

PP-OCRv5_API
PP-OCRv5 服务化部署调用示例及 API 介绍:
PaddleOCR 开源项目 GitHub 地址,本服务基于该开源项目的 PP-OCRv5 模型构建。
版本说明:PaddleOCR 官网当前对应的 PaddleX 版本为 3.3.12,PaddlePaddle 版本为 3.2.1。
1. PP-OCRv5 介绍
OCR(光学字符识别,Optical Character Recognition)是一项将图片中的文字内容转换为可编辑文本的技术,广泛应用于文档数字化、信息提取、数据处理等场景。OCR 能够识别印刷体、手写体等多种类型的文本,帮助用户高效获取图像中的关键信息。
PP-OCRv5 是 PP-OCR 系列最新一代的文字识别解决方案,专为多场景、多文字类型的识别任务设计。相比前代版本,PP-OCRv5 在文字类型支持和应用场景适应性方面实现了全面升级。该方案不仅能够返回文本行的坐标信息,还可输出对应文本内容及其置信度,有效提升了文字检测与识别的准确性和实用性,该方案具有如下特点:
- 支持五大主流文字类型:简体中文、中文拼音、繁体中文、英文、日文。
- 具备强大的多场景适应能力:包括中英复杂手写体、竖排文本、生僻字等多种挑战性场景。
- 在内部多场景复杂评估集上,PP-OCRv5 相比上一代 PP-OCRv4 端到端识别精度提升了 13 个百分点。
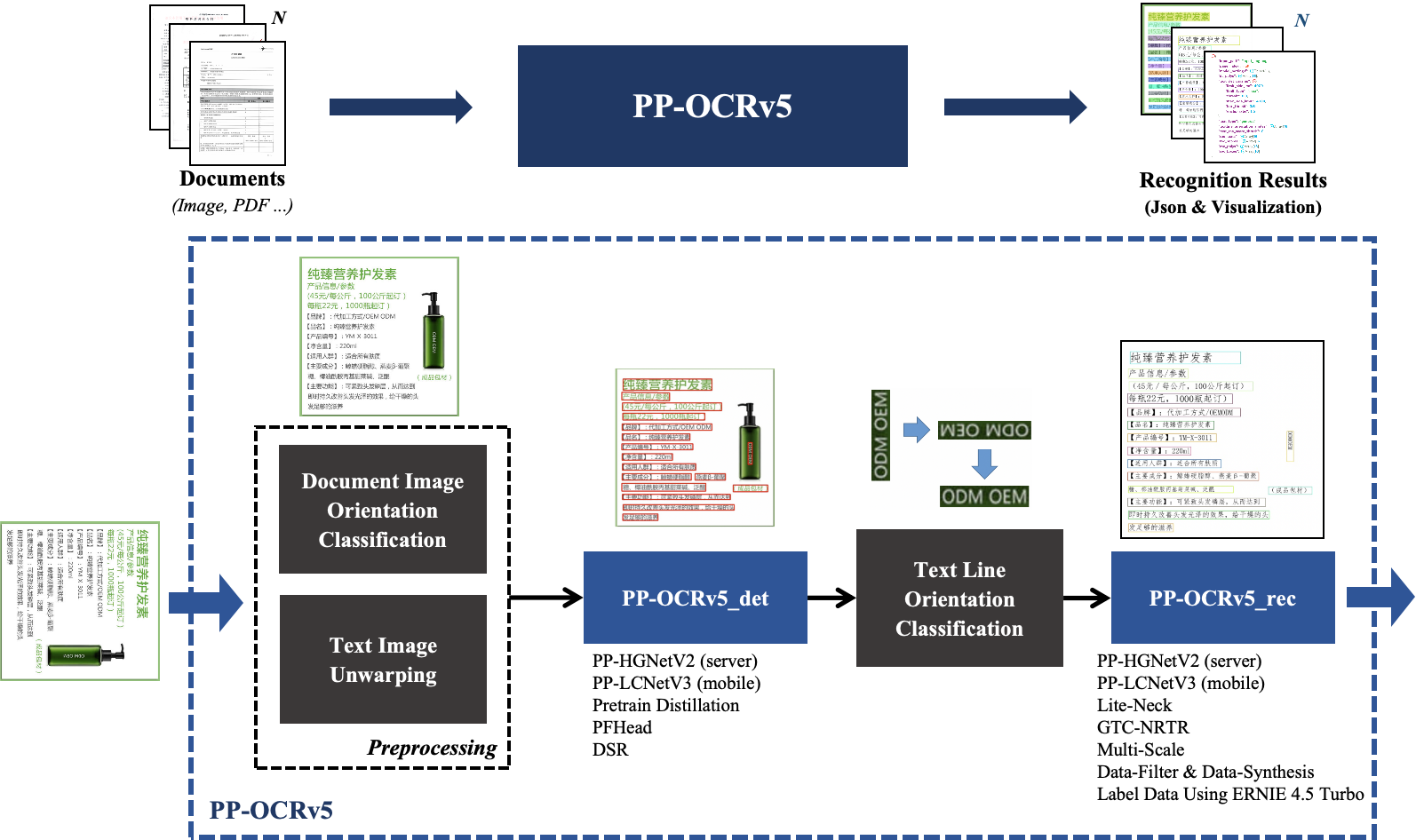
PP-OCRv5 产线整体流程如下图所示:
2. API 配额规则及错误码说明
请查看文档
3. 服务调用示例(python)
# Please make sure the requests library is installed
# pip install requests
import os
import base64
import requests
# API_URL 及 TOKEN 请访问 https://aistudio.baidu.com/paddleocr/task,在 API 调用示例中获取。
API_URL = "<your url>"
TOKEN = "<access token>"
file_path = "<local file path>"
input_filename = os.path.splitext(os.path.basename(file_path))[0]
with open(file_path, "rb") as file:
file_bytes = file.read()
file_data = base64.b64encode(file_bytes).decode("ascii")
headers = {
"Authorization": f"token {TOKEN}",
"Content-Type": "application/json"
}
required_payload = {
"file": file_data,
"fileType": <file type>, # For PDF documents, set `fileType` to 0; for images, set `fileType` to 1
}
optional_payload = {
"useDocOrientationClassify": False,
"useDocUnwarping": False,
"useTextlineOrientation": False,
}
payload = {**required_payload, **optional_payload}
response = requests.post(API_URL, json=payload, headers=headers)
assert response.status_code == 200
result = response.json()["result"]
os.makedirs("output", exist_ok=True)
for i, res in enumerate(result["ocrResults"]):
print(res["prunedResult"])
image_url = res["ocrImage"]
img_response = requests.get(image_url)
if img_response.status_code == 200:
# Save image to local
filename = f"output/{input_filename}_{i}.jpg"
with open(filename, "wb") as f:
f.write(img_response.content)
print(f"Image saved to: {filename}")
else:
print(f"Failed to download image, status code: {img_response.status_code}")对于服务提供的主要操作:
- HTTP请求方法为POST。
- 请求体和响应体均为JSON数据(JSON对象)。
- 当请求处理成功时,响应状态码为
200,响应体的属性如下:
| 名称 | 类型 | 含义 |
|---|---|---|
logId |
string |
请求的UUID。 |
errorCode |
integer |
错误码。固定为0。 |
errorMsg |
string |
错误说明。固定为"Success"。 |
result |
object |
操作结果。 |
- 当请求处理未成功时,响应体的属性如下:
| 名称 | 类型 | 含义 |
|---|---|---|
logId |
string |
请求的UUID。 |
errorCode |
integer |
错误码。与响应状态码相同。 |
errorMsg |
string |
错误说明。 |
服务提供的主要操作如下:
infer
获取图像OCR结果。
POST /ocr
4. 请求参数说明
| 名称 | 参数 | 类型 | 含义 | 是否必填 |
|---|---|---|---|---|
输入文件 |
file |
string |
服务器可访问的图像文件或PDF文件的URL,或上述类型文件内容的Base64编码结果。默认对于超过10页的PDF文件,只有前10页的内容会被处理。 要解除页数限制,请在产线配置文件中添加以下配置: |
是 |
文件类型 |
fileType |
integer | null |
文件类型。0表示PDF文件,1表示图像文件。若请求体无此属性,则将根据URL推断文件类型。 |
否 |
图片方向矫正 |
useDocOrientationClassify |
boolean | null |
是否在推理时使用文档方向分类模块,开启后,可以自动识别并矫正 0°、90°、180°、270°的图片,默认初始化为 False。 |
否 |
图片扭曲矫正 |
useDocUnwarping |
boolean | null |
是否在推理时使用文本图像矫正模块,开启后,可以自动矫正扭曲图片,例如褶皱、倾斜等情况,默认初始化为 False。 |
否 |
文本行方向矫正 |
useTextlineOrientation |
boolean | null |
是否在推理时使用文本行方向分类模块,开启后,可以自动识别和矫正 0° 和 180° 的文本行,默认初始化为 False。 |
否 |
图像边长限制 |
textDetLimitSideLen |
integer | null |
文本检测的图像边长限制。 大于0 的任意整数。如果不设置,将使用产线初始化的该参数值,默认初始化为 64。 |
否 |
图像边长限制类型 |
textDetLimitType |
string | null |
文本检测的边长度限制类型。支持 min 和 max,min 表示保证图像最短边不小于 textDetLimitSideLen,max 表示保证图像最长边不大于 textDetLimitSideLen。如果不设置,将使用产线初始化的该参数值,默认初始化为 min。 |
否 |
文本检测像素阈值 |
textDetThresh |
number | null |
文本检测像素阈值,输出的概率图中,得分大于该阈值的像素点才会被认为是文字像素点。 大于 0 的任意浮点数。如果不设置,将使用产线初始化的该参数值(默认为 0.3)。 |
否 |
文本检测框阈值 |
textDetBoxThresh |
number | null |
文本检测框阈值,检测结果边框内,所有像素点的平均得分大于该阈值时,该结果会被认为是文字区域。 大于 0 的任意浮点数。如果不设置,将使用产线初始化的该参数值(默认为 0.6)。 |
否 |
扩张系数 |
textDetUnclipRatio |
number | null |
文本检测扩张系数,使用该方法对文字区域进行扩张,该值越大,扩张的面积越大。大于 0 的任意浮点数。如果不设置,将使用产线初始化的该参数值(默认为 1.5)。 |
否 |
文本识别阈值 |
textRecScoreThresh |
number | null |
文本识别阈值,得分大于该阈值的文本结果会被保留。 大于 0 的任意浮点数。如果不设置,将使用产线初始化的该参数值(默认为 0.0,即不设阈值)。 |
否 |
可视化 |
visualize |
boolean | null |
支持返回可视化结果图及处理过程中的中间图像。开启此功能后,将增加结果返回时间。
例如,在产线配置文件中添加如下字段: visualize参数可以覆盖默认行为。如果请求体和配置文件中均未设置(或请求体传入null、配置文件中未设置),则默认返回图像。
|
否 |
- 请求处理成功时,响应体的
result具有如下属性:
| 名称 | 类型 | 含义 |
|---|---|---|
ocrResults |
object |
OCR结果。数组长度为1(对于图像输入)或实际处理的文档页数(对于PDF输入)。对于PDF输入,数组中的每个元素依次表示PDF文件中实际处理的每一页的结果。 |
dataInfo |
object |
输入数据信息。 |
ocrResults中的每个元素为一个object,具有如下属性:
| 名称 | 类型 | 含义 |
|---|---|---|
prunedResult |
object |
产线对象的 predict 方法生成结果的 JSON 表示中 res 字段的简化版本,其中去除了 input_path 和 page_index 字段。 |
ocrImage |
string | null |
OCR结果图,其中标注检测到的文本位置。图像为JPEG格式,使用Base64编码。 |
docPreprocessingImage |
string | null |
可视化结果图像。图像为JPEG格式,使用Base64编码。 |
inputImage |
string | null |
输入图像。图像为JPEG格式,使用Base64编码。 |
对于返回的数据结构及字段说明,请查阅文档。
注:如果在使用过程中遇到问题,欢迎随时在 issue 区提交反馈。
PP-OCRv6 服务化部署调用示例及 API 介绍:
PaddleOCR 开源项目 GitHub 地址,本服务基于该开源项目的 PP-OCRv6 模型构建。
版本说明:PaddleOCR 官网当前对应的 PaddleX 版本为 3.7.0,PaddlePaddle 版本为 3.2.1。
1. PP-OCRv6 介绍
PP-OCRv6 是 PP-OCR 最新一代通用文字识别解决方案。PP-OCRv6 基于全新设计的 PPLCNetV4 统一骨干网络,提供 tiny、small、medium 三档模型,分别面向端侧/IoT、移动端/桌面端、服务端场景。PP-OCRv6 在语言覆盖方面实现重大突破,medium/small 档单一模型统一支持简体中文、繁体中文、英文、日文及 46 种拉丁语系语言共 50 种语言(tiny 档支持 49 种,不含日文)。在内部多场景综合评估集上,PP-OCRv6_medium 相比 PP-OCRv5_server 识别精度提升 5.1%、检测精度提升 4.6%,同时 GPU 推理速度提升 2.37×;以仅 34.5M 参数的规模,精度超越 Qwen3-VL-235B、GPT-5.5 等大型视觉语言模型。
PP-OCRv6 的主要贡献如下:
- 统一可扩展的模型族:提供覆盖 1.5M 至 34.5M 参数的三档完整 OCR 模型族。medium 档达到 86.2% 检测 Hmean 和 83.2% 识别准确率,可作为工业部署和大规模数据管线的高效生产级基础设施。
- 面向 OCR 的轻量级架构创新:提出一系列专为 OCR 任务定制的轻量级架构组件——(i) LCNetV4:集成结构重参数化的 MetaFormer 风格轻量骨干;(ii) RepLKFPN:利用膨胀可重参数化深度卷积实现大感受野的检测颈部;(iii) EncoderWithLightSVTR:基于局部-全局注意力和加性跳跃连接的识别颈部。
- 广泛的多语言与多场景泛化:单一模型扩展至支持 50 种语言和多种挑战性工业场景(如数码显示屏、点阵字符、轮胎印字等),显著提升了传统通用视觉语言模型难以覆盖的专业场景 OCR 性能。

图:PP-OCRv6 与 PP-OCRv5 及视觉语言模型的性能对比。左:文本检测平均 Hmean(%);右:文本识别加权平均准确率(%)。