

EasyDL文本-文本分类单标签快速开始
目录
场景介绍
目前不少互联网内容平台或者电商平台中有用户评论模块,往往都需要人工维护评论信息,如将评论信息中好的评论与坏的评论进行分类,或者将评论信息中的广告信息能有效过滤/甄别出来,当评论内容越来越高时,人工维护评论的成本就越高。而越来越多的垂直内容平台由于评论信息内容多样,内容不一,为实现更好的文本分类效果,往往需要定制企业专属的文本分类能力。
某个酒店信息聚合平台,希望在其官网的评论模块中增加自动分类功能,能支持将好的评价和不好的评价自动分类,方便酒店管理者在后台查看,同时该网站缺少相关AI算法工程师及算力资源,如何能更高效更低成本的获取定制文本分类服务,成为该服务商面临的一大难题。无意中了解到百度EasyDL可以灵活定制并可以快速上手获得业务所需的高精度AI能力,刚好可以解决该服务商面临的问题。
实现步骤
只需四步即可完成自定义AI模型的训练及发布的全过程。
Step1:成为百度AI开放平台的开发者
要使用百度EasyDL的模型训练能力首先需要注册成为百度AI开放平台的开发者,首先让我们用5分钟来注册百度AI开放平台的开发者(如您已经是开发者,可直接登录使用)。
先点击此处注册百度账号进入,如下图的页面快速的注册一个百度账号吧。
Step2:提前准备训练数据
文本分类单标签可实现文本内容的自动分类,为每个文本定义一个标签类型。数据数量越多理论上训练效果越好,本次示例以线上公开数据集为例,具体数据处理全过程可参考文本分类数据集创建
Step3:使用EasyDL训练文本分类
创建模型
进入EasyDL官方平台 点击【立即使用】

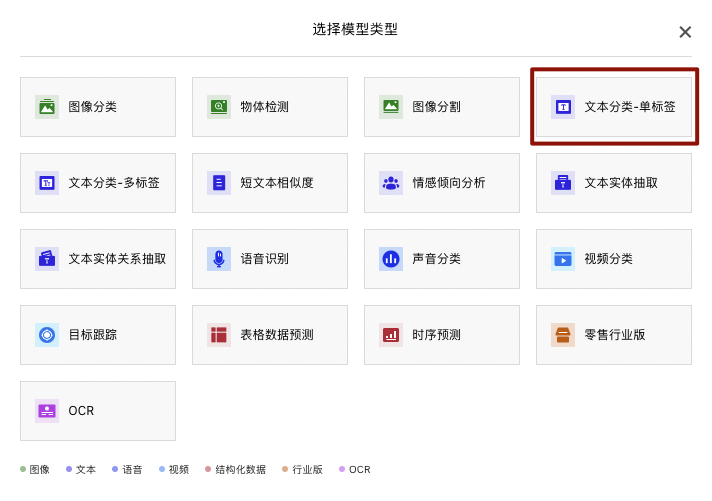
点击【文本分类-单标签】,进入操作台
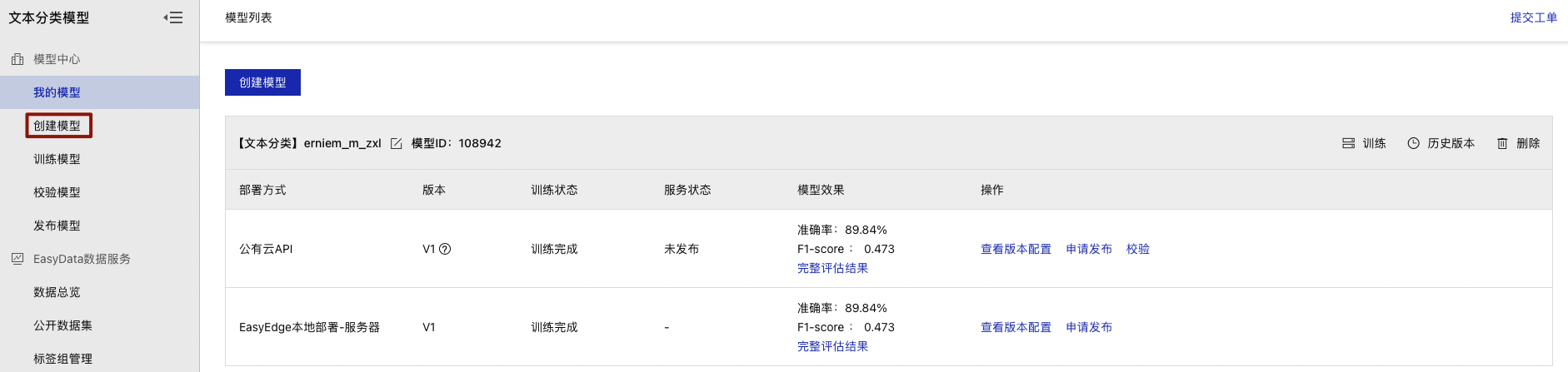
在模型列表下点击【创建模型】
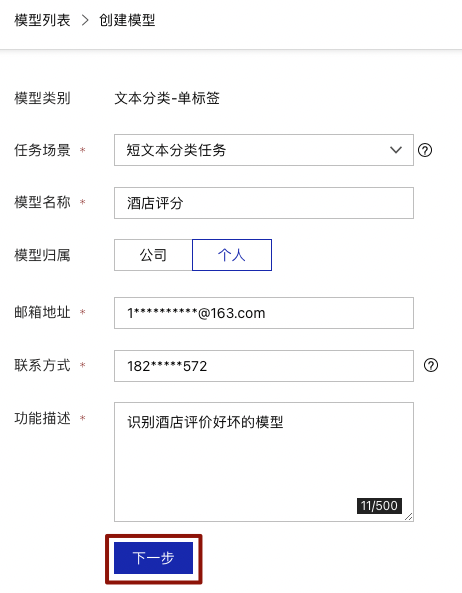
填写模型信息后,点击【下一步】
模型创建完成后可在【我的模型】栏查看已创建的模型信息

选择数据集
在模型列表页找到新建的模型并选择【公开数据集】查看现有公开数据集

本次训练将使用chnsenticorp情感分类-评测数据集
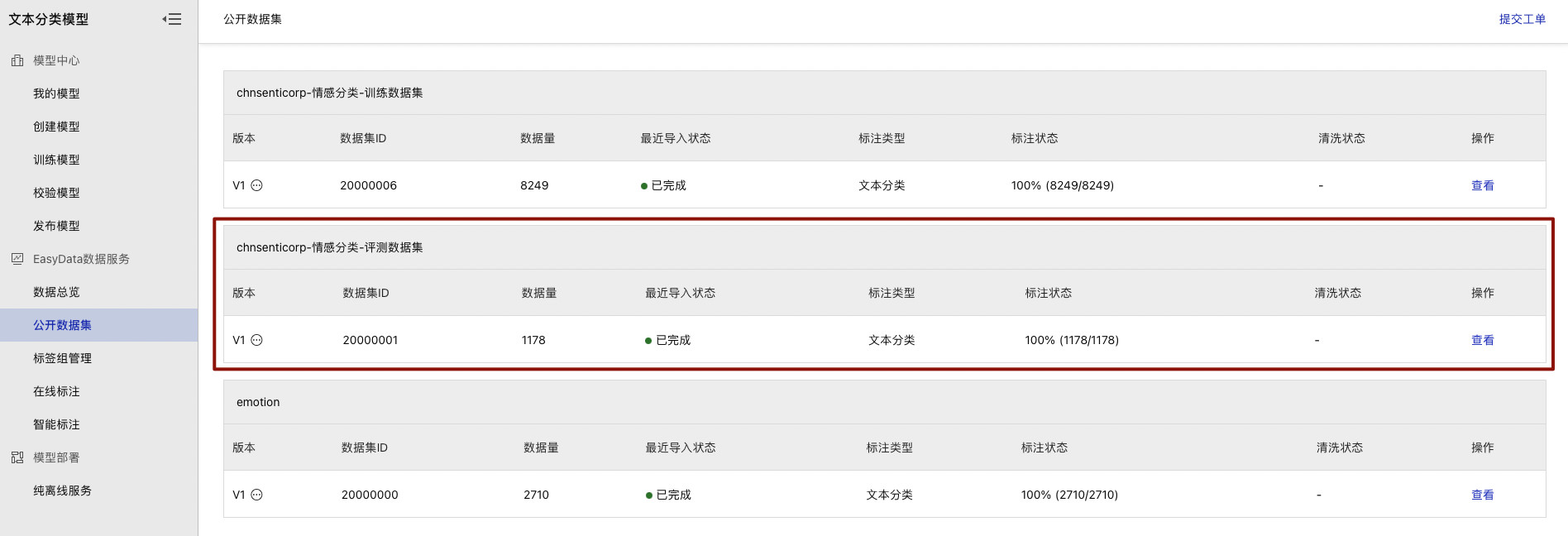
在模型列表页点击【模型训练】进入到数据集选择界面

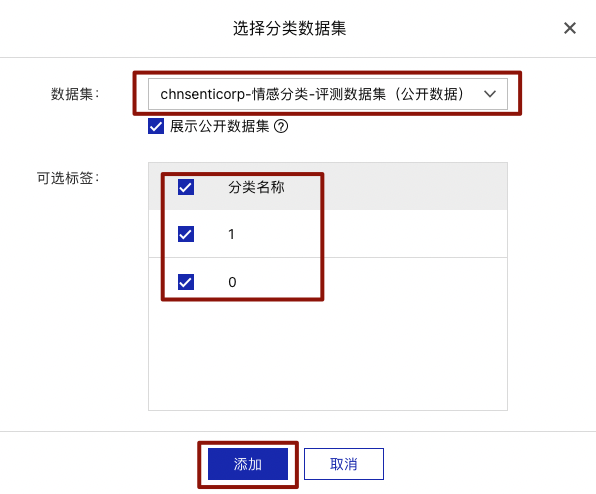
选择chnsenticorp情感分类-评测数据集并勾选全部分类名称,点击【添加】
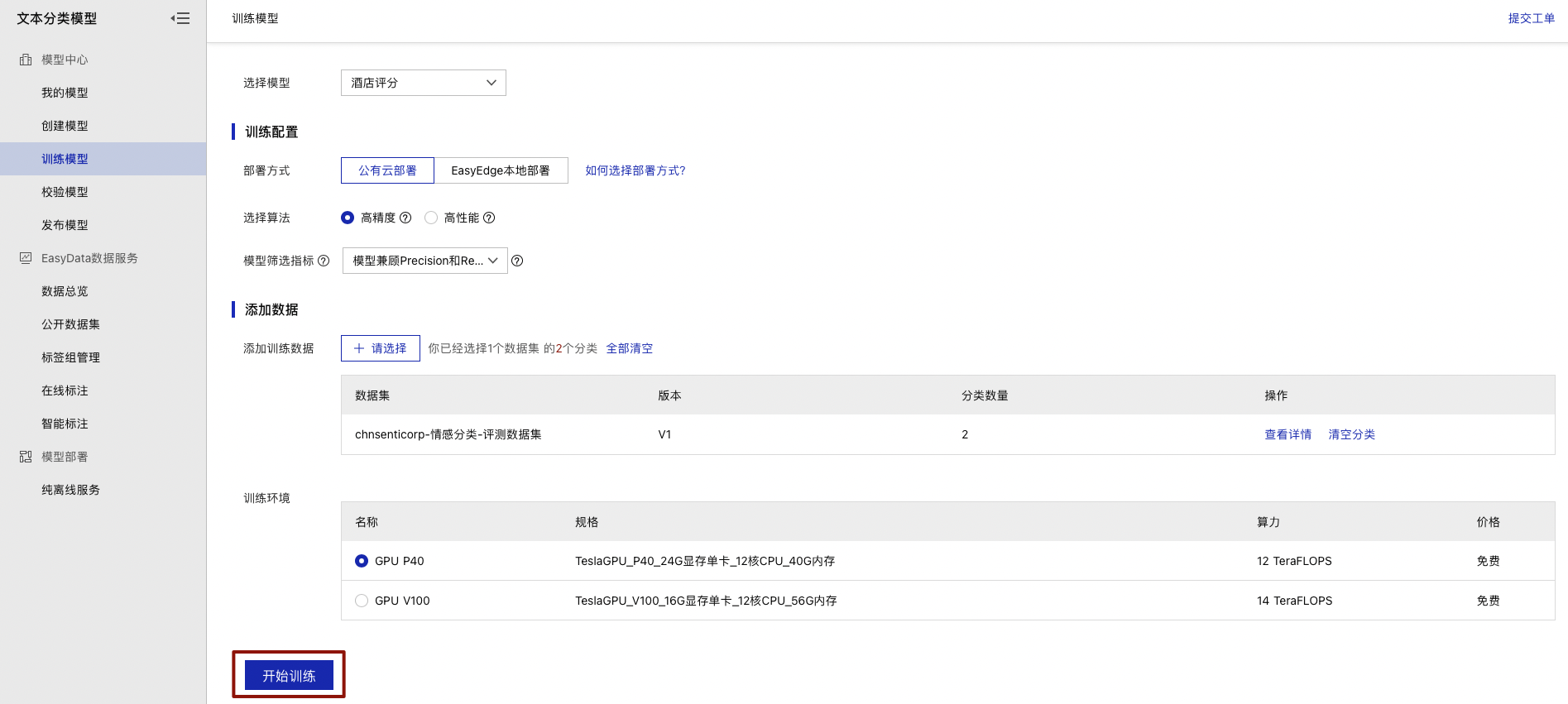
点击【开始训练】进入到模型训练阶段
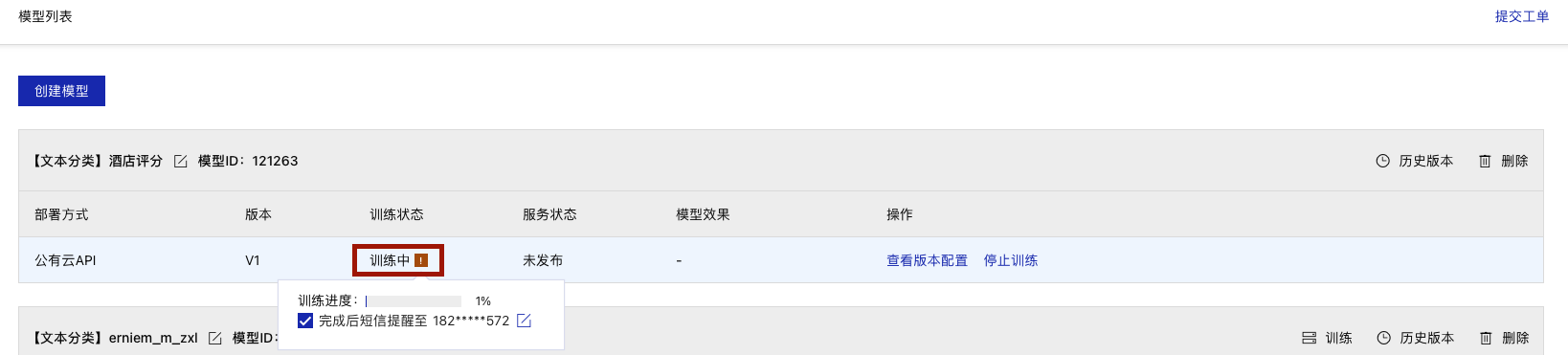
在模型列表下,可以看到处于训练状态的模型,将鼠标放置感叹号图标处,即可查看训练进度,同时若勾选短信提醒,在模型训练完成后会以短信的形式通知
模型校验
模型训练完成后,可在模型列表下,点击【校验】

点击【启动模型校验服务】,需等待几分钟

输入校验文本,进行模型校验
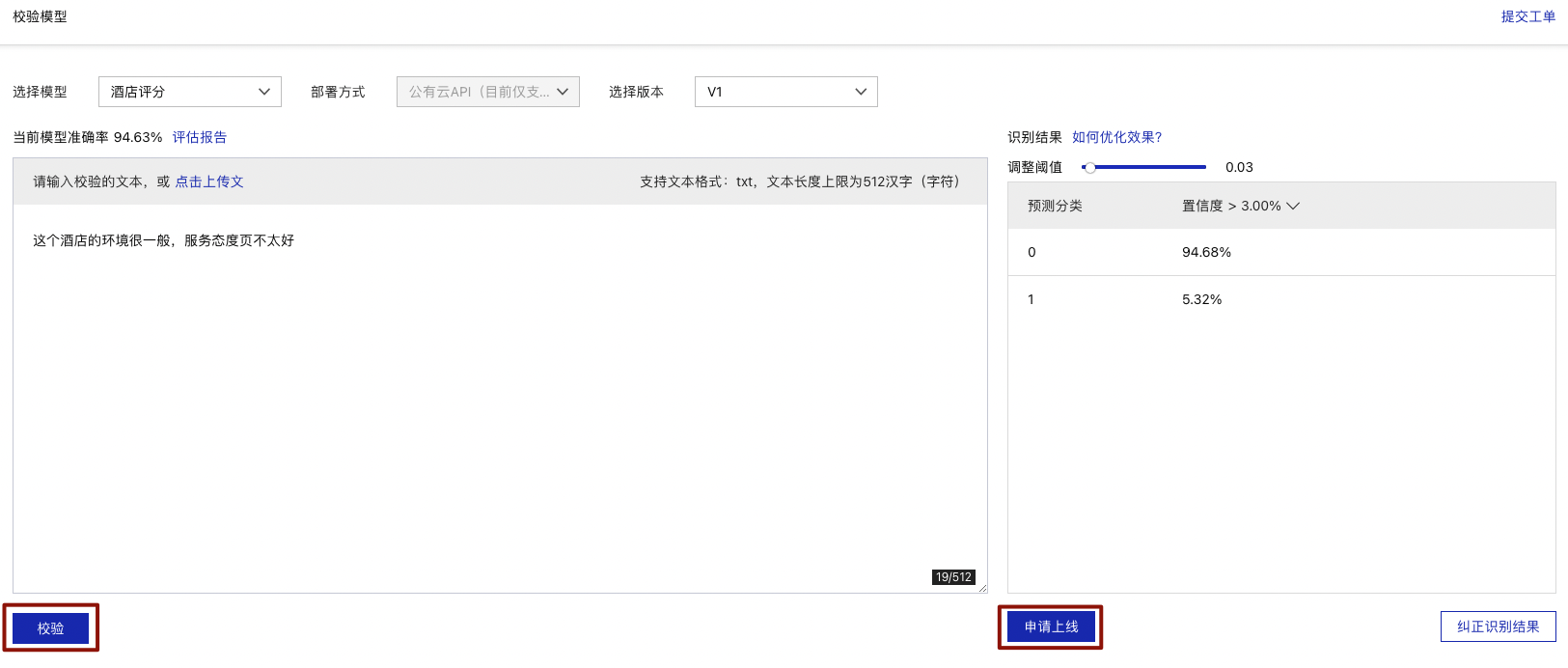
在此处可以点击【申请上线】,进行模型发布,跳转到模型发布
模型发布
模型训练完成后,点击【申请发布】

按要求填写相应信息后,点击【提交申请】

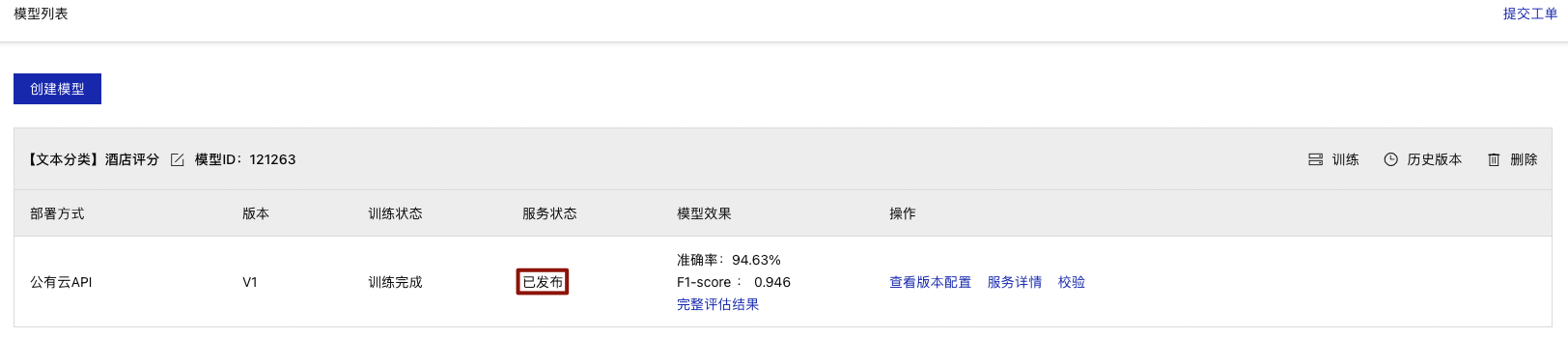
提交申请后跳转至【我的模型】栏,服务状态变为【发布中】

等待几分钟,此状态就会变为【已发布】,即发布成功
Step4: 模型调用
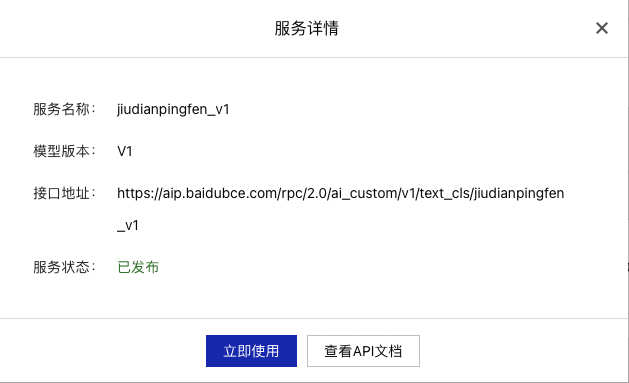
在【我的模型】栏找到发布完成的模型点击【服务详情】

接口地址在模型调用代码中将会用到,点击【立即使用】跳转至EasyDL控制台
在EasyDL控制台中点击【创建应用】

信息填写完成后点击【立即创建】

创建完成后即刻在应用列表页获取到AK SK密钥

在获取到API KEY 以及 Secret KEY后,我们就可以写一个示例代码调用我们之前创建并训练完成酒店评论文本分类模型
准备开发环境
我们选择用python来快速搭建一个原型,如果没有接下来需要安装以下python。可以参考下表列出的不同操作系统的安装方法进行安装。
Python的官方下载地址:下载python
Windows 快速测试包
windows平台的用户如果对上述的python安装感到困难,可以下载我们的一键测试包,下载地址:windows测试包。
解压zip文件后,双击run.bat即可测试。
编写代码
新建一个 main.py
粘贴以下内容,不要忘记替换你的 API_KEY 以及 SECRET_KEY:
# coding=utf-8
import sys
import json
# 保证兼容python2以及python3
IS_PY3 = sys.version_info.major == 3
if IS_PY3:
from urllib.request import urlopen
from urllib.request import Request
from urllib.error import URLError
from urllib.parse import urlencode
from urllib.parse import quote_plus
else:
import urllib2
from urllib import quote_plus
from urllib2 import urlopen
from urllib2 import Request
from urllib2 import URLError
from urllib import urlencode
reload(sys)
sys.setdefaultencoding('utf8')
# 防止https证书校验不正确
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
# 百度云控制台获取到ak,sk以及
# EasyDL官网获取到URL
# ak
API_KEY = 'RgdpDFjOHmRQvphsi8bLhIYE'
# sk
SECRET_KEY = 'ja1pDyGaF3vgwPNW3T0EqEkkd5hgl8ug'
# url
EASYDL_TEXT_CLASSIFY_URL = "https://aip.baidubce.com/rpc/2.0/ai_custom/v1/text_cls/hotel_comment"
""" TOKEN start """
TOKEN_URL = 'https://aip.baidubce.com/oauth/2.0/token'
"""
获取token
"""
def fetch_token():
params = {'grant_type': 'client_credentials',
'client_id': API_KEY,
'client_secret': SECRET_KEY}
post_data = urlencode(params)
if (IS_PY3):
post_data = post_data.encode('utf-8')
req = Request(TOKEN_URL, post_data)
try:
f = urlopen(req, timeout=5)
result_str = f.read()
except URLError as err:
print(err)
if (IS_PY3):
result_str = result_str.decode()
result = json.loads(result_str)
if ('access_token' in result.keys() and 'scope' in result.keys()):
if not 'brain_all_scope' in result['scope'].split(' '):
print ('please ensure has check the ability')
exit()
return result['access_token']
else:
print ('please overwrite the correct API_KEY and SECRET_KEY')
exit()
"""
调用远程服务
"""
def request(url, data):
if IS_PY3:
req = Request(url, json.dumps(data).encode('utf-8'))
else:
req = Request(url, json.dumps(data))
has_error = False
try:
f = urlopen(req)
result_str = f.read()
if (IS_PY3):
result_str = result_str.decode()
return result_str
except URLError as err:
print(err)
if __name__ == '__main__':
# 获取access token
token = fetch_token()
# 拼接url
url = EASYDL_TEXT_CLASSIFY_URL + "?access_token=" + token
# 好评
text_good = "这个酒店不错,干净而且安静,早餐也好吃"
# 差评
text_bad = "不怎么干净,服务员态度也差强人意,以后不会在预订了"
# 请求接口
# 测试好评
response = request(url,
{
'text': text_good,
'top_num': 2
})
result_json = json.loads(response)
result = result_json["results"]
# 打印好评结果
print(text_good)
for obj in result:
print(" 评论类别:" + obj['name'] + " 置信度:" + str(obj['score']))
print("")
# 请求接口
# 测试差评
response = request(url,
{
'text': text_bad,
'top_num': 2
})
result_json = json.loads(response)
result = result_json["results"]
# 打印差评结果
print(text_bad)
for obj in result:
print(" 评论类别:" + obj['name'] + " 置信度:" + str(obj['score']))运行代码
在命令行中运行python main.py
您还可以在我们的github地址中找到main.py
结果
若代码正确运行,命令行界面上会显示出运行结果:
这个酒店不错,干净而且安静,早餐也好吃
评论类别:good 置信度:0.974235713482
评论类别:bad 置信度:0.0257642995566
不怎么干净,服务员态度也差强人意,以后不会在预订了
评论类别:bad 置信度:0.850781261921
评论类别:good 置信度:0.149218738079结果中返回了每个待分类文本的分类以及置信度,置信度高的分类说明预测的文本属于这个分类的可能越大,这样我们就能将上述酒店评论分为好评,差评了,详细的返回和参数文档需要参照API文档EasyDL文本分类API参考文档
产品特色
可视化操作: 无需机器学习专业知识,模型创建-数据上传-模型训练-模型发布全流程可视化便捷操作,最快15分钟即可获得一个高精度模型
高精度效果:EasyDL底层结合百度 AutoDL/AutoML技术,针对用户数据自动获得最优网络和超参组合,基于少量数据就能获得出色效果和性能的模型
端云结合:训练完成的模型可发布为云端API或离线SDK,灵活适配各种使用场景及运行环境
数据支持:全方位支持训练数据的高质量采集与高效标注,支持在模型迭代过程中不断扩充数据,助力提升模型效果
更多参考
如对文档说明有疑问或建议,请微信搜索“BaiduEasyDL”添加小助手交流
备注:文档如使用中遇到报错等问题,请在控制台中通过“工单”联系我们,售后团队为您及时解决问题