

创建自动搜索作业
创建自动搜索作业
1.前提条件
2.新建作业
3.使用自动搜索作业训练模型
3.1 基本信息
3.2 算法配置
3.3 数据集配置
3.4 自动搜索配置
3.5 资源配置
3.6 查看搜索结果及可视化
4.发布模型
前提条件
- 自定义作业需要依赖于BOS对象存储读取输入文件,创建自定义作业之前需要保证您已经开通了BOS对象存储的服务。
- 授权自定义作业读写您的BOS对象存储,以顺利进行自定义作业的配置。
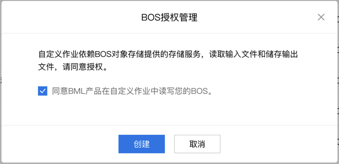
- 在BOS中存储创建Bucket,并且存储用于训练的代码文件和数据集,创建一个空文件夹用于存储代码的输出文件。
新建作业
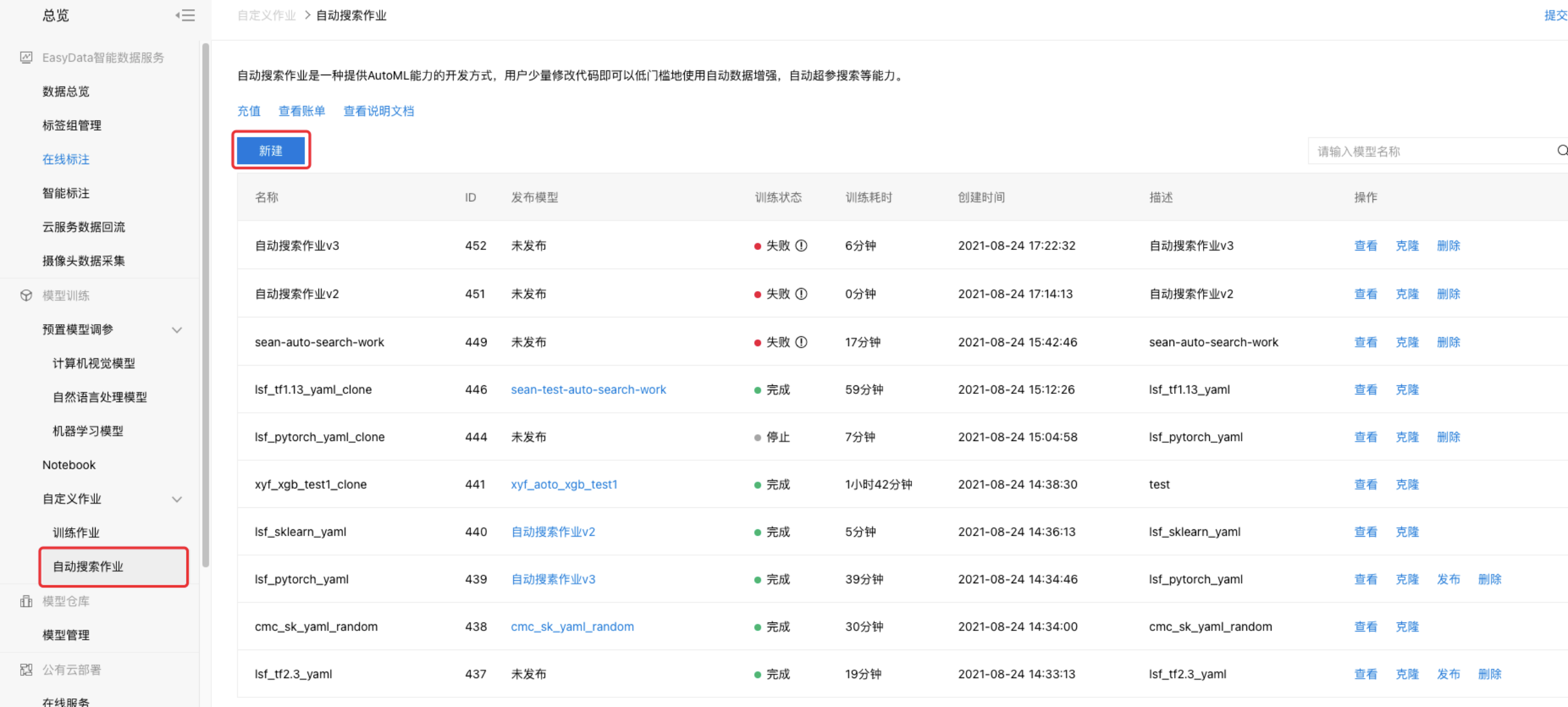
- 在导航栏选择『自定义作业-自动搜索作业』,进入自动搜索作业的列表页。
- 点击『新建作业』,进入配置自动搜索作业流程
使用自动搜索作业训练模型
自动搜索作业提供了多种开源框架、搜索算法以及优质的训练资源。您可以上传代码文件,数据集到BOS对象存储,通过自动搜索作业完成训练后,平台提供了每组超参数组合的参数值及其对应的模型评估指标、训练结果会输出到BOS中的指定输出目录,同时您也可以通过链接进入可视化界面查看具体搜索结果。
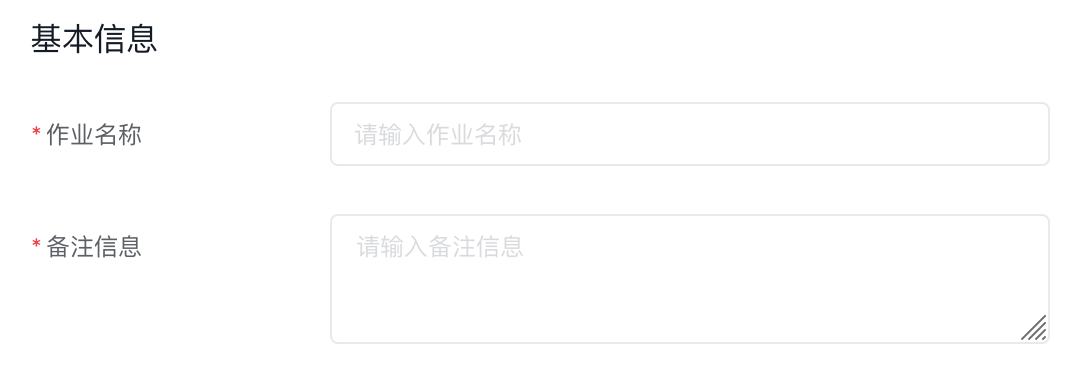
基本信息
填写作业名称和备注信息
算法配置
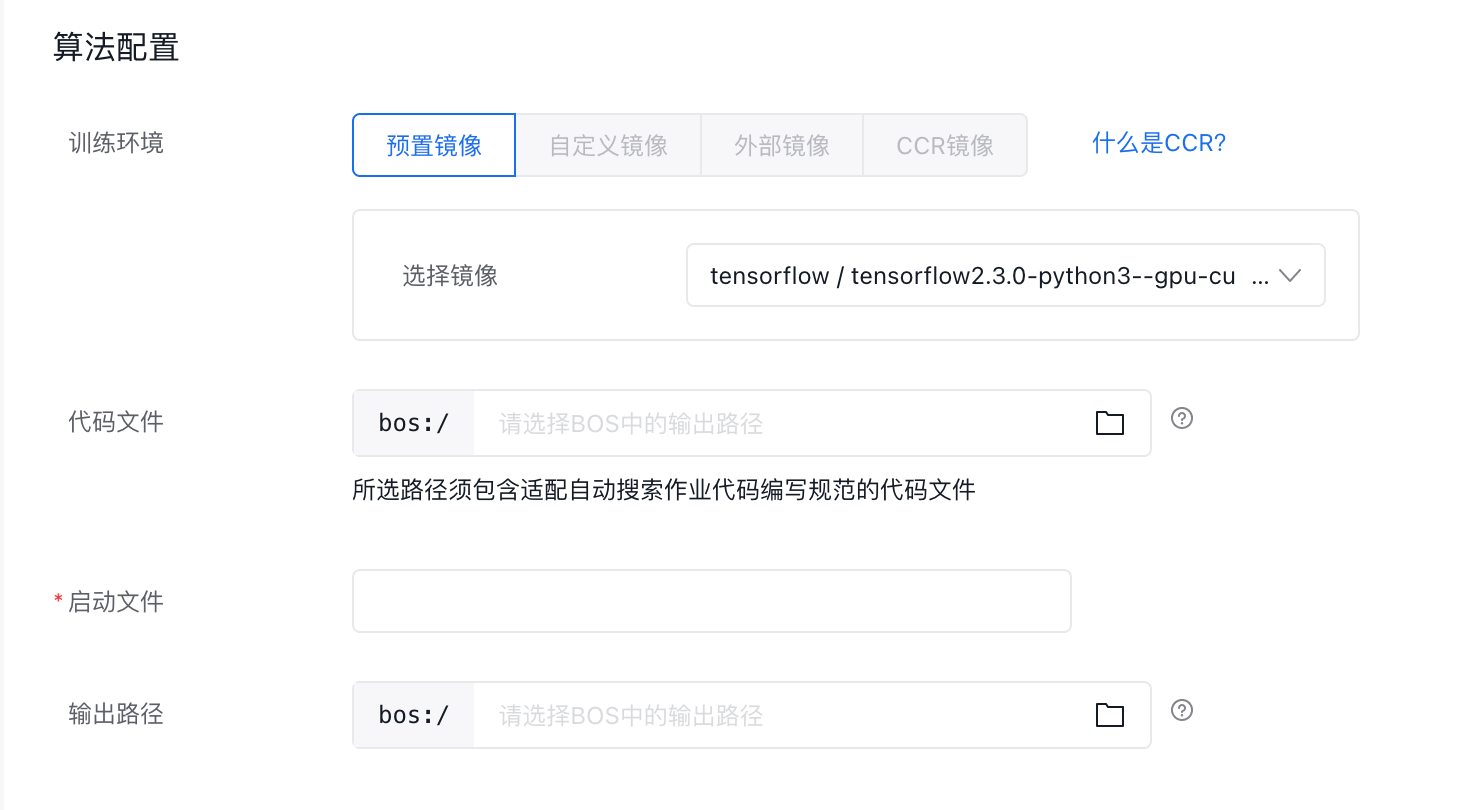
- 选择算法框架:选择训练代码文件使用的算法框架,目前BML支持Paddle,TensorFlow,Pytorch,Sklearn,XGBoost五种主流算法框架。
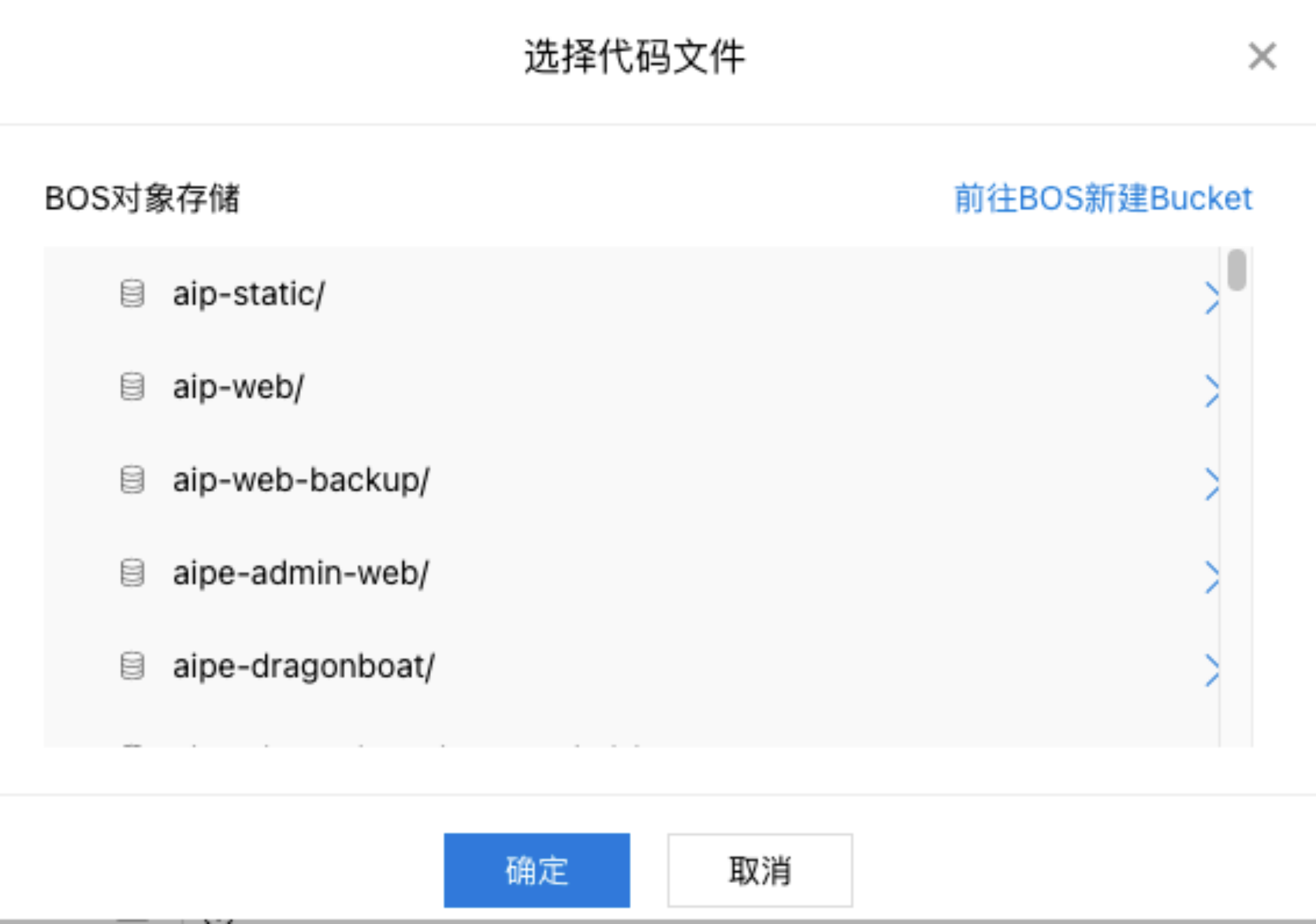
- 选择代码文件:从BOS对象存储中选取代码文件,完成代码录入。单击文件夹符号,从弹窗中选择bucket及文件夹。双击bucket或者单击『>』图标,即可进入下一级。
-
代码文件要求如下:
- 选取对象可以是一个文件或者文件夹
- 所选代码文件必须与所选算法框架对应,所选路径必须包含适配自动搜索作业代码编写规范的代码文件,查看代码文件编写规范(链接到代码文件编写规范)。
-
输入启动命令,支持python和shell两类脚本:
- 当代码文件项选择一个单独文件时,启动命令指向该启动文件
- 当代码文件项选择一个文件夹时,启动命令需指向该文件夹下的特定启动脚本,例如bash bml_job.sh
-
可选高级配置。提交训练作业时,可以通过高级配置来自定义环境变量。
- 手动配置:通过手动填写环境变量来配置,包括配置变量名称与对应取值。

- YAML文件:通过上传YAML文件来配置环境变量,支持本地上传和BOS存储导入两种方式。注意:环境变量最多配置100组,平台将在解析时对超出部分做自动截断处理。
此外,BML平台亦提供预置环境变量,由BML平台预先定义,不建议您自行覆盖修改。
预置环境变量
| 作业类型 | 变量名 | 变量含义 | 示例 | 默认值 |
| 自动搜索作业 | MANAGER_ADDRESS | 管理自动搜索作业节点exp-manager的svc地址 | 172.16.227.135:8888 | 无 |
| NVIDIA_VISIBLE_DEVICES | 训练节点可见的gpu卡设备 | GPU-ae58e6cc-1dec-bcb9-820c-e433d01afda6 | 无 | |
| PYTHONPATH | 训练任务节点汇报训练结果管理节点的sdk路径 | /home/sdk/output | /home/sdk/output |
数据集配置
自动搜索作业数据集配置方式是从BOS中选取数据集。在弹出的对话框中选择数据集对应的bucket和文件夹。注:选择的数据集路径与代码训练时传入代码的训练集、测试集路径一致。为保证训练效率,最好将数据存放在压缩包内。

自动搜索配置
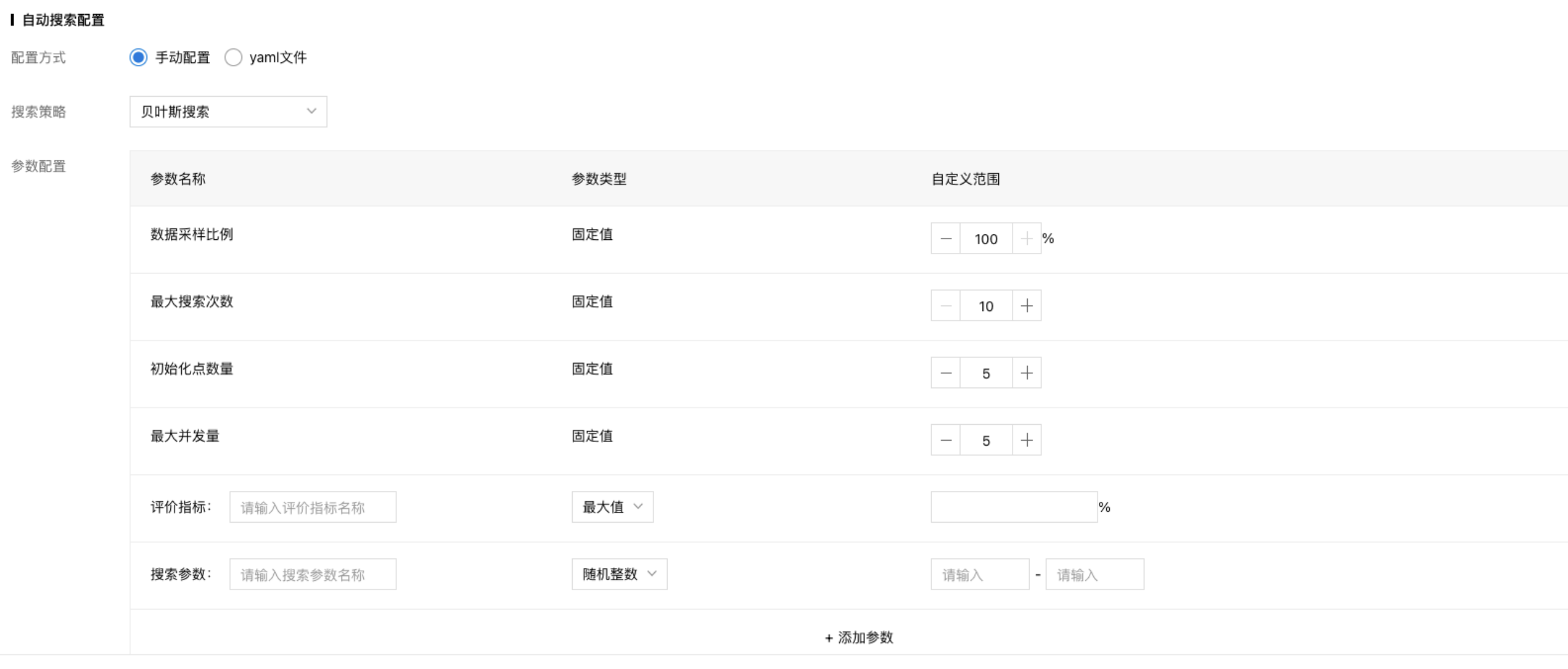
- 配置方式:
- 手动配置:用户需要在平台上手动选择搜索策略以及配置对应的参数。
- yaml文件:用户可以通过yaml文件来设置自动搜索配置,文件上传方式分为本地上传与从BOS中选取两种。

- 搜索策略:
自动搜索作业目前提供了5种搜索算法,见搜索算法简介。
- 参数配置:
- 选择搜索策略后,参数配置表格会提供对应的参数进行选择,其中关于搜索算法的参数说明见搜索算法简介。
-
非搜索参数的说明如下:
- 数据采样比例:超参搜索需要进行多个模型的训练,因此为了提高效率,减少总的搜索耗时,可以设置训练集的数据采样比例。
- 评价指标:用户在代码中可以自定义评价指标的计算方式,只需要在平台参数配置表格中填写评价指标的名称、优化方向(最大值/最小值)以及早停指标即可。下图是一个填写实例,评价指标:acc,最大值优化,当搜索实验的某个训练结果,acc的数值达到100%时,终止整个自动搜索任务。

-
搜索参数:用户需要将待搜索的超参数填入显示框内,搜索参数的名称需要与代码中的名称保持严格一致!如搜索任务中有多个参数需要搜索,点击『+添加参数』即可,如下为搜索参数的参数类型以及对应的取值范围说明:
- 随机整数:参数范围中填写搜索参数的上下界,算法在其中随机取整。
- 离散值:参数范围中填写搜索参数的所有可能取值,以英文逗号隔开,算法会随机从中取值。
- 平均采样:参数范围中填写搜索参数的上下界,算法在其中随机取值,包括整数和小数。
- 对数平均采样:参数范围中填写搜索参数的上下界,算法在其对数尺度上随机取值,该参数类型适用于学习率等参数范围有尺度差异的超参数。

资源配置
BML提供CPU和GPU两类训练机型。
CPU机型供算法框架为sklearn,XGBoost时使用,用于机器学习训练:
| 机型 | 规格说明 |
|---|---|
| CPU 4核 | CPU 4核16GB内存 |
| CPU 16核 | CPU 16核64GB内存 |
GPU机型供算法框架为Paddle,TensorFlow,Pytorch时使用,用于深度学习训练:
| 机型 | 规格说明 |
|---|---|
| GPU V100 | TeslaGPU_V100_32G显存单卡_12核CPU_56G内存 |
| GPU P4 | TeslaGPU_P4_8G显存单卡_12核CPU_40G内存 |
查看搜索结果及可视化
查看搜索结果
自动搜索作业运行完成后,在任务列表页中点击查看进入任务详情界面(任务运行时,也可点击查看实时信息)
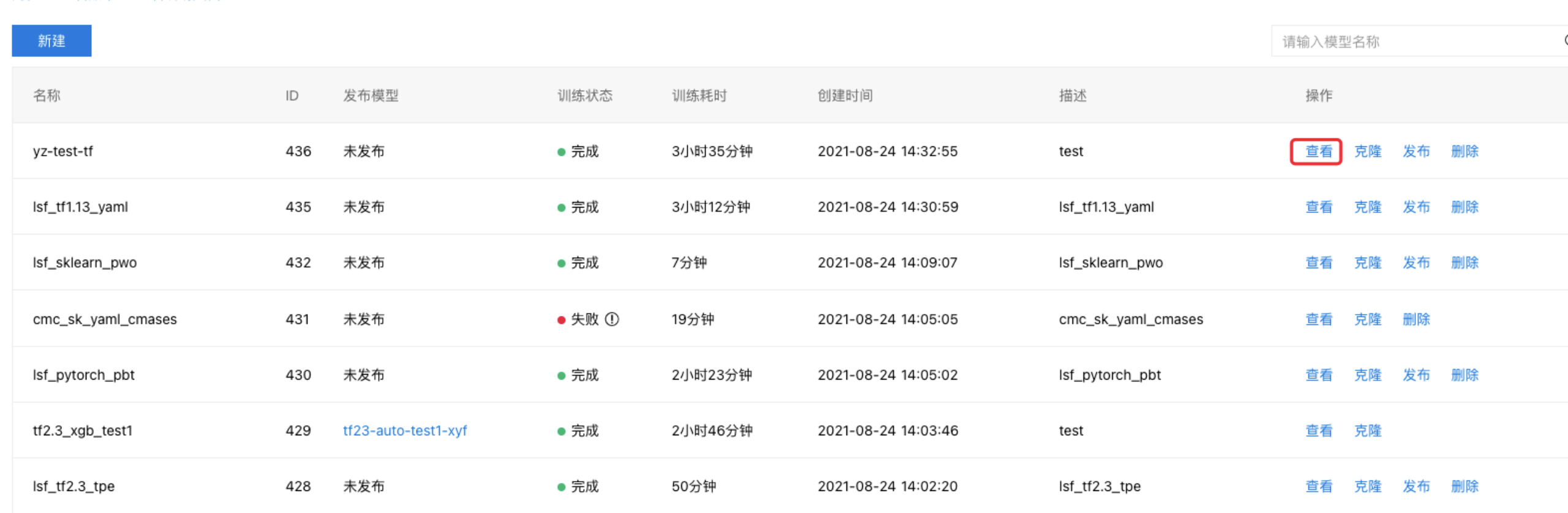
点击搜索结果,表格中会显示所有试验的详细信息,如评价指标的值、搜索耗时,试验状态等;点击日志,可以查看每个试验的运行日志。
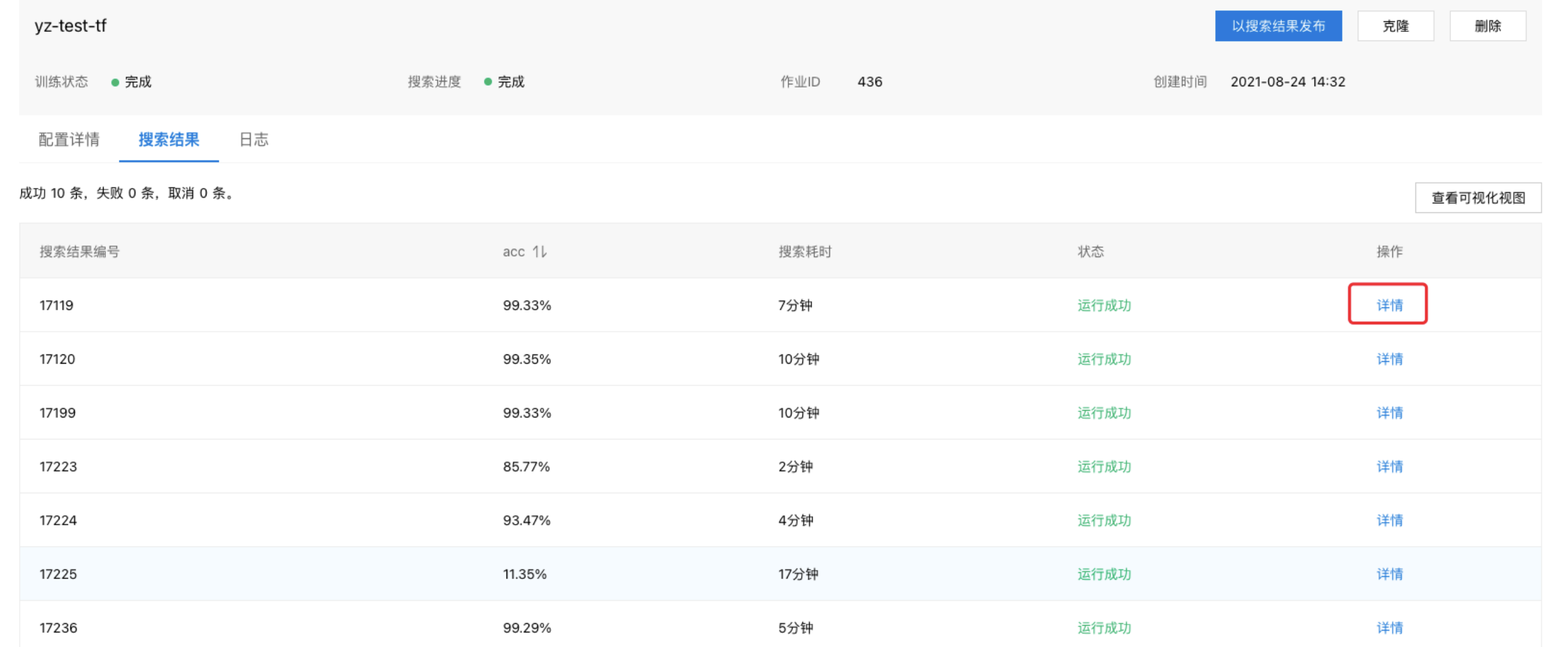
点击详情可以查看每个试验的超参数取值。
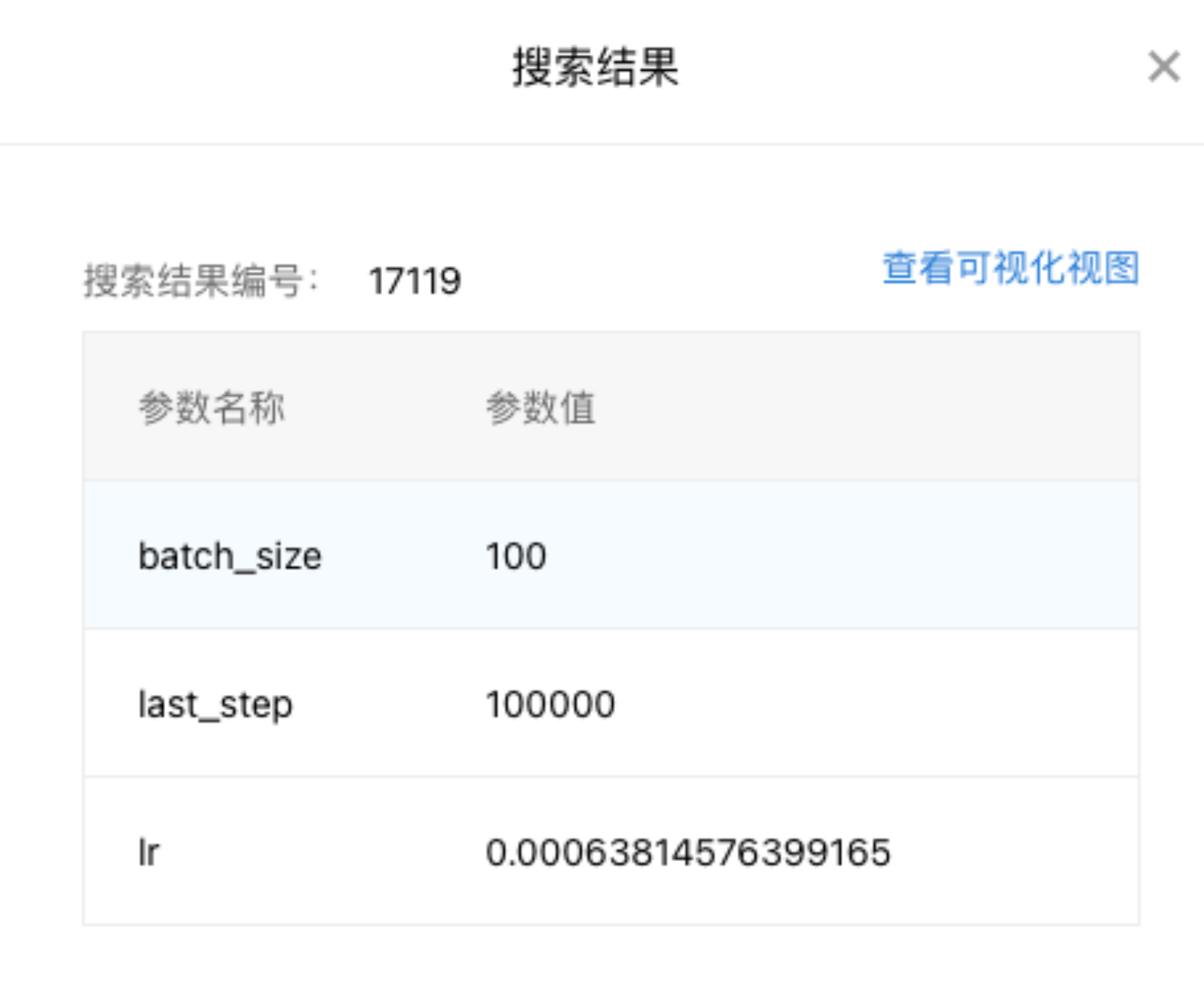
查看可视化视图
可视化界面目前仅保存了所有试验中指标最好的5个结果。
- 点击查看可视化视图,可以进入飞桨VisualDL可视化界面。
- 点击标题栏的超参可视化,自动搜索作业一共提供了三种图:
- 表格视图:搜索结果以表格的形式呈现。
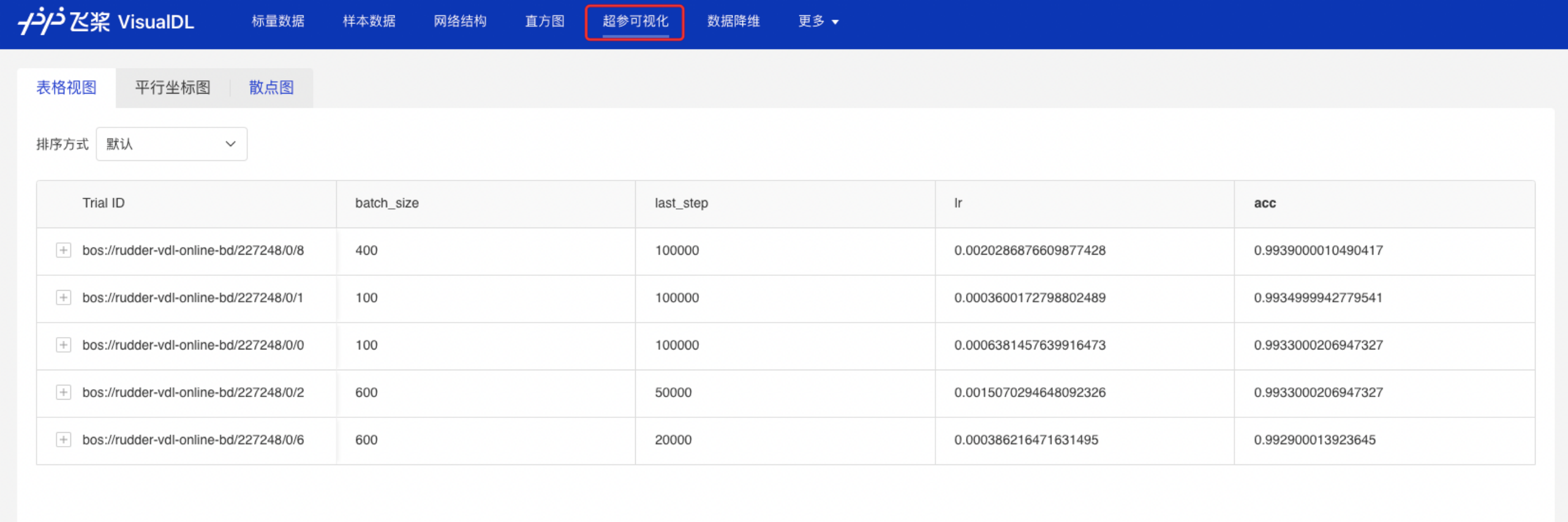
-
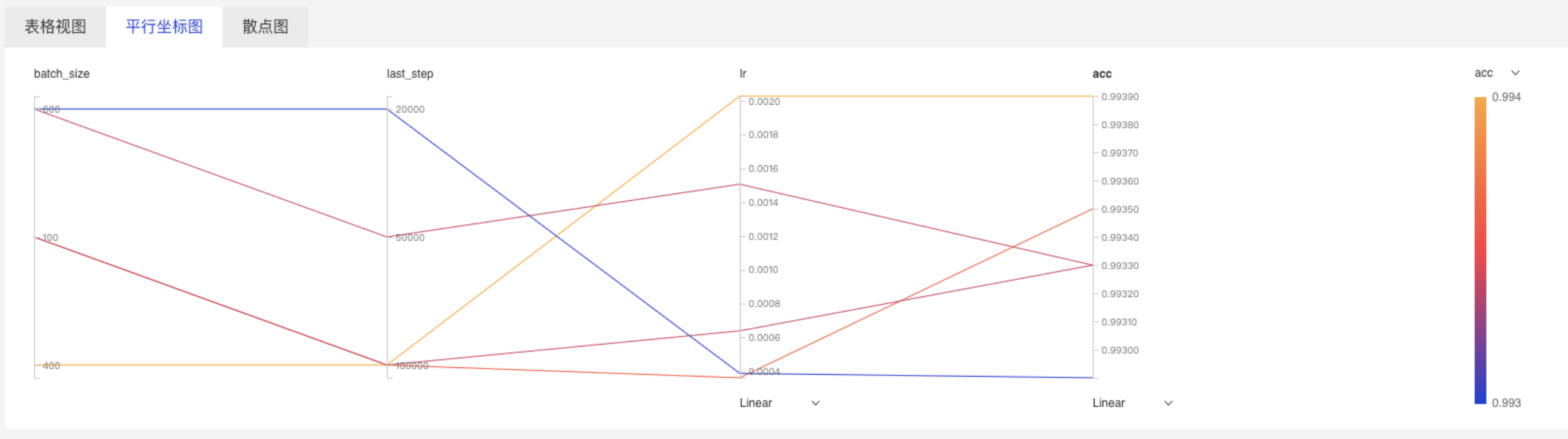
平行坐标图
- 图中右方为柱状热力图,当在右上方选择一个参数时,平行坐标图便会以该参数作为基准结果,参数组合的折线颜色便会依据该组合在选择参数上的取值而改变。
- 自动搜索作业中,选择评价指标(图中为acc)作为基准结果,然后观察各个超参数对其的影响大小。若某个超参数上相同颜色的折线较为集中,不同颜色有一定的距离,则说明该参数对于结果影响很大;而如果某个超参数上线条颜色混乱,则较大可能该参数对于结果的影响很小。
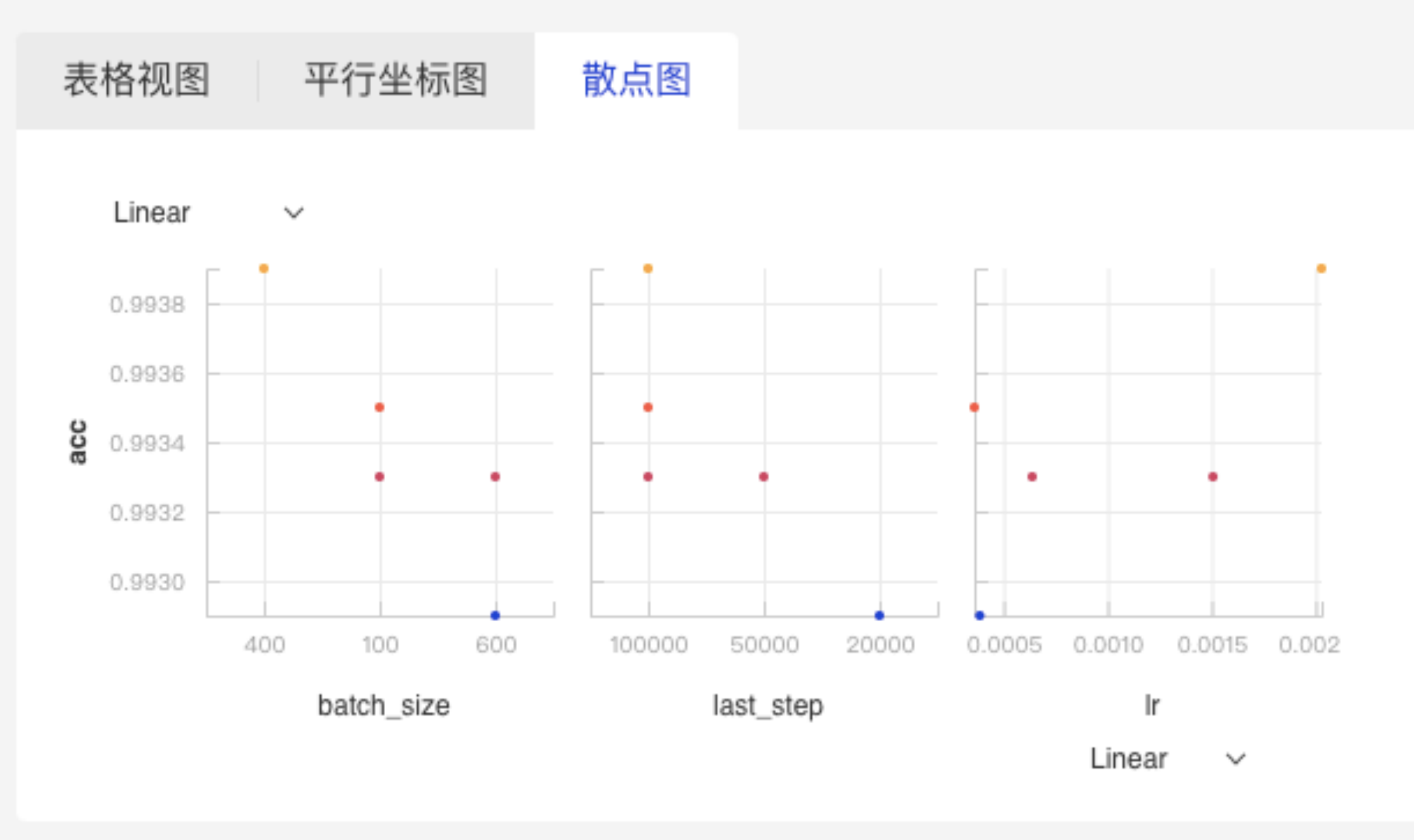
- 散点图:呈现超参数与指标之间的分布关系。
发布模型
自动搜索作业训练完成后支持将最好的5个模型直接发布到模型仓库。
- 模型列表中,训练完成的模型支持『发布』操作,点击『发布』进入发布界面。
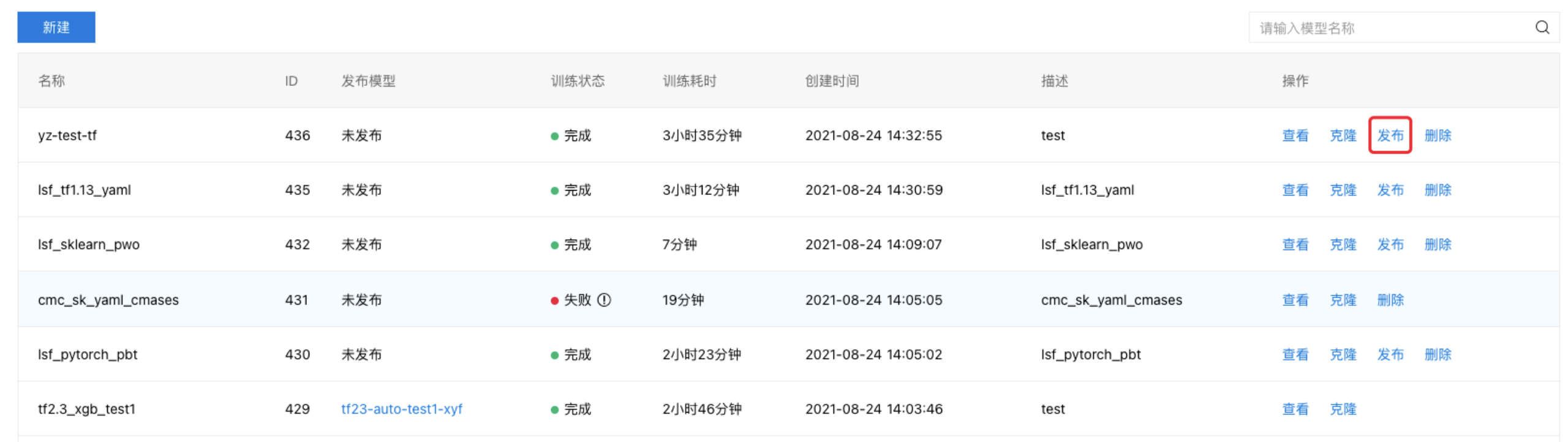
- 在发布界面,完成相关配置,如下所示:
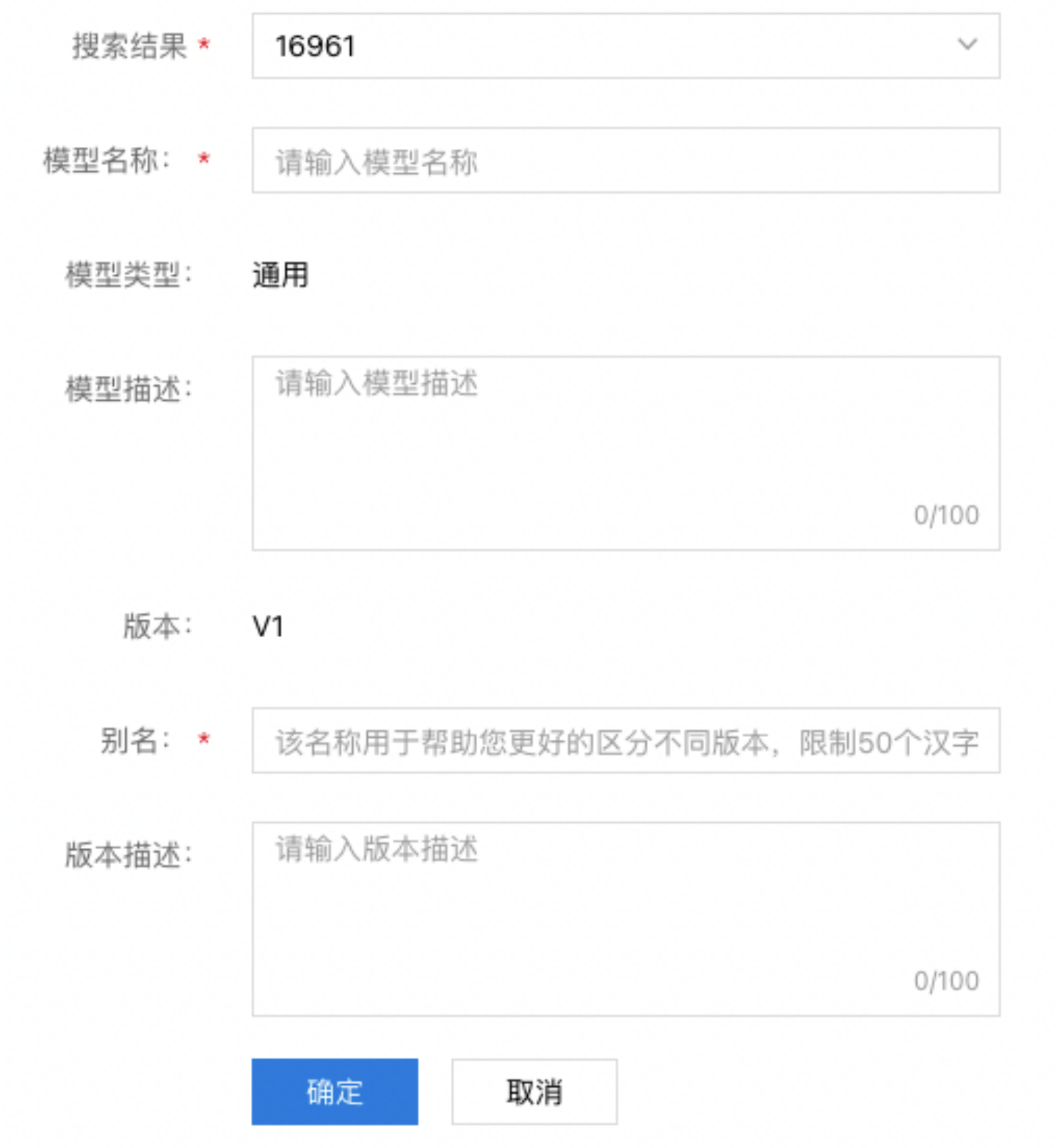
- 填写下图所示基本信息。『模型类型』和『版本』由系统自动生成,不支持修改。重新发布时,『模型名称和『模型描述』会自动填充,无需再次填写。
- 根据算法框架的不同,您还需要在发布界面填写响应的额外配置项信息。
| 算法框架 | 额外配置项 |
|---|---|
| PaddlePaddle | 无 |
| TensorFlow | 无。说明:自动搜索作业支持发布pb格式的模型文件到模型仓库,因此代码中需要保存pb格式的模型 |
| Pytorch | 从BOS中选择源代码并输入源代码的主文件名。说明:选取的代码为启动服务的推理代码,具体说明点击这里(链接到pytorch代码示例中的推理代码部分) |
| Sklearn/XGBoost | 模型文件格式:支持发布pickle格式或joblib格式模型到模型仓库。模型文件:选择一个搜索结果后,下方模型文件会自动填充对应试验的路径,用户只需要在对应路径下选中保存的模型即可。说明:其他框架在保存模型时,模型名称是固定的,而机器学习框架中通常是用户指定,因此在发布模型时需要手动选择 |