

文本创作字数控制 V2
一、什么是RLHF
在SFT中,模型通过学习大量的标注数据(输入和正确输出对)来微调。它被直接告知在特定输入下应该输出什么。就像老师给学生一本参考书和答案。学生根据这些教材来学习,并尝试在考试中用一样的方式回答问题。RLHF的过程更像是长时间的交互和迭代优化。模型先生成输出,然后通过人类的反馈(奖励模型)来获取关于输出好坏的信息,之后通过这些信息调整其行为。学生不仅从书本上学习,还通过参加日常⽣活活动并根据别人的反馈来改善自己。例如,一个学生写了一篇文章,然后根据老师或同学的反馈进行改进。SFT是让模型去记住正确答案,而RLHF是让模型去理解如何根据反馈进行改进,从而更接近人类的期望和标准。SFT是直接给出问题的具体答案,RLHF则是通过试错和反馈逐渐靠近理想答案。
二、RLHF训练的主要流程
使用RLHF训练的核心流程可拆解为三个重要阶段:(1)构建和整理人类反馈数据集以训练奖励模型(Reward Model);(2)用奖励模型学习人类偏好评分规则;(3)基于奖励模型进行强化学习优化语言模型策略。这一流程循序渐进,逐步让模型生成的结果更符合人类预期。以下将对各阶段展开详细说明。
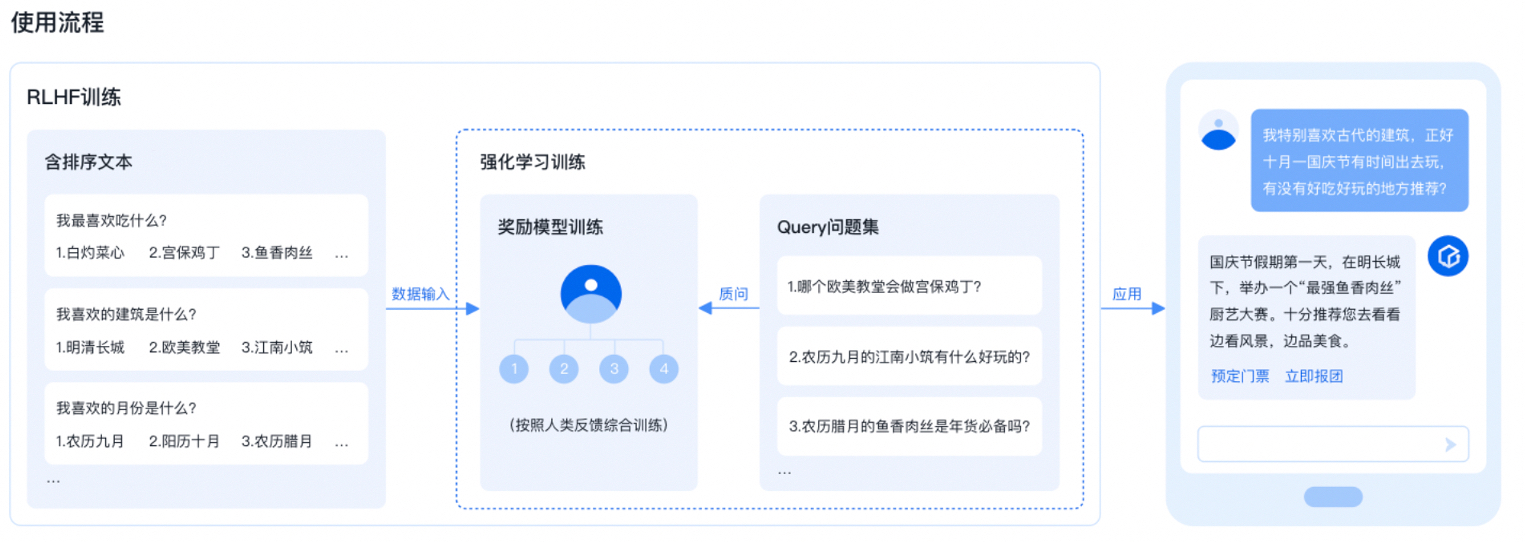
1、准备阶段:Prompt与多Response排序的人类反馈数据集整理
在这一阶段,您首先需要收集大量的Prompt和对应的多个回答(Response),这些回答将被用于训练奖励模型,以评估回答的质量。其中,您需要对同一Prompt下的多个回答进行排序,以表达自己的偏好,通过比较不同回答的优劣,您可以构建出一个反映人类偏好的数据集。
2、训练奖励模型
接着,您需要构建并训练一个奖励模型。奖励模型的目标从生成语言转变为预测分数,通过监督学习,模型会接收多组排序对,并调整自身参数,使得其输出分数尽量与人类排序的优劣关系一致。这样的训练方式能够使模型学习到如何根据人类的排序偏好来评价回答的质量。
需要注意的是,一个好的奖励模型不仅能准确评分,还可以应对模型产生偏差和过拟合。例如,奖励模型可能倾向于“表面优雅”的回答而忽略内容深度。因此,在训练奖励模型时,需注意反馈数据的多样性和模型的泛化能力。
3、训练强化学习任务
在这一阶段,您需要即利用奖励模型的评分作为反馈,通过强化学习优化语言模型的策略,以生成更符合人类偏好的文本。具体来说,在强化学习的过程中,模型生成的回答会通过奖励模型得到一个评分,这个评分作为反馈信号,用于更新语言模型的参数。这样,模型在生成回答时会尝试获得更高的奖励,从而生成更符合人类偏好的内容
三、文本创作字数控制场景描述
在文本创作的场景中,大模型能够充当一个高效且智能的写作助手。凭借其强大的文本理解、生成和编辑能力,我们可以通过调优场景的Prompt或者通过精调的方式,使大模型生成既精准又贴合主题的内容。
此外,在利用大模型进行文本创作时,实现对字数的精确控制同样至关重要。特别是在撰写新闻摘要、微博等社交媒体内容时,控制文本长度显得尤为关键。基于这样的情况,通过RLHF训练,可以有效的使得大模型明白对指定文本长度的偏好,进而使得大模型在文本创作时符合字数要求。
四、文本创作字数控制的难点问题
经过第一版文本创作字数控制DPO训练后的模型在整体的回复效果上有较大提升,但是仍然存在部分的问题有待提高,如:调用训练后的大模型时,仍然存在其字数约束能力不强的问题。具体示例如下:
| Prompt | DPO后回复Response |
|---|---|
| 请将这段描述浓缩成30字的要义。春节家庭游,温馨又有趣!------------春节不只在家围炉,还有全新的家庭旅行套餐等你探索!感受别样的团圆,一起踏上寻找年味的旅程。我们为您精选了适合全家大小的旅游目的地,从雪景滑冰到热带海滩,应有尽有。旅途中,丰富的亲子活动、传统年俗体验,让您和家人共享欢乐时光。住宿方面,我们更提供家庭式温馨客房,让您在外也能感受家的温暖。春节出行,就选我们的家庭旅游套餐,为您留下难忘的回忆。快来预订吧,让这个春节,成为家人心中最美的风景!温馨提示:春节旅游热门,提前预订更享优惠哦! | 春节家庭游,选我们!雪景、海滩任你挑,亲子活动多,住宿温馨,留美好回忆。 |
以上要求中明确指出字数范围限制为30字,但生成的内容字数为36字,严重不符合字数长度规则,字数约束能力不足。
五、实验步骤
1、初始实验探索
针对于此任务,我们在第一版文本创作字数控制样板间构建了评价规则。规则为首先计算预测字符数与输入字符限制的比例减一的绝对值,明确两者之间的差距,然后根据这个绝对值的大小返回不同的得分。如果这个绝对值在0到0.05之间(也就是说,预测字符数与输入字符限制的比例在1±0.05之间),则得分为1;随着这个绝对值的增大,得分逐渐降低,当绝对值超过0.25时,得分为0。这意味着,预测字符数接近输入字符限制时,得分较高;而预测字符数与输入字符限制相差较远时,得分较低。具体得分细则见如下表格,其中绝对值范围遵循左开右闭原则,例如0.05~0.10表示的范围是大于0.05,小于等于0.10。
| 绝对值范围 | 长度控制得分 |
|---|---|
| <=0.05 | 1 |
| 0.05~0.10 | 0.9 |
| 0.10~0.15 | 0.8 |
| 0.15~0.20 | 0.7 |
| 0.20~0.25 | 0.6 |
| >0.25 | 0 |
我们使用7785条训练集文本创作字数控制SFT精调数据集 V1以及260条测试集文本创作字数控制评估数据集 V1进行了初始的实验探索。基于ERNIE-Lite-8K-0308进行了SFT的训练,同时使用文本创作字数控制DPO精调数据集进行了实验。
| ERNIE-4.0-8K | SFT实验1 | SFT实验2 | SFT实验3 | SFT实验4 | DPO实验1 | DPO实验2 | |
|---|---|---|---|---|---|---|---|
| Epoch | 3 | 1 | 1 | 3 | 1 | 3 | |
| 学习率 | 1e-5 | 1e-5 | 3e-5 | 3e-5 | 3e-5 | 3e-5 | |
| 长度控制平均分 | 0.726 | 0.582 | 0.354 | 0.270 | 0.633 | 0.677 | 0.749 |
我们发现仅在DPO实验2上效果相较于ERNIE-4.0-8K有提升,但仍有很大的效果提升空间。
2、收集原始数据
在第一版文本创作字数控制样板间中,我们选择了通过SFT、DPO的方式产出了用于指定字数的文本创作大模型。我们将DPO中的Chosen、Rejected以及使用SFT实验4对训练数据进行回复,将三种回复当作一组多排序的输出,其中三种回复按照字数长度控制规则进行排序。整理后我们得到了7900条的训练数据,每一条数据都具有三条带着排序属性的回复。数据样例如下:
| jsonl数据样例 |
|---|
| [{"prompt": "请简化下面这句话,保证限制在5字以内。\n行业精英必备:专业提升,职场无敌!\n===============\n\n身处高速发展的时代,您是否渴望在职场中脱颖而出?我们为行业专家量身打造的专业发展培训课程,助您技能飞跃,职场竞争力直线上升!\n\n核心技能,一网打尽\n\n课程内容涵盖行业前沿知识,紧扣核心技能。让您在短时间内迅速掌握,成为行业翘楚。\n\n职场竞争力,从此不同\n\n通过培训,您的职场视野将得到极大拓展,竞争力大幅提升。升职加薪,不再是梦!\n\n选择我们,选择职场成功的捷径。与行业精英并肩,共创辉煌未来!\n\n联系我们,开启您的职场升级之旅![网站链接/电话号码]", "response": [["专业提升快"], ["培课助升职"], ["精培"]], "score": [3, 2, 1]}] |
3、奖励模型的构建与训练
我们选取ERNIE-Lite-8K-0308进行RLHF-奖励模型的训练,该模型是百度自主研发的大语言模型,覆盖海量中文数据,具有更强的对话问答、内容创作生成等能力。
拿到一个训练场景或者任务后,往往比较难判断参数应该如何调整。一般使用默认的参数值进行训练即可,平台中的默认参数是多次实验的经验结晶。
接下来介绍参数配置中有两个较为关键的参数:
- 迭代轮次(Epoch): 迭代轮次(Epoch),控制模型训练过程中遍历整个数据集的次数。建议设置在1-5之间,小数据集可增大Epoch以促进模型收敛。
- 学习率(Learning Rate): 学习率(Learning Rate),控制模型参数更新步长的速度。过高会导致模型难以收敛,过低则会导致模型收敛速度过慢,平台已给出默认推荐值,可根据经验调整。
本次也针对Epoch和Learning Rate进行简要的调参实验,同时由于千帆平台支持基于SFT的模型做增量的奖励模型训练,我们也采取了第一版文本创作字数控制的SFT模型做增量训练进而进行实验对比。
如果您是模型训练的专家,千帆也提供了训练更多的高级参数供您选择。
我们基于ERNIE-Lite-8K-0308模型做了以下RLHF-奖励模型精调,先抽取1000条数据确定合适的学习率,参数和训练方法配置如下:
| 实验1 | 实验2 | 实验3 | 实验4 | 实验5 | 实验6 | |
|---|---|---|---|---|---|---|
| 是否基于SFT任务增量训练 | 是 | 是 | 是 | 否 | 否 | 是 |
| Epoch | 1 | 3 | 3 | 3 | 5 | 5 |
| Learning Rate | 1e-6 | 1e-6 | 2e-6 | 2e-6 | 2e-6 | 2e-6 |
| 训练数据条数 | 1000 | 1000 | 1000 | 1000 | 1000 | 1000 |
| 最后一步train_loss | 0.702 | 0.645 | 0.547 | 0.415 | 0.221 | 0.349 |
| 最后一步eval_loss | 0.688 | 0.663 | 0.607 | 0.438 | 0.276 | 0.451 |
对于奖励模型来说,常见的损失函数包括均方误差(MSE)、交叉熵损失和对比损失等,损失函数帮助我们了解模型预测的奖励与人类标注的真实奖励之间的差距。损失值越低,说明模型的预测越接近真实情况。低损失意味着模型能够更准确地为不同质量的输出分配奖励。这样,模型在后续的强化学习过程中,能够更好地根据这些奖励信号调整自己的行为,生成更符合人类偏好的输出。因此奖励模型我们通过loss的拟合情况判断实验的优劣,经过六组实验后,我们看到在学习率为2e-6时模型的拟合程度更好,因此我们基于2e-6的学习长度做更多数据的后续实验,参数和训练方法配置如下:
| 实验7 | 实验8 | 实验9 | 实验10 | |
|---|---|---|---|---|
| 是否基于SFT任务增量训练 | 否 | 是 | 否 | 是 |
| Epoch | 2 | 2 | 2 | 2 |
| Learning Rate | 2e-6 | 2e-6 | 2e-6 | 2e-6 |
| 训练数据条数 | 3000 | 3000 | 7900 | 7900 |
| 最后一步train_loss | 0.107 | 0.229 | 0.058 | 0.089 |
| 最后一步eval_loss | 0.192 | 0.266 | 0.115 | 0.171 |
通过实验结果发现,在不开启增量训练、Epoch为2使用7900条数据训练时,模型拟合情况最好。且当扩大训练数据条数时,会对使得整体模型更拟合。实验9的评估报告如下,可以看到loss曲线的不断降低,且实现了良好收敛。
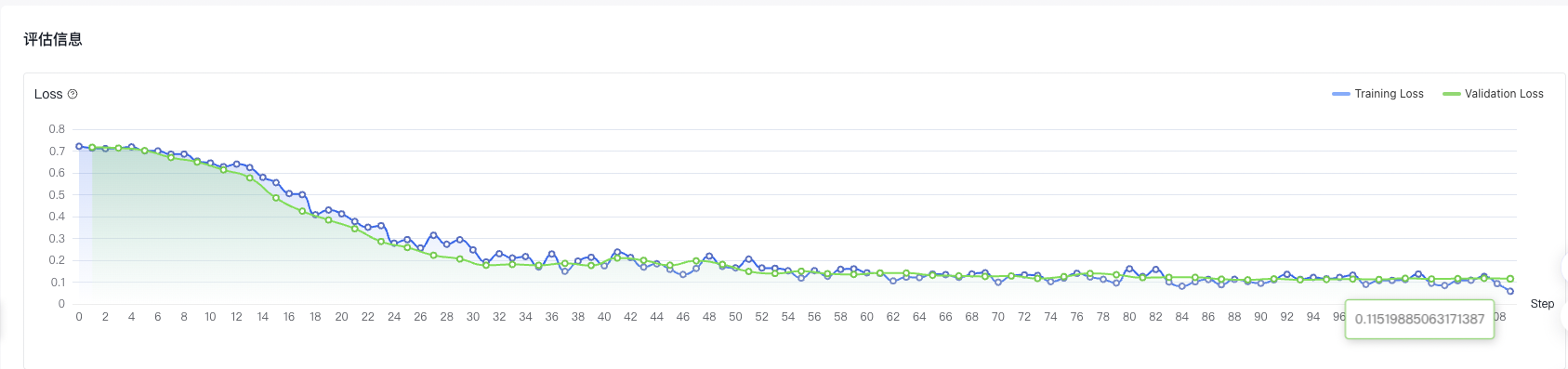
4、基于奖励模型的强化学习训练
奖励模型训练完成后,我们进行强化学习的训练。在后续的强化学习实验中我们全部开启了增量训练,选取SFT实验4作为基础模型。这样的优势是模型在见过数据后,会对数据有更多的知识和更好的指令遵循能力。因为模型已经有一个相对不错的起点,可以有效减少策略搜索的空间,从而让强化学习过程更加高效。因此如果您有其他场景进行RLHF训练时,我们也建议使用SFT后的模型作为基础模型做增量的强化学习。
强化学习后产出的模型评估我们按照上述的字数评分规则进行验证,其中我们使用选取了文本创作字数控制评估数据集共260条。在260条的数据进行长度控制打分取平均,进而校验产出模型在长度遵循的合理性。实验结果如下:
| 实验11 | 实验12 | 实验13 | 实验14 | 实验15 | 实验16 | |
|---|---|---|---|---|---|---|
| Epoch | 1 | 1 | 1 | 1 | 1 | 1 |
| 奖励模型 | 实验5 | 实验6 | 实验7 | 实验8 | 实验9 | 实验10 |
| 奖励模型是否基于SFT任务增量训练 | 否 | 是 | 否 | 是 | 否 | 是 |
| 训练数据条数 | 1000 | 1000 | 3000 | 3000 | 7900 | 7900 |
| 长度控制平均分 | 0.653 | 0.647 | 0.751 | 0.685 | 0.824 | 0.812 |
可以看出基于实验9的强化学习训练在长度控制上表现更好。且更多的数据条数会对最终的长度控制得分有一个较为显著的提升。实验15的评估报告以及训练过程可视化的结果如下:
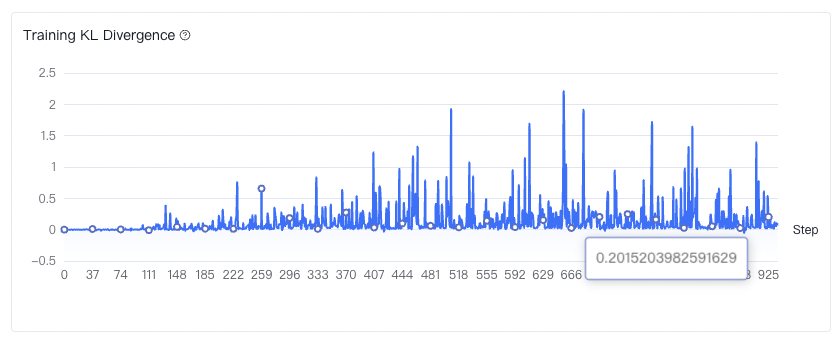
Training KL Divergence代表了新旧策略分布之间的Kullback-Leibler散度,衡量当前策略分布和起始策略分布之间的差异。我们可以看到实验7的Training KL Divergence是震荡上升的。这个震荡上升的意义在于,在训练过程中,策略模型需要在探索新策略和利用已知策略(参考模型)之间取得平衡。震荡的KL散度意味着策略模型在探索不同的策略,这有助于发现更多潜在的高质量策略,从而提高整体的性能。那么我们的KL散度越大,也进一步说明了新策略模型逐渐探索到了比参考模型更好的输出分布。
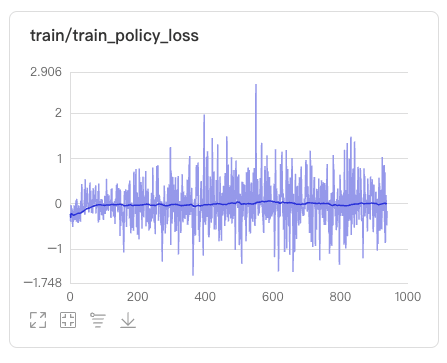
这里面提到了一个新的概念,策略模型,那么策略模型在强化学习中扮演什么样的角色呢?可以理解为它可以根据反馈来判断如何在训练数据上最大化奖励。我们整个强化学习训练过程中,就是要得到一个智慧的策略模型可以判断如何最大化奖励,还要得到一个可以提供可靠的励信号的价值模型。通过强化学习不断的更新策略和价值模型。
如上图显示,策略模型损失和价值模型损失逐渐收敛到0附近,这代表着策略模型已经很好地学会了如何在训练数据上最大化奖励。价值模型也能够准确评估训练数据中的状态或动作,提供可靠的奖励信号。
同时我们也使用了第一版文本创作字数控制的数据进行了Lite模型的DPO训练以及直接调用ERNIE-4.0-8K做结果对比,实验结果如下:
| ERNIE-4.0-8K | SFT实验4 | DPO实验2 | 实验13 | |
|---|---|---|---|---|
| Epoch | 3 | 3 | 1 | |
| 训练数据条数 | 3e-5 | 7900 | 7900 | |
| 长度控制平均分 | 0.726 | 0.633 | 0.749 | 0.824 |
我们可以看出,直接调用ERNIE-4.0-8K的长度控制平均分为0.726,经过强化学习链路产出的实验13模型在长度控制平均分可达0.824,显著提高了模型长度控制的能力。
5、模型调用对比示例
针对于上述DPO训练后表现不好的输出,在RLHF后有了好的表现,以下是在同样Prompt下分别使用ERNIE 4.0、ERNIE-Lite-8K-0308 DPO、ERNIE-Lite-8K-0308 RLHF的调用结果对比。
| Prompt | ERNIE 4.0 | Response-**ERNIE-Lite-8K-0308 DPO** | Response-**ERNIE-Lite-8K-0308 RLHF** |
|---|---|---|---|
| 请将这段描述浓缩成30字的要义。春节期间,传统文化知识小测验是亲朋好友欢聚一堂的趣味活动。通过问答形式,大家既可以检验对春节习俗、年俗典故的了解,又能在轻松愉快的氛围中增进感情。比如:“春节为什么要放鞭炮?”答案:“古人认为鞭炮能驱邪避祟,带来新一年的好运。”这样的题目既富有知识性,又充满年味。快来参与吧,让我们一起在欢笑中传承和弘扬中华传统文化!正确答案示例:春节贴对联的传统寓意着祈福迎祥,希望新的一年平安吉祥。 | 春节家庭旅游套餐,寻年味、享亲子时光,家庭式客房,提前订更优惠。 | 春节家庭游,选我们!雪景、海滩任你挑,亲子活动多,住宿温馨,留美好回忆。 | 春节游选我们!温馨家庭房,亲子活动多,年味十足,度美好时光! |
以上要求中明确指出字数范围限制30字,但基于ERNIE 4.0的模型生成的内容字数为32字,超出长度限制;通过对ERNIE-Lite-8K-0308模型进行DPO精调,其模型生成的内容字数为36字,字数约束能力仍可继续改善;对ERNIE-Lite-8K-0308模型进行RLHF,其生成的内容字数为30字,长度控制得分为1.0,符合我们的输出预期。
五、最佳实践总结
1、训练建议
(1)针对于奖励模型的训练,我们建议适当的增加奖励模型训练数据条数,会对最后奖励模型的训练和验证损失产生明显的下降,使得模型的预测越接近真实情况。
(2)针对于强化学习的训练,我们建议使用SFT后的基础模型进行增量训练,这样可以有效减少策略搜索的空间,从而让强化学习过程更加高效。
(3)针对于强化学习的训练,我们建议Epoch通常设置为1即可,进一步增加训练的轮数可能反而对训练结果有着不好的影响。
(4)RLHF训练后的模型在整体的任务上会表现出比DPO更强的泛化性。
2、费用
由于我们选择更高性价比的模型作为基础模型,通过精调使得模型在特定场景如文本创作字数控制中效果媲美甚至赶超超大规模参数的模型。因此精调模型的部署成本和调用成本都远比超大规模参数模型要低。
例如,本文选择了ERNIE Lite基础模型,经过调优后按照调用量付费模式,调用价格仅为0.003元/千tokens,ERNIE 4.0直接调用的价格为0.03元/千tokens。因此可看出,经过调优后的推理成本也将能够较大降低。
| 模型 | 调用成本 |
|---|---|
| ERNIE 4.0 | 0.03元/千tokens |
| ERNIE Lite | 0.003元/千tokens |
总结来看,经过数据优化和模型精调,我们得到了一个又好又便宜的模型,赶快体验试试吧!