

通用表格识别产线使用文档
产线介绍
表格识别任务是文本图像分析的子任务之一,旨在从图像中找到表格区域,并预测表格结构和文本内容,将表格恢复成HTML格式用于后续编辑或处理。本应用提供了1个高精度表格方案,可以端到端的完成表格识别任务。
效果展示
| 无线表 | 发票 |
|---|---|
 |
 |
模型方案介绍
本产线的模型方案包含4个模块,分别对应 在线体验应用 中的3个中间结果:表格检测结果(版面分析)、OCR 识别结果(文本检测、文本识别)、表格识别结果(表格识别),如果你对识别结果满意,可以回退上一步选择直接部署,使用官方模型权重组合你自己的模型方案。如果你希望对其中某个模块的效果做优化,可以向下查找对应模块的模型介绍,选择合适的模型做训练。
版面分析
版面分析指的是对图片形式的文档进行区域划分,定位其中的关键区域,如文字、标题、表格、图片等。 PicoDet_layout_1x 基于 PP-PicoDet 的轻量级版面分析模型,并针对版面分析场景定制图像尺度,同时使用FGD(Focal and Global Knowledge Distillation for Detectors)知识蒸馏算法,进一步提升模型精度。
在CDLA中文文档版面分析数据集上的benchmark如下:
| 模型 | 精度(%) | GPU 推理耗时(ms) | CPU 推理耗时(ms) | 模型存储大小(M) |
|---|---|---|---|---|
| PicoDet_layout_1x | 86.80 | 2.75 | 55.07 | 9.7 |
OCR 串联系统
通用 OCR 系统用于解决光学字符识别任务,提取图片中的文字信息并以文本形式输出,PP-OCRv4 是一个端到端 OCR 串联系统(包含文本检测模型和文本识别模型),可实现 CPU 上毫秒级的文本内容精准预测,在通用场景上达到开源 SOTA。
本产线考虑精度和性能的不同需求,提供了 server 和 mobile 两种方案,当 OCR 识别效果无法满足特定场景时,推荐基于自有数据进行模型训练,benchmark 如下:
| 模型 | 检测 Hmean(%) | 识别 Avg Accuracy(%) | GPU 推理耗时(ms) | CPU 推理耗时(ms) | 模型存储大小(M) |
|---|---|---|---|---|---|
| PP-OCRv4-server | 82.69 | 79.20 | 22.20346 | 2662.158 | 198 |
| PP-OCRv4-mobile | 77.79 | 78.20 | 2.719474 | 79.1097 | 15 |
注:评估集是 PaddleOCR 自建的中文数据集,覆盖街景、网图、文档、手写多个场景,其中文本识别包含1.1w张图片,检测包含500张图片。GPU 推理耗时基于 NVIDIA Tesla T4 机器,精度类型为 FP32, CPU 推理速度基于 Intel(R) Xeon(R) Gold 5117 CPU @ 2.00GHz,线程数为 8,精度类型为 FP32。
表格识别
SLANet 是 PaddleOCR 发布的轻量级表格识别模型,负责对文档中出现的表格区域进行结构化识别,广泛应用于通用、医疗、金融等多个场景下的表格结构识别。算法采用 CPU 友好型轻量级骨干网络 PP-LCNet、轻量级高低层特征融合模块 CSP-PAN 和结构与位置信息对齐的特征解码模块 SLAHead 来实现表格结构的准确识别。在PubtabNet英文表格识别数据上的benchmark如下:
| 模型 | 精度(%) | GPU 推理耗时(ms) | CPU 推理耗时(ms) | 模型存储大小(M) |
|---|---|---|---|---|
| SLANet | 76.31 | 791.73 | 379.87 | 9.3 |
数据准备
TextDetDataset
文本检测要求的数据集格式。
数据集目录结构
请按照如下格式准备数据,以确保产线可以正确读取数据集,进行模型训练。
dataset_dir # 数据集根目录,目录名称可以改变
├── images # 存放图像的目录,目录名称可以改变,但要注意和train.txt val.txt的内容对应
├── train.txt # 训练集标注文件,文件名称不可改变,内容举例:images/img_0.jpg \t [{"transcription": "MASA", "points": [[310, 104], [416, 141], [418, 216], [312, 179]]}, {...}]
└── val.txt # 验证集标注文件,文件名称不可改变,内容举例:images/img_61.jpg \t [{"transcription": "TEXT", "points": [[31, 10], [310, 140], [420, 220], [310, 170]]}, {...}]标注格式要求
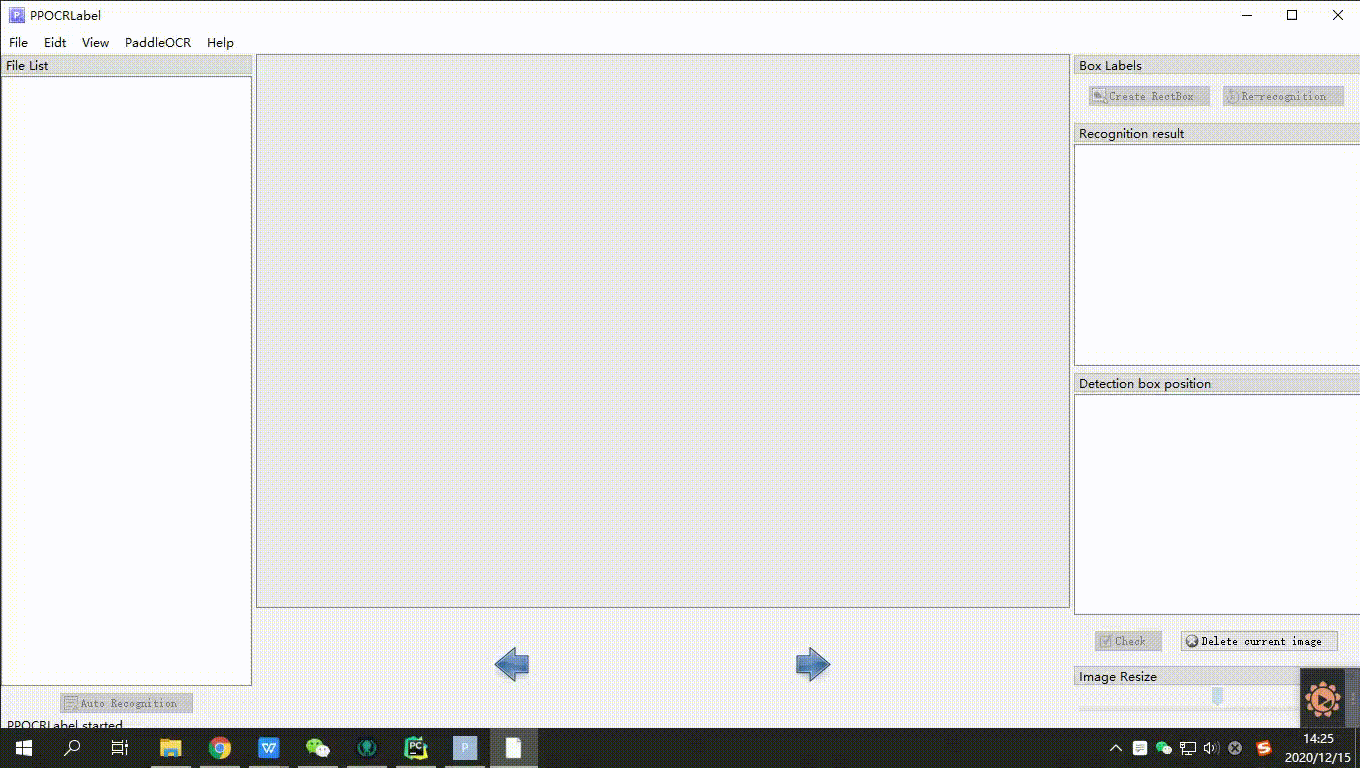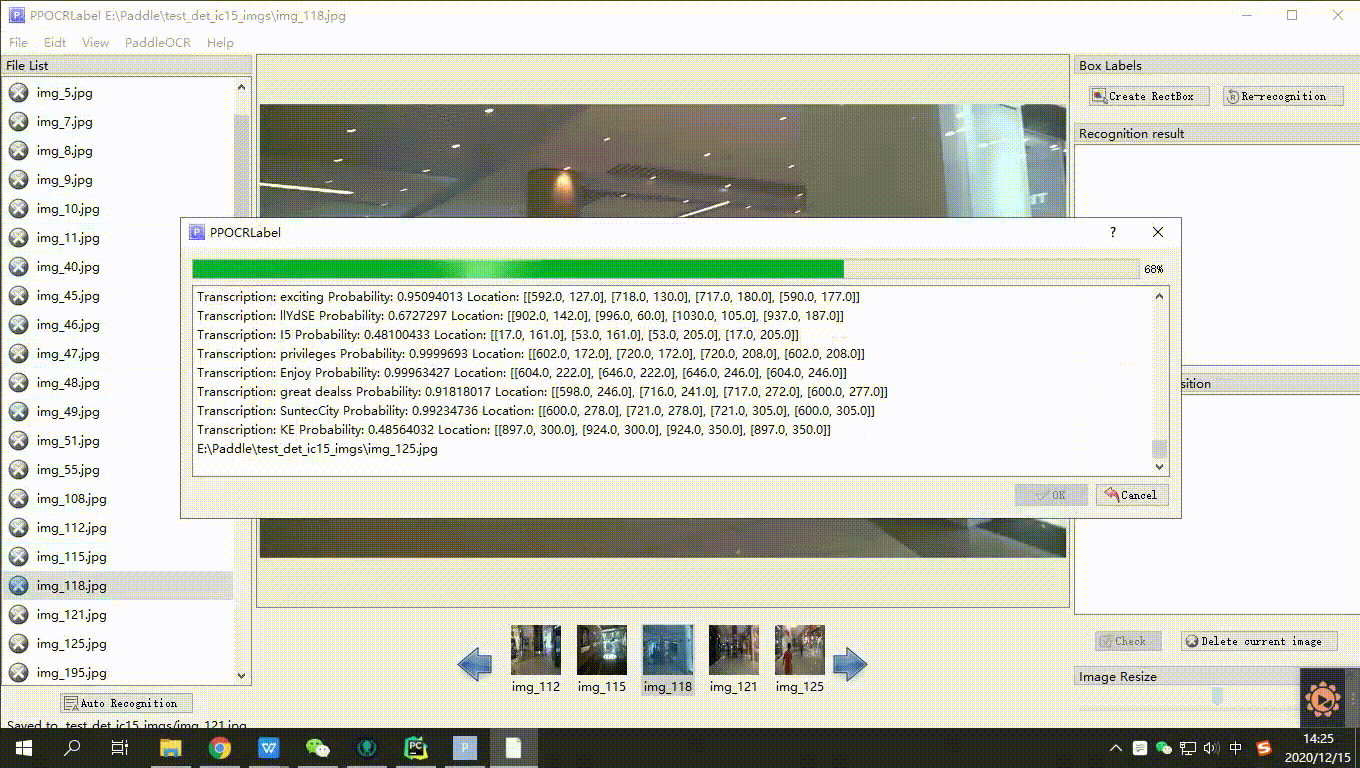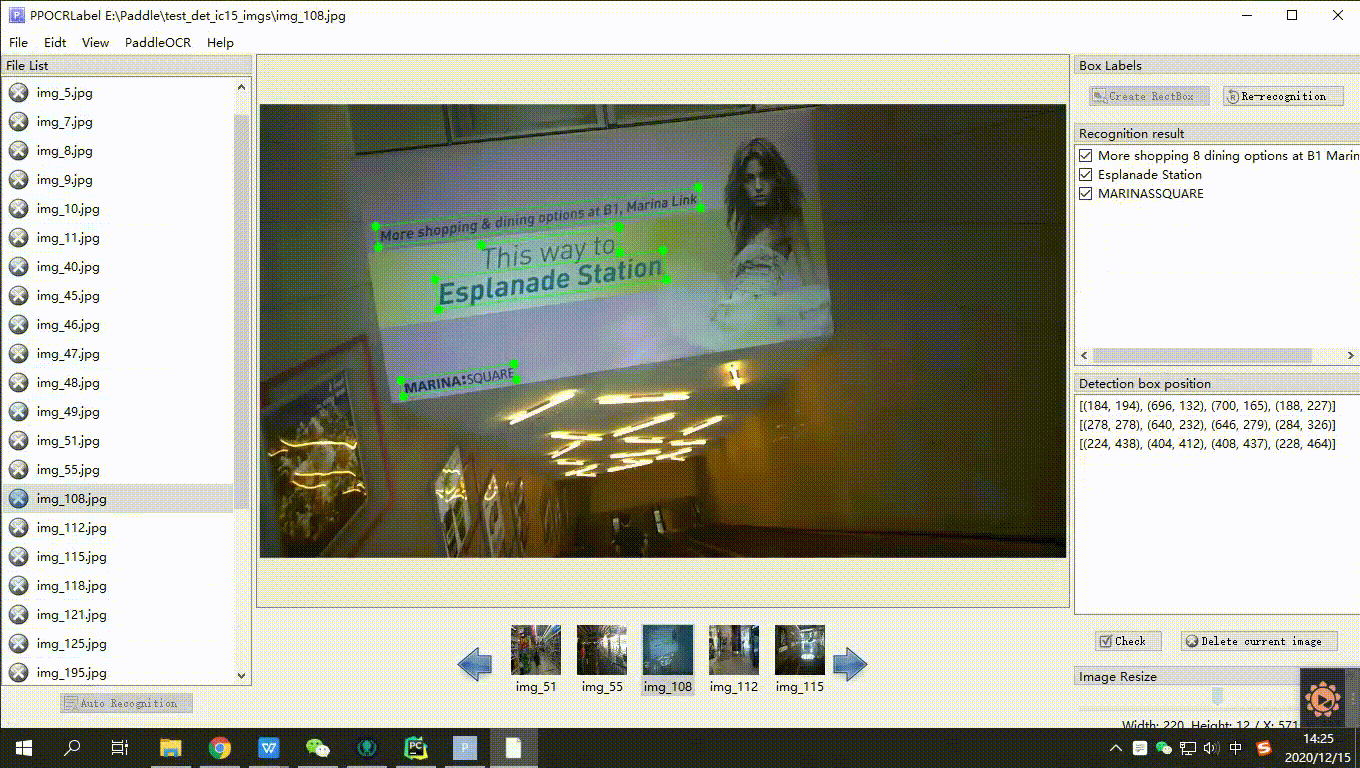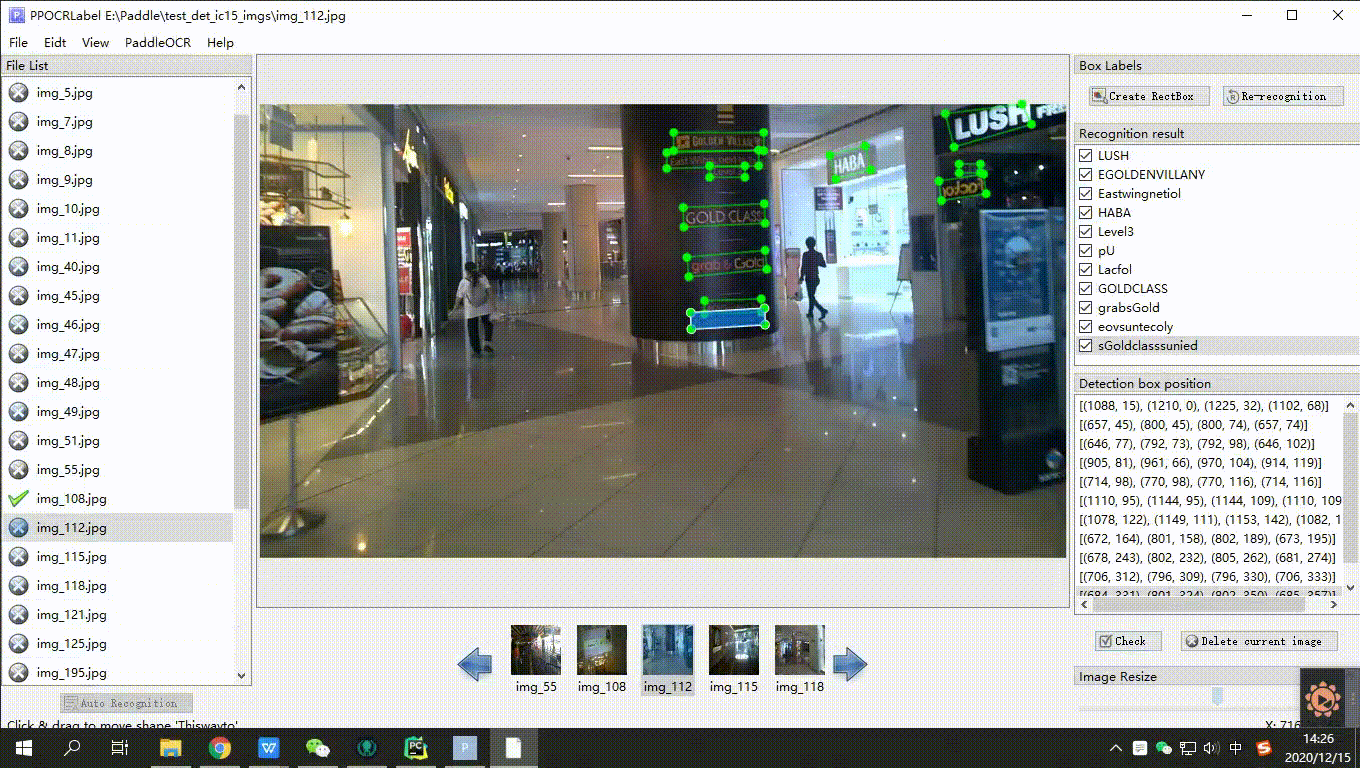
PaddleOCR 数据格式,如果你有一批未标注数据,请使用 PPOCRLabel 进行标注,在完成数据集划分后将文字检测(det)目录中的det_gt_train.txt改名为train.txt、det_gt_test.txt改名为val.txt即可。
| 常规标注 |
|---|
 |
MSTextRecDataset
文本识别要求的数据集格式。
数据集目录结构
请按照如下格式准备数据,以确保产线可以正确读取数据集,进行模型训练。
dataset_dir # 数据集根目录,目录名称可以改变
├── images # 存放图像的目录,目录名称可以改变,但要注意和train.txt val.txt的内容对应
├── train.txt # 训练集标注文件,文件名称不可改变,内容举例:images/111085122871_0.JPG \t 百度
├── val.txt # 验证集标注文件,文件名称不可改变,内容举例:images/111085122871_0.JPG \t 百度
└── dict.txt # 字典文件,文件名称不可改变。字典文件将所有出现的字符映射为字典的索引,每行为一个单字,内容举例:百标注格式要求
PaddleOCR 数据格式,如果你有一批未标注数据,请使用 PPOCRLabel 进行标注,在完成数据集划分后将文字识别(rec)目录中的rec_gt_train.txt改名为train.txt、rec_gt_test.txt改名为val.txt即可。
| 常规标注 |
|---|
|
与文本检测不同的是,文本识别数据集增加了一个字典文件 dict.txt,每行为一个单字,如"a"、"度"、"3"等,用于字符索引。如果你没有特殊的要求,我们推荐使用 PP-OCR 默认字典,也可使用脚本 gen_dict.py 根据训练/评估数据自动生成字典:
# 将脚本下载至 {dataset_dir} 目录下wget https://paddleocr.bj.bcebos.com/script/gen_dict.py
# 执行转化,默认训练集标注文件为"train.txt", 验证集标注文件为"val.txt", 生成的字典文件为"dict.txt"
python gen_dict.pyPubTabTableRecDataset
表格识别要求的数据集格式。
数据集目录结构
请按照如下格式准备数据,以确保产线可以正确读取数据集,进行模型训练。
dataset_dir # 数据集根目录,目录名称可以改变
├── images # 图像的保存目录,目录名称可以改变,但要注意和train.txt val.txt的内容对应
├── train.txt # 训练集标注文件,文件名称不可改变
└── val.txt # 验证集标注文件,文件名称不可改变标注格式要求
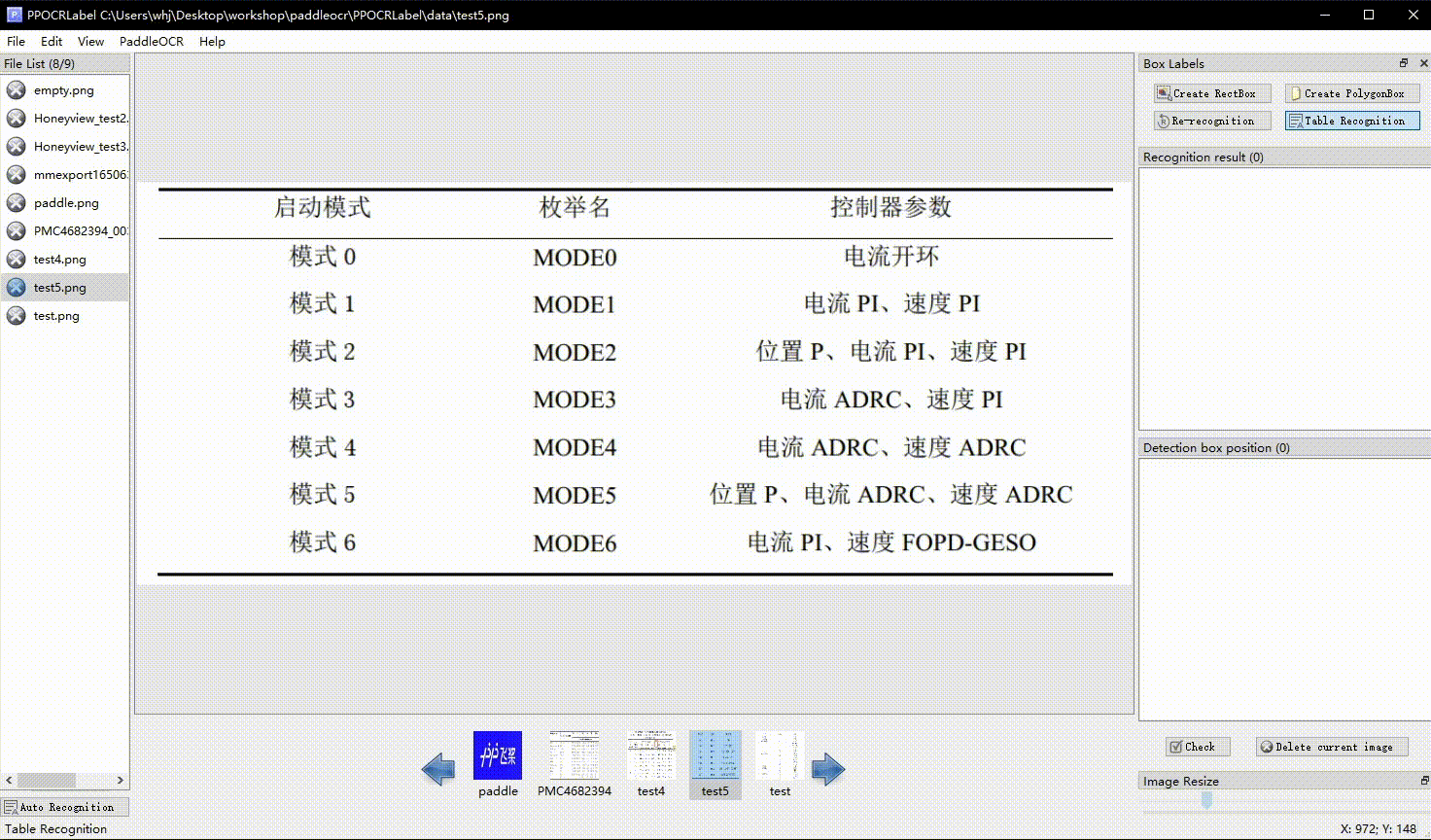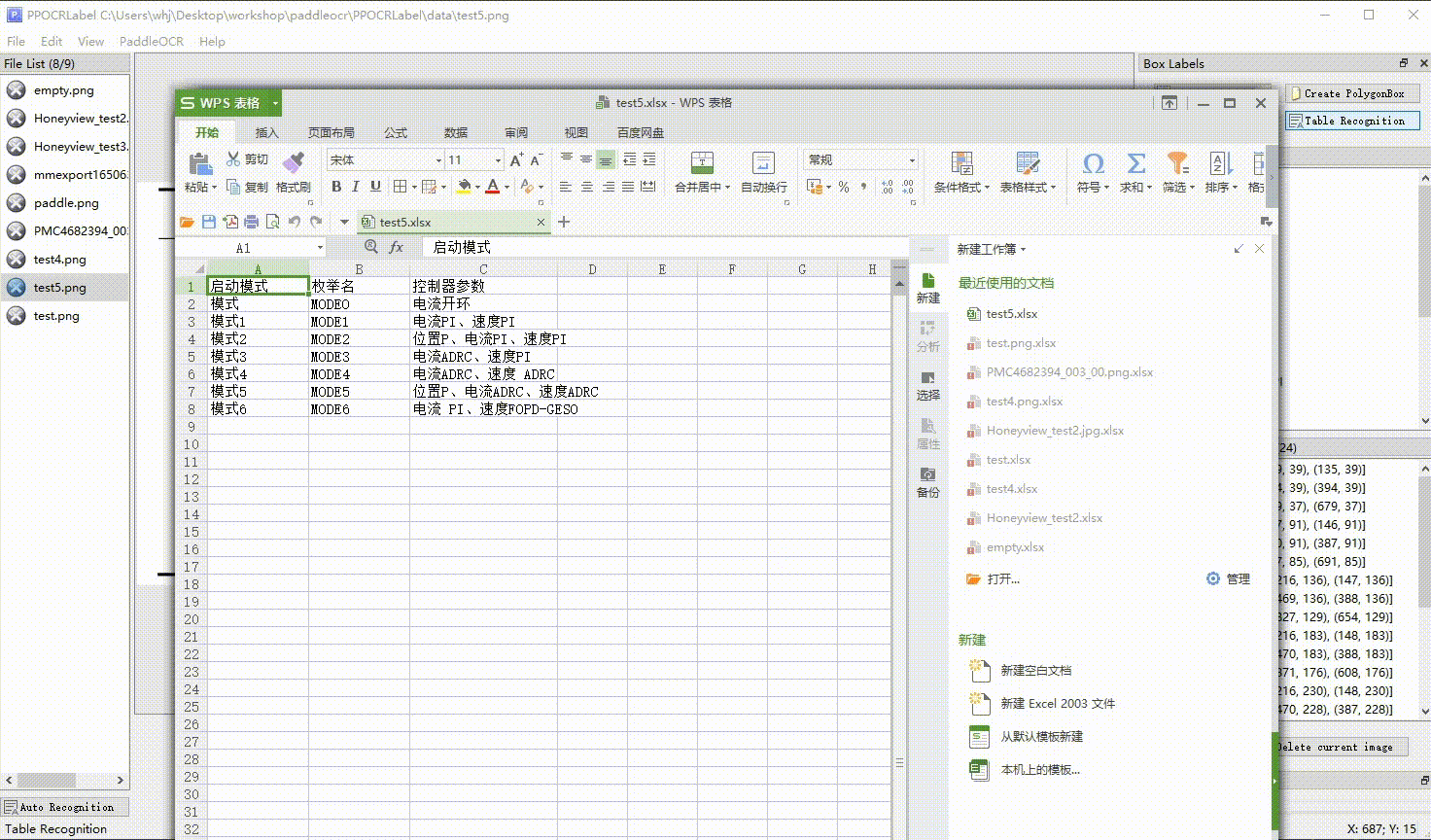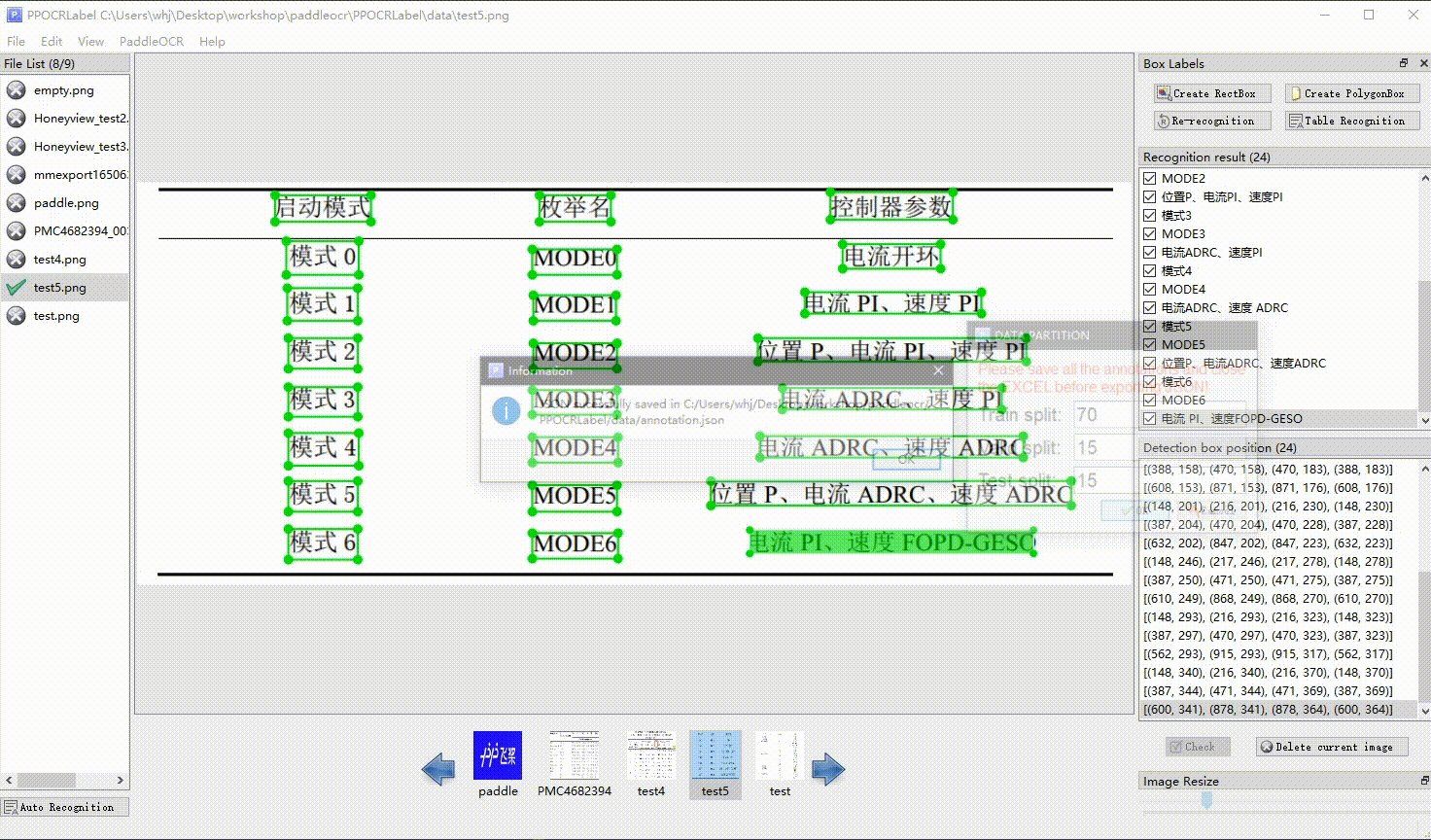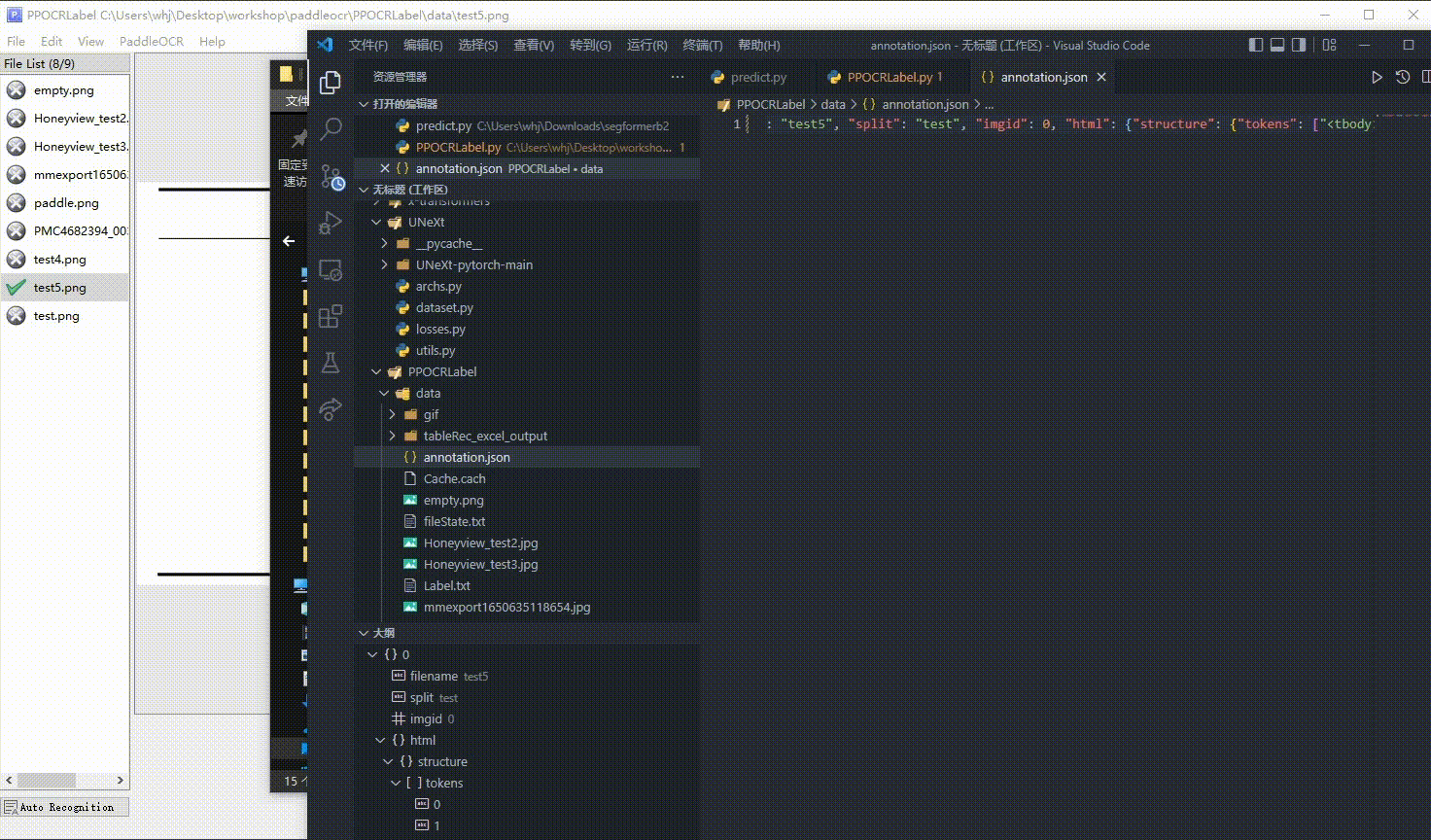
PaddleOCR 数据格式,如果你有一批未标注数据,请使用 PPOCRLabel 进行标注。
| 表格标注 |
|---|
 |
参数准备
正确设置训练参数对于模型训练至关重要,本产线支持两种参数设置方式:修改表单和修改配置文件,常见训练参数推荐使用表单修改,可展开高级设置修改更多参数,对飞桨套件参数较熟悉的用户可以通过表单修改全部训练参数。训练模型的基础配置和高级配置参数如下:
基础配置
- 轮次(Epochs):模型对训练数据的重复学习次数,一般来说,轮次越大,模型训练时间越长,模型精度越高,但是如果设置特别大,可能会导致模型过拟合。如果对轮次没有特别的要求,可以使用默认值进行训练。
- 批大小(Batch Size):由于训练数据量一般较大,模型每轮次的训练是分批读取数据的,批大小是每一批数据的数据量,和显存直接相关,批大小越大模型训练的速度越快,显存占用越高。为确保训练不会因为显存溢出而终止,我们将 V100 32G 单卡可以运行的最大值作为批大小的可设置最大值。
- 类别数量(Class Num):数据集中检测结果的类别数,由于类别数量和数据集直接相关,我们无法填充默认值,请根据数据校验的结果进行填写,类别数量需要准确,否则可能引起训练失败。
- 学习率(Learning Rate):模型训练过程中梯度调整的步长,通常与批大小成正比例关系,学习率设置过大可能会导致模型训练不收敛,设置过小可能会导致模型收敛速度过慢。在不同的数据集上学习率可能不同,对结果影响较大,需要不断调试。
高级配置
- 断点训练权重:在模型训练过程中发生人为或意外终止的情况时,加载训练中断之前保存的断点权重路径,完成继续训练,避免算力资源浪费。
- 预训练权重:基于已经在大数据集上训练好的模型权重进行微调训练,可提高模型训练开始前的初始经验,提高训练效率。
- 热启动步数(WarmUp Steps):在训练初始阶段以较小学习率缓慢增加到设置学习率的批次数量,该值的设置可以避免模型在初始阶段以较大学习率迭代模型最终破坏预训练权重,一定程度上提升模型的精度。
- log 打印间隔(Log Interval) / step:训练日志中打印日志信息的批次数量间隔。
- 评估、保存间隔(Eval Interval) / epoch:训练过程中对验证集进行评估以及保存权重的轮数间隔。
提交训练
训练套餐包括:
- V100 32G 1卡 3算力点/小时
- V100 32G 1卡 30A币/小时
- V100 32G 4卡 120A币/小时
- V100 32G 8卡 240A币/小时
支持用户选择算力点或 A 币支付 GPU 使用花费。你可以根据自己的需求和平台 GPU 占用情况选择合适的训练套餐。
为鼓励更多用户体验模型产线新功能,每个账户赠送 3 张限时免费卡,前三次使用 V100 32G 1卡 30A币/小时训练套餐免费,之后将按对应训练时长计费,此外,训练过程中主动停止或因配置信息有误导致的训练失败,限免卡不返还。
产线详情页
提交训练后,页面会刷新为产线详情页,展示用户设置的全部训练配置信息,包括:产线模板、微调模型、训练参数配置、数据集、输出路径、资源选择和任务状态。当 GPU 集群可以执行训练任务时,任务状态显示为运行中,日志详情实时打印当前训练 log;当 GPU 集群暂无资源执行训练任务时,任务状态显示为排队中,此时可选择取消排队,返回配置中状态,如使用限免卡,限免卡会原路返还。
产线评估
产线状态为完成态(含运行成功、已停止、运行失败)时,产线内通常有结果产出,支持用户对产出的模型权重进行评估。训练中使用验证集评估的结果被提前保存,以表单的形式展示在评估页面,方便用户查看和标记模型权重。
注:直接部署的产线无产出结果,仅提供官方权重,不支持评估。
标记模型权重
每条产线产出的模型权重通常不止一个,为方便用户查找和管理,你可以在这里对满意的模型权重做个标记,并为它取一个昵称(例如:数据集A评估最佳)。标记过的模型权重支持跨产线导入,也就是说,你可以在其他产线的同模型名选择权重(如模型部署、断点训练)的下拉菜单中,找到在本产线标记过的权重。当然,权重也可以取消标记,以减少选择成本。
创建评估任务
除了在验证集上评估模型权重外,如果你还有一批新的测试数据,可以选择自定义测试集的方式,上传测试数据并进行评估。请注意数据集的格式要求与训练数据集相同,但此处不会进行数据校验,如果数据格式存在问题,可能会引发评估任务失败。
历史评估任务的设置信息与日志会完整保留,可以通过历史记录查看详细情况。
产线部署
本产线支持两种部署方式:在线服务化部署和导出离线部署包。你可以根据自己的实际需求选择合适的部署方式,使用你满意的模型方案。
在线服务化部署
服务化部署指的是将模型方案部署为一个云端可调用 API,服务成功运行后,你可以使用自己的访问令牌鉴权后调用 API。此外,在线体验的应用中也可以找到这个 API 进行小样本可视化测试哦。
注:这种方式适用于数据不敏感且无部署机器的用户使用,API 为用户私有,仅能通过用户个人的访问令牌鉴权后调用。
导出离线部署包
如果你有离线部署的需求,产线也支持用户导出离线部署包。与在线服务化部署不同的是,你需要选择本地运行环境,产线会依据运行环境的不同导出相应的部署包,支持用户下载后本地运行。
此外,特色产线的离线部署包需付费使用,请在产线内购买部署包序列号,本地激活后使用。购买注意事项及商务对接,可点击 立即咨询。