

工具箱模式
工具箱模式
工具箱模式提供基于webUI的低代码开发方式,方便初阶的开发者快速上手,资深开发者也可以用它来提升开发效率。
- 「支持模型训练」的模型产线:对于所有的基础模型产线和大部分特色模型产线,工具箱模式提供的功能包括数据准备、模型训练、模型评估和模型部署四个环节。您可以根据实际需求选择模型和数据,以及对应的训练参数、优化策略,使得任务效果最佳。
- 「不支持模型训练」的模型产线:对于其它模型产线,工具箱模式暂不支持模型训练,仅提供根据所选模型执行模型推理以及获取部署SDK的功能。
下面主要介绍「支持模型训练」的工具箱模式使用方式,以RT-DETR_HGNetV2_l为例。关于特色模型产线的工具箱模式使用说明,请参考这里。注意,不同的模型所提供的工具箱模式功能可能有所差异,请以实际为准。
请注意,对于具体模型,工具箱模式所提供的功能可能有所差异,且有可能随版本更新发生变化。目前PaddleX处于快速更新迭代中,界面和功能请以实际为准。
数据准备
数据准备环节的核心任务是通过数据校验,否则将影响后续的模型训练、评估等环节。为了顺利通过数据校验,PaddleX给大家准备了数据分析工具、数据格式转换工具、数据划分工具等实用工具,并内置数据规范说明方便大家查看。
「数据设置」界面如下图
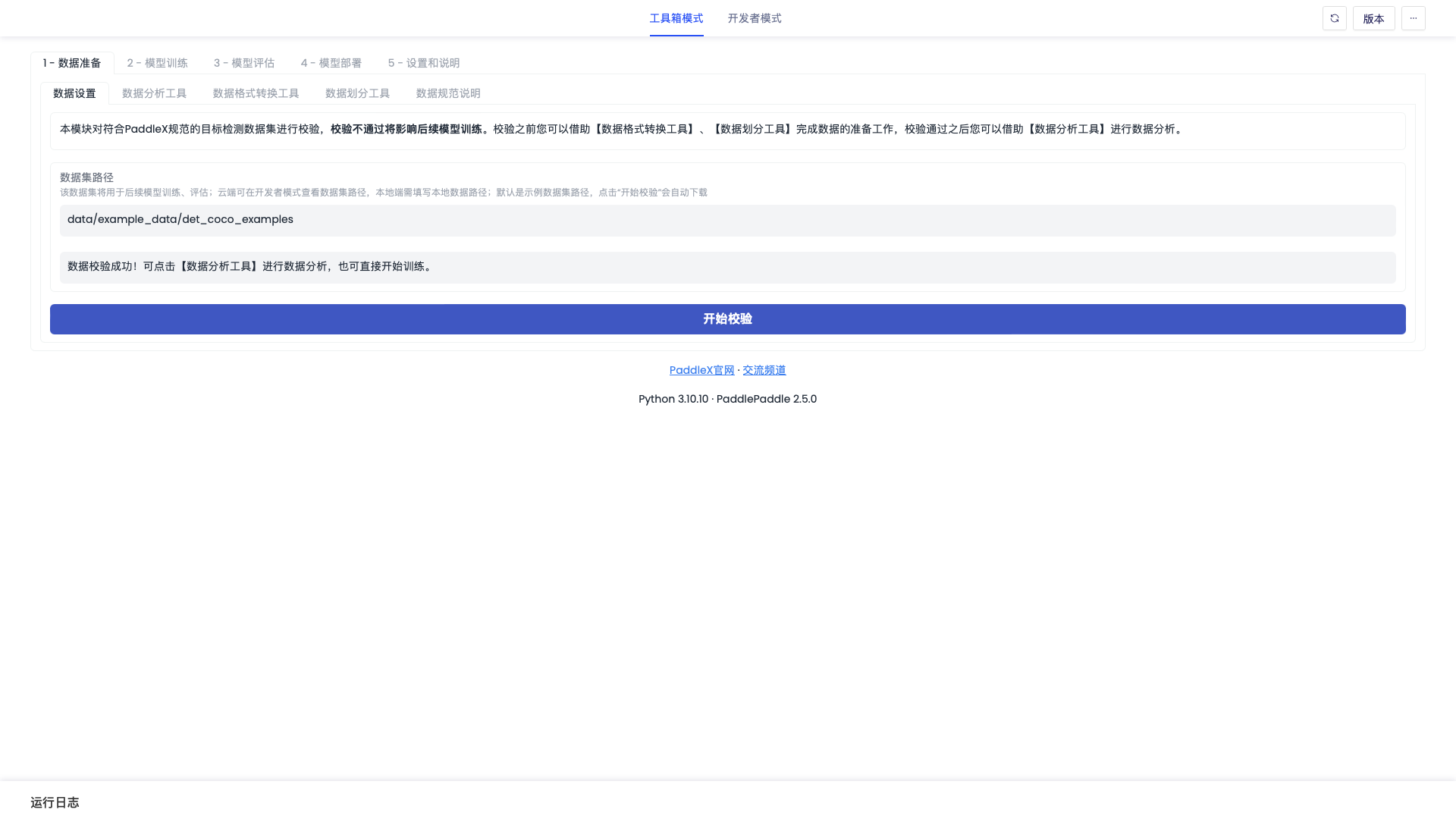
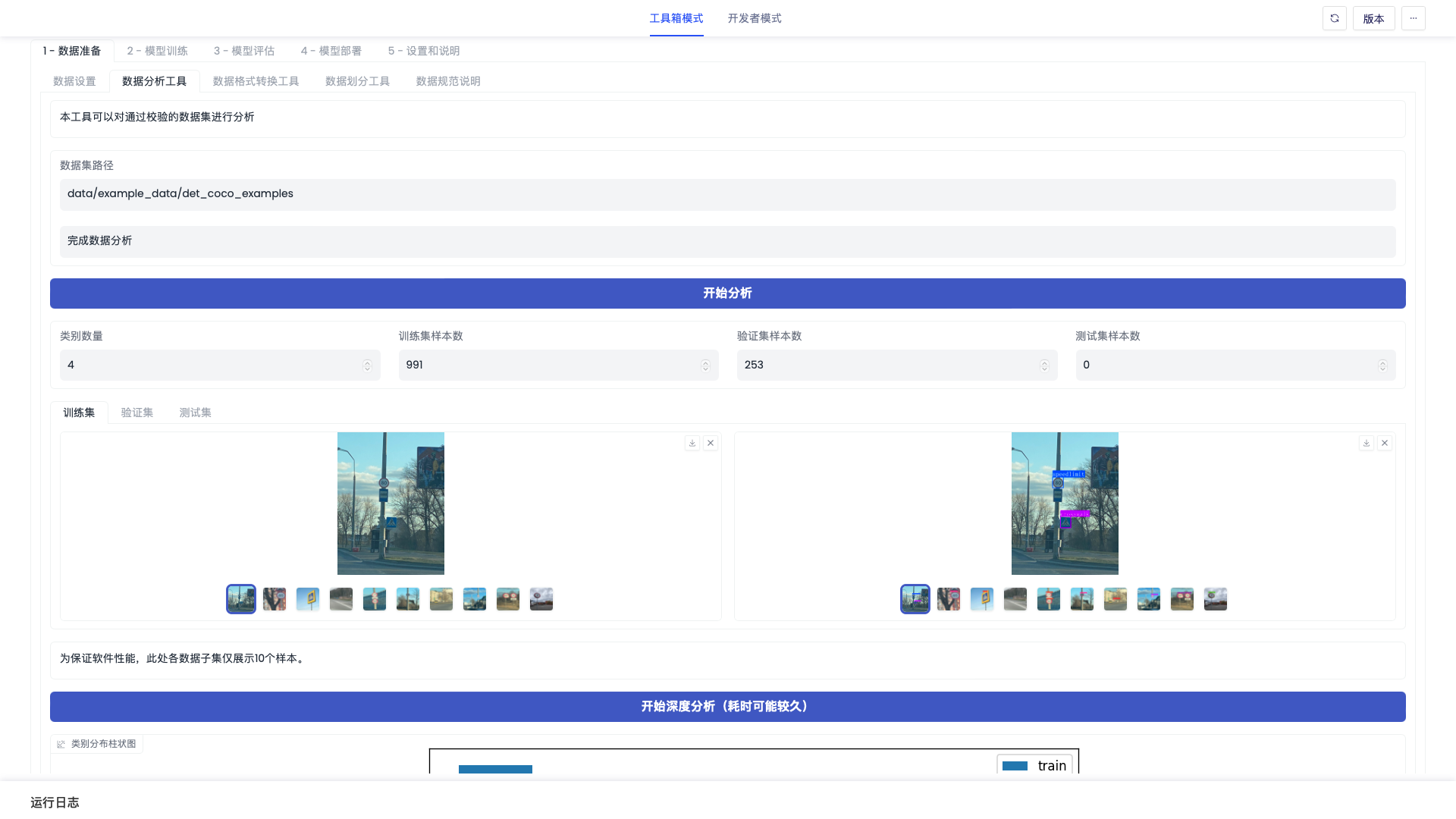
「数据分析工具」界面如下图
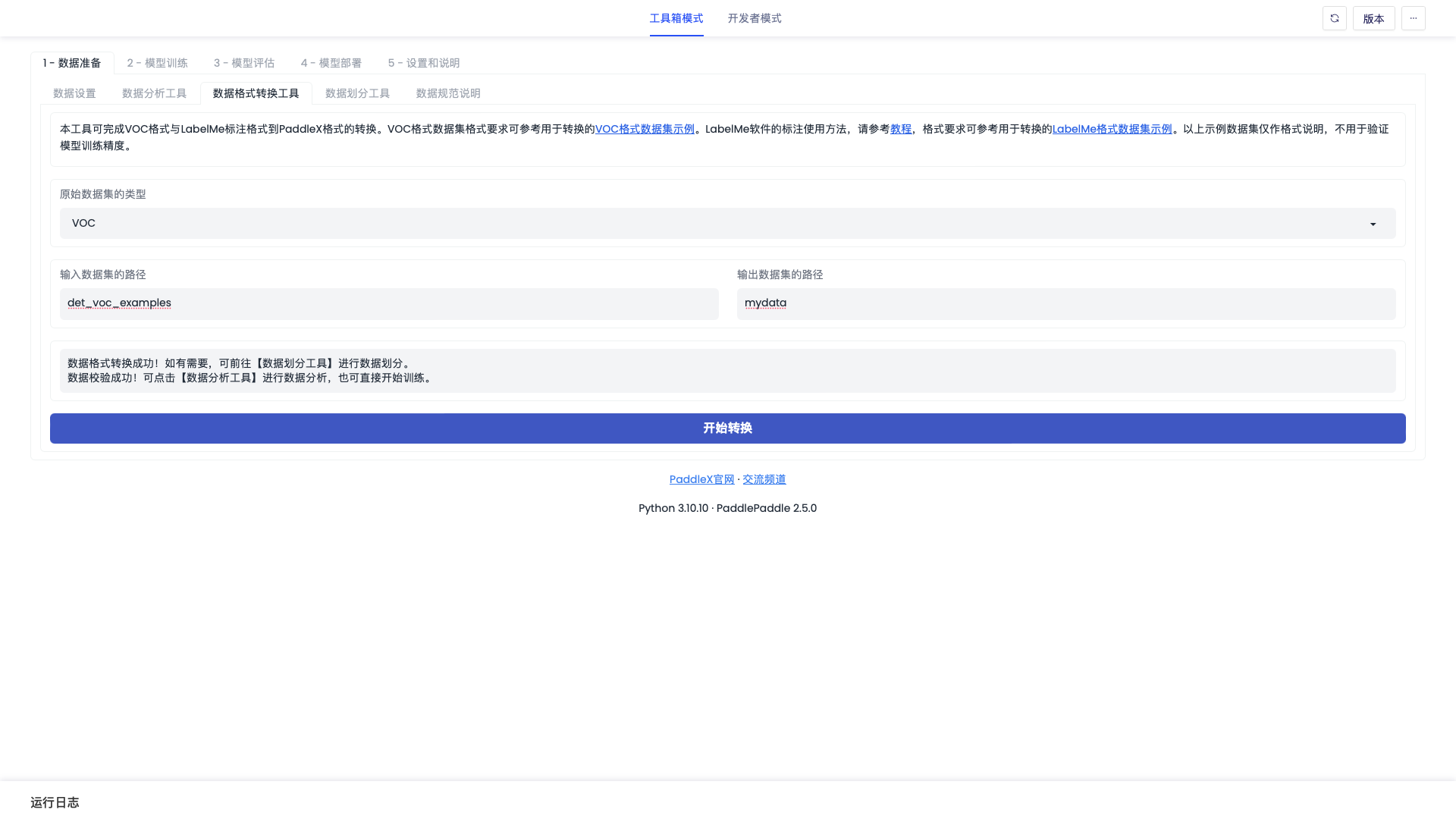
「数据格式转换工具」界面如下图
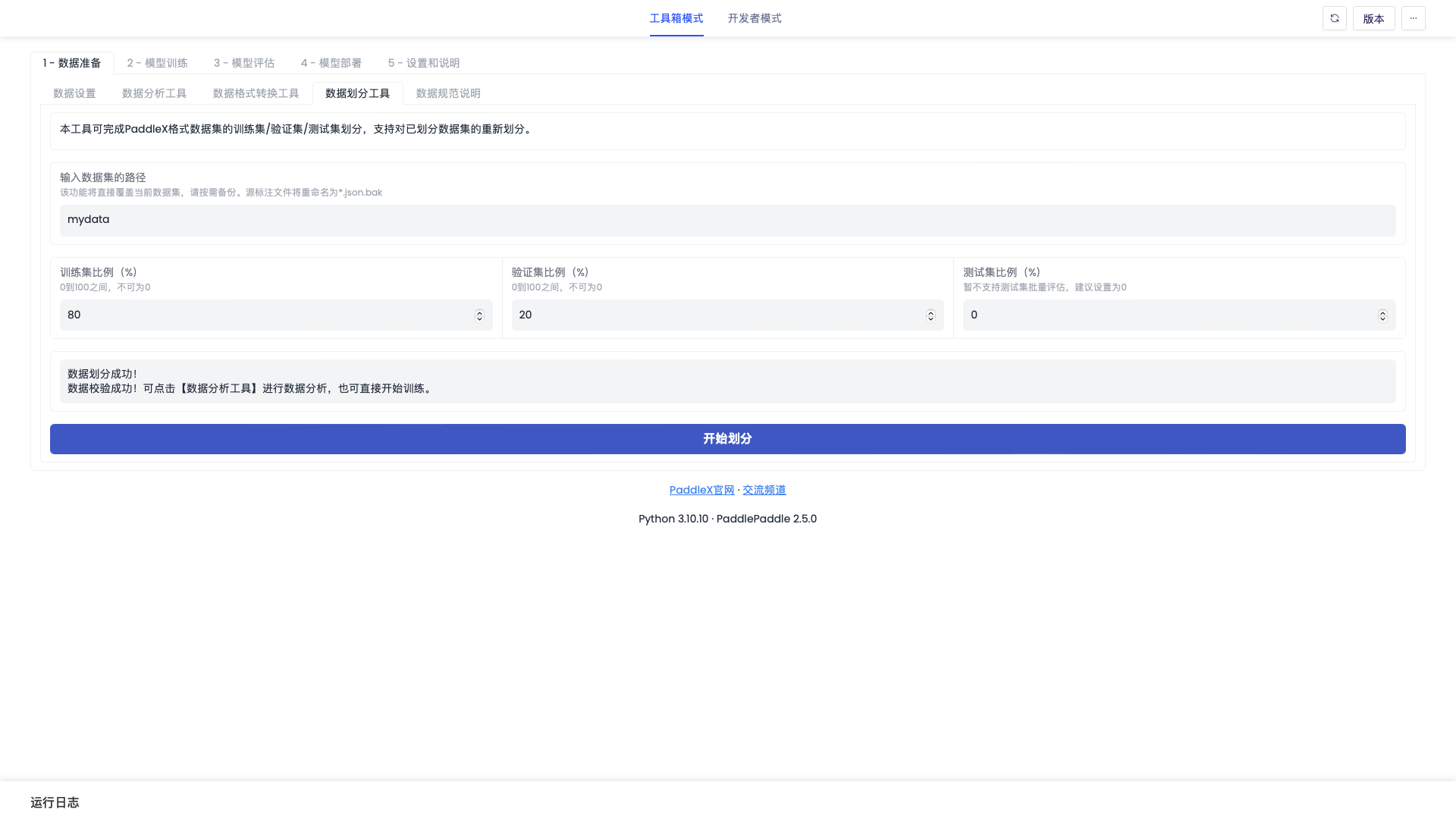
「数据划分工具」界面如下图
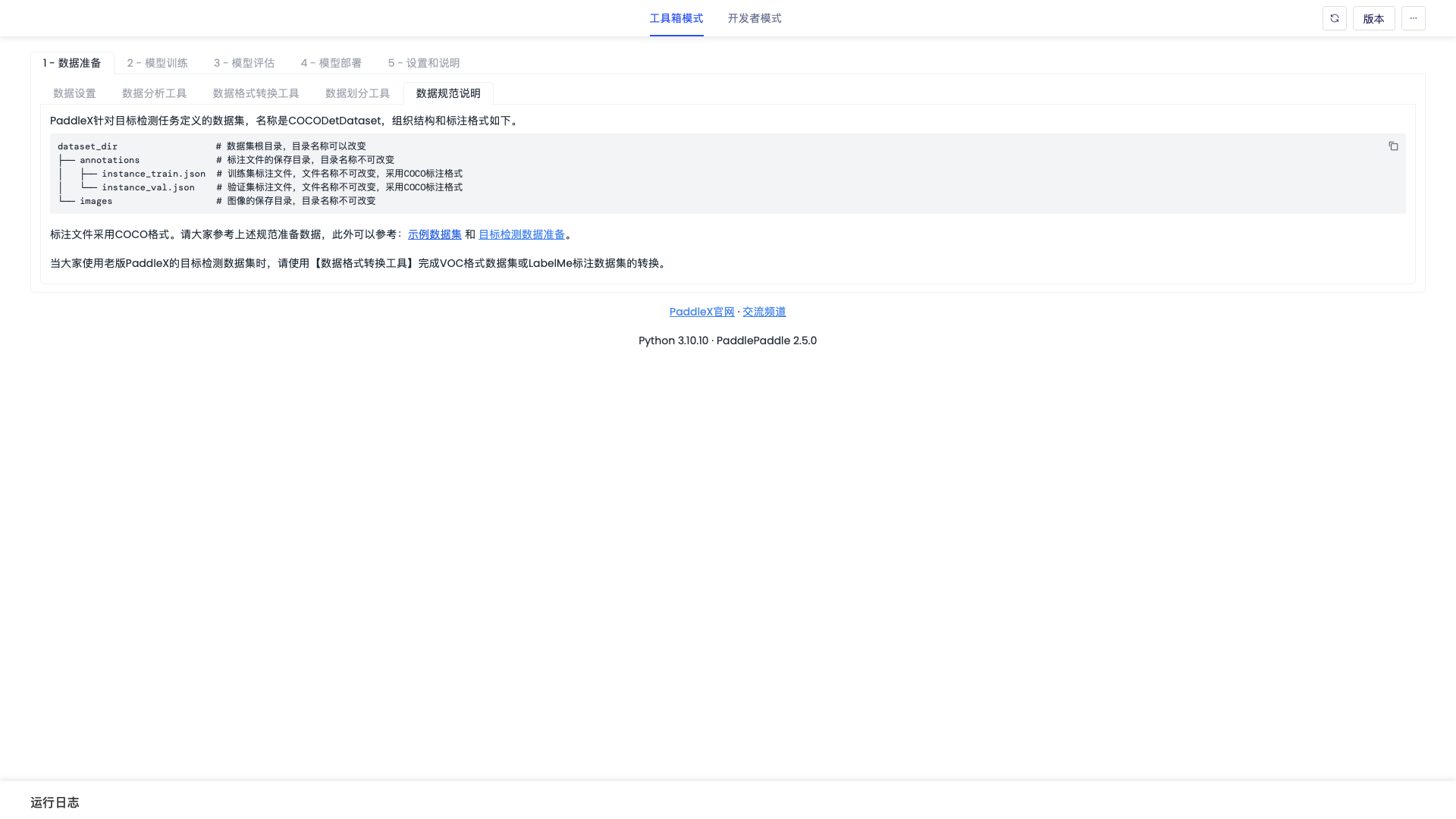
「数据规范说明」界面如下图
备注:完善的数据准备功能目前仅上线了关注度较高的模型,后续将覆盖全部模型
使用说明
本环节使用工具箱模式完成模型训练前的数据准备工作。
- 格式转换与切分(按需)。需注意,PaddleX目前没有内置数据标注工具,需要大家自行选用主流标注工具完成数据标注。对于目标检测、语义分割等视觉任务,推荐大家使用Labelme软件进行标注;对于OCR任务,推荐大家使用PPOCRLabel进行标注。PaddleX相关模型已内置上述推荐标注软件的数据格式转换工具,可产出符合PaddleX数据规范的数据集,还支持对训练集/验证集/测试集的自定义比例切分。
- 通过数据校验。准备好符合PaddleX规范的数据集之后,可以在【数据设置】中完成数据校验,这一步非常重要,是进行后续模型训练等操作的前提依赖。如果未通过校验,请根据报错提示进行格式的修改。【数据设置】中的默认路径是官方提供的示例数据集路径,您可以使用示例数据集快速体验整个工具箱模式的全流程。
- 进行数据分析。在开始训练之前,您可以选择进行数据分析,预览原始数据及其标注、获取数据集中各类别的样本数量分布等,方便您更好地了解数据集特点。
如何使用自己的数据集
- 在 AI Studio 云端,可以通过挂载数据集的方式来使用自己的数据。项目修改窗口可以挂载和管理数据集,如下图所示。
「项目修改入口」界面如下图

「项目修改窗口」界面如下图
数据集挂载成功后,需在开发者模式中查看并解压挂载的数据集,数据集路径查看方式为【开发者模式】-左侧【资源管理器】,在目录 data 下,数据集解压方式为【开发者模式】-左侧【菜单】-【终端】-【新建终端】,在【终端】中通过命令行方式解压(如tar -xf mydata.tar、unzip mydata.zip),并将解压后的数据集路径拷贝到【工具箱模式】-【数据设置】-【数据集路径】进行数据校验,或拷贝到【工具箱模式】-【数据格式转换工具】-【输入数据集的路径】进行数据格式转换。注意:在 AI Studio 云端,data 目录不持久化存储,目录中的内容在重启项目时会重置。如需持久化存储,需要将数据解压至其它目录。
- 在本地端-工具箱模式中,您可以直接在【工具箱模式】-【数据设置】-【数据集路径】中填写本地数据路径来使用自己的数据集,如
D:\data\mydataset。
Tips:后续操作可能会在数据集路径中进行文件的修改与新增,所以建议您做好数据集的备份。
参数说明
| 参数名称 | 数值样例 | 说明 |
|---|---|---|
| 数据设置-数据集路径 | data/example_data/seg_optic_examples | 将进行校验的数据集路径,默认值为官方提供的示例数据集,可修改成想要训练的数据集路径。支持压缩包格式,将自动解压。 |
| 数据设置-开始校验 | - | 点击后开始检查数据集是否符合标准规范,并返回校验结果。 |
| 数据分析工具-数据集路径 | data/example_data/seg_optic_examples | 待分析的数据集路径。数据校验通过后,可将数据集路径复制至此进行数据分析。 |
| 数据分析工具-开始分析 | - | 执行数据分析,返回类别数量、训练集/验证集/测试集样本数量等,并提供部分数据的预览。点击切换数据预览部分左侧的原始图像,将同步切换右侧的标注图像。 |
| 数据分析工具-开始深度分析 | - | 执行深度分析,耗时可能较长。输出类别分布图。 |
| 数据格式转换工具-原始数据集的类型 | VOC | 选择转换之前数据集的类型。 |
| 数据格式转换工具-输入数据集的路径 | mydata | 填入转换之前数据集的路径。 |
| 数据格式转换工具-输出数据集的路径 | mydata_convert | 填入转换后数据集的保存路径。 |
| 数据格式转换工具-开始转换 | - | 执行数据集格式转换。 |
| 数据划分工具-输入数据集的路径 | mydata_convert | 待划分的数据集路径。没有划分训练集/验证集的数据集需要先进行划分,才能通过数据校验。这里也支持对已划分数据集的重新划分。 |
| 数据划分工具-训练集比例(%) | 80 | 要划分的训练集比例。 |
| 数据划分工具-验证集比例(%) | 20 | 要划分的验证集比例。 |
| 数据划分工具-测试集比例(%) | 0 | 要划分的测试集比例。暂不支持测试集批量评估,建议设置为0。 |
| 数据划分工具-开始划分 | - | 按照设置的训练/验证/测试集比例进行数据集划分。 |
| 数据规范说明 | - | PaddleX数据格式规范说明,数据集格式须满足该说明才能通过数据校验。 |
模型训练
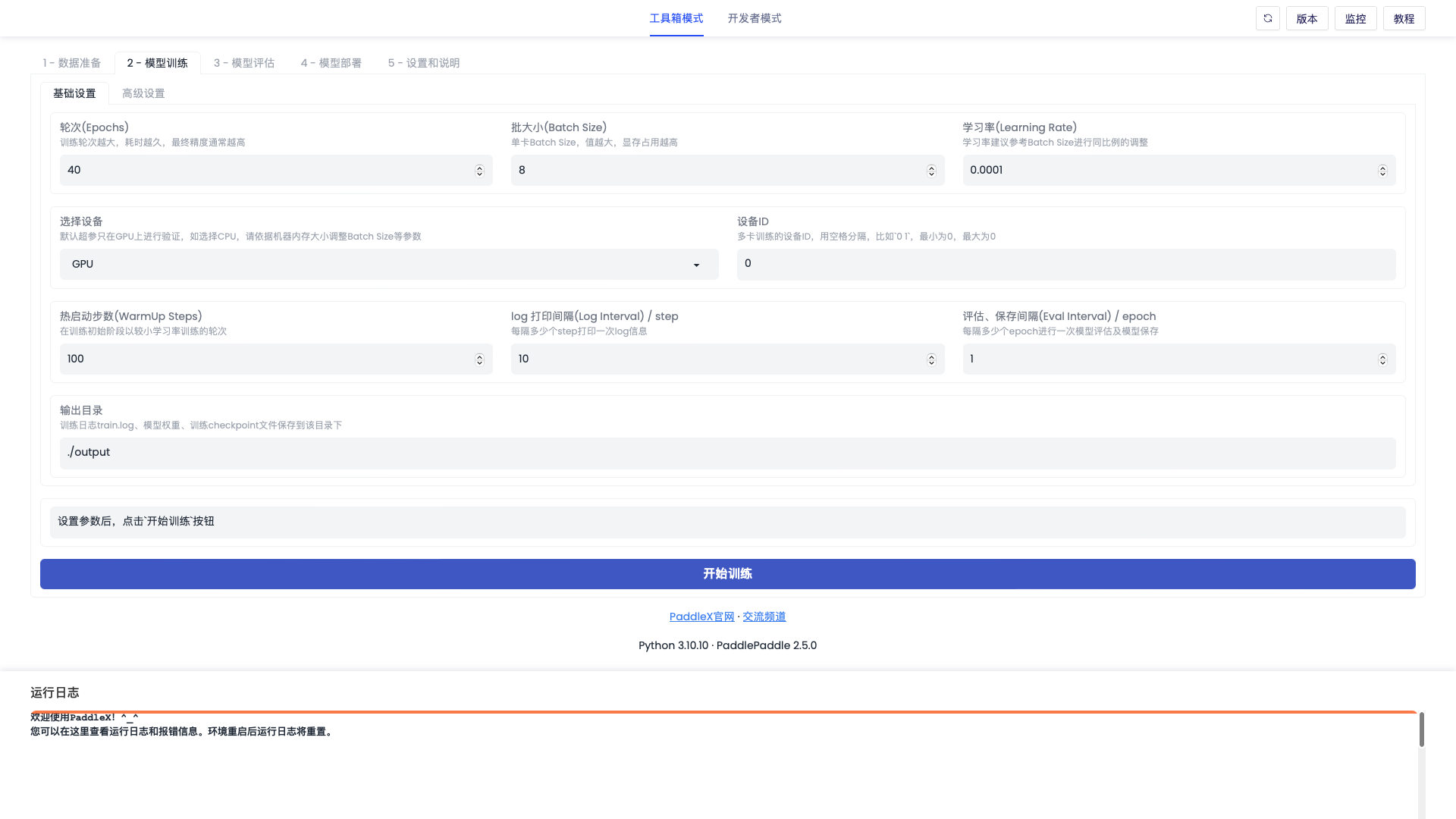
「模型训练-基础设置」界面如下图
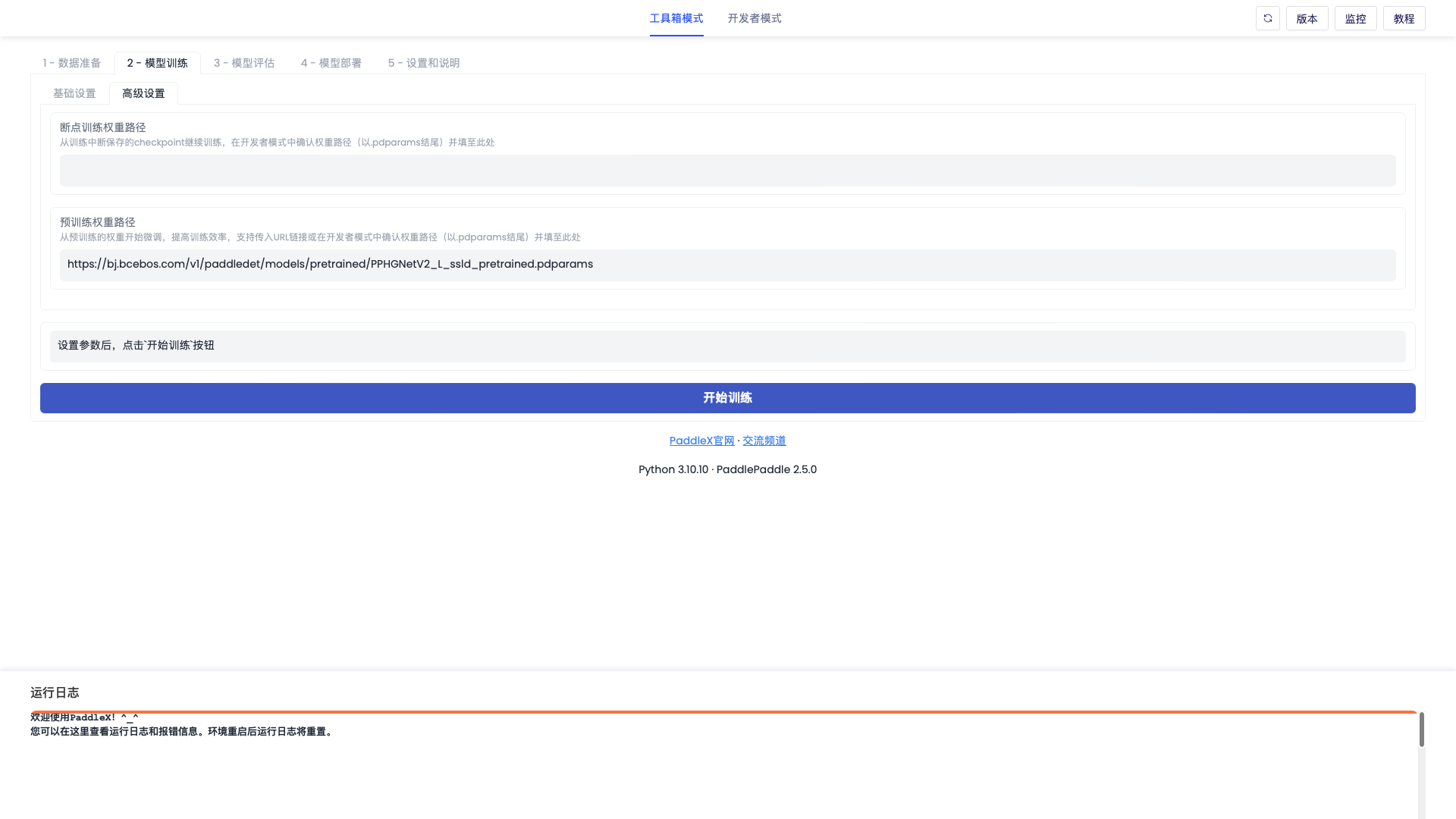
「模型训练-高级设置」界面如下图
使用说明
模型训练相关配置,支持训练轮次(iters / epochs, 不同模型训练方式有差异)、批大小、学习率、训练设备、模型输出路径等基础配置,同时支持断点训练权重路径,预训练权重路径,混合精度训练,动转静训练等高级配置(部分高级配置未来逐步上线)。
工具箱中的修改会同步修改config/ui_config.yaml文件(详见开发者模式说明文档)。点击【开始训练】,训练自己的模型。
关于数据增强等高级配置
目前工具箱模式没有暴露数据增强等高级配置,如需调整,可切换至开发者模式,编辑config/model_config.yaml文件中的对应字段,详细说明可参考这里。
请注意:
- 在AI Studio云端,如果您需要长时间训练模型,建议您使用后台任务功能。如果不使用后台任务,请不要关闭PaddleX开发环境页面,且保证机器不进入休眠状态,否则开发环境将在10分钟后自动关闭,训练过程将终止。
- 显示器熄屏可能导致工具箱模式error,可以刷新页面重新进入,训练中的任务不会终止,可以在底部的“运行日志”查看训练进度。此时如果需要终止训练任务,需要到开发者模式下查看训练进程ID并手动kill,如下图所示。

- 默认的训练超参只适用于示例数据集,已在32GB显存条件下经过验证。使用其他数据集或在其他显存条件下,需要视情況调整训练超参。
参数说明
| 参数名称 | 数值样例 | 说明 |
|---|---|---|
| 轮次(Epochs) | 40 | 可修改,模型训练的轮次,不同模型的训练轮次单位有所差异(Epochs or Iters) 。训练轮次越大,训练耗时越长,最后的精度也往往较高。 |
| 批大小(Batch Size) | 8 | 可修改,模型训练批处理大小(单卡),实际的总Batch Size等于该数值乘以GPU数量。Batch Size越大,显存占用越高,训练耗时也越短(轮次单位为Epochs时)。如果您遇到显存不足的问题,可以尝试使用较小的Batch Size。 |
| 学习率(Learning Rate) | 0.0001 | 可修改,模型优化器的学习率。如果减小Batch Size,一般需要等比例减小学习率。 |
| 选择设备 | GPU/CPU | 可选GPU或者CPU作为训练设备,强烈建议使用GPU进行训练,CPU训练耗时很长且不稳定。 |
| 设备编号 | 0 1 2 3 | 当【设备选择】为GPU时,可选设备编号,使用空格分隔。 |
| 热启动步数(WarmUp Steps) | 100 | 在训练初始阶段以较小学习率训练的轮次,有助于训练稳定收敛。 |
| log 打印间隔(Log Interval) / step | 10 | log信息打印间隔,决定了在模型训练时底部运行日志的刷新频率。 |
| 评估、保存间隔(Eval Interval) / epoch | 5 | 评估和报错模型的间隔。在训练时,每隔若干个epoch将会进行一次模型评估(基于验证集)和权重文件的保存(便于断点训练)。该间隔不宜过小,否则保存大量权重文件会占据大量存储空间,甚至超出存储限制。 |
| 输出目录 | ./output | 可修改,模型训练过程中,日志文件和模型文件存储路径。训练过程会在该目录下输出train.log,记录完整的训练日志。 |
| 开始训练 | - | 可点击,点击后开始训练。 |
| 断点训练权重路径 | - | 可修改,如果之前有训练模型,想在之前中断的基础上继续训练,可以在这里填入模型checkpoint的路径(.pdparams文件),然后点击【开始训练】即可继续进行训练。 |
| 预训练权重路径 | - | 可修改,如果您想使用相关的预训练模型进行微调,则可以把预训练模型路径(.pdparams文件)放在这里。 |
| 混合精度训练模式(规划中,敬请期待) | O1 | 可修改,是否开启混合精度训练模式及其开启后的级别。 |
| 是否动转静训练(规划中,敬请期待) | 否 | 可修改,是否开启混合精度训练。 |
模型评估
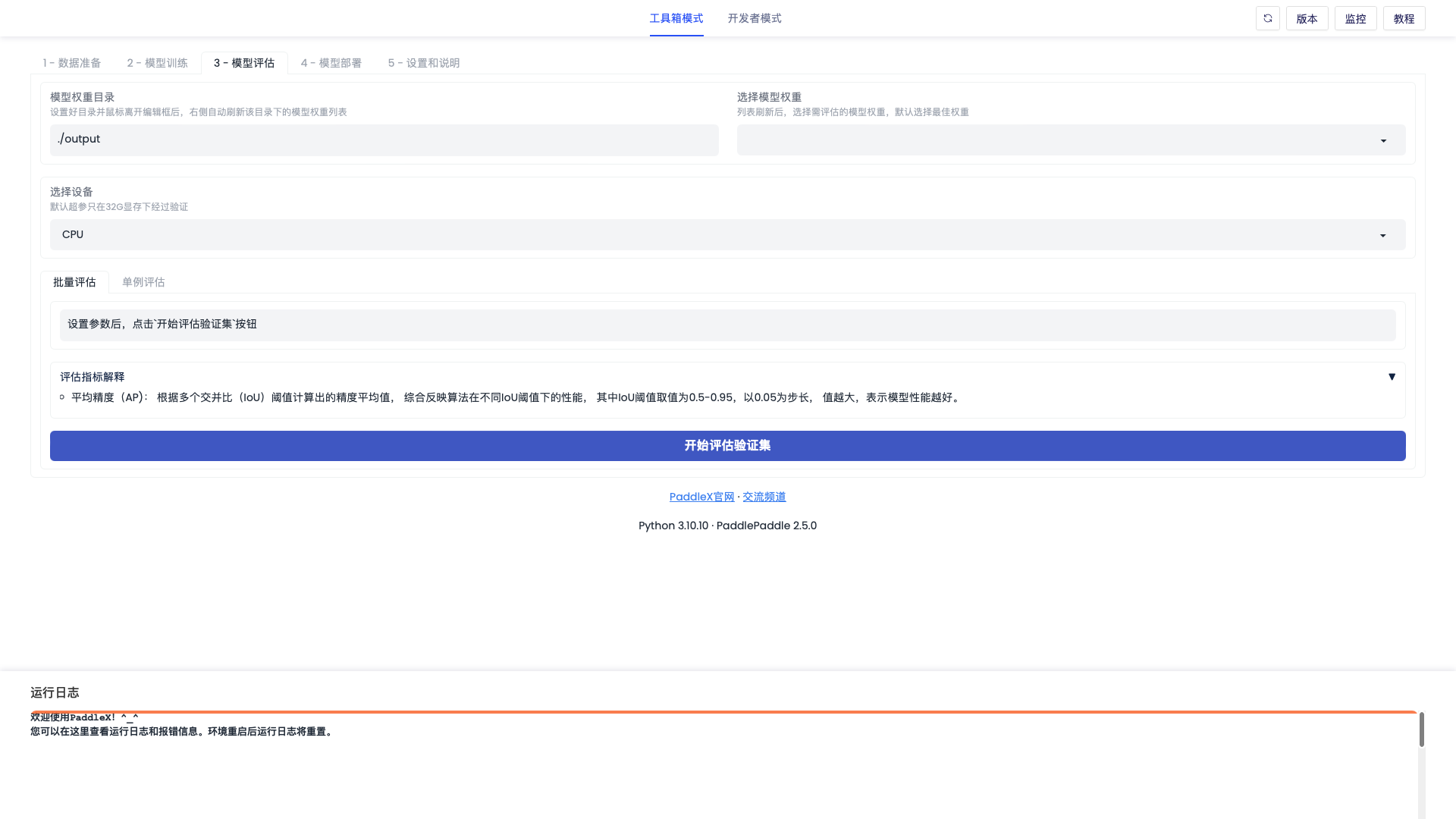
「模型评估」界面如下图
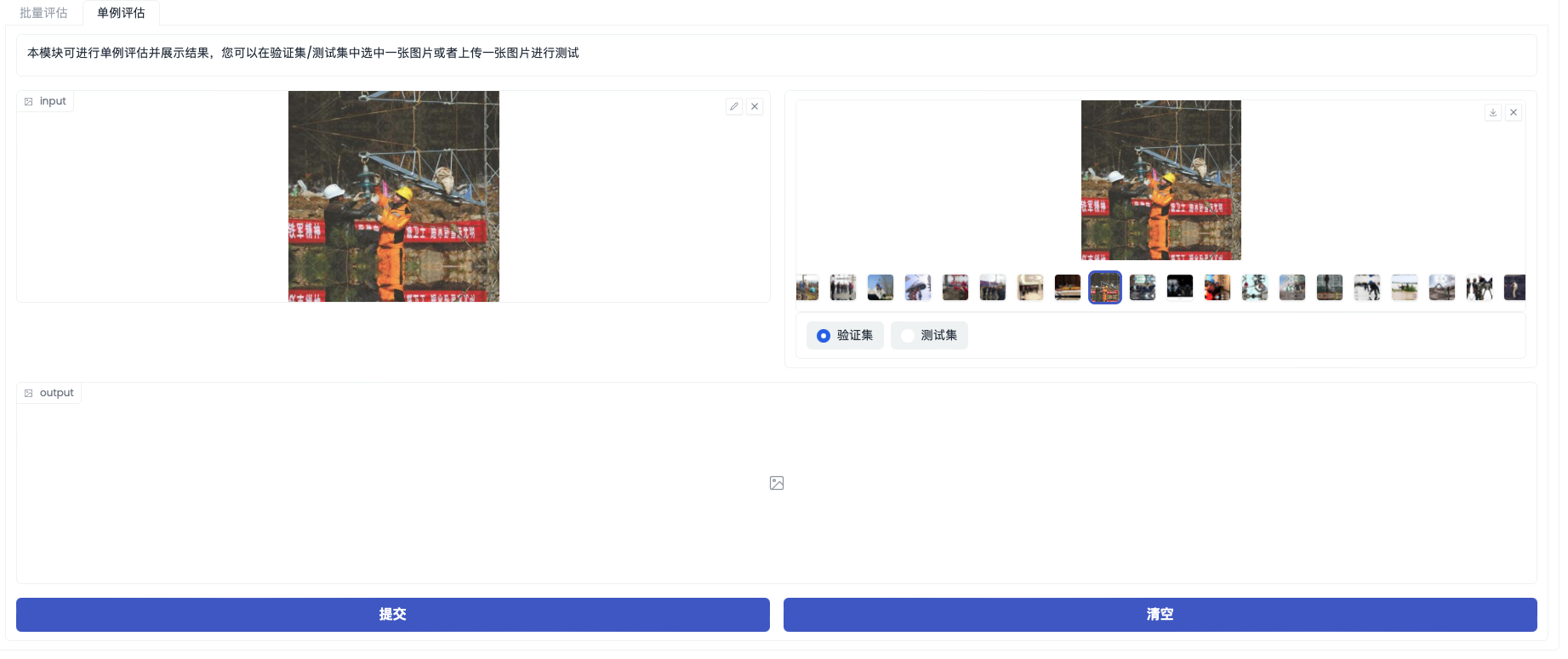
「单例评估」界面如下图
使用说明
当训练完成后,点击或修改【模型权重目录】,当光标移开时,会更新模型列表,通过【选择模型权重】,下拉选择想要测试的模型,进行评估设备选择,点击【开始评估验证集】,则会计算并展示当前模型在验证集中的评估结果。
也可以进行单例评估,可以通过选择验证集/测试集样本或者上传数据的方式,来验证当前模型的效果。
参数说明
| 参数名称 | 数值样例 | 说明 |
|---|---|---|
| 模型权重目录 | ./output | 可修改,默认使用output目录,如果修改了训练环节的output目录,这里需要选择对应的输出目录。设置好目录并鼠标离开编辑框后,右侧自动刷新该目录下的模型权重列表。 |
| 选择模型权重 | 可修改,默认选择【使用训练环节产出的最优模型】,您也可以选择其它合适的模型做测试。 | |
| 选择设备 | GPU/CPU | 可选GPU或CPU作为模型评估设备。 |
| 设备编号 | 0 | 当【设备选择】为GPU时,可选设备编号,使用空格分隔。 |
| 评估指标解释 | - | 当前评估指标的解释。 |
| 开始评估验证集 | - | 可点击,点击后开始执行验证集评估。目前不支持测试集批量评估。 |
| 单例评估-input | - | 可点击从本地上传图片样本。或者在右侧选择验证集/测试集的样本。 |
| 单例评估-output | - | 提交单例评估后,在这里展示模型推理结果。 |
| 单例评估-提交 | - | 可点击,根据当前的input进行模型推理,结果将展示在output。 |
| 单例评估-清空 | - | 可点击,清空input与output。 |
模型部署
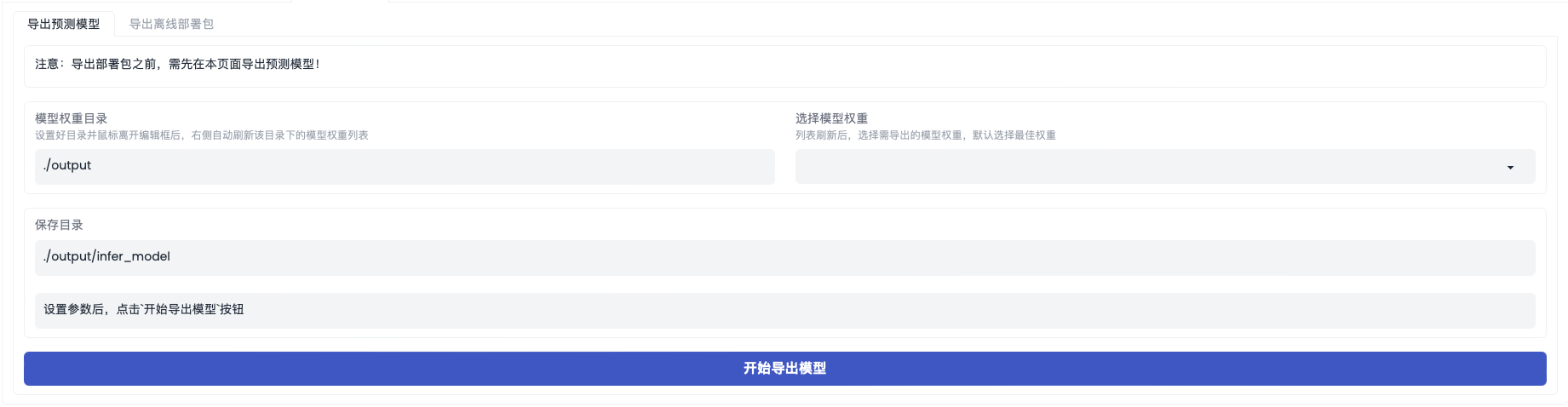
「导出预测模型」界面如下图
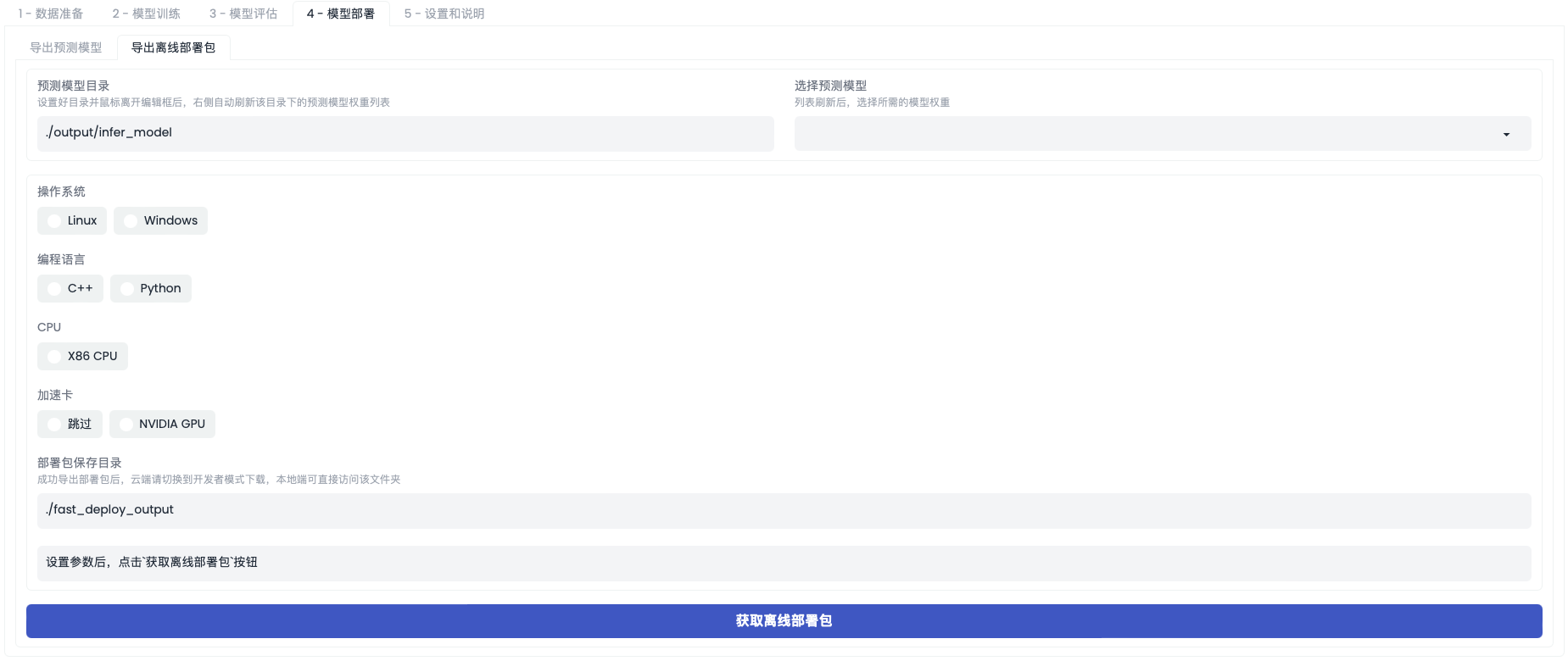
「导出离线部署包」界面如下图
使用说明
模型部署功能仅支持工具箱模式使用,提供了导出预测模型以及导出部署包的功能。部署包为模型在不同系统、不同语言、不同硬件条件下用于模型部署的SDK。
导出预测模型:支持开发者将训练好的模型以静态图的形式导出,方便模型部署。通过【选择模型权重】,下拉选择想要导出的预测模型,设置好保存目录后即可导出模型。
导出部署包:
- 部署模型有两种来源:在PaddleX训练好并导出的预测模型,或者开发者自己上传的模型。开发者需要选择好模型路径,并注意选择静态图模型(后缀为
pdiparams而不是pdparams)。 - 先从操作系统选择,选择操作系统后,会根据该操作系统支持的情况显示对应内容;依次选择编程语言、CPU、加速卡,后台会将模型和部署SDK等自动打包好,提供给开发者。
- 部署包保存路径:最终打包的部署包,会保存到项目空间,具体路径见于【部署包保存路径】,注意在AI Studio云端需要切换到开发者模式下载部署包。
- 部署包使用文档:部署包中包含详细使用文档,开发者根据文档即可完成模型在项目中的集成。
参数说明
导出预测模型
| 参数名称 | 数值样例 | 说明 |
|---|---|---|
| 模型权重目录 | ./output | 可修改,默认使用output目录,如果修改了训练环节的output目录,这里需要选择对应的输出目录,点击或修改【模型权重目录】,会更新右边【选择模型权重】的下拉表单。 |
| 选择模型权重 | - | 可修改,默认选择【使用训练环节产出的最优模型】,您也可以选择其它合适的模型做测试。 |
| 保存目录 | ./output/infer_model | 可修改,会将预测模型保存至对应的目录地址。 |
| 开始导出模型 | - | 点击后开始导出预测模型。 |
导出部署包
| 参数名称 | 数值样例 | 说明 |
|---|---|---|
| 预测模型目录 | ./output/infer_model | 可修改,默认使用./output/infer_model目录,这里请使用“导出预测模型”时设置的“保存目录”。 |
| 选择预测模型 | - | 编辑好“预测模型目录”后,这里将刷新目录下的文件列表,选择对应的静态图文件(.pdiparams)即可。 |
| 操作系统 | Linux | 可在Linux和Windows中进行选择。 |
| 编程语言 | 可在C++和Python中进行选择。 | |
| CPU | X86 CPU | 可按需选择。 |
| 加速卡 | - | 可按需选择。 |
| 输出目录 | - | 可修改,指定导出部署包的目录。 |
| 获取部署包 | - | 可点击,点击后获得对应部署包,返回部署包保存路径。 |
设置和说明
「全局设置」界面如下

「温馨提示」界面如下

使用说明
全局设置中,目前提供了「日志自动刷新」和选择「界面主题」的功能。其中「日志自动更新」默认勾选,将使得底部的「运行日志」在有新内容产生时自动刷新并向下滚动。
「界面主题」目前提供三种主题风格供大家选择,分别是PaddleX默认使用的nota-ai主题、gradio内置的soft主题和gradio默认的default主题。选定主题后,点击右上角「重新加载」按钮,即可实现切换主题。
「soft主题」界面如下
「default主题」界面如下
「温馨提示」中则提醒了使用PaddleX时需要注意的一些问题,建议使用前仔细阅读,避免踩坑。
运行日志
最底部的运行日志是工具箱模式的重要组成部分,上述AI模型开发的各个环节所执行的动作,都会在此处输出日志,您可以通过日志查看运行状态、进度与报错信息。
「运行日志」界面如下
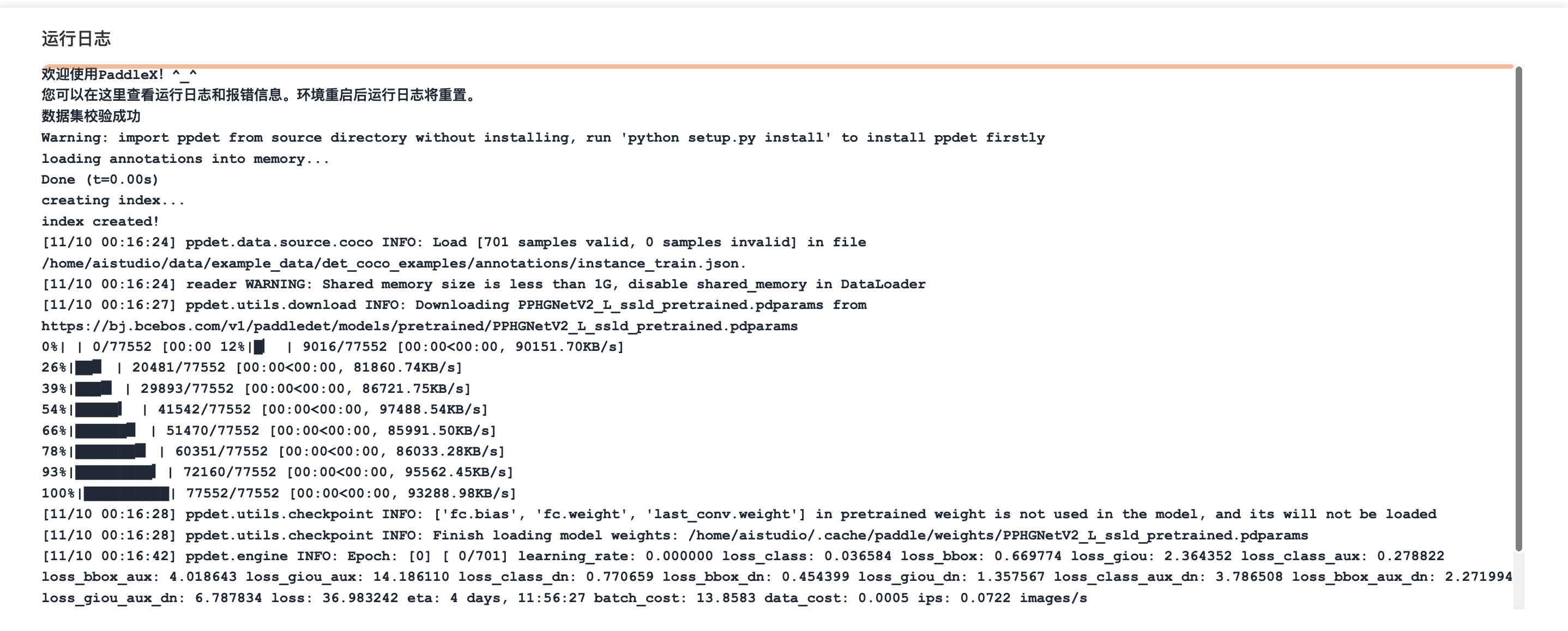
通过鼠标上下拖动运行日志面板顶部边缘,可以自行调整运行日志面板大小。
【自动刷新】功能默认开启,当有新日志产生时,将刷新日志并滚动到最底部,方便您查看最新日志。如果您想详细查阅某一段历史日志,可以取消勾选【自动刷新】后向上翻阅查找。您可以随时开启或关闭【自动刷新】。
Tips:运行日志部分的源码对应开发者模式中的logger.webui.gradio.py,您可以轻松修改源码来实现您想要的日志效果,比如修改字体、字号等。修改完成并保存后,切换至工具箱模式并点击右上角的「重新加载」,即可生效。