016-统计分析组件
统计分析组件
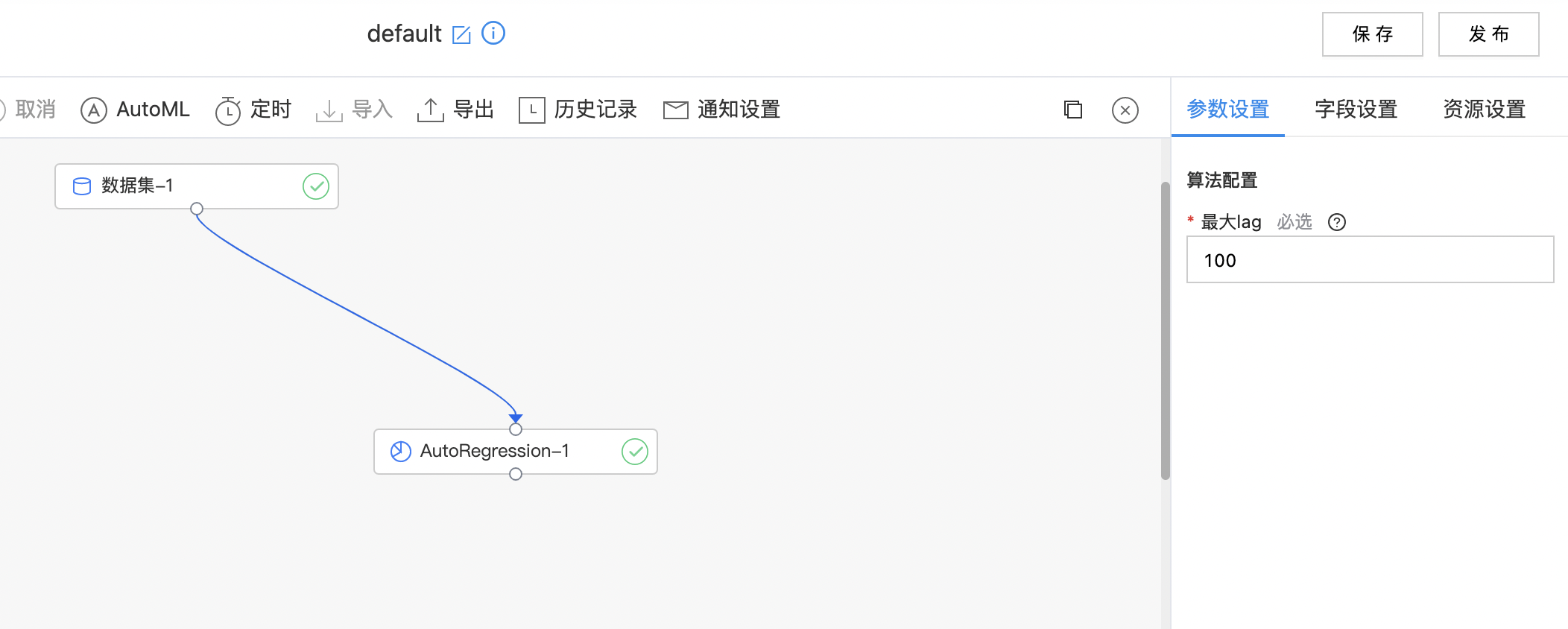
AutoRegression
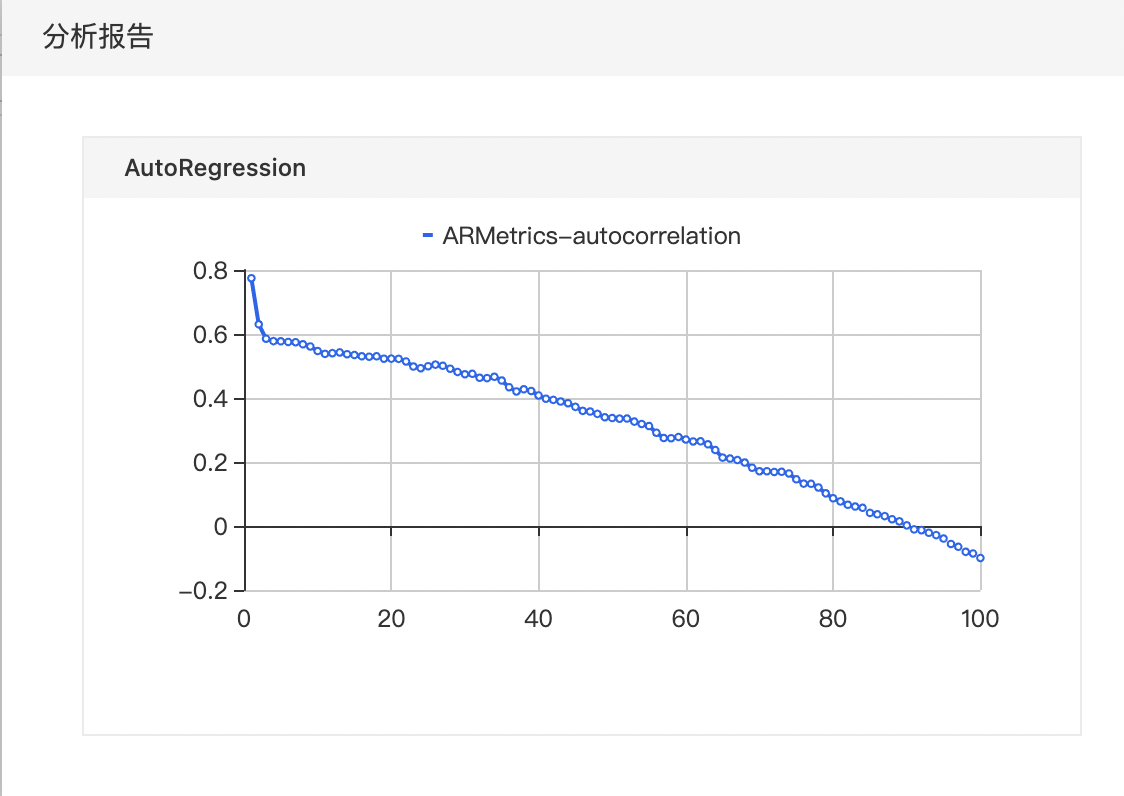
自相关函数,求解时间序列的自相关性,可以表现出模型的平稳性。
输入
- 输入是一个数据集,需要选择要做AR的两列。选择的检验列需要是数值类型,排序列用于排序。
输出
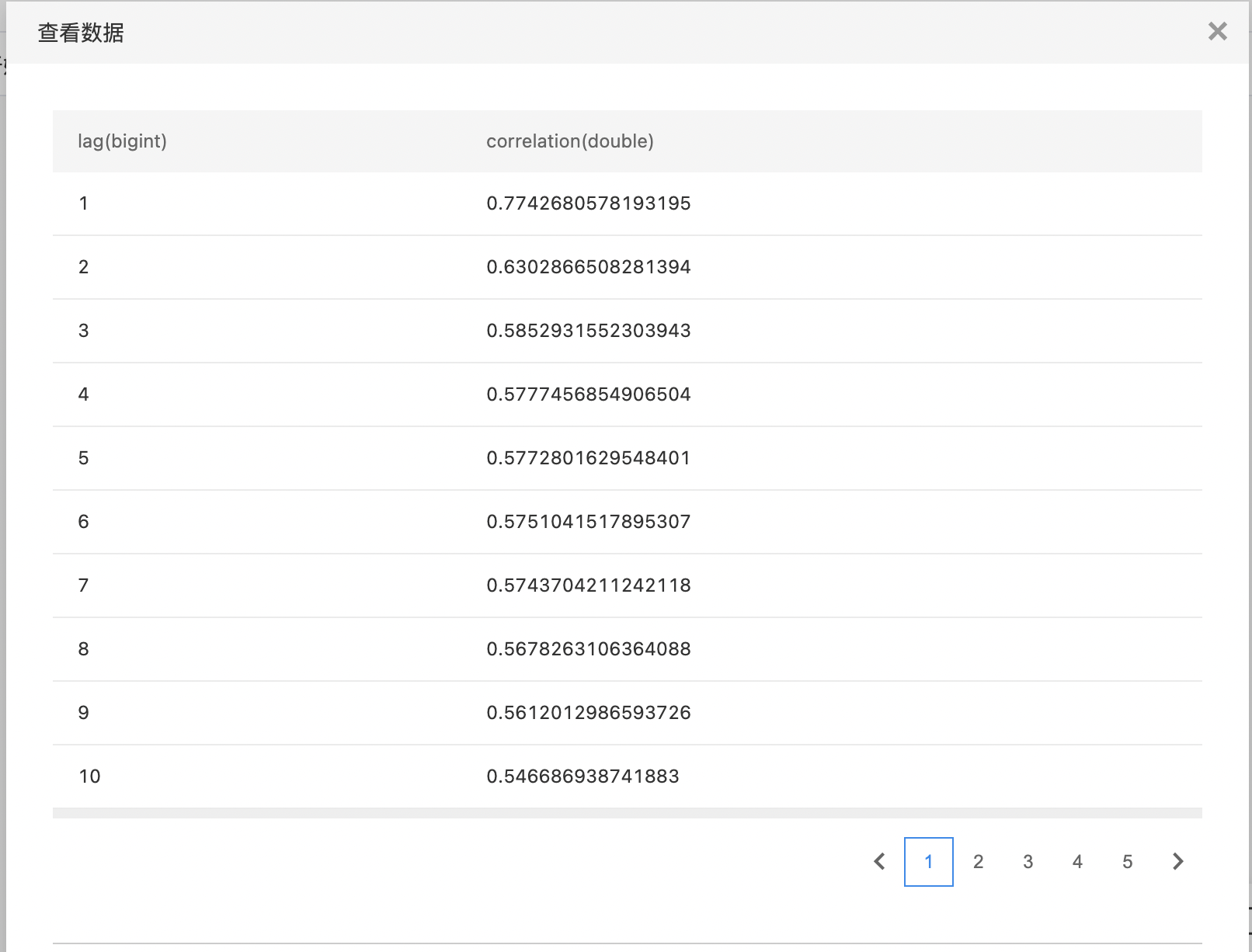
- 输出是一个结果数据集。包含两列:lag,correlation,列的类型分别是bigint和double。
算子参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 最大lag | 是 | 统计时考虑的最大lag 范围:[1, 3653]。 | 100 |
字段参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 检验列 | 是 | 选择一列检验列,数值类型。 | 无 |
| 排序列 | 是 | AR检验列依据此列由小到大排序,一般选择日期列。 | 无 |
使用示例
- 输入数据集为天气数据,Date代表日期,Temp代表温度。
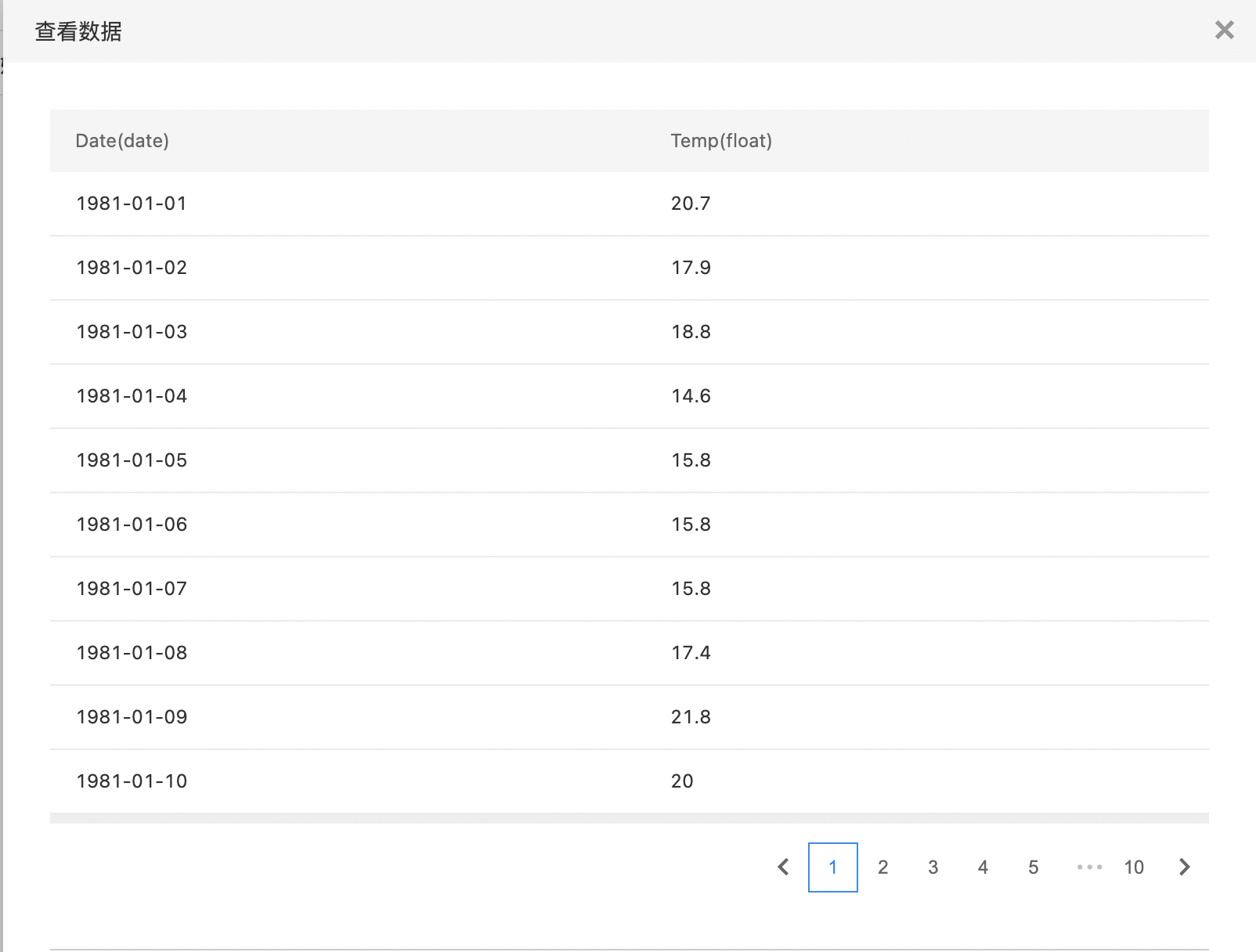
- 构建算子结构,配置参数,完成训练。
- 查看输出数据。
- 查看分析报告结果。
F检验
F检验(F-test),最常用的别名叫做联合假设检验(英语:joint hypotheses test),此外也称方差比率检验、方差齐性检验。它是一种在零假设(null hypothesis, H0)之下,统计值服从 F-分布 的检验。其通常是用来分析用了超过一个参数的统计模型,以判断该模型中的全部或一部分参数是否适合用来估计母体。
输入
- 输入是一个数据集,需要选择要做F检验的一列。选择的列需要是数值类型。进一步地,还需要选择F检验对应的标签列。标签列要求是整数或字符串类型。
输出
- 输出是一个结果数据集。包含两列:f值(f_value),置信度(p_value)。列的类型是double。
字段参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 检验列 | 是 | 选择一列检验列,数值类型。 | 无 |
| 排序列 | 是 | 分组依据,要求是整数或字符串类型;不能存在nan(缺失值)。 | 无 |
使用示例
1.构建算子结构,配置参数,完成训练。
2.查看输出数据集结果。
KS检验
KS 检验(Kolmogorov-Smirnov 检验)是基于累计分布函数的,用于检验一个分布是否符合某种理论分布或比较两个经验分布是否有显著差异。系统中实现的为比较两个经验分布是否有显著差异。原假设为两个样本的分布相同,如果 ks 统计量小或者 p 值高,则我们不能拒绝原假设。
输入
- 输入是一个数据集。用户需要选择要做KS检验的两列(必须为两列),选择的列需要是数值类型。
输出
- 输出是一个结果数据集。包含两列:KS值(statistic),置信度(pValue),列的类型是double。
算子参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 替代方式 | 否 | 替代假设方式: two-sided greater less |
two-sided |
| 计算模式 | 否 | 计算p值的方式: auto asym exact |
auto |
字段参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 检验列 | 是 | 必须是两列,并且是数值类型。 | 无 |
使用示例
- 构建算子结构,配置参数,完成训练。
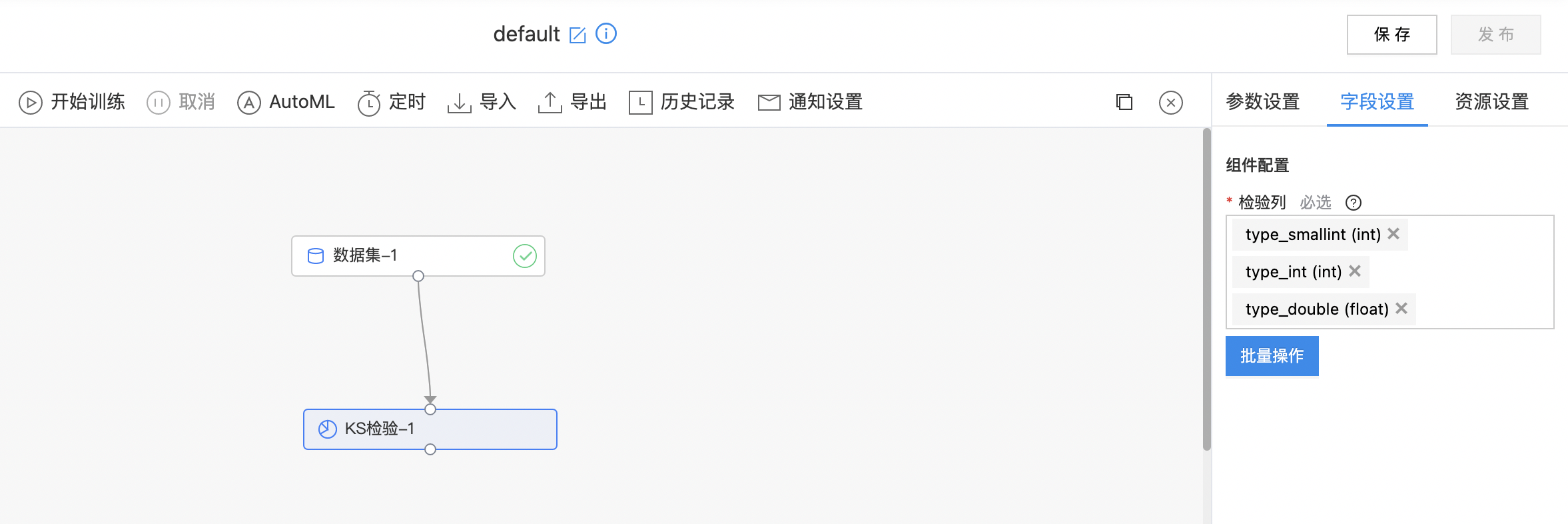
- 查看输出结果。
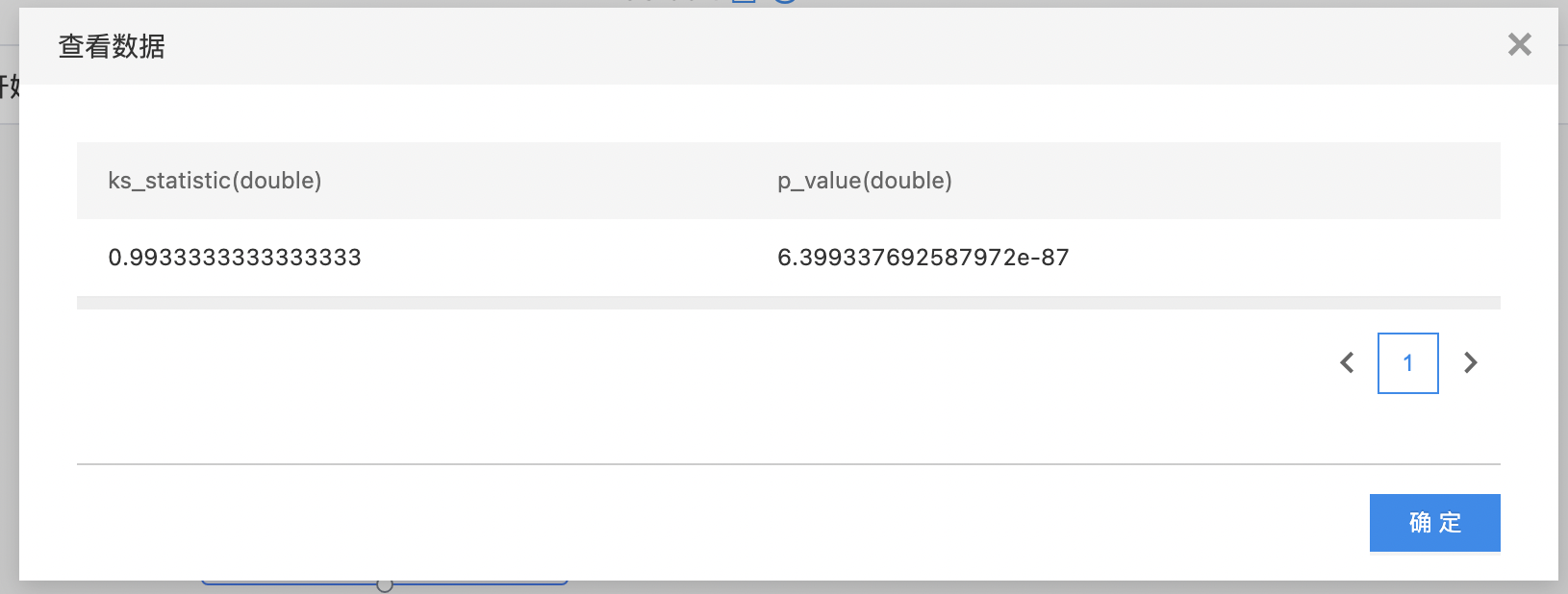
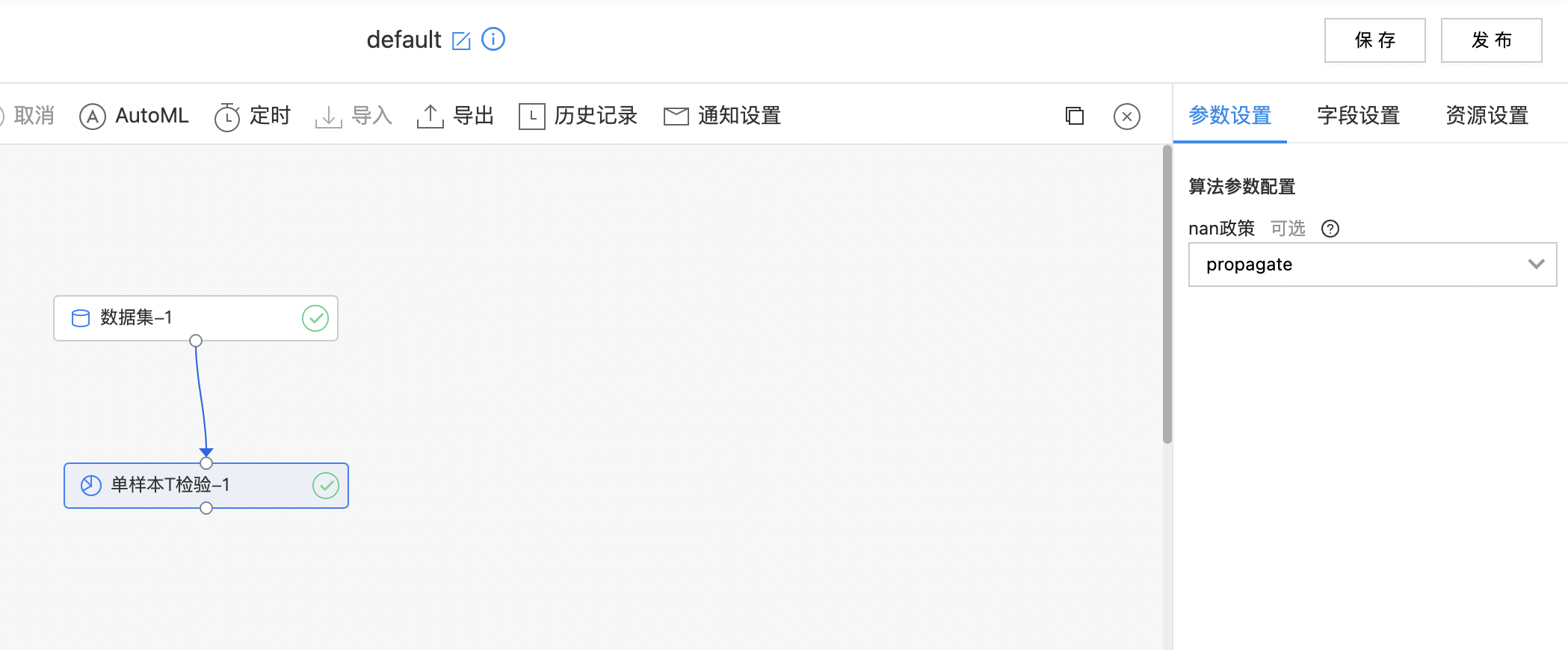
单样本T检验
T 检验,亦称 student T 检验(Student's T test),主要用于样本含量较小(例如 n < 30),总体标准差 σ 未知的正态分布。T 检验是用 T 分布理论来推论差异发生的概率,从而比较两个平均数的差异是否显著。 单样本 T 检验是检验一个样本平均数与一个已知的总体平均数的差异是否显著。
输入
- 输入是一个数据集。用户需要选择要做单样本T检验的一列。选择的列需要是数值类型。进一步地,还需要输入总体均值(零假设中的期望值)。
输出
- 输出是一个结果数据集。包含两列:t值(t_statistic),置信度(p_value),列的类型是double。
算子参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| nan政策 | 否 | 当输入包含nan时如何处理: “propagate”(默认)返回nan “raise”引发错误 “omit”忽略nan值计算 |
propagate |
字段参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 检验列 | 是 | 选择一列检验列,数值类型。 | 无 |
| 总体均值 | 是 | 零假设中的期望值。 | 无 |
使用示例
- 构建算子结构,配置参数,完成训练。
- 查看输出结果。
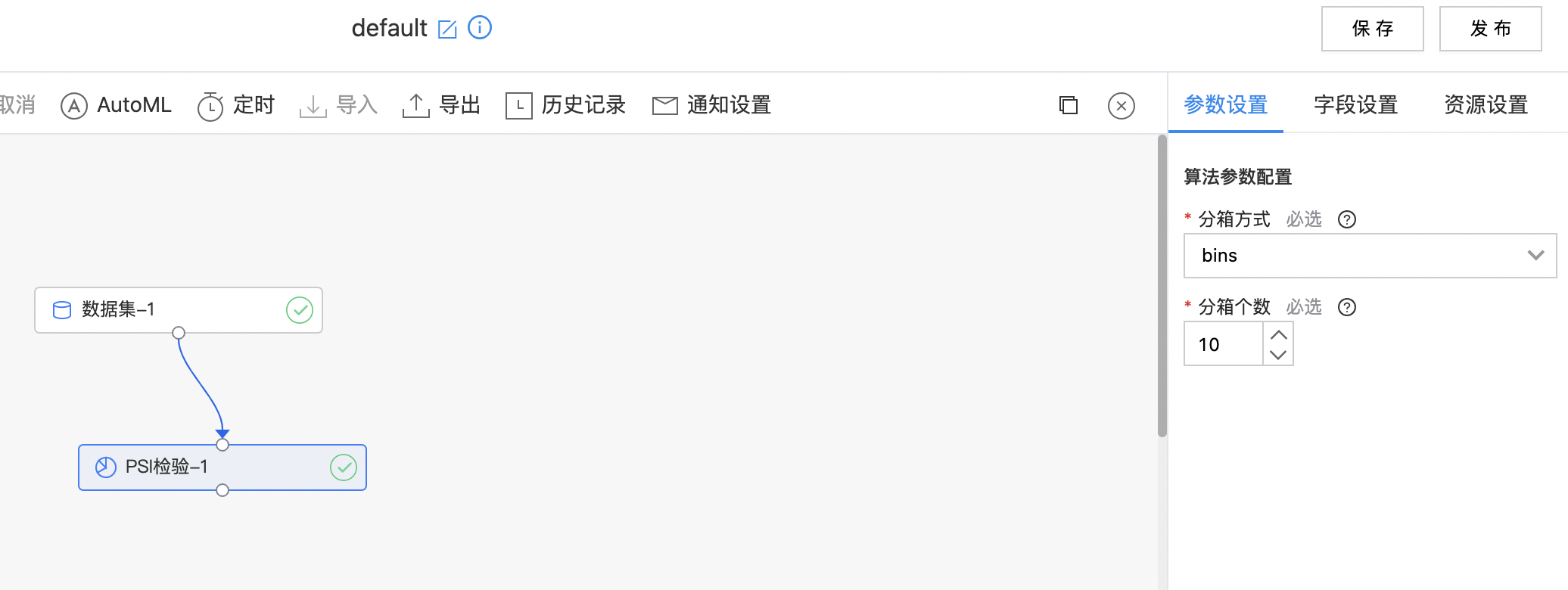
PSI检验
群体稳定性指标 PSI(Population Stability Index)是衡量模型的预测值与实际值偏差大小的指标。
输入
- 输入是一个数据集。用户需要选择要做PSI检验列。选择的列需要是数值类型,其中包括实际值列和预测值列。
输出
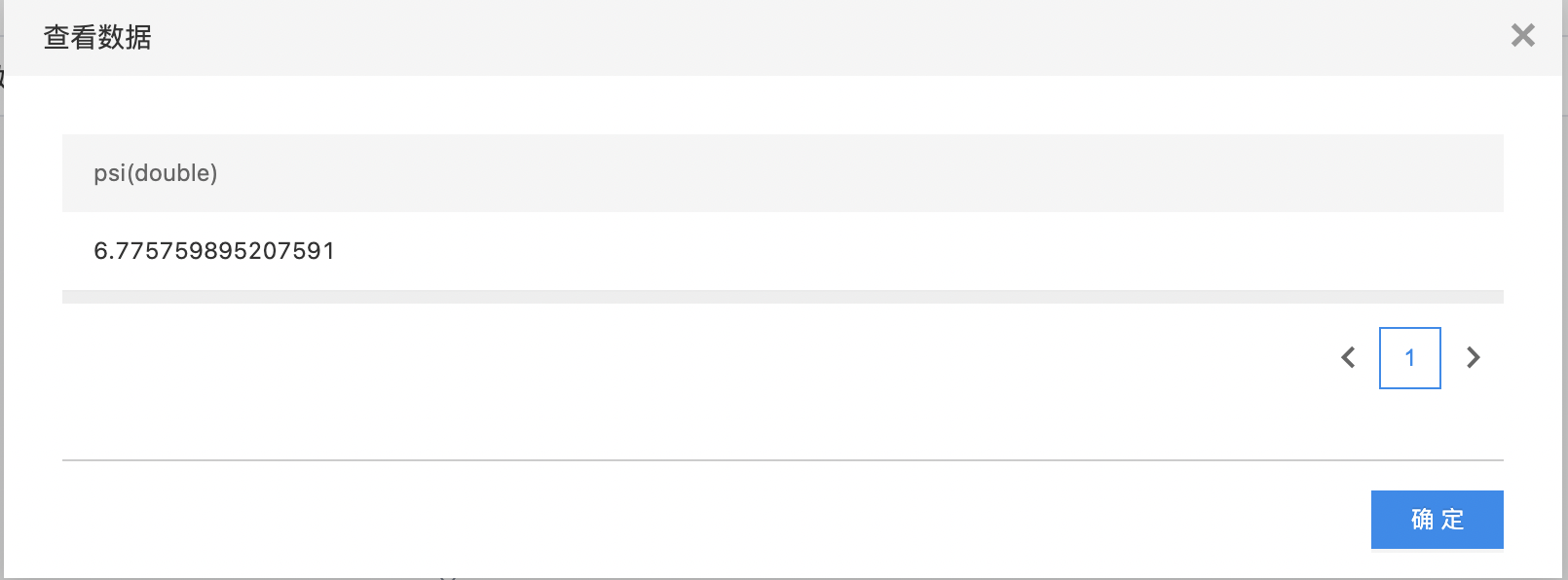
- 输出是一个结果数据集。包含一列:稳定度指标(psi),列的类型是double。
算子参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 分箱方式 | 是 | 计算PSI分箱方式支持: bins 均匀分箱 quantiles 分位数分箱 |
bins |
| 分箱个数 | 是 | 计算PSI时分箱个数 | 10 |
字段参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 实际值列 | 是 | 实际值,要求是数值类型 | 无 |
| 预测值列 | 是 | 预测值,要求是数值类型 | 无 |
计算逻辑

使用示例
- 构建算子结构,配置参数,完成训练。
- 查看输出结果。
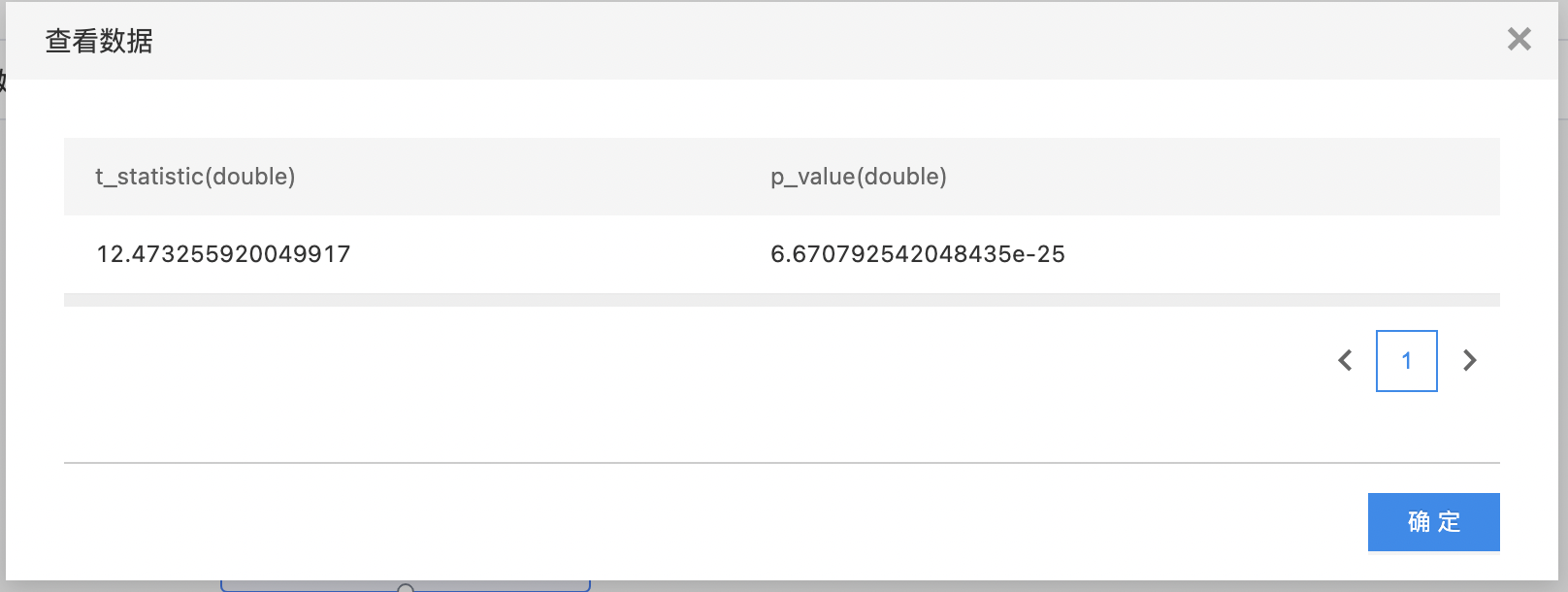
双样本T检验
双样本 T 检验利用 T 分布理论来检验两个总体均值是否显著差异。
输入
- 输入是一个数据集。用户需要选择要做双样本T检验的两列。选择的列需要是数值类型。
输出
- 输出是一个结果数据集。包含两列:t值(t_statistic),置信度(p_value),列的类型是double。
算子参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 假定总体方差相等 | 否 | 如果为True(默认),则执行一个标准的独立2样本t检验,该检验假定总体方差相等。如果为False,则执行Welch的t检验,该检验不假定总体方差相等。 | 开启 |
| nan政策 | 否 | 当输入包含nan时如何处理: “propagate”(默认)返回nan “raise”引发错误 “omit”忽略nan值计算 |
propagate |
字段参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 检验列 | 是 | 必须是两列,并且是数值类型。 | 无 |
使用示例
- 构建算子结构,配置参数,完成训练。
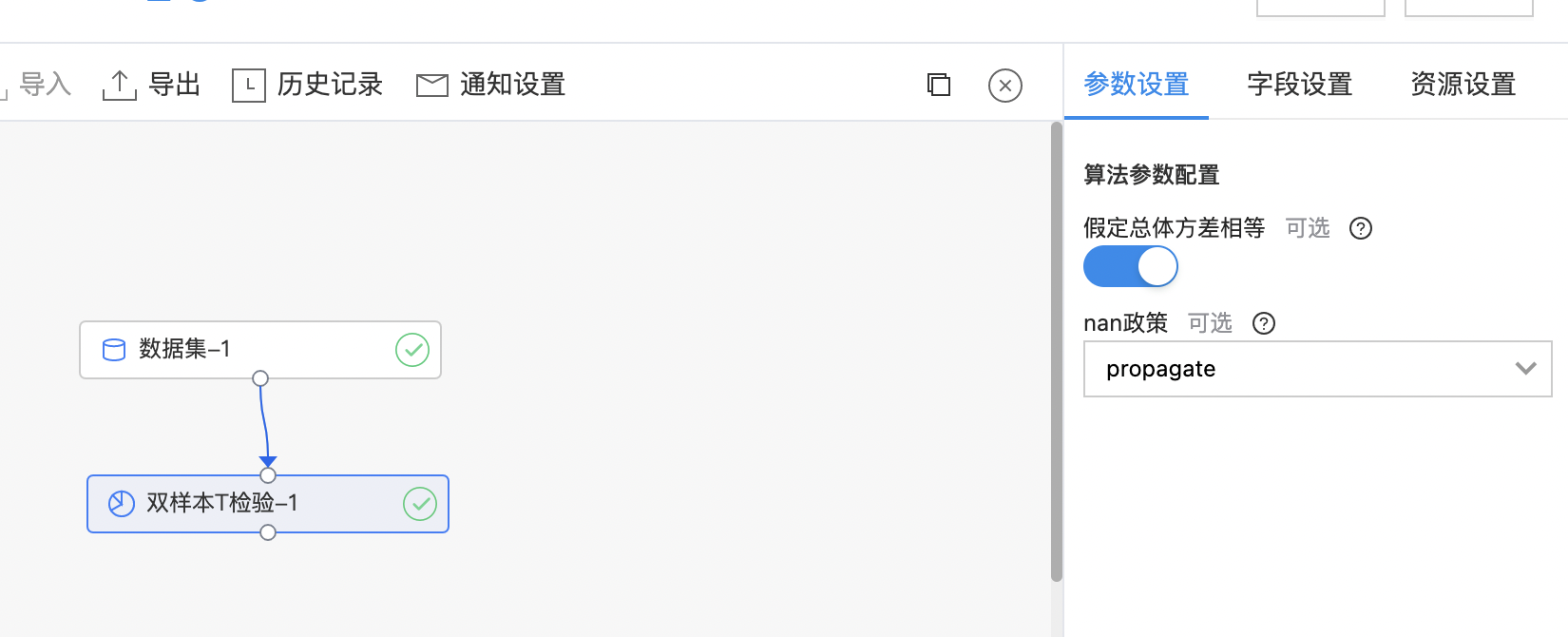
- 查看输出结果。
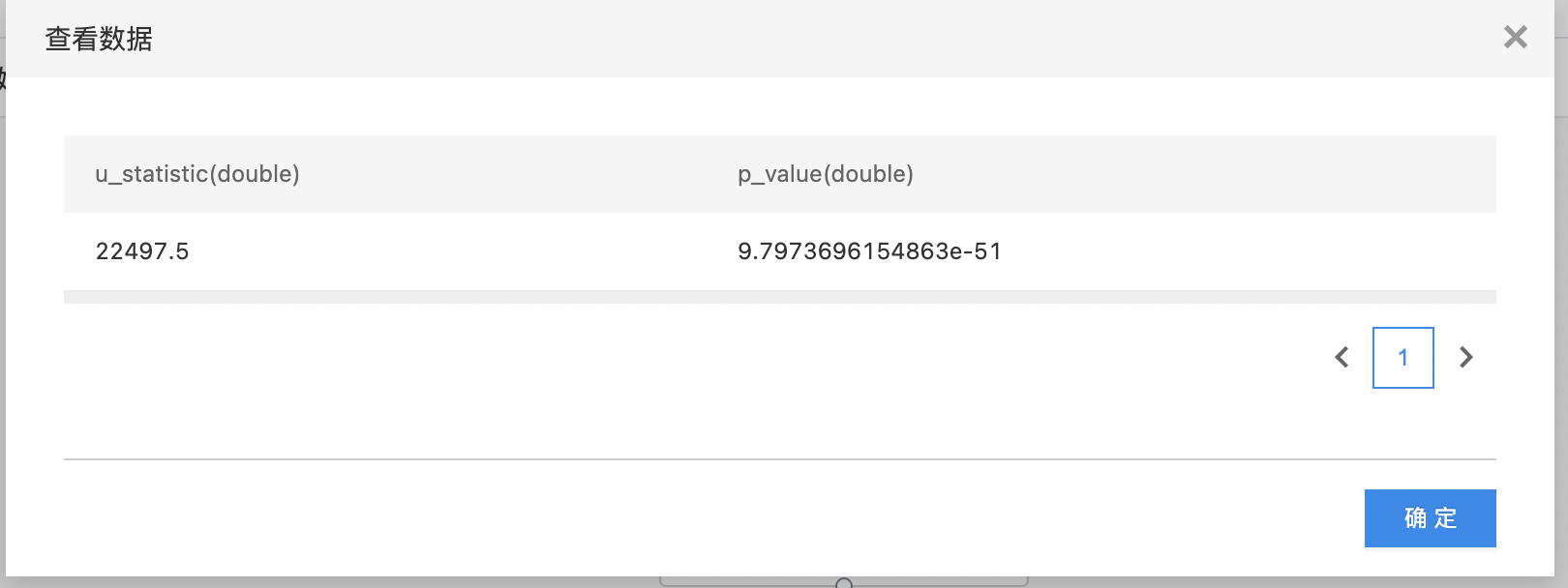
U检验
U 检验是一种用来评估两个独立的顺序数据样本是否来自同一个总体的非参数检验。系统中实现的为 Mann-Whitney U 检验(曼-惠特尼 U 检验),它假设两个样本分别来自除了总体均值以外完全相同的两个总体,目的是检验这两个总体的均值是否有显著的差别。
输入
- 输入是一个数据集。用户需要选择要做U检验的两列(必须为两列),选择的列需要是数值类型。
输出
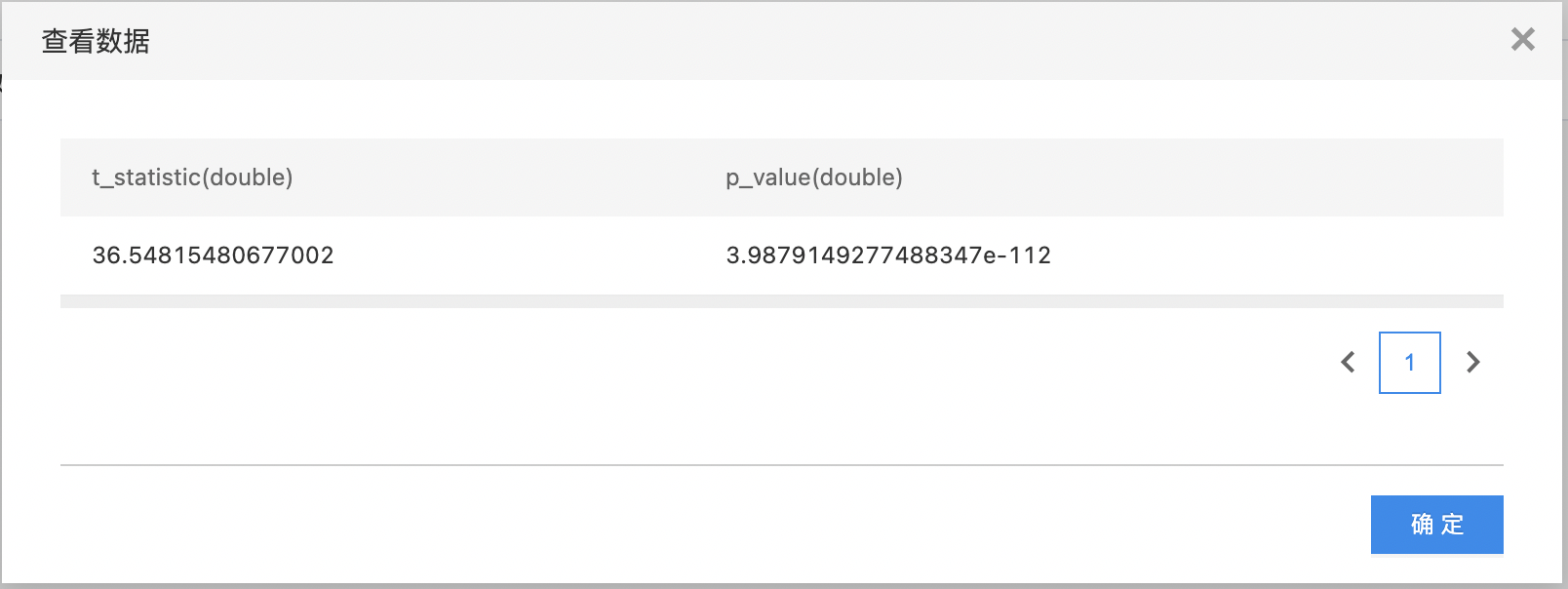
- 输出是一个结果数据集。包含两列:U值(u_statistic),置信度(p_value),列的类型是double。
算子参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 替代方式 | 是 | 替代假设方式: two-sided greater less |
two-sided |
| 连续性校正 | 否 | 是否考虑连续性校正 | 开启 |
字段参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 检验列 | 是 | 必须是两列,并且是数值类型。 | 无 |
使用示例
- 构建算子结构,配置参数,完成训练。
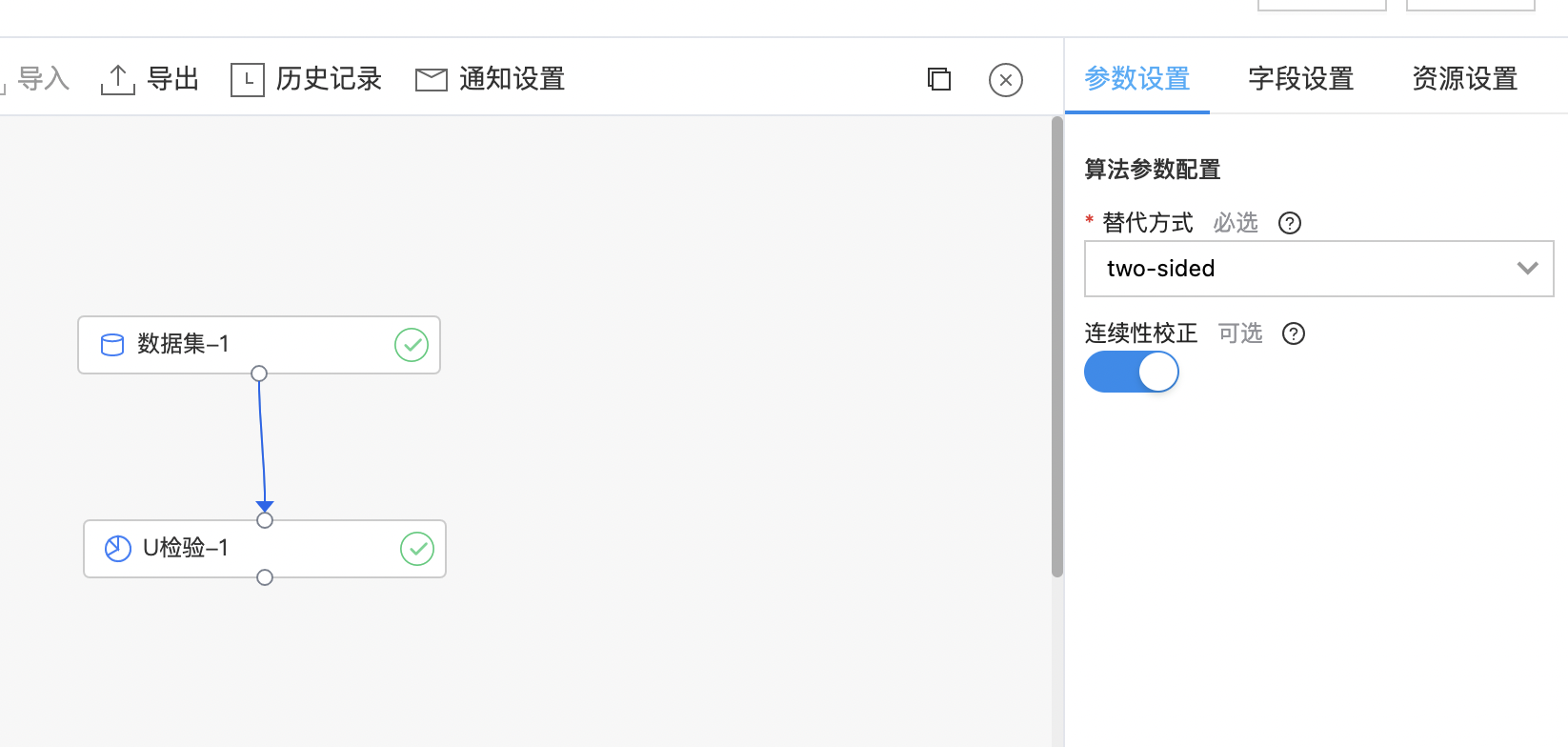
- 查看输出结果。
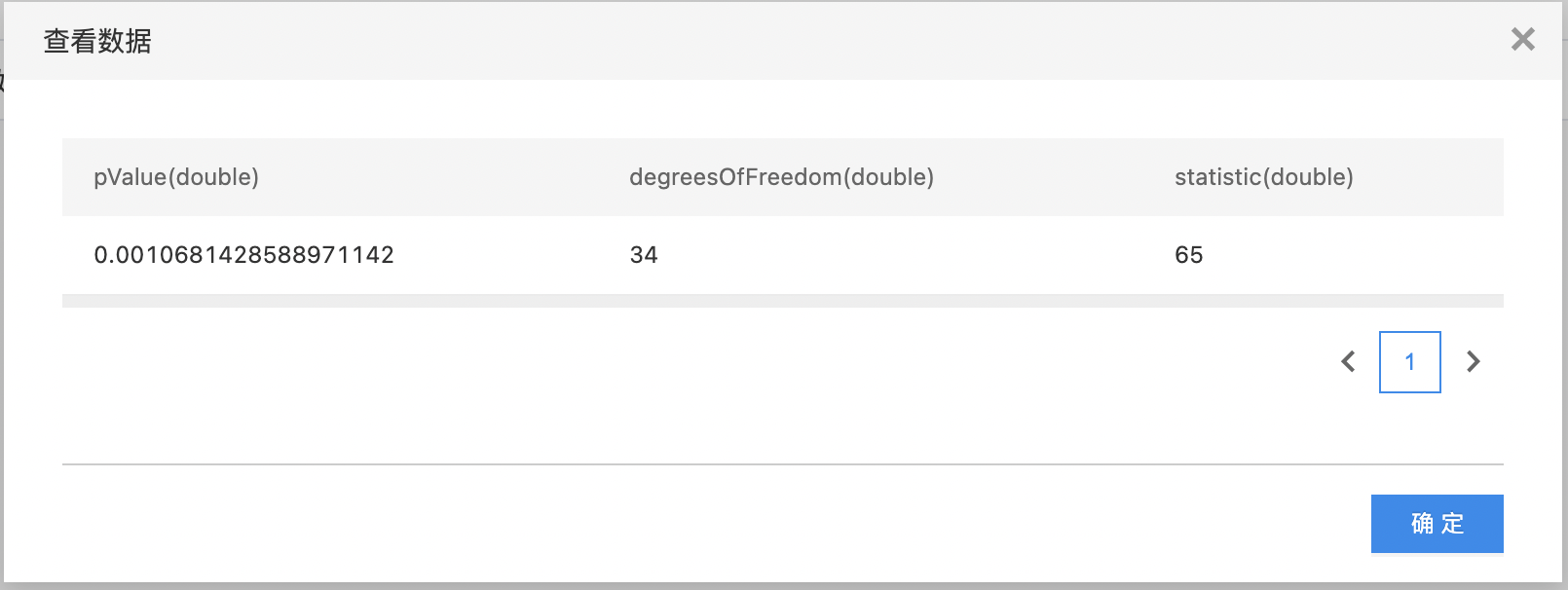
卡方拟合性检验
卡方拟合性检验用于检验单个多项分类名义型变量各分类间的实际观测次数与理论次数之间是否一致的问题,其中实际观测次数是根据样本数据得到的实计数,理论次数则是根据理论或经验得到的期望次数。 卡方拟合性检验的零假设是观测次数与理论次数之间无差异。
输入
- 输入是一个数据集。用户需要选择要做卡方拟合性检验的一列,选择的列需要是数值类型。
输出
- 输出是一个结果数据集。包含三列:卡方值,自由度,置信度,列的类型是double。
字段参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 检验列 | 是 | 选择一列检验列,必须是数值类行。 | 无 |
计算逻辑
卡方拟合性检验统计量:
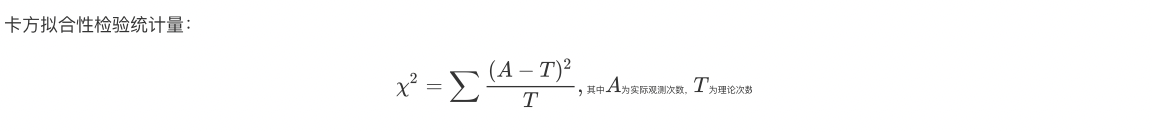
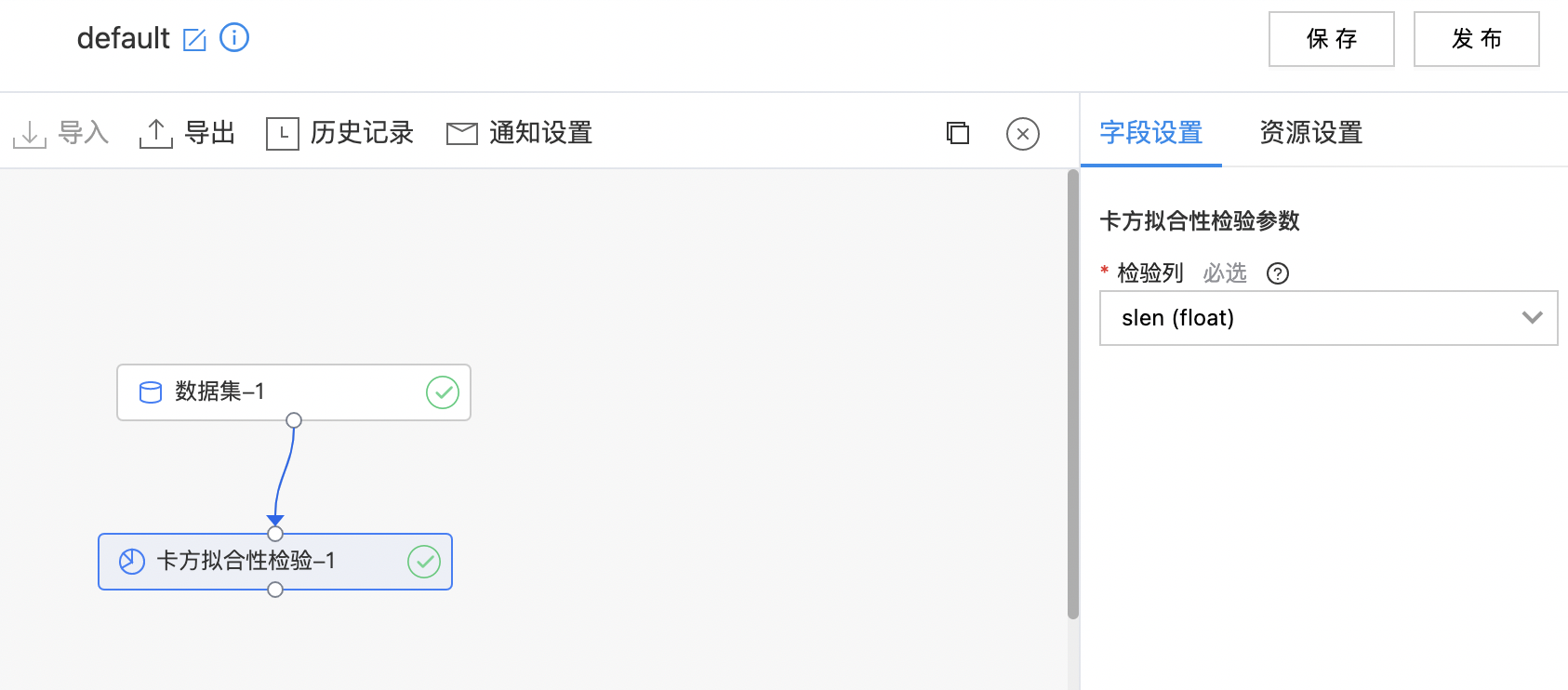
使用示例
- 构建算子结构,配置参数,完成训练。
- 查看输出结果。
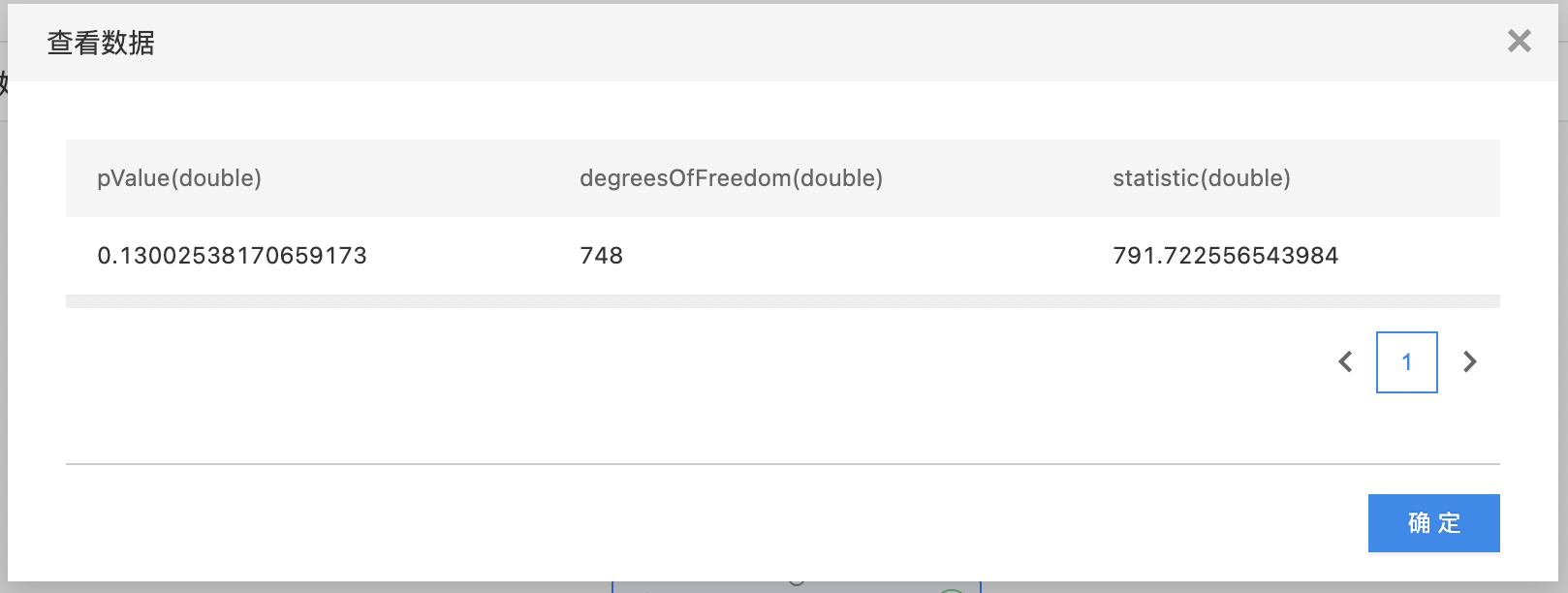
卡方独立性检验
卡方独立性检验用于检验两个或两个以上因素(各有两项或以上的分类)之间是否相互影响的问题。所谓独立,即无关联,互不影响,就意味着一个因素各个分类之间的比例关系,在另一个因素的各项分类下都是相同的。 卡方独立性检验的零假设是各因素之间相互独立。 卡方独立性检验统计量与卡方拟合性检验统计量计算公式一致,统称为卡方检验统计量。
输入
- 输入是一个数据集。用户需要选择要做卡方独立性检验的两列(必须是两列),选择的列需要是数值类型。
输出
- 输出是一个结果数据集。包含三列:卡方值,自由度,置信度,列的类型是double。
字段参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 检验列 | 是 | 必须是两列,并且是数值类型。 | 无 |
使用示例
- 构建算子结构,配置参数,完成训练。
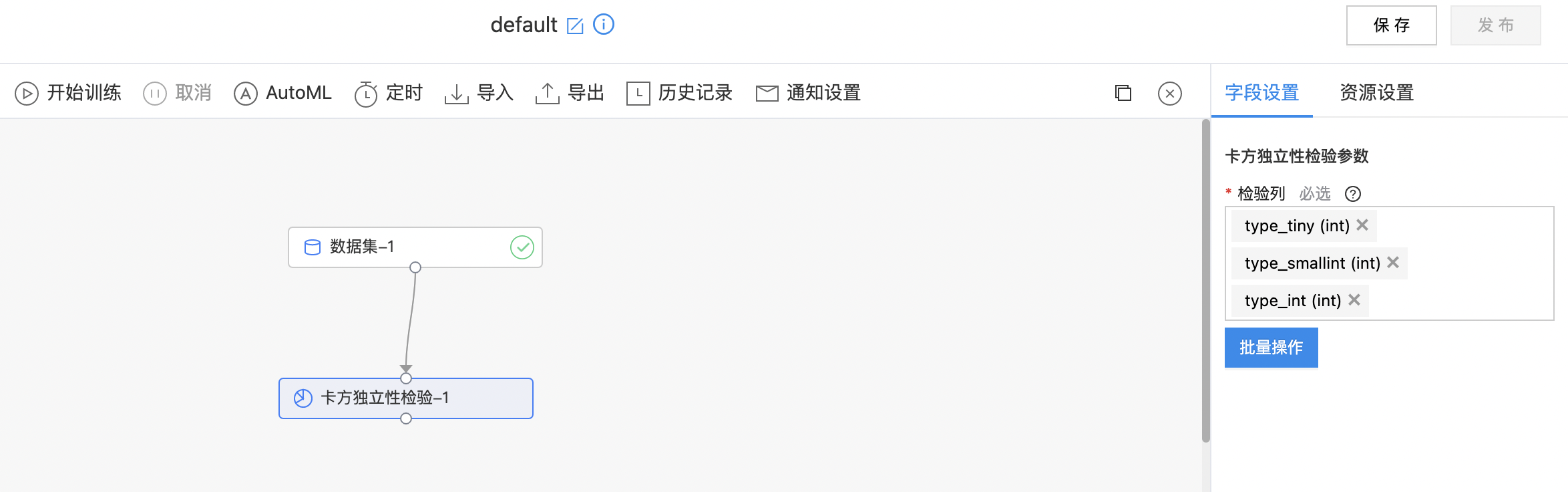
- 查看训练结果。
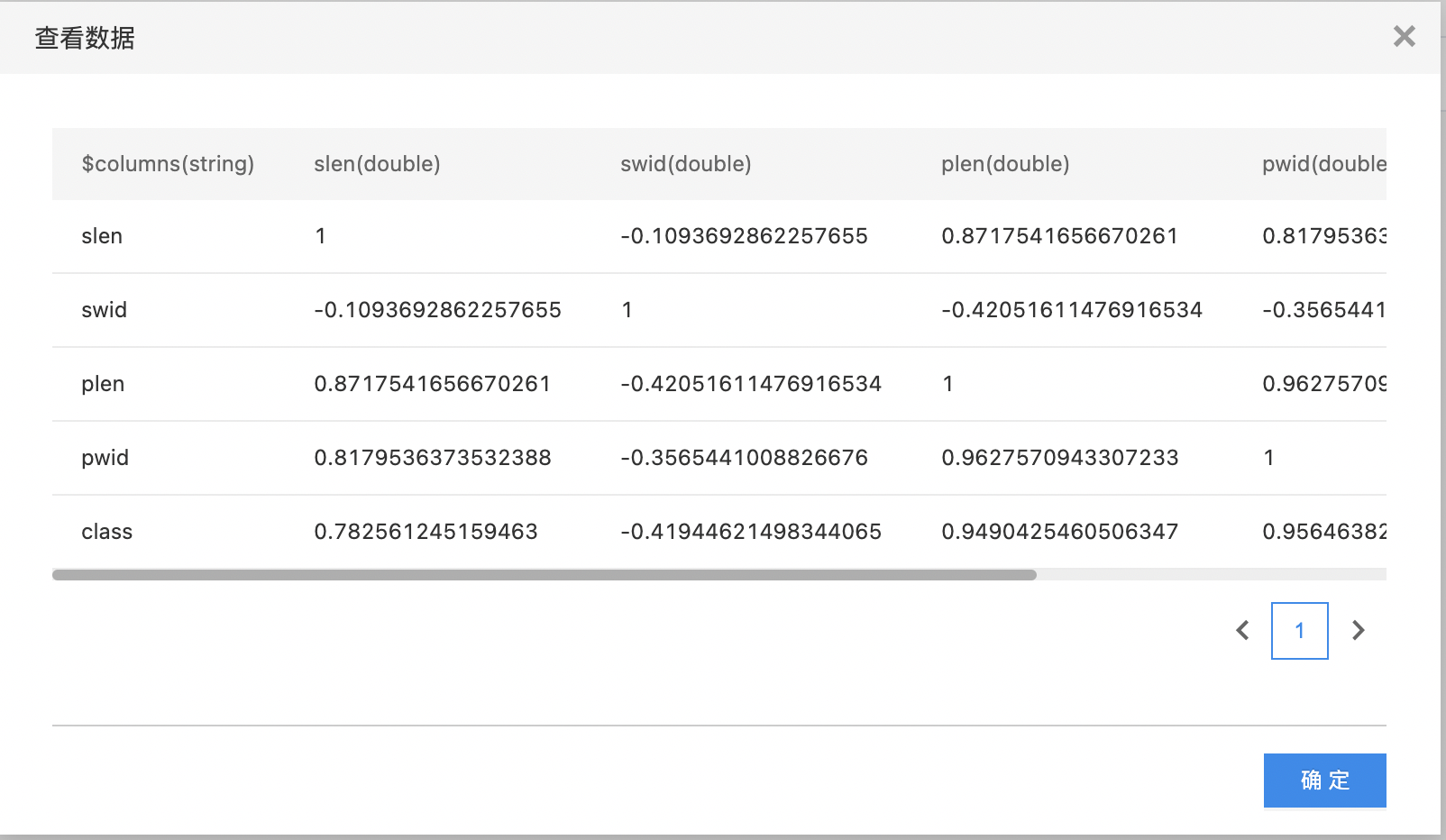
相关系数矩阵
相关系数矩阵是由矩阵各列对应的变量间的相关系数构成的。也就是说,相关系数矩阵的第 i 行第 j 列元素是矩阵第 i 列和第 j 列对应变量的相关系数。组件支持皮尔森(pearson)相关系数和斯皮尔曼(spearman)相关系数。
输入
- 输入是一个数据集,选择任意几列数据,所有选择的列都必须是数字类型。
输出
- 输出数据之间的相关系数矩阵。
字段参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 计算方法 | 是 | 相关系数的计算方法: pearson spearman |
无 |
使用示例
- 构建算子结构,配置参数,完成训练。
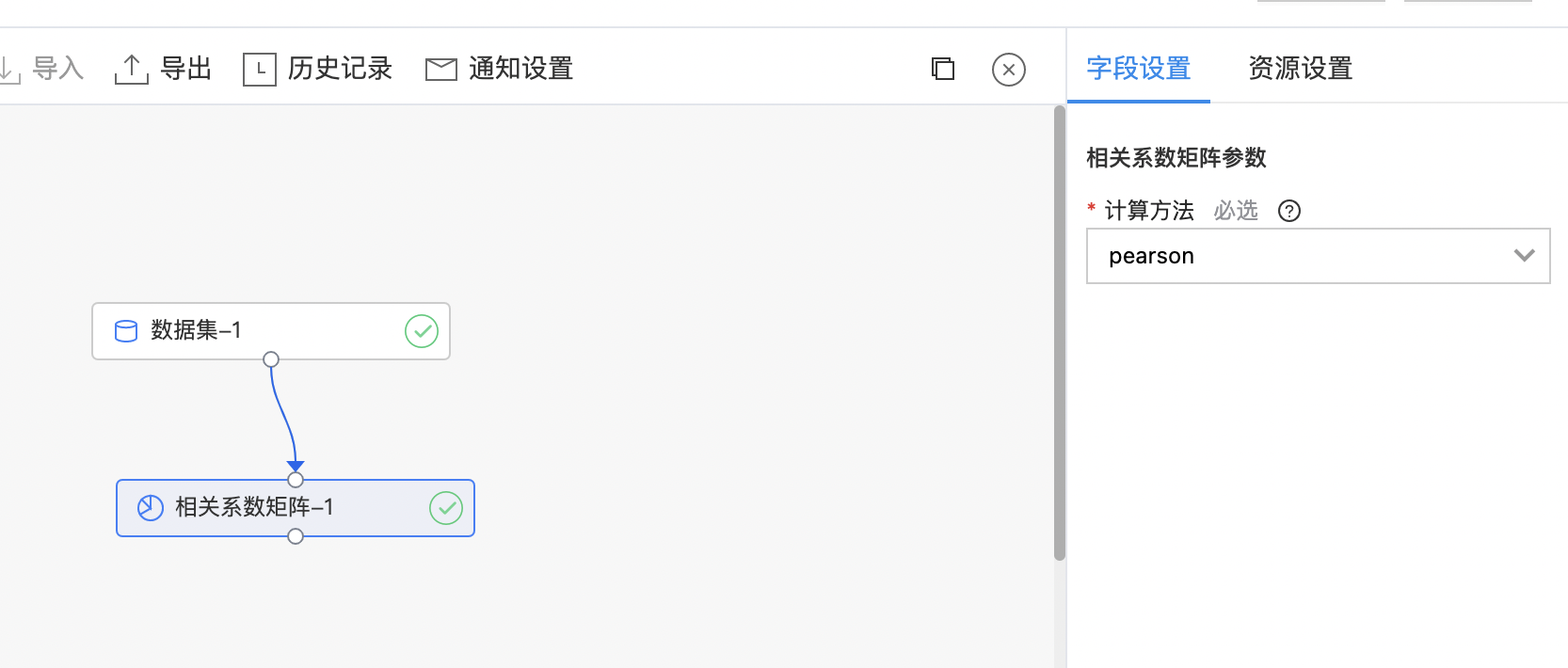
- 查看训练结果。
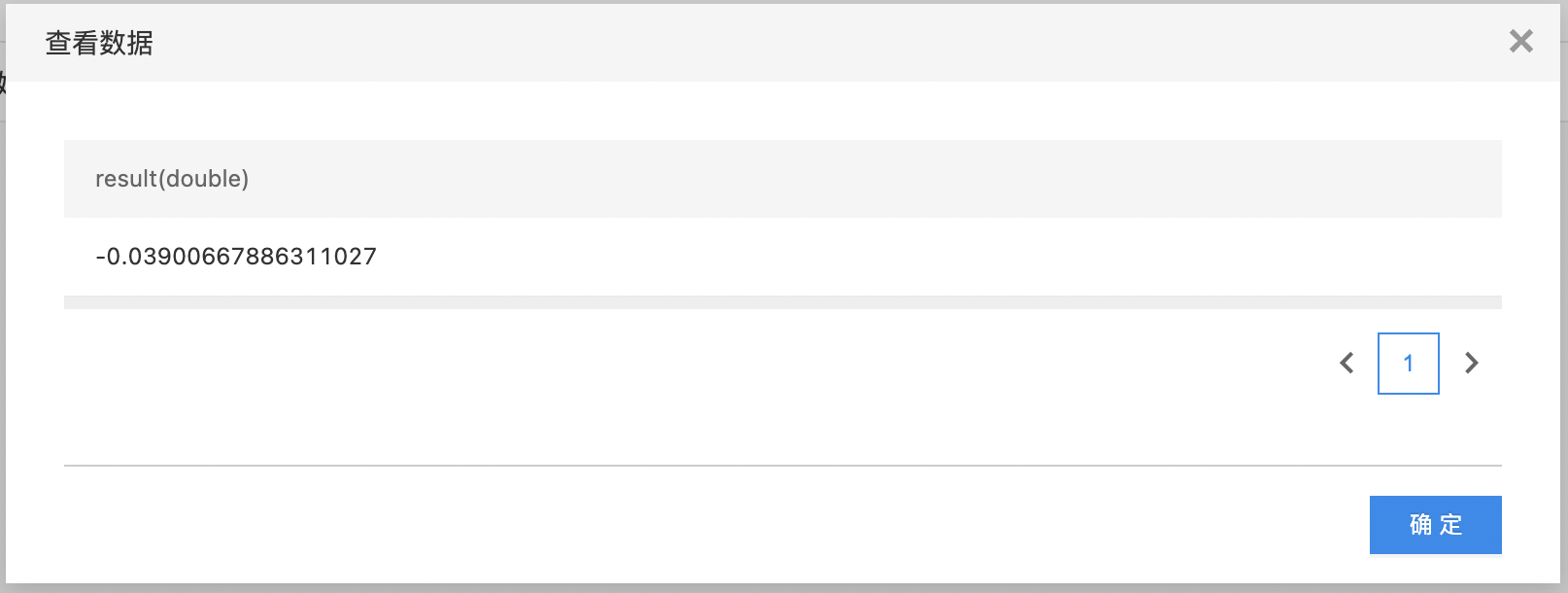
协方差
协方差在概率论和统计学中用于衡量两个变量的总体误差。而方差是协方差的一种特殊情况,即当两个变量是相同的情况。 如果协方差为正,说明两个变量同向变化,协方差越大说明同向程度越高;如果协方差为负,说明两个变量反向变化,协方差越小说明反向程度越高。
输入
- 输入是一个数据集。用户需要选择要计算协方差的两列(必须是两列),选择的列需要是数值类型。
输出
- 输出协方差计算结果。
字段参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 选择两列数据 | 是 | 必须是数值类型。 | 无 |
计算逻辑

使用示例
- 构建算子结构,配置参数,完成训练。
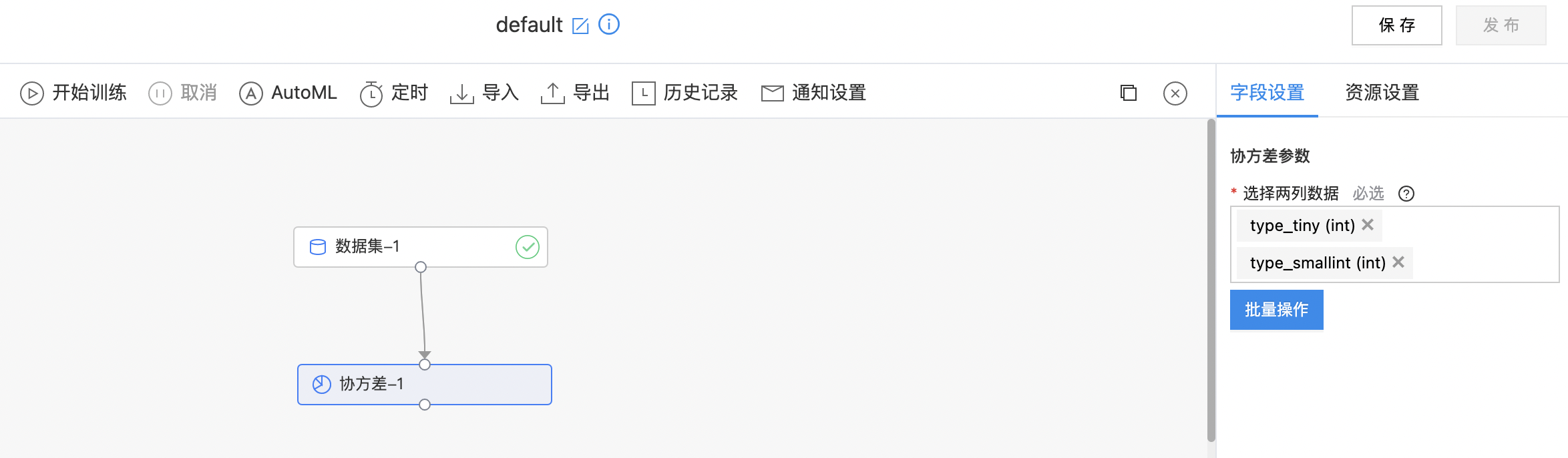
- 查看输出数据。
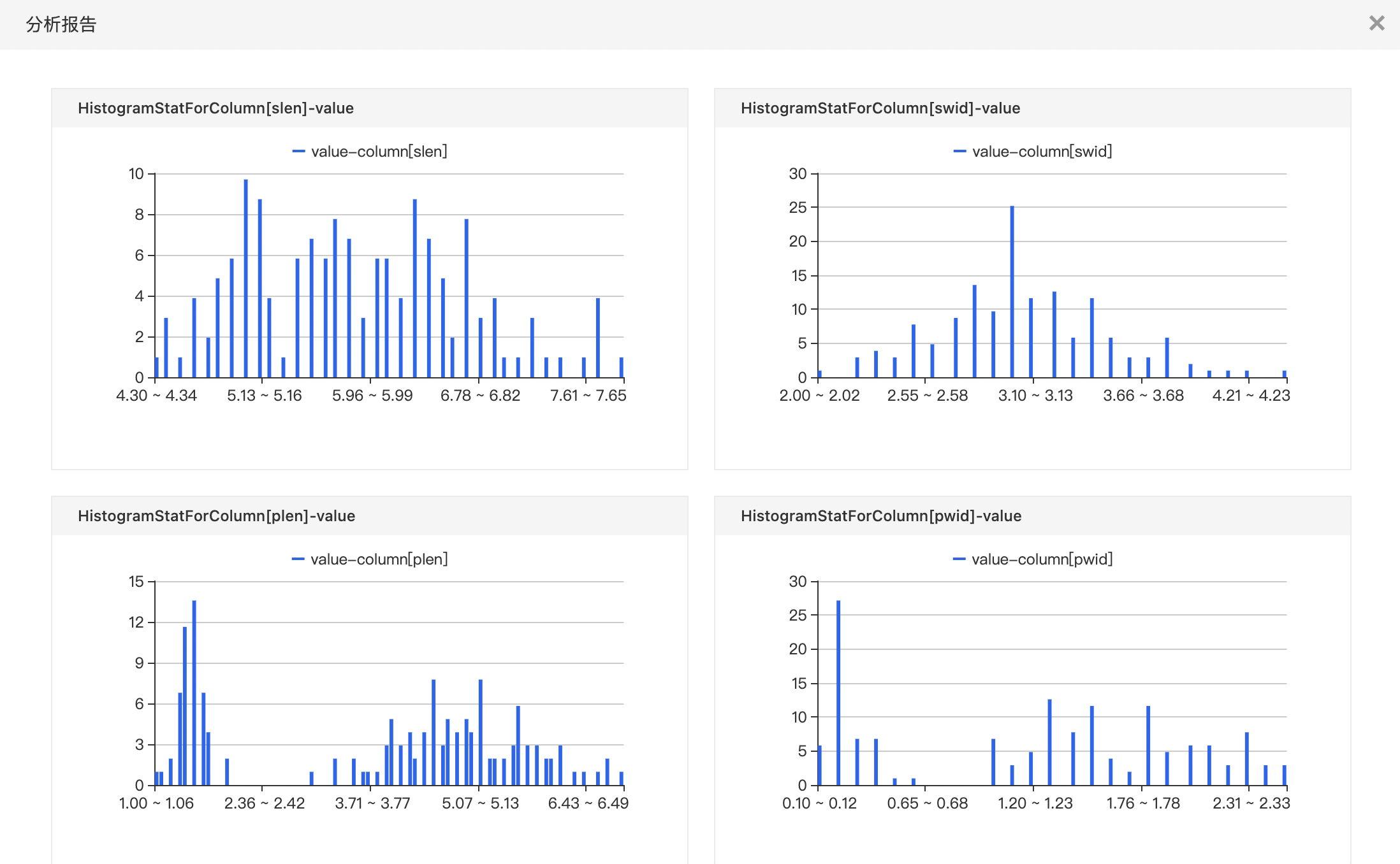
直方图
在统计学中,直方图是一种对数据分布情况的图形表示,是一种二维统计图表,它的两个坐标分别是统计样本和该样本对应的某个属性的度量。
输入
- 输入是一个数据集,选择任意几列需要绘制直方图的数据,数据必须是数字类型。
输出
-
所有选择列的直方图数据
- 格式: start0,end0,count0;start1,end1,count1;.....;start(n-1),end(n-1),count(n-1)
- start,end: 区间的最小值和最大值
- count:区间的数据个数
- 右键查看分析报告展示所选数据的直方图。
字段参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 字段选择 | 是 | 需要是数值类型。 | 无 |
| 区间个数 | 是 | 配置区间个数,范围:[2, inf)。 | 100 |
使用示例
- 构建算子结构,配置参数,完成训练。
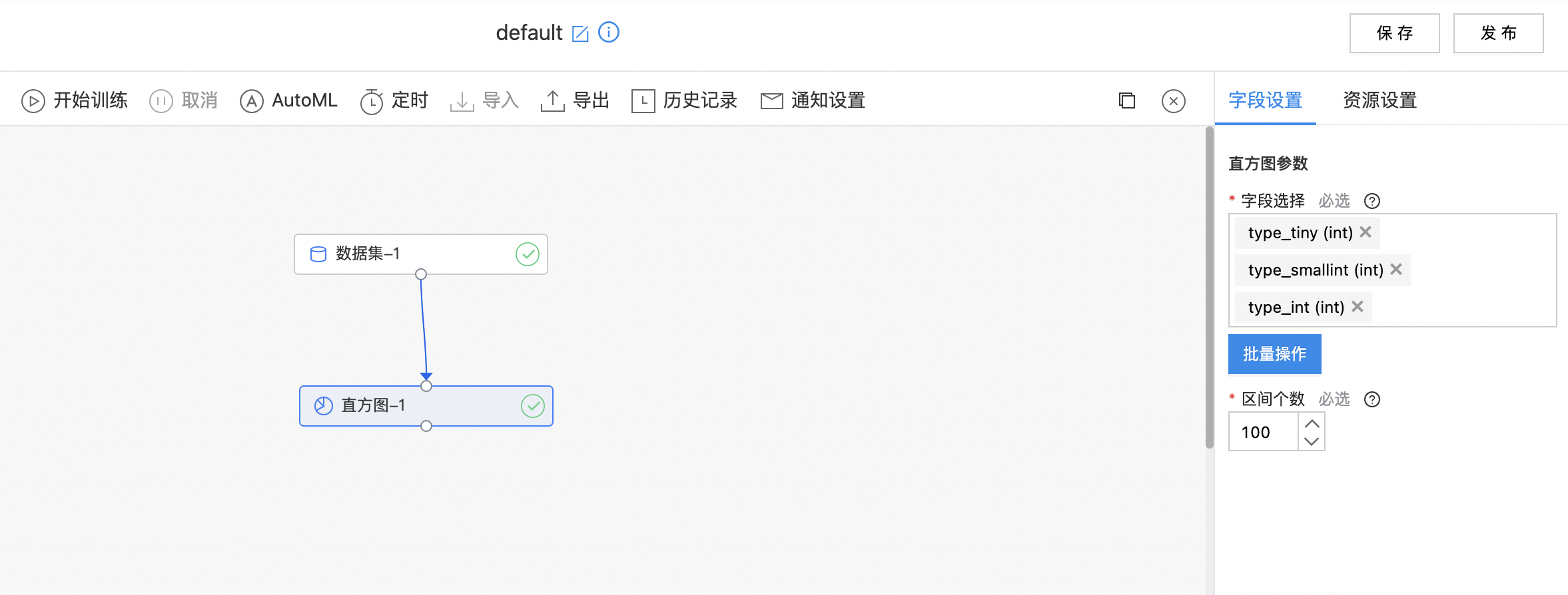
- 查看输出数据。
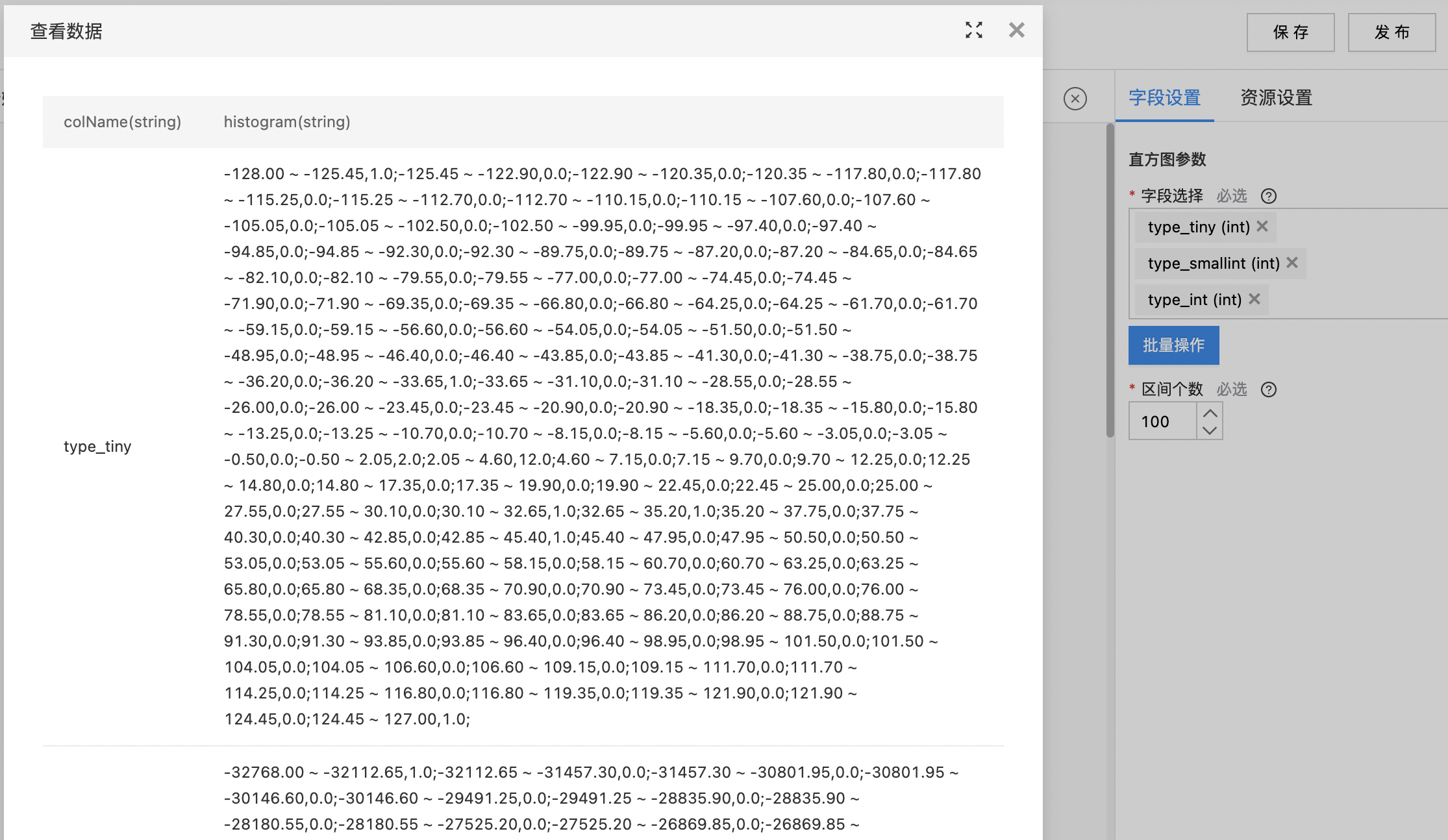
- 查看分析报告结果。
洛伦兹曲线
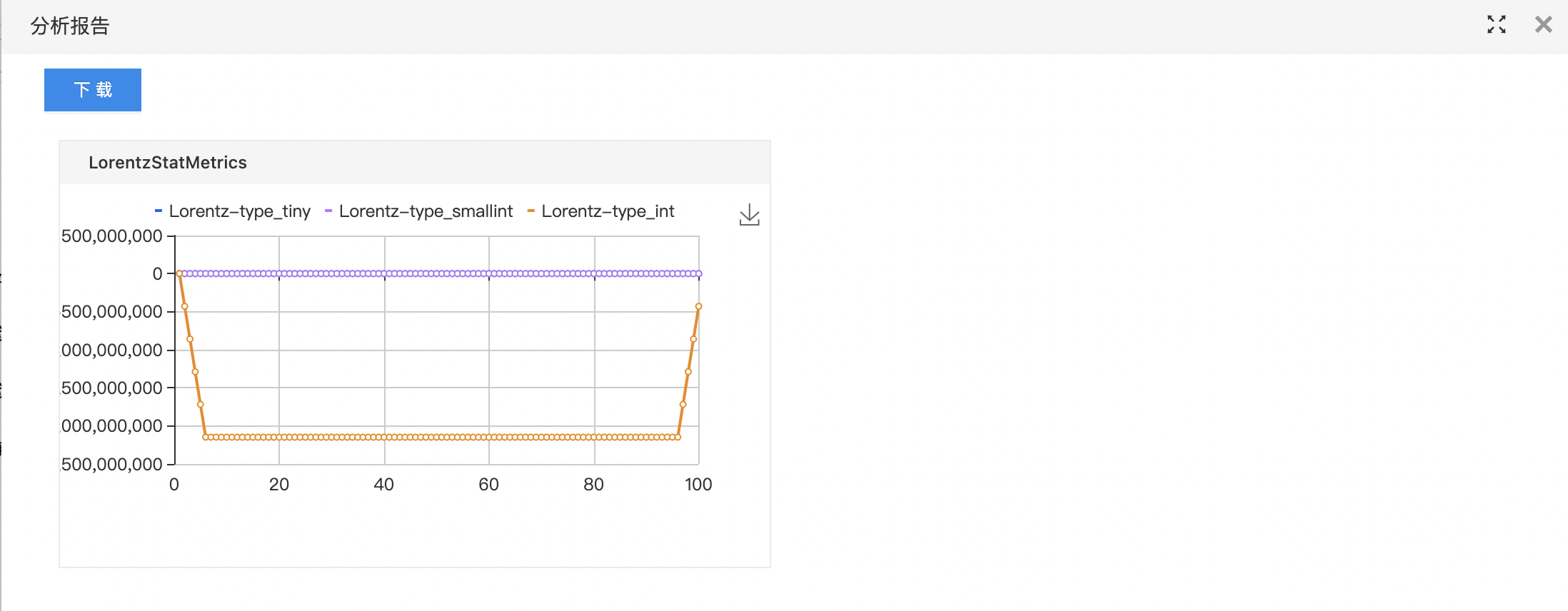
洛伦兹曲线研究的是国民收入在国民之间的分配问题,它用以比较和分析一个国家在不同时代或者不同国家在同一时代的财富不平等状况。 洛伦兹曲线的横轴表示人口(按收入由低到高分组)的累积百分比,纵轴表示收入的累积百分比。 洛伦兹曲线的弯曲程度有重要意义。一般来讲,它反映了收入分配的不平等程度。弯曲程度越大,收入分配越不平等,反之亦然。
输入
- 输入是一个数据集,选择任意几列需要绘制洛伦兹曲线的数据,配置区间个数。
输出
- 输出洛伦兹曲线对应值与绘制图标。
字段参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 字段选择 | 是 | 需要是数值类型。 | 无 |
| 区间个数 | 是 | 配置区间个数,范围:[2, inf)。 | 100 |
使用示例
- 构建算子结构,配置参数,完成训练。
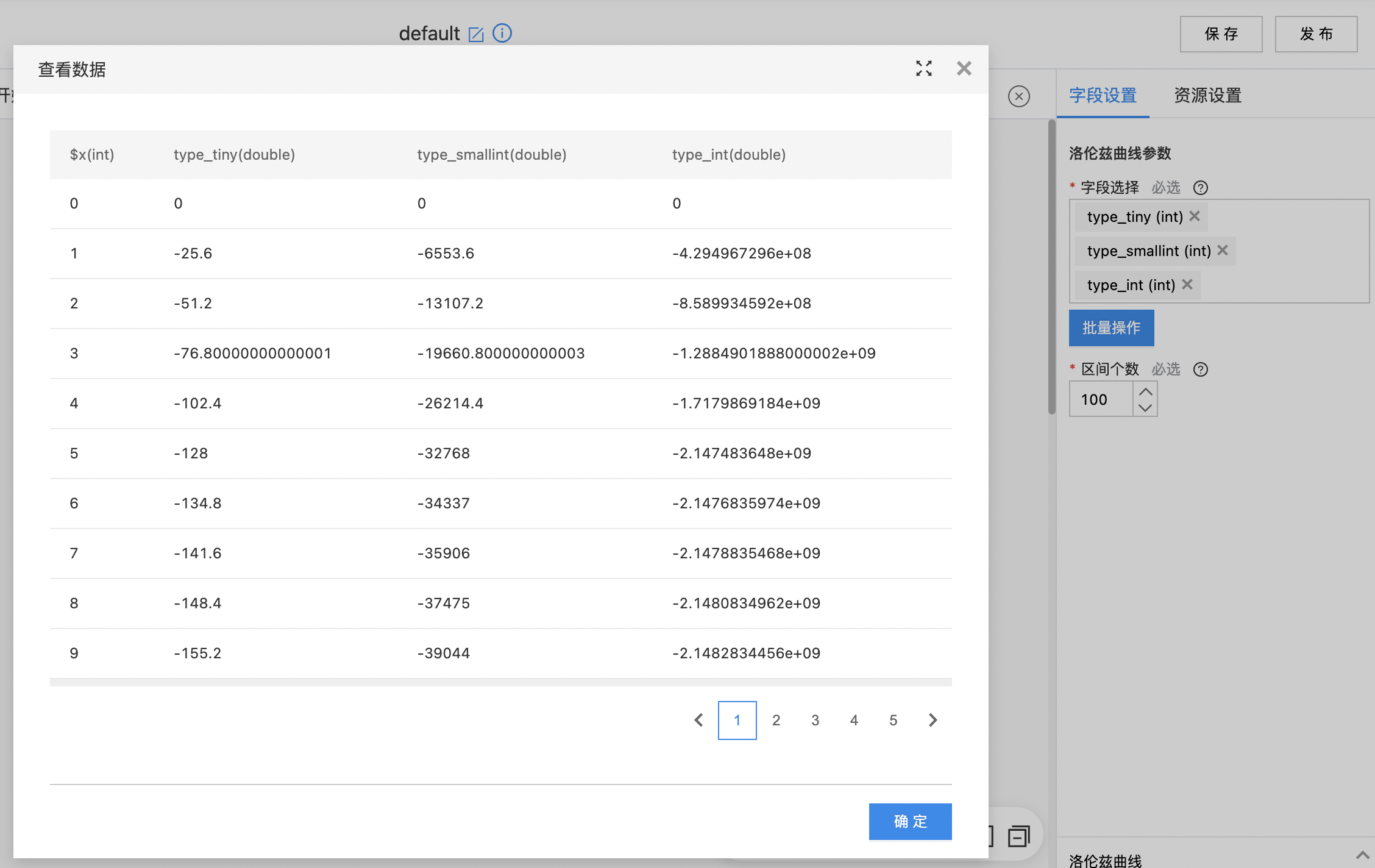
- 查看输出数据。
- 查看分析报告。
正态检验
利用观测数据判断总体是否服从正态分布的检验称为正态检验,它是统计判决中重要的一种特殊的拟合优度假设检验。常用的正态检验方法有正态概率纸、柯尔莫可洛夫-斯米洛夫检验等。
输入
- 输入是一个数据集,需要制定进行正态检验的数据列,列类型是数值类型。
输出
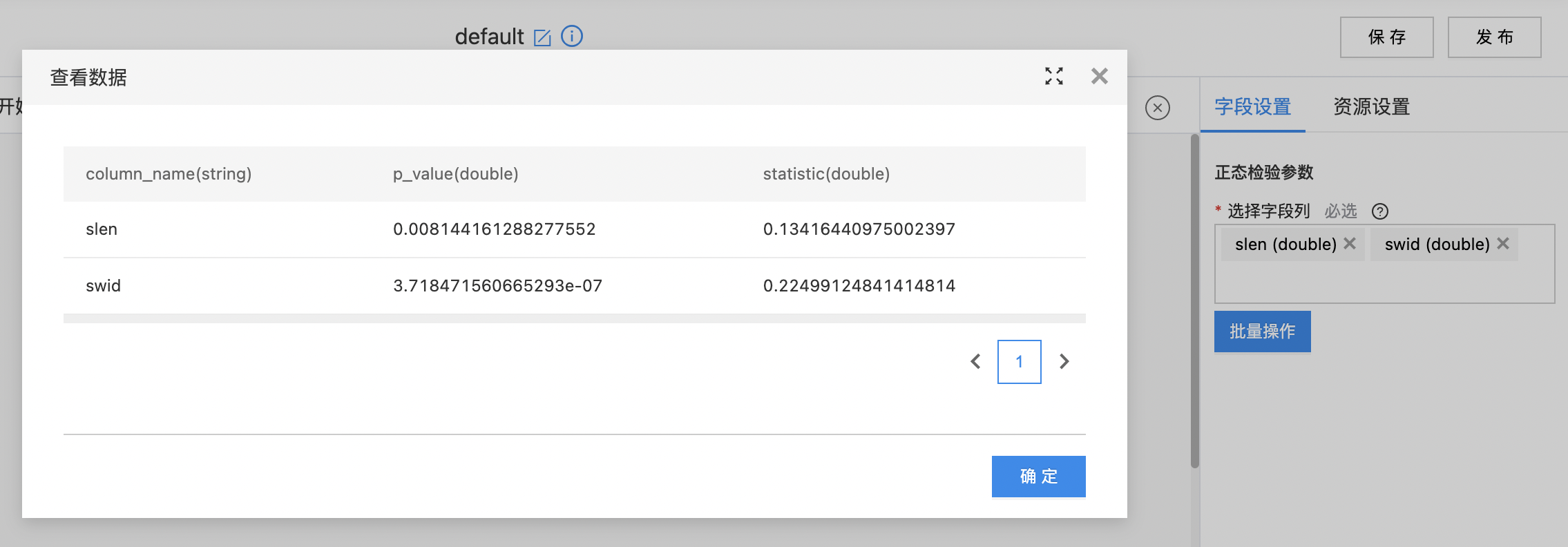
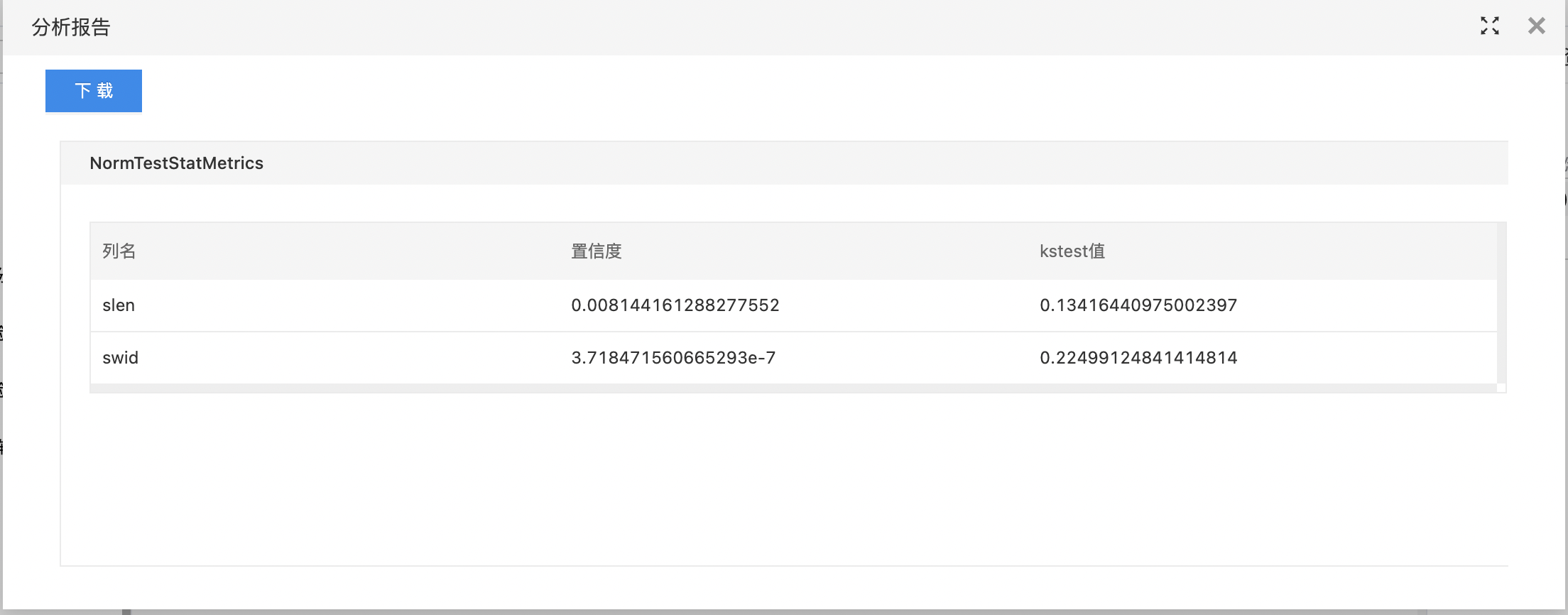
- 输出正态检验的置信度和kstest值。
字段参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 选择字段列 | 是 | 需要是数值类型。 | 无 |
使用示例
- 构建算子结构,配置参数,完成训练。
- 查看输出结果。
- 查看分析报告。
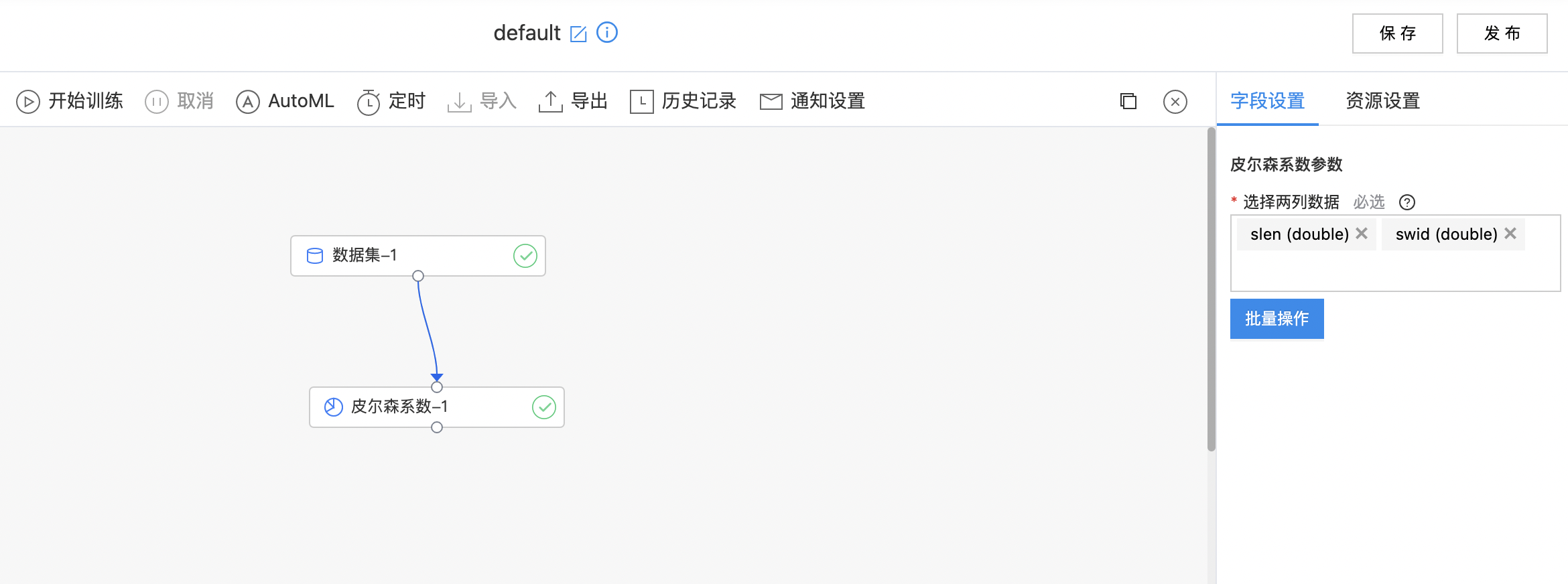
皮尔森系数
柯尔莫可洛夫-斯米洛夫检验基于累计分布函数,用以检验两个经验分布是否不同或一个经验分布与另一个理想分布是否不同。 K-S检验的基本思路是:先将理论累积频率分布与观测的经验累积频率分布加以比较,求出它们最大的偏离值,然后在给定的显著性水平上检验这种偏离值是否是偶然出现的。
输入
- 输入是一个数据集,需要选择计算皮尔森系数的两列数据,必须是数值类型。
输出
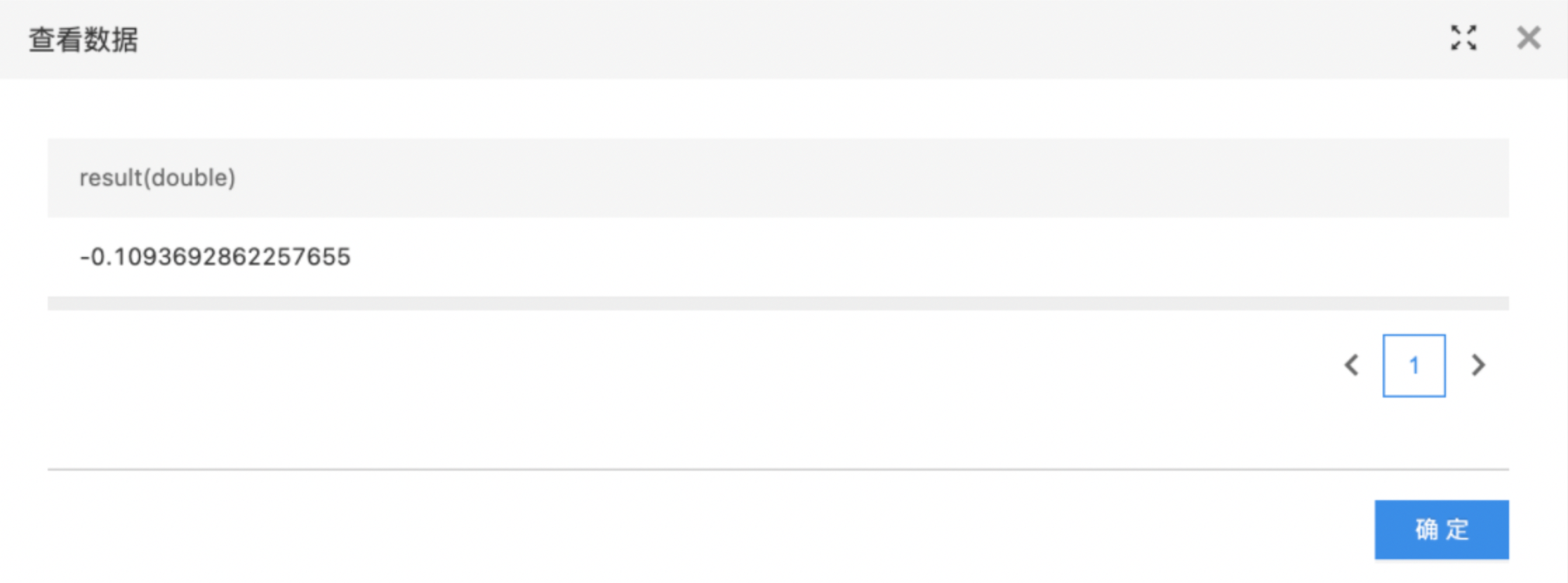
- 输出是计算后的皮尔森系数结果。
字段参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 选择两列数据 | 是 | 必须是数值类型。 | 无 |
计算逻辑
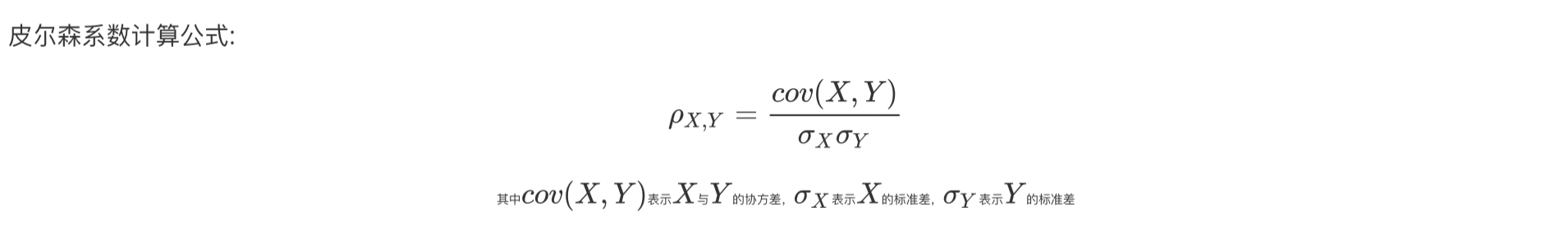
使用示例
- 构建算子结构,配置参数,完成训练。
- 输出皮尔森系数计算结果。
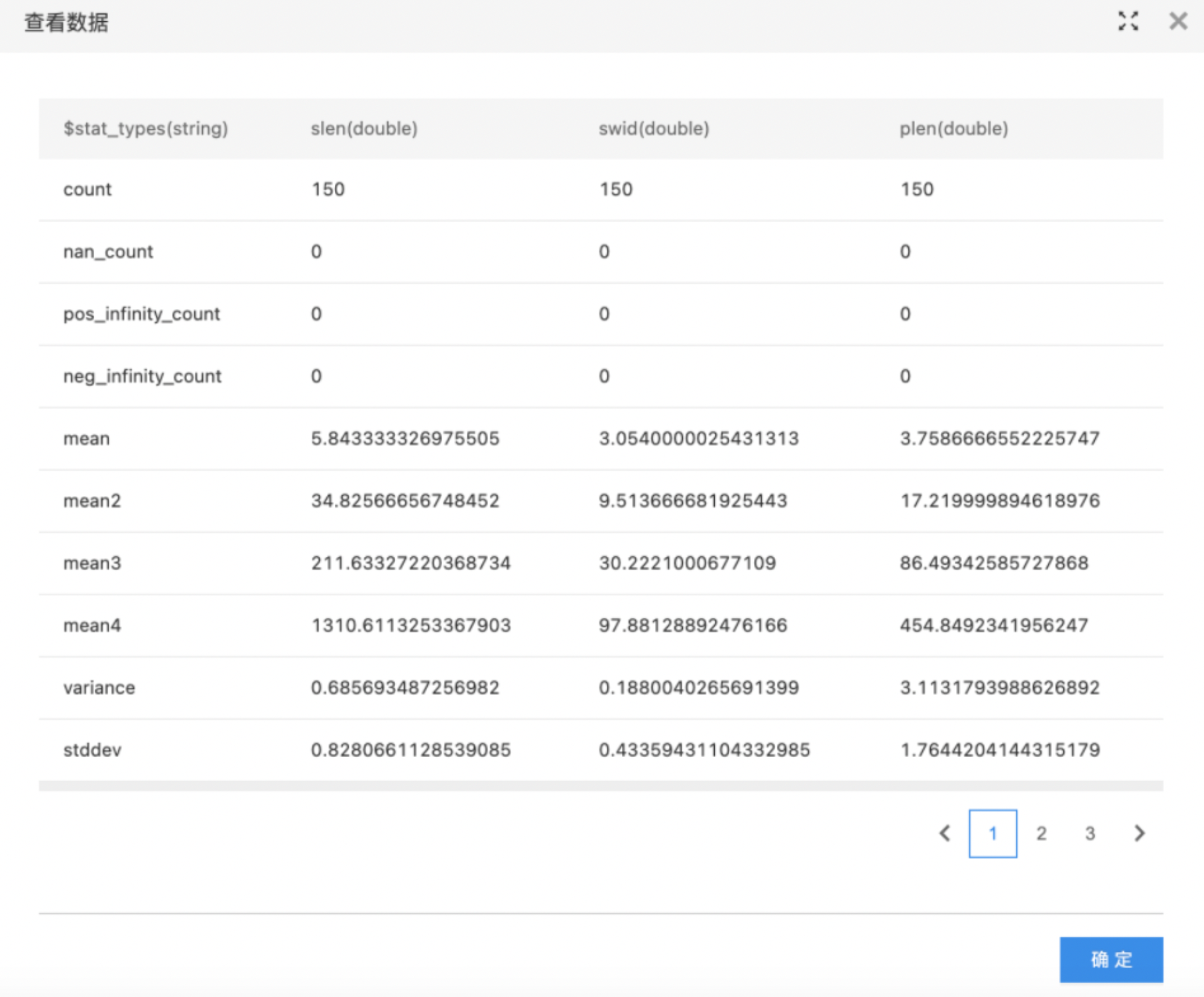
全表统计
统计各种指标信息,包括总数、NAN、正无穷数量、负无穷数量、标准误差、偏度、峰度、二阶矩、三阶矩、四阶矩、二阶中心距、三阶中心距、四阶中心距、总和等。
输入
- 输入是一个数据集,选择需要进行统计的数据列,仅会统计数值类型的列。
输出
- 输出已选择数据列的统计结果。
字段参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 选择需要统计的列 | 是 | 仅会统计数值类型的列。 | 无 |
使用示例
- 构建算子结构,配置参数,完成训练。
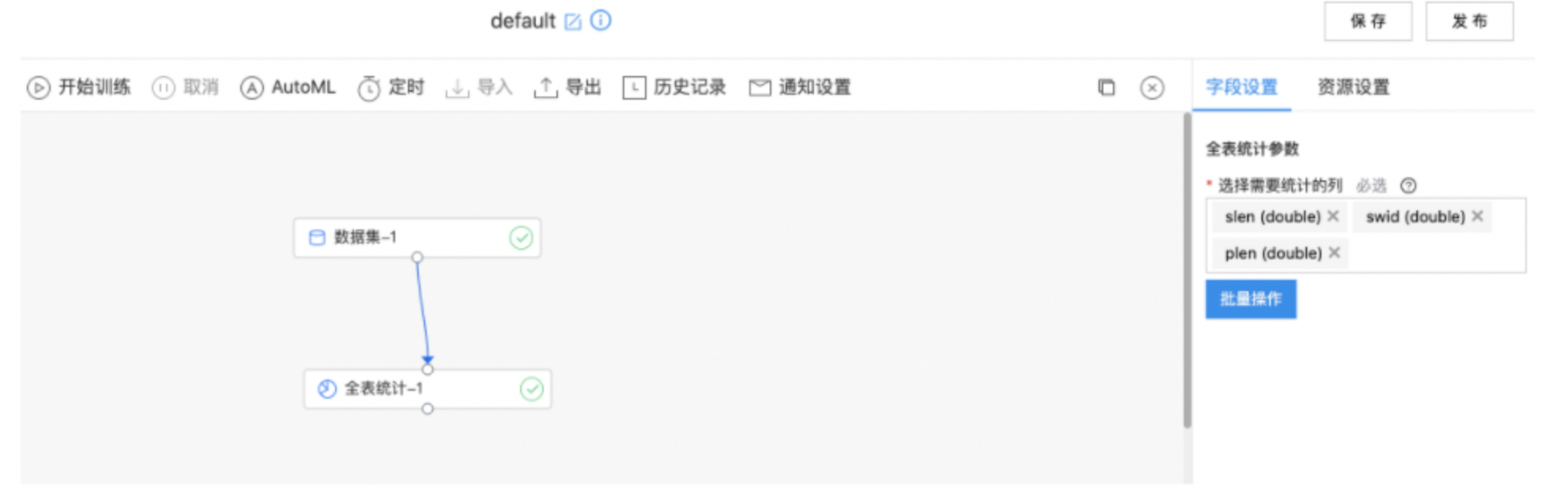
- 右键“全表统计"组件,选择“查看数据” > "输出数据集",查看输出结果。