

通用目标检测产线使用文档
产线简介
通用目标检测产线汇聚了多个不同量级的目标检测模型。目标检测任务是计算机视觉领域的核心任务之一,旨在从图像或视频中找出所有感兴趣的目标(物体),并确定它们的类别和位置。你可以通过 在线体验应用,单图测试不同模型方案的效果,并选择合适的模型方案做部署。
效果展示
| 人物 | 动物 | 食物 | 生活 |
|---|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
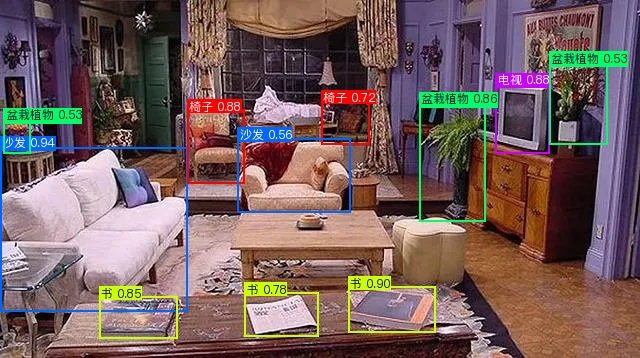
| 室内 | 交通 | 运动 | 工具 |
 |
 |
 |
 |
 |
 |
 |
 |
如果你有一批数据,并且想要在自有数据上训练模型,可以前往 模型产线,创建 通用目标检测 产线,并参考以下内容进行模型选型和训练部署。
模型方案介绍
本产线包含6个端到端算法模型,benchmark如下:
| 模型列表 | mAP(%) | GPU 推理耗时(ms) | CPU 推理耗时(ms) | 模型存储大小(M) |
|---|---|---|---|---|
| RT-DETR-H | 56.3 | 100.65 | 8451.92 | 471 |
| RT-DETR-L | 53.0 | 27.89 | 841.00 | 125 |
| PP-YOLOE_plus-L | 52.9 | 29.67 | 700.97 | 200 |
| PP-YOLOE_plus-S | 43.7 | 8.11 | 137.23 | 31 |
| PicoDet-L | 42.6 | 10.09 | 129.32 | 23 |
| PicoDet-S | 29.1 | 3.17 | 13.36 | 5 |
注:以上精度指标为 COCO2017 验证集 mAP(0.5:0.95),GPU 推理耗时基于 NVIDIA Tesla T4 机器,精度类型为 FP32, CPU 推理速度基于 Intel(R) Xeon(R) Gold 5117 CPU @ 2.00GHz,线程数为8,精度类型为 FP32。
简单来说,表格从上到下,模型推理速度更快,从下到上,模型精度更高。你可以依据自己的实际使用场景,判断并选择一个合适的模型做训练,训练完成后可在产线内评估合适的模型权重,并最终部署为一个服务 API 或离线 SDK,用于实际使用场景中。
数据准备
COCODetDataset
目标检测、版面分析要求的数据集格式,支持 VOC、LabelMe 格式的数据集转换为 COCO 格式。
数据集目录结构
请按照如下格式准备数据,以确保产线可以正确读取数据集,进行模型训练。
dataset_dir # 数据集根目录,目录名称可以改变
├── annotations # 标注文件的保存目录,目录名称不可改变
│ ├── instance_train.json # 训练集标注文件,文件名称不可改变,采用COCO标注格式
│ └── instance_val.json # 验证集标注文件,文件名称不可改变,采用COCO标注格式
└── images # 图像的保存目录,目录名称不可改变标注格式要求
目标检测数据要求标注出数据集中每张图像各个目标区域的位置和类别,产线要求的 COCO 数据格式采用 [x1,y1,w,h] 表示物体的边界框(bounding box)。其中,(x1,y1) 表示左上角坐标,w 为目标区域宽度,h 为目标区域高度。标注信息存放到 annotations 目录下的 json 文件中,训练集 instance_train.json 和验证集 instance_val.json 分开存放。
如果你有一批未标注数据,我们推荐使用 LabelMe 进行数据标注。对于使用 LabelMe 标注的数据集,或是 VOC 格式的数据集,产线支持进行数据格式转换,请选择对应的格式后,点击「开始校验」按钮。
为确保格式转换顺利完成,请严格遵循示例数据集的文件命名和组织方式: VOC 示例数据集 | LabelMe 示例数据集
注:以上示例数据集仅作格式说明,不用于验证模型训练精度。
完成格式转换和校验的数据集会保存在个人数据集中,支持用户跨产线导入数据集。
参数准备
正确设置训练参数对于模型训练至关重要,本产线支持两种参数设置方式:修改表单和修改配置文件,常见训练参数推荐使用表单修改,可展开高级设置修改更多参数,对飞桨套件参数较熟悉的用户可以通过表单修改全部训练参数。训练模型的基础配置和高级配置参数如下:
基础配置
- 轮次(Epochs):模型对训练数据的重复学习次数,一般来说,轮次越大,模型训练时间越长,模型精度越高,但是如果设置特别大,可能会导致模型过拟合。如果对轮次没有特别的要求,可以使用默认值进行训练。
- 批大小(Batch Size):由于训练数据量一般较大,模型每轮次的训练是分批读取数据的,批大小是每一批数据的数据量,和显存直接相关,批大小越大模型训练的速度越快,显存占用越高。为确保训练不会因为显存溢出而终止,我们将 V100 32G 单卡可以运行的最大值作为批大小的可设置最大值。
- 类别数量(Class Num):数据集中检测结果的类别数,由于类别数量和数据集直接相关,我们无法填充默认值,请根据数据校验的结果进行填写,类别数量需要准确,否则可能引起训练失败。
- 学习率(Learning Rate):模型训练过程中梯度调整的步长,通常与批大小成正比例关系,学习率设置过大可能会导致模型训练不收敛,设置过小可能会导致模型收敛速度过慢。在不同的数据集上学习率可能不同,对结果影响较大,需要不断调试。
高级配置
- 断点训练权重:在模型训练过程中发生人为或意外终止的情况时,加载训练中断之前保存的断点权重路径,完成继续训练,避免算力资源浪费。
- 预训练权重:基于已经在大数据集上训练好的模型权重进行微调训练,可提高模型训练开始前的初始经验,提高训练效率。
- 热启动步数(WarmUp Steps):在训练初始阶段以较小学习率缓慢增加到设置学习率的批次数量,该值的设置可以避免模型在初始阶段以较大学习率迭代模型最终破坏预训练权重,一定程度上提升模型的精度。
- log 打印间隔(Log Interval) / step:训练日志中打印日志信息的批次数量间隔。
- 评估、保存间隔(Eval Interval) / epoch:训练过程中对验证集进行评估以及保存权重的轮数间隔。
提交训练
训练套餐包括:
- V100 32G 1卡 3算力点/小时
- V100 32G 1卡 30A币/小时
- V100 32G 4卡 120A币/小时
- V100 32G 8卡 240A币/小时
支持用户选择算力点或 A 币支付 GPU 使用花费。你可以根据自己的需求和平台 GPU 占用情况选择合适的训练套餐。
为鼓励更多用户体验模型产线新功能,每个账户赠送 3 张限时免费卡,前三次使用 V100 32G 1卡 30A币/小时训练套餐免费,之后将按对应训练时长计费,此外,训练过程中主动停止或因配置信息有误导致的训练失败,限免卡不返还。
产线详情页
提交训练后,页面会刷新为产线详情页,展示用户设置的全部训练配置信息,包括:产线模板、微调模型、训练参数配置、数据集、输出路径、资源选择和任务状态。当 GPU 集群可以执行训练任务时,任务状态显示为运行中,日志详情实时打印当前训练 log;当 GPU 集群暂无资源执行训练任务时,任务状态显示为排队中,此时可选择取消排队,返回配置中状态,如使用限免卡,限免卡会原路返还。
产线评估
产线状态为完成态(含运行成功、已停止、运行失败)时,产线内通常有结果产出,支持用户对产出的模型权重进行评估。训练中使用验证集评估的结果被提前保存,以表单的形式展示在评估页面,方便用户查看和标记模型权重。
注:直接部署的产线无产出结果,仅提供官方权重,不支持评估。
标记模型权重
每条产线产出的模型权重通常不止一个,为方便用户查找和管理,你可以在这里对满意的模型权重做个标记,并为它取一个昵称(例如:数据集A评估最佳)。标记过的模型权重支持跨产线导入,也就是说,你可以在其他产线的同模型名选择权重(如模型部署、断点训练)的下拉菜单中,找到在本产线标记过的权重。当然,权重也可以取消标记,以减少选择成本。
创建评估任务
除了在验证集上评估模型权重外,如果你还有一批新的测试数据,可以选择自定义测试集的方式,上传测试数据并进行评估。请注意数据集的格式要求与训练数据集相同,但此处不会进行数据校验,如果数据格式存在问题,可能会引发评估任务失败。
历史评估任务的设置信息与日志会完整保留,可以通过历史记录查看详细情况。
产线部署
本产线支持两种部署方式:在线服务化部署和导出离线部署包。你可以根据自己的实际需求选择合适的部署方式,使用你满意的模型方案。
在线服务化部署
服务化部署指的是将模型方案部署为一个云端可调用 API,服务成功运行后,你可以使用自己的访问令牌鉴权后调用 API。此外,在线体验的应用中也可以找到这个 API 进行小样本可视化测试哦。
注:这种方式适用于数据不敏感且无部署机器的用户使用,API 为用户私有,仅能通过用户个人的访问令牌鉴权后调用。
导出离线部署包
如果你有离线部署的需求,产线也支持用户导出离线部署包。与在线服务化部署不同的是,你需要选择本地运行环境,产线会依据运行环境的不同导出相应的部署包,支持用户下载后本地运行。
以下是一个简单的使用示例:
# 安装离线whl包
pip install fastdeploy_python-0.0.0-cp310-cp310-manylinux1_x86_64.whl
# 使用inference model进行单图推理
python ./example/infer.py --model model --image ./example/test.jpg --device cpu --backend paddle结果可视化展示:
