

零代码产线
模型产线介绍
零代码产线是AI Studio星河社区为开发者提供的基于图形用户界面(GUI)的全流程高效模型训练与部署工具。开发者无需代码开发经验,只需要准备符合产线要求的数据集即可快速启动模型训练。
创建产线
模型产线创建入口:https://aistudio.baidu.com/pipeline/mine ,可通过点击一级导航栏「模型」快速进入,点击右上角「创建产线」
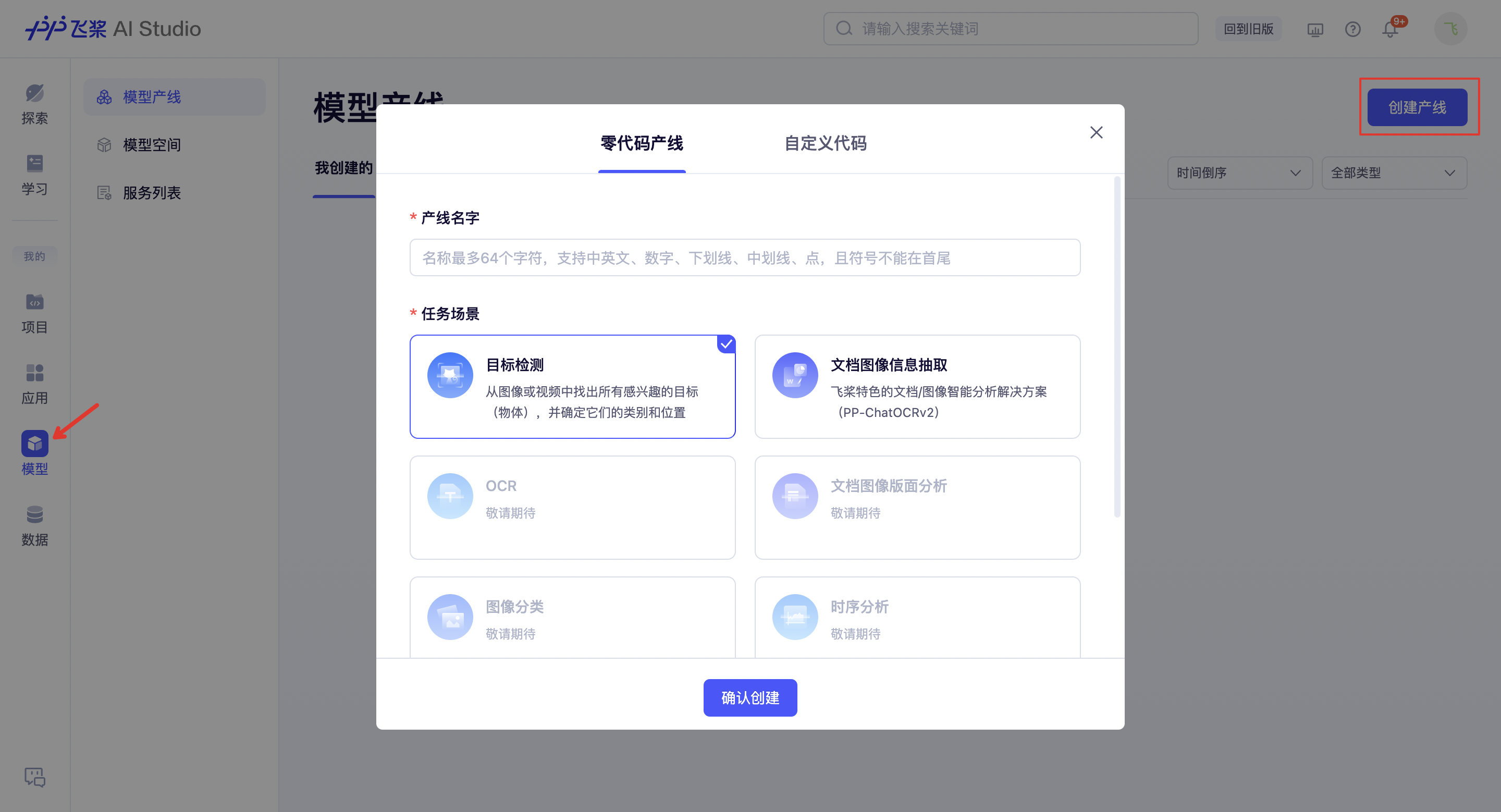
1. 选择产线
我们以目标检测任务场景为例,为产线命名后进入选择产线页面。场景内提供两条产线选择:通用目标检测 与 大模型半监督学习-目标检测,大模型半监督学习是飞桨特色的模型训练方式,支持引入无标签数据,得到精度更高的模型权重,该训练方式需要消耗更多算力和时间,适合对精度要求较高的用户。
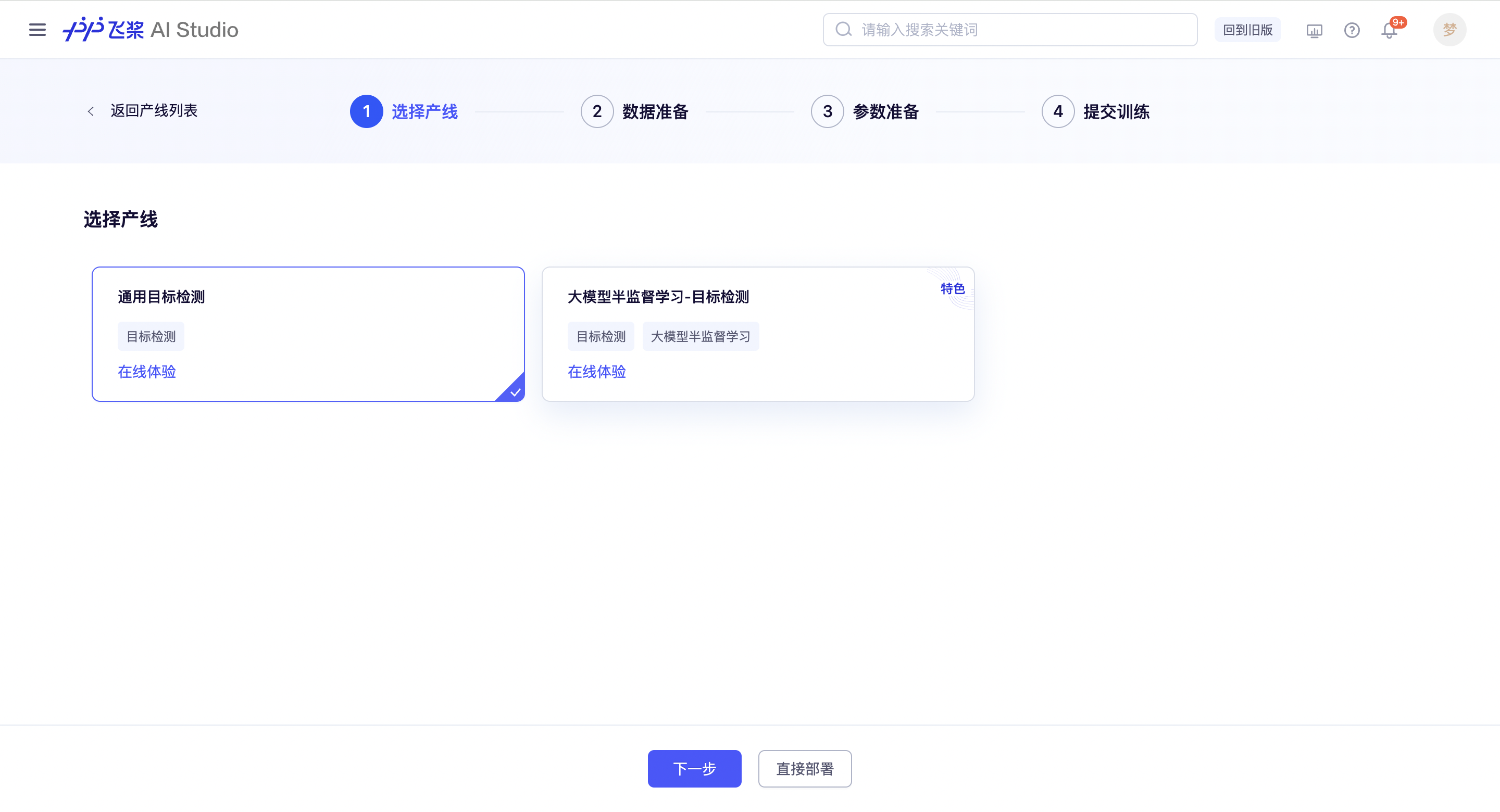
在线体验
为了对模型方案的效果有更直观的体验,产线内支持用户呼起弹窗,上传测试样例体验模型效果。如果对模型方案的效果满意,可以选择点击「直接部署」按钮,使用官方模型权重部署与使用;如果想要在自己的数据集上进行训练/微调,可点击下一步进行数据准备。
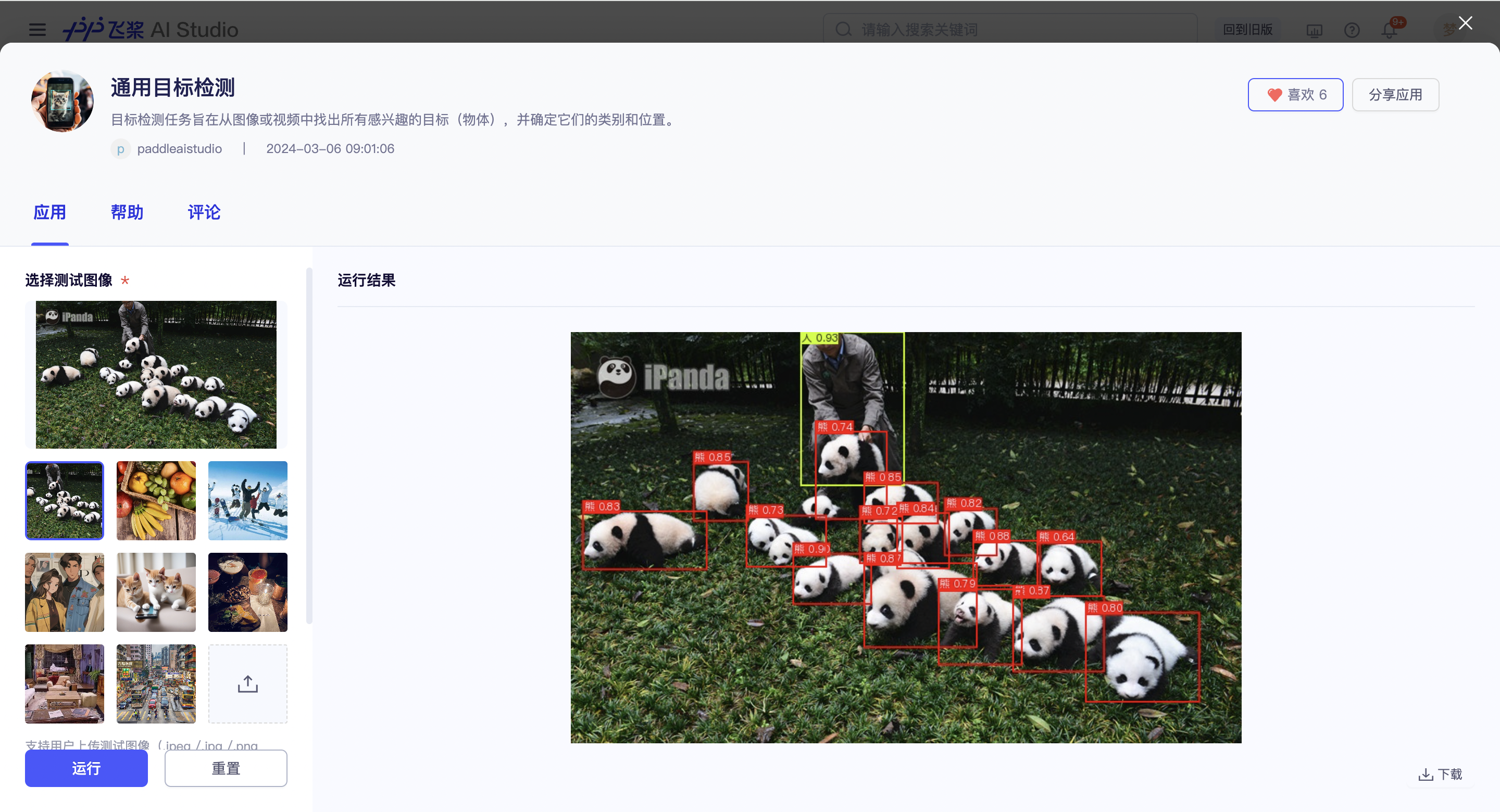
2. 数据准备
用户首先需要选择本产线要训练的模型,当前模型产线仅支持单模型训练。模型选型可以参考右侧的操作须知-模型选择说明。
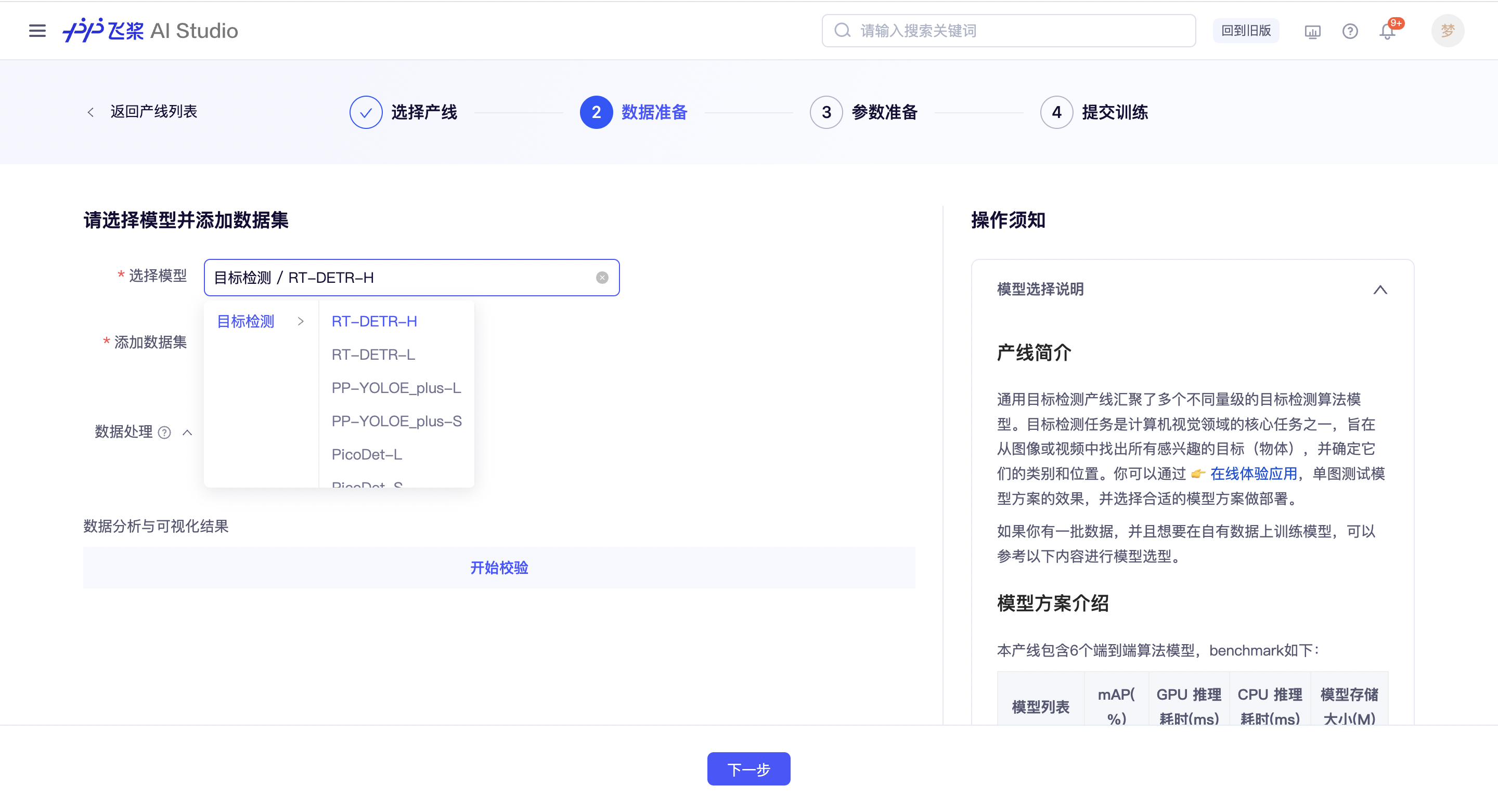
接下来需要按照数据集格式要求准备训练数据,支持用户上传数据包,或导入已经通过校验的数据集。
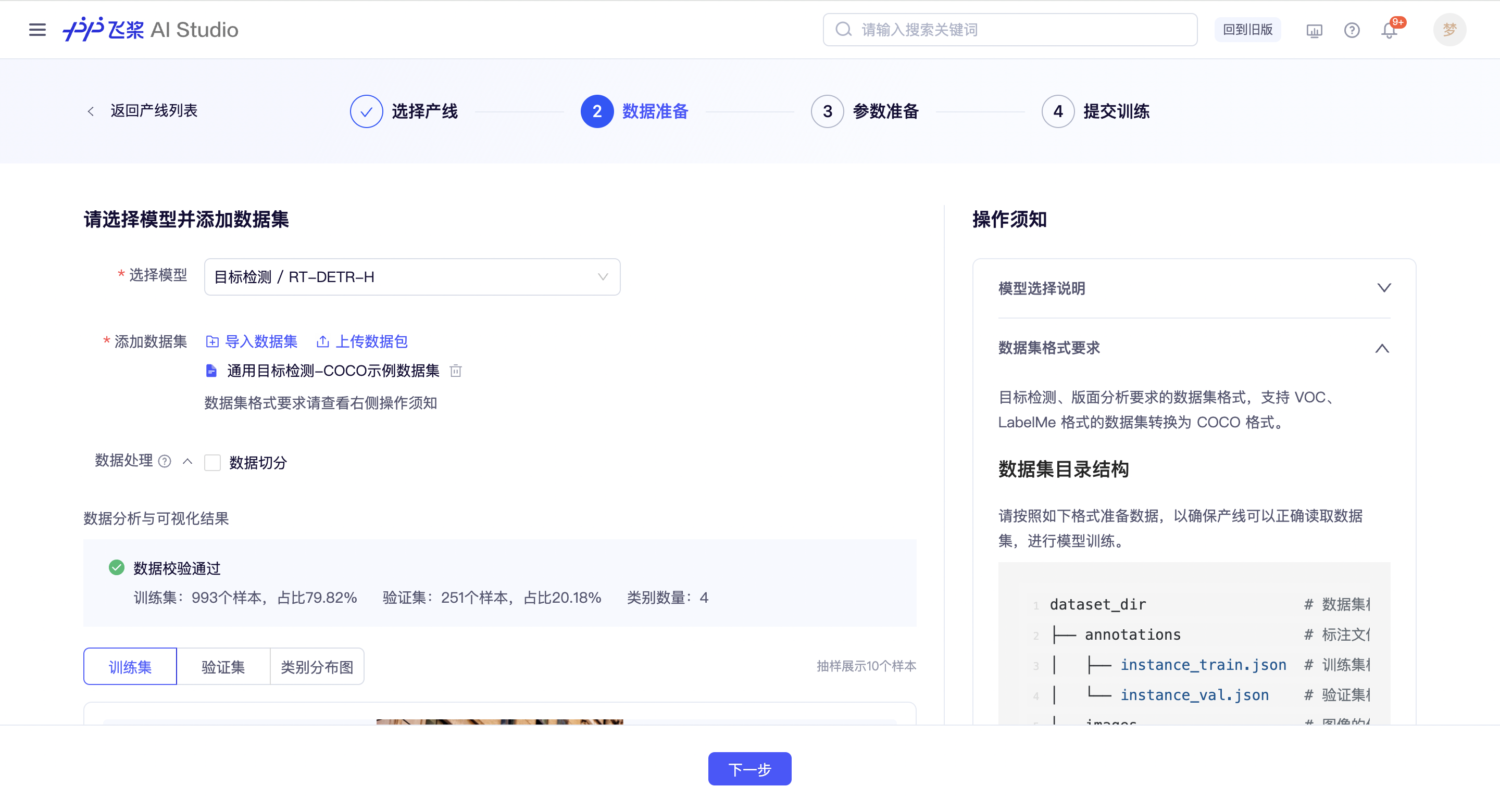
请注意,为确保模型可以正确读取数据集进行训练,只有通过数据校验的数据集才能进入下一步,同时会保存为结构化的数据集,支持在其他产线中导入。
3. 参数准备
正确设置训练参数对于模型训练至关重要,产线支持两种参数设置方式:修改表单和修改配置文件,常见训练参数推荐使用表单修改,可展开高级设置修改更多参数,对飞桨套件参数较熟悉的用户可以通过表单修改全部训练参数。训练模型的基础配置和高级配置参数如下:
基础配置
- 轮次(Epochs):模型对训练数据的重复学习次数,一般来说,轮次越大,模型训练时间越长,模型精度越高,但是如果设置特别大,可能会导致模型过拟合。如果对轮次没有特别的要求,可以使用默认值进行训练。
- 批大小(Batch Size):由于训练数据量一般较大,模型每轮次的训练是分批读取数据的,批大小是每一批数据的数据量,和显存直接相关,批大小越大模型训练的速度越快,显存占用越高。为确保训练不会因为显存溢出而终止,我们将 V100 32G 单卡可以运行的最大值作为批大小的可设置最大值。
- 类别数量(Class Num):数据集中检测结果的类别数,由于类别数量和数据集直接相关,我们无法填充默认值,请根据数据校验的结果进行填写,类别数量需要准确,否则可能引起训练失败。
- 学习率(Learning Rate):模型训练过程中梯度调整的步长,通常与批大小成正比例关系,学习率设置过大可能会导致模型训练不收敛,设置过小可能会导致模型收敛速度过慢。在不同的数据集上学习率可能不同,对结果影响较大,需要不断调试。
高级配置
- 断点训练权重:在模型训练过程中发生人为或意外终止的情况时,加载训练中断之前保存的断点权重路径,完成继续训练,避免算力资源浪费。
- 预训练权重:基于已经在大数据集上训练好的模型权重进行微调训练,可提高模型训练开始前的初始经验,提高训练效率。
- 热启动步数(WarmUp Steps):在训练初始阶段以较小学习率缓慢增加到设置学习率的批次数量,该值的设置可以避免模型在初始阶段以较大学习率迭代模型最终破坏预训练权重,一定程度上提升模型的精度。
- log 打印间隔(Log Interval) / step:训练日志中打印日志信息的批次数量间隔。
- 评估、保存间隔(Eval Interval) / epoch:训练过程中对验证集进行评估以及保存权重的轮数间隔。
4. 提交训练
训练套餐包括:
- V100 32G 1卡 3算力点/小时
- V100 32G 1卡 30A币/小时
- V100 32G 4卡 120A币/小时
- V100 32G 8卡 240A币/小时
支持用户选择算力点或 A 币支付 GPU 使用花费。您可以根据自己的需求和平台 GPU 占用情况选择合适的训练套餐。
为鼓励更多用户体验模型产线新功能,每个账户赠送 3 张限时免费卡,前三次使用 V100 32G 1卡 30A币/小时训练套餐免费,之后将按对应训练时长计费,此外,训练过程中主动停止或因配置信息有误导致的训练失败,限免卡不返还。
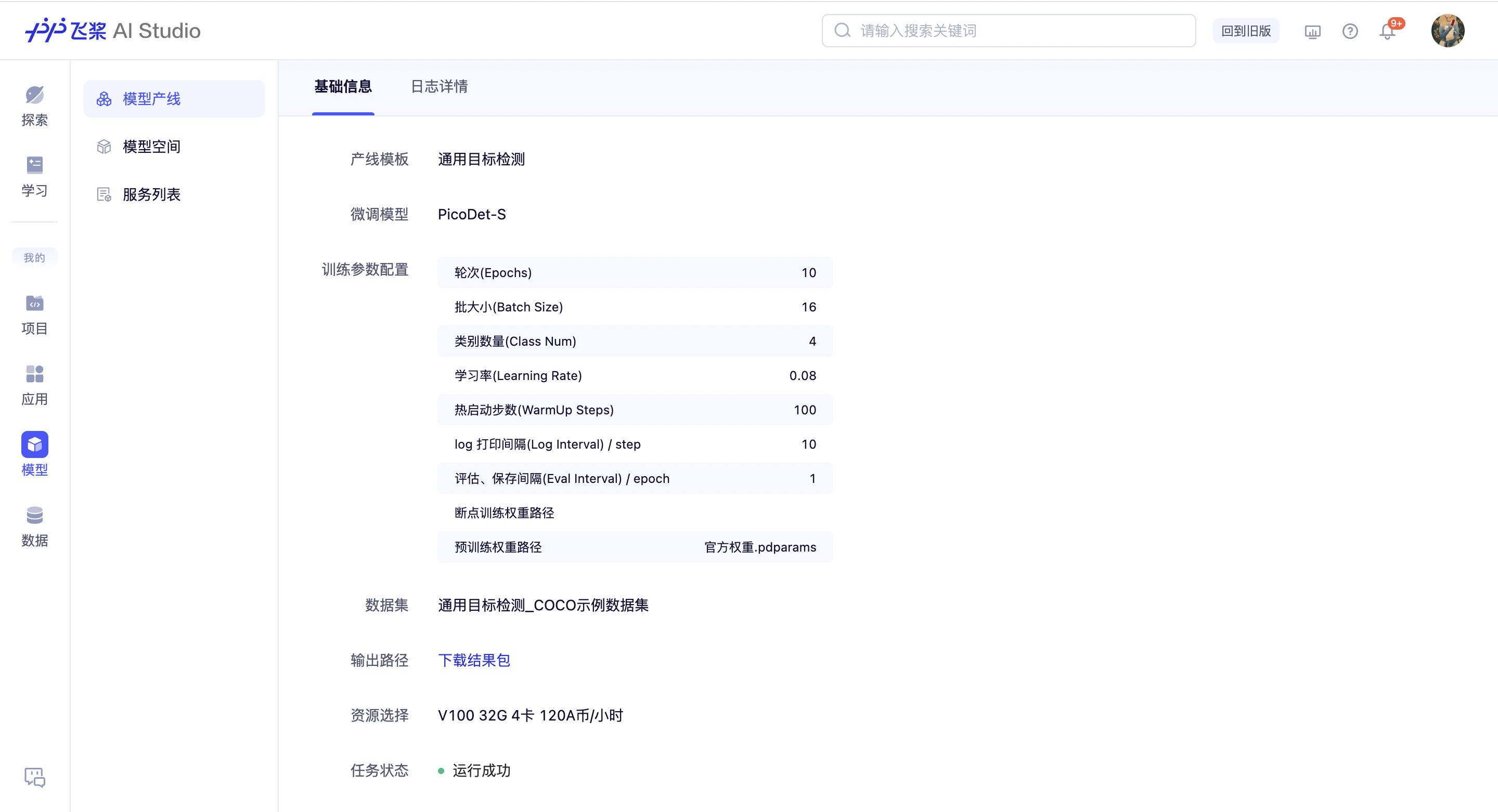
产线详情页
提交训练后,页面会刷新为产线详情页,展示用户设置的全部训练配置信息,包括:产线模板、微调模型、训练参数配置、数据集、输出路径、资源选择和任务状态。
当 GPU 集群可以执行训练任务时,任务状态显示为运行中,日志详情实时打印当前训练 log;当 GPU 集群暂无资源执行训练任务时,任务状态显示为排队中,此时可选择取消排队,返回配置中状态,如使用限免卡,限免卡会原路返还。
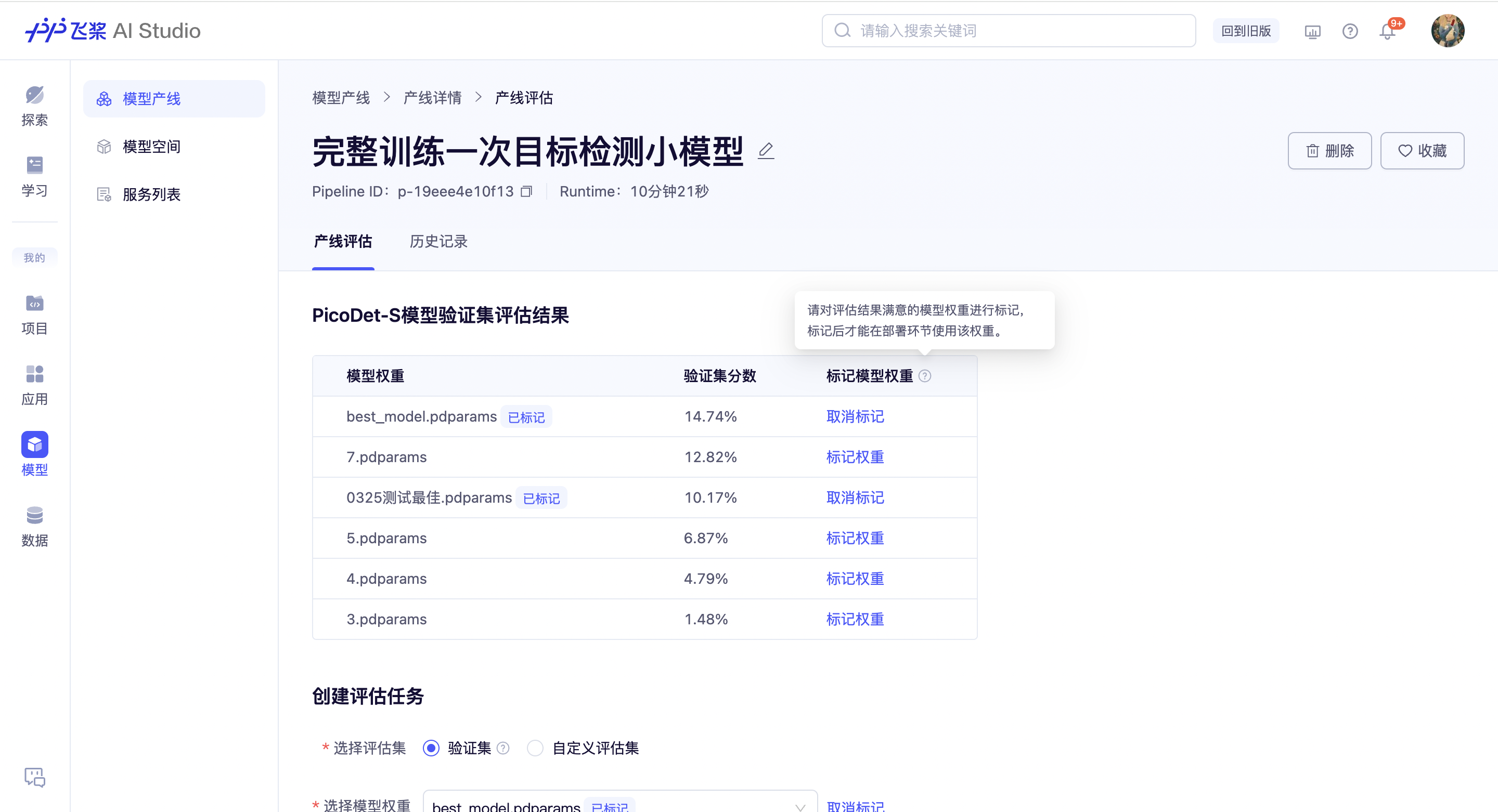
产线评估
产线状态为完成态(含运行成功、已停止、运行失败)时,产线内通常有结果产出,支持用户对产出的模型权重进行评估。训练中使用验证集评估的结果被提前保存,以表单的形式展示在评估页面,方便用户查看和标记模型权重。
注:直接部署的产线无产出结果,仅提供官方权重,不支持评估。大模型半监督学习的特点是引入用户的无标签数据集进行训练,因此不提供官方模型权重,不支持直接部署,需训练后评估模型权重。
标记模型权重
每条产线产出的模型权重通常不止一个,为方便用户查找和管理,您可以在这里对满意的模型权重做个标记,并为它取一个昵称(例如:数据集A评估最佳)。标记过的模型权重支持跨产线导入,也就是说,您可以在其他产线的同模型名选择权重(如模型部署、断点训练)的下拉菜单中,找到在本产线标记过的权重。当然,权重也可以取消标记,以减少选择成本。
创建评估任务
除了在验证集上评估模型权重外,如果您还有一批新的测试数据,可以选择自定义测试集的方式,上传测试数据并进行评估。请注意数据集的格式要求与训练数据集相同,但此处不会进行数据校验,如果数据格式存在问题,可能会引发评估任务失败。
历史评估任务的设置信息与日志会完整保留,可以通过历史记录查看详细情况。
产线部署
本产线支持两种部署方式:在线服务化部署和导出离线部署包。您可以根据自己的实际需求选择合适的部署方式,使用您满意的模型方案。
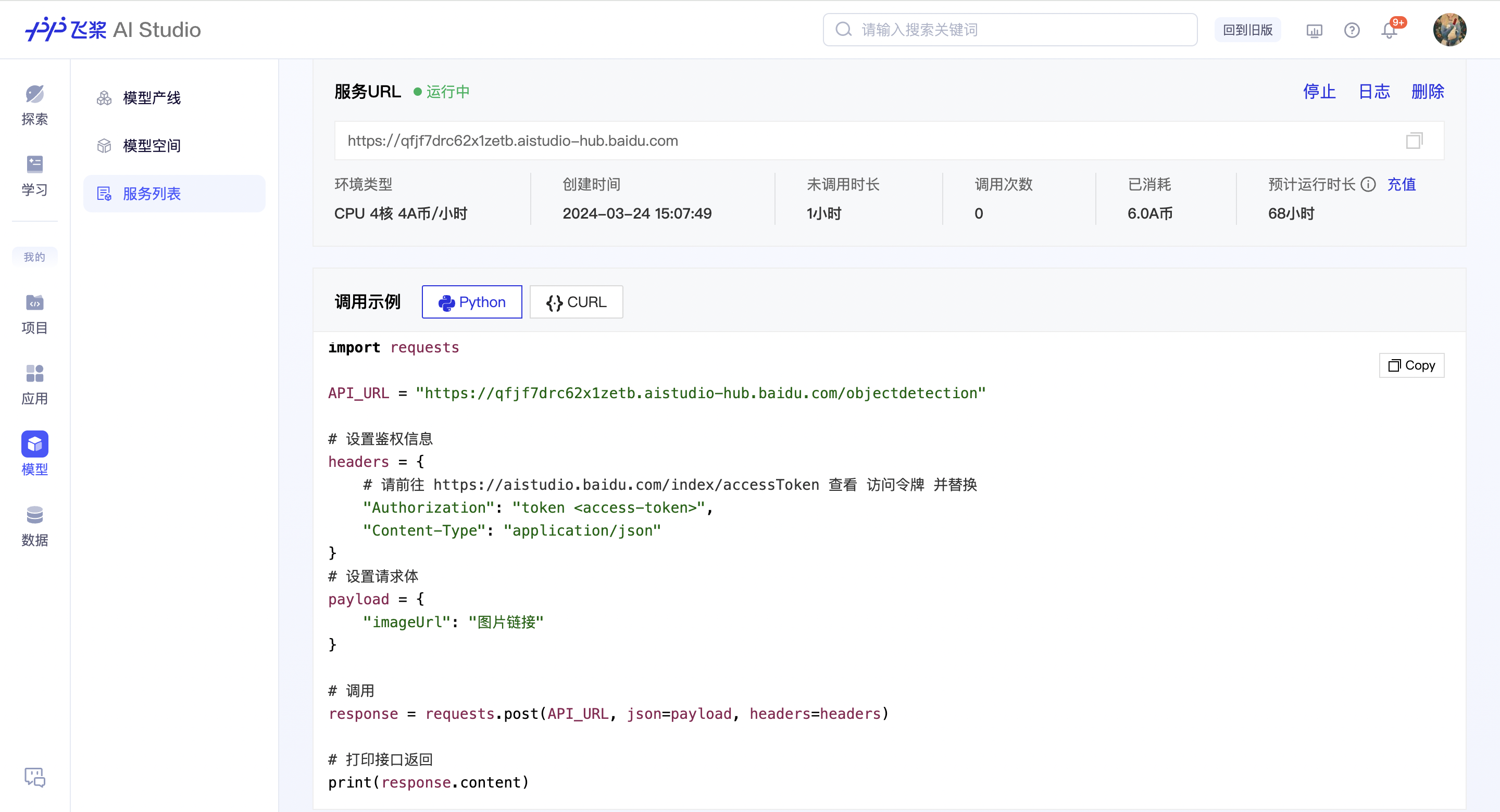
在线服务化部署
服务化部署指的是将模型方案部署为一个云端可调用 API,服务成功运行后,您可以使用自己的访问令牌鉴权后调用 API。此外,在线体验的应用中也可以找到这个 API 进行小样本可视化测试哦。
注:这种方式适用于数据不敏感且无部署机器的用户使用,API 为用户私有,仅能通过用户个人的访问令牌鉴权后调用。
导出离线部署包
如果您有离线部署的需求,产线也支持用户导出离线部署包。与在线服务化部署不同的是,您需要选择本地运行环境,产线会依据运行环境的不同导出相应的部署包,支持用户下载后本地运行。
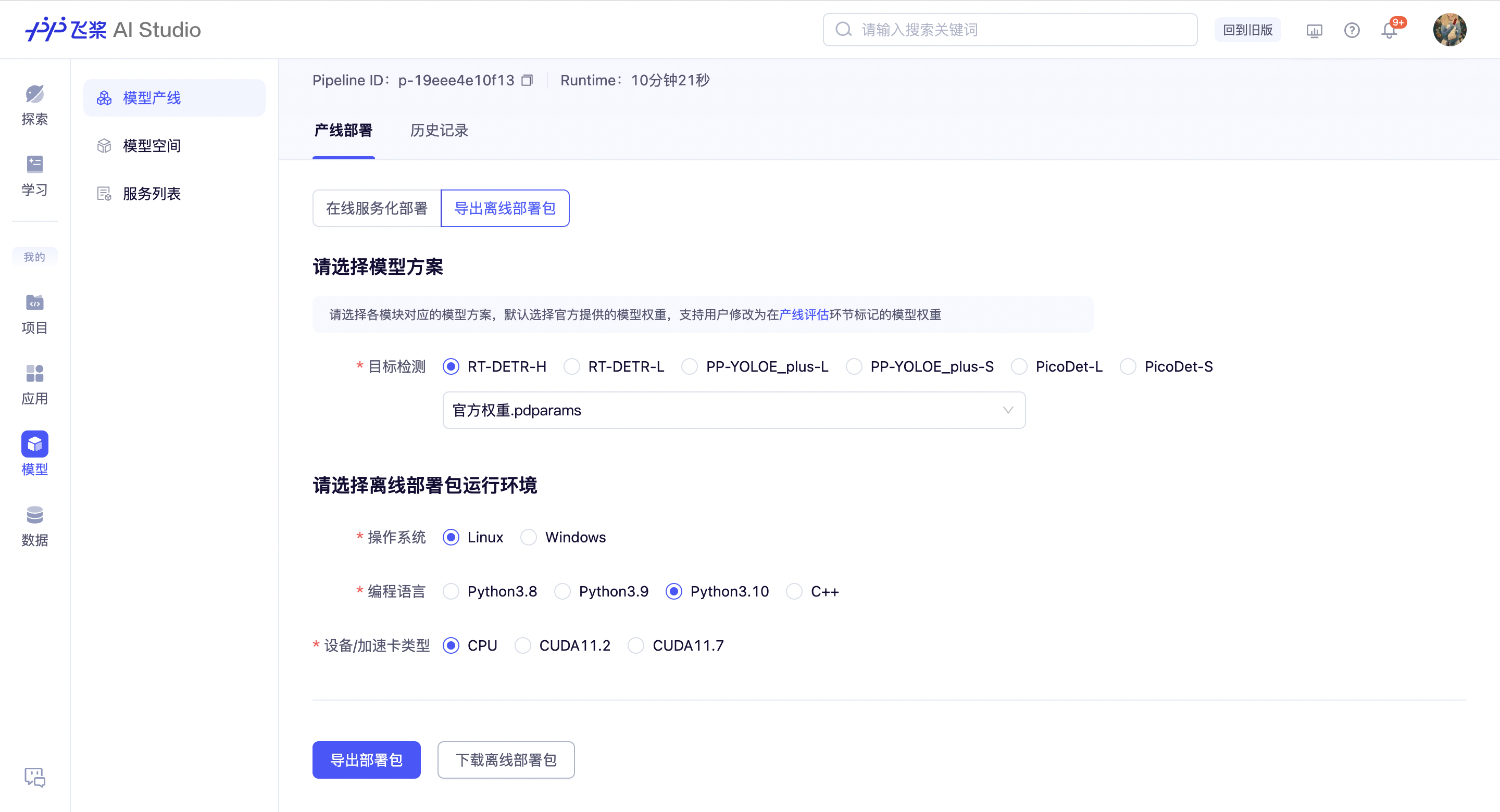
此外,特色产线的离线部署包需付费使用,请在产线内购买部署包序列号,本地激活后使用。购买注意事项及商务对接,可点击产线内对应的咨询入口。