

BML Codelab环境使用说明
目录
- 页面概览
- Comate智能编码助手
- 菜单栏
- 快捷工具栏
- 编辑区 Code Cell
4.1 命令/编辑模式
4.2 Code Cell操作 - 编辑区 Markdown Cell
5.1 命令/编辑模式
5.2 Markdown Cell操作 - 终端
- 侧边栏
7.1 文件浏览器
7.2 数据集
7.3 版本管理
7.4 任务
7.5 代码片段
7.6 包管理
7.7 环境信息
7.8 数据模型可视化
7.9 资源监控 - 应用
- 快捷键操作
- 常见问题解答
页面概览
Notebook是用户运行Notebook类型的项目后,在浏览器端所看到的交互式编程界面。
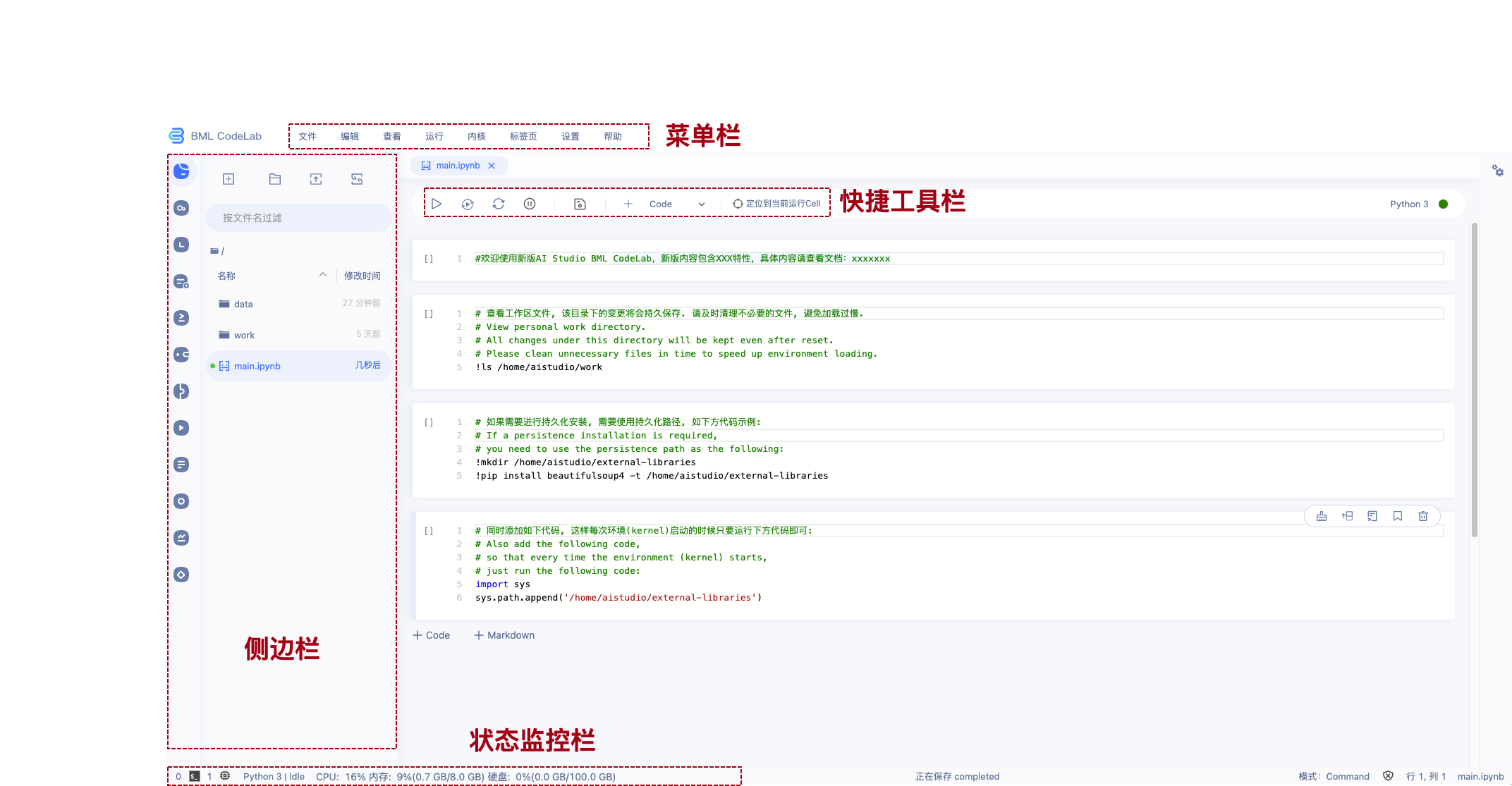
Notebook由以下这几个部分构成:
- 菜单栏
- 快捷工具栏
- 代码编辑区 Code Cell
- 代码编辑区 Markdown Cell
- 侧边栏
- 状态监控区
以下对每个部分的操作分别说明.
Comate智能编码助手
JuypterLab中解锁使用方式
- 使用Comate注释生成代码:启动项目进入BML CodeLab环境,创建Jupyter Notebook,在Code区块中写完注释后,【回车键】触发Comate根据注释生成代码,【Tab键】采纳代码
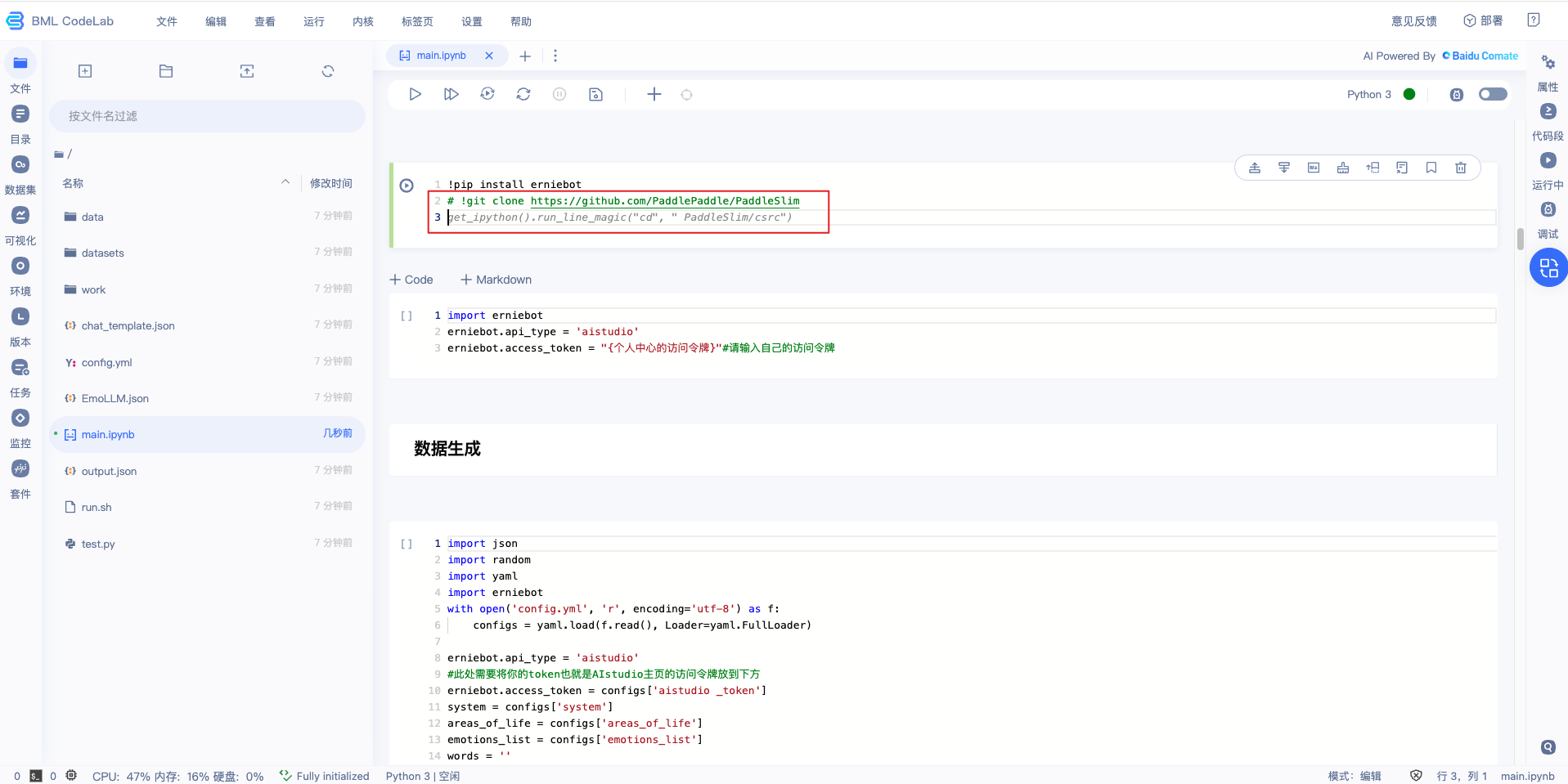
- 使用Comate代码续写:在编码过程中,【回车键】触发Comate自动推荐后续代码,【Tab键】采纳代码
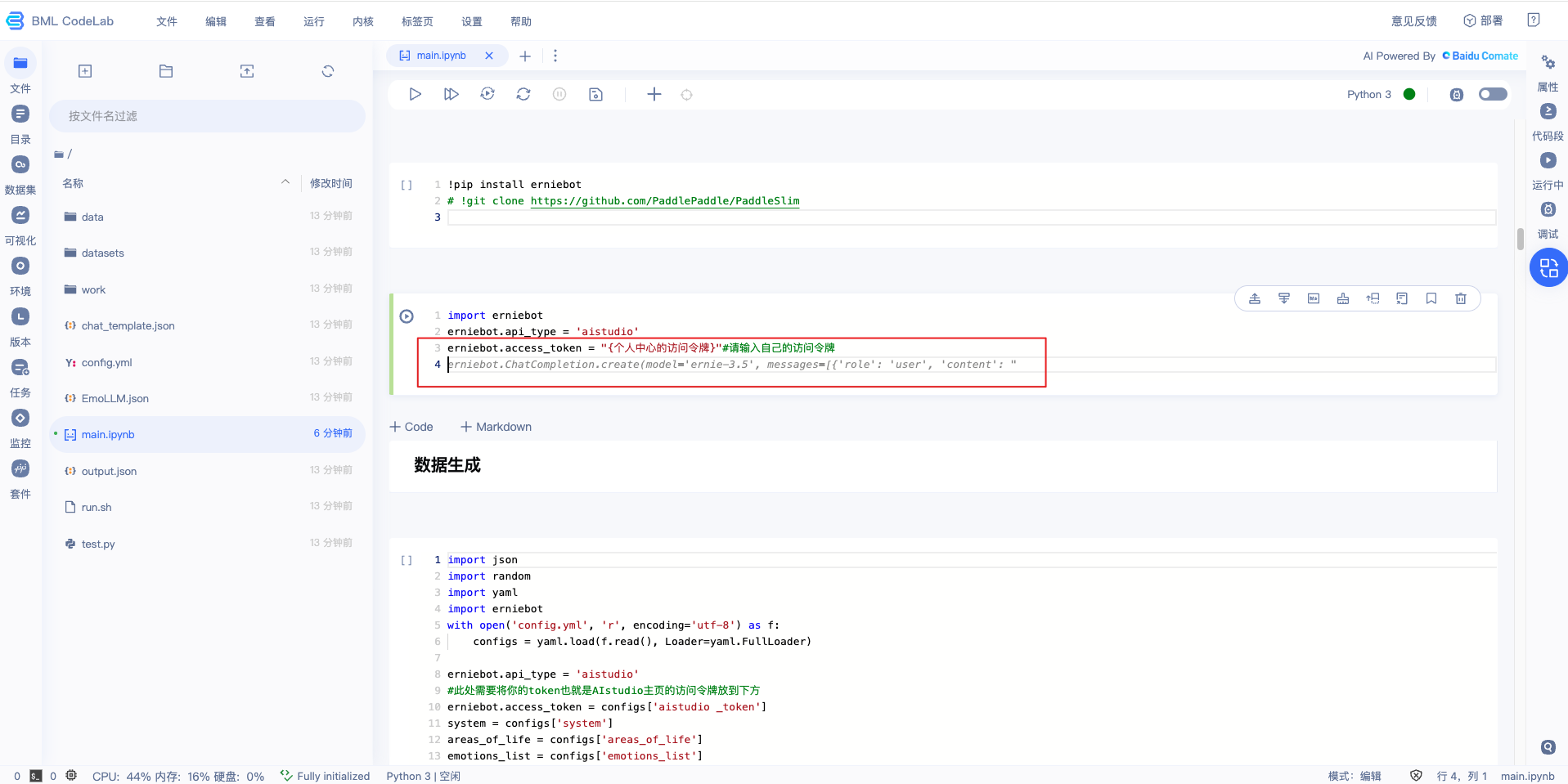
VS Code中解锁使用方式
- 切换至VS Code:启动项目进入BML CodeLab环境,点击右上角浮窗,切换至VS Code
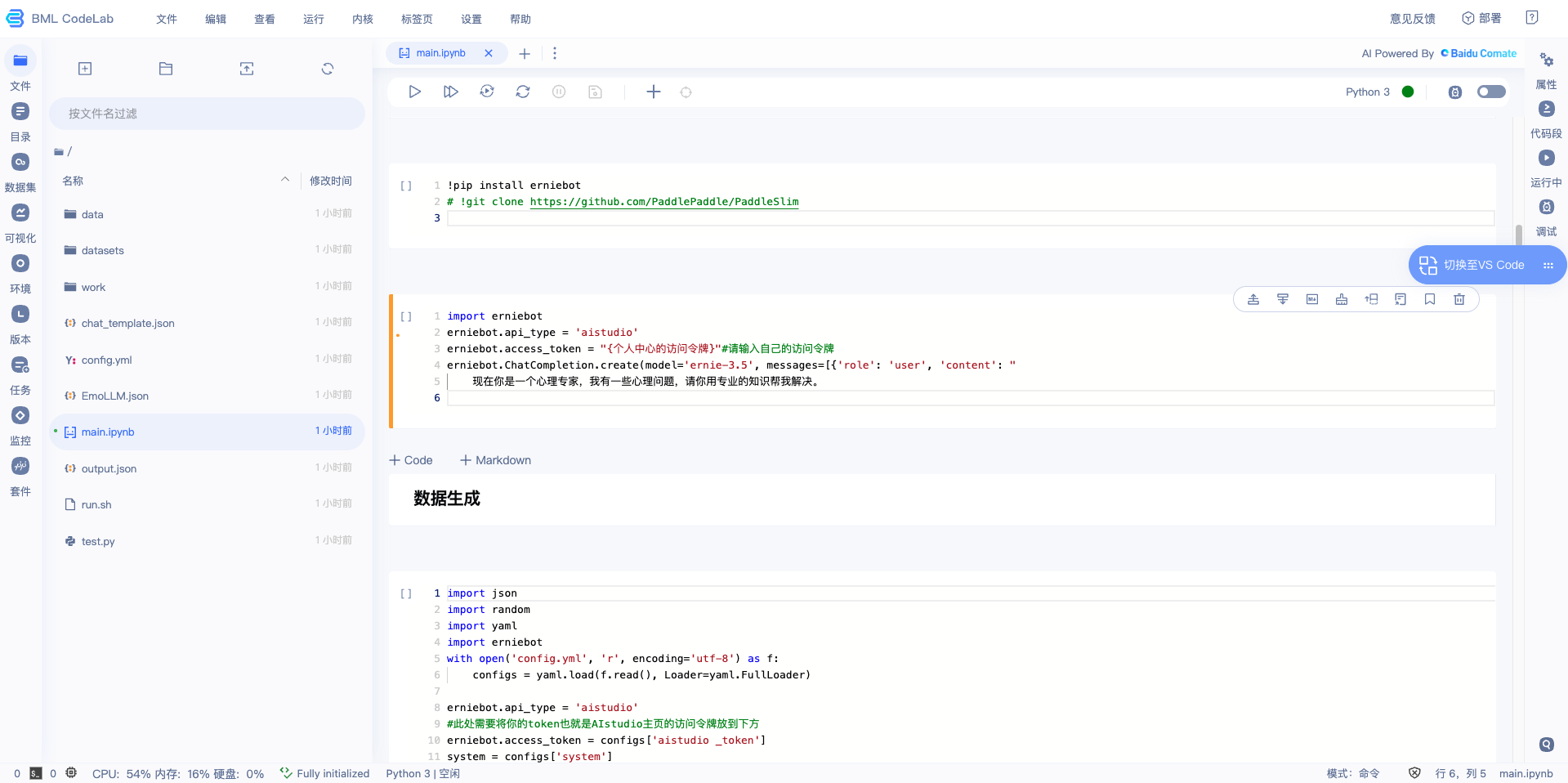
- 使用Comate智能编程:在VS Code中编程,Comate智能助手自动触发,体验代码生成、代码解释能力
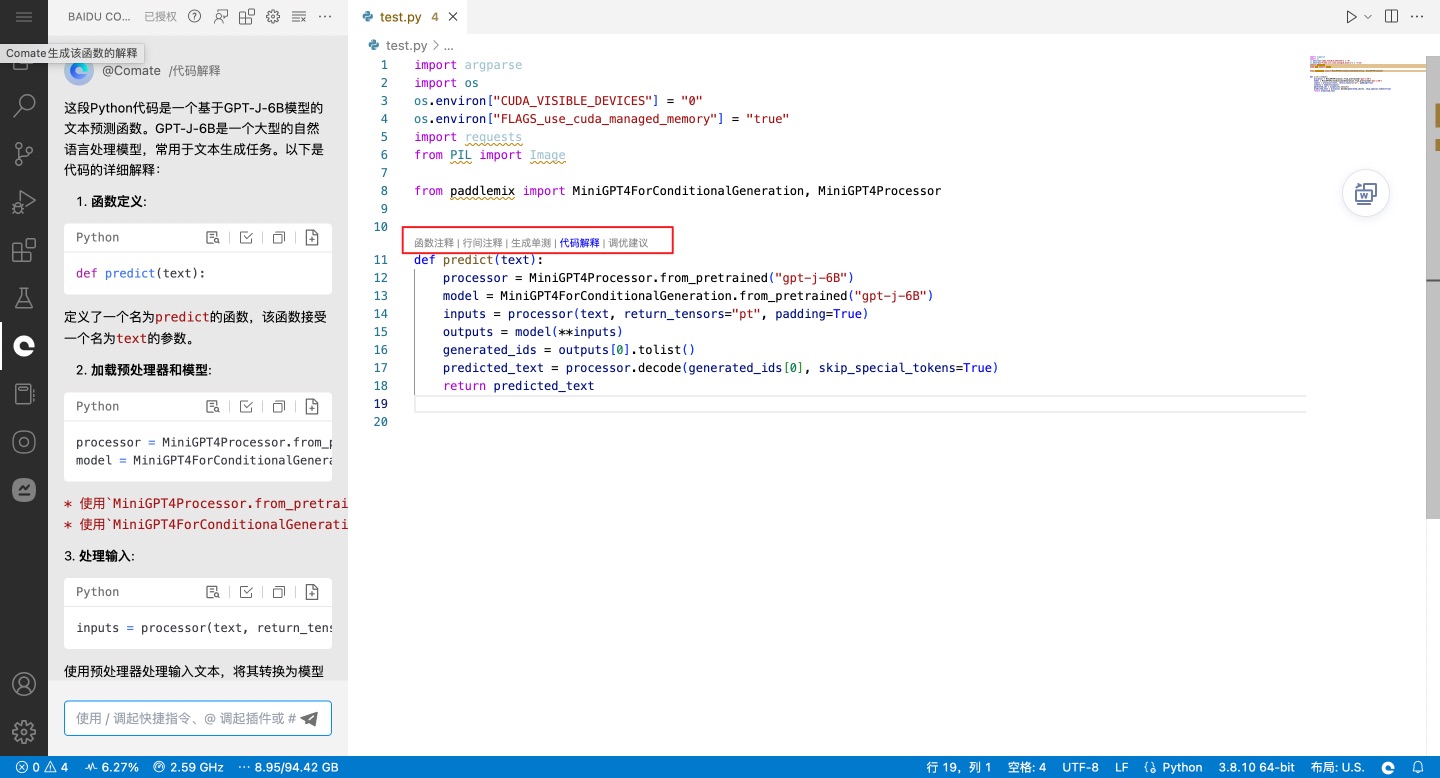
- 唤起Comate智能问答:一键@调用更多官方插件,通过智能问答解决开发问题
- 详细使用方式请参考课程:用Baidu Comate大幅提升编码效率
菜单栏
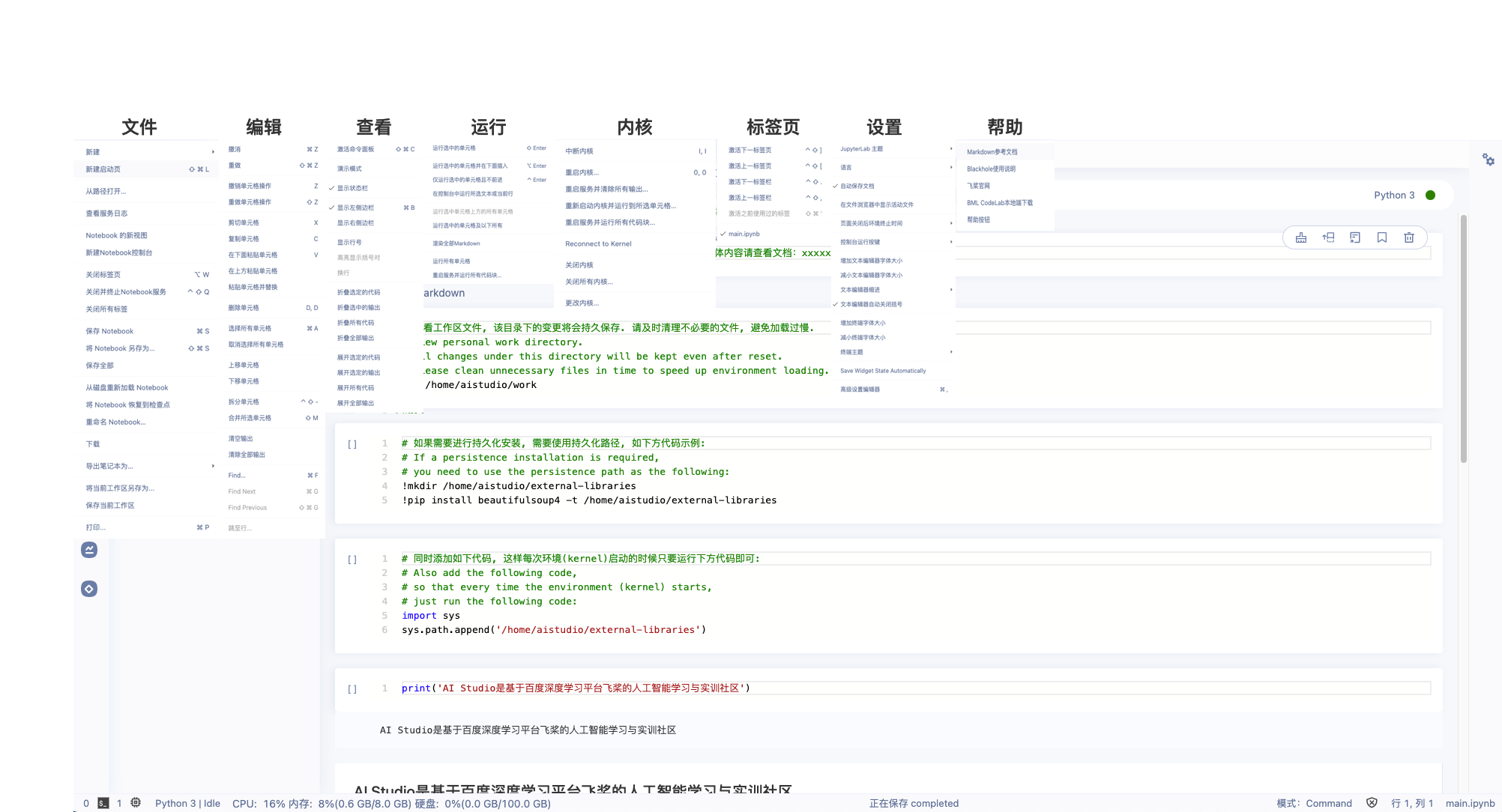
- 文件 :对整体项目文件的操作.
- 编辑 :对单元格的操作.
- 查看 :关于视图的操作.
- 运行 :不同方式的cell运行命令.
- 内核 :关于内核的操作.
- 标签页 :关于标签页的操作.
- 设置 :关于notebook的系统设置操作.
- 帮助 :使用帮助,包括Markdown参考文档、Blackhole使用说明、飞桨官网、BML CodeLab本地端下载、帮助按钮.
快捷工具栏

- 运行 :运行当前选中的Code cell.
- 终止运行 :停止Notebook运行状态.
- 重启内核 :重启代码内核,清空环境中的环境变量、缓存变量、输出结果等.
- 保存 :保存Notebook项目文件.
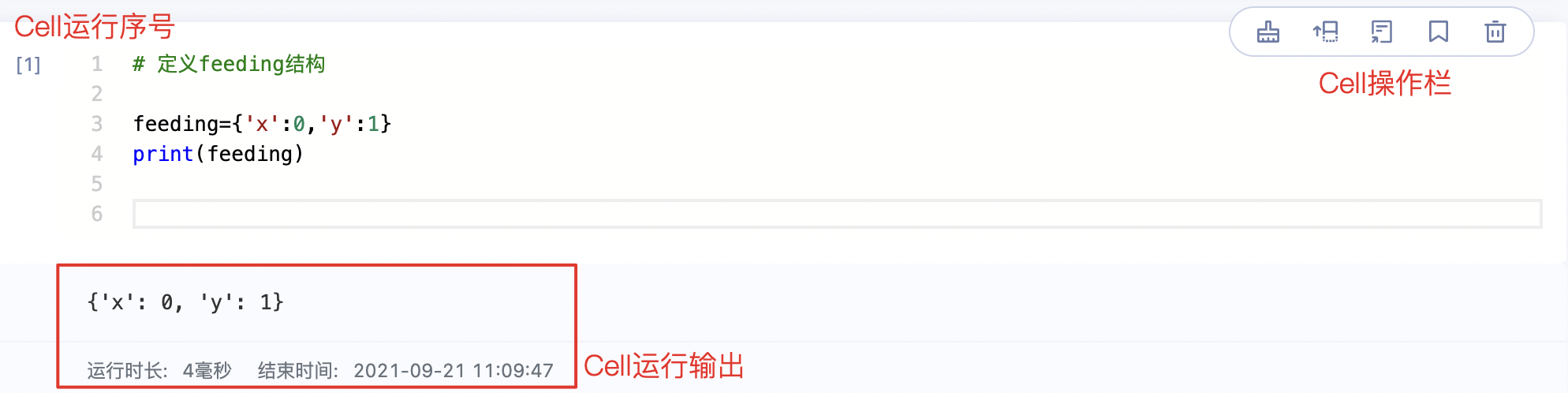
编辑区 Code Cell
Code Cell是Notebook的代码编写单元。用户在Code Cell内编写代码(支持Python3)和shell命令,代码/命令在云端执行,并返回结果到Code Cell.
命令/编辑模式
绿色代表块内容可编辑状态-编辑模式(比如输入代码),蓝色代表块可操作状态-命令模式(比如删除Cell,必须回到蓝色),与linux编辑器vi/vim类似,编辑模式和命令模式之间可以用Esc和Enter来切换。
- 编辑模式

- 命令模式

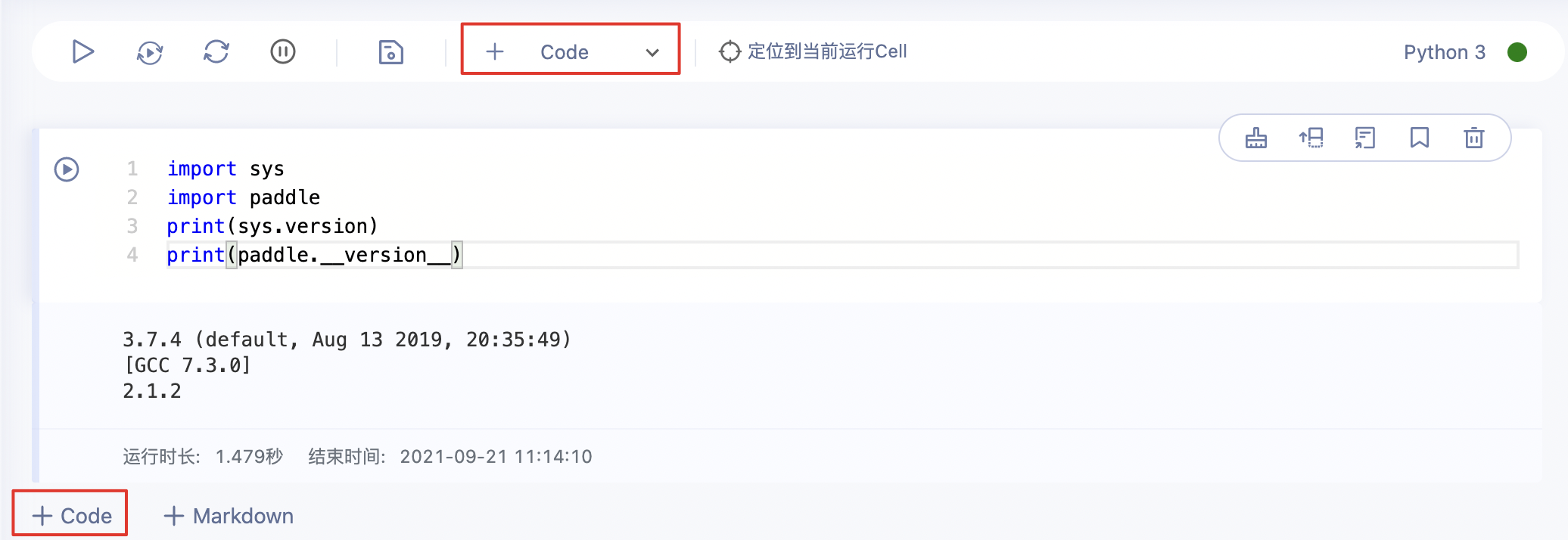
Code Cell操作
- 新建Cell
- 从快捷工具栏中点击【+Code】新建Code Cell
- 在Cell下方点击【+Code】新建Code Cell
- 运行Cell

- 运行中状态:

- 折叠Cell
- 其他操作

-
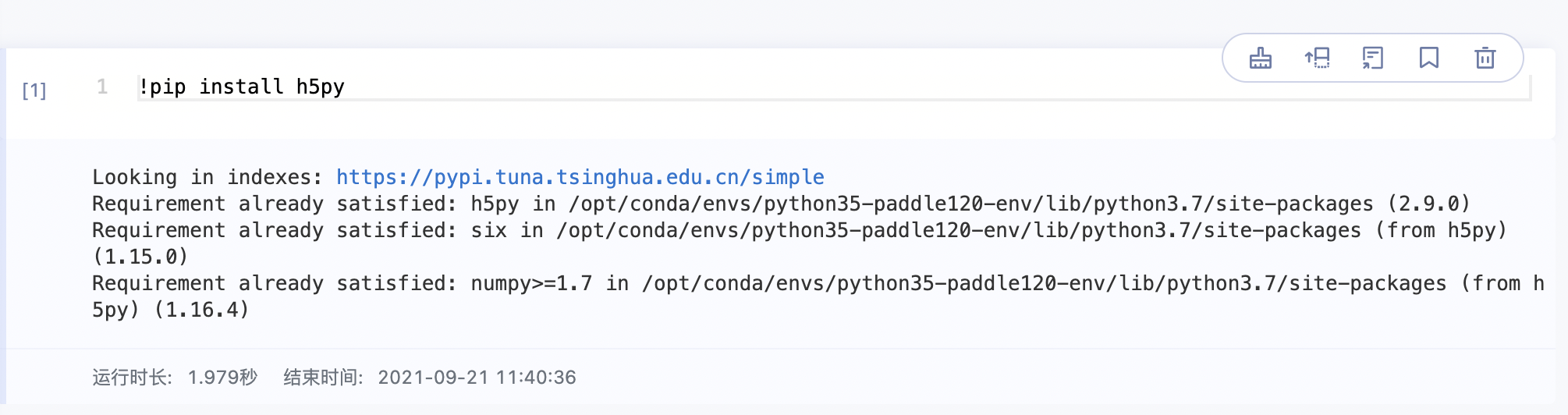
Linux命令
运行Linux命令的方式是在Linux命令前加一个
!,就可以在块里运行示例1:安装第三方包
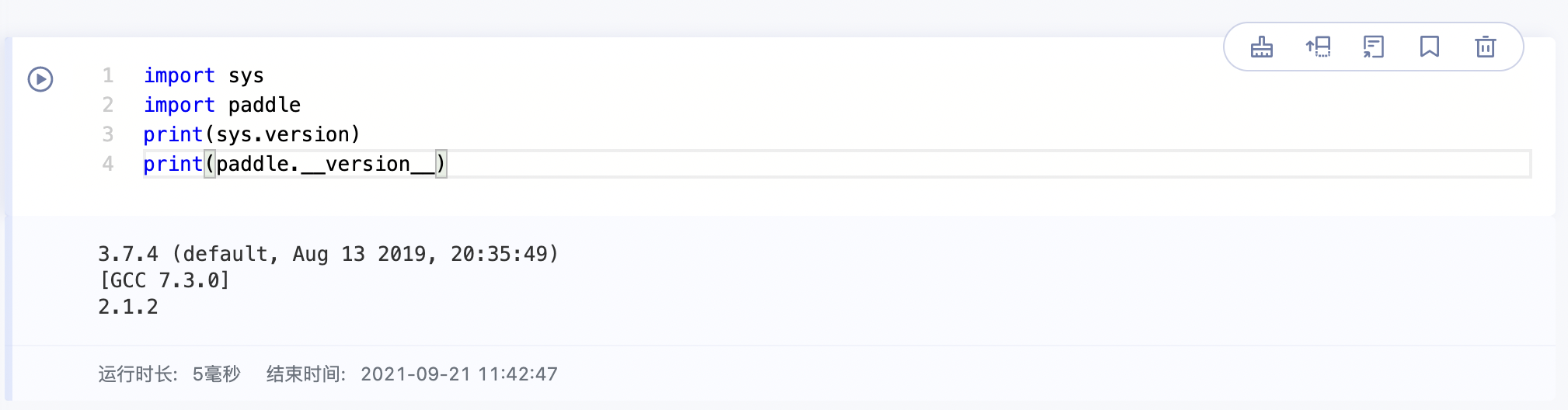
示例2:查看当前环境中的Python版本和Paddle版本
-
Magic关键字
Magic关键字是可以运行特殊的命令. Magic 命令的前面带有一个或两个百分号(% 或 %%), 分别代表
行Magic命令和Cell Magic命令.行Magic命令仅应用于编写Magic命令时所在的行, 而Cell Magic命令应用于整个Cell.
| Magic关键字 | 含义 |
|---|---|
| %timeit | 测试单行语句的执行时间 |
| %%timeit | 测试整个块中代码的执行时间 |
| %matplotlib inline | 显示 matplotlib 包生成的图形 |
| %run | 调用外部python脚本 |
| %pdb | 调试程序 |
| %pwd | 查看当前工作目录 |
| %ls | 查看目录文件列表 |
| %reset | 清除全部变量 |
| %who | 查看所有全局变量的名称,若给定类型参数,只返回该类型的变量列表 |
| %whos | 显示所有的全局变量名称、类型、值/信息 |
| %xmode Plain | 设置为当异常发生时只展示简单的异常信息 |
| %xmode Verbose | 设置为当异常发生时展示详细的异常信息 |
| %debug | bug调试,输入quit退出调试 |
| %bug | 调试,输入quit退出调试 |
| %env | 列出全部环境变量 |
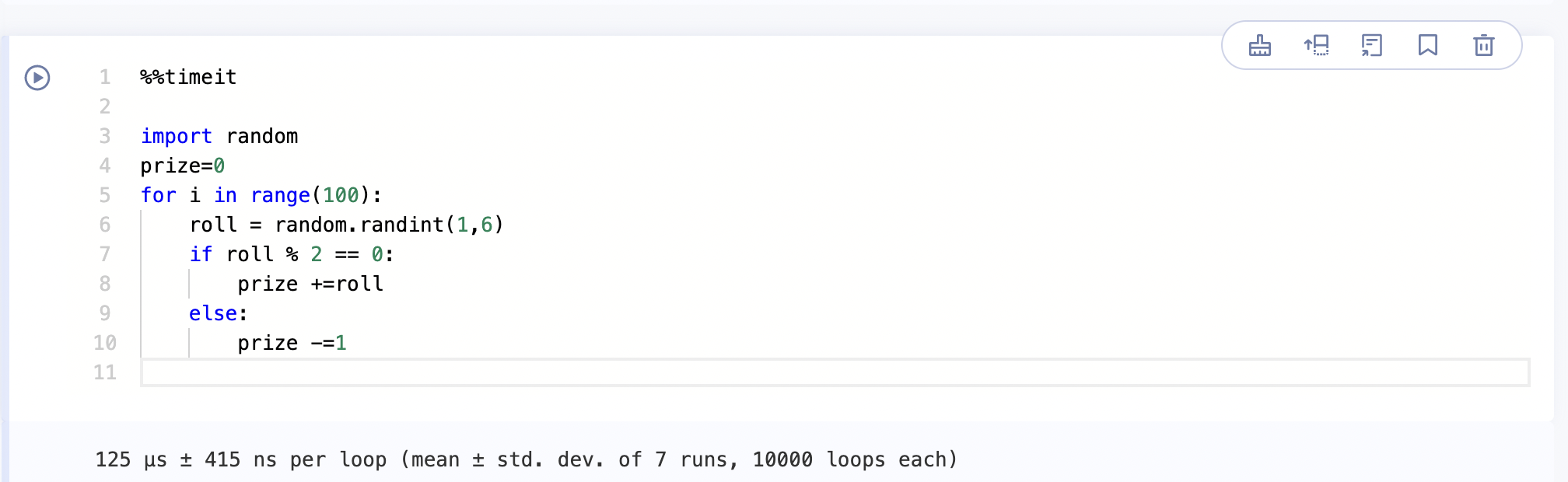
示例1: 使用 %%timeit测算整个块的运行时间.
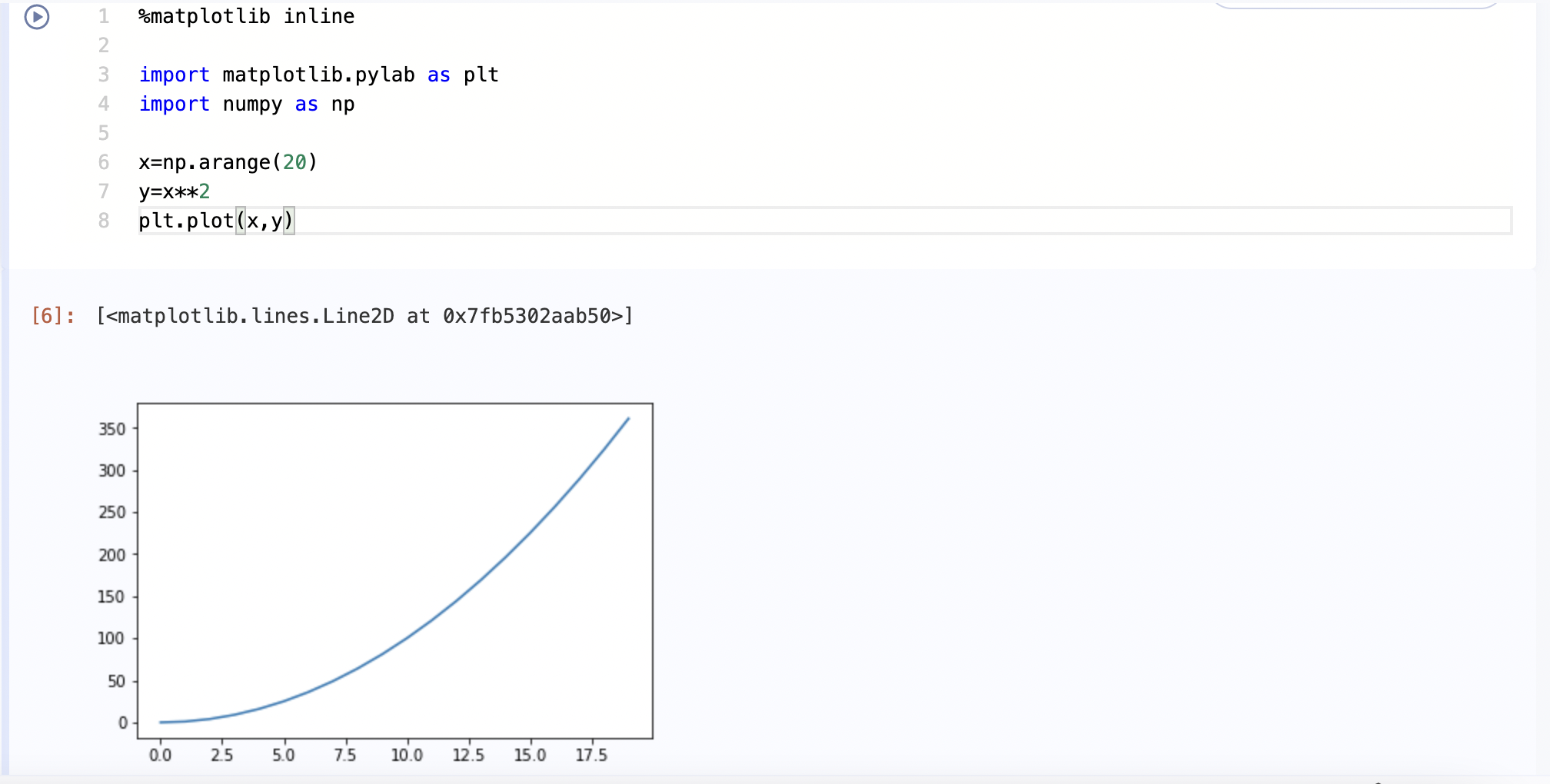
示例2: 块可集成Matplotlib,从而进行绘图, 但需要注意绘图前需要输入%Matplotlib inline并运行, 否则即使运行终端可用的绘图代码段, cell也只会返回一个文件说明, 如下图所示
编辑区 Markdown Cell
Markdown Cell是Notebook中文本编辑单元,通过在Markdown Cell中输入Markdown格式的文本,可以编写文字教程说明.
命令/编辑模式
绿色代表块内容可编辑状态-编辑模式(比如输入文字),蓝色代表块可操作状态-命令模式(预览md展示样式),编辑模式和命令模式之间可以用Esc和Enter来切换。
- 编辑模式

- 命令模式(预览样式)

Markdown Cell操作
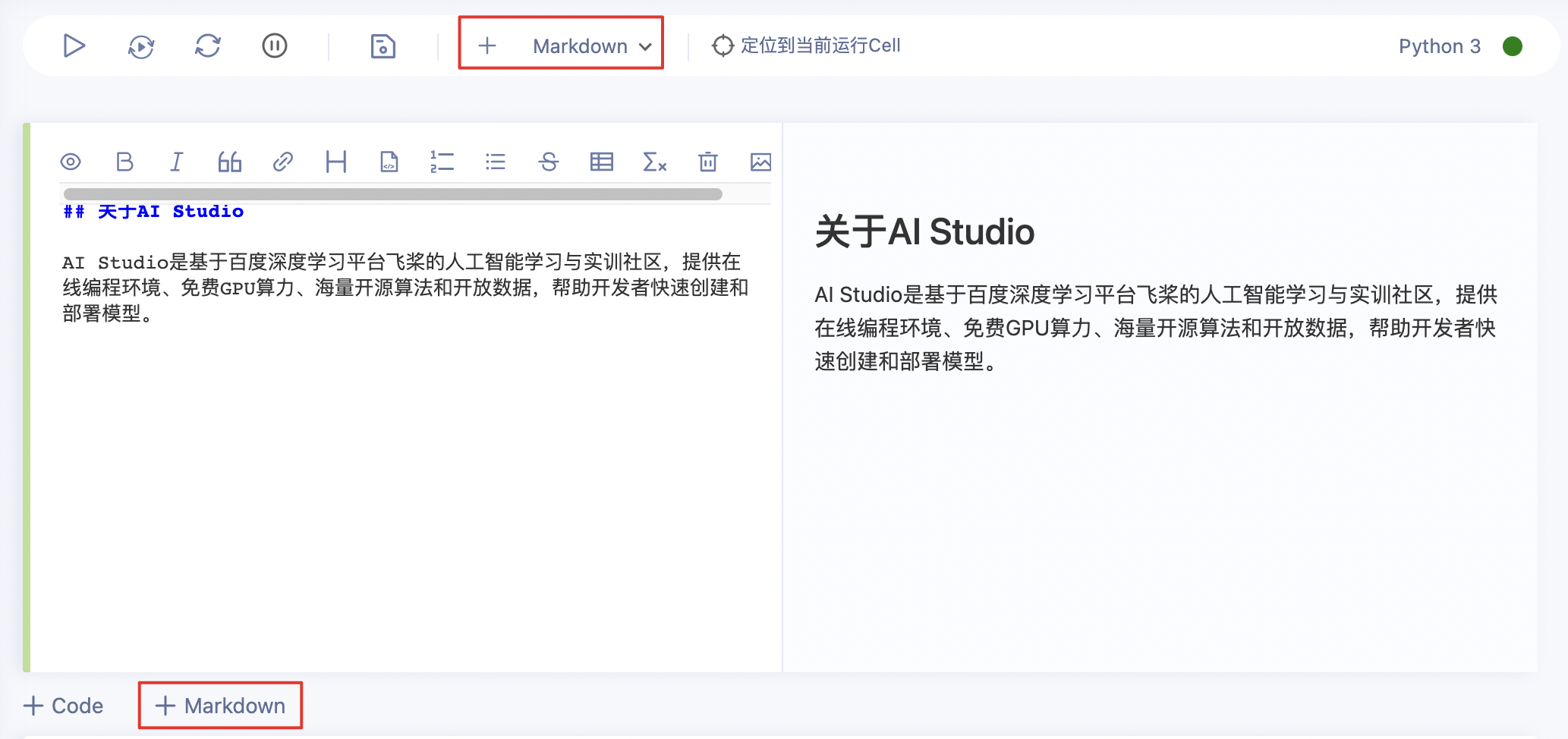
- 新建Cell
- 从快捷工具栏中点击【+Markdown】新建Markdown Cell
- 在Cell下方点击【+Markdown】新建Markdown Cell
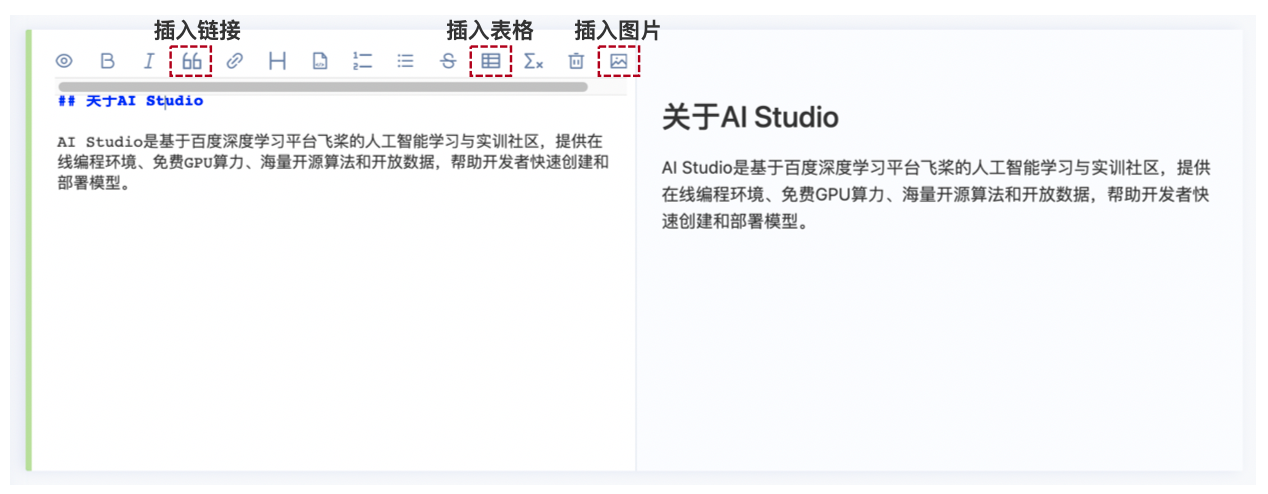
- 编辑Cell 支持插入公式、表格、图片、音乐、视频、网页等. 相关Markdown用法可以参考Markdown官网.
终端
用户可以使用终端来进行一些操作,例如查询GPU占用率. 或进行文本编辑.
用户可以从启动页点击终端打开终端界面.
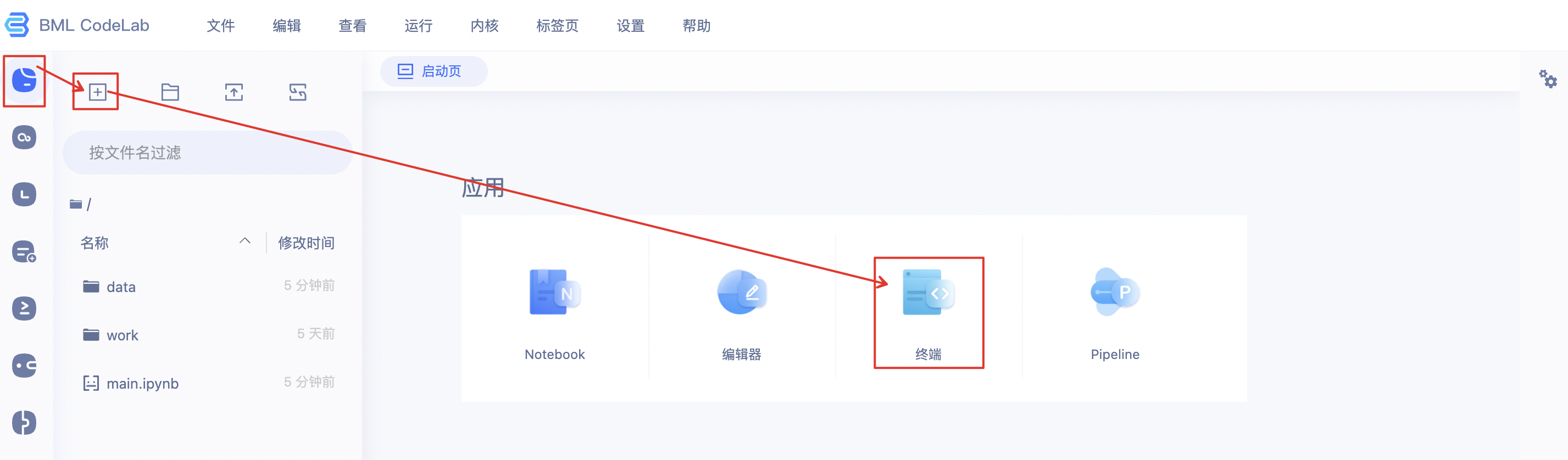
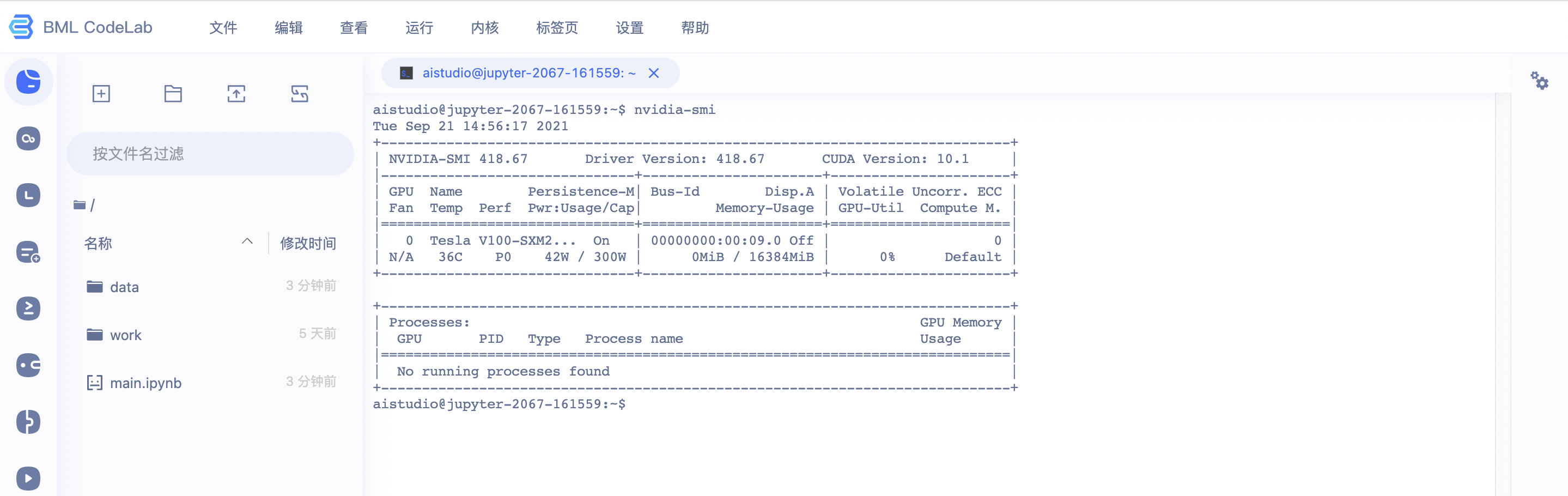
注意:
- Terminal未开放sudo权限.
- 最多可同时使用5个终端.
侧边栏
文件浏览器
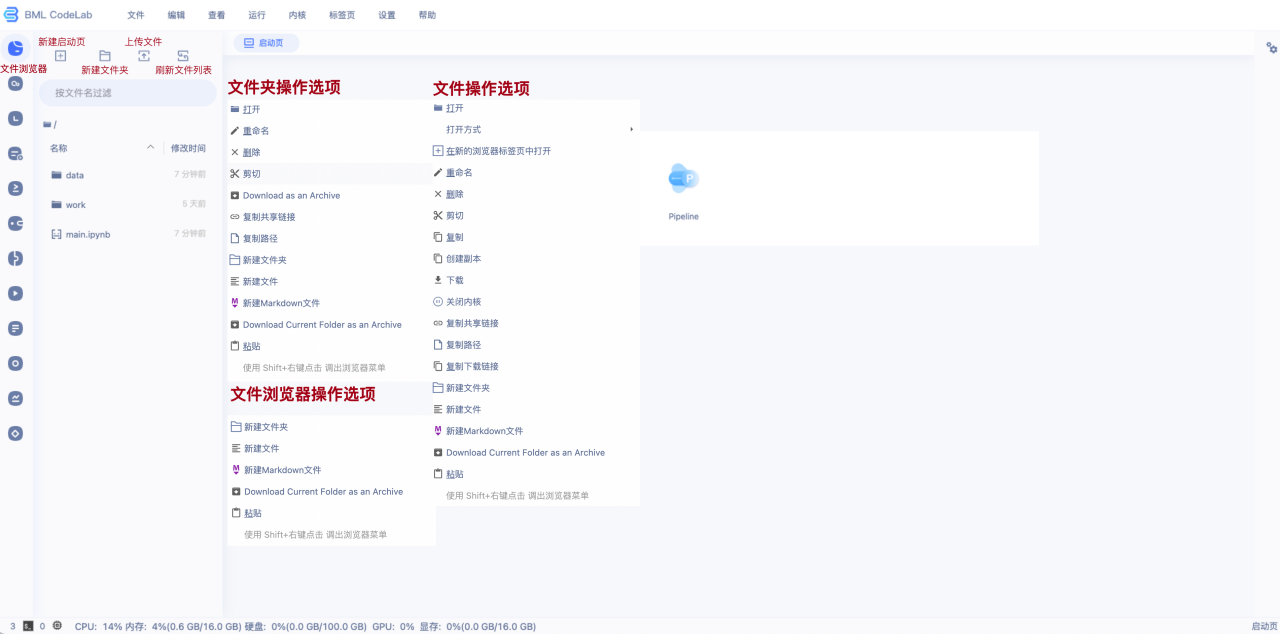
按照树形结构展示/home/aistudio路径下的文件夹和文件。可以在该目录下进行如下操作:
- 文件浏览器操作选项: 右键文件浏览器目录页空白处,可以实现新建操作.
- 文件夹操作: 右键文件夹,会出现操作按钮, 包括下载文件、重命名文件、路径复制等.
- 文件操作: 右键文件, 会出现操作按钮, 包括下载文件、重命名文件、路径复制等.
- 注意:
/home/aistudio/data是非持久化目录,请不要将您的文件放到该目录下,重启后,文件将会丢失.
文件浏览器上方有4个按钮,具体含义如下:
- 新建启动页:打开启动页,可快速实现Notebook创建、TXT文件创建、终端创建、Pipeline创建.
- 新建文件夹:快速实现文件夹创建.
- 上传文件: 上传的单个文件最大 150 MB.
- 刷新文件列表:如果在代码运行过程中磁盘里的文件更新了,可以点击刷新,并在文件浏览器界面查看文件更新的状态.
数据集
在数据集栏中, 可以复制数据集文件的路径, 并置于代码中. 复制数据集路径成功则出现对应提示:
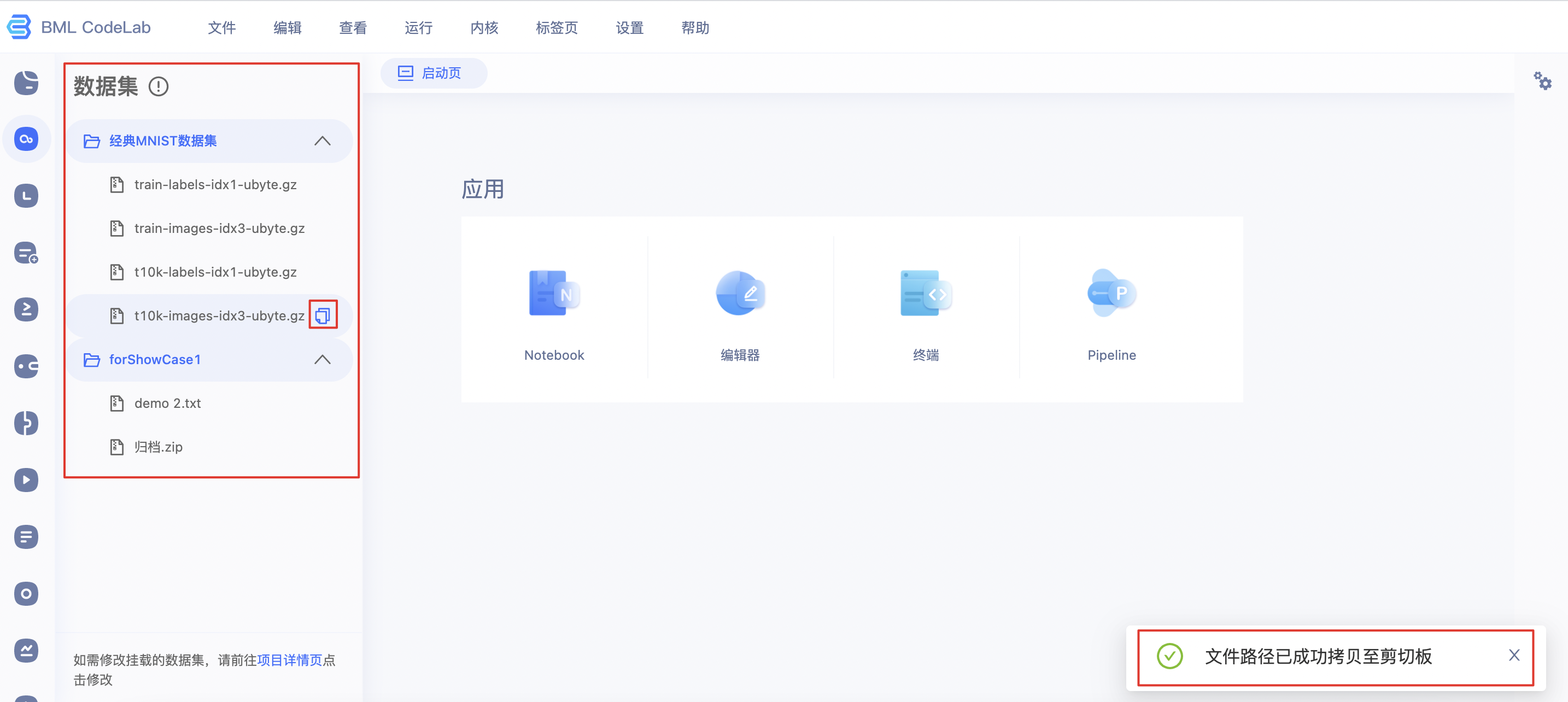
在运行过程中, 如数据集内容发生变化, 并不会自动变更, 需要项目环境重启后才能看到.
数据集文件通常存于文件夹/data/路径下.
版本管理
版本是用于保存项目空间中的重要文件, 以及恢复;用户最多可以生成20个版本, 并制定不同的版本名称.
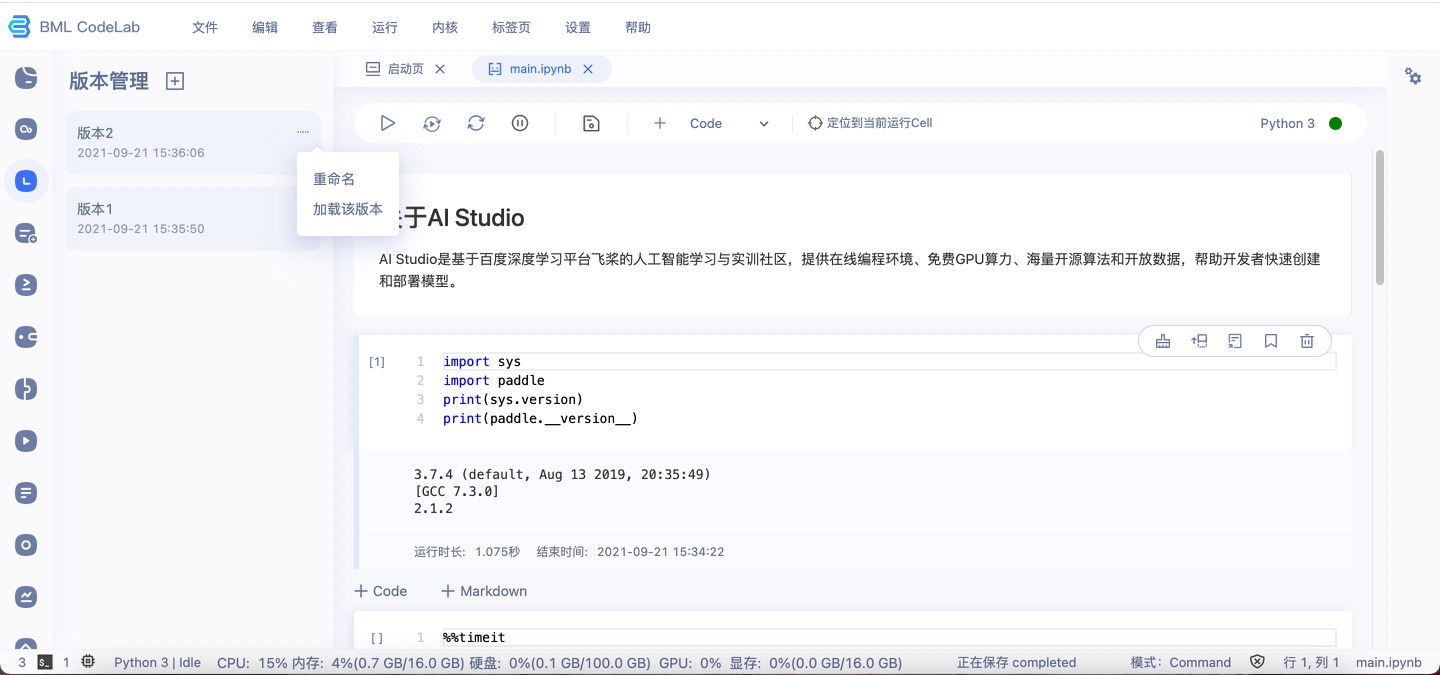
创建版本
用户可以点击左侧"版本"->"版本目录头部【+】", 来生成一个新版本. 每个版本最少会包含一个文件(其中.ipynb文件并非默认选中,用户可根据自己的需要添加文件至版本), 最大可以达到1GB, 可包含至多1000个附带文件.
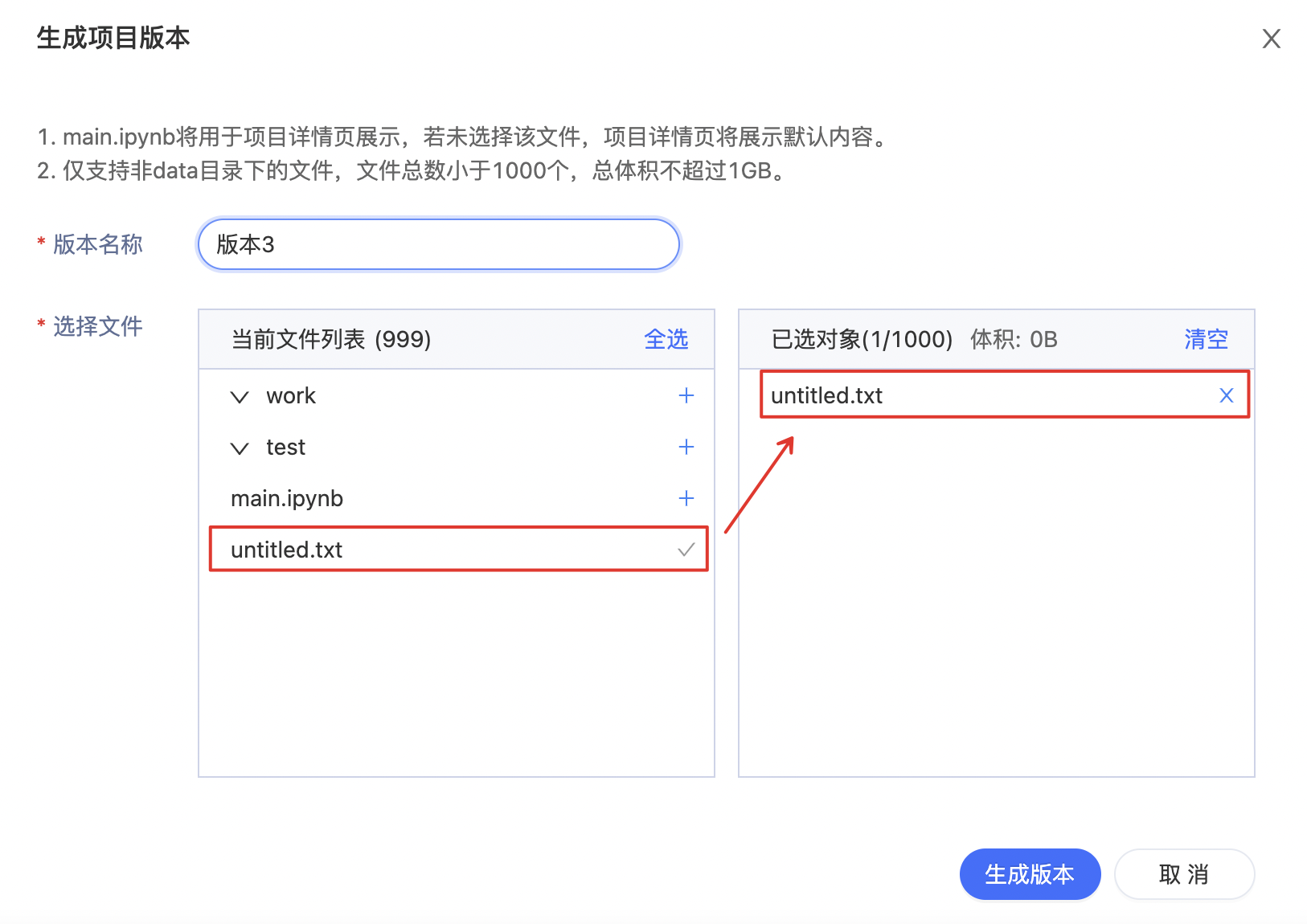
加载历史版本
用户正在编辑的内容会自动置为"草稿"版本, 如果用户对草稿版本的内容不满意, 可以重新加载历史上的版本以重新开始.
注意: 加载历史版本为全量操作, 即当前草稿版本的内容会被全部清空.
任务
由于Notebook有高级版GPU、尊享版GPU环境每周运行总时长限制, 以及Notebook离线运行时长最多2小时, 如果需要突破这两种限制, 可以使用Notebook中的后台任务.
后台任务基于一个版本, 可以将全部版本内容提交至后台的GPU服务器上进行运行, 然后可以将运行后的结果全量返回并再次导入Notebook环境中的一种机制.
BML Codelab中,后台任务依赖于版本中根目录(/home/aistudio/)下的ipynb文件,用户可将运行内容写在ipynb文件中,如根目录(/home/aistudio/)下的ipynb文件,则任务无法创建.
后台任务不依赖当前Notebook的硬件环境, 因此无论在普通版(CPU)环境, 还是在高级版(GPU)环境中, 均可以创建并提交.
后台任务创建流程
1、通过左侧工具栏点击「任务」,切换至任务窗口。
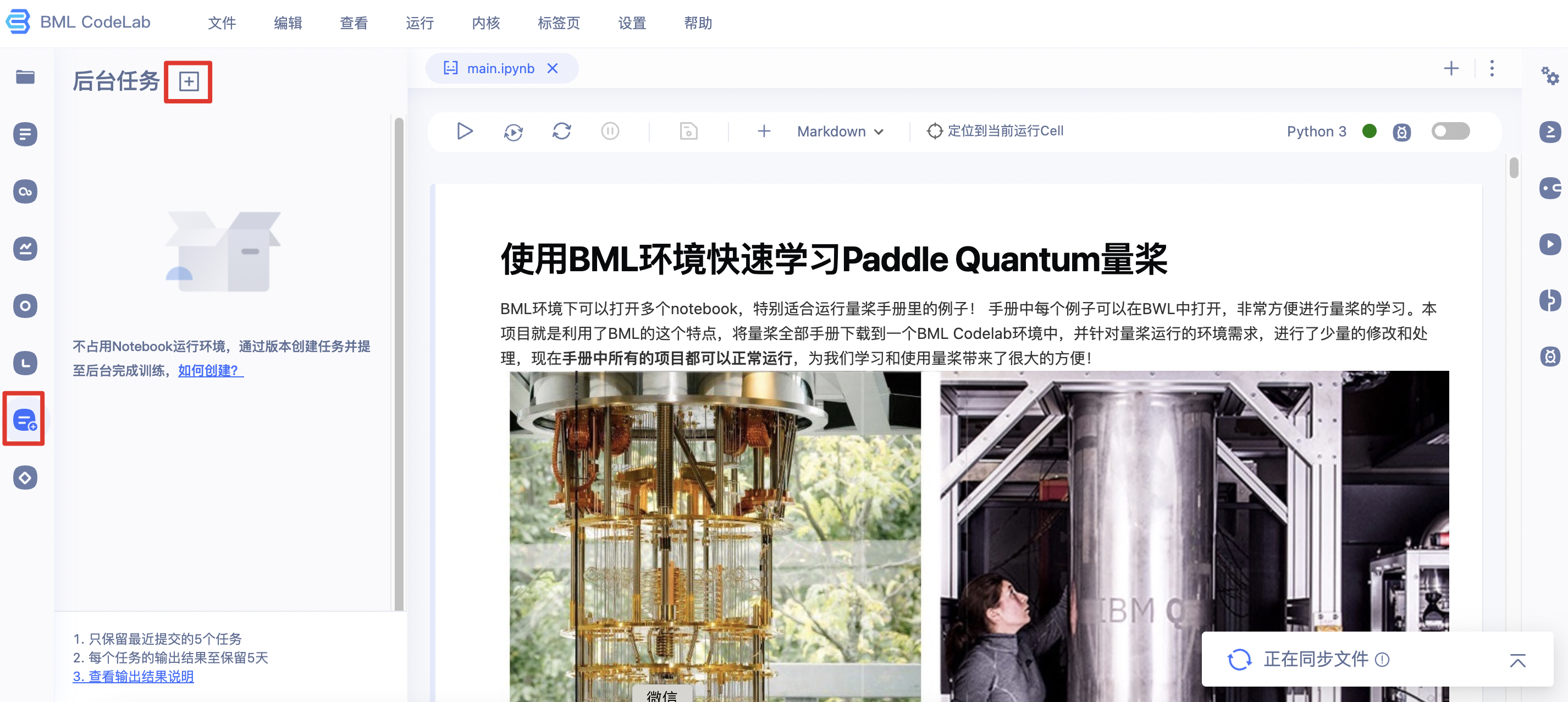
2、点击「创建任务」弹窗显示创建任务页面【1】。因为后台任务依赖与版本中根目录下的ipynb文件,因此您可根据实际情况选择「新建版本」或使用已有版本填写必要信息。若选择「新建版本」则进入创建版本页面。
注意:为保证任务的高效且正常运行,建议您在 Notebook 环境中完成项目调试,调试通过后再生成对应的任务版本。
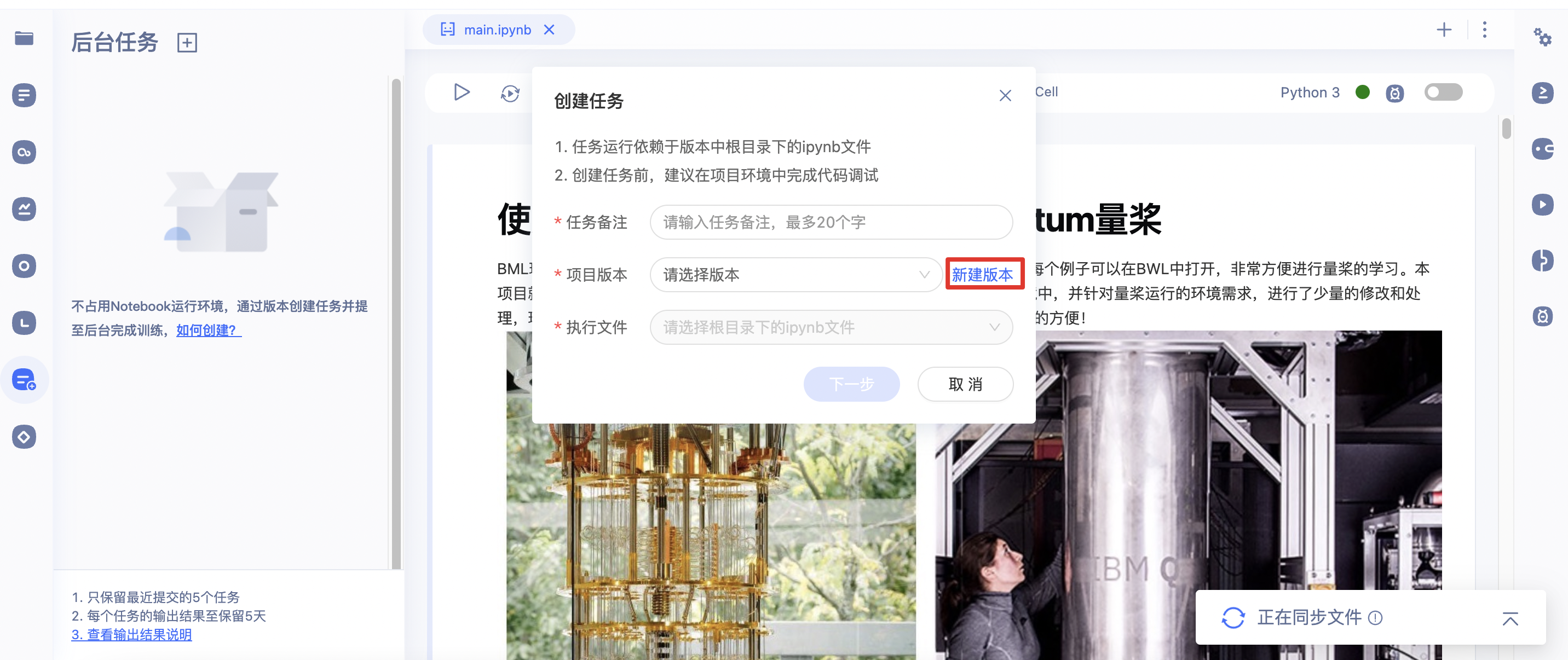
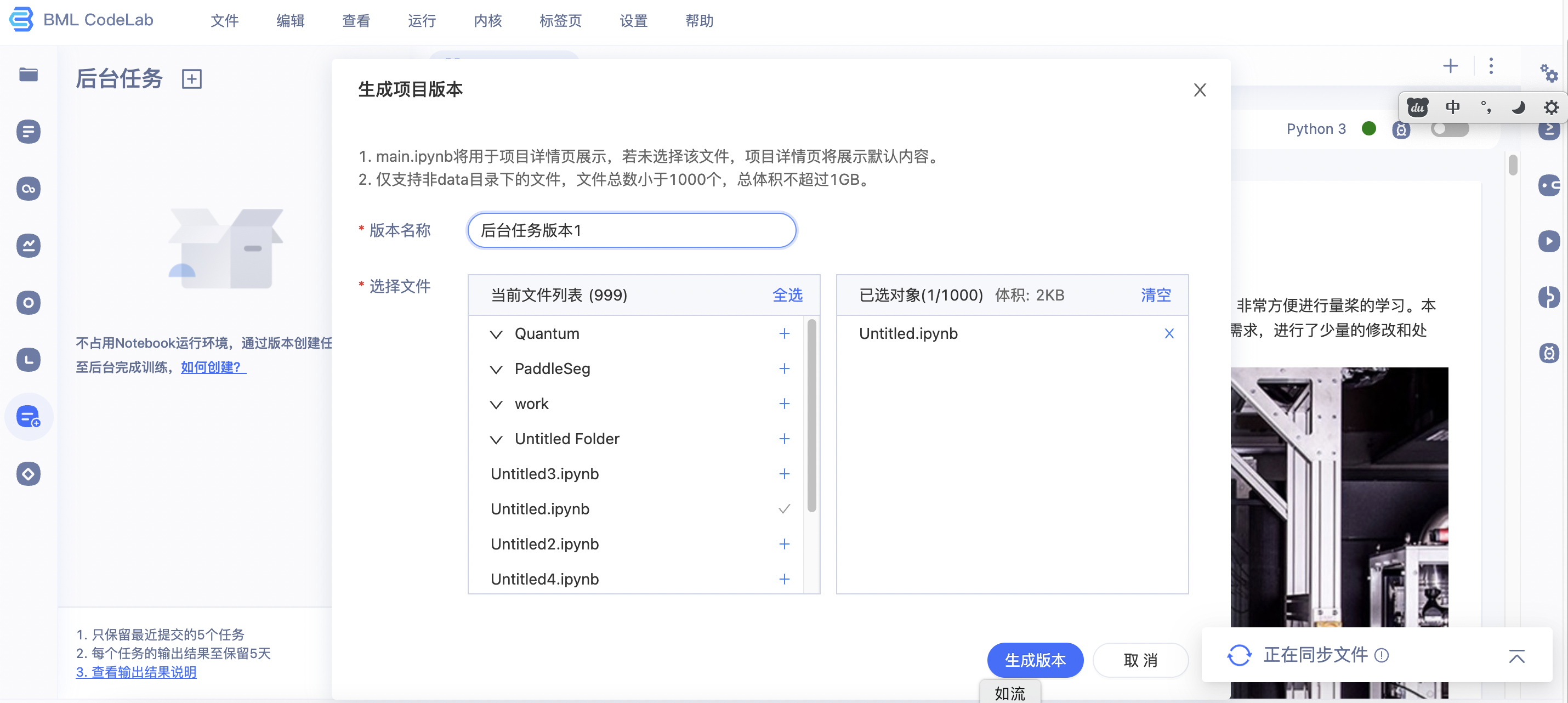
3、在创建任务页面【1】中需要填写任务备注、选择项目版本以及执行文件.填写完成后,点击下一步进入创建任务页面【2】。

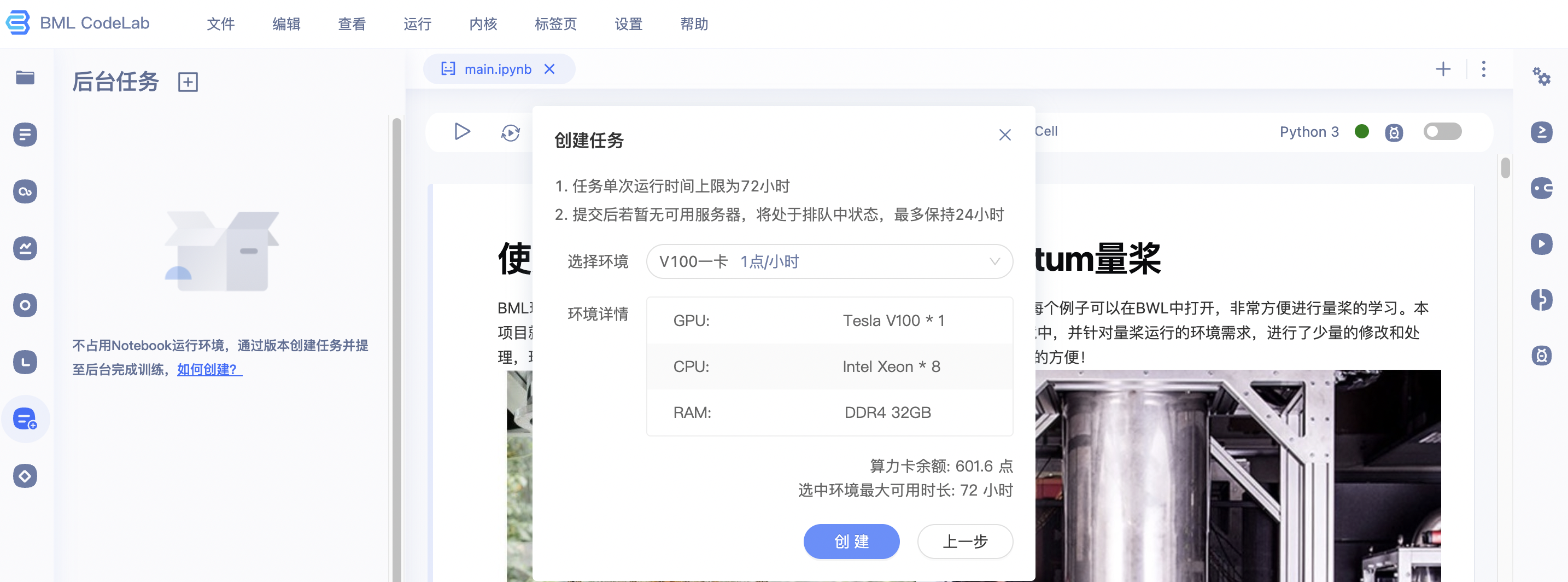
4、您可在创建任务页面【3】中根据任务的实际需要选择不同的运行环境。需要注意的是后台任务消耗算力卡,因此需要保证在提交任务时算力点余额>=1。
5、后台任务共提供2种运行环境,分别为V100 1卡 1点/小时和V100 4卡 8点/小时,选择不同的环境会展示对应环境的详细配置。
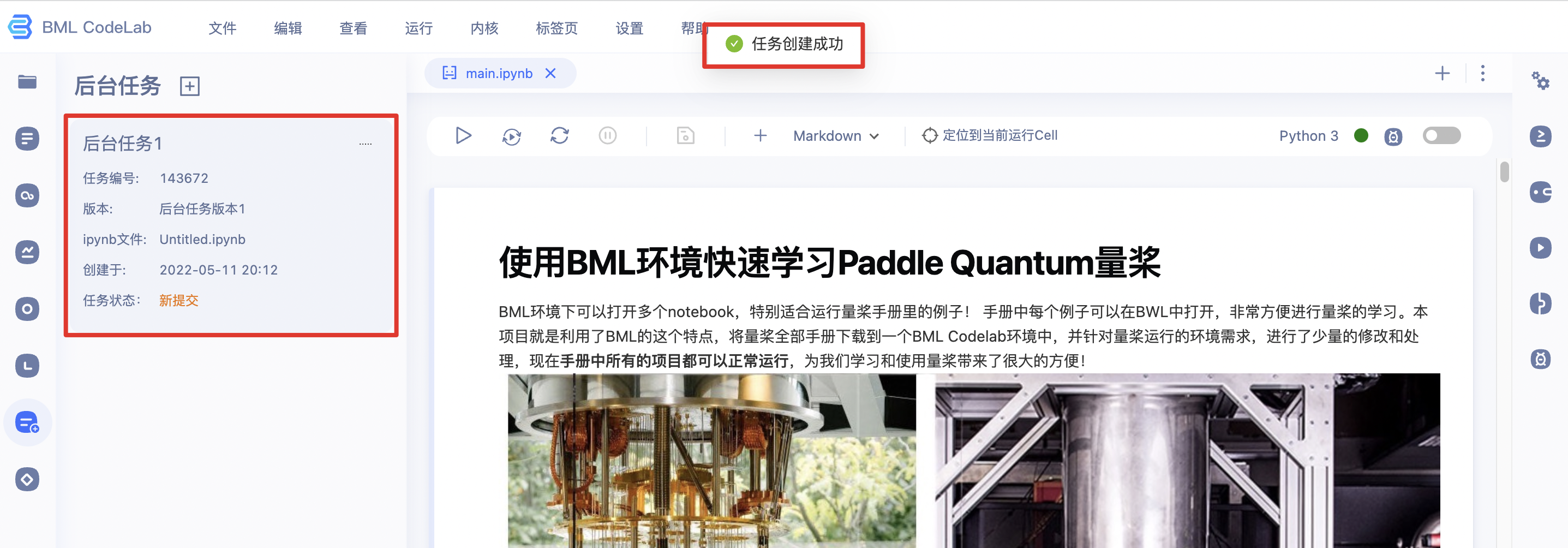
6、创建任务后,页面头部会弹窗提示"后台任务创建成功"并在左侧的任务列表中生成记录。
注意:若所选服务器爆满时,任务将处于'排队中'状态。排队中状态最多保持24小时,超过24小时任务将自动失败且任务处于排队状态不会消耗算力卡。
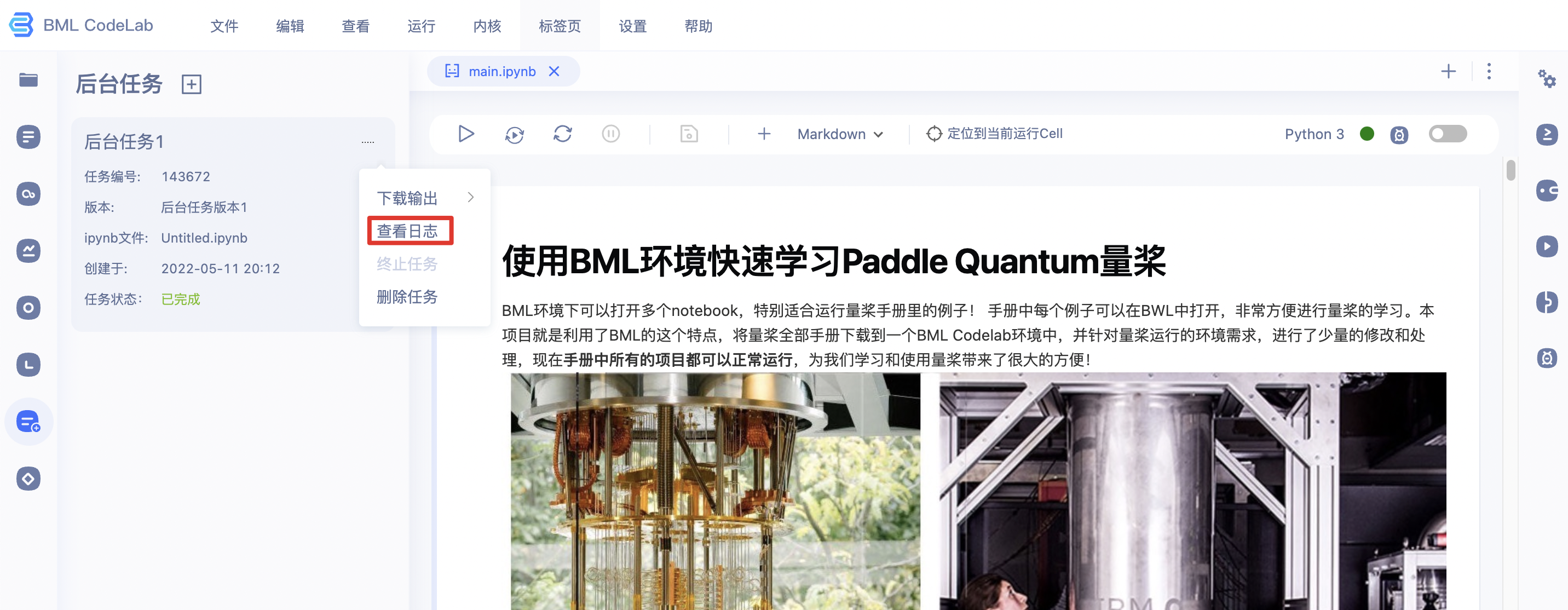
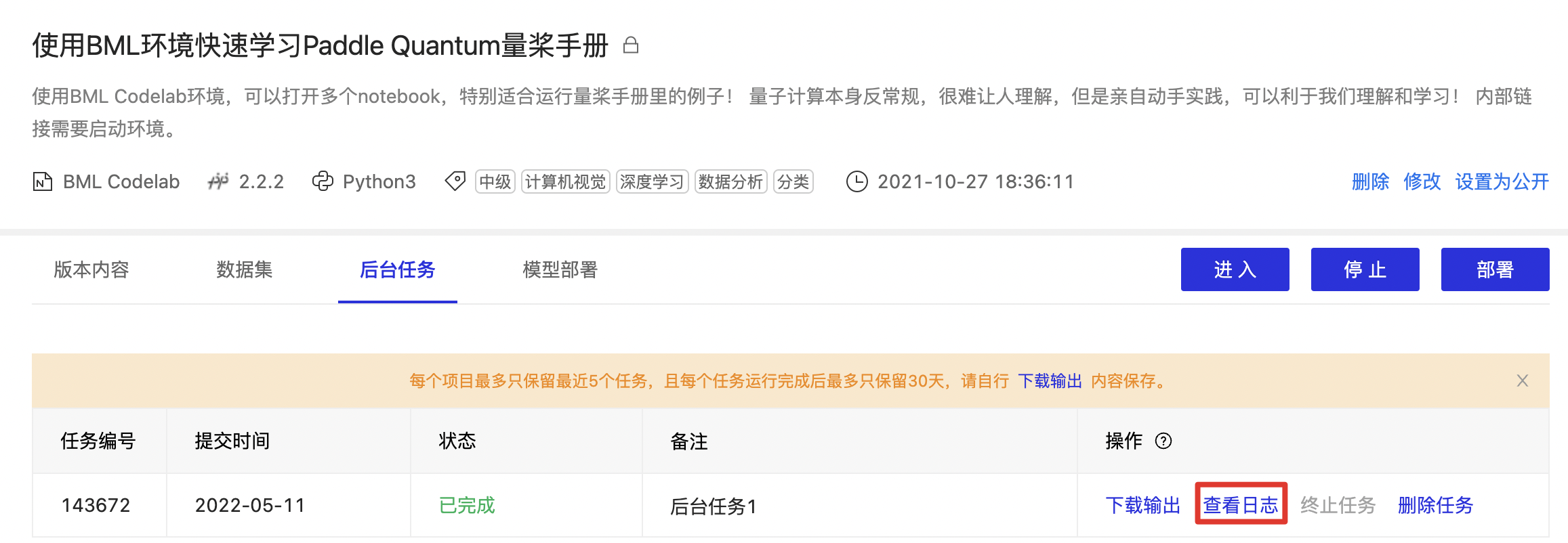
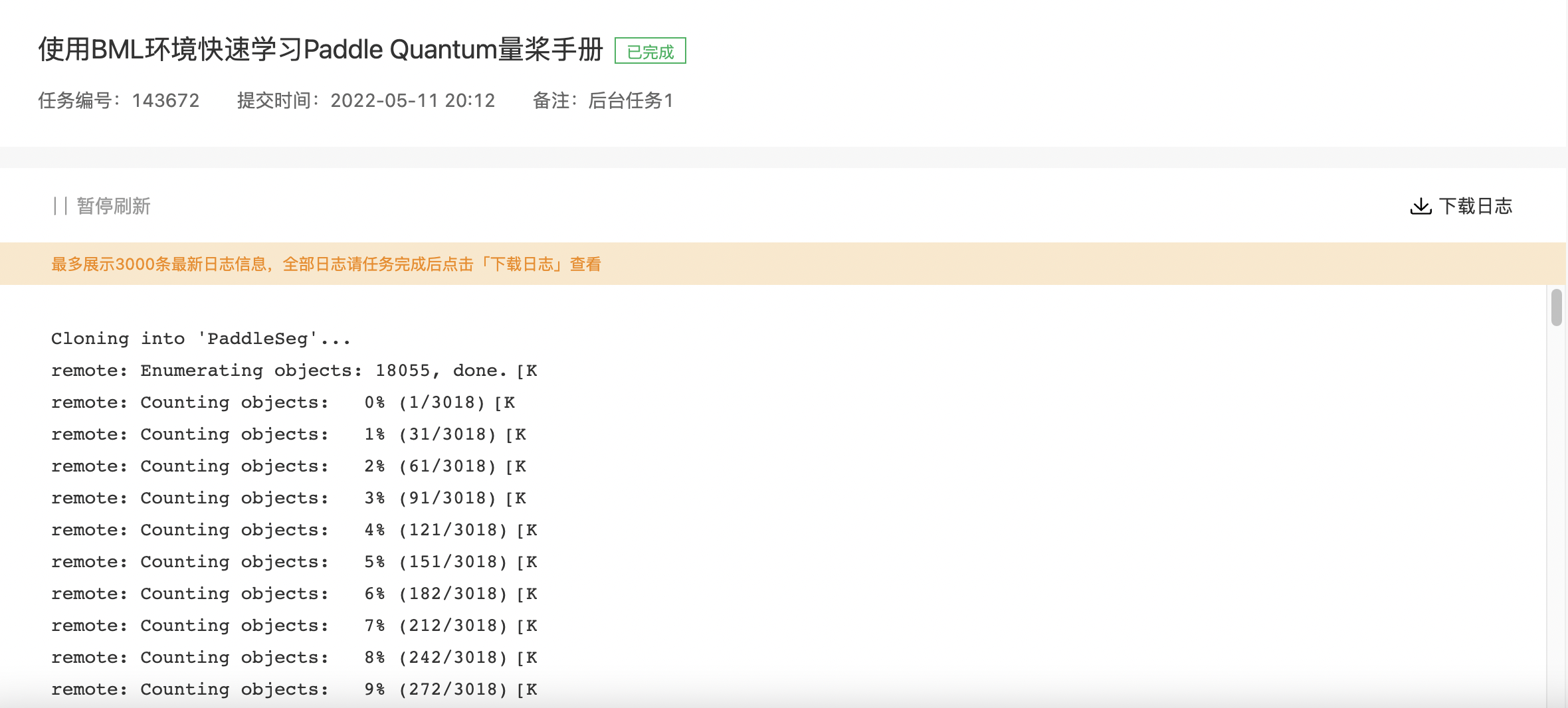
7、任务处于'运行中'状态时,您可通过项目详情页的后台任务板块或任务列表中对应任务的复选框中选择「查看日志」跳转至查看日志页面,观察任务运行情况。您也可以通过「终止任务」终止当前中正在排队或运行中的任务。
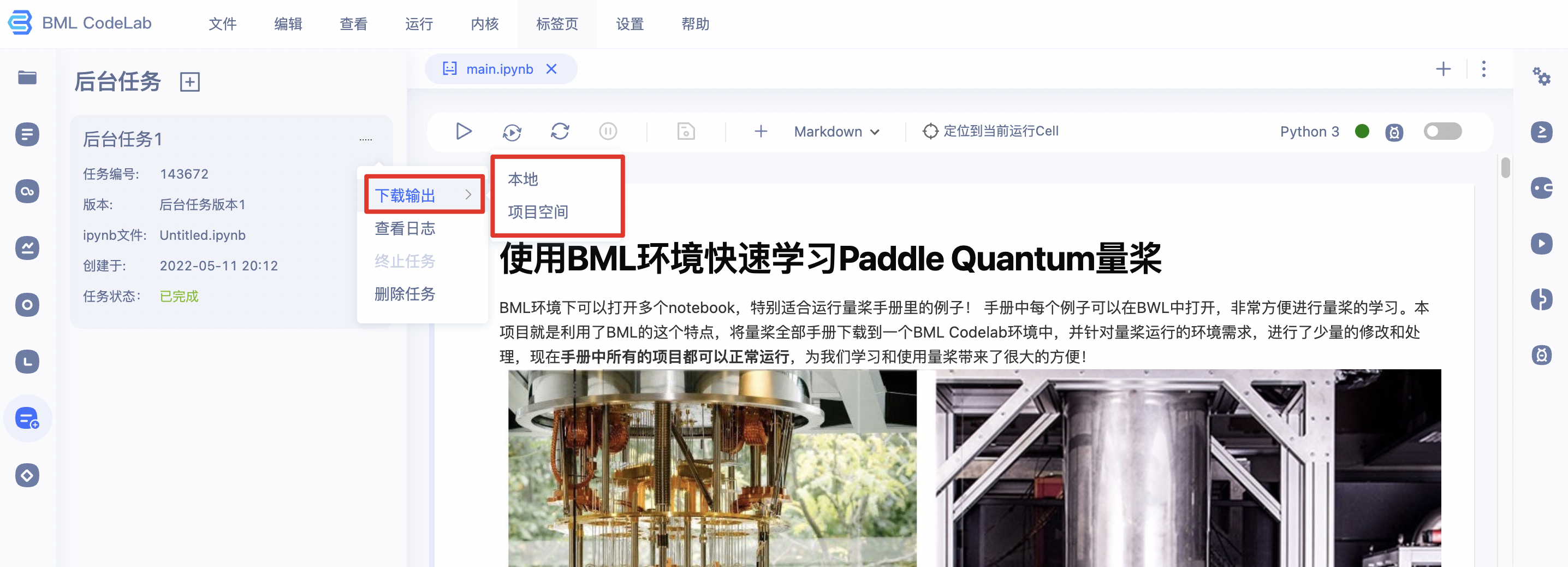
8、当任务完成后, 用户可以将任务输出结果下载至项目空间或本地。选择下载输出结果至项目空间时,会将您的任务结果压缩包保存在'/home/aistudio/任务编号/'路径下。
9、将结果导入项目空间或下载到用户本地电脑后,任务可以删除. 同时, 在项目预览页面中, 用户也可以管理已经提交任务, 进行终止, 删除, 下载输出结果。
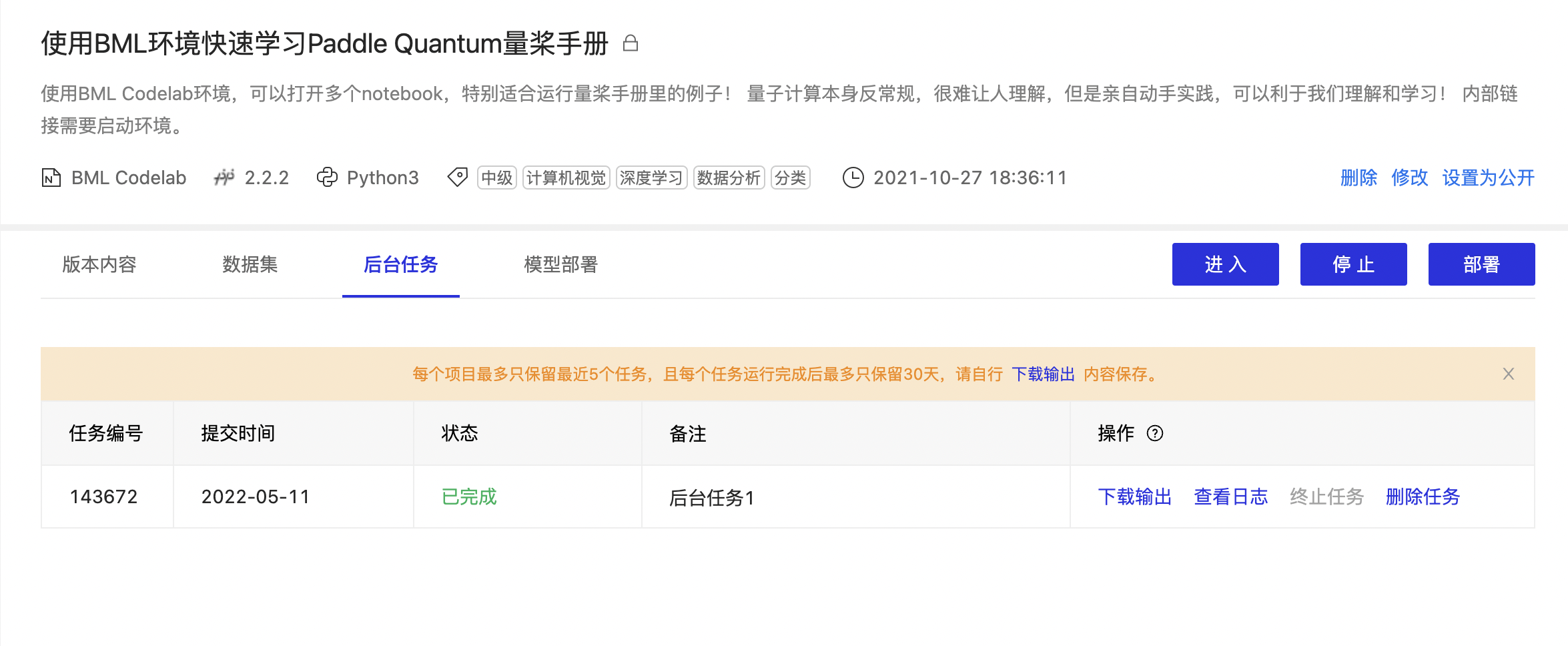
注意事项:
- 只保留最近的5个任务;
- 每个任务的运行输出结果最多保留30天;
- 任务单次运行时间上限为72小时(不含排队时间);
- 任务输出结果体积 > 20GB或文件数量 > 10000时,任务将会失败 ;
- 项目空间 > 60GB时,暂不支持下载输出至项目空间;
代码片段
BML CodeLab提供常用机器学习和深度学习代码片段,支持一键插入到Notebook代码文件中。AI开发者编码过程中如果遇到重复性的代码,也可以将其收藏为自己的代码片段,一键插入使用,提高开发效率。
代码片段提供公共代码片段库和我的代码片段库管理能力。
公共代码片段库
公共代码片段库中内置了常见的机器学习片段,您可直接插入使用,双击可浏览代码片段内容。
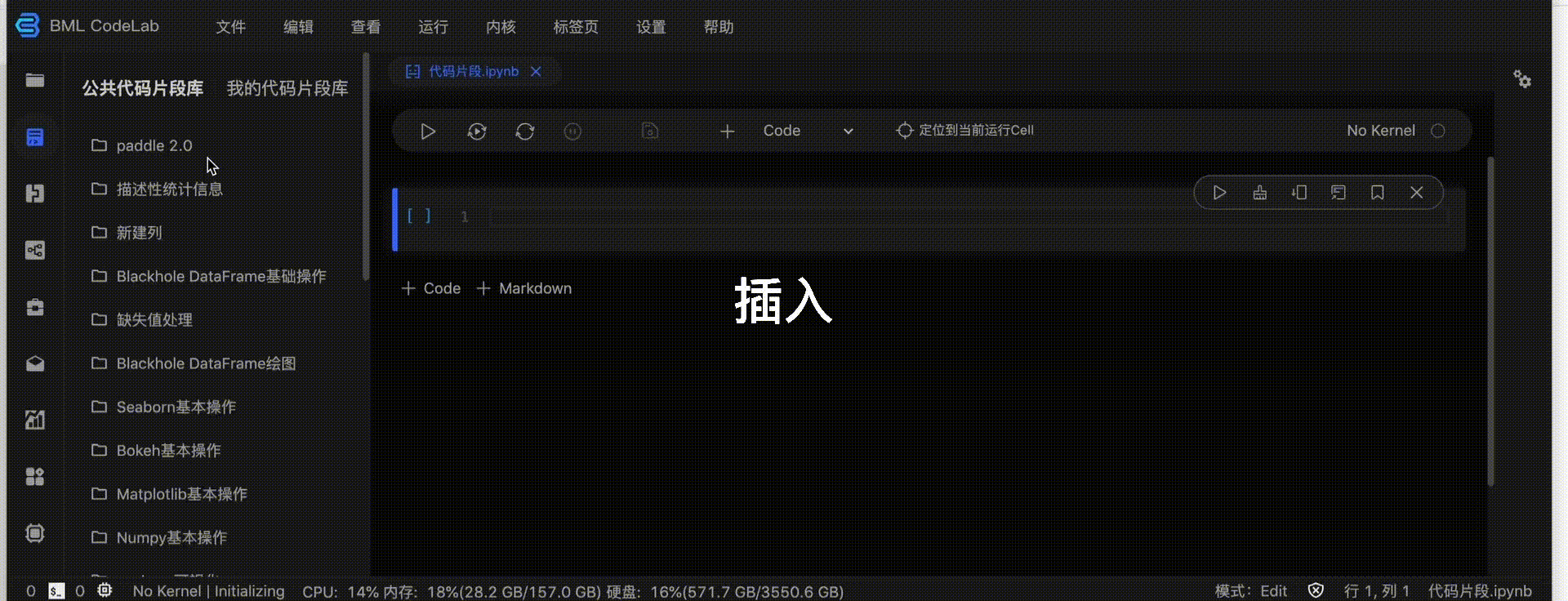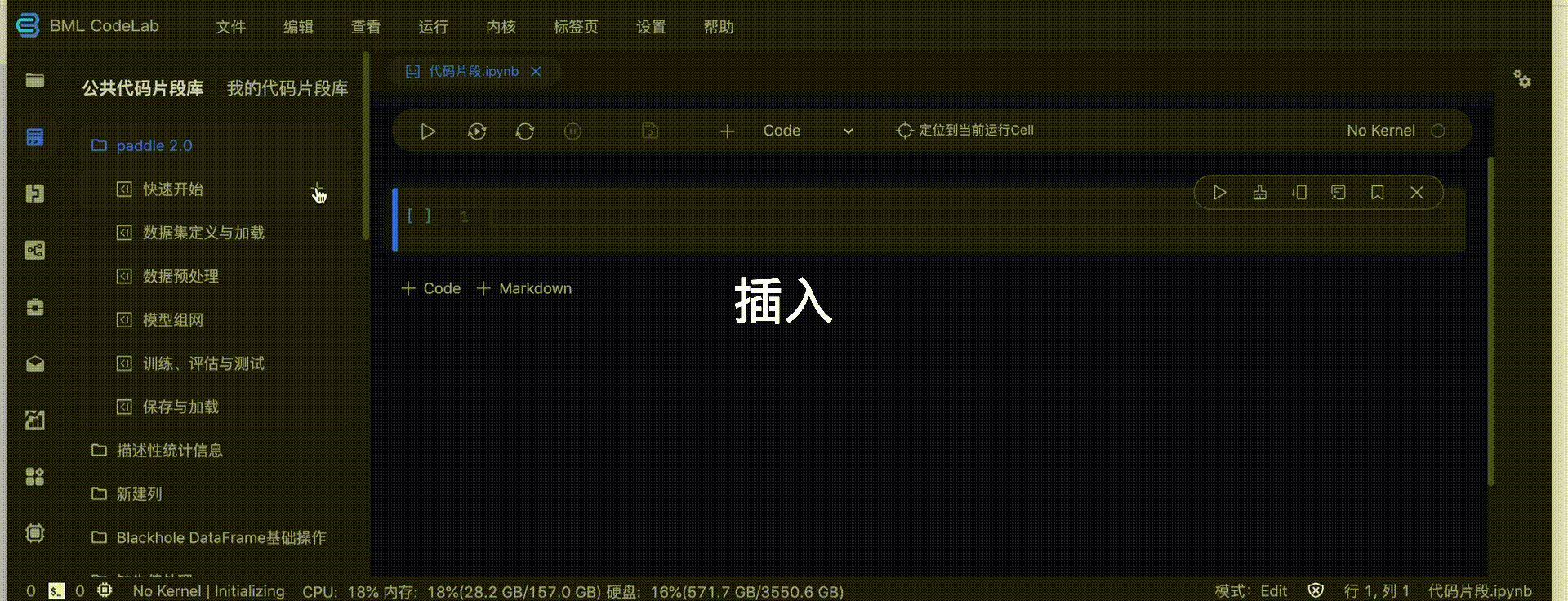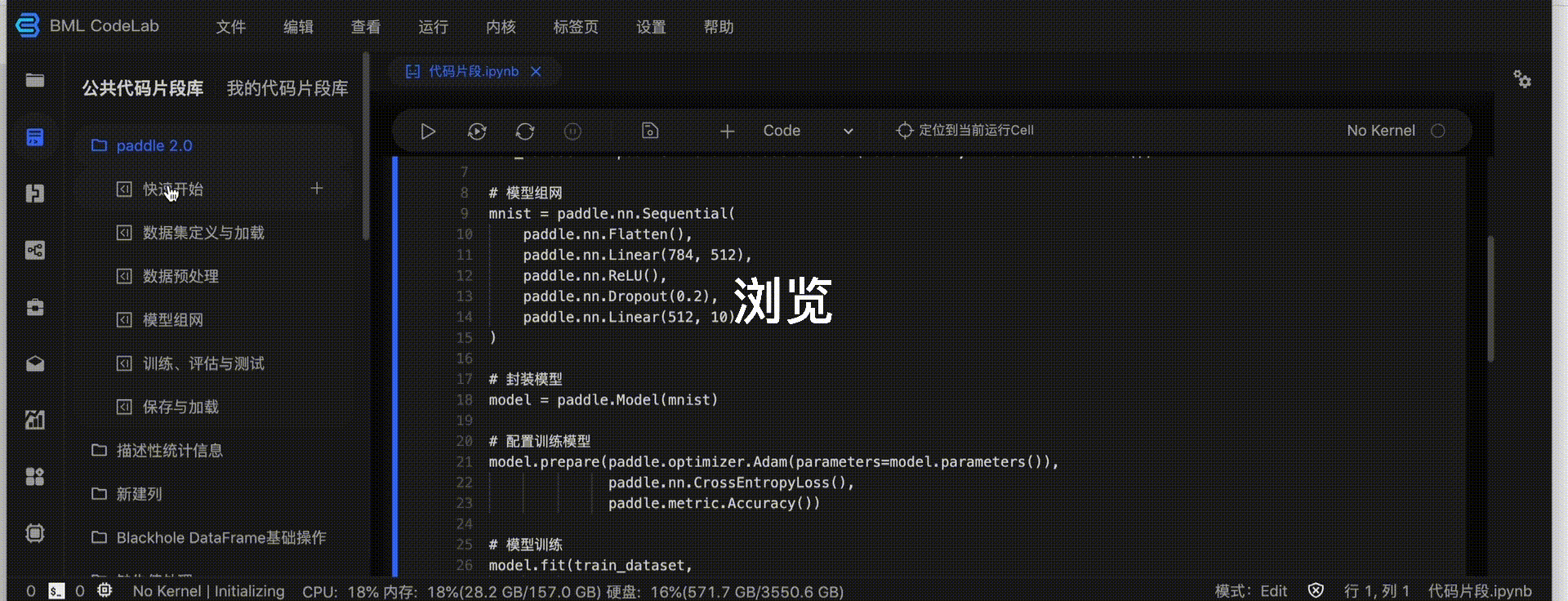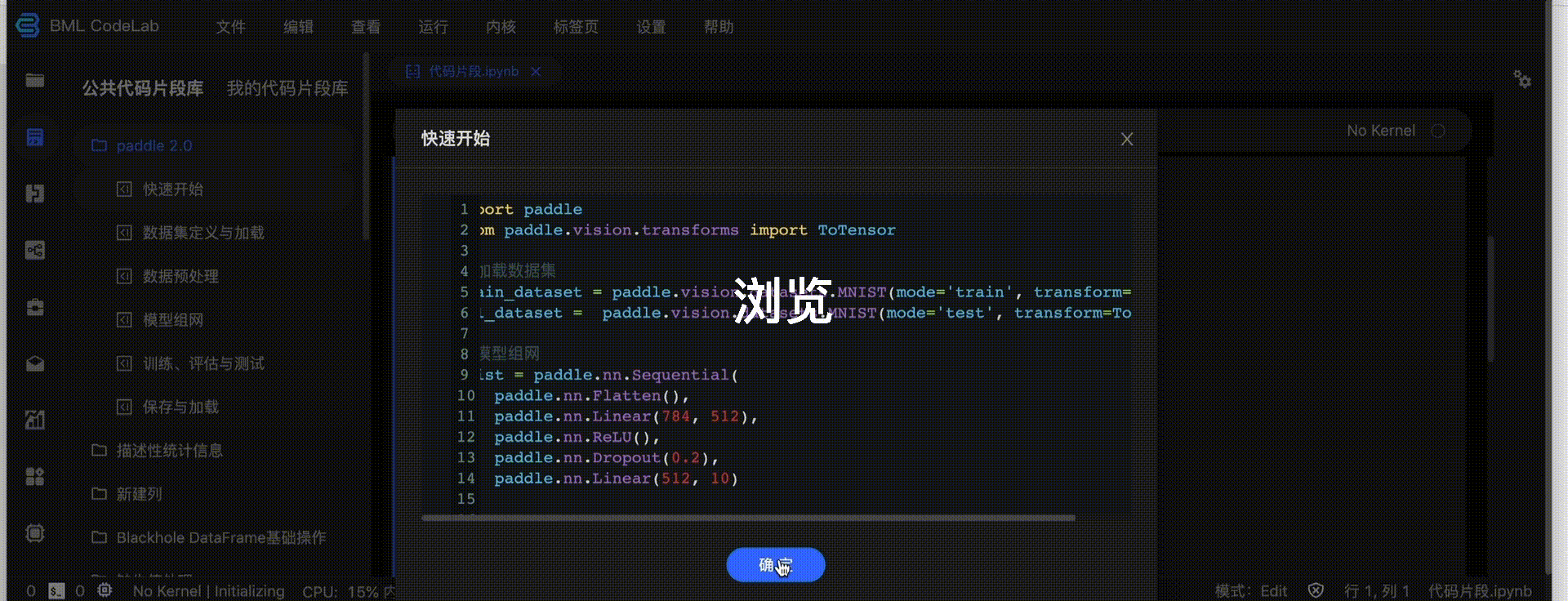
我的代码片段库
您可管理自己的代码片段。我的代码片段库支持插入、编辑、重命名、删除和浏览。
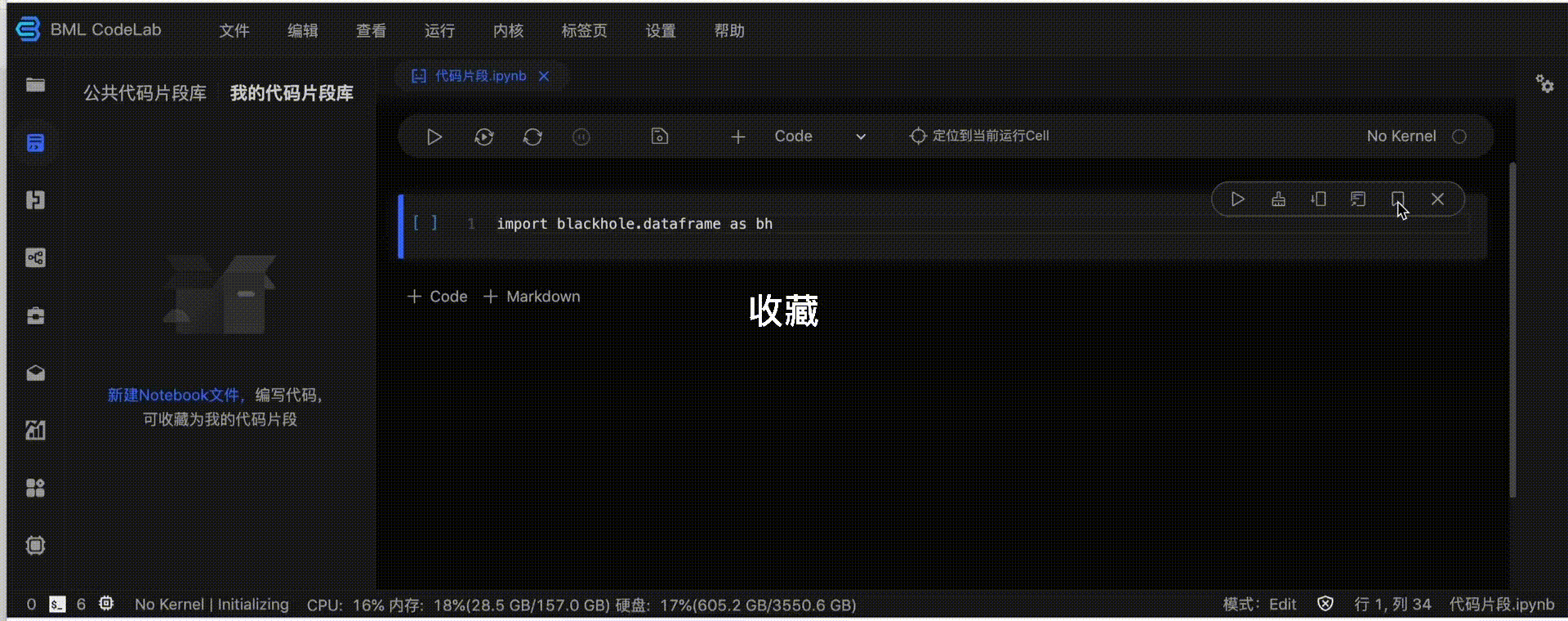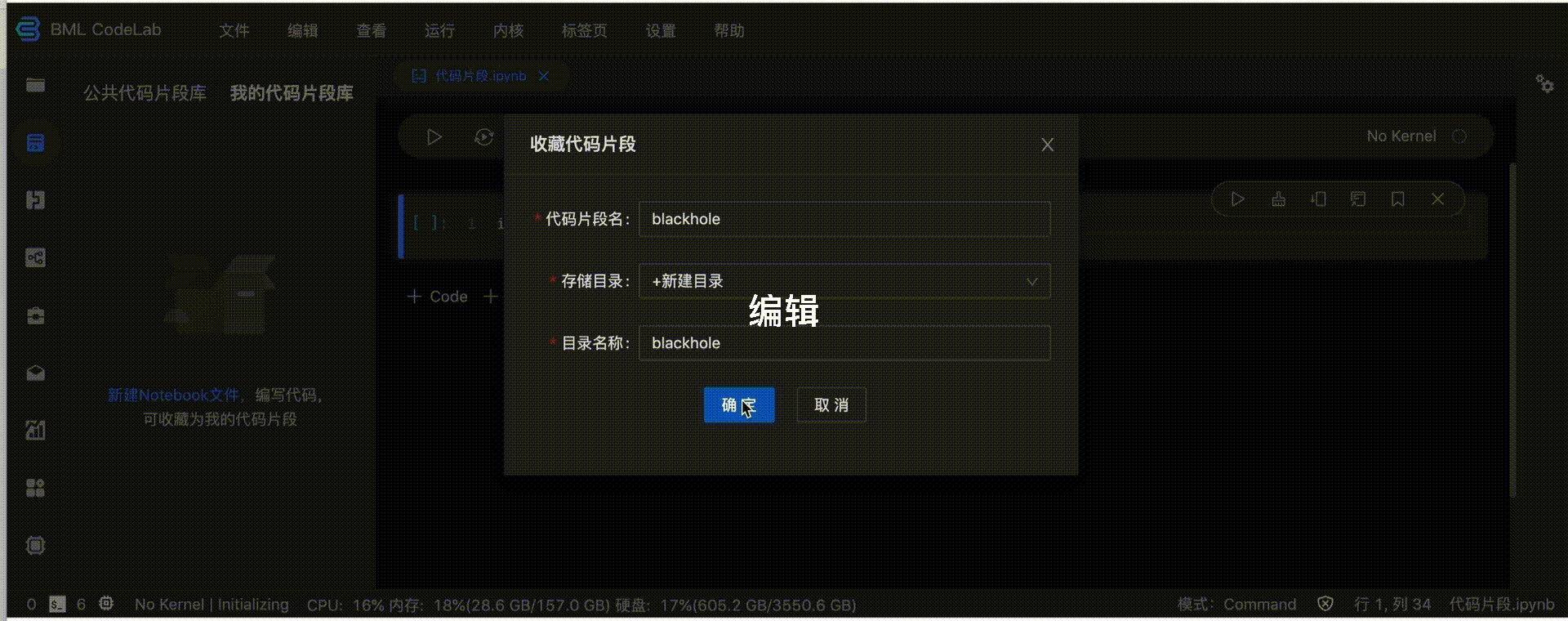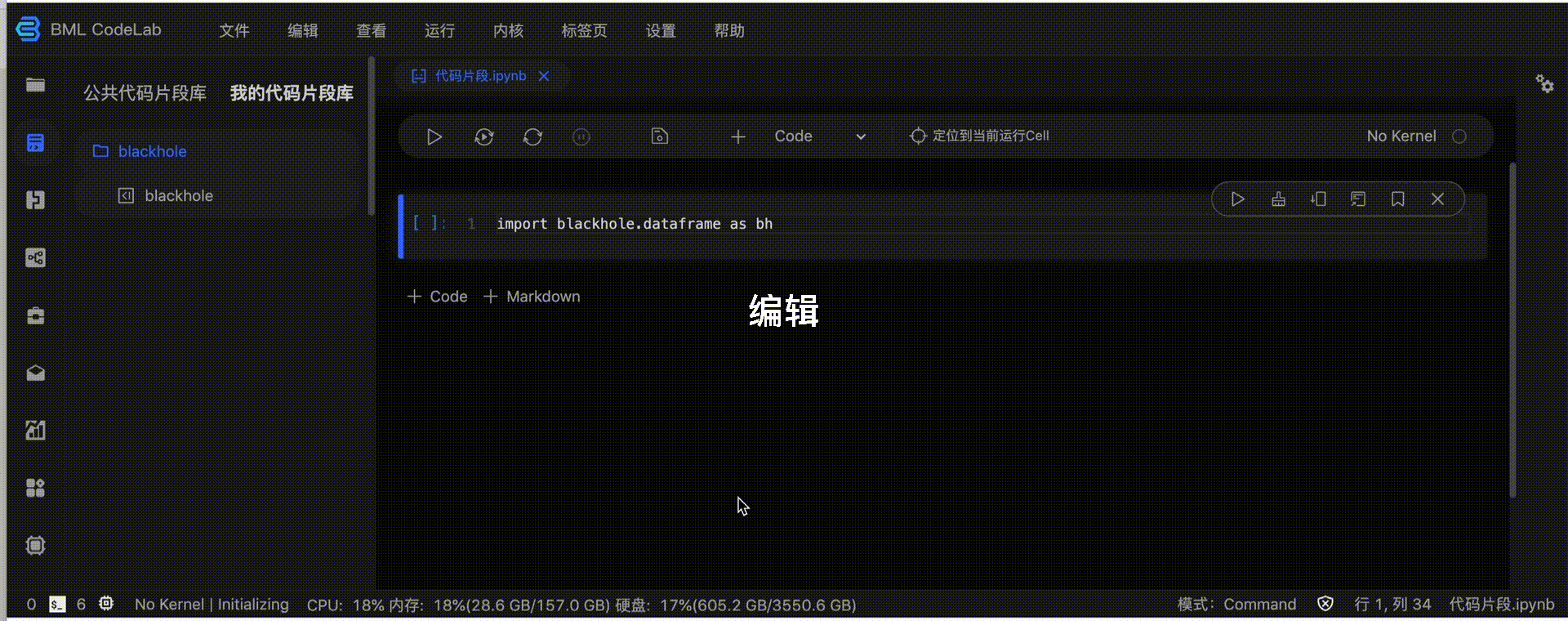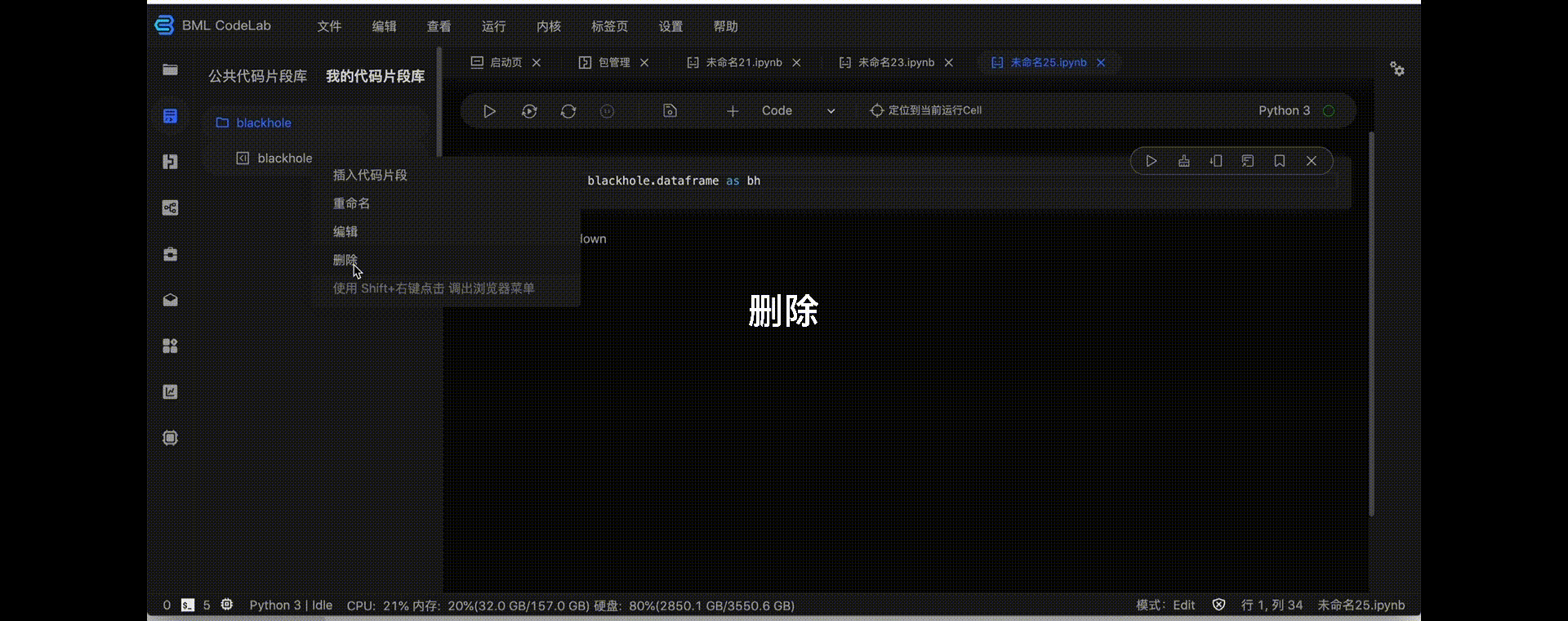
使用规范
- 代码片段内容不容许重复,若重复会提示:当前代码片段已存在;
- 若云端同步过来的片段内容与本地代码片段有重复,会根据时间新的覆盖旧的;名称也会替换成最新时间编写的;
- 在不登录情况下,可以保存代码片段到本地;
- 登录后,会自动将我的代码片段同步到云端,用户更换设备,我的代码片段会同时同步过去;
- 代码片段名称容许重复;
包管理
BML CodeLab 提供可视化包管理能力,内含 160 多种常用包及精选的百度自研能力,用户可按需安装、卸载、更换版本。
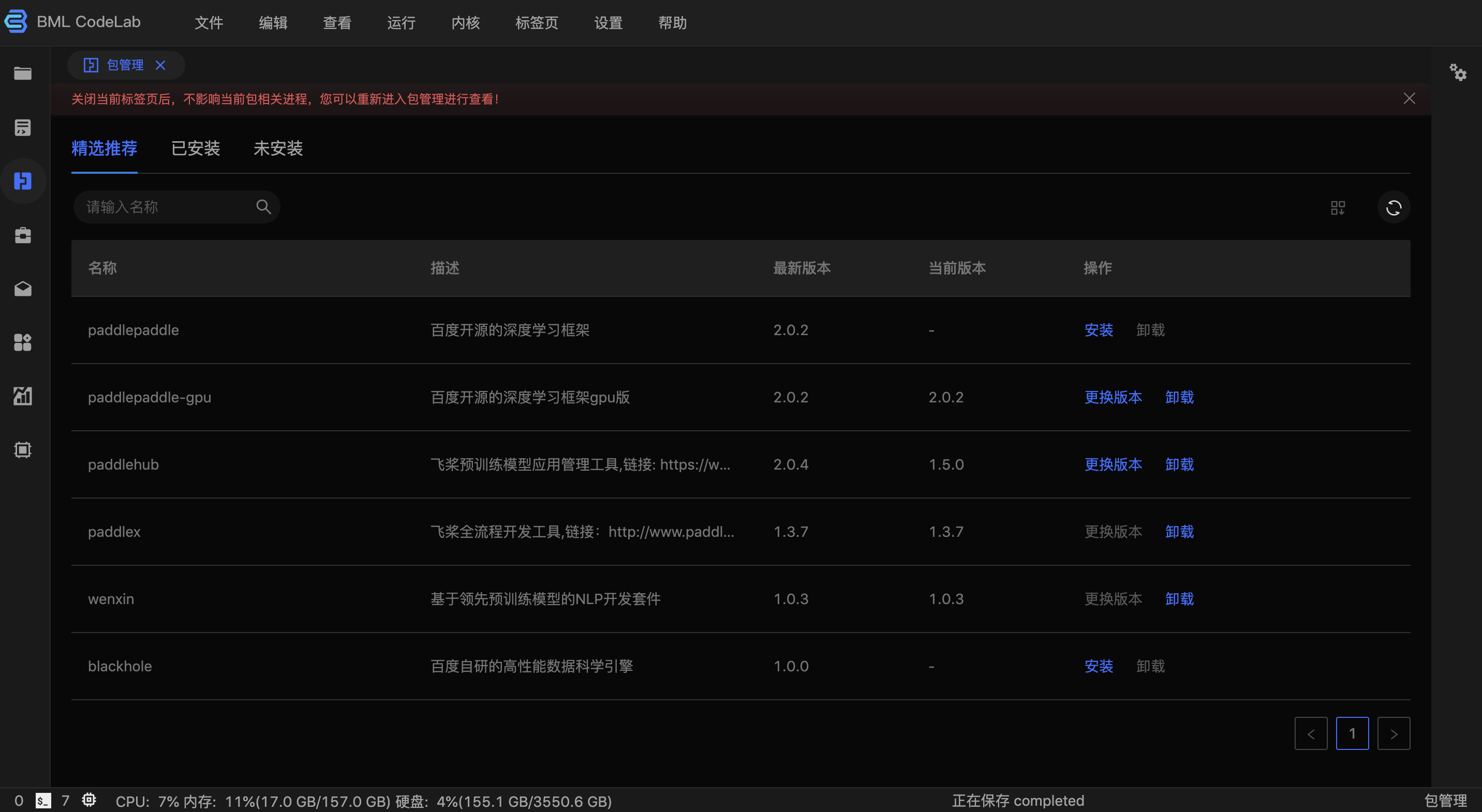
这里需要注意:
- 每个包仅能处于一种操作中(安装/卸载/更换版本);
- 若您对某个包下载多个版本,环境中只保留最新下载的版本
精选推荐
提供:
* wenxin
* Blackhole
* PaddlePaddle
* PaddlePaddle-gpu
* PaddleX
* PaddleHubBML CodeLab 会定期对以上能力进行版本更新,用户可根据实际需要进行安装和更新版本。
已安装
展示的是当前环境下已安装的所有包,可通过精准匹配查找已经安装的包。
这里需要注意: Blackhole和wenxin 如果通过精选推荐安装,不会出现在已安装列表中。
未安装
展示的是当前环境下未安装的常用Python包,可通过精准匹配查找已经安装的包。
环境信息
您可查看当前运行环境的硬件信息和镜像基础信息。
硬件信息:
展示CPU(CPU核数)、GPU(GPU卡详细信息)、总显存、总内存、总硬盘信息;
环境配置:
展示 Python版本;
操作步骤
点击侧边栏环境信息按钮,查看具体信息
数据模型可视化
VisualDL是一个面向深度学习任务设计的可视化工具。VisualDL 通过丰富的图表来展示数据,使用户可以更直观、清晰地查看数据的特征与变化趋势,有助于分析数据、及时发现错误,进而改进神经网络模型的设计。喜欢的同学可以去star支持一下哦~
BML CodeLab已经集成VisualDL工具以便于您的使用,您可在侧边栏点击VDL启动数据模型可视化服务。
BML CodeLab数据可视化服务操作说明
Step1 创建日志文件LogWriter,训练代码中增加 Loggers 来记录不同种类的数据,设置实验结果存放路径. 注意我们的logdir = "./log", 即需要把log目录放到/home/work/log.
from visualdl import LogWriter
if __name__ == '__main__':
value = [i/1000.0 for i in range(1000)]
# 初始化一个记录器
with LogWriter(logdir="./log/scalar_test/train") as writer:Step2 训练过程中插入数据打点语句,将结果储存至日志文件中
for step in range(1000):
# 向记录器添加一个tag为`acc`的数据
writer.add_scalar(tag="acc", step=step, value=value[step])
# 向记录器添加一个tag为`loss`的数据
writer.add_scalar(tag="loss", step=step, value=1/(value[step] + 1))Step3 切换到「VDL」数据模型可视化页签,指定日志文件与模型文件(不指定日志文件无法启动VisualDL)
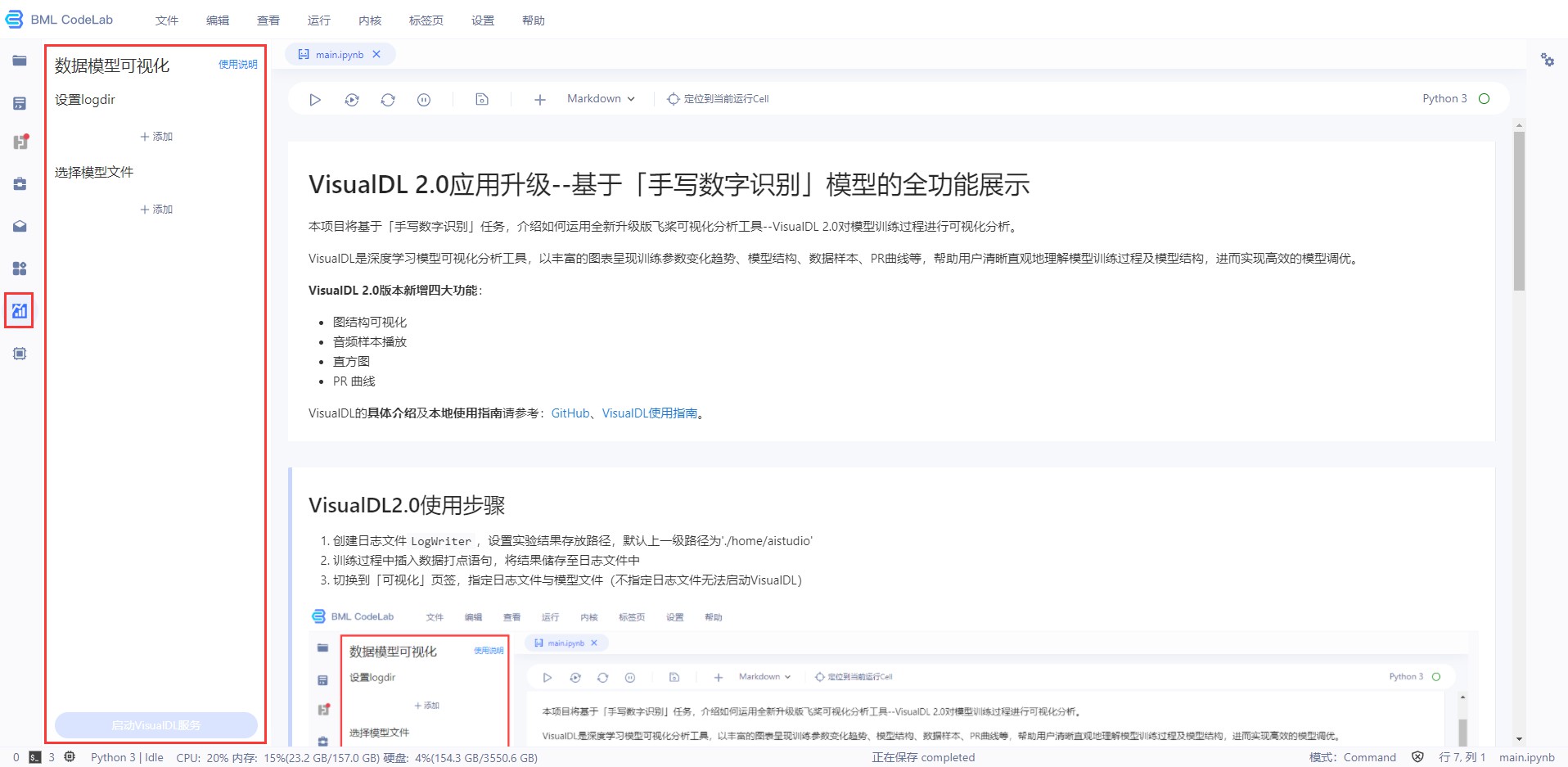
*注意:VisualDL启动中不可删除或替换日志/模型文件;日志文件可多选,模型文件一次只能上传一个,且模型文件暂只支持模型网络结构,不支持展示各层参数
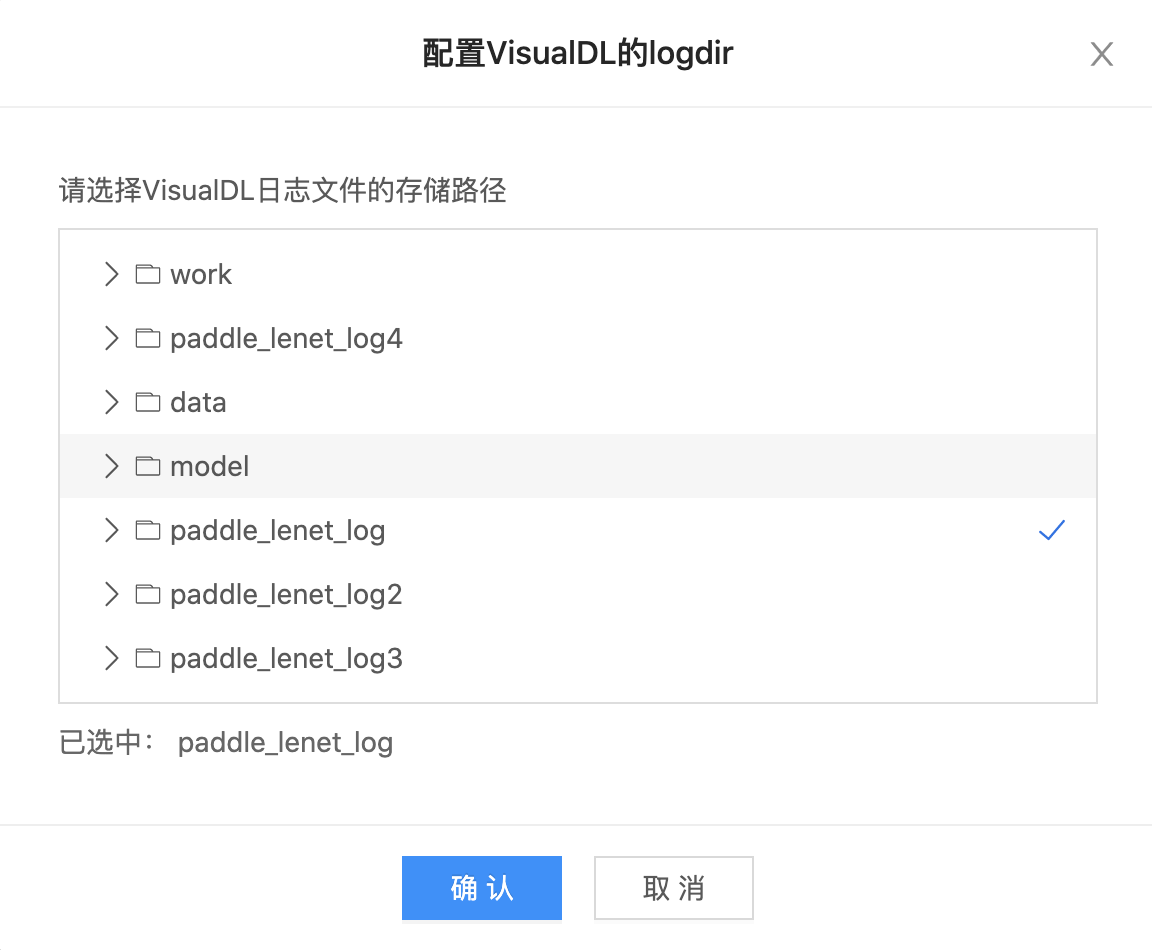
-
选择日志文件
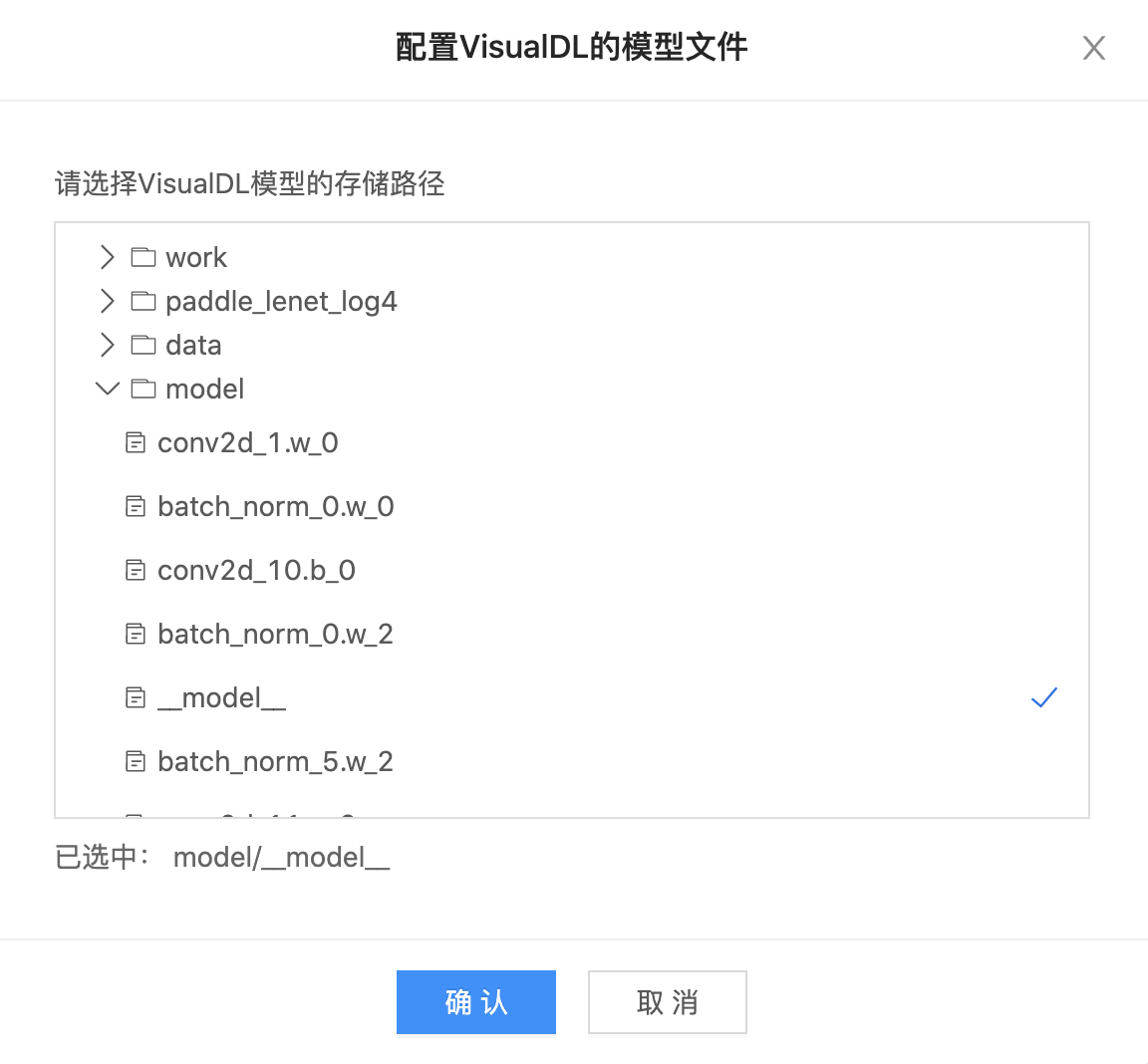
-
选择模型文件
Step4 点击「启动VisualDL」后,再点击「进入VisualDL」即可打开可视化界面
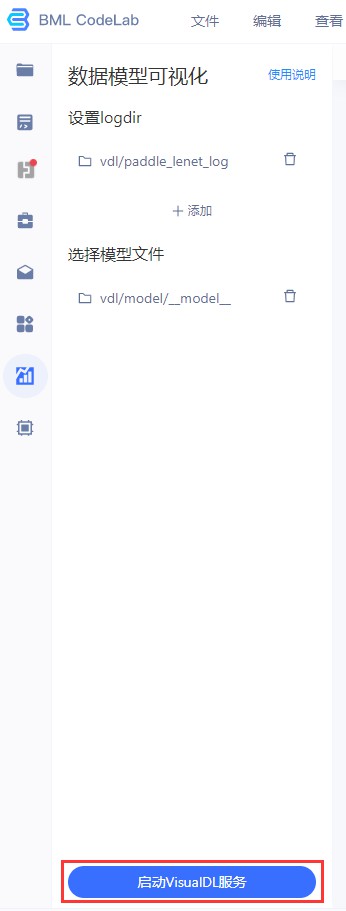
*注意:使用VisualDL需要Python3以上版本;端口8080是VisualDL的专用端口,严禁占用,否则无法正常启动VisualDL
资源监控
BML CodeLab提供资源实时监控功能,您可查看资源实时使用情况。
| 资源监控指标 | 介绍 |
|---|---|
| CPU占用率 | 当前已使用CPU量/CPU总可使用量 |
| 内存占用率 | 当前已使用的内存/内存总可使用量 |
| 硬盘占用率 | 当前已使用的磁盘大小/磁盘总可用量 |
| GPU占用率 | 可选择GPU卡,显示已使用的GPU量/该卡总可用量 |
| 显存占用率 | 可选择GPU卡,显示选择GPU卡已使用显存大小/该卡总可用量 |
操作步骤
点击侧边栏资源监控按钮,进入资源页面,您可选择具体GPU卡进行监控
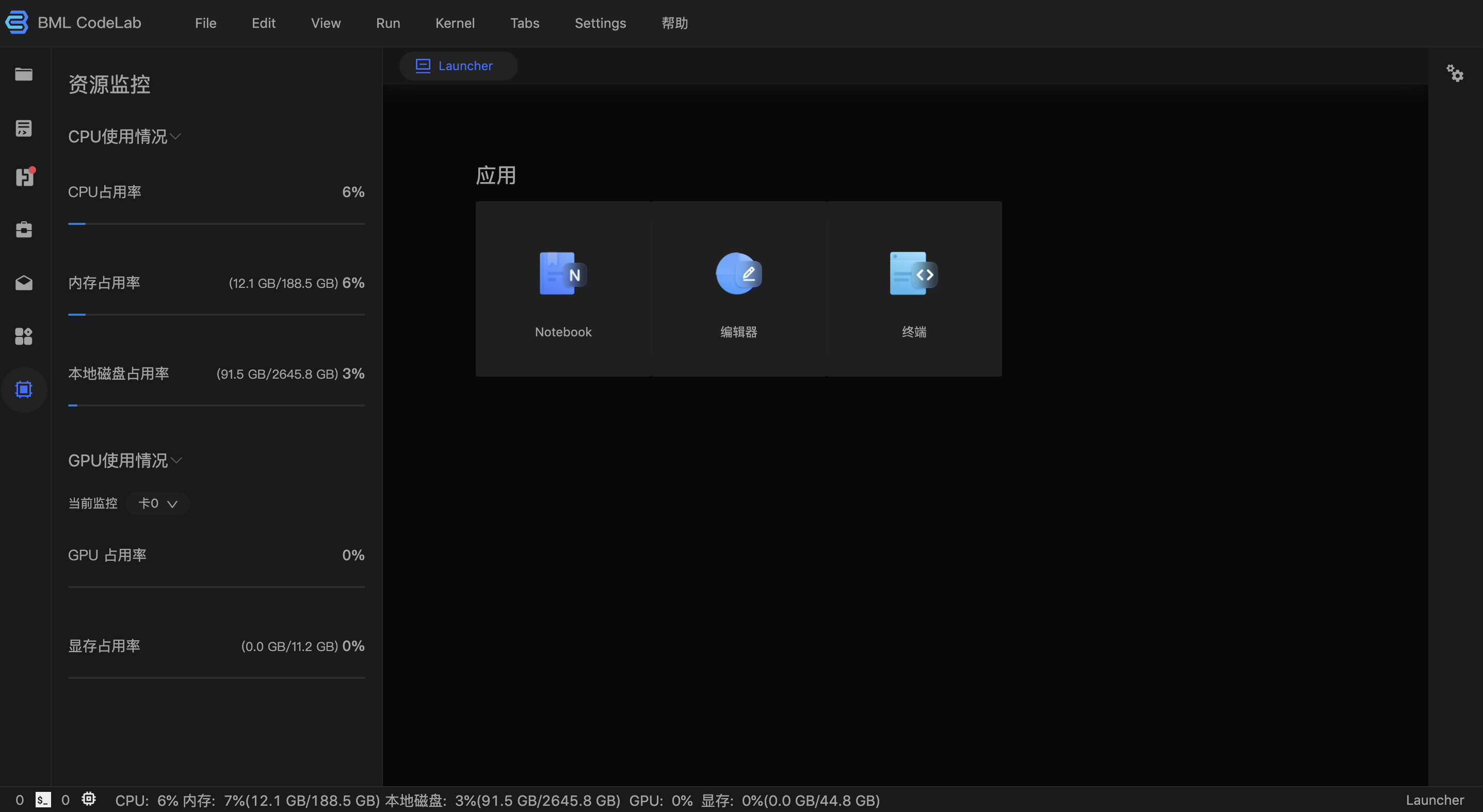
应用
BML CodeLab提供用户创建应用、调试应用和部署应用等功能。相关功能以Streamlit和Gradio作为底层技术,为用户提供快速搭建交互式图形化界面的能力,只需要几行代码即可搭建一个炫酷的图形化界面。
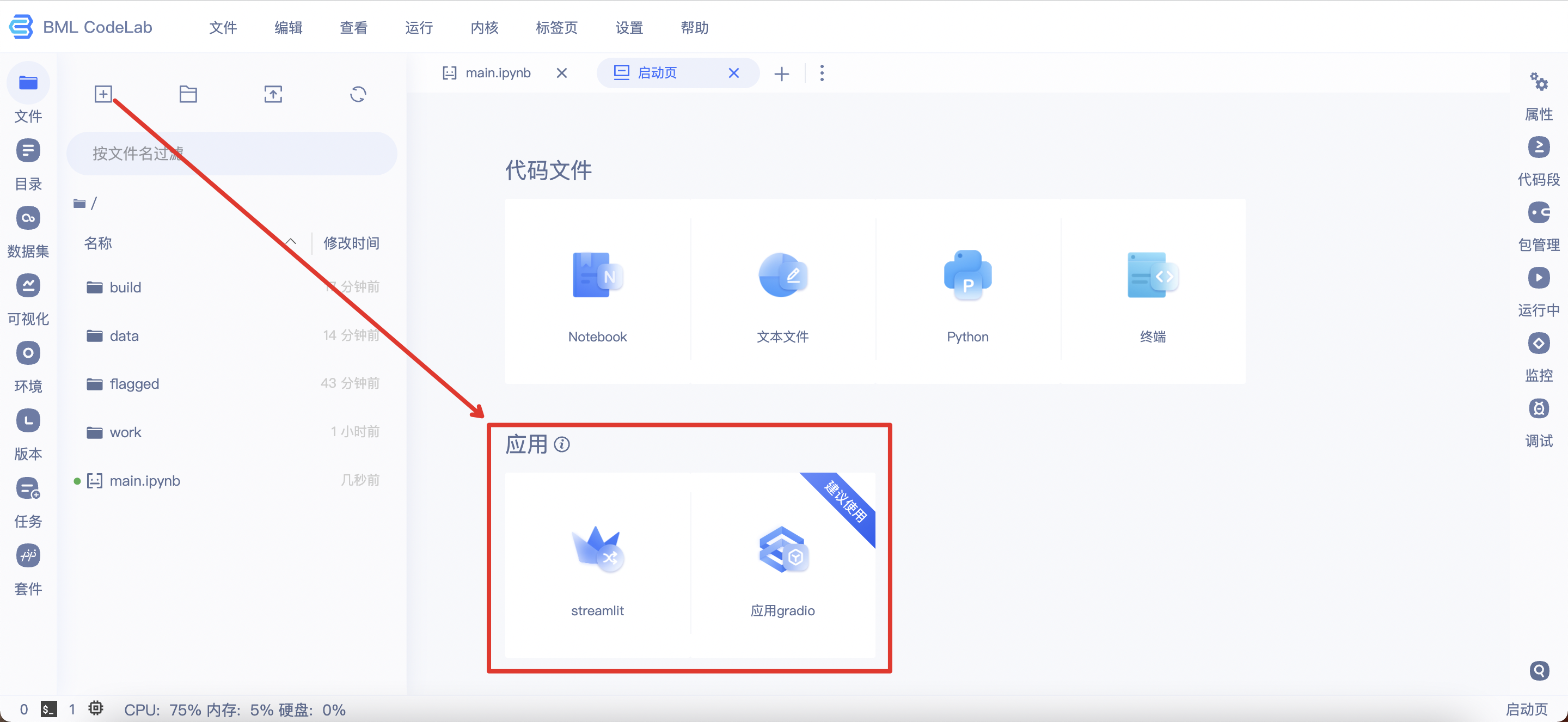
创建应用
BML CodeLab启动页新增2种应用选项。点击该Gradio或Streamlit,即在文件列表自动创建一个应用文件,文件默认命名为untitled.streamlit.py/untitled.gradio.py(应用文件的独特命名形式)。
调试应用
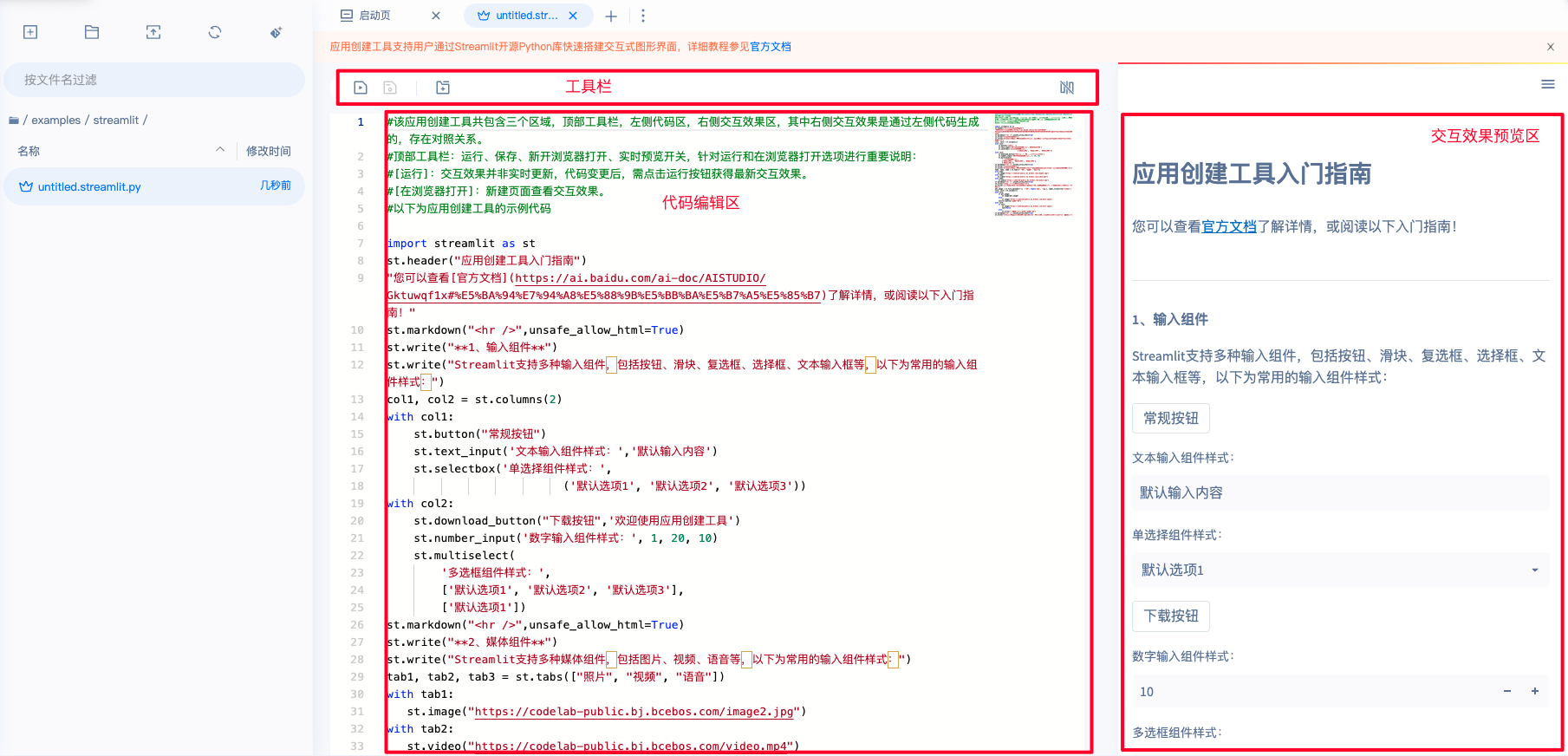
进入应用文件,即可开始编写并调试应用代码。整个页面分为工具栏、代码编辑区、交互效果预览区三部分,以下将详细说明:
-
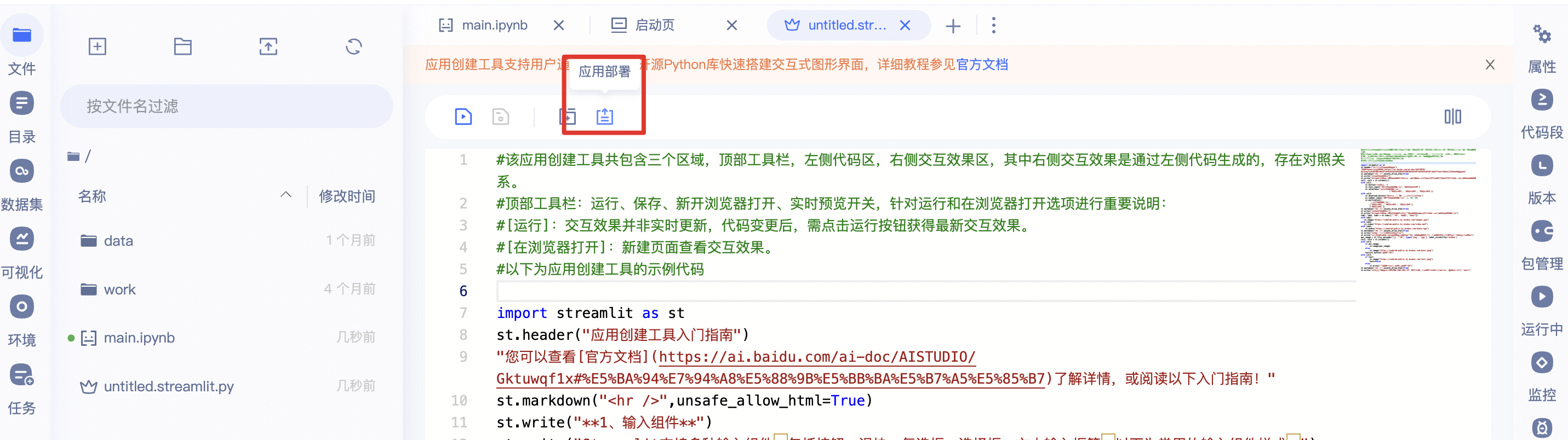
工具栏:共包含4个选项,从左至右分别为运行、保存、在浏览器打开、应用部署:
- 运行:提交代码编辑区代码并运行,在交互效果预览区得到最新的交互内容。
- 保存:保存代码编辑区中的代码。
- 在浏览器打开:打开一个新的浏览器页面,更好的查看交互效果。需要注意的是,每次运行都需要重新点击在浏览器打开,查看最新的交互效果,已经打开的浏览器页面不会实时刷新。
- 应用部署:应用部署至项目详情页。
- 预览开关:控制交互效果预览区的展示。为了获得更多的代码编辑区,建议在编写代码时关闭预览,在样式调整时打开预览。
- 代码编辑区:编写Python代码,串联模型推理和交互,获得完整的应用。
- 交互效果预览区:运行当前文件代码所得到的交互效果。每次打开该类文件系统均会默认运行,一般需要几秒钟的等待时间。
部署应用
- 请适当考虑显存和并发问题,添加相关代码至应用文件,以确保应用的正常运行。
- 如部署环境需要其他的框架版本,请根据CUDA版本(11.2)自行安装。
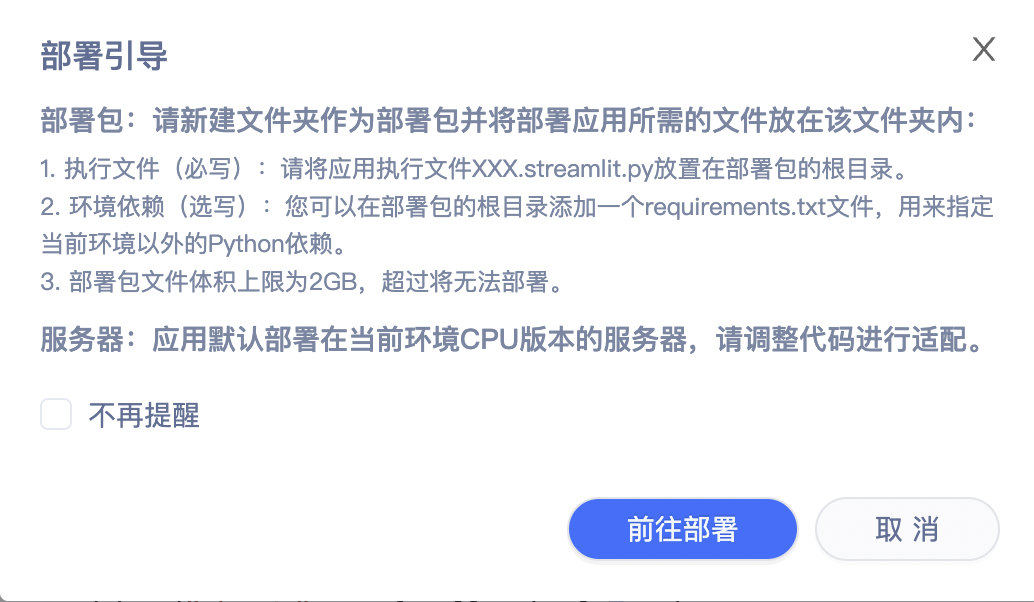
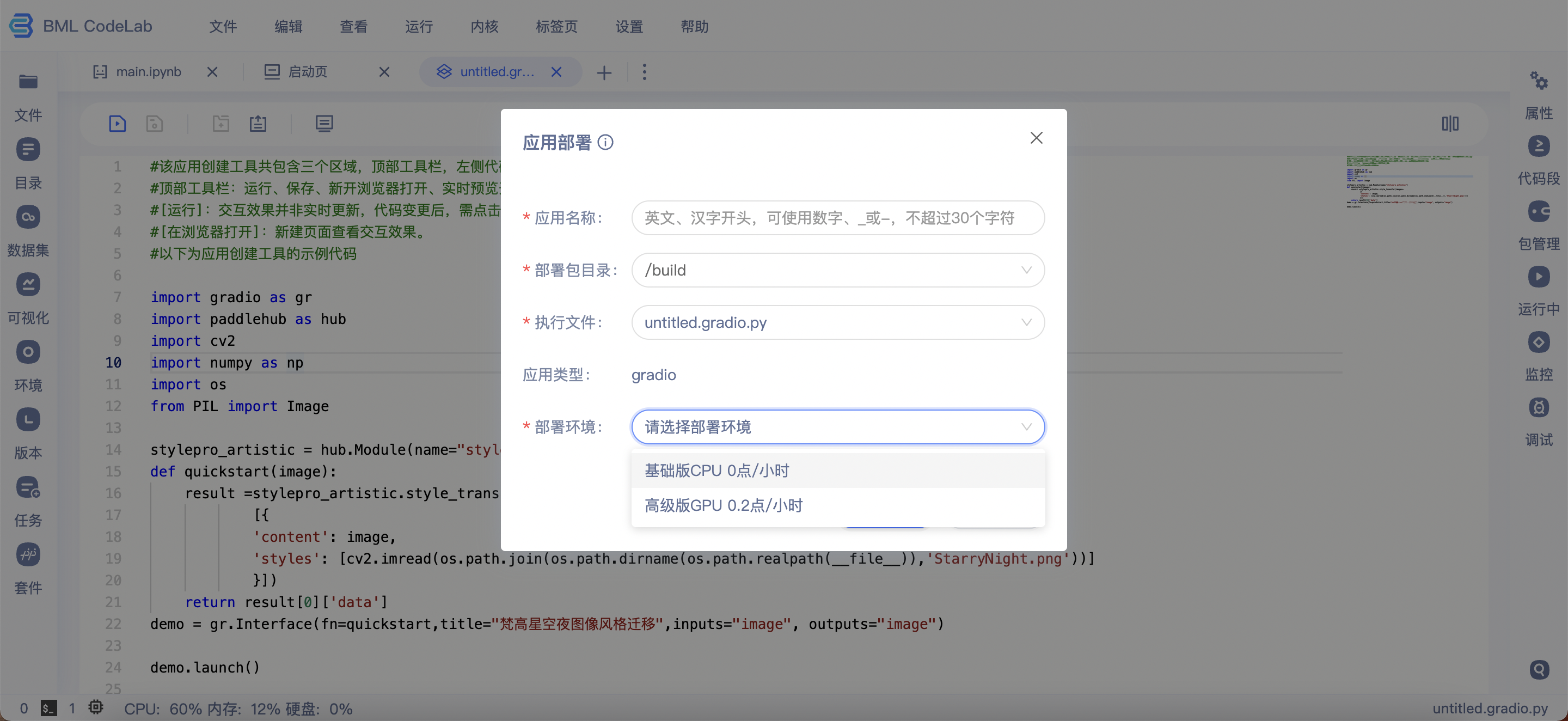
点击应用部署按钮即可进入部署流程。部署前,请详细阅读部署引导并按照要求将相关文件存放在部署包中,为方便文件管理建议新建一个文件夹作为部署包。部署时,请根据要求填写应用名称、部署包目录、执行文件。部署时间(30秒~2分钟)受相关依赖安装时间影响,部署成功后出现提示'应用部署成功,请跳转至项目详情页查看应用效果'。
- 应用名称:应用命名,仅作为自己备注查看。
- 部署包目录:部署包所在的目录,所有文件均需要放在部署包目录。
- 执行文件:应用文件。
- 部署环境:根据应用实际情况选择合适的部署环境。需要说明的是,GPU部署需要额外使用算力卡。
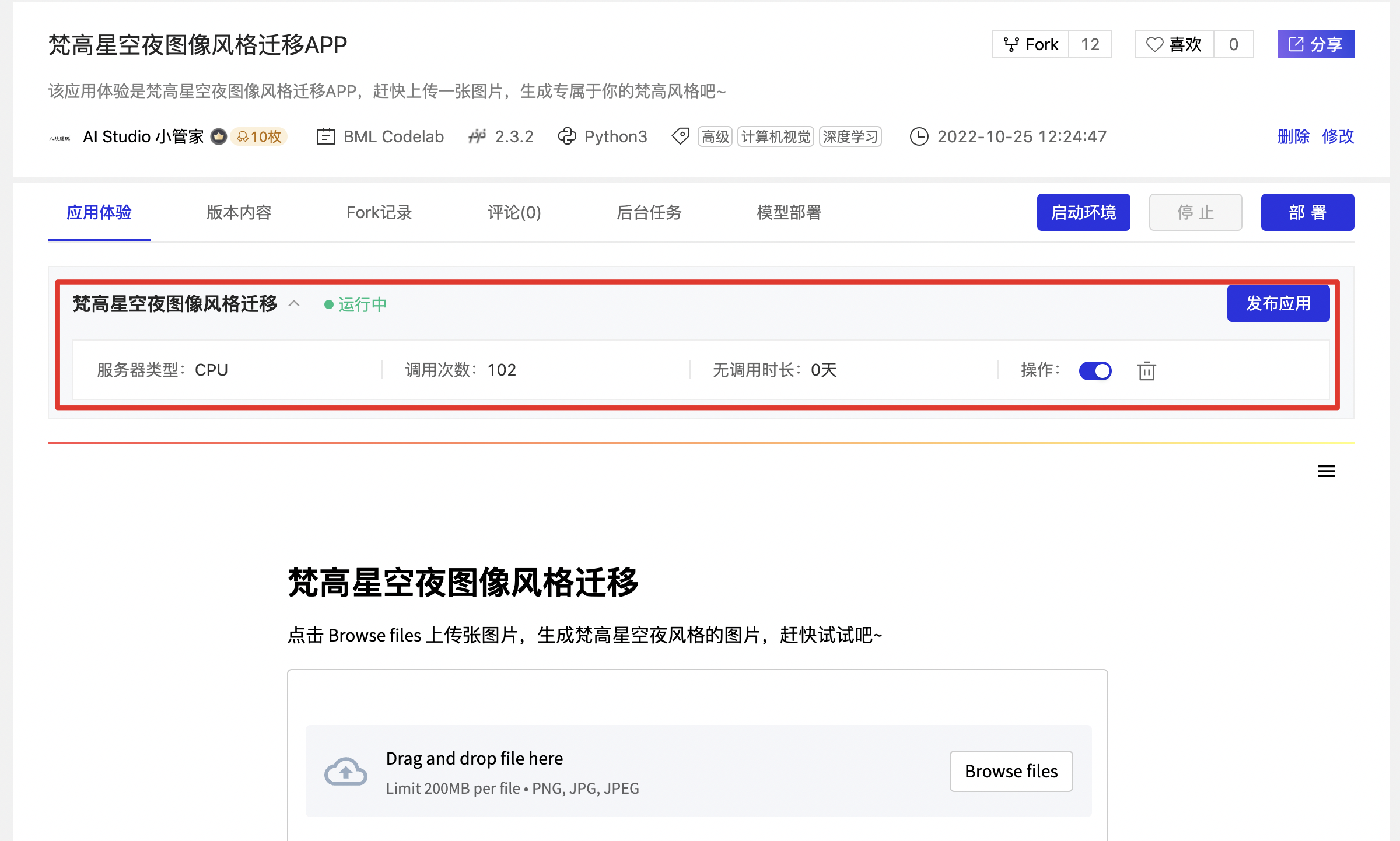
部署成功后的项目详情页将优先展示应用体验内容。作者可以额外看到应用名称、应用类型、部署时间、服务器类型、调用次数、无调用时间、操作(删除应用、打开/关闭应用、部署日志)。
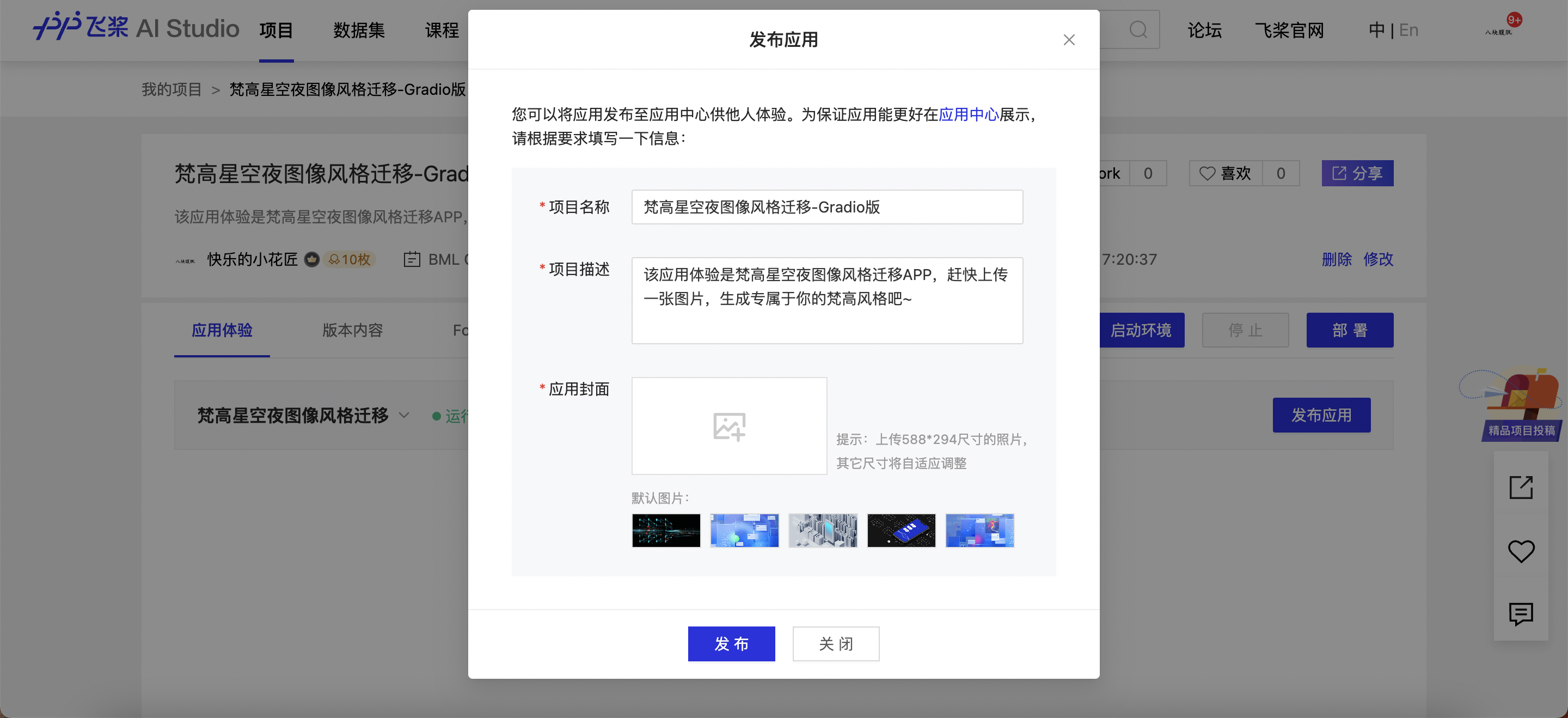
如您想将应用发布至应用中心,请点击右上角的'发布应用'按钮,填写发布必要信息并上传应用封面。
部署详细教程和注意事项请点击此处查看。
使用样例-Streamlit
以下是基于Streamlit应用创建工具使用PaddleHub中stylepro_artistic模型实现图片风格迁移的应用代码和交互效果。需要注意的是代码中迁移风格图片(StarryNight.png)需要您手动下载并上传至应用文件的同级目录。
示例代码:
import streamlit as st
import paddlehub as hub
import cv2
from PIL import Image
import numpy as np
import os
import paddlehub as hub
import cv2
stylepro_artistic = hub.Module(name="stylepro_artistic")
st.markdown('### 梵高星空夜图像风格迁移')
st.write('点击 Browse files 上传张图片,生成梵高星空夜风格的图片,赶快试试吧~')
with st.form(key="图像风格迁移"):
per_image = st.file_uploader("上传图片", type=['png', 'jpg','jpeg'], label_visibility='hidden')
col1, col2 = st.columns(2)
with col1:
st.markdown('#### 原始图片')
if per_image:
st.image(per_image)
else:
st.image("https://codelab-public.bj.bcebos.com/base.jpeg")
submit = st.form_submit_button("开始生成")
with col2:
st.markdown('#### 预测结果')
if per_image:
img = Image.open(per_image)
img = cv2.cvtColor(np.asarray(img), cv2.COLOR_RGB2BGR)
result =stylepro_artistic.style_transfer(images=
[{
'content': img,
'styles': [cv2.imread(os.path.join(os.path.dirname(os.path.realpath(__file__)),'StarryNight.png'))]
}])
st.image(result[0]['data'])
else:
st.image("https://codelab-public.bj.bcebos.com/test.jpeg")
st.markdown('#### 梵高星空夜作品展示')
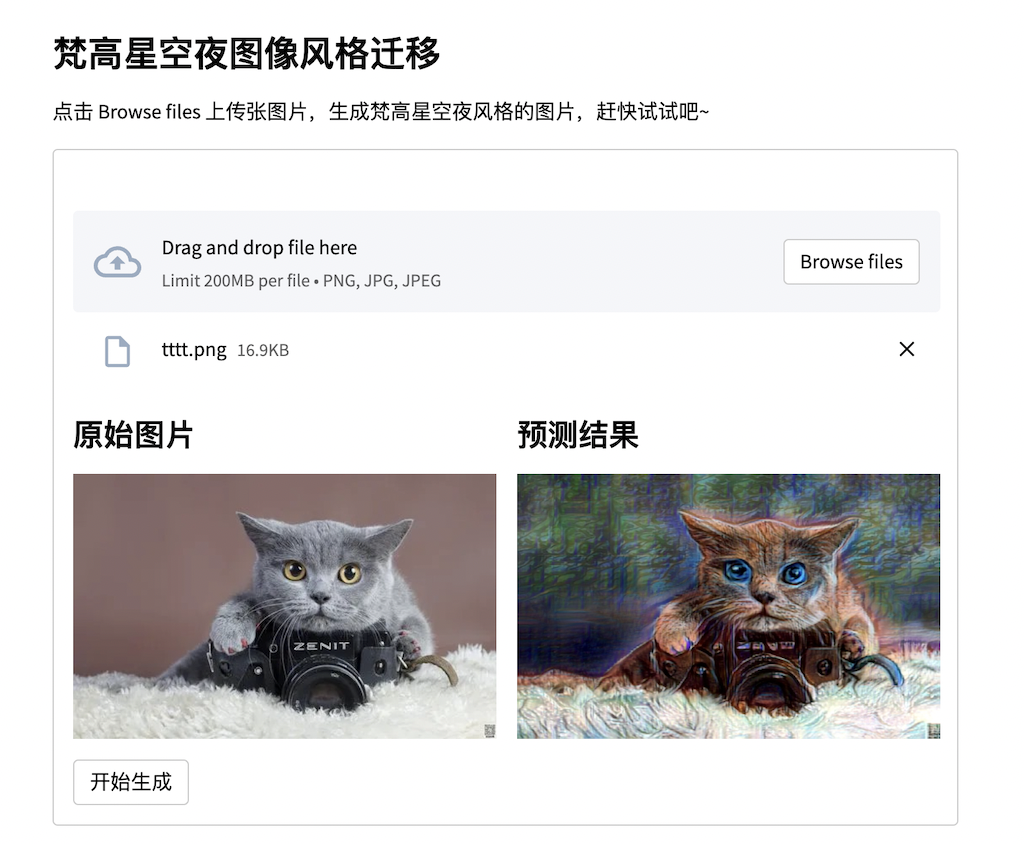
st.image("https://bkimg.cdn.bcebos.com/pic/d01373f082025aafcce937a8f7edab64024f1afd?x-bce-process=image/resize,m_lfit,w_1280,limit_1")交互效果:
 相关代码教程请点击此处
查看。
相关代码教程请点击此处
查看。
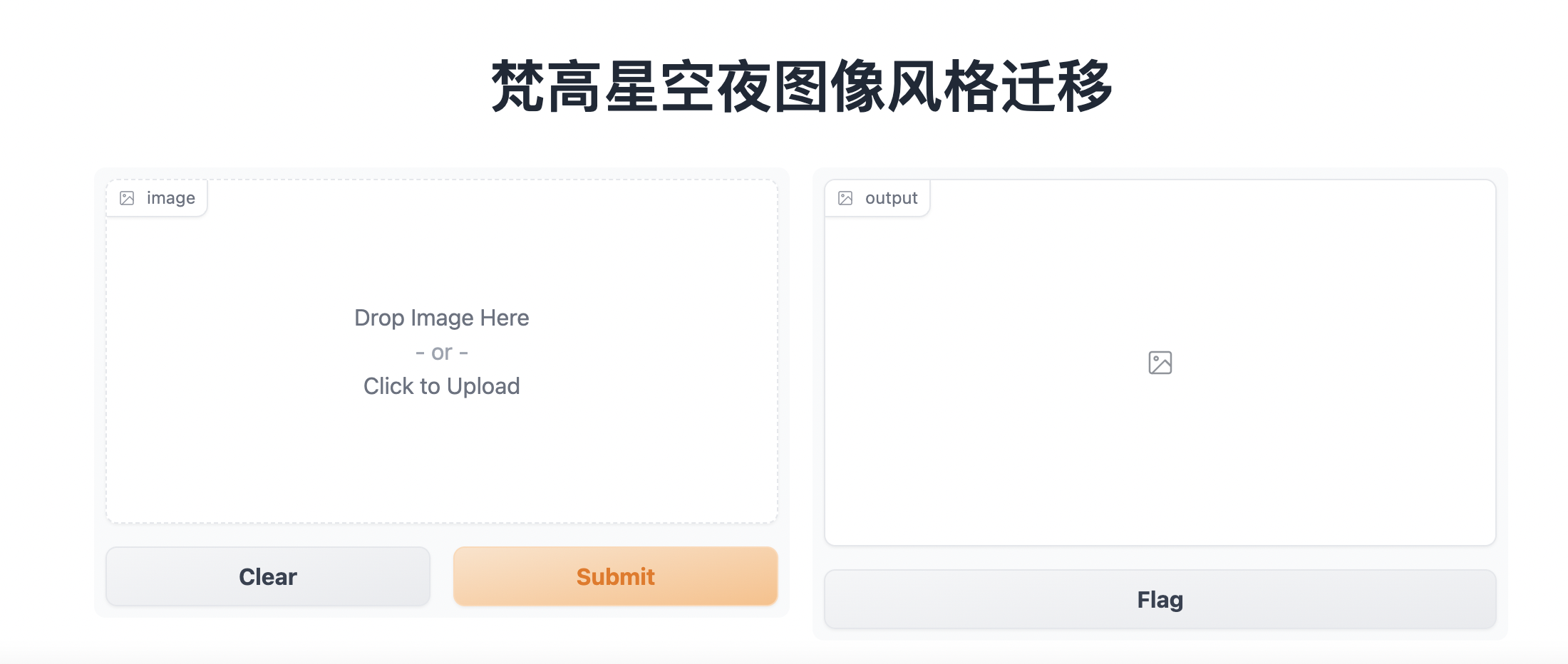
使用样例-Gradio
以下是基于Gradio应用创建工具使用PaddleHub中stylepro_artistic模型实现图片风格迁移的应用代码和交互效果。需要注意的是代码中迁移风格图片(StarryNight.png)需要您手动下载并上传至应用文件的同级目录。
示例代码:
import gradio as gr
import paddlehub as hub
import cv2
import numpy as np
import os
from PIL import Image
stylepro_artistic = hub.Module(name="stylepro_artistic")
def quickstart(image):
result =stylepro_artistic.style_transfer(images=
[{
'content': image,
'styles': [cv2.imread(os.path.join(os.path.dirname(os.path.realpath(__file__)),'StarryNight.png'))]
}])
return result[0]['data']
demo = gr.Interface(fn=quickstart,title="梵高星空夜图像风格迁移",inputs="image", outputs="image")
demo.launch()交互效果:
 相关代码教程请点击此处
查看。
相关代码教程请点击此处
查看。
快捷键操作
- 常用操作列表
| 模式 | 内容 | 快捷键(Windows) | 快捷键(Mac) |
|---|---|---|---|
命令模式 (Esc切换) |
运行块 | Shift-Enter | Shift-Enter |
| 命令模式 | 在下方插入块 | B | B |
| 命令模式 | 在上方插入块 | A | A |
| 命令模式 | 删除块 | d-d | d-d |
| 命令模式 | 切换到编辑模式 | Enter | Enter |
编辑模式 (Enter切换) |
运行块 | Shift-Enter | Shift-Enter |
| 编辑模式 | 缩进 | Clrl-] | Command-] |
| 编辑模式 | 取消缩进 | Ctrl-[ | Command-[ |
| 编辑模式 | 注释 | Ctrl-/ | Command-/ |
| 编辑模式 | 函数内省 | Tab | Tab |
常见问题解答
1、切换环境后,之前配置的暗色系以及字体为何复原?
答:由于切换环境涉及硬件环境的改变和执行器的重启,当前对于一些偏好设置暂未进行记录,将于后期进行优化,提升您的使用体验.