

标准模型部署
一、资源规划
资源规划文档旨在系统资源使用层对真实交付场景做产品层面的通用指导
文档涵盖了构建百度OCR算子服务所需要的服务器主机、 CPU、内存、 GPU、网络等内容方面的规划。 本文档所列出的所有数量数字方面的值均需针对实际场景需求和限制做针对性调整。
名词定义
| 名称 | 含义 |
|---|---|
| 鉴权服务 | 鉴权服务包含百度发布的服务授权证书,如果不安装鉴权服务,后续的应用服务也将无法启动,目前支持加密狗(硬件)和提取机器指纹(软件)两种鉴权方式 |
| 应用服务 | 包含Docker等基础环境以及相关技术方向的算法模型,是私有化产品的的核心。部署应用服务的前提是部署鉴权服务,应用服务在运行时会实时请求鉴权服务,需要保障两个服务之间能够顺利通信 |
| 单机一键部署 | 适用于鉴权服务、应用服务部署在一台物理机上的场景。即执行一条命令将鉴权服务、应用服务安装完成。 |
| 多机分离部署 | 适用于鉴权服务、应用服务不在一台机器上部署的场景。首先部署鉴权服务、然后部署应用服务 |
| 测试环境 | 客户方提供的进行产品、场景测试的环境,一般与生产环境隔离,开发、测试能够方便接触到的环境,对部署的可用性要求较低 |
| 生产环境 | 客户的生产环境,一般的业务系统真实提供服务的环境,具备较高的可用性要求,包括异地多活的灾备要求。一般只有运维人员有该环境的超管权限 |
物理架构拓扑图
文字识别私有化部署产品包含鉴权服务和应用服务,其中
- 鉴权服务通过客户网关系统连接到应用服务器为应用服务提供鉴权认证
- 应用服务部分直接或通过生产级网关被客户业务场景直接使用
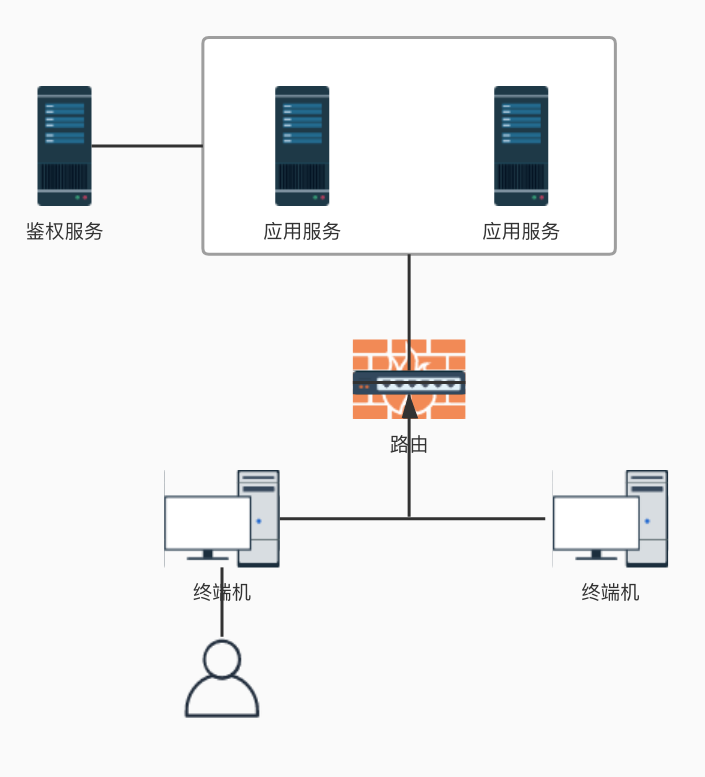
鉴权应用
规划原则:
鉴权服务是运行百度文字识别应用服务的基础,如果鉴权异常,将直接导致模型的API接口不可用。鉴权服务的高可用通过Raft算法实现。 鉴于Raft算法的特性,我们建议您选择“奇数”个节点来部署鉴权集群。
鉴权集群不同节点的容错能力如下。
| 集群节点数量 | 最大容错 |
|---|---|
| 1 | 0 |
| 2 | 0 |
| 3 | 1 |
| 4 | 1 |
| 5 | 2 |
| 6 | 2 |
规划流程:
一般建议鉴权节点数量为1或3个。
模型算子应用
规划原则:
- 单模型应用实例承担流量,根据业务逻辑复杂度(请求报文)、机器节点硬件条件(CPU、内存、网络、显存)强相关
- 单模型应用实例的内存分配依赖模型的大小
- 单模型应用实例的CPU资源与请求报文相关
- 单模型应用实例占用网路IO与请求报文和返回结果相关
- 单模型应用实例占用磁盘空间大小与请求报文、日志输出量等特性相关
- 场景需要的模型应用服务资源与整体业务QPS、单模型实例性能、高可用方案相关
规划流程:
根据实际场景进行性能测试,得出单模型实例性能指标(QPS、响应延时、内存占用、显存占用),结合场景高峰流量预估和高可用要求,以及服务器实际显卡数量等计算需要模型应用实例数,根据机器节点硬件资源指标,最终确定硬件节点数。
资源规划示例
模块清单
| 模块名 | 模块角色说明 |
|---|---|
| openresty | 基础依赖服务,提供负载均衡能力 |
| docker | 基础依赖服务 |
| nvidia | 基础依赖服务 |
| redis | 基础依赖服务 |
| …… | 基础依赖服务 |
| c-offline-security-server | 鉴权服务 |
| auth-manage-service | 鉴权服务,用于鉴权管理,提供web页面查看鉴权信息。 |
| ocr-x x x x x | 模型应用服务 |
| …… | 模型应用服务 |
以上模块清单针对不同的模型部署包稍有差异,可以通过下面的命令查询当前部署包内详细的模块清单。
# se :表示search,根据模块名称查询安装包里是否包括某个模块,不区分大小写,如果没有指定名称则输出安装包里所有模块信息
cd origin/package/Install && python install.py se您可以根据模型的数量适当调整cpu,内存,显存,存储等资源,下面以在单台服务器部署1个模型为例说明:
|
资源需求 |
节点 |
部署模块 |
单节点CPU |
单节点内存 |
单节点显卡数 |
单节点存储 |
单节点网络 |
|
测试环境 |
节点A |
基础依赖服务 |
4核 |
8G |
视模型情况而定 |
50G |
>1000Mbps |
|
鉴权服务和鉴权管理服务 |
|||||||
|
模型应用服务 |
|||||||
|
生产环境 |
节点A |
基础依赖服务
|
8核 |
16G |
视模型情况而定 |
500G |
>1000Mbps |
|
模型应用服务 |
|||||||
|
节点B |
鉴权服务 |
1核 |
2G |
不需要 |
10G |
>1000Mbps |
|
|
生产环境 |
节点A |
鉴权服务 |
8核 |
16G |
视模型情况而定 |
500G |
>1000Mbps |
|
基础依赖服务 |
|||||||
|
模型应用服务 |
|||||||
|
节点B |
基础依赖服务 |
8核 |
16G |
视模型情况而定 |
500G |
>1000Mbps |
|
|
模型应用服务 |
如果您有多个服务器节点,可以参考以上示例,选择每台服务器节点需要部署的服务。
二、场景与名词
场景说明
- (无环境)全新部署:服务器环境为第一次部署,该服务器之前没有部署过百度文字识别产品的任何模型。
- (有环境)升级模型:是指用户之前部署过老版本的百度文字识别产品模型,需要对模型进行升级操作。
- (有环境)新增模型:是指用户当前服务器或者其他服务器已经部署过百度文字识别产品部分模型,需要新增其他模型
- 回滚:回滚到最近一次升级前的版本
- 卸载: 删除已经安装的模块
名词解释
| 名词 | 说明 | 示例 |
|---|---|---|
| package_dir | 存放部署包、升级包的路径,包体积较大,尽量不要放在/下 | 如 /mnt/disk0/baidu_ocr_install_20111009 |
| work_dir | 应用程序文件存储地址,默认为/home/baidu/work | 如 /home/baidu/work |
三 、准备工作
环境检查
部署之前请务必参考此文档部署前环境检查必看进行硬件、网络、及软件环境检查,以避免在安装部署过程中出现问题。
获取部署包
1、申请正式模型部署包安装文件下载链接,下载模型部署包并重命名。
# 示例如下,-O --output-document=FILE 对文件重名名,O为大写英文字母
# 请将示例中的9C20XXXXXXXX.tar.gz替换为真实的文件名
wget -O 9C20XXXXXXXX.tar.gz https://bj.bcebos.com/v1/private-ai-online/9C20XXXXXXX.tar.gz?authorization=bce-authXXXXXXX132187fcf81 2、将9C20XXXXXXXX.tar.gz上传到待部署的服务器,为方便区分不同的部署包,建议以【baidu_ocr_install + 日期】命名,如 baidu_ocr_install_20111009,该目录我们将其命名为package_dir
3、进入package_dir 执行以下命令解压部署包
# baidu_ocr_install_20111009 部署包的根目录,次处仅为示例,实际操作时换成您上一步命令的路径
cd baidu_ocr_install_20111009 && tar zxvf 9C20XXXXXXXX.tar.gz4、解压后进入original目录执行bash download.sh命令获取全部安装文件,执行脚本后会自动下载以下安装文件:数据库服务安装包、鉴权服务安装包、应用服务安装包以及docker安装包等基础依赖环境。如果已经提前在办公网络下载完毕,请忽略该步骤。
cd original && bash download.sh执行结束后,会在download.sh同级目录下生成download.log日志记录下载详情。
若您在此过程出现问题,请提交工单联系百度的工作人员
接下来您可以根据实际使用场景和前文的资源规划,从下文选择一种部署方式来部署。
四、全新部署
指服务器环境为第一次部署,该服务器之前没有部署过任何百度文字识别产品的任何模型。
您可以进入模型部署包的存储路径,执行下面的命令查看程序help信息:
cd original/package/Install
python install.py返回结果如下:
install.py usage:
inall: 安装所有的产品以及鉴权服务和基础服务,适用于在单台物理机上安装所有模块的场景
in, install: 安装一个模块,名称不区分大小写,适用于产品模块和鉴权服务分机器部署的场景
se, search: 根据模块名称查询安装包里是否包括某个模块,不区分大小写,如果没有指定名称则输出安装包里所有模块信息
li, list: 根据模块名称查询某个模块是否已经安装,如果没有指定名称则输出所有已经安装的模块
rm, remove: 根据模块名称删除某个已经安装的模块;如果有其他模块依赖这个模块,则不允许删除
rmall: 删除所有已经安装的模块
lu, licenseupdate: 更新license文件,适用于授权延期、实例数扩容、增加产品授权
up, upgrade: 升级指定模块,不区分大小写,不指定参数时输出所有可升级模块信息
rb, rollback: 回滚指定模块,不区分大小写,回滚到最近一次升级前的版本
du, safestoredataupdate: 安全存储数据更新,包括敏感数据、模型解密密钥等相关文件的更新请根据前文的资源规划和实际的使用场景从【单机一键部署】和【多机分离部署】选择一种方式部署。
单机一键部署
如果您只有一台服务器,可以使用inall参数来部署,inall 表示install all,安装所有的产品以及鉴权服务和基础服务,适用于在单台服务器上安装所有模块的场景,容易和 install 混淆,在使用时请注意。
1、使用root权限启动一键部署脚本进行安装:
# inall: 安装所有的产品以及鉴权服务和基础服务,适用于在单台物理机上安装所有模块的场景
python install.py inall执行安装后,首先进行环境检查
未通过的检查项详情如下:
+---------------------------+-------------+--------------+----------+--------------------+
| 模块 | 检查项 | 含义 | 指标要求 | 实际参数或报错信息 |
+---------------------------+-------------+--------------+----------+--------------------+
| default | * disk_home | HOME磁盘空间 | >=512 GB | 201 GB |
| c-offline-security-server | machine | 宿主机环境 | | 当前环境为虚拟机 |
+---------------------------+-------------+--------------+----------+--------------------+
带*的检查项非强制,可以选择跳过
2021-08-27 21:44:37,414 - 2712 - install - ERROR - 环境检查失败!请修复未通过的检查项后重新安装,如有问题请联系技术支持。
按任意键结束。输入continue后回车可跳过环境检查,跳过后不保证安装成功。其中带 * 项 (如 disk_home等)非强制要求,可以忽略。确认无误后请输入 continue 英文字符,继续下一步
之后会要求手动输入IP地址和选用的显卡编号,示例如下:
请输入鉴权集群的IP列表,逗号分隔,列入:192.168.1.101
# 参考上文资源规划,如鉴权节点唯一,只需要输入真实机器IP即可,如106.12.141.217
# 如果鉴权节点有多个,请以英文逗号分隔,如106.12.141.217,106.12.141.218,106.12.141.219
106.12.141.217# 输入您要使用的显卡编号,仅输入1个。可通过nvidia-smi查看显卡编号
enter value for gpu index numbers used by this application,separated by comma, e.g. 0,1,2:注:建议填写docker0网卡的ip地址,如后续服务器IP地址发生变化,不会影响服务。
2、确认本次安装模块是否完整:
执行docker ps -a |grep baidu查看相关容器是否包含以下且状态均正常
以【通用文字识别模型(CPU)版本】为例:
[root@instance-wch0lkwp Install]# docker ps -a|grep baidu
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
c1643ee21c44 registry.baidu.com/aipe/openresty:1.11.2.3-trusty "/usr/local/openre..." 40 seconds ago Restarting (1) 6 seconds ago nginx-1
c766cdbbdb73 iregistry.baidu-int.com/aipe/public/centos:cuda10.0-cudnn7-c7-gcc8-ocr "sh start.sh" 40 seconds ago Up 3 seconds 0.0.0.0:8138->8256/tcp ocr-finance-gpu-1如果只有一个模型应用实例,则不需要部署负载均衡服务,可以执行以下命令移除nginx容器
docker rm -f nginx-1如何单独部署某个模块?
1.首入通过se参数检索当前部署包内包含的所有模块清单
# se :表示search,根据模块名称查询安装包里是否包括某个模块,不区分大小写,如果没有指定名称则输出安装包里所有模块信息
python install.py se 返回结果如下:
……
模块名: openresty, 内置版本 7, 依赖模块 []
模块名: docker, 版本号:1.0, 内置版本 5, 依赖模块 []
……2.如需卸载openresty,可以执行如下命令(此处仅为示例,实际操作中根据需要执行)
# rm :remove, 根据模块名称删除某个已经安装的模块;如果有其他模块依赖这个模块,则不允许删除
python install.py rm openresty3.重新安装openresty,则可以执行(此处仅为示例,实际操作中根据需要执行)
# in :install, 安装某个模块,名称不区分大小写
python install.py in openresty多机分离部署
如果您有多台服务器需要部署服务,可以参考第一章节的资源规划示例,尝试规划每台服务器需要部署的服务类型
1、查询当前部署包内包含的模块清单
# se :表示search,根据模块名称查询安装包里是否包括某个模块,不区分大小写,如果没有指定名称则输出安装包里所有模块信息
python install.py se 2、选择您要安装的模块部署
# in :install, 安装某个模块,名称不区分大小写
python install.py in 模型名接下来请直接进入【九、验证服务可用性】章节。
五、升级模型
升级模型部署,是指您之前部署过老版本的百度文字识别产品模型,需要对模型进行升级操作。
方法一:
1、首先查询新的部署包内包含的模块清单
# se :表示search,根据模块名称查询安装包里是否包括某个模块,不区分大小写,如果没有指定名称则输出安装包里所有模块信息
python install.py se 2、选择您要升级的模型模块并更新授权证书
# up, upgrade: 升级指定模块,不区分大小写,不指定参数时输出所有可升级模块信息
python install.py up 模块名(这里指模型)
# lu, licenseupdate: 更新license文件,适用于授权延期、实例数扩容、增加产品授权
python install.py lu方法二:
进入旧模型部署包(可以参考上文约束的命令规范:baidu_ocr_install_日期找到历史部署包)卸载当前版本的模型,之后进入新申请的部署包选择要升级的模型安装。
示例:
ll
### 返回结果如下:
# drwxr-xr-x 2 root root 4096 10月 26 16:56 baidu_ocr_install_20211025
# drwxr-xr-x 2 root root 4096 10月 26 16:56 baidu_ocr_install_20211026
# 进入旧部署包
cd baidu_ocr_install_20211025/original/package/Install
# 查看当前部署包内置的模块
python install.py se
# 卸载指定模型
python install.py rm 模型模块名
# 进入新申请的部署包
cd baidu_ocr_install_20211026/original/package/Install
# 查看当前部署包内置的模块,找到该模型的模块
python install.py se
# 安装同名模型
python install.py in 该模型的模块名接下来请直接进入【九、验证服务可用性】章节。
六、新增模型
1、查询新的部署包内包含的模块清单,依次部署所需要的依赖
# 进入新申请的部署包
cd original/package/Install
# se :表示search,根据模块名称查询安装包里是否包括某个模块,不区分大小写,如果没有指定名称则输出安装包里所有模块信息
python install.py se
# in :install, 安装某个模块,名称不区分大小写
python install.py in docker如果有其他依赖需要安装的话(如您需要使用GPU等,需要额外安装nvidia模块),步骤同上。此处不再提供示例。
2、部署指定模型模块并更新授权证书
# in :install, 安装某个模块,名称不区分大小写
python install.py in 模型名(模型模块)
# lu, licenseupdate: 更新license文件,适用于授权延期、实例数扩容、增加产品授权
python install.py lu接下来请直接进入【九、验证服务可用性】章节。
七、回滚
license回滚
在新申请获取的部署包内执行license更新操作后,如果发现证书异常可以通过下面的方法回滚,
找到旧部署包(可以参考上文约束的命令规范:baidu_ocr_install_日期),执行license update操作
# 进入旧的部署安装包,执行如下命令替换当前的license文件
# lu,表示 license update
cd original/package/Install && python install.py lu应用回滚
1、查询部署包内包含的模块清单
# se :表示search,根据模块名称查询安装包里是否包括某个模块,不区分大小写,如果没有指定名称则输出安装包里所有模块信息
python install.py se2、选择您要回滚的模块
# rb, rollback: 回滚指定模块,不区分大小写,回滚到最近一次升级前的版本
python install.py rb 模块名若您在此过程出现问题,请提交工单联系百度的工作人员
八、 销毁
支持一键卸载所有模块
cd original/package/Install
# rmall: 删除所有已经安装的模块
python install.py rmall或者卸载指定模块
# rm, remove: 根据模块名称删除某个已经安装的模块;如果有其他模块依赖这个模块,则不允许删除
python install.py rm 模块名九、验证服务可用性
健康检查
百度OCR产品为您提供了私有化应用健康检查(或故障排查)脚本:trouble_shooting.tar,保障您在局域网内部署完毕后进行服务可用性检查或者在遇到突发故障时进行故障排查,方便又快捷,祝您使用愉快!
使用方法: 将脚本上传至服务器任意目录(或在服务器直接下载),并解压后运行。
# 解压
tar vxf trouble_shooting.tar
# 执行
bash trouble_shooting.sh接口测试
接口文档存储路径: 私有化部署包内 original/docs目录,如该目录不存在或者目录为空请联系对应AM(商务经理)线下获取对应模型接口文档。
您可根据接口说明文档中的接口地址(GeneralClassifyService/classify 或 GeneralClassifyService/process)来选择对应的代码示例。
GeneralClassifyService/classify
如果接口路径为“/GeneralClassifyService/classify”,请参考如下代码示例:
#!/usr/bin/python2
#-*- coding:UTF-8 -*-
import SimpleHTTPServer
import SocketServer
import sys
import urllib2,urllib
import base64
import hashlib
import json
url = "http://127.0.0.1:<模型应用端口号>/GeneralClassifyService/classify" #此处ip需填写部署ocr的机器ip,端口填写ocr服务端口,端口号可参考troulbe_shooting.sh返回结果
with open('./test.jpg', "rb") as f: #此处需填写请求图片的地址
img = f.read()
base64Data = base64.b64encode(img) # 第一层base64转换
request_str = '<请参考对应接口文档填写对应的请求参数request_str>' #此处需按照接口文档中的参数填写
data = request_str + "&image=" + base64Data
postData = {'data':base64.b64encode(data)} # 第二层base64转换
req_json = json.dumps(postData) #转json格式
req = urllib2.Request(url)
req.add_header('Content-Type', 'application/json')
response = urllib2.urlopen(req, req_json, 1000).read()
res = json.loads(response)
#print res
res1 = res['result']
res2 = base64.decodestring(res1)
print res2#!/usr/bin/python3
#-*- coding:UTF-8 -*-
import base64
import requests
import json
url = "http://127.0.0.1:<模型应用端口号>/GeneralClassifyService/classify" #此处ip需填写部署ocr的机器ip,端口填写ocr服务端口,端口号可参考troulbe_shooting.sh返回结果
with open('./test.jpg', "rb") as f: #此处需填写请求图片的地址
img = f.read()
base64Data = base64.b64encode(img).decode() # 第一层base64转换
request_str = '<请参考对应接口文档填写对应的请求参数request_str>' # 请参考接口文档中实际请求参数填写
data = request_str + "&image=" + base64Data
postData = {'data':base64.b64encode(bytes(data, encoding='utf-8')).decode()} # 第二层base64转换
ret = requests.post(url,headers={'Content-Type': 'application/json'}, data=json.dumps(postData))
if ret.status_code == 200:
res = ret.json()["result"]
res = str(base64.b64decode(res), 'utf-8')
print(res)<?php
/**
* 发起http post请求(REST API), 并获取REST请求的结果
* @param string $url
* @param string $param
* @return - http response body if succeeds, else false.
*/
function request_post($url = "", $param = "")
{
if(empty($url) || empty($param)) {
return false;
}
echo "Request: \n";
echo $url,"\n";
$postUrl = $url;
$curlPost = json_encode($param);
$curl = curl_init();
$header[] = "Content-Type:application/json;charset=utf-8";
curl_setopt($curl, CURLOPT_URL, $postUrl);
curl_setopt($curl, CURLOPT_HEADER, 0);
curl_setopt($curl,CURLOPT_HTTPHEADER,$header);
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($curl, CURLOPT_SSL_VERIFYPEER, false);
curl_setopt($curl, CURLOPT_POST, 1);
curl_setopt($curl, CURLOPT_POSTFIELDS, $curlPost);
$data = curl_exec($curl);
curl_close($curl);
echo "Response: \n";
$json_data = json_decode($data, TRUE);
if($data && $json_data["err_no"] === 0) {
// 如果识别成功获取result并base64解码
$data = base64_decode($json_data["result"]);
}
var_dump($data);
echo "\n";
return $data;
}
$img_data1 = base64_encode(file_get_contents("./图片.jpg"));
// 宿主机IP地址和端口号,请按照实际信息填写
// 模型应用端口号可参考troulbe_shooting.sh返回结果
$host = "172.17.0.1";
$port = "<模型应用端口号>";
echo "----------文字识别接口功能验证------------\n";
$baseUrl = "http://".$host.":".$port."/GeneralClassifyService/";
echo "----------通用文字识别: classify------------\n";
$url = $baseUrl."classify";
// 请参考接口文档实际请求参数填写,以下仅为示例。
$request_str = "<请参考对应接口文档填写对应的请求参数request_str>";
$data = $request_str."&image=".$img_data1;
$param = array(
"data" => base64_encode($data)
);
$res = request_post($url, $param);const request = require("request");
const fs = require("fs");
// 宿主机IP地址和端口号,
// 端口号可参考troulbe_shooting.sh返回结果
const host = "172.17.0.1";
const port = "<模型应用端口号>";
const bitmap1 = fs.readFileSync("./图片.jpg");
const img_data1 = Buffer.from(bitmap1, "binary").toString("base64");
const baseUrl = "http://" + host + ":" + port + "/GeneralClassifyService/";
const url = baseUrl + "classify";
// 此处需按照接口文档中的参数填写
const request_str = "<请参考对应接口文档填写对应的请求参数request_str>";
data = request_str + "&image=" + base64Data
const data = request_str + "&image=" +img_data1;
request({
method: "POST",
url: url,
headers: {
"content-type": "Content-Type:application/json;charset=utf-8",
},
form: JSON.stringify({
"data": Buffer.from(data).toString("base64")
})
},function (error, response, body) {
if (!error && response.statusCode == 200) {
let body_json = JSON.parse(body);
if (body_json["err_no"] === 0) {
let result = Buffer.from(body_json["result"], "base64").toString();
console.log(result);
} else {
console.log(body);
}
}else{
console.log("error");
}
});package com.baidu.easypack;
import com.baidu.aip.util.Base64Util;
import com.baidu.utils.FileUtil;
import com.baidu.utils.GsonUtils;
import com.baidu.utils.HttpUtil;
import com.google.gson.Gson;
import org.json.JSONObject;
import java.nio.charset.StandardCharsets;
import java.util.Base64;
import java.util.HashMap;
import java.util.Map;
/**
* 通用文字识别
*/
public class gen {
/**
* 重要提示代码中所需工具类
* FileUtil,Base64Util,HttpUtil,GsonUtils请从
* https://ai.baidu.com/file/658A35ABAB2D404FBF903F64D47C1F72
* https://ai.baidu.com/file/C8D81F3301E24D2892968F09AE1AD6E2
* https://ai.baidu.com/file/544D677F5D4E4F17B4122FBD60DB82B3
* https://ai.baidu.com/file/470B3ACCA3FE43788B5A963BF0B625F3
* 下载
*/
public static String generalBasic() {
// 请求url
//ip = 内网ip地址 , port = docker中ocr容器映射的端口
// 端口号可参考troulbe_shooting.sh返回结果
// String url = "http://ip:port/GeneralClassifyService/classify";
String url = "http://172.17.0.1:<模型应用端口号>/GeneralClassifyService/classify";
try {
// 本地文件路径
String filePath = "C:\\Users\\zhaoc\\Desktop\\123.jpg";
byte[] imgData = FileUtil.readFileByBytes(filePath);
String imgStr = Base64Util.encode(imgData);
//此处需按照接口文档中的参数填写
String request_st1 = "<请参考对应接口文档填写对应的请求参数request_str>";
String data = request_st1 + "&image=" + imgStr;
byte[] ddata = data.getBytes();
String params = Base64Util.encode(ddata);
Map<String, Object> map1 = new HashMap<>();
map1.put("data",params);
String request_str1 = GsonUtils.toJson(map1);
String contentType = "application/json";
String encoding = "UTF-8";
String result = HttpUtil.postGeneralUrl(url,contentType, request_str1,encoding);
JSONObject jso=new JSONObject(result);
String res=jso.getString("result");
byte[] decode = Base64.getDecoder().decode(res.getBytes(StandardCharsets.UTF_8));
System.out.println(new String(decode, StandardCharsets.UTF_8));
return result;
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
public static void main(String[] args) {
com.baidu.easypack.gen.generalBasic();
}
}using System;
using System.IO;
using System.Net;
using System.Text;
using System.Web;
using Newtonsoft.Json;
using Newtonsoft.Json.Linq;
namespace com.baidu.ai
{
public class Accurate
{
// 通用文字识别
public static string accurate()
{
// 填写宿主机IP和端口号
// 端口号可参考troulbe_shooting.sh返回结果
string url = "http://172.17.0.1:<模型应用端口号>/GeneralClassifyService/classify";
// 下面参数需按照接口文档中的参数填写
string request_str = "<请参考对应接口文档填写对应的请求参数request_str>";
Encoding encoding = Encoding.UTF8;
// 图片的base64编码
string img64data = getFileBase64("./医疗发票.jpeg");
// 请求参数拼接
byte[] b = encoding.GetBytes(request_str + "&image=" + img64data);
string request_bs64 = Convert.ToBase64String(b); // 第2次base64 转换
var obj = new {
data = request_bs64
};
var postdata = JsonConvert.SerializeObject(obj);
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url);
request.Method = "post";
request.KeepAlive = true;
request.ContentType = "application/json";
byte[] data = encoding.GetBytes(postdata);
request.GetRequestStream().Write(data, 0, data.Length);
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
StreamReader reader = new StreamReader(response.GetResponseStream(), Encoding.Default);
string result = reader.ReadToEnd();
Console.WriteLine("文字识别:");
// 对请求返回对Json参数进行base64解码
JObject stuff = (JObject)JsonConvert.DeserializeObject(result);
string rr = stuff["result"].ToString();
byte[] bytes_r = Convert.FromBase64String(rr);
string decode = encoding.GetString(bytes_r);
Console.WriteLine(decode);
return decode;
}
public static String getFileBase64(String fileName) {
FileStream filestream = new FileStream(fileName, FileMode.Open);
byte[] arr = new byte[filestream.Length];
filestream.Read(arr, 0, (int)filestream.Length);
string baser64 = Convert.ToBase64String(arr);
filestream.Close();
return baser64;
}
// main
public static void Main() {
accurate();
}
}
}package main
import (
"bytes"
"encoding/json"
"fmt"
"io/ioutil"
"net/http"
"encoding/base64"
)
func main() {
// 根据宿主机实际IP和PORT来填写
// 端口号可参考troulbe_shooting.sh返回结果
host := "172.17.0.1"
port := "<模型应用端口号>"
strbytes, _ := ioutil.ReadFile("./图片.jpg")
img_data1 := base64.StdEncoding.EncodeToString(strbytes)
url := "http://" + host + ":" + port + "/GeneralClassifyService/classify";
// 参考接口文档中实际请求参数来填写,以下仅为示例
request_str := "<请参考对应接口文档填写对应的请求参数request_str>"
data_str := request_str + "&image=" +img_data1;
client := &http.Client{}
data := make(map[string]interface{})
data["data"] = base64.StdEncoding.EncodeToString([]byte(data_str))
bytesData, _ := json.Marshal(data)
req, _ := http.NewRequest("POST", url, bytes.NewReader(bytesData))
req.Header.Set("Content-Type", "Content-Type:application/json;charset=utf-8")
resp, _ := client.Do(req)
defer resp.Body.Close()
body, _ := ioutil.ReadAll(resp.Body)
body_json := make(map[string]interface{})
json.Unmarshal(body, &body_json)
if body_json["err_no"].(float64) == 0 {
result, _ := base64.StdEncoding.DecodeString(body_json["result"].(string))
fmt.Println(string(result))
} else {
fmt.Println(string(body))
}
}GeneralClassifyService/process
如果接口地址为“/GeneralClassifyService/process”,请参考如下代码示例:
#!/usr/bin/python2
#-*- coding:UTF-8 -*-
import SimpleHTTPServer
import SocketServer
import sys
import urllib2,urllib
import base64
import hashlib
import json
url = "http://127.0.0.1:<模型应用端口号>/GeneralClassifyService/process" #此处ip需填写部署ocr的机器ip,端口填写ocr服务端口
with open('./test.jpg', "rb") as f: #此处需填写请求图片的地址
img = f.read()
base64Data = base64.b64encode(img) #base64转换
# 请参考对应接口文档修改下面的请求参数
input={
'logid':'test_9527', #无实际意义,可不传
'format':'json',
'object_type': 'general_v5',#识别对象类型,根据接口文档调整
'type': 'st_ocrapi',
'image': base64Data
}
postData = {
'provider':'default', #默认值
'input': json.dumps(input)
}
req_json = json.dumps(postData)
req = urllib2.Request(url)
req.add_header('Content-Type', 'application/json')
response = urllib2.urlopen(req, req_json, 1000).read()
res = json.loads(response) #将结果的json数据格式转化为字典类型
print res十、运维
您可以前往「私有化部署服务」/「常见问题」查找常见问题排查思路
您可以前往 「私有化部署服务」/「运维手册」查看常用运维文档