

创建SFT任务
SFT实际上是Fine-Tuning的训练模式,开发者可以选择适合自己任务场景的训练模式并加以调参训练,从而实现理想的模型效果。
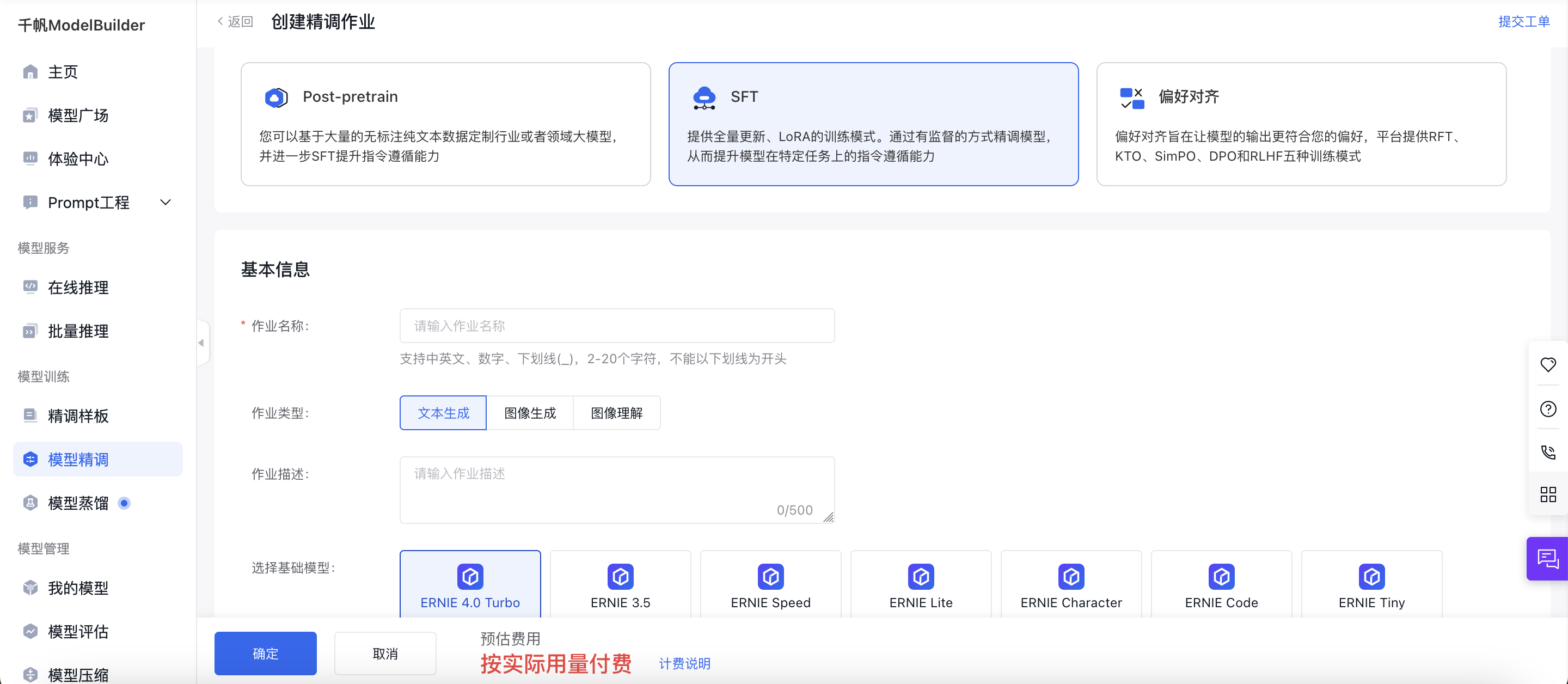
创建任务
如果您在任务列表已经有创建好的模型任务,可以直接点击“新建任务”创作模型的迭代版本,如果已有运行中的的版本,再次创建的运行任务不可切换基础模型类型。
基本信息
填写好作业名称后,选择作业类型,再进行500字内的作业描述即可。
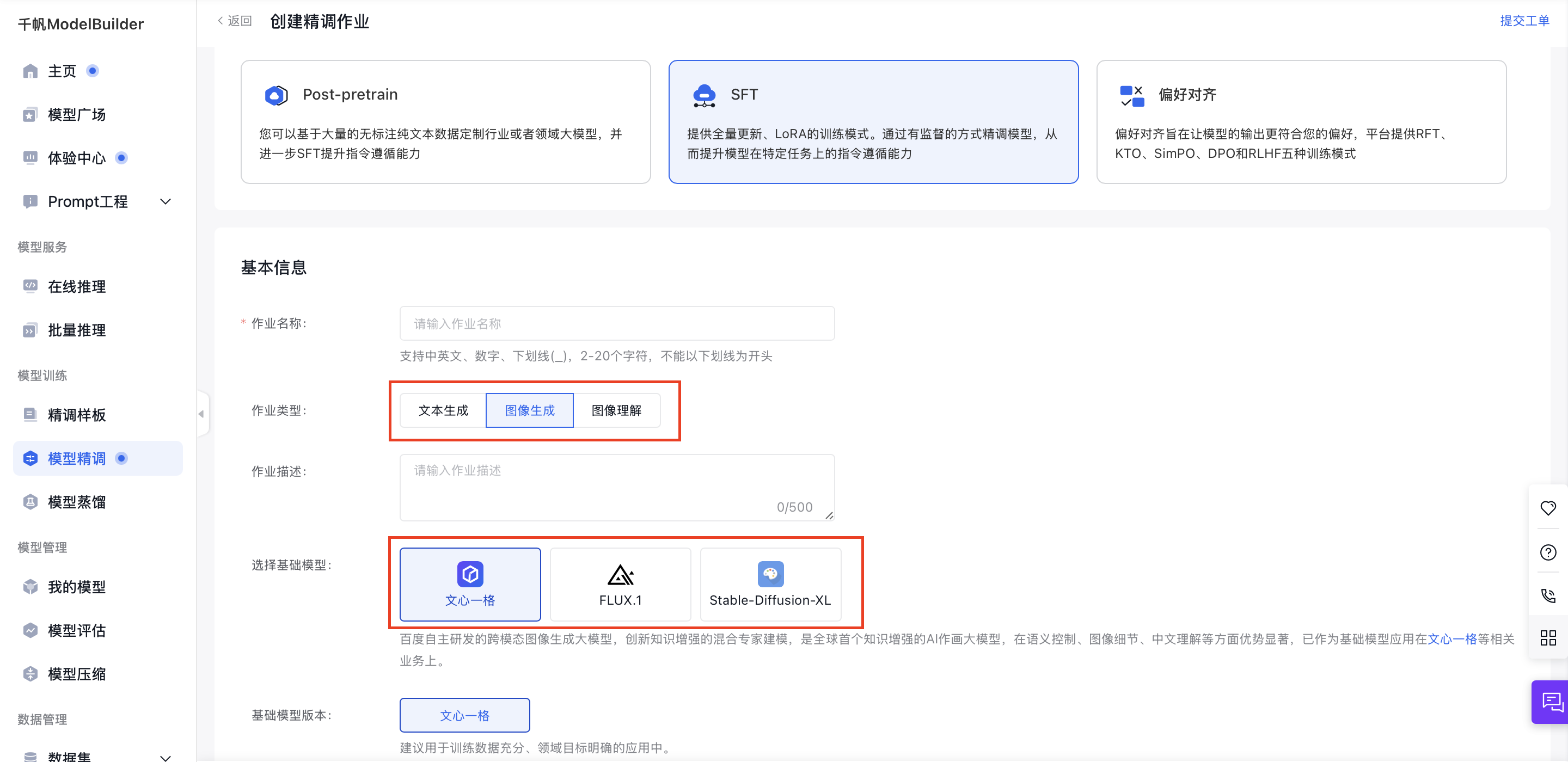
当前SFT任务支持以下任务类型:大语言模型、文生图大模型、图像理解模型。
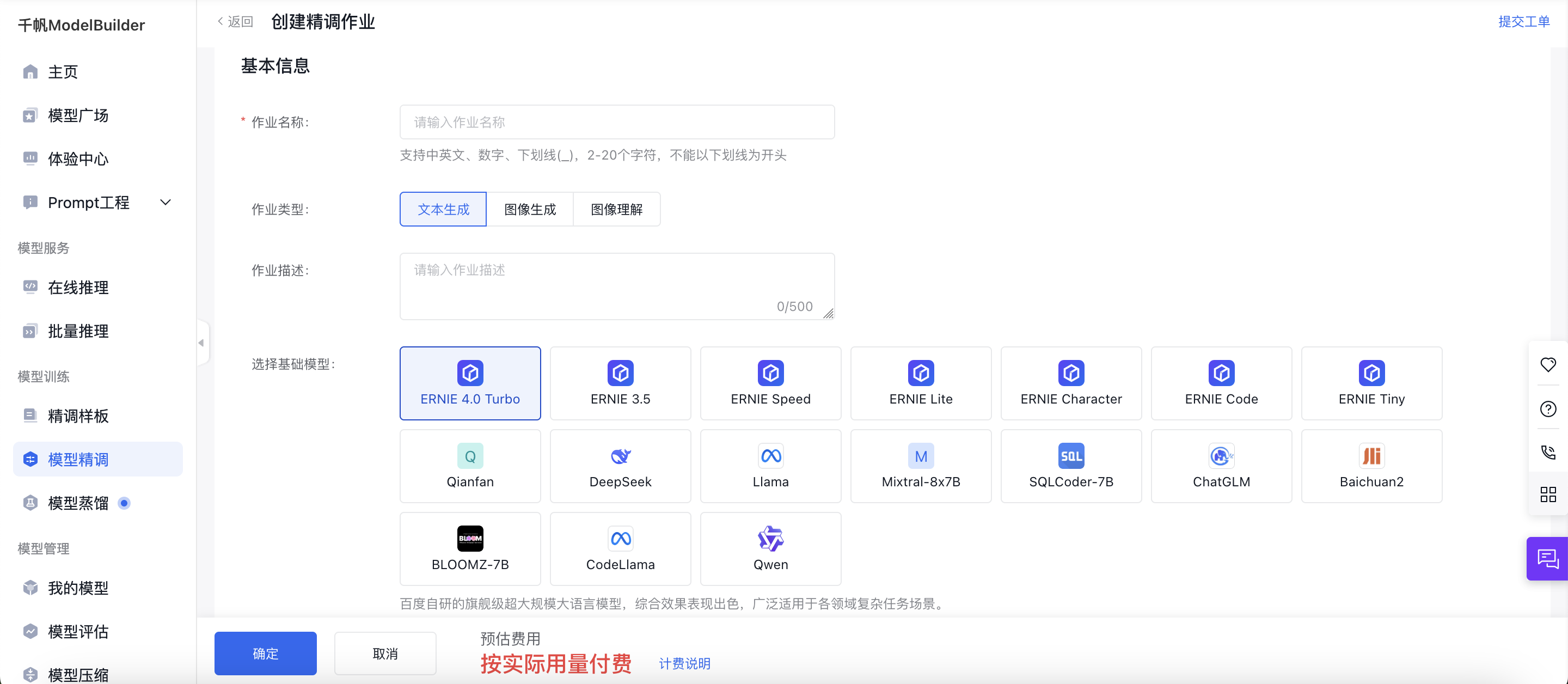
模型选择
训练配置
训练配置大模型参数,调整好基本配置。
- 在SFT训练任务中,可以选择开启增量训练开关。需注意的是,基准模型为“全量更新”训练出来的模型,才支持开启此开关。

为保证增量训练效果,开启增量训练后默认选取10%训练基准模型的数据混合进行训练
注意:基础模型继承基准模型(全量更新所得)版本,所以当您选定基准模型后,基础模型及版本不可变更,支持选择SFT、DPO和KTO训练后的模型。由于大模型权重占用较大存储,只能选择三个月内训练的模型发起增量训练。
- 若基准模型有保存Checkpoint的最新的Step,则显示 【名称+版本+Step】。
- 您也可以选择直接不使用增量训练,这样直接在基础模型上进行SFT。
大语言模型
模型随时更新,请在操作界面选择适合的模型并查看模型介绍与模型版本,在创建作业界面选择SFT进行操作。

训练方式
| 训练方法 | 简单描述 |
|---|---|
| 全量更新 | 全量更新在训练过程中对大模型的全部参数进行更新 |
| LoRA | 在固定预训练大模型本身的参数的基础上,在保留自注意力模块中原始权重矩阵的基础上,对权重矩阵进行低秩分解,训练过程中只更新低秩部分的参数。 |
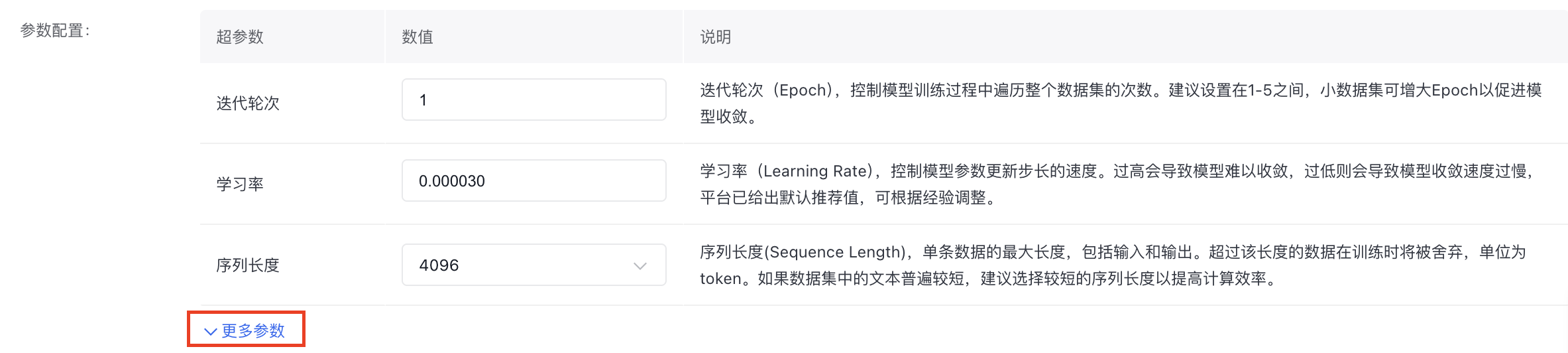
- 参数配置
部分重要参数如下,详细参数介绍可以在操作界面查看说明并自由配置。
数据配置
训练任务的选择数据及相关配置,大模型调优任务需要匹配多轮对话-非排序类的数据集。至少需要100条数据才可发起训练。
- 数据1 x 采样率1 大于100条时,允许提交
- 数据1x 采样率1+数据2 x 采样率2 大于100条时,允许提交,即便数据1、数据2的和小于100
-
数据1 x 采样率1+千帆混合语料大于100条时允许提交
数据格式上需要选择Prompt+Response或Role(user+assistant)数据进行训练。其中Role(user+assistant)数据格式支持多角色类型与Function Call工具调用进行SFT大语言模型训练。Role格式支持Function Call工具调用场景,可以帮助您实现模型与外部工具、系统的连接,这有利于增强您的模型推理效果或拓展AI助手的能力,具体Function Call数据格式配置可参考Function Call 工具调用。
注意:当前仅ERNIE-Lite-128K-0722模型支持Function Call训练。
数据集来源可以为本平台已发布的数据集版本、BOS存储中的数据集或者预置数据集,如果平台没有您准备好的训练数据,您也可以选择创建数据集并发布,选择两个及以上的数据集,支持数据配比,数据占比总和等于100%。
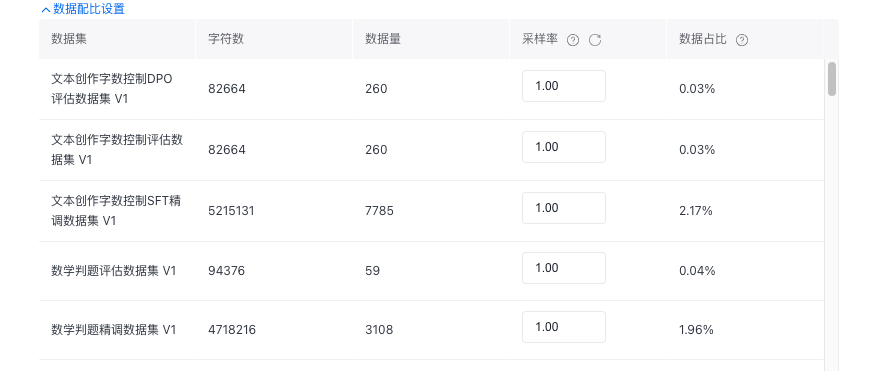
您可以通过提高采样率,来提升数据集的占比。 采样率(按照字符数计算占比):对数据集进⾏随机采样,取值范围为[0.01-10]。当数据集过⼤或质量不⾼,可以利⽤⽋采样(采样率⼩于1)来缩减训练数据的⼤⼩;当数据集过⼩或质量较⾼,可以利⽤过采样(采样率⼤于1)来增加训练数据的⼤⼩,数值越⼤训练时对该部分数据的关注度越⾼,但训练时⻓及费⽤越⾼,推荐过采样率范围为[1-5]。
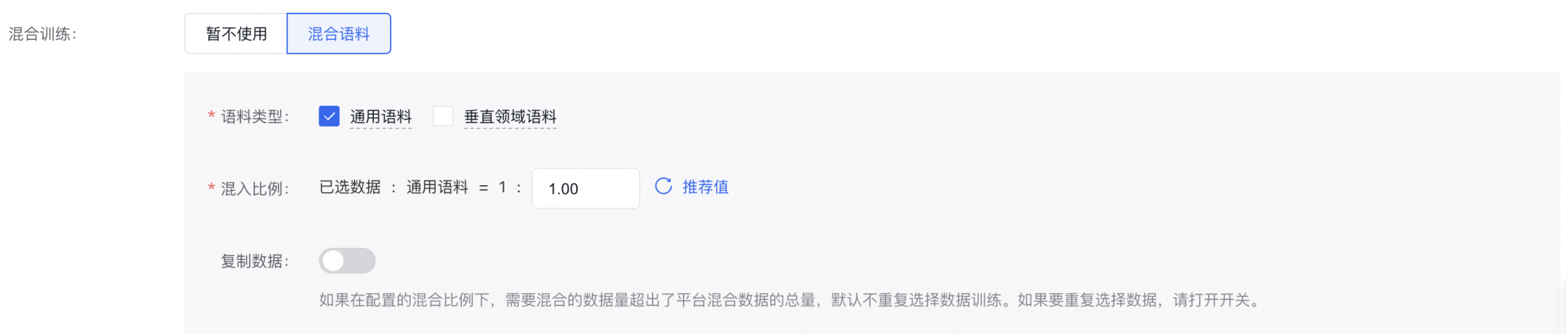
混合训练:支持用户使用自身数据与通用语料数据混合训练,其中包含多行业、多维度的通用语料数据由本平台提供。
注意:开启数据配比后,会增加整体训练tokens数,参与计费。
通用语料数据共四百万条问答对,请您根据自身样本数进行配比,推荐默认选择的数据配比为混合语料:用户数据=1:5

测试集:您可以选择对上面已选择的数据集进行拆分作为测试集,或者指定数据作为测试集。
- 数据拆分比例:比如设置20,则表示选定数据集版本总数的80%作为训练集,20%作为验证集。
- 平台数据集:需要选择多轮对话-非排序类的数据集。最多支持1000条数据用于测试。如果数据集大于1000条,将取前1000条数据做测试集。
若数据集保存在BOS中,请勿在提交任务后修改BOS数据。修改后可能会导致任务失败!
需注意:当选择BOS目录导入数据集时,数据放在jsonl文件夹下。您需要选择jsonl的父目录:
- 奖励模型支持单轮对话、多轮对话有排序数据。
- SFT支持单轮对话,多轮对话需要有标注数据。
- BOS目录导入数据要严格遵守其格式要求,如不符合此格式要求,训练作业无法成功开启。详情参考BOS导入无标注信息格式和BOS导入有标注信息格式。
另外本训练任务支持您选择开启闲时训练,任务提交后,等待平台资源空闲时进行调度。不保证资源的独占,训练过程中可能会被抢占。适合对时效性要求不高的任务。其支持范围和价格可查看计费明细
以上所有操作完成后,点击“开始训练”,则发起模型训练的任务。
发布模型
开启“自动发布”按钮后,模型在训练完成后会自动发布;若模型训练失败,则不自动发布模型。
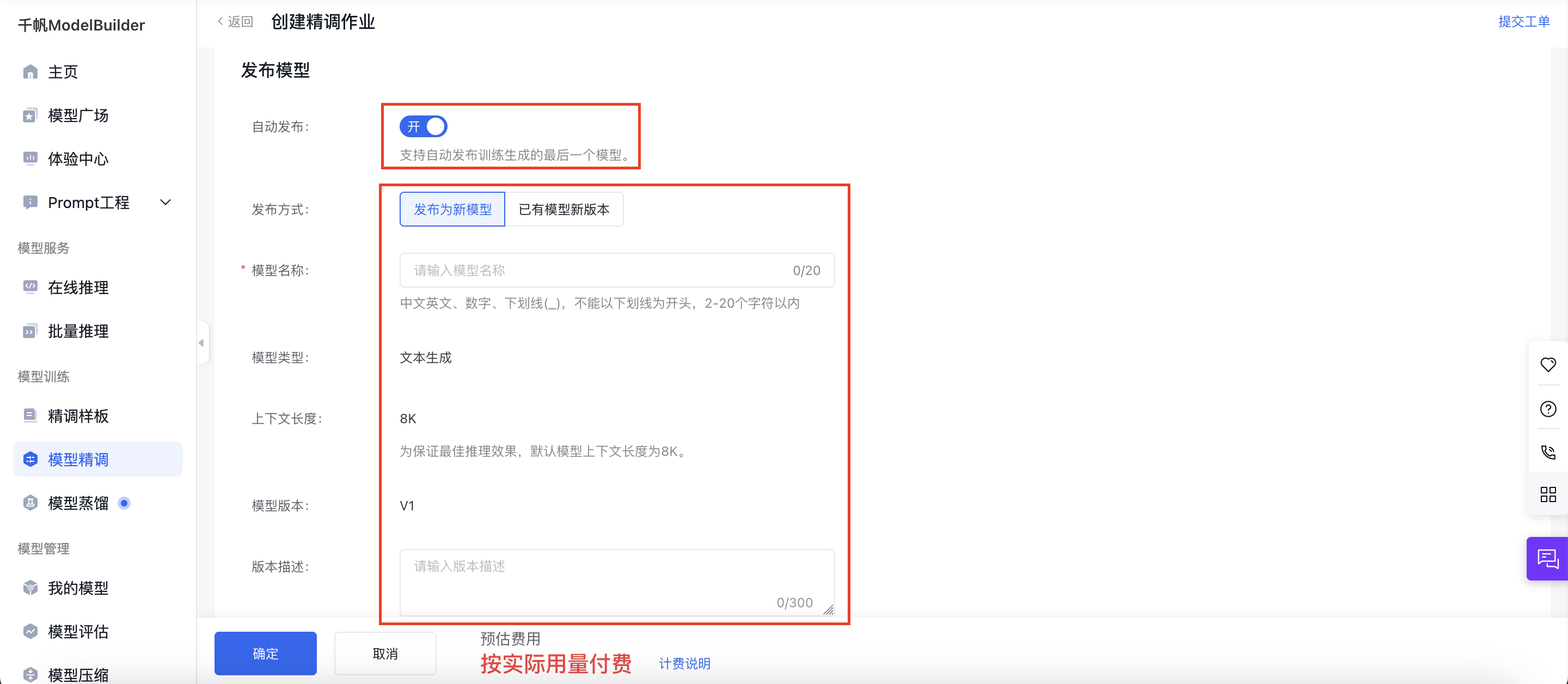
PS:模型在训练过程中被删除、模型名称重复、模型版本重复都不会自动发布模型。
文生图大模型
新建运行
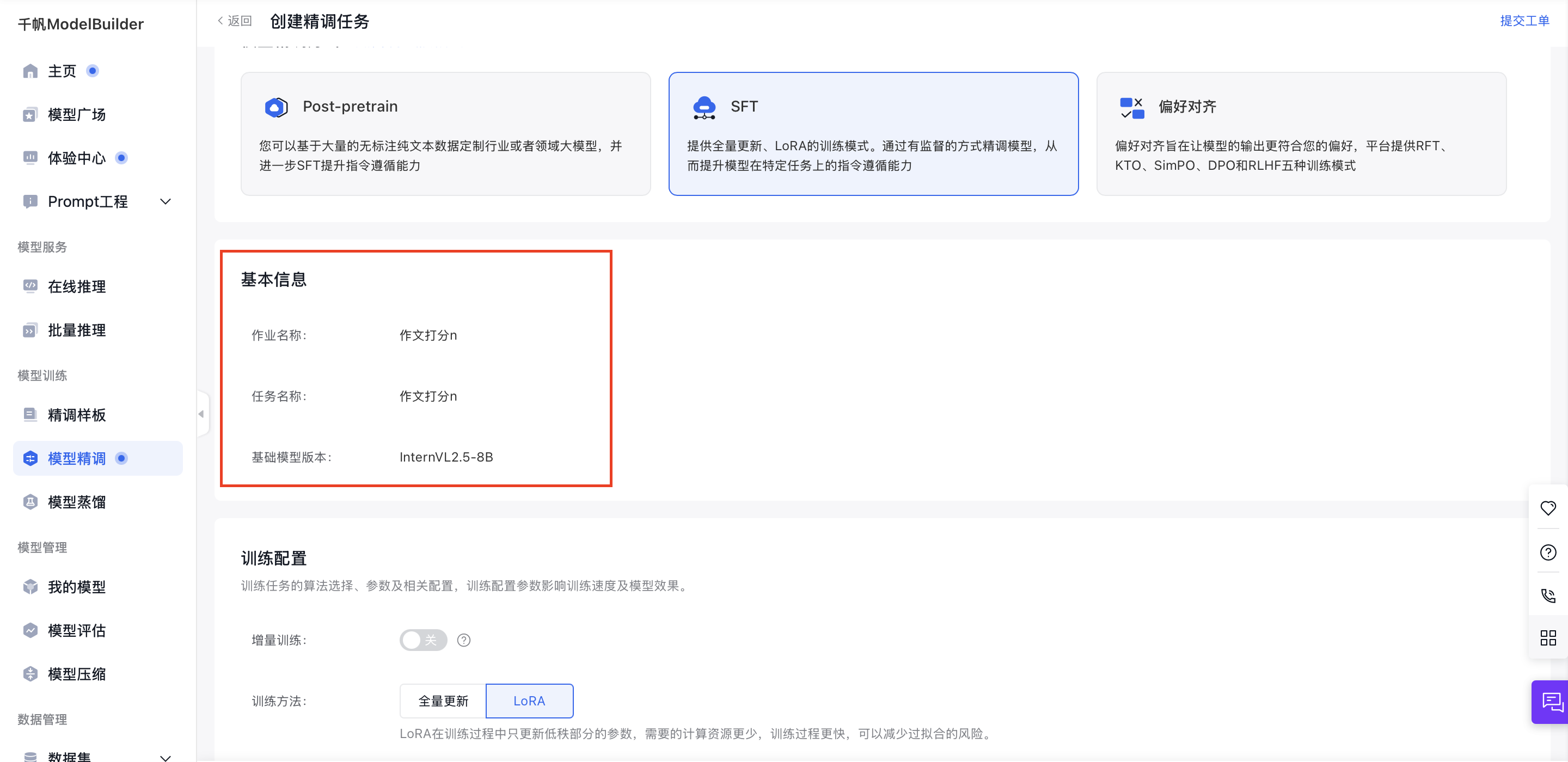
您可以在创建作业完成后,在SFT任务列表,选择指定任务的“新建任务”按钮。
进入模型训练的任务运行配置页,查看基本信息。
训练配置
如您直接创建SFT作业,可以调整大模型参数,选择基本配置。
- 在SFT训练任务中,可以选择开启增量训练开关。
开关打开后,需要选择SFT的基准模型,此模型来源于运行中的SFT任务。所以您开启增量训练任务的前提有已经在运行中的SFT任务。

为保证增量训练效果,开启增量训练后默认选取10%训练基准模型的数据混合进行训练
注意:基础模型继承基准模型(全量更新所得)版本,所以当您选定基准模型后,基础模型及版本不可变更。
- 您也可以选择直接不使用增量训练,这样直接在基础模型上进行SFT。
模型介绍
模型随时更新,请在操作界面选择适合的模型并查看模型介绍与模型版本,在创建作业界面选择SFT进行操作。

训练方式
| 训练方法 | 简单描述 |
|---|---|
| 全量更新 | 全量更新在训练过程中对大模型的全部参数进行更新 |
| LoRA | 在固定预训练大模型本身的参数的基础上,在保留自注意力模块中原始权重矩阵的基础上,对权重矩阵进行低秩分解,训练过程中只更新低秩部分的参数。 |
- 参数配置
参数如下,详细参数介绍可以在操作界面查看说明并自由配置。

数据配置
训练任务的选择数据及相关配置,支持选择该模型可使用的数据。
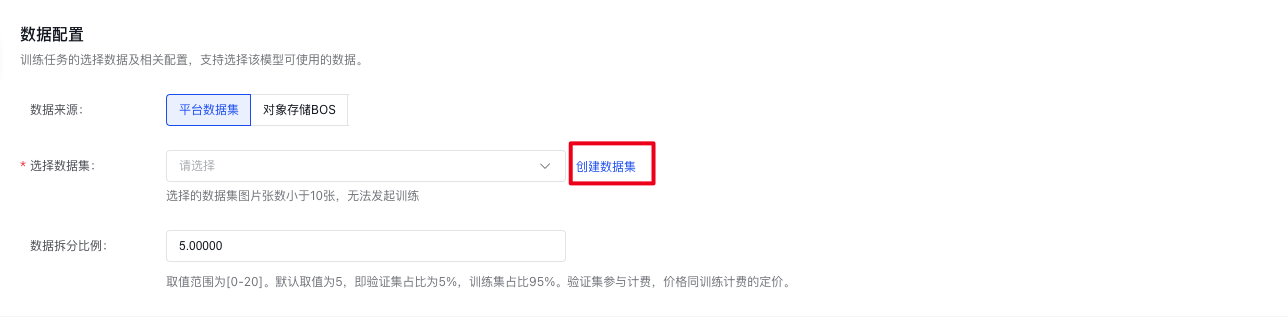
文生图大模型调优任务需要选择图片类型的数据集,且数据集个数应为10-2000张图片,若大于2000张,将会随机选择2000张作为训练数据。
数据集来源可以为本平台已发布的数据集版本,也可以为已有数据集的BOS地址(文心一格暂不支持),详细内容可查看数据集部分内容。
数据拆分比例:比如设置20,则表示选定数据集版本总数的80%作为训练集,20%作为验证集。
资源配置
文生图大模型支持将训练加入GPU,当前默认规格如下:

以上所有内容完成后,即可发起模型训练任务。
关于训练费用可查看价格文档。大模型训练模块会根据数据集大小,预估训练时长,其中最小计量粒度为0.01小时,不足0.01小时按0.01小时计算。
发布模型
开启“自动发布”按钮后,模型在训练完成后会自动发布;若模型训练失败,则不自动发布模型。
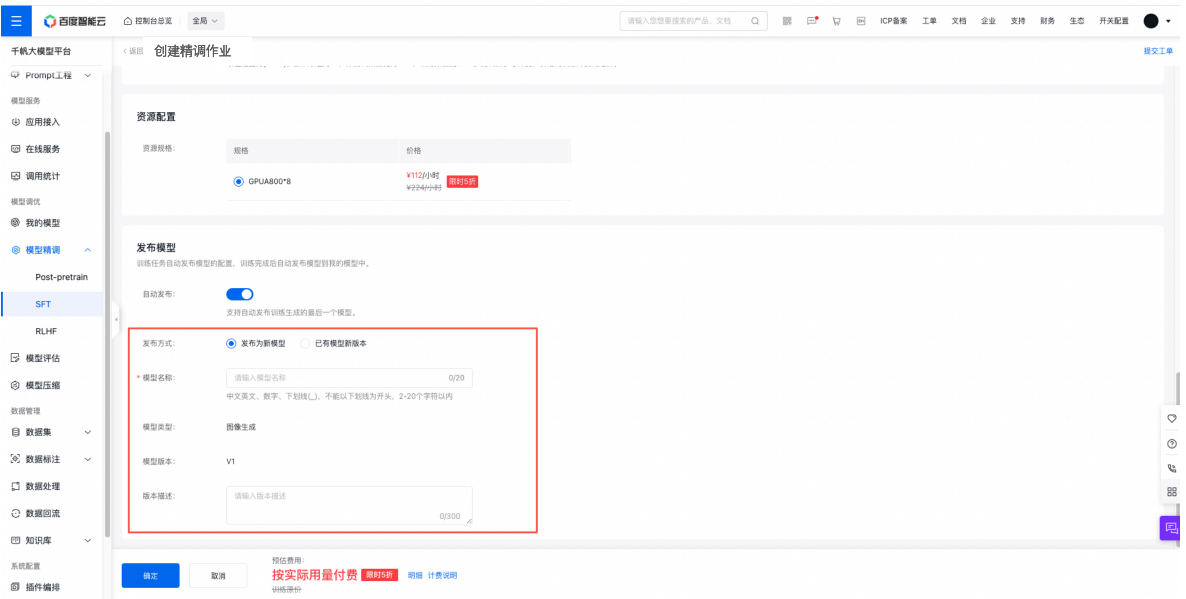
PS:模型在训练过程中被删除、模型名称重复、模型版本重复都不会自动发布模型。
图像理解大模型
您可以通过【模型精调】-【SFT】-【创建训练作业】来从零创建图像理解SFT作业。在该创建页面,有不同配置模块,包括基本信息、训练配置、数据配置、资源配置、发布模型等,完成上述各项配置后,即可完成整个训练作业的创建。
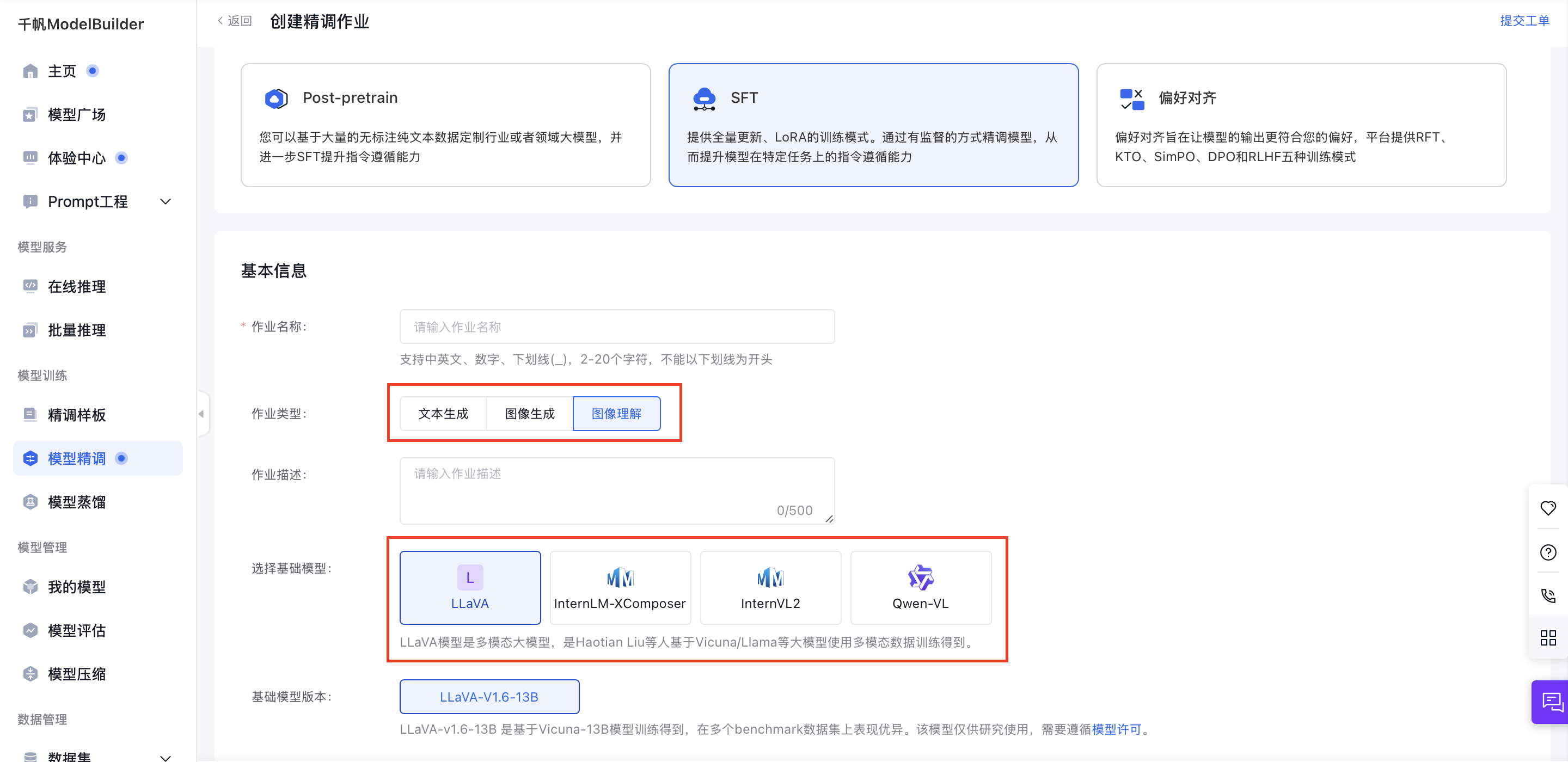
在【基本信息】模块,您可以设置作业的名称等信息,并选择训练使用的基础模型和其版本。其他模块的详细配置教程请见下文。
创建方式上,除了从零创建,您也可以在创建作业完成后,在训练任务列表,点击指定任务的【新建任务】按钮,创建新的SFT任务,这将创建相同模型的不同版本作业。
训练配置
训练配置模块包含增量训练、训练方法、参数配置几项设置。您可以先进行增量训练配置,然后根据您在基本信息模块选用的基础模型及版本,从下方找到对应模型版本的训练方法和参数介绍,然后配置。
增量训练
在SFT训练任务中,可以选择开启增量训练开关。开关打开后,需要选择SFT的基准模型,此模型来源于运行中的SFT任务。所以您开启增量训练任务的前提是有已经在运行中的SFT任务。请注意:基础模型继承基准模型(全量更新所得)版本,所以当您选定基准模型后,基础模型及版本不可变更。为保证增量训练效果,开启增量训练后默认选取10%训练基准模型的数据混合进行训练。
您也可以选择不使用增量训练,直接在基础模型上进行SFT。
模型介绍
模型随时更新,请在操作界面选择适合的模型并查看模型介绍与模型版本,在创建作业界面选择SFT进行操作。

训练方式
| 训练方法 | 简单描述 |
|---|---|
| 全量更新 | 全量更新在训练过程中对大模型的全部参数进行更新 |
| LoRA | 在固定预训练大模型本身的参数的基础上,在保留自注意力模块中原始权重矩阵的基础上,对权重矩阵进行低秩分解,训练过程中只更新低秩部分的参数。 |
- 参数配置
部分重要参数如下,详细参数介绍可以在操作界面查看说明并自由配置。

数据配置
训练任务的选择数据及相关配置,支持选择该模型可使用的数据。
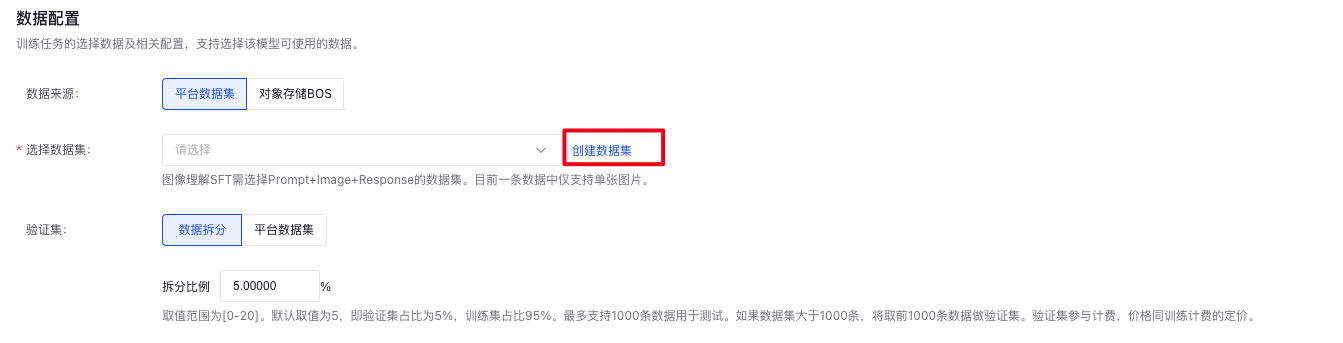
图像理解SFT需选择Prompt+Image+Response的数据集。目前一条数据中仅支持单张图片。
数据集来源为本平台已发布的数据集版本,也可以为已有数据集的BOS地址,详细内容可查看数据集部分内容。
数据拆分比例:比如设置20,则表示选定数据集版本总数的80%作为训练集,20%作为验证集。取值范围为[0-20]。默认取值为5,即验证集占比为5%,训练集占比95%。最多支持1000条数据用于测试。如果数据集大于1000条,将取前1000条数据做验证集。验证集参与计费,价格同训练计费的定价。
图像理解最少需要100条的数据量限制,还限制了需要大于8*batchsize*并发节点数,如果batchsize=16,则需要100条以上的数据量。
百度BOS服务开通申请。
发布模型
开启“自动发布”按钮后,模型在训练完成后会自动发布;若模型训练失败,则不自动发布模型。
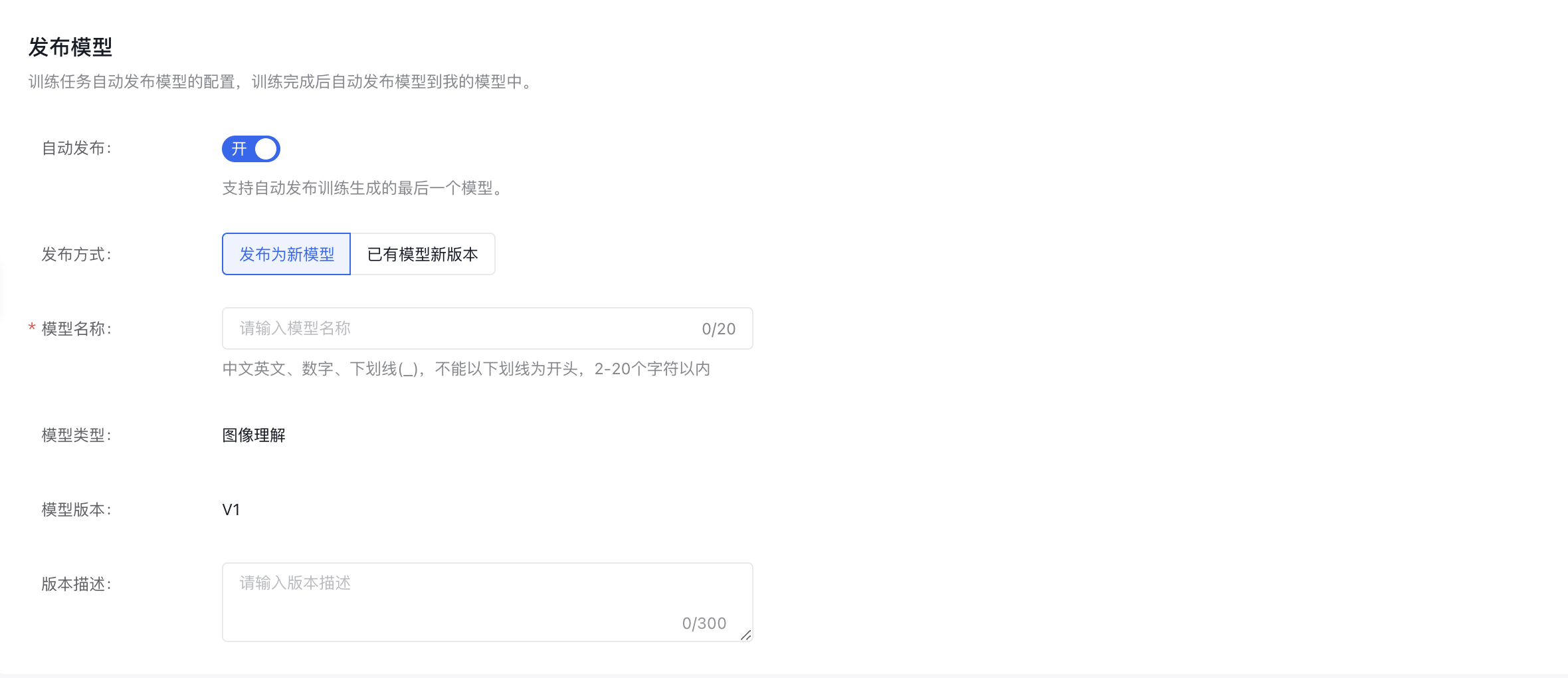
PS:模型在训练过程中被删除、模型名称重复、模型版本重复都不会自动发布模型。