

PaddleOCR-VL_API
更新时间:2025-12-29
PaddleOCR-VL 服务化部署调用示例及 API 介绍:
PaddleOCR 开源项目 GitHub 地址,本服务基于该开源项目的 PaddleOCR-VL 模型构建。
版本说明:PaddleOCR 官网当前对应的 PaddleX 版本为 3.3.12,PaddlePaddle 版本为 3.2.1。
1. PaddleOCR-VL 介绍
PaddleOCR-VL 是一款先进、高效的文档解析模型,专为文档中的元素识别设计。其核心组件为 PaddleOCR-VL-0.9B,这是一种紧凑而强大的视觉语言模型(VLM),它由 NaViT 风格的动态分辨率视觉编码器与 ERNIE-4.5-0.3B 语言模型组成,能够实现精准的元素识别。该模型支持 109 种语言,并在识别复杂元素(如文本、表格、公式和图表)方面表现出色,同时保持极低的资源消耗。通过在广泛使用的公开基准与内部基准上的全面评测,PaddleOCR-VL 在页级级文档解析与元素级识别均达到 SOTA 表现。它显著优于现有的基于Pipeline方案和文档解析多模态方案以及先进的通用多模态大模型,并具备更快的推理速度。这些优势使其非常适合在真实场景中落地部署。
关键指标:
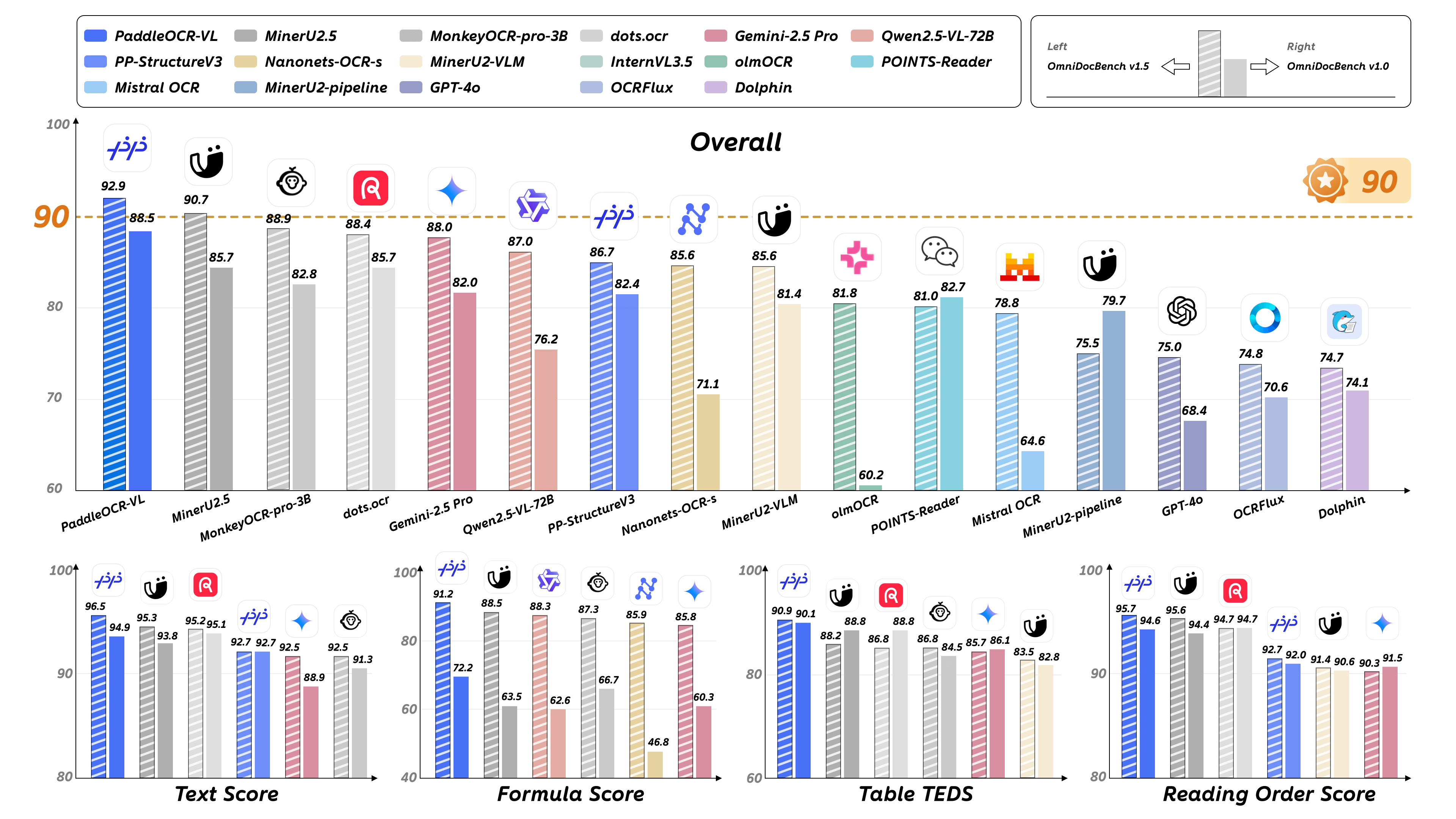
核心特性:
- 紧凑而强大的视觉语言模型架构: 我们提出了一种新的视觉语言模型,专为资源高效的推理而设计,在元素识别方面表现出色。通过将 NaViT 风格的动态高分辨率视觉编码器与轻量级的 ERNIE-4.5-0.3B 语言模型结合,我们显著增强了模型的识别能力和解码效率。这种集成在保持高准确率的同时降低了计算需求,使其非常适合高效且实用的文档处理应用。
- 文档解析的SOTA性能: PaddleOCR-VL 在页面级文档解析和元素级识别中达到了最先进的性能。它显著优于现有的基于流水线的解决方案,并在文档解析中展现出与领先的视觉语言模型(VLMs)竞争的强劲实力。此外,它在识别复杂的文档元素(如文本、表格、公式和图表)方面表现出色,使其适用于包括手写文本和历史文献在内的各种具有挑战性的内容类型。这使得它具有高度的多功能性,适用于广泛的文档类型和场景。
- 多语言支持: PaddleOCR-VL 支持 109 种语言,覆盖了主要的全球语言,包括但不限于中文、英文、日文、拉丁文和韩文,以及使用不同文字和结构的语言,如俄语(西里尔字母)、阿拉伯语、印地语(天城文)和泰语。这种广泛的语言覆盖大大增强了我们系统在多语言和全球化文档处理场景中的适用性。
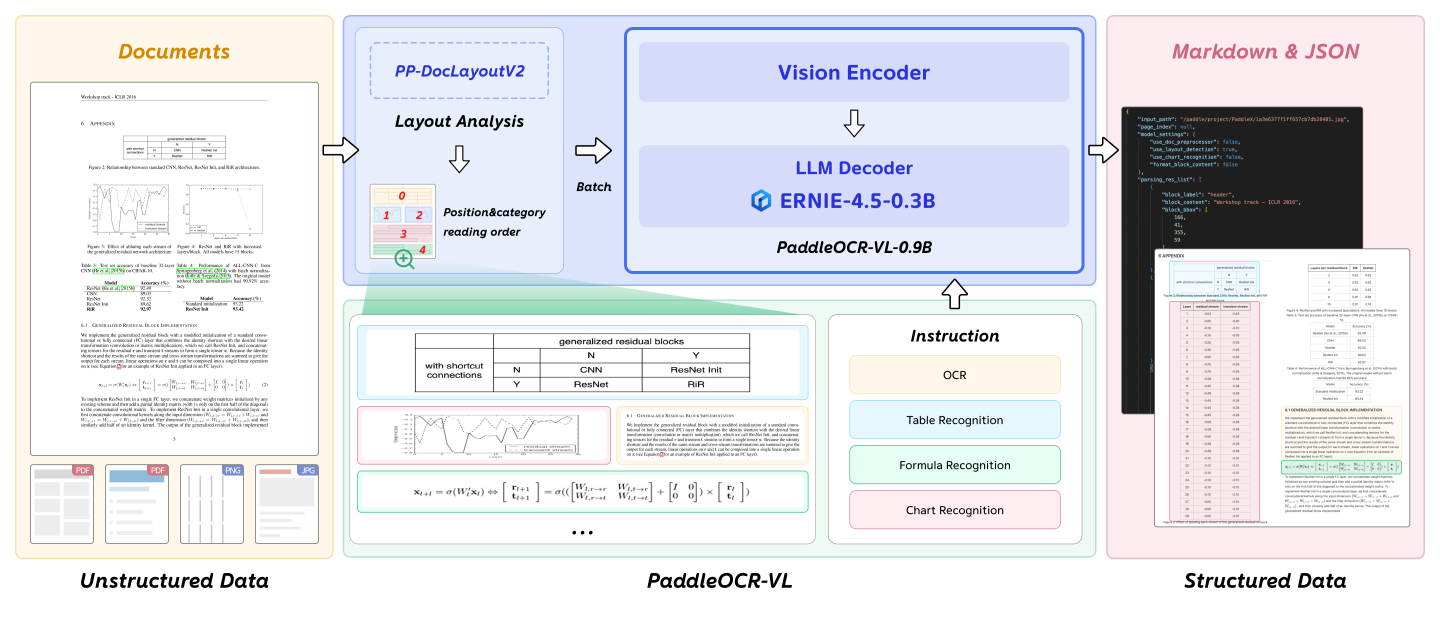
下图展示了 PaddleOCR-VL 的整体流程:
2. 接口说明
请查看文档
3. 服务调用示例(python)
# Please make sure the requests library is installed
# pip install requests
import base64
import os
import requests
# API_URL 及 TOKEN 请访问 [PaddleOCR 官网](https://aistudio.baidu.com/paddleocr/task) 在 API 调用示例中获取。
API_URL = "<your url>"
TOKEN = "<access token>"
file_path = "<local file path>"
with open(file_path, "rb") as file:
file_bytes = file.read()
file_data = base64.b64encode(file_bytes).decode("ascii")
headers = {
"Authorization": f"token {TOKEN}",
"Content-Type": "application/json"
}
required_payload = {
"file": file_data,
"fileType": <file type>, # For PDF documents, set `fileType` to 0; for images, set `fileType` to 1
}
optional_payload = {
"useDocOrientationClassify": False,
"useDocUnwarping": False,
"useChartRecognition": False,
}
payload = {**required_payload, **optional_payload}
response = requests.post(API_URL, json=payload, headers=headers)
print(response.status_code)
assert response.status_code == 200
result = response.json()["result"]
output_dir = "output"
os.makedirs(output_dir, exist_ok=True)
for i, res in enumerate(result["layoutParsingResults"]):
md_filename = os.path.join(output_dir, f"doc_{i}.md")
with open(md_filename, "w", encoding="utf-8") as md_file:
md_file.write(res["markdown"]["text"])
print(f"Markdown document saved at {md_filename}")
for img_path, img in res["markdown"]["images"].items():
full_img_path = os.path.join(output_dir, img_path)
os.makedirs(os.path.dirname(full_img_path), exist_ok=True)
img_bytes = requests.get(img).content
with open(full_img_path, "wb") as img_file:
img_file.write(img_bytes)
print(f"Image saved to: {full_img_path}")
for img_name, img in res["outputImages"].items():
img_response = requests.get(img)
if img_response.status_code == 200:
# Save image to local
filename = os.path.join(output_dir, f"{img_name}_{i}.jpg")
with open(filename, "wb") as f:
f.write(img_response.content)
print(f"Image saved to: {filename}")
else:
print(f"Failed to download image, status code: {img_response.status_code}")对于服务提供的主要操作:
- HTTP请求方法为POST。
- 请求体和响应体均为JSON数据(JSON对象)。
- 当请求处理成功时,响应状态码为
200,响应体的属性如下:
| 名称 | 类型 | 含义 |
|---|---|---|
logId |
string |
请求的UUID。 |
errorCode |
integer |
错误码。固定为0。 |
errorMsg |
string |
错误说明。固定为"Success"。 |
result |
object |
操作结果。 |
- 当请求处理未成功时,响应体的属性如下:
| 名称 | 类型 | 含义 |
|---|---|---|
logId |
string |
请求的UUID。 |
errorCode |
integer |
错误码。与响应状态码相同。 |
errorMsg |
string |
错误说明。 |
服务提供的主要操作如下:
infer
进行版面解析。
POST /layout-parsing
4. 请求参数说明
| 名称 | 参数 | 类型 | 含义 | 是否必填 |
|---|---|---|---|---|
输入文件 |
file |
string |
服务器可访问的图像文件或PDF文件的URL,或上述类型文件内容的Base64编码结果。默认对于超过10页的PDF文件,只有前10页的内容会被处理。 要解除页数限制,请在产线配置文件中添加以下配置: |
是 |
文件类型 |
fileType |
integer|null |
文件类型。0表示PDF文件,1表示图像文件。若请求体无此属性,则将根据URL推断文件类型。 |
否 |
图片方向矫正 |
useDocOrientationClassify |
boolean | null |
是否在推理时使用文本图像方向矫正模块,开启后,可以自动识别并矫正 0°、90°、180°、270°的图片。 | 否 |
图片扭曲矫正 |
useDocUnwarping |
boolean | null |
是否在推理时使用文本图像矫正模块,开启后,可以自动矫正扭曲图片,例如褶皱、倾斜等情况。 | 否 |
版面分析 |
useLayoutDetection |
boolean | null |
是否在推理时使用版面区域检测排序模块,开启后,可以自动检测文档中不同区域并排序。 | 否 |
图表识别 |
useChartRecognition |
boolean | null |
是否在推理时使用图表解析模块,开启后,可以自动解析文档中的图表(如柱状图、饼图等)并转换为表格形式,方便查看和编辑数据。 | 否 |
版面区域过滤强度 |
layoutThreshold |
number | object | null |
版面模型得分阈值。0-1 之间的任意浮点数。如果不设置,将使用产线初始化的该参数值,默认初始化为 0.5。 |
否 |
NMS后处理 |
layoutNms |
boolean | null |
版面检测是否使用后处理NMS,开启后,会自动移除重复或高度重叠的区域框。 | 否 |
扩张系数 |
layoutUnclipRatio |
number | array | object | null |
版面区域检测模型检测框的扩张系数。 任意大于 0 浮点数。如果不设置,将使用产线初始化的该参数值,默认初始化为 1.0。 |
否 |
版面区域检测的重叠框过滤方式 |
layoutMergeBboxesMode |
string | object | null |
large。
|
否 |
prompt类型设置 |
promptLabel |
string | null |
VL模型的 prompt 类型设置,当且仅当 useLayoutDetection=False 时生效。 |
否 |
重复抑制强度 |
repetitionPenalty |
number | null |
结果中出现重复文字、重复表格内容时,可适当调高。 | 否 |
识别稳定性 |
temperature |
number | null |
结果不稳定或出现明显幻觉时调低,漏识别或者重复较多时可略微调高。 | 否 |
结果可信范围 |
topP |
number | null |
结果发散、不够可信时可适当调低,让模型更保守。 | 否 |
最小图像尺寸 |
minPixels |
number | null |
输入图片太小、文字看不清时可适当调高,一般无需调整。 | 否 |
最大图像尺寸 |
maxPixels |
number | null |
输入图片特别大、处理变慢或显存压力较大时可适当调低。 | 否 |
公式编号展示 |
showFormulaNumber |
boolean |
输出的 Markdown 文本中是否包含公式编号。 | 否 |
Markdown 美化 |
prettifyMarkdown |
boolean |
是否输出美化后的 Markdown 文本。 | 否 |
可视化 |
visualize |
boolean | null |
支持返回可视化结果图及处理过程中的中间图像。开启此功能后,将增加结果返回时间。
例如,在产线配置文件中添加如下字段: visualize参数可以覆盖默认行为。如果请求体和配置文件中均未设置(或请求体传入null、配置文件中未设置),则默认返回图像。
|
否 |
- 请求处理成功时,响应体的
result具有如下属性:
| 名称 | 类型 | 含义 |
|---|---|---|
layoutParsingResults |
array |
版面解析结果。数组长度为1(对于图像输入)或实际处理的文档页数(对于PDF输入)。对于PDF输入,数组中的每个元素依次表示PDF文件中实际处理的每一页的结果。 |
dataInfo |
object |
输入数据信息。 |
layoutParsingResults中的每个元素为一个object,具有如下属性:
| 名称 | 类型 | 含义 |
|---|---|---|
prunedResult |
object |
对象的 predict 方法生成结果的 JSON 表示中 res 字段的简化版本,其中去除了 input_path 和 page_index 字段。 |
markdown |
object |
Markdown结果。 |
outputImages |
object | null |
参见预测结果的 img 属性说明。图像为JPEG格式,使用Base64编码。 |
inputImage |
string | null |
输入图像。图像为JPEG格式,使用Base64编码。 |
markdown为一个object,具有如下属性:
| 名称 | 类型 | 含义 |
|---|---|---|
text |
string |
Markdown文本。 |
images |
object |
Markdown图片相对路径和Base64编码图像的键值对。 |
isStart |
boolean |
当前页面第一个元素是否为段开始。 |
isEnd |
boolean |
当前页面最后一个元素是否为段结束。 |
对于返回的数据结构及字段说明,请查阅文档。
注:如果在使用过程中遇到问题,欢迎随时在 issue 区提交反馈。