

模型广场操作
更新时间:2025-04-23
平台预置了多款大模型供您使用,包括文心一言及业内知名的开源大模型,您可在模型列表查看置入的模型,千帆平台推出千帆 AI 应用开发者中心,提供大模型资源、工具与服务支持。
登录到本平台,在左侧功能列中选择模型广场,查看平台预置模型和预置服务的列表。
模型检索
通过模型广场的标签区可检索您所需的模型列表,支持标签多选和清空筛选条件。
其中,可以针对模型类别、供应商、上下文长度、语言以及扩展能力进行筛选。
同时,在模型列表上方支持综合排序、按模型更新时间、按模型名称进行排序。搜索框内可输入模型名称、描述、模型ID、版本ID进行检索。
模型操作
点击模型卡片,进入模型详情页。
- 模型介绍: 基本信息包含模型名称、模型类型、模型描述等基本信息。
- 版本列表: 点击模型版本名称或查看版本详情;同时支持部分模型创建精调任务、查看API文档、在线体验和部署。
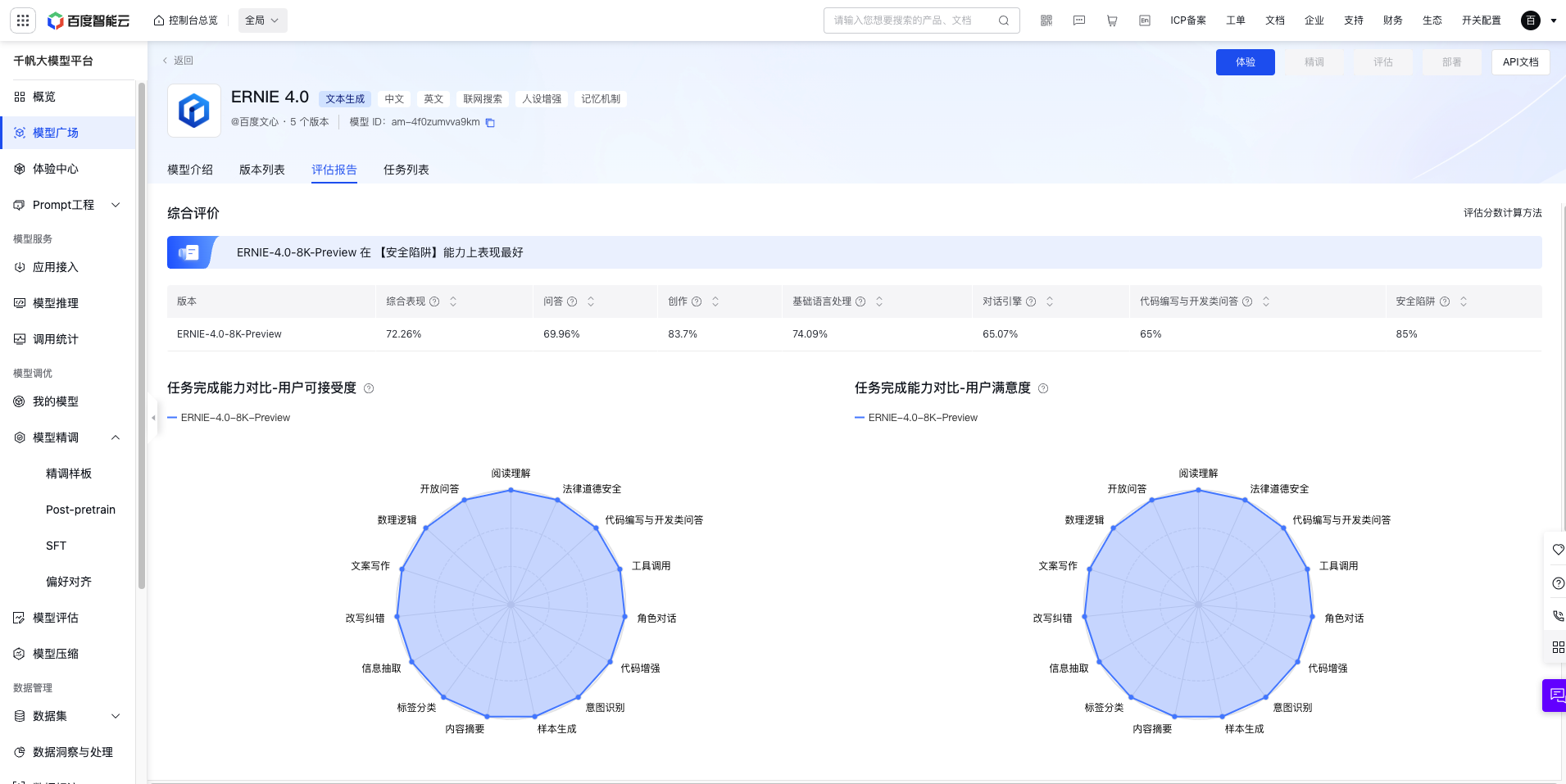
- 评估报告: 支持查看预置模型评估报告,包括综合评价、任务完成能力对比和对话指令违背比例等信息。
- 任务列表: 任务列表下展示预置模型各类任务的记录,如模型评估、模型压缩和删除版本等。
进一步精调
支持对模型广场部分预置模型、用户精调的部分模型进行进一步精调,可将光标移至“使用此模型”,点击“进一步精调”直接创建精调任务。详情支持范围请参考模型精调相关内容。
评估模型效果
支持对模型广场部分预置模型、用户精调的部分模型进行评估,可将光标移至“使用此模型”,点击“评估模型效果”直接发起评估任务。详情支持范围请参考模型评估相关内容。
部署模型推理
预置模型支持通过特定资源池部署为预测服务,可将光标移至“使用此模型”,点击“部署模型推理”跳转至在线服务进行模型部署,详情操作参考在线服务相关内容。