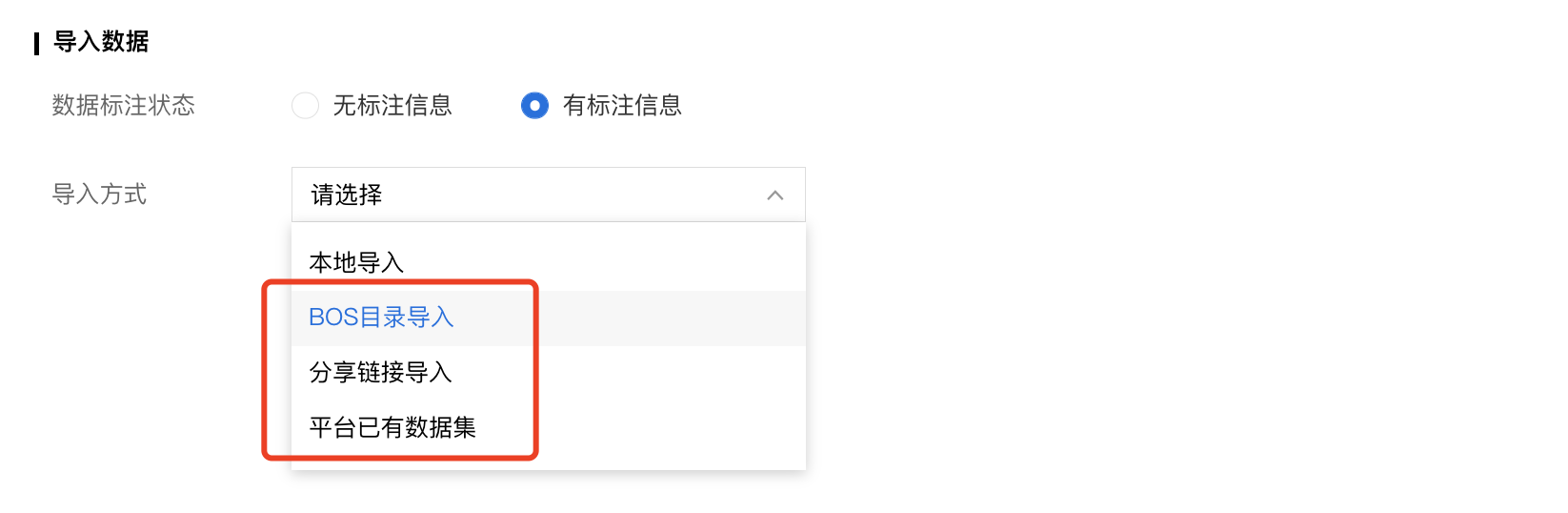
经典版声音分类上传数据集
上传数据要求说明
这里我们对上传数据的要求不仅是格式上的要求,更重要的是介绍怎样的数据可以更有效提升模型效果
设计分类
首先想好分类如何设计,每个分类为你希望识别出的一种结果,如要识别猫狗的叫声,则可以以“猫”、“狗”等分别作为一个分类;如果安防监控通过声音判断是否出现异常状态,可以以“正常”“不异常”设计为两类,或者“正常”“异常原因一”、“异常原因二”、“异常原因三”……设计为多类。
注意:目前单个模型的上限为1000类,如果要超过这个量级请在百度云控制台内提交工单反馈
准备数据
基于设计好的分类准备音频数据,每个分类需要准备50个音频文件以上,如果想要较好的效果,建议100个起音频文件,如果某些分类的声音具有相似性,需要增加更多音频。
音频的基本格式要求: 目前支持音频文件 类型为支持wav,mp3,m4a ,音频文件大小限制在4M以内。一个模型的音频总量限制10万个音频文件。
注意1:训练集音频需要和实际场景要识别的音频环境一致,举例:如果实际场景要识别的声音都是手机采集的,那训练的音频文件也需要同样的场景获得,而不要采用网上随便下载的音频 注意2:考虑实际应用场景可能有的种种可能性,每个分类的音频需要覆盖实际场景里面可能有的可能性,如噪音干扰、多种可能的采集设备,训练集覆盖的场景越多,模型的泛化能力越强。 注意3:如果需要寻求第三方数据采集团队协助数据采集,请在百度云控制台内提交工单反馈
你可能会有的问题:如果训练音频数据无法全部覆盖实际场景要识别的音频,怎么办?
答:本身模型算法会有一定的泛化能力,尽可能覆盖即可。
导入未标注数据
本地数据
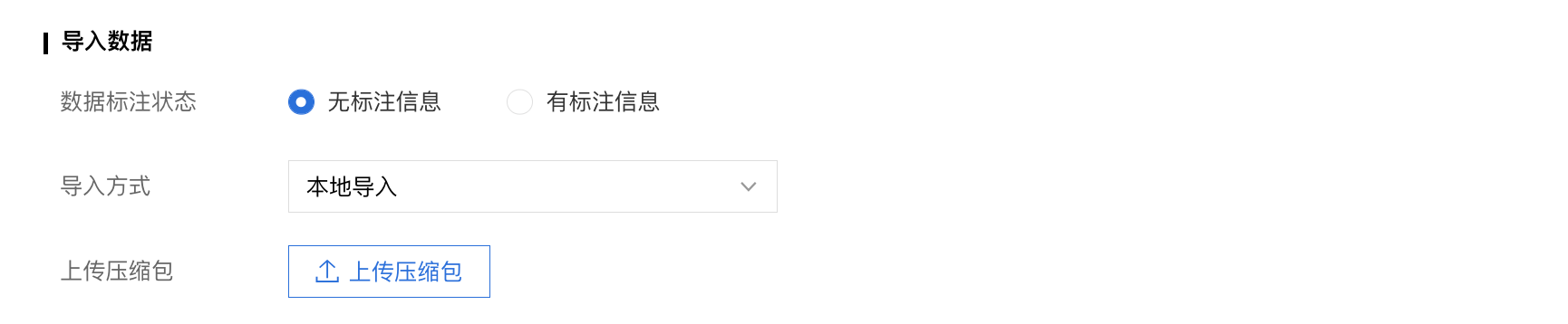
已有数据集
支持选择百度云BOS导入、分享链接导入、平台已有数据集导入;支持选择线上已有的数据集,包括其他语音类模型的数据集
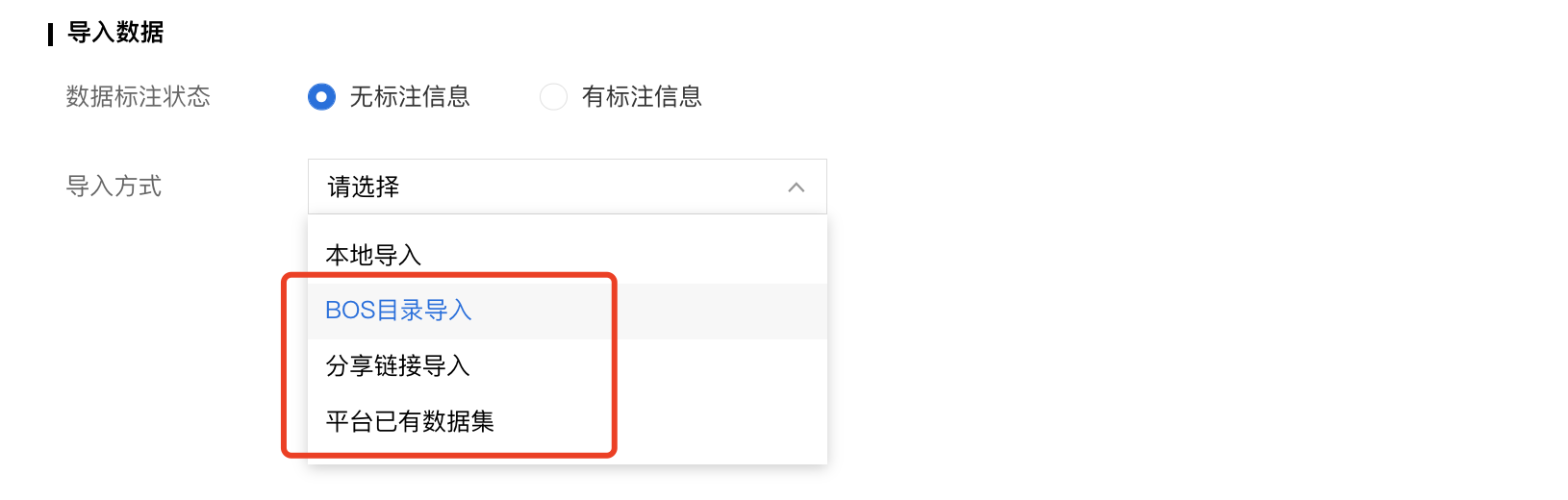
导入已标注数据
本地数据
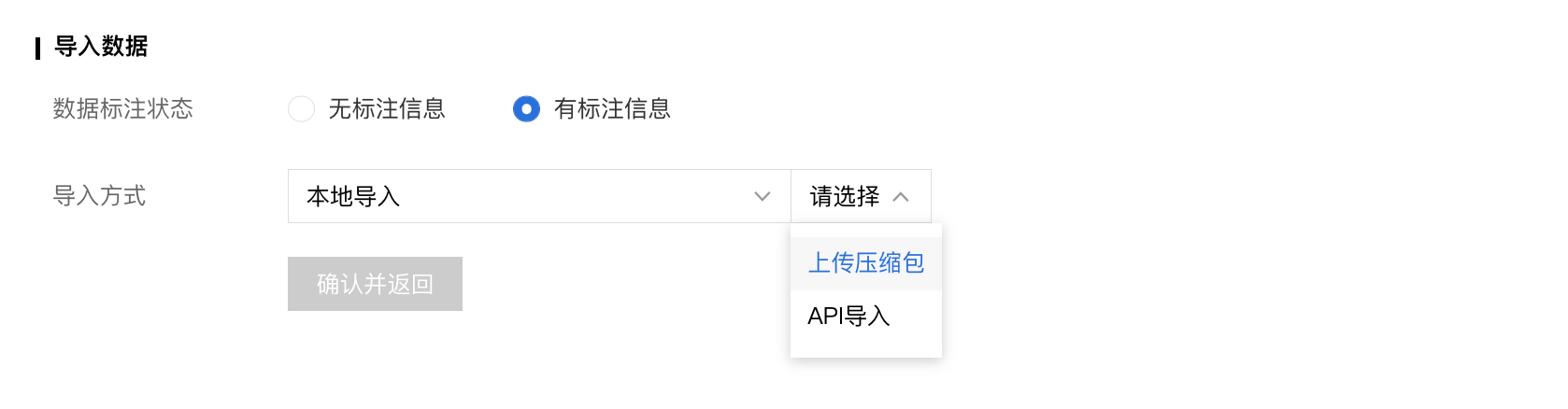
已有数据集
支持选择百度云BOS导入、分享链接导入、平台已有数据集导入;支持选择线上已有的数据集,包括其他语音类模型的数据集