

模型压缩
更新时间:2025-08-08
量化压缩策略说明
WxAxCx中W、A、C分别代表模型权重(weight)、激活(activation)和键值缓存(kv cache),数字x代表模型压缩后相应部分的比特数。模型压缩过程后,高比特浮点数会映射到低比特量化空间,从而达到降低显存占用、提升推理性能等目的。
- 量化方法:开源模型量化方式默认SimplePTQ,即基础的线性量化。部分支持GPTQ、AWQ、SmoothQuant等量化算法
- 精度说明:未压缩前的精度都是BF16;压缩后精度默认为INT;FP精度特殊标识。举例说明:
| 策略 | 权重 | 激活 | KV Cache |
|---|---|---|---|
| W8A16(WINT8) | INT8 | BF16 | BF16 |
| W4A16 | INT8 | BF16 | BF16 |
| Wfp8Afp8Cfp8 | FP8 | FP8 | FP8 |
| W4A6Cfp8 | INT4 | BF16 | FP8 |
模型压缩支持范围
文心模型
| 模型 | 压缩策略 |
|---|---|
| ERNIE-Tiny-8K | w8a8c4 w8a8c8 w8a8c16 |
| ERNIE-Tiny-128K | w8a8c8 w8a8c16 |
| ERNIE-Speed-Pro-128K | w8a8c4 w8a8c8 w8a8c16 |
| ERNIE-Speed-8K | w8a8c4、w8a8c8、w8a8c16 |
| ERNIE-Lite-8K | w8a8c4 w8a8c8 w8a8c16 |
| ERNIE-Lite-128K | w4a8c4 w8a8c4 w8a8c8 w8a8c16 wfp8afp8c4 wfp8afp8c8 wfp8afp8c16 |
| ERNIE-Character-8K-0321 | w8a8c4 w8a8c8 w8a8c16 |
| ERNIE-Character-8K-250124 | w8a8c8 w8a8c16 |
| ERNIE-Character-Fiction-8K | w8a8c8 w8a8c16 |
| ERNIE-Character-8K-250124 | w8a8c8 w8a8c16 |
开源模型
| 模型 | 压缩策略 | 备注 |
|---|---|---|
| Qwen3-0.6B | W8A16、W4A16、W8A8 | |
| Qwen3-1.7B | W8A16、W4A16、W8A8 | |
| Qwen3-4B | W8A16、W4A16、W8A8 | |
| Qwen3-8B | W8A16、W4A16、W8A8 | |
| Qwen3-14B | W8A16、W4A16、W8A8 | |
| Qwen3-32B | W8A16 | |
| QWQ-32B | W8A8C16、W4A16 | 注:当部署至V型卡上,上下文长度从32K缩短到8K |
| Qwen2.5-VL-7B-Instruct | W8A8C16 | |
| Qwen2.5-1.5b-instruct | W8A8C16 | |
| Qwen2.5-7b-instruct | W8A8C16 | |
| Qwen2.5-14b-instruct | W8A8C16 | |
| Qwen2.5-32b-instruct | W8A8C16、W4A16 | |
| Deepseek-R1-Distill-Qwen-14B | W8A16、Wfp8Afp8Cfp8、W4A16Cfp8 | |
| Deepseek-R1-Distill-Qwen-7B | W8A16、Wfp8Afp8Cfp8、W4A16Cfp8 | |
| Deepseek-R1-Distill-Qwen-1.5B | W8A16、W4A16、W8A8 | |
| DeepSeek R1 | W8A16 | 当前压缩后仅支持在VII型号卡部署 |
| DeepSeek V3 | W8A16 | 当前压缩后仅支持在VII型号卡部署 |
| BLOOMZ-7B | W8A16、W4A16 |
注意:1. 除开源模型SimplePTQ量化方式外,其余量化方式均依赖精调时所用数据集,该数据集有删除时无法进行压缩。开源模型压缩时,压缩任务会从模型全部精调数据集中随机抽样512条作为校准数据集。
压缩效果说明
- 提升吞吐建议对权重做量化;提升模型速度,建议权重和激活同时量化
- 不同量化策略对显存占用不是成倍递减的,需要考虑不同模型weight/activation/cache的显存占比。比如:当cache显存占用较小时,C8相比C16的显存减少并不明显。
- Cache量化的作用是减少显存占用,并不能保证提升推理性能。性能提升来源为显存占用减少(即cache低比特最直观的作用是降显存而不是加速),在相同推理资源的情况下可以增加批量处理数据量,从而进一步提升推理性能。建议在输入输出较长的情况下使用kv cache量化,否则可能带来性能退化。
- 所有模型的推理性能收益均需要通过实际测试获得
操作指南
创建模型压缩任务
登录到本平台,在左侧功能列选择模型压缩,进入模型压缩主任务界面。
点击“创建压缩任务”按钮,进入新建压缩任务页面。
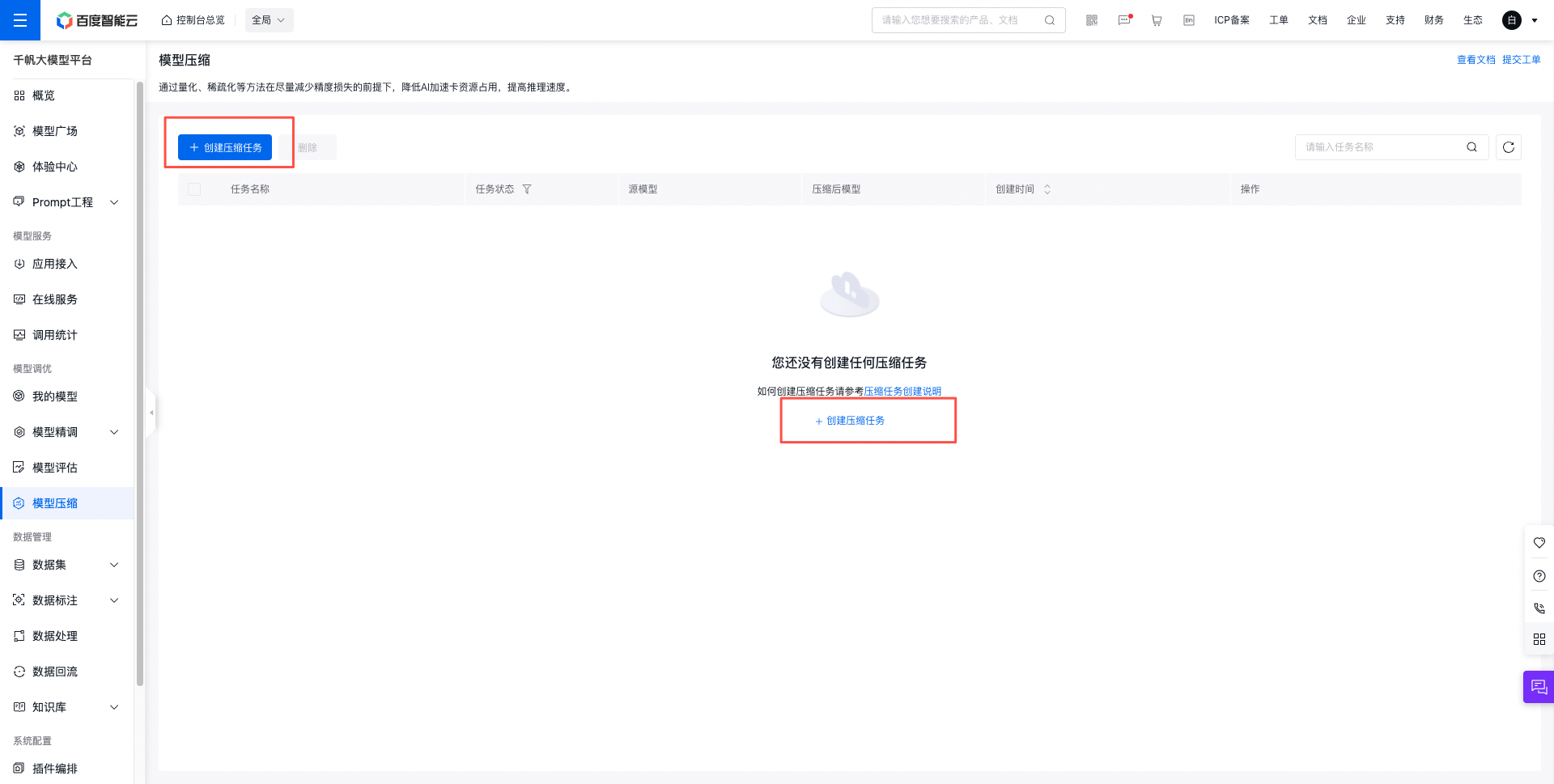
由用户填写压缩任务所需的基本信息、量化方法、压缩策略等。
基本信息
填写压缩任务名称、压缩任务描述。
压缩配置
- 选择源模型: 此处支持选择用户希望压缩的模型,支持从『我的模型』中选择(不支持选择预置模型)。具体支持范围详见模型压缩支持范围 。
- 模型创建方式:选择压缩后模型的保存方式,支持保存为已有模型新版本(默认为最新版本)或保存为新模型(默认V1版本)。
- 选择已有模型:同一模型各版本的基础模型需保持一致,已自动过滤不符合要求的模型。
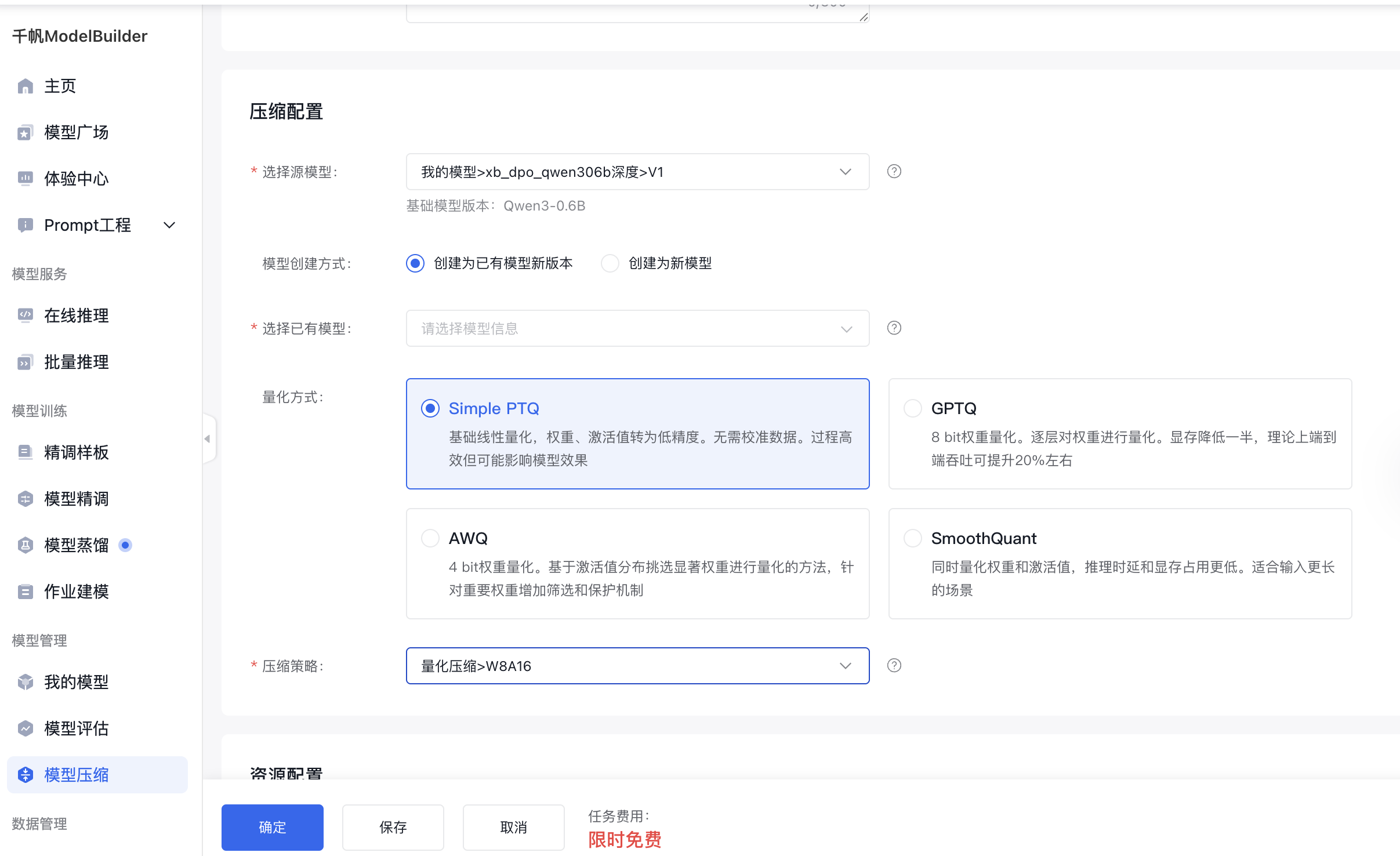
- 当前压缩能力主要面向NV系列卡型。 如需压缩后部署在VII型卡上,请在压缩时修改目标卡型,当前仅qwen3-4b/14b/32b支持面向VII型卡量化。量化方式支持Simple PTQ,策略支持W8A16
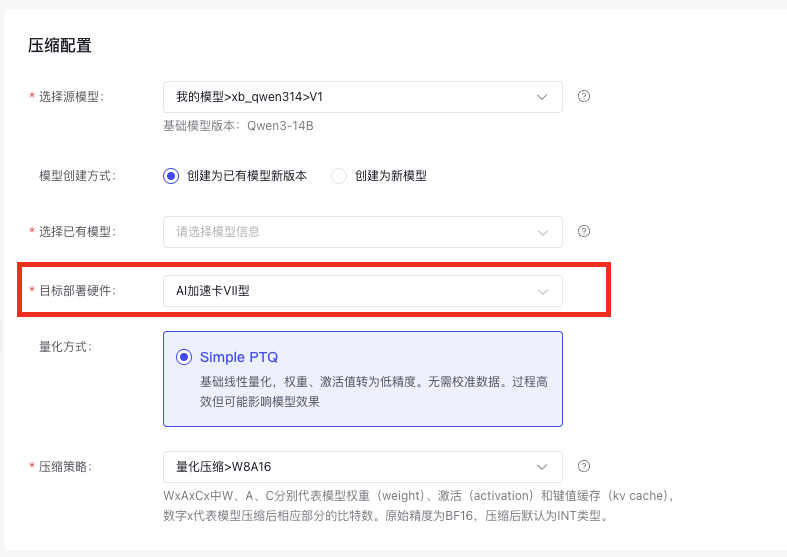
查看压缩任务详情
进入“模型压缩 > 详情 > 任务详情“中查看压缩任务详情页,回溯压缩任务相关配置。
查看压缩任务日志
平台支持查看本次模型压缩任务的详细日志。可以查看其从创建开始到任务结束的日志内容,支持下载到本地保存(txt格式)。
以下为部分日志展示:
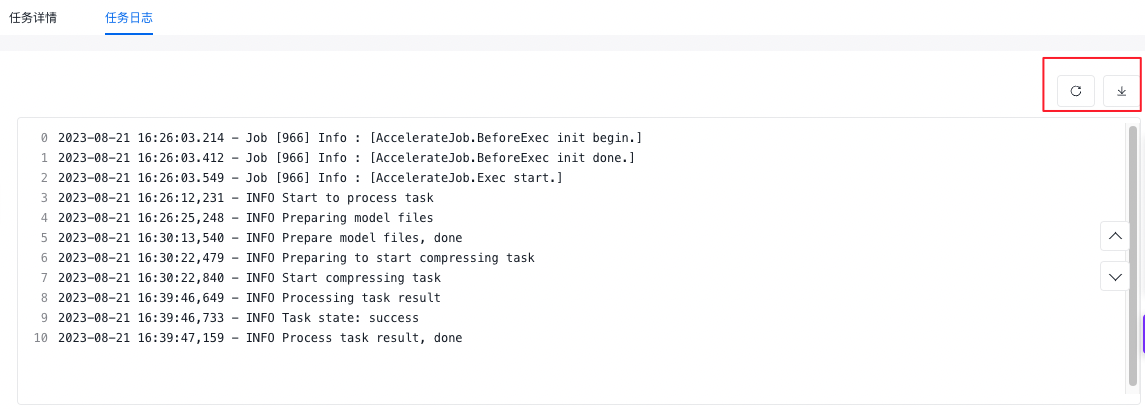
可通过日志查看报错,调整任务配置重新发起;或在提交工单时,粘贴日志中的报错由百度技术服务团队协助排查。
压缩任务计费说明
当前模型压缩功能限时免费。