

使用训练作业训练模型
更新时间:2024-03-01
使用训练作业训练模型
训练作业训练提供多种开源框架和优质的训练资源。您可以上传代码文件,数据集到BOS对象存储,通过训练作业完成训练后,训练结果会输出到BOS中的指定位置。
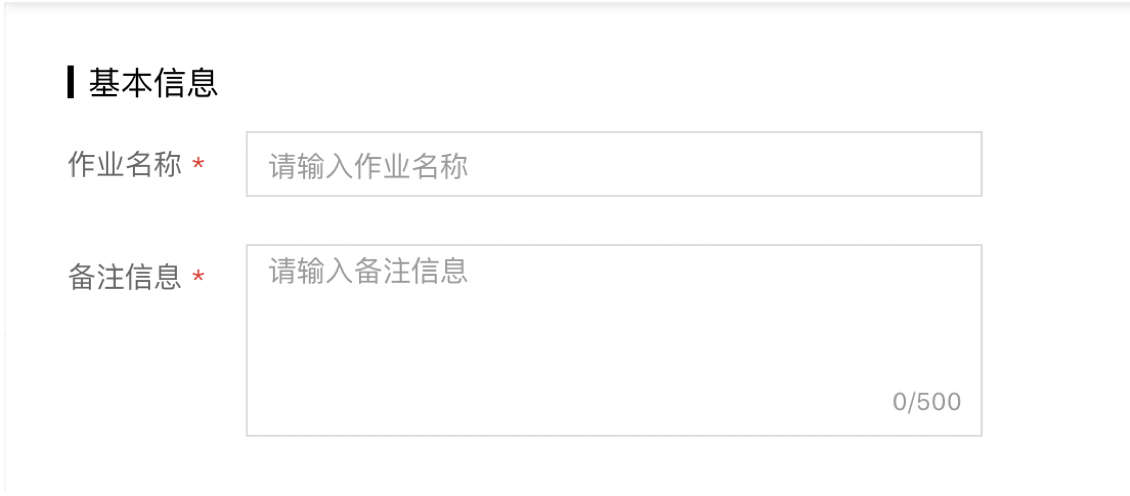
基本信息
填写作业名称和备注信息。作业名称填写完成后,训练作业才可以保存。
算法配置
- 选择算法框架:选择训练代码文件使用的算法框架,目前BML支持Paddle,TensorFlow,Pytorch,Sklearn,XGBoost,Blackhole六种主流算法框架
- 选择代码文件:从BOS对象存储中选取代码文件,完成代码录入。单击显示框任何位置,都可以打开选择代码文件弹窗,从弹窗中选择bucke及文件夹。双击bucket或者单击『>』图标,即可进入下一级
-
代码文件要求如下:
- 选取对象可以是一个文件或者文件夹
- 所选代码文件必须和所选算法框架对应
-
输入启动命令,支持python和shell两类脚本:
- 当代码文件项选择一个单独文件时,启动命令指向该启动文件
- 当代码文件项选择一个文件夹时,启动命令需指向该文件夹下的特定启动脚本,例如bash bml_job.sh
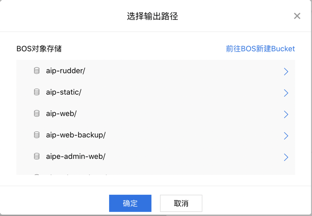
- 选择输出路径:选择输出路径存放训练产生的模型和日志文件。为避免出错,建议您选择空文件夹作为输出路径。日志文件需要打印到标准输出,才能保证系统中『日志』功能能够正常读取。
-
可选高级配置。提交训练作业时,可以通过高级配置来自定义环境变量。
- 手动配置:通过手动填写环境变量来配置,包括配置变量名称与对应取值。

-
YAML文件:通过上传YAML文件来配置环境变量,支持本地上传和BOS存储导入两种方式。注意:环境变量最多配置100组,平台将在解析时对超出部分做自动截断处理。
此外,BML平台亦提供预置环境变量,由BML平台预先定义,不建议您自行覆盖修改。
预置环境变量
| 作业类型 | 变量名 | 变量含义 | 示例 | 默认值 |
| Pytorch 作业 | PYTHONUNBUFFERED | 控制Python的标准输出和标准错误输出是否被缓冲。'1'代表输出将不会被缓冲 | 0 | 0 |
| PET_RDZV_ENDPOINT | 分布式任务同步服务的地址 | job-qcu5m5-1984-master-0:23456 | MASTER_ADDR:MASTER_PORT | |
| PET_NNODES | {实例数}:{实例数} ,代表训练任务的节点个数 | 2:2 | 无 | |
| PET_MAX_RESTARTS | 训练进程的最大重启次数 | 100 | 0 | |
| PET_NPROC_PER_NODE | 当前节点创建的进程数 | 10 | 无 | |
| MASTER_PORT | 分布式任务主节点的端口 | 23456 | 23456 | |
| MASTER_ADDR | 分布式任务主节点的地址 | job-qcu5m5-1984-master-0 | 主节点名称 | |
| NVIDIA_VISIBLE_DEVICES | 训练节点可见的gpu卡设备 | GPU-ae58e6cc-1dec-bcb9-820c-e433d01afda6 | 无 | |
| PaddlePaddle 作业 | POD_IP | 当前节点的IP | 172.16.5.9 | 无 |
| PADDLE_TRAINER_ID | 当前节点的ID,从0开始编号,取值为 0,1,...,(PADDLE_TRAINERS_NUM-1) | 0 | 无 | |
| TRAINING_ROLE | 当前节点的角色 | PSERVER或TRAINER | 无 | |
| PADDLE_TRAINING_ROLE | 当前节点的角色 | PSERVER或TRAINER | 无 | |
| PADDLE_TRAINERS_NUM | 分布式训练节点的数量 | 2 | 无 | |
| PADDLE_TRAINERS | 所有分布式训练节点的ip,使用逗号 ',' 分隔 | 172.16.5.9,172.16.5.1 | 无 | |
| PADDLE_TRAINER_ENDPOINTS | 所有分布式训练节点的ip、端口,取值为【node1-ip:端口, node2-ip:端口】 | 172.16.5.9:43817,172.16.5.1:45492 | 无 | |
| NVIDIA_VISIBLE_DEVICES | 训练节点可见的gpu卡设备 | GPU-ae58e6cc-1dec-bcb9-820c-e433d01afda6 | 无 | |
| Horovod 作业 | K_MPI_JOB_ROLE | 当前节点的角色,取值为worker或者launcher | worker或launcher | 无 |
| OMPI_MCA_orte_keep_fqdn_hostnames | 是否保留FQDN hostnames(全限定域名) | true | true | |
| OMPI_MCA_orte_default_hostfile | mpirun命令指定hostfile,在平台中可以自动生成hostfile,无需手动修改。 | /etc/mpi/hostfile | /etc/mpi/hostfile | |
| OMPI_MCA_plm_rsh_args | 训练节点之间ssh连接使用的参数配置 | "-o ConnectionAttempts=10" | "-o ConnectionAttempts=10" | |
| NVIDIA_VISIBLE_DEVICES | 训练节点可见的gpu卡设备 | GPU-ae58e6cc-1dec-bcb9-820c-e433d01afda6 | 无 | |
| OMPI_MCA_plm_rsh_agent | 指定远程代理命令,用于launcher节点给worker节点发送命令。在平台中可以自动生成,无需手动修改。 | /etc/mpi/kubexec.sh | /etc/mpi/kubexec.sh |
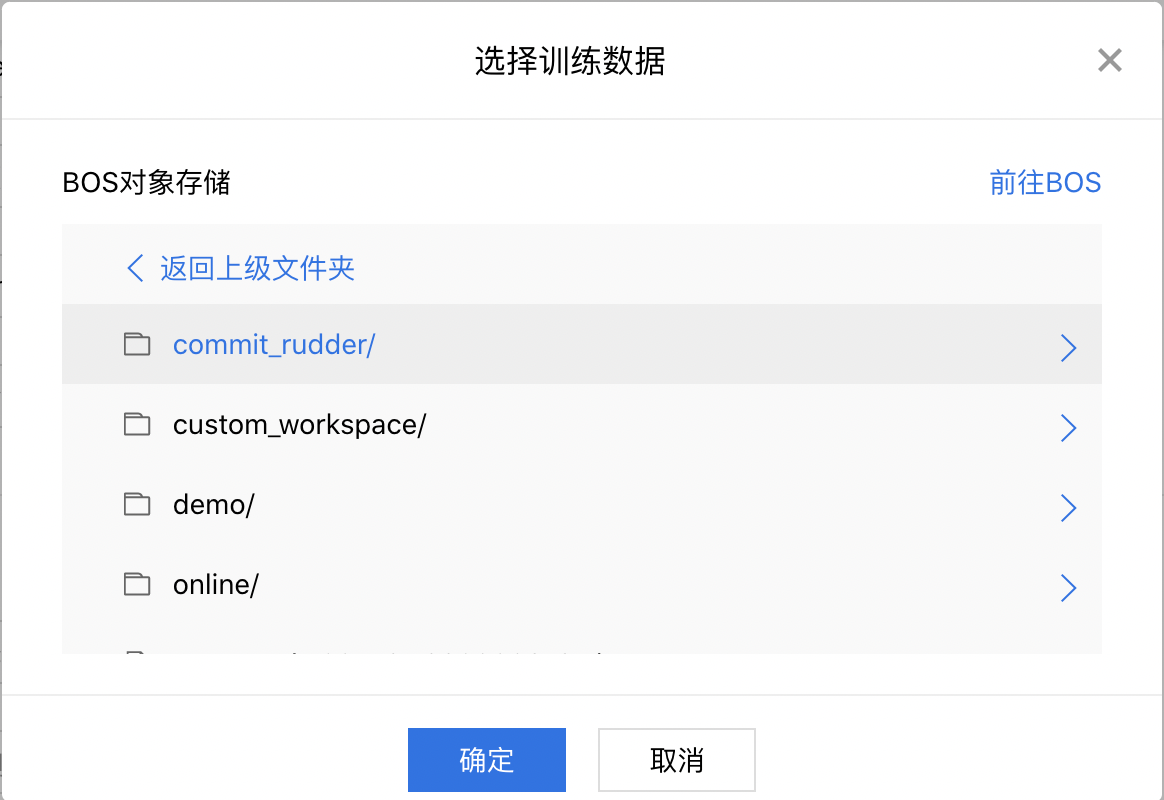
数据集配置
训练作业数据集配置方式是从BOS中选取数据集。在弹出的对话框中选择数据集对应的bucket和文件夹。
资源配置
BML提供CPU和GPU两类训练机型。
CPU机型供算法框架为sklearn,XGBoost,Blackhole时使用,用于机器学习训练:
| 机型 | 规格说明 |
|---|---|
| CPU 4核 | CPU 4核16GB内存 |
| CPU 16核 | CPU 16核64GB内存 |
GPU机型供算法框架为Paddle,TensorFlow,Pytorch时使用,用于深度学习训练:
| 机型 | 规格说明 |
|---|---|
| GPU V100 | TeslaGPU_V100_32G显存单卡_12核CPU_56G内存 |
| GPU P4 | TeslaGPU_P4_8G显存单卡_12核CPU_40G内存 |
温馨提示: 未开通付费的情况下,可选的运行环境为CPU 4核,GPU P4,我们为每位用户提供了CPU 4核环境下100(小时×节点),GPU P4运行环境下100(小时×节点)的免费算力支持,超出后请您付费购买。详见页面提示的价格说明。
查看作业结果
作业运行完成后,会将训练结果与运行日志存储到BOS中指定的输出路径,您可以前往BOS查看或下载作业运行结果。日志文件打印到标准输出时可以直接在日志界面查看。
两种情况下,会导致作业结果及日志无法保存:1. 手动终止作业;2. 作业运行超时被自动终止