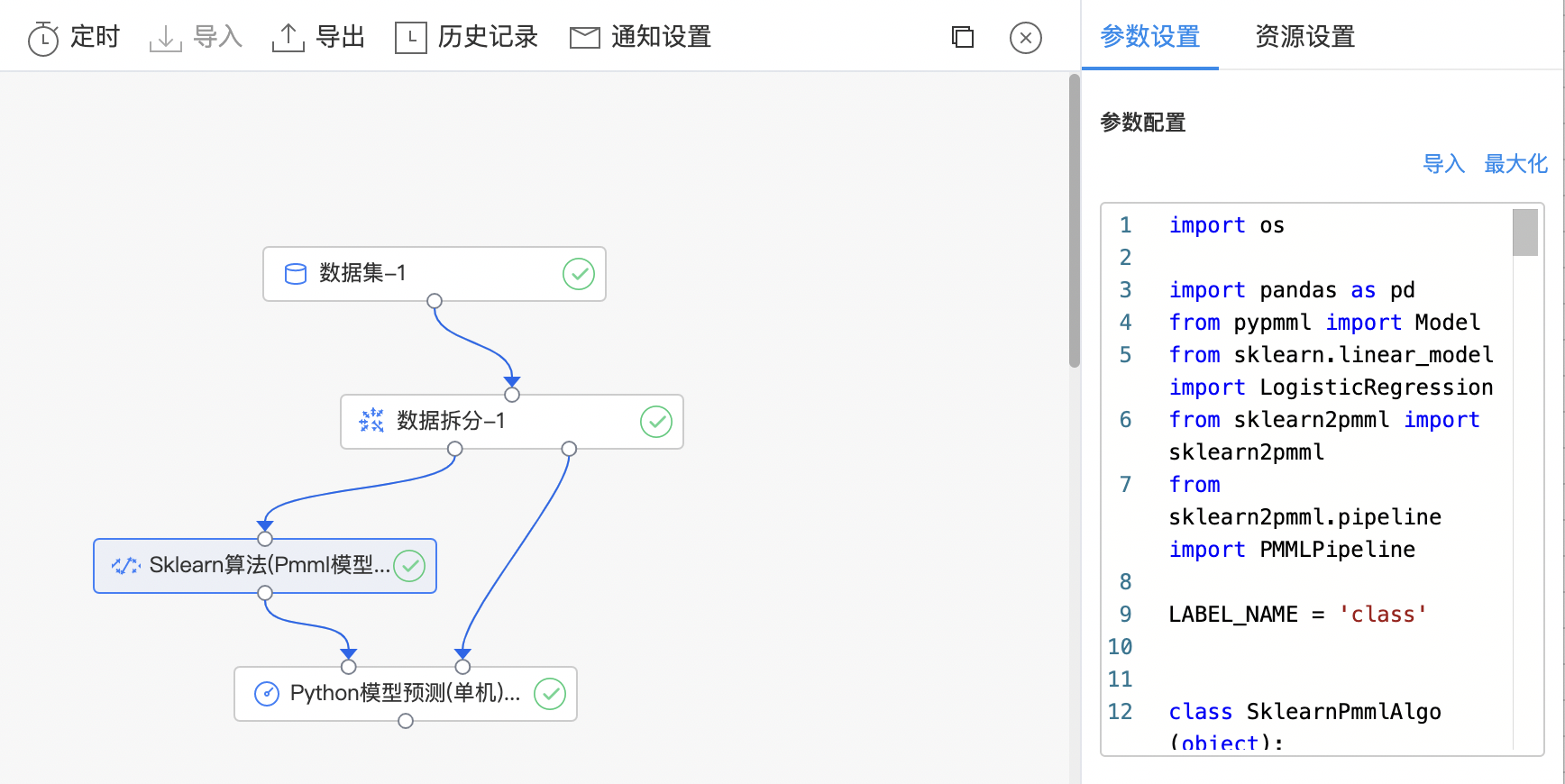
- 查看代码,本例中特征列为slen、swid、plen、pwid,标签列为class。
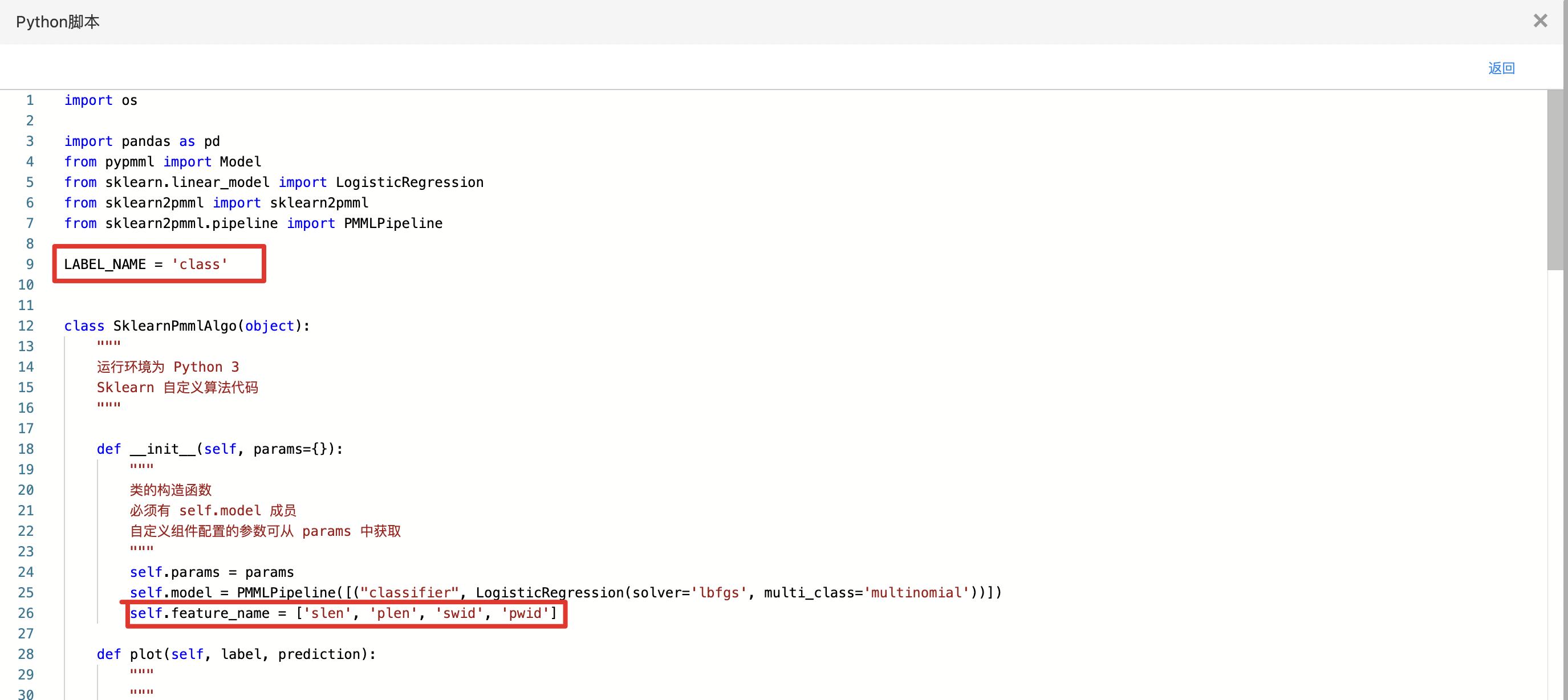
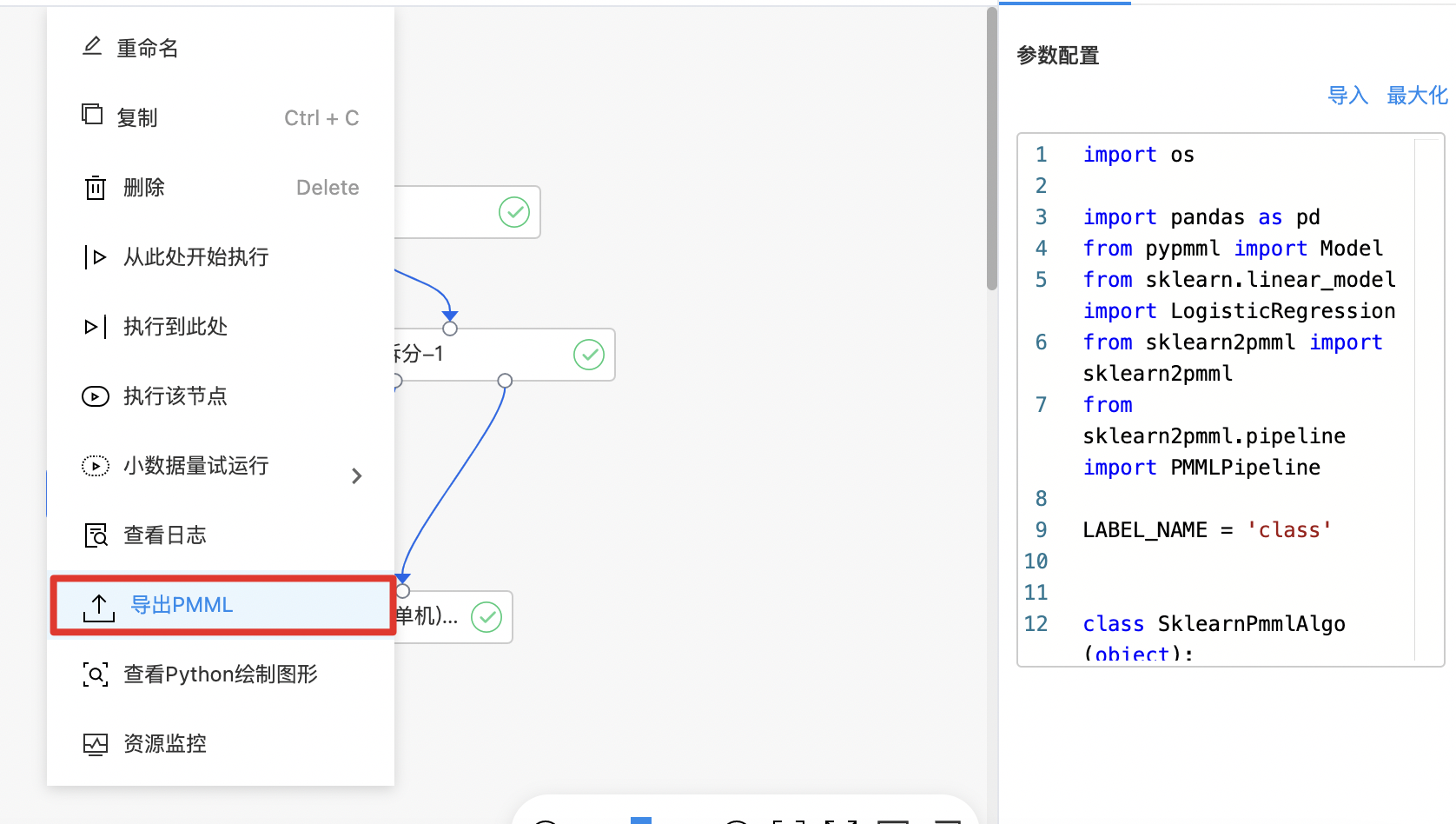
- 训练完成后的模型可以导出为PMML格式文件。
Tensorflow算法
TensorFlow 是一个端到端开源机器学习平台。它拥有一个包含各种工具、库和社区资源的全面灵活生态系统,可以让研究人员推动机器学习领域的先进技术的发展,并让开发者轻松地构建和部署由机器学习提供支持的应用。 自定义 Tensorflow 代码组件:利用 Tensorflow 库写自定义 python 代码,完成各类深度学习任务。
输入
- 输入一个数据集作为训练集,编写Python代码。
输出
- 输出Tensorflow算法模型。
算子参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| Python 代码编辑窗口 | 是 | 输入Python 代码 |
函数说明
fit:模型训练方法,有且仅有dataset参数
transform:模型预测方法,有且仅有dataset参数,返回的预测结果为pandas.DataFrame
save:模型保存方法,有且仅有model_path参数
load:模型加载方法,有且仅有model_path参数使用示例
- 构建算子结构,编写python代码,完成训练。
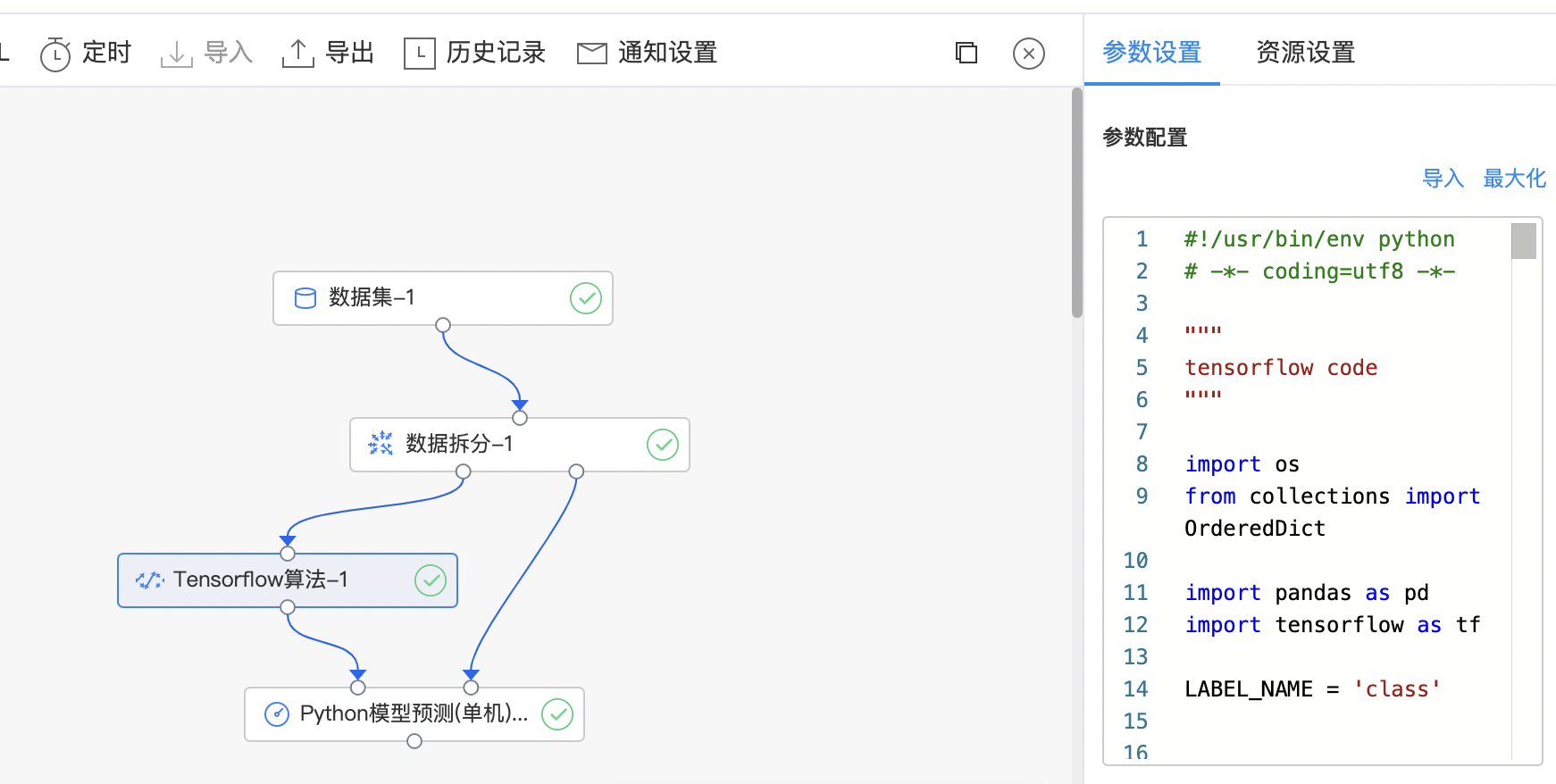
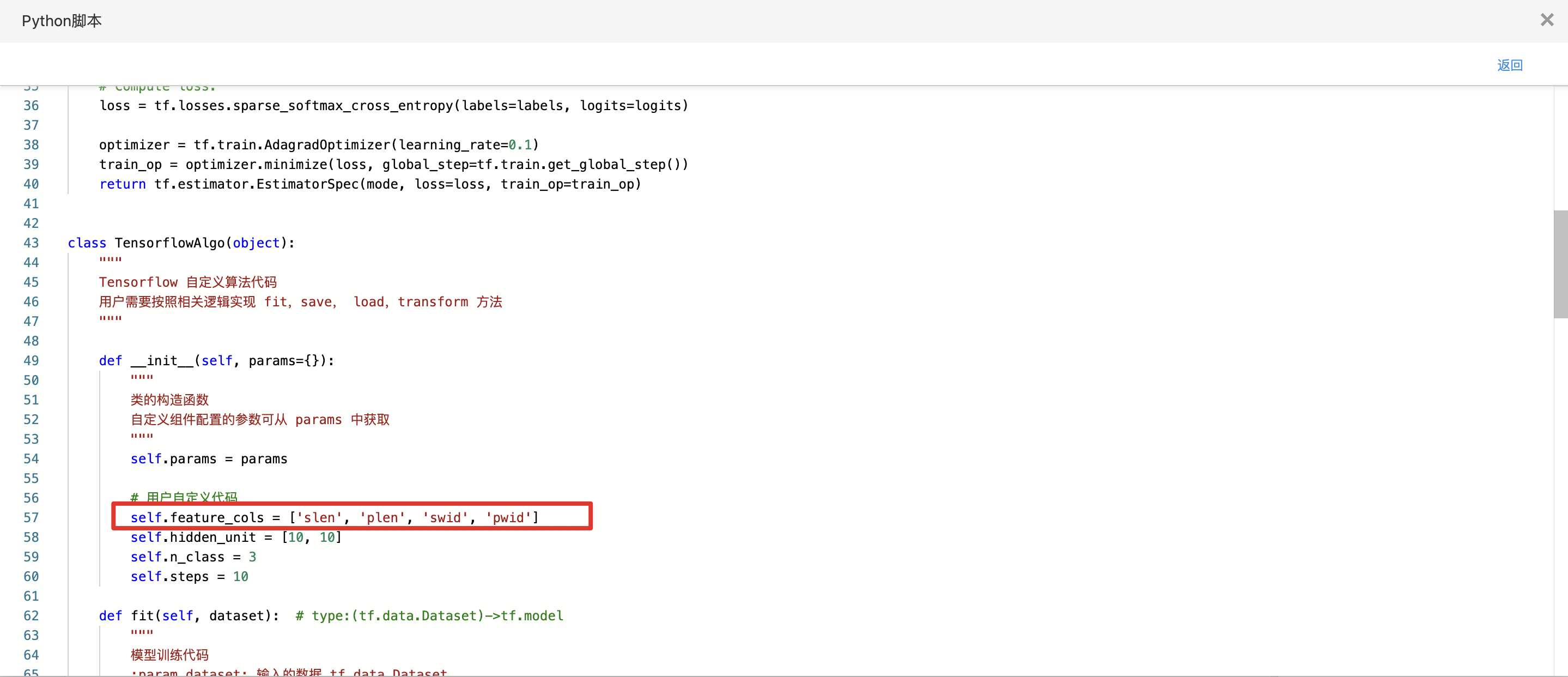
- 查看代码,本例中特征列为slen、swid、plen、pwid,标签列为class。
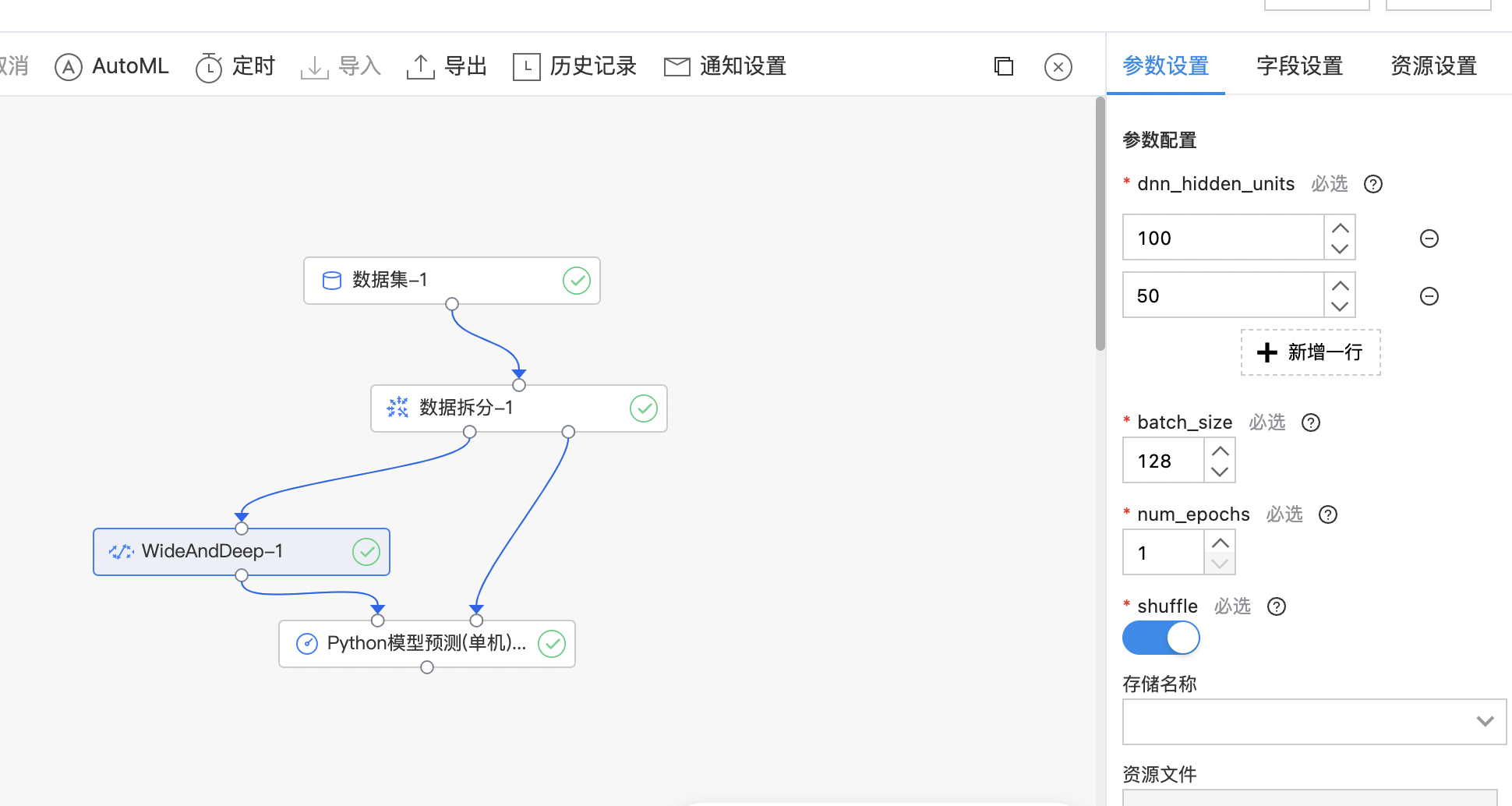
WideAndDeep
WideAndDeep 模型是 Google 发布的一类用于分类和回归的模型,并应用到了 Google Play 的应用推荐中。WideAndDeep 模型的核心思想是结合线性模型的记忆能力(memorization)和 DNN 模型的泛化能力(generalization),在训练过程中同时优化 2 个模型的参数,从而达到整体模型的预测能力最优。 记忆(memorization)即从历史数据中发现 item 或者特征之间的相关性。 泛化(generalization)即相关性的传递,发现在历史数据中很少或者没有出现的新的特征组合。 WideAndDeep组件:利用 WideAndDeep 模型完成二分类任务。
输入
- 输入一个数据集,需要指定标签列,deep模式配置列,wide模式配置列。
输出
- 输出WideAndDeep模型。
算子参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| dnn_hidden_units | 是 | 设置DEEP中神经网络的隐藏层节点数,数组中必须为正整数 范围:[2, inf)。 | 初始有两行数据,默认值分别是100和50 |
| batch_size | 是 | 训练过程中的batch_size 范围:[1, inf)。 | 128 |
| num_epochs | 是 | 训练过程中的训练轮数 范围:[1, inf)。 | 1 |
| shuffle | 是 | 在训练过程中数据是否进行打乱。 | 开启 |
| 存储名称 | 是 | 选择项目内存储名称。 | 无 |
| 资源文件 | 是 | 选择对应存储内的代码文件。 | 无 |
字段参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 标签列 | 是 | 标签列,要求是整数类型且标签列值为0或1,唯一值是2。 | 无 |
| numeric_column | 是 | 设置需要numeric_column的列,需要为数值类型数据列。 | 无 |
| embedding_column | 是 | 设置需要embedding_column的列,需要为string类别型数据列。 | 无 |
| embedding_column中的dimension参数 | 是 | 设置embedding_column中的dimension参数 范围:[1, inf)。 | 8 |
| categorical_column_with_vocabulary_list | 否 | 设置WIDE模型中categorical_column_with_vocabulary_list列,需要为string类别型数据列 | 无 |
| categorical_column_with_hash_bucket | 是 | 设置WIDE模型中categorical_column_with_hash_bucket列,需要为string类别型数据列。 | 无 |
| categorical_column_with_hash_bucket中hash_bucket_size参数 | 是 | categorical_column_with_hash_bucket中hash_bucket_size参数 范围:[1, inf)。 | 1000 |
| crossed_column | 否 | 设置WIDE模型中交叉特征列,最少选择两列数据,需要为string类别型数据。 | 无 |
使用示例
构建算子结构,配置参数,完成训练。
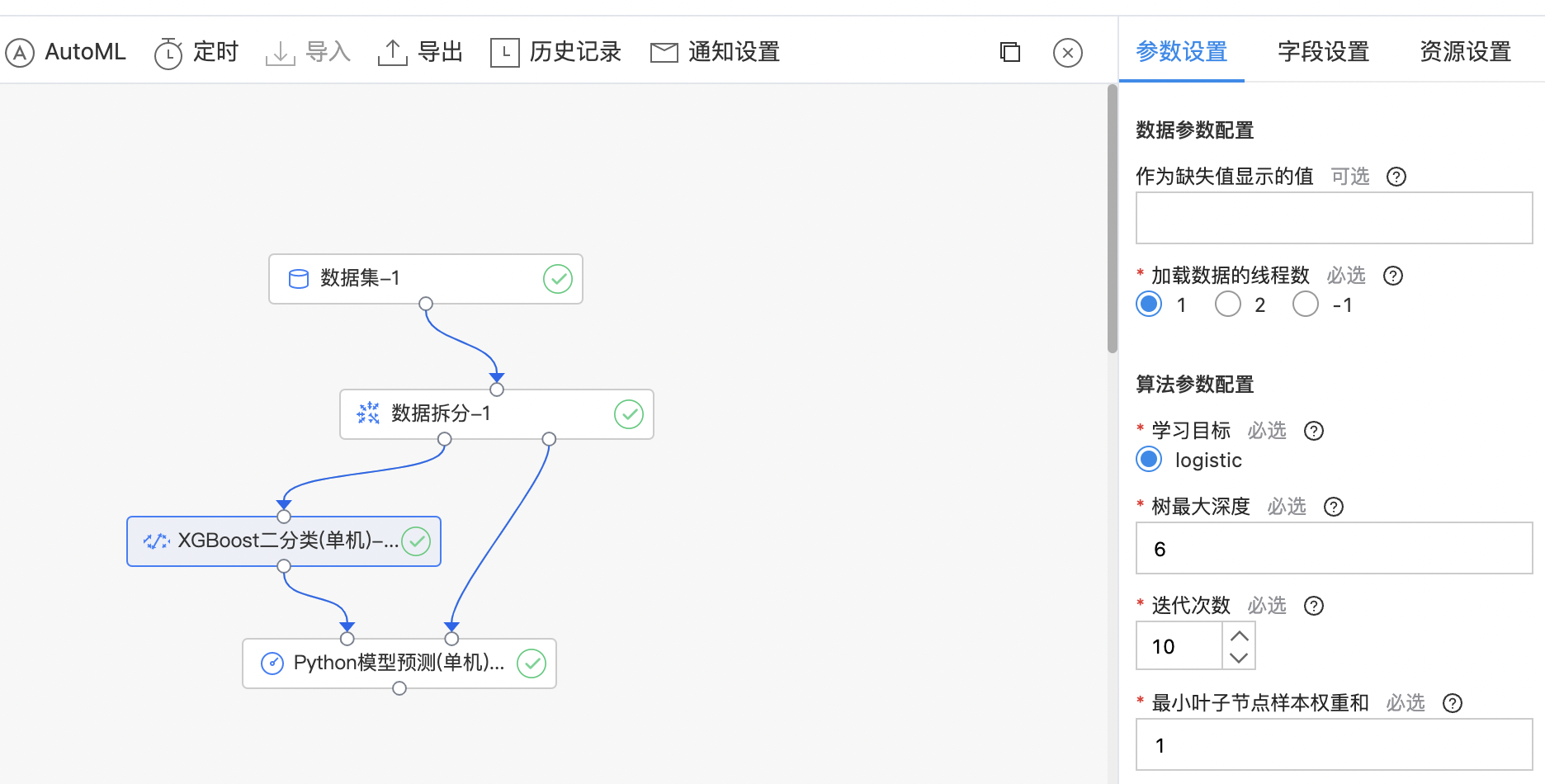
XGBoost二分类(单机)
XGBoost是一种提升树模型,它是将多个树模型(CART)集成在一起,形成一个很强的分类器。 对于一个样本,每棵树都会预测出一个结果(分数),对于二分类问题来说,学习目标为logistic。
输入
- 输入数据集。特征列需要是数值或数值数组类型,标签列需要是整数或字符串类型,标签唯一值为2。
输出
- 输出XGBoost二分类(单机)模型。
算子参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 作为缺失值显示的值 | 否 | 输入特征数据中需要作为缺失值显示的值(浮点型)。若没有设置,则默认为np.nan。 | 无 |
| 加载数据的线程数 | 是 | 适用并行化时用于加载数据的线程数。默认为1;如果为-1,则使用系统上可用的最大线程数。 | 1 |
| 学习目标 | 是 | 二分类任务的学习目标。 | logistic |
| 树最大深度 | 是 | 每棵树的最大深度。树越深,模型越复杂,越容易过拟合 范围:[1, inf)。 | 6 |
| 迭代次数 | 是 | 提升迭代次数,范围:[1, 200]。 | 10 |
| 最小叶子样本权重和 | 是 | 叶子节点需要的最小样本权重和,范围:[0.0, inf)。 | 1 |
| 正样本缩放比例 | 是 | 控制正负权重的平衡,对于不平衡的类别很有用。 典型值:sum(负实例)/ sum(正实例) 范围:[1e-08, inf)。 | 1 |
| 学习率 | 是 | 更新中使用的步长缩小,以防止过拟合 范围:[0.0, 1.0]。 | 0.30 |
| gamma | 是 | 节点分裂所需的最小损失函数下降值。gamma越大,算法越保守 范围:[0.0, inf)。 | 0 |
| 随机采样比例 | 是 | 构造每棵树的所用样本比例(样本采样比例) 范围:[0.01, 1.0]。 | 1.00 |
| 随机采样的特征比例 | 是 | 构造每棵树的所用特征比例(特征采样比例) 范围:[0.01, 1.0]。 | 1.00 |
| L1正则化系数 | 是 | 权重的L1正则化项。值越大,模型越保守 范围:[0.0, inf)。 | 0 |
| L2正则化系数 | 是 | 权重的L2正则化项。值越大,模型越保守 范围:[0.0, inf)。 | 1 |
| 随机种子 | 是 | 随机数种子 | 0 |
| 并行运行线程数 | 否 | 用于训练模型的并行线程数。若没有设置,则默认为最大可用线程数 范围:[1, 16]。 | 无 |
字段参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 特征列 | 是 | 预测使用的特征列,要求必须是数值或数值数组类型。 | 无 |
| 标签列 | 是 | 预测目标列,要求是整数或字符串类型,唯一值是2。 | 无 |
| 正样本标签值 | 否 | 二分类的正样本的标签值,应在标签列中存在。 | 无 |
使用示例
- 构建算子结构,配置参数,完成训练,算子支持查看全量特征重要性。
- 查看训练结果。
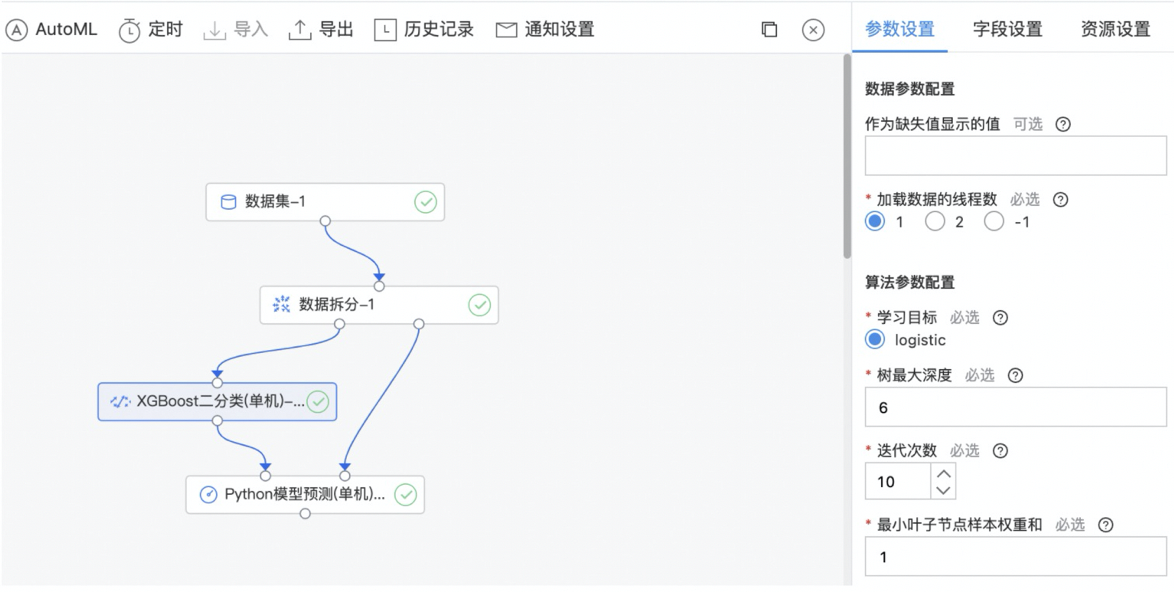
XGBoost多分类(单机)
XGBoost 是一种提升树模型,它是将多个树模型(CART)集成在一起,形成一个很强的分类器。 对于一个样本,每棵树都会预测出一个结果(分数),对于多分类问题来说,学习目标为softprob。
输入
- 输入一个数据集,特征列需要是数值或数值数组类型,多分类任务标签列需要是整数或字符串类型,标签唯一值大于2。
输出
- 输出XGBoost多分类(单机)模型,支持查看Top10分类的概率。
算子参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 作为缺失值显示的值 | 否 | 输入特征数据中需要作为缺失值显示的值(浮点型)。若没有设置,则默认为np.nan。 | 无 |
| 加载数据的线程数 | 是 | 适用并行化时用于加载数据的线程数。默认为1;如果为-1,则使用系统上可用的最大线程数。 | 1 |
| 学习目标 | 是 | 多分类任务的学习目标。 | softprob |
| 树最大深度 | 是 | 每棵树的最大深度。树越深,模型越复杂,越容易过拟合 范围:[1, inf)。 | 6 |
| 迭代次数 | 是 | 提升迭代次数,范围:[1, 200]。 | 10 |
| 最小叶子样本权重和 | 是 | 叶子节点需要的最小样本权重和,范围:[0.0, inf)。 | 1 |
| 学习率 | 是 | 更新中使用的步长缩小,以防止过拟合 范围:[0.0, 1.0]。 | 0.30 |
| gamma | 是 | 节点分裂所需的最小损失函数下降值。gamma越大,算法越保守 范围:[0.0, inf)。 | 0 |
| 随机采样比例 | 是 | 构造每棵树的所用样本比例(样本采样比例) 范围:[0.01, 1.0]。 | 1.00 |
| 随机采样的特征比例 | 是 | 构造每棵树的所用特征比例(特征采样比例) 范围:[0.01, 1.0]。 | 1.00 |
| L1正则化系数 | 是 | 权重的L1正则化项。值越大,模型越保守 范围:[0.0, inf)。 | 0 |
| L2正则化系数 | 是 | 权重的L2正则化项。值越大,模型越保守 范围:[0.0, inf)。 | 1 |
| 随机种子 | 是 | 随机数种子 | 0 |
| 并行运行线程数 | 否 | 用于训练模型的并行线程数。若没有设置,则默认为最大可用线程数 范围:[1, 16]。 | 无 |
字段参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 特征列 | 是 | 预测使用的特征列,要求必须是数值或数值数组类型。 | 无 |
| 标签列 | 是 | 预测目标列,要求是整数或字符串类型。 | 无 |
使用示例
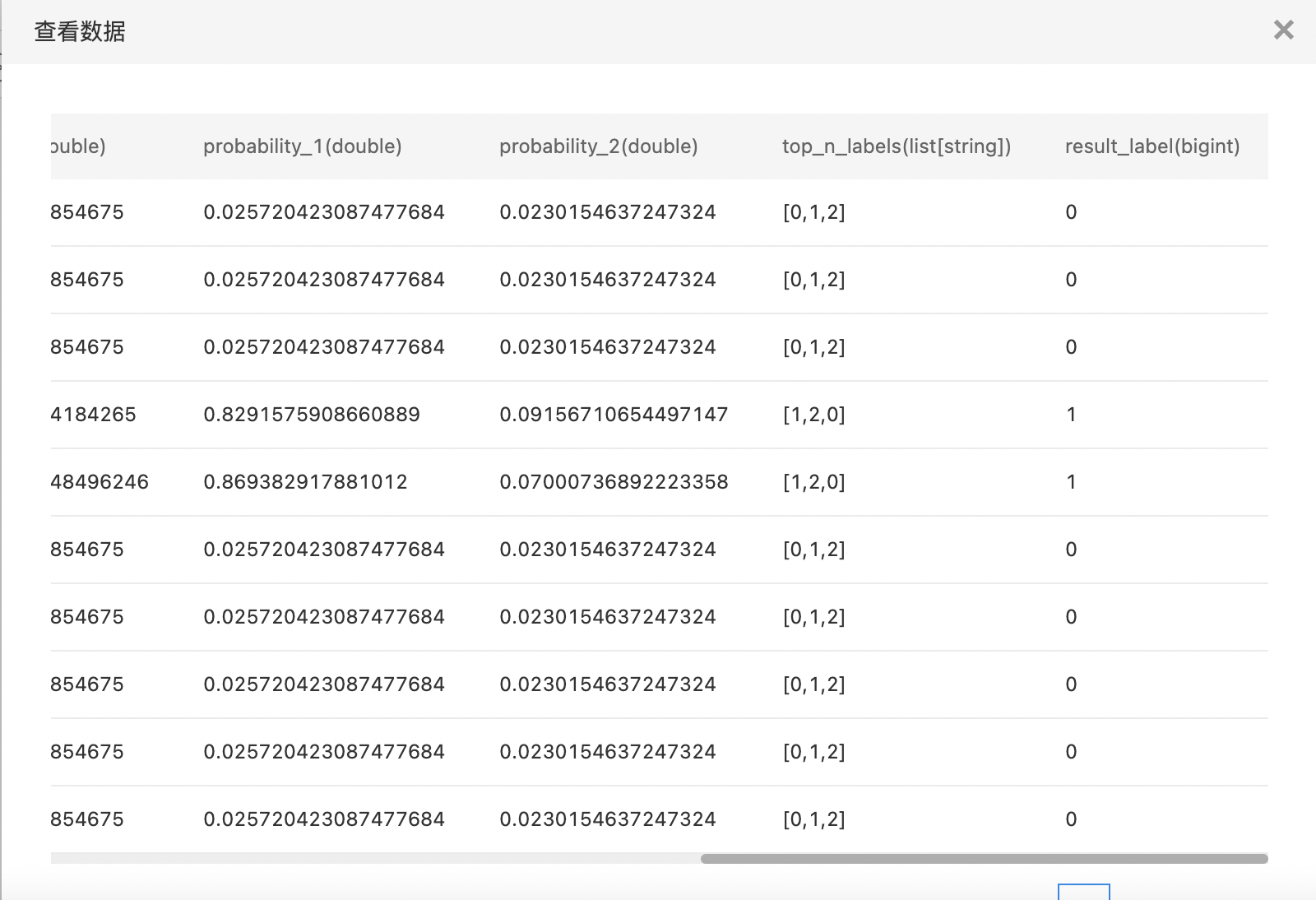
- 构建算子结构,配置参数,完成训练,算子支持查看全量特征重要性。
- 查看训练结果。
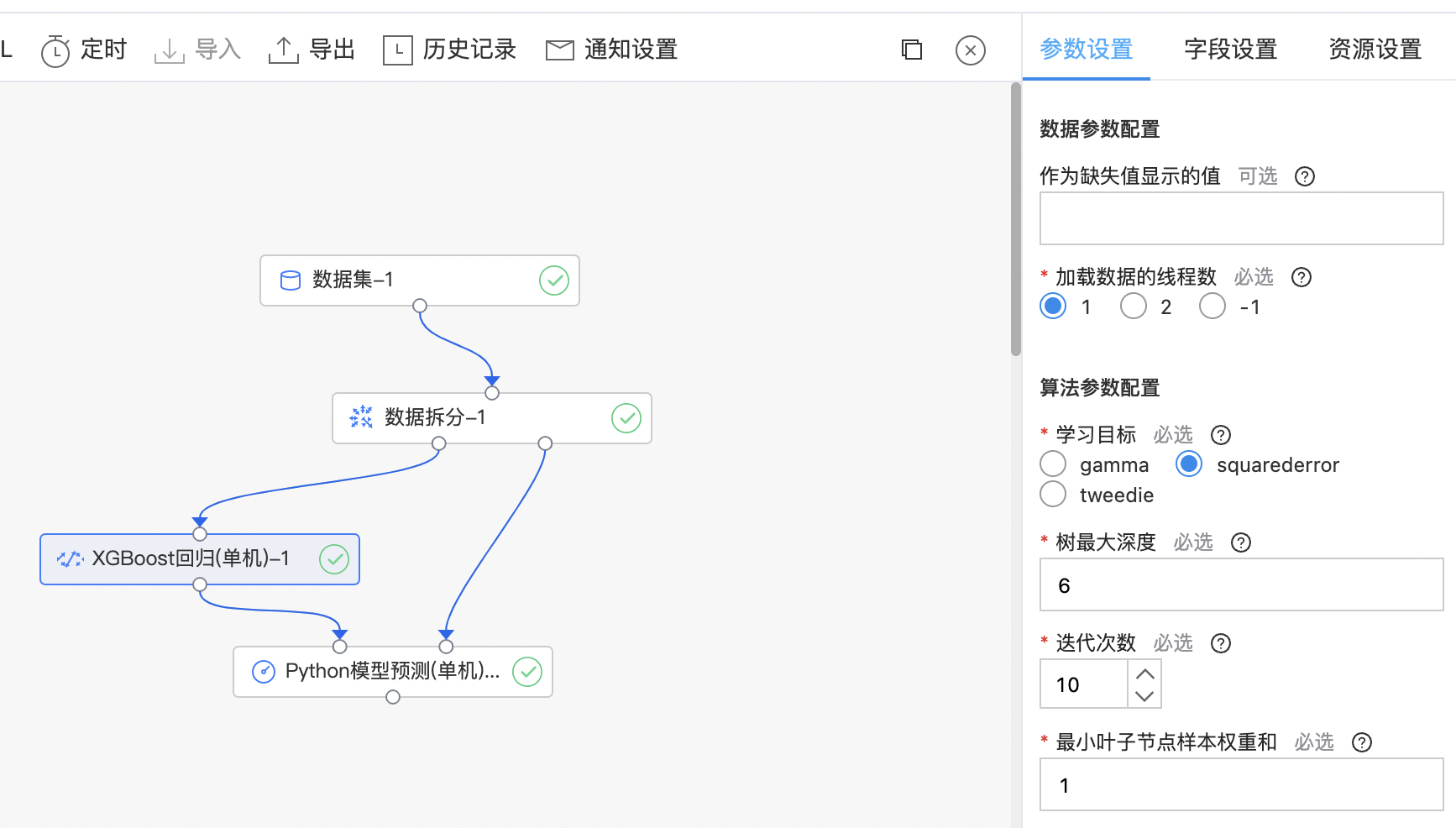
XGBoost回归 (单机)
XGBoost 是一种迭代的决策树算法,它是由多棵决策树组成,所有树的结论累加起来做最终答案。XGBoost 几乎可用于所有回归问题(线性/非线性)。
输入
- 输入一个数据集,特征列需要是数值或数值数组类型,回归任务标签列需要是数值类型,对于回归任务目标函数gamma及tweedie,要求标签列是非负的。
输出
- 输出XGBoost回归(单机)模型
算子参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 作为缺失值显示的值 | 否 | 输入特征数据中需要作为缺失值显示的值(浮点型)。若没有设置,则默认为np.nan。 | 无 |
| 加载数据的线程数 | 是 | 适用并行化时用于加载数据的线程数。默认为1;如果为-1,则使用系统上可用的最大线程数。 | 1 |
| 学习目标 | 是 | 回归任务的学习目标,目前支持: gamma squarederror tweedie |
squarederror |
| 树最大深度 | 是 | 每棵树的最大深度。树越深,模型越复杂,越容易过拟合 范围:[1, inf)。 | 6 |
| 迭代次数 | 是 | 提升迭代次数,范围:[1, 200]。 | 10 |
| 最小叶子样本权重和 | 是 | 叶子节点需要的最小样本权重和,范围:[0.0, inf)。 | 1 |
| 学习率 | 是 | 更新中使用的步长缩小,以防止过拟合 范围:[0.0, 1.0]。 | 0.30 |
| gamma | 是 | 节点分裂所需的最小损失函数下降值。gamma越大,算法越保守 范围:[0.0, inf)。 | 0 |
| 随机采样比例 | 是 | 构造每棵树的所用样本比例(样本采样比例) 范围:[0.01, 1.0]。 | 1.00 |
| 随机采样的特征比例 | 是 | 构造每棵树的所用特征比例(特征采样比例) 范围:[0.01, 1.0]。 | 1.00 |
| L1正则化系数 | 是 | 权重的L1正则化项。值越大,模型越保守 范围:[0.0, inf)。 | 0 |
| L2正则化系数 | 是 | 权重的L2正则化项。值越大,模型越保守 范围:[0.0, inf)。 | 1 |
| 随机种子 | 是 | 随机数种子 | 0 |
| 并行运行线程数 | 否 | 用于训练模型的并行线程数。若没有设置,则默认为最大可用线程数 范围:[1, 16]。 | 无 |
字段参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 特征列 | 是 | 预测使用的特征列,要求必须是数值或数值数组类型。 | 无 |
| 标签列 | 是 | 预测目标列,要求是数值类型。 | 无 |
使用示例
构建算子结构,配置参数,完成训练,算子支持查看全量特征重要性。