015-图算法
更新时间:2025-12-08
图算法
FastUnfolding
FastUnfolding 算法是基于模块度对社区划分的算法。FastUnfolding 算法是一种迭代的算法,主要目标是不断划分社区使得划分后的整个网络的模块度不断增大。
输入
- 输入数据集,包括源顶点列,目标顶点列,边权值列(可选)。
输出
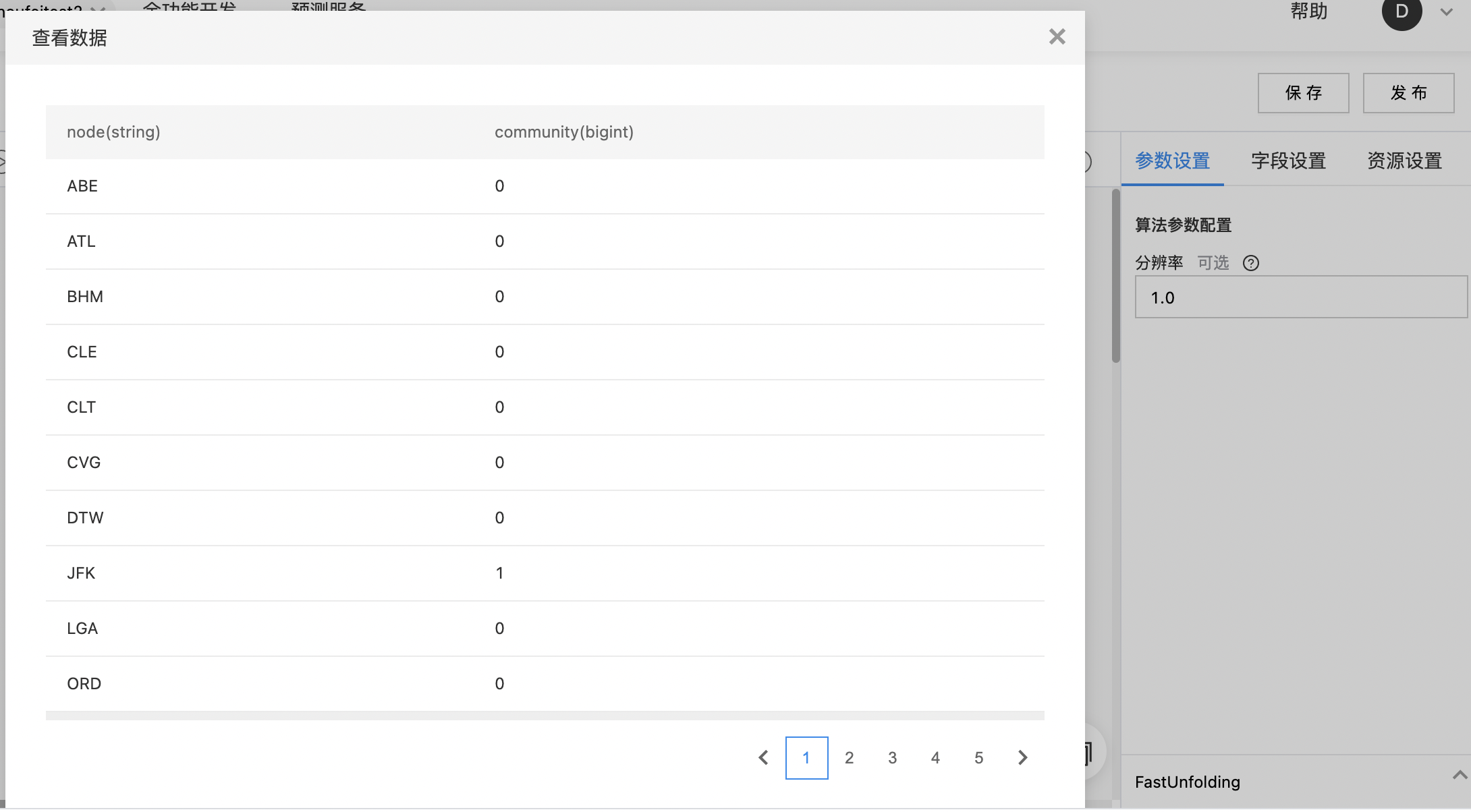
- 输出结果数据集,包括两列:node(源/目标顶点名称),community(社区id),community一致表示属于同一个社区。
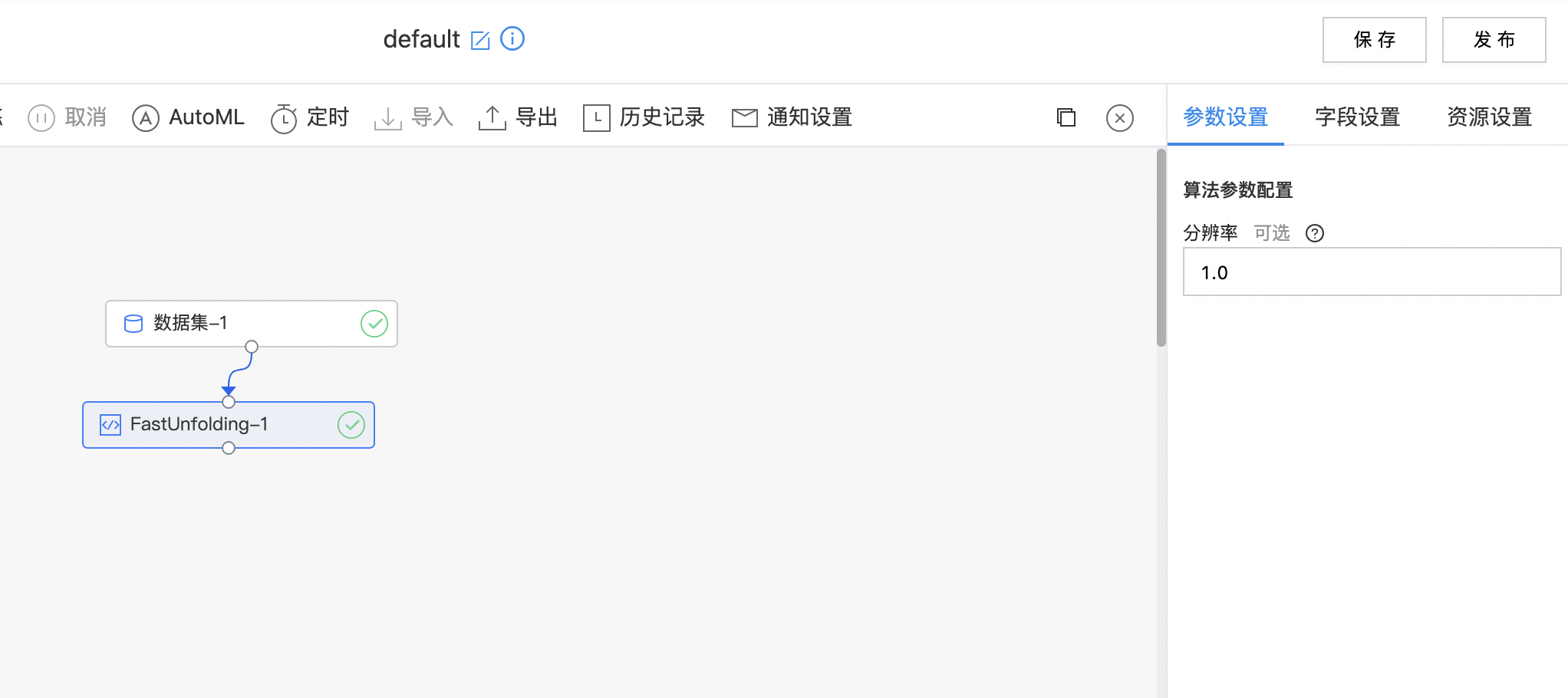
算子参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 分辨率 | 否 | 非负数值,可改变社区的大小,默认值:1.0;随着分辨率的增大,所划分的社区个数会减少 范围:[0.0, inf)。 | 1.0 |
字段参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 源顶点列 | 是 | 选择源顶点列,数值或字符串类型。 | 无 |
| 目标顶点列 | 是 | 选择目标顶点列,数值或字符串类型。 | 无 |
| 边权值列 | 否 | 选择边权值列,数值类型,要求非负;若没有选择边权值列,则表示边权值均为1。 | 无 |
计算逻辑

使用示例
- 构建算子结构,配置参数,完成训练。
- 查看输出结果。
LINE
LINE也是一种基于邻域相似假设的方法, 引入了两个核心概念: first-order proximity (一阶邻近) 和 second-order proximity (二阶邻近).,其中一阶邻近描述的是直接相连的节点之间的关系, 而二阶邻近则指的是节点之间虽然不直接相连, 但是它们会有一些共同的邻居。
输入
- 输入数据集,包括源顶点列,目标顶点列,边权值列(可选)。
输出
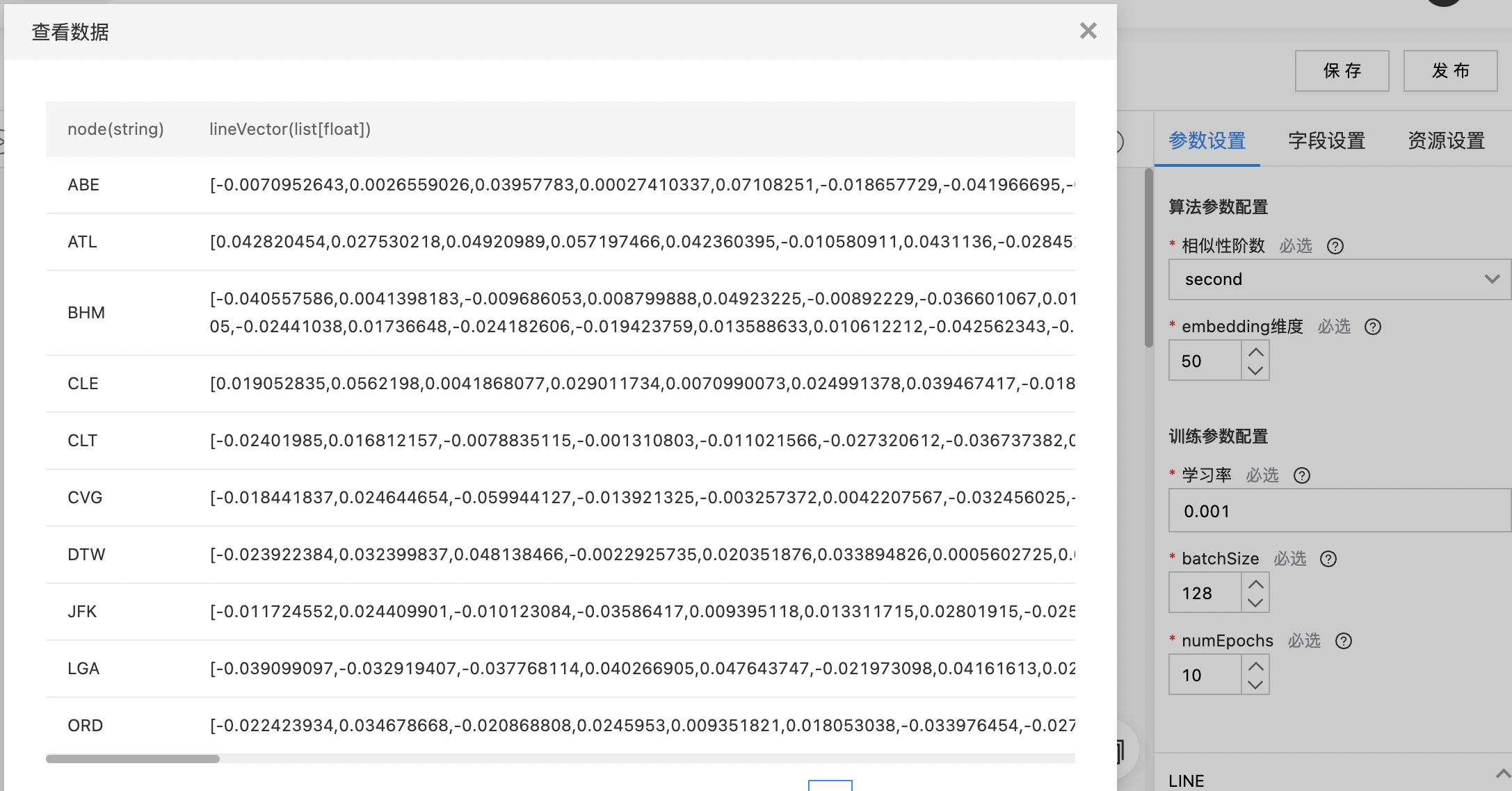
- 输出结果数据集,包括两列:node(源/目标顶点名称),lineVector(相似度向量)。
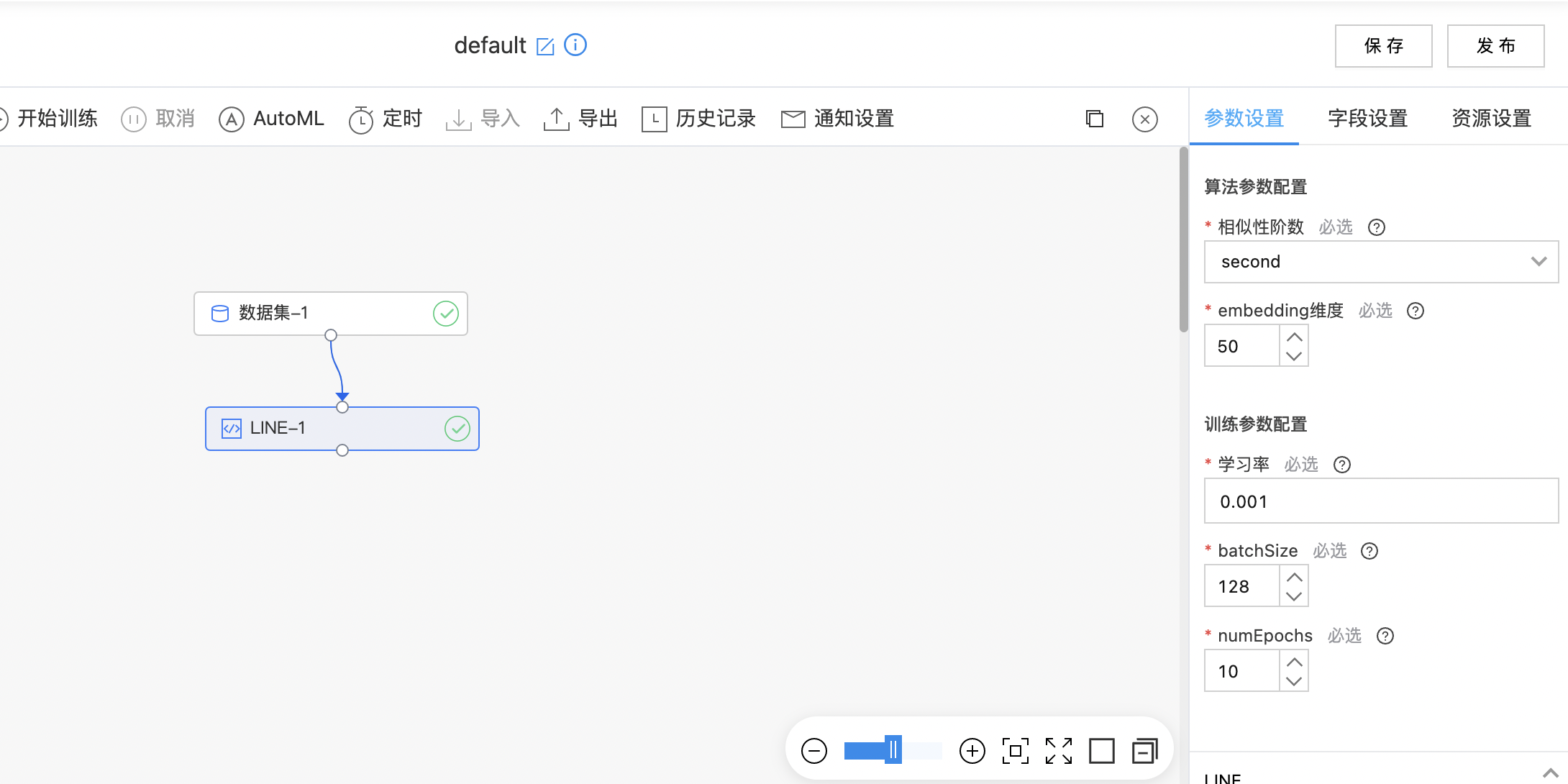
算子参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 相似性阶数 | 是 | 顶点之间的相似度,当设置相似度为all时,为一阶相似度和二阶相似度的拼接,输出的embedding维度为设置维度的二倍。 | second |
| embedding维度 | 是 | embedding维度,当设置相似度为all时,为一阶相似度和二阶相似度的拼接,输出的embedding维度为设置维度的二倍 范围:[2, inf)。 | 50 |
| 学习率 | 是 | 学习率 范围:[1e-05, 1.0]。 | 0.001 |
| batchSize | 是 | 训练过程中的batch_size 范围:[1, inf)。 | 128 |
| numEpochs | 是 | 训练过程中的训练轮数 范围:[1, inf)。 | 10 |
字段参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 源顶点列 | 是 | 选择源顶点列,数值或字符串类型。 | 无 |
| 目标顶点列 | 是 | 选择目标顶点列,数值或字符串类型。 | 无 |
| 边权值列 | 否 | 数值类型,要求非负。 | 无 |
使用示例
- 构建算子结构,配置参数,完成训练。
- 查看输出结果。
LPA
LPA算法是一种基于图的半监督学习方法,其基本思路是用已标记节点的标签信息去预测未标记节点的标签信息。利用样本间的关系建立关系完全图模型,在完全图中,节点包括已标注和未标注数据,其边表示两个节点的相似度,节点的标签按相似度传递给其他节点。
输入
- 输入数据集,包括源顶点列,目标顶点列。
输出
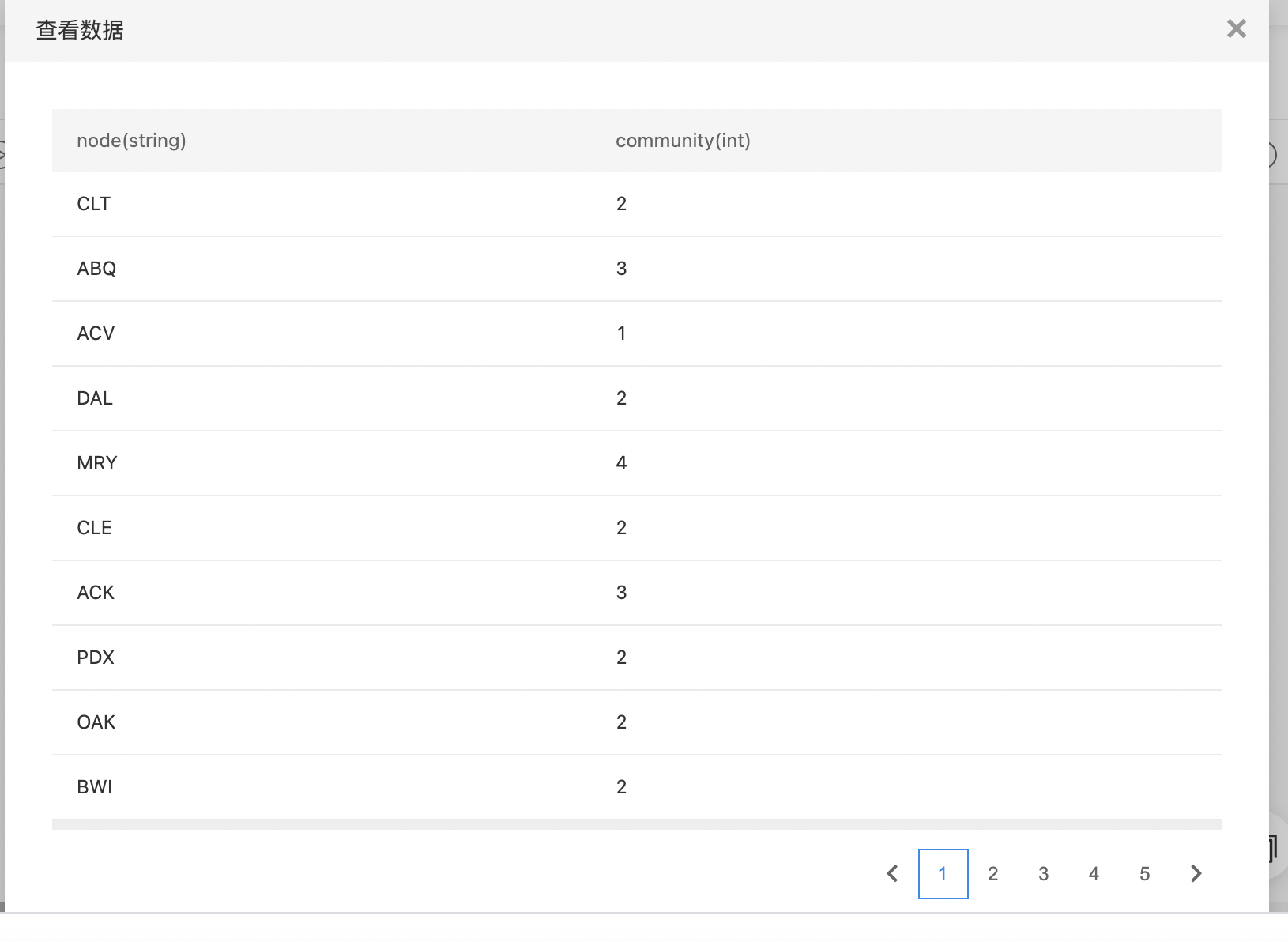
- 输出结果数据集,包括两列:node(源/目标顶点名称),community(社区id),community一致表示属于同一个社区。
算子参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
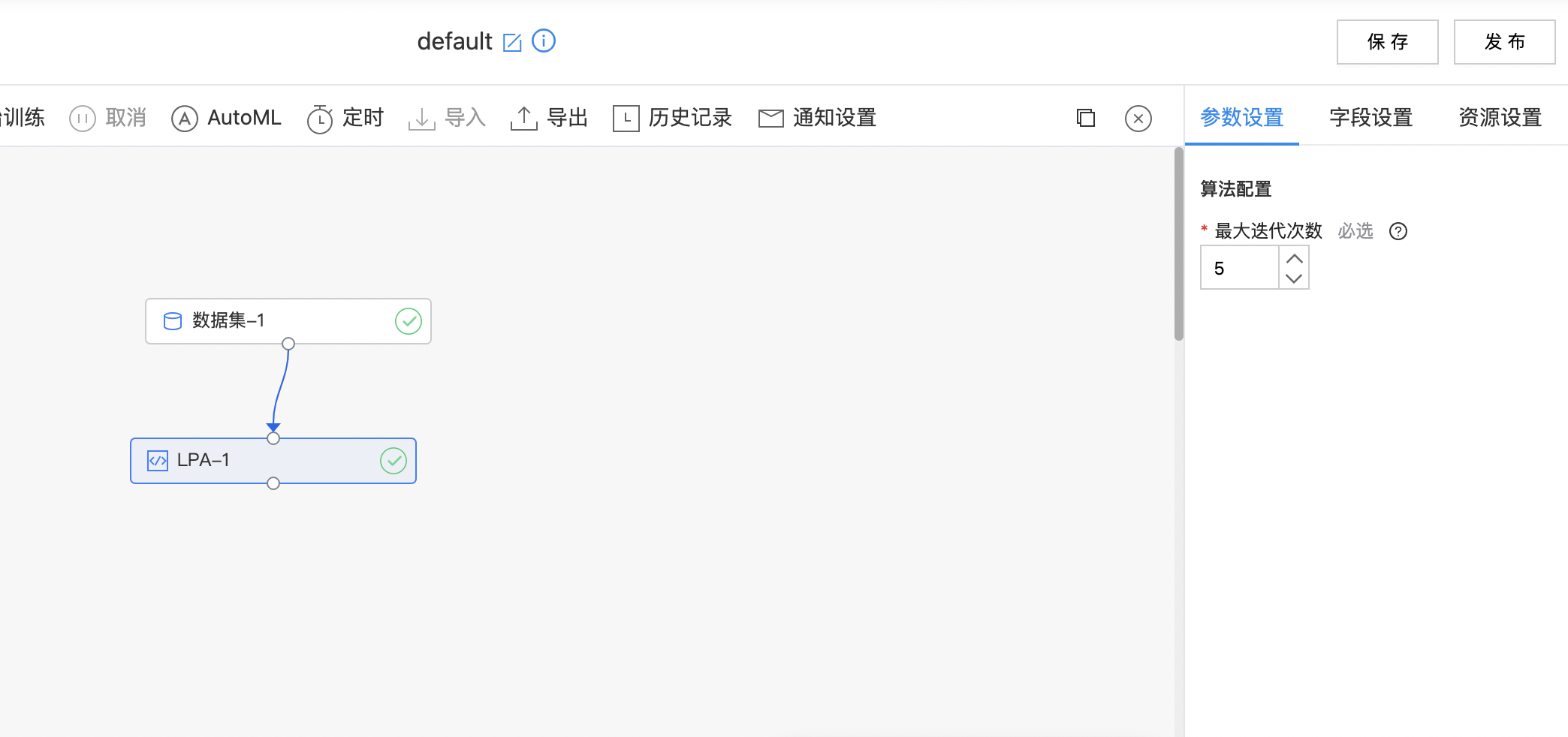
| 最大迭代次数 | 是 | LPA的迭代步数 范围:[1, inf)。 | 5 |
字段参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 源顶点列 | 是 | 边的起始节点。 | 无 |
| 目标顶点列 | 是 | 边的终止节点。 | 无 |
使用示例
- 构建算子结构,配置参数,完成训练。
- 查看输出结果。
PageRank
以网页排序举例,PageRank算法简单来说分为两步:
- 给每个网页一个PR值(下面用PR值指代PageRank值)
- 通过(投票)算法不断迭代,直至达到平稳分布为止。
- 如果一个网页被很多其他网页链接到的话说明这个网页比较重要,也就是PageRank值会相对较高
- 如果一个PageRank值很高的网页链接到一个其他的网页,那么被链接到的网页的PageRank值会相应地因此而提高
输入
- 输入数据集,包括源节点列,目的节点列。
输出
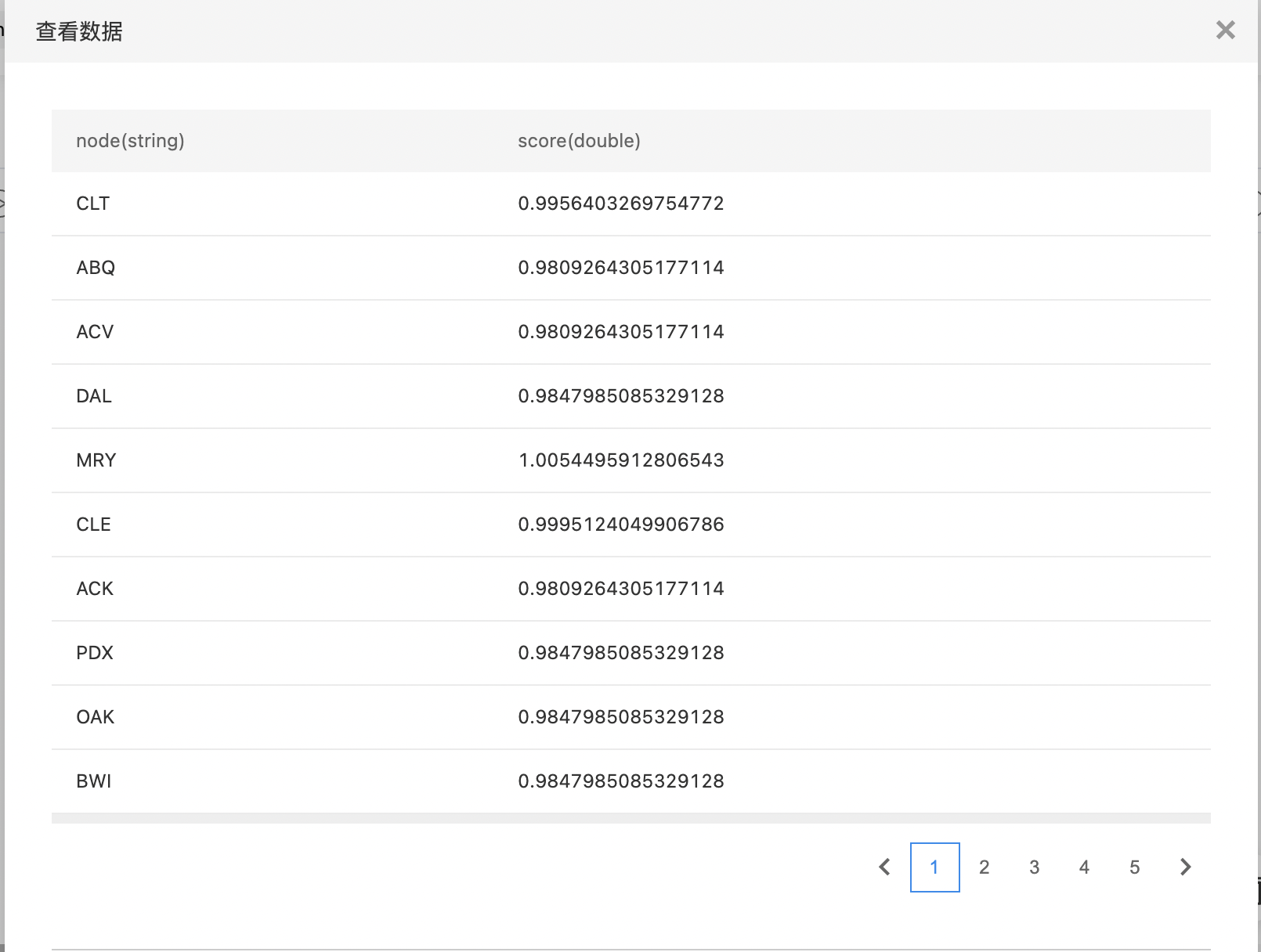
- 输出PageRank处理后的结果。
算子参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 最小容差 | 否 | 当本轮pr与上轮的差值的最大值小于最小容差时,迭代结束 范围:[0.0, 1.0]。 | 无 |
| 最大迭代次数 | 否 | 当迭代次数大于该数值时,停止迭代。未填写最小容差时,此参数有效。 范围:[1, inf)。 | 无 |
| 阻尼系数 | 是 | 该节点随机链接到下一个节点的概率,默认设为0.85 范围:[0.0, 1.0]。 | 0.85 |
字段参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 源节点 | 是 | 边的起始节点 | 无 |
| 目的节点 | 是 | 边的终止节点 | 无 |
计算逻辑
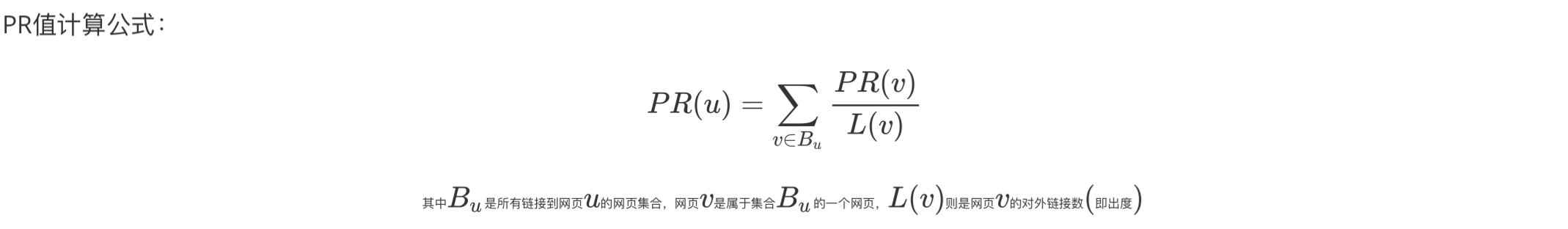
使用示例
- 构建算子结构,配置参数,完成训练。
- 查看输出结果。
PowerIterationClustering
幂迭代聚类(Power iteration clustering,PIC) 是一个可尺度化的有效聚类算法。幂迭代算法是将数据点嵌入到由相似矩阵推导出来的低维子空间中,然后通过k-means算法得出聚类结果。幂迭代算法利用数据归一化的逐对相似度矩阵,采用截断的迭代法,寻找数据集的一个超低维嵌入,低维空间的嵌入是由拉普拉斯矩阵迭代生成的伪特征向量,这种嵌入恰好是有效的聚类指标,使他在真实的数据集上好于谱聚类算法而不需要求解矩阵的特征值。
输入
- 输入一个数据集,需要选择源顶点列,目标顶点列,边权值列 。
输出
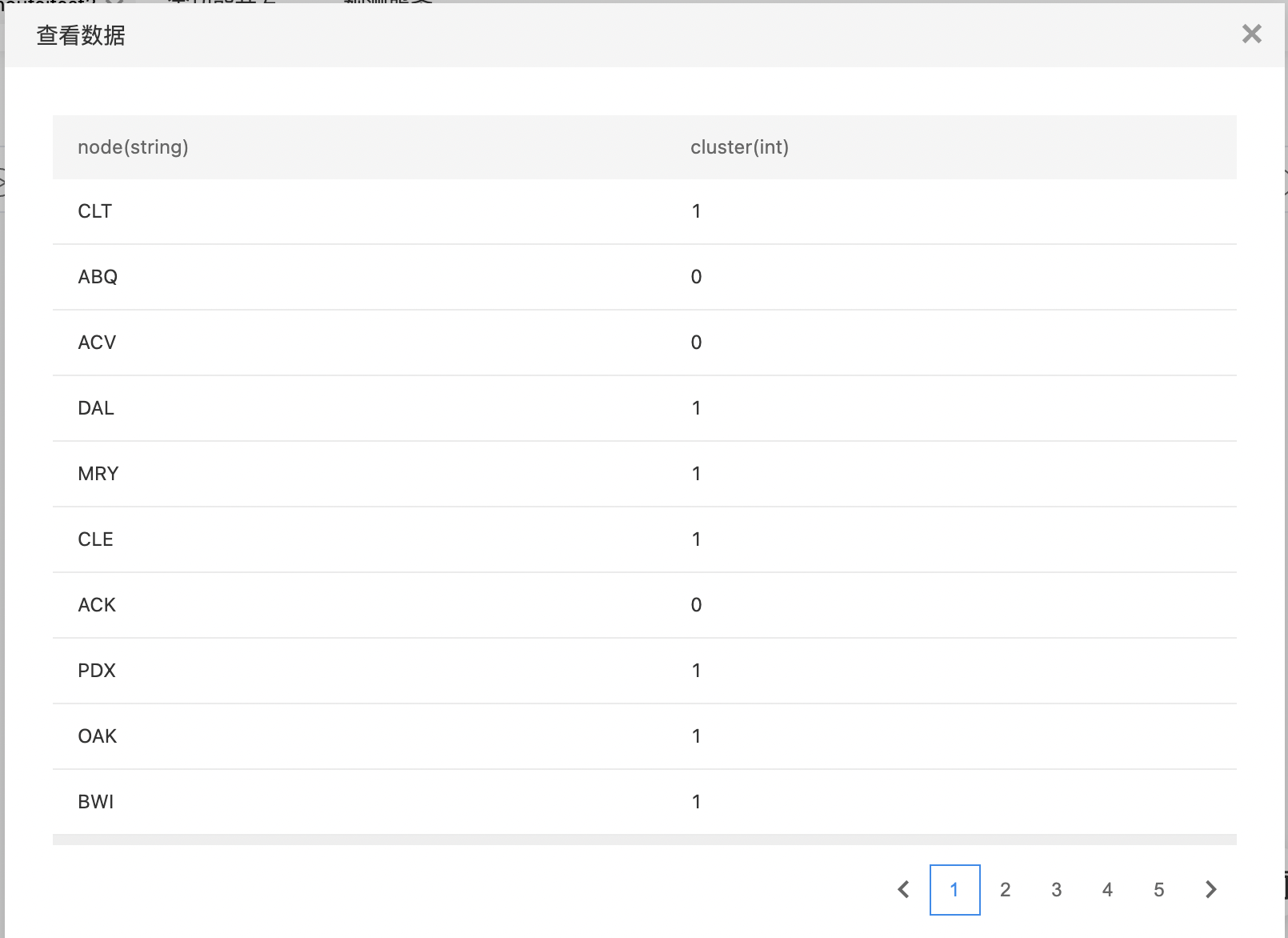
- 输出结果数据集,包括两列:node(源/目标顶点名称),cluster(聚类结果)。
算子参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 聚类中心个数 | 是 | PIC的聚类中心个数 范围:[2, inf)。 | 2 |
| 向量的初始化模式 | 是 | PIC对向量的初始化模式,分为随机初始化和度初始化。 | random |
| 最大迭代次数 | 是 | PIC的最大迭代步数 范围:[1, inf)。 | 100 |
字段参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 源顶点列 | 是 | 边的起始节点。 | 无 |
| 目标顶点列 | 是 | 边的终止节点。 | 无 |
| 边权值列 | 是 | 边的权重列,即为点之间的相似度列,需要为数值类型的列且值应该为非负数。 | 无 |
使用示例
- 构建算子结构,配置参数,完成训练。
- 查看输出结果。