

零代码产线 | 产业实践:圆珠笔瑕疵检测
一、需求描述
圆珠笔作为每位学子必备的书写工具,在我国每年售出上百亿支。然而,每一支笔的完美出品,背后都离不开严格的品质把控。在装盒包装之前,每一支笔都要接受细致的外观检查,以确保产品质量的无懈可击。但当前,这一品质检验环节还主要依赖人工完成,每条生产线都需要两名质检员轮班工作,这无疑增加了人力成本。特别是在国内制造业面临用工紧张的背景下,生产成本的逐年上升已成为企业不得不面对的现实。

二、方案概览
2.1 项目难点

2.1.1 检测难度大
- 目标细微多样;
- 目标面积占比小;
- 同类目标特征共性少;
- 不同类目标特征近似;
2.1.2 数据集质量较低
- 类别不均衡问题严重,不同类别数据数量相差极大,如『脏污』类别较多,『鼓包』类别较少;
- 标注数据量少,训练集仅有 1974 张标注数据,另有 3000 张无标注数据;
2.1.3 推理速度要求高:
- NVIDIA Tesla T4 上推理时间小于 20ms;
- 端侧设备上可达到实时推理;
2.2 任务思路
- 任务抽象:该任务数据集可视为 8 个类别的目标检测任务,将这8类瑕疵作为我们待检测的目标。在评测指标方面,目标检测常用的评测指标有 mAP@0.5 和 mAP@[0.5:0.95],mAP@0.5 是指目标检测器在交并比(IOU)阈值为 0.5 的条件下在数据集各个类别上的平均精度,mAP@[0.5:0.95] 是指目标检测器在 IOU=0.5 至 IOU=0.95 以 5% 为步长得到的不同阈值为条件而得到的平均精度,mAP@[0.5:0.95] 通常更加侧重反映的是目标检测器的位置检测精度,而在该任务的场景中,我们更加关注目标的检出准确性,需要保证能够有效的防止出现漏检或者误检的情况,因此我们采用 mAP@0.5 作为检测器的精度评测指标。
- 模型选型:考虑到在 T4 GPU 上的耗时需要小于 20ms,我们需要考虑相对轻量的目标检测模型作为我们的备选模型。考虑到需要在端侧设备上需要达到实时状态,所以,我们尽可能选择已经在端侧验证过的且速度较快的模型。
- 模型部署:将训练得到的动态图模型转换为推理模型,部署在目标设备上,通过推理引擎,即可完成模型的推理预测,从而实现对不良品的筛选。如果本机不方便部署,也可以将该模型部署为在线服务,通过调用服务的方式,完成同样的功能。这里推荐采用部署为服务的方式,这样服务的部署和调用分离,使得后续模型可以独立于业务逻辑进行更新和优化。
三、数据收集/处理
本项目旨在训练一个目标检测模型,在训练模型之前,需要收集带标注的数据集。目标检测数据集有多种形式,常见的有 COCO 格式、VOC 格式、LabelMe 格式。目前零代码产线主推的数据格式为 COCO 格式,用户需要准备好 COCO 格式的数据集。当然,零代码产线也支持 VOC 格式或者 LabelMe 格式转换为 COCO 格式。所以如果只有 VOC 或者 LabelMe 格式的数据,也可以一键完成转换。你可以参考示例数据集和目标检测数据准备文档。
在通用目标检测产线中,如果是 COCO 格式的数据,数据格式需要满足以下要求:
dataset_dir # 数据集根目录,目录名称可以改变
├── annotations # 标注文件的保存目录,目录名称不可改变
│ ├── instance_train.json # 训练集标注文件,文件名称不可改变,采用COCO标注格式
│ └── instance_val.json # 验证集标注文件,文件名称不可改变,采用COCO标注格式
└── images # 图像的保存目录,目录名称不可改变在大模型半监督学习-目标检测产线中,数据格式需要满足以下要求(只是比通用目标检测的数据格式增加了unlabeled.txt文件):
dataset_dir # 数据集根目录,目录名称可以改变
├── annotations # 标注文件的保存目录,目录名称不可改变
│ ├── instance_train.json # 训练集标注文件,文件名称不可改变,采用COCO标注格式
│ ├── instance_val.json # 验证集标注文件,文件名称不可改变,采用COCO标注格式
│ └── unlabeled.txt # 无标注数据,文件名称不可改变,每行给出图像路径,内容举例:images/image_06765.jpg
└── images # 图像的保存目录,目录名称不可改变与目标检测要求的 COCODetDataset 数据集格式相比,需要在 annotations 目录下增加 unlabeled.txt 文件,其内容为所有无标注图像路径,需要按行整理。
如果你有一批未标注数据,我们推荐使用 LabelMe 进行数据标注。对于使用LabelMe标注的数据集,或是 VOC 格式的数据集,产线支持进行数据格式转换。为确保格式转换顺利完成,请严格遵循示例数据集的文件命名和组织方式: VOC 示例数据集,LabelMe 示例数据集。
四、零代码开发
4.1 选择产线
首先,需要选择零代码产线,然后,需要给我们产线命名,方便后续实验的跟踪和记录,如在此处,我们将其命名为 yuanzhubi_det,在零代码产线中,包含若干任务场景,如目标检测、图像分类、OCR 等,此处,我们的任务是目标检测,所以需要选择『目标检测』的任务场景,选择场景之后,点击【确认创建】即可看到目标检测任务中的所有可选产线。
进入第一步选择产线,我们可以看到在目标检测任务下提供通用目标检测产线和大模型半监督学习-目标检测产线两条产线,这两条产线都可以完成目标检测的任务,不同的是,通用目标检测产线训练速度更快,可以快速确定模型的超参数,大模型半监督学习-目标检测产线可以利用更多无标注的数据,产出更高精度的模型。此处,我们为了确定基本的超参数,选择通用目标检测产线,然后点击【下一步】。

4.2 数据准备
4.2.1 选择模型
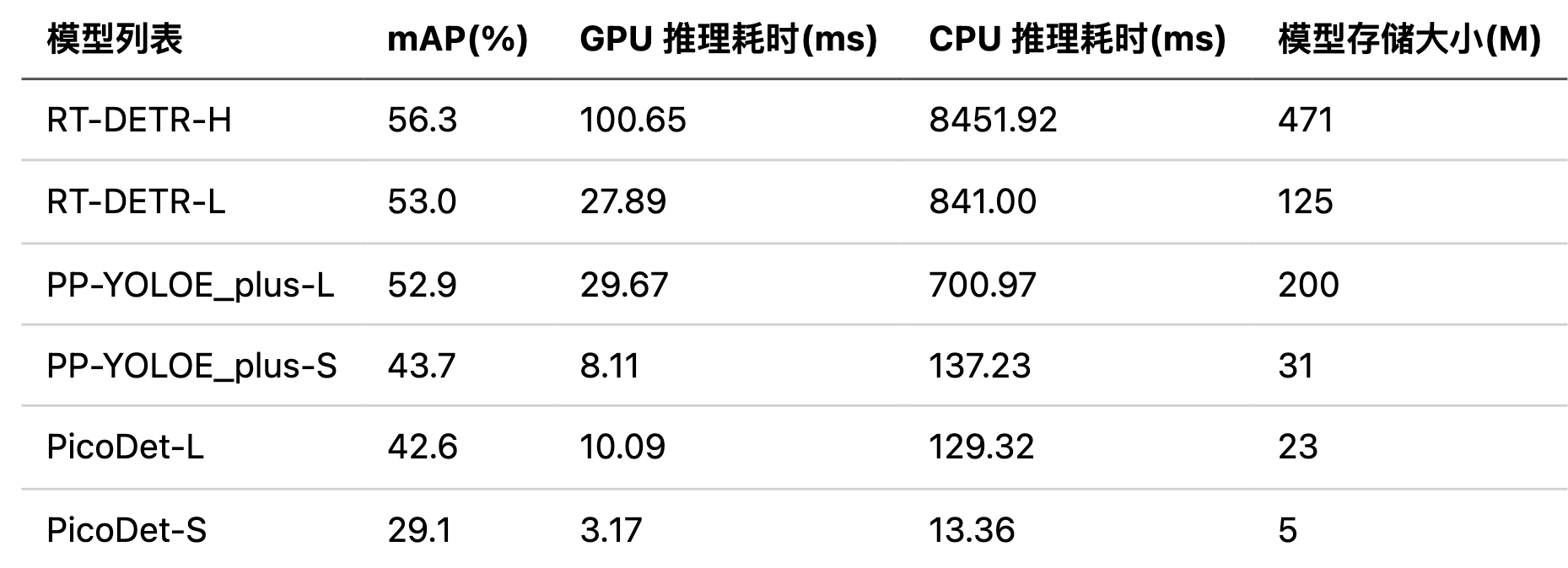
此处提供了 3 档 6 种 SOTA 目标检测模型,分别是高精度模型: RT-DETR-H;精度-效率均衡模型:RT-DETR-L、PP-YOLOE_plus-L;高效率模型: PP-YOLOE_plus-S、PicoDet-L、PicoDet-S,考虑到在该场景的模型部署在 NVIDIA T4 上,单模型推理时间要求是小于 20ms,且在端侧部署可以达到实时状态,所以我们根据提供的模型耗时表选择了高效率模型作为我们的待选模型方案,在高效率的三个模型中,PP-YOLOE_plus-L 和 PicoDet-L 精度速度相差不大,但是考虑到在端侧部署的情况,所以我们选择了模型存储更小的 PicoDet-L 作为我们最终的模型方案。此处提供的 6 个端到端的 SOTA 目标检测算法在 COCO 数据集上的 benchmark 如下:
4.2.2 添加数据集
在确定好产线后,即可添加数据集。在添加数据集时,可以选择导入数据集或者上传数据包,导入数据集支持选择之前通过校验的个人数据集或官方示例数据集,上传数据包支持上传用户自定义数据集,由于我们还并未上传过数据集,所以此处我们选择『上传数据包』后进行数据校验,通过校验后支持以导入的方式选择。
4.2.3 数据校验
在上传数据后,我们即可启动数据校验。为确保后续的训练和评估不会因为数据原因失败,这一步是十分必要的。数据校验有以下四方面的能力,即:
- 检查检查数据格式是否符合要求(必选)
- 返回数据集抽样10个样本的带标签可视化图及其他的一些数据集属性(必选)
- 对数据集做格式换转,如将VOC格式转换为 COCO 格式(按需选择)
- 对数据集的训练集和验证集新的比例进行重新划分(按需选择)
由于我们的数据集为 VOC 格式的数据集,所以需要在数据处理中额外选择『数据格式转换』,选择原始格式为 VOC。
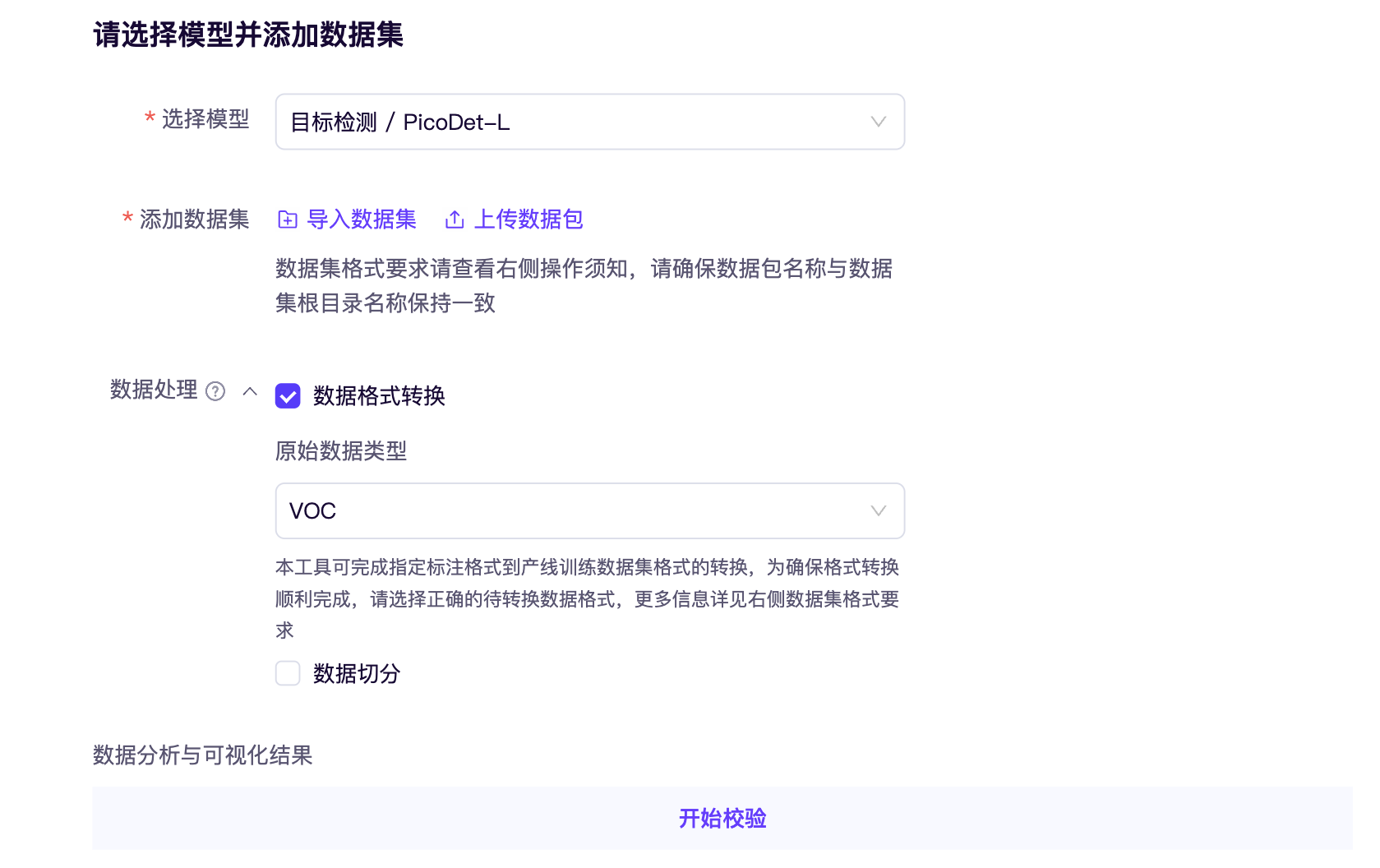
全部选择完毕后,即可进行数据校验,数据校验会同时做格式转换、数据分析和数据可视化。经过数据校验后我们可以得到如下结果,包含了训练集、验证集的部分样本带标签可视化图像,以及数据集的类别分布图。


数据校验的结果:训练集:1974个样本,占比80.02% 验证集:493个样本,占比19.98% 类别数量:8
- 注: 样本的类别分布图可以展示出数据的类别分布是否均衡以及训练集和验证集是否同分布,如果训练集和验证集不是同分布,则最好做一次数据切分,因为数据切分可以将训练集和验证集进行混合再切分,这样可以保证二者是同分布。如果需要数据切分,只需在数据校验时,选中数据切分,并且设置训练集和验证集的占比即可。
4.3 参数准备
正确设置训练参数对于模型训练至关重要,本产线支持两种参数设置方式:修改表单和修改配置文件,常见训练参数推荐使用表单修改,可展开高级设置修改更多参数,对飞桨套件参数较熟悉的用户可以通过表单修改全部训练参数。训练模型的基础配置和高级配置参数如下:
4.3.1 基础配置
- 轮次(Epochs): 模型对训练数据的重复学习次数,一般来说,轮次越大,模型训练时间越长,模型精度越高,但是如果设置特别大,可能会导致模型过拟合。如果对轮次没有特别的要求,可以使用默认值进行训练。
- 批大小(Batch Size): 由于训练数据量一般较大,模型每轮次的训练是分批读取数据的,批大小是每一批数据的数据量,和显存直接相关,批大小越大模型训练的速度越快,显存占用越高。为确保训练不会因为显存溢出而终止,我们将 V100 32G 单卡可以运行的最大值作为批大小的可设置最大值。
- 类别数量(Class Num): 数据集中检测结果的类别数,由于类别数量和数据集直接相关,我们无法填充默认值,请根据数据校验的结果进行填写,类别数量需要准确,否则可能导致训练失败。
- 学习率(Learning Rate): 模型训练过程中梯度调整的步长,通常与批大小成正比例关系,学习率设置过大可能会导致模型训练不收敛,设置过小可能会导致模型收敛速度过慢。在不同的数据集上学习率可能不同,对结果影响较大,需要不断调试。
4.3.2 高级配置
- 断点训练权重: 在 模型训练过程中发生人为或意外终止的情况时,加载训练中断之前保存的断点权重路径,完成继续训练,避免算力资源浪费。
- 预训练权重: 基于已经在大数据集上训练好的模型权重进行微调训练,可提高模型训练开始前的初始经验,提高训练效率。
- 热启动步数(WarmUp Steps): 在训练初始阶段以较小学习率缓慢增加到设置学习率的批次数量,该值的设置可以避免模型在初始阶段以较大学习率迭代模型最终破坏预训练权重,一定程度上提升模型的精度。
- log 打印间隔(Log Interval) / step: 训练日志中打印日志信息的批次数量间隔。
- 评估、保存间隔(Eval Interval) / epoch: 训练过程中对验证集进行评估以及保存权重的轮数间隔。
4.4 模型训练
4.4.1 默认超参数训练
零代码产线提供了默认的超参数,使用默认配置后可以一键发起训练。我们的单卡 batchsize 选用了默认的 16,启用 8 卡的训练,这样我们的 Global batchsize 将是 128,所以此处我们将学习率设置为了 0.01(该值是之前我们训练 PicoDet 等目标检测模型在 batchsize 为 128 时常用的默认学习率,未必最佳,但是是比较好的初始化值),训练轮数设置为 50,点击【提交训练】按钮,一键启动训练。此处我们经过了半个小时的训练,最终的 mAP@0.5 精度为 0.336。
4.4.2 调参训练
众所周知,超参数对模型精度的影响非常大,零代码产线将影响最大的一些超参数在前端展示了出来,方便用户调试。我们的任务是中性笔的瑕疵检测,是一个目标检测的任务,在这类任务上,当选择了合适的模型后,对精度影响最大的超参数是学习率和训练轮数,我们将这两个超参数作为了我们的调试选项。为了让我们的实验尽可能可靠准确,我们进行了超参数的控制变量实验。具体如下:
控制训练轮数为 50,寻找精度最佳时对应的学习率:
| 训练轮数 | 学习率 | mAP@0.5 |
|---|---|---|
| 50 | 0.004 | 0.191 |
| 50 | 0.01 | 0.336 |
| 50 | 0.04 | 0.444 |
| 50 | 0.08 | 0.439 |
| 50 | 0.1 | 0.384 |
从上表可知,精度最佳模型对应的学习率为 0.04,接下来我们在最佳学习率(0.04)的基础上,寻找最佳训练轮数(训练轮数并不是越多越好):
| 学习率 | 训练轮数 | mAP@0.5 |
|---|---|---|
| 0.04 | 50 | 0.444 |
| 0.04 | 80 | 0.502 |
| 0.04 | 100 | 0.561 |
从上表可知,在训练轮数为 100 时,精度达到了最佳(为了节省训练时间,此处只设置到了 100,轮数大于 100 后,精度有可能更高)。截止到现在,我们就的得到了一个 mAP@0.5 为 0.561 的中性笔的瑕疵检测模型。
注:
- 上述最佳学习率和最佳训练轮数是一个相对的值,为了节省时间,我们没有对这些值做更细致的划分,如果做更细致的划分,我们也许可以得到精度更高的模型;
- 超参数的调试一直都比较繁琐,不同的值相互影响。但是先获得最佳学习率再基于最佳学习率获得最佳的轮数这种方案是可以比较快速地接近全局最优的值,非常推荐大家使用类似的方法确定超参数。
4.5 模型评估/模型标记
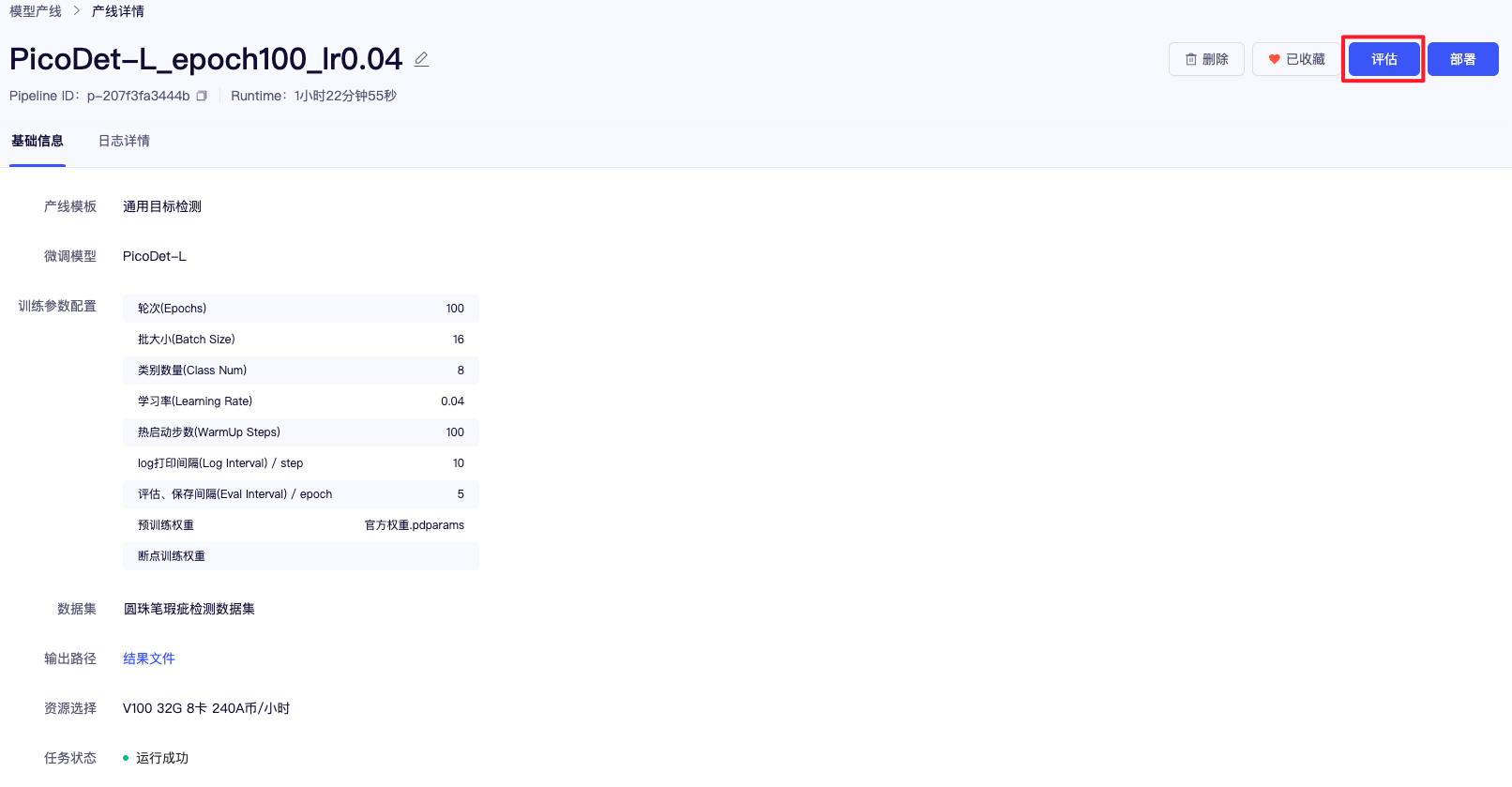
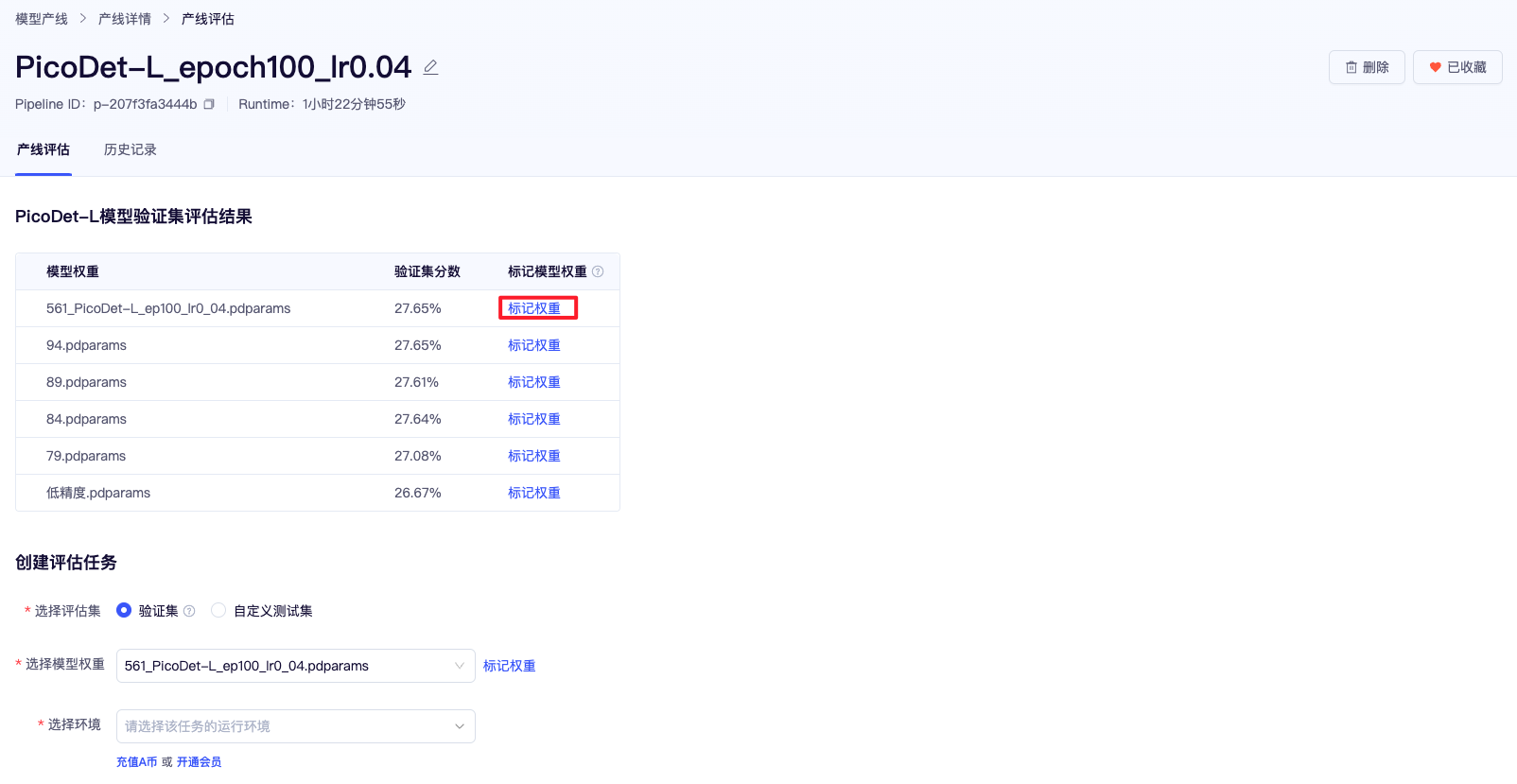
在我们训练完成后,可以点击右上角的【评估】按钮,对模型进行评估。这里可以使用验证集评估,也可以上传自定义的测试集进行评估。在这个页面中,最近训练的 5 个模型权重以及最佳的模型权重以及其对应的精度会被展现出来,在这里,我们可以将后续用于部署的模型权重进行标记,标记后,即可在部署的模型下拉选框中找到(模型标记除了用于部署外,还用于保存有价值的模型,同时支持跨产线载入预训练权重和断点训练权重)。
4.6 模型部署
4.6.1 在线服务化部署
部署零代码产线为在线服务后,可以快速体验模型的单图测试效果, 或本地调用 API。在部署界面选择『在线服务化部署』选项卡,填写服务名称,选择要部署的模型以及在评估阶段标记的权重,最后选择部署环境并提交即可完成一次服务化部署。部署服务启动后,支持在其他联网设备以 API 的形式调用该部署服务,可以参考服务详情页提供的调用示例。

部署服务启动后,同时支持用户在对应应用中切换模型方案,找到自己部署的服务,进行数据的测试体验。

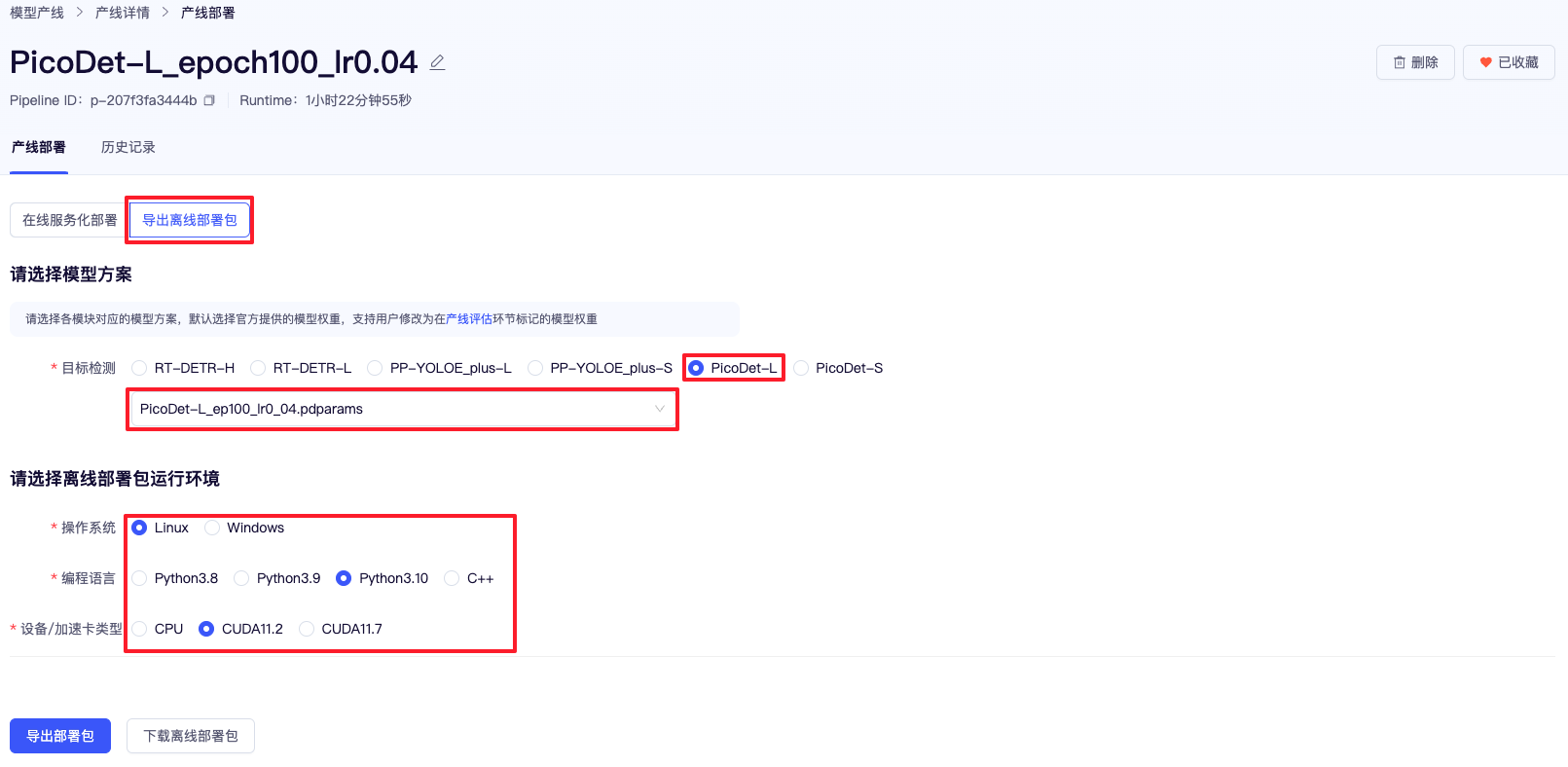
4.6.2 导出离线部署包
如需将模型部署到自己的设备上,可通过导出离线部署包的方式获取,在部署界面选择『导出离线部署包』选项卡,选择要部署的模型已经标记过的权重,最后根据离线部署环境选择对应的选项并点击导出部署包即可获取离线部署包。离线部署包中除了包括标记权重外,还包含了指定环境的示例代码,根据其中的示例文档即可在自己的设备上实现快速部署。
4.7 效果进一步优化
4.7.1 方案选择
当前我们的模型的 mAP@0.5 为 0.561,一定程度解决了我们的问题,但是一些比较难的 case(如目标较小或特征不明显)依旧解决地不是很好。为了能让我们的模型的精度更高,我们采用了零代码产线提供的大模型半监督-目标检测产线。该产线可以利用大量无标注的数据学习更强的特征,同时产出高精度的大模型和精度较之前方案进一步提升的小模型。只需一键启动,即可完成模型的训练。为此,我们可以使用额外的 3000 张没有标注过的训练数据,我们将这些数据和之前的有标注数据按照该产线要求的格式重新组织后并进行训练。
4.7.2 模型训练
- 模式选择: 在大模型半监督学习-目标检测产线里,我们有三种训练模式可以选择,即只训练大模型、只训练小模型、同时训练大模型和小模型,由于我们目前还没有训练出带无标注数据的大模型,所以我们选择了同时训练大模型和小模型的模式,在这个模式里,我们选择的大模型是高精度的
RT-DETR-H,小模型我们依旧选择的是先前迭代的PicoDet-L。 - 超参数选择: 在先前训练单模型
PicoDet-L时,我们已经找到了较佳的学习率和训练轮数,所以我们此时训练PicoDet-L的超参数直接复用了这些值,大模型的超参数除了训练轮数改为了 100 后,其他值我们使用了默认值。 - 模型产出: 经过了 15 个小时的训练,我们完成了大模型半监督学习-目标检测的训练,最终,大模型(
RT-DETR-H)的 mAP@0.5 为 81.2%,小模型(PicoDet-L)的精度为 74.5%,小模型较之前提升 13 个百分点。 - 模型部署: 我们采用了和通用目标检测产线相同的在线服务部署,并且对通用目标检测没有处理好的 case 做了对比,发现之前很多高难度 case 都得到了很好的解决,部分 case 的对比如下:

五、总结与展望
不写一行代码就可以完成模型的全流程迭代和部署,而且这个过程竟然如此丝滑,完全超出了我们预期,更惊喜的是,竟然有大模型半监督学习这种神器,企业只需少量无标注的数据,精度竟然会有十几个点的提升,这相当于是直接省掉了我们很多提升模型精度的过程中各种繁杂的工作。未来将进一步在内部其他场景中使用和验证。
立即体验 - 飞桨星河零代码工具:https://aistudio.baidu.com/pipeline/mine