知识库节点
整体概述
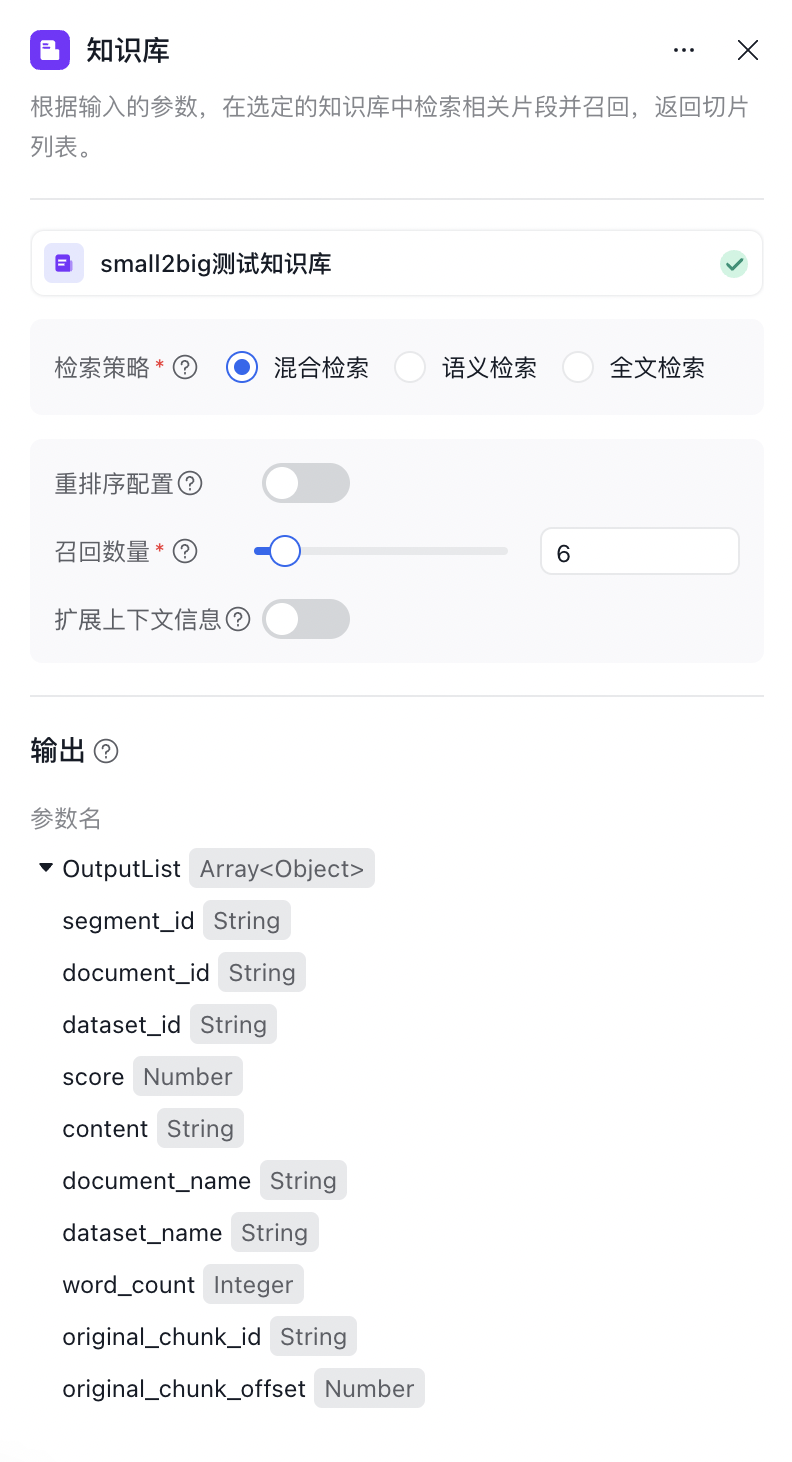
知识库节点支持根据输入的query,在选定的知识库中检索相关片段并召回,返回切片列表。你可以上传文件并建立知识库,在知识库节点中勾选想要使用的知识库进行检索。
参数配置
输入参数:参数名不可修改,参数类型为string,上级节点的输出参数会强制转换为string类型作为知识库节点的输入,输入参数有两种类型:1)引用类型为引用上一个节点的输出变量,2)常量类型,可以输入一个string类型的入参。
选择知识库:选择需要检索的知识库,支持选择多个知识库,需要保证知识库节点中的多个知识库都属于相同的向量模型。
检索策略:按照指定的检索策略从知识库中寻找匹配的片段,不同的检索策略可以更有效地找到正确的信息,提高最终生成的答案的准确性和可用性。
| 检索策略 | 定义 |
|---|---|
| 混合检索 | 使用倒排索引和语义检索两种策略进行召回,推荐在需要对句子理解和语义关联性的场景下使用,综合效果更优。 |
| 语义检索 | 语义检索将返回与查询Query含义相匹配的内容,而不是与查询字面意思相匹配的内容。推荐在需要对上下文相关性和意图相关性的场景下使用。 |
| 全文检索 | 使用倒排索引策略进行检索召回,推荐在需要对关键词精准匹配的场景下使用。 |
召回数量:设置从知识库中召回与输入Query匹配的知识片段的个数,设定的数量越大,召回的片段越多。
匹配分:在检索过程中,用来计算输入Query和知识库片段的相似度,高于匹配分数的片段将会被检索召回。
拓展上下文信息:采用了 Small-to-Big 策略,可以提升 RAG(检索增强生成)的能力。该功能开启后,会拓展命中切片的上下文,并将包含上下文信息的大切片提供给大模型,使大模型能获取更多相关信息,从而更好地解答用户提出的问题。需注意,开启"拓展上下文信息"功能后,会增加召回切片内容,导致模型输入token数量增加、降低模型响应速度、增加成本消耗。建议配合大上下文的模型组合使用,避免token超出模型输入范围。
输出参数:在知识库中检索输出的变量信息及变量类型。
| 字段名 | 含义 |
|---|---|
| segment_id | 获取切片的标识符 |
| document_id | 切片所在文档的标识符 |
| dataset_id | 数据集的标识符 |
| content | 实际抓取的内容 |
| document_name | 该文档的标题 |
| dataset_name | 该数据集的标题 |
| word_count | 抓取内容的字数统计 |
| original_chunk_id | 被扩展切片的标识符 |
| original_chunk_offset | 与被扩展切片的位置关系,-1是左边第一个邻居,1是右边第一个邻居 |
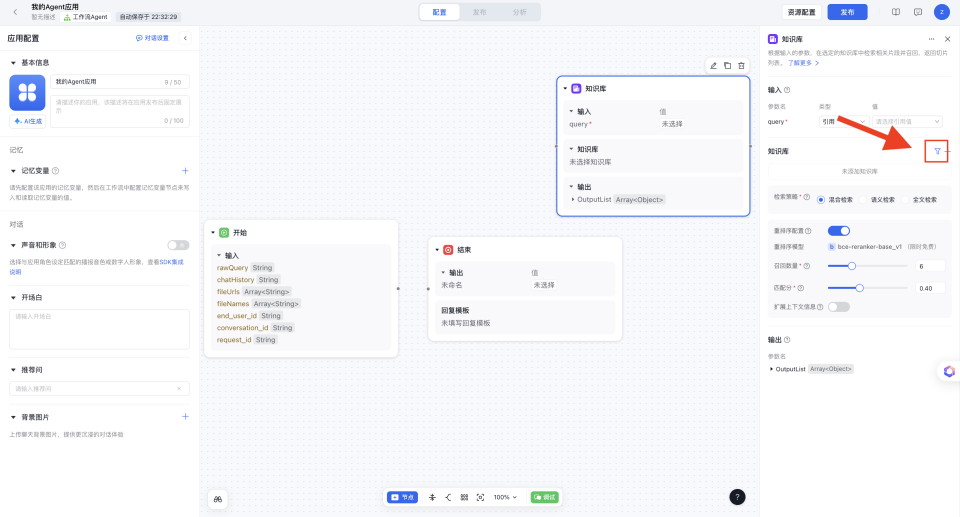
文档与标签筛选配置
功能使用场景:产品问答时可按产品标签筛选文档,实现更精准知识问答效果。企业可为员工按角色设定知识范围权限。 API调用时用户可根据每个query按场景或用户权限区分知识问答范围。可参考对话接口文档
操作方法:点击如下按钮,可配置文档与标签筛选,通过文档与标签配置限定知识库检索范围
支持添加标签筛选、文档筛选作为筛选条件,筛选条件配置支持 “且” “或”关系,可添加10个筛选条件
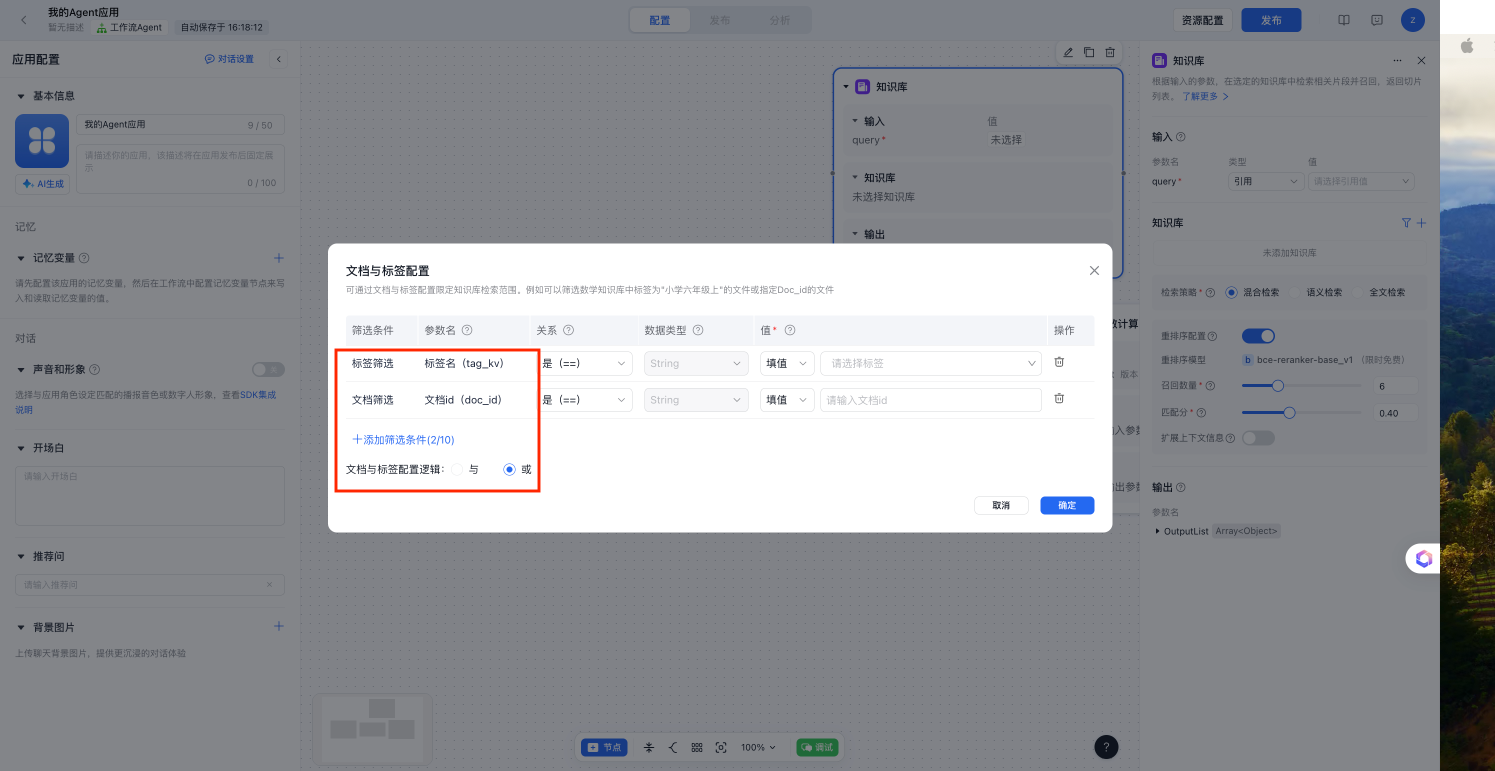
标签与检索值的关系有三种,"不包含":在后面的string数组中的范围、"包含":不在后面的string数组范围中、"是":等于后的string类型值。数据类型可以选择“String”或者“Array[String]",单个标签或文档id时为String类型,指定标签值或文档id值范围时为Array[String]类型
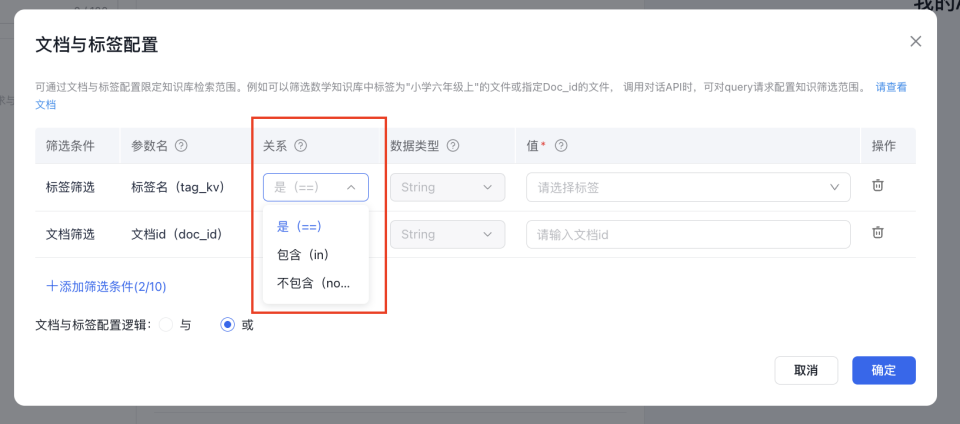
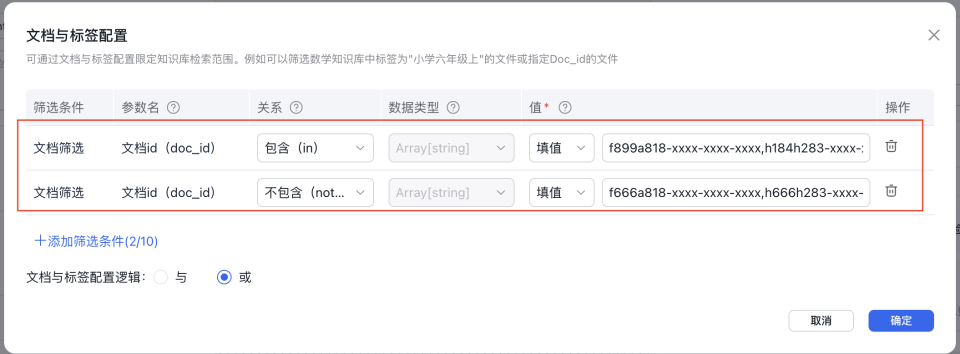
当筛选条件为文档筛选,关系为包含(in)、不包含(not in)时,文档id值之间用逗号(,)做分隔,如“f899a818-xxxx-xxxx-xxxx,h184h283-xxxx-xxxx-xxxx。”