

导入Prompt+多Response排序数据
更新时间:2025-05-15
登录到千帆ModelBuilder操作台,在左侧功能列选择通用数据集,进入训练数据集主任务界面。
数据格式说明
Prompt+多Response排序:单轮或多轮的文本对话数据,每个提示词对应多个已排序的回答。适用于模型精调的RLHF奖励模型训练。
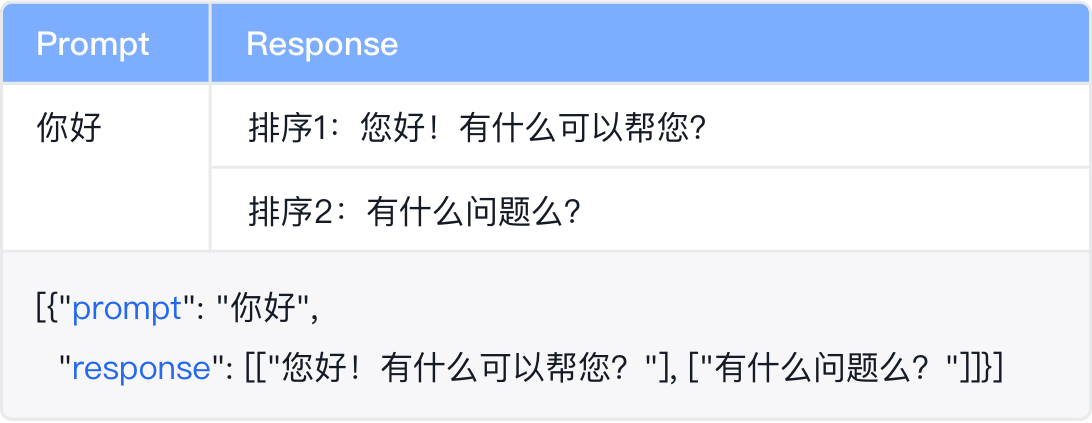
- 无标注样例
# "system"为选填字段,代表系统角色设定信息。
[{"system": "你是一个人工智能助手。", "prompt": "请根据下面的新闻生成摘要, 内容如下:新华社受权于18日全...\n生成摘要如下:"}]平台支持上传无标注样例,您可在平台上进行数据标注,标注方式包括在线标注、多人标注和众测标注。只有标注完成的数据集,才能被发布并用于训练。
- 单轮对话(含标注)
# "system"为选填字段,代表系统角色设定信息。
# 单个样本的"response", 需包含两个或两个以上的排序候选内容
# "score"为整数,代表 "response" 各候选内容的偏好得分,得分越高表示偏好程度越高
[{"system":"你是一个AI学习助手。","prompt":"我想了解一下机器学习.", "response": [["机器学习是跨学科的..."], ["机器学习是人工智能的分支..."]], "score": [1, 0]}]- 多轮对话(含标注)
[{"system": "你是一个人工智能助手。", "prompt": "生成一个关于人工智能的标题吧。", "response": [["好的,给您生成一些标题..."]]}, {"prompt": "具体一些.", "response": [["当然可以,以下是几个例子:1) ...2) ...3) ..."]]}, {"prompt": "我想了解一下机器学习是什么。", "response": [["机器学习是跨学科的..."], ["机器学习是人工智能的分支..."]], "score": [1, 0]}]平台支持上传多轮对话,但每个样例中的对话限制不超过150轮,超出部分将会被截断。
数据文件要求
| 文件类型 | 格式要求 |
|---|---|
| jsonl文件 |
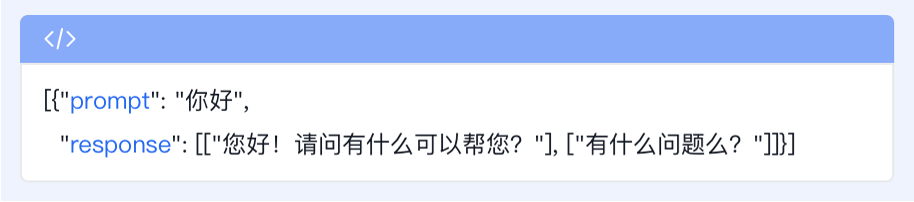 |
| 压缩包 |
|
- 文件编码仅支持UTF-8。
数据导入方式
创建数据集完成后,在数据集管理页面中,找到该数据集,点击右侧操作列下的“导入”按钮,即可进入导入数据页面。
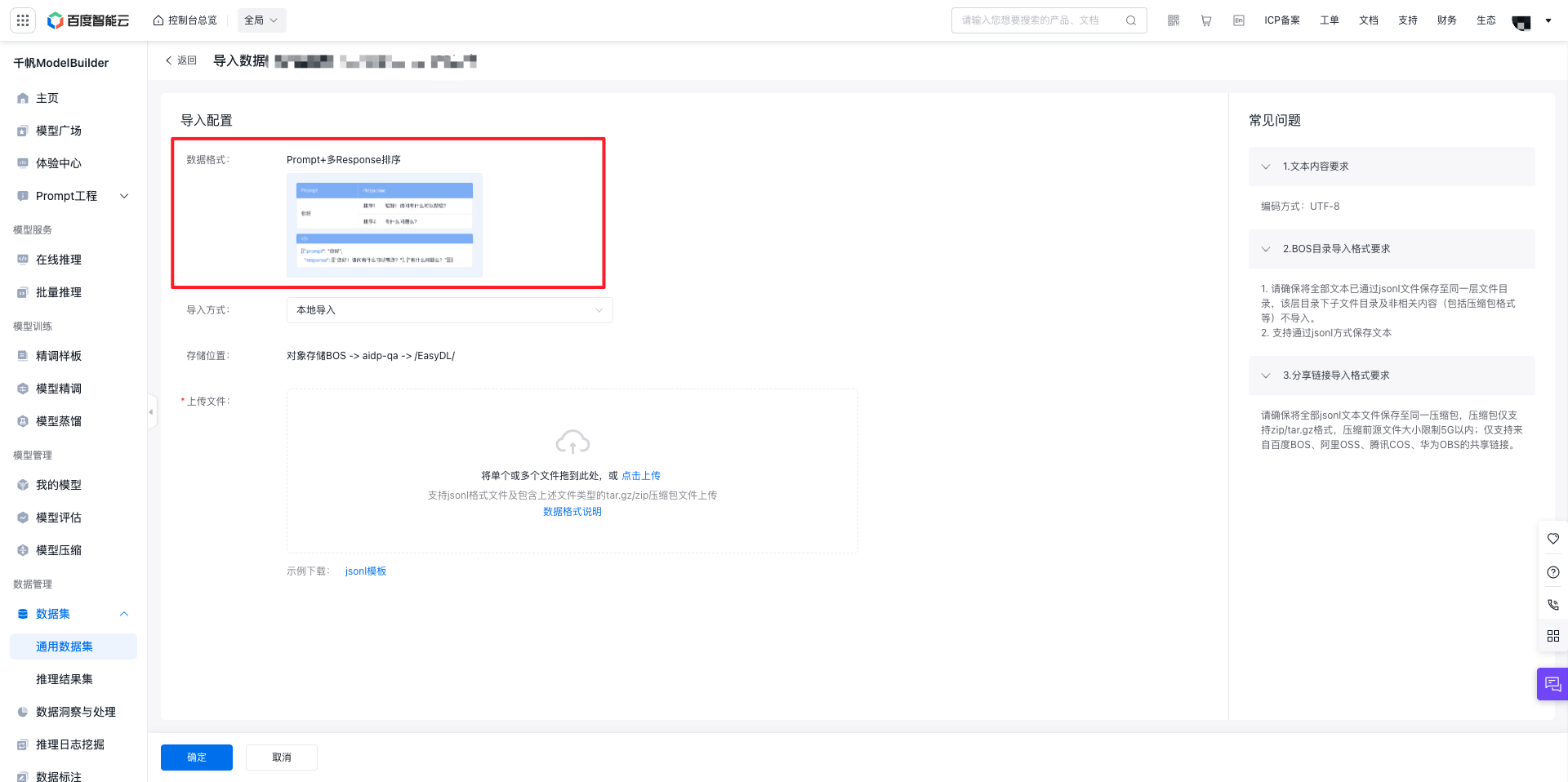
您可以使用以下方案上传文本数据:本地导入、BOS导入、分享链接导入、平台已有数据集。
| 导入方式 | 存储类型:对象存储BOS | 存储类型:平台共享存储 |
|---|---|---|
| 本地导入 |
|
|
| BOS导入 |

|
|
| 分享链接导入 |

|
|
| 平台已有数据集 |
|
|