

批量任务管理
一、批量任务概述
定位
『批量任务』是为应用/组件开发者提供自动化批量处理数据的核心功能模块,支持对大规模数据的高效处理与效果验证。
功能简介
『批量任务』通过任务编排能力,允许用户对应用/组件进行数据的批量运行或效果评估。该模块包括两种核心任务类型
- 『跑批任务』:针对应用/组件创建跑批任务,支持自定义数据集,支持下载跑批结果。
- 『效果评测任务』:创建应用/组件跑批任务,并使用大模型进行效果评测,支持自定义数据集,支持自定义评测规则,支持下载评测结果。
核心价值
- 规模化处理:支持大规模数据集批量运行,减少人工逐条操作成本。
- 自动化流程:任务执行过程无需人工干预,可后台异步运行并查看进度。
- 结果可追溯:完整保存任务输入、输出及评估数据,便于问题定位与效果分析。
二、跑批任务
『跑批任务』主要面向应用/组件对批量数据进行执行,适用于数据验证、压力测试等场景。用户可上传包含多个输入内容的数据集,系统将自动调度应用/组件逐条处理数据,生成输出结果,最终生产包含输入输出对应关系的明细报告。
具体操作如下:
1、创建任务
- 点击登录百度智能云千帆AppBuilder平台
-
在左侧导航栏中点击批量任务,然后进入批量任务管理空间
- 初次进入会有新手引导页面,选择『跑批任务』,点击『立即创建』,出现创建批量任务弹窗;
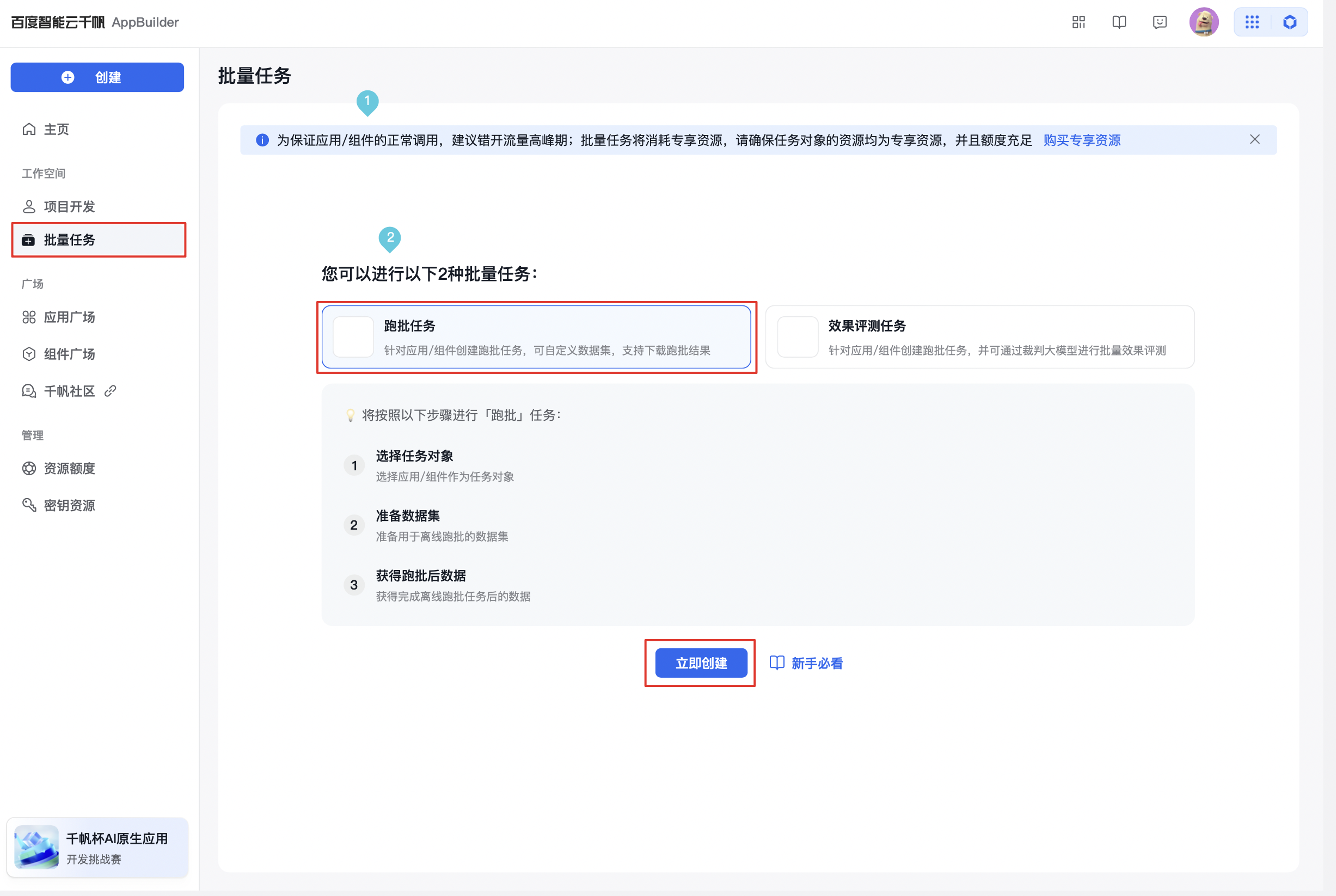
- 如果是非初次创建,则点击批量任务管理空间的『创建批量任务』,出现创建批量任务弹窗。
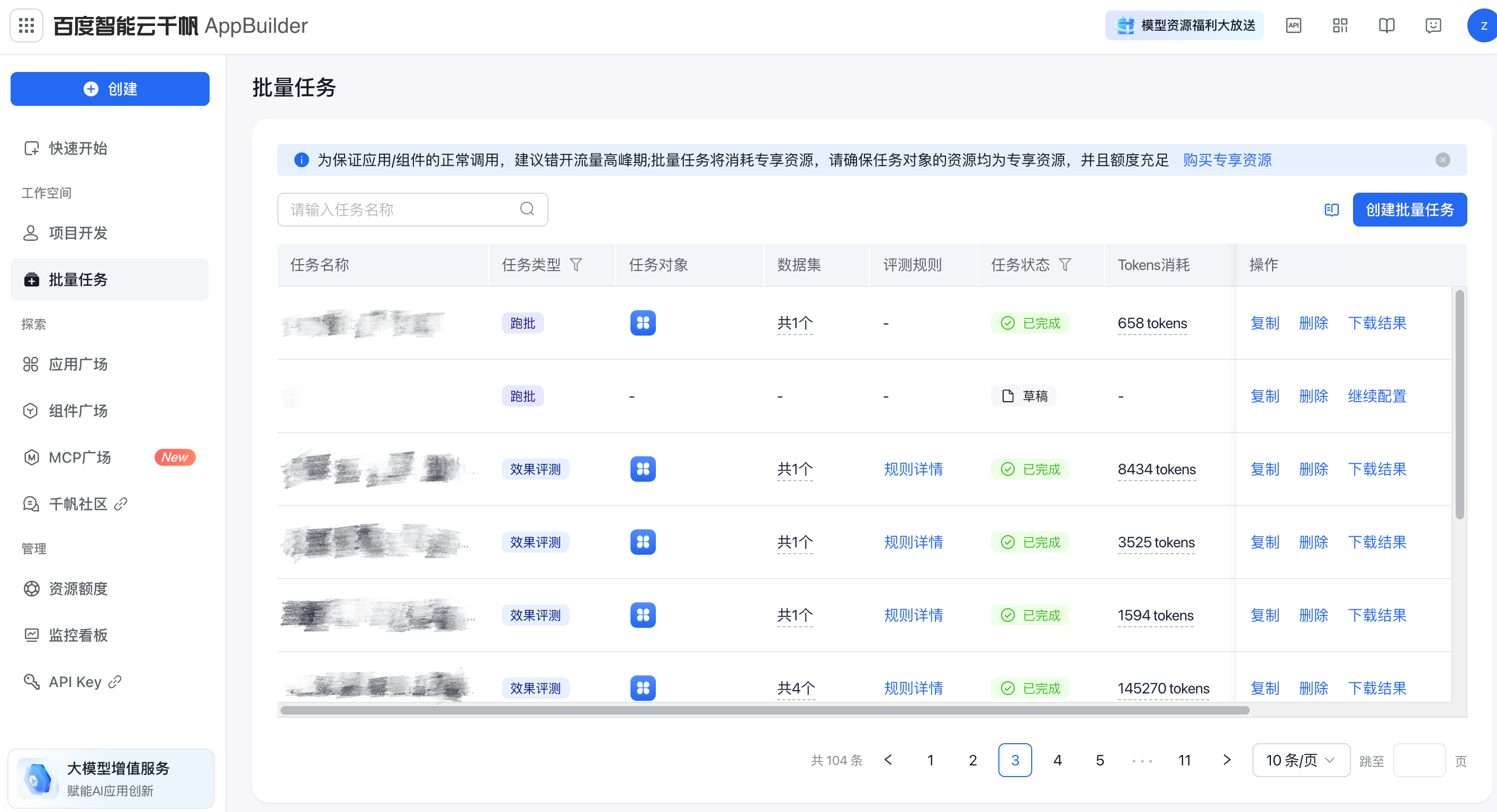
- 初次进入会有新手引导页面,选择『跑批任务』,点击『立即创建』,出现创建批量任务弹窗;
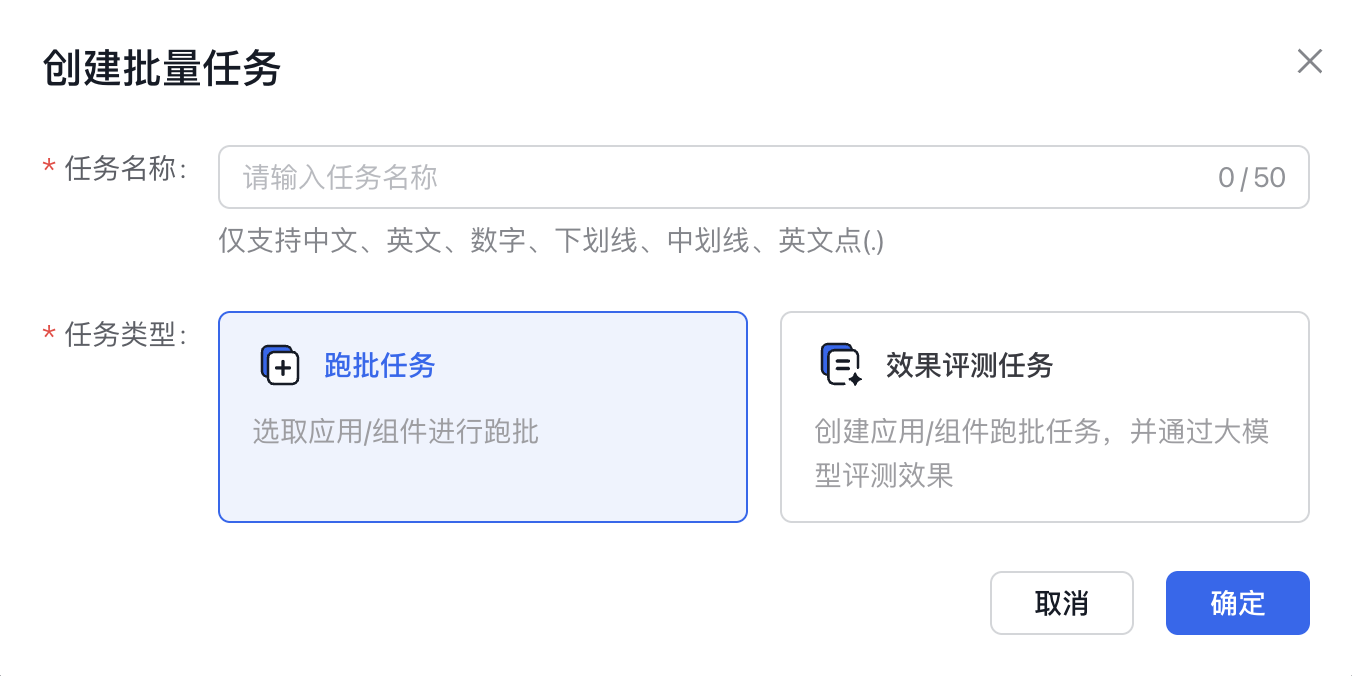
- 在弹窗中输入任务名称(任务名称仅支持中文、英文、数字、下划线、中划线、英文点(.)),确定好任务类型为『跑批任务』后,点击确定,然后进入任务配置页面
2、选择任务对象
在任务配置页面,首先进行对象的选择,跑批任务的任务对象可选择应用或组件。选择跑批对象需要遵守以下规则:
- 应用和组件不可同时选择,选择组件时,需要具体到组件版本。
- 应用中仅支持选择自主规划Agent和工作流Agent两种应用进行跑批或评测。
- 一个跑批任务最多可选择五个应用/组件。
- 只有已发布的应用/组件才能进行跑批,未发布的应用/组件需要先进行发布。
- 只有使用专享资源的应用/组件才能进行跑批任务。

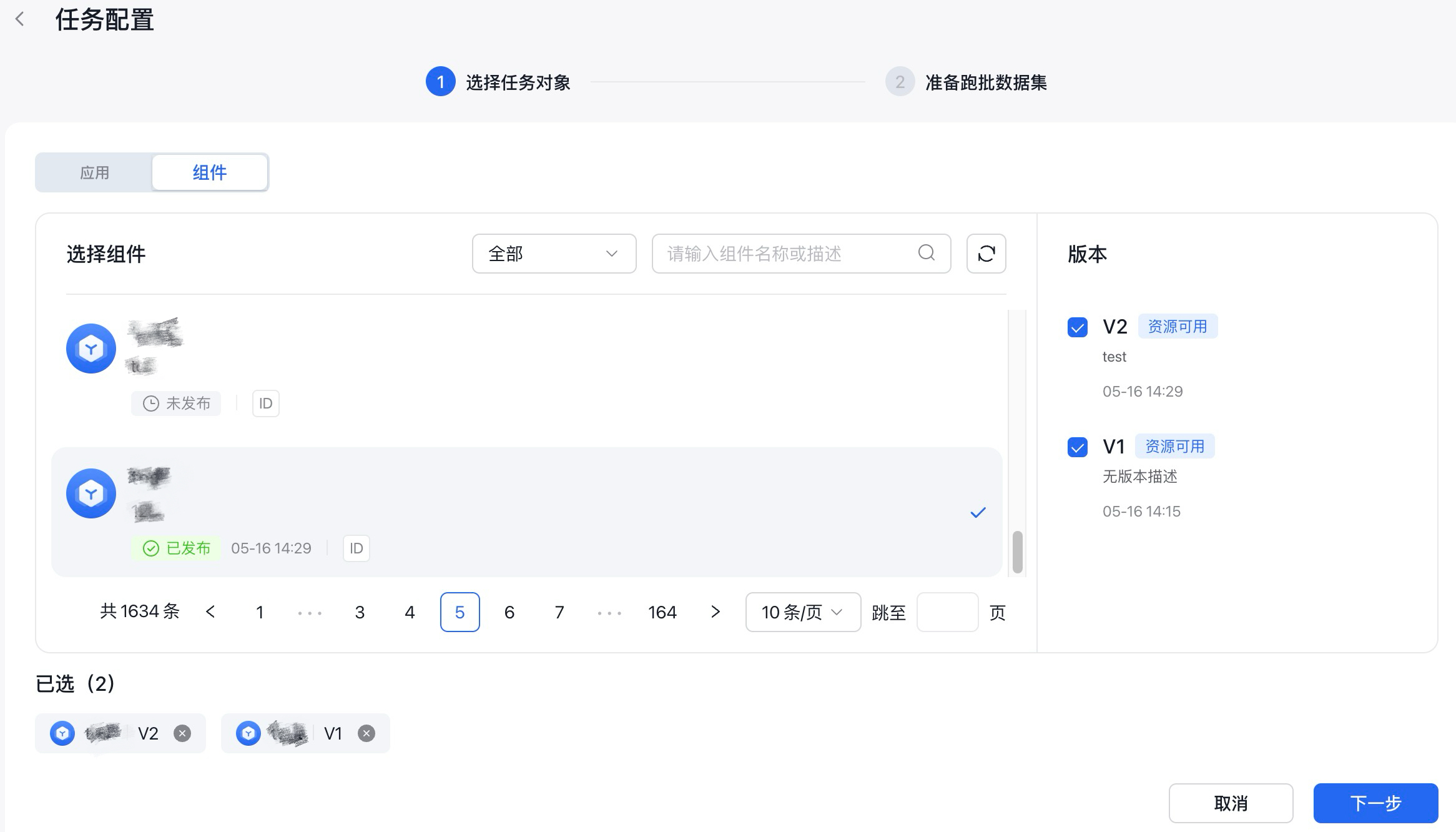
选择好需要跑批的任务对象后,点击『下一步』,进行跑批数据集的准备。
3、准备跑批数据集
跑批数据集是用户需要任务对象进行批量运行的数据集合,上传跑批数据集需要使用平台提供的数据集模板,用户下载数据集模板后,可根据跑批需求增加数据集模板的列字段,同时还要满足以下限制:
| 应用 | 组件 |
|---|---|
| 最多可上传五个评测数据集文件。 | 最多可上传五个评测数据集文件。 |
| 上传多个文件时,应确保多个文件列名一致。 | 上传多个文件时,应确保多个文件列名一致。 |
| 单个文件大小不超过10MB,支持一个sheet工作表(超出范围的内容会被自动忽略)。 | 单个文件大小不超过10MB,支持一个sheet工作表(超出范围的内容会被自动忽略)。 |
| session_id、case_id和query这三列必填,不能删除,且不能修改列名。 | case_id和query这两列必填,不能删除,且不能修改列名。 |
| 每个单元格最大长度为10000。 | 每个单元格最大长度为10000。 |
| 最多上传10000行评测用例。 | 最多上传10000行评测用例。 |
| 最多添加50个自定义列。 | 最多添加50个自定义列。 |
| 支持填写文件URL | 支持填写文件URL |
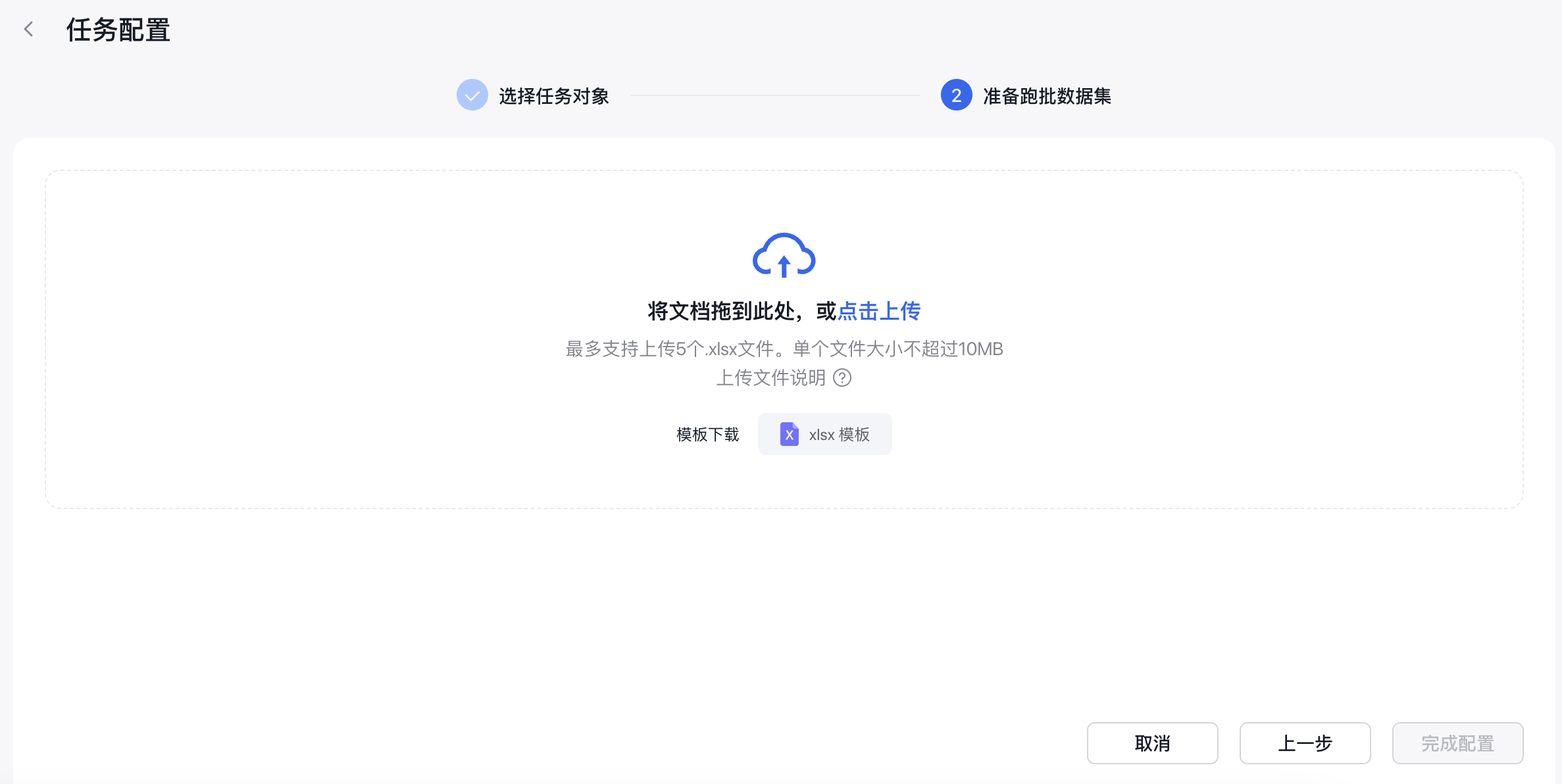
完成跑批数据集的上传后,点击完成配置,然后出现以下弹窗:
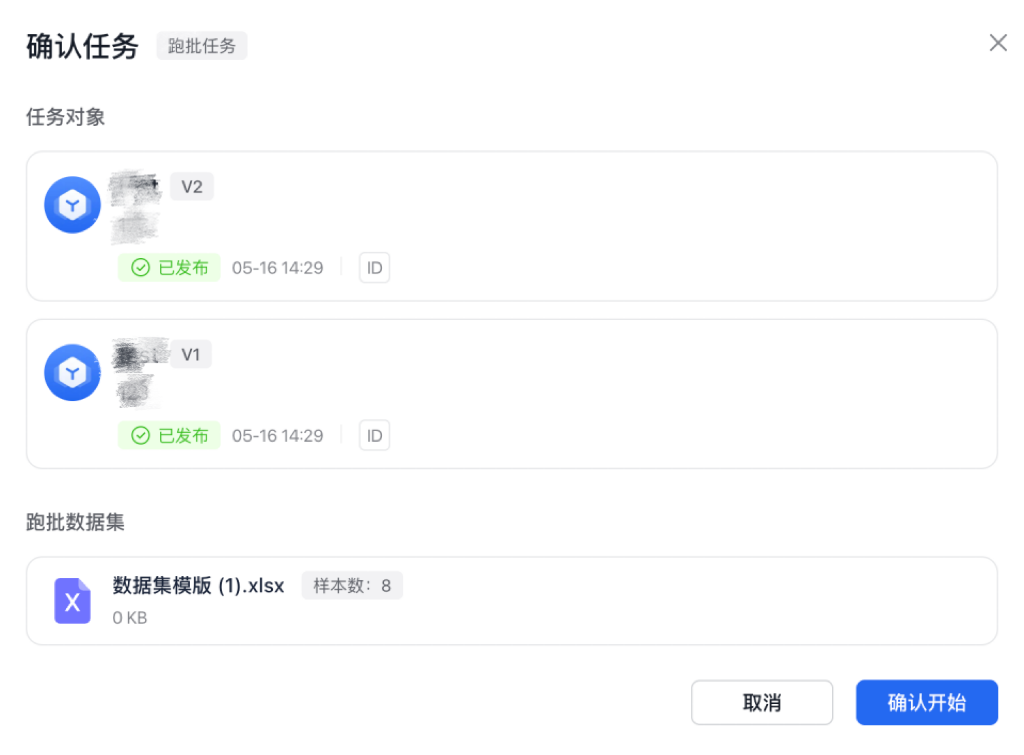
任务确认无误后,点击『确认开始』,确认开始之后,可在任务管理空间查看该任务的状态,如果还有其他任务正在进行,该任务进入『排队中』状态,如果当前没有其他任务,则进入『进行中』状态,开始运行该任务,任务结束后,可在任务管理空间下载跑批结果。
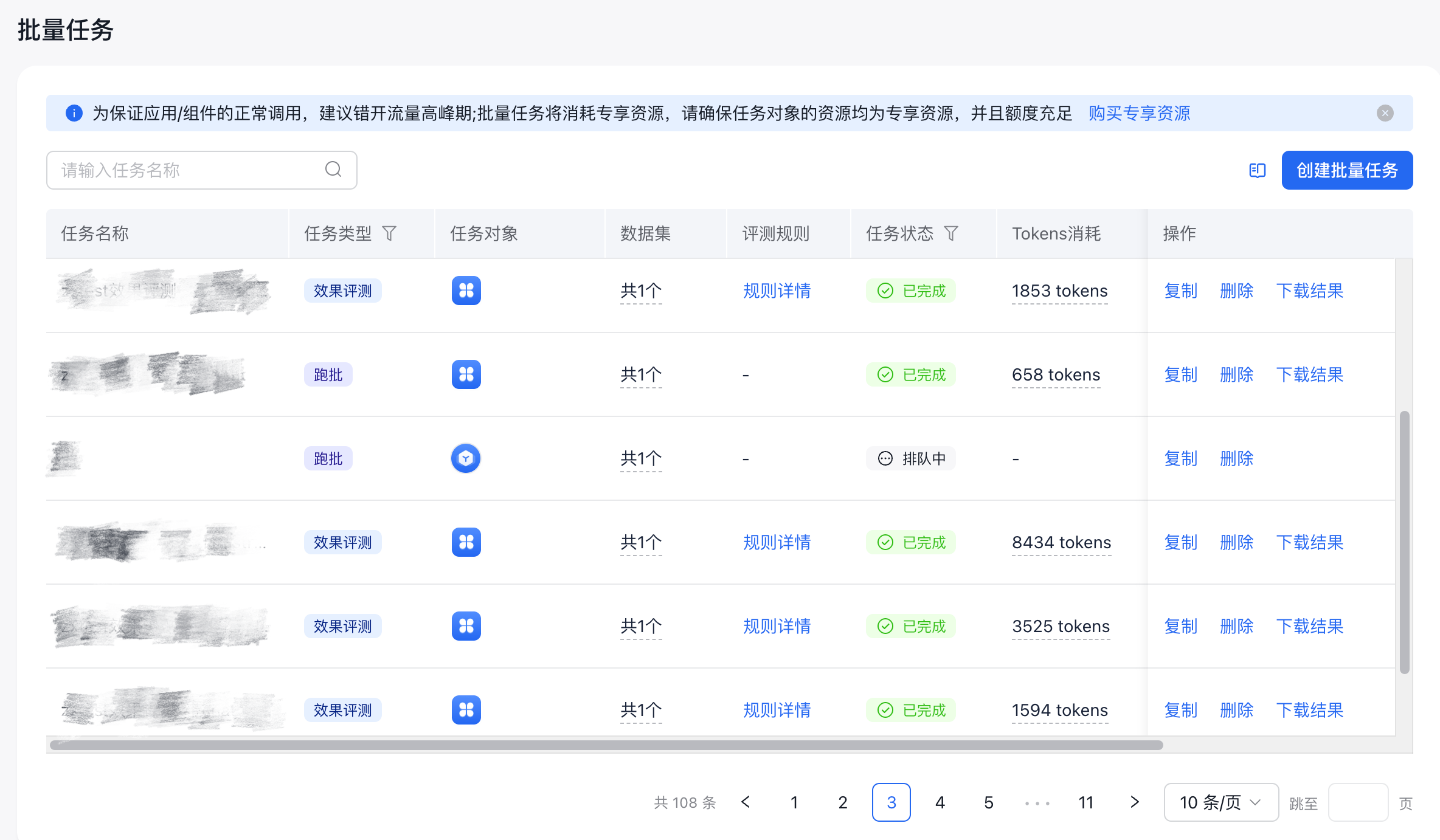
三、效果评测任务
『效果评测任务』主要是对用/组件的效果质量进行自动化评估,提供可量化的性能指标。用户可上传包含多个输入内容的数据集(如Excel文件),系统将自动调度应用/组件逐条处理数据,生成输出结果,然后用户可引入裁判大模型对应用/组件输出结果进行多维度评测。用户可自定义评测维度(如客观事实性、问题相关性、角色贴合度),系统将自动生成包含评分及评分原因的评估报告。
具体操作如下:
1、创建任务
- 点击登录百度智能云千帆AppBuilder平台
-
在左侧导航栏中点击批量任务,然后进入批量任务管理管理空间。
- 初次进入会有新手引导页面,选择『效果评测任务』,点击『立即创建』;
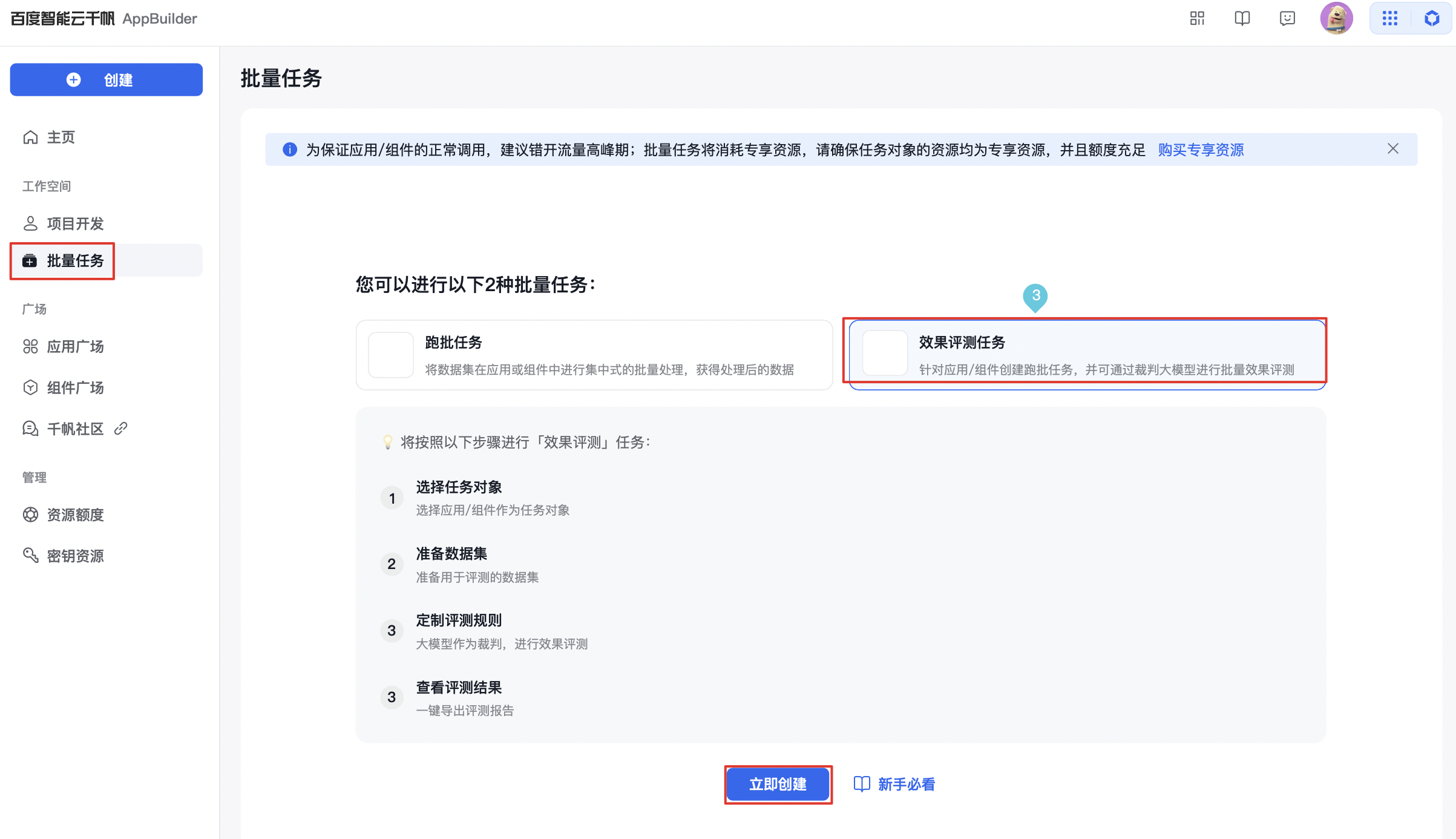
- 非初次创建则点击批量任务管理空间的『创建批量任务』。
- 初次进入会有新手引导页面,选择『效果评测任务』,点击『立即创建』;
- 在弹窗中输入任务名称(任务名称仅支持中文、英文、数字、下划线、中划线、英文点(.)),确定好任务类型为『效果评测任务』后,点击确定,然后进入任务配置页面。
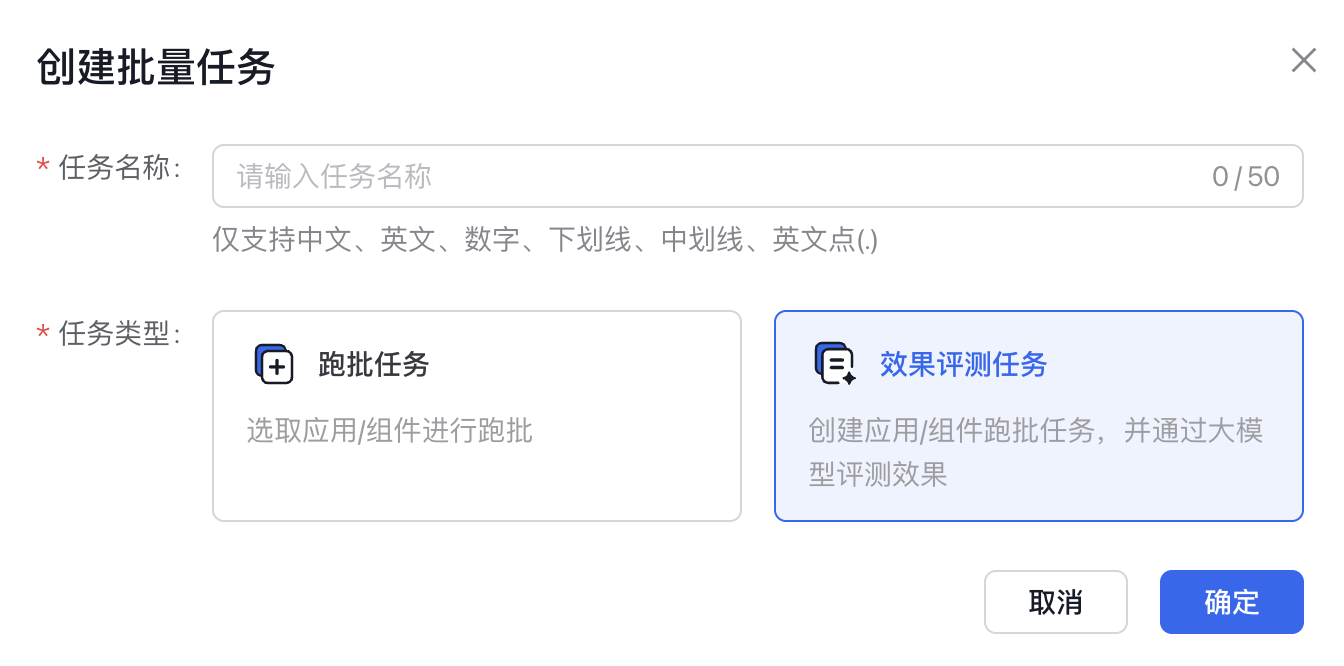
2、选择任务对象
在任务配置页面,首先进行对象的选择,效果评测任务的任务对象可选择应用或组件。选效果评测对象需要遵守以下规则:
- 应用和组件不可同时选择,选择组件时,需要具体到组件版本。
- 一个效果评测任务最多可选择五个应用/组件。
- 只有已发布的应用/组件才能进行效果评测,未发布的应用/组件需要先进行发布。
- 只有使用专享资源的应用/组件才能进行效果评测任务。
选择好评测对象后,点击下一步,准备评测数据。
3、准备评测数据
用户可选择平台的预置数据集,也可选择上传自己本地的评测数据集。
- 选择平台预置数据集:平台预置了四个数据集模版,用户可进行多选。预置数据集暂不支持在线预览,用户可下载浏览各个数据集内容后进行选择,需要注意的是:所选择的数据集需要保持列名一致。
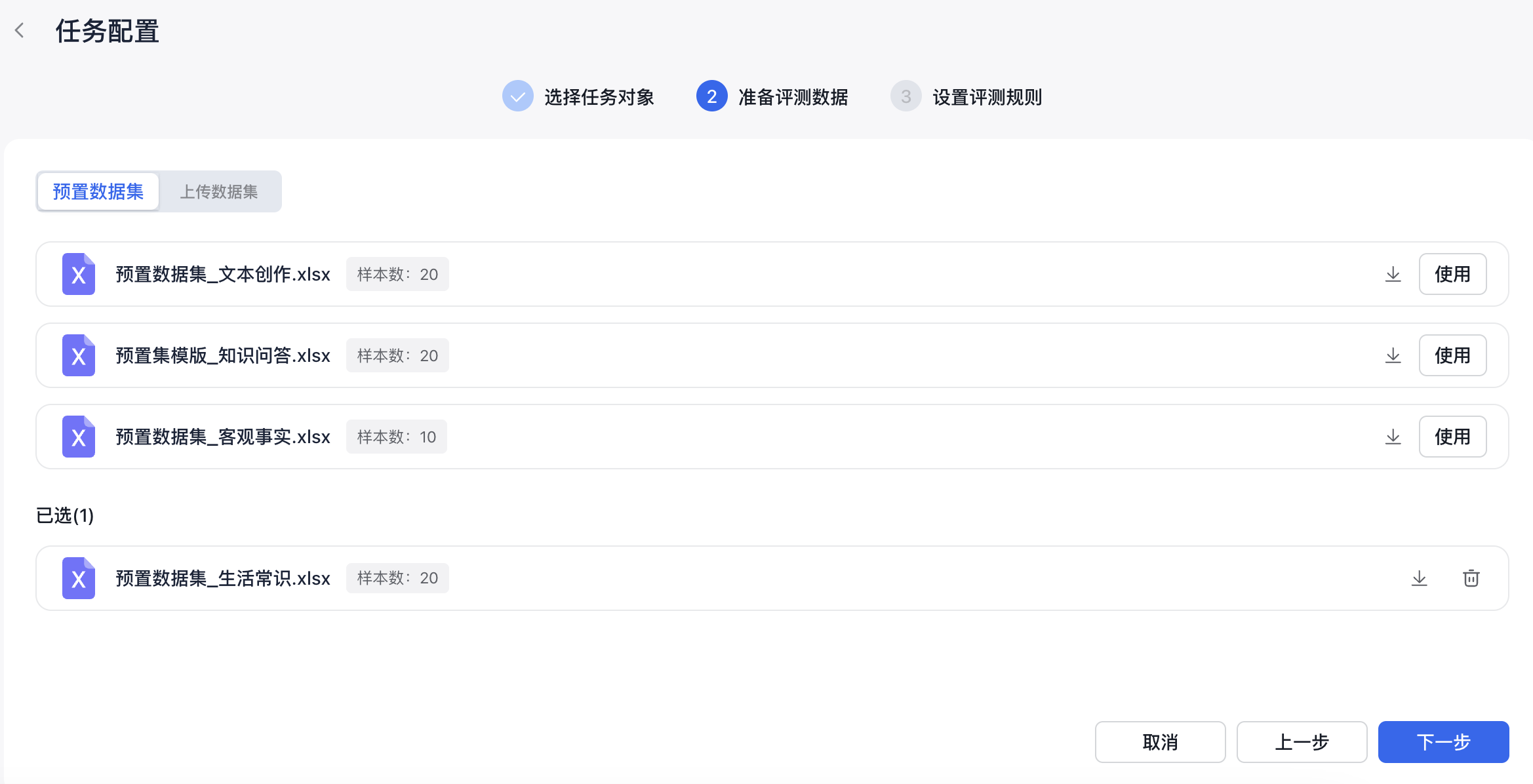
- 上传本地评测数据集:上传本地评测数据集需要使用平台提供的数据集模板,用户下载数据集模板后,可根据评测需求增加数据集模板的列字段,同时还要满足以下限制:
| 应用 | 组件 |
|---|---|
| 最多可上传五个评测数据集文件。 | 最多可上传五个评测数据集文件。 |
| 上传多个文件时,应确保多个文件列名一致。 | 上传多个文件时,应确保多个文件列名一致。 |
| 单个文件大小不超过10MB,支持一个sheet工作表(超出范围的内容会被自动忽略)。 | 单个文件大小不超过10MB,支持一个sheet工作表(超出范围的内容会被自动忽略)。 |
| session_id、case_id和query这三列必填,不能删除,且不能修改列名。 | case_id和query这两列必填,不能删除,且不能修改列名。 |
| 每个单元格最大长度为10000。 | 每个单元格最大长度为10000。 |
| 最多上传10000行评测用例。 | 最多上传10000行评测用例。 |
| 最多添加50个自定义列。 | 最多添加50个自定义列。 |
| 支持填写文件URL | 支持填写文件URL |
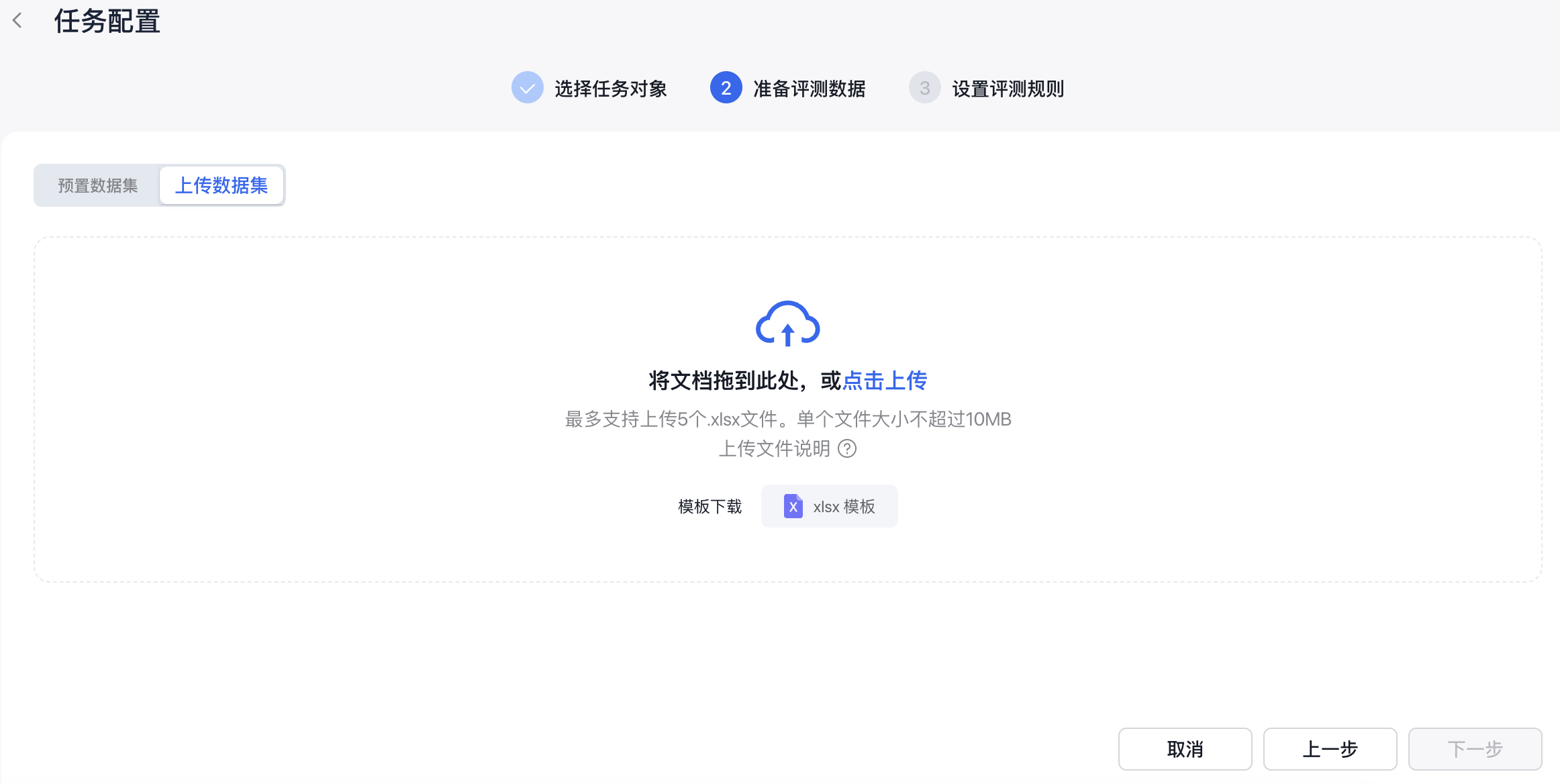
准备好评测数据之后,点击『下一步』,设置评测规则。
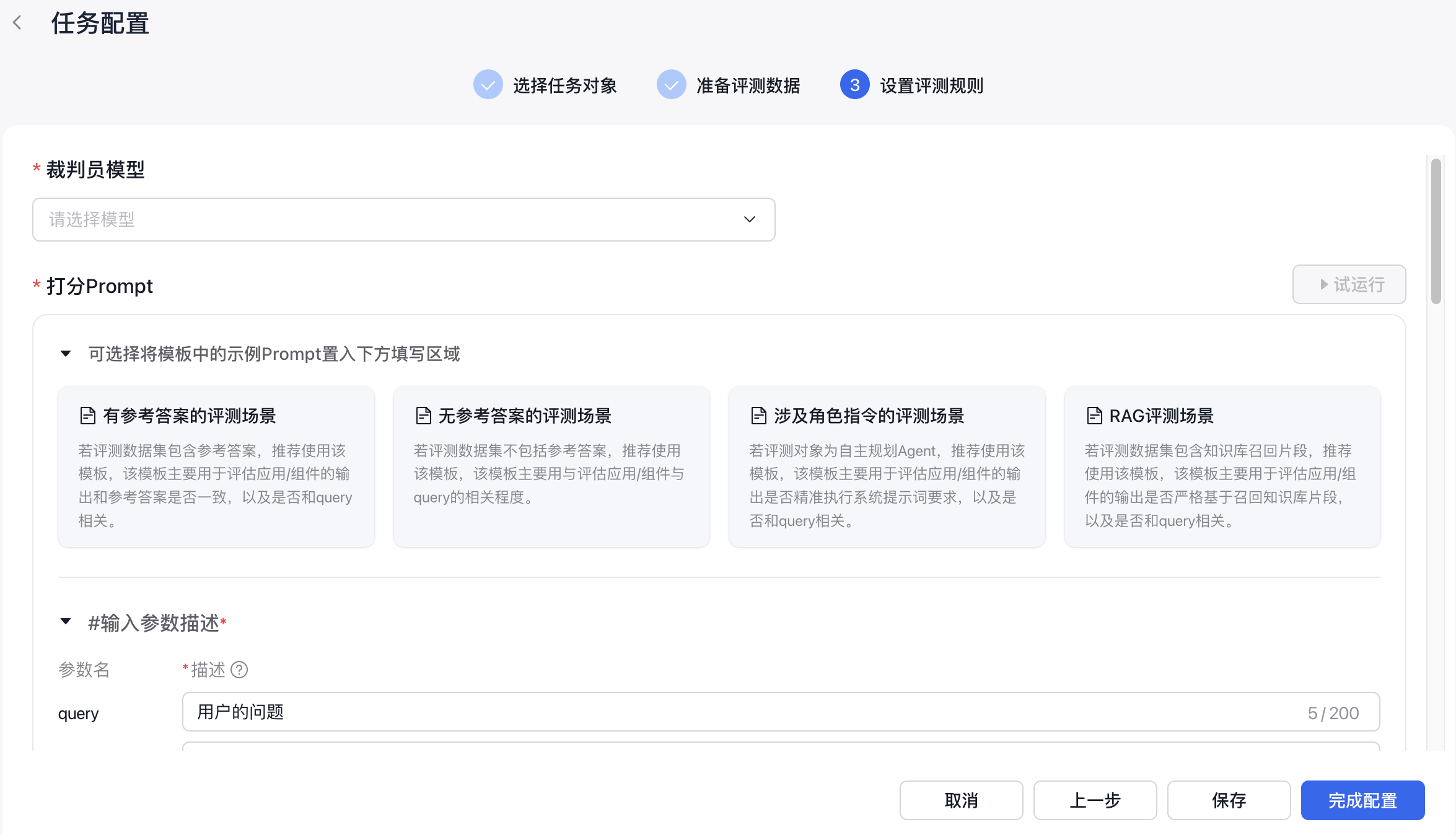
4、设置评测规则
设置评测规则分为选择裁判员模型,填写打分prompt两部分。
1、选择裁判员模型:裁判员模型用于对评测对象的输出结果进行评测,是决定评测效果的关键因素之一,选择较好的模型能够有效提升评测结果的准确性。如果评测任务涉及知识问答等长文本输入输出,建议使用ERNIE-4.0-Turbo、DeepSeek-V3、DeepSeek-R1。
2、填写打分prompt:打分prompt中角色设定、评估流程和评估维度的质量,对评测效果的准确性起着决定性的作用。针对不同的场景,平台预置了四个prompt模板供用户选择,用户选择模板后,可根据自己的需求,对模板内容进行修改。
-
输入参数:
- 输入参数包括了评测数据集的列名和评测对象的query、answer、chat_history;参数描述为必填字段,用来帮助裁判模型判断参数的用途。针对query、answer、chat_history和reference_answer,平台提供了默认的参数描述,用户可修改。
| 参数描述(必填) | 备注 | |
|---|---|---|
| 评测数据集的列名 | (用户自定义填写) | |
| query | 用户的问题 | |
| answer | 评测对象的回复内容 | |
| chat_history | 对话历史 | 若上传的评测数据集有对话历史,则优先数据集传入,若数据集没有对话历史,则使用应用本身的对话历史。 仅支持传入至自主规划agent或组件。 |
| reference_answer | 参考答案 | 只有上传的评测数据集里面有此列名,才会同步到当前的输入参数中。 参考答案可与评测对象的回复内容进行比较以评测应用或组件的性能。 |
- 角色设定:用来描述大模型的角色,建议结合评测对象的应用场景,对裁判大模型的角色进行设定。
- 评估流程:根据评测对象的应用场景和设置的评估维度,设置裁判大模型的评估流程。
-
评估维度:最多可设置5个评估维度,为了保证评估效果,建议将评估维度的个数设置在三个以内。
- 量级:量级共10级,设置后的量级为评分维度的分数上限,当量级设置为3时,大模型的打分结果为0分、1分、2分、3分。为保证效果,建议最大量级不超过3。
- 维度说明:对评分维度的说明,输入上限500字。
- 最小量级说明:对该维度评分下限的说明,输入上限500字。
- 最大量级说明:对该维度评分上限的说明,输入上限500字。
- 样例:非必填,prompt中提供给裁判大模型的样例,分为输入、输出两部分。
4、试运行:点击试运行按钮,将会试运行评测任务,试运行结束后,会给出每个评测维度的打分结果和对应的打分原因,用户可根据试运行结果对打分prompt进行调整。
- 试运行对象:仅允许一个试运行对象,从选定的对象中,选取一个作为试运行对象,默认选择第一个作为试运行对象。
- 试运行的评测数据:默认上传的评测数据的前三个样本,点击换一换,评测数据往后顺延三个。
- 试运行Tokens消耗:试运行消耗专享资源,请确定专享资源充足。
5、保存:点击保存,可对当前任务进行保存,保存后退出,任务会被存为『草稿』状态,可在任务管理列表进行查看。