训练数据
添加训练数据后,模型才能正确的识别意图和词槽。
对话模板:按照模板规则匹配语句,符合规则即可识别。
对话样本:真实对话数据,标注样本的意图、词槽之后,可以识别样本原句和原句的相似语句。
词槽词典值:为技能提供识别语句中的关键参数的能力。比如手机推荐中的手机品牌,就需要通过添加词槽词典值来识别。
对话模板
在没有真实对话数据,但需要快速启动项目的情况下,首选配置对话模板,可以快速让模型有一定的识别效果。精确识别语句,输入的语句符合模板就能识别到意图、词槽等信息。
我们先简单了解几个概念:
模板片段:由词槽、特征词、固定文本组成。一般情况下,一个词槽或特征词或固定文本即是一个模板片段。
特征词:当一个词具有多个同义表述时,我们将这些词加到一个词组里,就是特征词。例如:问题"支持退换货嘛?"中,"支持"的同义表述有:有、能、可以、享受等。
必须匹配:必须匹配选择【是】的模板片段,必须在用户问题中出现,才能命中当前模板。
阈值:
1. 当用户语句中可识别部分内容字数除以模板内容总字数 > 阈值时,语句可匹配该模板。
2. 可识别部分包括:词槽,特征词,固定汉字,口语化词。计算字数时,汉字是1,数字、字母、标点符号是0.5。
解析返回所有词槽:选择是,表示匹配到该模板时,只要语句包含该词槽,即使未在模板配置,也会返回该词槽的解析结果。
词表黑名单:可以配置词槽、特征词,只要语句包含词表黑名单的内容,模板将不会识别该语句。
模板优先级:靠前的模板优先级高。如果语句可以匹配两个模板,会根据优先级高的模板给出识别结果。
接下来我们来看如何为导航场景下的问题"肯德基在哪?"创建一个问题模板。
首先,这句话里有两个关键词,分别是:肯德基、在哪。其中,"肯德基"是规划导航路径的关键参数,需要设置为词槽才能传给业务系统进行路径规划;"在哪"是有多个同义表述的,我们将其设为特征词。
点击【新建问题模板】即可开始配置模版,选择【新建特征词】并在对话框中输入特征词信息,如下示例:
【名称】:kw_where
【描述】:把"在哪"定义为特征词。
【词典值】:在哪,在什么地方,哪里,哪有

接下来,将词槽和特征词分别加入到两个模板片段中。
这时,我们发现,"肯德基在哪?"这句话中,"肯德基"和"在哪"必须都有,我们才能完整理解句子意思的词。所以,我们分别在"肯德基"和"在哪"的片段前,【必须匹配】选项选【是】。
我们还会发现一个问题,就是用户还可能会说:"哪里有肯德基",这句话特征词的出现顺序发生了明显的变化,为了解决这个问题,UNIT为模板片段提供了顺序的概念:
当顺序为0时,意味着这个模板片段可以出现在用户问题中的任意位置;当顺序大于1时,模板按照从小到大的顺序,需要依次在用户问题中从左至右出现。我们来看两个例子:
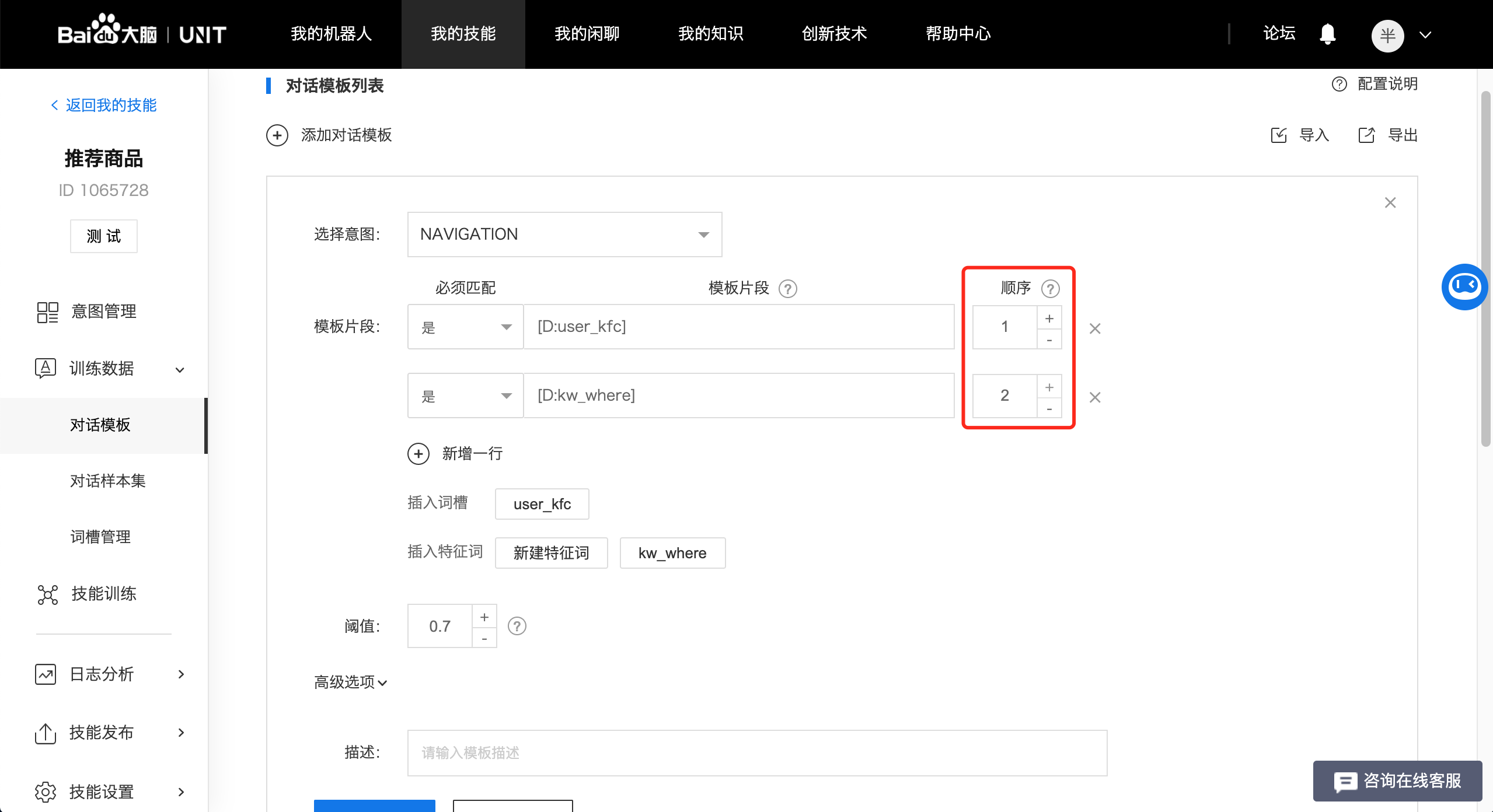
此配置下,当用户说:"肯德基在什么地方?"、"肯德基在哪?"才能命中模板
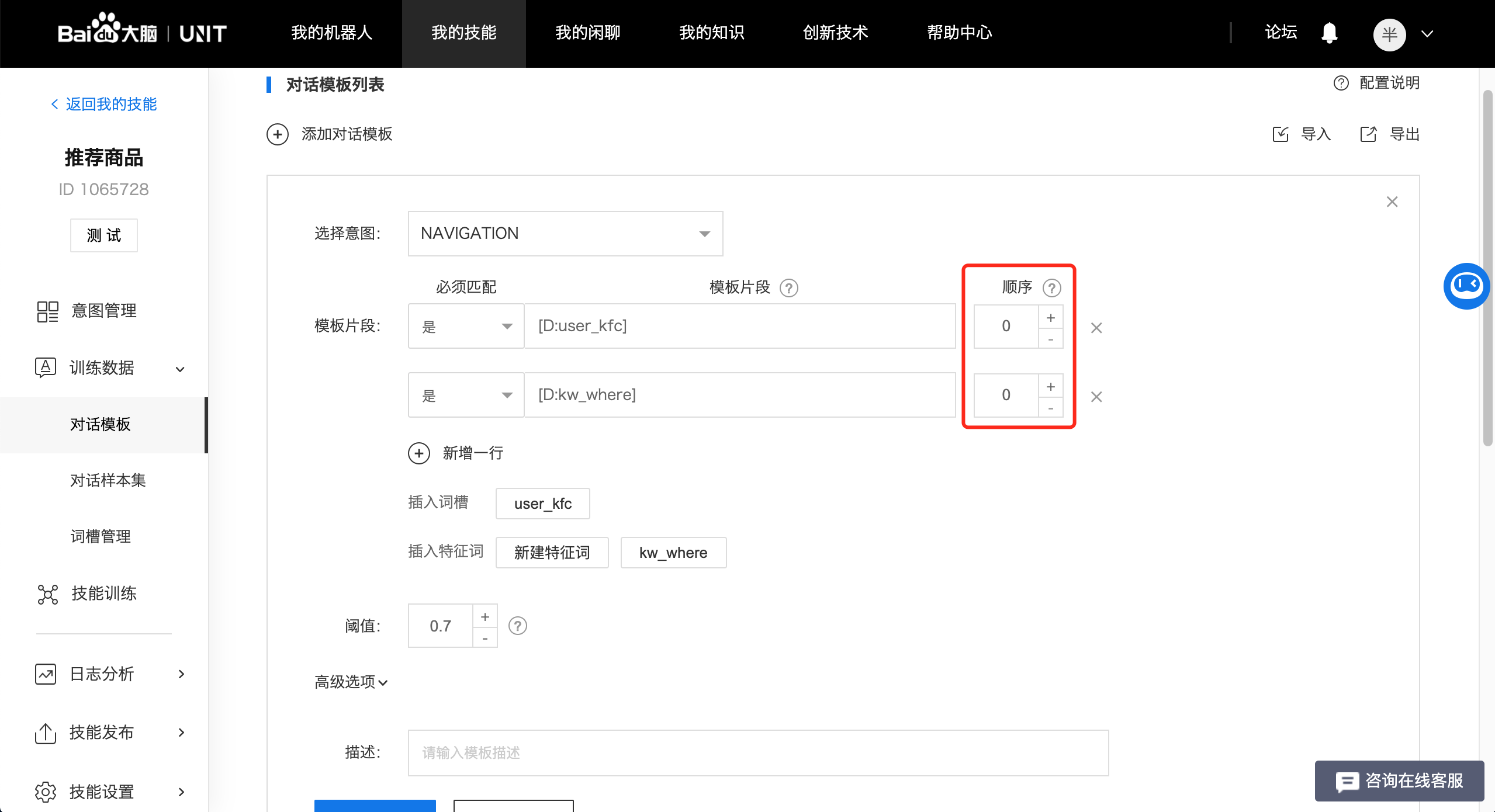
此配置下,无论用户说:"哪有肯德基?"、"肯德基在哪里?"、"在什么地方啊,肯德基"都可以命中模板。
注意:
单模板片段不是完全不能使用,如果词槽或者特征词之间必须紧挨,不期望中间有其他内容,就需要使用;或者意图下有两个相同词典的不同词槽,为了区分识别这两个词槽,就需要用特征词对其中一个进行限定。比如订火车票意图,有起点和终点,真实语句中,包含终点的词一般都是"去北京""到北京""回北京",此时就需要将包含"去""到""回"的特征词与终点词槽配置在一个模板片段中。
返回数据json中有模板ID(template_id),可在对话模板界面通过搜索定位具体匹配的模板。
对话样本集
对话样本是真实的对话数据,模型可以从标注后的样本学习到样本对应的意图,以及样本中包含的词槽都是什么。
1. 对话样本集
UNIT为开发者提供了三种样本集:
a. 待优化样本集
b. 系统推荐样本集
c. 自建样本集
2. 新建对话样本
UNIT为开发者提供了两种新建对话样本的方式:
a. 逐条添加
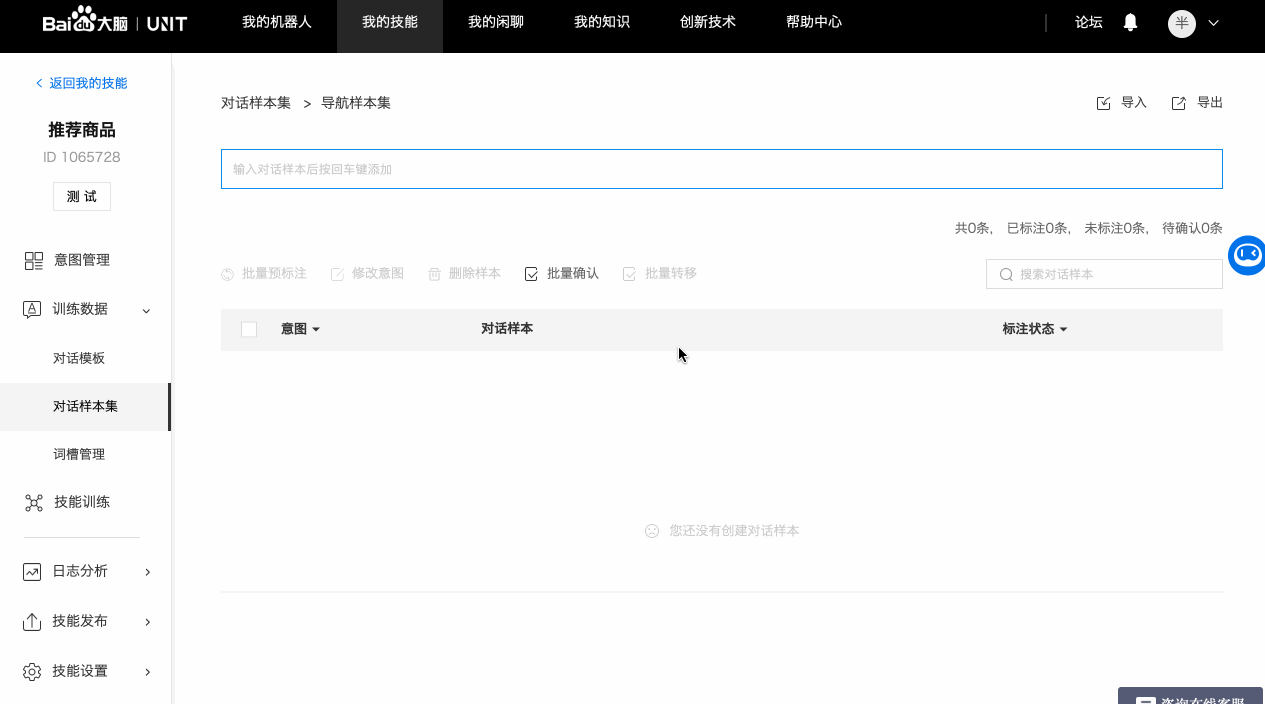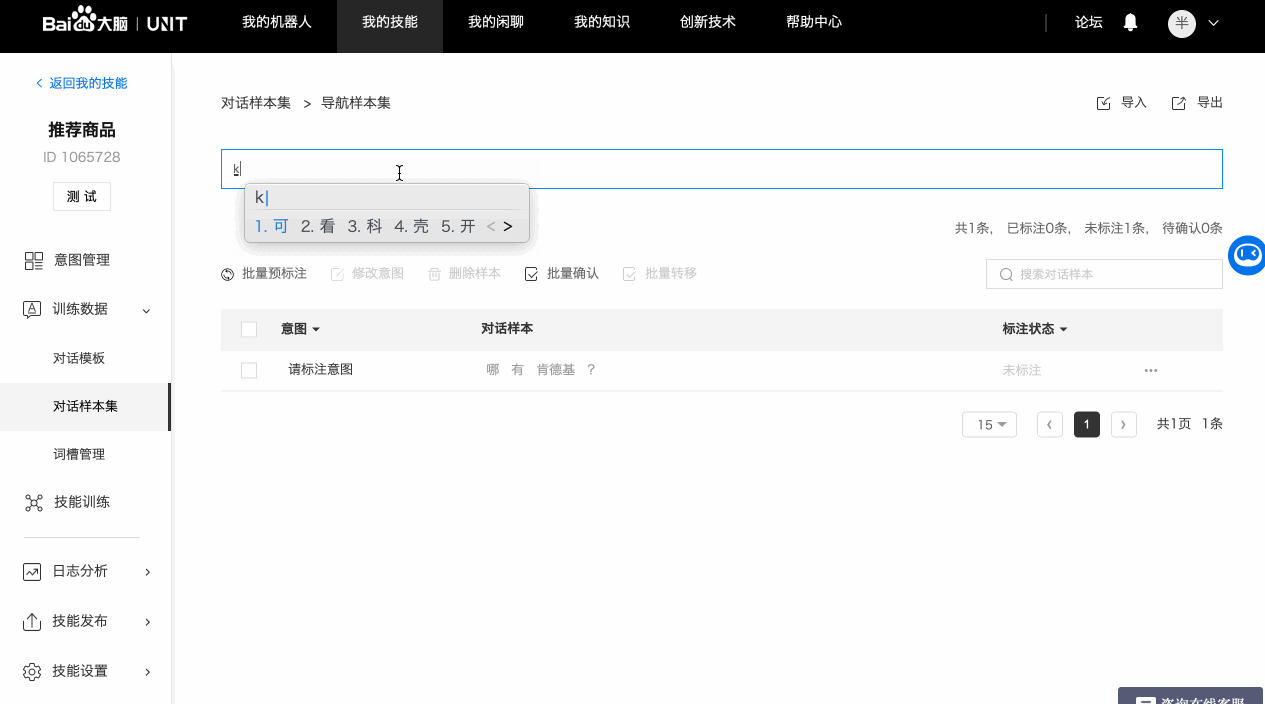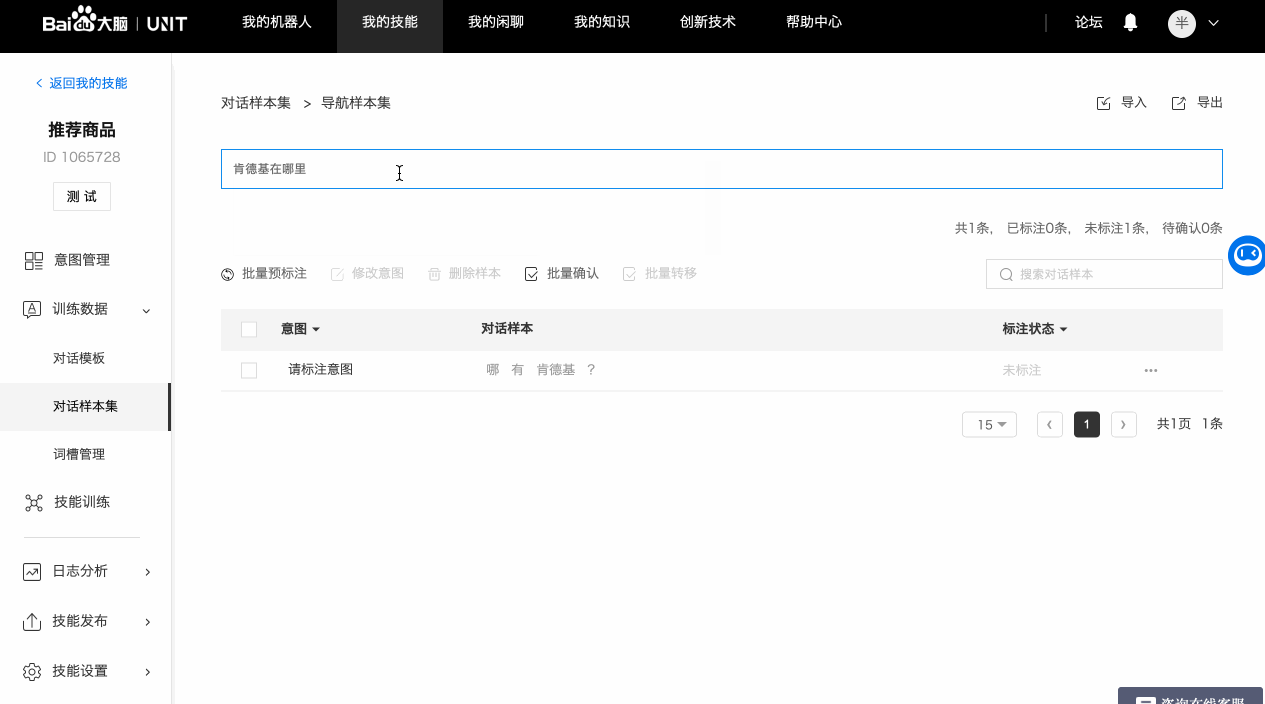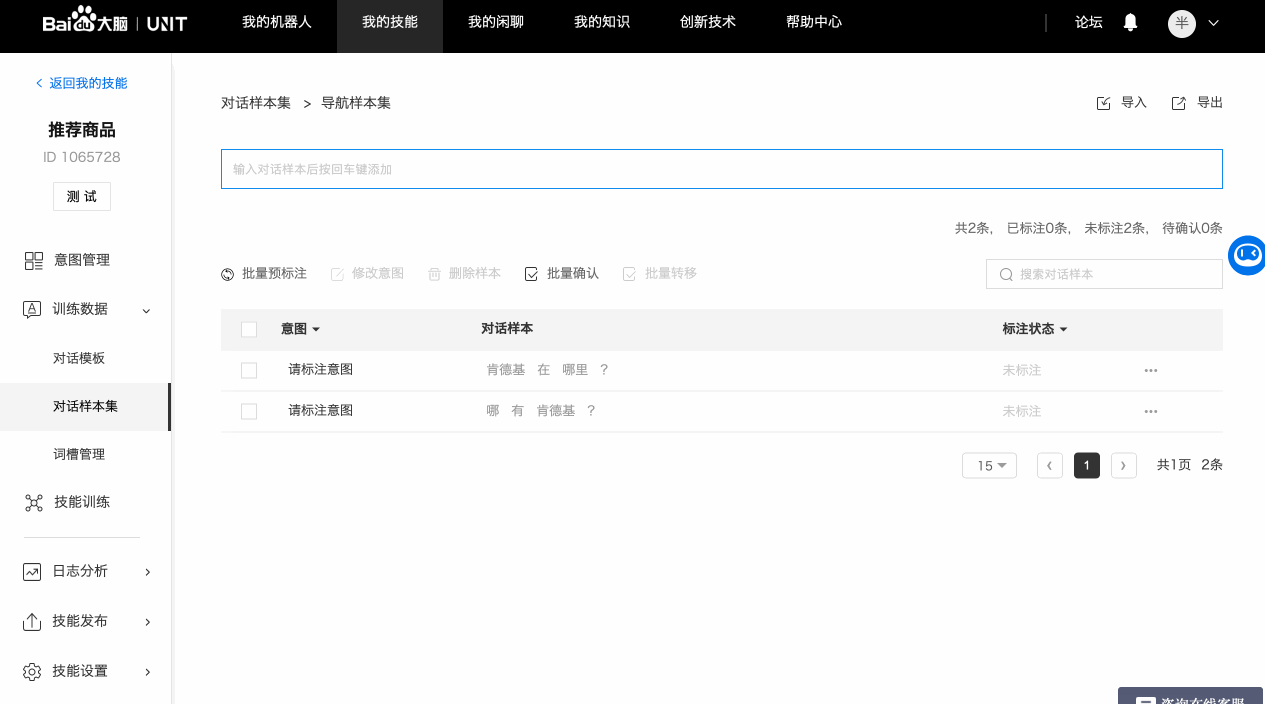
b. 批量导入
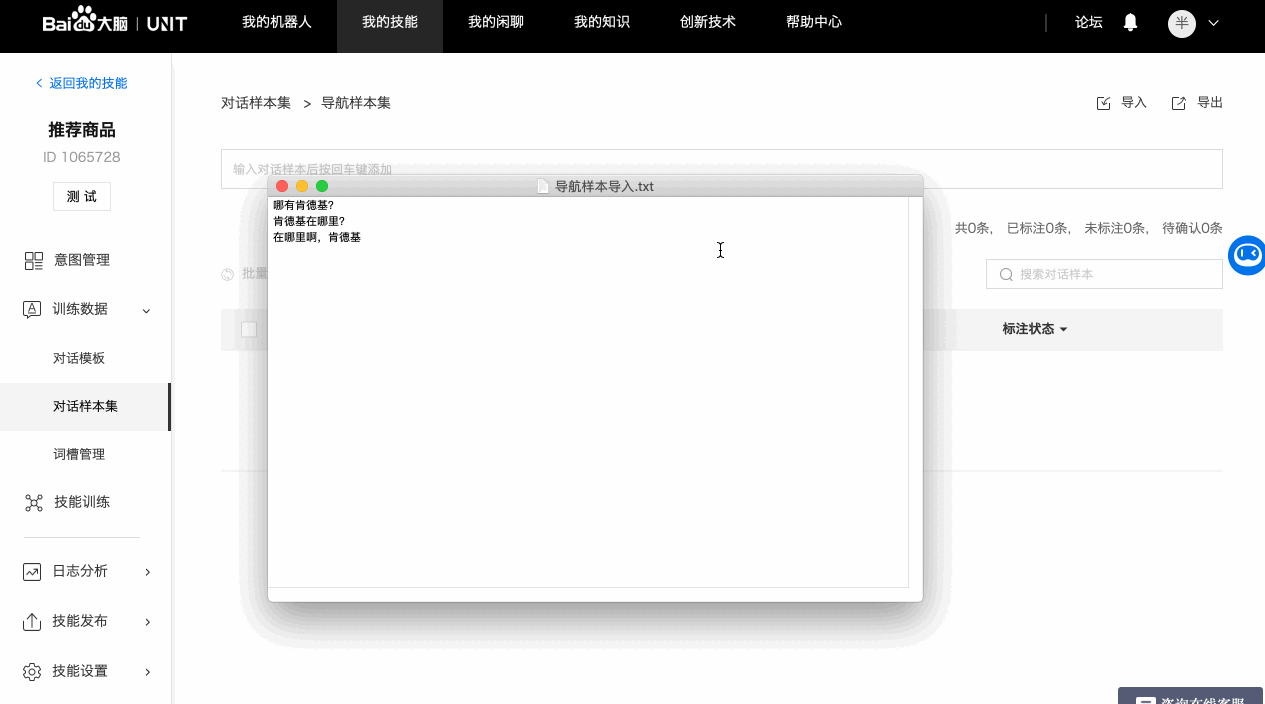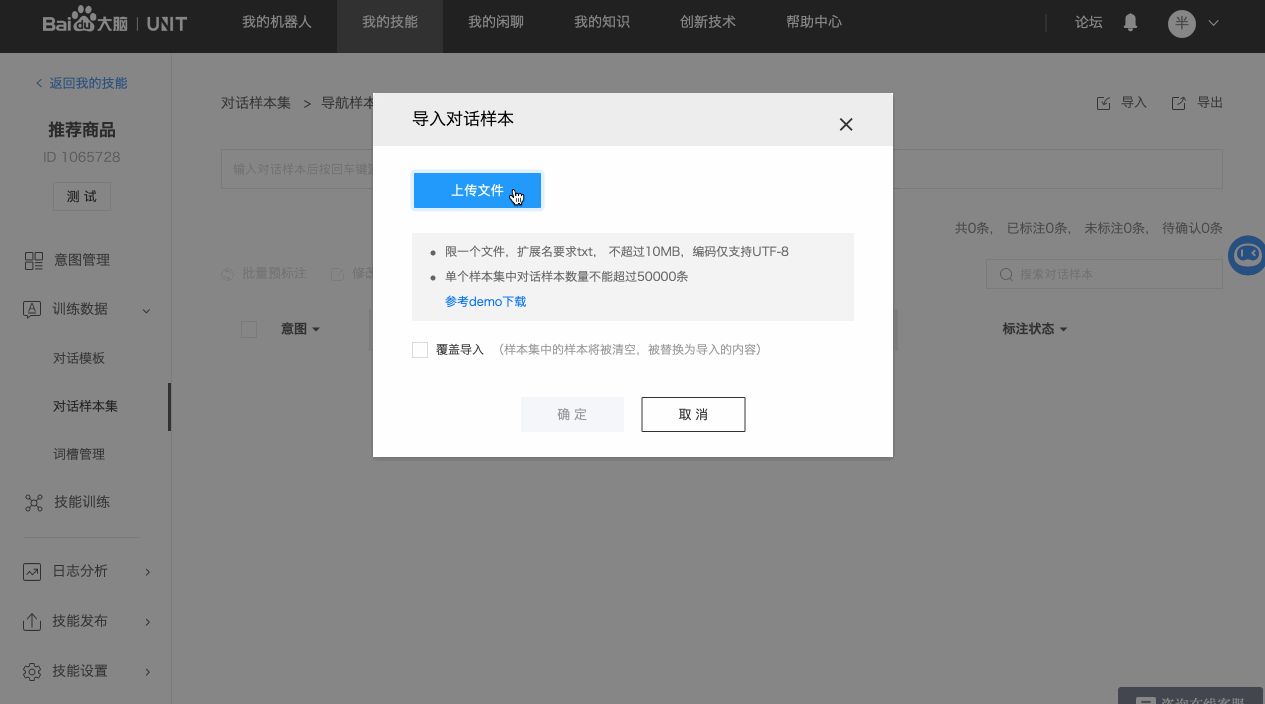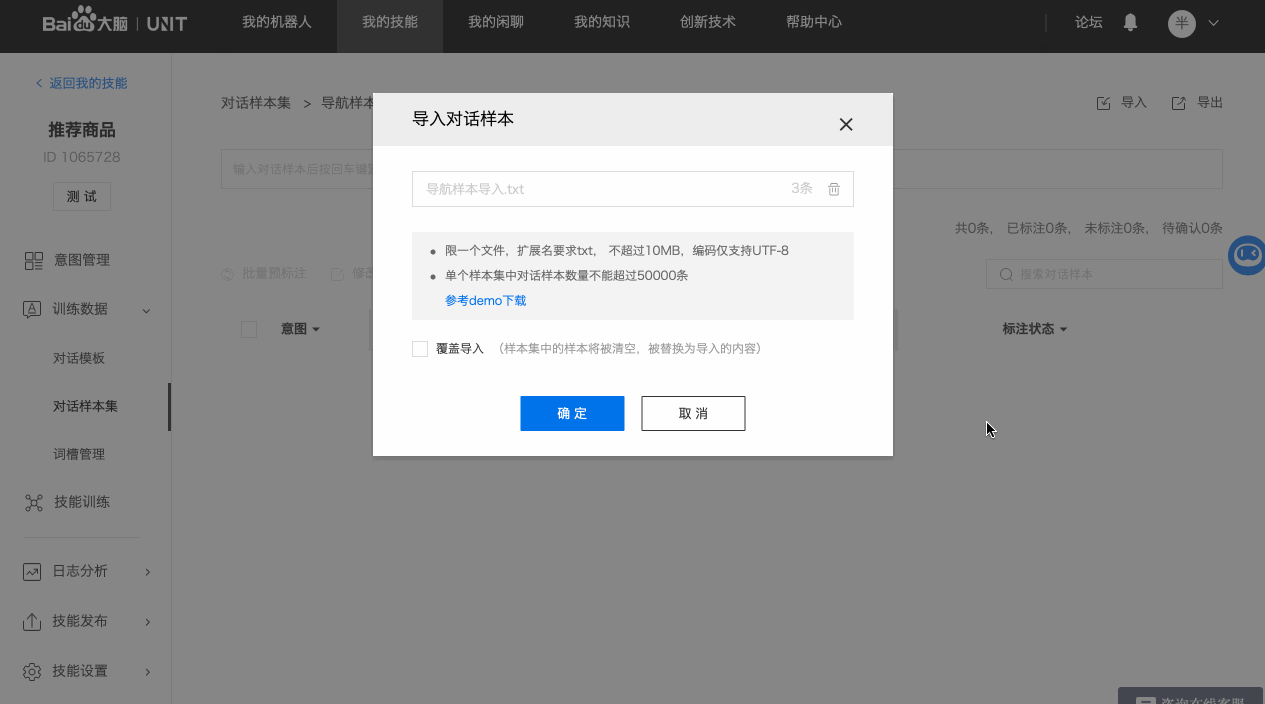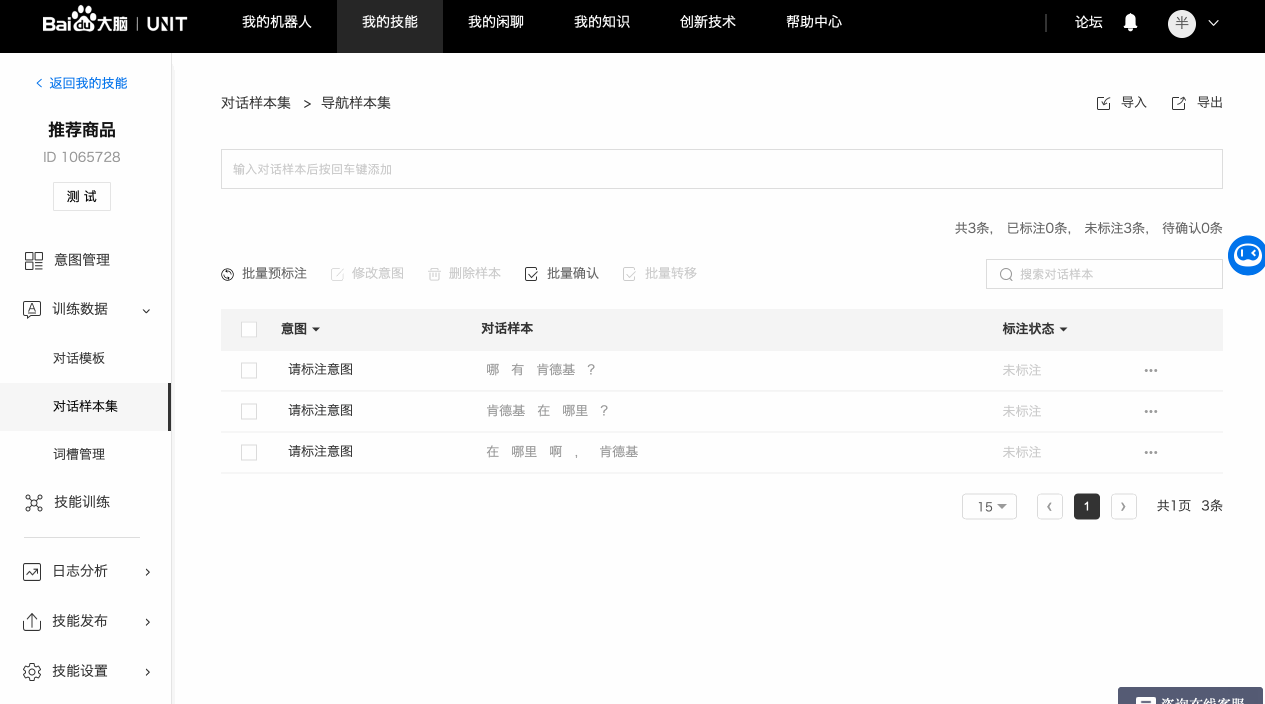
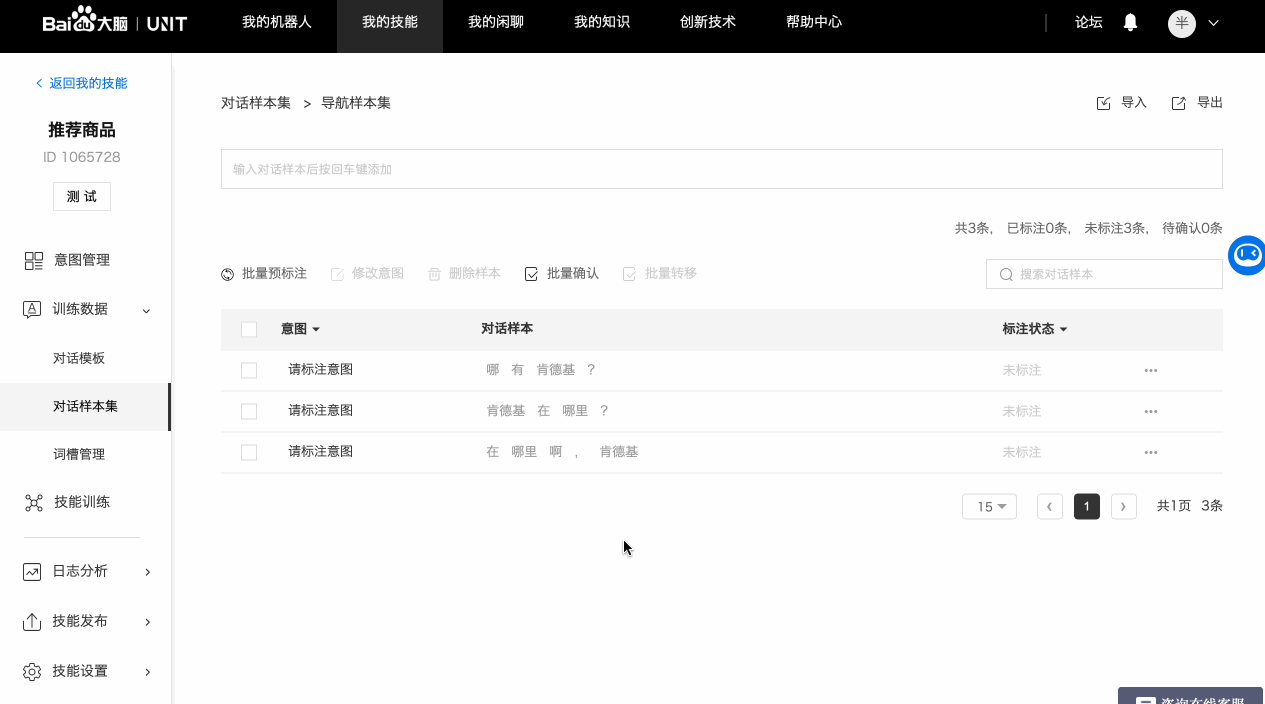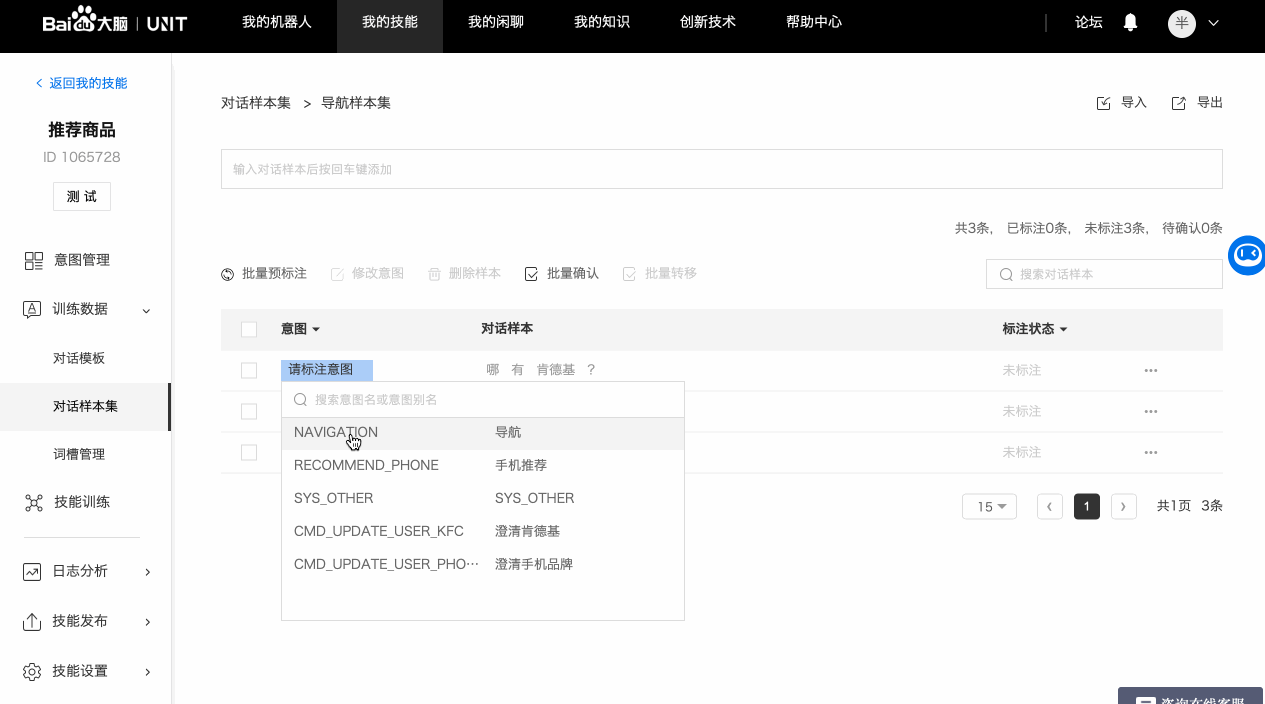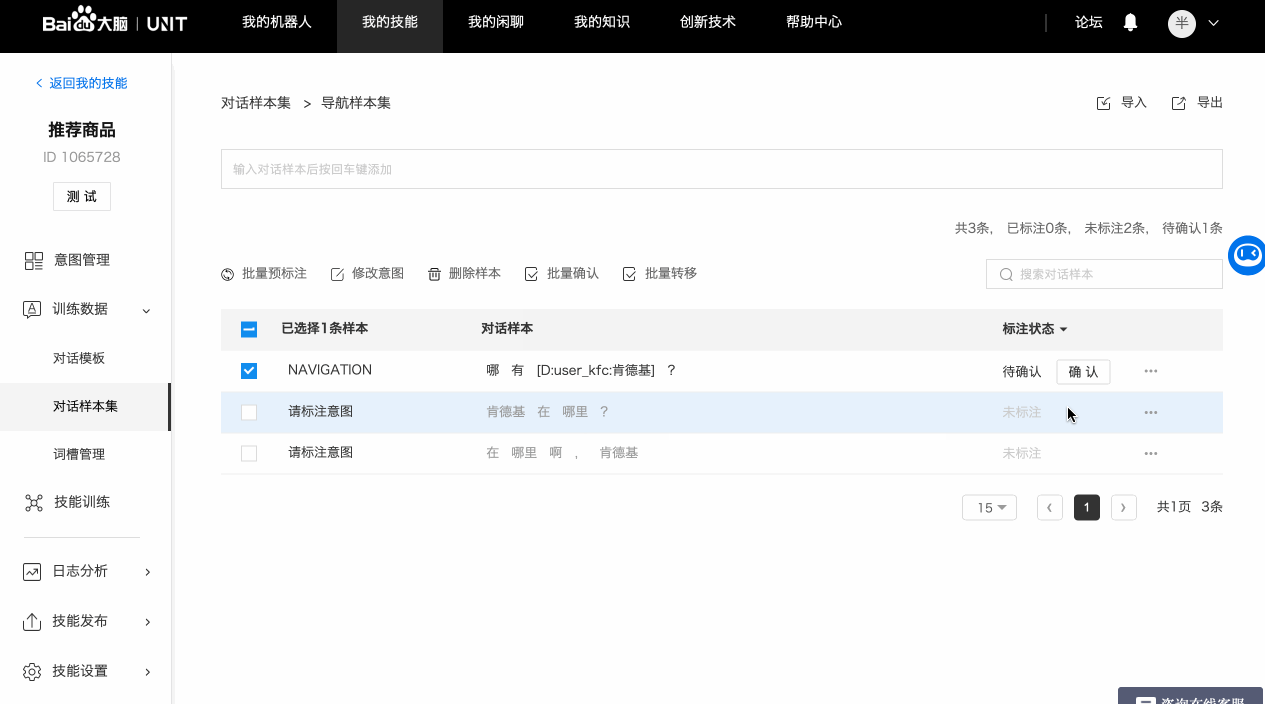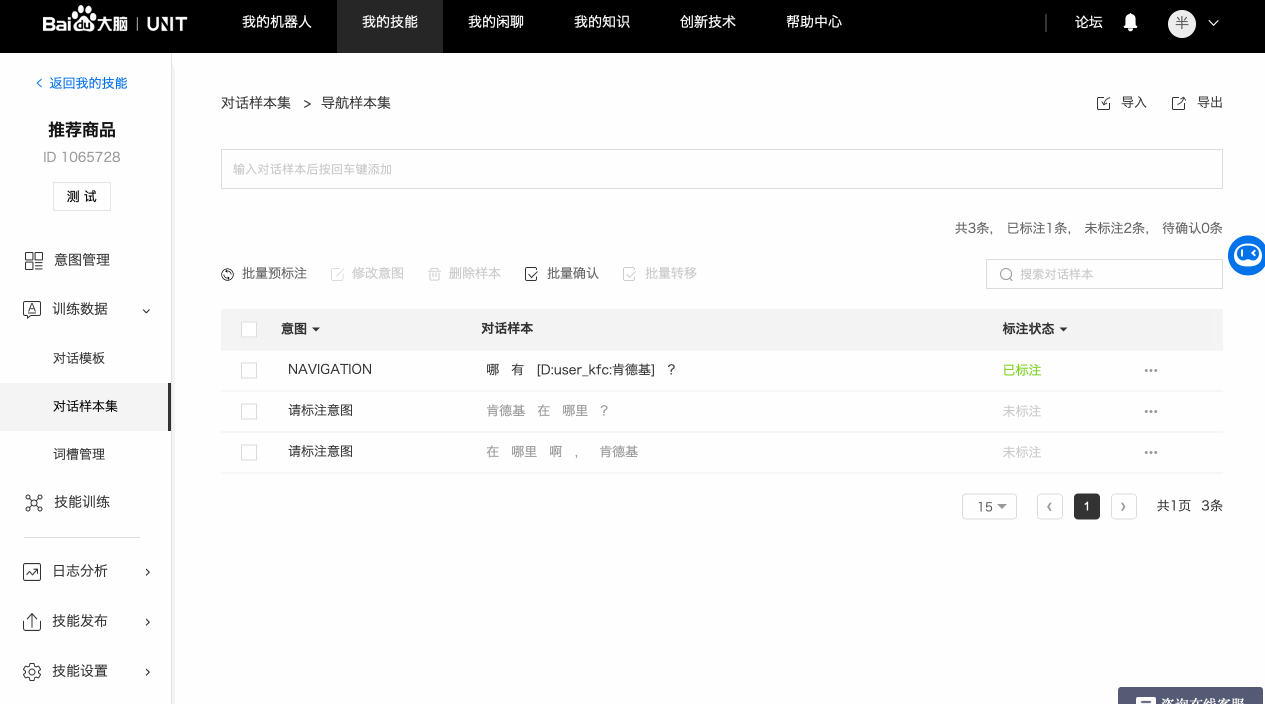
3. 单条标注对话样本
完整的对话样本标注需要经历三个步骤:标注意图->标注词槽->确认标注。
注意:
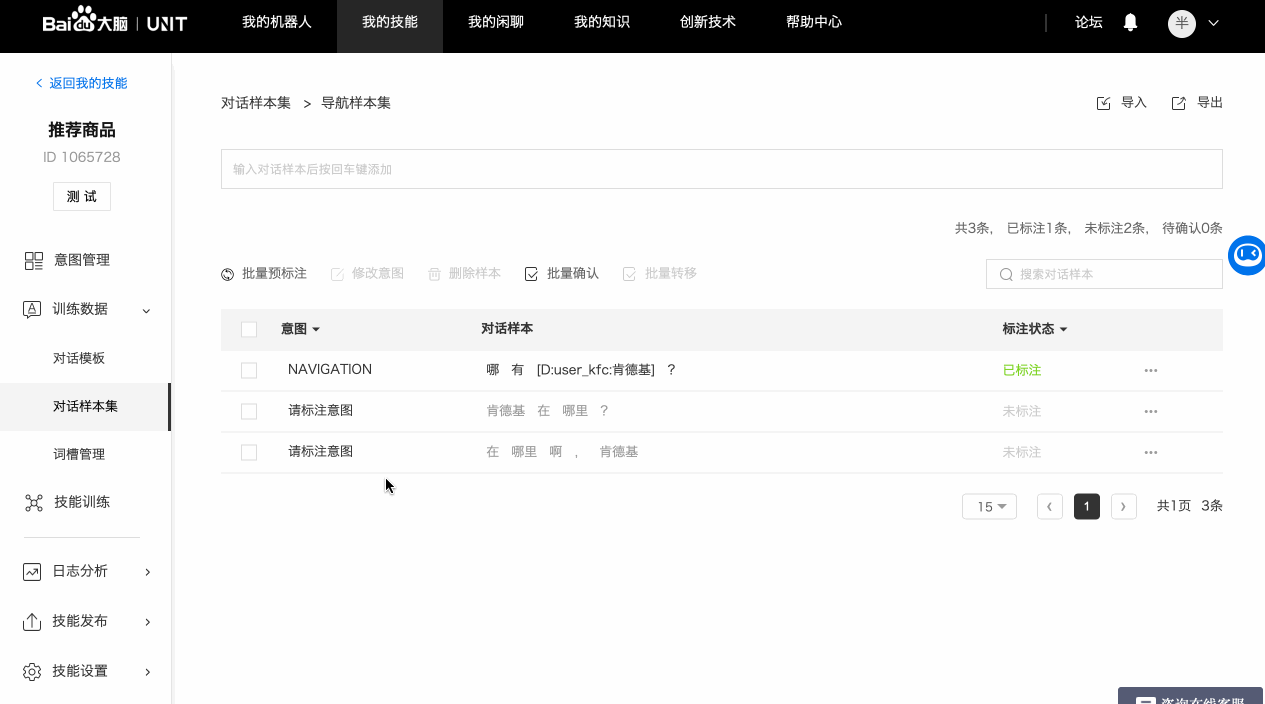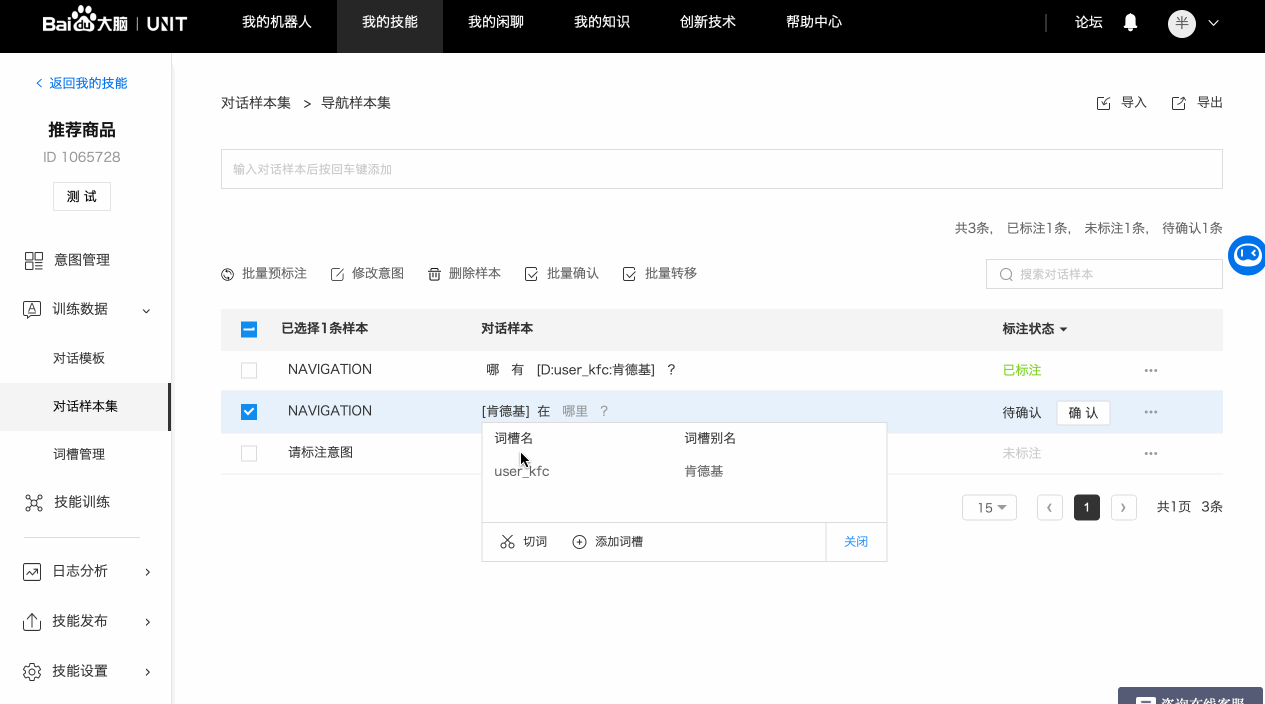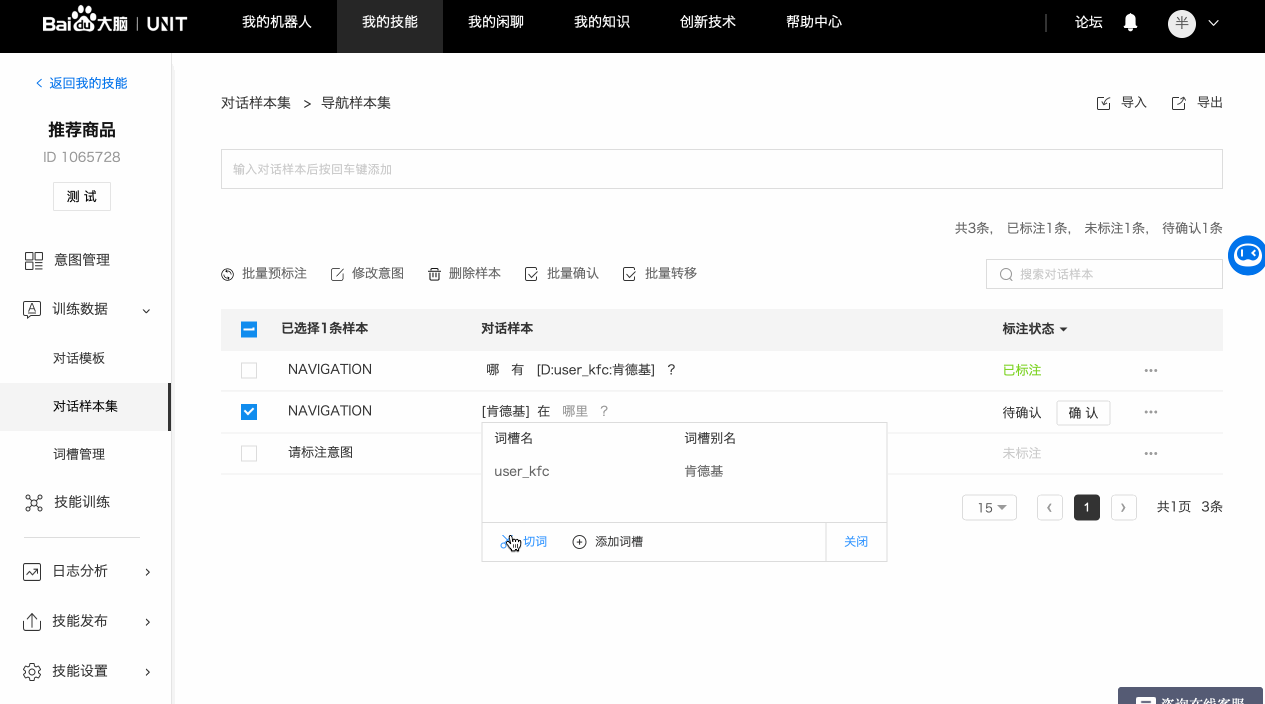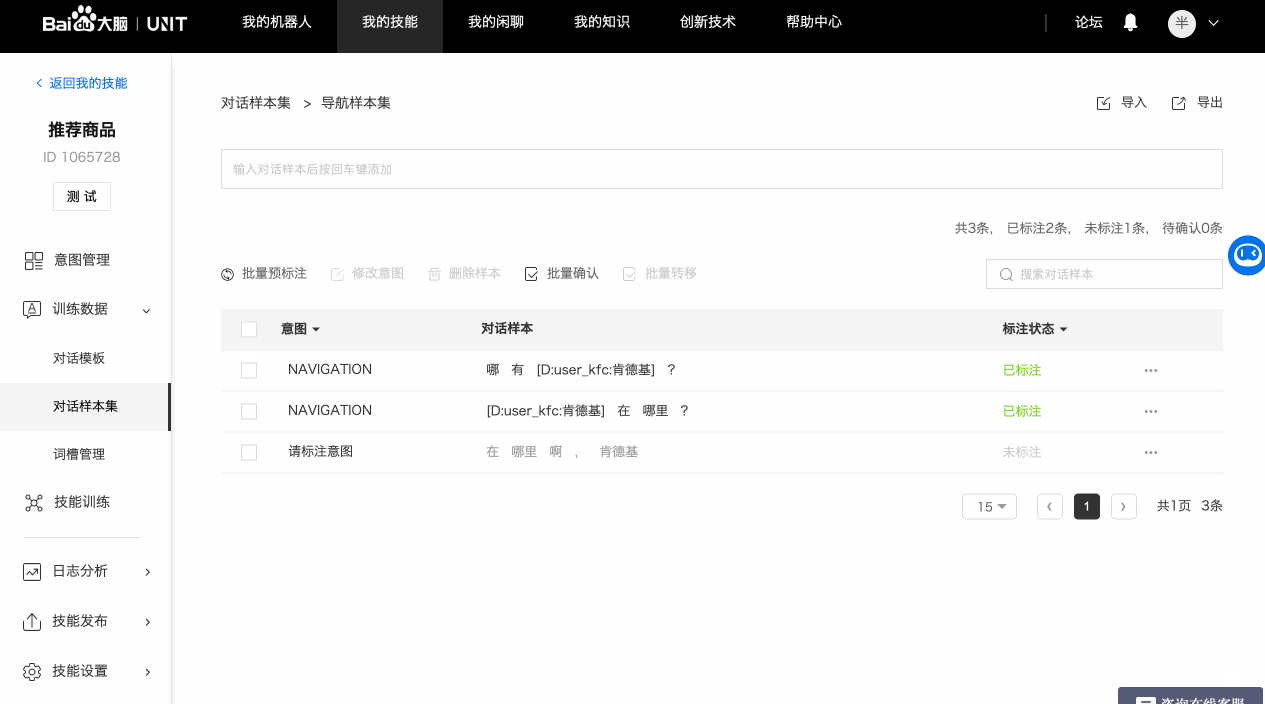
平台默认会对样本进行分词,看起来的效果就是有些字之间的间距较大,如果分词结果与需要标注的词槽不同,可以进行重新分词或者合并操作。
为了更好的识别效果,样本标注的词槽词典值如果在词典里不存在,建议补充到词典中。
4.分词与合并
5. 批量预标注
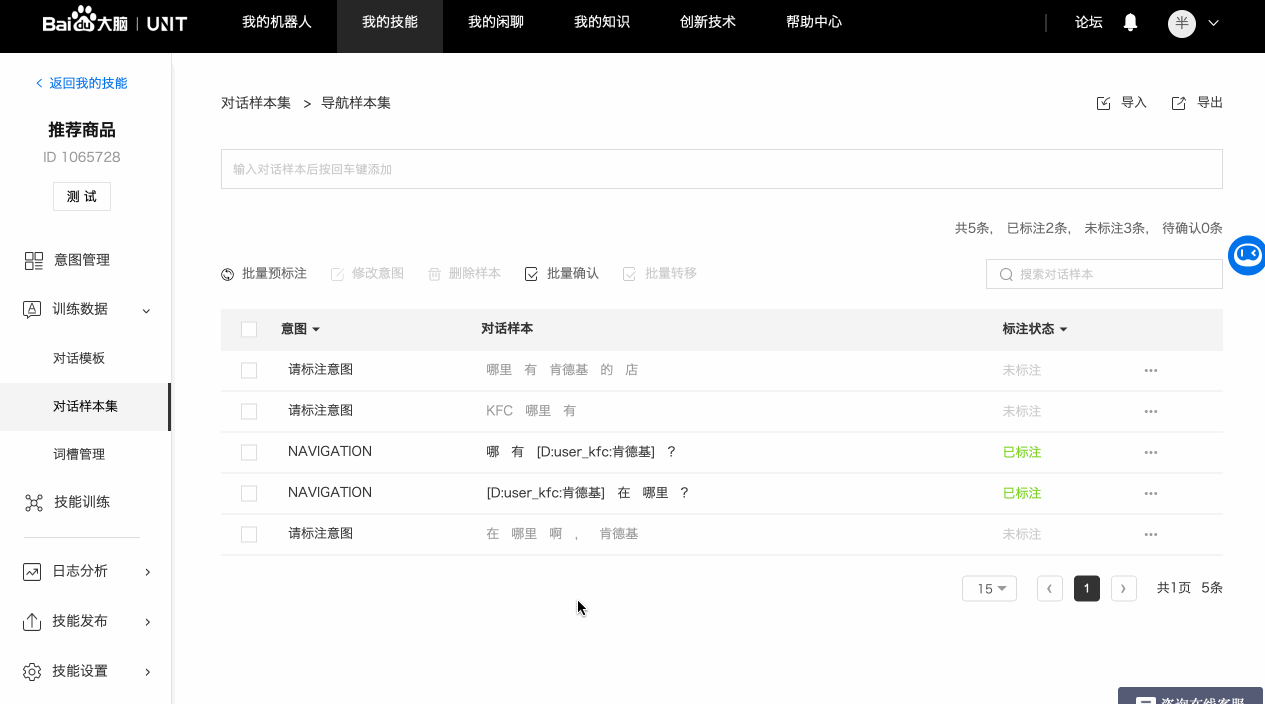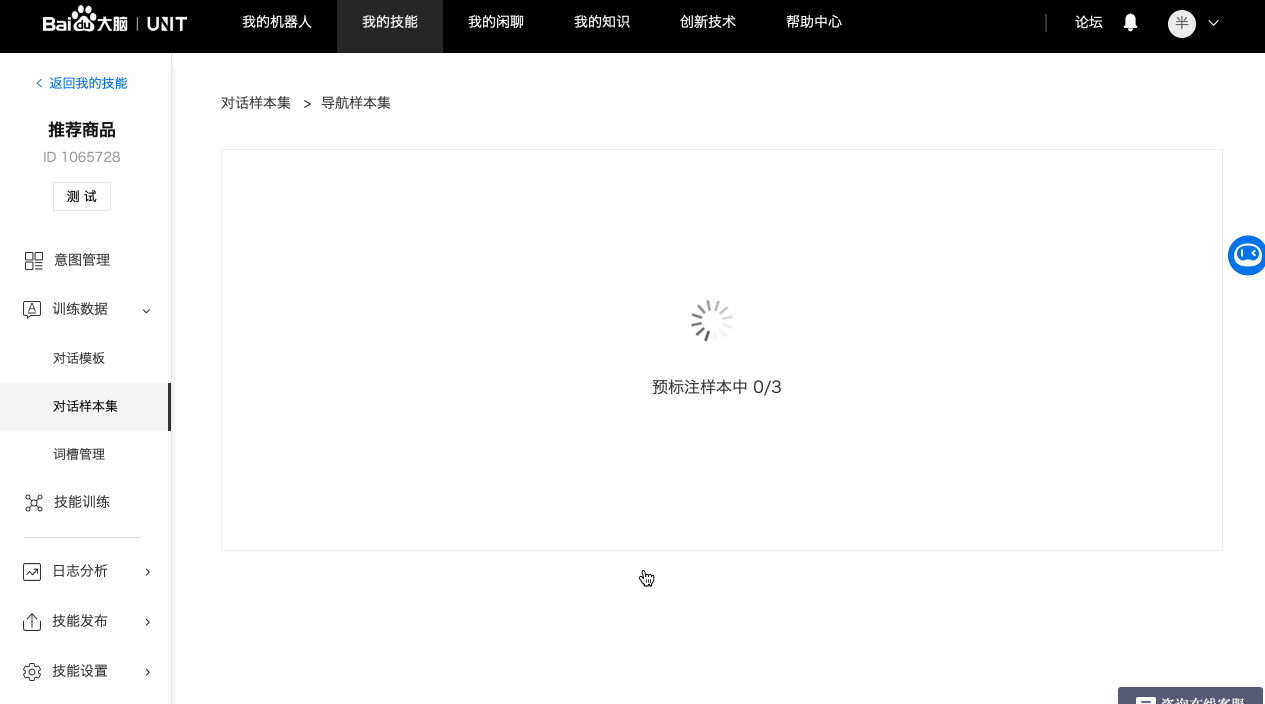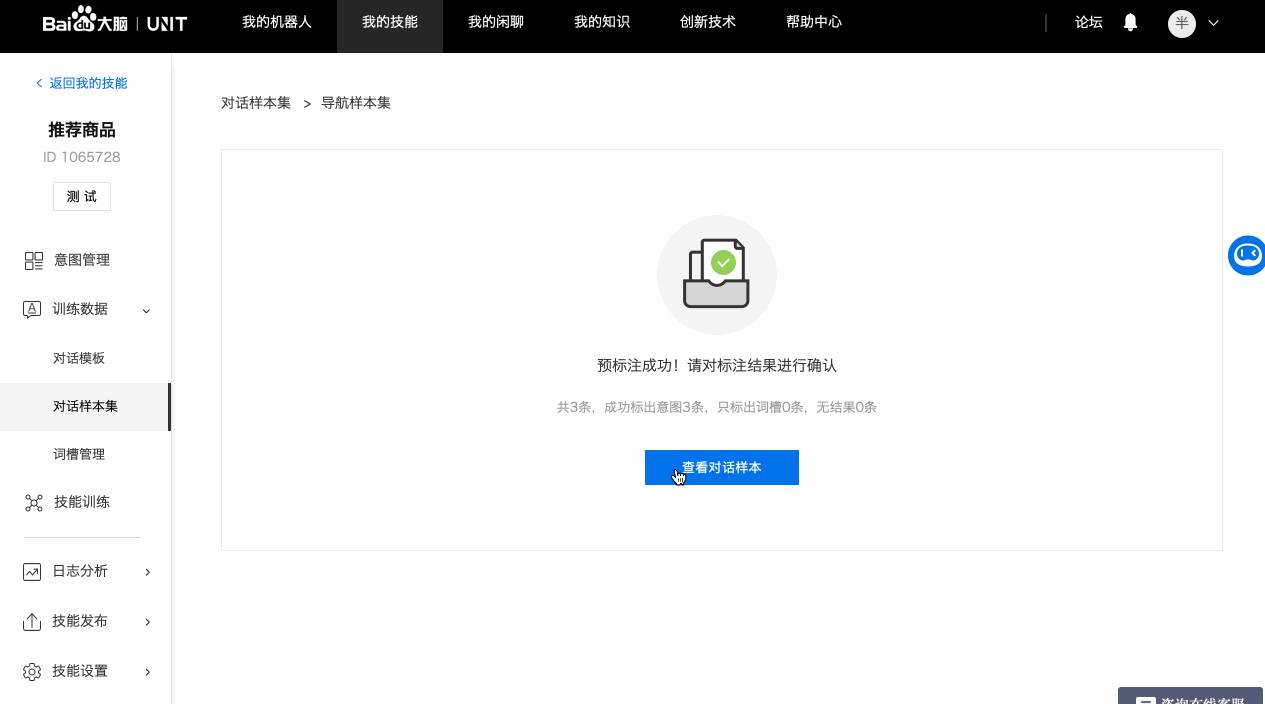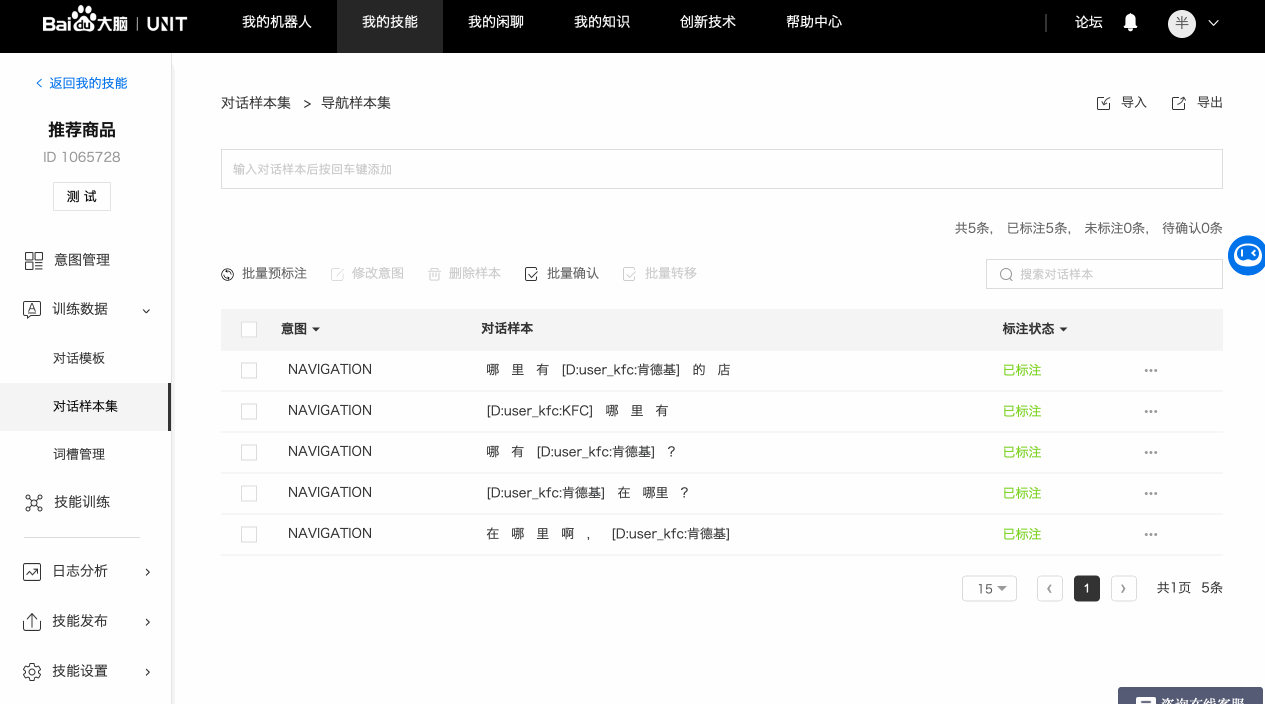
如果对话技能已有正在运行中的模型,即可使用批量预标注功能自动标注样本的意图与词槽。
词槽管理
1. 新建词槽
UNIT为开发者提供了两种词槽:
1. 普通词槽
2. 通配词槽
注意:
在词槽管理下新建的词槽,默认不会关联自定义意图,只关联了系统内置的CMD_UPDATE_词槽名意图。想要使用,需要在对话意图中【新建词槽】,复用该词槽。
2. 词典值配置
UNIT为开发者提供了多种词典值配置方式:
a. 系统词典
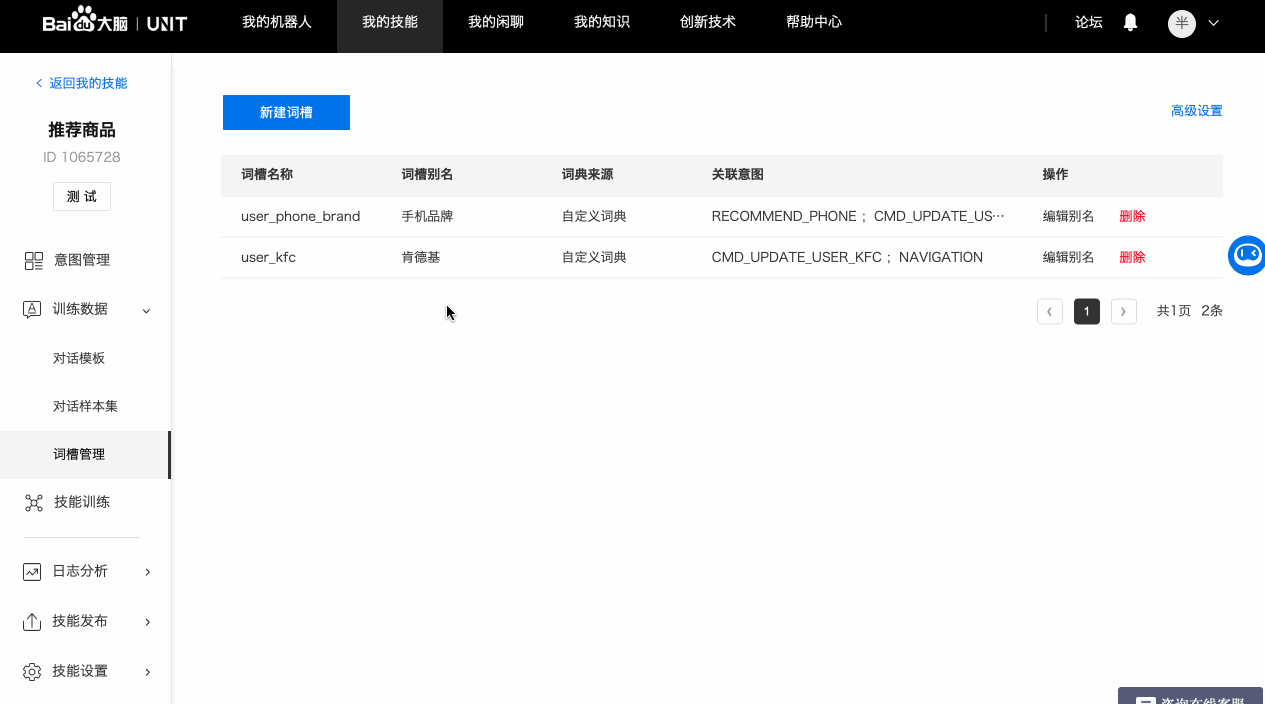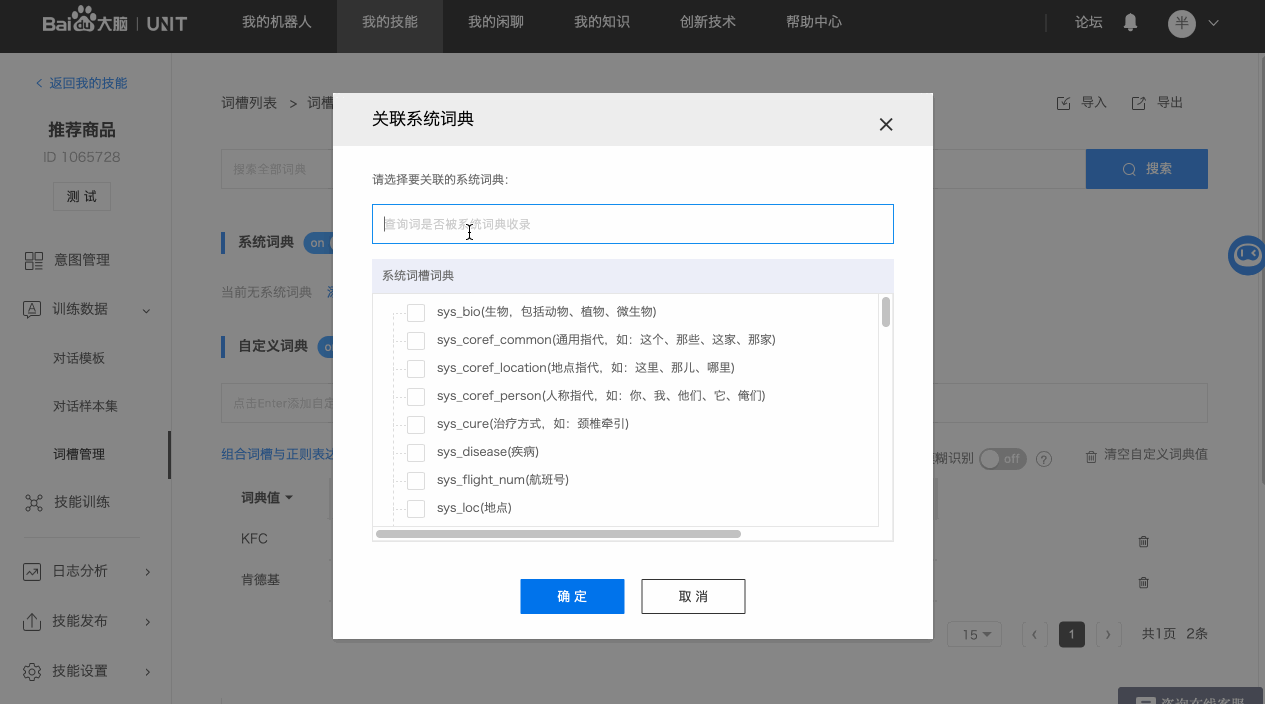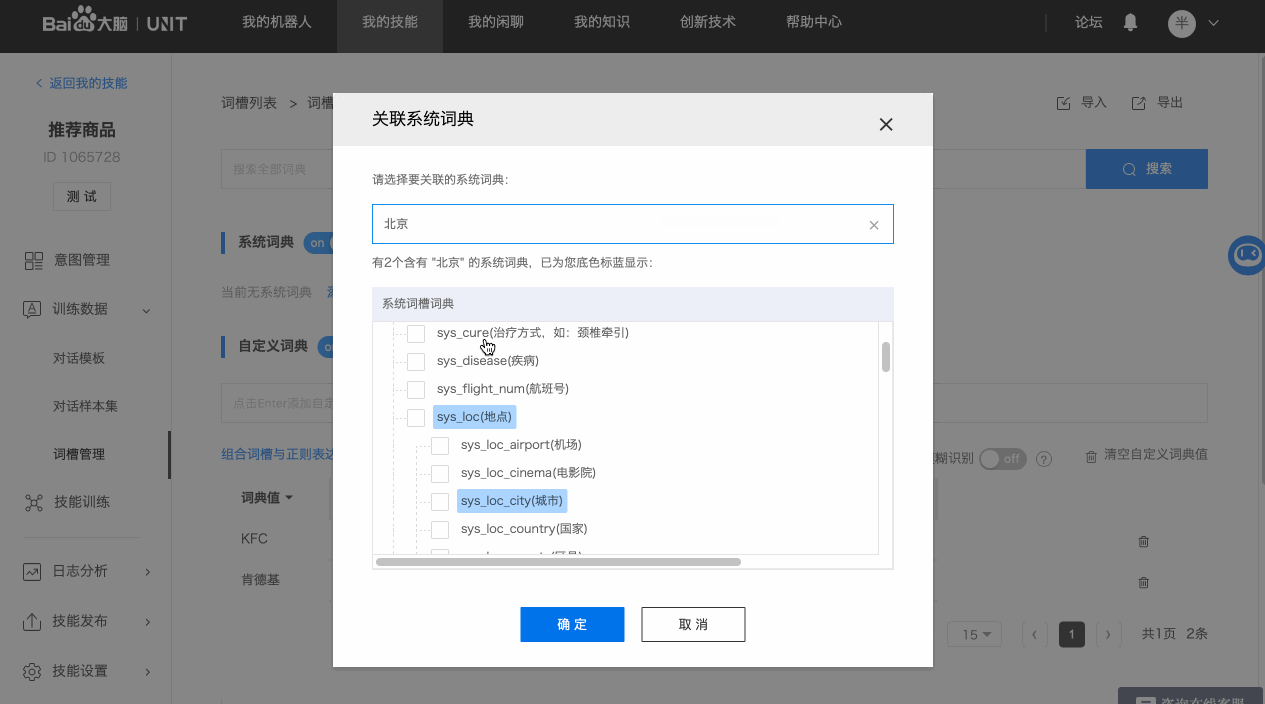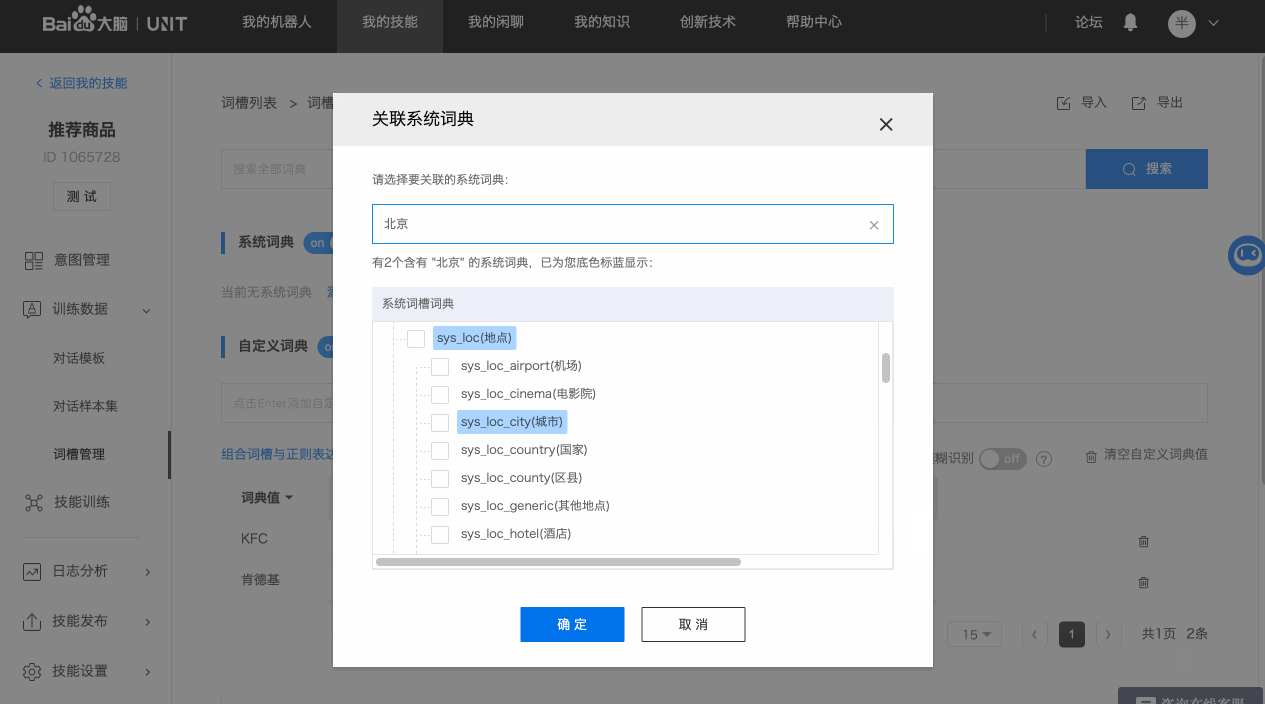
内置的直接可用的词典,选择之后即可使用该系统词典识别相应的数据。系统词典说明文档包含词槽词典值举例和归一化值说明,点击查看。
系统词典无法查看具体的词典值数据,但是可通过搜索功能查询某些词是否被系统词典收录。
b. 自定义词典
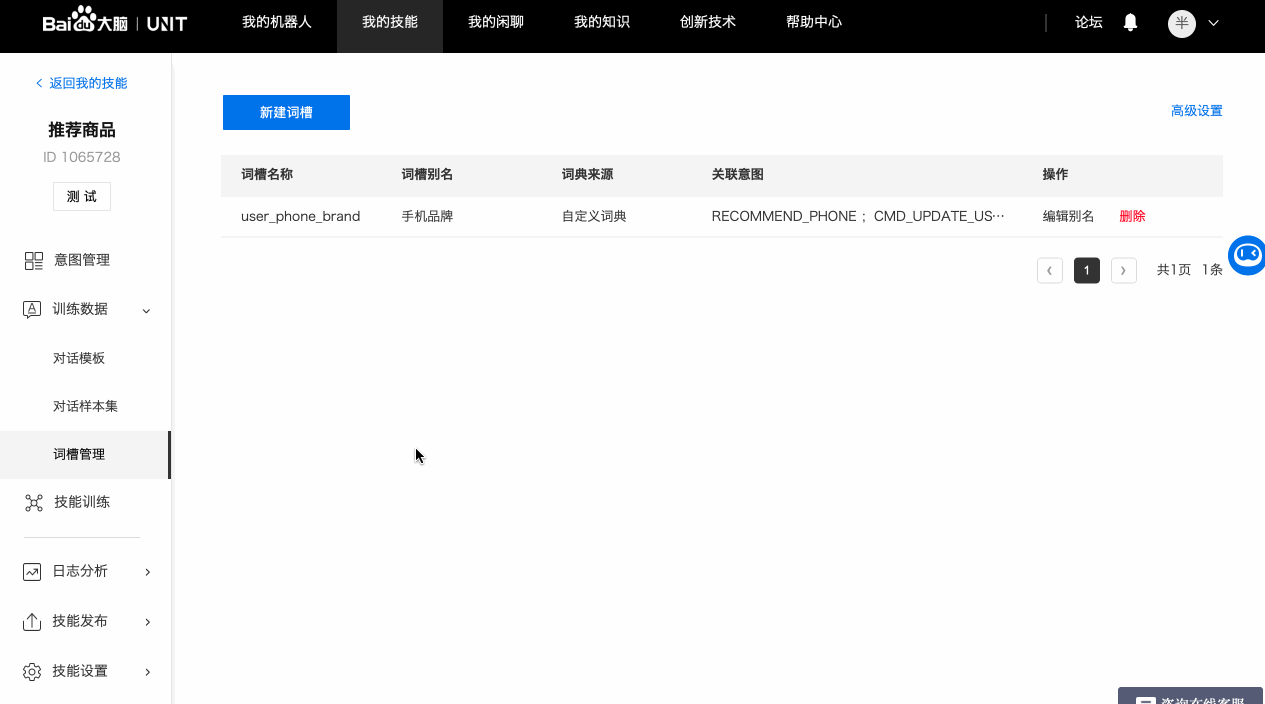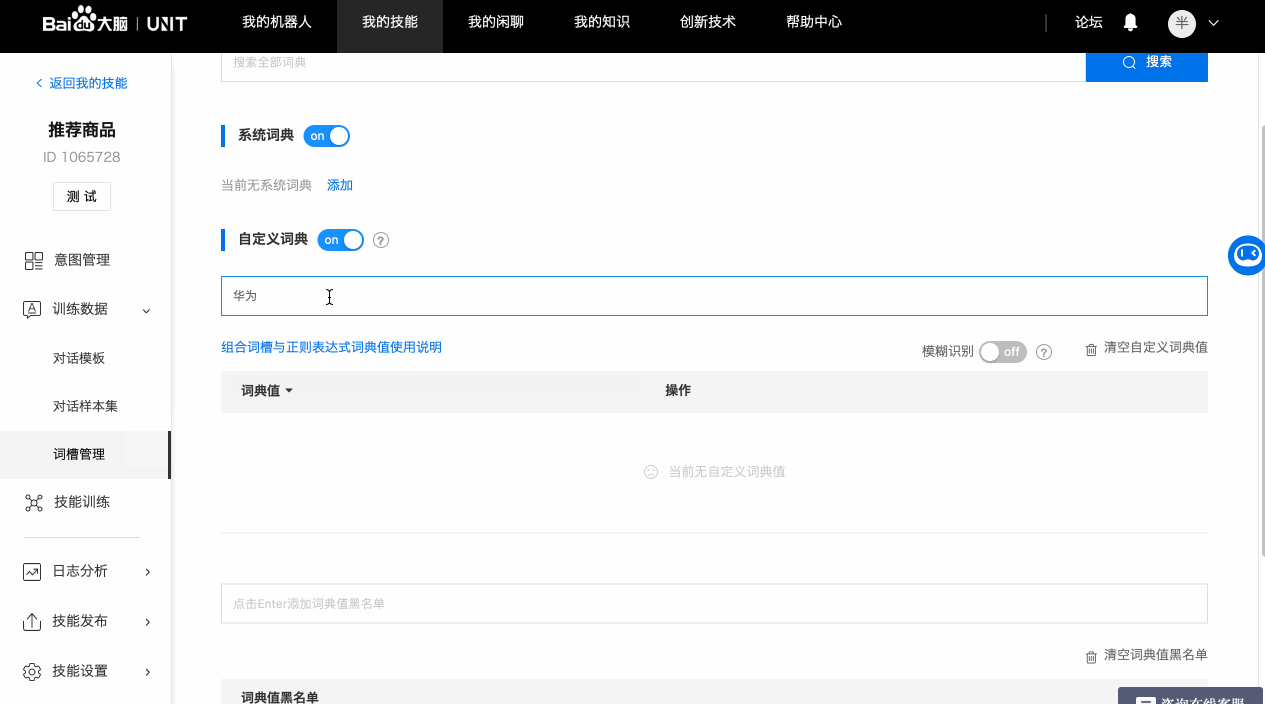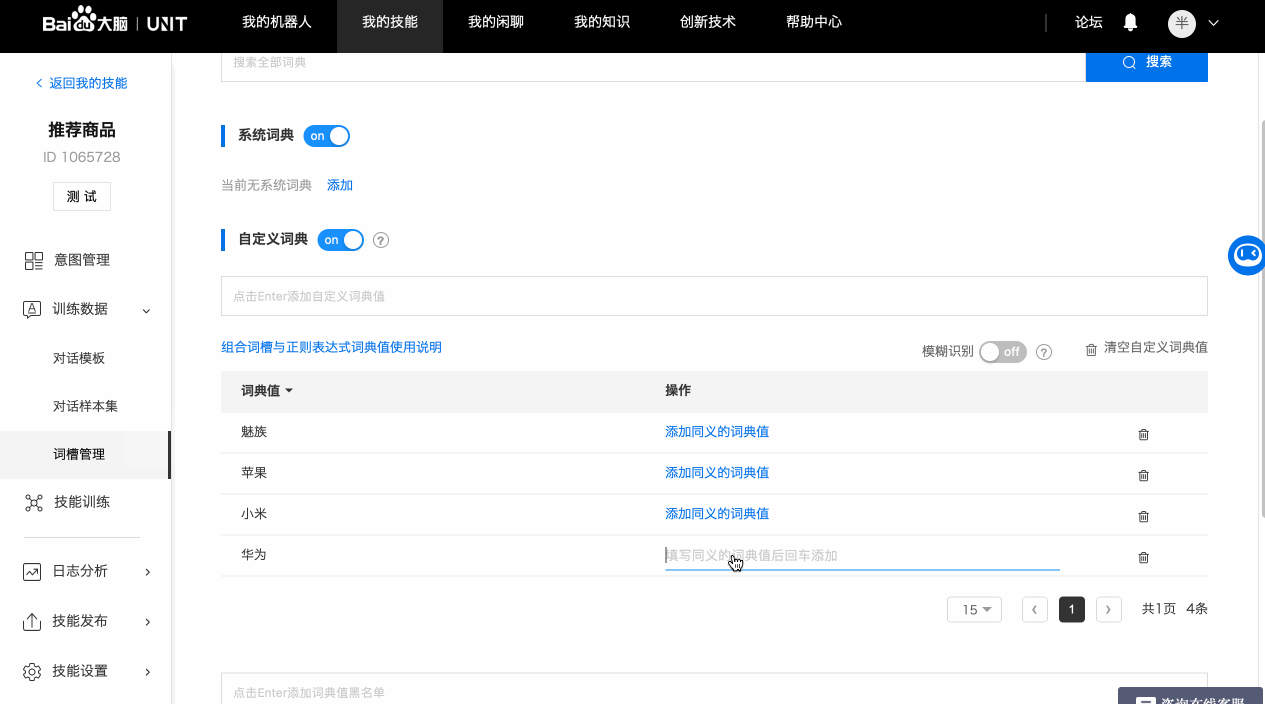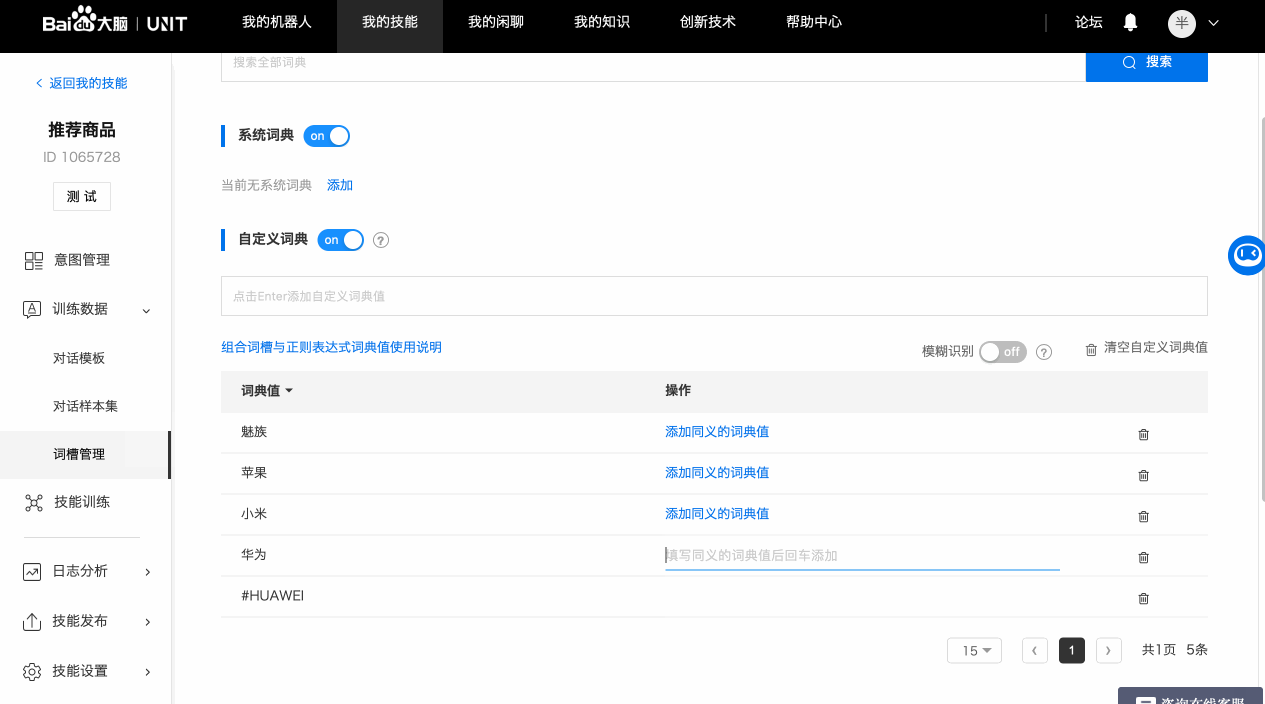
如果词槽需要识别的内容没有可用的系统词典,就需要配置自定义词典。
以手机品牌词槽为例,可以添加品牌名及其同义词。
如果词典值是无法穷举的内容,可以考虑使用正则词典值或者通配词槽。
1. 正则文档:点击查看
2. 通配文档:点击查看
c. 词典值黑名单
词典值黑名单一般用于过滤掉不期望系统词典识别的词典值。加入黑名单的值,该词槽就不会识别到。
d. 动态词典
比如某厂家想让自家的智能音箱可以更改名字,不同买家取的名字无法预知且需要实时生效,就可以使用动态词典,使用接口直接传入相关动态词典信息,对话接口调用时传入动态词典即可。文档:点击查看
e. 高级设置
分词干预
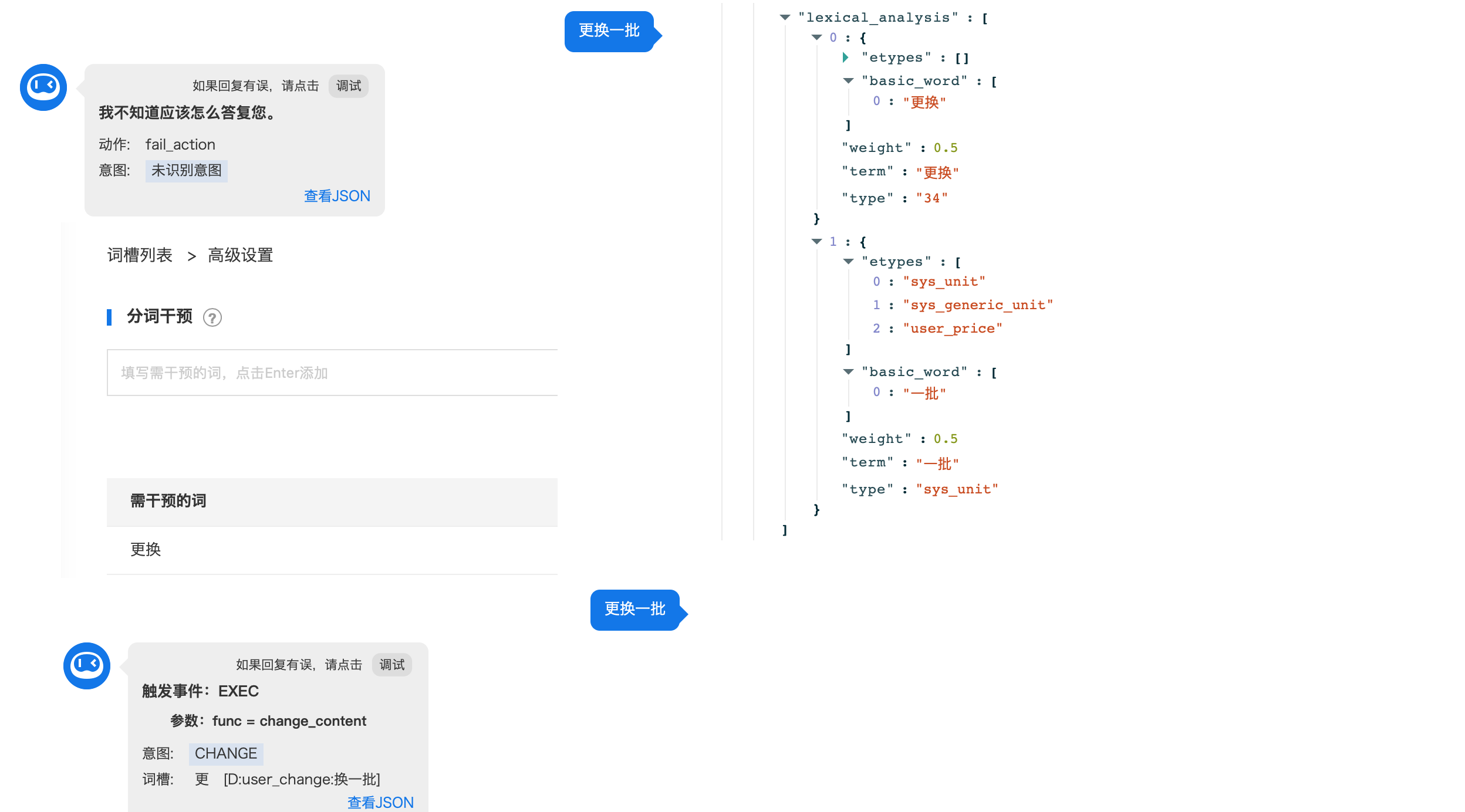
词槽因分词错误导致无法识别时,可以在这里输入需要干预的词语,系统将把对应词语按单个字的粒度进行分析,解决词槽无法识别问题。
下面就以更换数据意图进行具体的功能讲解。比如,输入"更换一批",因为user_change词槽的词典值包含"换一批",语句也符合模板阈值,所以理论上这句话应该被识别,但是因为分词结果是"更换""一批",无法识别出"换一批",所以语句识别失败,此时需要将"更换"进行分词干预,才能识别到"换一批"。