

Notebook项目
更新时间:2024-03-20
目录
概述
AI Studio现支持BML Codelab(推荐)和AI Studio 经典版两种Notebook形式:
- AI Studio经典版是平台初期提供的Notebook产品,具备的能力有限,适用于刚入门的开发者;
- BML CodeLab是基于JupyterLab 3.0进行优化扩展,支持多ipynb查看和编辑、双语言、亮暗主题切换、代码实时自动补全、变量重命名和实时提醒等众多新特性,详见BML Codelab环境使用说明.
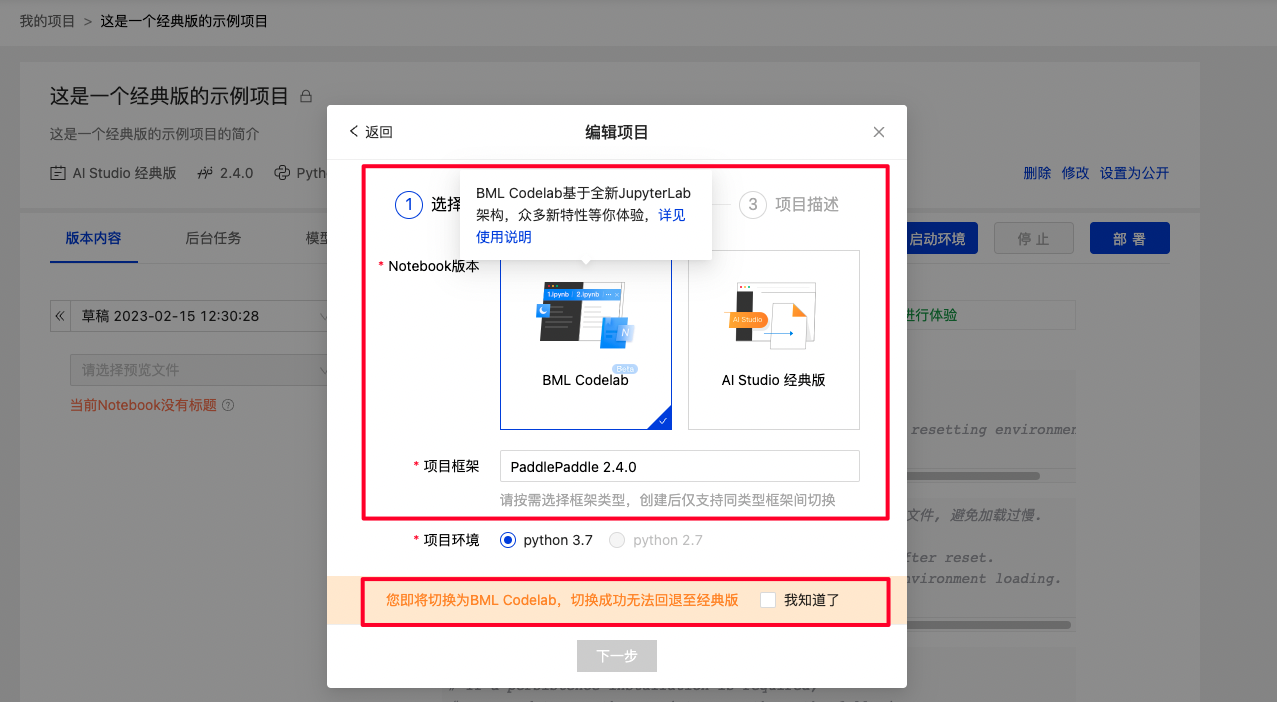
注意:
由于基础架构不同, 目前仅支持AI Studio经典版转换为BML Codelab.
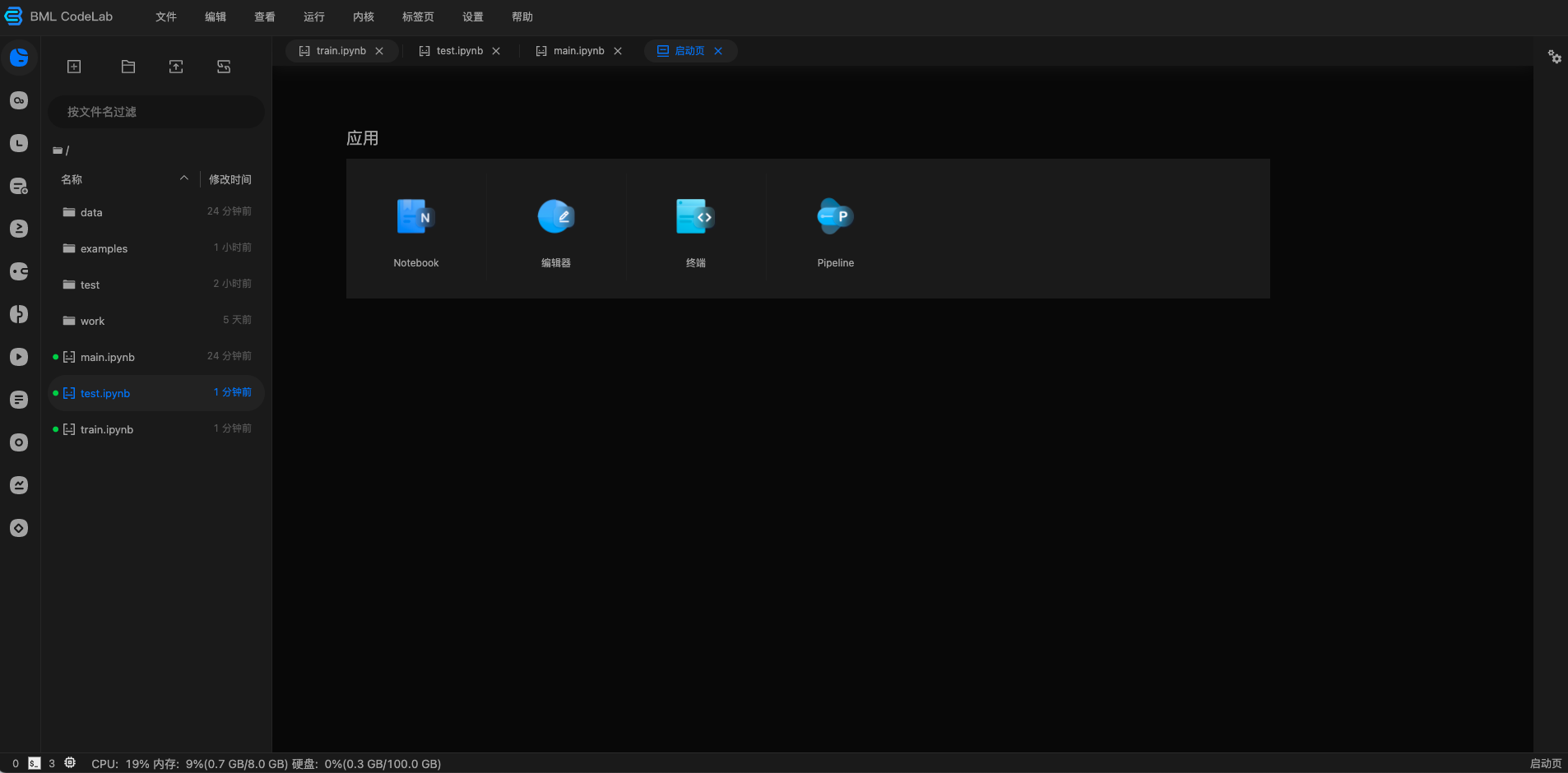
创建并运行Notebook项目
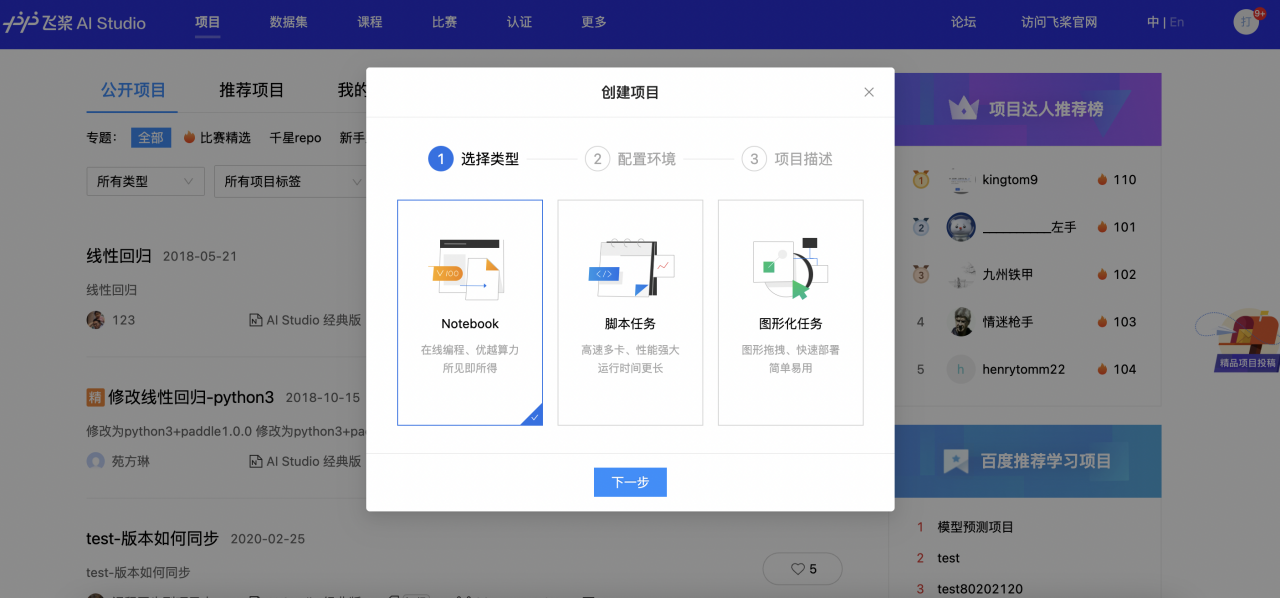
1、点击项目大厅页面的「创建项目」,选择创建「Notebook」.

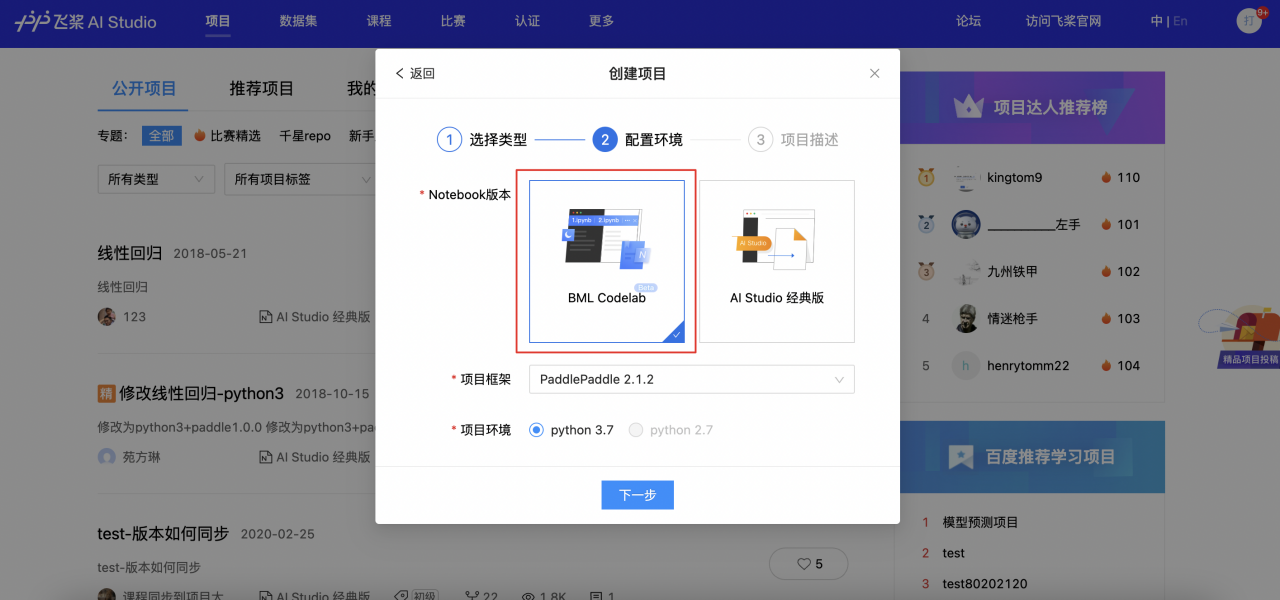
2、Notebook版本选择「BML Codelab」之后完善项目信息,点击「创建」.
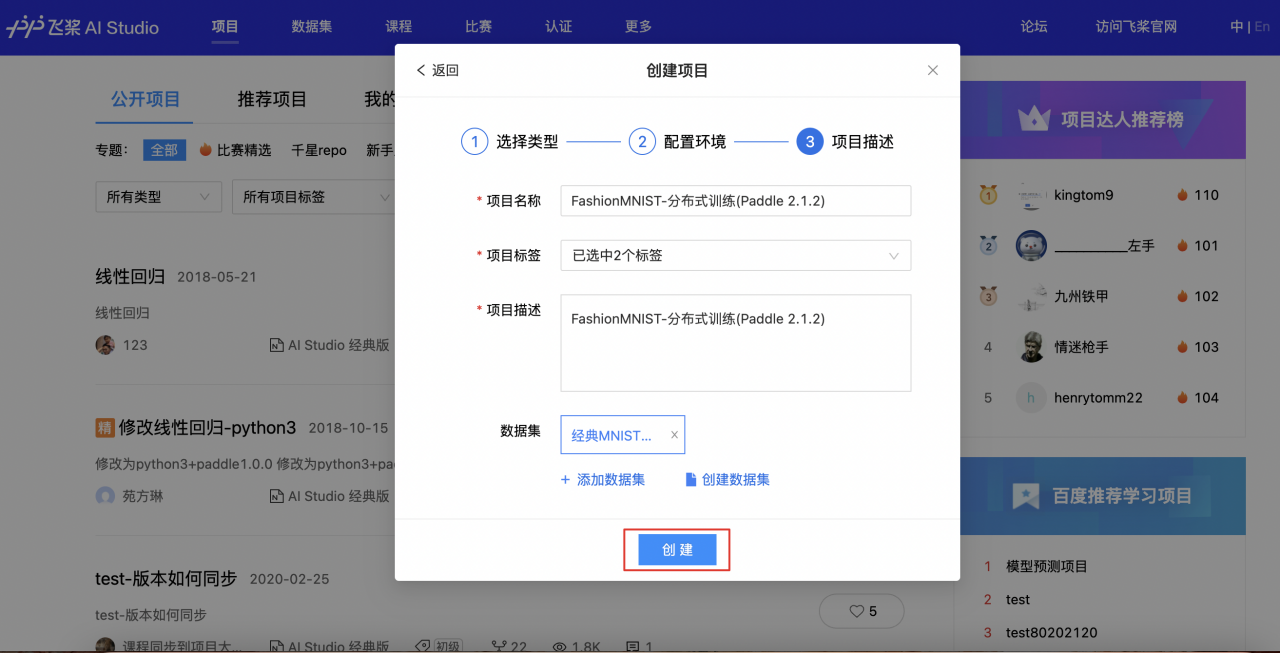
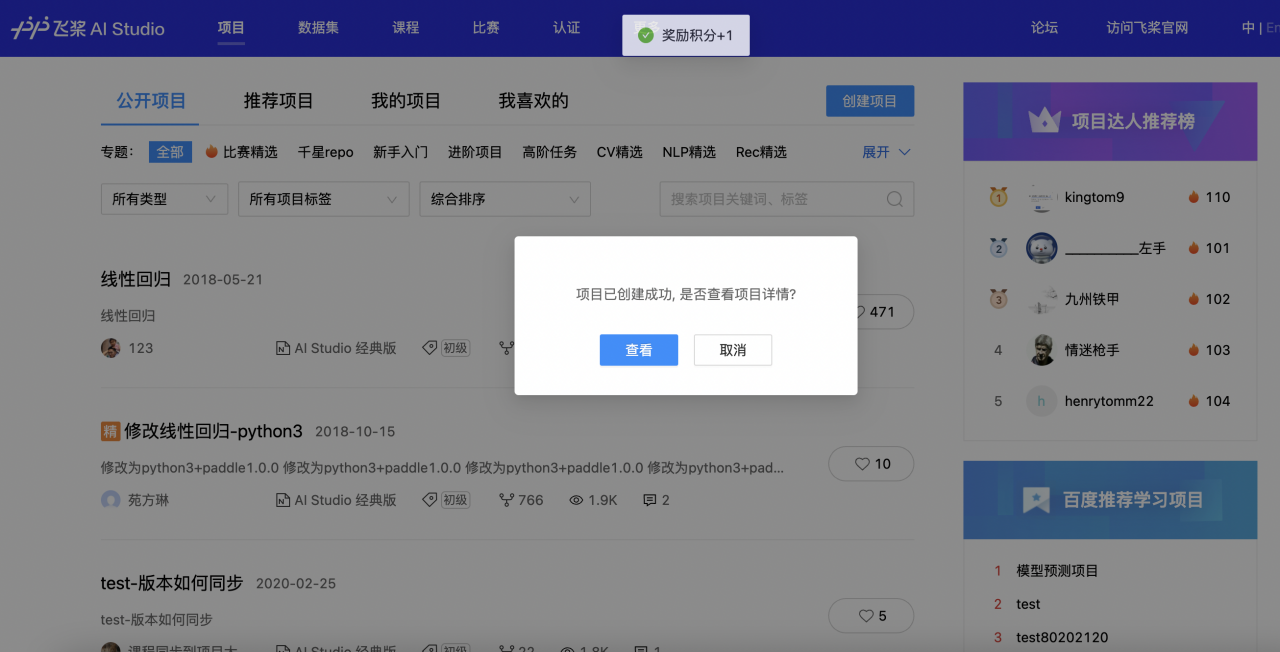
3、项目创建成功,点击「查看」.
4、我的项目-项目详情页
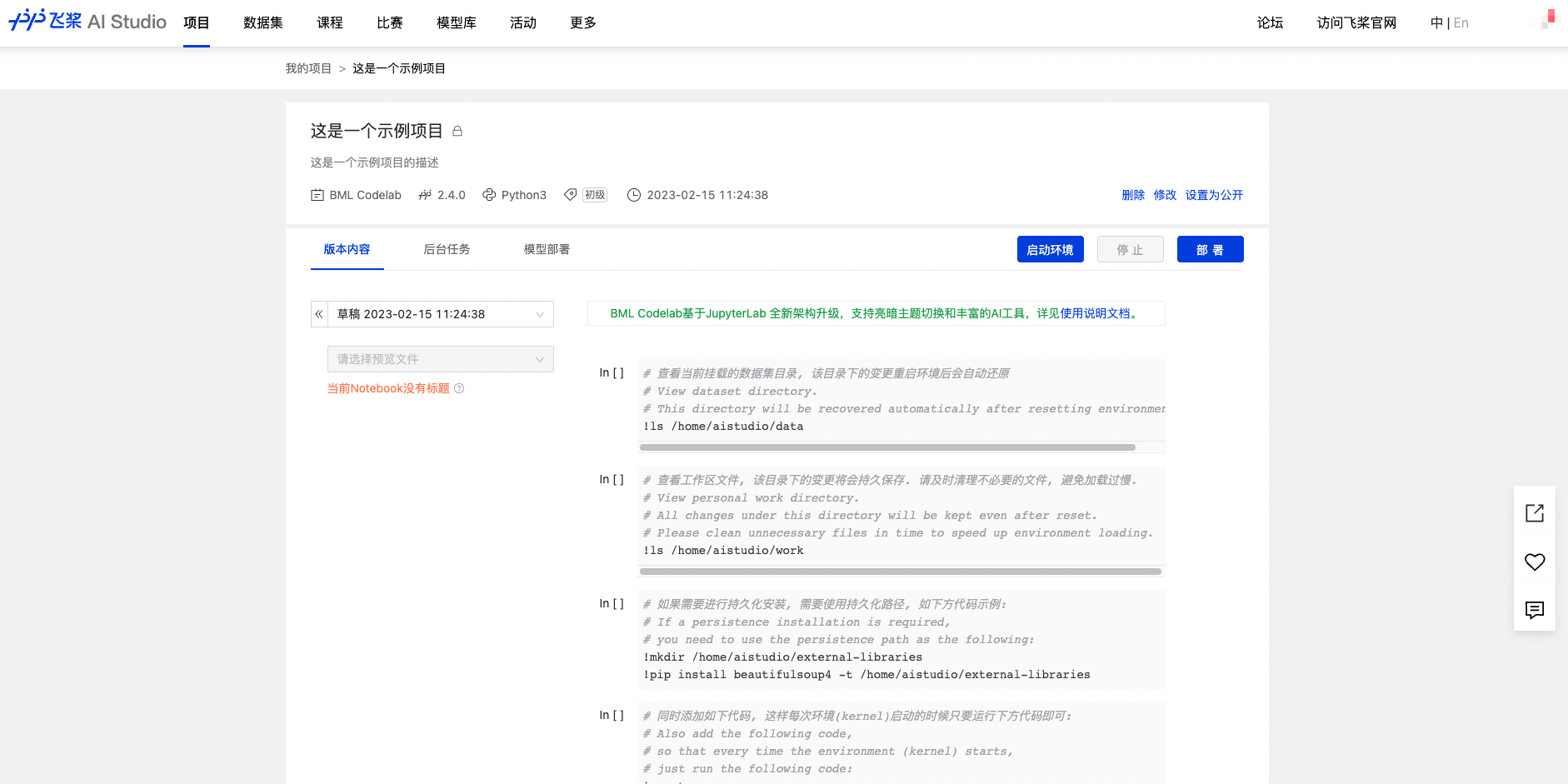
- 项目删除、修改及设置为公开项目操作;修改项目时,不支持修改Notebook版本.

- 版本内容: 展示当前Notebook最新内容.
- 数据集:支持部分数据类型预览.
- 后台任务:基于ipynb文件在后台完成训练任务.
- 模型部署: 用于生成在线API服务和趣味体验馆.
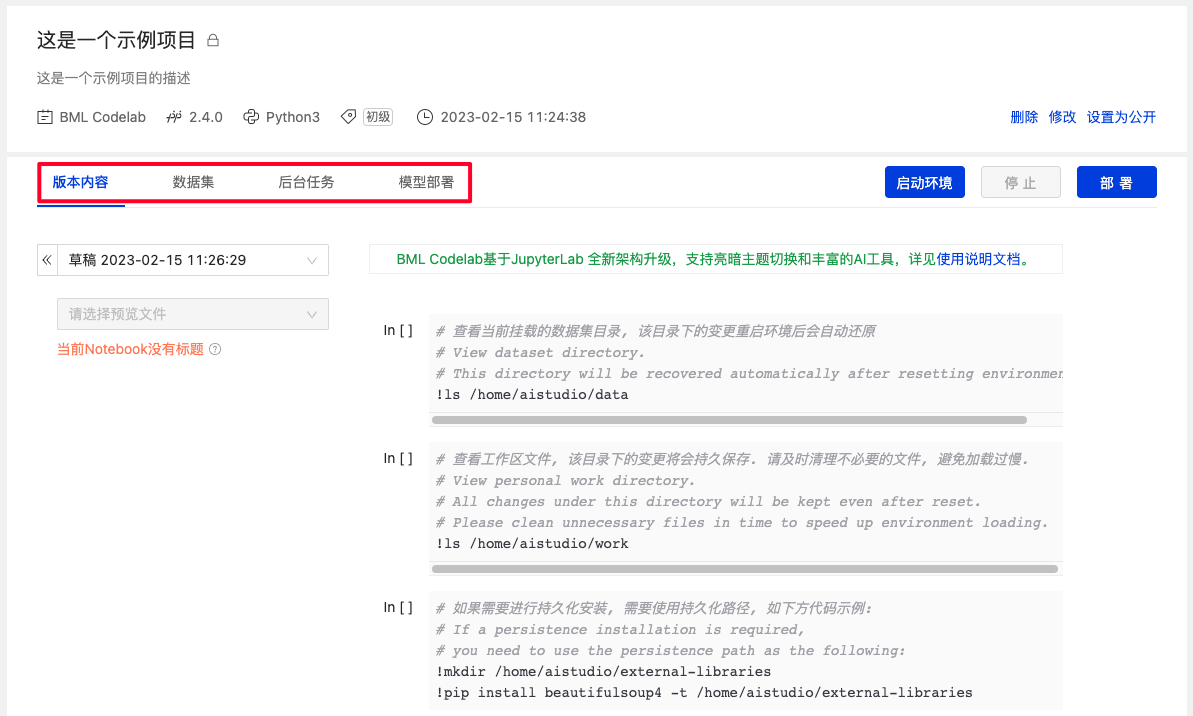
- 项目启停与部署操作.
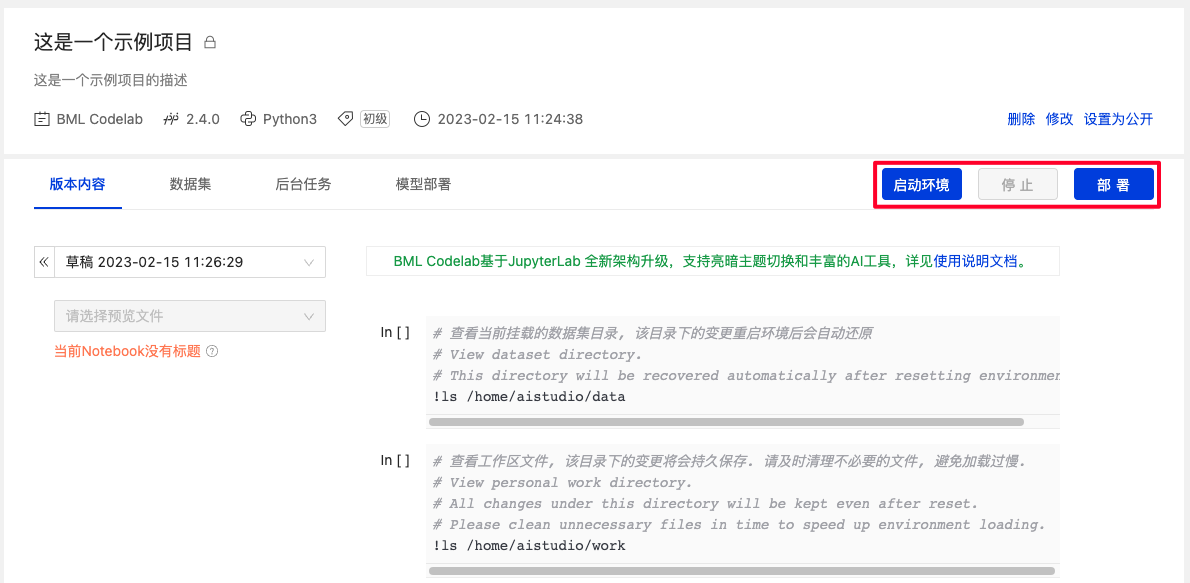
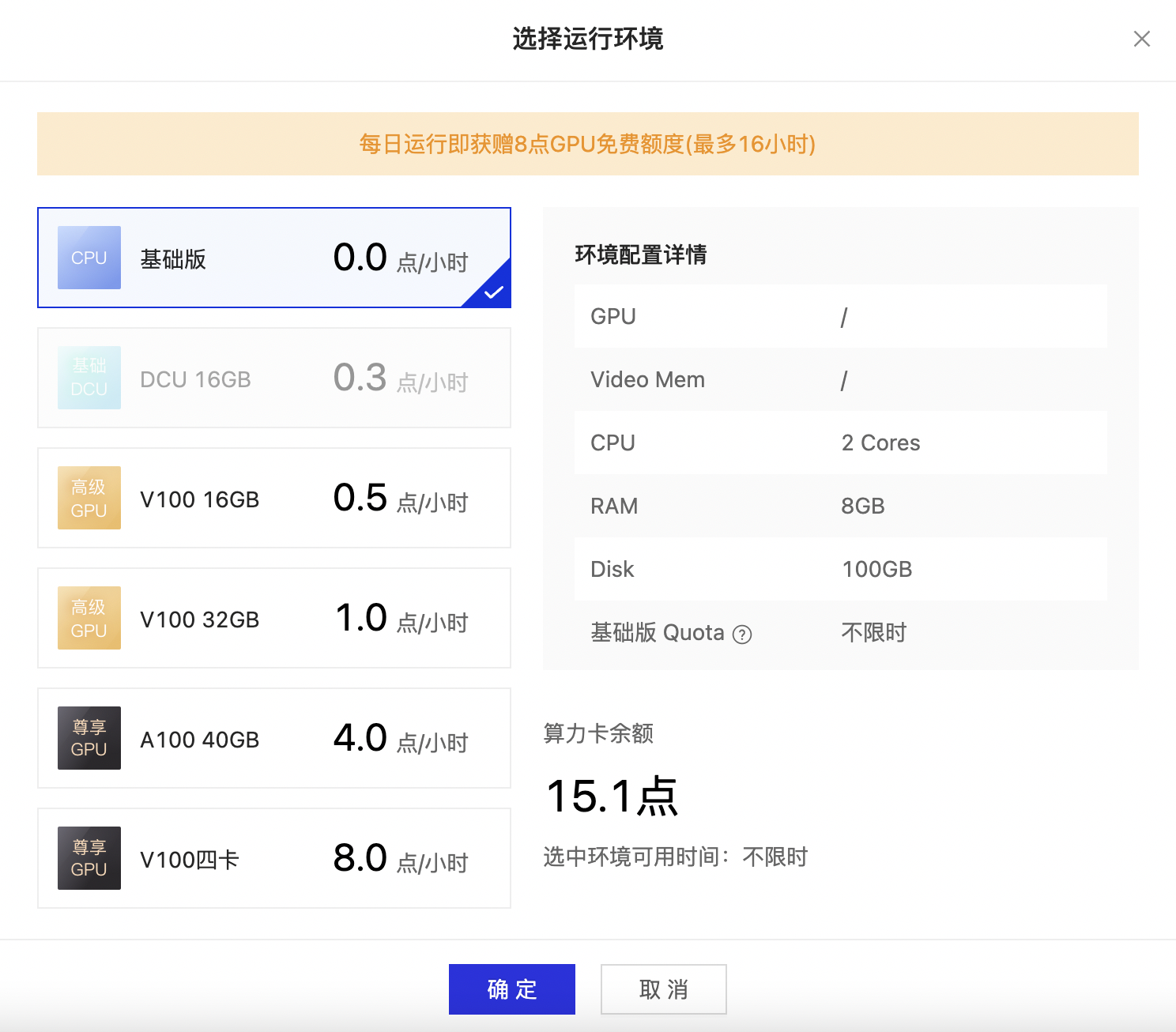
5、点击右方「运行」进行项目环境选择.
- 支持基础版(CPU)、基础版(DCU-16GB)、高级版(GPU-V100-16GB)、高级版(GPU-V100-32GB)、尊享版(GPU-A100-GB)、尊享版(GPU-4×V100-4×32GB)三种模式选择,默认为基础版,选择完毕点击确认.
- 需要额外说明的是,基础版(DCU-16GB)仅支持 DCU 框架运行,其余框架仅允许通用框架运行.
6、点击「确定」跳转到Notebook环境,即可开始代码编辑与运行,关于 AI Studio 经典版和BML CodeLab的使用说明详见下一节《BML Codelab环境使用说明》和《AI Studio 经典版环境使用说明》.