

创建知识蒸馏任务
模型蒸馏通过调用教师模型产生问答对,再通过精调得到成本更低、特定任务效果更好的学生模型。
知识蒸馏是指学生模型学习真实标签(硬标签)和教师模型的输出概率分布(软标签)。
登录到本平台,选择模型蒸馏板块,创建蒸馏作业。
创建蒸馏作业
如果您在模型蒸馏作业列表中有创建好的模型任务,可以直接点击“新建任务”创作模型的迭代版本,如果已有运行中的版本,再次创建的运行任务不可切换教师模型和学生模型的类型。
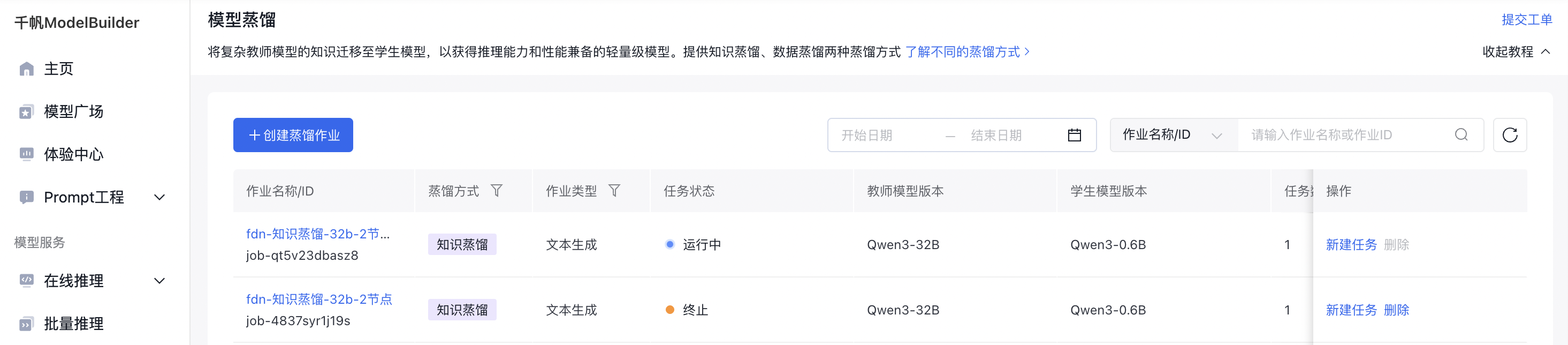
选择蒸馏方式
在选择蒸馏方式中,选择知识蒸馏。
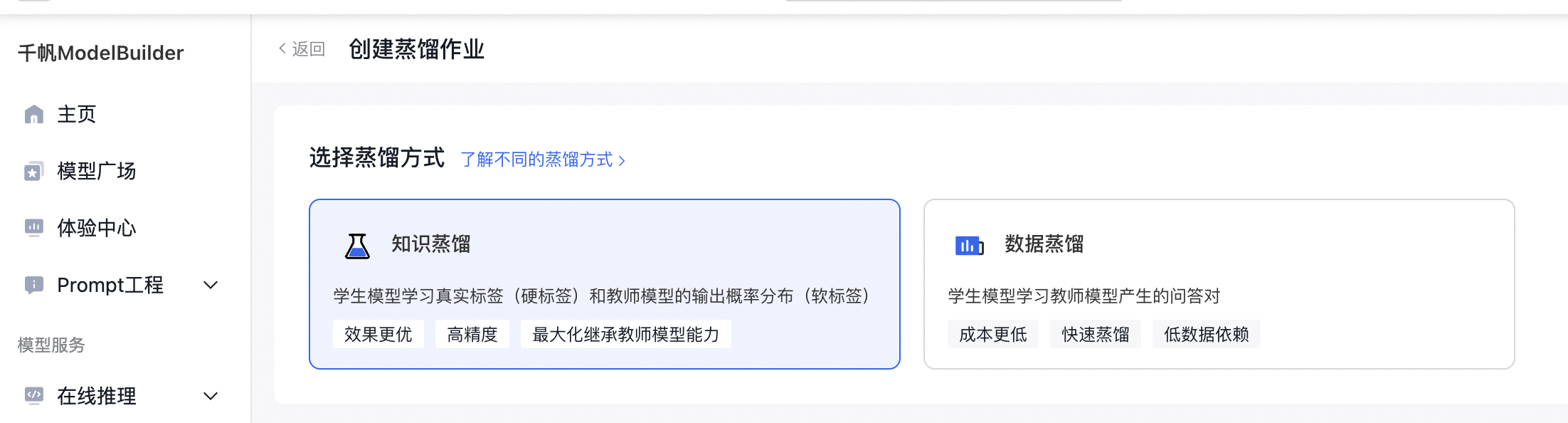
基本信息
填写好作业名称后,再进行500字内的作业描述即可。
在作业类型中,支持创建文本生成或图像理解作业。
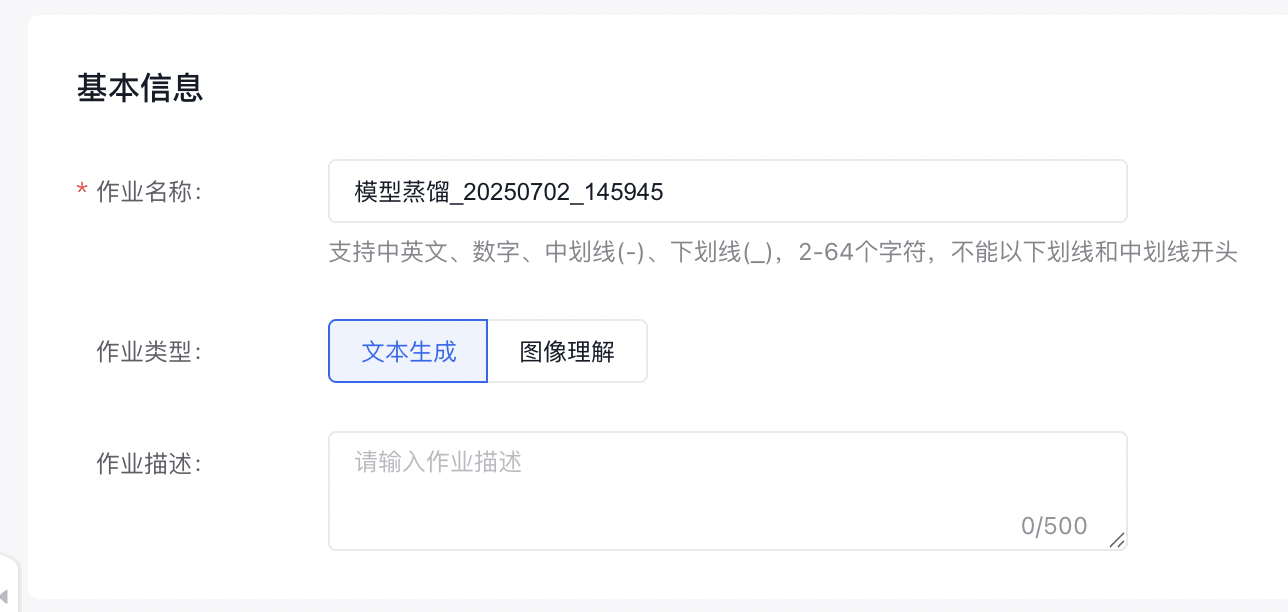
训练框架配置
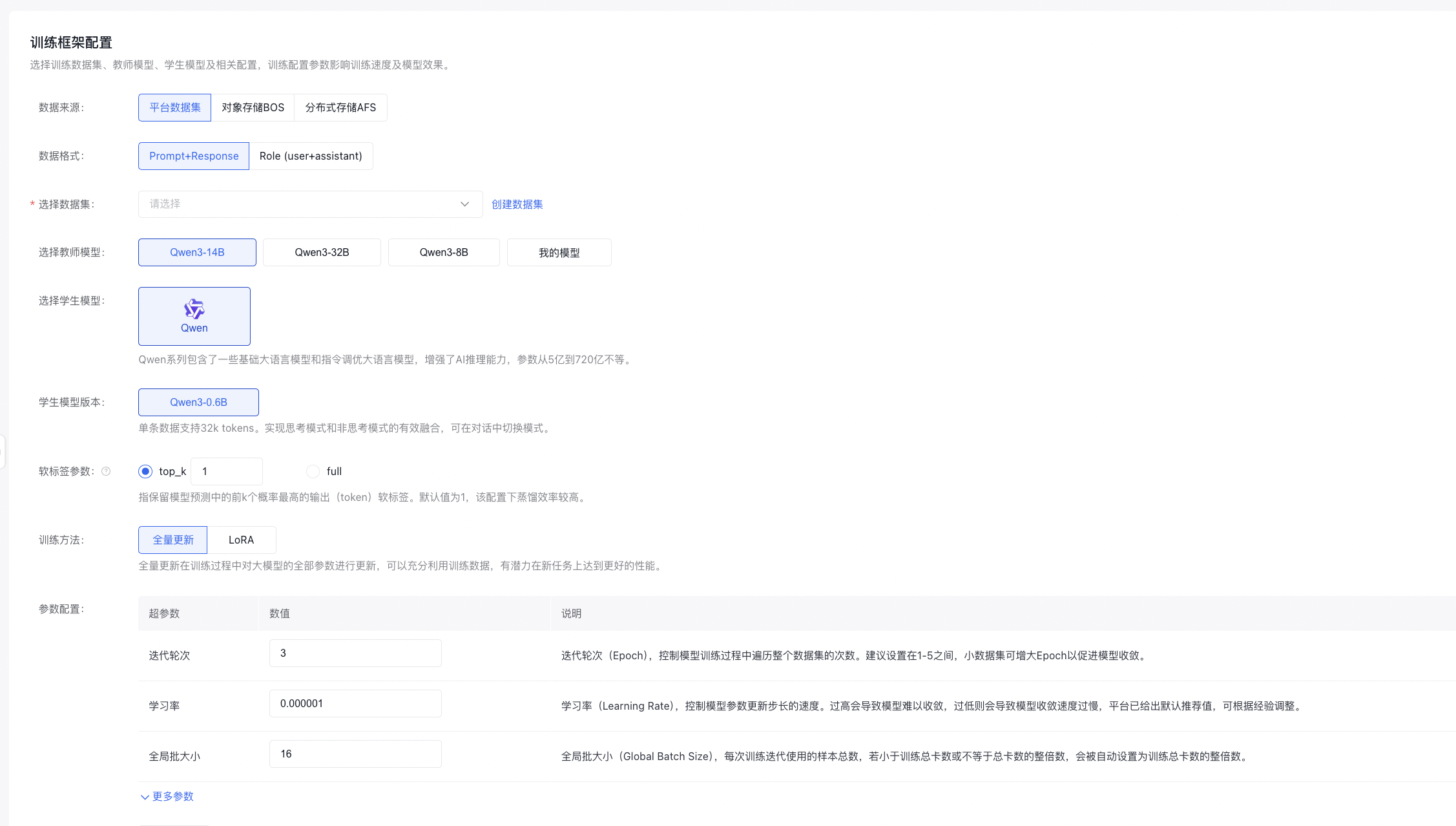
数据配置
- 原始数据来源支持选择平台数据集、对象存储BOS、分布式存储AFS。
- 若要发起蒸馏,仅支持选择一个数据集并多于100条,若数据集超过10000条,蒸馏数据构造耗时可能较长,请耐心等待。数据格式可以选择Prompt+Response、Role(user+assistant)数据进行蒸馏。
教师模型版本
文本生成作业中,教师模型版本默认值为Qwen3-32B,分别支持Qwen3-14B、Qwen3-8B,以及可以选择训练后或导入的模型。
图像理解作业中,教师模型版本默认值为Qwen2.5-VL-32B-Instruct,同时支持选择Qwen2.5-VL-7B-Instruct,以及可以选择训练后或导入的模型。
学生模型版本
文本生成作业中,学生模型版本当前支持Qwen3-0.6B。
图像理解作业中,学生模型版本当前支持Qwen2.5-VL-3B-Instruct。
训练方法与参数配置
支持配置软标签参数,软标签是指指每个 token 输出概率分布中,保留前 k 个词(token)和其对应概率(即软标签)。k 越大,信息保留越多,占用资源越多。默认值为1,该配置下蒸馏效率较高。
共有两种训练方式,根据模型的类型选择不同的方式。
| 训练方法 | 简单描述 |
|---|---|
| 全量更新 | 全量更新在训练过程中对大模型的全部参数进行更新 |
| LoRA | 训练过程中只更新低秩部分的参数,需要的计算资源更少,训练过程更快,可以减少过拟合的风险。 |
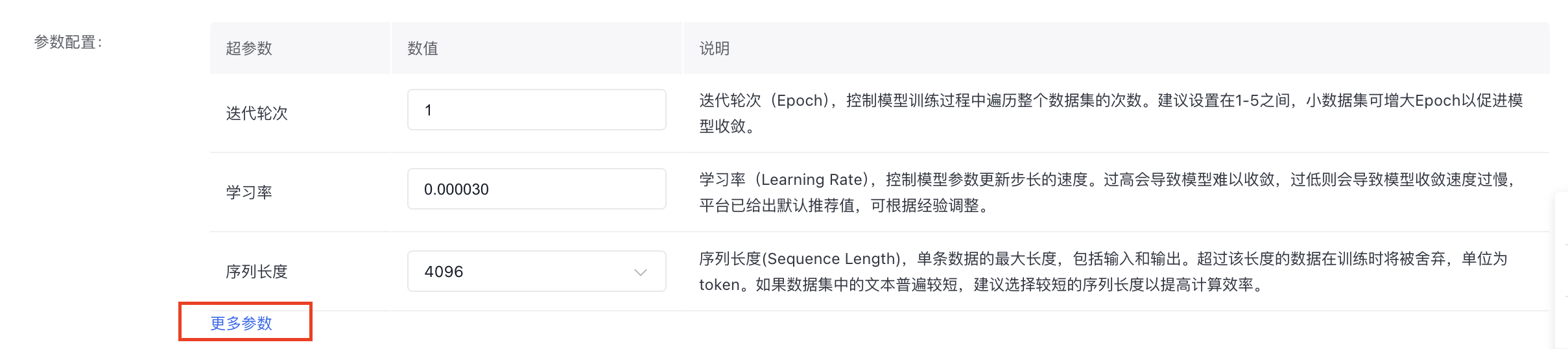
- 参数配置
所有蒸馏任务都提供基础的超参数选择,**迭代轮次(Epoch)**控制模型训练过程中遍历整个数据集的次数;**学习率(Learning Rate)**控制模型参数更新步长的速度;**序列长度(Sequence Length)**控制单条数据的最大长度,包括输入和输出。其他超参数详见模型蒸馏页面,可自由配置。
发布蒸馏模型
以上所有操作完成后,点击“确定”,则发起学生模型训练的任务。 开启“自动发布”按钮后,模型在蒸馏完成后会自动发布到我的模型中;若模型训练失败,则不自动发布模型。