013-模型评估组件
更新时间:2025-12-08
模型评估组件
二分类评估
评估模块支持计算 AUC、KS 及 F1 score,同时输出数据用于画 PR 曲线、ROC 曲线、KS 曲线、LIFT chart、Gain chart,同时也支持分组评估。
输入
- 最多可输入4个数据集,用户需要选择原始标签列、预测标签列和正样本标签值,还可以提供scoreColumn获得更多指标。
输出
- 第一个输出是summary数据集,第二个输出是metricsByThreshold数据集,运行后在组件的右键菜单可查看图形化的衡量指标。
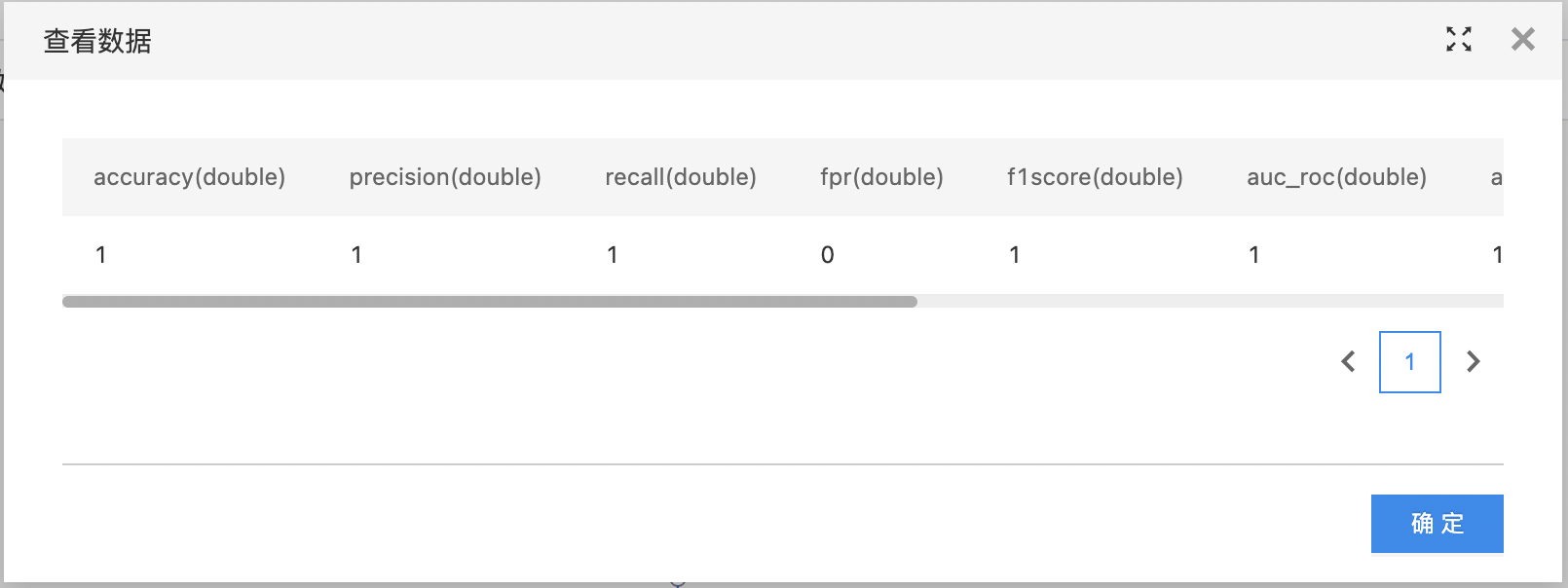
- summary数据集:只有一行,每一列是一个评价指标,包括以下指标:accuracy、precision、recall、FPR、f1score、auc(roc曲线下的面积。如果参数未提供scoreColumn则没有此项指标)、area under pr(pr曲线下的面积。如果参数未提供scoreColumn则没有此项指标)。
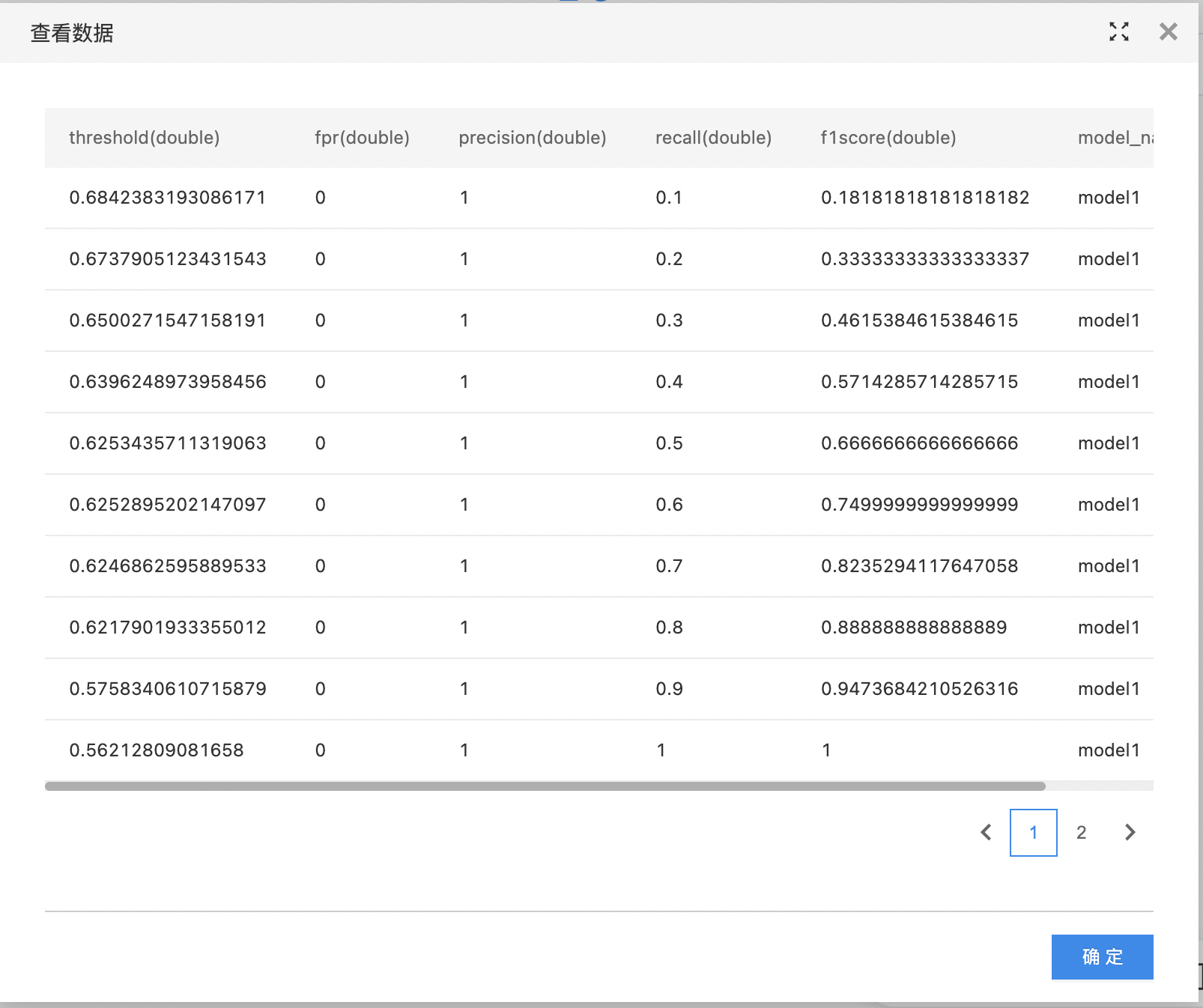
- metricsByThreshold数据集:描述了阈值变化时fp率、precision、recall、f1score的变化。如果参数未提供scoreColumn则此数据集为空。
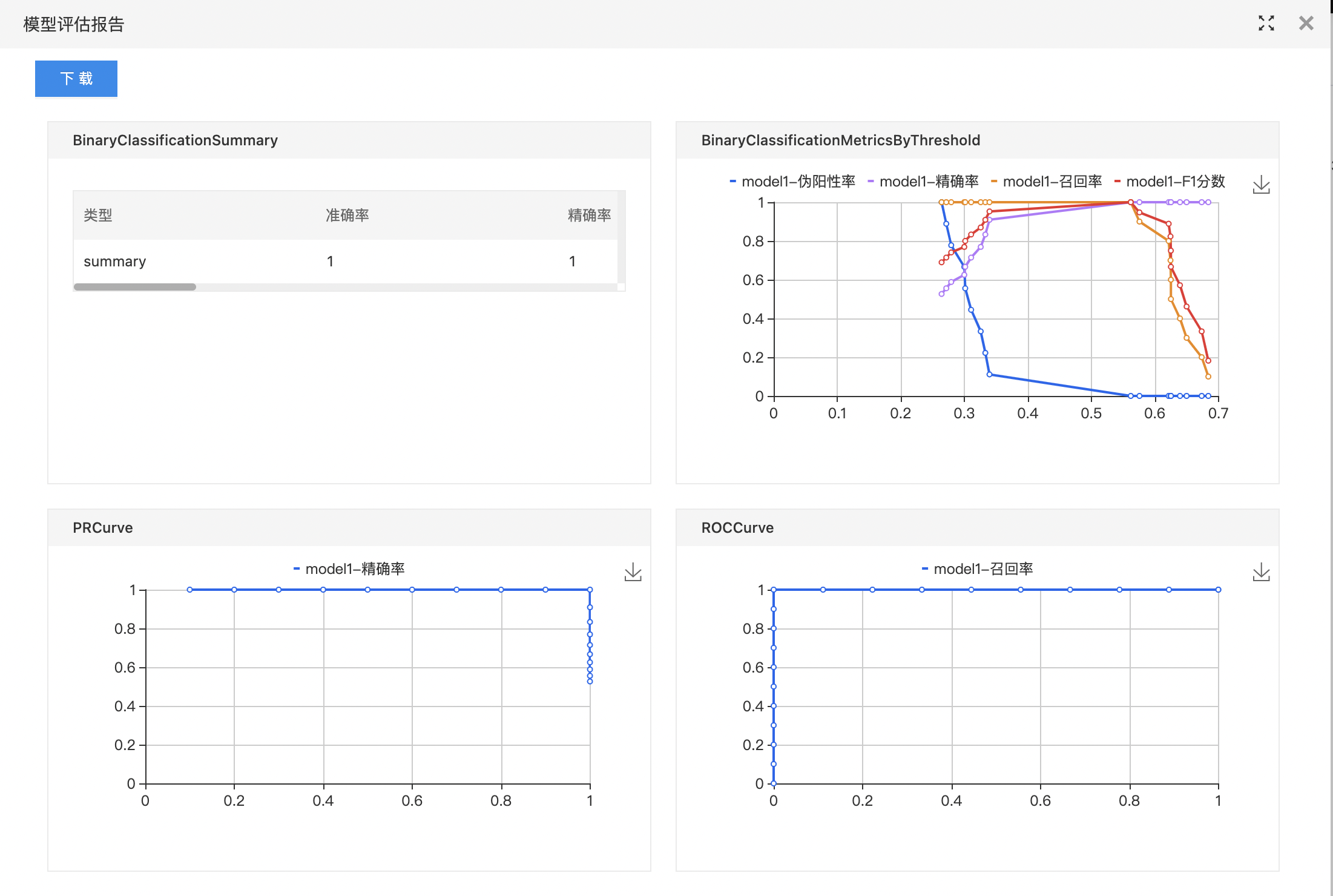
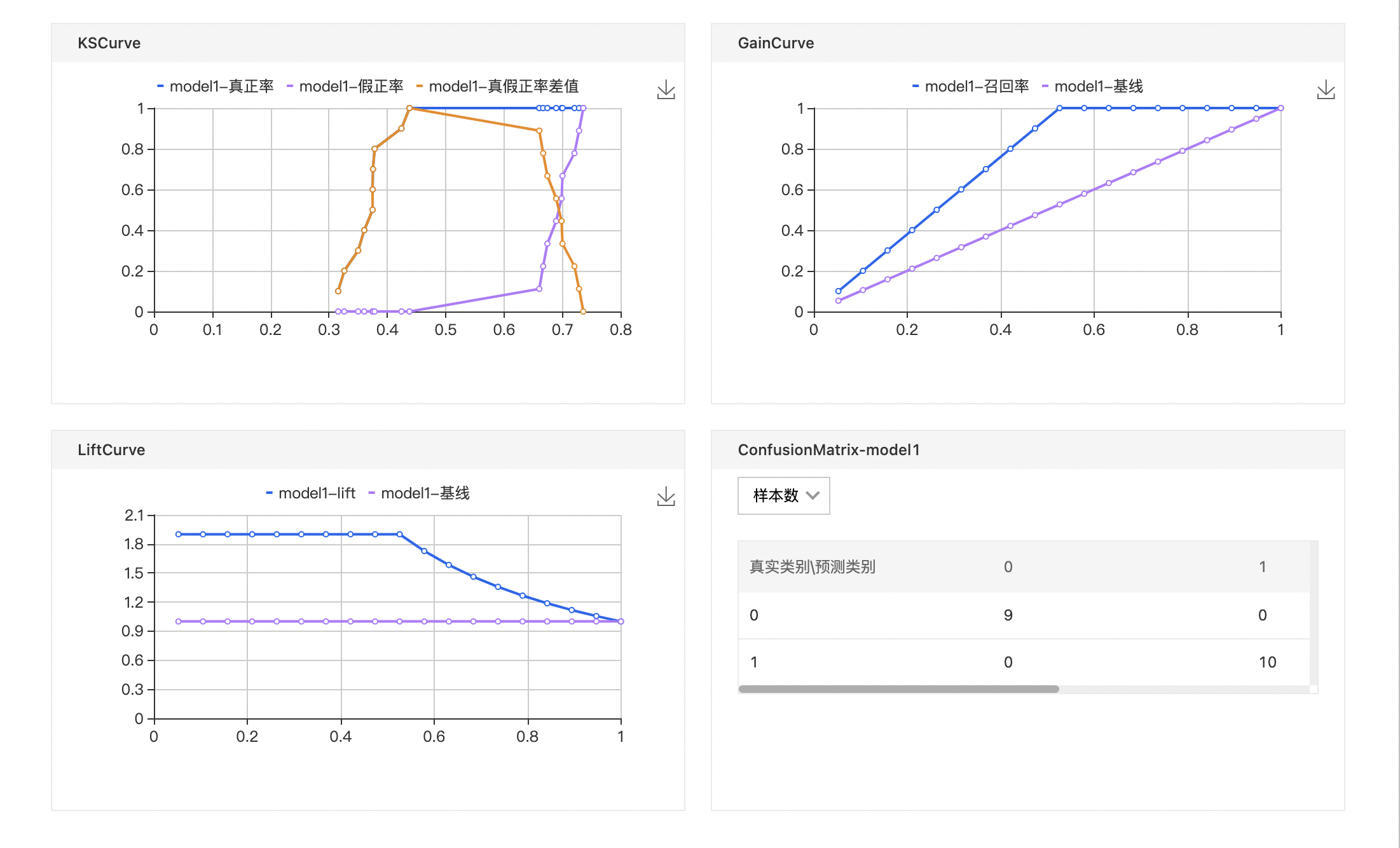
- 右键菜单查看模型评估报告:包含多张可视化的衡量指标图。
字段参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 真实标签列列名 | 是 | 该列代表真实的标签,需要是非数组类型,唯一值最多是2,最多可选择4个真实标签列(仅第1个必选)。 | 无 |
| 评估列选择 | 是 | 自动配置会根据系统默认字段配置字段。手动配置可以手动选择要预测标签列。 | 自动配置 |
| 评估内容配置 | 是 | 基础评估只进行基本指标的评估。详细评估在有预测概率列时使用,提供详细的评估。 | 基础评估 |
| 预测概率列 | 否 | 输入数据集中的该列代表从0到1的预测概率,概率越大表示越接近正样本。必须是Double类型 | |
| 正样本标签 | 否 | 二分类的正样本的标签值 | 无 |
| 预测标签列列名 | 否 | 该列代表预测得到的标签,是评估的对象,最多可选择4个预测标签列。 | 无 |
| 分桶数 | 是 | 计算ROC曲线、F-score by threshold等指标时把数据分成多少份 范围:[5, 1000] | 20 |
评估指标
| 名称 | 介绍 |
|---|---|
| accuracy | 准确率 |
| precision | 精准率 |
| recall | 召回率 |
| FPR | 伪阳性率 |
| f1score | F1分数 |
| auc | roc曲线下面积 |
| area under pr | pr曲线下面积 |
使用示例
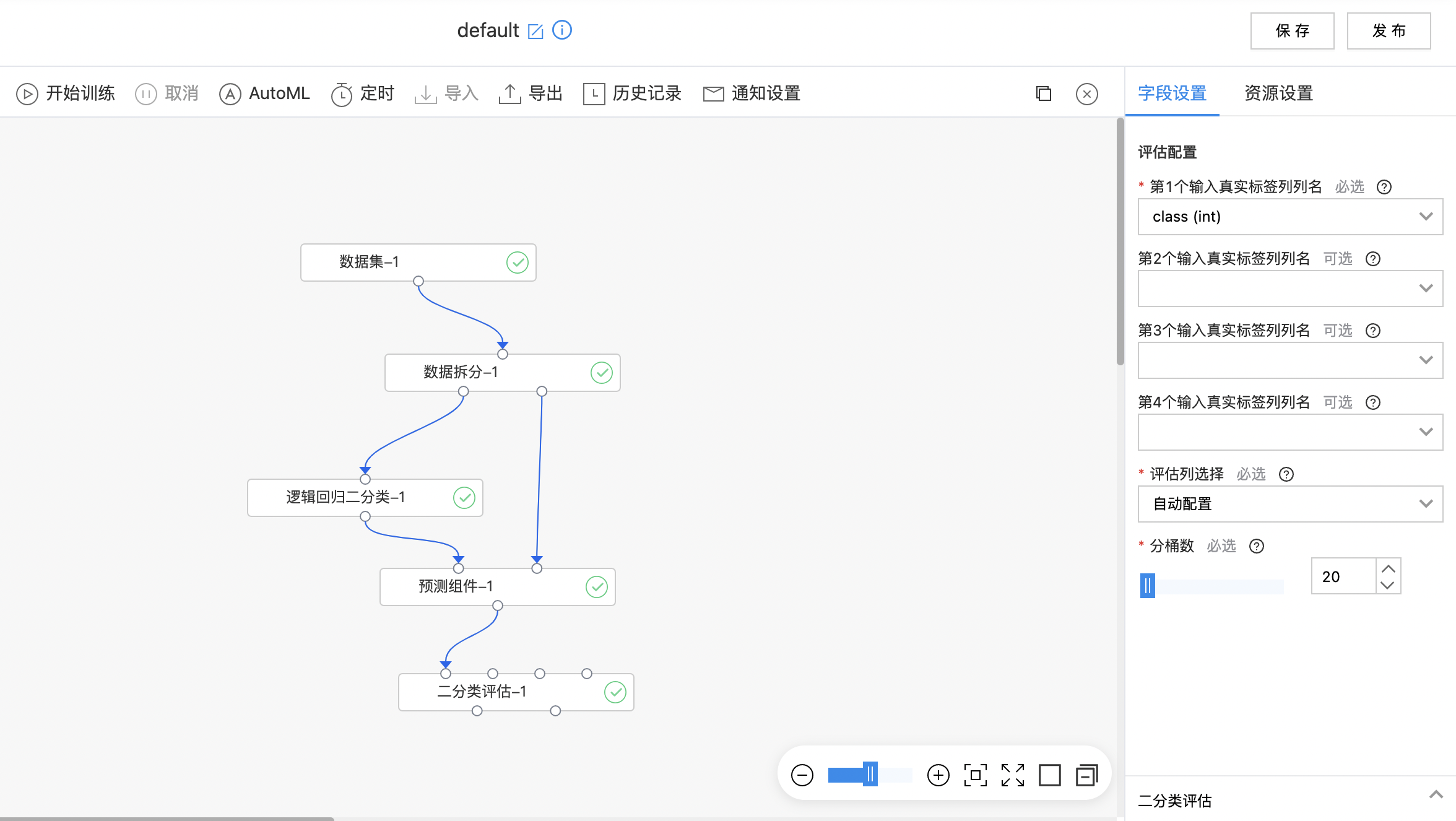
- 搭建算子结构如下图所示,配置二分类评估组件参数,运行算子。
- 查看summary数据集。
- 查看metricsByThreshold数据集。
- 右键查看模型评估报告。
多分类评估
基于分类模型的预测结果和原始结果,评价多分类算法模型的优劣,指标包括 Accuracy、F1-Score 等。
输入
- 最多可输入4个数据集,用户需要选择原始标签列、预测标签列。
输出
- 第一个输出是summary数据集,第二个输出是分类指标表,右键可以查看模型评估报告。
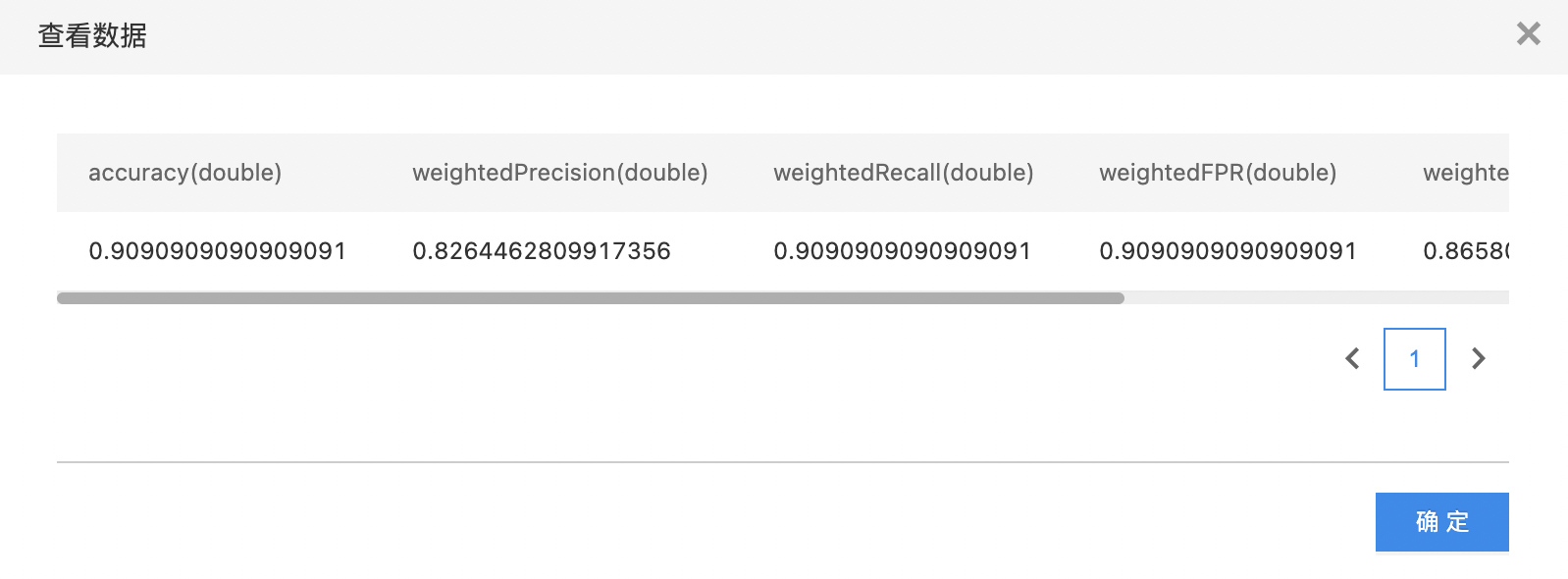
- summary数据集只有一行,每一列是一个评价指标,包括以下指标:accuracy、weighted recall、weighted precision、weighted FPR、weighted f1score。
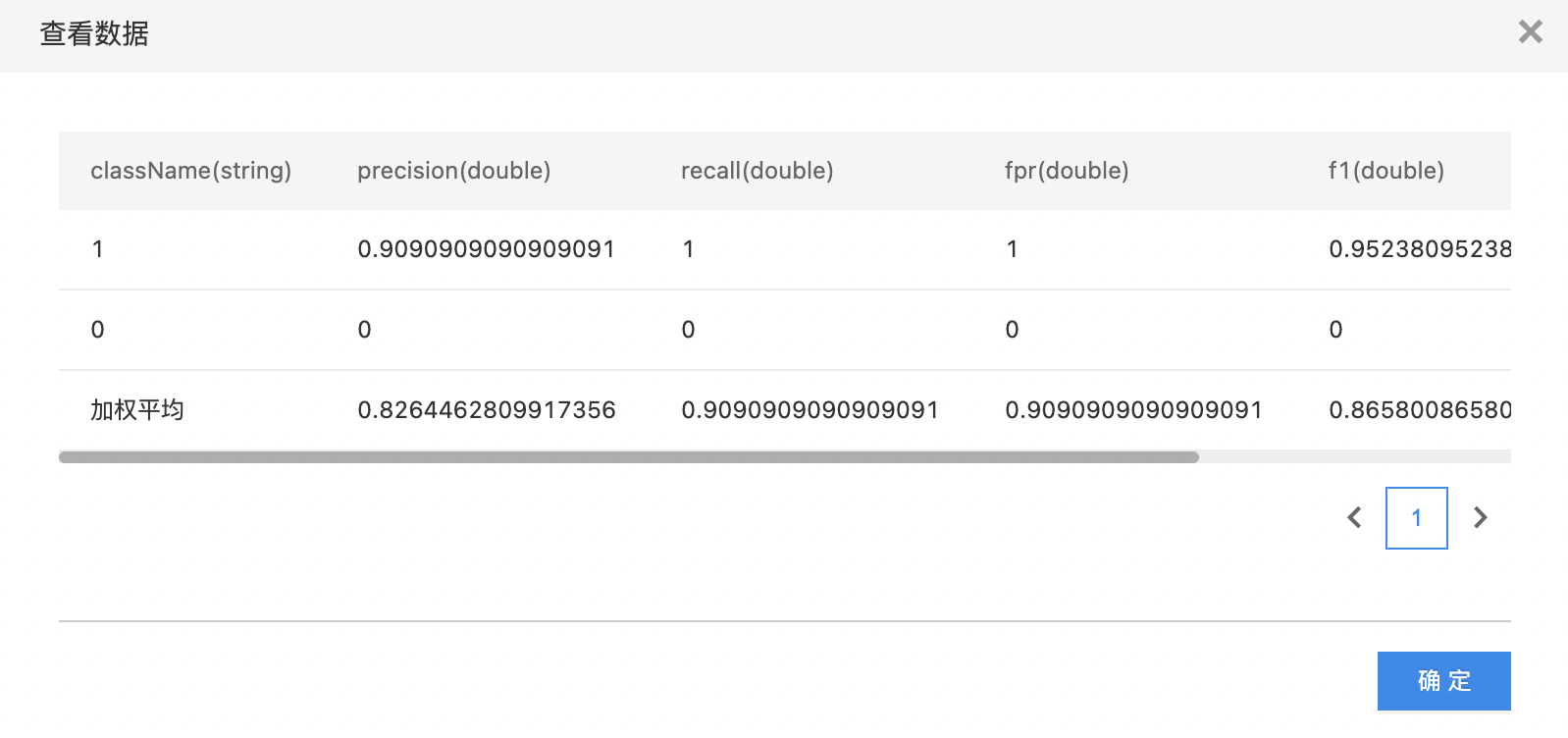
- metricsByLabel数据集:描述了不同标签的fp率、precision、recall、f1score。
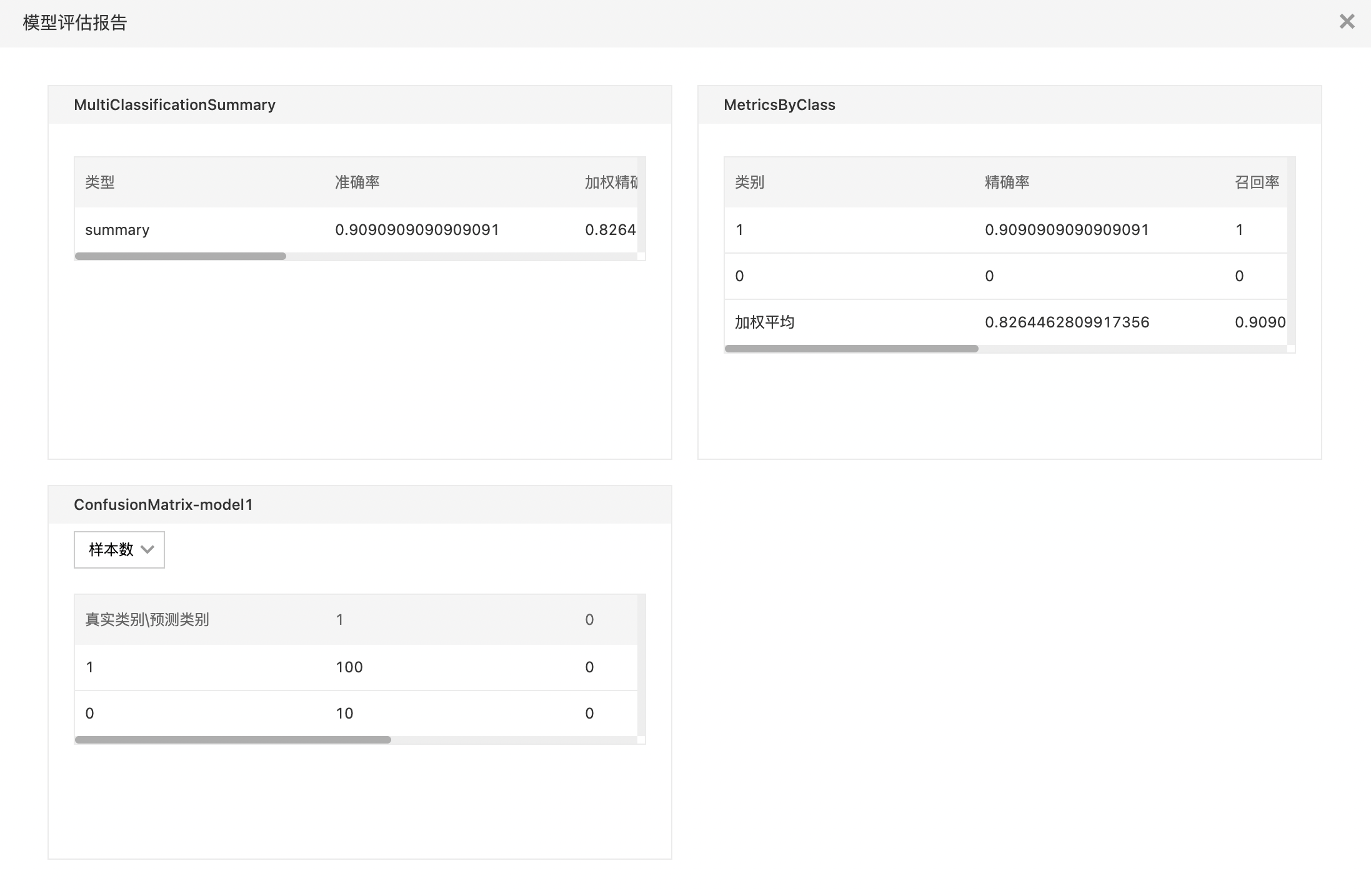
- 模型评估报告:展示了上面两个表格与混淆矩阵。
字段参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 真实标签列列名 | 是 | 该列代表真实的标签,需要是非数组类型,最多选择4个真实标签列列名(仅第1个必选)。 | 无 |
| 评估列选择 | 是 | 自动配置会根据系统默认字段配置字段。手动配置可以手动选择要预测标签列。 | 自动配置 |
| 标签列列名 | 否 | 该列代表预测得到的标签,是评估的对象,最多选择4个标签列列名。 | 无 |
评估指标
| 名称 | 介绍 |
|---|---|
| weighted recall | 加权精准率 |
| weighted precision | 加权召回率 |
| weighted FPR | 加权伪阳性 |
| weighted f1score | 加权f1分数 |
| recall | 召回率 |
| precision | 精准率 |
| fpr | fp率 |
| f1score | f1分数 |
| accuracy | 准确率 |
使用示例
- 多分类与二分类的使用方法一样,将模型更换为多分类即可,该示例只展示评估指标。
- 查看summary数据集。
- 查看分类指标表。
- 查看模型评估报告。
回归评估
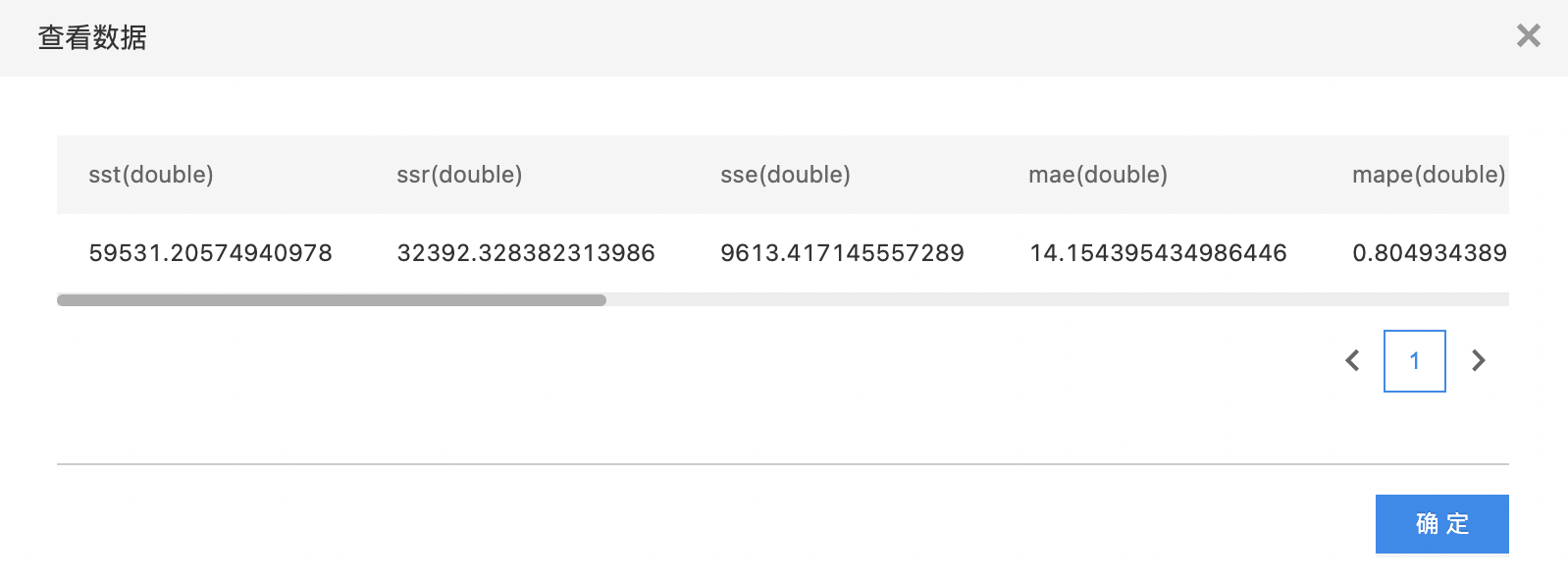
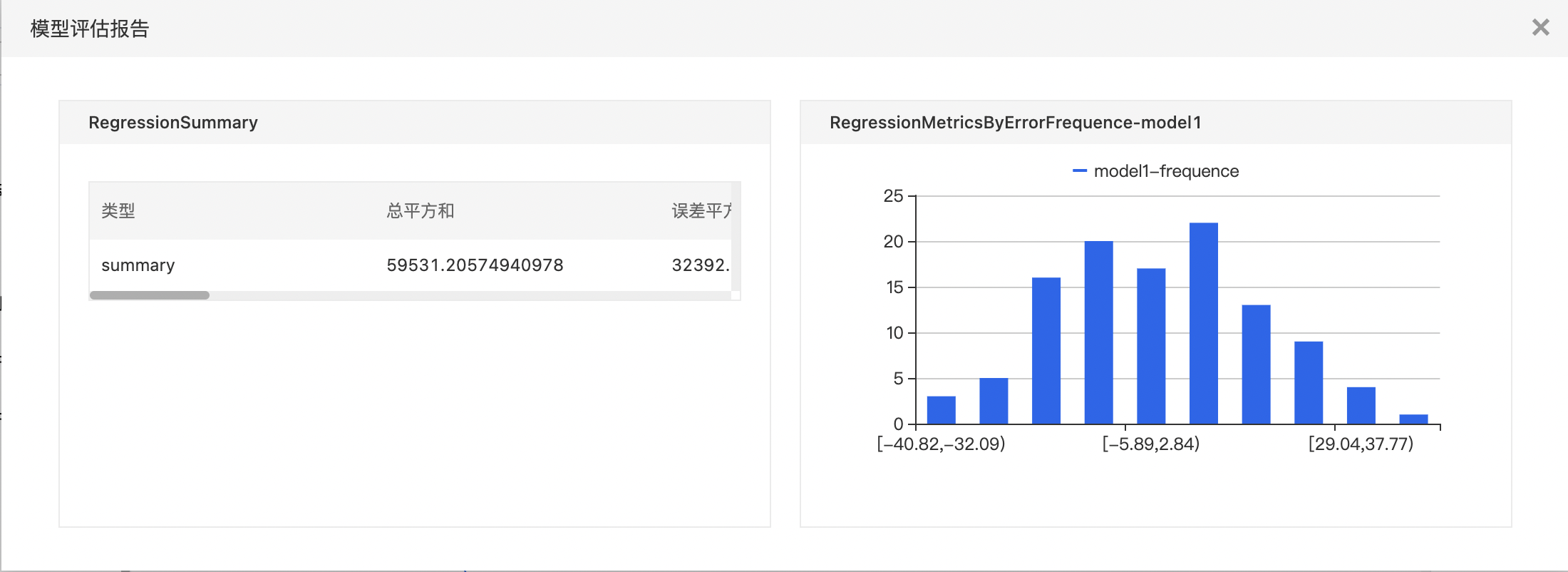
基于预测结果和原始结果,评价回归算法模型的优劣,包含指标和残差直返图。其中指标包括 SST、SSE、SSR、R2、R、 MSE、RMSE、MAE、MAD、MAPE、count、yMean 和 predictMean。
输入
- 最多可输入4个数据集,用户需要选择原始标签列、预测标签列。
输出
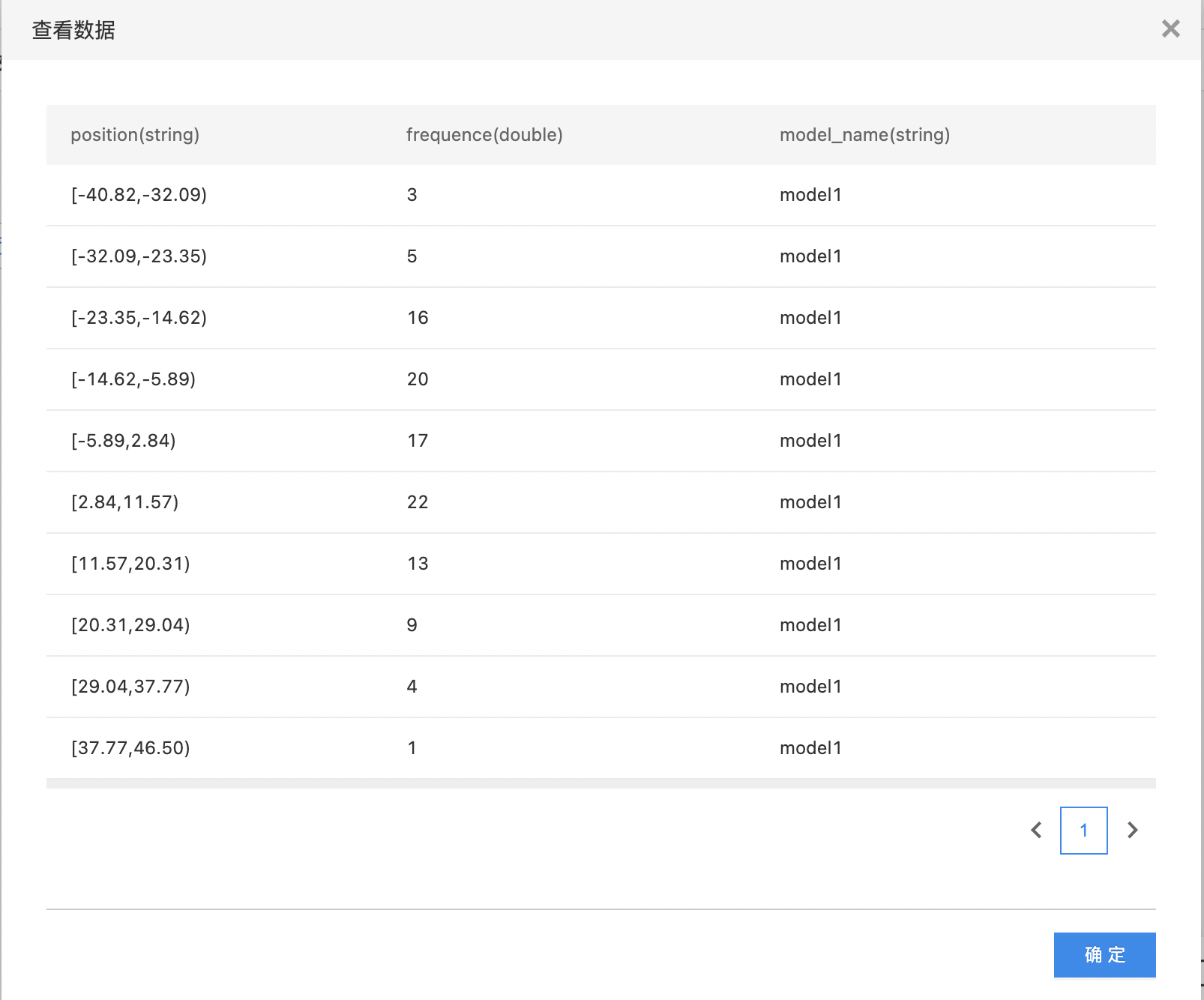
- 第一个输出是summary数据表,第二个输出是误差统计,对误差划分为10等份,统计每个区间内样本数量,右键可以查看模型评估报告。
字段参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 真实标签列列名 | 是 | 该列代表真实的标签,需要是数值类型,最多可选择4个真实标签列(仅第1个必选)。 | 无 |
| 评估列选择 | 是 | 自动配置会根据系统默认字段配置字段。手动配置可以手动选择要预测标签列。 | 自动配置 |
| 预测标签列列名 | 否 | 该列代表预测得到的标签,是评估的对象,最多可选择4个预测标签列。 | 无 |
评估指标
| 名称 | 介绍 |
|---|---|
| SST | 总平方和 |
| SSE | 误差平方和 |
| SSR | 回归平方和 |
| R2 | 判定系数 |
| MSE | 均方误差 |
| RMSE | 均方根误差 |
| MAE | 平均绝对误差 |
| MAPE | 平均绝对百分误差 |
| explained variance | 可解释方差 |
| yMean | 原始列均值 |
| predictionMean | 预测列均值 |
使用示例
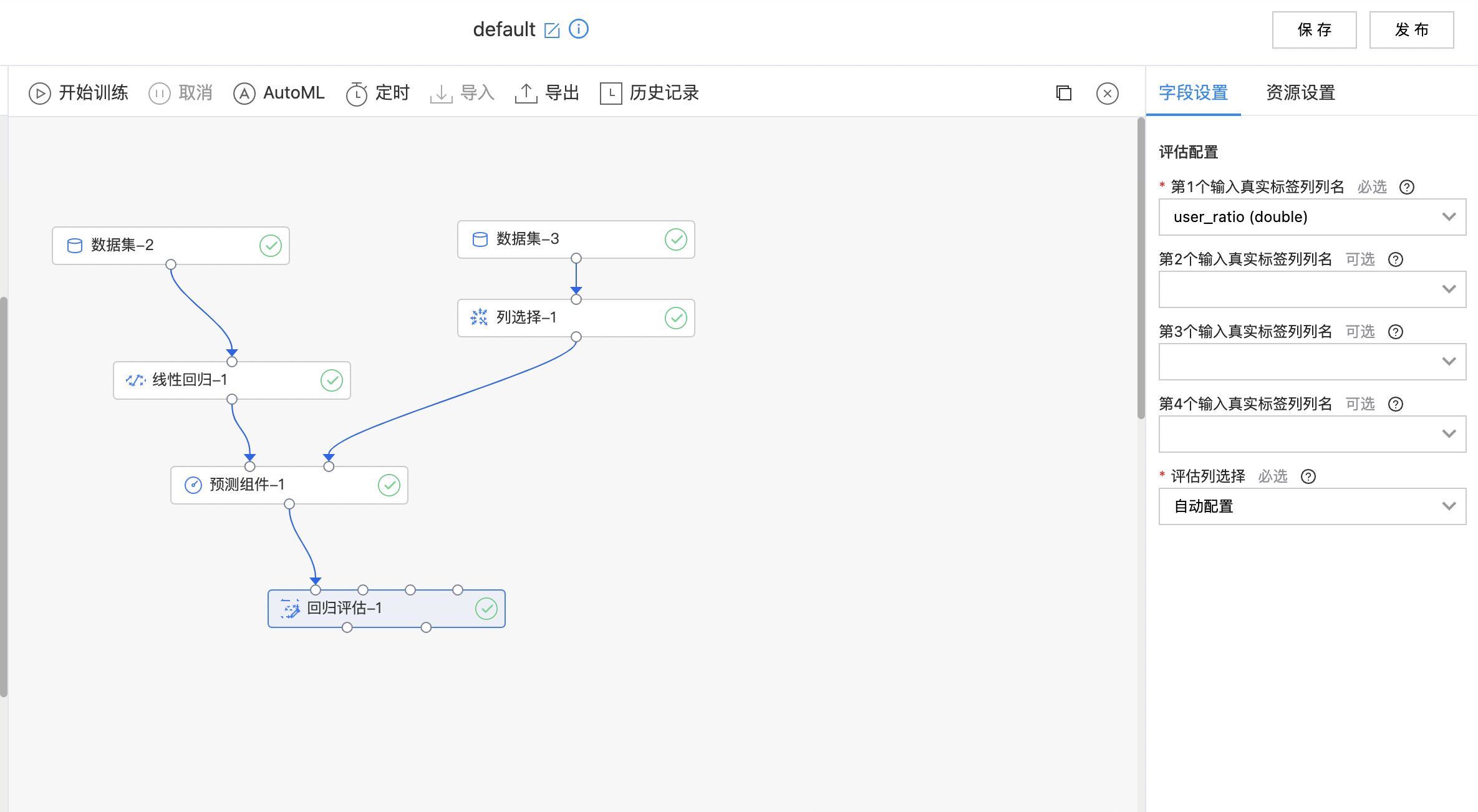
- 搭建算子结构如下图所示,配置回归评估组件参数,运行算子。
- 查看summary数据集。
- 查看误差统计。
- 查看模型评估报告。
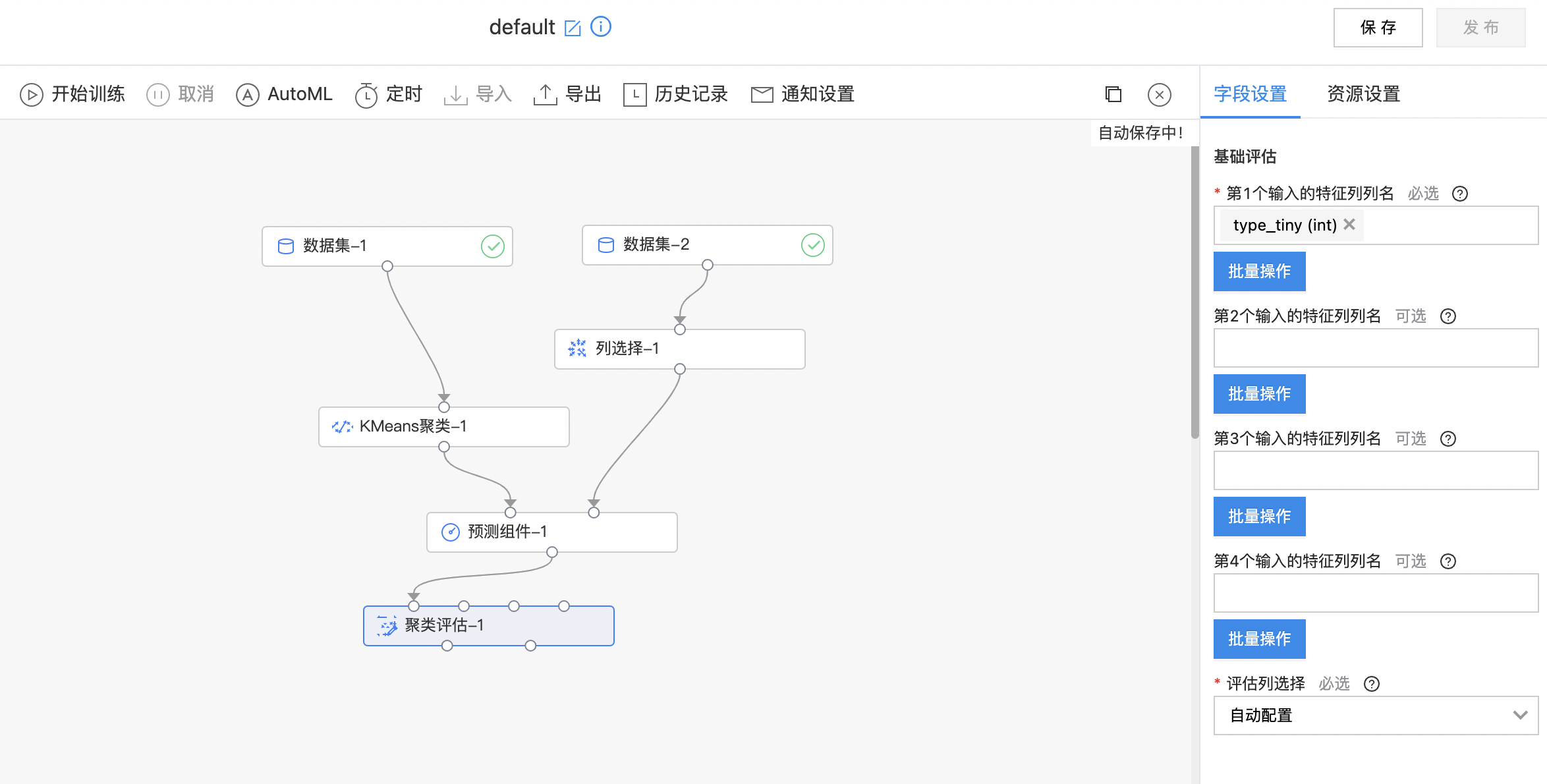
聚类评估
基于原始数据和聚类模型,评价聚类模型的优劣,包含指标和图标。
输入
- 输入聚类评估后的数据集,需要选择模型评估时使用的特征列,要求必须是模型存储特征值一致,预测标签列,离质心距离。
输出
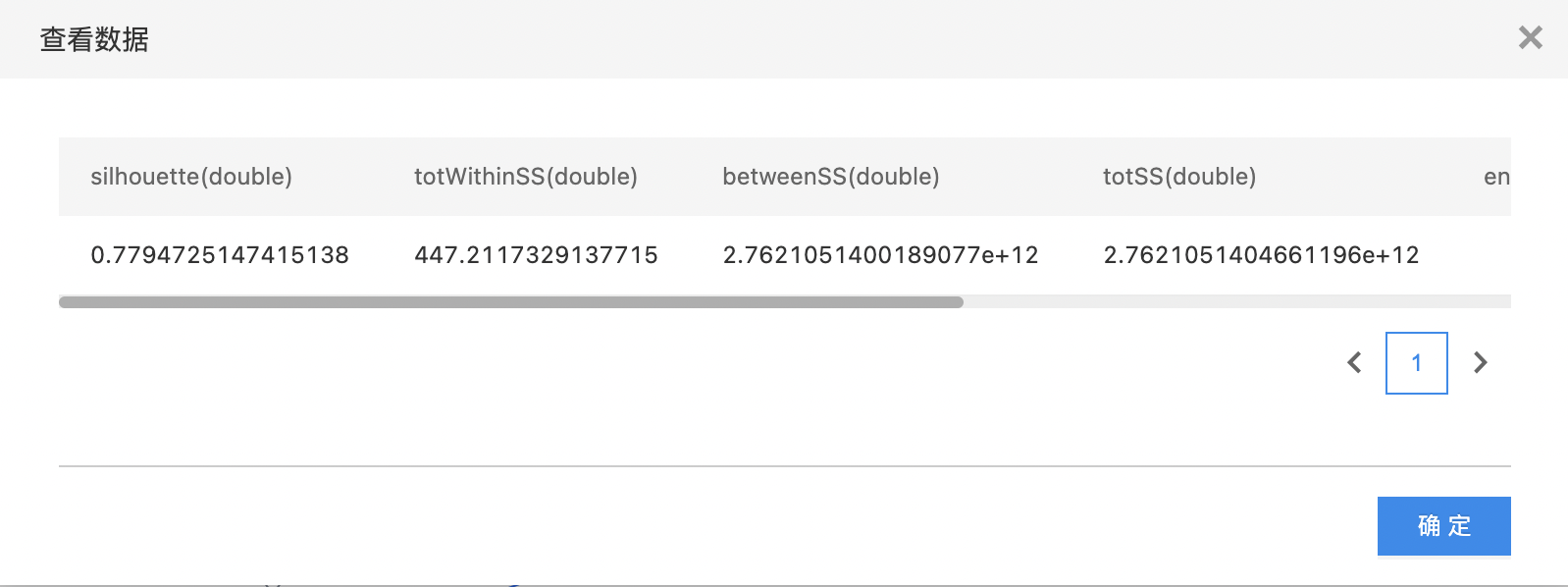
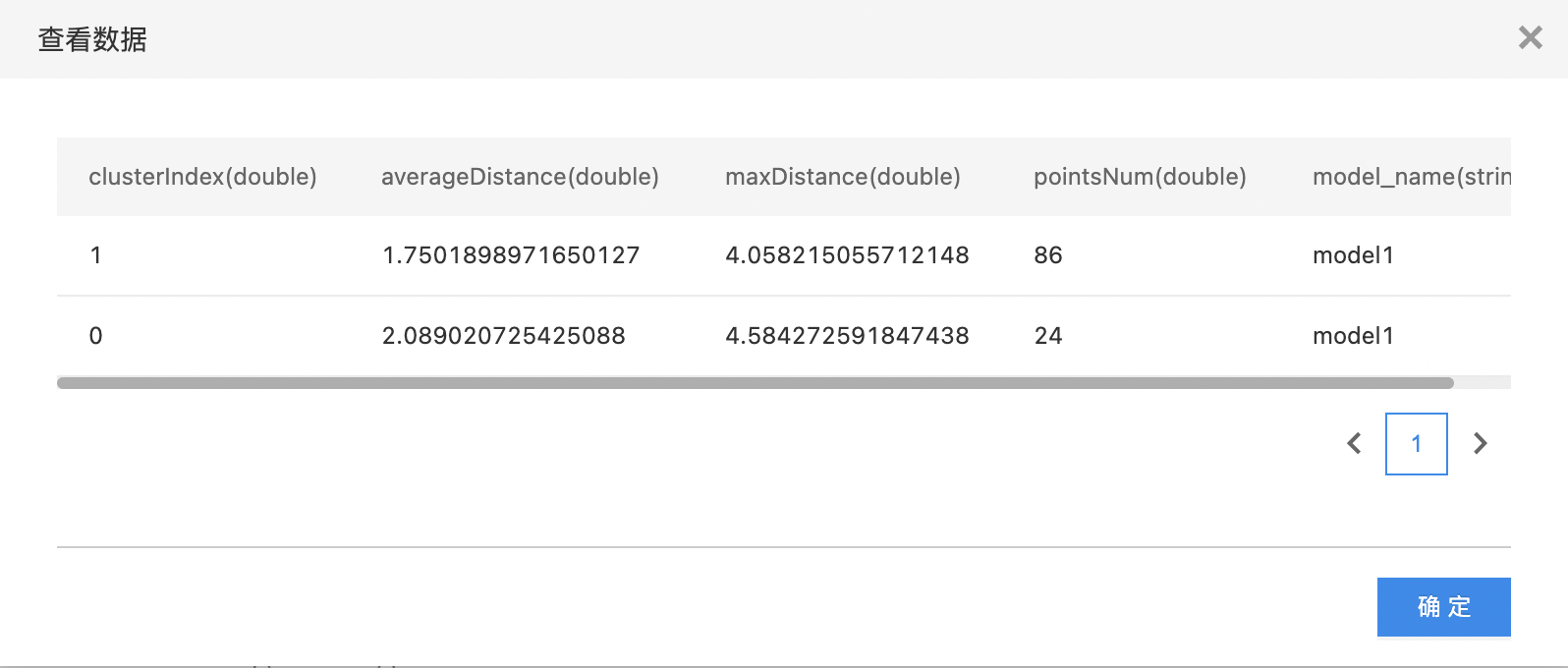
- 第一个输出是summary数据集,第二个输出是每个cluster统计信息,右键可以查看模型评估报告。
字段参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 特征列列名 | 是 | 模型评估时使用的特征列,要求必须是模型存储特征值一致,必须是数值或数值数组类型,最多配置4个特征列多选框(仅第1个必选)。 | 无 |
| 评估列选择 | 是 | 自动配置会根据系统默认字段配置字段。手动配置可以手动选择要预测标签列。 | 自动配置 |
| 预测标签列名 | 否 | 该列代表预测的聚类簇索引,必须是整数类型。 | 无 |
| 距离质心距离列 | 否 | 该列代表每个例子距离所有质心的距离,必须是数值数组类型。 | 无 |
| 真实标签列列名 | 否 | 该列代表每个例子距离所有质心的距离,必须是数值数组类型。 | 无 |
评估指标
| 名称 | 介绍 |
|---|---|
| Silhouette coefficient | 轮廓系数 |
| tot_withinss | 凝聚度 |
| totss | 总离差平方和 |
| betweenss | 分离度 |
| Average Distance to Cluster Center | 距质心平均距离 |
| Max Distance to Cluster Center | 距质心最大距离 |
| Number of Points | 簇内样本数 |
使用示例
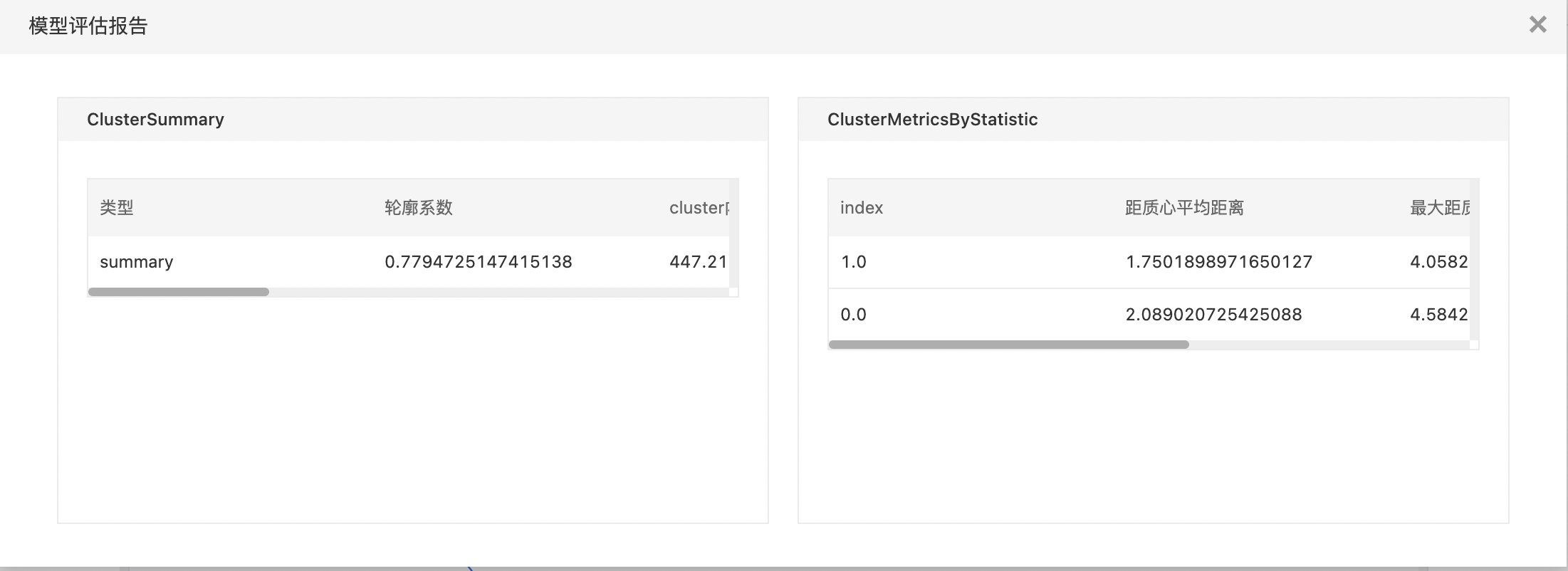
- 搭建算子结构如下图所示,配置聚类评估组件参数,运行算子。
- 查看summary数据集。
- 查看cluster统计信息。
- 查看模型评估报告。
异常检测评估
评估模块支持计算 AUC、KS,同时输出数据用于画 PR 曲线、ROC 曲线 KS 曲线,同时也支持分组评估。
输入
- 输入异常检测处理后的数据集,评估需要标签列和分数列。标签列的唯一值必须是2,需要指明异常标签是哪个,默认是1;分数列的值越大越可能是异常;如果使用自动配置,使用组件库中异常检测算子的预测结果诸位输入,则无需配置分数列,只需配置标签列。
输出
- 第一个输出是summary数据集,第二个输出是metricsByThreshold数据集,右键可以查询模型评估报告。
字段参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 真实标签列列名 | 是 | 该列代表真实的标签,需要是非数组类型,唯一值最多是2。 | 无 |
| 异常样本标签值 | 是 | 真实标签列中异常样本的标签值。 | 无 |
| 分桶数 | 是 | 计算时把数据分成多少份 范围:[5, 1000]。 | 20 |
| 评估列选择 | 是 | 自动配置会根据系统默认字段配置字段。手动配置可以手动选择要预测标签列。 | 自动配置 |
| 预测分数列 | 是 | 输入数据集中的该列代表异常分数,分数越大表示越可能是异常值。必须是Double类型 | 无 |
评估指标
| 名称 | 介绍 |
|---|---|
| auc_roc | auc_roc |
| auc_pr | auc_pr值 |
| ks | ks值 |
使用示例
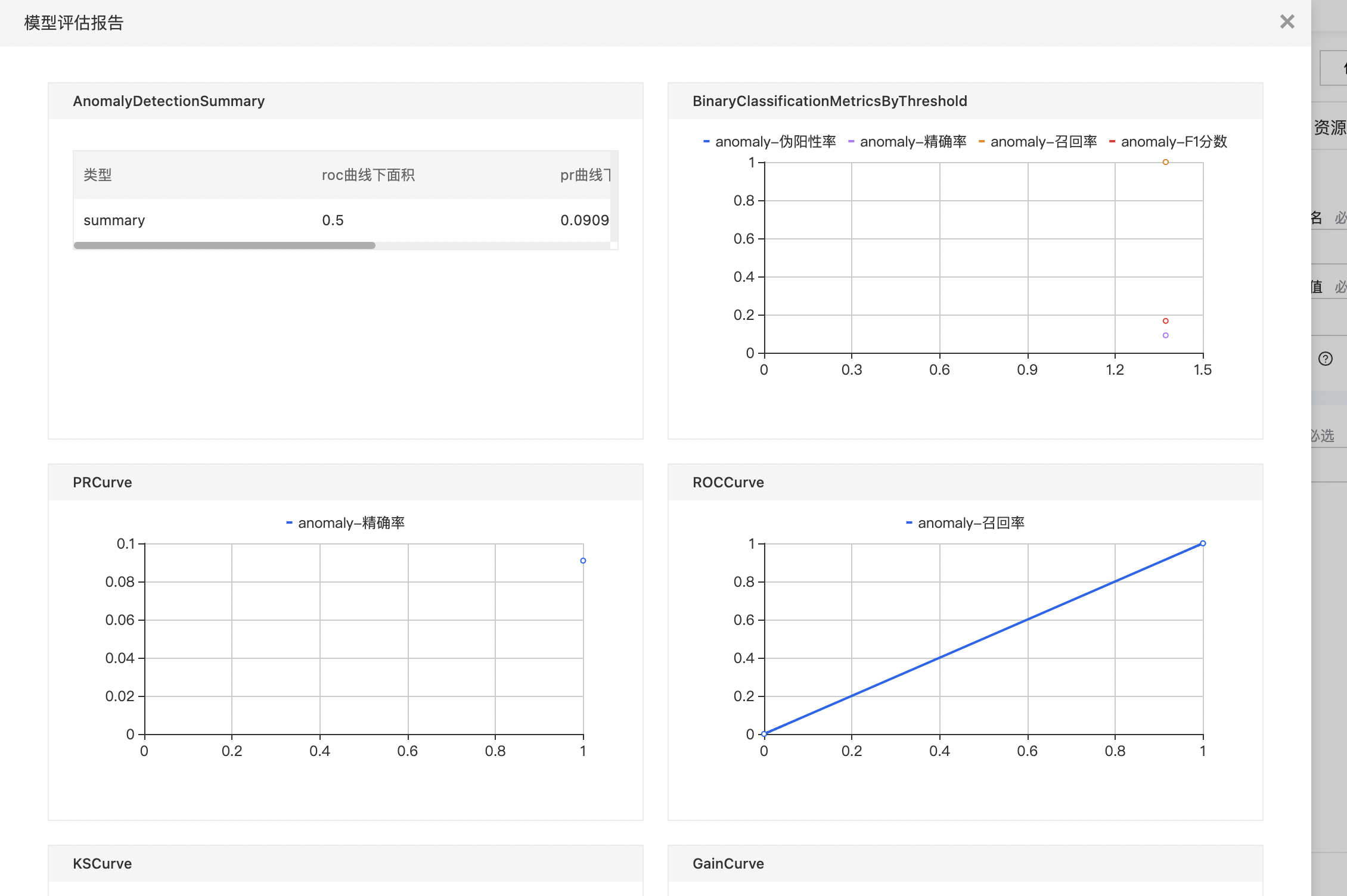
- 搭建算子结构如下图所示,配置异常检测评估组件参数,运行算子。
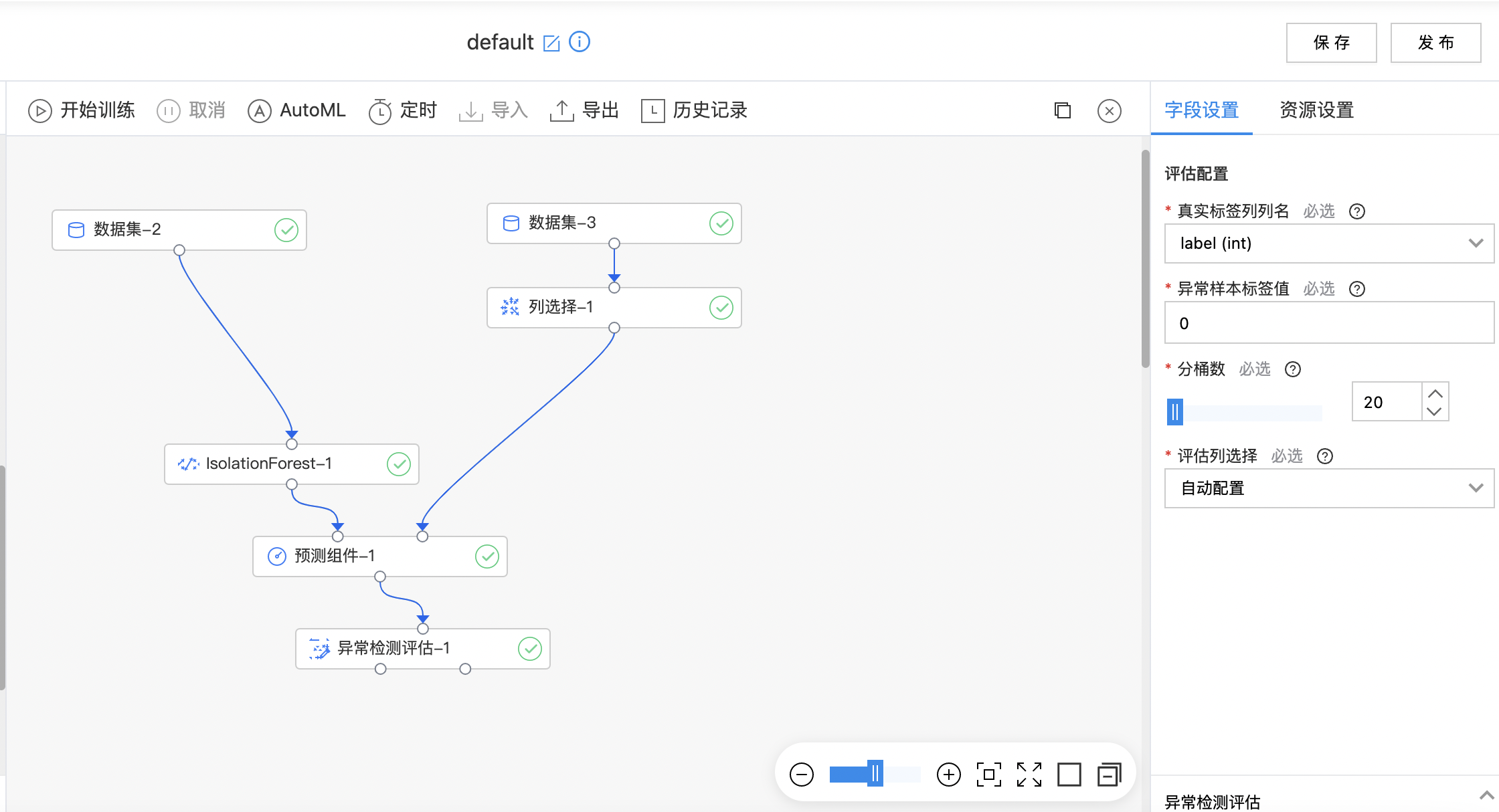
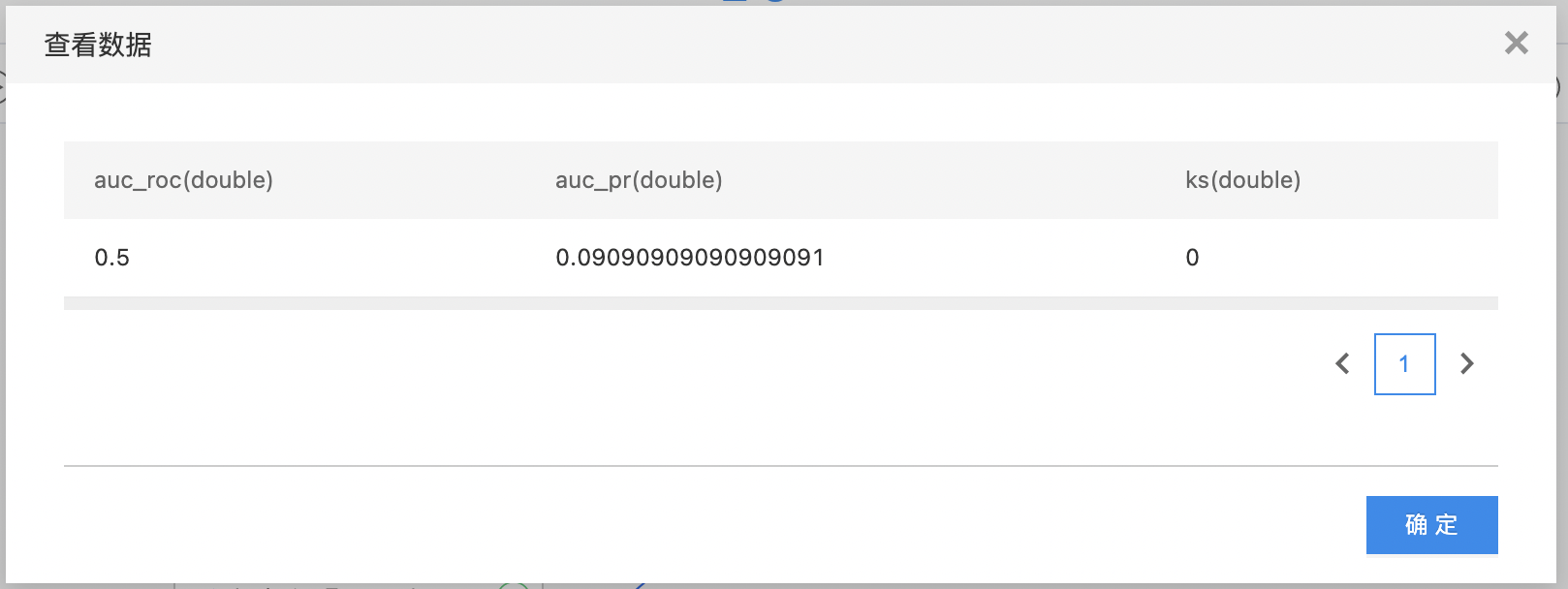
- 查看summary数据集。
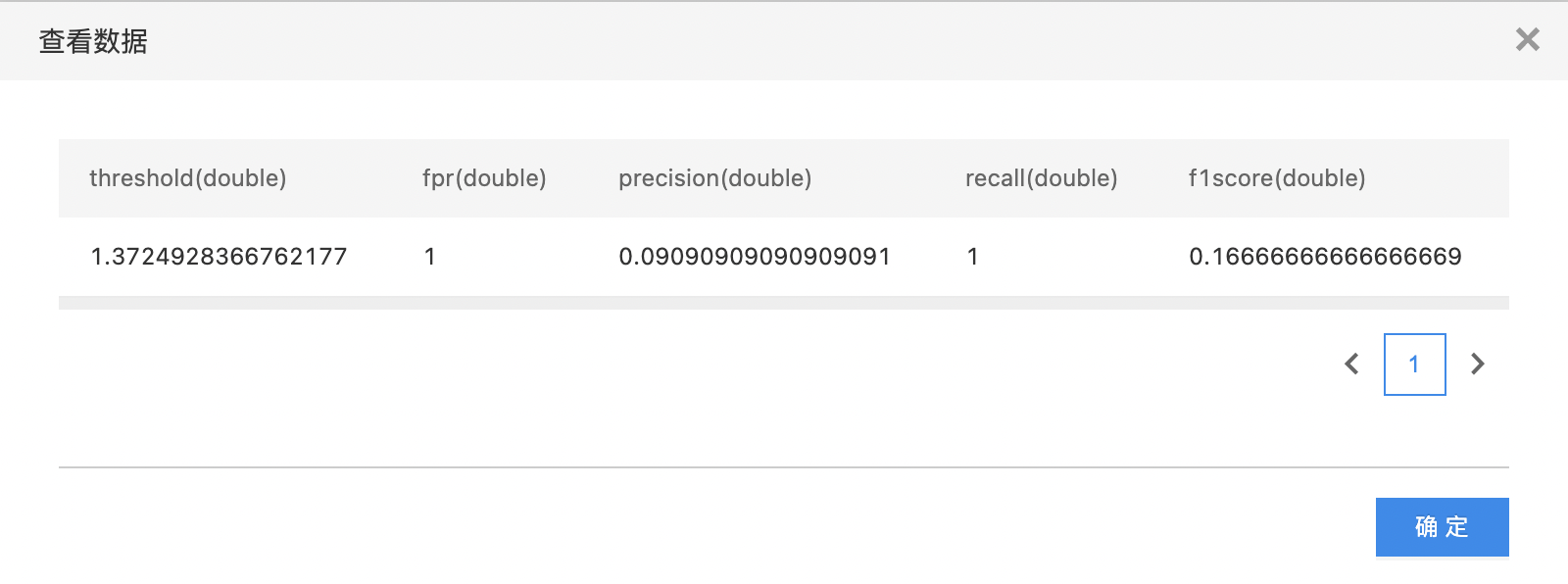
- 查看metricsByThreshold数据集。
- 查看模型评估报告。
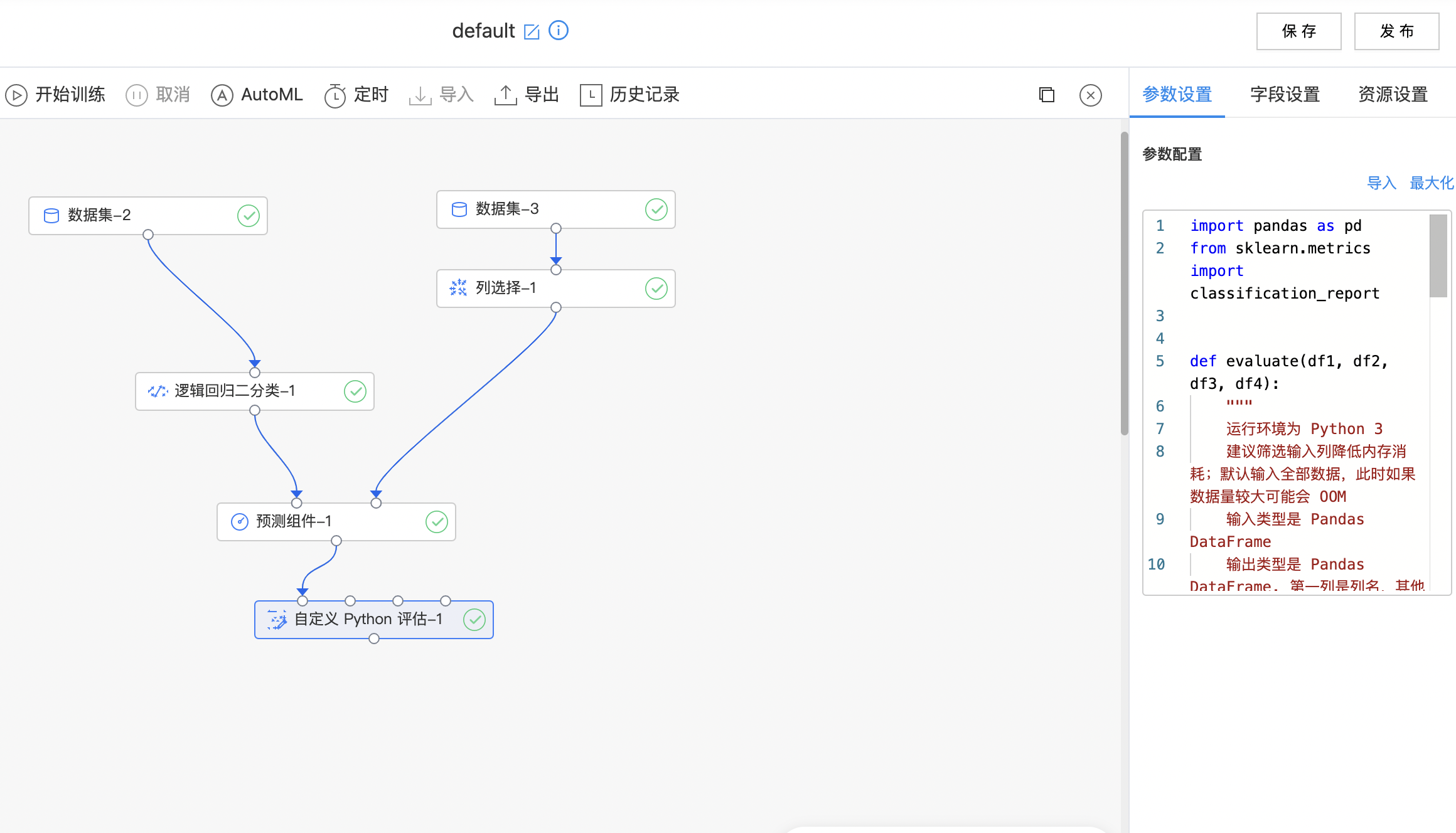
自定义Python评估
自定义 Python 评估组件:写自定义 python 代码,完成模型评估任务。
输入
- 输入数据集,编辑python代码自定义评估组件。
输出
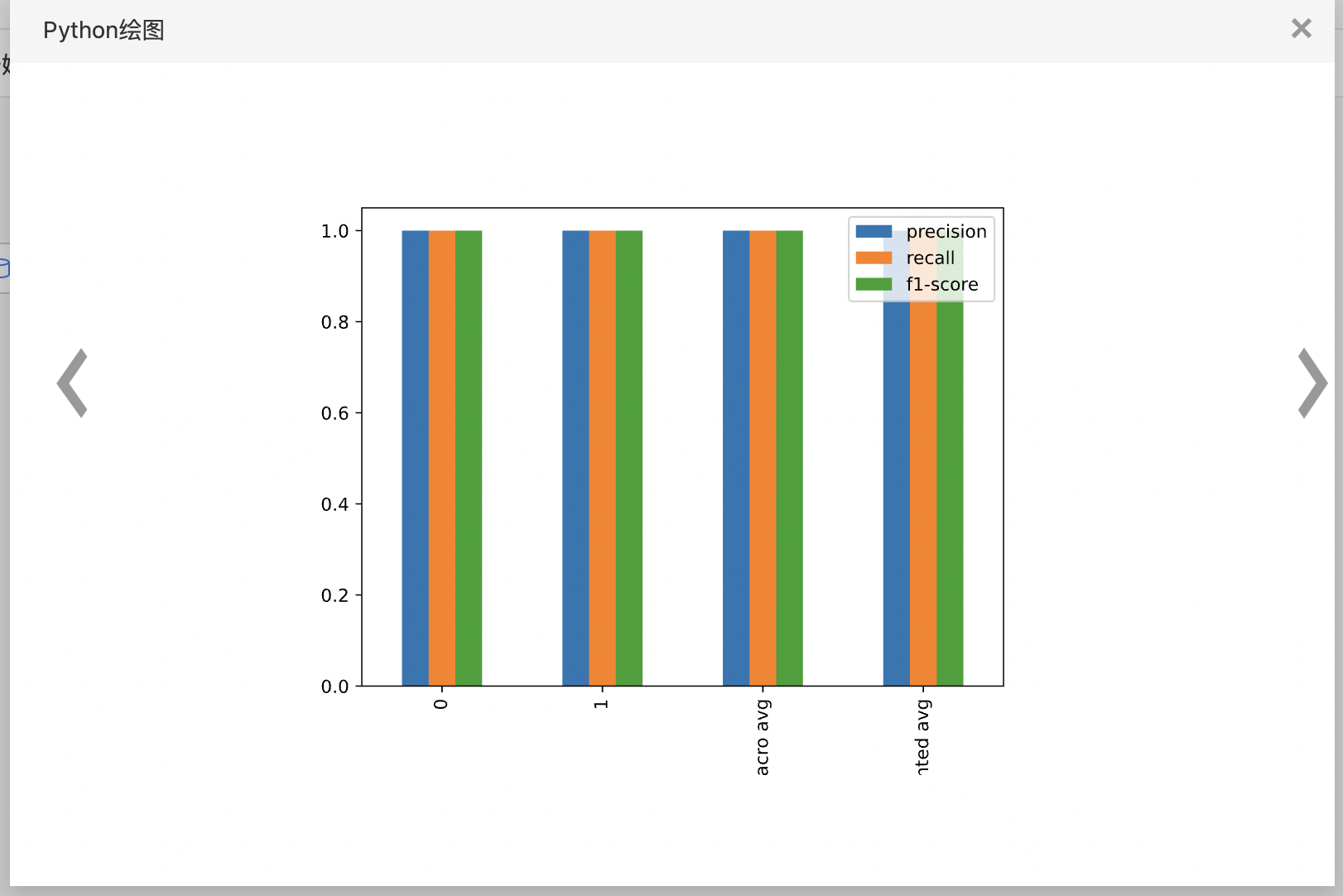
- 输出自定义评估组件结果,右键查看python绘制图表。
算子参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| python代码编辑窗口 | 是 | 编写python代码,自定义评估组件 |
字段参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 第1个输入列列名,默认加载全部列 | 否 | 只加载选择的列,减少内存占用 | 无 |
| 第2个输入列列名,默认加载全部列 | 否 | 只加载选择的列,减少内存占用 | 无 |
| 第3个输入列列名,默认加载全部列 | 否 | 只加载选择的列,减少内存占用 | 无 |
| 第4个输入列列名,默认加载全部列 | 否 | 只加载选择的列,减少内存占用 | 无 |
使用示例
- 搭建算子结构如下图所示,编写python代码,运行算子。
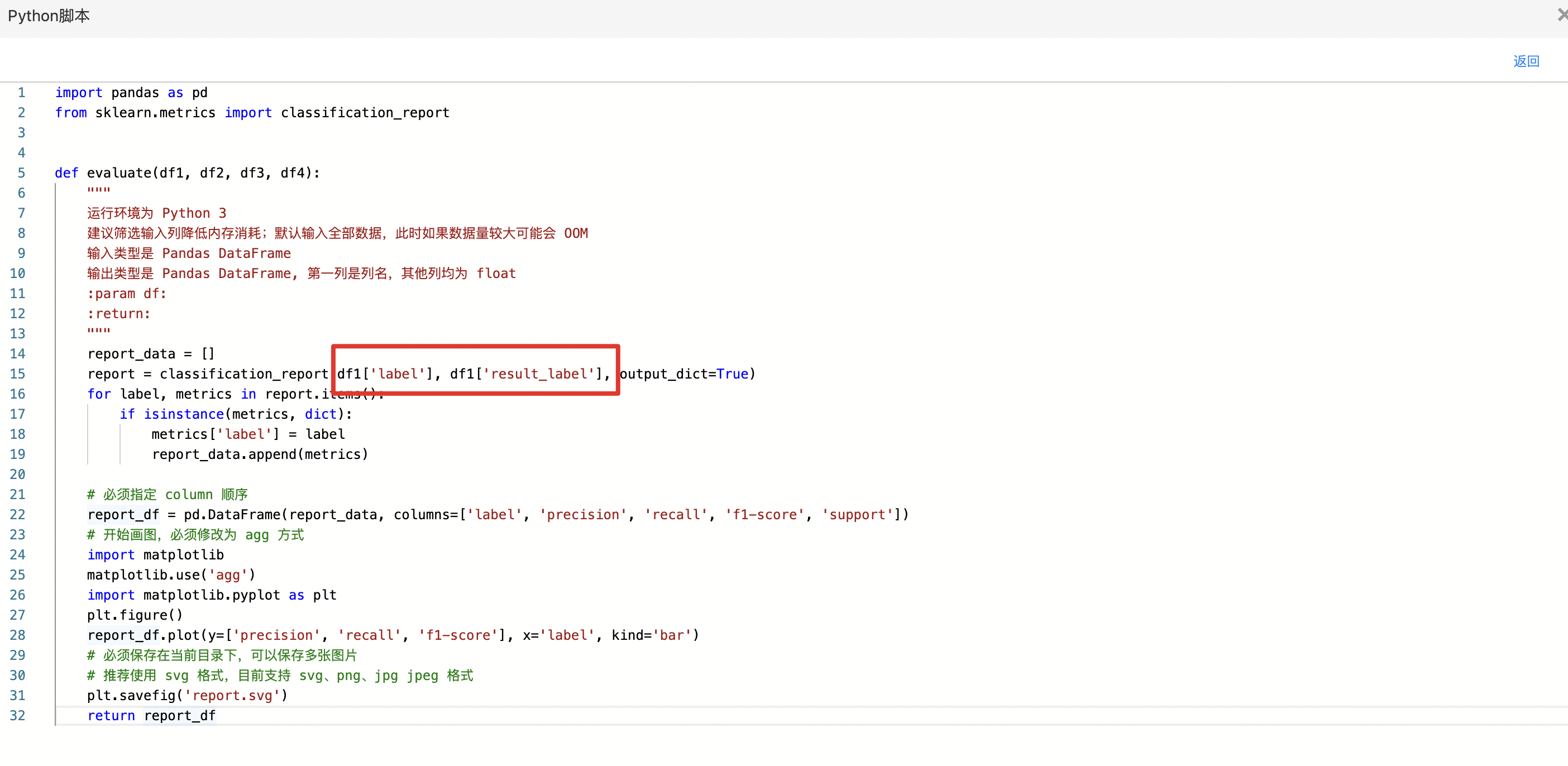
- 代码如下,classification_report中参数df1['label']和df1['result_label']需要与输入数据集的真实标签列名与预测标签列名对应。
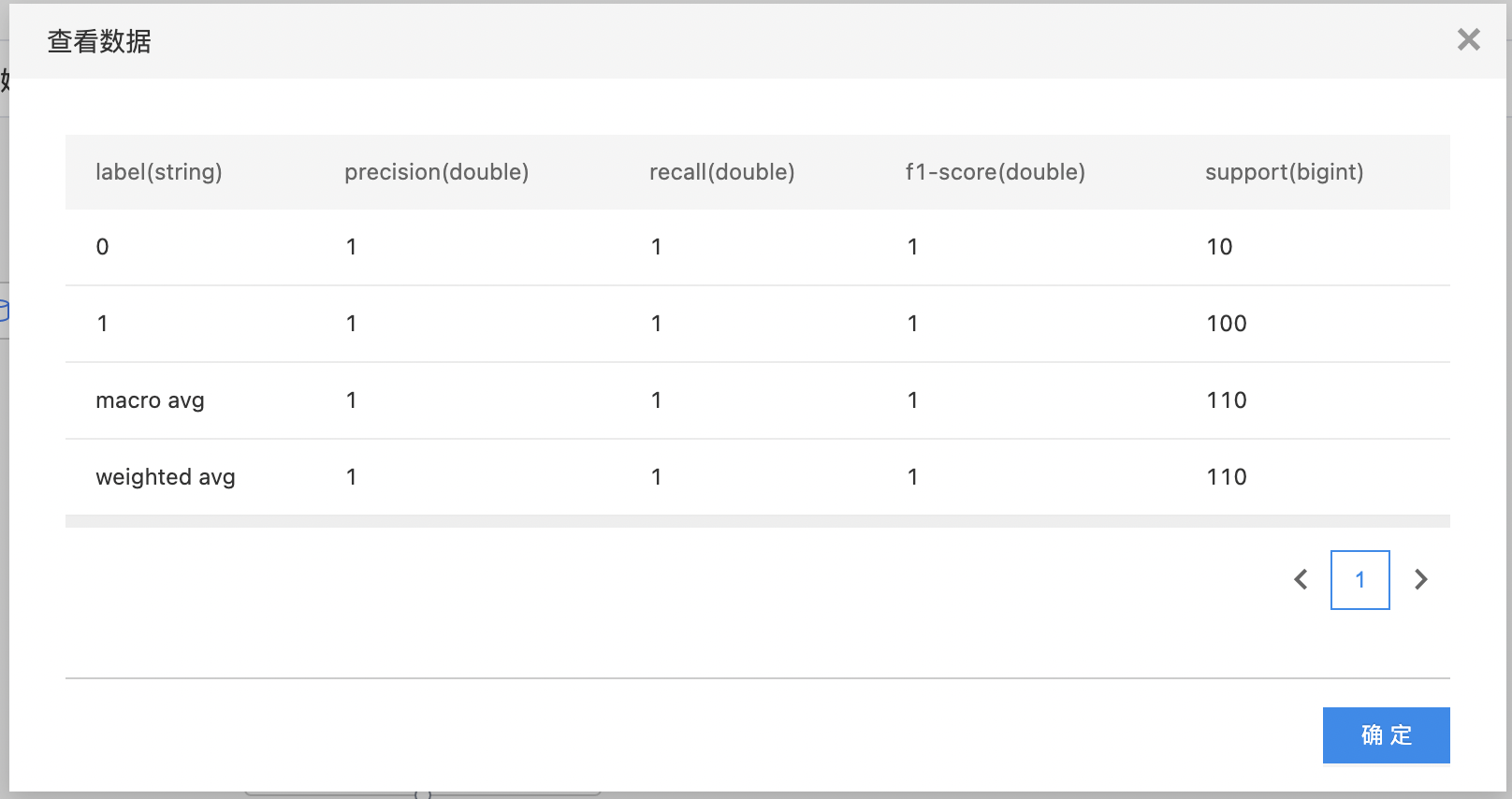
- 查看输出结果。
- 查看python绘制图表。