

零代码产线 | 基于 FashionPedia 开源数据集训练部署目标检测模型
演示视频
立即体验 - 飞桨星河零代码工具:https://aistudio.baidu.com/pipeline/mine
快速开始
单图测试
在应用中心找到 通用目标检测 应用,选择官方提供的模型方案单图测试模型效果。检测目标是时尚服饰,可以看到检测类别偏少,不太符合使用要求(左:测试图像;右:官方模型测试结果)
 |
 |
让我们前往 模型产线 重新训练一个目标检测模型。
模型选型
创建模型产线,命名为时尚服饰目标检测,选择通用目标检测产线后,可以看到产线内有6个不同的目标检测模型选择,分别是:RT-DETR-H, RT-DETR-L, PP-YOLOE_plus-L, PP-YOLOE_plus-S, PicoDet-L, PicoDet-S,benchmark 如下:
| 模型列表 | mAP(%) | GPU 推理耗时(ms) | CPU 推理耗时(ms) | 模型存储大小(M) |
|---|---|---|---|---|
| RT-DETR-H | 56.3 | 100.65 | 8451.92 | 471 |
| RT-DETR-L | 53.0 | 27.89 | 841.00 | 125 |
| PP-YOLOE_plus-L | 52.9 | 29.67 | 700.97 | 200 |
| PP-YOLOE_plus-S | 43.7 | 8.11 | 137.23 | 31 |
| PicoDet-L | 42.6 | 10.09 | 129.32 | 23 |
| PicoDet-S | 29.1 | 3.17 | 13.36 | 5 |
注:以上精度指标为 COCO2017 验证集 mAP(0.5:0.95),GPU 推理耗时基于 NVIDIA Tesla T4 机器,精度类型为 FP32, CPU 推理速度基于 Intel(R) Xeon(R) Gold 5117 CPU @ 2.00GHz,线程数为8,精度类型为 FP32。
简单来说,表格从上到下,模型推理速度更快,从下到上,模型精度更高。本次模型计划部署在服务器上,效果要求较高而对于模型体积大小不敏感,因此我们选择精度最高的 RT-DETR-H 进行训练。
数据准备
数据来源于 FashionPedia 开源数据集,数据标注使用标准的 COCO 格式,模型产线可以直接数据验证后使用。
由于这个开源数据集的图片样本量巨大(训练集:333401个样本,占比97.43%;验证集:8781个样本,占比2.57%;类别数量:46),我们对其进行抽样构造出了 MiniFashionPedia,目前这个数据已公开在星河社区数据集,可访问链接进行下载和使用:https://aistudio.baidu.com/datasetdetail/264391
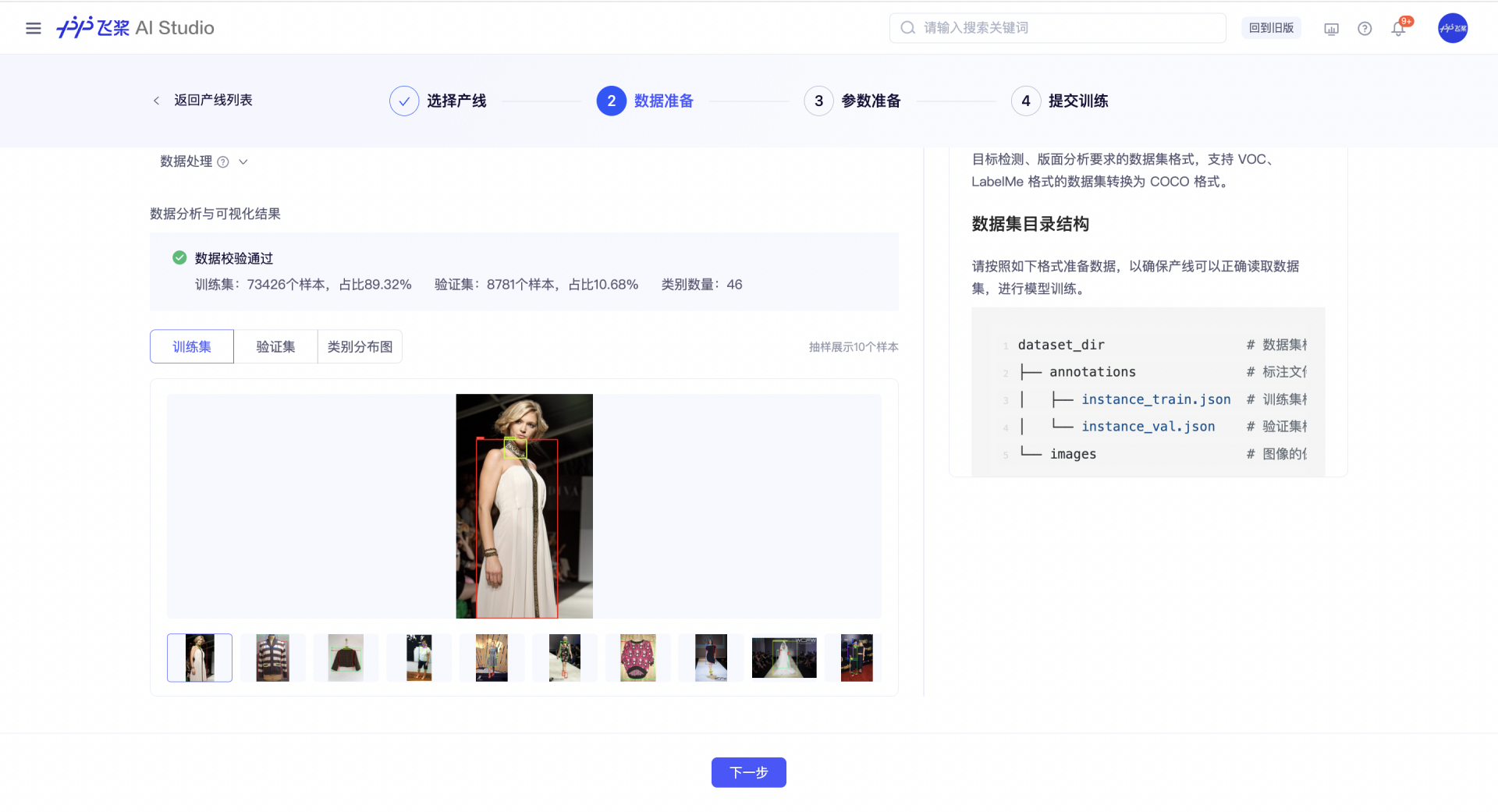
通过数据校验后,我们可以可视化的看到 MiniFashionPedia 数据集的情况:
训练集:73426个样本,占比89.32%;验证集:8781个样本,占比10.68%;类别数量:46。训练集和验证集各抽样10个样本,并画出了46个类别的分布情况。
模型训练
训练参数使用默认配置,具体参数信息和调参建议可参考下面的内容:
基础配置
- 轮次(Epochs): 模型对训练数据的重复学习次数,一般来说,轮次越大,模型训练时间越长,模型精度越高,但是如果设置特别大,可能会导致模型过拟合。如果对轮次没有特别的要求,可以使用默认值进行训练。
- 批大小(Batch Size): 由于训练数据量一般较大,模型每轮次的训练是分批读取数据的,批大小是每一批数据的数据量,和显存直接相关,批大小越大模型训练的速度越快,显存占用越高。为确保训练不会因为显存溢出而终止,我们将 V100 32G 单卡可以运行的最大值作为批大小的可设置最大值。
- 类别数量(Class Num): 数据集中检测结果的类别数,由于类别数量和数据集直接相关,我们无法填充默认值,请根据数据校验的结果进行填写,类别数量需要准确,否则可能引起训练失败。
- 学习率(Learning Rate): 模型训练过程中梯度调整的步长,通常与批大小成正比例关系,学习率设置过大可能会导致模型训练不收敛,设置过小可能会导致模型收敛速度过慢。在不同的数据集上学习率可能不同,对结果影响较大,需要不断调试。
高级配置
- 断点训练权重: 在模型训练过程中发生人为或意外终止的情况时,加载训练中断之前保存的断点权重路径,完成继续训练,避免算力资源浪费。
- 预训练权重: 基于已经在大数据集上训练好的模型权重进行微调训练,可提高模型训练开始前的初始经验,提高训练效率。
- 热启动步数(WarmUp Steps): 在训练初始阶段以较小学习率缓慢增加到设置学习率的批次数量,该值的设置可以避免模型在初始阶段以较大学习率迭代模型最终破坏预训练权重,一定程度上提升模型的精度。
- log 打印间隔(Log Interval) / step: 训练日志中打印日志信息的批次数量间隔。
- 评估、保存间隔(Eval Interval) / epoch: 训练过程中对验证集进行评估以及保存权重的轮数间隔。
评估和部署
基于验证集的评估结果,我们对 best_model 进行模型权重标记,用于后续的服务部署。
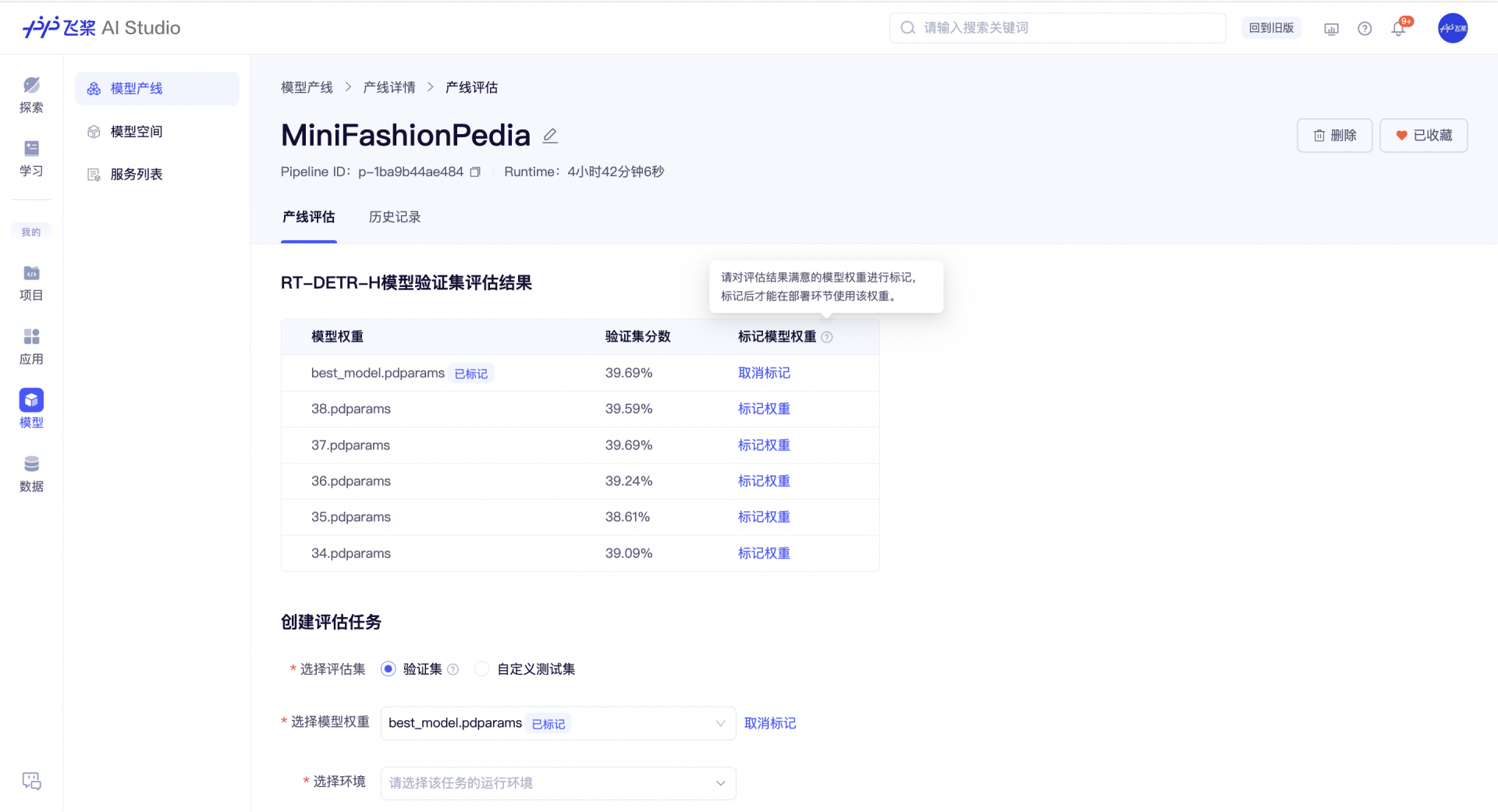
当然,如果你有一批新的数据,也可以通过上传自定义测试集的方式,创建评估任务,对模型权重进行其他评估。
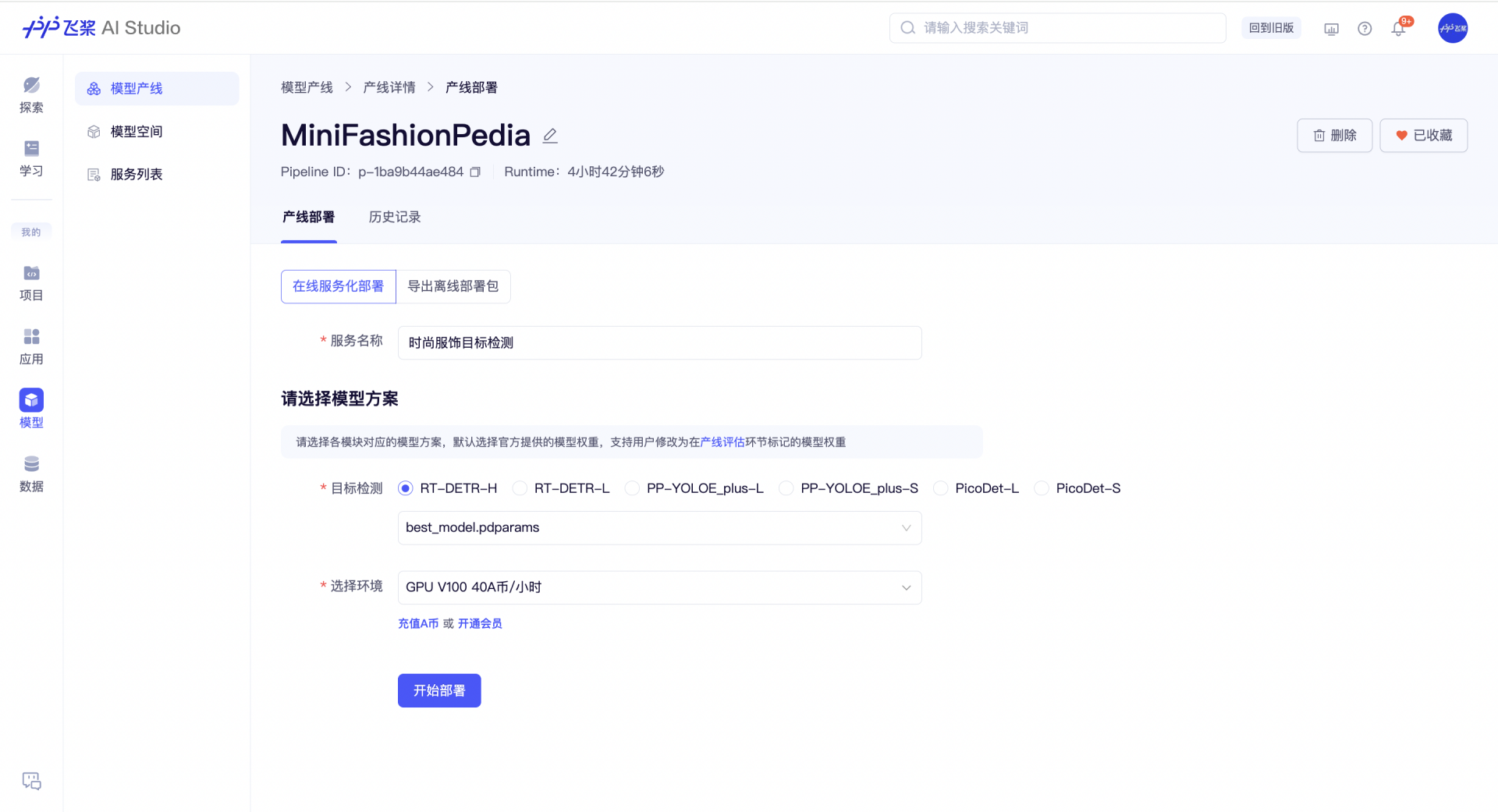
标记模型权重后,我们可以在产线内对应的模型 RT-DETR-H 的权重选择列表中找到 best_model,选择部署环境后,生成一个服务。
效果展示
应用内切换模型方案
零代码产线发布出来的服务支持在应用中调用,即我们可以在应用的模型方案中切换为个人服务,并进行单图测试。
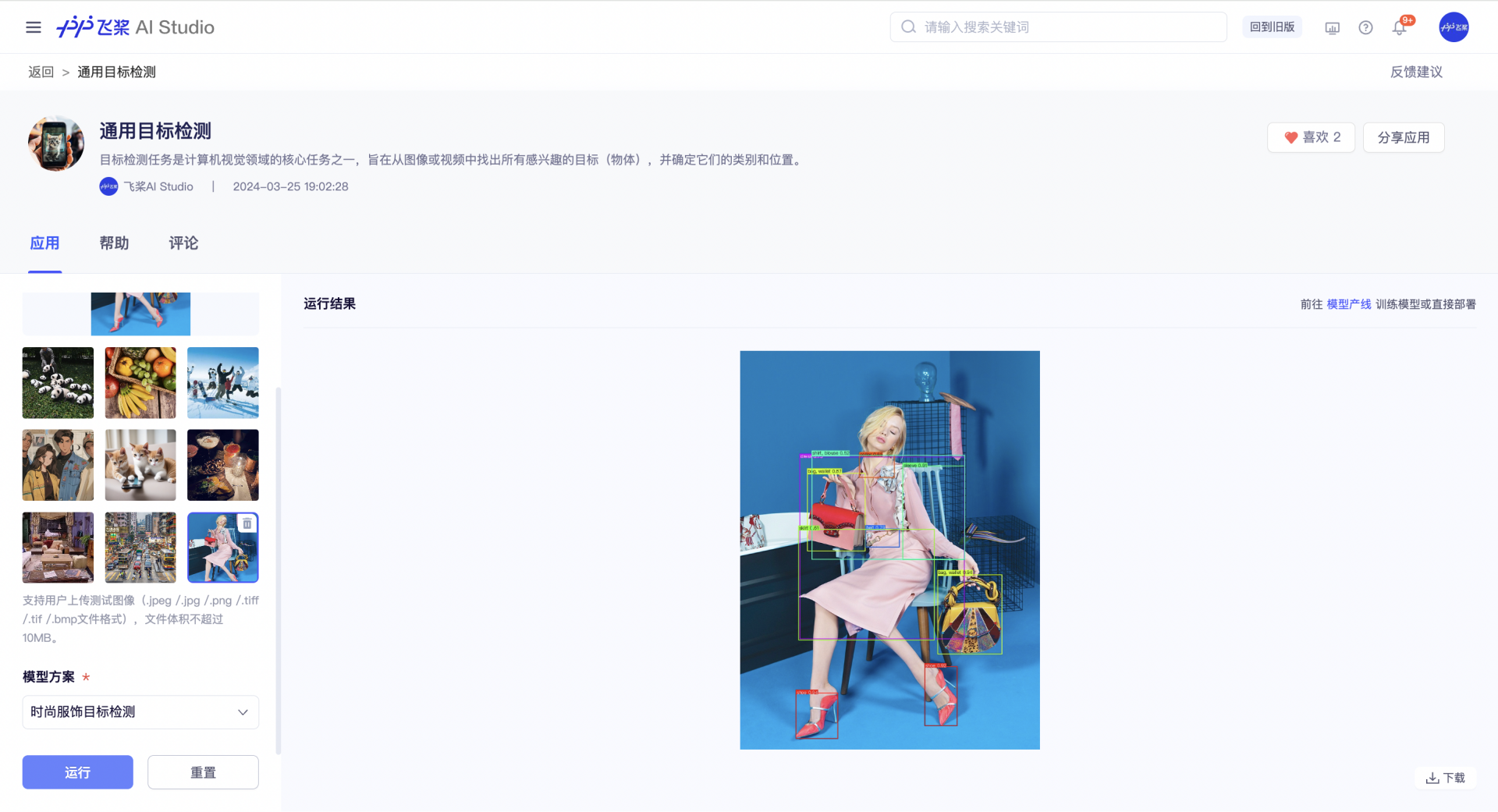
对比下官方模型和我的模型效果(左:官方模型测试结果;右:我的模型测试结果),可以看到训练效果很不错
|
 |
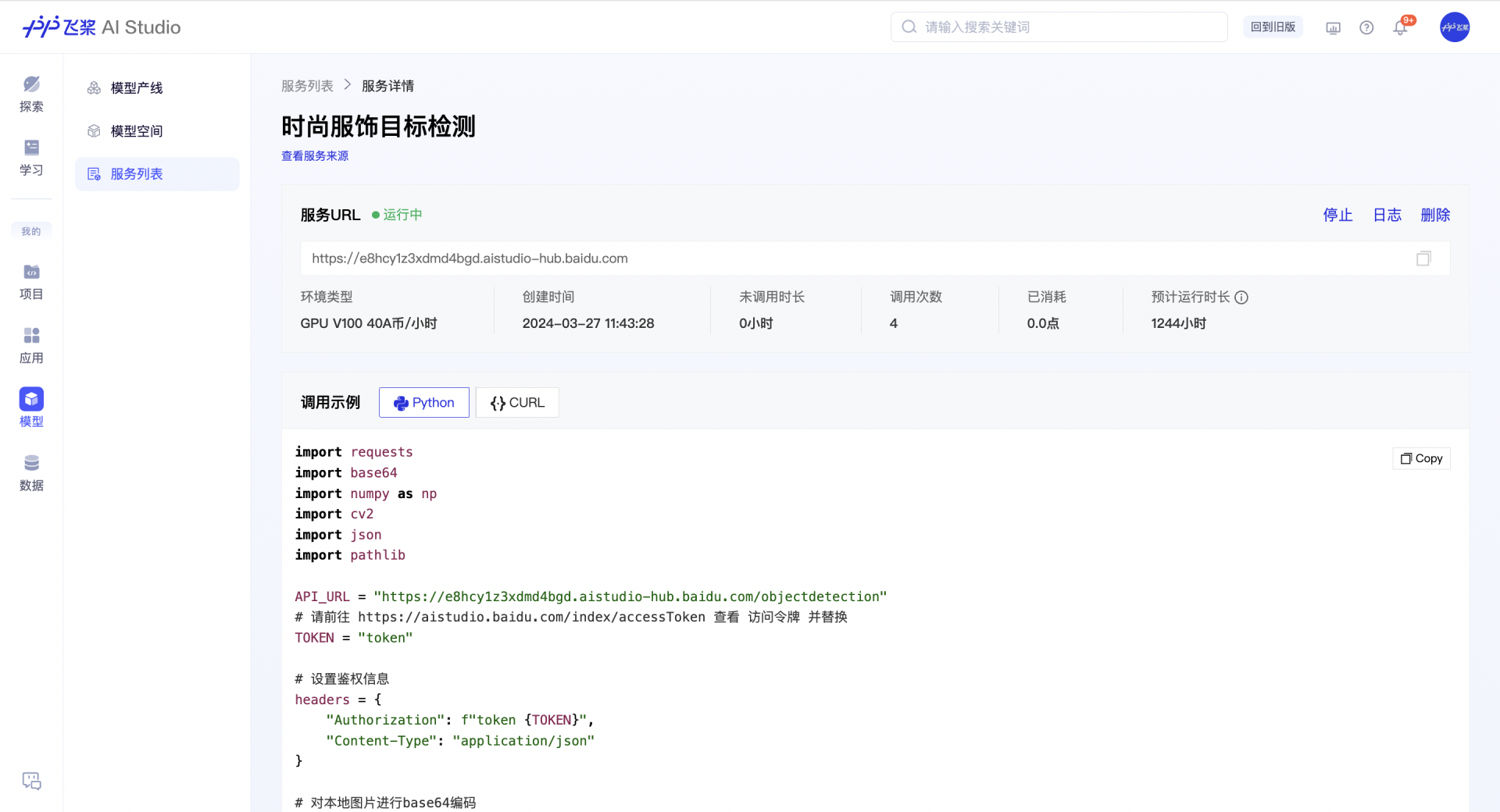
服务 API 调用展示
使用服务内提供的 API 调用示例代码,可以进行本地调用:
import requests
import base64
import numpy as np
import cv2
import json
import pathlib
API_URL = "https://e8hcy1z3xdmd4bgd.aistudio-hub.baidu.com/objectdetection"
# 请前往 https://aistudio.baidu.com/index/accessToken 查看 访问令牌 并替换
TOKEN = "token"
# 设置鉴权信息
headers = {
"Authorization": f"token {TOKEN}",
"Content-Type": "application/json"
}
# 对本地图片进行base64编码
image_path = "test.png"
image_bytes = pathlib.Path(image_path).read_bytes()
image_base64 = base64.b64encode(image_bytes).decode('ascii')
# 设置请求体
payload = {
# 可选本地图片和url,二选一
# "imageUrl": "图片链接",
"image": image_base64,
}
# 调用
response = requests.post(API_URL, json=payload, headers=headers)
# 解析接口返回数据
# 保存bbox数据
response = json.loads(response.content)
bbox_result = response["result"]["bboxResult"]
with open("bbox.json", "w") as f:
json.dump(bbox_result, f)
# 保存可视化图像数据
image_base64 = response["result"]["image"]
image_bytes = base64.b64decode(image_base64)
image_array = np.frombuffer(image_bytes, dtype=np.uint8)
prediction_image = cv2.imdecode(image_array, flags=cv2.IMREAD_COLOR)
cv2.imwrite('output.jpg', prediction_image)