用BML实现图片分类
目录
1.图片分类简介
2.平台入口
3.准备数据
3.1 抽油机工况分类数据介绍
3.2 创建及导入数据集
4.训练模型
5.模型分析和调优
6.部署模型
用BML实现图片分类:以抽油机工况分类为例
图片分类简介
亲爱的开发者您好,欢迎使用百度BML全功能AI开发平台开启您的AI开发之旅!
图像分类是经典的计算机视觉任务,也是所有计算机视觉任务的基础。图像分类的主要功能为识别一张图中是否是某类物体/状态/场景,适用于图片内容单一、需要给整张图片分类的场景。其主要应用场景有:
- 图片内容检索:定制训练需要识别的各种物体,并结合业务信息展现更丰富识别结果。
- 图片审核:定制图像审核规则,如训练直播场景中抽烟等违规现象。
- 制造业分拣或质检:定制生产线上各种产品识别,进而实现自动分拣或者质检。
- 医疗诊断:定制识别医疗图像,辅助医生肉眼诊断。
下文中将以抽油机工况分类任务为例,分步骤向您详细介绍如何使用百度BML全功能AI开发平台开发您自己的图像分类模型。
抽油机工况分类任务简介:
抽油机井采油是目前油田开发中普遍应用的方式,抽油机井的管理水平的好坏,关系到油田整体经济效益的高低。要做好抽油机井的生产管理工作,必须取准取全各项生产资料,制定抽油机井合理的工作制度,不断进行分析,适应不断变化的油藏动态,加强并提高抽油机井的日常管理水平。而分析和解释示功图,就是直接了解深井泵工作状况好坏的一个主要手段,不但深井泵工作中的一切异常现象可以在示功图上比较直观的反映出来,而且,还可以结合有关资料,来分析判断油井工作制度是否合理,抽油设备与油层和原油性质是否适应,还可以通过“示功图法”对低产、低能井制定出合理的开关井时间,减少设备的磨损和电能的浪费等。
平台入口
BML全功能AI开发平台为企业及个人开发者提供机器学习和深度学习一站式AI开发服务,并提供高性价比的算力资源,助力企业快速构建高精度AI应用,进入官方网站点击【立即使用】。
准备数据
准备数据是AI模型开发的关键一环,训练数据的质量决定了训练所得模型效果可达到的上限,下面来介绍数据规范与相关操作步骤。
抽油机工况分类数据介绍
抽油机工况分类数据集来自于百度与昆仑数智合作的『中石油·第二届梦想云创新大赛』比赛数据,是中石油实际业务场景采集的真实数据,其中训练集包含12059个样本数据,每个样本数据包含1个json格式标注数据以及1张对应的png格式图片。其中包含12类典型工况:
| 序号 | 类别名 | 序号 | 类别名 |
|---|---|---|---|
| A01 | 工作正常 | A07 | 游动阀关闭迟缓 |
| A02 | 供液不足 | A08 | 柱塞脱出泵工作筒 |
| A03 | 气体影响 | A09 | 游动阀漏 |
| A04 | 气锁 | A10 | 固定阀漏 |
| A05 | 上碰泵 | A11 | 砂影响+供液不足 |
| A06 | 下碰泵 | A12 | 惯性影响+工作正常 |
导入平台即可用,数据下载链接:抽油机工况分类-json格式
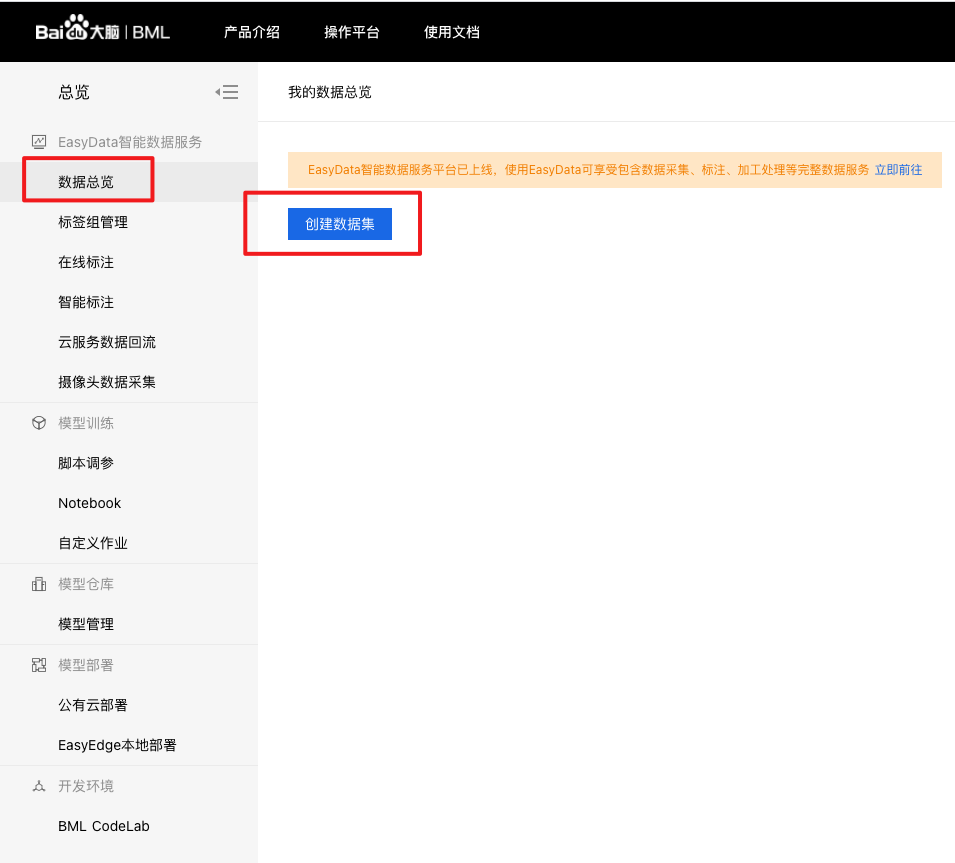
创建及导入数据集
1、在官网界面点击【数据总览】,进入数据集操作界面,点击【创建数据集】。
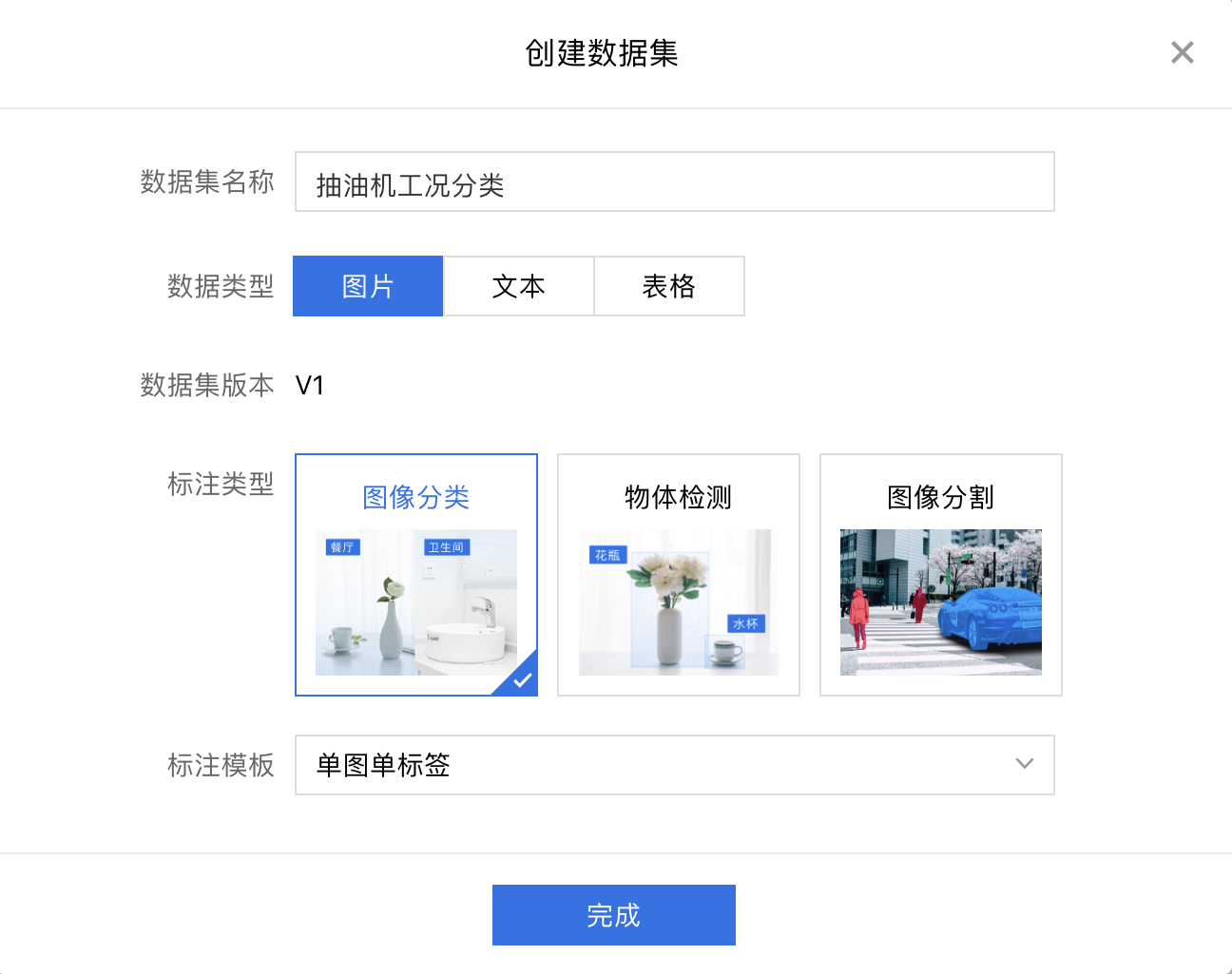
2、进入创建数据集界面,填写相关信息,选择数据和标注类型(注意训练集、验证集、测试集需要分开创建)。
3、数据集创建完成后,可以在数据总览界面看到刚才创建好的数据集ID,点击【导入】,将自己要训练的数据集导入。
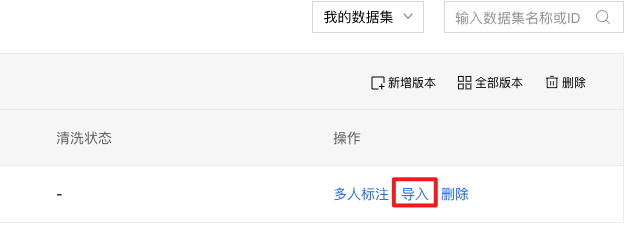
以本地导入-上传压缩包为例:导入方式选择【本地导入】,选择标注格式,点击【上传压缩包】。
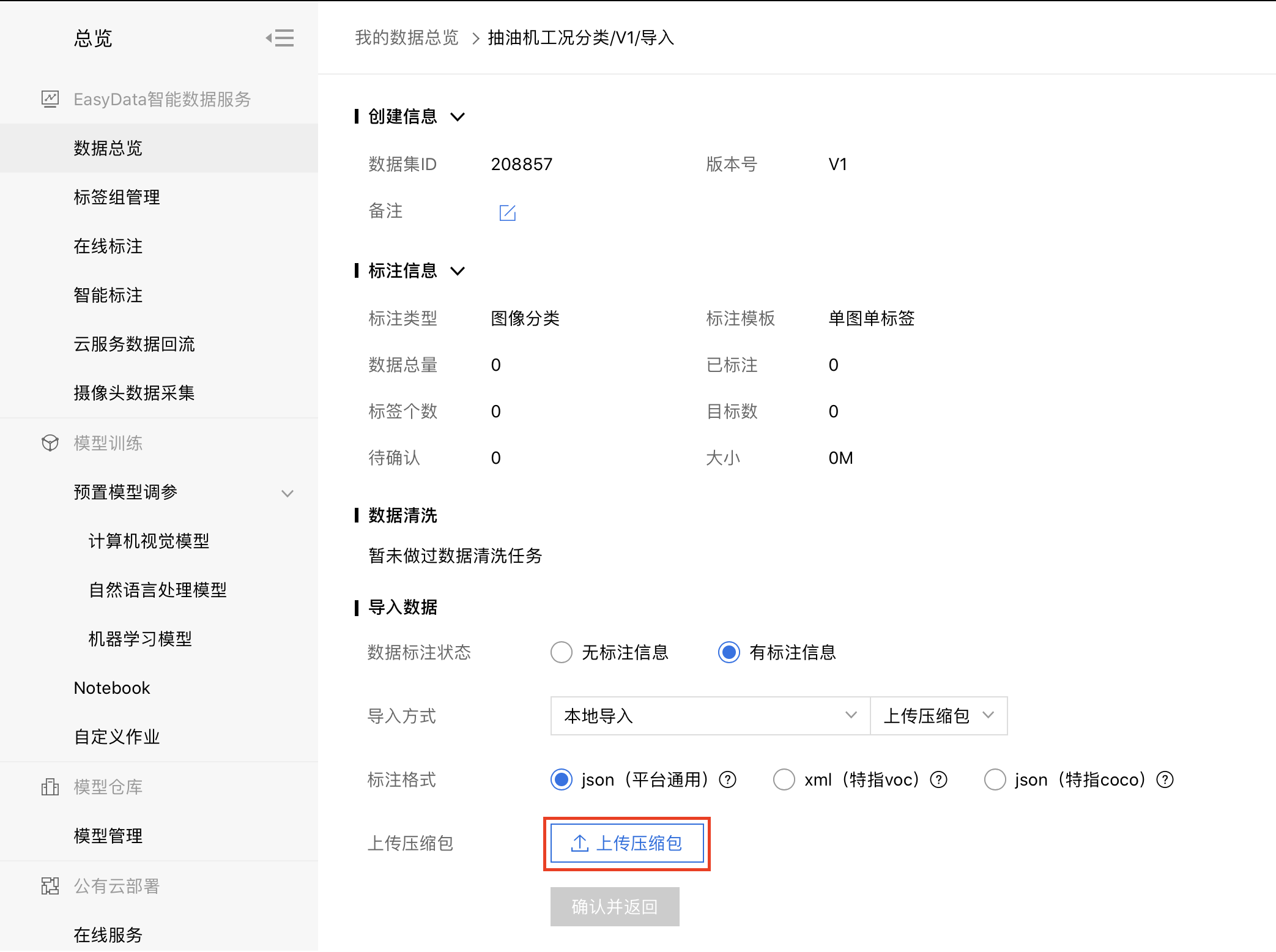
仔细阅读上传压缩包格式要求,可点击【下载示例压缩包】确认格式:
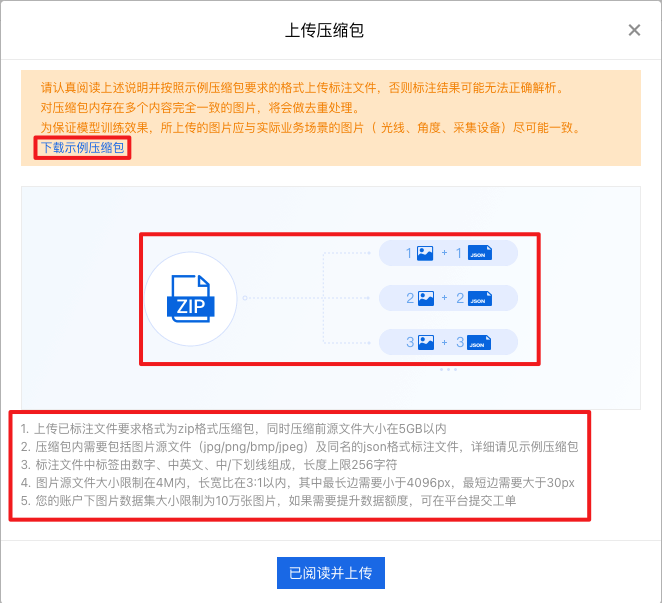
确认格式无误后,点击【已阅读并上传】, 注意上传时不要关闭网页:
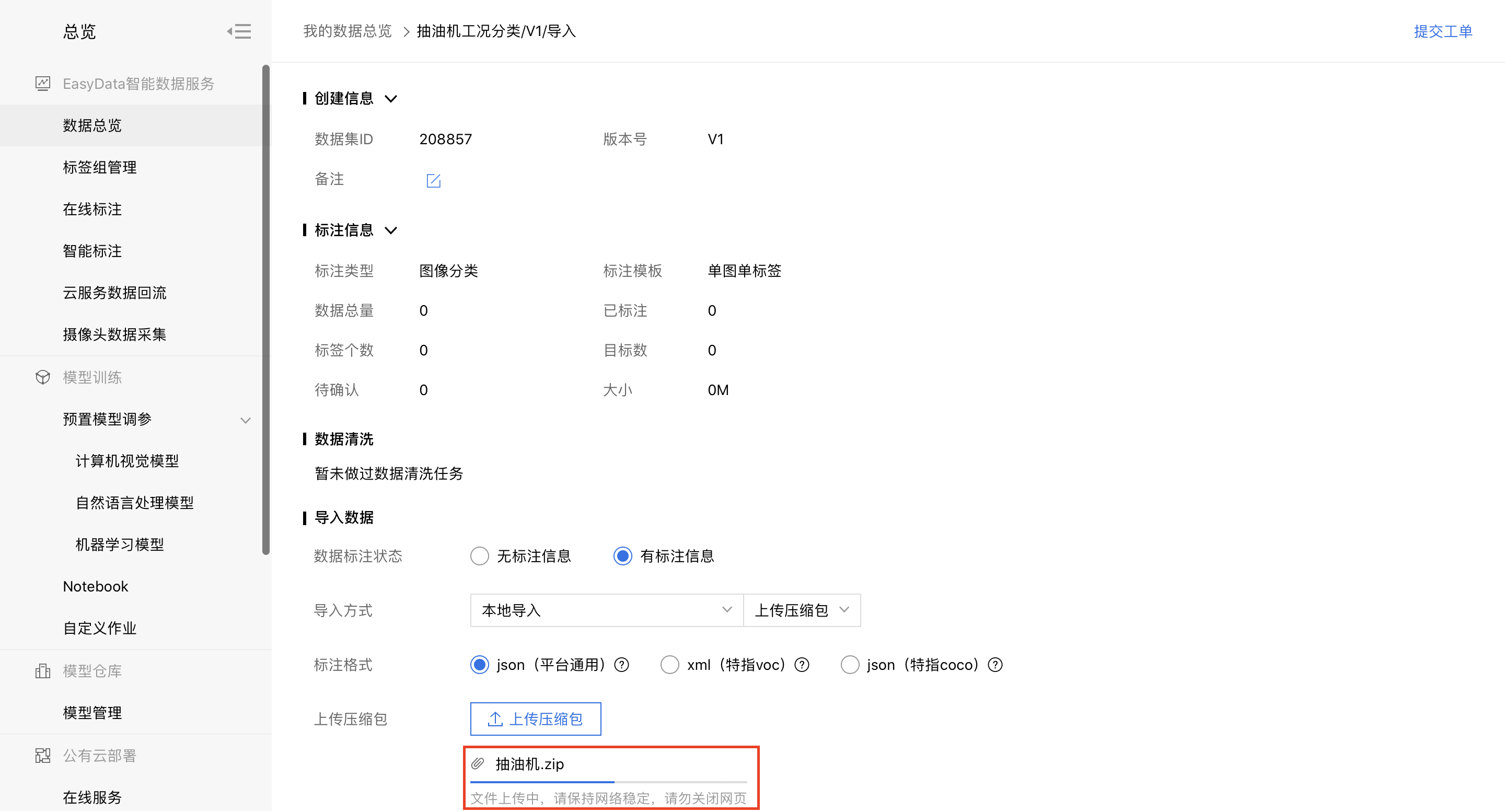
点击【确认并返回】后自动开始导入:
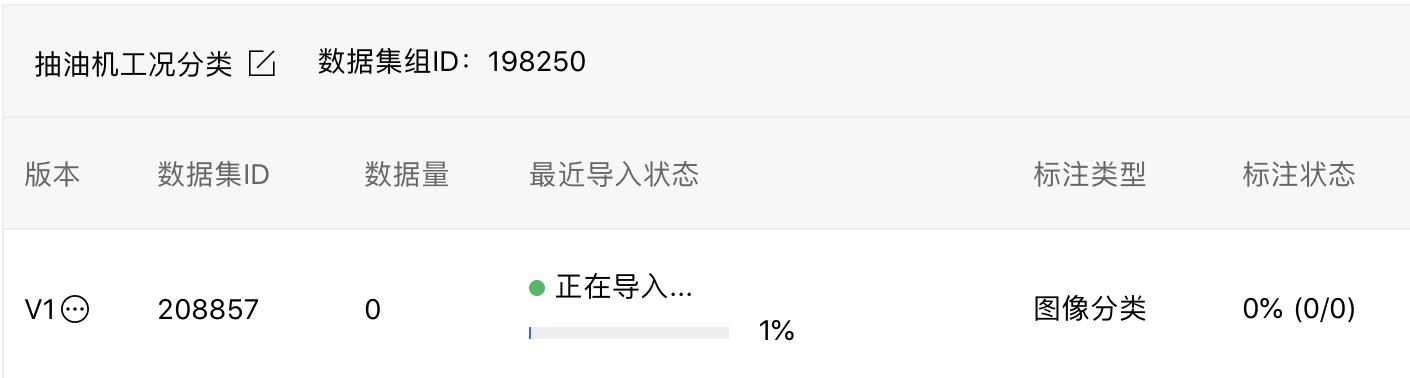
可看到【标注状态】为100%,如果数据集没有全部标注,可使用平台【智能标注】功能。
训练模型
BML上提供了预置模型调参、NoteBook建模、自定义作业三种开发模式,开发难度和开发的灵活性程度不一,分别满足不同水平和需求的开发者。
本文以使用者最多的预置模型调参开发模式为例,示意训练模型的基本步骤。
1、进入bml官方平台点击【预置模型调参】-【计算机视觉模型】,点击【创建】。
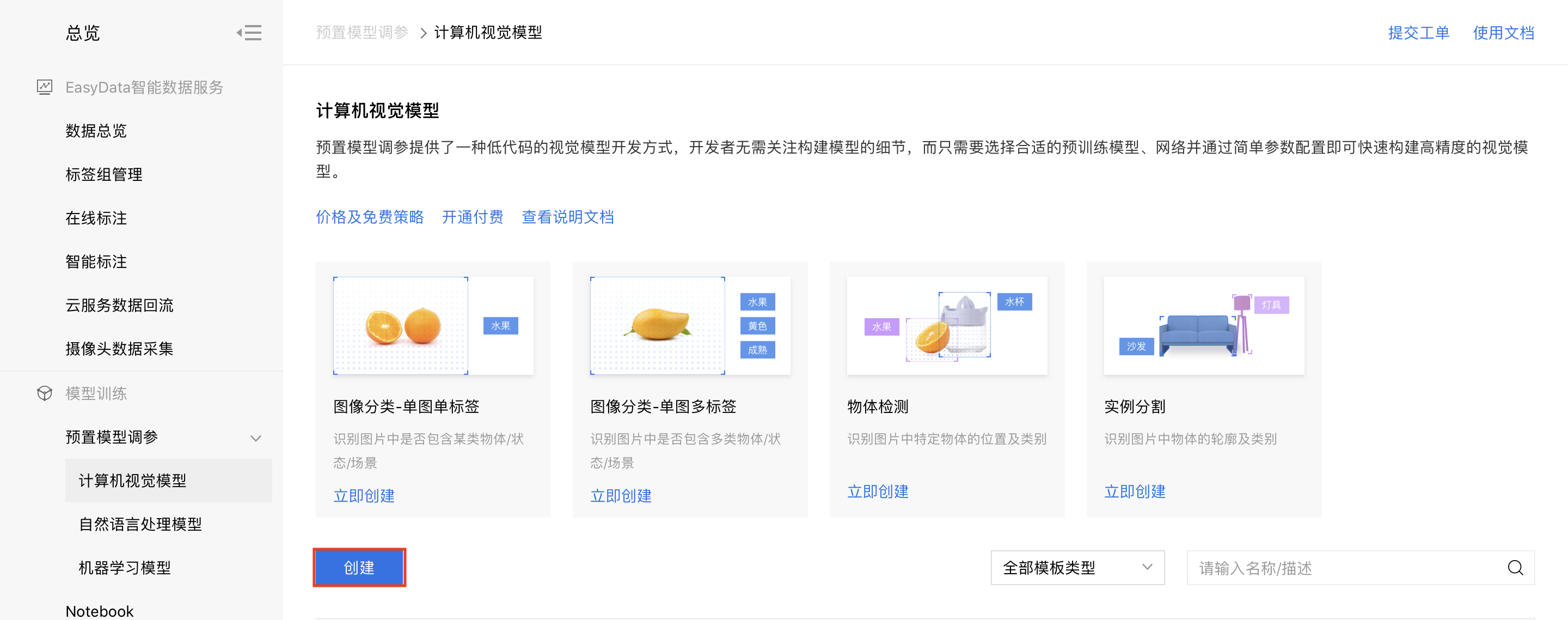
2、填写项目信息并点击【新建】。
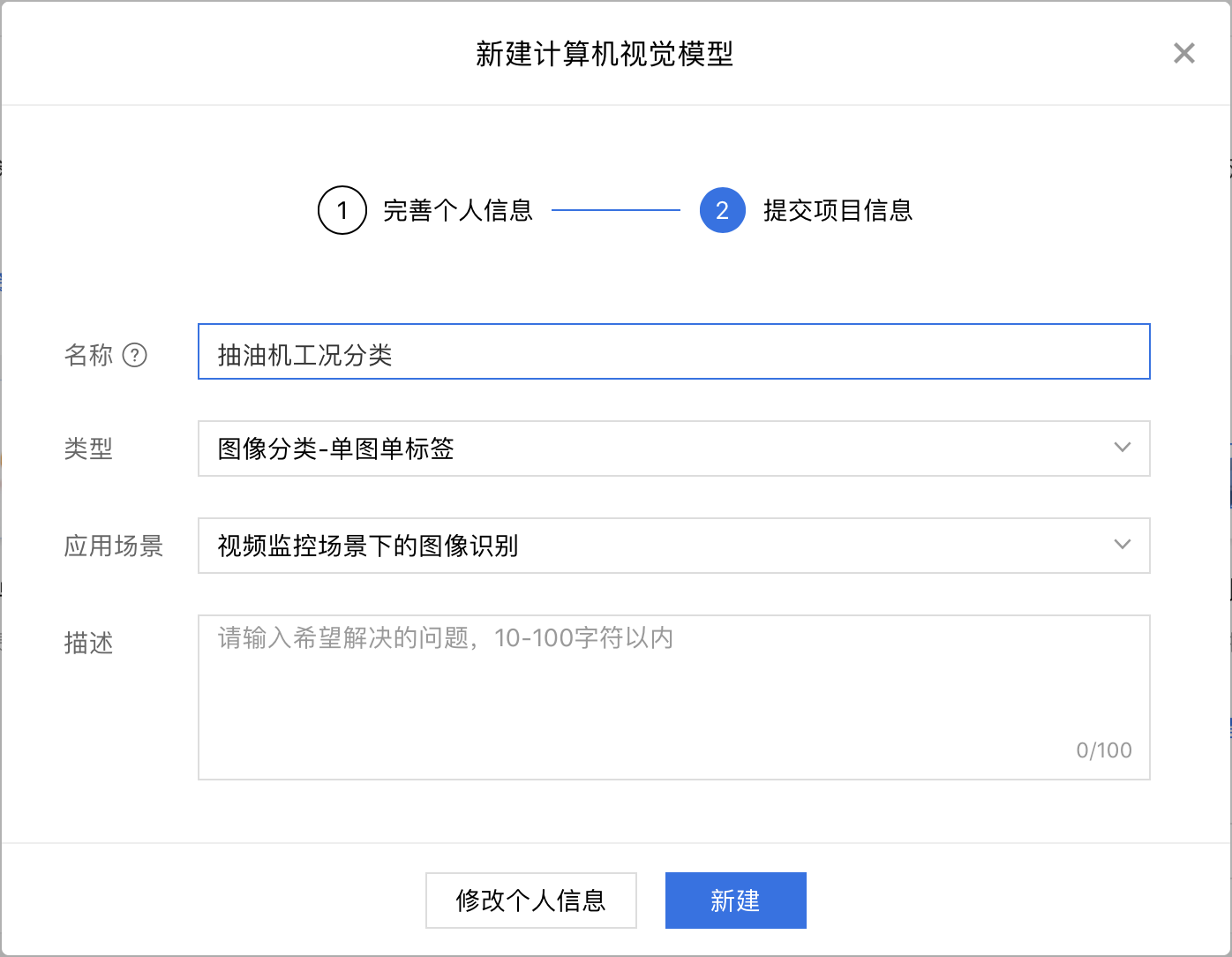
3、点击【新建任务】。
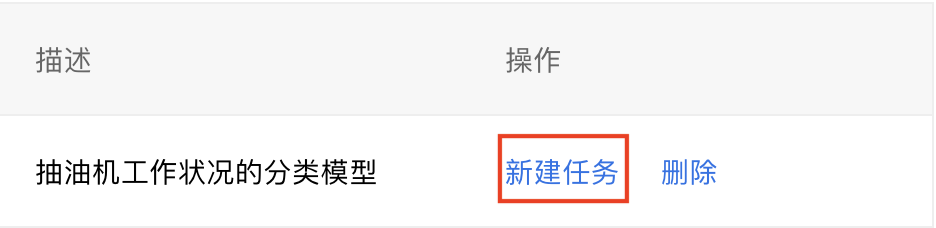
4、点击【+请选择】,勾选刚刚上传数据集下的所有标签类,点击右下角【确定】。
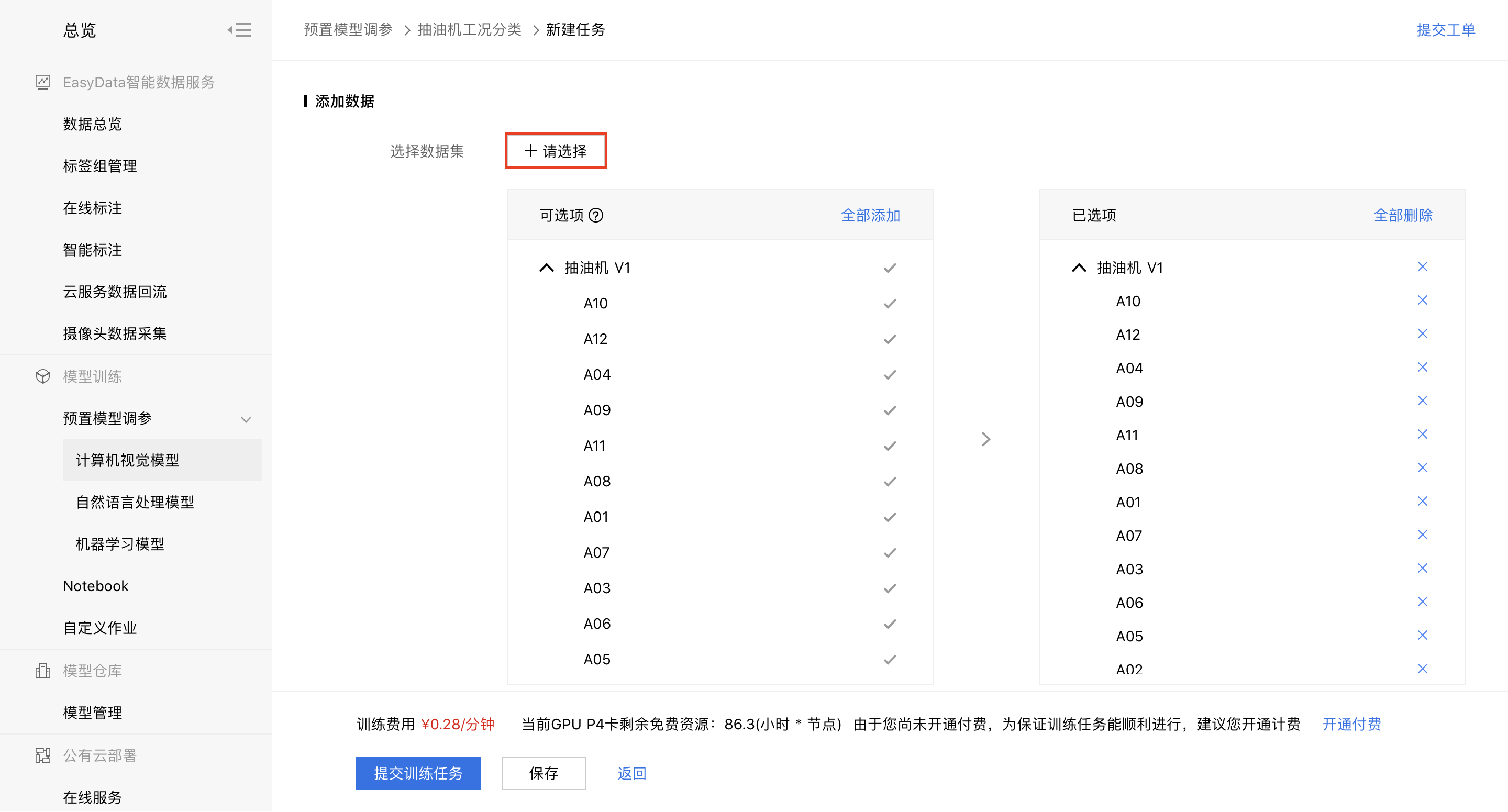
5、可以选择上传验证集和测试集。验证集用来确定模型训练过程中超参数的调整。测试集用来获得更客观的模型效果评估结果。如果选择不上传,系统也会自动从已上传的训练集中分割出验证和测试集。

6、配置网络,如果选择网络选型参考:网络选型介绍。
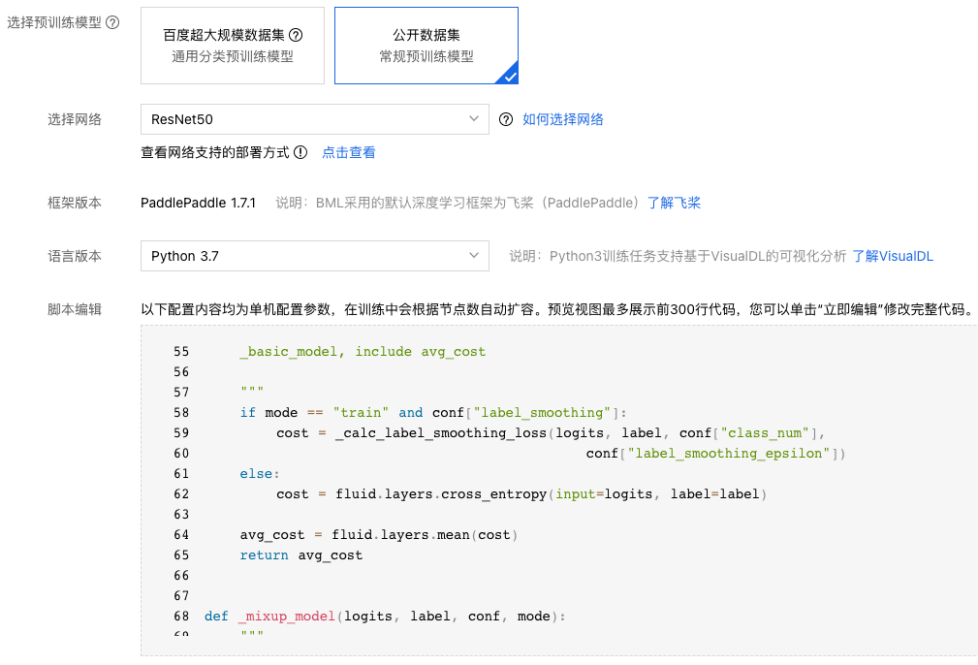
7、配置超参数。如果选择脚本编辑为超参来源, 可在脚本编辑部分代码框内自定义超参数。超参数配置参考:超参数选择。

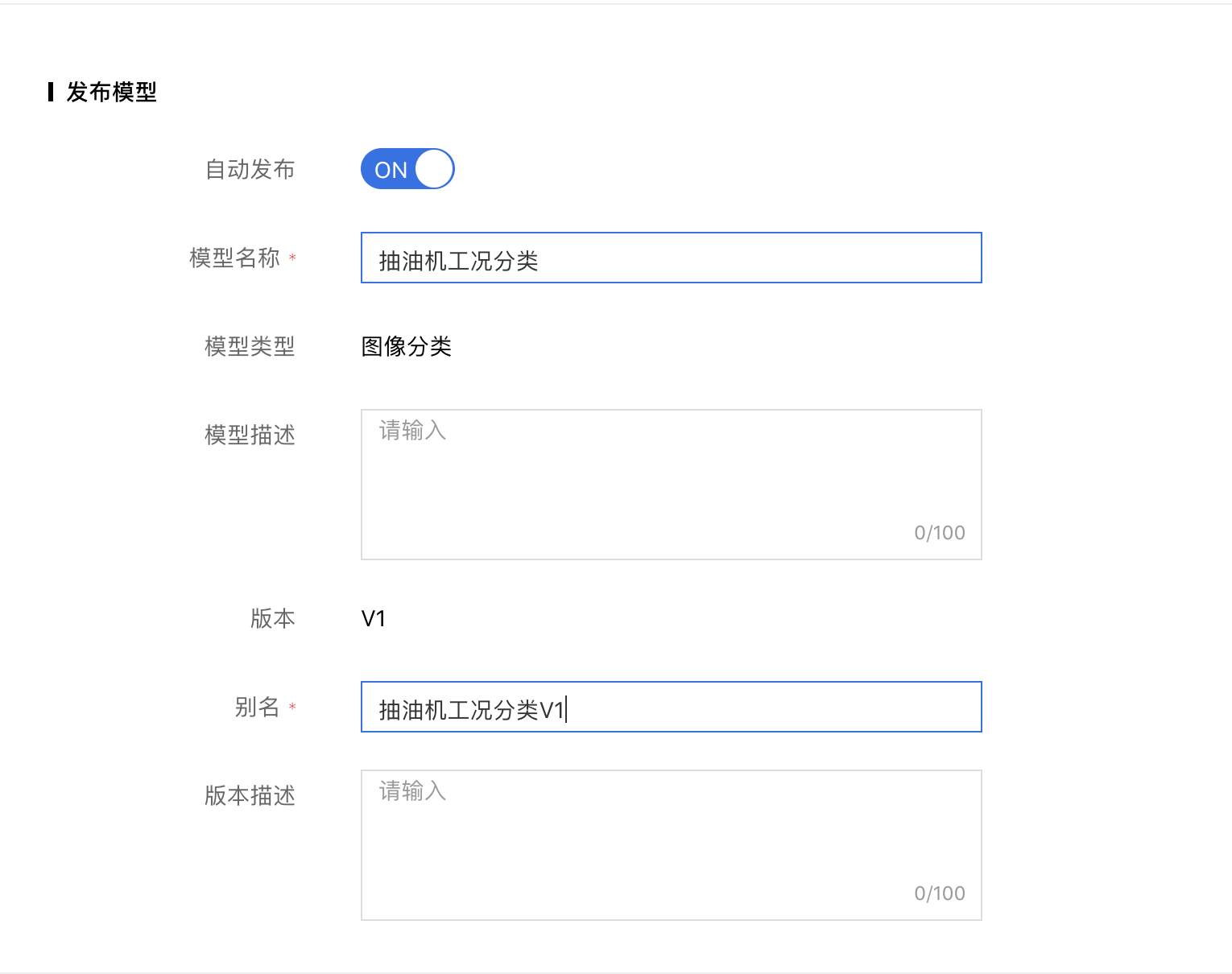
8、可填写相关信息,并发布模型。也可以模型训练完成后再根据训练结果决定是否发布。
9、根据自身的周期和经费安排,配置计算资源。
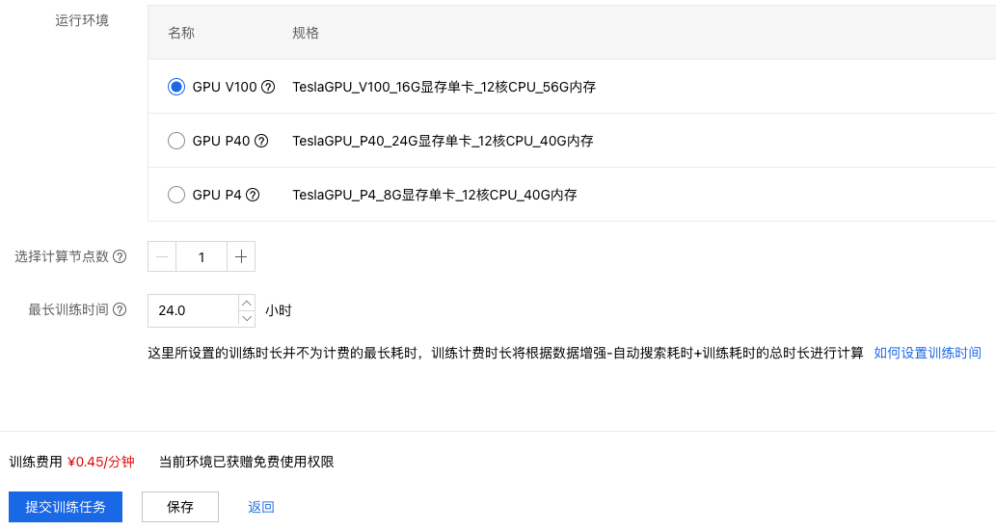
10、最后点击【提交训练任务】,进入模型训练。
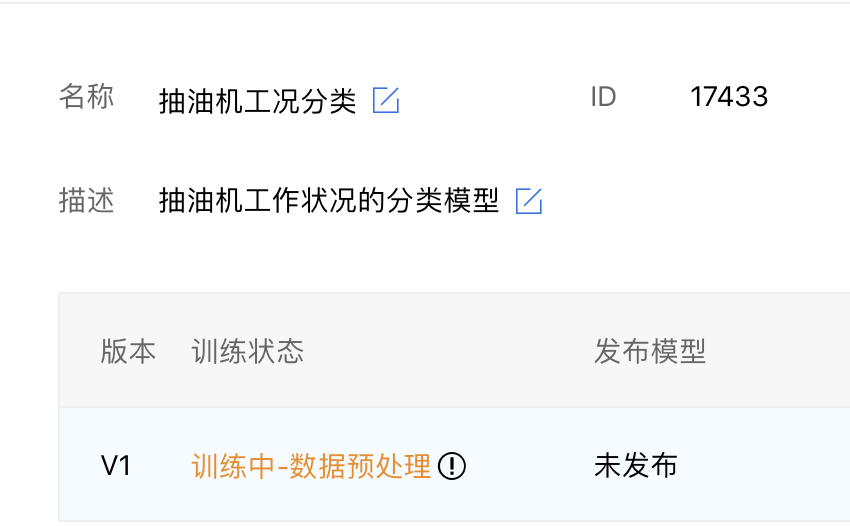
模型分析和调优
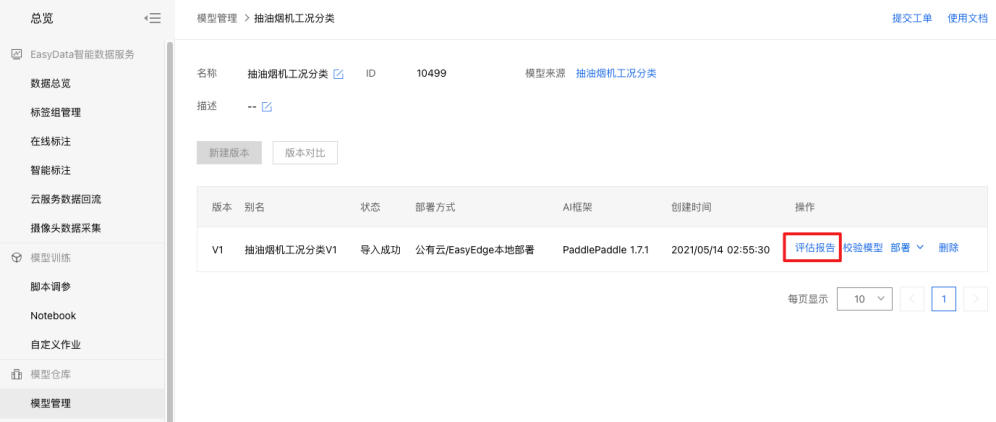
1、获取评估报告:点击【模型仓库】-【模型管理】,点击对应任务的【版本列表】查看训练好的模型,点击【评估报告】。
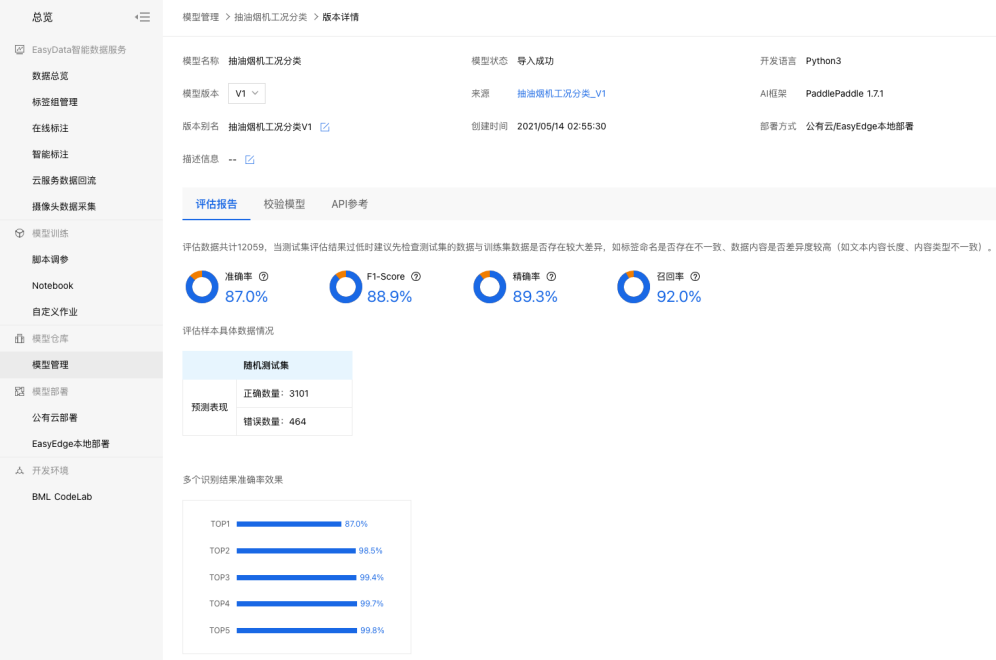
评估报告如下所示:
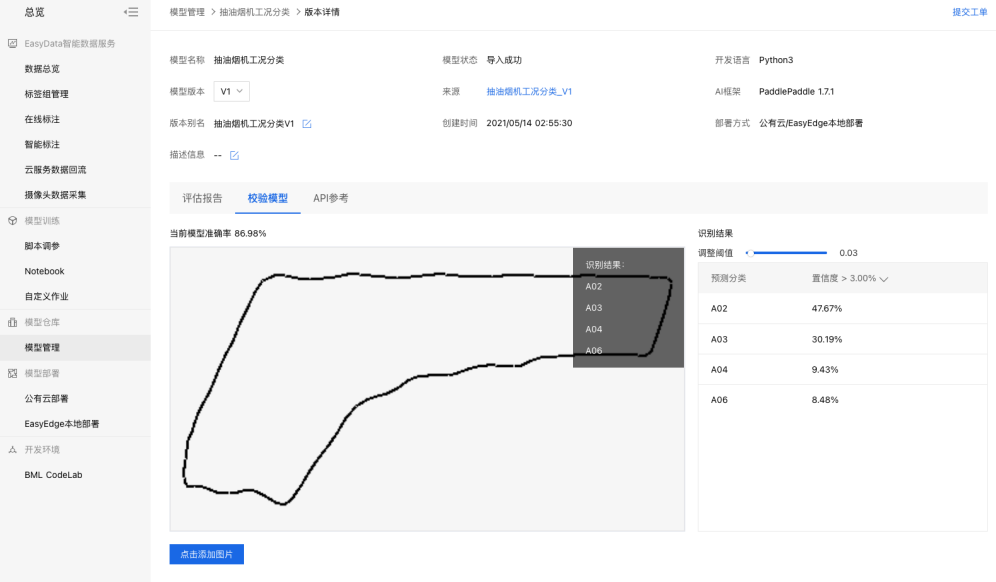
2、点击【校验模型】。
3、模型调优:新建模型时添加如下配置,可提高模型效果。
策略一:数据增强策略(数据增强算子参考)
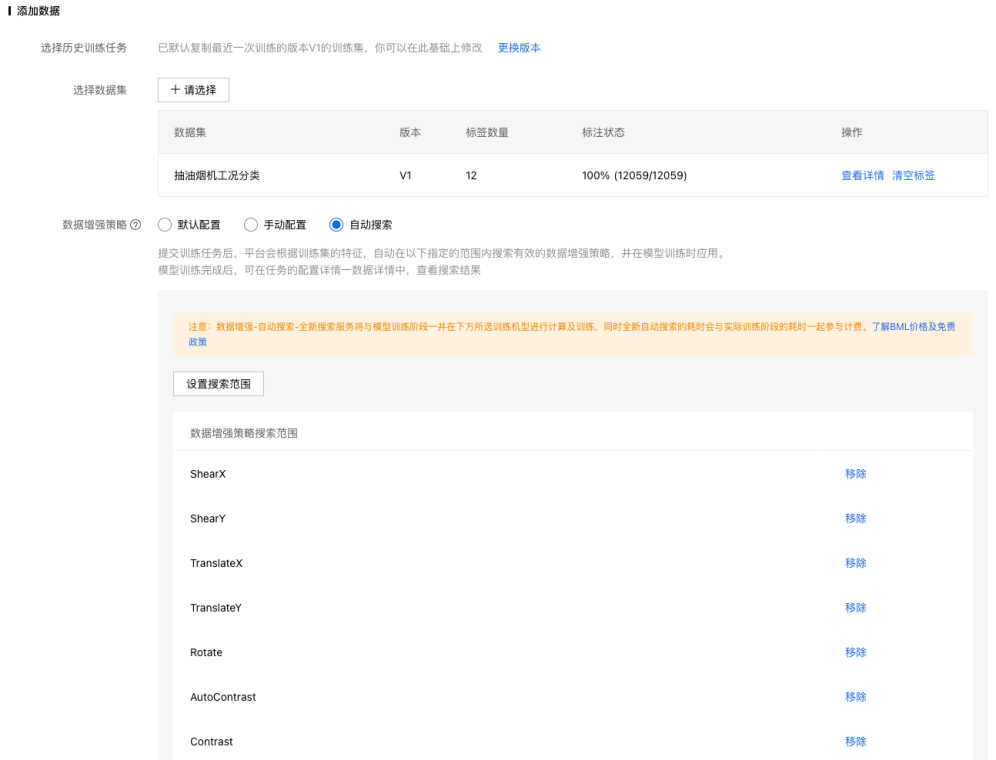
策略二:百度超大规模数据集预训练(预训练模型参考)
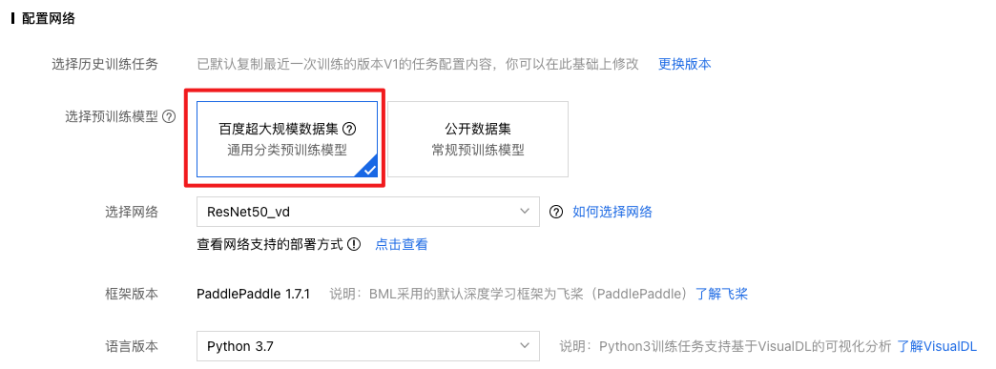
策略三:自动超参搜索(自动超参配置参考)
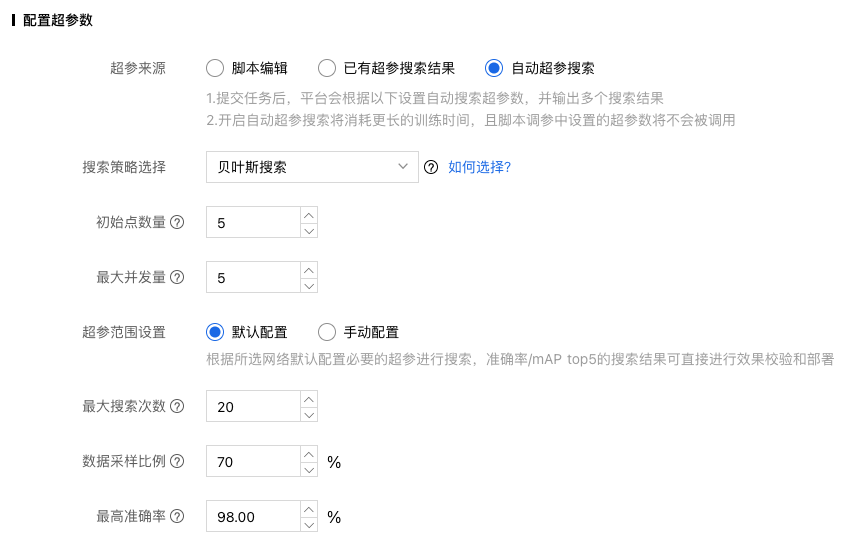
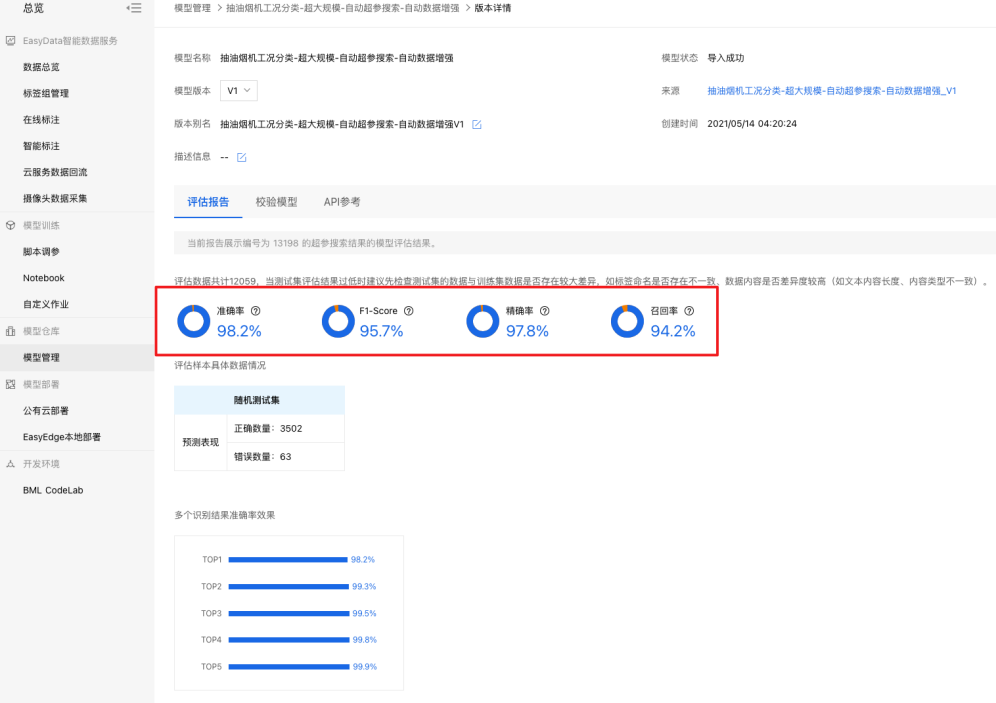
采用以上优化策略之后,重新打开评估报告,可以看到效果有明显的提升。
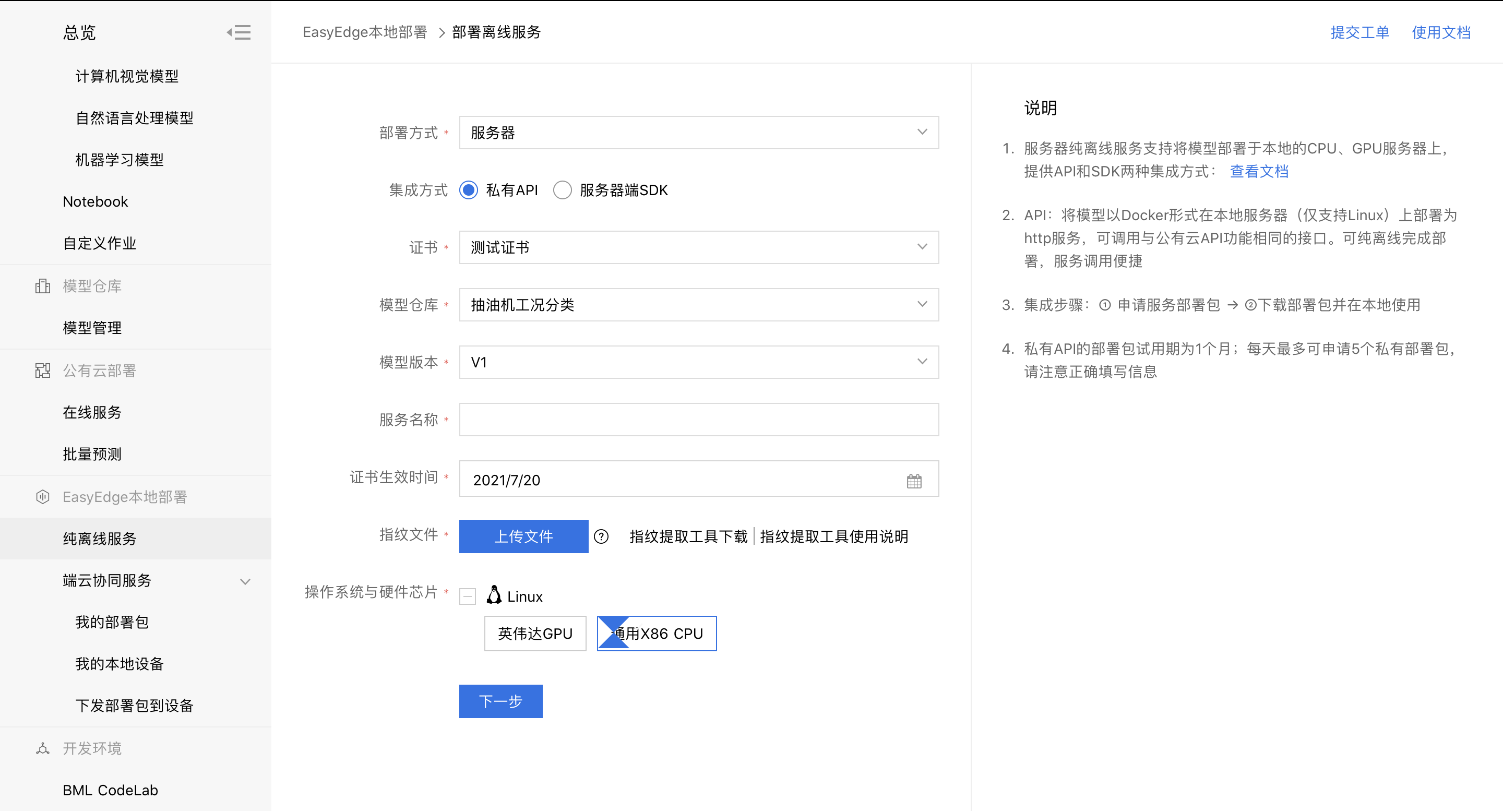
部署模型
1、在模型管理中,可选择公有云部署,端云协同服务,批量预测,和纯离线服务四种方式部署模型。具体参考:如何选择部署方式
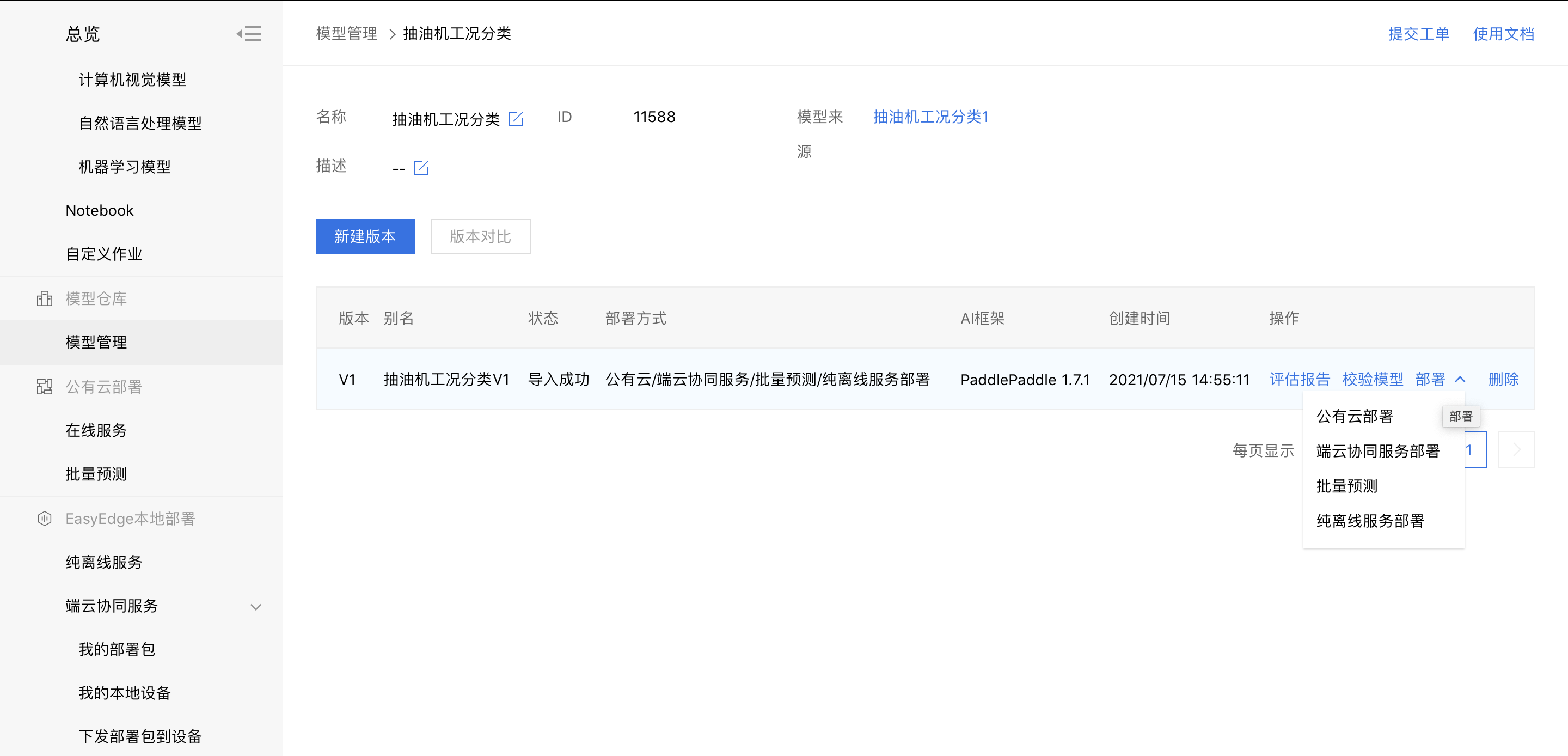
2、在模型部署中,用户按照自己情况填写信息完成模型部署。下图以本地部署纯离线服务为例。