在线服务压测指南
千帆ModelBuilder Python SDK 提供了基于locust工具的对大模型服务进行单轮、多轮快速压测以及性能评估功能。
使用场景
千帆ModelBuilder给用户提供标准的压测工具,可以在以下或其他场景使用:
- 测试sft模型部署到算力单元后,实际的性能效果
- 对比模型压缩后的性能效果
- 测试预置服务的性能
压测流程
步骤一:安装相关依赖。
步骤二:准备压测数据。
步骤三:启动压测,包括以下:
(1)初始化认证。推荐使用安全认证AK/SK鉴权,如何获取可参考获取AK/SK文档。
(2)初始化数据集对象。调用Dataset.load()初始化数据对象。
(3)启动压测。调用单轮压测函数或多轮压测函数设置相关参数,发起压测。
步骤四:查看压测结果。有多种方式查看结果,开发者可以选择合适的方式。
安装相关依赖
压测需要使用以下方式进行依赖安装:
注意:python版本建议3.9及以上的版本,不超过3.12
pip install 'qianfan[dataset_base]'准备压测数据
用于压测的数据集,目前支持以下三种格式,分别为jsonl格式、json格式、txt格式。
- jsonl格式示例
注意:如果导出千帆ModelBuilder data数据集,可直接作为压测数据集。
主要用于多轮对话的场景,其中一个括号就是一段对话。最后的回答会在输入中被忽略。示例如下:
[{"prompt": "请根据下面的新闻生成摘要, 内容如下:新华社受权于18日全文播发修改后的《中华人民共和国立法法》,修改后的立法法分为“总则”“法律”“行政法规”“地方性法规、自治条例和单行条例、规章”“适用与备案审查”“附则”等6章,共计105条。\n生成摘要如下:"}]
[{"prompt": "请根据下面的新闻生成摘要, 内容如下:一辆小轿车,一名女司机,竟造成9死24伤。日前,深圳市交警局对事故进行通报:从目前证据看,事故系司机超速行驶且操作不当导致。目前24名伤员已有6名治愈出院,其余正接受治疗,预计事故赔偿费或超一千万元。\n生成摘要如下:"}]- json格式示例
示例如下:
[
{"prompt": "地球的自转周期是多久?", "response": "大约24小时"},
{"prompt": "人类的基本单位是什么?", "response": "人类"}
]- txt格式
数据集格式最简单,用户数据整理更方便快捷。示例如下:
人体最重要的有机物质是什么?
化学中PH值用来表示什么?
第一个登上月球的人是谁?启动压测
注意以下事项:
- 压测入口在Dataset对象的stress_test方法以及multi_stress_test方法中。两种方法的使用场景不同,stress_test方法用于单轮压测,multi_stress_test方法用于多轮压测。
- 对大模型服务进行性能测试,需要在导入 qianfan 模块之前设置环境变量 QIANFAN_ENABLE_STRESS_TEST 为 true
单轮压测
单轮压测示例如下,示例说明:
- 以下展示了全部参数,用户在使用中,可根据实际场景设置合适的参数。各函数参数说明请参考本文函数列表。
import os
os.environ['QIANFAN_ENABLE_STRESS_TEST'] = "true"
from qianfan.dataset import Dataset
# 步骤一,接口调用认证
# 【推荐】使用安全认证AK/SK鉴权,通过环境变量初始化认证信息
# 替换下列示例中参数,安全认证Access Key替换your_iam_ak,Secret Key替换your_iam_sk
os.environ["QIANFAN_ACCESS_KEY"] = "百度智能云IAM的AccessKey"
os.environ["QIANFAN_SECRET_KEY"] = "百度智能云IAM的SecretKey"
# 通过千帆ModelBuilder应用认证
# os.environ["QIANFAN_AK"] = "千帆ModelBuilder控制台-应用接入-创建的应用AK"
# os.environ["QIANFAN_SK"] = "千帆ModelBuilder控制台-应用接入-创建的应用SK"
# 步骤二,初始化一个数据集对象
ds = Dataset.load(data_file="./stress_test_data.jsonl")
# 步骤三,设置压测相关参数
"""
* workers:启动10个进程来模拟并发请求。
* users:总模拟并发100。
* spawn_rate:每秒新增5个,一直增加到100个以后,不再新增, 后续从第11s开始,全部都按照100并发发压。
* model/ endpoint: 预置服务名称/ 定制服务Endpoint,注意两个参数只能填写其一。
* runtime:15m为15分钟。表示该次发压的时限为15分钟,超过该时限,脚本会自动停止,压测结束。
"""
ds.stress_test(
users=100,
workers=10,
spawn_rate=5,
# model="ERNIE-Speed-8K", # 此处填写预置服务名称,与endpoint二选一
endpoint="YourEndpoint", # 此处填写您的定制服务Endpoint
model_type="ChatCompletion", # 可选参数
runtime="15m", # 可选参数
hyperparameters={"temperature":0.9} # 可选参数
)多轮压测
当用户希望一次压测任务测试不同并发下的qps,可以使用multi_stress_test进行多轮压测。
以下为多轮压测示例。该示例展示了全部参数,用户在使用中,可根据实际场景设置合适的参数。各函数参数说明请参考本文函数列表。
import os
os.environ['QIANFAN_ENABLE_STRESS_TEST'] = "true"
from qianfan.dataset import Dataset
# 步骤一,接口调用认证
#【推荐】使用安全认证AK/SK鉴权,通过环境变量初始化认证信息
# 替换下列示例中参数,安全认证Access Key替换your_iam_ak,Secret Key替换your_iam_sk
os.environ["QIANFAN_ACCESS_KEY"] = "百度智能云IAM的AccessKey"
os.environ["QIANFAN_SECRET_KEY"] = "百度智能云IAM的SecretKey"
# 通过千帆ModelBuilder应用认证
# os.environ["QIANFAN_AK"] = "千帆ModelBuilder控制台-应用接入-创建的应用AK"
# os.environ["QIANFAN_SK"] = "千帆ModelBuilder控制台-应用接入-创建的应用SK"
# 步骤二,初始化一个数据集对象
# 需要初始化一个数据集对象
ds = Dataset.load(data_file="./stress_test_data.jsonl")
# 步骤三,设置压测相关参数
"""
* workers:启动10个进程来模拟并发请求。
* origin_users:初始发压并发数为100。users数量即为并发数量。
* spawn_rate:每秒新增5个user,一直增加到100个以后,不再新增, 后续从第11s开始,全部都按照100并发发压。
* model/ endpoint: 预置服务名称/ 定制服务Endpoint,注意两个参数只能填写其一。
* first_latency_threshold: 首token时延阈值。首token返回时延超过20秒,则不会再发起下轮压测,压测在本轮停止。
* round_latency_threshold: 单轮压测时延阈值。单轮压测时延超过100秒,则不会再发起下轮压测,压测在本轮停止。
* success_rate_threshold: 单轮成功率阈值。本轮压测的请求成功率低于80%,则不会再发起下轮压测,压测在本轮停止。
* rounds:指定压测轮数。
* interval:指定压测轮之间的加压并发数。
"""
ds.multi_stress_test(
origin_users=100,
workers=10,
spawn_rate=5,
# model="ERNIE-Speed-8K", # 此处填写预置服务名称,与endpoint二选一
endpoint="YourEndpoint", # 此处填写服务Endpoint
model_type="ChatCompletion", # 可选参数
runtime="15m", # 可选参数
rounds=10,
interval=5,
hyperparameters={"temperature":0.9} # 可选参数
#first_latency_threshold = 20,
#round_latency_threshold = 100,
#success_rate_threshold = 80,
)函数列表
初始化数据集对象
- 示例
Dataset.load(data_file="./stress_test_data.jsonl")- 请求参数
| 参数 | 类型 | 必填 | 描述 |
|---|---|---|---|
| data_file | str | 是 | 压测数据集,支持以下数据格式,详情请参考本文准备压测数据章节: · jsonl · json · txt |
- 调用结果
完成初始化数据集对象。
发起单轮压测
- 请求参数
名称 |
类型 | 必填 | 描述 |
|---|---|---|---|
| users | int | 是 | 指定发压使用的总user数,也就最终的发压并发数。说明: (1)建议值:100 (2)users必须大于等于workers数目 (3)每个worker负责模拟${users}/${workers}个虚拟用户 |
| workers | int | 是 | 指定发压使用的worker数目,说明: (1)建议值:10 (2)每个worker为1个进程 |
| spawn_rate | int | 是 | 指定每秒真实启动的user数目,一直增长到users大小以后,不再新增启动。说明:建议值为5 |
| runtime | str | 否 | 指定发压任务的最大运行时间,说明: (1)格式为带时间单位的字符串,例如:300s,20m,3h,1h,30m (2)压测任务启动后会一直运行到数据集内所有数据都请求完毕,或到达该参数指定的最大运行时间 (3)默认值为0,表示不设最大运行时间 |
| model_type | str | 否 | 指定被测服务的模型类型,说明: (1)当前支持 ChatCompletion 与 Completion (2)默认值为ChatCompletion (3)当前大部分模型都是ChatCompletion类型,所以此参数可以不用设置 |
| endpoint | str | 否 | 用于指定用户自行发布的模型服务,该参数与model只能填写一个,说明: · 如果是用户自行发布的模型服务,该字段值可以通过查看服务地址获取:打开模型服务-模型推理页面,选择创建的服务-点击详情页查看服务地址,endpoint值为 https://aip.baidubce.com/rpc/2.0/ai_custom/v1/wenxinworkshop/chat/或https://aip.baidubce.com/rpc/2.0/ai_custom/v1/wenxinworkshop/completions/后面的地址,以对话Chat为例,如下图所示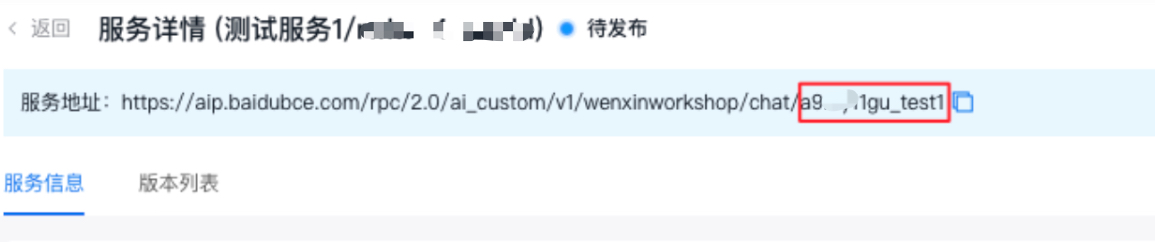 注意: 在创建服务页面,选择模型后,API地址会自动新增个后缀。例如选择某模型,输入API地址为“test1”,endpoint的取值即为“ngxxxol8_test1”,如下图所示,如何发布服务请参考发布平台预置的模型服务、快速部署自定义模型 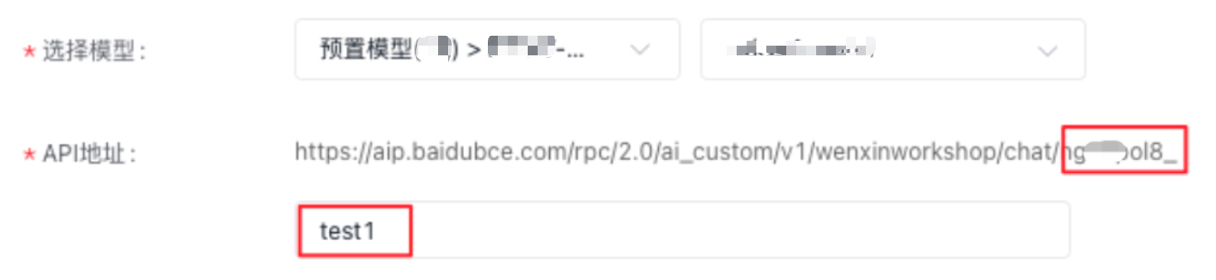 |
| model | str | 否 | 指定需要压测服务的模型名称,说明:该参数与endpoint只能填写一个 |
| hyperparameters | Optional[Dict[str, Any]] | 否 | 说明:指定压测时使用的超参数,例如:hyperparameters={"temperature":0.5} |
- 调用结果
启动单轮压测。
发起多轮压测
- 请求参数
名称 |
类型 | 必填 | 描述 |
|---|---|---|---|
| origin_users | int | 是 | 指定发压使用的初始用户数,说明: (1)建议值为10 (2)origin_users必须大于等于workers数目 (3)每个worker负责模拟${users}/${workers}个虚拟用户 |
| workers | int | 是 | 指定发压使用的worker数目,每个worker为1个进程,说明:建议值为10 |
| spawn_rate | int | 是 | 指定每秒真实启动的user数目,一直增长到users大小以后,不再新增启动。说明:建议值为5 |
| rounds | int | 是 | 指定压测轮数,说明:建议值为10 |
| interval | int | 是 | 指定压测轮之间的加压并发数,说明: (1)建议值:5 (2)若设置interval=2,表示在第1轮压测结束后,会在第2轮开始时,额外启动两个user的并发,以此类推 |
| first_latency_threshold | float | 否 | 指定首句时延的阈值,超过该阈值会停止在本轮压测,单位为秒 |
| round_latency_threshold | float | 否 | 指定全长时延的阈值,超过该阈值会停止在本轮压测,单位为秒 |
| success_rate_threshold | float | 否 | 指定请求成功率的阈值,低于该阈值会停止在本轮压测,单位为百分比 |
| runtime | str | 否 | 指定发压任务的最大运行时间,说明: (1)格式为带时间单位的字符串,例如:300s,20m,3h,1h,30m (2)压测任务启动后会一直运行到数据集内所有数据都请求完毕,或到达该参数指定的最大运行时间 (3)该参数默认值为0,表示不设最大运行时间 |
| model_type | str | 否 | 指定被测服务的模型类型,说明: (1)当前支持ChatCompletion与Completion,默认值为ChatCompletion (2)当前大部分模型都是ChatCompletion类型,所以此参数可以不用设置 |
| endpoint | str | 否 | 用于指定用户自行发布的模型服务,该参数与model只能填写一个,说明: · 如果是用户自行发布的模型服务,该字段值可以通过查看服务地址获取:打开模型服务-模型推理页面,选择创建的服务-点击详情页查看服务地址,endpoint值为 https://aip.baidubce.com/rpc/2.0/ai_custom/v1/wenxinworkshop/chat/或https://aip.baidubce.com/rpc/2.0/ai_custom/v1/wenxinworkshop/completions/后面的地址,以对话Chatw为例,如下图所示注意: 在创建服务页面,选择模型后,API地址会自动新增个后缀。例如选择某模型,输入API地址为“test1”,endpoint的取值即为“ngxxxol8_test1”,如下图所示,如何发布服务请参考发布平台预置的模型服务、快速部署自定义模型 |
| model | str | 否 | 指定需要压测服务的模型名称,说明:该参数与endpoint只能填写一个 |
| hyperparameters | Optional[Dict[str, Any]] | 否 | 说明:指定压测时使用的超参数,例如:hyperparameters={"temperature":0.5} |
- 调用结果
启动多轮压测。
查看压测结果
单轮压测
有多种查看压测结果方式,用户可以根据需要选择查看结果。
- 控制台输出压测结果
压测结果示例如下。
[2024-07-11 14:11:15,009] [INFO] run completed.
[2024-07-11 14:11:15,018] [INFO] Log path: record/20240711T135612Z/run.log
[2024-07-11 14:11:15,020] [INFO] Load Test Statistics
QPS: 3.59
RPM: 215.4
Latency Avg: 25.47
Latency Min: 0.28
Latency Max: 46.75
Latency 50%: 24.94
Latency 80%: 30.82
FirstTokenLatency Avg: 19.06
FirstTokenLatency Min: 0.09
FirstTokenLatency Max: 27.32
FirstTokenLatency 50%: 19.27
FirstTokenLatency 80%: 21.73
TotalInputTokens Avg: 2088.0
TotalOutputTokens Avg: 1266.33
SendQuery: 30
SuccessQuery:29
FailureQuery: 1
TotalQuery: 30
TotalTime: 28.63
SuccessRate: 96.67%- Locust可视化压测报告
查看Locust可视化压测报告。
(1)在当前工作目录下的record目录中,按照压测时间找到对应的压测日志目录。部分内容如下:

(2)打开report.html打开查看压测数据
示例报告如下:
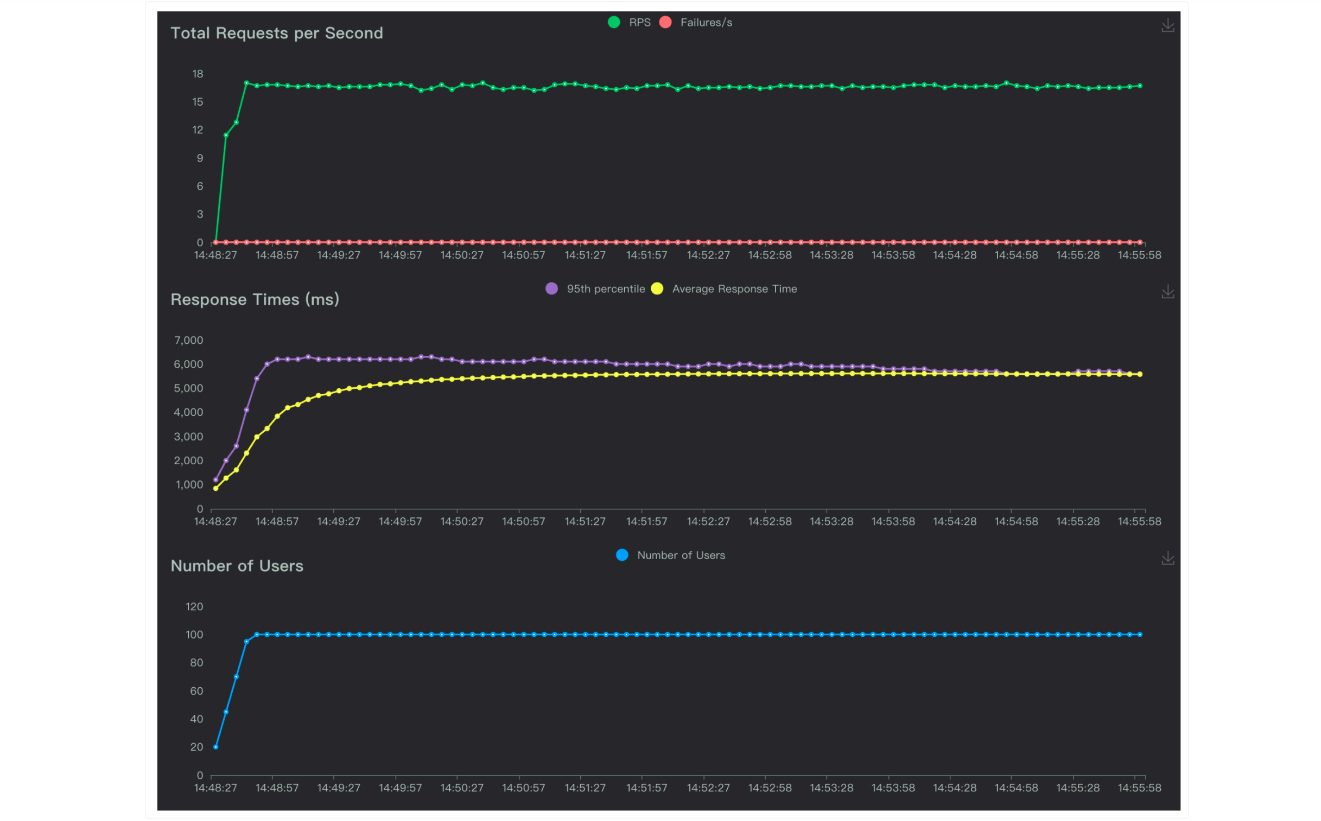
- 报表形式化压测报告
查看报表化压测报告。
(1)在当前工作目录下的record目录中,按照发压时间找到对应的压测日志目录。

(2)打开performance_table.html查看压测表格数据
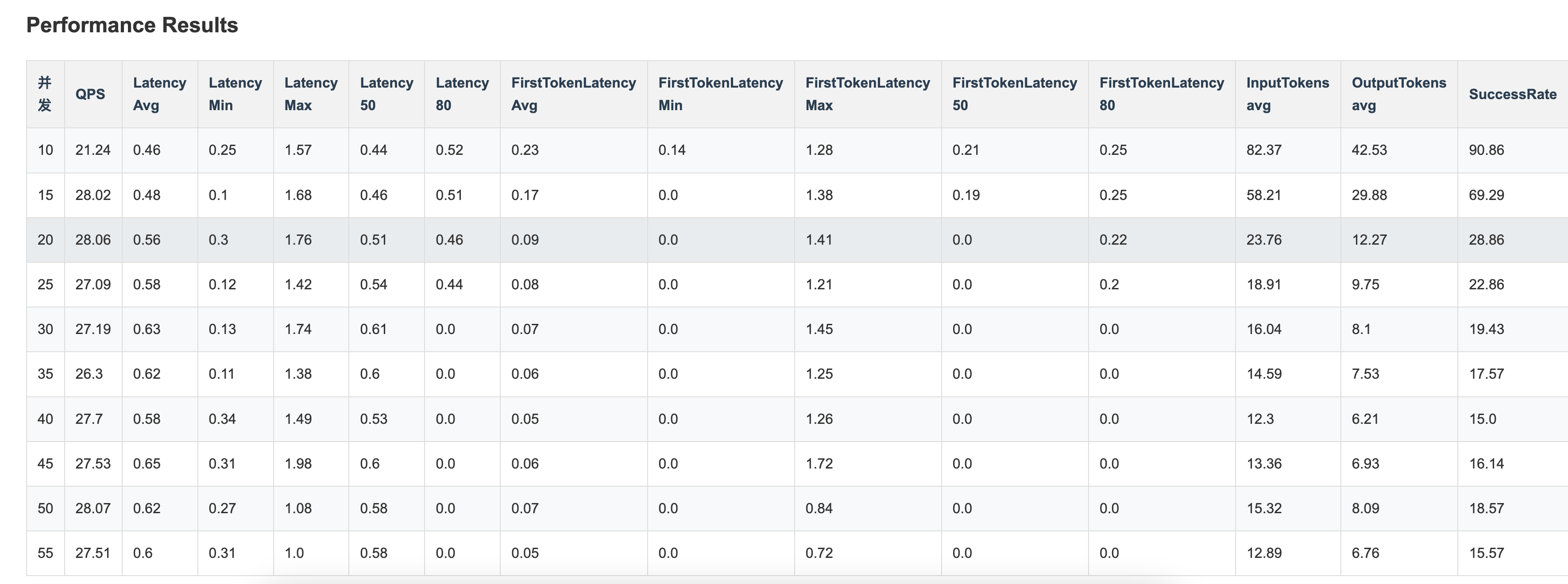
示例报告如下:
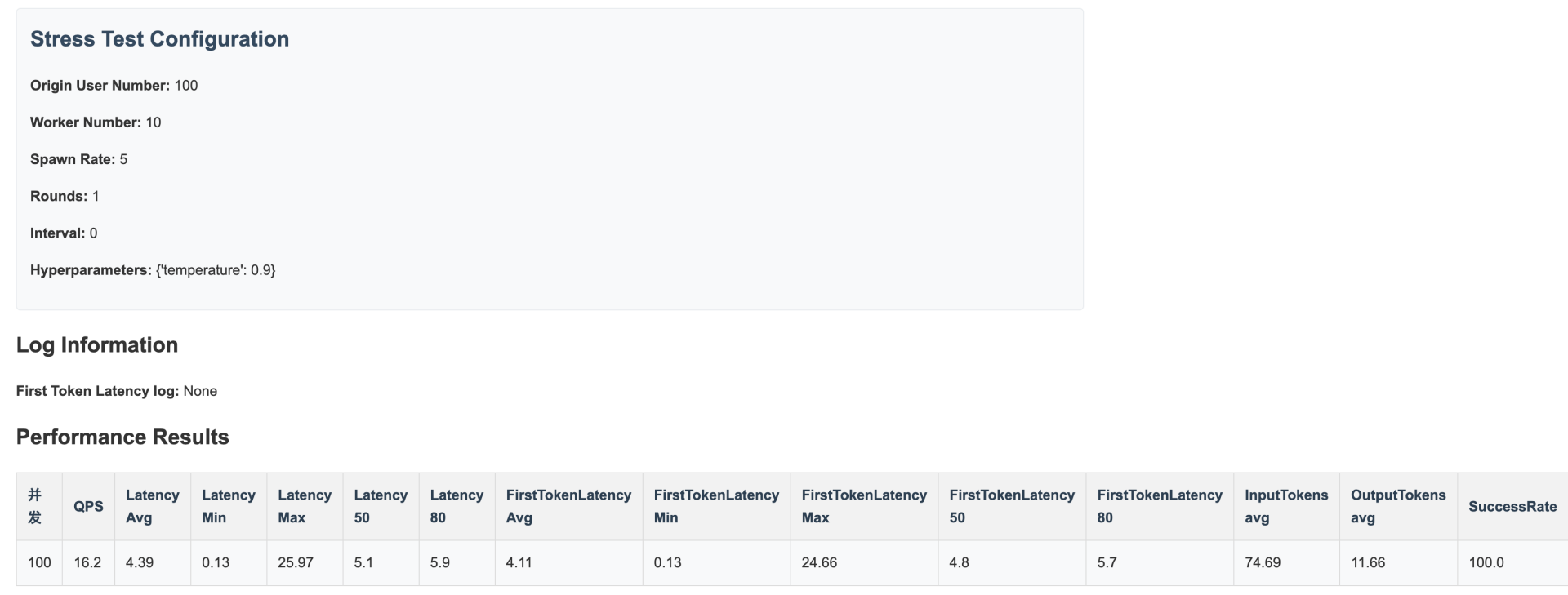
- 云端调用查看统计
通过云端调用统计查看压测数据示例如下:
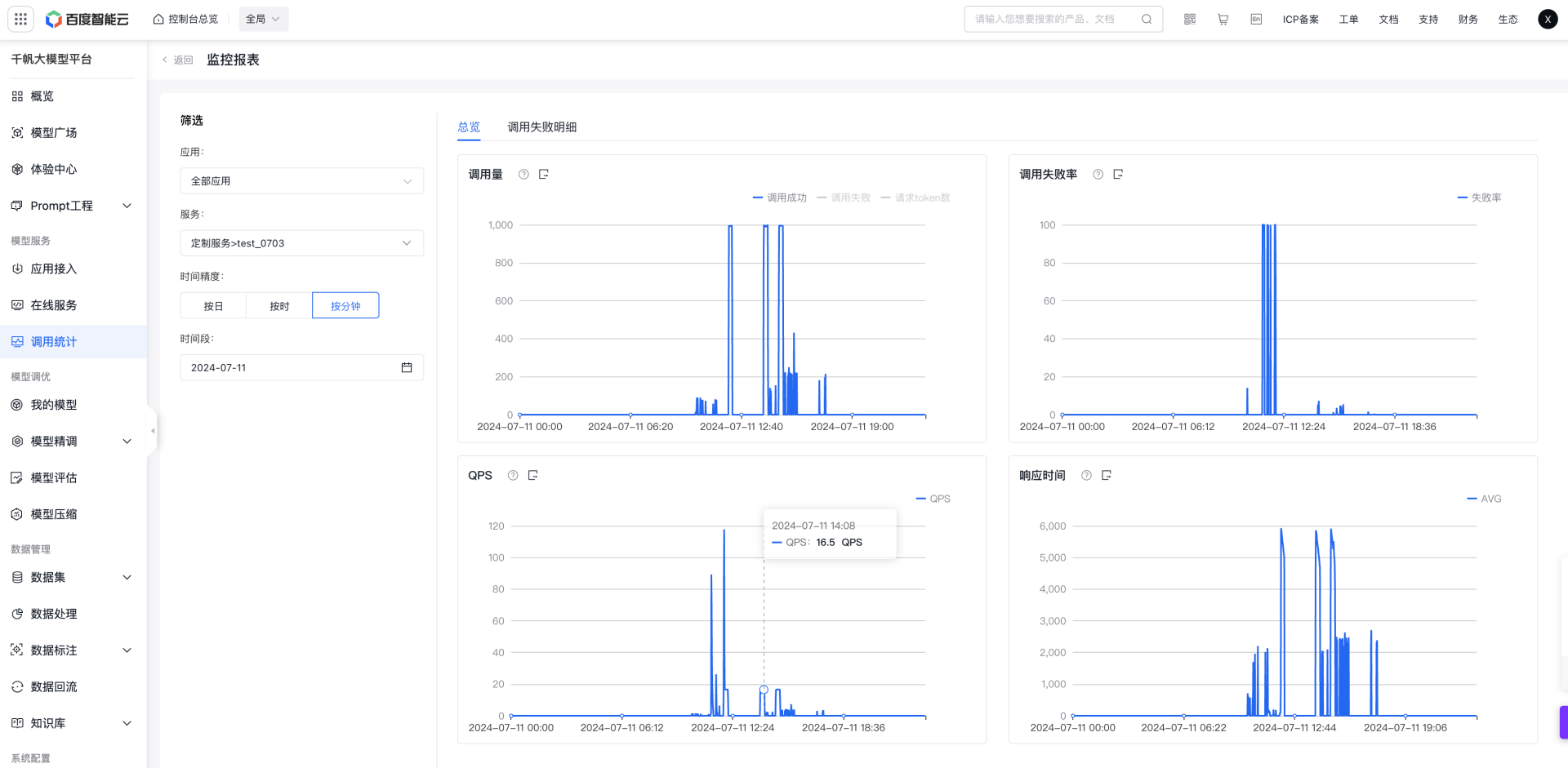
多轮压测
部分压测报告形式如下,可自行选择查看。
- Locust可视化压测报告
查看Locust可视化压测报告。
(1)在当前工作目录下的record目录中,按照压测时间找到对应的压测日志目录。部分内容如下:
(2)打开report.html查看压测表格数据
示例报告如下:
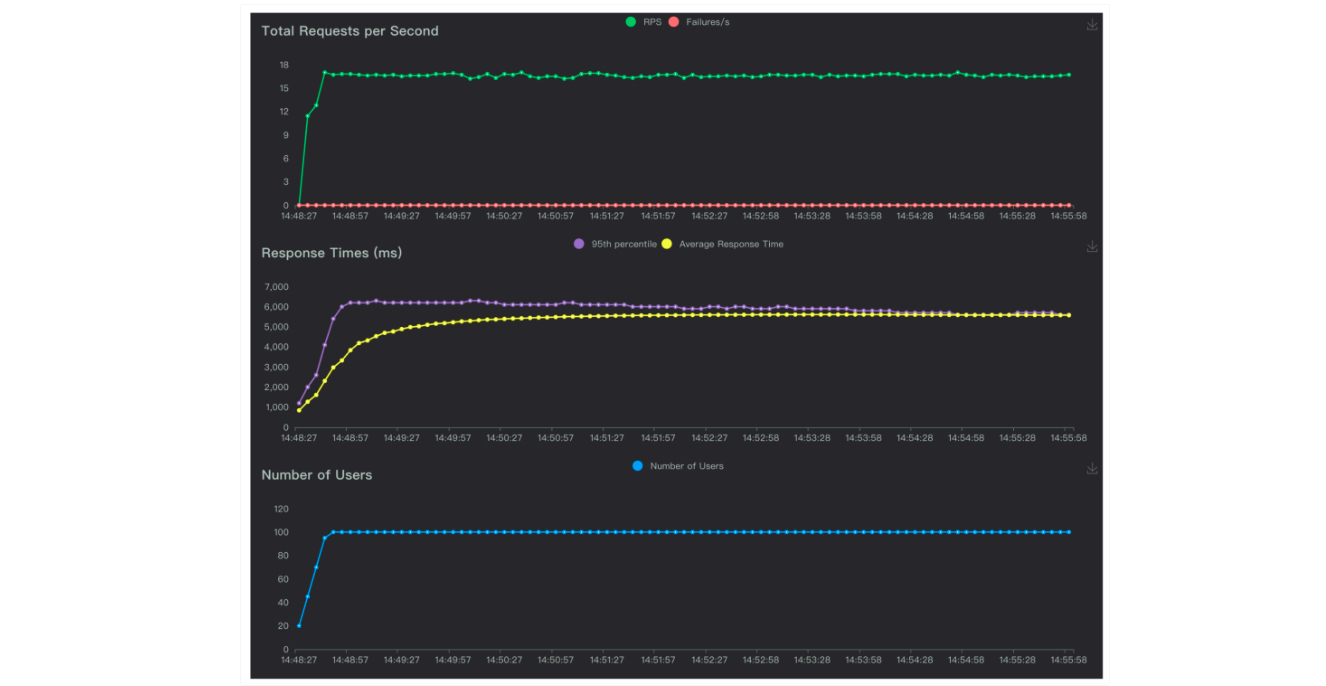
- 报表形式化压测报告
查看报表化压测报告。
(1)在当前工作目录下的record目录中,按照发压时间找到对应的压测日志目录。部分内容如下:
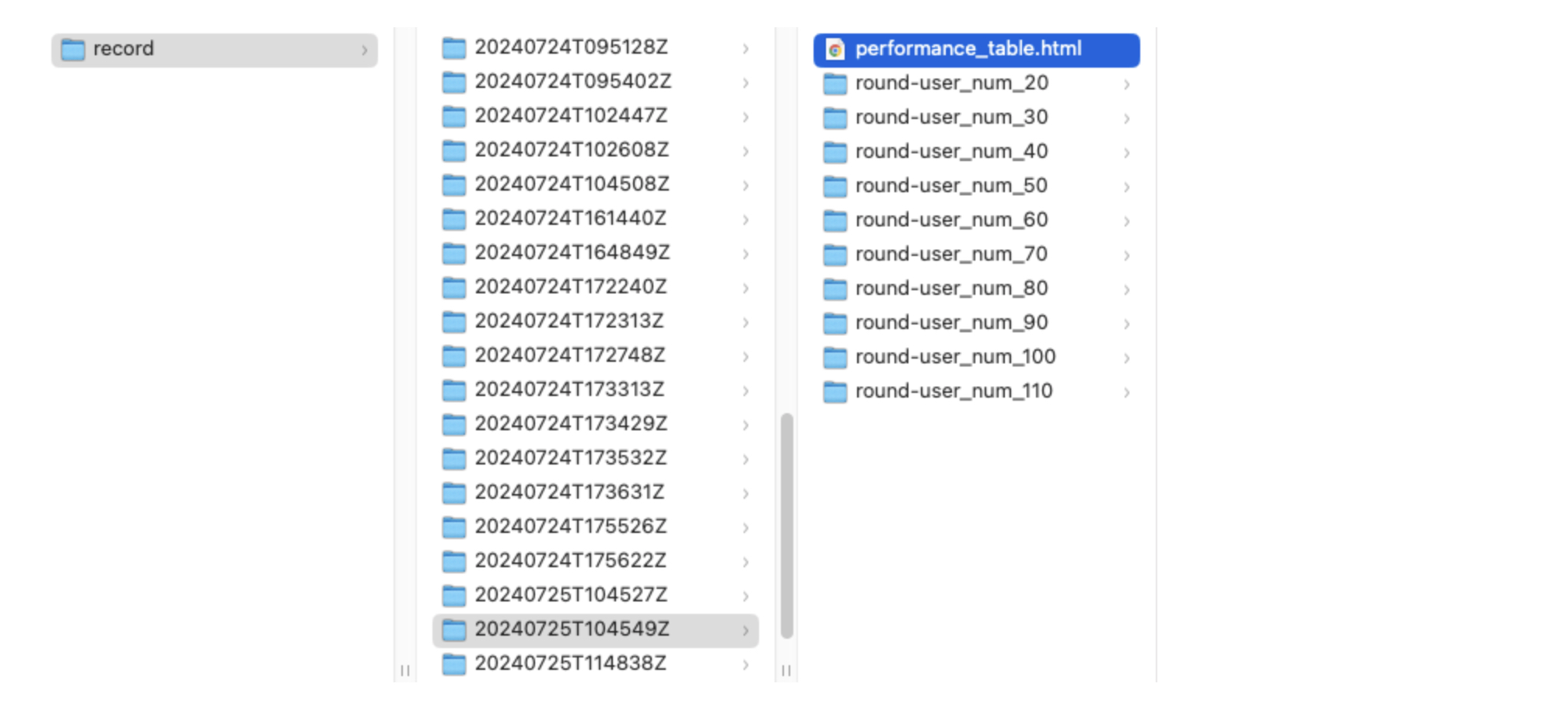
(2)打开performance_table.html查看压测表格数据
示例报告如下: