

图像理解SFT最佳实践
一、图像理解模型微调的方式选择
方法一:Prompt工程
什么情况下适合Prompt ? 当任务需求较简单、模型已有基础能力覆盖目标场景时,优先选择Prompt工程。例如:
- 基础识别任务:检测图像中是否包含特定物体(如“识别图片中的猫”)、提取基础属性(如“判断图片颜色基调”)。
- 格式简单且稳定的输出需求:需要模型返回固定格式的结果(如“是/否”“包含XX物体”),且现有模型通过Prompt优化即可满足精度要求。
- 快速验证场景:无需长期部署或高频迭代,仅需临时调用模型能力验证业务逻辑。
优势:
- 成本低:无需训练模型,直接利用预训练模型能力,节省算力、时间和开发成本。
- 通用性强:不改变模型参数,避免因微调导致的通用能力下降,适合跨场景复用。
方法二:SFT(监督微调)
什么情况下适合SFT? 当Prompt工程无法满足需求时,需通过SFT进一步优化模型,典型场景包括:
- 任务能力不足:
- 模型对目标任务“完全不会”或“基本不会”(如检测AI生成图的人体结构异常、复杂场景下的违规内容识别)。
- 输出格式不稳定或错误率高(如需要模型输出多维度检测结果时,Prompt无法保证结构化数据的准确性)。
- 精度要求高:
- 业务场景对检测准确率、召回率有严格指标(如医疗影像瑕疵检测),需通过定制化训练提升模型针对性。
- 长期部署需求:
- 需将模型集成至业务系统中高频调用,且需持续优化迭代(如UGC图片质检员)。
优势:
- 针对性强:通过标注数据定向优化模型,提升特定任务的检测精度,解决Prompt无法覆盖的复杂逻辑(如结合图像+文本的多模态审核)。
- 输出可控:可强制约束模型按业务需求输出固定格式(如JSON结构化结果),减少随机性。
注意事项:
- 成本权衡:需投入数据标注、模型训练、部署维护成本,且可能导致模型通用能力下降,需优先评估业务必要性。
- 数据门槛:需准备高质量标注数据(如瑕疵类型标注、违规内容样本),数据量与任务复杂度正相关。
|
补充说明:强化学习(RL)的应用边界 在图像理解业务场景中,强化学习非优先选项,仅适用于以下极端情况: 建议:业务落地中优先通过Prompt+SFT组合解决核心问题,强化学习仅作为“最后一公里”的优化手段。 |
二、数据准备与模型训练
1.数据准备
数据质量与规模是图像理解SFT成功的核心基础,需从内容、格式、数量三方面精细化把控,具体要求如下:
A. 数据质量:宁缺毋滥,对标业务需求
- 内容与格式双重对齐
- 内容一致性:标注数据需严格匹配目标任务输出逻辑。例如,若需检测“AI生成图人体结构异常”,标注需明确区分关节扭曲、比例失调等细分问题,避免模糊描述。
- 格式标准化:输出格式需与业务系统兼容(如JSON结构化结果、文本分类标签),避免依赖模型泛化能力转换格式,建议通过**手工标注+大模型改写**生成高质量数据,确保格式统一。操作示例:先用人工标注100条标准数据,再通过Prompt指令让大模型参考人工标注逻辑,批量改写剩余数据(如“请按照示例格式,为图像生成包含‘瑕疵类型+位置’的JSON结果”)。
- 拒绝低质数据
- 低质数据(如标注错误、模糊样本)会导致模型学习噪声,宁可减少数据量也不盲目扩充。
B. 数据组合策略
- 通用数据价值:补充模型在预训练阶段未覆盖的长尾场景,提升泛化能力。
- 比例建议:普通任务按业务数据:通用数据=10:1配置;复杂任务按5:1增强模型对新领域的适应性。
总结:数据准备需遵循“质量优先、量随难增、动态调参”原则,通过精准标注、合理配比、科学训练轮次,最大化提升图像理解模型的微调效率与业务落地效果。
C. 数据量:按任务难度阶梯式配置
| 任务难度等级 | 模型能力基础 | 业务数据量 | 通用数据量 | 典型场景 |
|---|---|---|---|---|
| 简单任务 | 模型已具备能力,仅输出格式不稳定(如JSON格式错误) | 几十~上百条 | 无需 | 基础图像分类(如“是否包含猫”) |
| 普通任务 | 模型处于“会与不会”区间(如预训练接触过类似数据但未专精) | 千条级 | 业务数据量1/10 | UGC图瑕疵检测(暗角、畸变) |
| 复杂任务 | 模型完全未接触过的领域(如文生图关联文本生成) | 1~2万条 | 业务数据量1/5 | AI生成图语义一致性审核 |
2.模型训练策略
Step1: 数据清洗与增广
对收集到的原始业务数据进行清洗,去除噪声、错误标注等无效数据;通过数据增强等手段(如图像变换、文本改写)扩充数据集规模,增强模型泛化能力。
Step2:模型训练预实验
- 实验模型选择:在数据量充足的情况下,7B小模型与72B大模型在业务垂域任务上的性能差异较小,建议优先考虑7B模型以降低成本,聚焦业务场景需求。可以先选用2B - 7B规模的小体量图像理解模型,快速验证训练流程和数据可行性;不满足需求时,可以选择较大体量模型训练并查看效果。
- 参数设置:采用较高学习率(1e - 5)和较长训练轮次(10轮),同时可以开启Checkpoint保存策略,按照Epoch保存的方式保存10个模型权重,加速模型训练进程,促使模型在训练集上充分学习数据特征。
- 训练集验证:训练完成后,优先在训练集上进行测试,以验证数据质量、训练框架底层逻辑是否存在问题。若模型在训练集上无法有效学习,需回溯检查数据标注或训练配置。
- 数据形态配比消融:若业务数据存在多种形式,在此阶段进行不同形态数据的配比实验,确定最优数据组合方式,提升模型训练效果。
Step3:超参数优化与确定
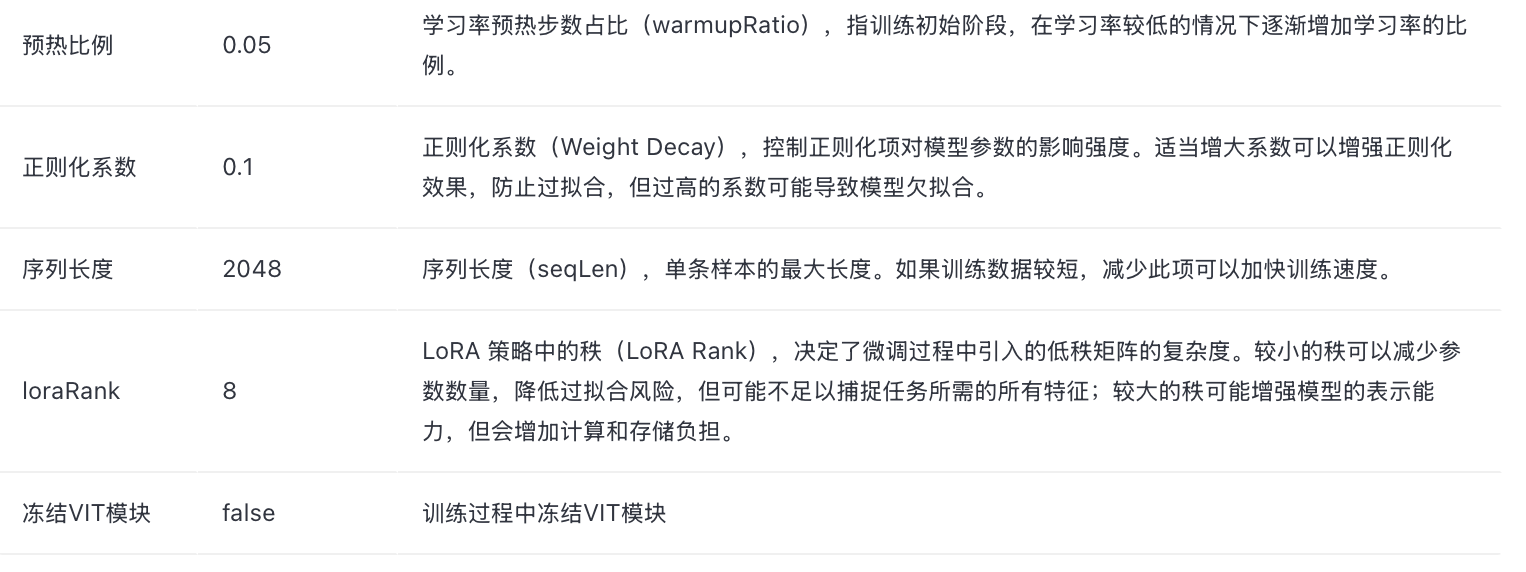
- 结合验证集调整:在训练集测试通过后,利用验证集上的loss曲线,对训练轮次(epoch)、业务数据与通用数据配比、学习率、batch_size、序列长度等超参数进行系统性调整与优化。
- 多轮迭代优化:通过多轮训练与参数调整,观察模型在验证集上的性能变化,找到各超参数的最优组合,平衡模型的拟合能力与泛化能力。
- 建议的训练轮次:
- 小模型(如4B参数):复杂任务需训练10个epoch以上,测试集Loss可能持续下降(需监控过拟合风险)。
-
中大型模型(7B~70B参数):
- 7B模型:常规任务训练5个epoch左右,超过易过拟合;
- 70B模型:仅需2个epoch即可收敛,过多轮次易导致泛化能力下降。
- 关键动作:通过验证集监控Loss曲线,在Loss停止下降或开始上升时及时终止训练,避免过拟合。
Step4:训练方法与策略选择
- 微调方式选择:
- 学界常用LoRA:适用于资源有限场景,可有效减少参数量,降低计算成本。
- 工业届全量调优:在资源充足、追求极致性能的场景下使用,可充分利用模型参数进行优化。
- 模型层调整策略:
- 输出格式优化:若仅需调整输出格式,重点微调LLM部分即可,可以选择冻结VIT模块。
- 新知识学习:当涉及全新知识时,需同时放开VIT、LLM及中间层进行训练;若业务数据与预训练数据差异大,建议解冻VIT层以提升收敛稳定性;对于复杂任务,全放开训练更有助于模型学习。
三、图像理解最佳实践
| 对于图像理解模型的微调,为控制模型输出更符合预期的理解内容,关键的可控因素在于格式化数据准备、Prompt编写和参数调节,下文将结合以上技巧,详细说明在千帆ModelBuilder平台实践图像理解大模型微调的步骤,展示如何调优得到一个“UGC图片质检员”。 |
1.UGC图片质检场景描述
随着AI生图工具普及与用户创作热情高涨,UGC生态迎来爆发式增长,无论是社交平台的创意作品,还是电商场景的商品图,都展现出全民创作的活力。但繁荣之下,质量与安全问题凸显:AI生成图像因模型缺陷出现模糊、失真、比例扭曲及人体结构异常等问题;用户自主上传内容也因拍摄或后期处理不当,存在暗角、畸变等瑕疵,甚至包含违规展示。这些低质与违规图像不仅影响用户体验,还可能引发消费纠纷、触碰内容安全红线。因此,构建完善的UGC图片审核与质检体系,成为保障数字生态健康发展的关键。
2.平台实现步骤
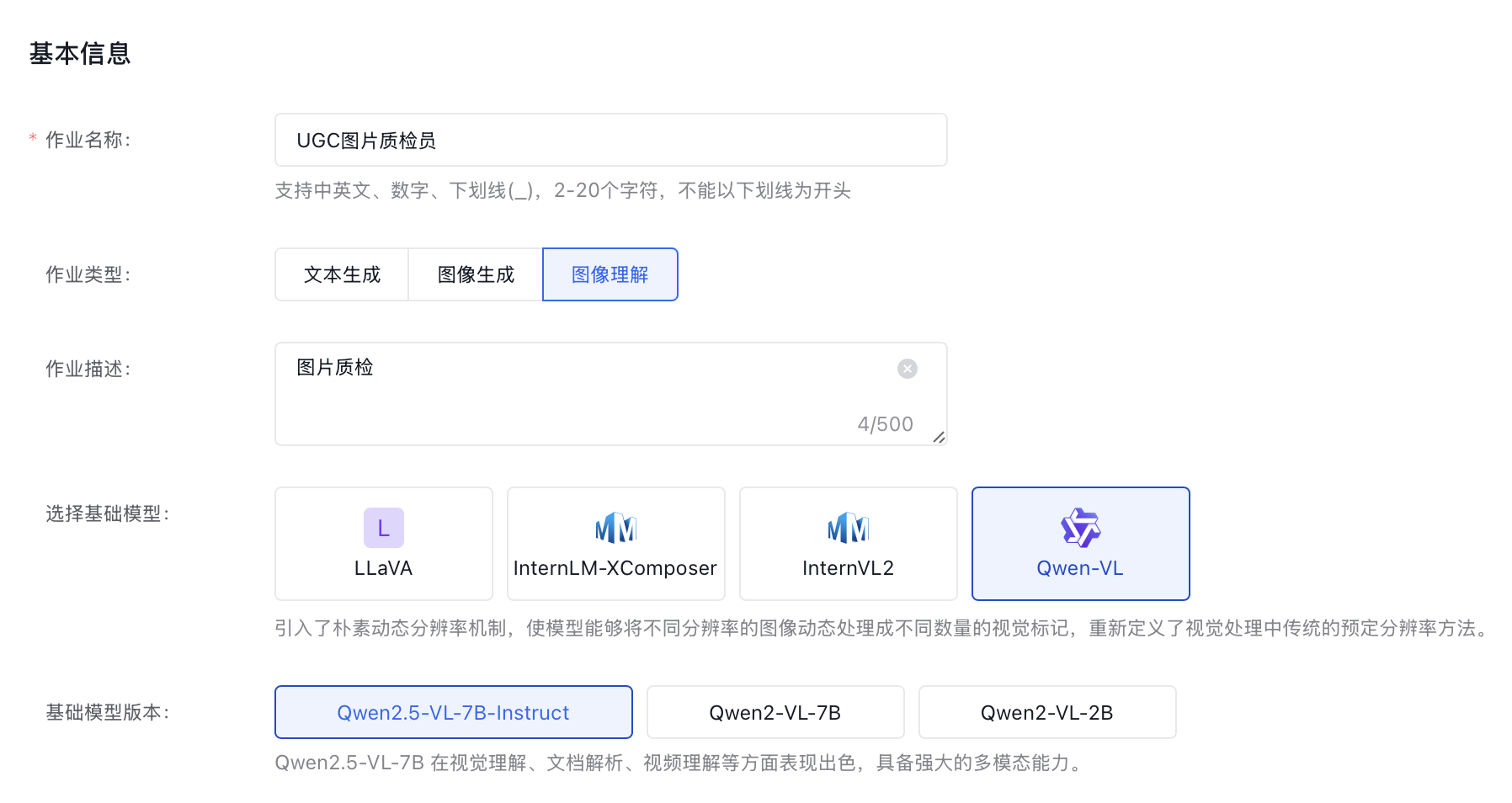
Step1: 创建SFT图像理解任务
- 在千帆ModelBuilder上,选择「模型精调」→「SFT」,作业类型选择「图像理解」,并选择基础模型Qwen2.5-VL-7B-Instruct,此模型在视觉理解、文档解析、视频理解等方面表现出色,具备强大的多模态能力。
- 选择「LoRA」训练方法,仅更新少量参数,能大幅降低计算量与内存占用,适配有限算力环境;同时,不修改预训练模型原始权重,可避免灾难性遗忘,在增强图像理解能力时保留模型多模态任务的原有性能,实现高效灵活的优化。
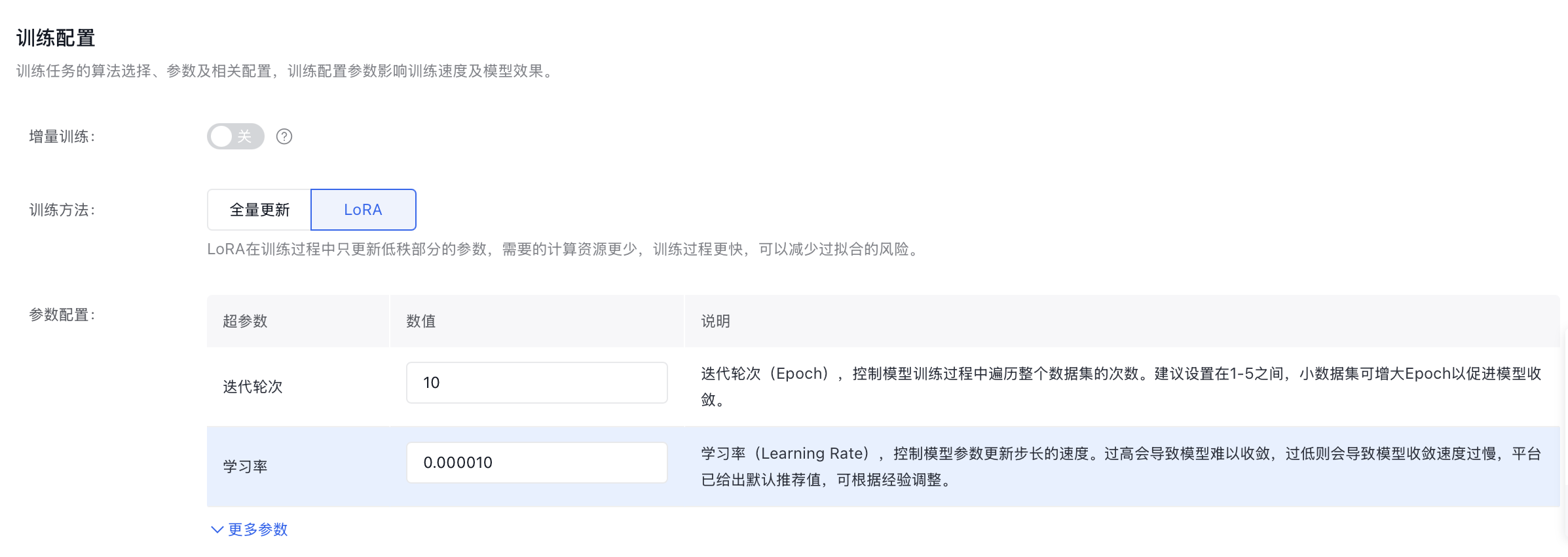
- 参数配置如下,基于前期重复实验数据,对关键参数进行了针对性优化调整(下文中做出解释),以提升模型在复杂图像场景下的整体表现。
| 超参数配置 | 解释 |
|---|---|
| 迭代轮次(Epoch)= 10 | 小参数模型需要适当增大 Epoch 以促进模型收敛。在图像理解模型训练过程中,可以设置相对较大的 Epoch 值,并持续观察 Loss 曲线变化趋势,以便及时调整训练策略,平衡模型的拟合效果与泛化能力。 |
| 批处理大小 = 1 | 图像数据占用内存较大,批处理大小设为 1 可以有效避免内存溢出问题,虽然会降低训练速度,但能在资源有限的情况下保证训练的顺利进行,提高训练效率。 |
| Checkpoint 按 Epoch 保存,保存个数设为 10 | 按 Epoch 保存 Checkpoint 能够在每个完整的数据集遍历后保存模型状态,方便在不同训练阶段评估和选择模型。保存 10 个 Checkpoint,一方面可以在系统故障时从最近的 Checkpoint 恢复训练,减少训练中断带来的损失;另一方面,通过对比不同阶段的模型,能够分析模型的训练过程,了解模型是如何随着训练逐渐收敛或出现过拟合等情况的,从而为改进模型提供依据。 |

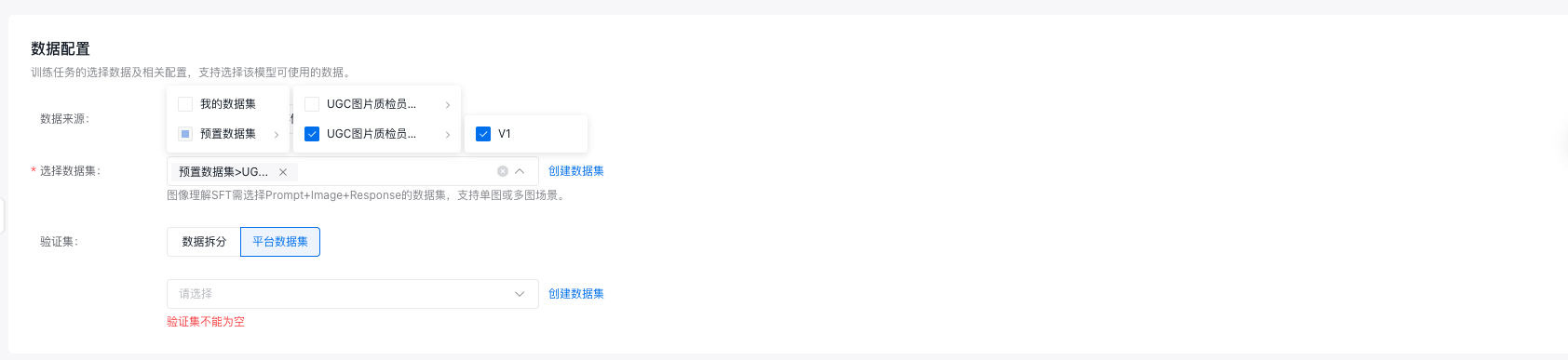
Step2: 数据配置
本平台提供预置数据集,涵盖UGC场景中 6 种常见瑕疵类型:
- 图像模糊:包括对焦不准、动态模糊等导致主体细节丢失的图像问题;
- 颜色失真:因色彩偏差、过曝、偏色等导致视觉效果偏离真实场景的现象;
- 比例扭曲:图像中主体或构图出现拉伸、压缩等比例异常问题;
- 边框:非内容主体的多余边框、黑边或装饰性边框干扰视觉效果;
- 暗角:图像四角出现亮度显著低于中心区域的暗化现象;
- 残肢缺陷或多肢异常:人物或生物肢体结构缺失、变形或多出异常肢体的缺陷。
数据收集采用公开平台采集与AIGC生成双轨制,并进行人工复核:
- 公开平台采集:通过图搜工具,以瑕疵类型关键词定向抓取 UGC 公开平台的真实图像数据。
- AIGC 图像生成:针对残肢缺陷或多肢异常等难以通过现实采集覆盖的瑕疵,采用 AI 生成技术补充数据。您也可以探索千帆精选大模型,自行使用如ERNIE iRAG等图像生成模型(文生图模型)进行数据生成。
基于实际需求与数据获取的可行性,数据分布如下。正常图像获取相对容易、在UGC场景中占比较高;“图像模糊”等瑕疵通过数据增强批量生成,该类瑕疵间数量相近;“残肢缺陷或多肢异常”瑕疵,因AIGC生成成本高、审核严格,数量较少,同时保证一定样本量以满足模型对特殊瑕疵的学习需求,确保模型能准确识别各类瑕疵并良好泛化。
| 类型 | 正常 | 图像模糊 | 颜色失真 | 比例扭曲 | 边框 | 暗角 | 残肢缺陷或多肢异常 | 全部 |
|---|---|---|---|---|---|---|---|---|
| 数量 | 662 | 120 | 120 | 120 | 120 | 120 | 225 | 1487 |
部分数据样例如下:采用Prompt+Image+Response的格式,并在提示词中给出审核标准与回答规则。
| Prompt | Image | Response |
|---|---|---|
| {"role": "user", "content": "\n你是一个专业的UGC图片质检审核员,我会提供一张用户上传的图片、一系列质量问题和对应的质检标准,以及我希望的输出格式要求。请根据提供的图片和质检标准,判断该图片是否符合每个标准,并按照固定 JSON 格式返回结果。\n\n# 可能的质量问题: 图像模糊、颜色失真、比例扭曲、边框、暗角、残肢缺陷或多肢异常;\n\n# 质检标准\n1. 图像模糊: 图片模糊不清,细节不清晰,无法辨认物体或文字;\n2. 颜色失真: 图片颜色失真,色彩不自然或过于鲜艳,或者颜色偏差明显;\n3. 比例扭曲: 图片中出现比例扭曲,如图像拉长、拉宽、变形等;\n4. 边框: 图片四周有明显的边框或边缘处理不当;\n5. 暗角: 图片四个角落的亮度明显暗于图片中央区域;\n6. 残肢缺陷或多肢异常: 重点关注图片中出现的人体存在不合理的地方,例如,奇怪的形体,多余或缺少的四肢,奇怪的手指或脚趾等异常情况,只要存在任何不合理的情况,就存在该质量问题;\n\n# 输出格式:\n一个完整的JSON, 不需要任何其它无关解释\n# 输出格式说明:\n一共返回1行JSON, 包含1个字段:result。result的值是你的判断结果, 如果存在某个质量问题, 则出现该质量问题, 否则不出现。如果存在多个质量问题, 用","分隔。如果一个质量问题都没有, 则返回"正常"。\n\n<输入图片>: |
 |
{ "result": "图像模糊"} |
| {"role": "user", "content": "\n你是一个专业的UGC图片质检审核员,我会提供一张用户上传的图片、一系列质量问题和对应的质检标准,以及我希望的输出格式要求。请根据提供的图片和质检标准,判断该图片是否符合每个标准,并按照固定 JSON 格式返回结果。\n\n# 可能的质量问题: 图像模糊、颜色失真、比例扭曲、边框、暗角、残肢缺陷或多肢异常;\n\n# 质检标准\n1. 图像模糊: 图片模糊不清,细节不清晰,无法辨认物体或文字;\n2. 颜色失真: 图片颜色失真,色彩不自然或过于鲜艳,或者颜色偏差明显;\n3. 比例扭曲: 图片中出现比例扭曲,如图像拉长、拉宽、变形等;\n4. 边框: 图片四周有明显的边框或边缘处理不当;\n5. 暗角: 图片四个角落的亮度明显暗于图片中央区域;\n6. 残肢缺陷或多肢异常: 重点关注图片中出现的人体存在不合理的地方,例如,奇怪的形体,多余或缺少的四肢,奇怪的手指或脚趾等异常情况,只要存在任何不合理的情况,就存在该质量问题;\n\n# 输出格式:\n一个完整的JSON, 不需要任何其它无关解释\n# 输出格式说明:\n一共返回1行JSON, 包含1个字段:result。result的值是你的判断结果, 如果存在某个质量问题, 则出现该质量问题, 否则不出现。如果存在多个质量问题, 用","分隔。如果一个质量问题都没有, 则返回"正常"。\n\n<输入图片>: |
 |
{ "result": "残肢缺陷或多肢异常"} |
Prompt设计如下:在监督微调(SFT)阶段进行数据准备时,可将以下独立Prompt设计作为参考标准;同时,该设计也适用于模型完成微调并部署后的调用测试环节,用以验证模型对指令的响应准确性与任务执行能力。
PROMPT = """
你是一个专业的UGC图片质检审核员,我会提供一张用户上传的图片、一系列质量问题和对应的质检标准,以及我希望的输出格式要求。请根据提供的图片和质检标准,判断该图片是否符合每个标准,并按照固定 JSON 格式返回结果。
# 可能的质量问题: 图像模糊、颜色失真、比例扭曲、边框、暗角、残肢缺陷或多肢异常;
# 质检标准
1. 图像模糊: 图片模糊不清,细节不清晰,无法辨认物体或文字;
2. 颜色失真: 图片颜色失真,色彩不自然或过于鲜艳,或者颜色偏差明显;
3. 比例扭曲: 图片中出现比例扭曲,如图像拉长、拉宽、变形等;
4. 边框: 图片四周有明显的边框或边缘处理不当;
5. 暗角: 图片四个角落的亮度明显暗于图片中央区域;
6. 残肢缺陷或多肢异常: 重点关注图片中出现的人体存在不合理的地方,例如,奇怪的形体,多余或缺少的四肢,奇怪的手指或脚趾等异常情况,只要存在任何不合理的情况,就存在该质量问题;
# 输出格式:
一个完整的JSON, 不需要任何其它无关解释
# 输出格式说明:
一共返回1行JSON, 包含1个字段:result。result的值是你的判断结果, 如果存在某个质量问题, 则出现该质量问题, 否则不出现。如果存在多个质量问题, 用","分隔。如果一个质量问题都没有, 则返回"正常"。
<输入图片>:<ImageHere>
<输出>:
"""Step3: 发布模型与开始训练
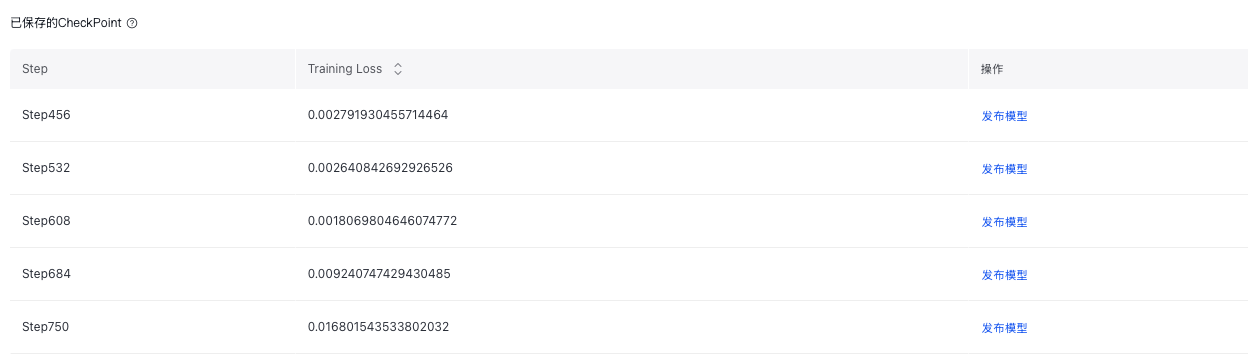
训练结束后发布为新模型,也可以在训练后的评估报告中选择合适的Checkpoint进行模型发布。
|
在此说明checkpoint 保存的目的: |
在此说明checkpoint 保存的目的:
- 模型恢复:在训练过程中,可能会因为各种原因导致训练中断。保存 checkpoint 可以让训练从上次保存的状态继续,而不必从头开始,节省大量的时间和计算资源。
- 模型评估与选择:通过保存不同训练阶段的 checkpoint,可以在验证集上评估模型在各个阶段的性能。这样有助于确定模型是否出现过拟合,以及选择在验证集上表现最佳的模型作为最终模型。例如,如果在某个 checkpoint 之后,模型在验证集上的准确率开始下降,而训练集上的准确率仍在上升,就可能出现了过拟合现象,此时可以选择之前表现较好的 checkpoint 对应的模型。
- 模型对比与分析:保存多个 checkpoint 可以方便对比不同训练阶段模型的参数变化,分析模型的训练过程,了解模型是如何随着训练逐渐收敛或出现过拟合等情况的,从而为改进模型提供依据。
Step4: 结果查看与分析
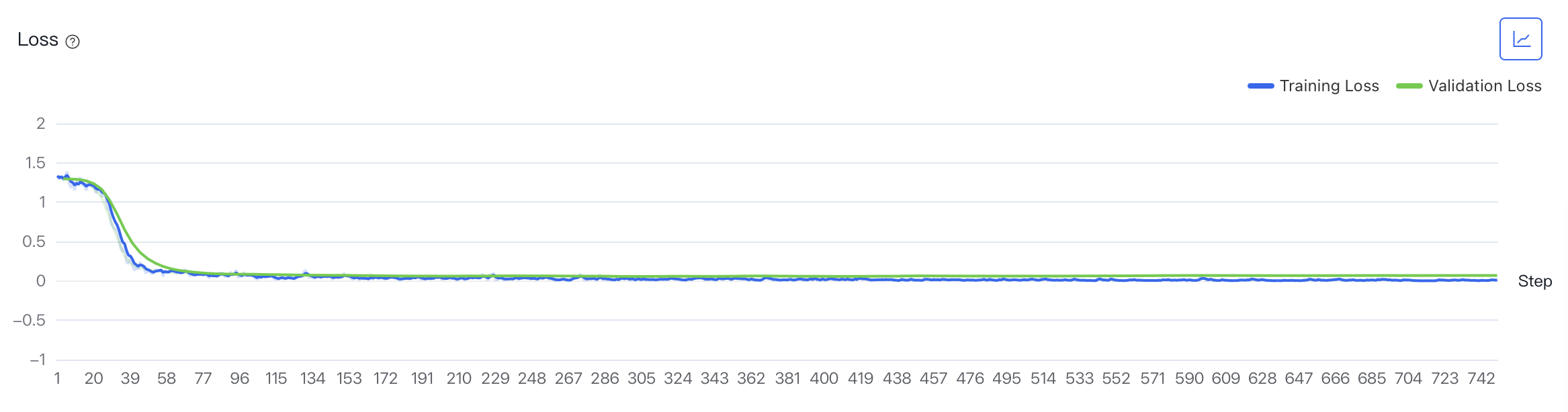
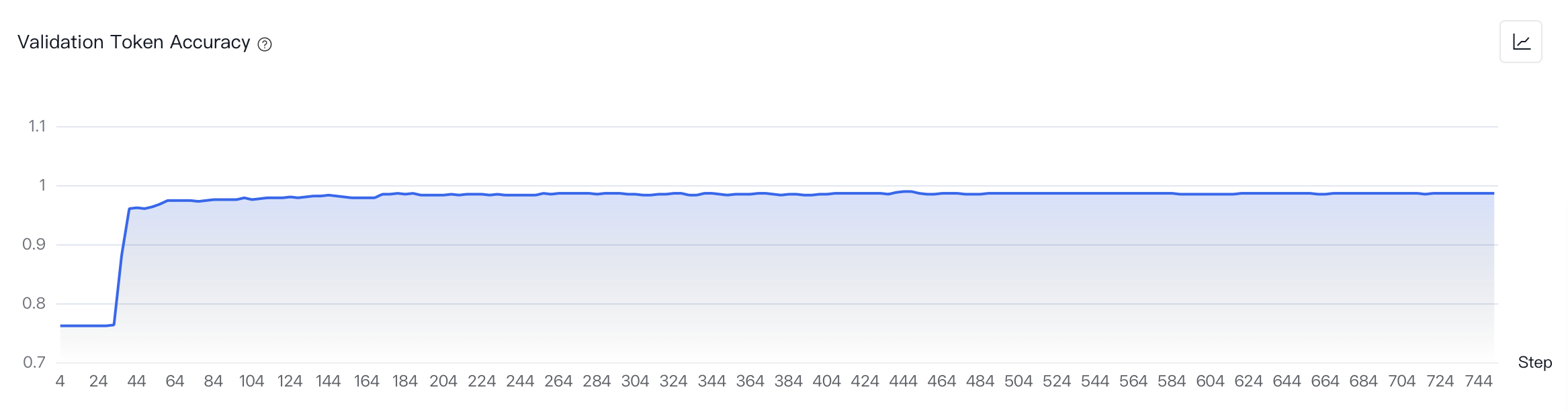
- 您可以通过查看“评估报告”以及在训练过程中或结束后的“训练过程可视化”来监测实验进度和训练情况。平台提供多种指标以评估训练效果,主要关注指标Loss(训练集、验证集每个Step的损失)和Validation Token Accuracy(验证集每个Step中token正确预测的比例)以确认模型效果。观察结果,Training Loss和Validation Loss曲线趋势大致吻合,最后收敛。观察Validation Token Accuracy,预测正确率达到98%以上,满足实际使用场景需要。
Step5: 模型部署与效果快速评估
- 配置成功后,在平台即可一键开启模型训练,训练完成后一键部署至千帆ModelBuilder,部署后即可创建在线推理服务。在创建服务中,选择合适的算力单元进行购买,即可在业务上部署属于您自己精调后的大模型。部署完成后,您不仅可以调用API实现业务效果,在调用前也可以在体验中心验证模型效果,进而再进行选择。
- 对图像理解模型可以进行测试评估,在下文中【3.2 评估结果】展示了我们的评估效果,供您参考。您可以在平台部署模型,参考【2.2 数据样例】中的Prompt对具体case进行调用测试。
3.模型调用结果
3.1 模型调用效果对比
结论1:SFT在多模态领域效果显著,能强化模型对图像类多模态数据的关联学习与综合处理能力,提升复杂场景下的任务表现。
您可通过平台便捷完成模型部署流程,对检测结果中的不良案例(bad case)进行深度溯源与归因分析,精准定位模型误判、漏检的关键因素。模型调用时,建议采用以下标准化Prompt指令;经实际测试验证,调用前后的检测结果对比如下所示,呈现模型的优化效果与应用表现。
| Prompt | 基座模型 | SFT后模型 | 检验标准参照 |
|---|---|---|---|
| 检查这张图片中人体的结构是否合理,如果不合理,请指出具体的问题。 | 这张图片中的人体结构看起来是合理的。腿的长度和比例与身体其他部分相协调,没有明显的比例失调或姿势问题。整体构图也显得自然,没有明显的不自然的扭曲或变形。 | 这张图片中人体的结构不合理。具体问题如下:1. 右腿的形状不自然,显得扭曲,尤其是膝盖下方的线条看起来不连贯。2. 右手的手指看起来有些不协调,尤其是小指和无名指似乎有缺失或不完整的迹象。3. 左手的手指也有类似的不协调现象,特别是小指和无名指看起来不完整。这些异常表明这张图片可能是由AI生成的,或者是经过了不自然的编辑处理。 | >>> 1.残肢缺陷或多肢异常: 图片中出现的人体结构存在不合理的地方,例如,奇怪的形体,多余或缺少的四肢,奇怪的手指或脚趾等异常情况,只要存在任何不合理的情况,就存在该质量问题;>>> 正常>>> 1.残肢缺陷或多肢异常: 图片中出现的人体结构存在不合理的地方,只要存在任何不合理的情况,就存在该质量问题;>>> 残肢缺陷或多肢异常 |
| 针对人体结构畸变(残肢/多肢异常)场景分析 | |
|---|---|
| 基座模型 | SFT后模型 |
| 在未进行SFT前,基础模型因缺乏AIGC肢体异常检测场景的针对性训练,无法有效识别该场景下的图像瑕疵,在实际测试中部分类别表现出零判别能力,难以满足UGC图像质检需求。 | 经SFT训练后,模型具备手指异常检测能力,在更复杂的异常肢体检测任务中也有明显的效果提升。 |
3.2 评估结果
结论2:在整体准确率与瑕疵召回率指标上,SFT模型实现了突破性提升,针对比例扭曲、边框异常、暗角缺陷及人体结构畸变(残肢/多肢异常)等高复杂度瑕疵类型,检测精度提升尤为显著,有效验证了SFT策略在强化UGC图像质检能力方面的有效性与优越性。
在评估集上,对比<基模型>和<SFT模型>的效果,指标结果见下文。选择准确率和召回率评估,准确率能直观体现模型整体预测的正确性,避免误判;召回率则专注衡量模型对正例样本的捕捉能力,防止漏检,二者从不同关键维度全面反映模型性能。 实验结果表明,经SFT训练后的模型在检测性能上显著优于基础模型,整体模型准确率上升30%,不同类型下,召回率平均上升49%。
- 准确率
| 基模型 | SFT模型 | |
|---|---|---|
| 准确率 | 57.73% (127 / 220) | 87.73% (193 / 220) |
- 召回率
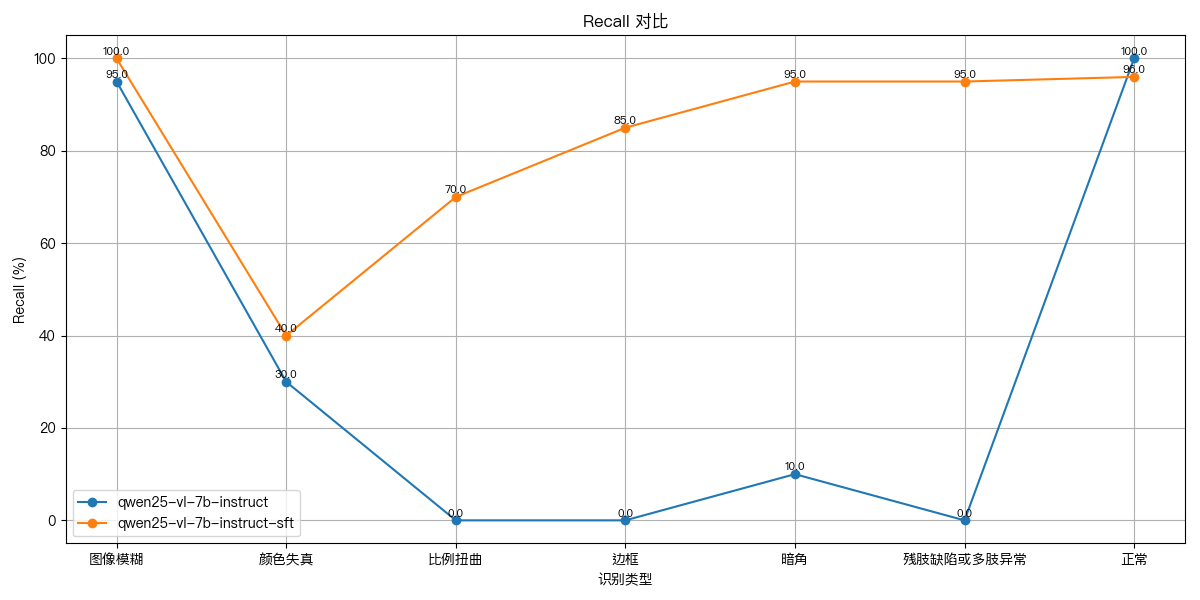
3.3 总结
千帆ModelBuilder所提供的多模态训练方式在图像理解SFT任务中展现出优异性能,不仅适用于当前UGC内容审核、图片质检等场景,还可拓展至医疗影像分析、智能安防监控等跨领域应用,有效解决多模态数据融合与复杂场景识别难题。同时,平台集成丰富的基础模型资源,并构建了覆盖数据准备、专业标注、高效训练及便捷部署的全链路流程,通过标准化与自动化的工具链,大幅降低多模态大模型微调的技术门槛与成本,为企业及开发者提供从技术研发到业务落地的一站式解决方案,加速多模态AI技术的创新与产业化进程。