用BML实现文本分类
目录
1.文本分类简介
2.平台入口
3.准备数据
3.1 数据规范
3.2 创建及导入数据集
4.训练模型
5.校验模型
6.部署模型
用BML实现文本分类:以中文新闻文本标题分类为例
文本分类简介
亲爱的开发者您好,欢迎使用百度BML全功能AI开发平台开启您的AI开发之旅!
在我们的生活和工作中,很多事情都可以转化为一个分类问题来解决,比如“上班坐公交还是坐地铁”、“吃米饭还是吃面条”等等可以转化为二分类问题。自然语言处理领域也是这样,大量的任务可以用文本分类的方式来解决,比如垃圾文本识别、涉黄涉暴文本识别、意图识别、文本匹配、命名实体识别等,有着极其广泛的应用场景:
- 投诉信息分类:训练客服投诉信息的自动分类,将每个用户投诉的内容进行分类管理,节省大量客服人力。
- 媒体文章分类:训练网络媒体文章的自动分类,进而实现各类文章的自动分类。
- 文本审核:定制训练文本审核的模型,如训练文本中是否含有违规/偏激性质的描述。
- 其他:尽情脑洞大开,训练你希望实现的文本分类(单标签)模型。
定制文本分类的模型,是基于自建分类体系的机器学习方法,可实现文本按内容类型做自动分类。平台目前提供的文本分类模型包括:文本分类(单标签)和文本分类(多标签)两种模型类型,请您根据自己的业务场景来选择合适的模型。
- 文本分类(单标签)场景:如您对网络文章进行舆情分析,判断舆情是正向评价还是负向评价,此问题属于单标签的文本分类场景;
- 文本分类(多标签)场景:如您对网络文章进行板块划分,文章可能属于娱乐、国际、生活等多个标签,则可使用多标签的文本分类模型;
下文中将以中文新闻文本标题分类为例,分步骤向您详细介绍如何使用百度BML全功能AI开发平台开发您自己的文本分类模型。
中文新闻文本标题分类任务简介:
新闻分类是文本分类中常见的应用场景。在传统分类模式下,往往是通过人工对新闻内容进行核对,从而将新闻划分到合适的类别中。这种方式会消耗大量的人力资源,并且效率不高。采用深度学习的方法可以取得较高的分类精度,是新闻推荐等场景下的基础任务。
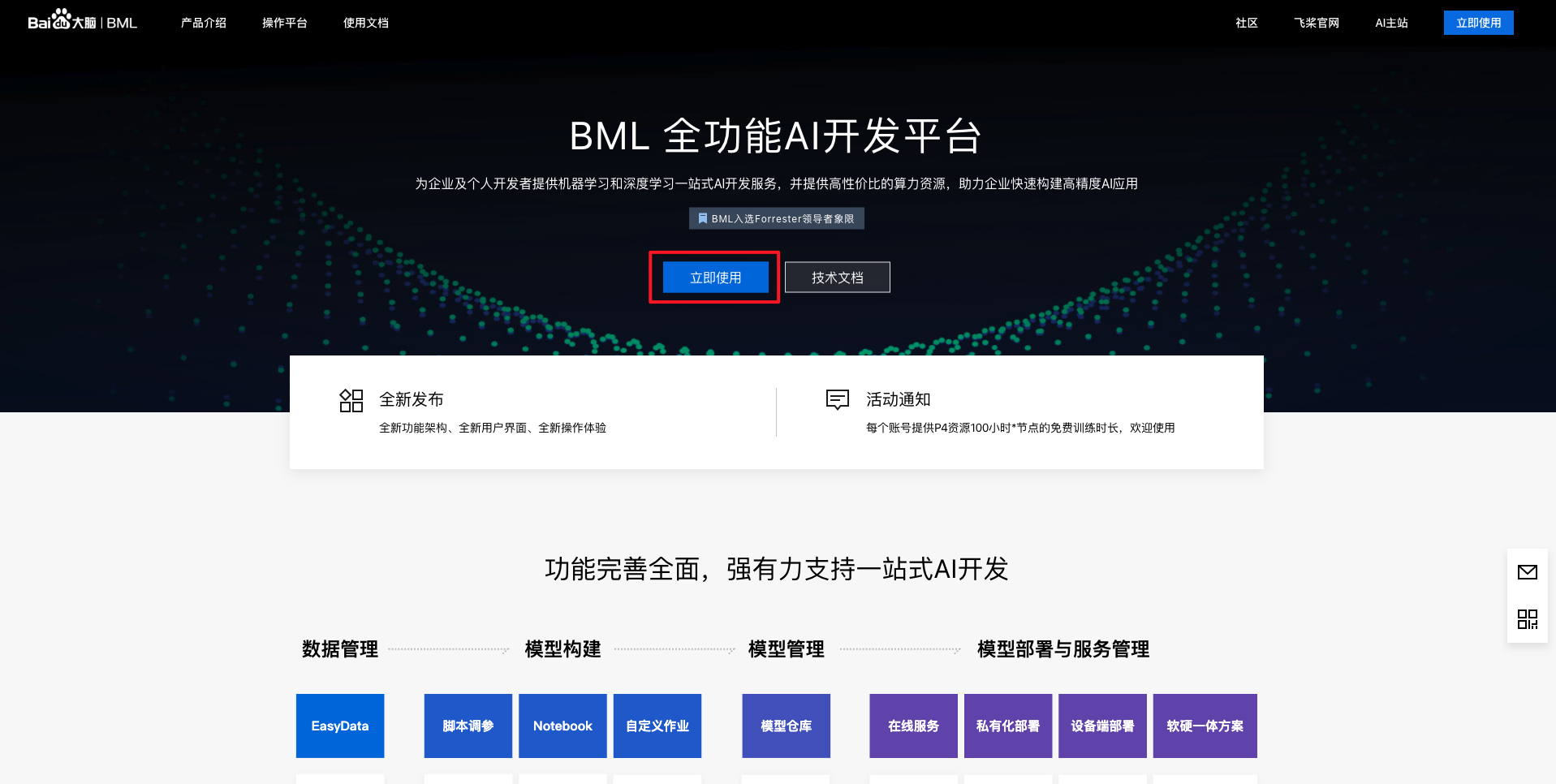
平台入口
BML全功能AI开发平台为企业及个人开发者提供机器学习和深度学习一站式AI开发服务,并提供高性价比的算力资源,助力企业快速构建高精度AI应用,进入官方网站点击【立即使用】。
准备数据
准备数据是AI模型开发的关键一环,训练数据的质量决定了训练所得模型效果可达到的上限。
本文采用中文新闻文本标题分类数据集进行示例,数据链接:中文新闻文本标题分类
下面来介绍数据规范与相关操作步骤。
数据规范
本地上传数据规范:
- 可支持单个txt文本文件上传、Excel上传,或将多个文本文件以压缩包的方式统一上传。
- 压缩包内的一个文本文件将作为一个样本上传,压缩包格式为.zip格式,压缩包内文件类型支持txt,编码仅支持UTF-8
- 上传过程中存在文本内容完全一样的样本,将会做去重处理。
- 文本文件类型为txt,单次上传限制100个文本文件。
- 单个文本大小限制在4M以内,文本文件大小限制长度最大4096个UTF-8字符。
- 文本文件内数据格式要求为"文本内容\n"(即每行一个未标注样本,使用回车换行),每一行表示一组数据,每组数据的字符数建议不超过512个,超出将被截断。
- 单个数据集大小限制为10万文本文件,超出后会被忽略。
创建及导入数据集
1、在官网界面点击【数据总览】,进入数据集操作界面。
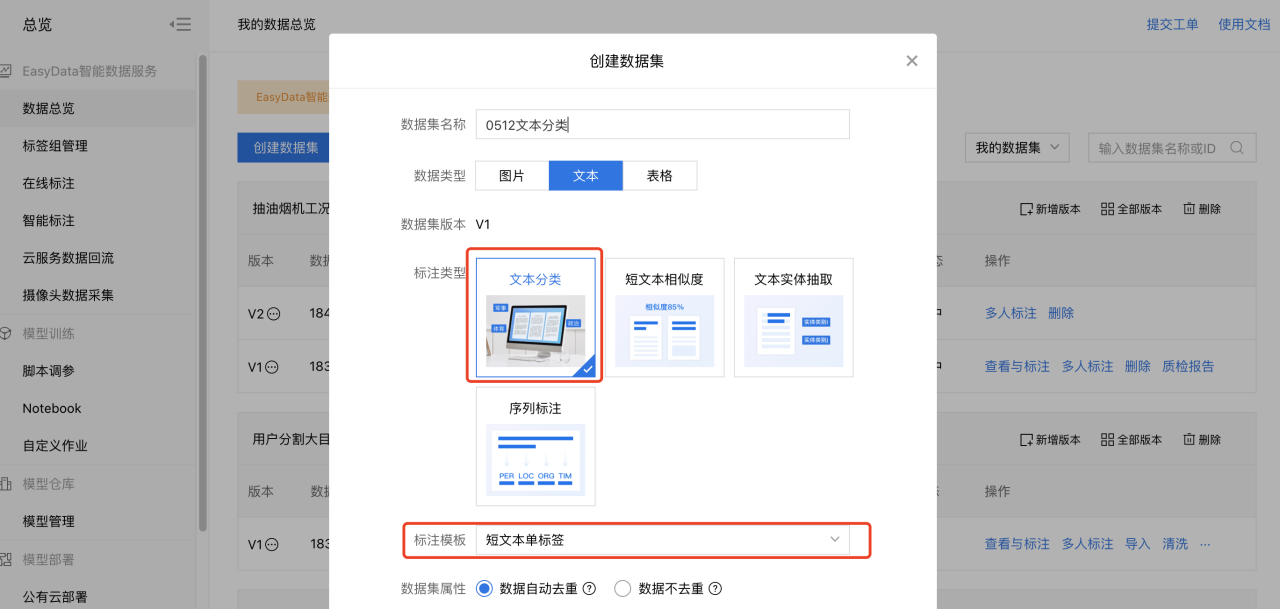
2、进入创建数据集界面,选择好数据类型和标注类型等信息,点击完成。
3、数据集创建完成后,可以在数据总览界面看到刚才创建好的数据集ID。
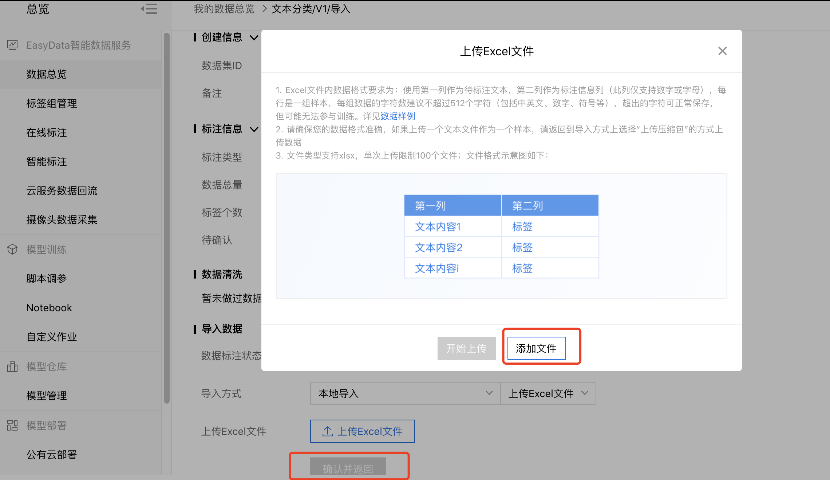
4、点击【导入】,将自己要训练的数据集导入,如这里选择本地导入Excel文件方式导入数据集,点击添加文件,然后确认并返回,完成数据集的导入。
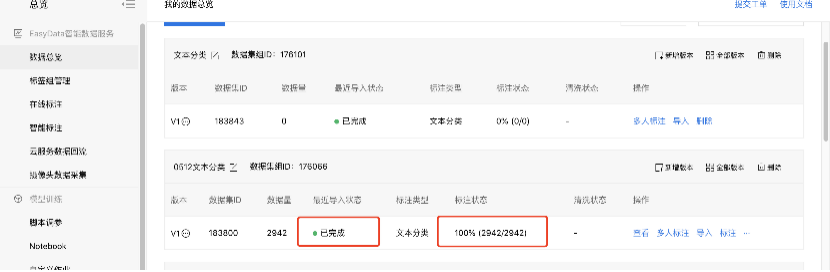
5、回到数据总览界面,可实时查看导入状态信息和标注状态,最终成功则显示已完成。
训练模型
BML上提供了预置模型调参、NoteBook建模、自定义作业三种开发模式,开发难度和开发的灵活性程度不一,分别满足不同水平和需求的开发者。
当前NLP方向仅支持使用者最多的预置模型调参模式,后续将陆续支持NoteBook建模、自定义作业开发模式。
本文将采用预置模型调参模式示意训练模型的基本步骤。
1、进入bml官方平台点击立即使用预置模型调参,点击【预置模型调参】-【自然语言处理模型】,进入操作台。
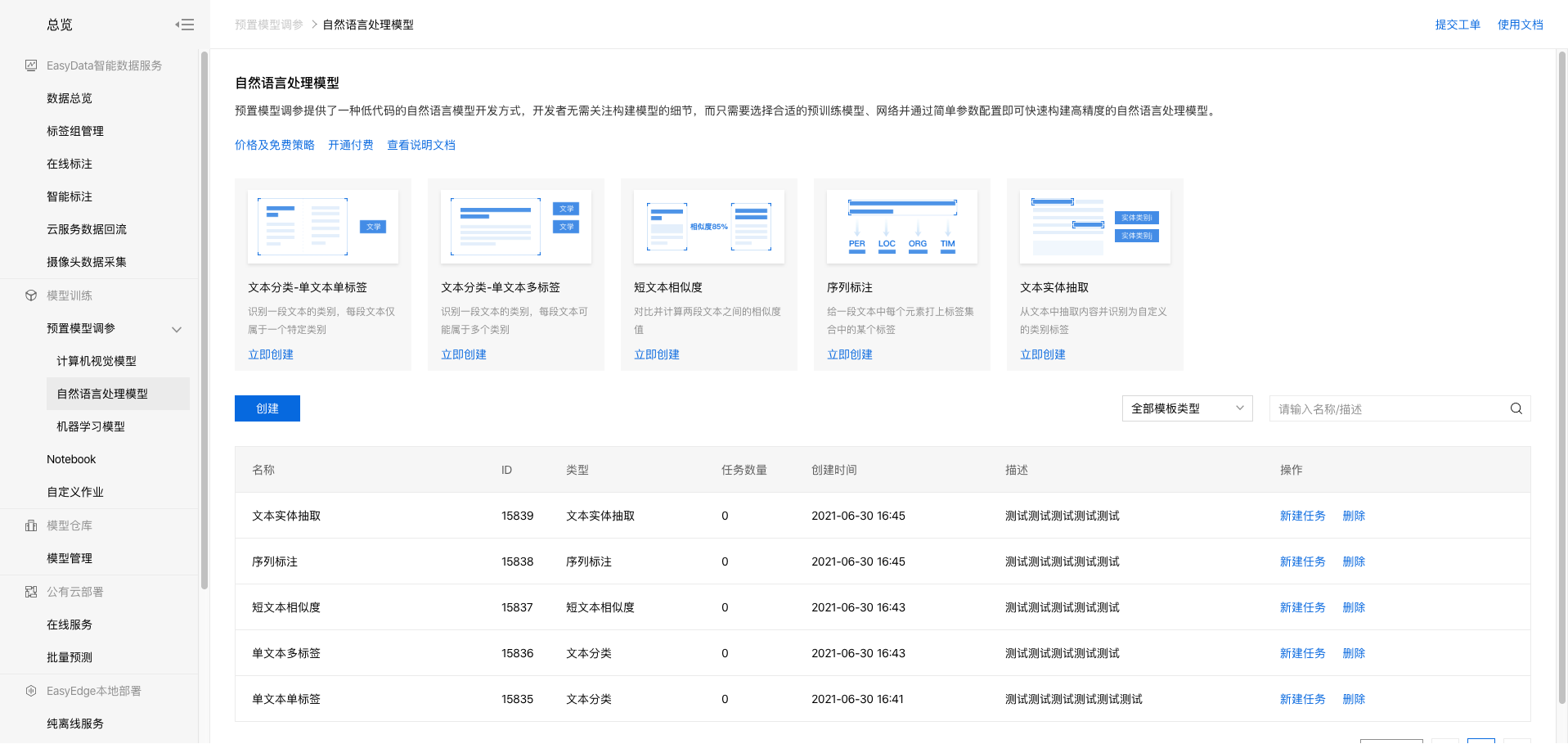
2、在模型列表下点击创建模型。
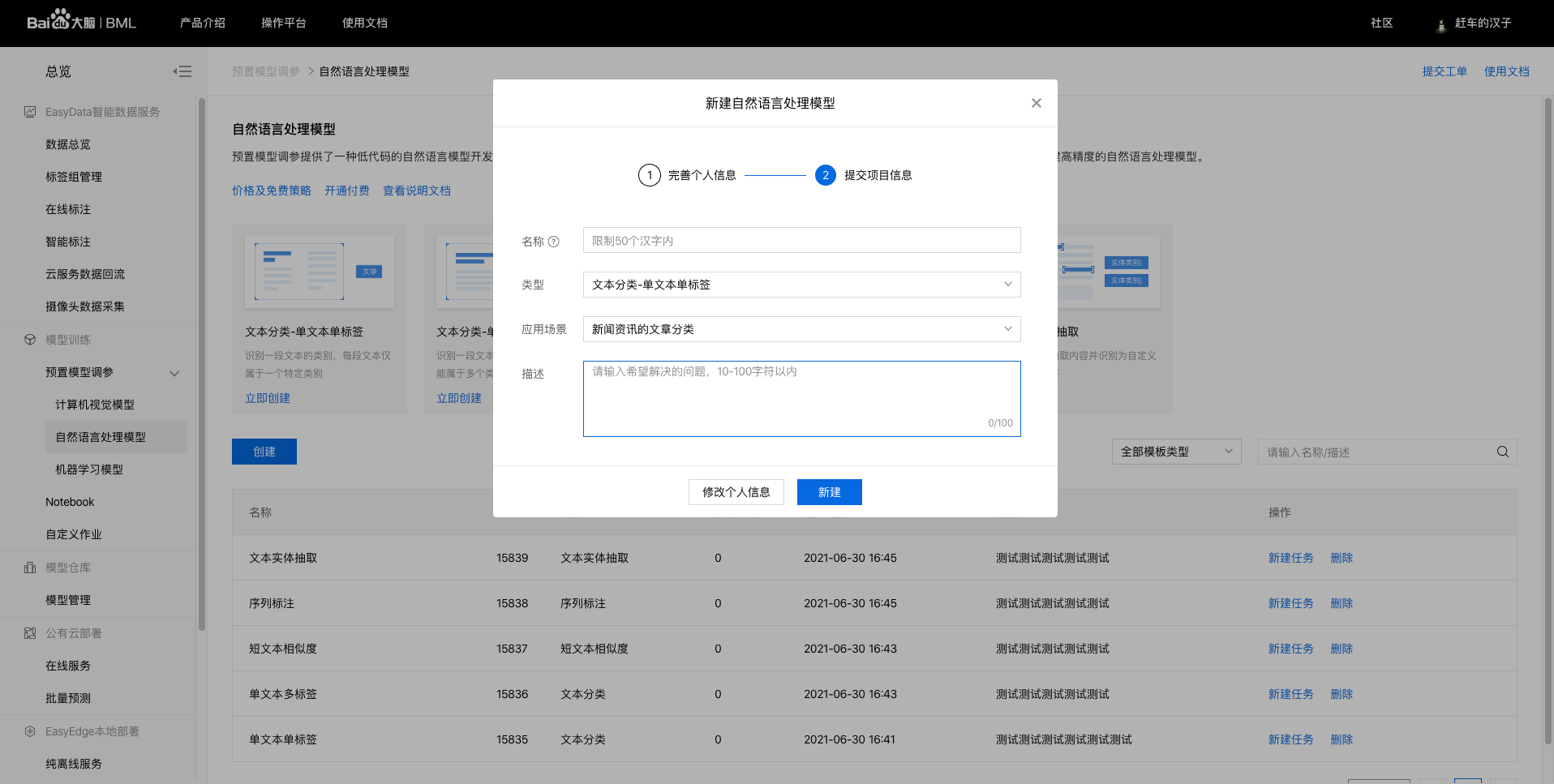
选择训练类型为文本分类-单文本单标签,填写模型信息(名称、描述信息等)后,点击【创建】。
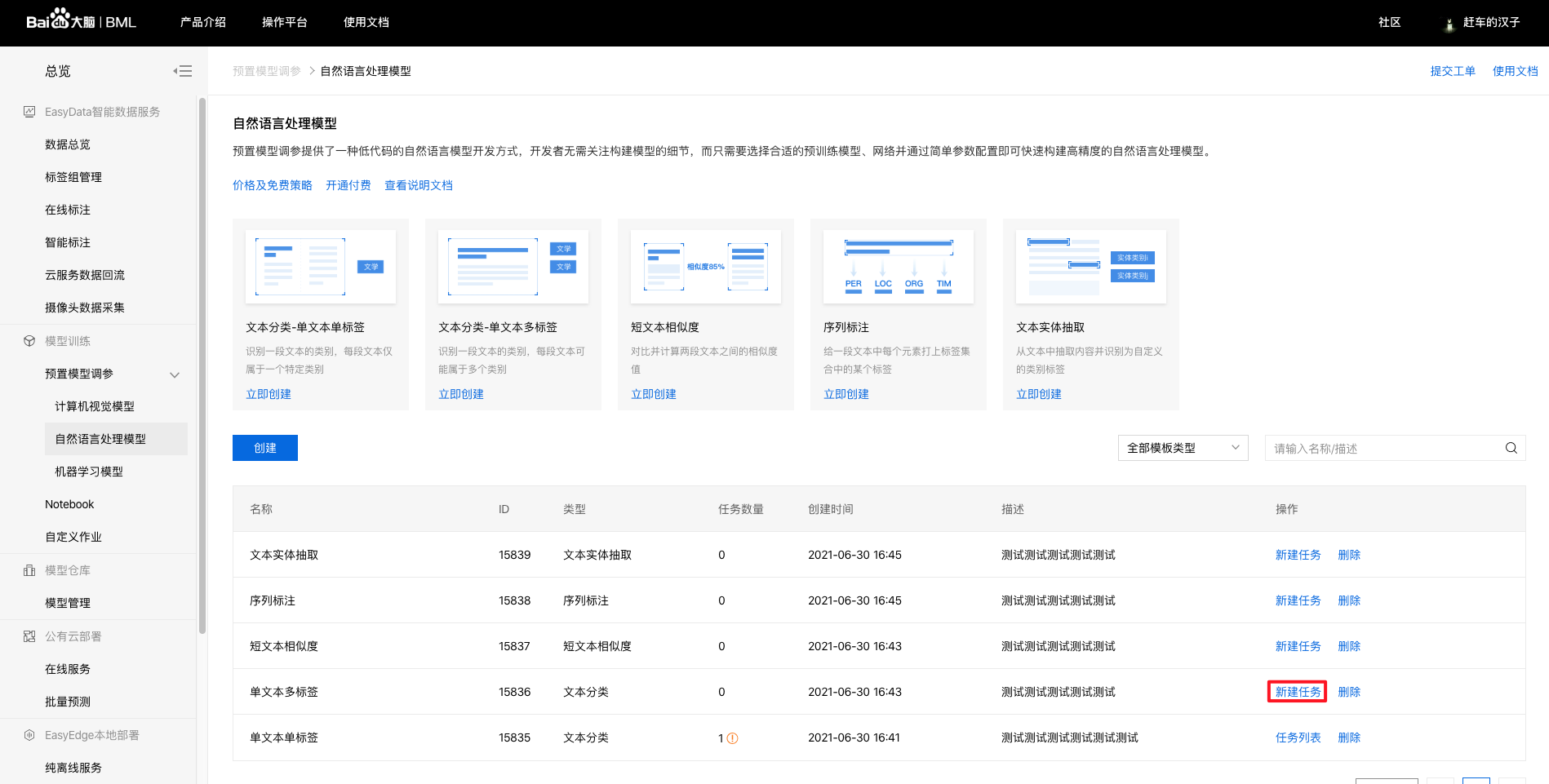
3、配置NLP分类训练任务。
之前已经建立好训练模型,现在开始配置NLP训练训练,点击【新建任务】。
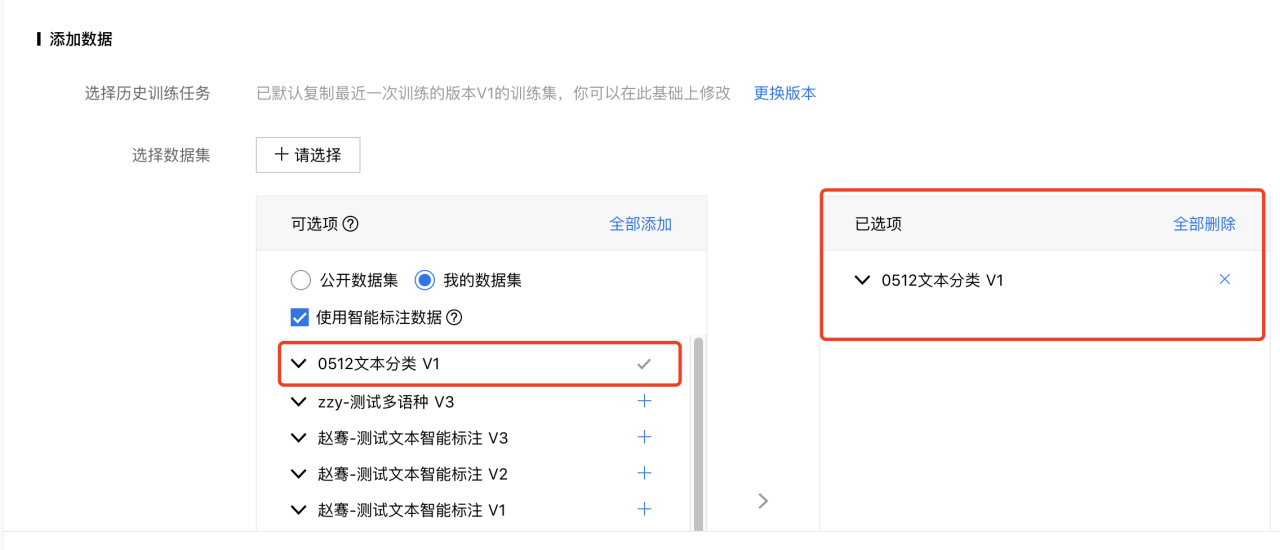
在新建任务面板中,可查看相关项目“基本信息”、“配置任务类型”、“添加数据”、“配置网络”等操作,在添加任务时添加刚才数据集确定添加。
配置模型网络,选择显卡类型和是否启用分布式训练等。
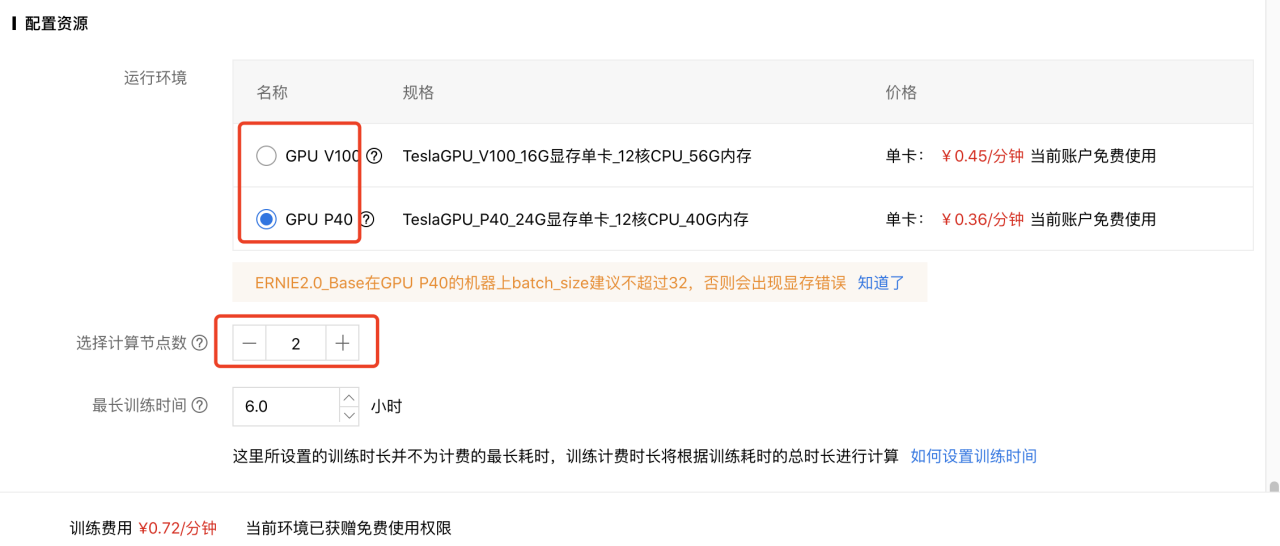
配置好后,可提交训练任务开始训练。
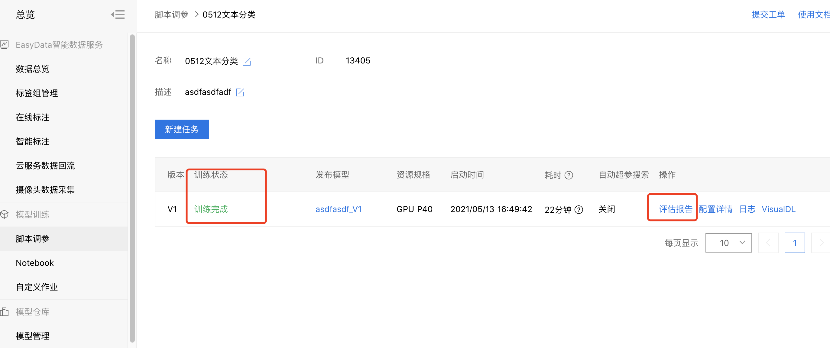
5、训练完成。
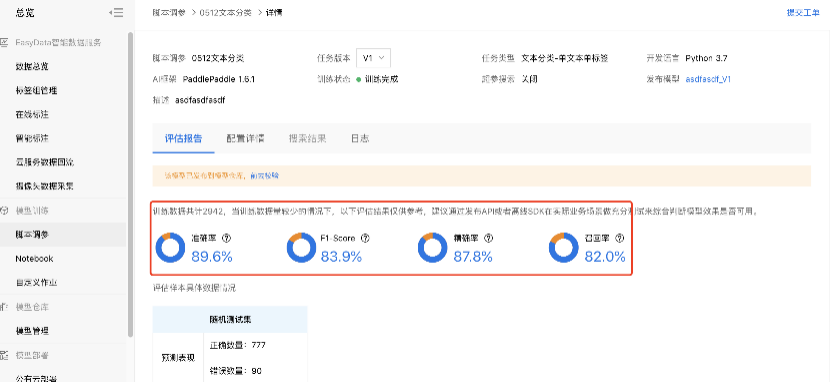
等待训练过程,完成后显示训练完成,用户可查看训练时长,训练结果的评估报告等信息。
在评估报告中可查看本次训练过程的准确率,精确率等指标报告信息。
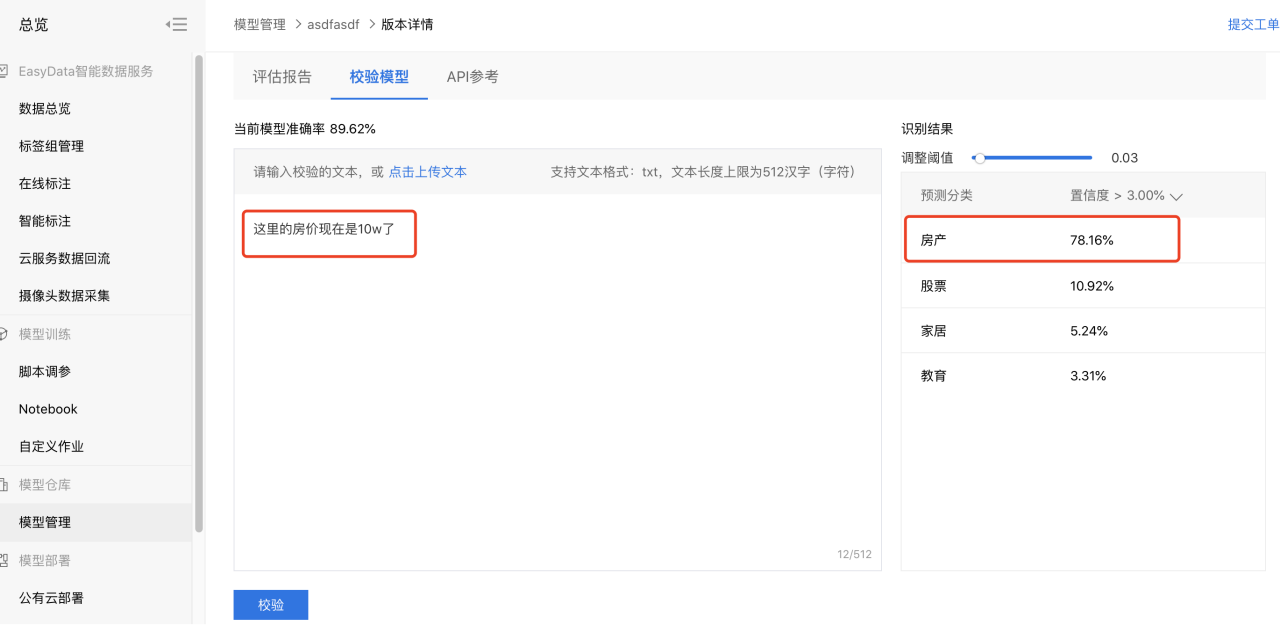
校验模型
启动模型校验。
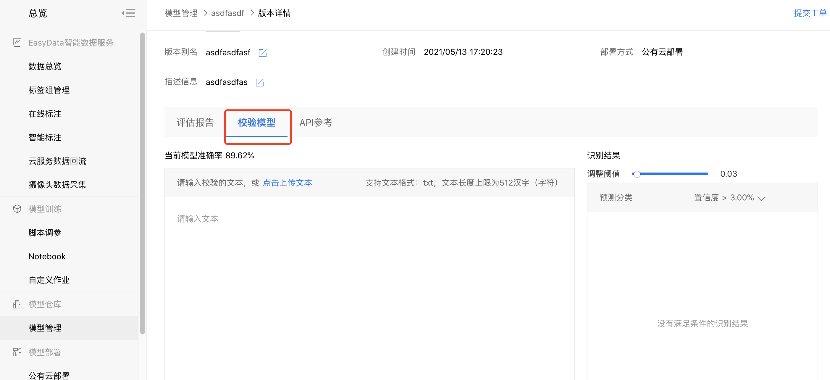
用训练好的模型对本次的新闻类型文本(可实时输入或用户上传)进行分类校验。
部署模型
1、在模型管理中,可选择公有云和本地部署两种方式发布模型。
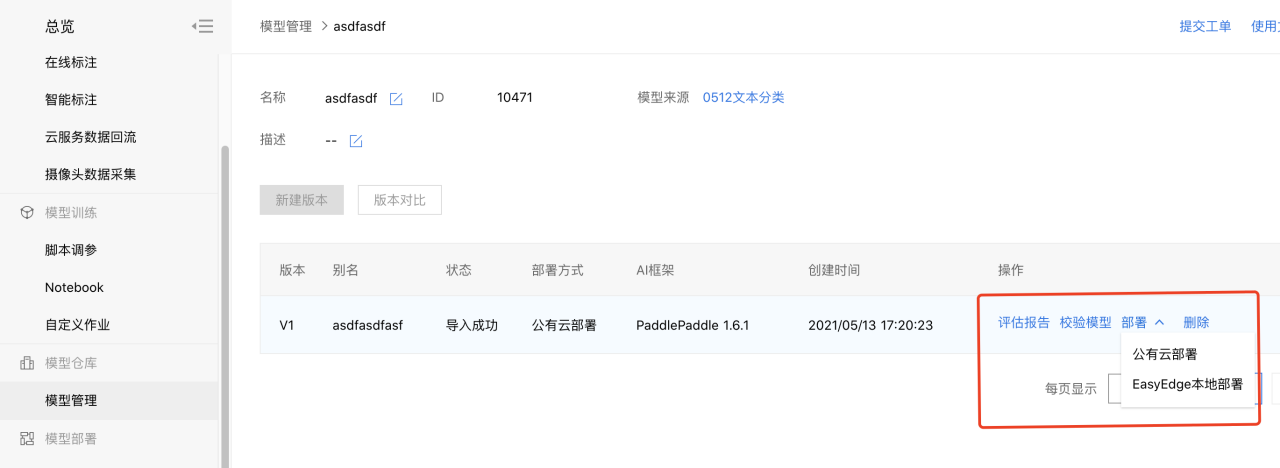
2、在模型部署中,用户按照自己情况填写信息完成模型部署。