

经典版声音分类创建数据集
更新时间:2022-04-12
在训练之前需要在数据中心【创建数据集】
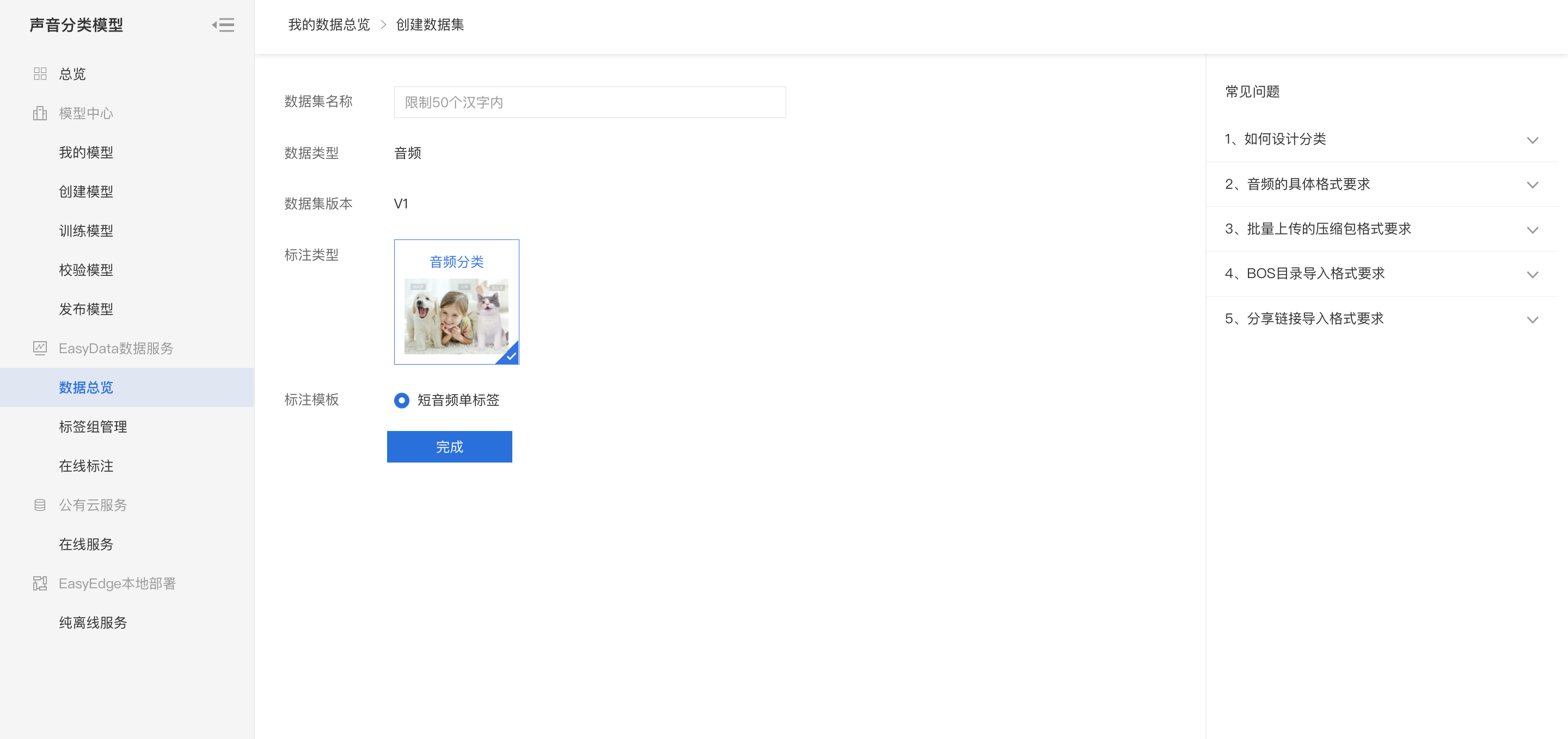
设计分类
- 每个标签就是对这个音频希望识别出的全部结果。标签的上限为1000种。
- 标签名由数字、中英文、中/下划线组成,长度上限256字符。
音频的具体格式要求
- 训练集音频需要和实际场景要识别的音频环境一致,举例:如果实际场景要识别的音频都是手机摄录的,那训练的音频也需要同样的场景获得,而不要采用网上随便下载的音频。
- 每个标签的音频需要覆盖实际场景里面的可能性,如不同环境下,训练集覆盖的场景越多,模型的泛化能力越强。
- 如果需要寻求第三方数据采集团队协助数据采集,可以加入官方QQ群(群号:679517246)联系群管咨询了解。
- 音频支持mp3, m4a, wav格式,单个音频大小在4M内且时长小于15s。