

特色模型产线使用说明
1.通用文本图像智能分析产线
1.1.简介
PP-ChatOCRv2是一个融合了LLM大模型和OCR技术的通用文本图像智能分析产线,覆盖20+高频应用场景,支持5种文本图像智能分析能力和部署。具有以下强大能力:
- 场景丰富:支持5种智能文本图像分析能力,覆盖20+高频应用场景,尤其针对复杂文档场景进行了专项优化。
- 精准度高:「PP-OCR」与「文心一言」强强结合,支持1.5万+大字库,解决生僻字、多页PDF、表格等难题,无需训练即可在20+场景关键信息抽取平均准确率80%以上。
- 一键部署:一键获取PP-ChatOCRv2离线部署SDK,助力企业快速实现工程落地。
- 便捷开发:针对垂类业务场景,通过简单点击UI界面按钮,可完成Prompt优化、模型训练和微调。
「注意本产线目前需要联网调用大模型API」
1.2.使用说明
1.2.1.效果体验
任务说明
「效果体验」整体界面如下图
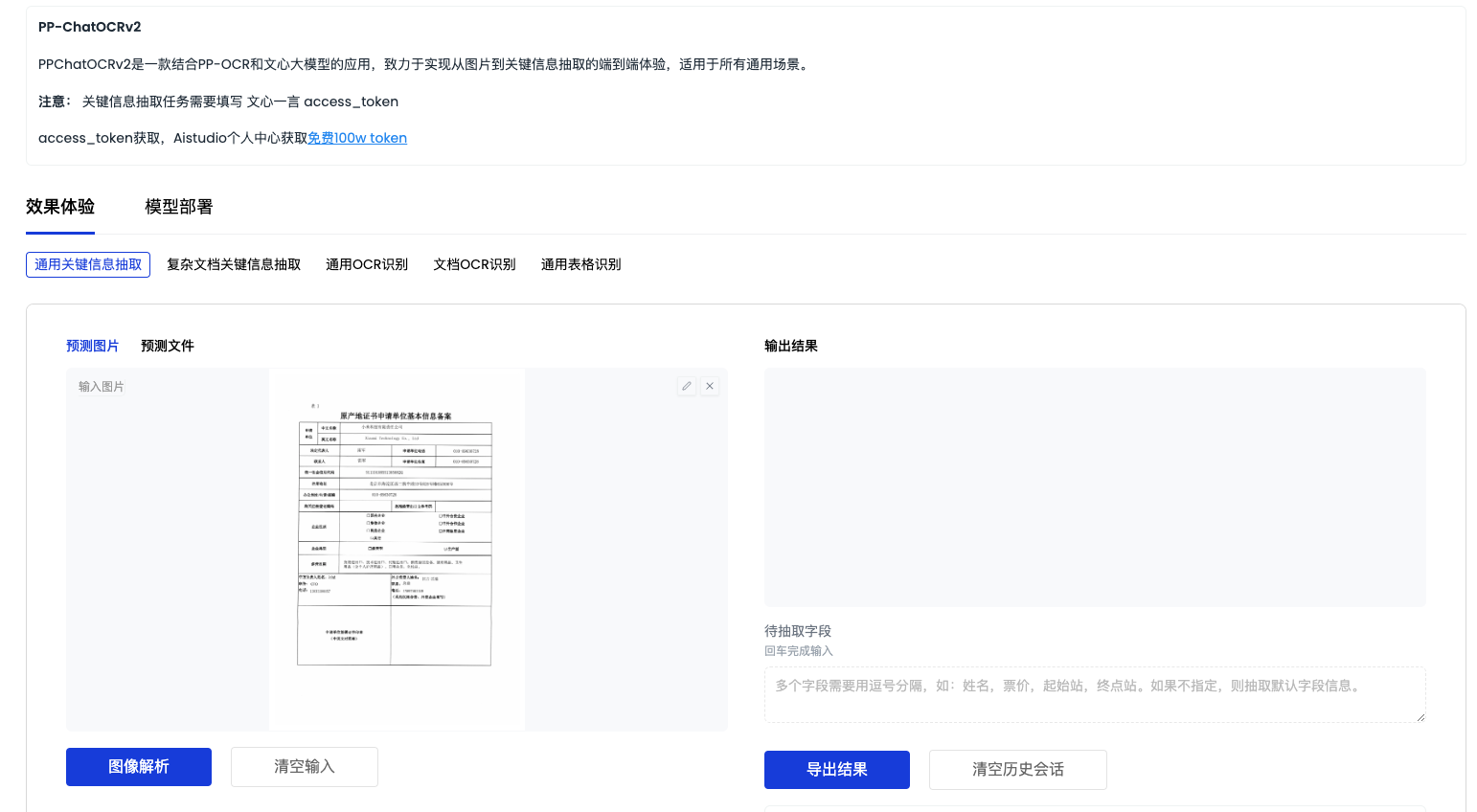
支持 5种 智能文本图像分析能力
| 功能点 | 效果展示 | 高精度模型 | 高效率模型 | 功能描述 |
|---|---|---|---|---|
| 通用场景关键信息抽取 |  |
✅ | ✅ | 支持通用文本图像场景关键信息抽取,针对20+高频场景进行专项Prompt优化 可选高精度/高效率两种配置 |
| 复杂文档场景关键信息抽取 |  |
✅ | ❌ | 支持复杂文档场景的关键信息抽取,支持1.5万+大字库,专项优化生僻字、多页pdf、表格等难题 |
| 通用OCR |  |
✅ | ✅ | 支持通用本图像OCR识别,支持常见的汉字识别 可选高精度/高效率两种配置 |
| 文档场景专用OCR |  |
✅ | ❌ | 文档场景专用OCR识别,支持1.5万+大字库,专项优化生僻字、标点符号识别等 |
| 通用表格识别 | 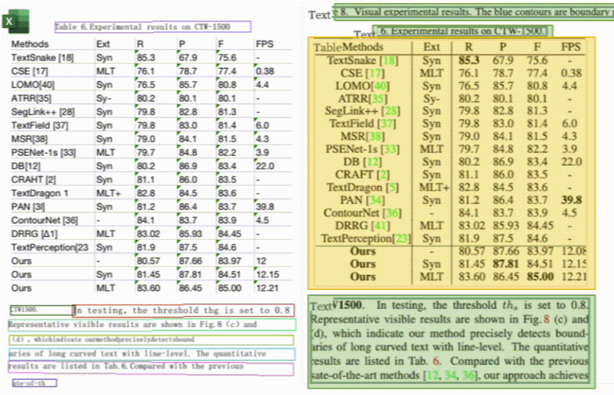 |
✅ | ❌ | 支持通用图像中表格识别,提取图像中的表格结构并转成excel |
其中关键信息抽取任务将 PP-OCR/PP-Structure 与 文心一言 强强结合,同时解决通用场景和复杂文档场景的信息抽取
- 通用场景关键信息抽取: 调用高精度OCR模型(PP-OCRv4-server)预测输入图像/文件的文本结果,利用文心一言抽取给定关键词的信息,结果将以
key-value形式返回至前端界面 - 复杂文档关键信息抽取: 调用文档专用OCR模型与版面分析模型预测输入图像/文件的文本结果和表格结构,利用文心一言抽取给定关键词的信息,结果将以
key-value形式返回至前端界面
信息抽取任务内置了20个高频场景Prompt,平均预测精度达到82%
- 通用OCR识别: 调用高精度OCR模型(PP-OCRv4-server)模型对输入图像/文件进行检测与识别,识别可视化结果将返回至前端界面
- 文档OCR识别: 调用文档专用OCR模型对输入图像/文件进行检测与识别,识别可视化结果将返回至前端界面
- 通用表格OCR识别: 调用高精度OCR模型(PP-OCRv4-server)、版面分析模型和表格识别模型,对上传表格文件进行页面分析与内容检测识别后,将预测结果转换成Excel表格返回至前端界面,用户可击即可下载Excel文件
预测流程
-
a.任务选择
-
通用关键信息抽取 & 复杂文档关键信息抽取
信息抽取任务必须填写「大模型相关配置」,完成后可点击三角符号收起,如下图所示:

-
输入文心一言的access_token(必填):
此处须指定文心一言access_token来源,并在下方输入正确的access_token后续才能正常调用文心一言(ERNIE-BOT)完成信息抽取任务。
若暂无文心一言access_token,可前往AI Studio个人中心获取免费100w token , 或通过API Key生成 。(在PaddleX Linux本地端中,目前需配置千帆接口)
✅ 完成以上内容填写后点击 图像解析 按钮,等待右上角弹出解析完毕的提示,即可在右侧对话框中输入待抽取的字段信息,回车提交。
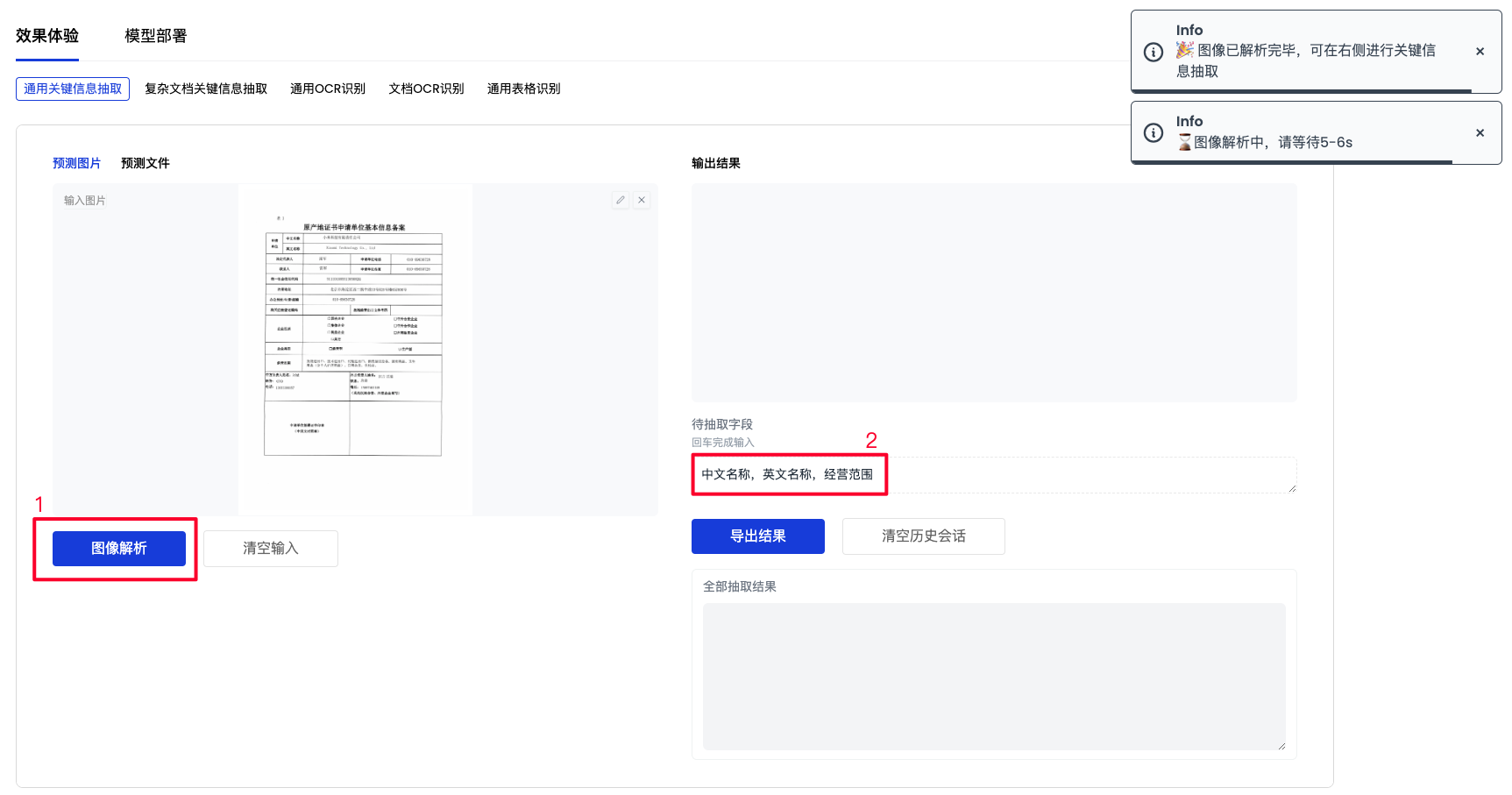
-
-
OCR识别任务/通用表格识别任务
直接指定任务类型点击 图像解析 按钮即可开始文档识别
-
-
b.文件上传
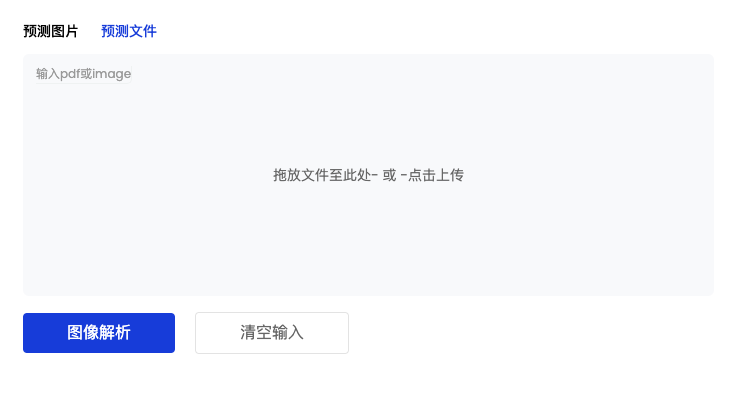
「样例图片 & 文件上传」界面如下图
- 「预测图片Tab」,可选择下方现有图片样例,或上传本地图片用于各类任务测试

-
「预测文件Tab」,可选择本地图片或PDF文件进行上传,上传成功后即可用于后续各类任务测试
-
c.输出结果
-
通用关键信息抽取 & 复杂文档关键信息抽取
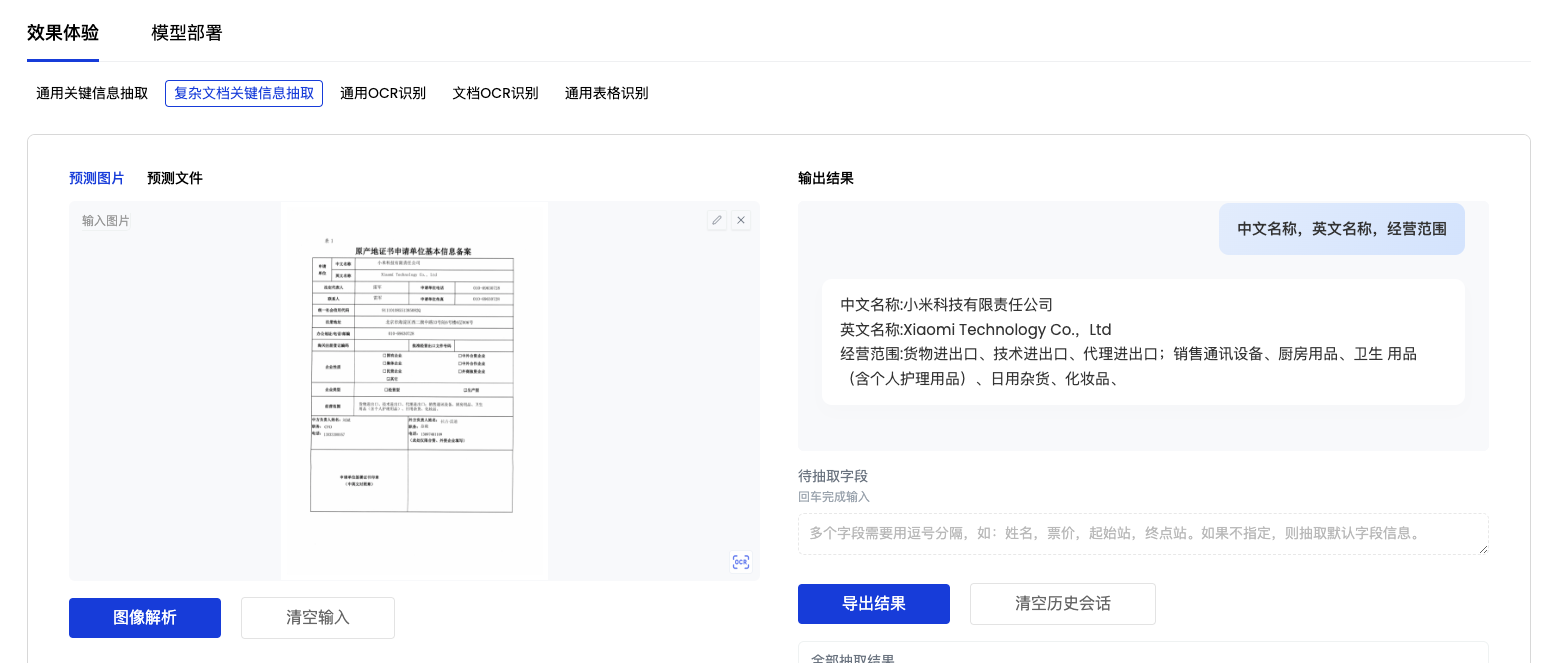
「信息抽取任务结果」界面示例如下图
输入框需输入待抽取的字段信息,关键词间以逗号
,分隔,若不指定该字段信息且文件类型属于内置的20+个高频场景,将抽取默认字段信息。输入示例如下:
中文名称,英文名称,经营范围
-
通用OCR识别 & 文档OCR识别
「通用 & 文档OCR识别任务结果」界面示例如下图

-
通用表格识别
「表格OCR识别任务结果」界面示例如下图
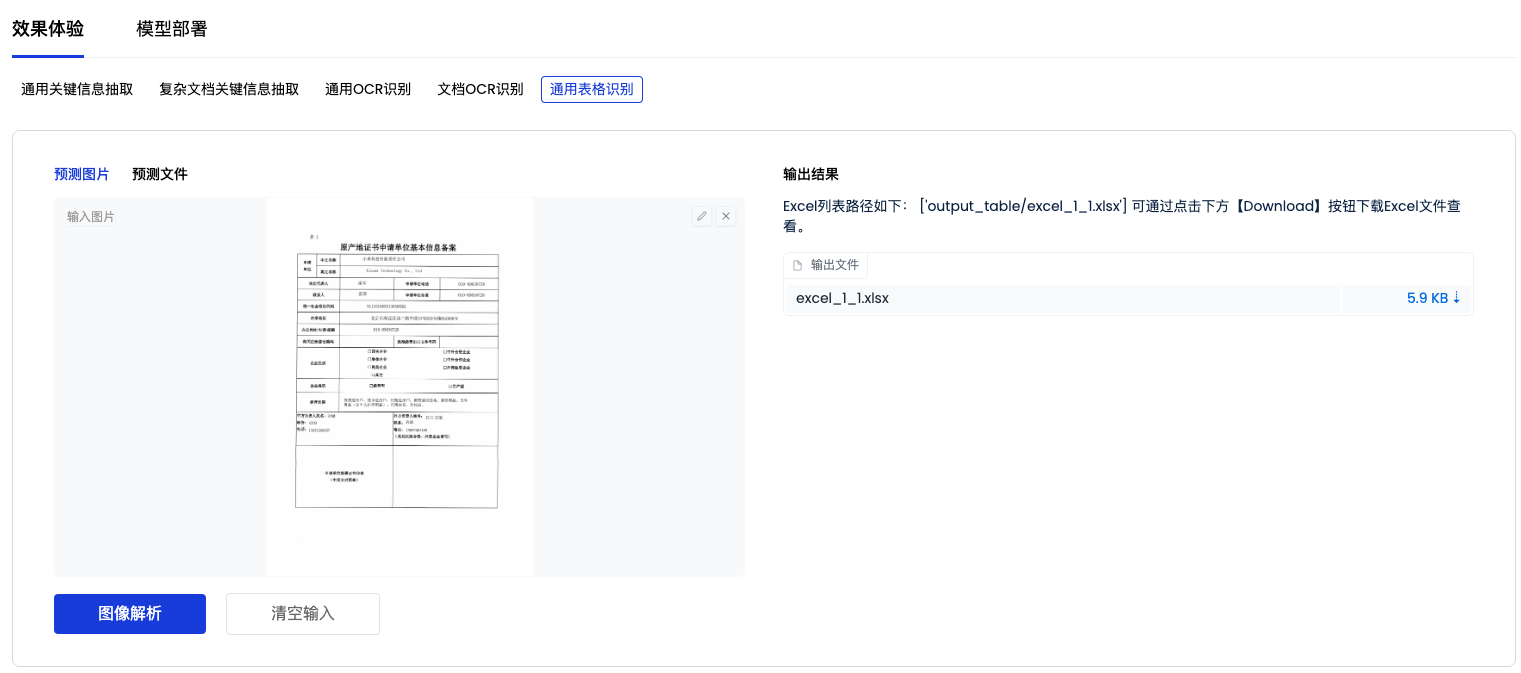
点击下载按钮可查看生成的Excel文件。
-
1.2.2.模型部署
「模型部署」界面如下图
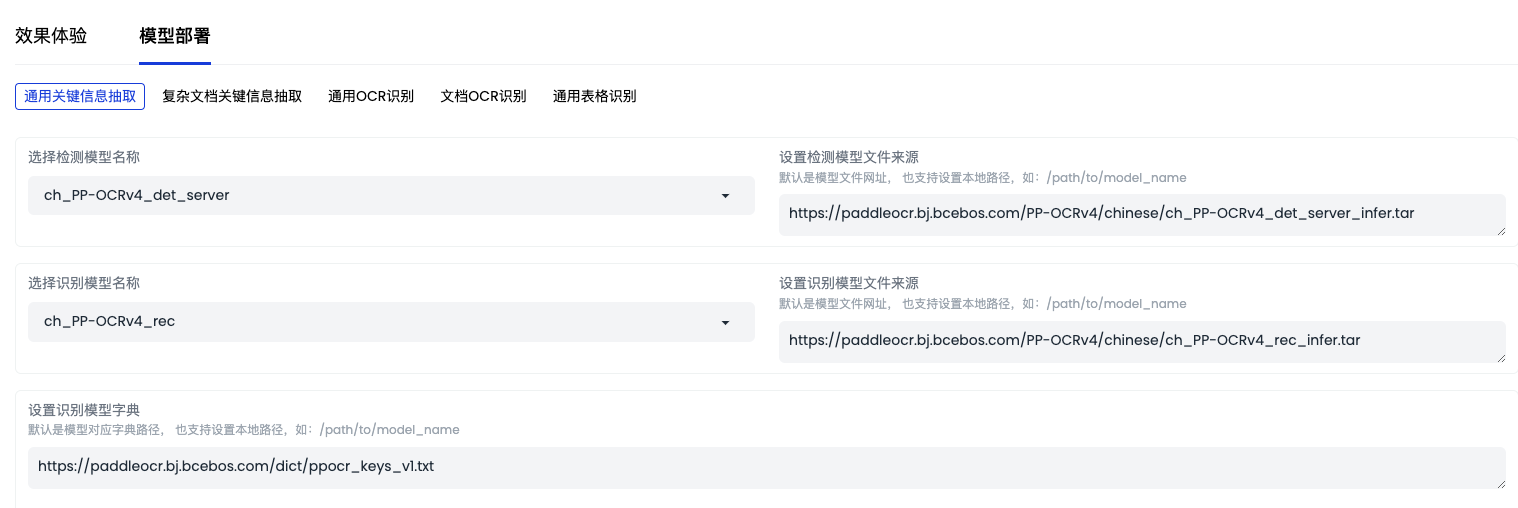
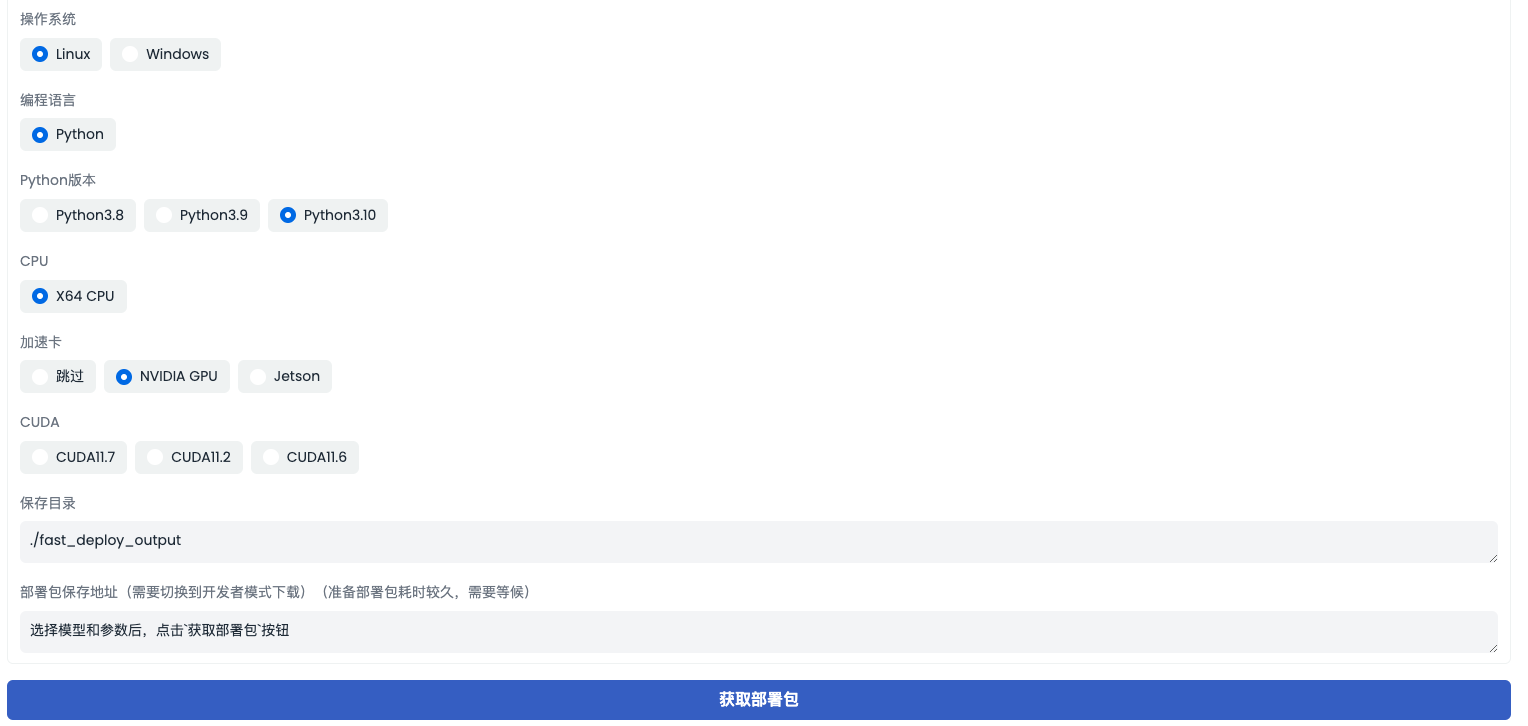
根据实际业务需求选择所需要的操作系统、部署硬件、接口语言等条件后,获取 FastDeploy 部署包,完成之后到开发者模式下进行下载(文件右击选择下载即可),其中包括部署代码和预测模型。最后就可以参考部署包里面的 README 使用说明,在目标硬件上进行部署了。如果需要手动更新预测模型,可以直接修改部署包中的预测模型。
PP-ChatOCRv2目前的部署支持的情况如下:
- 操作系统:Linux
- 支持硬件:NVIDIA GPU、 X86 CPU
| License 类型 | 产品描述 |
|---|---|
| 单节点SDK部署- 绑定机器码 |
PP-ChatOCRv2 通用文本图像智能分析产线X86_CPU/GPU部署SDK a.支持通用文本图像场景关键信息抽取 提供20+高频场景Prompt模版,可选高精度/高效率两种配置。 b.支持复杂文档场景的关键信息抽取 支持1.5万+大字库,解决生僻字、多页pdf、表格等难题。 c.支持通用文本图像OCR识别 支持常见的汉字识别,可选高精度/高效率两种配置。 d.文档场景专用OCR识别 支持文档场景的文字识别,含1.5万+大字库,解决生僻字、标点符号识别等难题。 e.支持通用图像中表格识别 提取图像中的表格结构并转成excel。 f.支持SDK里面的模型更新(非大模型)和Prompt优化 模型必须通过 PaddleX 云端或本地端软件对应的模型产线得到。 |
备注: 1.含1年ALC维护(享受百度飞桨提供的软件安装、使用层面的技术服务支持,以及免费的升级/移机服务1次) 2.Ernie-Bot的Token需自行购买
注意: 本产线是飞桨低代码开发工具 PaddleX 特色产线,在线预测流程不做任何限制,但使用部署包在具体设备中部署模型时,需要付费进行激活部署。
欢迎填写表单与官方人员取得联系,批量采购可享受折扣价格。
2.大模型半监督学习产线
2.1.简介
大模型半监督学习产线 是 PaddleX 推出的一个特色模型训练产线,其特点是用户可以借助少量有标注数据和大量无标注数据大大提升模型的精度,从而大幅度减少人工迭代模型和标注数据的成本。该产线的输入是用户的有标注数据和无标注数据,输出是训练好的精度高的大模型和小模型。用户可以根据自己的真实环境选择其中的大模型或者小模型进行部署。目前覆盖了图像分类、目标检测、OCR识别三类AI任务。对应的产线分别是大模型半监督学习产线-DET、大模型半监督学习产线-CLS、大模型半监督学习产线-OCR。
2.2.特性

2.3.使用
下面以「大模型半监督学习产线-DET」为例,介绍本产线的使用方法。
数据准备
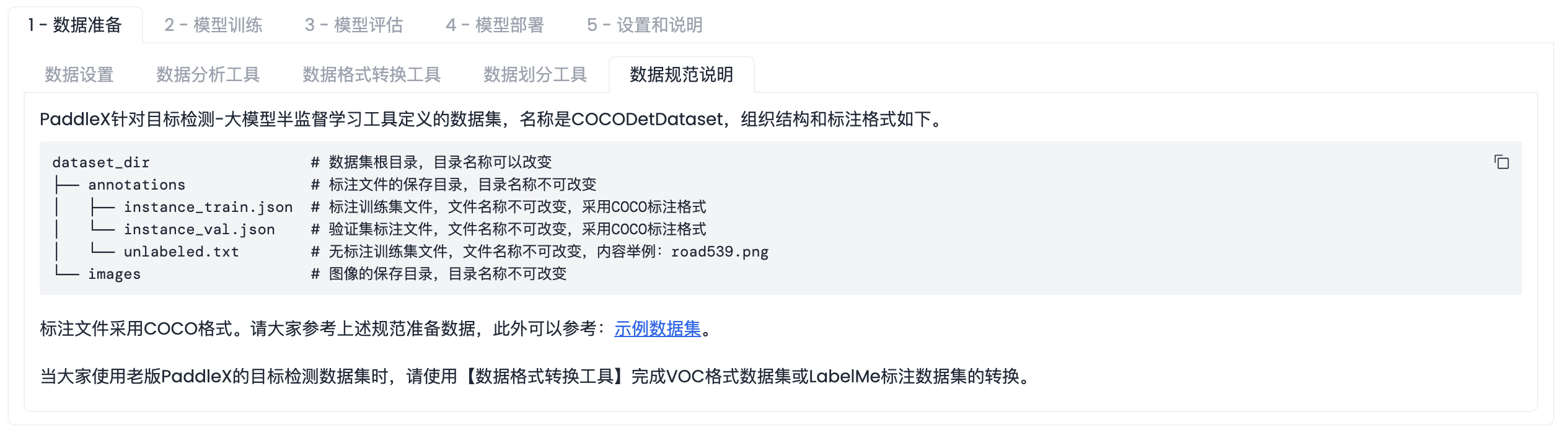
在完成数据标注工作后,请按照【工具箱模式】中给出的数据集规范说明检查数据组织格式是否满足要求。如果不满足,请参照规范说明进行调整,否则将导致数据校验无法通过,影响后续的模型训练。
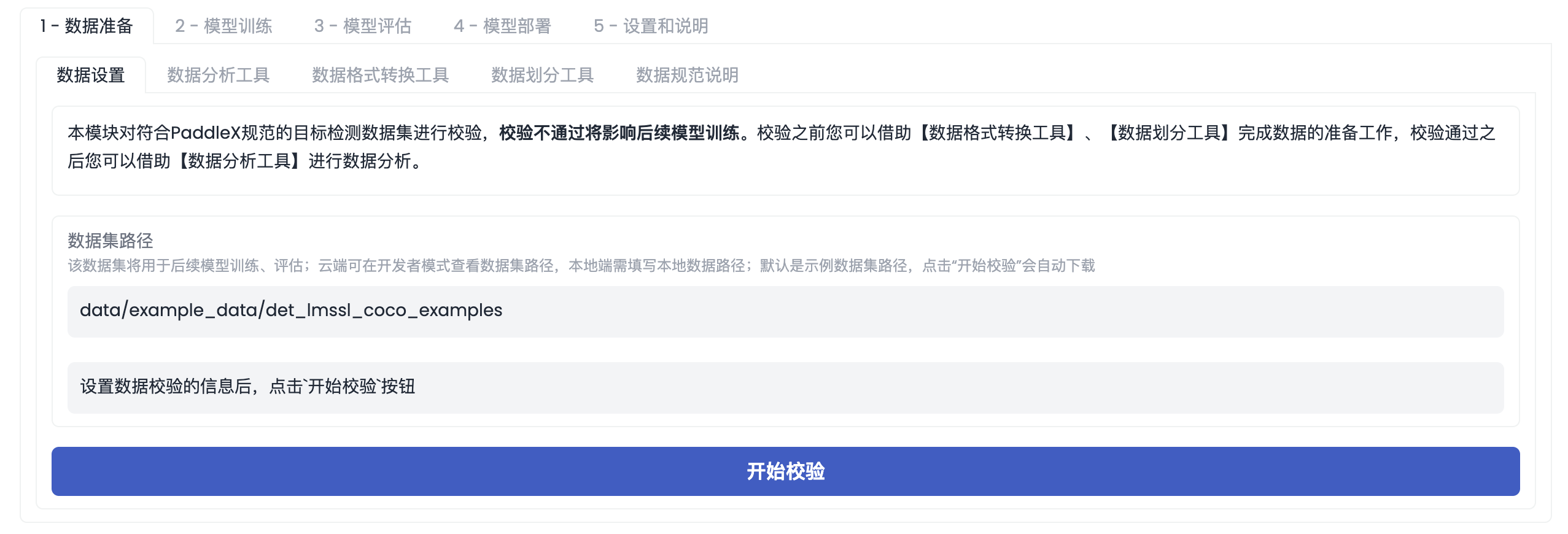
「数据设置」界面如下图
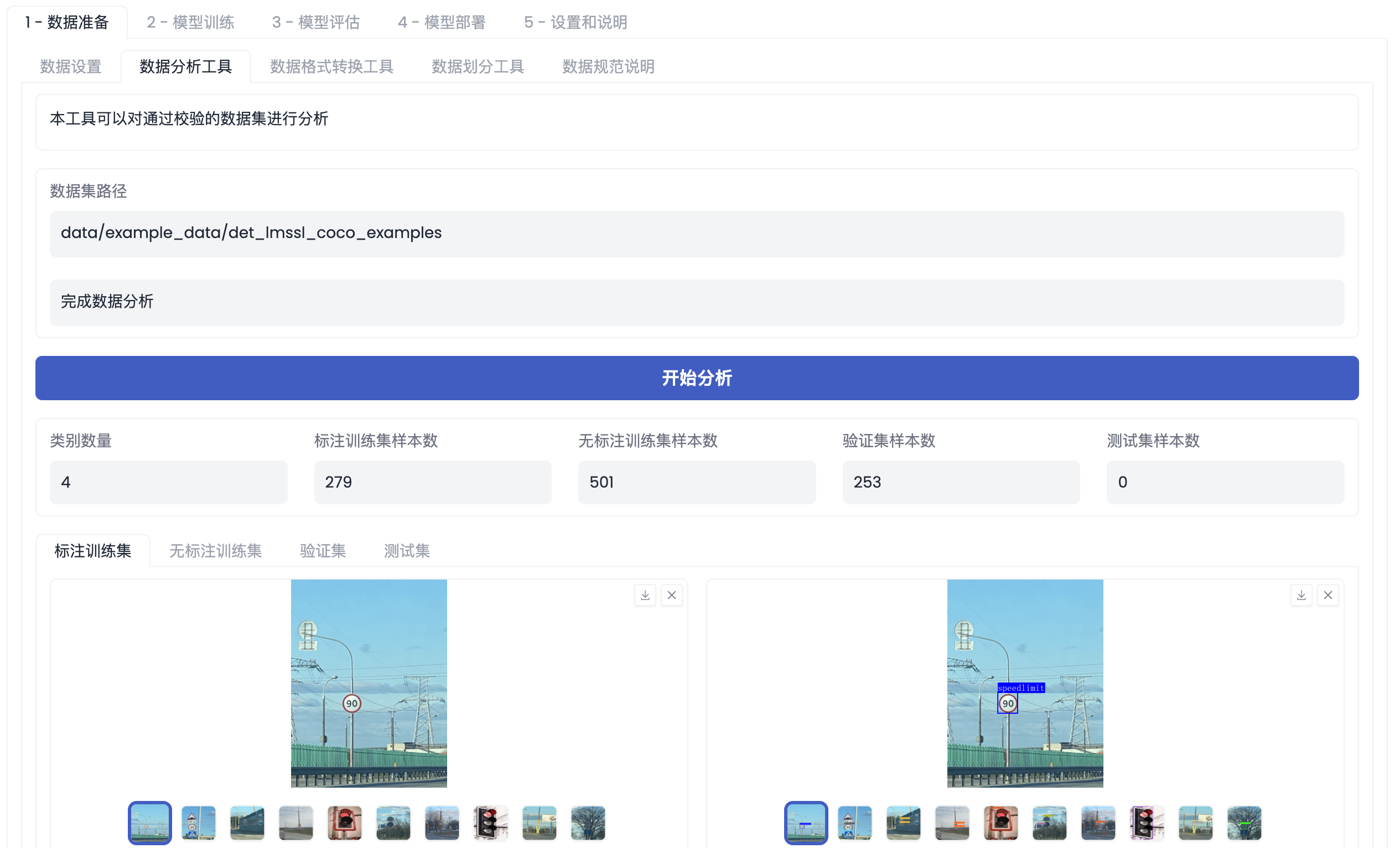
「数据分析工具」界面如下图
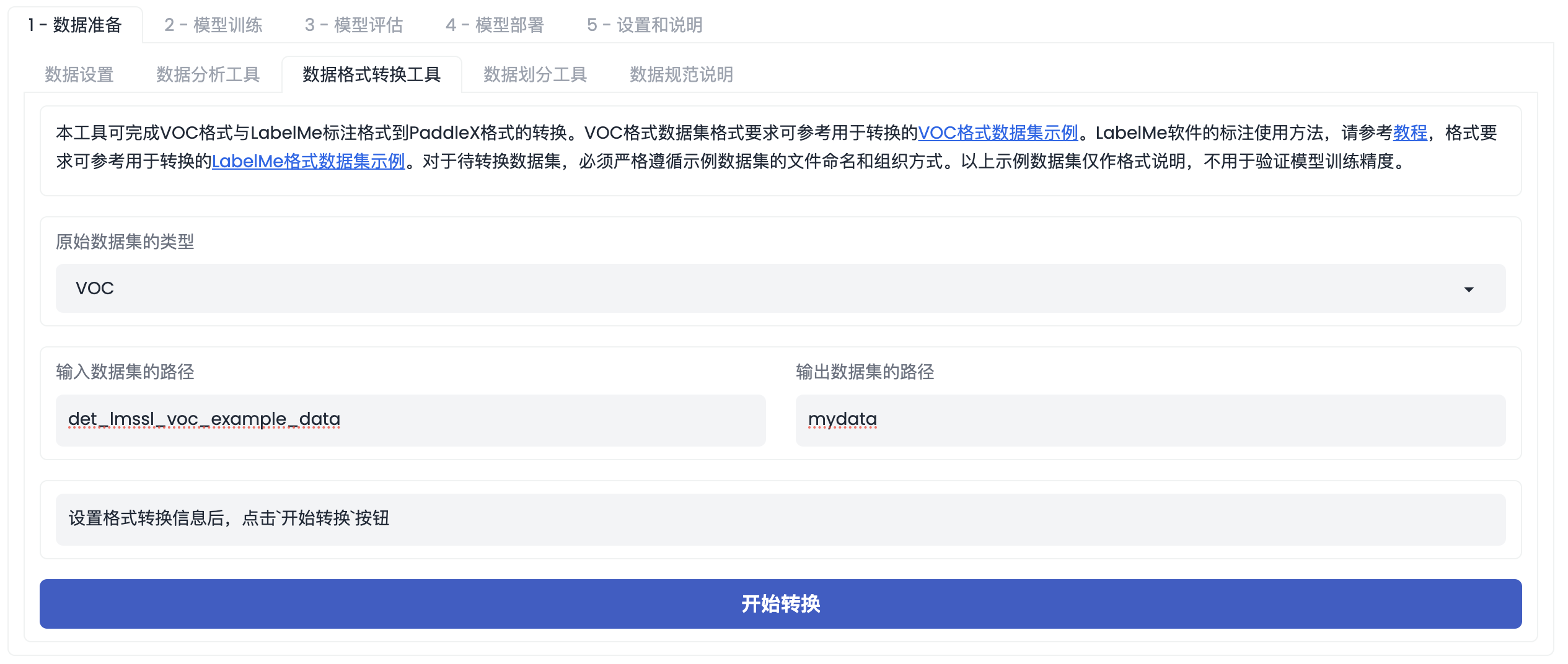
「数据格式转换工具」界面如下图
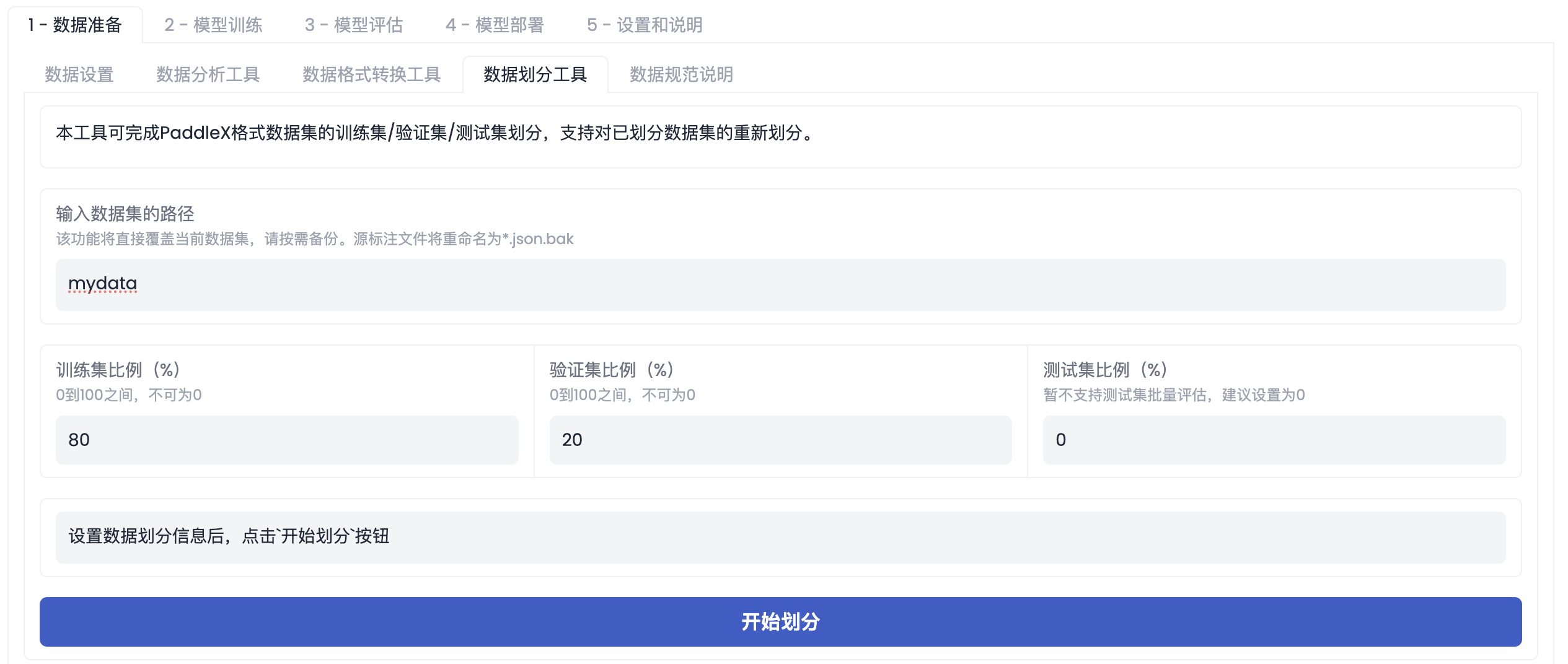
「数据划分工具」界面如下图
「数据规范说明」界面如下图
模型训练
大模型训练
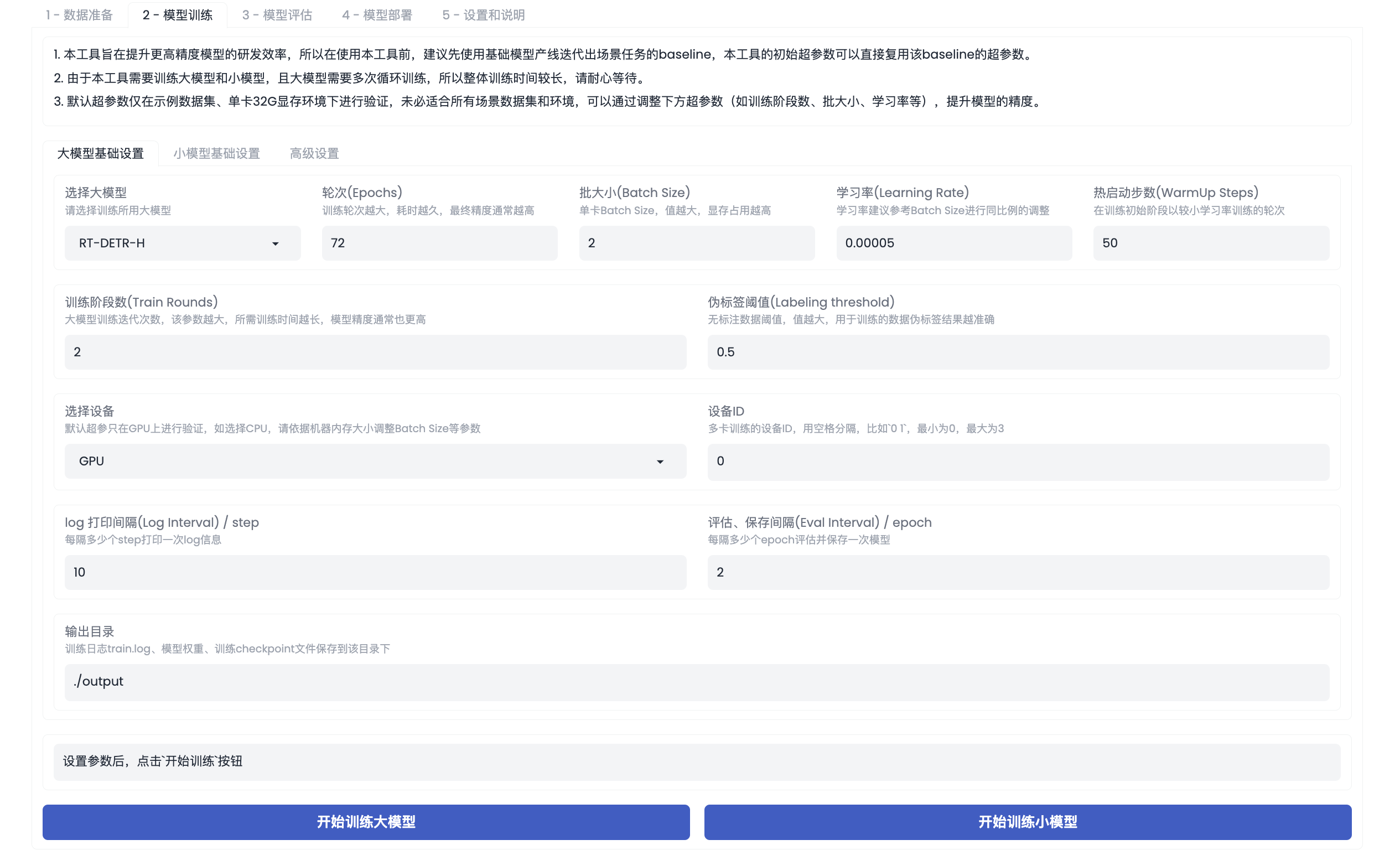
- 启动训练:在该产线中,必须执行大模型的训练。点击【开始训练大模型】后,即可启动大模型的训练。大模型的训练是一个循环训练的过程,耗时较长,当大模型训练结束后,屏幕提示【训练完成】,并展示循环训练的每个阶段的精度情况。
-
超参数介绍:
- 选择大模型:可以选择不同的大模型训练,目前该产线提供了
RT-DETR-H大模型。 - 训练阶段数(Train Rounds):取值范围为 1~4,大模型训练的循环轮数,该值代表了大模型循环训练的次数,最少为 1,该值越大,训练时间越久,效果可能也越好,默认为 2。
- 选择大模型:可以选择不同的大模型训练,目前该产线提供了
小模型训练
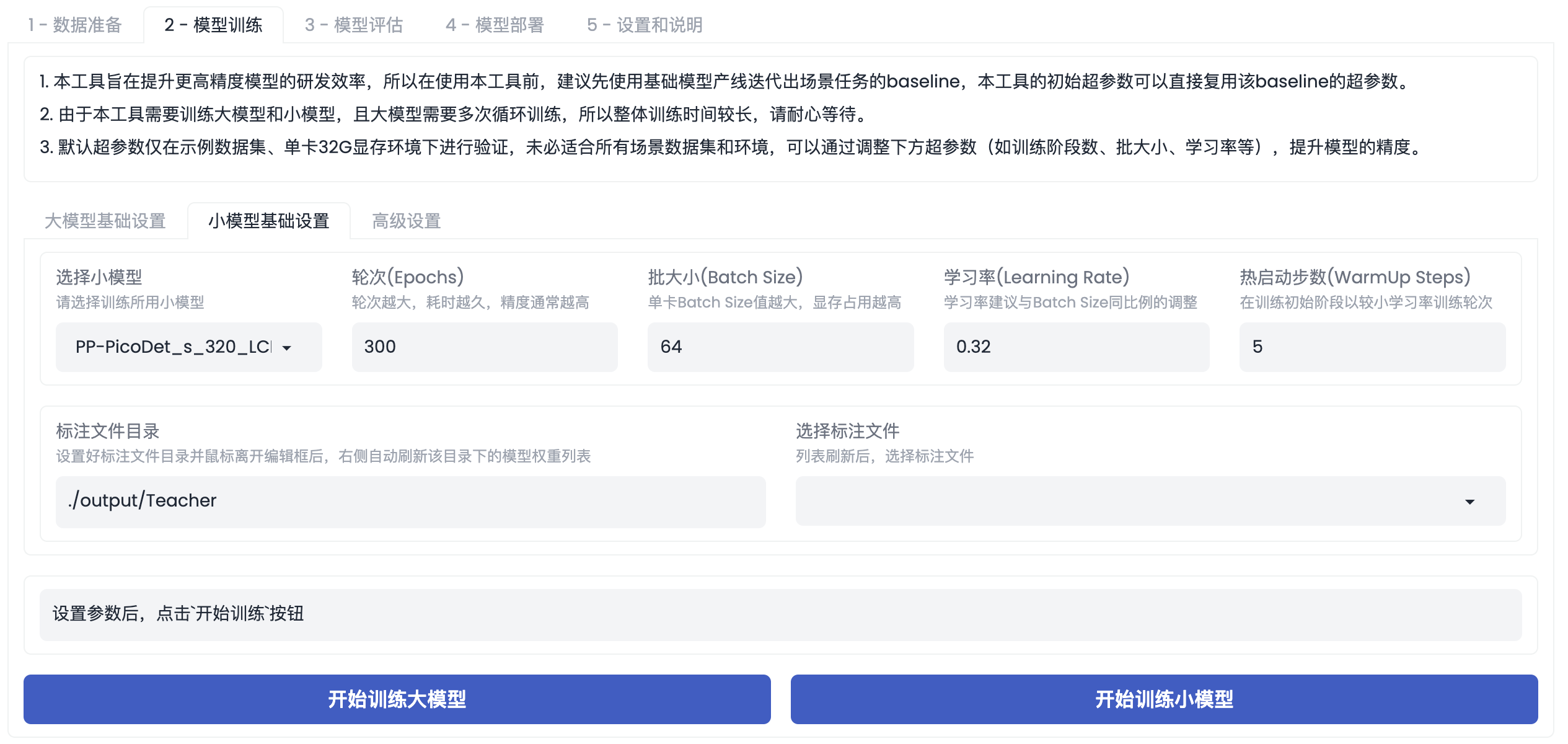
- 启动训练:在该产线中,小模型训练是可选的步骤。点击【开始训练小模型】后,即可启动小模型的训练。当小模型训练结束后,屏幕提示【训练完成】,并展示小模型的精度情况。
-
超参数介绍:
- 选择小模型:可以选择不同的小模型训练,目前该产线提供了 4 个模型可供选择,分别是
PP-PicoDet_s_320_LCNet、PP-PicoDet_l_640_LCNet、PP-YOLOE+_crn_s_80e、PP-YOLOE+_crn_l_80e。 - 标注文件目录/选择标注文件:大模型为无标注数据生成的伪标签。一般无需改变,默认为训练得到的最佳大模型生成的伪标签。
- 选择小模型:可以选择不同的小模型训练,目前该产线提供了 4 个模型可供选择,分别是
注: 由于使用本工具训练模型涉及多次循环训练,所以完成大模型/小模型训练后,会产生多条「模型训练」运行记录,这属于正常现象。
高级设置
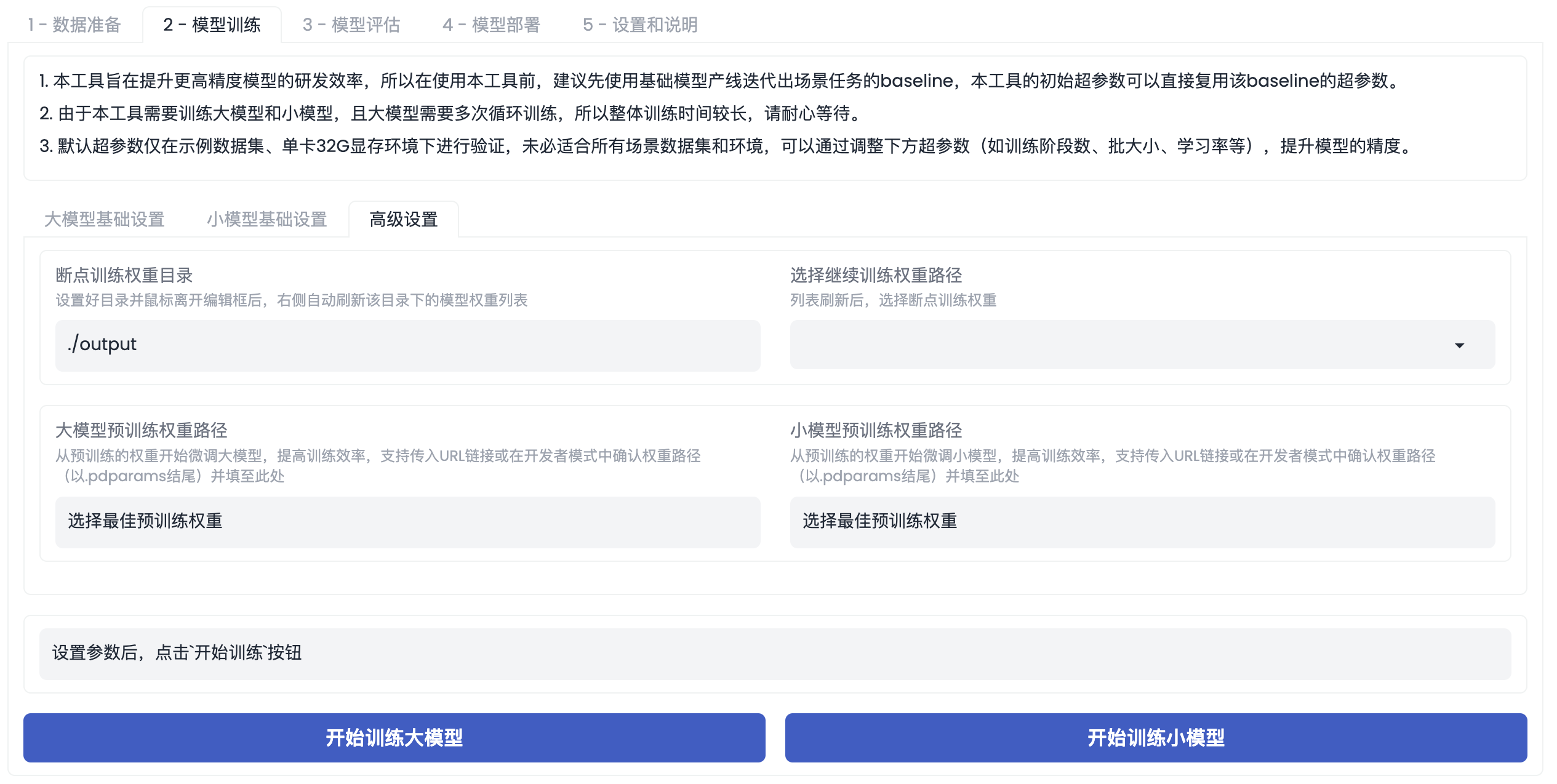
该产线同时提供了【高级设置】,在【高级设置】里,用户可以根据需要,配置相关超参数,具体超参数如下:
-
断点训练:
- 断点训练权重目录:默认为
./output。 - 选择断点训练权重路径:点击【断点训练权重目录】后,可以在右侧点击【选择断点训练权重路径】,这里提供了整个训练过程中大模型和小模型的权重路径,用户可以根据选择需求选择相应的断点位置。如当用户选择了
Teacher/round2_pt/10.pdparams,点击【开始训练大模型】后,程序会自动定位当前所处的循环训练位置,并加载round2_pt/10中所保存的参数,进行当前的端点训练,round2_pt训练结束后,会自动进行round2_ft和之后阶段的训练。
- 断点训练权重目录:默认为
-
预训练模型:
- 大模型预训练权重路径:默认为 PaddleX 提供的大模型最佳预训练权重,用户可以根据需求选择选择加载自己准备的大模型的预训练权重。
- 小模型预训练权重路径:默认为 PaddleX 提供的小模型最佳预训练权重,用户可以根据需求选择选择加载自己准备的小模型的预训练权重。
注: 在选择断点训练时,需要选择合适的断点权重。其中,round 代表循环训练数,每一个 round 中顺序执行 pt 和 ft 的过程,每一个 pt 和 ft 包含若干个 epoch。
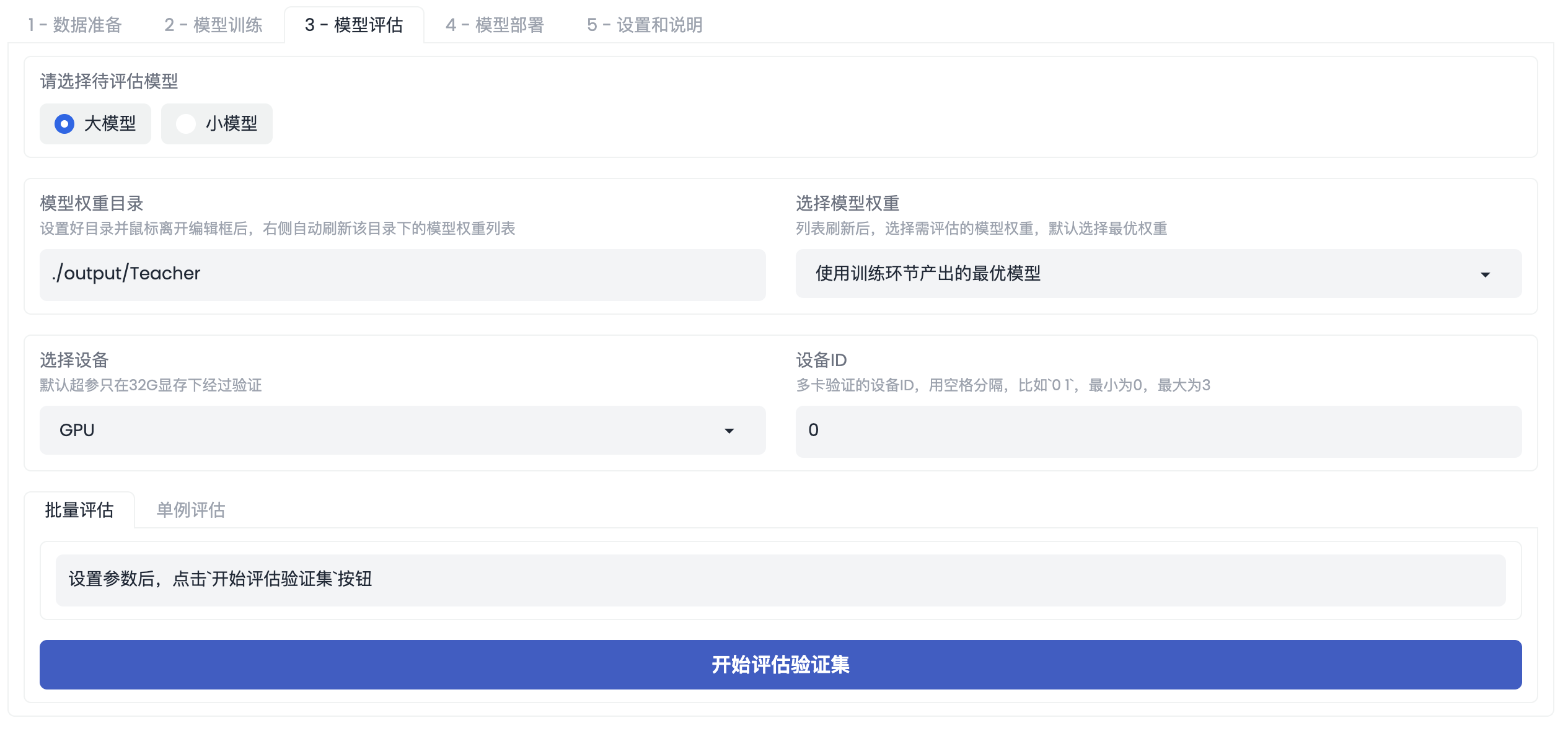
模型评估
在工具箱模式中,可以直接评估训练得到的大模型和小模型的精度,这里支持对评估集的批量评估、对单张图片的测试。用户选择其中的大模型或者小模型,点击【开始评估验证集】即可完成对验证集的评估,上传图片,点击【提交】,即可完成对单张图片的预测。
模型部署
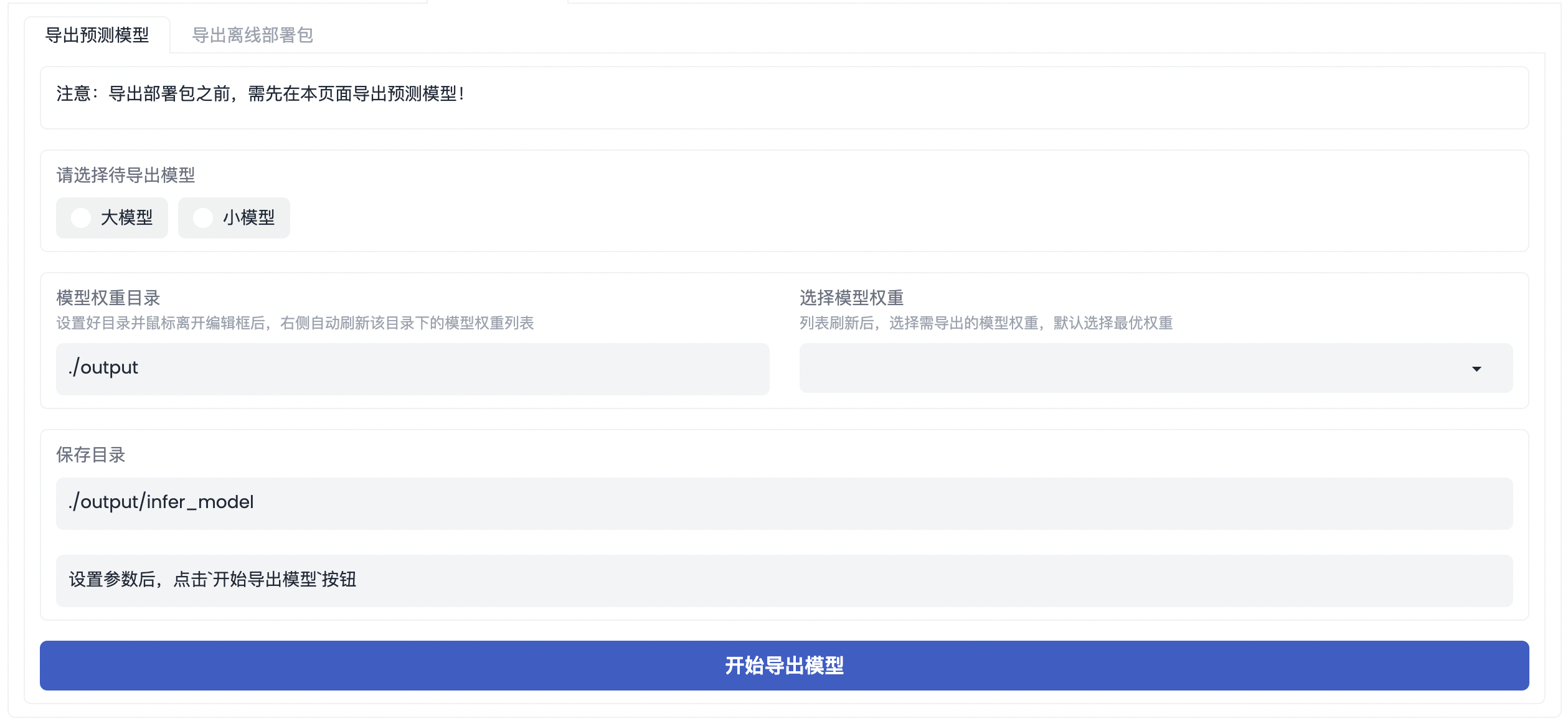
使用工具箱模式完成模型训练后,就可以在工具箱模式进行模型部署了。需注意,目前必须经过导出预测模型后才会产生用于部署的静态图模型。目前提供了模型在不同操作系统、不同部署硬件、不同接口语言条件下的部署包 SDK 获取方式。选择不同的模型即可导出相应模型的用于部署的静态图模型,导出模型后,即可导出相应模型的部署包。
注意:
- 使用本产线进行模型训练和评估等流程不做任何限制,但使用部署包在具体设备中部署模型时,需要购买序列号进行激活部署。序列号购买请前往这里的【序列号管理】。
- 欢迎填写表单与官方人员取得联系,批量采购可享受折扣价格。
- 本文档仅针对「大模型半监督学习产线-DET」产线,更多其他的大模型半监督学习产线,可以查看大模型半监督学习产线-CLS、大模型半监督学习产线-OCR。
3.多模型融合时序分析产线
3.1.简介
多模型融合时序分析产线(PP-TSv2 )是 PaddleX 推出的兼容 时序预测 和 时序异常检测 两大场景任务的模型训练产线。其特点是针对不同任务场景,能够自适应的选择和集成模型,提升任务的精度。该产线同时具有数据的划分,预处理去重等功能,支持离线和服务化部署。用户可以根据自己的需求场景选择时序预测或异常检测任务,训练模型后进行部署,便捷易用。
3.2.特性

3.3.使用
下面以「多模型融合时序分析产线」中的时序预测任务为例,介绍本产线的使用方法。
数据准备
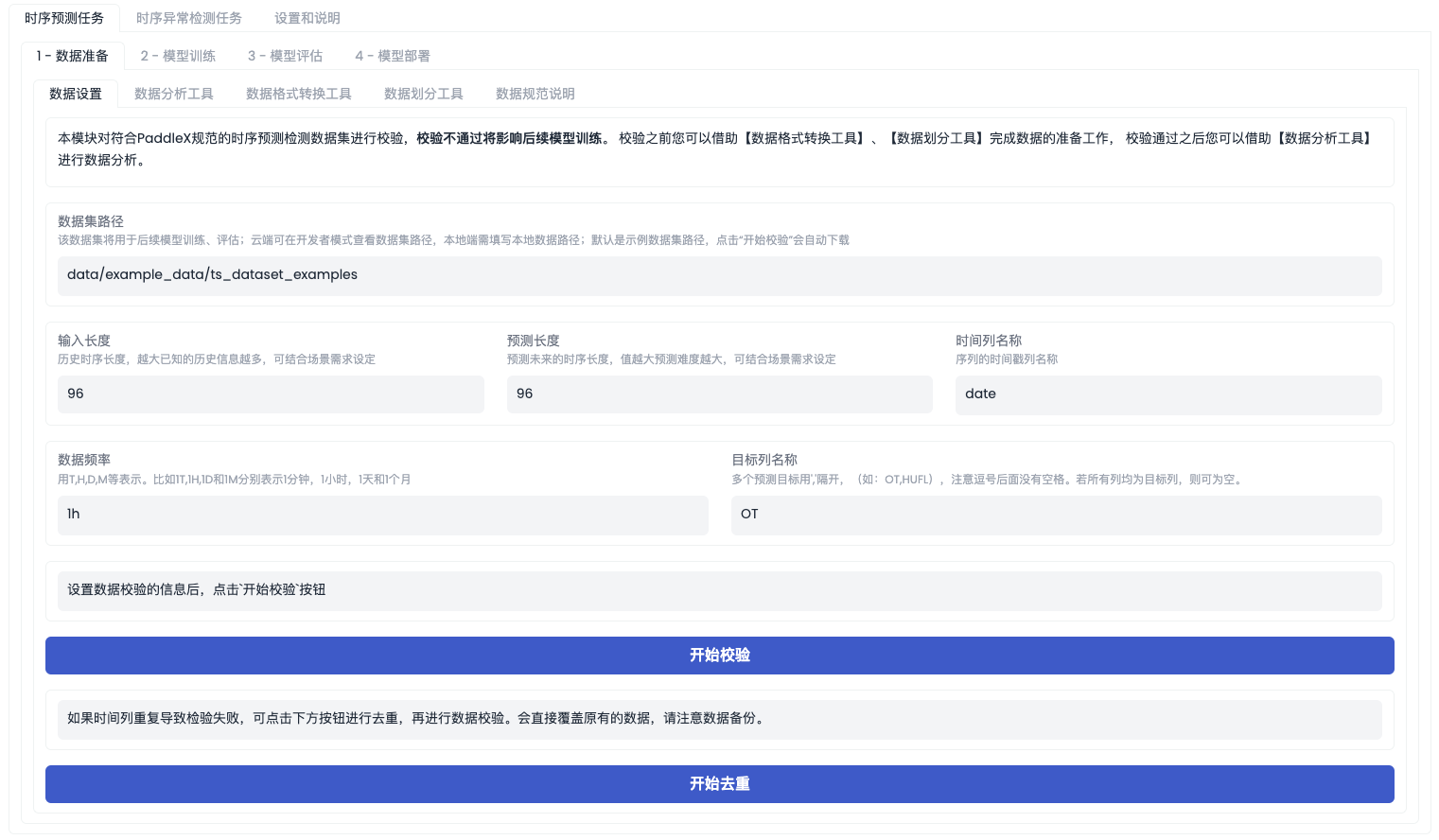
在完成数据标注工作后,请按照【工具箱模式】中给出的数据集规范说明检查数据组织格式是否满足要求。如果不满足,请参照规范说明进行调整,否则将导致数据校验无法通过,影响后续的模型训练。
「数据设置」界面如下图
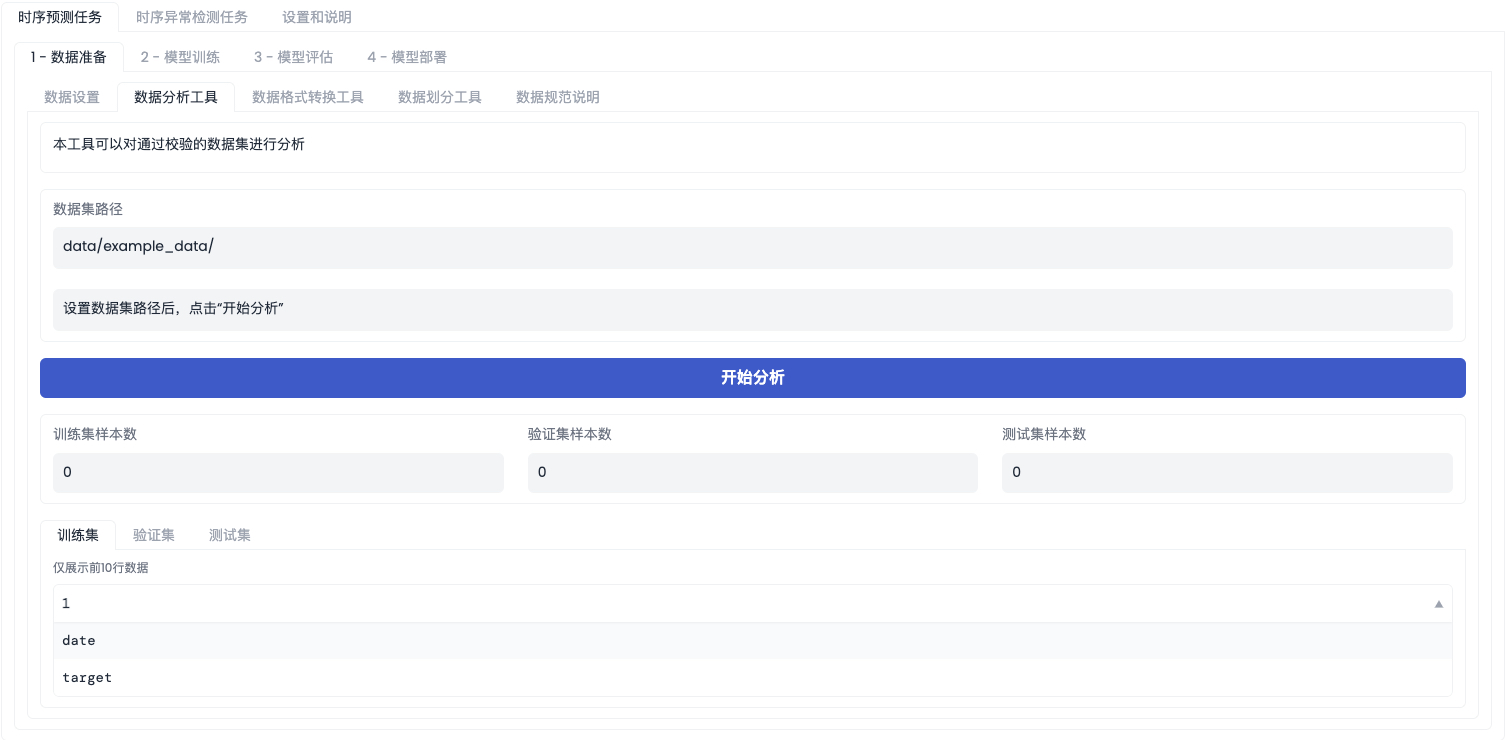
「数据分析工具」界面如下图
「数据格式转换工具」界面如下图
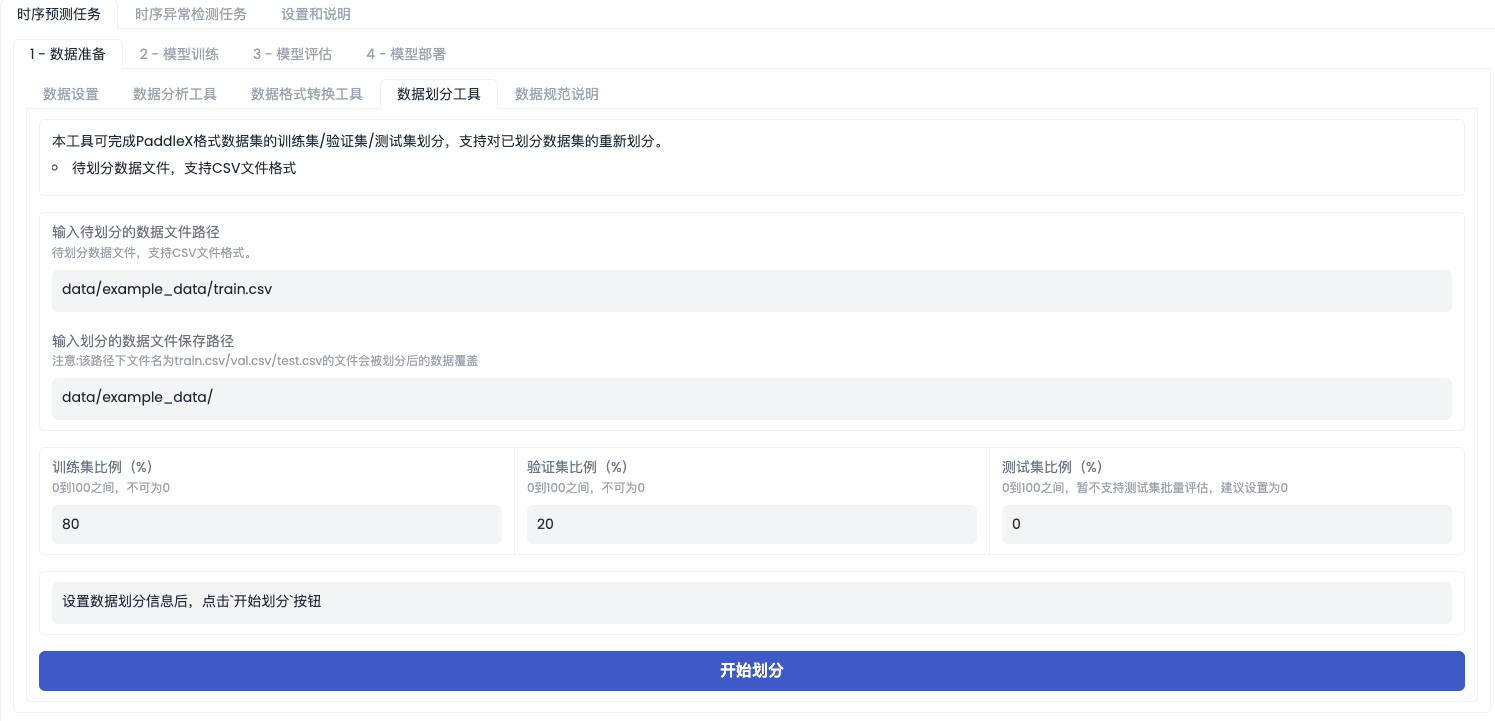
「数据划分工具」界面如下图
「数据规范说明」界面如下图
模型训练
模型训练
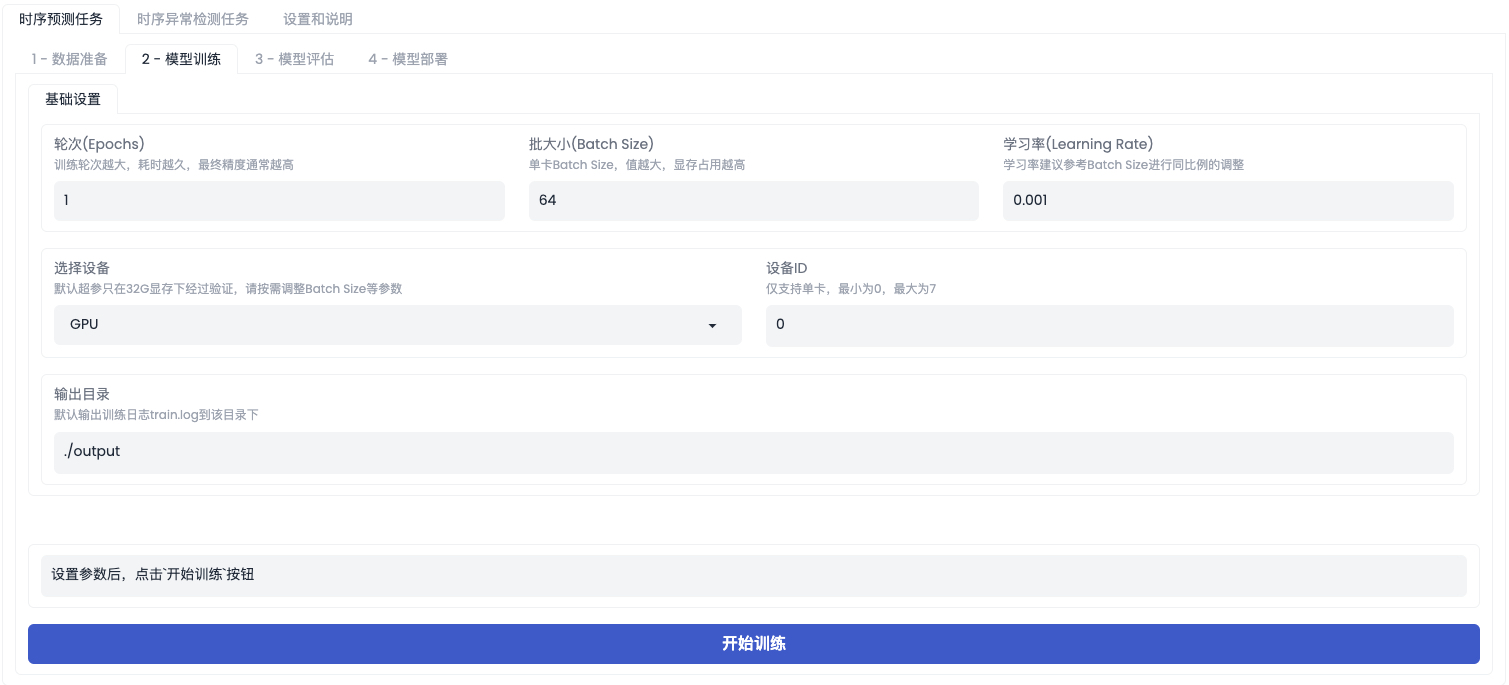
- 启动训练:在该产线中,点击【开始训练模型】后,即可启动模型的训练。
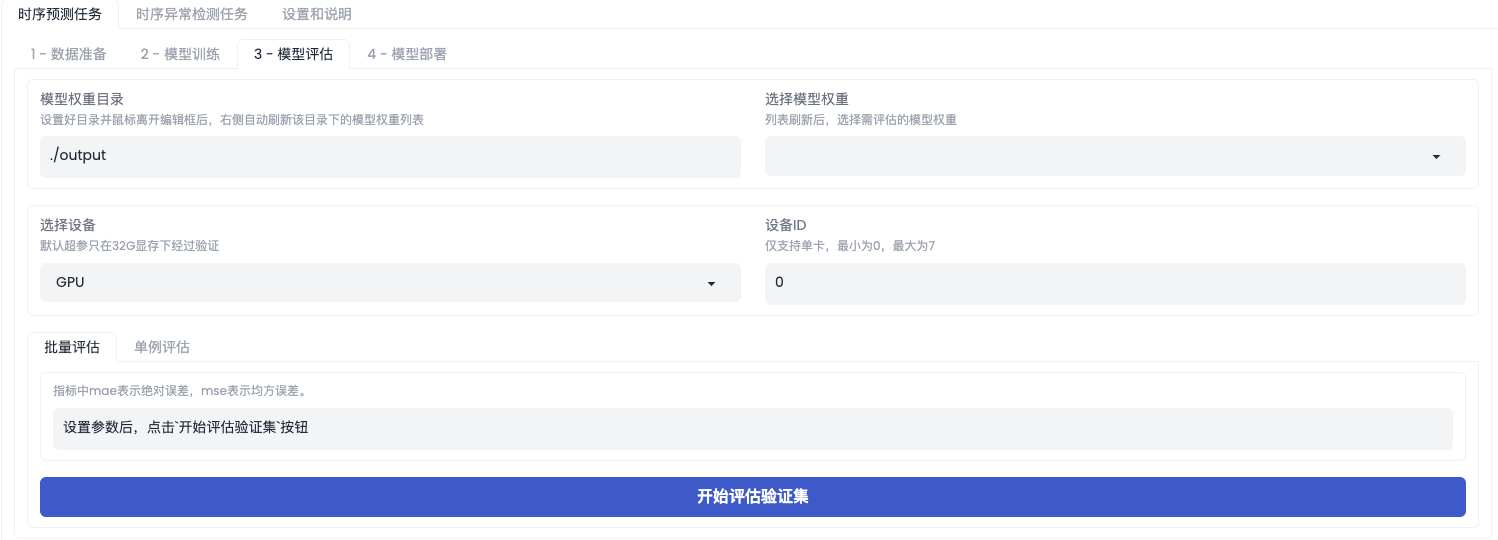
模型评估
在工具箱模式中,可以直接评估训练得到的模型精度,这里支持对评估集的批量评估、对单个序列的测试。用户选择训练后得到的模型,点击【开始评估验证集】即可完成对验证集的评估,上传时序序列的csv格式文件,点击【提交】,即可完成对单时序序列的预测。
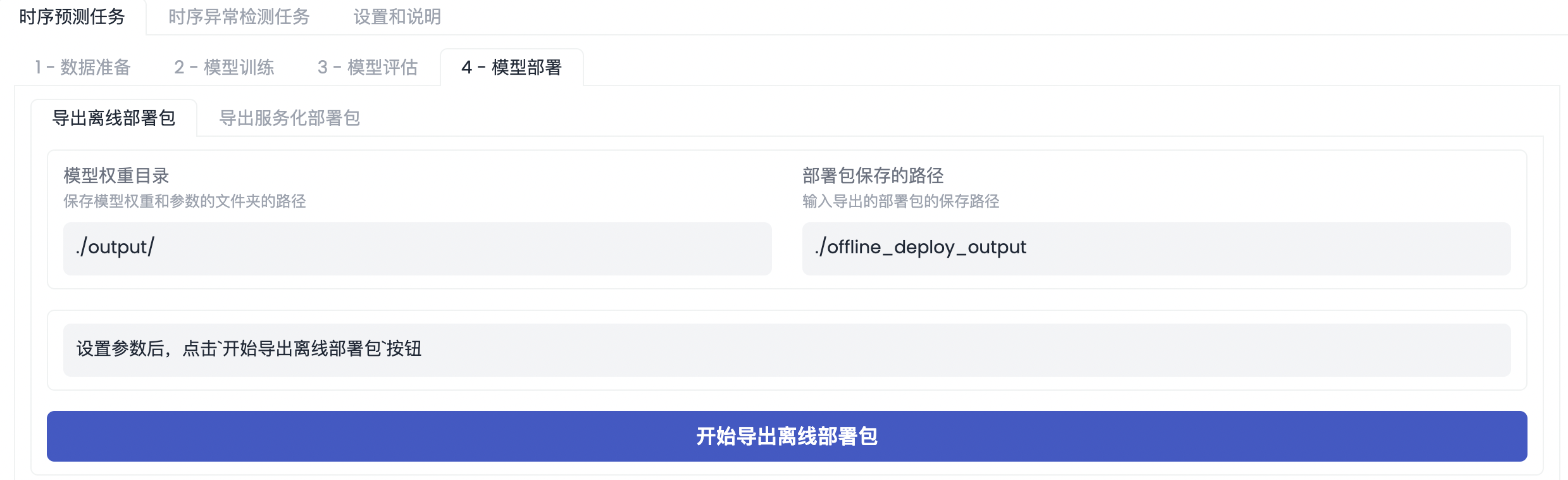
模型部署
使用工具箱或开发者模式完成模型训练后,就可以在工具箱模式进行模型部署了。目前提供了【离线部署包】和【服务化部署包】的获取方式。
注意: 本产线是飞桨 AI 套件 PaddleX 特色产线,训练和评估等流程不做任何限制,但使用部署包在具体设备中部署模型时,需要购买序列号进行激活部署。序列号购买请前往这里的【序列号管理】。欢迎填写表单与官方人员取得联系,批量采购可享受折扣价格。