

发起训练
训练模型
完成数据的标注,或提交已标注的数据后,即可在「模型中心」目录中点击「训练模型」,开始模型的训练。
按以下步骤操作,启动模型训练:
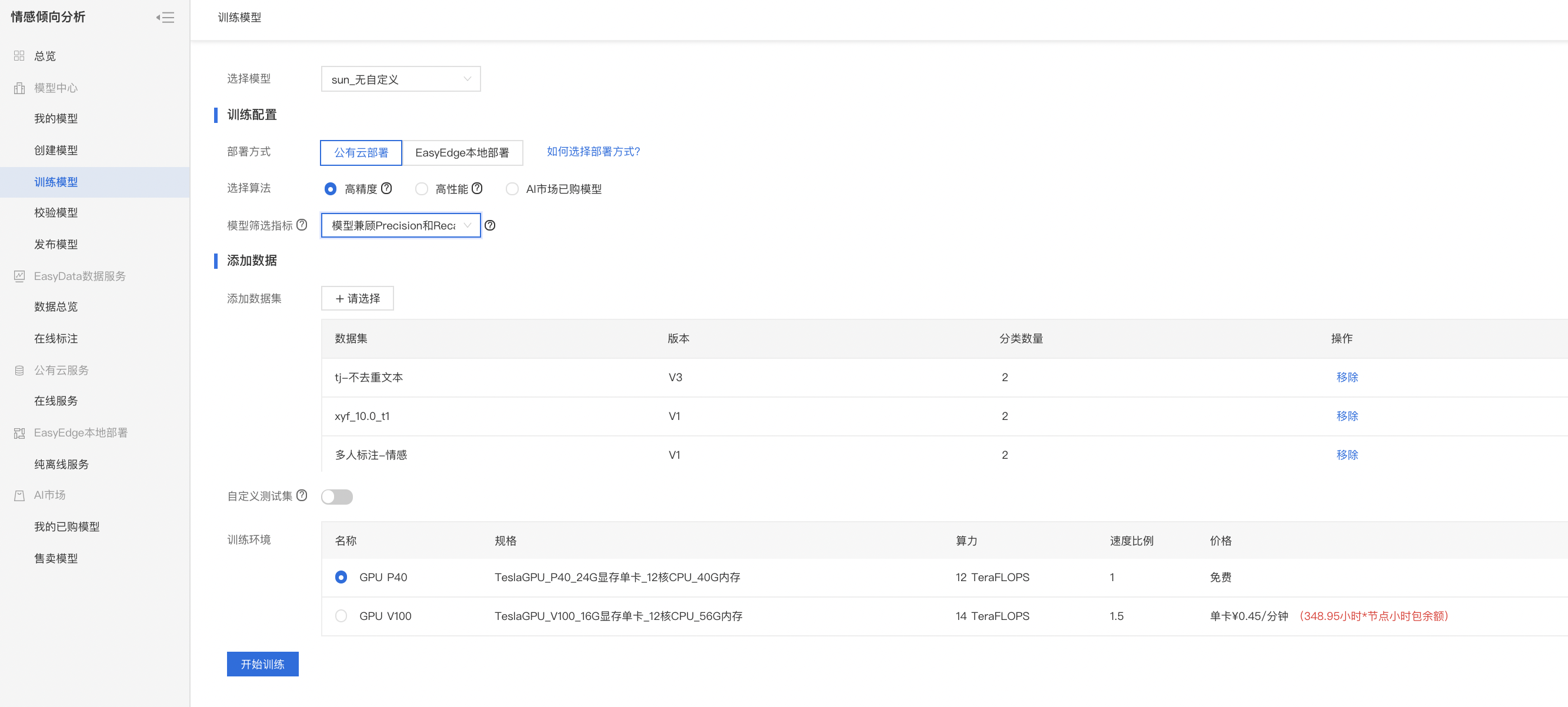
Step 1 选择模型
选择此次训练的模型
Step 2 训练配置
部署方式
可选择「公有云部署」、「EasyEdge本地部署」。
选择设备
- 如果您选择了「EasyEdge本地部署」,请根据实际部署设备选择
- 如果您选择了「公有云部署」,无需选择设备
选择算法
您可以根据训练的需求,选择「高精度」或「高性能」算法。不同的算法将影响训练时间、预测速度与模型准确率。
- 如果您选择了高精度的模型,模型预测准确率将更高。使用10000条训练样本,将在60-100min完成训练
- 如果您选择了高性能的模型,相同训练数据量的情况下,训练耗时更短,模型预测速度更快。使用10000条训练样本,将在5min内完成训练
如果您已从AI市场购买了模型算法,也可以基于已购模型的算法训练: 前往AI市场购买
「高精度」算法内置文心大模型,将大数据预训练与多源丰富知识相结合,通过持续学习技术,不断吸收海量文本数据中词汇、结构、语义等方面的新知识,实现模型效果不断进化
模型筛选指标
选择不同的模型选择方式,对应的模型各项效果指标将有所不同。如果没有特殊场景的要求,使用默认即可。有以下指标可供选择:
- 模型兼顾Precision和Recall:挑选模型时,兼顾Precision精确度和Recall召回率,如场景中没有对精度或召回的特别要求,建议您使用此默认指标
- Precision最高的模型:挑选模型时,优先挑选Precision精度最高的模型作为部署模型
- Recall最多的模型:挑选模型时,优先选择召回率最高的模型作为部署模型
- ACC最大的模型:挑选模型时,优先挑选预测样本数最多的模型作为部署模型
- Loss最小的模型:挑选模型时,优先挑选预测偏差最小的模型
Step 3 添加数据
添加训练数据
- 先选择数据集,再按标签(positive、negative)选择数据集里的文本,可从多个数据集选择文本
- 训练时间与数据量大小、选择的算法、训练环境有关。在选择GPU P40、高性能的模型时,10000条训练样本,将在5min内完成训练
添加自定义测试集
上传不包含在训练集的测试数据,可获得更客观的模型效果评估结果。
添加自定义测试集的目的:
如果学生的期末考试是平时的练习题,那么学生可能通过记忆去解题,而不是通过学习的方法去做题,所以期末考试的试题应与平时作业不能一样,才能检验学生的学习成果。那么同理,AI模型的效果测试不能使用训练数据进行测试,应使用训练数据集外的数据测试,这样才能真实的反映模型效果
期末考试的内容属于学期的内容,但不一定需要完全包括所学内容。同理,测试集的标签是训练集的全集或者子集即可
Step 4 训练模型
点击「开始训练」,即可开始训练模型。
- 训练时间与数据量大小、选择的算法、训练环境有关
- 模型训练过程中,可以设置训练完成的短信提醒并离开页面
- 平台提供付费算力,付费算力可用于模型训练,可根据实际需求购买算力使用时长。
各类算力价格如下:
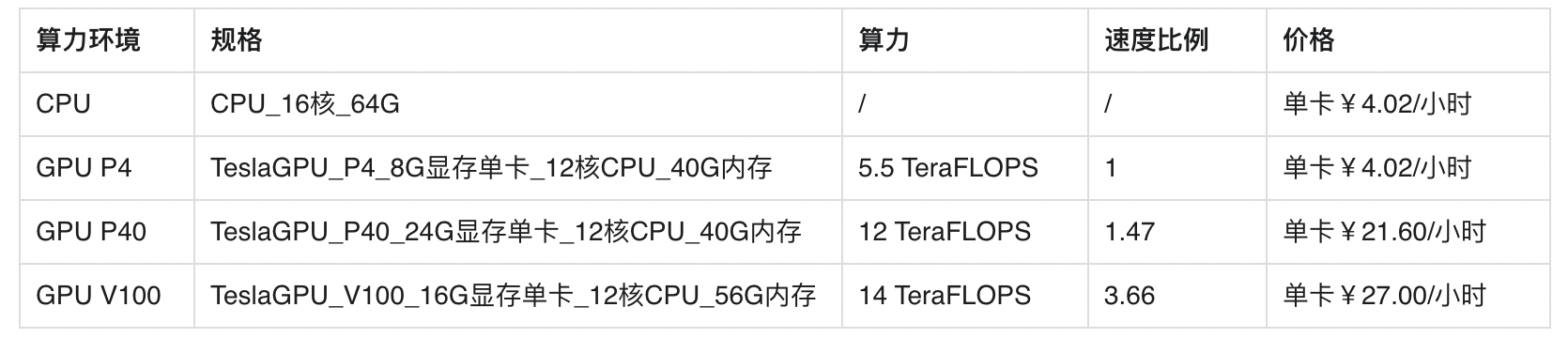
优惠政策:
为回馈开发者长期以来对EasyDL平台的大力支持,训练算力将针对单账户 x 单操作台粒度提供5小时免费训练时长(例如,每账户享有声音分类操作台5小时免费训练时长)。
同时,用户此前购买的算力小时包仍生效使用,支持算力小时包和储值两种付费方式。算力按分钟计费,账单金额精确至小数点后2位。训练失败、训练状态为排队中时长均不纳入收费时长。可参考价格说明