自定义代码 | 基于 FashionPedia 开源数据集训练部署目标检测模型
推荐项目
使用星河社区命令行工具(AI Studio CLI)高效进行模型训练
点击「fork」或「运行一下」,上手实操使用命令行工具
快速开始
星河社区命令行工具(AI Studio CLI) 是基于aistudio_hub sdk 建立的管理工具,借助此工具,用户可以不受开发环境限制,方便快捷地提交模型训练任务,并通过模型产线完成日志监控、效果评估与在线部署。
用户认证
首次使用 AI Studio CLI 提交与管理任务,需要安装 aistudio-sdk 库,并通过 访问令牌 完成身份认证。
安装方式:
$ pip install --upgrade aistudio-sdk认证方式:
$ aistudio config --token <yourToken>代码准备
本教程基于开源项目 PaddleDetection,自定义代码包命名为 code,仅包含三个文件(run.sh、eval.sh、config.yml),文件可从项目 使用星河社区命令行工具(AI Studio CLI)高效进行模型训练 中获得,其余作业相关文件在任务环境中通过 git clone 和 pip install 的方式获取。数据集选择 MiniFashionPedia(dataset_id=264391),数据包需要解压缩后放到 ./data 目录下。
以 run.sh 为例,我们在执行脚本中分别完成了:处理数据集、拉取PaddleDetection开源代码、安装环境依赖,最后启动了单卡训练。如需启动多卡训练,可以取消多卡训练的注释,并在 CLI 中设置--gpus 为 4。
######处理数据集######
tar -xf ./data/data264391/MiniFashionPedia.tar -C ./data
rm -rf ./data/data264391/MiniFashionPedia.tar
######拉取PaddleDetection开源代码,安装环境依赖######
git clone https://gitee.com/paddlepaddle/PaddleDetection
pip install -r ./PaddleDetection/requirements.txt -Uq
######启动单卡训练######
export CUDA_VISIBLE_DEVICES=0
python ./PaddleDetection/tools/train.py -c config.yml --eval
######启动多卡训练######
# export CUDA_VISIBLE_DEVICES=0,1,2,3
# python -m paddle.distributed.launch --gpus 0,1,2,3 ./PaddleDetection/tools/train.py -c config.yml --fleet --eval因此,在代码包、数据集和相关开源项目拉取完成后,我们会获得如下的文件目录结构:
/home/aistudio # 任务环境的根目录
├── data # 挂载数据的存储目录
│ ├── data264391 # 空文件夹
│ └── MiniFashionPedia # MiniFashionPedia数据集
├── output # 产出文件的保存路径,持久化存储
│ ├── log # 训练日志
│ └── ...
├── PaddleDetection # 开源项目PaddleDetection代码仓库
│ ├── requirements.txt # 环境依赖
│ ├── tools/train.py # 模型训练执行文件
│ └── ...
├── run.sh # 可训练执行脚本
├── eval.sh # 可评估执行脚本
└── config.yml # 模型训练配置文件请注意,仅 /home/aistudio/output 目录下的文件会被持久化保存,训练中的重要文件请设置正确的保存路径,以免丢失。
任务提交
AI Studio CLI 的命令行结构如下:
$ aistudio submit job [flags]参数详情:
| 参数 | 是否必填 | 功能介绍 | 类型 | 默认值 |
|---|---|---|---|---|
| --name, -n | 是 | 产线名称:最多64个字符,支持中英文、数字、下划线、中划线、点,且符号不能在首尾 | String | |
| --path, -p | 是 | 任务代码本地路径(文件夹):文件夹内的文件总体积不超过50MB | String | |
| --cmd, -c | 是 | 任务代码启动命令,建议使用 ' ' 包裹 |
String | |
| --env, -e | 否 | 飞桨框架版本:paddle2.6_py3.10;paddle2.5_py3.10;paddle2.4_py3.7 | String | paddle2.6_py3.10 |
| --device, -d | 否 | 硬件资源型号:当前仅支持 v100 | String | v100 |
| --gpus, -g | 否 | gpu数量:1,4,8 | Int | 1 |
| --payment, -pay | 否 | 计费方式:acoin-A币支付;coupon-算力点支付 | String | acoin |
| --mount_dataset, -m | 否 | 数据集挂载:填写 {dataset_id},支持主站数据集挂载到任务盘(/home/aistudio/data),以便用户在任务中使用。单个任务最多挂载3个数据集 | String | none |
以本任务为例,我们要发起一个单卡训练任务,取名为 ppyoloe_MiniFashionPedia_gpu1,使用算力点支付,因此 CLI 命令为:
$ aistudio submit job \
--name ppyoloe_MiniFashionPedia_gpu1 \
--path ./code_gpu1 \
--cmd 'sh run.sh' \
--payment coupon \
--gpus 1 \
--mount_dataset 264391如果希望启动一个四卡训练任务,取名为 ppyoloe_MiniFashionPedia_gpu4,使用A币支付(多卡任务仅支持A币支付),则 CLI 命令为:
$ aistudio submit job \
--name ppyoloe_MiniFashionPedia_gpu4 \
--path ./code_gpus4 \
--cmd 'sh run.sh' \
--payment acoin \
--gpus 4 \
--mount_dataset 264391至此,我们就实现了一行 CLI 命令完成模型训练任务。
前往自定义产线查看训练日志
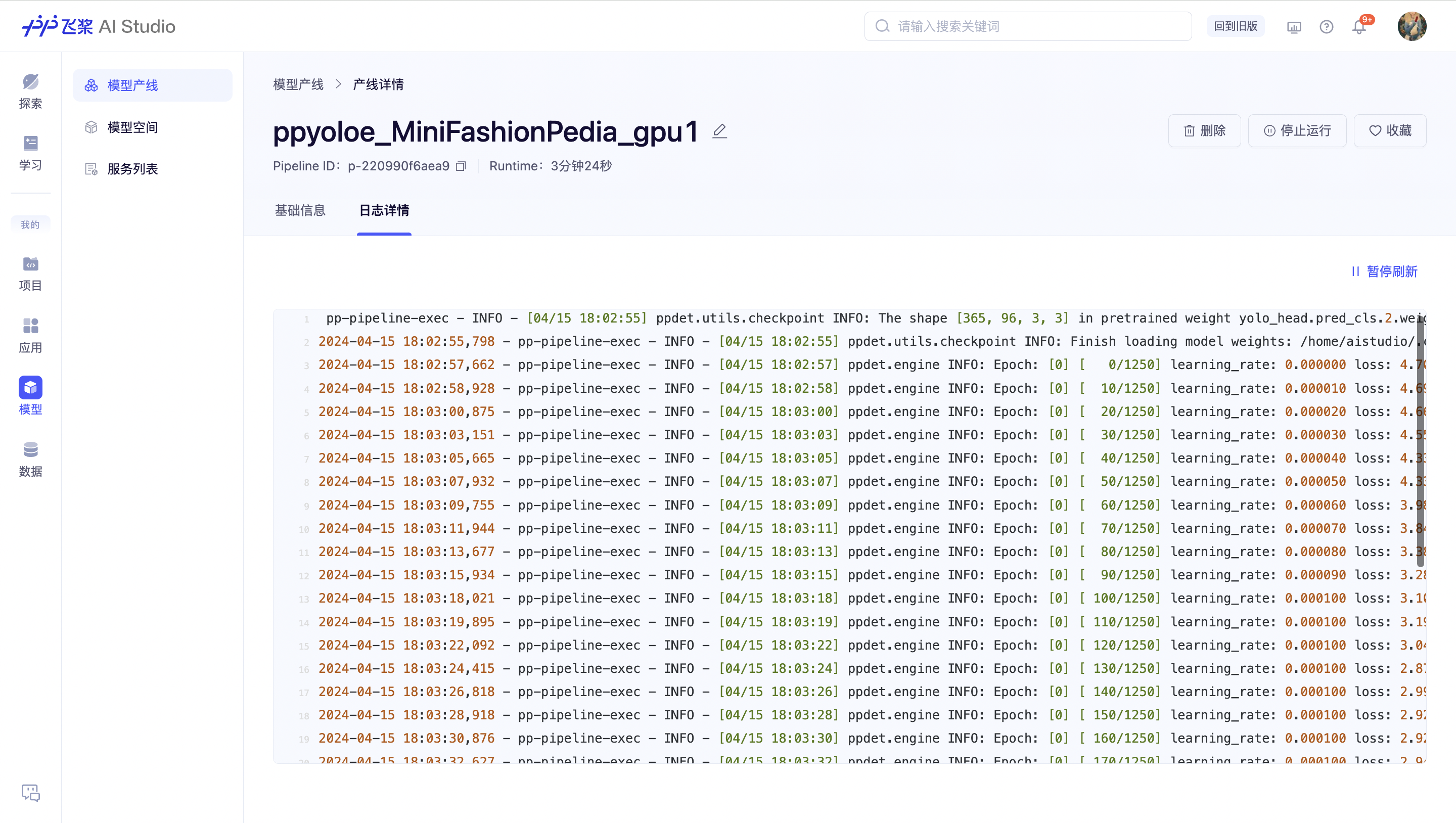
根据 CLI 返回的 url,可以跳转到自定义产线详情页查看任务运行情况,日志实时刷新。
此外,也可以通过 AI Studio 一级侧导航栏的「模型」板块,进入模型产线列表页,选择对应的自定义产线查看和管理。
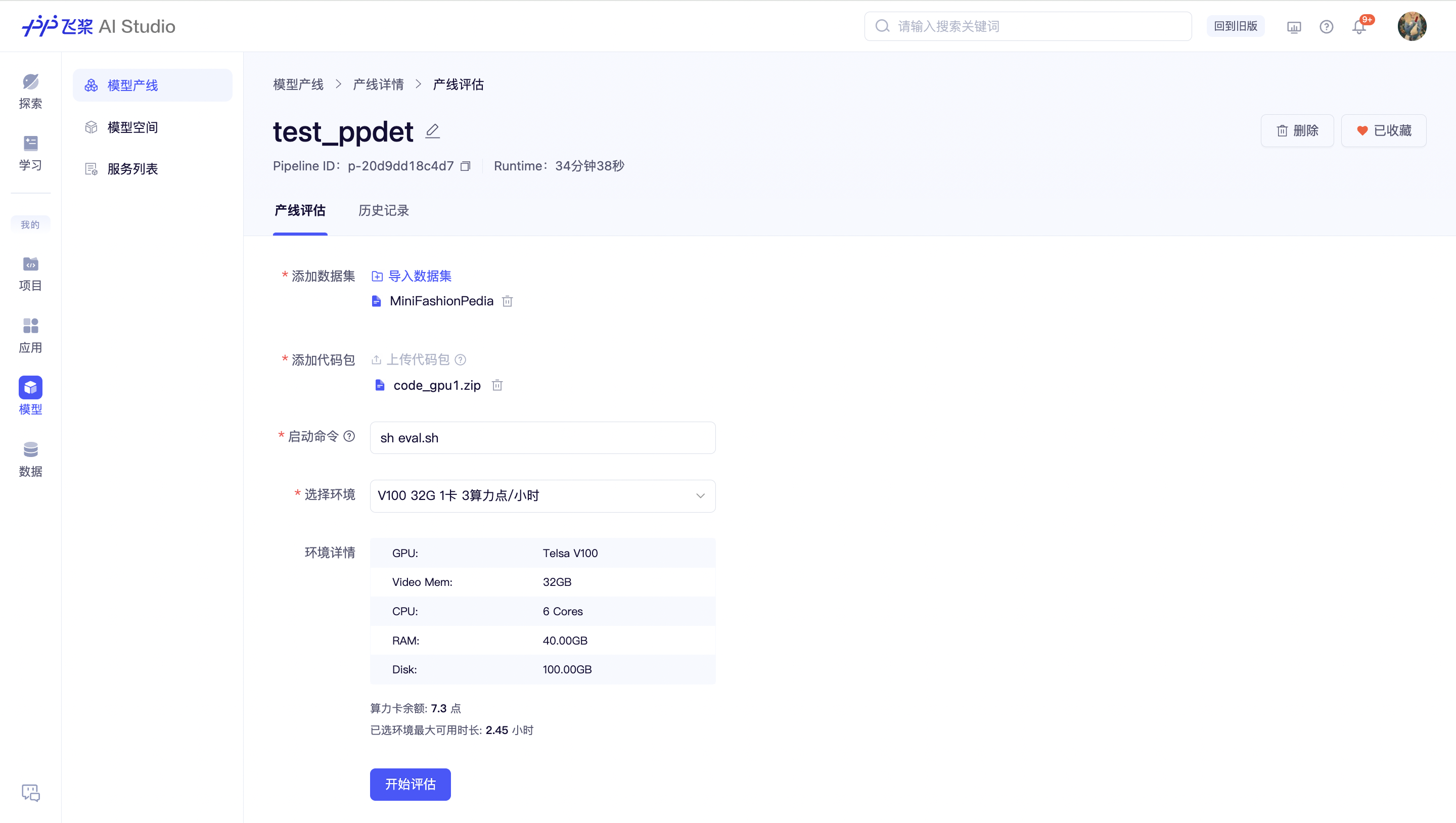
输出文件查询与模型评估
运行完成状态(运行成功/运行失败/已停止)的产线支持查看所有输出到 ./output 目录下的文件,以列表形式展示,支持单文件下载。
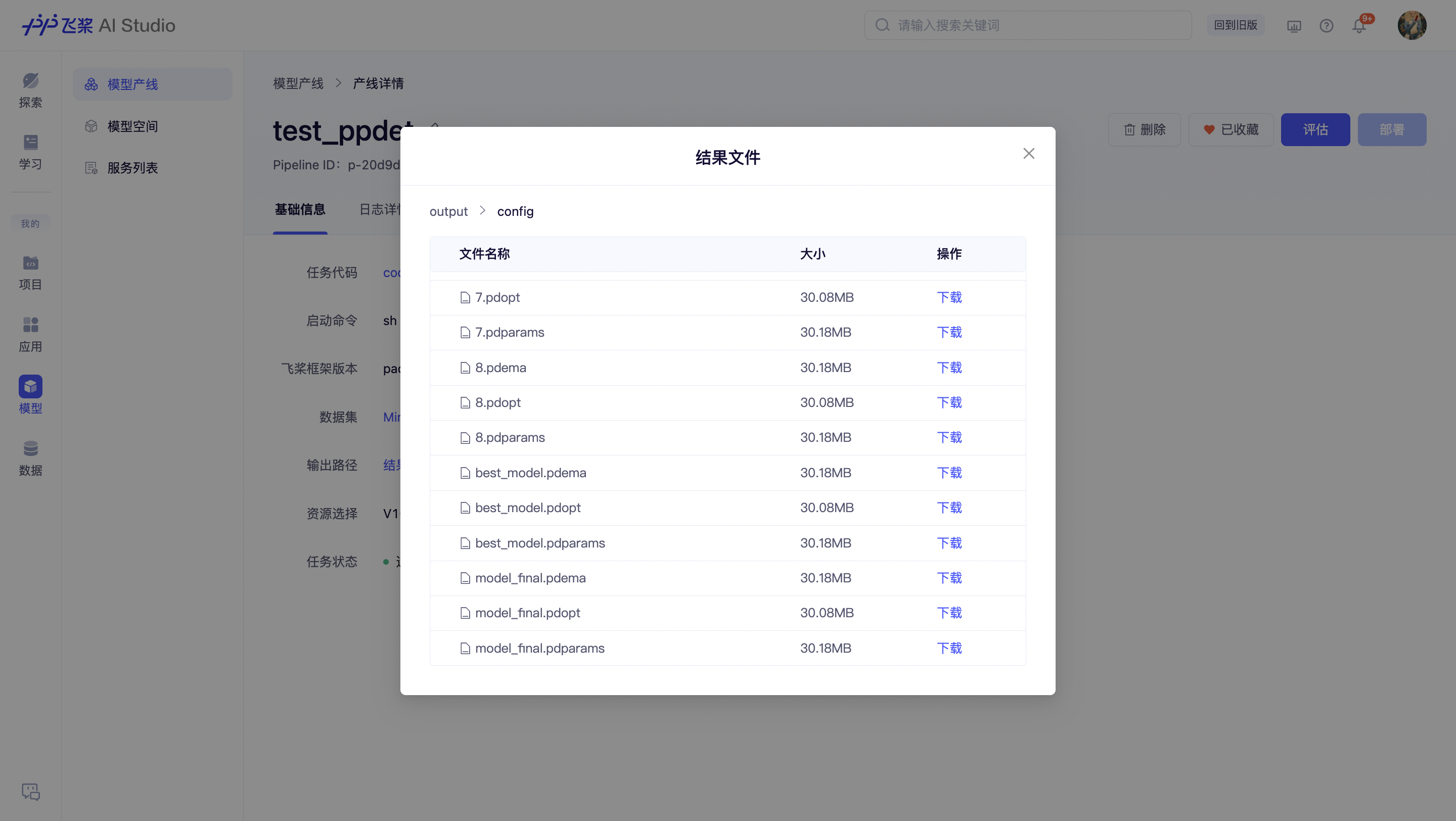
与此同时,可以调用 ./output 目录下的文件进行模型评估,评估脚本需要用户自己上传。在示例文件包中,已包含了评估脚本,只需要更改启动命令为 sh eval.sh 即可对 ./output/config/best_model.pdparams 文件进行评估。