工作流组件: API的增删查
整体概述
本次构建的是一款能够通过自然语言指令对数据进行【增】【删】【查】操作的组件。
输入:请帮我增加一个单词hello,实现向单词列表中添加hello。
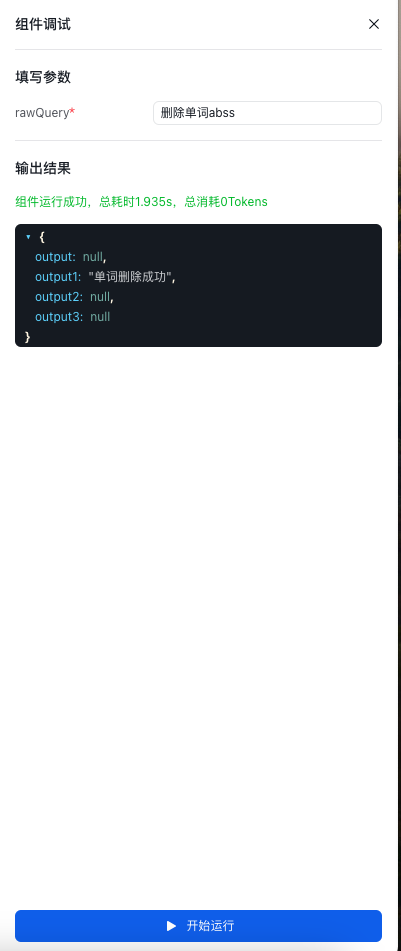
输入:请帮我删除hello,实现从单词列表中移除hello。
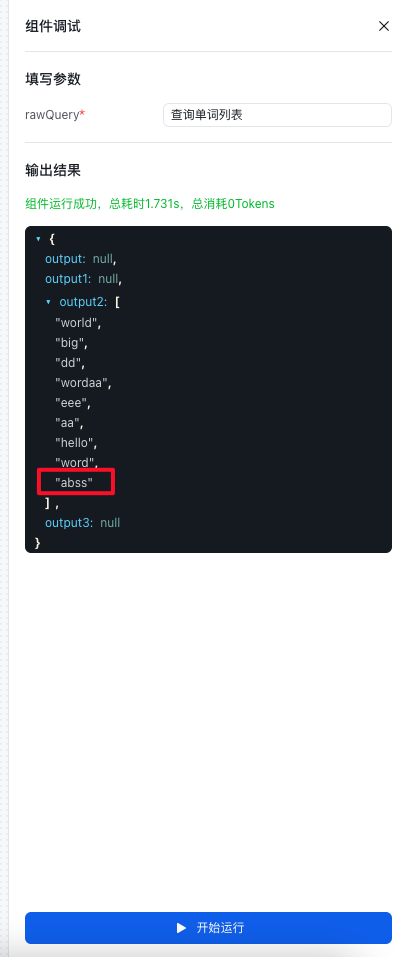
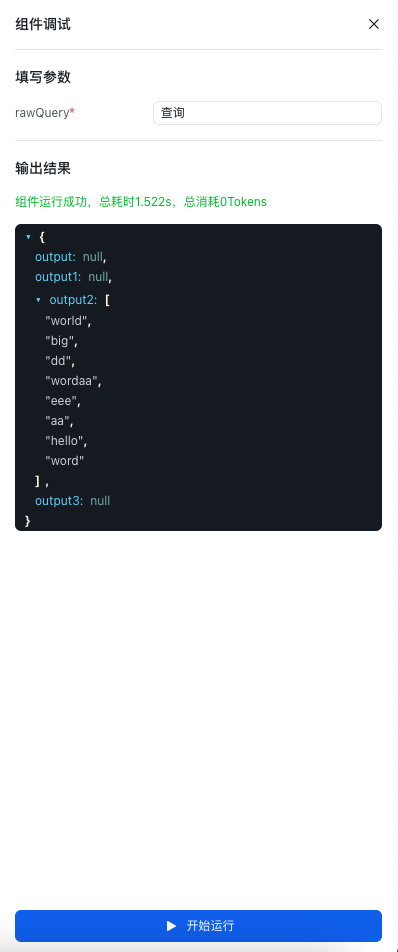
输入:查看一下单词列表中的内容,实现列表内容的展示。
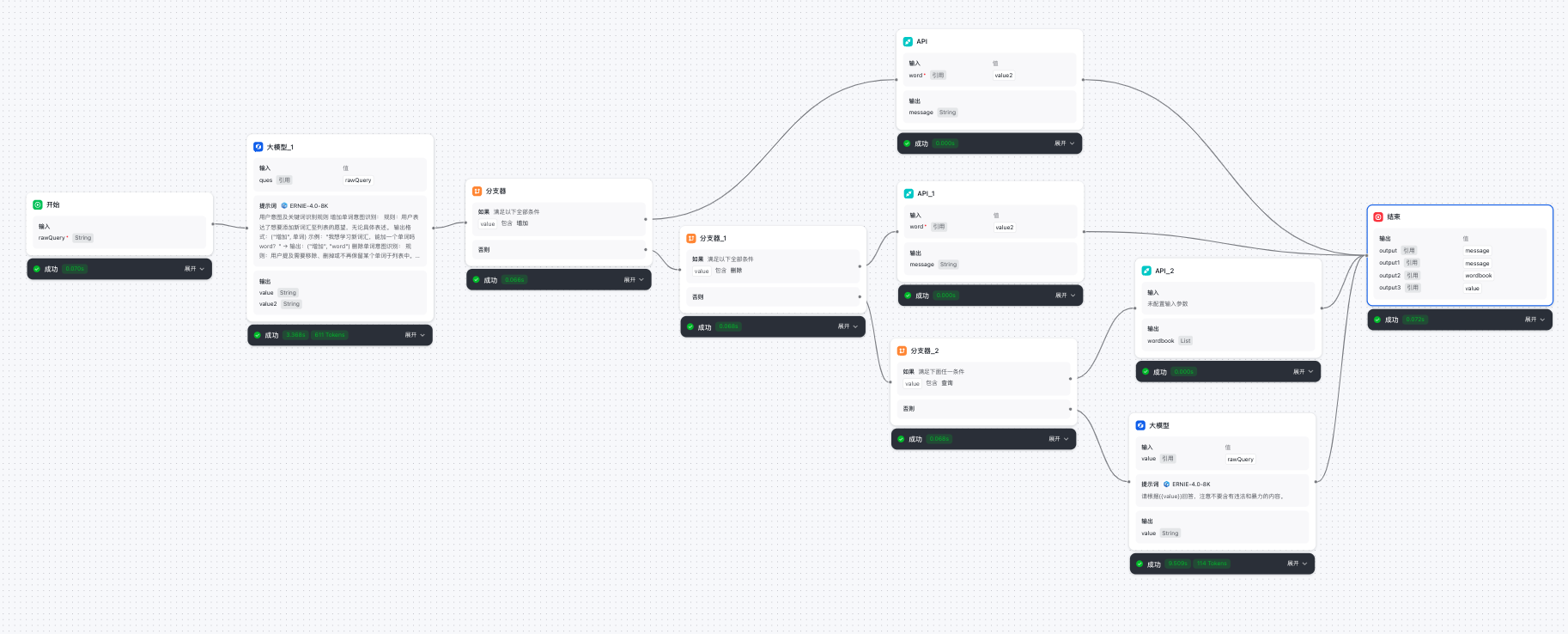
构建过程
准备
准备3个接口,分别是关于增删查的。
以下为代码参考示例,建议使用自己的api和服务器启动代码。
"""
样例配置参考:
1.添加单词hello:
{
"word": "hello"
}
2.删除单词hello:
?word=hello
3.展示单词列表
{}
"""
from flask import Flask, request, send_file, make_response
import json
import random
import os
app = Flask(__name__)
wordbook = []
current_directory = os.path.dirname(os.path.abspath(__file__))
def make_json_response(data, status_code=200):
response = make_response(json.dumps(data), status_code)
response.headers["Content-Type"] = "application/json"
return response
@app.route("/add_word", methods=['POST'])
async def add_word():
"""
添加一个单词
"""
word = request.json.get('word', "")
if word:
wordbook.append(word)
return make_json_response({"message": "单词添加成功"})
else:
return make_json_response({"message": "单词添加失败"})
@app.route("/delete_word", methods=['DELETE'])
async def delete_word():
"""
删除一个单词
"""
# word = request.json.get('word', "")
word = request.args.get('word', "")
if word in wordbook:
wordbook.remove(word)
return make_json_response({"message": "单词删除成功"})
else:
return make_json_response({"message": "单词不存在,删除失败"})
@app.route("/get_wordbook")
async def get_wordbook():
"""
获得单词本
"""
return make_json_response({"wordbook": wordbook})
@app.route('/')
def index():
return 'welcome to my webpage!'
if __name__ == "__main__":
app.run(debug=True, host="0.0.0.0", port=8082)流程梳理
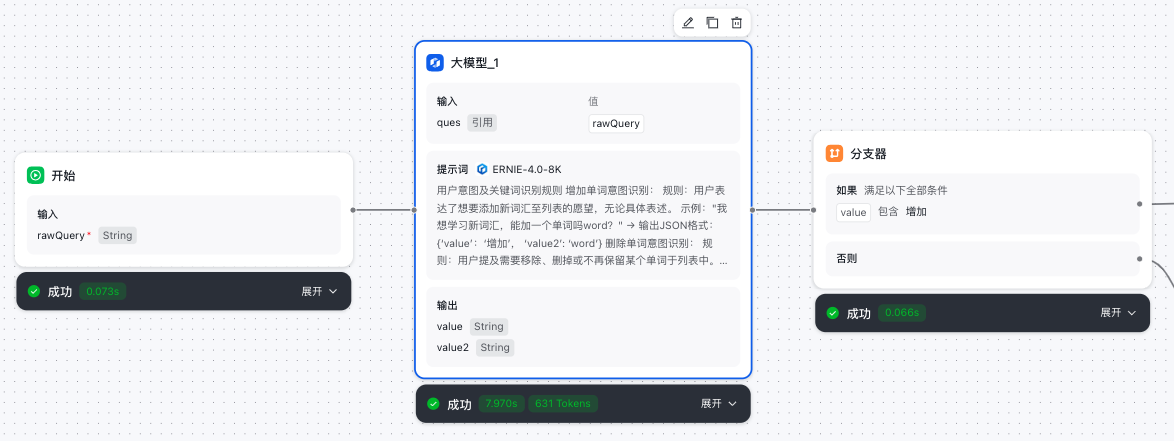
开始节点:用户query
- 添加大模型节点,进行用户意图识别(是增加,删除,查询,还是普通聊天),并输出对应的关键字(增加/删除/查询)。同时从用户的对话中提取出要执行的单词(如:world, hello)。
- 添加分支器节点,将上一环节大模型输出的值,作为条件判断的关键字。
- 对于增删查意图,通过添加不同类型的API节点(增/删/查 类型)对单词列表进行 “增/删” 单词和 “查询” 单词列表内容的操作。
- 对于普通聊天添加新的大模型节点进行处理。
- 结束节点输出前面环节中的结果。
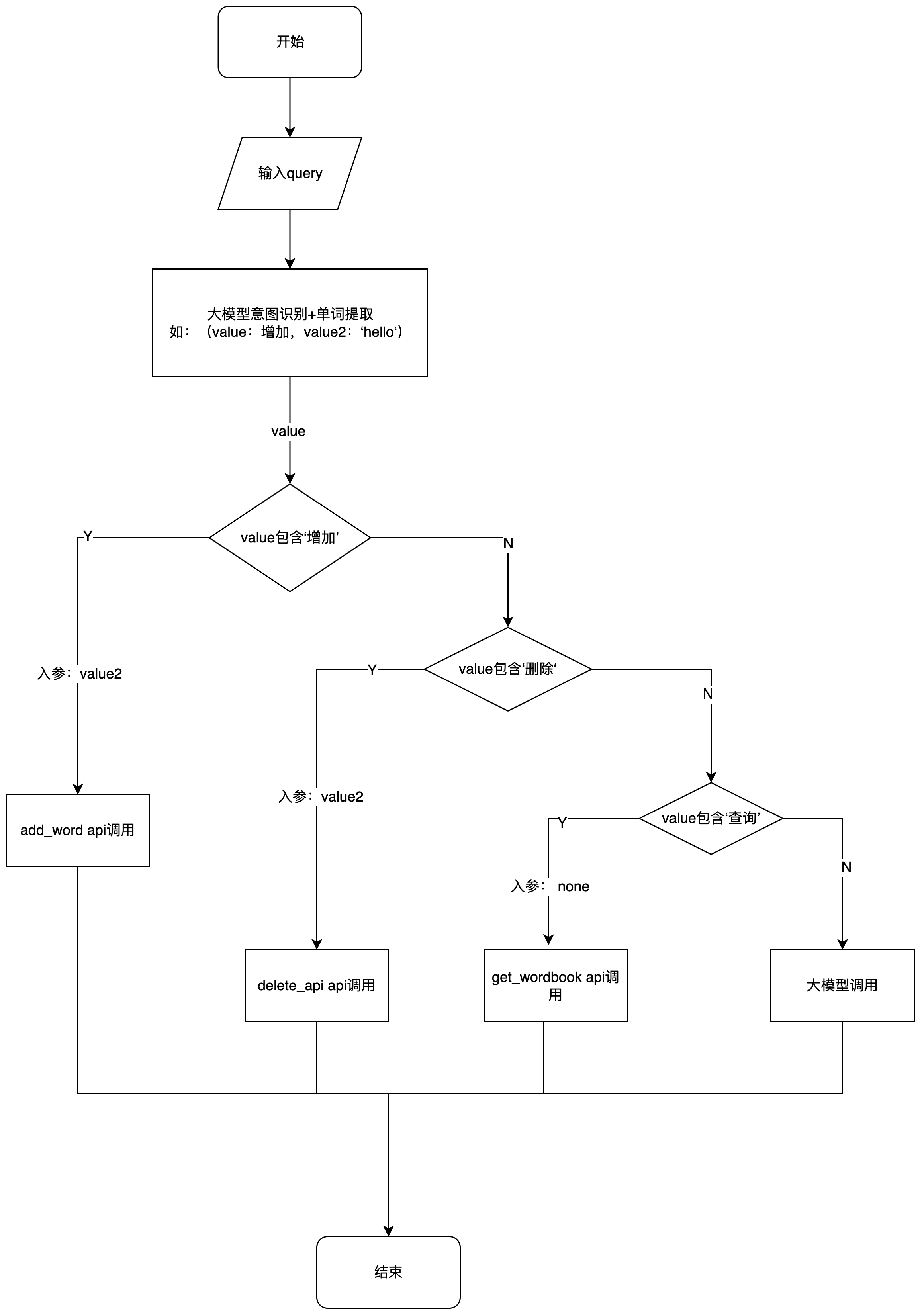
组件各节点创建
开始节点
- 勾选包含原对话选项,输入的rawQuery参数可在后续分支器节点中拿到。
- 将尾连结点和大模型的头连接点连接在一起,表示流转到大模型环节。
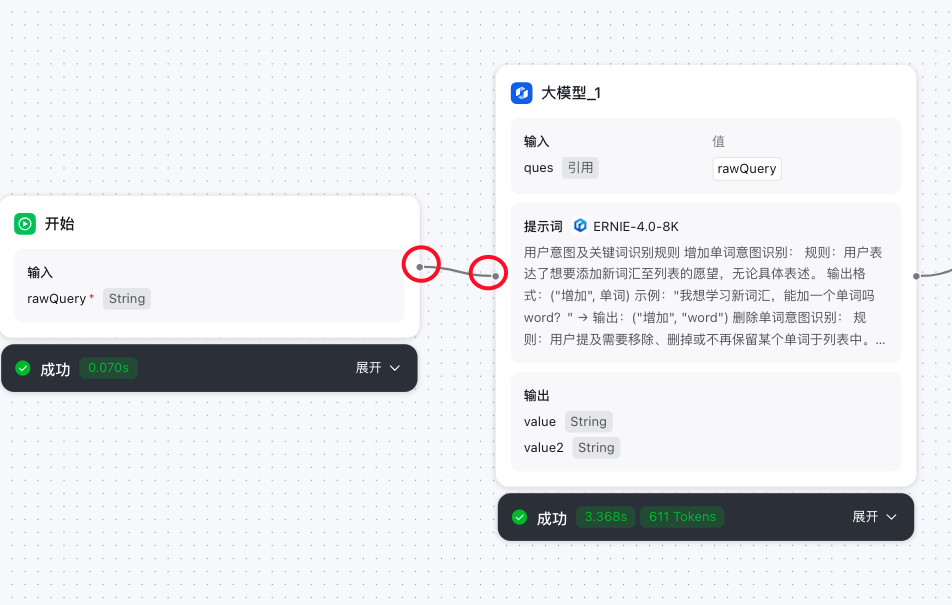
大模型意图识别节点
请使用 ERNIE-4.0-8K 和 ERNIE-3.5-8K 模型实现,以保证输出效果
prompt:
用户意图及关键词识别规则
增加单词意图识别: 规则:用户表达了想要添加新词汇至列表的愿望,无论具体表述。 示例:"我想学习新词汇,能加一个单词吗word?" → 输出JSON格式:{‘value’:‘增加’, ‘value2’: ‘word’}
删除单词意图识别: 规则:用户提及需要移除、删掉或不再保留某个单词于列表中。 示例:"‘amazing’这个词我学会了,可以删掉。" → 输出JSON格式:{‘value’:‘删除’, ‘value2’: ‘amazing’}
查询单词列表意图识别: 规则:用户请求查看、了解当前列表中所有单词。 示例:"我不记得‘sophisticated’怎么拼写了,能看看单词表吗?" 或 "查看一下单词列表" → 输出JSON格式:{‘value’:‘查询’,‘value2’: ‘None’}
其他情况: 规则:不属于上述三类明确意图的用户输入。 输出JSON格式:{‘value’:‘None’, ‘value2’: ‘None’}
请基于以上规则和示例对{{ques}}进行判断和响应。
以上prompt提示词可以直接复用
- 大模型环节具体配置如下图:
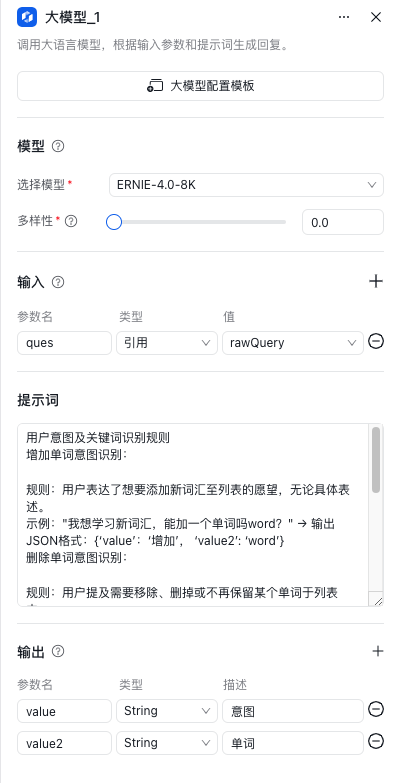
- 大模型意图识别成功后,将输出值value流转到下一环节(分支器节点)
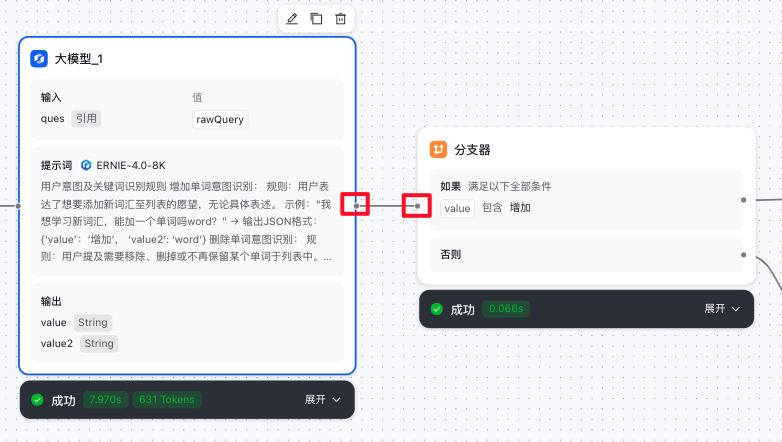
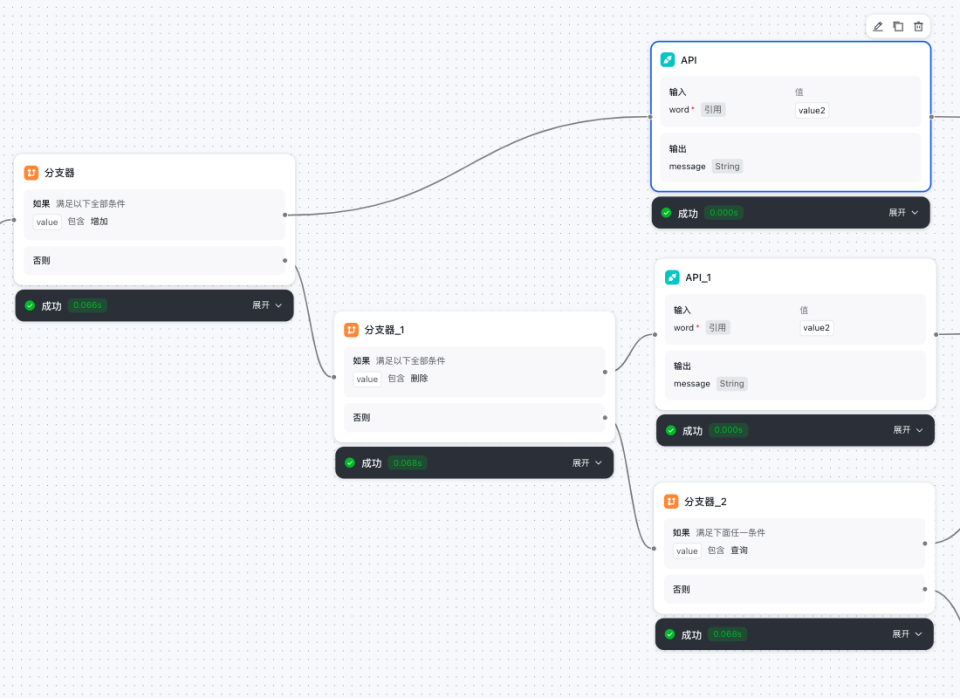
分支器节点
- 分支器节点中的引用变量来自大模型意图识别节点的value,选择条件关系,进行条件对比。
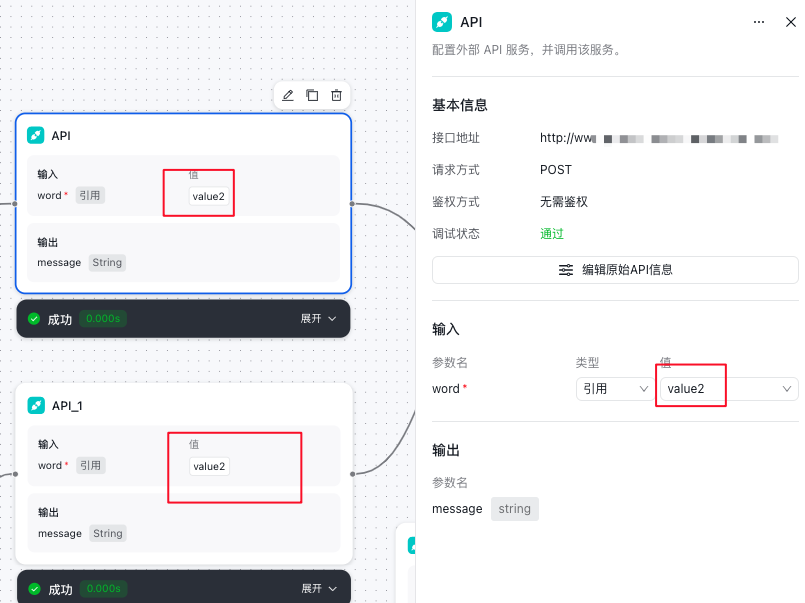
举例:下图配置的含义 是 让 rawQuery 和 ‘增加’ 这俩个字做对比,对比关系是 包含。即: rawQuery 中是否包含 ‘增加’ 二字,如果符合设定条件,则向api节点流转。
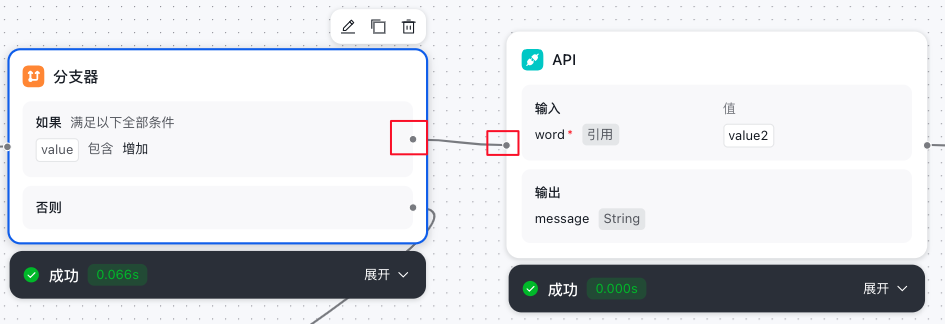
- 将满足‘如果‘条件的尾连结点 点接到 API节点的头连接点上,表示条件通过,流转到API节点(增加)进行接口调用。
- 上一个节点中大模型判断用户意图是 增加,满足了第一个分支器的如果条件,所以流转到API节点(增加)
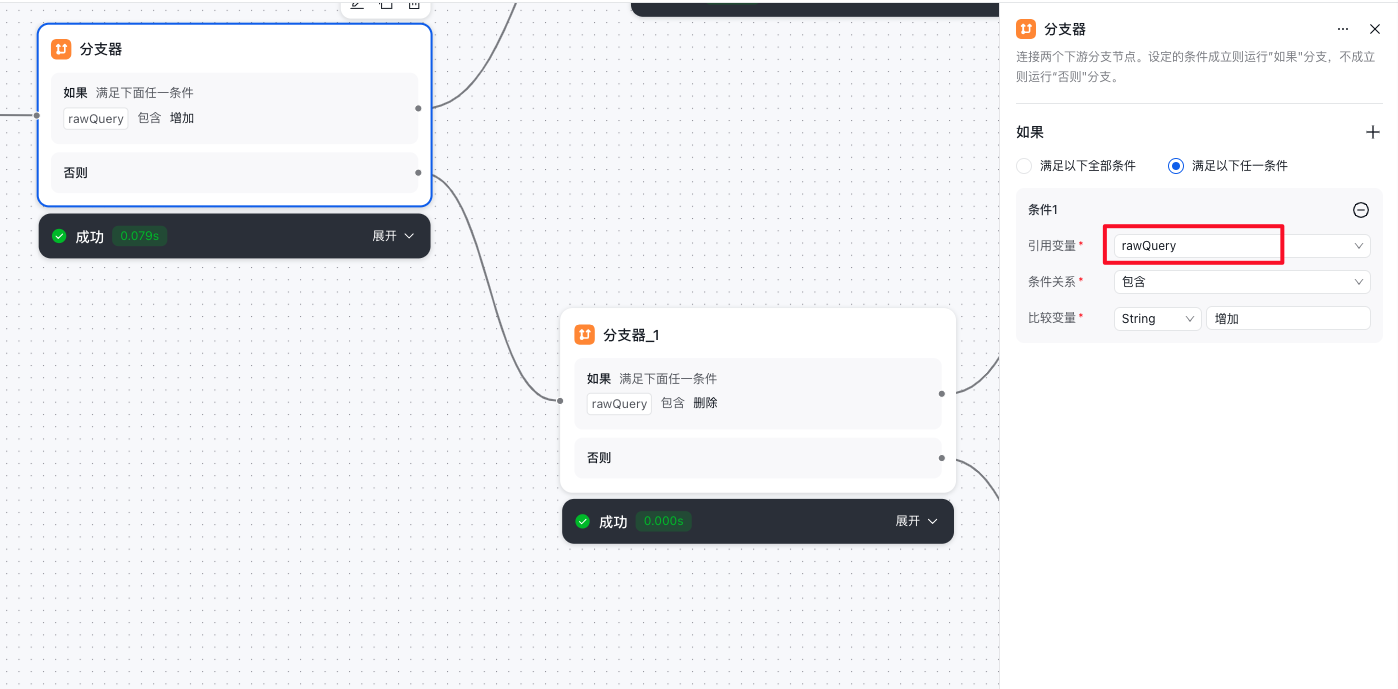
- 如果大模型判断的意图是 删除,则不满足第一个分支器的如果条件,则流转到下一个分支器节点。
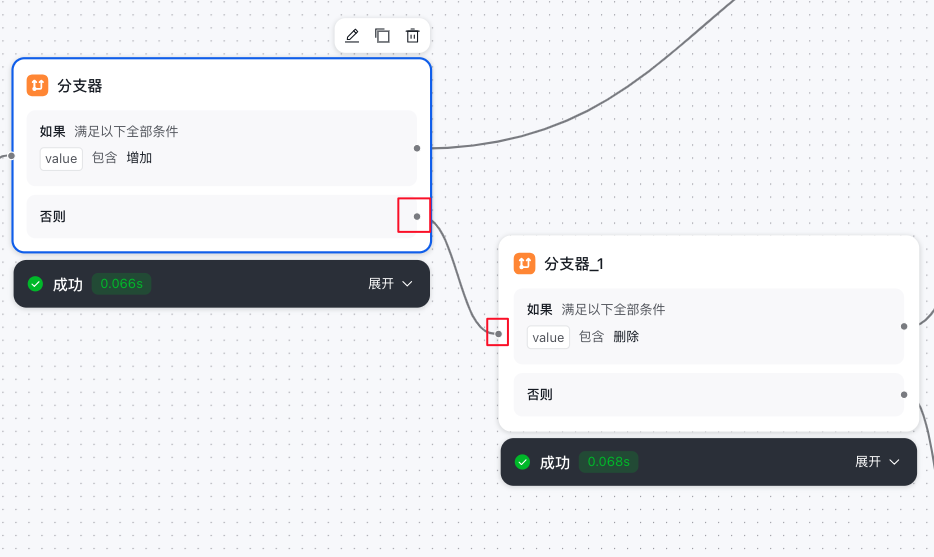
- 第二个分支器节点(分支器_1)执行,如果前面大模型判断意图是 删除,则满足第二个分支器的如果条件,那么第二个分支器流转到API节点(删除)。
- 如果大模型判断的意图 也不是删除,则不满足第二个分支器的如果条件,那么第二个分支器节点流转到第三个分支器节点。
- 第三个分支器是判断是否是查询意图,同理第1,2个分支器节点。
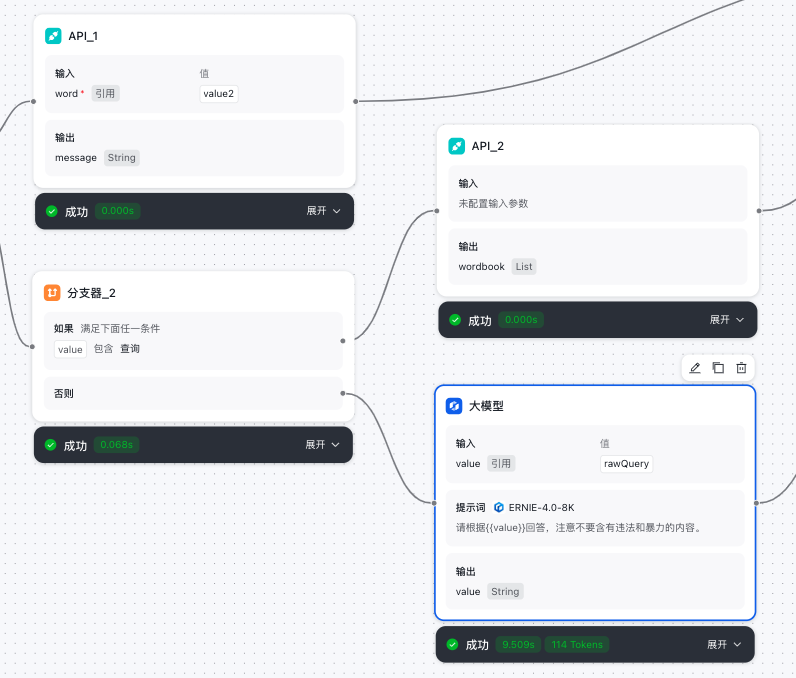
- 第三个分支器的否则条件会流转到下一个大模型节点,进行自然语言对话。
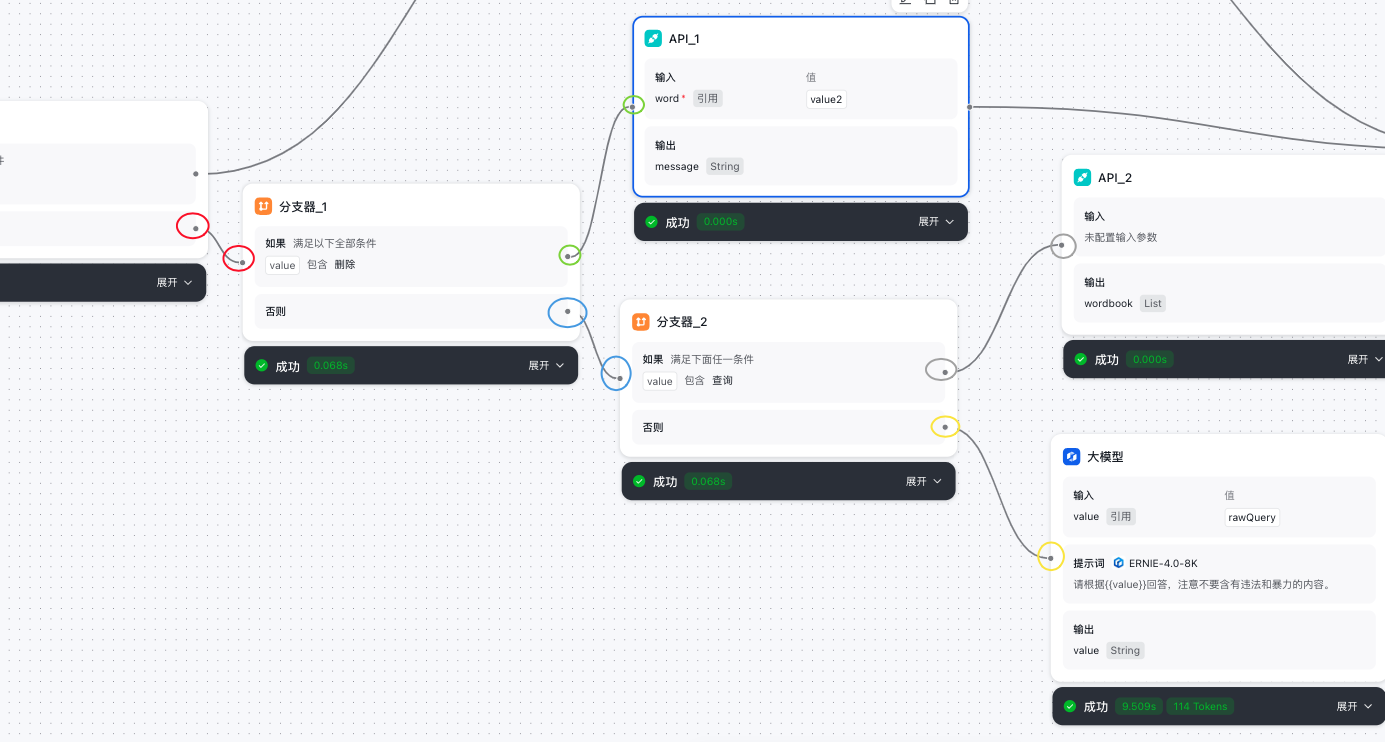
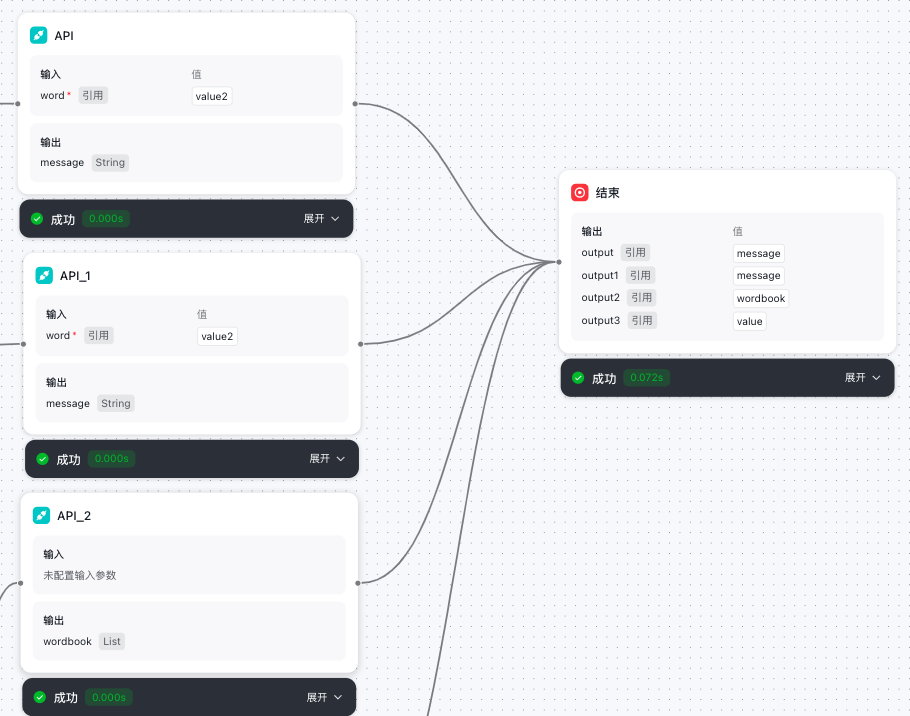
API节点
- 从代码节点流转到API节点
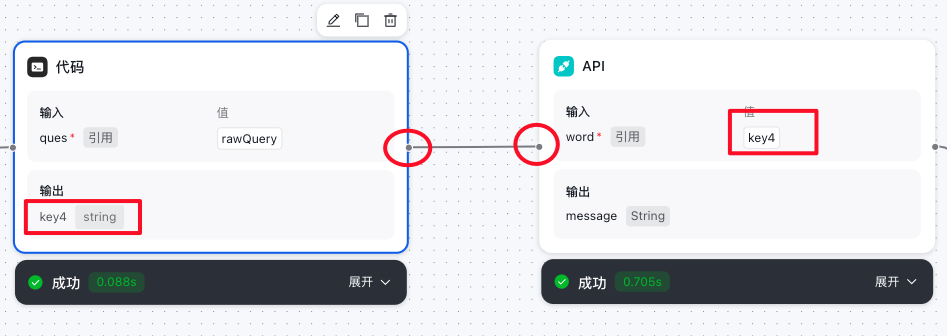
- 根据API的要求进行数据请求模块的编辑
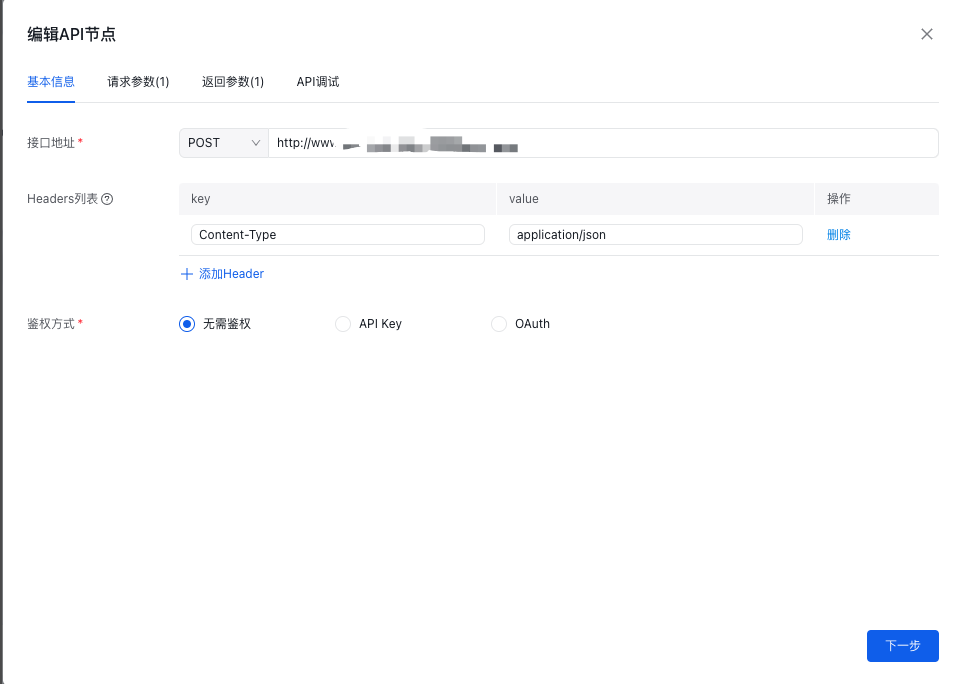
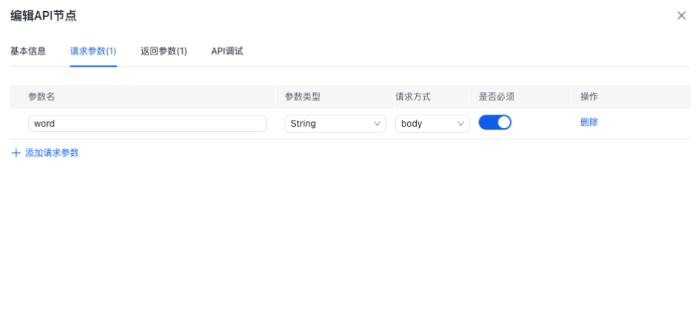
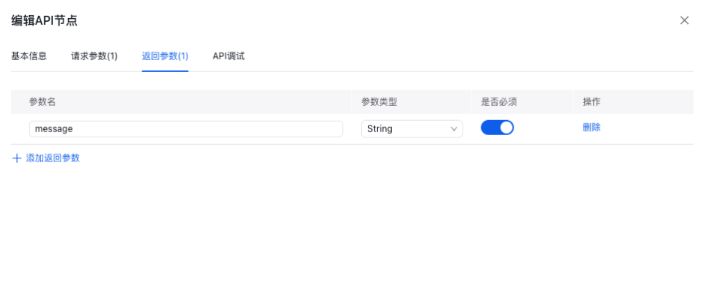
- API节点输出的内容给到结束节点
大模型节点
- 承接最后一个分支器节点的否则条件点
- 出参流转到结束节点
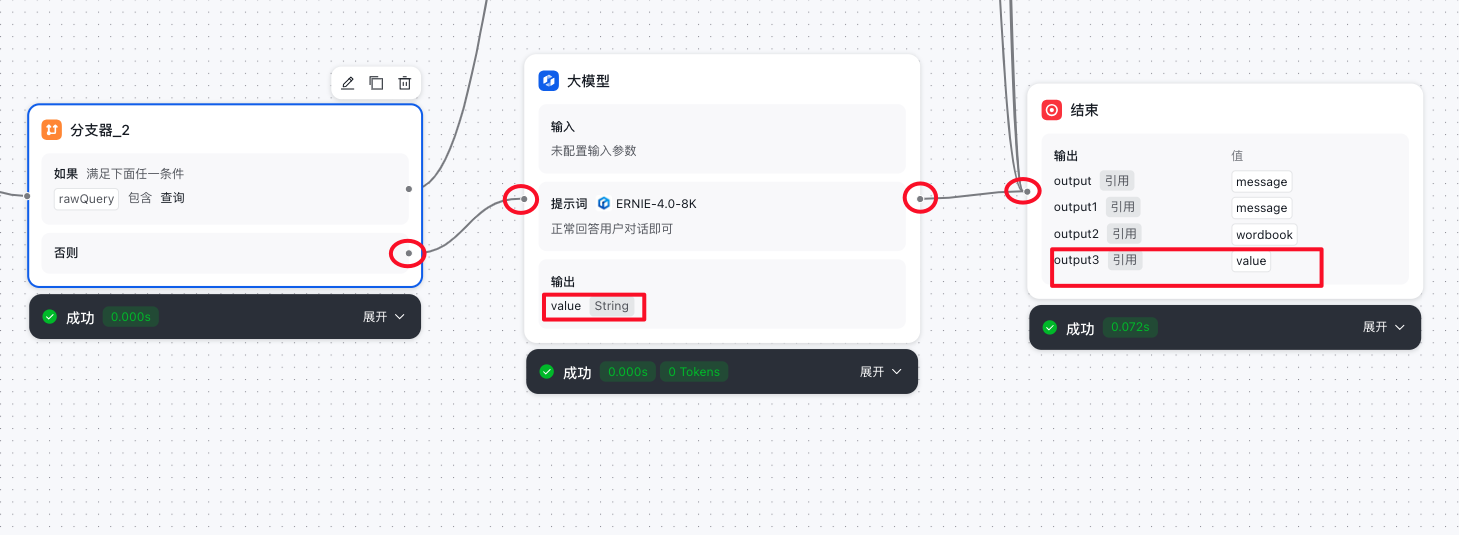
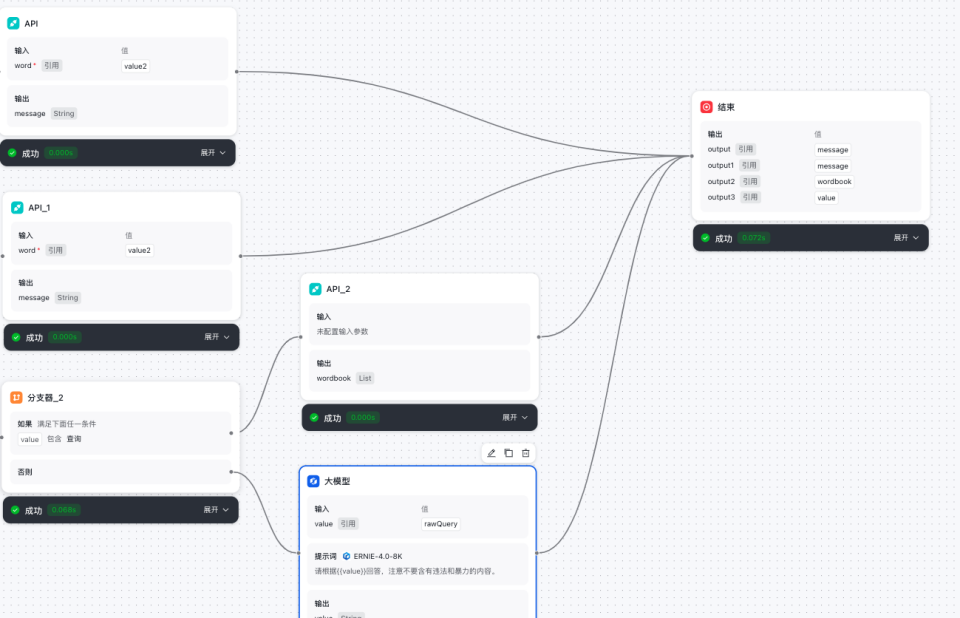
结束节点
- 结束节点输出前面所有节点的结果
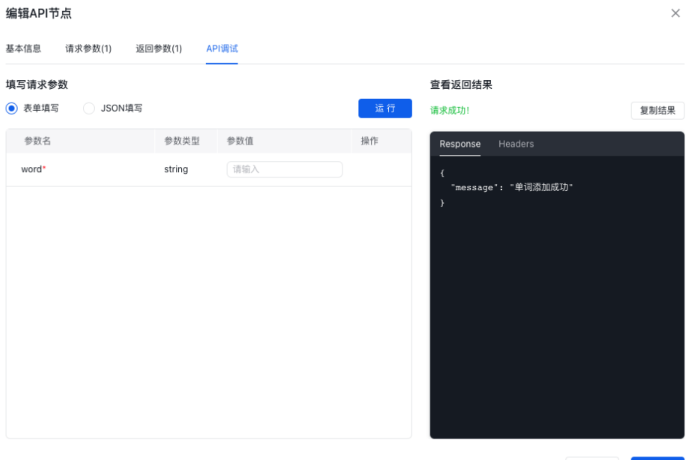
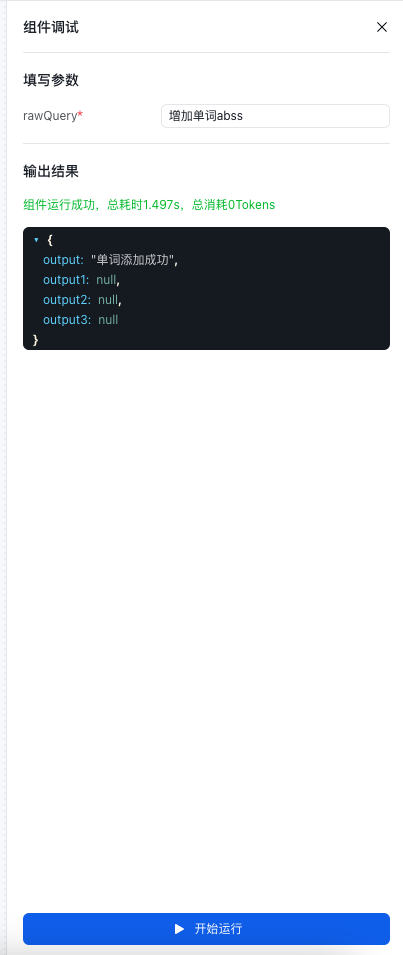
预览和调试
- 点击页面中间下方的运行按钮,进行预览和调试
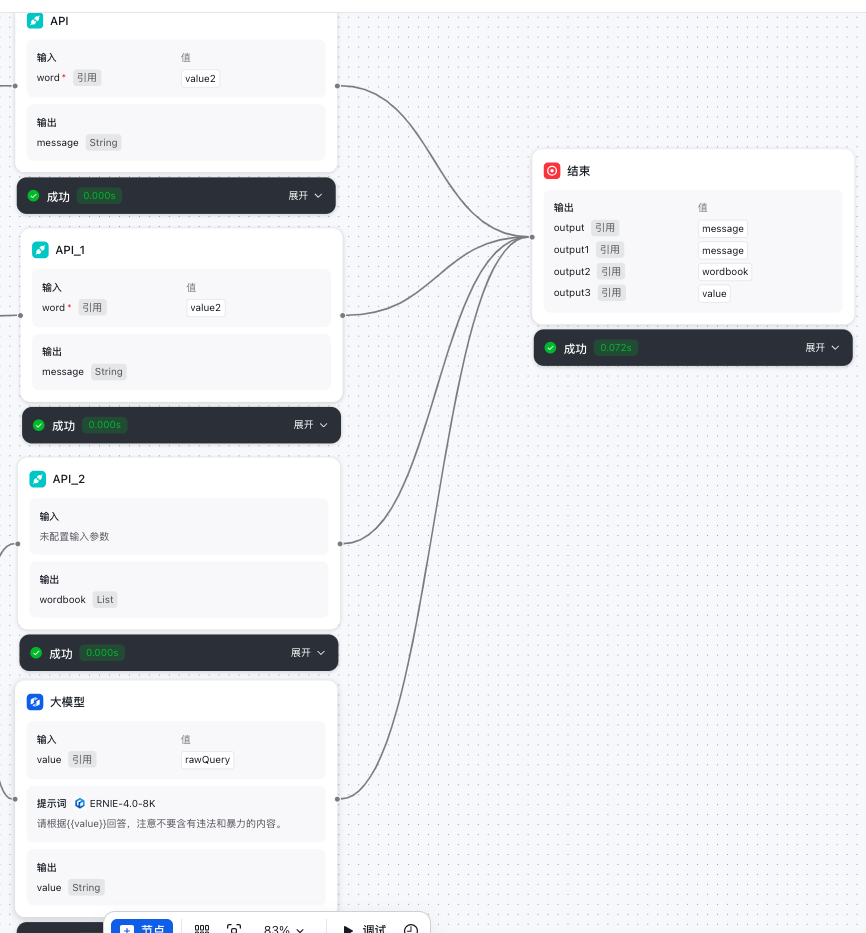
整体流程分解高清图