用BML实现表格预测
目录
1.表格预测简介
2.平台入口
3.准备数据
3.1 数据要求
3.2 创建及导入数据集
4.训练模型
4.1AutoML模式
4.2专家模式
5.模型分析和调优
6.部署模型
6.1公有云部署
用BML实现表格预测:以空气质量预测为例
表格预测简介
亲爱的开发者您好,欢迎使用百度BML全功能AI开发平台开启您的AI开发之旅!
定制表格数据预测模型,旨在帮助用户通过机器学习技术从表格化数据中发现潜在规律,从而创建机器学习模型,并基于机器学习模型处理新的数据,为业务应用生成预测结果。根据预测数据的不同,可以分为如下几种类型:
- 回归:目标列是连续的实数范围,或者属于某一段连续的实数区间。如在销量预测场景中,销量值可能是某个取值范围内的任意值,解决该问题的模型属于回归模型。
- 二分类:目标列是离散值,且只有两种可能的取值。如在精准营销场景中预测一个用户是否为潜在购买用户,其目标列仅存在“True”和“False”两种取值,解决该问题的模型属于二分类模型。
- 多分类:目标列是离散值,并具有有限的可能取值。如在用户分类场景中,根据用户的历史消费数据,将用户划分到不同消费偏好的类别中,解决该问题的模型属于多分类模型。
其应用场景包括:
- 精准营销:从客户消费记录中挖掘客户群的共有特征,分析出客户的购物偏好,从而实现广告的精准投放。
- 信用评分:金融公司分析客户的历史行为数据,建立用户信用模型,从而确定贷款额度等。
- 价格预测:从历史数据中发现商品的变化规律以及影响价格的因素,从而为未来的商业行为提供支持。
- 客户流失预测:根据客户历史数据获得数据挖掘模型,从而生成客户流失预测列表,为市场营销策略提供有价值的业务洞察力。
下文中将以空气质量预测为例,分步骤向您详细介绍如何使用百度BML全功能AI开发平台开发您自己的表格预测模型。
空气质量预测任务:
现代社会科技进步,人们的生活质量逐步提高,但伴随着各类工业和科技的发展,环境问题凸显,最初人们粗放式的经济发展方式在一定程度上对环境造成不可逆转的破坏。在各种环境污染问题,空气污染问题又是如今人们关注的重中之重。北京是我国首都,同时也是我国空气污染较为严重的几个北方城市之一,因此关注北京市空气污染情况是我国观测空气污染情况的重要关注对象之一。
平台入口
BML全功能AI开发平台为企业及个人开发者提供机器学习和深度学习一站式AI开发服务,并提供高性价比的算力资源,助力企业快速构建高精度AI应用,进入官方网站点击【立即使用】。
准备数据
准备数据是AI模型开发的关键一环,训练数据的质量决定了训练所得模型效果可达到的上限。
本文采用北京2010.1.1至2014.12.31之间的空气污染数据作为示例,数据集链接:空气污染数据。
下面来介绍数据规范与相关操作步骤。
数据要求
数据文件格式要求如下:
- 目前仅支持CSV格式的数据文件。
- 一次仅能上传一个文件,可以是一个CSV文件或由多个CSV文件压缩成的zip包。
- 单个上传文件大小不能超过5GB。
- 一个数据集包含的总文件大小不能超过20GB。
数据内容要求如下:
- 当数据文件包含列名时,列名称可以包含字母、数字和下划线(_),但不能以下划线开头。
- 文件内容以换行符(即字符“\n”,或称为LF)分隔各行,行内容以英文逗号(即字符“,”)分隔各列必须包含要预测的值即目标列,且目标列的数据类型会决定模型的类型。
- 文件中文本列取值长度不能超过4096个字符。
- 必须至少包含两列,且不得超过1000列。
- 数据集的总行数不能超过1000万行。
- zip包中的多个CSV文件必须使用相同的编码格式,都包含列名或都不包含列名;且列的顺序必须保持一致。
- 在扩充数据集时,新导入数据文件的首行与数据集的列名相同时,将被视为列名,否则将被视作数据。
创建及导入数据集
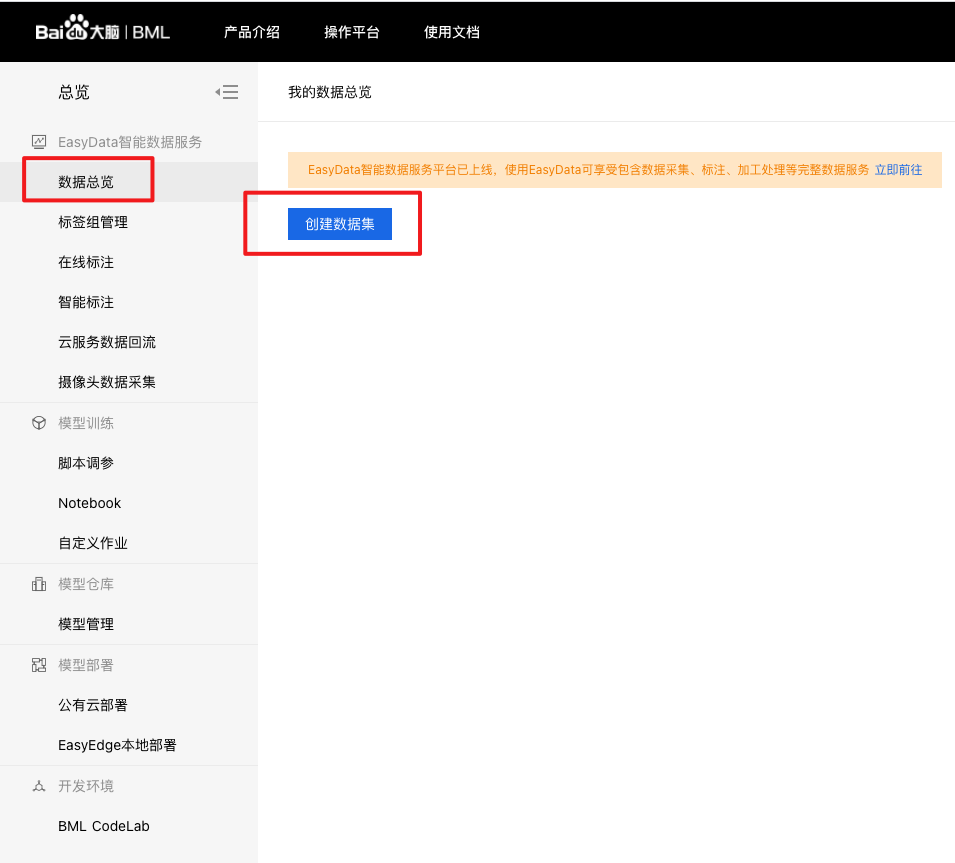
1、在官网界面点击【数据总览】,进入数据集操作界面,点击【创建数据集】。
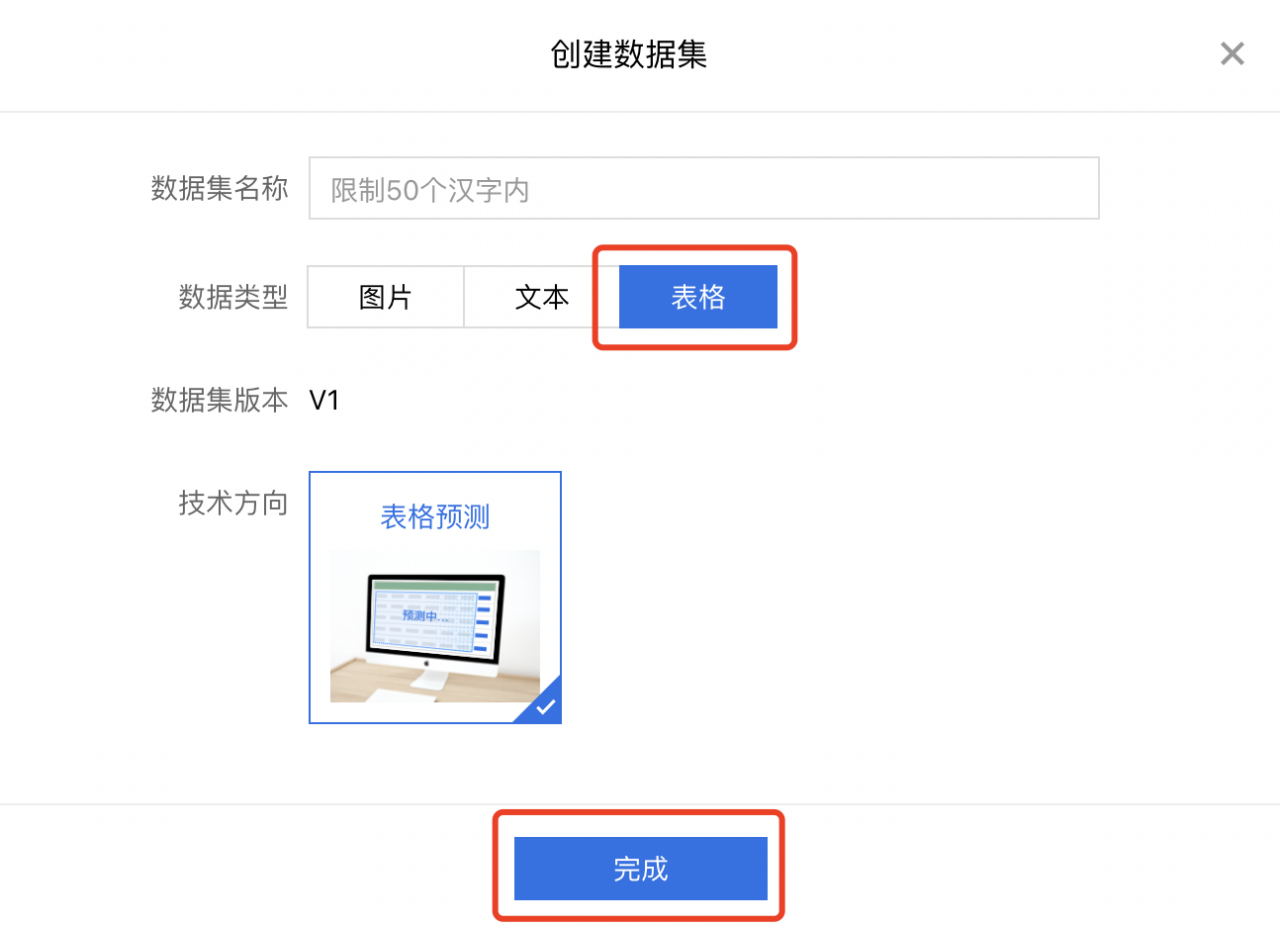
2、点击数据类型中的【表格】,输入数据集名称,点击【完成】结束创建。
完成创建后,可以在数据集列表中查看新建的数据集。系统默认生成V1版本,当前数据内容为空,可以通过导入的方式向其中添加数据。
3、数据集创建完成后,可以在数据总览界面看到刚才创建好的数据集ID,点击【导入】,将自己要训练的数据集导入。

在导入方式的下拉菜单中选择【上传CSV文件】或【上传压缩包】,前者支持数据预览,后者由多个CSV文件组成,不支持预览。
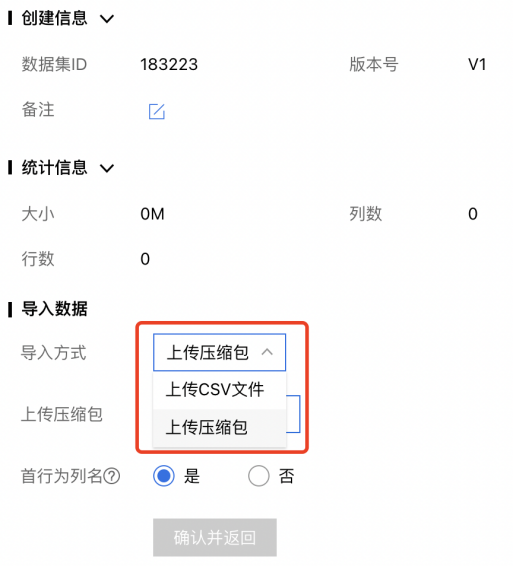
若导入方式为上传CSV文件,则点击【上传CSV文件】,上传压缩包步骤与其一致。
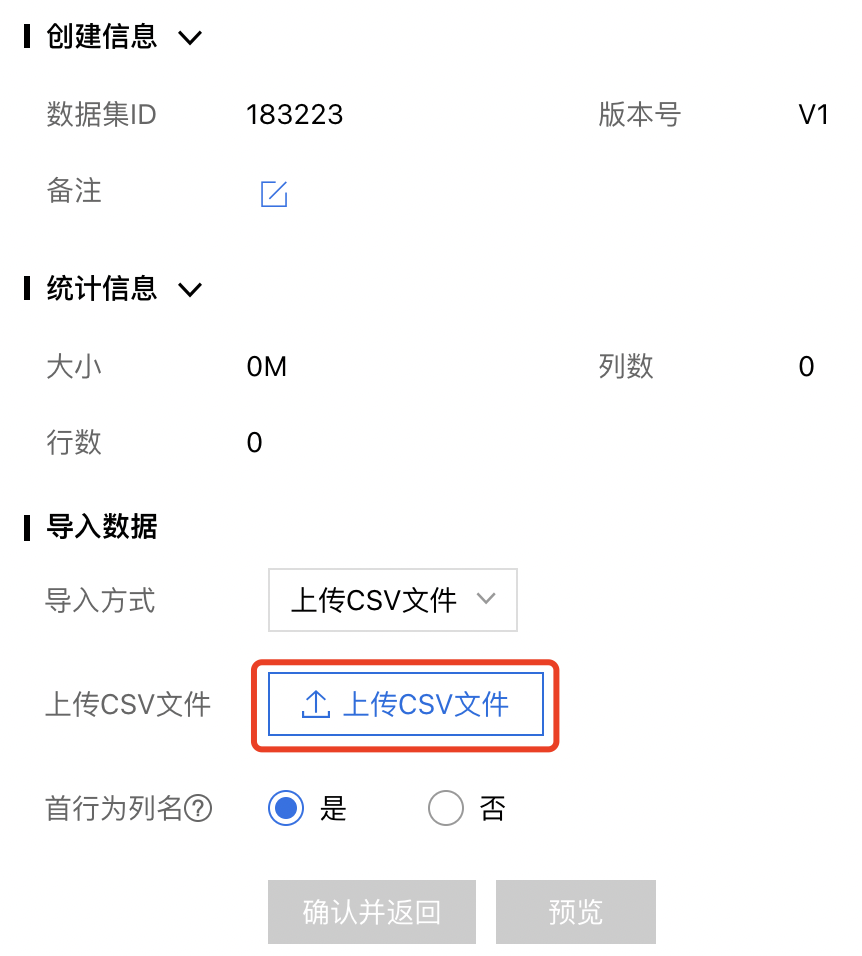
上传文件界面有上传数据的格式要求,数据符合要求,则点击【已阅读并上传】。

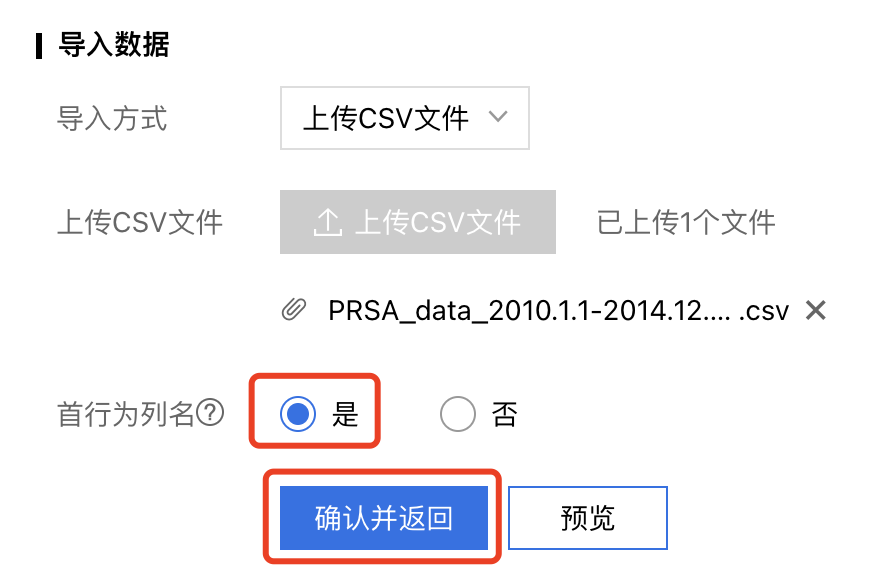
根据数据文件的实际情况进行列名设置:
- 设置首行为列名:将导入的数据文件中的首行作为列名。
- 设置首行非列名:此时系统会自动生成列名,而将首行作为数据。
点击【确认并返回】后自动开始导入:
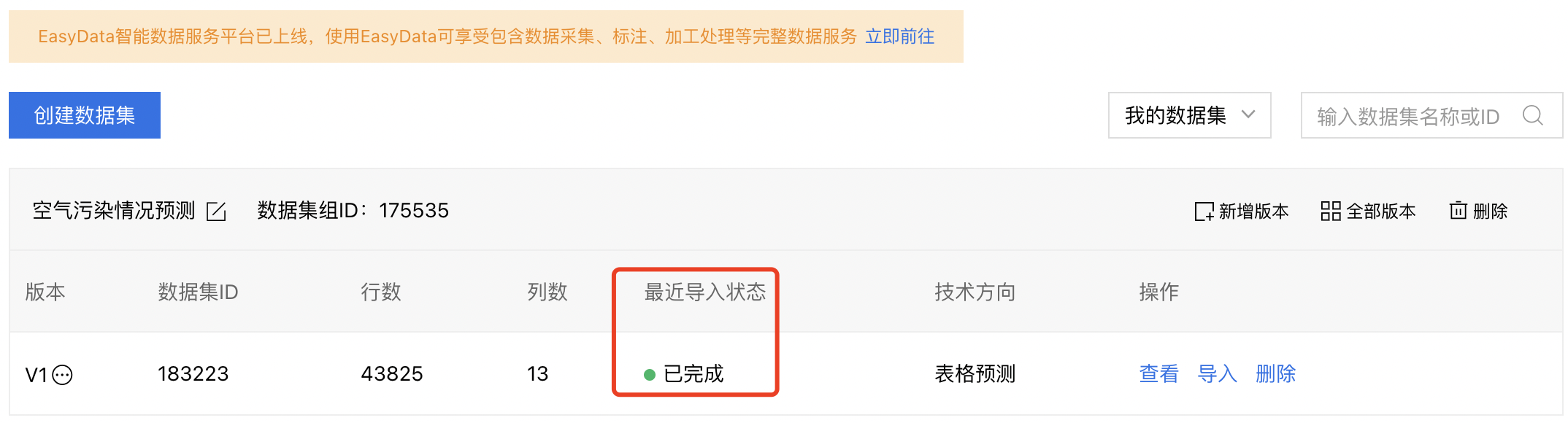
在数据集列表下可以看到所建数据集,数据上传后,需要等待一段时间,刷新后,当最近导入状态由【正在导入】转为【已完成】即为上传成功。
训练模型
BML上提供了脚本调参、NoteBook建模、自定义作业三种开发模式,开发难度和开发的灵活性程度不一,分别满足不同水平和需求的开发者。
本文以使用者最多的脚本调参开发模式为例,示意训练模型的基本步骤。
1、进入BML官方平台点击立即使用脚本调参,点击【脚本调参】,进入操作台。点击【新建】,进入模型创建信息页面。
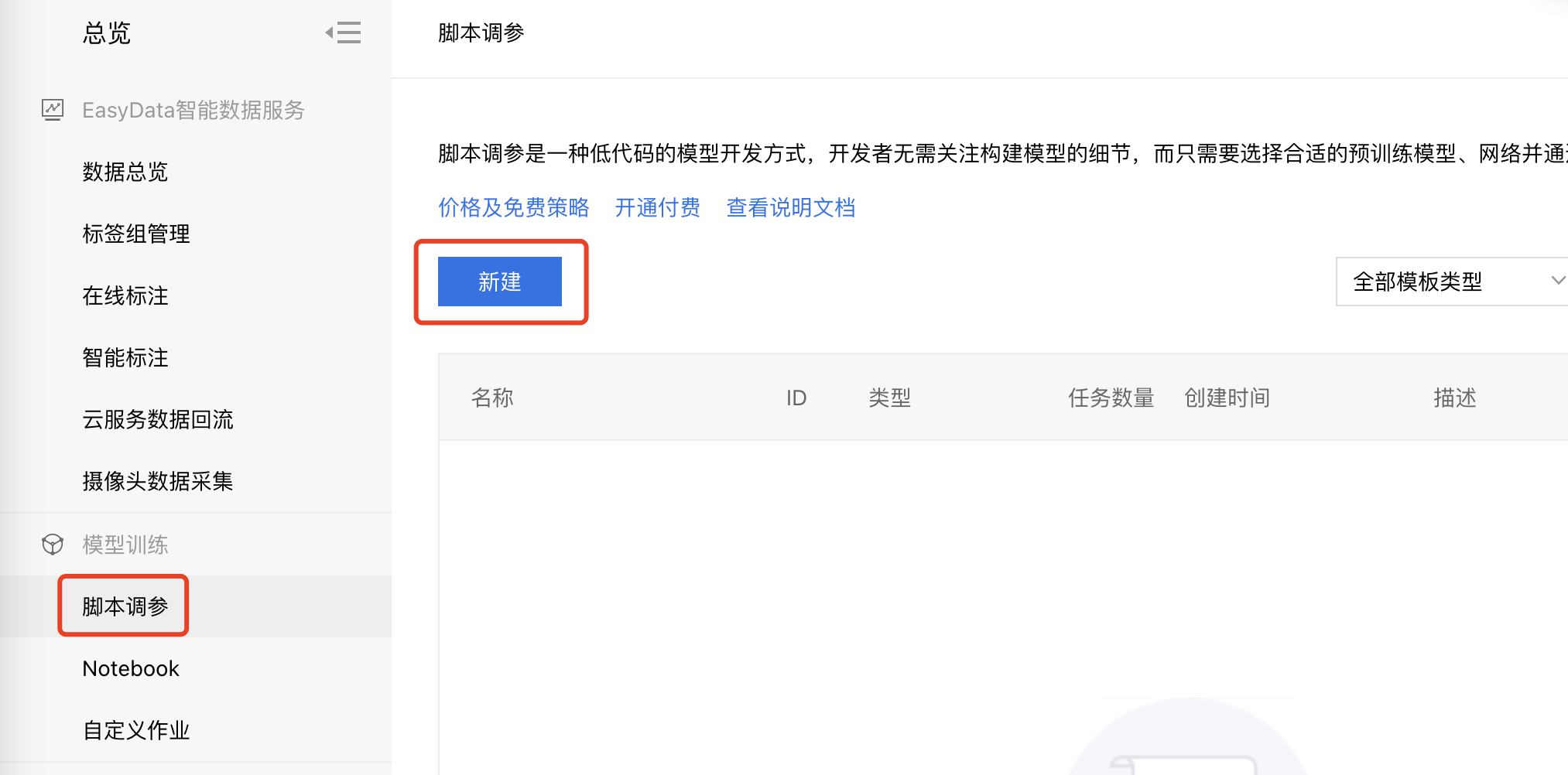
点击【结构化数据】,填写模型创建信息。点击【创建】,完成模型创建。
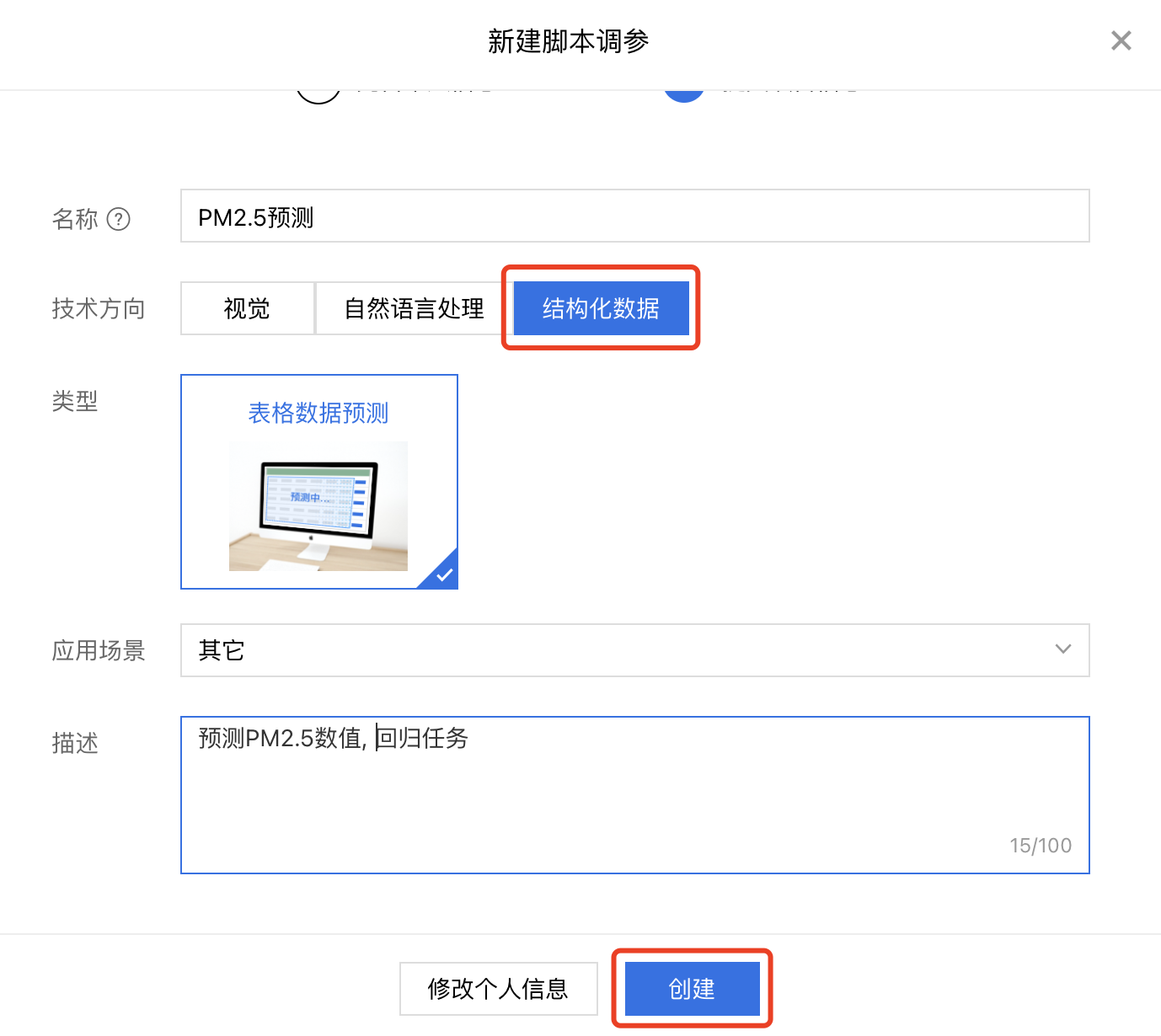
注:可点击【修改个人信息】更新正确账号信息,方便后续人工审核和官方支持。
2、点击【新建任务】,进入模型训练配置阶段。
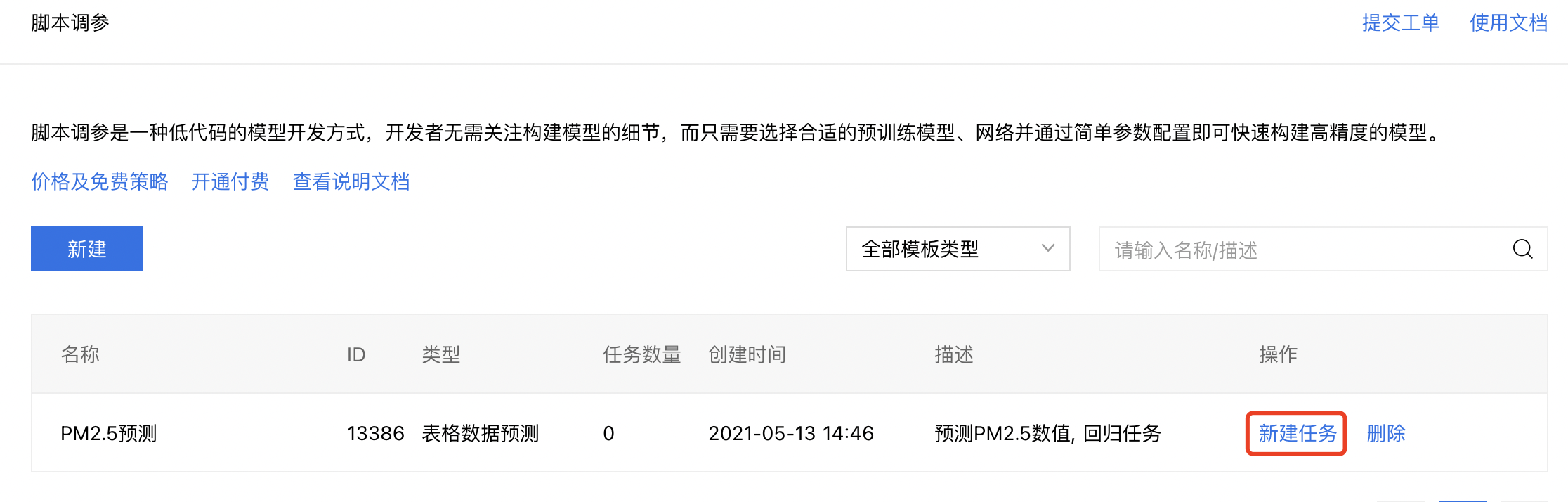
表格预测任务支持AutoML和专家两种运行方式:
- AutoML模式:全流程自动建模,用户只需设置数据集、目标列以及制定任务类型即可,而无需关注数据处理以及算法配置等过程,系统会自动完成建模过程,并从中挑选最优的模型作为训练任务的运行结果。
- 专家模式:高度开放的建模方式,用户可以进行特征工程、算法、超参搜索等配置,具备相关技能的开发者可以在方式下获得更多的开发自由度。
AutoML模式
配置参数如下所示:
1、基本信息:选择【AutoML模式】,并根据实际情况填写任务备注。
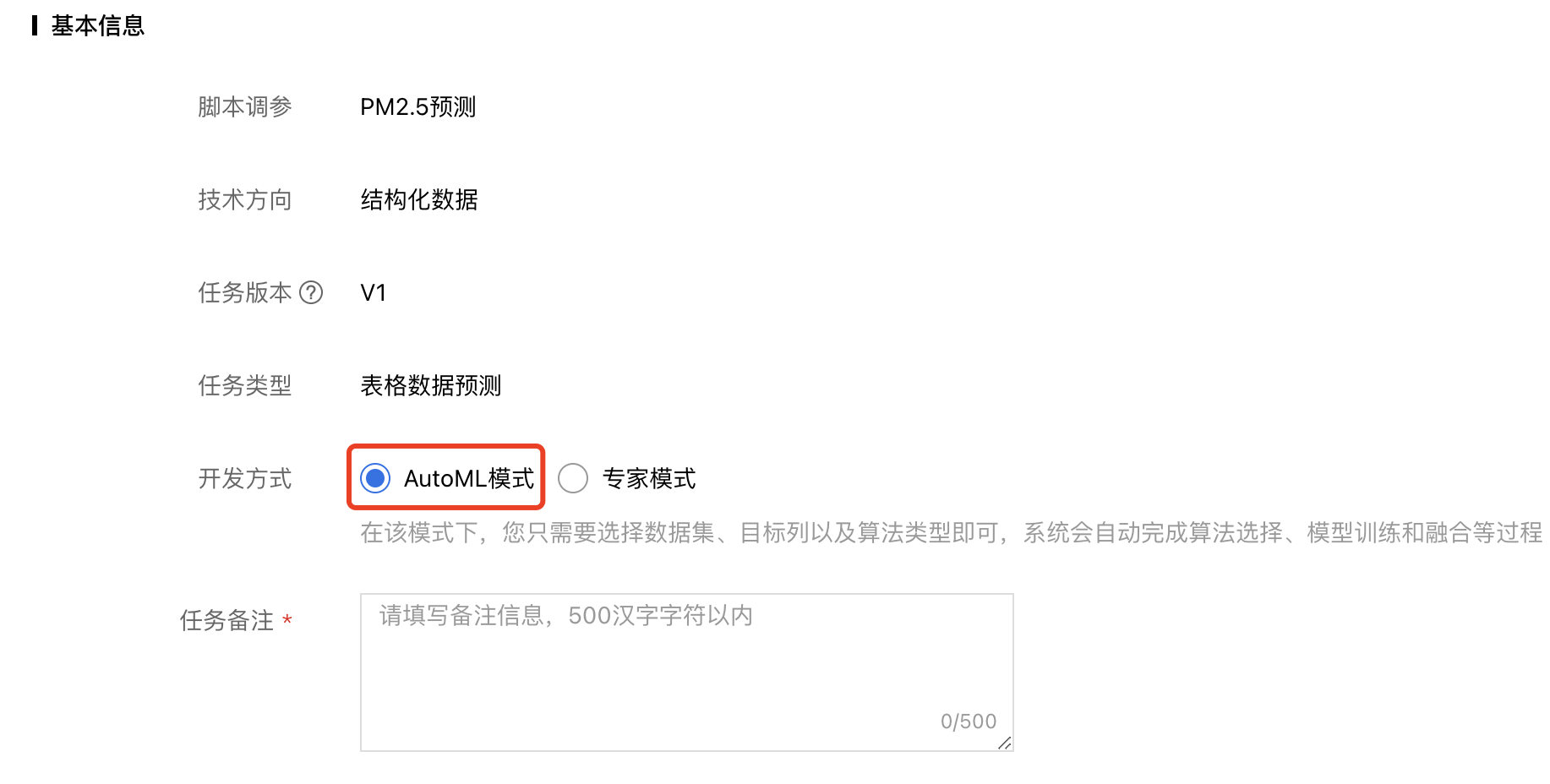
2、添加数据:选择之前创建的数据集,以及目标列名称,并设置算法类型,如不确定,可选择“自动”。

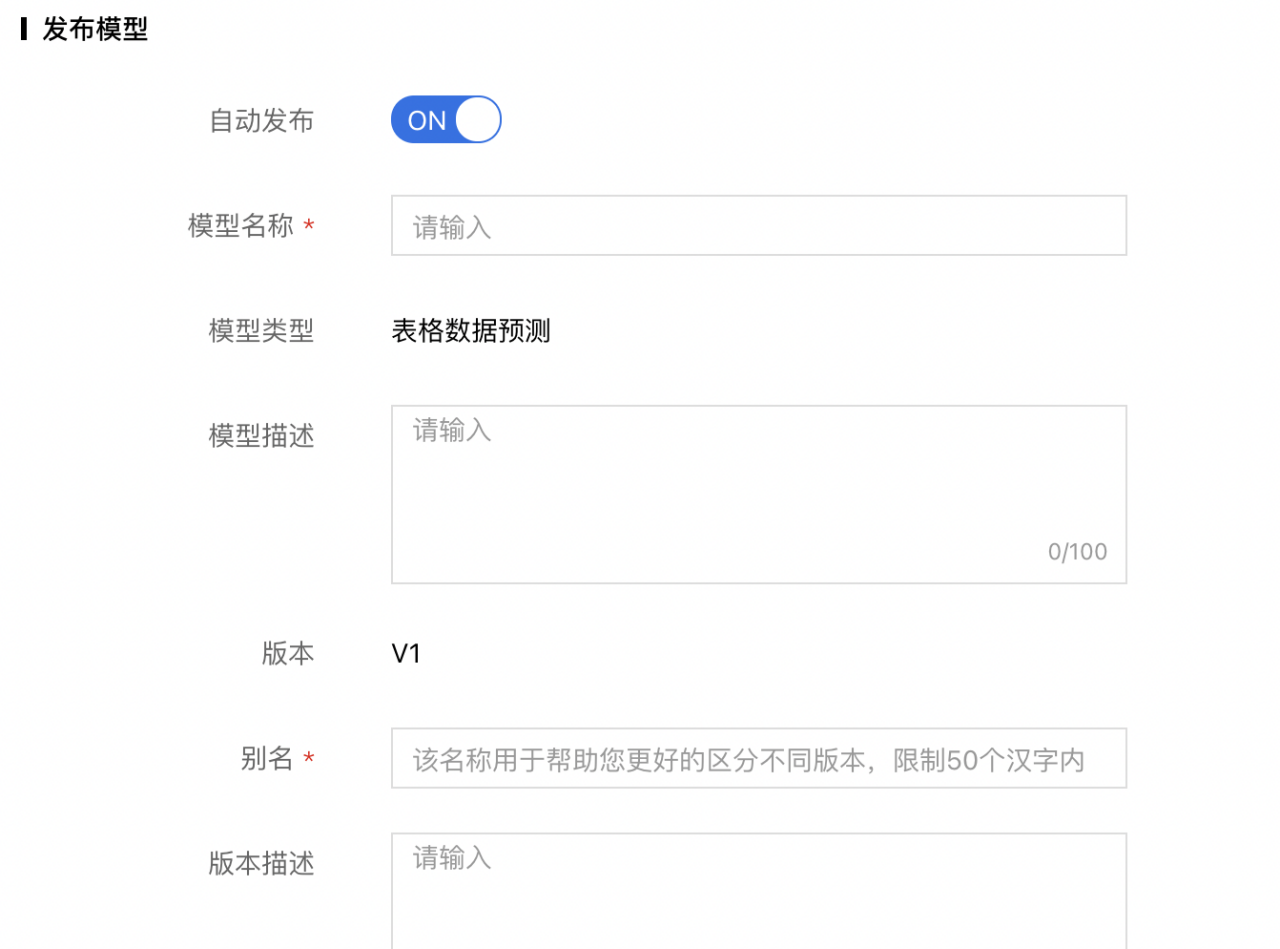
3、发布模型:
- 自动发布-开:即完成训练后,系统会自动将当前任务得到的模型发布到模型仓库中。
- 自动发布-关:完成训练后,用户可以根据模型精度等再决定是否将模型发布到模型仓库。
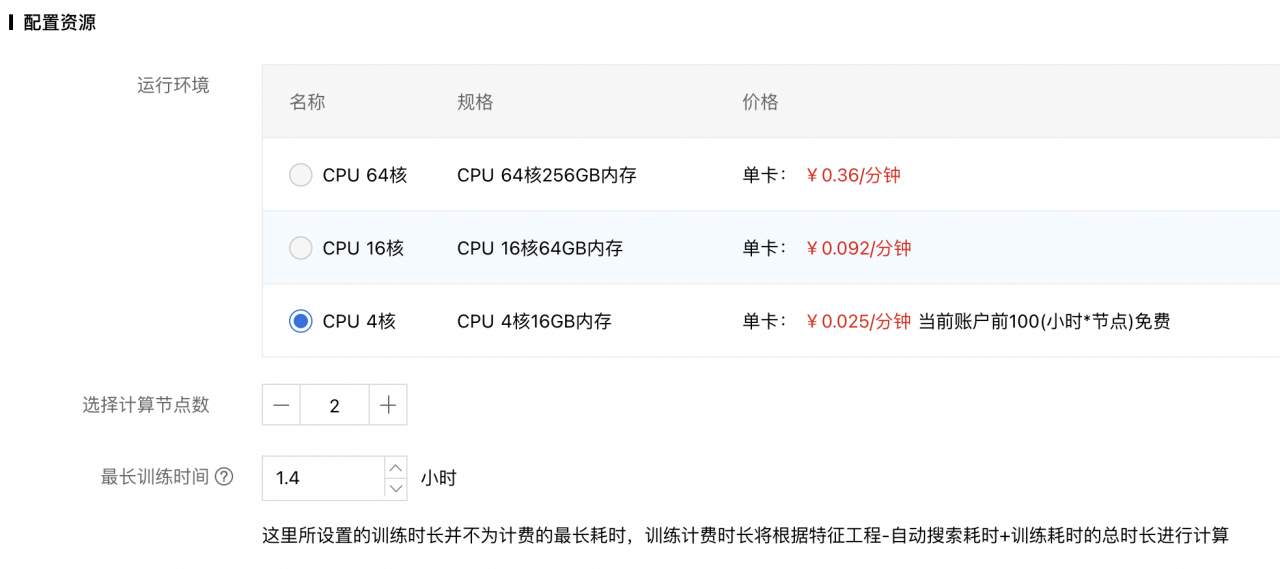
4、配置资源:
- 运行环境:请根据数据量以及期望的运行速度进行设置。根据经验值,在建模过程中,数据会在内存中膨胀为原始大小的10倍,为保证任务顺利完成,请尽量确保配置的资源的内存不小于原始数据集的10倍。
- 选择节点数:如果设置为1,则系统以单机算法进行建模,如果设置为大于1的值,则系统将使用分布式算法。单机算法比分布式算法更丰富。在单机资源满足要求的情况下,可优先使用单节点进行建模。
- 最长训练时间:该时长指算法求解阶段的最长时长,若超过该时长,算法仍未得到结果,系统会强制结束训练任务。
专家模式
配置参数如下所示:
1、基本信息:选择【专家模式】,训练方法支持单机和分布式两种模式,单机模式支持更多的算法,任务备注根据实际情况填写。

2、添加数据:选择之前创建的数据集,以及目标列名称,并设置算法类型,确保选择的算法与目标列的取值是匹配的,否则会造成训练失败。
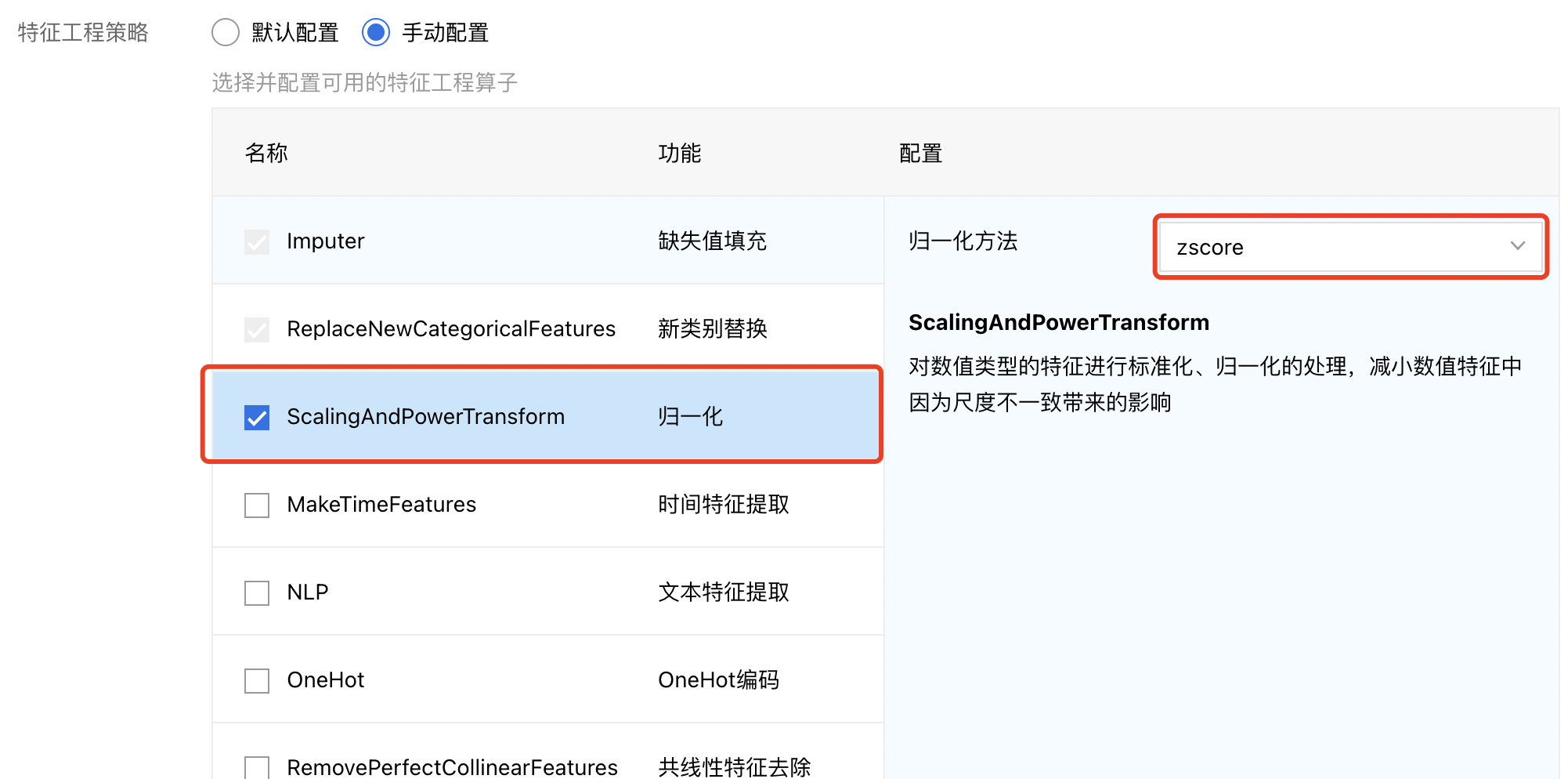
特征工程策略:
- 默认配置:执行系统默认的特征工程策略。
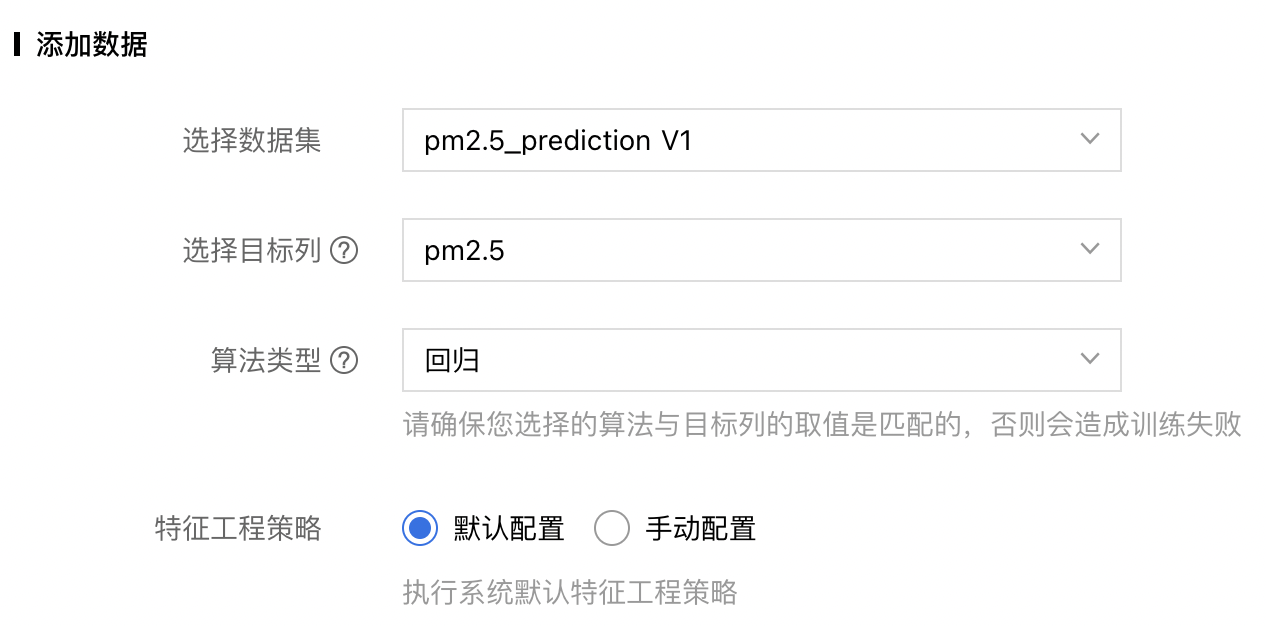
- 手动配置:用户可以手工配置各个特征工程算子的执行参数从而控制其执行方式。
3、配置任务:系统会根据用户选择的训练方式以及算法类型自动生成任务脚本,在不需要修改的情况下可直接启动训练。
如需自定义脚本内容,点击【立即编辑】。
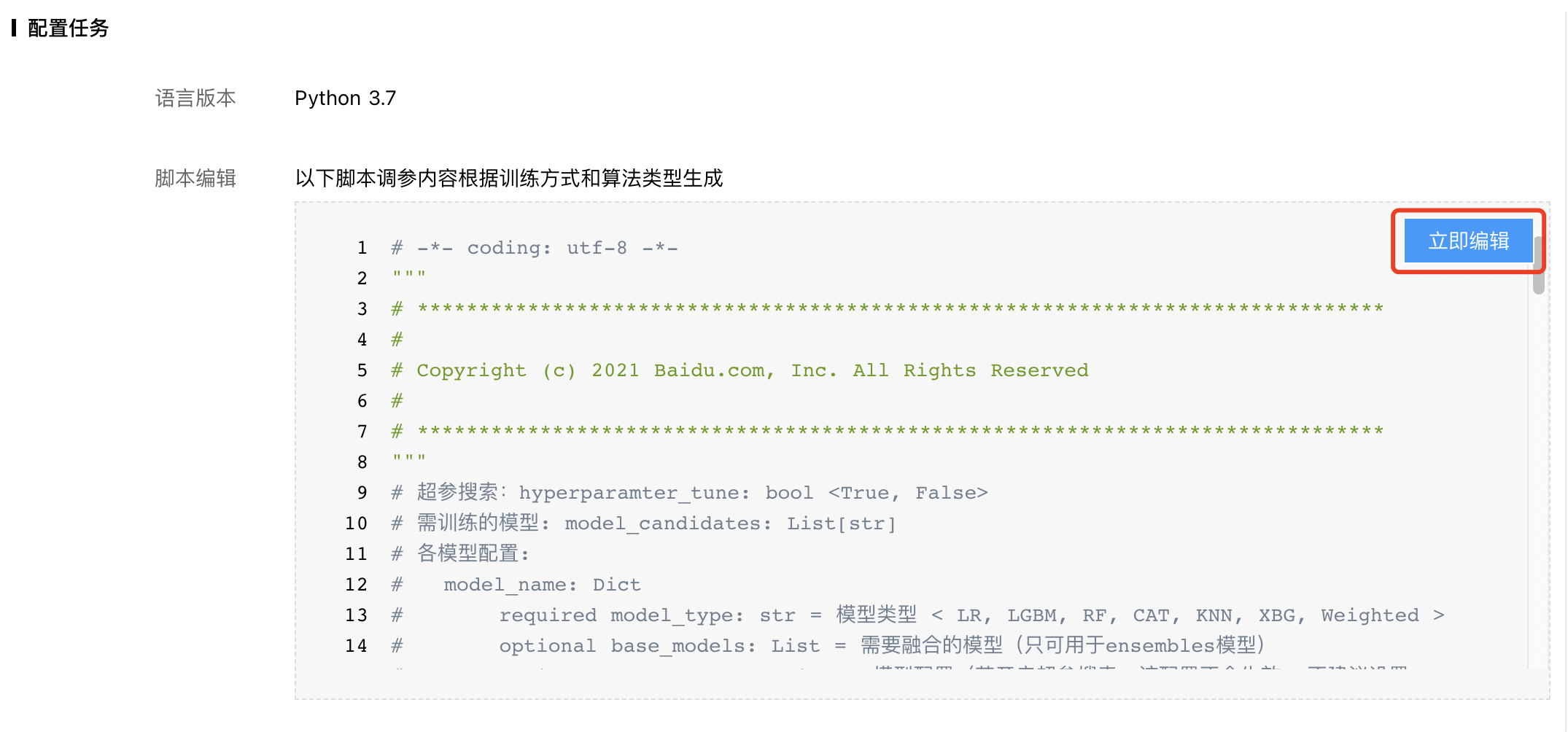
自定义脚本内容过程中有如下注意事项:
- 可以自定义的部分为超参配置字典conf部分,包括是否开启超参搜索,训练模型类型和模型配置,具体见脚本中的注释。
- 训练默认开启自动超参搜索,如需关闭请手动将"hyperparameter_tune"的参数值由"True"更改为"False"。
- BML当前表格数据预测支持模型为CAT(CatBoost), LGBM(LightGBM),RF(RandomForest), LR(Logistic Regression), XGB(Xgboost), KNN(k-NearestNeighbor)。
- 在"hp_space"中已经预置可搜索的超参数,用户无需修改参数名称,随意设置可能会导致训练失败。
- 在超参搜索范围内的取值方式支持:平均采样(uniform),非平均采样(quniform), 离散值(choice), 对数平均采样(loguniform),随机整数(randint)五种,超参搜索范围设置过大可能会导致训练时间过长。
- CAT模型支持搜索的超参数,已经预置默认搜索范围,详见脚本内容。
4、发布模型:
- 自动发布-开:即完成训练后,系统会自动将当前任务得到的模型发布到模型仓库中。
- 自动发布-关:完成训练后,用户可以根据模型精度等再决定是否将模型发布到模型仓库。
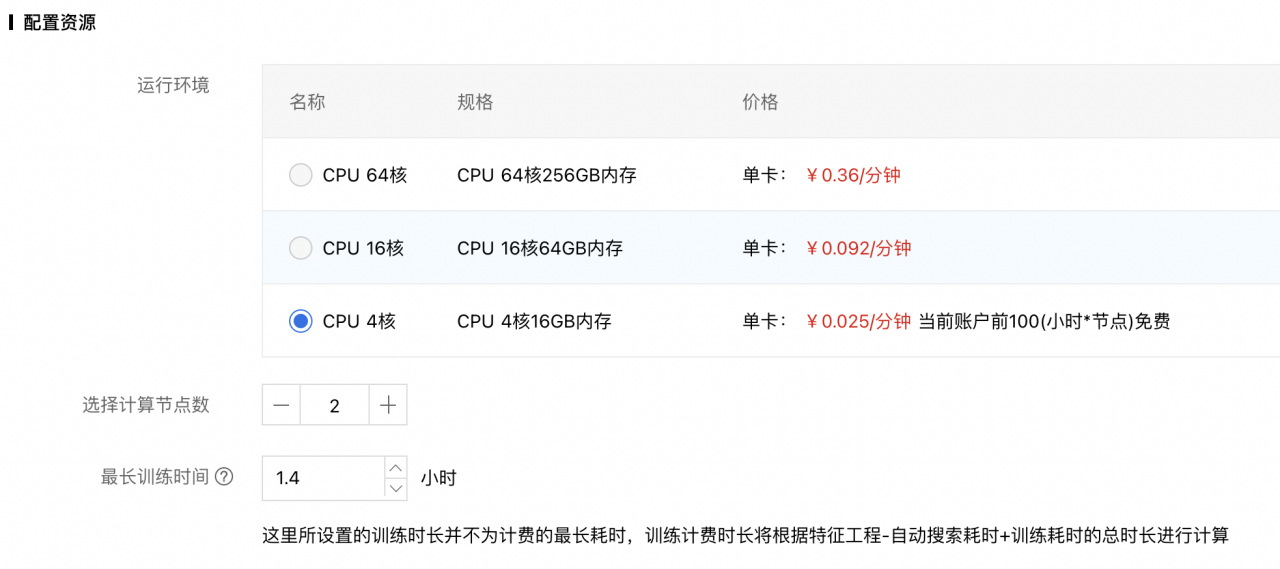
5、配置资源:
- 运行环境:请根据数据量以及期望的运行速度进行设置。根据经验值,在建模过程中,数据会在内存中膨胀为原始大小的10倍,为保证任务顺利完成,请尽量确保配置的资源的内存不小于原始数据集的10倍。
- 选择节点数:只有选择的“分布式”的训练方式才可以设置为大于1的值。
- 最长训练时间:该时长指算法求解阶段的最长时长,若超过该时长,算法仍未得到结果,系统会强制结束训练任务。
6、任务配置完成后,点击【提交训练任务】。
7、提交训练任务后,会进入任务列表页面,待训练状态由【训练中】变为【训练完成】时,训练结束。
8、发布模型选择自动发布时,训练结束,模型就会发布到模型仓库中。点击【评估报告】,可以查看任务结果。
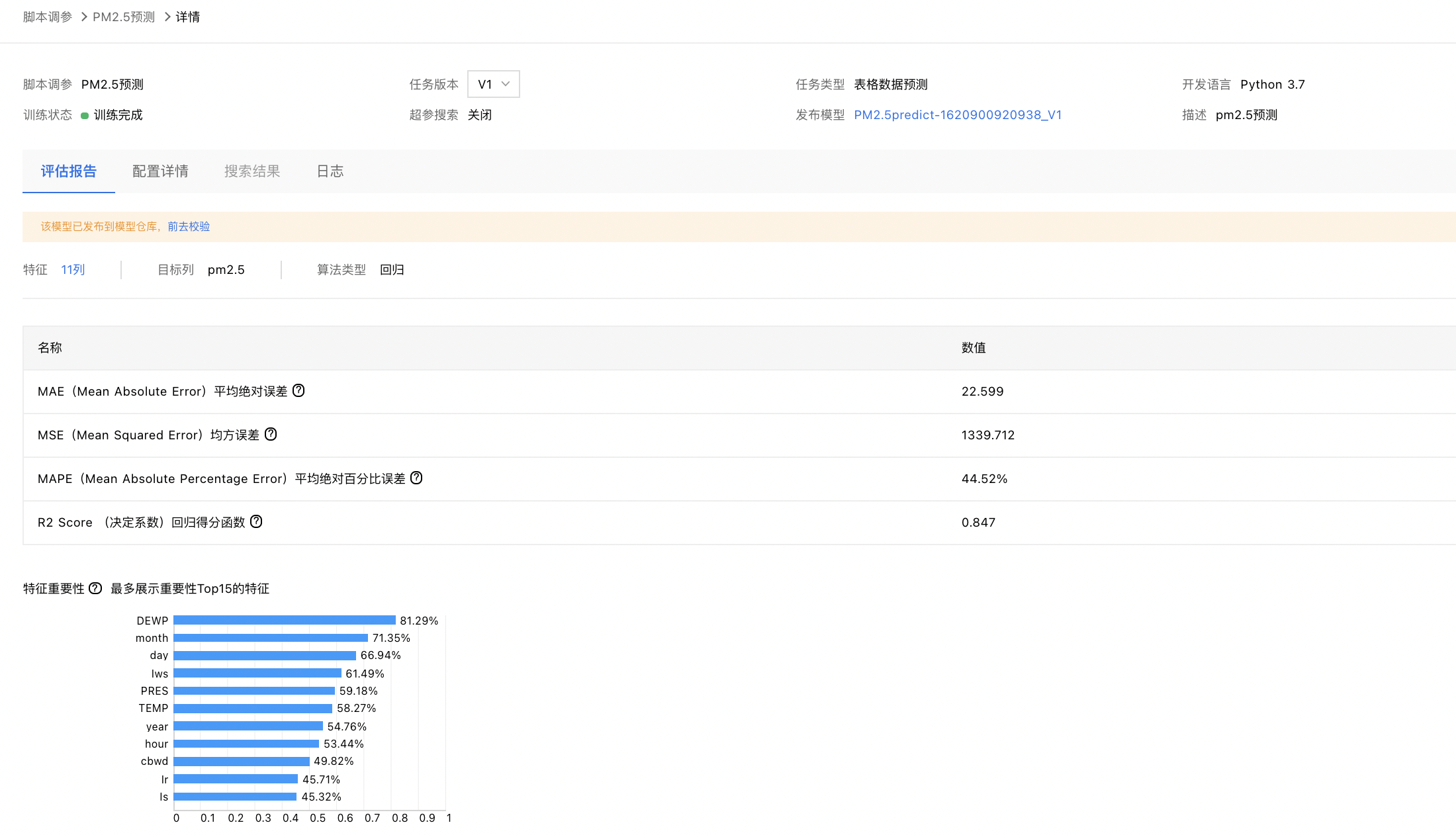
任务生成的模型的报告信息,如下所示:
模型发布与校验
1、未开启自动发布模型时,需要手动将模型发布到模型仓库中。点击【发布】,进入模型发布页面。

2、设置版本别名,点击【确认】。
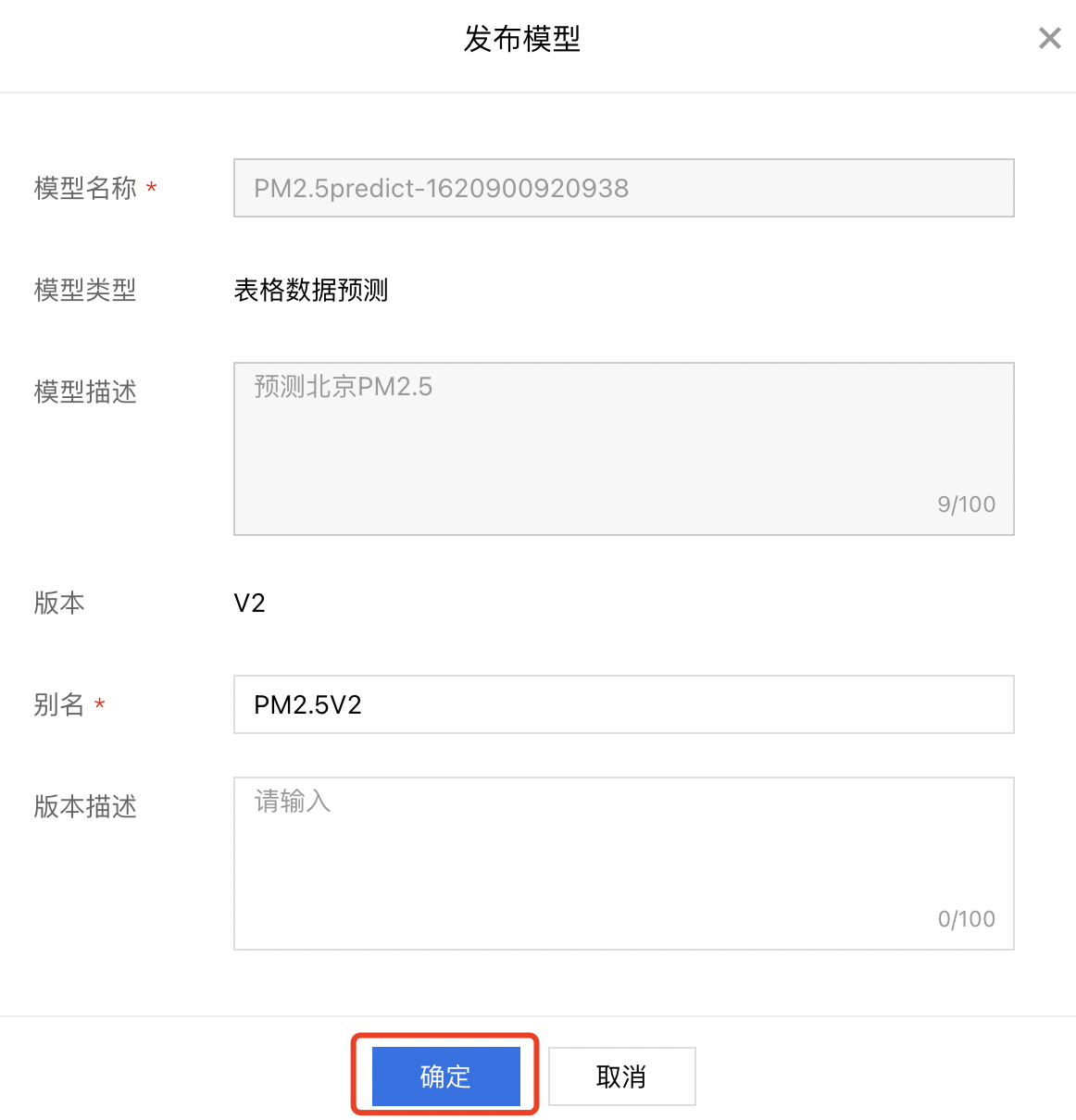
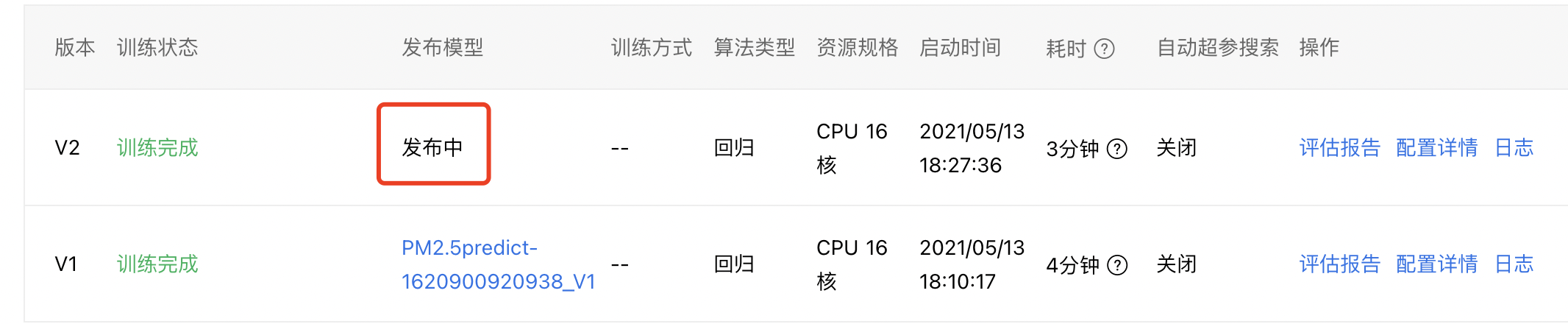
3、等待几分钟,待发布模型的状态由【发布中】变为模型名时,表明模型已导入到模型仓库中。
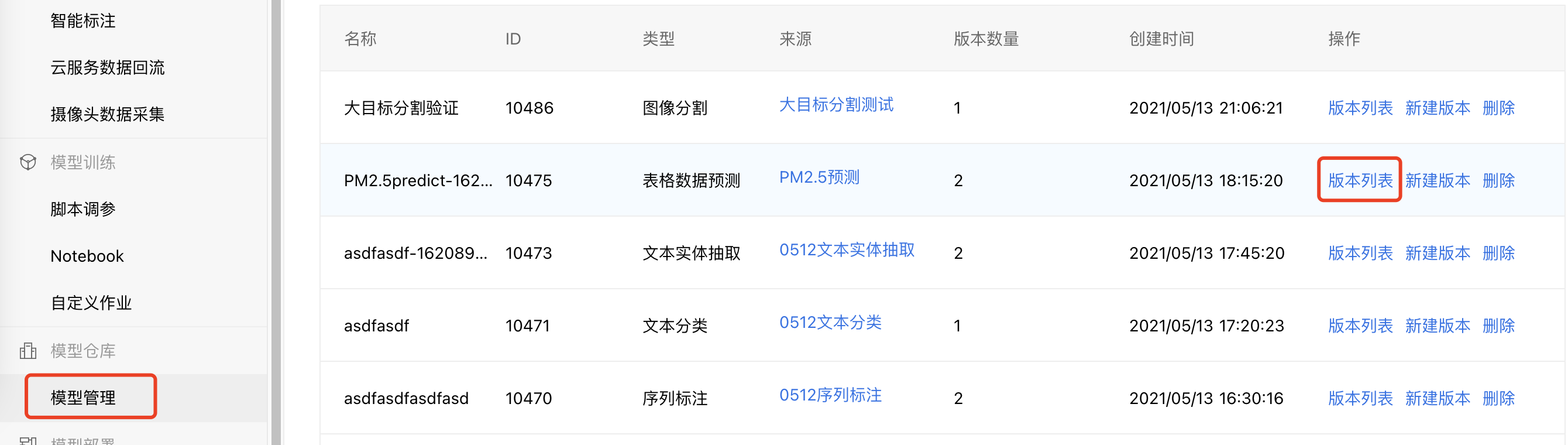
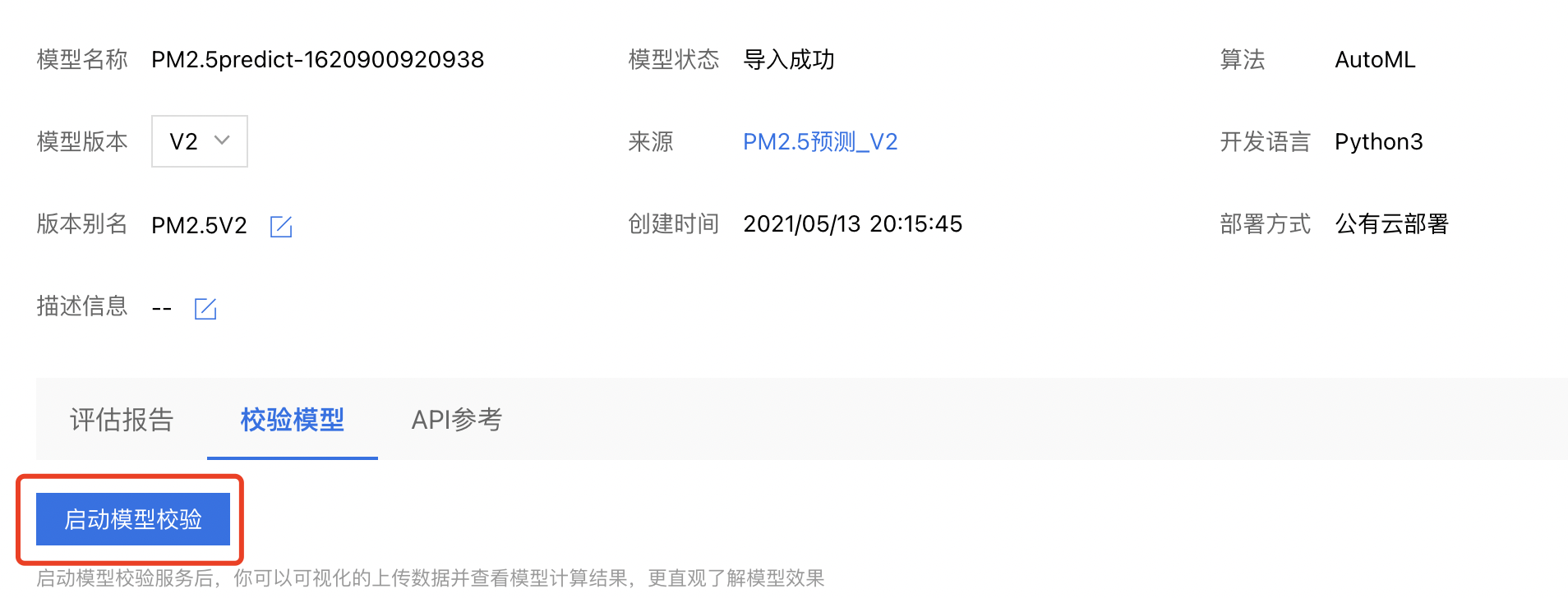
4、点击模型名称进入校验界面,或者点击导航栏模型仓库的【模型管理】,在右侧找到对应的模型,并点击【版本列表】,点击【校验模型】,进入模型校验界面。
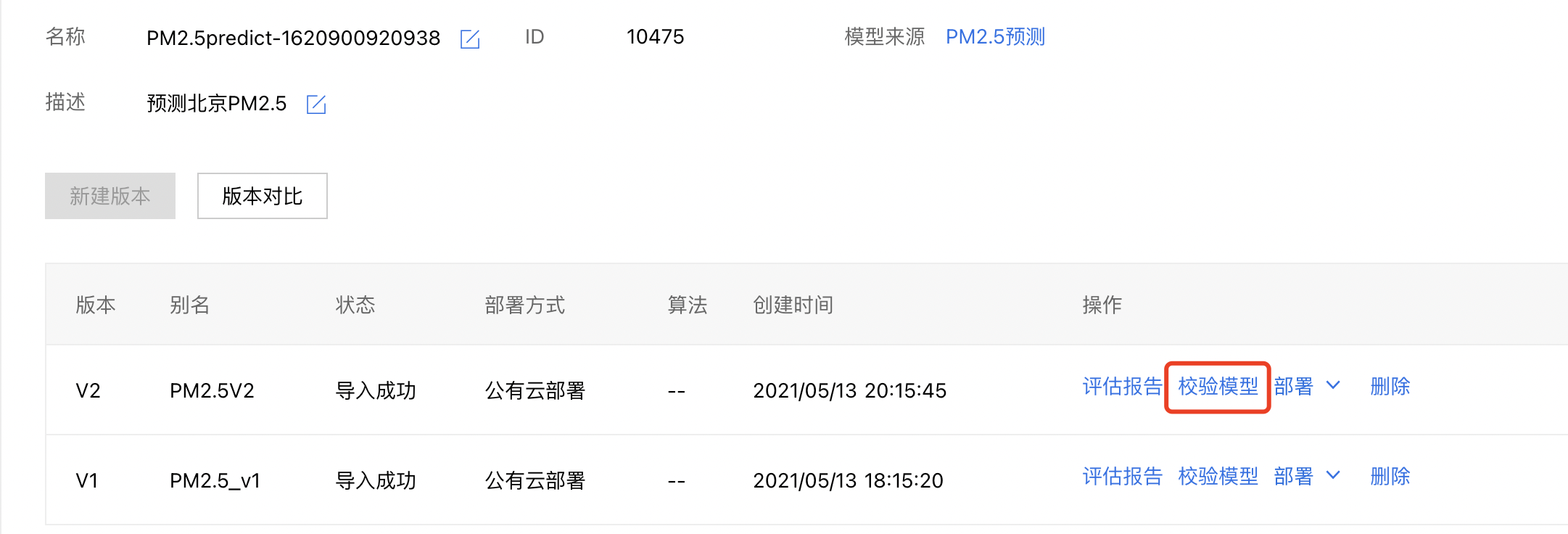
5、点击【启动模型校验】。校验模型需要在后端完成模型的部署,需要一定时间,请耐心等待。
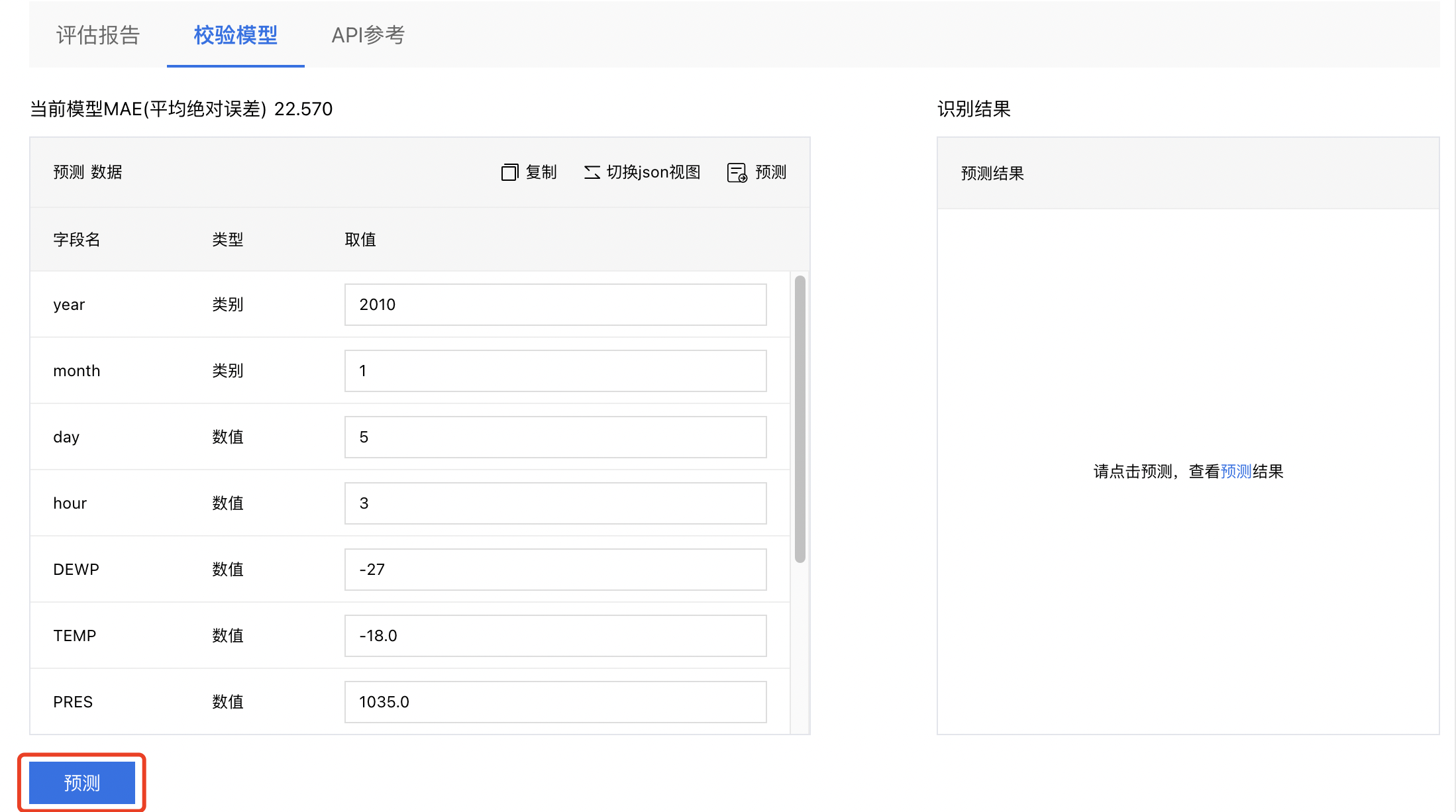
6、设置完特征的取值后,点击【预测】,即可得到预测结果。
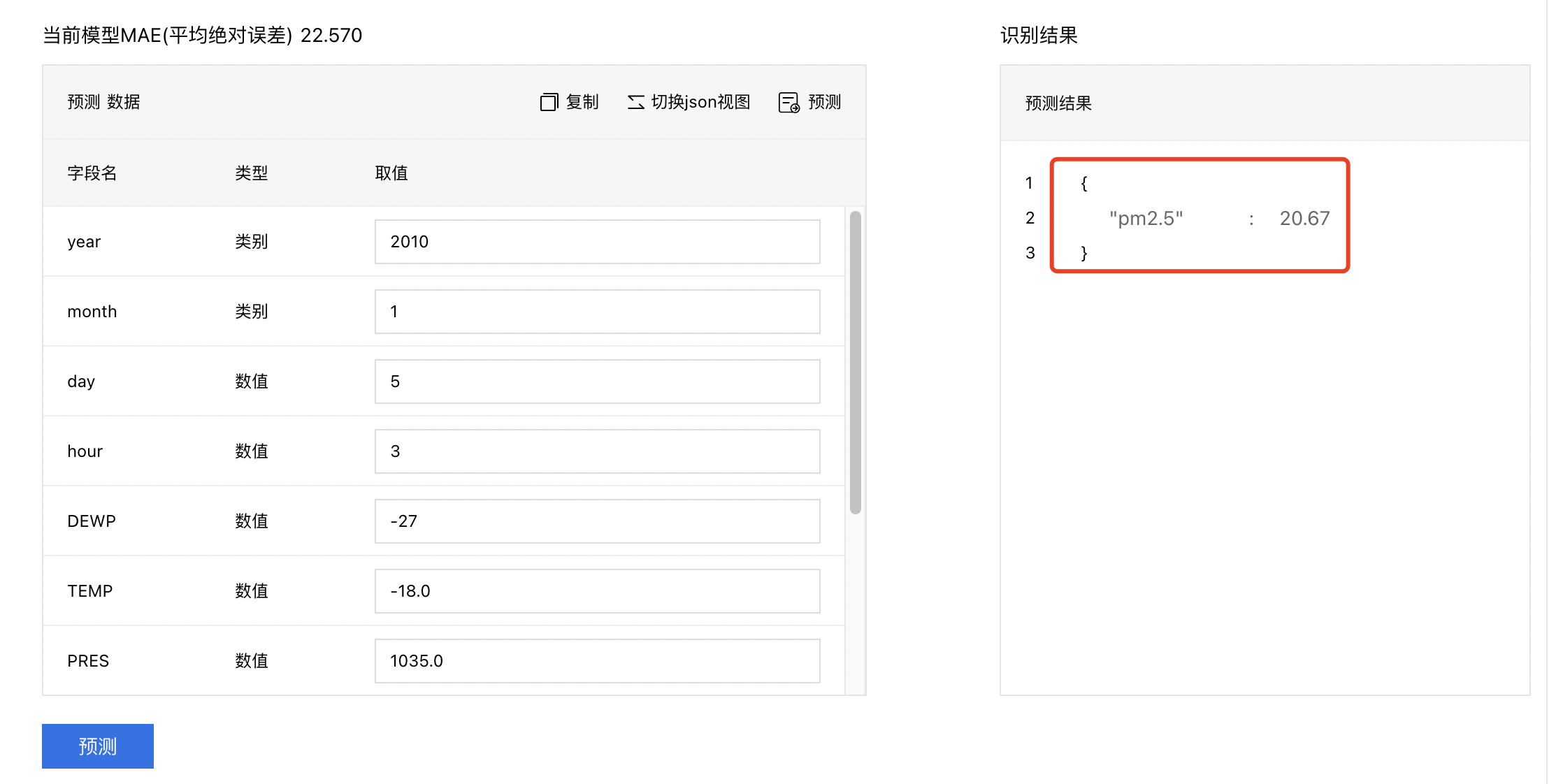
部署模型
训练完成后,可将模型部署在公有云服务器上,通过API进行调用。当前表格预测模型仅支持公有云部署,即将模型部署在BML提供的云端机器资源中,您可以通过访问在线API实时获取模型结果。
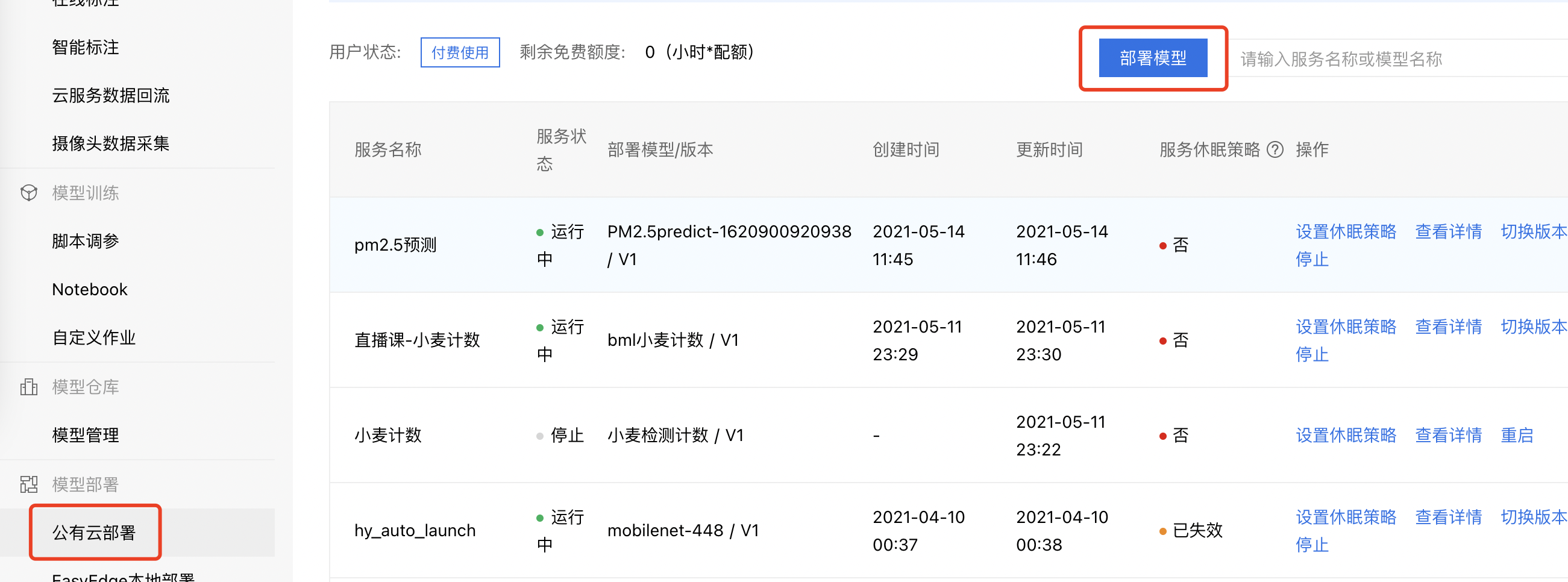
公有云部署
1、将预测模型发布到模型仓库后,在模型管理界面,点击对应模型的【版本列表】,进入后点击对应版本的【部署】,进入部署页面。
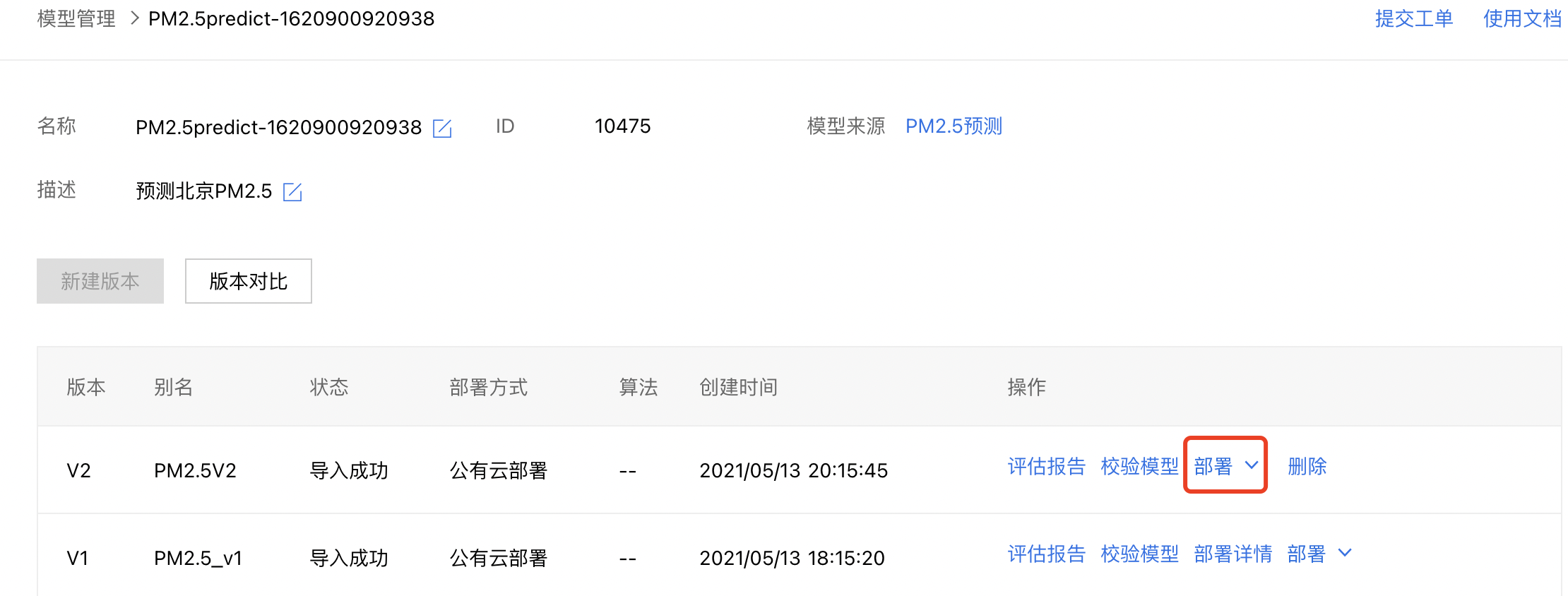
或者点击左侧导航栏的【公有云部署】,进入公有云部署界面后点击【部署模型】,进入部署页面。
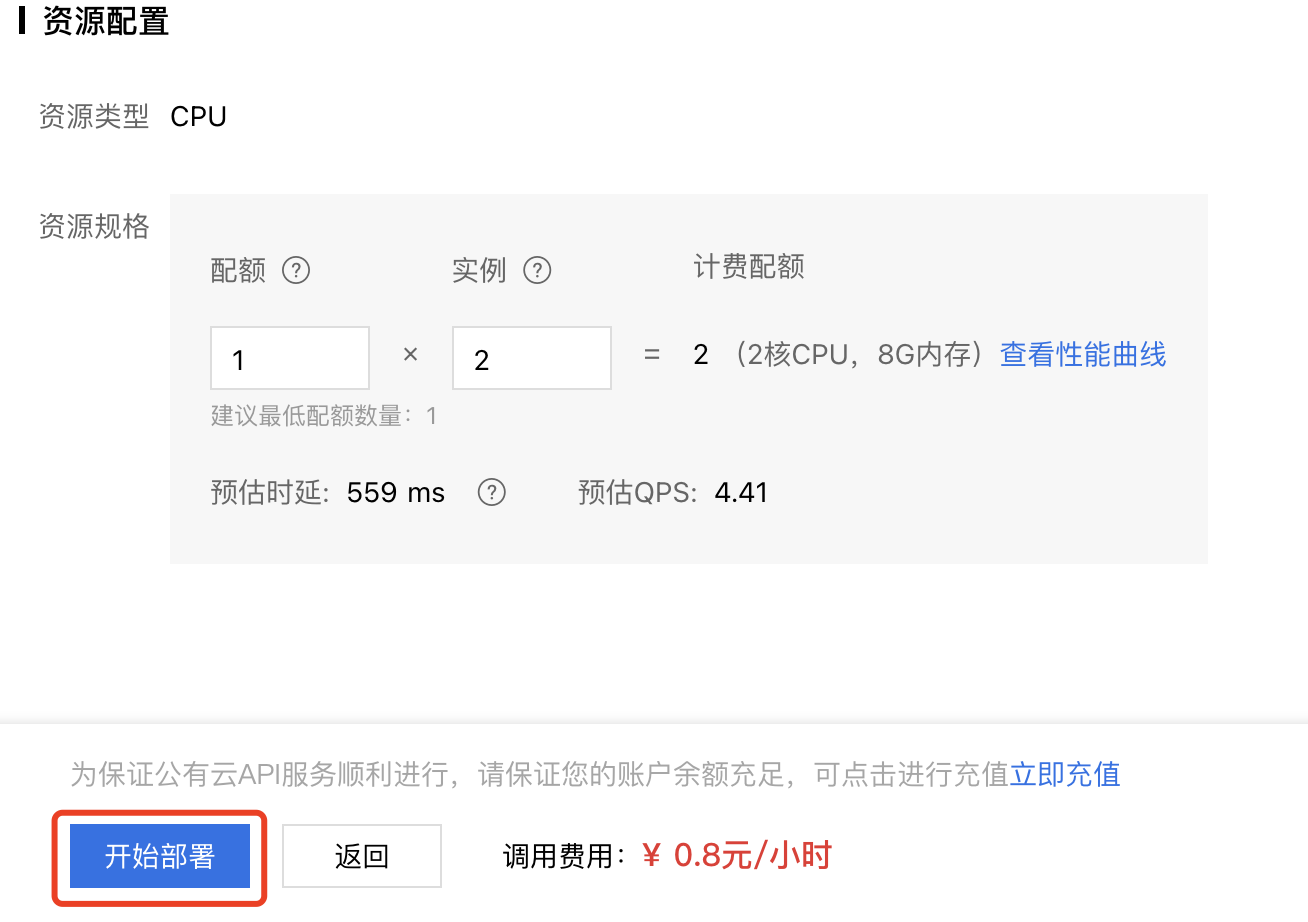
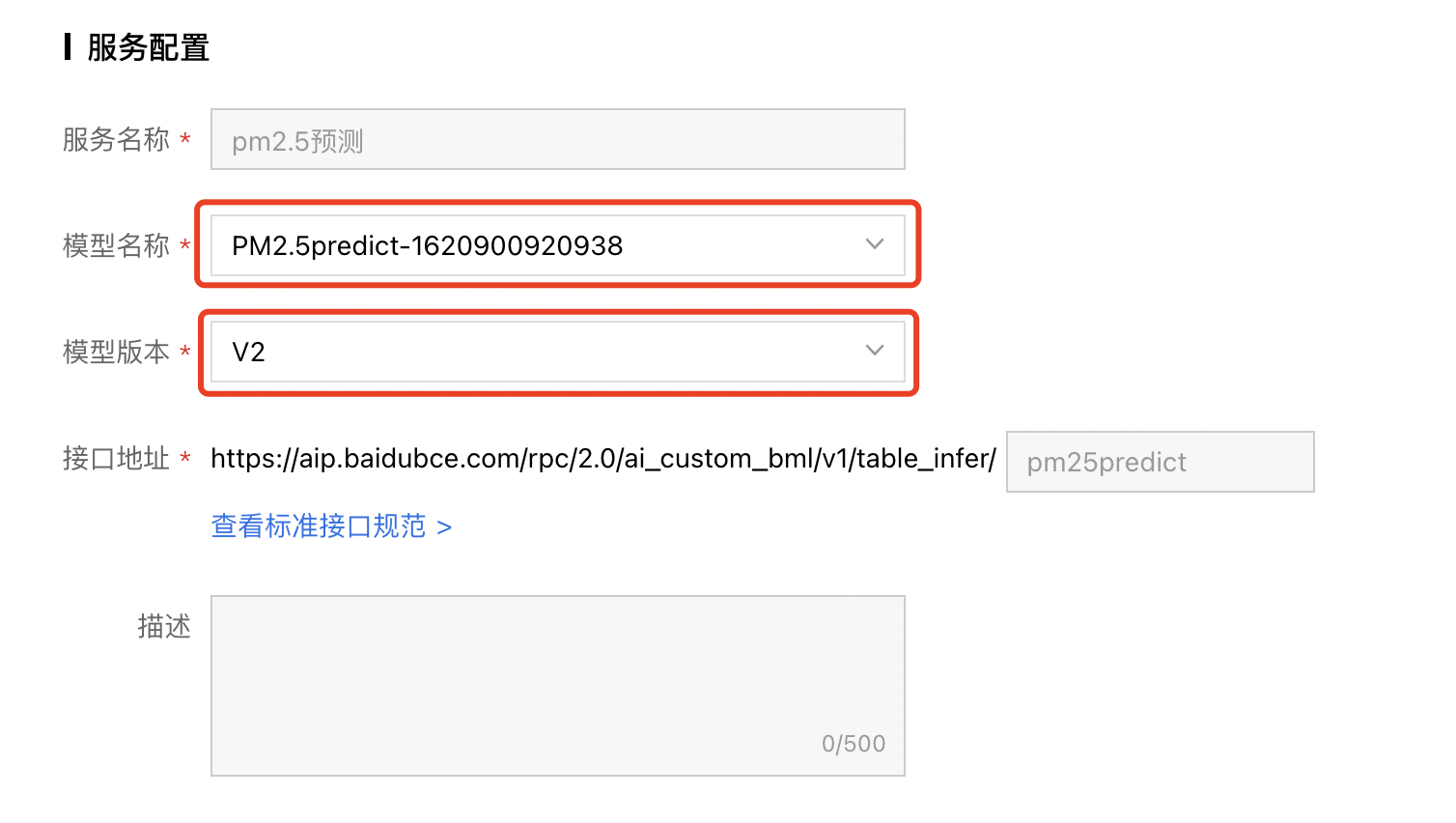
2、部署配置参数如下所示:
服务配置:选择对应的模型名称和模型版本,如果配置版本为模型的第一个版本,则需自定义服务名称以及接口地址后缀。
资源配置:对每个部署模型还需要进行资源配置,配置模型预测服务所需机器资源。目前仅支持CPU机型,支持按配额与实例进行灵活配置。
- 系统将运行公有云部署的机器资源1核cpu和4G内存折算为1配额,提高配额数量能提升QPS和降低推理时延。
- 实例为cpu资源运行的实例数,为保证服务的稳定性,实例数至少需要配置为2。实例数与QPS成正比关系,提高实例数时,QPS能正比增加。
3、配置完成后,点击【开始部署】,在完成部署后可以通过配置的API地址调用预测服务。