

创建DPO任务
DPO模型训练,直接偏好学习,您可以通过偏好数据直接优化模型。DPO方法能够简单、高效的训练得到符合您偏好的模型。
登录到本平台,在创建训练作业中选择DPO,进入DPO主任务界面。
创建任务
如果您在任务列表已经有创建好的模型任务,可以直接点击“新建任务”创作模型的迭代版本,如果已有任务中的的版本,再次创建的运行任务不可切换基础模型类型。
基本信息
填写好作业名称后,选择作业类型,再进行500字内的作业描述即可。
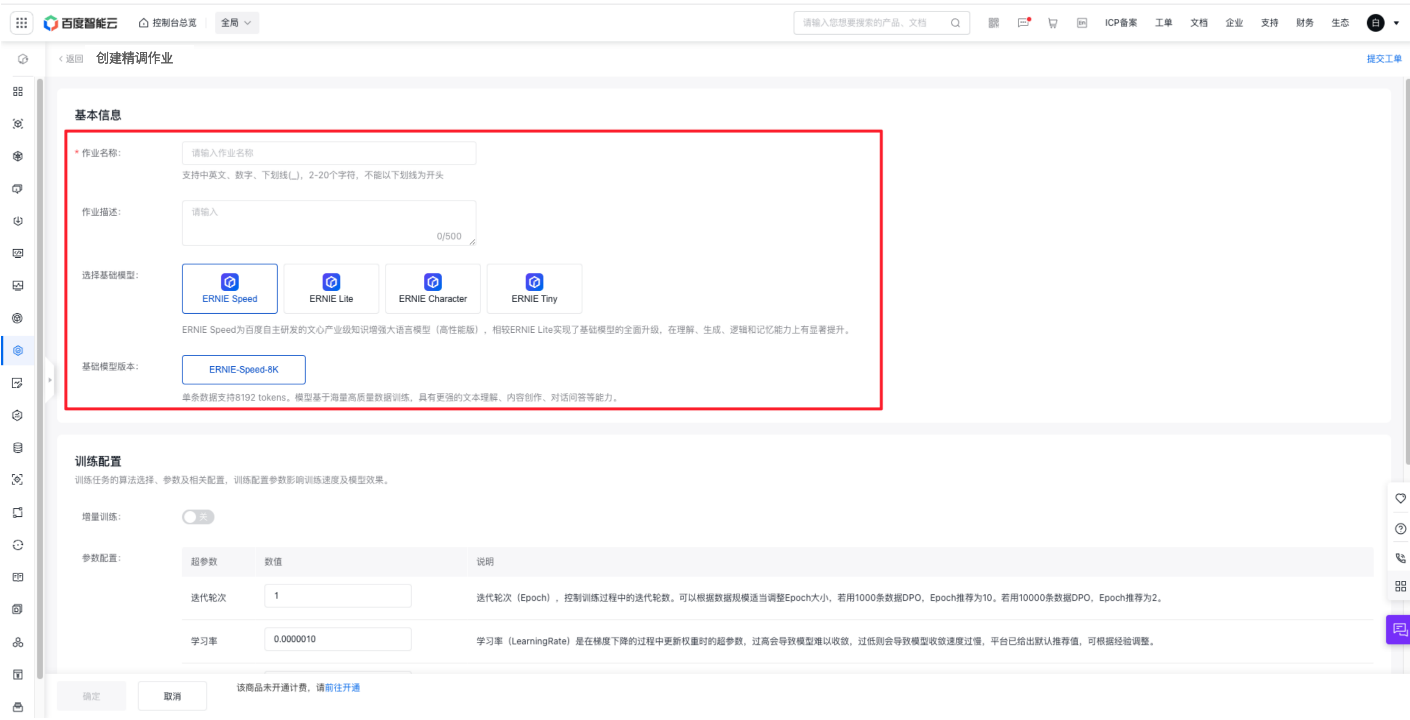
关于基础模型和版本的配置详情,可查看训练配置。
训练配置
训练配置大模型参数,调整好基本配置。
- 在DPO训练任务中,可以选择开启增量训练开关。

注意:基础模型继承基准模型(全量更新所得)版本,所以当您选定基准模型后,基础模型及版本不可变更,支持DPO和SFT后的模型。由于大模型权重占用较大存储,只能选择三个月内训练的模型发起增量训练。
- 若基准模型有保存Checkpoint的最新的Step,则显示 【名称+版本+Step】。
- 您也可以选择直接不使用增量训练,这样直接在基础模型上进行DPO。

ERNIE 4.0 Turbo
ERNIE-4.0-Turbo-8/128K
ERNIE-4.0-Turbo-8K单条数据支持8k tokens。ERNIE-4.0-Turbo-128K单条数据支持32k tokens。该系列模型在性能和效果上表现优异。
| 训练方法 | 简单描述 |
|---|---|
| 全量更新 | 在训练过程中对大模型的全部参数进行更新,可以充分利用训练数据,有潜力在新任务上达到更好的性能。 |
- 参数配置
| 超参数 | 简单描述 |
|---|---|
| 迭代轮次 | 迭代轮次(Epoch),控制模型训练过程中遍历整个数据集的次数。建议设置在1-5之间,小数据集可增大Epoch以促进模型收敛。 |
| 学习率 | 学习率(Learning Rate),控制模型参数更新步长的速度。过高会导致模型难以收敛,过低则会导致模型收敛速度过慢,平台已给出默认推荐值,可根据经验调整。 |
| 序列长度 | 序列长度(Sequence Length),单条数据的最大长度,包括输入和输出。该长度在模型的训练和推理过程中全部适用,超过该长度的部分将在推理时自动截断,单位为token。如果数据集中的文本普遍较短,建议选择较短的序列长度以提高计算效率。 |
| 全局批大小 | 全局批大小(GlobalBatchsize),每次训练迭代使用的样本数,为了加快训练效率,多条样本会使用Packing尽可能拼接到一个序列长度内。 |
| 保存日志间隔 | 保存日志间隔(Logging Interval),设定模型训练过程中记录日志的间隔步数。合理设置可以平衡日志记录的详细程度和存储、处理资源的消耗。 |
| 预热比例 | 预热比例(Learning Rate Warmup),训练初期学习率预热步数占用总的训练步数的比例。学习率预热可以提高模型稳定性和收敛速度。 |
| 正则化系数 | 正则化系数(Weight Decay),控制正则化项对模型参数的影响强度。适当增大系数可以增强正则化效果,防止过拟合,但过高的系数可能导致模型欠拟合。 |
| beta | 温度超参(beta),温度超参beta用于控制模型输出分布的集中程度。较高的beta值会使输出更具确定性,而较低的beta值则使输出更具多样性。 |
| Checkpoint保存策略 | Checkpoint保存策略(Checkpoint Save Strategy),训练过程保存模型Checkpoint的策略。按Step保存需要配置保存Checkpoint的间隔,按Epoch保存则在每个Epoch训练完成后自动保存模型Checkpoint。 |
| Checkpoint保存个数 | Checkpoint保存个数(Number of Checkpoint),训练过程最终要保存的Checkpoint个数。Checkpoint保存可以在系统故障时从最近的Checkpoint中恢复训练,但保存Checkpoint会增加训练时长。 |
| Checkpoint保存间隔数 | Checkpoint保存间隔数(Checkpoint Interval),训练过程中保存Checkpoint的间隔Step数。间隔太短可能导致频繁的Checkpoint操作增加训练时长,间隔太长则可能在故障时丢失更多的数据。注意:Checkpoint保存策略为按Step时使用 |
| 随机种子 | 随机种子(Random Seed),是在随机数生成算法中设定的一个初始值,用于确保随机数生成的可重复性。通过设置随机种子,可以在相同的算法和参数下,生成相同的随机数序列。 |
| 学习率调整计划 | 学习率调整计划(schedulerType),用于在训练过程中动态调整学习率,以优化模型的收敛速度和性能。根据模型的训练情况和任务需求,选择合适的学习率调整方式。 |
| cosine 策略的波数 | cosine 策略的波数(Period of Cosine),波数定义了余弦函数周期的长短。减少波数可以使模型训练过程稳定,增加波数可以避免陷入局部最优。 |
| polynomial 策略的末端 LR | polynomial 策略的末端 LR(Polynomial Decay End Learning Rate),指的是在多项式衰减策略中,学习率下降到最后所达到的最小值。这个值通常设置得较低,该值若生效需要比学习率小,保证在模型训练后期实现细致的优化。 |
| polynomial 策略的幂数 | polynomial 策略的幂数(Polynomial Decay Power),是指在多项式衰减学习率调整策略中,用于控制学习率下降曲线陡峭程度的指数。幂数越大,可以避免陷入局部最优;幂数越小,可以使模型训练过程稳定。 |
| 验证步数 | 验证步数(Validation Steps),计算验证集Loss的间隔步数;为0时不开启验证,没有相关指标。 |
| DPO偏好损失类型 | DPO中偏好损失类型(Loss Type),可选择的类型包括sigmoid、ipo、kto_pair。sigmoid适用于一般情况,提供稳定训练过程,ipo可以纠正模型过度自信的问题,kto可以使模型更符合用户偏好。 |
| 早停策略 | 早停策略(Early Stopping),监控精调任务的指标变化情况,指标连续不变则提前终止训练。 |
| 最长提示长度 | 最长提示长度(Max Prompt Length),DPO数据prompt最长长度,超出部分会截断,max_seq_length-max_prompt_len=response长度,超出长度会被截断。最长提示长度的最大取值为序列长度减去10。 |
| 最大训练步数 | 最大训练步数(Max Steps),训练过程中的最大step数。若无特殊需求,请保持默认值0,通过数据预估脚本来自动设定。 |
ERNIE 3.5
百度自研的超高性能大语言模型,精调成本在文心系列模型中最低。
ERNIE-3.5-8K
单条数据支持8192 tokens。
| 训练方法 | 简单描述 |
|---|---|
| 全量更新 | 在训练过程中对大模型的全部参数进行更新,可以充分利用训练数据,有潜力在新任务上达到更好的性能。 |
| LoRA | 训练过程中只更新低秩部分的参数,需要的计算资源更少,训练过程更快,可以减少过拟合的风险。 |
- 参数配置
| 超参数 | 简单描述 |
|---|---|
| 迭代轮次 | 迭代轮次(Epoch),控制模型训练过程中遍历整个数据集的次数。建议设置在1-5之间,小数据集可增大Epoch以促进模型收敛。 |
| 学习率 | 学习率(Learning Rate),控制模型参数更新步长的速度。过高会导致模型难以收敛,过低则会导致模型收敛速度过慢,平台已给出默认推荐值,可根据经验调整。 |
| 序列长度 | 序列长度(Sequence Length),单条数据的最大长度,包括输入和输出。该长度在模型的训练和推理过程中全部适用,超过该长度的部分将在推理时自动截断,单位为token。如果数据集中的文本普遍较短,建议选择较短的序列长度以提高计算效率。 |
| 全局批大小 | 全局批大小(GlobalBatchsize),每次训练迭代使用的样本数,为了加快训练效率,多条样本会使用Packing尽可能拼接到一个序列长度内。 |
| 保存日志间隔 | 保存日志间隔(Logging Interval),设定模型训练过程中记录日志的间隔步数。合理设置可以平衡日志记录的详细程度和存储、处理资源的消耗。 |
| 预热比例 | 预热比例(Learning Rate Warmup),训练初期学习率预热步数占用总的训练步数的比例。学习率预热可以提高模型稳定性和收敛速度。 |
| 正则化系数 | 正则化系数(Weight Decay),控制正则化项对模型参数的影响强度。适当增大系数可以增强正则化效果,防止过拟合,但过高的系数可能导致模型欠拟合。 |
| beta | 温度超参(beta),温度超参beta用于控制模型输出分布的集中程度。较高的beta值会使输出更具确定性,而较低的beta值则使输出更具多样性。 |
| Checkpoint保存策略 | Checkpoint保存策略(Checkpoint Save Strategy),训练过程保存模型Checkpoint的策略。按Step保存需要配置保存Checkpoint的间隔,按Epoch保存则在每个Epoch训练完成后自动保存模型Checkpoint。 |
| Checkpoint保存个数 | Checkpoint保存个数(Number of Checkpoint),训练过程最终要保存的Checkpoint个数。Checkpoint保存可以在系统故障时从最近的Checkpoint中恢复训练,但保存Checkpoint会增加训练时长。 |
| Checkpoint保存间隔数 | Checkpoint保存间隔数(Checkpoint Interval),训练过程中保存Checkpoint的间隔Step数。间隔太短可能导致频繁的Checkpoint操作增加训练时长,间隔太长则可能在故障时丢失更多的数据。注意:Checkpoint保存策略为按Step时使用 |
| 随机种子 | 随机种子(Random Seed),是在随机数生成算法中设定的一个初始值,用于确保随机数生成的可重复性。通过设置随机种子,可以在相同的算法和参数下,生成相同的随机数序列。 |
| 学习率调整计划 | 学习率调整计划(schedulerType),用于在训练过程中动态调整学习率,以优化模型的收敛速度和性能。根据模型的训练情况和任务需求,选择合适的学习率调整方式。 |
| cosine 策略的波数 | cosine 策略的波数(Period of Cosine),波数定义了余弦函数周期的长短。减少波数可以使模型训练过程稳定,增加波数可以避免陷入局部最优。 |
| polynomial 策略的末端 LR | polynomial 策略的末端 LR(Polynomial Decay End Learning Rate),指的是在多项式衰减策略中,学习率下降到最后所达到的最小值。这个值通常设置得较低,该值若生效需要比学习率小,保证在模型训练后期实现细致的优化。 |
| polynomial 策略的幂数 | polynomial 策略的幂数(Polynomial Decay Power),是指在多项式衰减学习率调整策略中,用于控制学习率下降曲线陡峭程度的指数。幂数越大,可以避免陷入局部最优;幂数越小,可以使模型训练过程稳定。 |
| 验证步数 | 验证步数(Validation Steps),计算验证集Loss的间隔步数;为0时不开启验证,没有相关指标。 |
| LoRA 策略中的秩 | LoRA 策略中的秩(LoRA Rank),决定了微调过程中引入的低秩矩阵的复杂度。较小的秩可以减少参数数量,降低过拟合风险,但可能不足以捕捉任务所需的所有特征;较大的秩可能增强模型的表示能力,但会增加计算和存储负担。 |
| DPO偏好损失类型 | DPO中偏好损失类型(Loss Type),可选择的类型包括sigmoid、ipo、kto_pair。sigmoid适用于一般情况,提供稳定训练过程,ipo可以纠正模型过度自信的问题,kto可以使模型更符合用户偏好。 |
| 早停策略 | 早停策略(Early Stopping),监控精调任务的指标变化情况,指标连续不变则提前终止训练。 |
| 早停指标 | 早停策略选择ture时,显示此指标。早停指标(Early Stopping Metric),根据该监控指标决定任务是否早停。 |
| 早停指标变化量 | 早停策略选择ture时,显示此指标。早停指标变化量(Early Stopping Metric Change),当精调任务指标的变化量超过早停指标变化量时才认为发生变化。根据实际损失曲线进行决定。 |
| 早停指标稳定次数 | 早停策略选择ture时,显示此指标。早停指标稳定次数(Early Stopping Patience),早停指标连续不变化的次数。如果设置的稳定次数较小,早停策略会更敏感,可能在模型尚未充分训练时就停止训练;如果设置的稳定次数较大,早停策略会更宽松,允许模型有更多的训练周期来改善性能。 |
·ERNIE Speed
百度自主研发的文心产业级知识增强大语言模型(高性能版),相较ERNIE Lite实现了基础模型的全面升级,在理解、生成、逻辑和记忆能力上有显著提升。
ERNIE-Speed-8K
单条数据支持8192 tokens。模型基于海量高质量数据训练,具有更强的文本理解、内容创作、对话问答等能力。
| 训练方法 | 简单描述 |
|---|---|
| 全量更新 | 在训练过程中对大模型的全部参数进行更新,可以充分利用训练数据,有潜力在新任务上达到更好的性能。 |
- 参数配置
| 超参数 | 简单描述 |
|---|---|
| 迭代轮次 | 迭代轮次(Epoch),控制模型训练过程中遍历整个数据集的次数。建议设置在1-5之间,小数据集可增大Epoch以促进模型收敛。 |
| 学习率 | 学习率(Learning Rate),控制模型参数更新步长的速度。过高会导致模型难以收敛,过低则会导致模型收敛速度过慢,平台已给出默认推荐值,可根据经验调整。 |
| 序列长度 | 序列长度(Sequence Length),单条数据的最大长度,包括输入和输出。该长度在模型的训练和推理过程中全部适用,超过该长度的部分将在推理时自动截断,单位为token。如果数据集中的文本普遍较短,建议选择较短的序列长度以提高计算效率。 |
| 全局批大小 | 全局批大小(GlobalBatchsize),每次训练迭代使用的样本数,为了加快训练效率,多条样本会使用Packing尽可能拼接到一个序列长度内。 |
| 保存日志间隔 | 保存日志间隔(Logging Interval),设定模型训练过程中记录日志的间隔步数。合理设置可以平衡日志记录的详细程度和存储、处理资源的消耗。 |
| 预热比例 | 预热比例(Learning Rate Warmup),训练初期学习率预热步数占用总的训练步数的比例。学习率预热可以提高模型稳定性和收敛速度。 |
| 正则化系数 | 正则化系数(Weight Decay),控制正则化项对模型参数的影响强度。适当增大系数可以增强正则化效果,防止过拟合,但过高的系数可能导致模型欠拟合。 |
| beta | 温度超参(beta),温度超参beta用于控制模型输出分布的集中程度。较高的beta值会使输出更具确定性,而较低的beta值则使输出更具多样性。 |
| Checkpoint保存策略 | Checkpoint保存策略(Checkpoint Save Strategy),训练过程保存模型Checkpoint的策略。按Step保存需要配置保存Checkpoint的间隔,按Epoch保存则在每个Epoch训练完成后自动保存模型Checkpoint。 |
| Checkpoint保存个数 | Checkpoint保存个数(Number of Checkpoint),训练过程最终要保存的Checkpoint个数。Checkpoint保存可以在系统故障时从最近的Checkpoint中恢复训练,但保存Checkpoint会增加训练时长。 |
| Checkpoint保存间隔数 | Checkpoint保存间隔数(Checkpoint Interval),训练过程中保存Checkpoint的间隔Step数。间隔太短可能导致频繁的Checkpoint操作增加训练时长,间隔太长则可能在故障时丢失更多的数据。注意:Checkpoint保存策略为按Step时使用 |
| 随机种子 | 随机种子(Random Seed),是在随机数生成算法中设定的一个初始值,用于确保随机数生成的可重复性。通过设置随机种子,可以在相同的算法和参数下,生成相同的随机数序列。 |
| 学习率调整计划 | 学习率调整计划(schedulerType),用于在训练过程中动态调整学习率,以优化模型的收敛速度和性能。根据模型的训练情况和任务需求,选择合适的学习率调整方式。 |
| cosine 策略的波数 | cosine 策略的波数(Period of Cosine),波数定义了余弦函数周期的长短。减少波数可以使模型训练过程稳定,增加波数可以避免陷入局部最优。 |
| polynomial 策略的末端 LR | polynomial 策略的末端 LR(Polynomial Decay End Learning Rate),指的是在多项式衰减策略中,学习率下降到最后所达到的最小值。这个值通常设置得较低,该值若生效需要比学习率小,保证在模型训练后期实现细致的优化。 |
| polynomial 策略的幂数 | polynomial 策略的幂数(Polynomial Decay Power),是指在多项式衰减学习率调整策略中,用于控制学习率下降曲线陡峭程度的指数。幂数越大,可以避免陷入局部最优;幂数越小,可以使模型训练过程稳定。 |
| 验证步数 | 验证步数(Validation Steps),计算验证集Loss的间隔步数;为0时不开启验证,没有相关指标。 |
| DPO偏好损失类型 | DPO中偏好损失类型(Loss Type),可选择的类型包括sigmoid、ipo、kto_pair。sigmoid适用于一般情况,提供稳定训练过程,ipo可以纠正模型过度自信的问题,kto可以使模型更符合用户偏好。 |
| 早停策略 | 早停策略(Early Stopping),监控精调任务的指标变化情况,指标连续不变则提前终止训练。 |
| 早停指标 | 早停策略选择ture时,显示此指标。早停指标(Early Stopping Metric),根据该监控指标决定任务是否早停。 |
| 早停指标变化量 | 早停策略选择ture时,显示此指标。早停指标变化量(Early Stopping Metric Change),当精调任务指标的变化量超过早停指标变化量时才认为发生变化。根据实际损失曲线进行决定。 |
| 早停指标稳定次数 | 早停策略选择ture时,显示此指标。早停指标稳定次数(Early Stopping Patience),早停指标连续不变化的次数。如果设置的稳定次数较小,早停策略会更敏感,可能在模型尚未充分训练时就停止训练;如果设置的稳定次数较大,早停策略会更宽松,允许模型有更多的训练周期来改善性能。 |
ERNIE-Speed-Pro-128K
单条数据支持128k tokens。模型基于海量高质量数据训练,具有更强的文本理解、内容创作、对话问答等能力。
| 训练方法 | 简单描述 |
|---|---|
| 全量更新 | 在训练过程中对大模型的全部参数进行更新,可以充分利用训练数据,有潜力在新任务上达到更好的性能。 |
| LoRA | 训练过程中只更新低秩部分的参数,需要的计算资源更少,训练过程更快,可以减少过拟合的风险。 |
- 参数配置
| 超参数 | 简单描述 |
|---|---|
| 迭代轮次 | 迭代轮次(Epoch),控制模型训练过程中遍历整个数据集的次数。建议设置在1-5之间,小数据集可增大Epoch以促进模型收敛。 |
| 学习率 | 学习率(Learning Rate),控制模型参数更新步长的速度。过高会导致模型难以收敛,过低则会导致模型收敛速度过慢,平台已给出默认推荐值,可根据经验调整。 |
| 序列长度 | 序列长度(Sequence Length),单条数据的最大长度,包括输入和输出。该长度在模型的训练和推理过程中全部适用,超过该长度的部分将在推理时自动截断,单位为token。如果数据集中的文本普遍较短,建议选择较短的序列长度以提高计算效率。 |
| 全局批大小 | 全局批大小(GlobalBatchsize),每次训练迭代使用的样本数,为了加快训练效率,多条样本会使用Packing尽可能拼接到一个序列长度内。 |
| 保存日志间隔 | 保存日志间隔(Logging Interval),设定模型训练过程中记录日志的间隔步数。合理设置可以平衡日志记录的详细程度和存储、处理资源的消耗。 |
| 预热比例 | 预热比例(Learning Rate Warmup),训练初期学习率预热步数占用总的训练步数的比例。学习率预热可以提高模型稳定性和收敛速度。 |
| 正则化系数 | 正则化系数(Weight Decay),控制正则化项对模型参数的影响强度。适当增大系数可以增强正则化效果,防止过拟合,但过高的系数可能导致模型欠拟合。 |
| beta | 温度超参(beta),温度超参beta用于控制模型输出分布的集中程度。较高的beta值会使输出更具确定性,而较低的beta值则使输出更具多样性。 |
| Checkpoint保存策略 | Checkpoint保存策略(Checkpoint Save Strategy),训练过程保存模型Checkpoint的策略。按Step保存需要配置保存Checkpoint的间隔,按Epoch保存则在每个Epoch训练完成后自动保存模型Checkpoint。 |
| Checkpoint保存个数 | Checkpoint保存个数(Number of Checkpoint),训练过程最终要保存的Checkpoint个数。Checkpoint保存可以在系统故障时从最近的Checkpoint中恢复训练,但保存Checkpoint会增加训练时长。 |
| Checkpoint保存间隔数 | Checkpoint保存间隔数(Checkpoint Interval),训练过程中保存Checkpoint的间隔Step数。间隔太短可能导致频繁的Checkpoint操作增加训练时长,间隔太长则可能在故障时丢失更多的数据。注意:Checkpoint保存策略为按Step时使用 |
| 随机种子 | 随机种子(Random Seed),是在随机数生成算法中设定的一个初始值,用于确保随机数生成的可重复性。通过设置随机种子,可以在相同的算法和参数下,生成相同的随机数序列。 |
| 学习率调整计划 | 学习率调整计划(schedulerType),用于在训练过程中动态调整学习率,以优化模型的收敛速度和性能。根据模型的训练情况和任务需求,选择合适的学习率调整方式。 |
| cosine 策略的波数 | cosine 策略的波数(Period of Cosine),波数定义了余弦函数周期的长短。减少波数可以使模型训练过程稳定,增加波数可以避免陷入局部最优。 |
| polynomial 策略的末端 LR | polynomial 策略的末端 LR(Polynomial Decay End Learning Rate),指的是在多项式衰减策略中,学习率下降到最后所达到的最小值。这个值通常设置得较低,该值若生效需要比学习率小,保证在模型训练后期实现细致的优化。 |
| polynomial 策略的幂数 | polynomial 策略的幂数(Polynomial Decay Power),是指在多项式衰减学习率调整策略中,用于控制学习率下降曲线陡峭程度的指数。幂数越大,可以避免陷入局部最优;幂数越小,可以使模型训练过程稳定。 |
| 验证步数 | 验证步数(Validation Steps),计算验证集Loss的间隔步数;为0时不开启验证,没有相关指标。 |
| LoRA 策略中的秩 | LoRA 策略中的秩(LoRA Rank),决定了微调过程中引入的低秩矩阵的复杂度。较小的秩可以减少参数数量,降低过拟合风险,但可能不足以捕捉任务所需的所有特征;较大的秩可能增强模型的表示能力,但会增加计算和存储负担。 |
| DPO偏好损失类型 | DPO中偏好损失类型(Loss Type),可选择的类型包括sigmoid、ipo、kto_pair。sigmoid适用于一般情况,提供稳定训练过程,ipo可以纠正模型过度自信的问题,kto可以使模型更符合用户偏好。 |
| 早停策略 | 早停策略(Early Stopping),监控精调任务的指标变化情况,指标连续不变则提前终止训练。 |
| 早停指标 | 早停策略选择ture时,显示此指标。早停指标(Early Stopping Metric),根据该监控指标决定任务是否早停。 |
| 早停指标变化量 | 早停策略选择ture时,显示此指标。早停指标变化量(Early Stopping Metric Change),当精调任务指标的变化量超过早停指标变化量时才认为发生变化。根据实际损失曲线进行决定。 |
| 早停指标稳定次数 | 早停策略选择ture时,显示此指标。早停指标稳定次数(Early Stopping Patience),早停指标连续不变化的次数。如果设置的稳定次数较小,早停策略会更敏感,可能在模型尚未充分训练时就停止训练;如果设置的稳定次数较大,早停策略会更宽松,允许模型有更多的训练周期来改善性能。 |
·ERNIE Lite
百度自行研发的大语言模型,覆盖海量中文数据,具有更强的对话问答、内容创作生成等能力。
ERNIE-Lite-8K-0308
单条数据支持8192 tokens。ERNIE Lite的最新版本,对效果和性能都进行了优化。
| 训练方法 | 简单描述 |
|---|---|
| 全量更新 | 在训练过程中对大模型的全部参数进行更新,可以充分利用训练数据,有潜力在新任务上达到更好的性能。 |
- 参数配置
| 超参数 | 简单描述 |
|---|---|
| 迭代轮次 | 迭代轮次(Epoch),控制训练过程中的迭代轮数。可以根据数据规模适当调整Epoch大小,建议设置在1-5之间,小数据集可以适当增大Epoch,让模型充分收敛。 |
| 学习率 | 学习率(LearningRate)是在梯度下降的过程中更新权重时的超参数,过高会导致模型难以收敛,过低则会导致模型收敛速度过慢,平台已给出默认推荐值,可根据经验调整。 |
| 序列长度 | 单条数据的长度,单位为token。由于长文本模型会默认采用packing策略,如果数据集中的长度较短,建议选择短的序列长度,并建议使用1000条数据以上。避免packing后样本量过小,导致训练效果变差。 |
| 全局批大小 | 全局批大小(GlobalBatchsize),每次训练迭代使用的样本数,为了加快训练效率,多条样本会使用Packing尽可能拼接到一个序列长度内。 |
| 保存日志间隔 | 日志保存间隔步数。 |
| 预热比例 | 学习率预热的步数占比。 |
| 正则化系数 | 正则化系数(Weight_decay),用于防止模型对训练数据过拟合。但系数过大,可能导致欠拟合。 |
| beta | DPO loss 温度超参beta。 |
| Checkpoint保存策略 | Checkpoint保存策略(Checkpoint Save Strategy),训练过程保存模型Checkpoint的策略。按Step保存需要配置保存Checkpoint的间隔,按Epoch保存则在每个Epoch训练完成后自动保存模型Checkpoint。 |
| Checkpoint保存个数 | Checkpoint保存个数(Number of Checkpoint),训练过程最终要保存的Checkpoint个数。Checkpoint保存可以在系统故障时从最近的Checkpoint中恢复训练,但保存Checkpoint会增加训练时长。 |
| Checkpoint保存间隔数 | Checkpoint保存间隔数(Checkpoint Interval),训练过程中保存Checkpoint的间隔Step数。间隔太短可能导致频繁的Checkpoint操作增加训练时长,间隔太长则可能在故障时丢失更多的数据。注意:Checkpoint保存策略为按Step时使用 |
| 随机种子 | 随机种子。 |
| 学习率调整计划 | 学习率调整计划(schedulerType),用于调整训练中学习率的变动方式。 |
| cosine 策略的波数 | 仅用于 cosine 策略,表示波数。 |
| polynomial 策略的末端 LR | 仅用于 polynomial 策略,表示末端 LR(注意,该值若生效需要比学习率小)。 |
| polynomial 策略的幂数 | 仅用于 polynomial 策略,表示幂数。 |
| 验证步数 | Validation Step,计算验证集Loss的间隔步数;为0时不开启验证,没有相关指标。 |
| DPO偏好损失类型 | DPO中偏好损失类型,可选择的类型包括sigmoid、ipo、kto_pair。 |
| 早停策略 | 监控精调任务的指标变化情况,指标连续不变则提前终止任务。 |
| 早停指标 | 早停策略选择true时填写,任务早停的监控指标。 |
| 早停指标变化量 | 早停策略选择true时填写,当精调任务指标的变化量超过早停指标变化量时才认为发生变化。 |
| 早停指标稳定次数 | 早停策略选择true时填写,早停指标连续不变化的次数。 |
ERNIE-Lite-128K-0722
单条数据支持8192 tokens。ERNIE Lite的最新版本,对效果和性能都进行了优化。
| 训练方法 | 简单描述 |
|---|---|
| 全量更新 | 在训练过程中对大模型的全部参数进行更新,可以充分利用训练数据,有潜力在新任务上达到更好的性能。 |
- 参数配置
| 超参数 | 简单描述 |
|---|---|
| 迭代轮次 | 迭代轮次(Epoch),控制模型训练过程中遍历整个数据集的次数。建议设置在1-5之间,小数据集可增大Epoch以促进模型收敛。 |
| 学习率 | 学习率(Learning Rate),控制模型参数更新步长的速度。过高会导致模型难以收敛,过低则会导致模型收敛速度过慢,平台已给出默认推荐值,可根据经验调整。 |
| 序列长度 | 序列长度(Sequence Length),单条数据的最大长度,包括输入和输出。该长度在模型的训练和推理过程中全部适用,超过该长度的部分将在推理时自动截断,单位为token。如果数据集中的文本普遍较短,建议选择较短的序列长度以提高计算效率。 |
| 全局批大小 | 全局批大小(GlobalBatchsize),每次训练迭代使用的样本数,为了加快训练效率,多条样本会使用Packing尽可能拼接到一个序列长度内。 |
| 保存日志间隔 | 保存日志间隔(Logging Interval),设定模型训练过程中记录日志的间隔步数。合理设置可以平衡日志记录的详细程度和存储、处理资源的消耗。 |
| 预热比例 | 预热比例(Learning Rate Warmup),训练初期学习率预热步数占用总的训练步数的比例。学习率预热可以提高模型稳定性和收敛速度。 |
| 正则化系数 | 正则化系数(Weight Decay),控制正则化项对模型参数的影响强度。适当增大系数可以增强正则化效果,防止过拟合,但过高的系数可能导致模型欠拟合。 |
| beta | 温度超参(beta),温度超参beta用于控制模型输出分布的集中程度。较高的beta值会使输出更具确定性,而较低的beta值则使输出更具多样性。 |
| Checkpoint保存策略 | Checkpoint保存策略(Checkpoint Save Strategy),训练过程保存模型Checkpoint的策略。按Step保存需要配置保存Checkpoint的间隔,按Epoch保存则在每个Epoch训练完成后自动保存模型Checkpoint。 |
| Checkpoint保存个数 | Checkpoint保存个数(Number of Checkpoint),训练过程最终要保存的Checkpoint个数。Checkpoint保存可以在系统故障时从最近的Checkpoint中恢复训练,但保存Checkpoint会增加训练时长。 |
| Checkpoint保存间隔数 | Checkpoint保存间隔数(Checkpoint Interval),训练过程中保存Checkpoint的间隔Step数。间隔太短可能导致频繁的Checkpoint操作增加训练时长,间隔太长则可能在故障时丢失更多的数据。注意:Checkpoint保存策略为按Step时使用 |
| 随机种子 | 随机种子(Random Seed),是在随机数生成算法中设定的一个初始值,用于确保随机数生成的可重复性。通过设置随机种子,可以在相同的算法和参数下,生成相同的随机数序列。 |
| 学习率调整计划 | 学习率调整计划(schedulerType),用于在训练过程中动态调整学习率,以优化模型的收敛速度和性能。根据模型的训练情况和任务需求,选择合适的学习率调整方式。 |
| cosine 策略的波数 | cosine 策略的波数(Period of Cosine),波数定义了余弦函数周期的长短。减少波数可以使模型训练过程稳定,增加波数可以避免陷入局部最优。 |
| polynomial 策略的末端 LR | polynomial 策略的末端 LR(Polynomial Decay End Learning Rate),指的是在多项式衰减策略中,学习率下降到最后所达到的最小值。这个值通常设置得较低,该值若生效需要比学习率小,保证在模型训练后期实现细致的优化。 |
| polynomial 策略的幂数 | polynomial 策略的幂数(Polynomial Decay Power),是指在多项式衰减学习率调整策略中,用于控制学习率下降曲线陡峭程度的指数。幂数越大,可以避免陷入局部最优;幂数越小,可以使模型训练过程稳定。 |
| 验证步数 | 验证步数(Validation Steps),计算验证集Loss的间隔步数;为0时不开启验证,没有相关指标。 |
| DPO偏好损失类型 | DPO中偏好损失类型(Loss Type),可选择的类型包括sigmoid、ipo、kto_pair。sigmoid适用于一般情况,提供稳定训练过程,ipo可以纠正模型过度自信的问题,kto可以使模型更符合用户偏好。 |
| 早停策略 | 早停策略(Early Stopping),监控精调任务的指标变化情况,指标连续不变则提前终止训练。 |
| 早停指标 | 早停策略选择ture时,显示此指标。早停指标(Early Stopping Metric),根据该监控指标决定任务是否早停。 |
| 早停指标变化量 | 早停策略选择ture时,显示此指标。早停指标变化量(Early Stopping Metric Change),当精调任务指标的变化量超过早停指标变化量时才认为发生变化。根据实际损失曲线进行决定。 |
| 早停指标稳定次数 | 早停策略选择ture时,显示此指标。早停指标稳定次数(Early Stopping Patience),早停指标连续不变化的次数。如果设置的稳定次数较小,早停策略会更敏感,可能在模型尚未充分训练时就停止训练;如果设置的稳定次数较大,早停策略会更宽松,允许模型有更多的训练周期来改善性能。 |
ERNIE-Lite-128K-0419
单条数据支持128k tokens。模型基于海量长文本数据训练,具有优秀的长文本创作能力。
| 训练方法 | 简单描述 |
|---|---|
| 全量更新 | 在训练过程中对大模型的全部参数进行更新,可以充分利用训练数据,有潜力在新任务上达到更好的性能。 |
- 参数配置
| 超参数 | 简单描述 |
|---|---|
| 迭代轮次 | 迭代轮次(Epoch),控制模型训练过程中遍历整个数据集的次数。建议设置在1-5之间,小数据集可增大Epoch以促进模型收敛。 |
| 学习率 | 学习率(Learning Rate),控制模型参数更新步长的速度。过高会导致模型难以收敛,过低则会导致模型收敛速度过慢,平台已给出默认推荐值,可根据经验调整。 |
| 序列长度 | 序列长度(Sequence Length),单条数据的最大长度,包括输入和输出。该长度在模型的训练和推理过程中全部适用,超过该长度的部分将在推理时自动截断,单位为token。如果数据集中的文本普遍较短,建议选择较短的序列长度以提高计算效率。 |
| 全局批大小 | 全局批大小(GlobalBatchsize),每次训练迭代使用的样本数,为了加快训练效率,多条样本会使用Packing尽可能拼接到一个序列长度内。 |
| 保存日志间隔 | 保存日志间隔(Logging Interval),设定模型训练过程中记录日志的间隔步数。合理设置可以平衡日志记录的详细程度和存储、处理资源的消耗。 |
| 预热比例 | 预热比例(Learning Rate Warmup),训练初期学习率预热步数占用总的训练步数的比例。学习率预热可以提高模型稳定性和收敛速度。 |
| 正则化系数 | 正则化系数(Weight Decay),控制正则化项对模型参数的影响强度。适当增大系数可以增强正则化效果,防止过拟合,但过高的系数可能导致模型欠拟合。 |
| beta | 温度超参(beta),温度超参beta用于控制模型输出分布的集中程度。较高的beta值会使输出更具确定性,而较低的beta值则使输出更具多样性。 |
| Checkpoint保存策略 | Checkpoint保存策略(Checkpoint Save Strategy),训练过程保存模型Checkpoint的策略。按Step保存需要配置保存Checkpoint的间隔,按Epoch保存则在每个Epoch训练完成后自动保存模型Checkpoint。 |
| Checkpoint保存个数 | Checkpoint保存个数(Number of Checkpoint),训练过程最终要保存的Checkpoint个数。Checkpoint保存可以在系统故障时从最近的Checkpoint中恢复训练,但保存Checkpoint会增加训练时长。 |
| Checkpoint保存间隔数 | Checkpoint保存间隔数(Checkpoint Interval),训练过程中保存Checkpoint的间隔Step数。间隔太短可能导致频繁的Checkpoint操作增加训练时长,间隔太长则可能在故障时丢失更多的数据。注意:Checkpoint保存策略为按Step时使用 |
| 随机种子 | 随机种子(Random Seed),是在随机数生成算法中设定的一个初始值,用于确保随机数生成的可重复性。通过设置随机种子,可以在相同的算法和参数下,生成相同的随机数序列。 |
| 学习率调整计划 | 学习率调整计划(schedulerType),用于在训练过程中动态调整学习率,以优化模型的收敛速度和性能。根据模型的训练情况和任务需求,选择合适的学习率调整方式。 |
| cosine 策略的波数 | cosine 策略的波数(Period of Cosine),波数定义了余弦函数周期的长短。减少波数可以使模型训练过程稳定,增加波数可以避免陷入局部最优。 |
| polynomial 策略的末端 LR | polynomial 策略的末端 LR(Polynomial Decay End Learning Rate),指的是在多项式衰减策略中,学习率下降到最后所达到的最小值。这个值通常设置得较低,该值若生效需要比学习率小,保证在模型训练后期实现细致的优化。 |
| polynomial 策略的幂数 | polynomial 策略的幂数(Polynomial Decay Power),是指在多项式衰减学习率调整策略中,用于控制学习率下降曲线陡峭程度的指数。幂数越大,可以避免陷入局部最优;幂数越小,可以使模型训练过程稳定。 |
| 验证步数 | 验证步数(Validation Steps),计算验证集Loss的间隔步数;为0时不开启验证,没有相关指标。 |
| DPO偏好损失类型 | DPO中偏好损失类型(Loss Type),可选择的类型包括sigmoid、ipo、kto_pair。sigmoid适用于一般情况,提供稳定训练过程,ipo可以纠正模型过度自信的问题,kto可以使模型更符合用户偏好。 |
| 早停策略 | 早停策略(Early Stopping),监控精调任务的指标变化情况,指标连续不变则提前终止训练。 |
| 早停指标 | 早停策略选择ture时,显示此指标。早停指标(Early Stopping Metric),根据该监控指标决定任务是否早停。 |
| 早停指标变化量 | 早停策略选择ture时,显示此指标。早停指标变化量(Early Stopping Metric Change),当精调任务指标的变化量超过早停指标变化量时才认为发生变化。根据实际损失曲线进行决定。 |
| 早停指标稳定次数 | 早停策略选择ture时,显示此指标。早停指标稳定次数(Early Stopping Patience),早停指标连续不变化的次数。如果设置的稳定次数较小,早停策略会更敏感,可能在模型尚未充分训练时就停止训练;如果设置的稳定次数较大,早停策略会更宽松,允许模型有更多的训练周期来改善性能。 |
ERNIE Character
百度自研的垂直场景大语言模型,适合游戏NPC、客服对话、对话角色扮演等应用场景,人设风格更为鲜明、一致,指令遵循能力更强,推理性能更优。
ERNIE-Character-8K-250124
百度自研的垂直场景大语言模型,适合游戏NPC、客服对话、对话角色扮演等应用场景,人设风格更为鲜明、一致,指令遵循能力更强,推理性能更优。
| 训练方法 | 简单描述 |
|---|---|
| 全量更新 | 在训练过程中对大模型的全部参数进行更新,可以充分利用训练数据,有潜力在新任务上达到更好的性能。 |
| LoRA | 训练过程中只更新低秩部分的参数,需要的计算资源更少,训练过程更快,可以减少过拟合的风险。 |
- 参数配置
| 超参数 | 简单描述 |
|---|---|
| 迭代轮次 | 迭代轮次(Epoch),控制模型训练过程中遍历整个数据集的次数。建议设置在1-5之间,小数据集可增大Epoch以促进模型收敛。 |
| 学习率 | 学习率(Learning Rate),控制模型参数更新步长的速度。过高会导致模型难以收敛,过低则会导致模型收敛速度过慢,平台已给出默认推荐值,可根据经验调整。 |
| 序列长度 | 序列长度(Sequence Length),单条数据的最大长度,包括输入和输出。该长度在模型的训练和推理过程中全部适用,超过该长度的部分将在推理时自动截断,单位为token。如果数据集中的文本普遍较短,建议选择较短的序列长度以提高计算效率。 |
| 全局批大小 | 全局批大小(GlobalBatchsize),每次训练迭代使用的样本数,为了加快训练效率,多条样本会使用Packing尽可能拼接到一个序列长度内。 |
| 保存日志间隔 | 保存日志间隔(Logging Interval),设定模型训练过程中记录日志的间隔步数。合理设置可以平衡日志记录的详细程度和存储、处理资源的消耗。 |
| 预热比例 | 预热比例(Learning Rate Warmup),训练初期学习率预热步数占用总的训练步数的比例。学习率预热可以提高模型稳定性和收敛速度。 |
| 正则化系数 | 正则化系数(Weight Decay),控制正则化项对模型参数的影响强度。适当增大系数可以增强正则化效果,防止过拟合,但过高的系数可能导致模型欠拟合。 |
| beta | 温度超参(beta),温度超参beta用于控制模型输出分布的集中程度。较高的beta值会使输出更具确定性,而较低的beta值则使输出更具多样性。 |
| Checkpoint保存策略 | Checkpoint保存策略(Checkpoint Save Strategy),训练过程保存模型Checkpoint的策略。按Step保存需要配置保存Checkpoint的间隔,按Epoch保存则在每个Epoch训练完成后自动保存模型Checkpoint。 |
| Checkpoint保存个数 | Checkpoint保存个数(Number of Checkpoint),训练过程最终要保存的Checkpoint个数。Checkpoint保存可以在系统故障时从最近的Checkpoint中恢复训练,但保存Checkpoint会增加训练时长。 |
| Checkpoint保存间隔数 | Checkpoint保存间隔数(Checkpoint Interval),训练过程中保存Checkpoint的间隔Step数。间隔太短可能导致频繁的Checkpoint操作增加训练时长,间隔太长则可能在故障时丢失更多的数据。注意:Checkpoint保存策略为按Step时使用 |
| 随机种子 | 随机种子(Random Seed),是在随机数生成算法中设定的一个初始值,用于确保随机数生成的可重复性。通过设置随机种子,可以在相同的算法和参数下,生成相同的随机数序列。 |
| 学习率调整计划 | 学习率调整计划(schedulerType),用于在训练过程中动态调整学习率,以优化模型的收敛速度和性能。根据模型的训练情况和任务需求,选择合适的学习率调整方式。 |
| cosine 策略的波数 | cosine 策略的波数(Period of Cosine),波数定义了余弦函数周期的长短。减少波数可以使模型训练过程稳定,增加波数可以避免陷入局部最优。 |
| polynomial 策略的末端 LR | polynomial 策略的末端 LR(Polynomial Decay End Learning Rate),指的是在多项式衰减策略中,学习率下降到最后所达到的最小值。这个值通常设置得较低,该值若生效需要比学习率小,保证在模型训练后期实现细致的优化。 |
| polynomial 策略的幂数 | polynomial 策略的幂数(Polynomial Decay Power),是指在多项式衰减学习率调整策略中,用于控制学习率下降曲线陡峭程度的指数。幂数越大,可以避免陷入局部最优;幂数越小,可以使模型训练过程稳定。 |
| 验证步数 | 验证步数(Validation Steps),计算验证集Loss的间隔步数;为0时不开启验证,没有相关指标。 |
| LoRA 策略中的秩 | LoRA 策略中的秩(LoRA Rank),决定了微调过程中引入的低秩矩阵的复杂度。较小的秩可以减少参数数量,降低过拟合风险,但可能不足以捕捉任务所需的所有特征;较大的秩可能增强模型的表示能力,但会增加计算和存储负担。 |
| DPO偏好损失类型 | DPO中偏好损失类型(Loss Type),可选择的类型包括sigmoid、ipo、kto_pair。sigmoid适用于一般情况,提供稳定训练过程,ipo可以纠正模型过度自信的问题,kto可以使模型更符合用户偏好。 |
| 早停策略 | 早停策略(Early Stopping),监控精调任务的指标变化情况,指标连续不变则提前终止训练。 |
| 早停指标 | 早停策略选择ture时,显示此指标。早停指标(Early Stopping Metric),根据该监控指标决定任务是否早停。 |
| 早停指标变化量 | 早停策略选择ture时,显示此指标。早停指标变化量(Early Stopping Metric Change),当精调任务指标的变化量超过早停指标变化量时才认为发生变化。根据实际损失曲线进行决定。 |
| 早停指标稳定次数 | 早停策略选择ture时,显示此指标。早停指标稳定次数(Early Stopping Patience),早停指标连续不变化的次数。如果设置的稳定次数较小,早停策略会更敏感,可能在模型尚未充分训练时就停止训练;如果设置的稳定次数较大,早停策略会更宽松,允许模型有更多的训练周期来改善性能。 |
ERNIE-Character-Fiction-8K
单条数据支持8192 tokens。在情节演绎和括号文字等指令遵循能力上表现优异。
| 训练方法 | 简单描述 |
|---|---|
| 全量更新 | 在训练过程中对大模型的全部参数进行更新,可以充分利用训练数据,有潜力在新任务上达到更好的性能。 |
- 参数配置
| 超参数 | 简单描述 |
|---|---|
| 迭代轮次 | 迭代轮次(Epoch),控制模型训练过程中遍历整个数据集的次数。建议设置在1-5之间,小数据集可增大Epoch以促进模型收敛。 |
| 学习率 | 学习率(Learning Rate),控制模型参数更新步长的速度。过高会导致模型难以收敛,过低则会导致模型收敛速度过慢,平台已给出默认推荐值,可根据经验调整。 |
| 序列长度 | 序列长度(Sequence Length),单条数据的最大长度,包括输入和输出。该长度在模型的训练和推理过程中全部适用,超过该长度的部分将在推理时自动截断,单位为token。如果数据集中的文本普遍较短,建议选择较短的序列长度以提高计算效率。 |
| 全局批大小 | 全局批大小(GlobalBatchsize),每次训练迭代使用的样本数,为了加快训练效率,多条样本会使用Packing尽可能拼接到一个序列长度内。 |
| 保存日志间隔 | 保存日志间隔(Logging Interval),设定模型训练过程中记录日志的间隔步数。合理设置可以平衡日志记录的详细程度和存储、处理资源的消耗。 |
| 预热比例 | 预热比例(Learning Rate Warmup),训练初期学习率预热步数占用总的训练步数的比例。学习率预热可以提高模型稳定性和收敛速度。 |
| 正则化系数 | 正则化系数(Weight Decay),控制正则化项对模型参数的影响强度。适当增大系数可以增强正则化效果,防止过拟合,但过高的系数可能导致模型欠拟合。 |
| beta | 温度超参(beta),温度超参beta用于控制模型输出分布的集中程度。较高的beta值会使输出更具确定性,而较低的beta值则使输出更具多样性。 |
| Checkpoint保存策略 | Checkpoint保存策略(Checkpoint Save Strategy),训练过程保存模型Checkpoint的策略。按Step保存需要配置保存Checkpoint的间隔,按Epoch保存则在每个Epoch训练完成后自动保存模型Checkpoint。 |
| Checkpoint保存个数 | Checkpoint保存个数(Number of Checkpoint),训练过程最终要保存的Checkpoint个数。Checkpoint保存可以在系统故障时从最近的Checkpoint中恢复训练,但保存Checkpoint会增加训练时长。 |
| Checkpoint保存间隔数 | Checkpoint保存间隔数(Checkpoint Interval),训练过程中保存Checkpoint的间隔Step数。间隔太短可能导致频繁的Checkpoint操作增加训练时长,间隔太长则可能在故障时丢失更多的数据。注意:Checkpoint保存策略为按Step时使用 |
| 随机种子 | 随机种子(Random Seed),是在随机数生成算法中设定的一个初始值,用于确保随机数生成的可重复性。通过设置随机种子,可以在相同的算法和参数下,生成相同的随机数序列。 |
| 学习率调整计划 | 学习率调整计划(schedulerType),用于在训练过程中动态调整学习率,以优化模型的收敛速度和性能。根据模型的训练情况和任务需求,选择合适的学习率调整方式。 |
| cosine 策略的波数 | cosine 策略的波数(Period of Cosine),波数定义了余弦函数周期的长短。减少波数可以使模型训练过程稳定,增加波数可以避免陷入局部最优。 |
| polynomial 策略的末端 LR | polynomial 策略的末端 LR(Polynomial Decay End Learning Rate),指的是在多项式衰减策略中,学习率下降到最后所达到的最小值。这个值通常设置得较低,该值若生效需要比学习率小,保证在模型训练后期实现细致的优化。 |
| polynomial 策略的幂数 | polynomial 策略的幂数(Polynomial Decay Power),是指在多项式衰减学习率调整策略中,用于控制学习率下降曲线陡峭程度的指数。幂数越大,可以避免陷入局部最优;幂数越小,可以使模型训练过程稳定。 |
| 验证步数 | 验证步数(Validation Steps),计算验证集Loss的间隔步数;为0时不开启验证,没有相关指标。 |
| DPO偏好损失类型 | DPO中偏好损失类型(Loss Type),可选择的类型包括sigmoid、ipo、kto_pair。sigmoid适用于一般情况,提供稳定训练过程,ipo可以纠正模型过度自信的问题,kto可以使模型更符合用户偏好。 |
| 早停策略 | 早停策略(Early Stopping),监控精调任务的指标变化情况,指标连续不变则提前终止训练。 |
| 早停指标 | 早停策略选择ture时,显示此指标。早停指标(Early Stopping Metric),根据该监控指标决定任务是否早停。 |
| 早停指标变化量 | 早停策略选择ture时,显示此指标。早停指标变化量(Early Stopping Metric Change),当精调任务指标的变化量超过早停指标变化量时才认为发生变化。根据实际损失曲线进行决定。 |
| 早停指标稳定次数 | 早停策略选择ture时,显示此指标。早停指标稳定次数(Early Stopping Patience),早停指标连续不变化的次数。如果设置的稳定次数较小,早停策略会更敏感,可能在模型尚未充分训练时就停止训练;如果设置的稳定次数较大,早停策略会更宽松,允许模型有更多的训练周期来改善性能。 |
ERNIE-Character-8K-0321
单条数据支持8192 tokens。2024年3月21日发布的初始版本。
| 训练方法 | 简单描述 |
|---|---|
| 全量更新 | 在训练过程中对大模型的全部参数进行更新,可以充分利用训练数据,有潜力在新任务上达到更好的性能。 |
| LoRA | 训练过程中只更新低秩部分的参数,需要的计算资源更少,训练过程更快,可以减少过拟合的风险。 |
- 参数配置
| 超参数 | 简单描述 |
|---|---|
| 迭代轮次 | 迭代轮次(Epoch),控制模型训练过程中遍历整个数据集的次数。建议设置在1-5之间,小数据集可增大Epoch以促进模型收敛。 |
| 学习率 | 学习率(Learning Rate),控制模型参数更新步长的速度。过高会导致模型难以收敛,过低则会导致模型收敛速度过慢,平台已给出默认推荐值,可根据经验调整。 |
| 序列长度 | 序列长度(Sequence Length),单条数据的最大长度,包括输入和输出。该长度在模型的训练和推理过程中全部适用,超过该长度的部分将在推理时自动截断,单位为token。如果数据集中的文本普遍较短,建议选择较短的序列长度以提高计算效率。 |
| 全局批大小 | 全局批大小(GlobalBatchsize),每次训练迭代使用的样本数,为了加快训练效率,多条样本会使用Packing尽可能拼接到一个序列长度内。 |
| 保存日志间隔 | 保存日志间隔(Logging Interval),设定模型训练过程中记录日志的间隔步数。合理设置可以平衡日志记录的详细程度和存储、处理资源的消耗。 |
| 预热比例 | 预热比例(Learning Rate Warmup),训练初期学习率预热步数占用总的训练步数的比例。学习率预热可以提高模型稳定性和收敛速度。 |
| 正则化系数 | 正则化系数(Weight Decay),控制正则化项对模型参数的影响强度。适当增大系数可以增强正则化效果,防止过拟合,但过高的系数可能导致模型欠拟合。 |
| beta | 温度超参(beta),温度超参beta用于控制模型输出分布的集中程度。较高的beta值会使输出更具确定性,而较低的beta值则使输出更具多样性。 |
| Checkpoint保存策略 | Checkpoint保存策略(Checkpoint Save Strategy),训练过程保存模型Checkpoint的策略。按Step保存需要配置保存Checkpoint的间隔,按Epoch保存则在每个Epoch训练完成后自动保存模型Checkpoint。 |
| Checkpoint保存个数 | Checkpoint保存个数(Number of Checkpoint),训练过程最终要保存的Checkpoint个数。Checkpoint保存可以在系统故障时从最近的Checkpoint中恢复训练,但保存Checkpoint会增加训练时长。 |
| Checkpoint保存间隔数 | Checkpoint保存间隔数(Checkpoint Interval),训练过程中保存Checkpoint的间隔Step数。间隔太短可能导致频繁的Checkpoint操作增加训练时长,间隔太长则可能在故障时丢失更多的数据。注意:Checkpoint保存策略为按Step时使用 |
| 随机种子 | 随机种子(Random Seed),是在随机数生成算法中设定的一个初始值,用于确保随机数生成的可重复性。通过设置随机种子,可以在相同的算法和参数下,生成相同的随机数序列。 |
| 学习率调整计划 | 学习率调整计划(schedulerType),用于在训练过程中动态调整学习率,以优化模型的收敛速度和性能。根据模型的训练情况和任务需求,选择合适的学习率调整方式。 |
| cosine 策略的波数 | cosine 策略的波数(Period of Cosine),波数定义了余弦函数周期的长短。减少波数可以使模型训练过程稳定,增加波数可以避免陷入局部最优。 |
| polynomial 策略的末端 LR | polynomial 策略的末端 LR(Polynomial Decay End Learning Rate),指的是在多项式衰减策略中,学习率下降到最后所达到的最小值。这个值通常设置得较低,该值若生效需要比学习率小,保证在模型训练后期实现细致的优化。 |
| polynomial 策略的幂数 | polynomial 策略的幂数(Polynomial Decay Power),是指在多项式衰减学习率调整策略中,用于控制学习率下降曲线陡峭程度的指数。幂数越大,可以避免陷入局部最优;幂数越小,可以使模型训练过程稳定。 |
| 验证步数 | 验证步数(Validation Steps),计算验证集Loss的间隔步数;为0时不开启验证,没有相关指标。 |
| LoRA 策略中的秩 | LoRA 策略中的秩(LoRA Rank),决定了微调过程中引入的低秩矩阵的复杂度。较小的秩可以减少参数数量,降低过拟合风险,但可能不足以捕捉任务所需的所有特征;较大的秩可能增强模型的表示能力,但会增加计算和存储负担。 |
| DPO偏好损失类型 | DPO中偏好损失类型(Loss Type),可选择的类型包括sigmoid、ipo、kto_pair。sigmoid适用于一般情况,提供稳定训练过程,ipo可以纠正模型过度自信的问题,kto可以使模型更符合用户偏好。 |
| 早停策略 | 早停策略(Early Stopping),监控精调任务的指标变化情况,指标连续不变则提前终止训练。 |
| 早停指标 | 早停策略选择ture时,显示此指标。早停指标(Early Stopping Metric),根据该监控指标决定任务是否早停。 |
| 早停指标变化量 | 早停策略选择ture时,显示此指标。早停指标变化量(Early Stopping Metric Change),当精调任务指标的变化量超过早停指标变化量时才认为发生变化。根据实际损失曲线进行决定。 |
| 早停指标稳定次数 | 早停策略选择ture时,显示此指标。早停指标稳定次数(Early Stopping Patience),早停指标连续不变化的次数。如果设置的稳定次数较小,早停策略会更敏感,可能在模型尚未充分训练时就停止训练;如果设置的稳定次数较大,早停策略会更宽松,允许模型有更多的训练周期来改善性能。 |
ERNIE Code
ERNIE Code是百度自研的代码专精大模型,支持 600+ 种编程语言,在 Go、Java、Python、CPP 等头部语言上优势显著。
ERNIE-Code3-128K
单条数据支持128k tokens。支持代码续写、自然语言生成代码、单元测试生成、代码优化、注释生成、代码解释、动作预测等多项编程相关能力。
| 训练方法 | 简单描述 |
|---|---|
| 全量更新 | 在训练过程中对大模型的全部参数进行更新,可以充分利用训练数据,有潜力在新任务上达到更好的性能。 |
| LoRA | 训练过程中只更新低秩部分的参数,需要的计算资源更少,训练过程更快,可以减少过拟合的风险。 |
- 参数配置
| 超参数 | 简单描述 |
|---|---|
| 迭代轮次 | 迭代轮次(Epoch),控制模型训练过程中遍历整个数据集的次数。建议设置在1-5之间,小数据集可增大Epoch以促进模型收敛。 |
| 学习率 | 学习率(Learning Rate),控制模型参数更新步长的速度。过高会导致模型难以收敛,过低则会导致模型收敛速度过慢,平台已给出默认推荐值,可根据经验调整。 |
| 序列长度 | 序列长度(Sequence Length),单条数据的最大长度,包括输入和输出。该长度在模型的训练和推理过程中全部适用,超过该长度的部分将在推理时自动截断,单位为token。如果数据集中的文本普遍较短,建议选择较短的序列长度以提高计算效率。 |
| 全局批大小 | 全局批大小(GlobalBatchsize),每次训练迭代使用的样本数,为了加快训练效率,多条样本会使用Packing尽可能拼接到一个序列长度内。 |
| 保存日志间隔 | 保存日志间隔(Logging Interval),设定模型训练过程中记录日志的间隔步数。合理设置可以平衡日志记录的详细程度和存储、处理资源的消耗。 |
| 预热比例 | 预热比例(Learning Rate Warmup),训练初期学习率预热步数占用总的训练步数的比例。学习率预热可以提高模型稳定性和收敛速度。 |
| 正则化系数 | 正则化系数(Weight Decay),控制正则化项对模型参数的影响强度。适当增大系数可以增强正则化效果,防止过拟合,但过高的系数可能导致模型欠拟合。 |
| beta | 温度超参(beta),温度超参beta用于控制模型输出分布的集中程度。较高的beta值会使输出更具确定性,而较低的beta值则使输出更具多样性。 |
| Checkpoint保存策略 | Checkpoint保存策略(Checkpoint Save Strategy),训练过程保存模型Checkpoint的策略。按Step保存需要配置保存Checkpoint的间隔,按Epoch保存则在每个Epoch训练完成后自动保存模型Checkpoint。 |
| Checkpoint保存个数 | Checkpoint保存个数(Number of Checkpoint),训练过程最终要保存的Checkpoint个数。Checkpoint保存可以在系统故障时从最近的Checkpoint中恢复训练,但保存Checkpoint会增加训练时长。 |
| Checkpoint保存间隔数 | Checkpoint保存间隔数(Checkpoint Interval),训练过程中保存Checkpoint的间隔Step数。间隔太短可能导致频繁的Checkpoint操作增加训练时长,间隔太长则可能在故障时丢失更多的数据。注意:Checkpoint保存策略为按Step时使用 |
| 随机种子 | 随机种子(Random Seed),是在随机数生成算法中设定的一个初始值,用于确保随机数生成的可重复性。通过设置随机种子,可以在相同的算法和参数下,生成相同的随机数序列。 |
| 学习率调整计划 | 学习率调整计划(schedulerType),用于在训练过程中动态调整学习率,以优化模型的收敛速度和性能。根据模型的训练情况和任务需求,选择合适的学习率调整方式。 |
| cosine 策略的波数 | cosine 策略的波数(Period of Cosine),波数定义了余弦函数周期的长短。减少波数可以使模型训练过程稳定,增加波数可以避免陷入局部最优。 |
| polynomial 策略的末端 LR | polynomial 策略的末端 LR(Polynomial Decay End Learning Rate),指的是在多项式衰减策略中,学习率下降到最后所达到的最小值。这个值通常设置得较低,该值若生效需要比学习率小,保证在模型训练后期实现细致的优化。 |
| polynomial 策略的幂数 | polynomial 策略的幂数(Polynomial Decay Power),是指在多项式衰减学习率调整策略中,用于控制学习率下降曲线陡峭程度的指数。幂数越大,可以避免陷入局部最优;幂数越小,可以使模型训练过程稳定。 |
| 验证步数 | 验证步数(Validation Steps),计算验证集Loss的间隔步数;为0时不开启验证,没有相关指标。 |
| LoRA 策略中的秩 | LoRA 策略中的秩(LoRA Rank),决定了微调过程中引入的低秩矩阵的复杂度。较小的秩可以减少参数数量,降低过拟合风险,但可能不足以捕捉任务所需的所有特征;较大的秩可能增强模型的表示能力,但会增加计算和存储负担。 |
| DPO偏好损失类型 | DPO中偏好损失类型(Loss Type),可选择的类型包括sigmoid、ipo、kto_pair。sigmoid适用于一般情况,提供稳定训练过程,ipo可以纠正模型过度自信的问题,kto可以使模型更符合用户偏好。 |
| 早停策略 | 早停策略(Early Stopping),监控精调任务的指标变化情况,指标连续不变则提前终止训练。 |
| 早停指标 | 早停策略选择ture时,显示此指标。早停指标(Early Stopping Metric),根据该监控指标决定任务是否早停。 |
| 早停指标变化量 | 早停策略选择ture时,显示此指标。早停指标变化量(Early Stopping Metric Change),当精调任务指标的变化量超过早停指标变化量时才认为发生变化。根据实际损失曲线进行决定。 |
| 早停指标稳定次数 | 早停策略选择ture时,显示此指标。早停指标稳定次数(Early Stopping Patience),早停指标连续不变化的次数。如果设置的稳定次数较小,早停策略会更敏感,可能在模型尚未充分训练时就停止训练;如果设置的稳定次数较大,早停策略会更宽松,允许模型有更多的训练周期来改善性能。 |
ERNIE Tiny
百度自研的超高性能大语言模型,精调成本在文心系列模型中最低。
ERNIE-Tiny-8K
单条数据支持8192 tokens。
| 训练方法 | 简单描述 |
|---|---|
| 全量更新 | 在训练过程中对大模型的全部参数进行更新,可以充分利用训练数据,有潜力在新任务上达到更好的性能。 |
| LoRA | 训练过程中只更新低秩部分的参数,需要的计算资源更少,训练过程更快,可以减少过拟合的风险。 |
- 参数配置
| 超参数 | 简单描述 |
|---|---|
| 迭代轮次 | 迭代轮次(Epoch),控制模型训练过程中遍历整个数据集的次数。建议设置在1-5之间,小数据集可增大Epoch以促进模型收敛。 |
| 学习率 | 学习率(Learning Rate),控制模型参数更新步长的速度。过高会导致模型难以收敛,过低则会导致模型收敛速度过慢,平台已给出默认推荐值,可根据经验调整。 |
| 序列长度 | 序列长度(Sequence Length),单条数据的最大长度,包括输入和输出。该长度在模型的训练和推理过程中全部适用,超过该长度的部分将在推理时自动截断,单位为token。如果数据集中的文本普遍较短,建议选择较短的序列长度以提高计算效率。 |
| 全局批大小 | 全局批大小(GlobalBatchsize),每次训练迭代使用的样本数,为了加快训练效率,多条样本会使用Packing尽可能拼接到一个序列长度内。 |
| 保存日志间隔 | 保存日志间隔(Logging Interval),设定模型训练过程中记录日志的间隔步数。合理设置可以平衡日志记录的详细程度和存储、处理资源的消耗。 |
| 预热比例 | 预热比例(Learning Rate Warmup),训练初期学习率预热步数占用总的训练步数的比例。学习率预热可以提高模型稳定性和收敛速度。 |
| 正则化系数 | 正则化系数(Weight Decay),控制正则化项对模型参数的影响强度。适当增大系数可以增强正则化效果,防止过拟合,但过高的系数可能导致模型欠拟合。 |
| beta | 温度超参(beta),温度超参beta用于控制模型输出分布的集中程度。较高的beta值会使输出更具确定性,而较低的beta值则使输出更具多样性。 |
| Checkpoint保存策略 | Checkpoint保存策略(Checkpoint Save Strategy),训练过程保存模型Checkpoint的策略。按Step保存需要配置保存Checkpoint的间隔,按Epoch保存则在每个Epoch训练完成后自动保存模型Checkpoint。 |
| Checkpoint保存个数 | Checkpoint保存个数(Number of Checkpoint),训练过程最终要保存的Checkpoint个数。Checkpoint保存可以在系统故障时从最近的Checkpoint中恢复训练,但保存Checkpoint会增加训练时长。 |
| Checkpoint保存间隔数 | Checkpoint保存间隔数(Checkpoint Interval),训练过程中保存Checkpoint的间隔Step数。间隔太短可能导致频繁的Checkpoint操作增加训练时长,间隔太长则可能在故障时丢失更多的数据。注意:Checkpoint保存策略为按Step时使用 |
| 随机种子 | 随机种子(Random Seed),是在随机数生成算法中设定的一个初始值,用于确保随机数生成的可重复性。通过设置随机种子,可以在相同的算法和参数下,生成相同的随机数序列。 |
| 学习率调整计划 | 学习率调整计划(schedulerType),用于在训练过程中动态调整学习率,以优化模型的收敛速度和性能。根据模型的训练情况和任务需求,选择合适的学习率调整方式。 |
| cosine 策略的波数 | cosine 策略的波数(Period of Cosine),波数定义了余弦函数周期的长短。减少波数可以使模型训练过程稳定,增加波数可以避免陷入局部最优。 |
| polynomial 策略的末端 LR | polynomial 策略的末端 LR(Polynomial Decay End Learning Rate),指的是在多项式衰减策略中,学习率下降到最后所达到的最小值。这个值通常设置得较低,该值若生效需要比学习率小,保证在模型训练后期实现细致的优化。 |
| polynomial 策略的幂数 | polynomial 策略的幂数(Polynomial Decay Power),是指在多项式衰减学习率调整策略中,用于控制学习率下降曲线陡峭程度的指数。幂数越大,可以避免陷入局部最优;幂数越小,可以使模型训练过程稳定。 |
| 验证步数 | 验证步数(Validation Steps),计算验证集Loss的间隔步数;为0时不开启验证,没有相关指标。 |
| LoRA 策略中的秩 | LoRA 策略中的秩(LoRA Rank),决定了微调过程中引入的低秩矩阵的复杂度。较小的秩可以减少参数数量,降低过拟合风险,但可能不足以捕捉任务所需的所有特征;较大的秩可能增强模型的表示能力,但会增加计算和存储负担。 |
| DPO偏好损失类型 | DPO中偏好损失类型(Loss Type),可选择的类型包括sigmoid、ipo、kto_pair。sigmoid适用于一般情况,提供稳定训练过程,ipo可以纠正模型过度自信的问题,kto可以使模型更符合用户偏好。 |
| 早停策略 | 早停策略(Early Stopping),监控精调任务的指标变化情况,指标连续不变则提前终止训练。 |
| 早停指标 | 早停策略选择ture时,显示此指标。早停指标(Early Stopping Metric),根据该监控指标决定任务是否早停。 |
| 早停指标变化量 | 早停策略选择ture时,显示此指标。早停指标变化量(Early Stopping Metric Change),当精调任务指标的变化量超过早停指标变化量时才认为发生变化。根据实际损失曲线进行决定。 |
| 早停指标稳定次数 | 早停策略选择ture时,显示此指标。早停指标稳定次数(Early Stopping Patience),早停指标连续不变化的次数。如果设置的稳定次数较小,早停策略会更敏感,可能在模型尚未充分训练时就停止训练;如果设置的稳定次数较大,早停策略会更宽松,允许模型有更多的训练周期来改善性能。 |
ERNIE-Tiny-128K-0929
单条数据支持128k tokens。
| 训练方法 | 简单描述 |
|---|---|
| 全量更新 | 在训练过程中对大模型的全部参数进行更新,可以充分利用训练数据,有潜力在新任务上达到更好的性能。 |
| LoRA | 训练过程中只更新低秩部分的参数,需要的计算资源更少,训练过程更快,可以减少过拟合的风险。 |
- 参数配置
| 超参数 | 简单描述 |
|---|---|
| 迭代轮次 | 迭代轮次(Epoch),控制模型训练过程中遍历整个数据集的次数。建议设置在1-5之间,小数据集可增大Epoch以促进模型收敛。 |
| 学习率 | 学习率(Learning Rate),控制模型参数更新步长的速度。过高会导致模型难以收敛,过低则会导致模型收敛速度过慢,平台已给出默认推荐值,可根据经验调整。 |
| 序列长度 | 序列长度(Sequence Length),单条数据的最大长度,包括输入和输出。该长度在模型的训练和推理过程中全部适用,超过该长度的部分将在推理时自动截断,单位为token。如果数据集中的文本普遍较短,建议选择较短的序列长度以提高计算效率。 |
| 全局批大小 | 全局批大小(GlobalBatchsize),每次训练迭代使用的样本数,为了加快训练效率,多条样本会使用Packing尽可能拼接到一个序列长度内。 |
| 保存日志间隔 | 保存日志间隔(Logging Interval),设定模型训练过程中记录日志的间隔步数。合理设置可以平衡日志记录的详细程度和存储、处理资源的消耗。 |
| 预热比例 | 预热比例(Learning Rate Warmup),训练初期学习率预热步数占用总的训练步数的比例。学习率预热可以提高模型稳定性和收敛速度。 |
| 正则化系数 | 正则化系数(Weight Decay),控制正则化项对模型参数的影响强度。适当增大系数可以增强正则化效果,防止过拟合,但过高的系数可能导致模型欠拟合。 |
| beta | 温度超参(beta),温度超参beta用于控制模型输出分布的集中程度。较高的beta值会使输出更具确定性,而较低的beta值则使输出更具多样性。 |
| Checkpoint保存策略 | Checkpoint保存策略(Checkpoint Save Strategy),训练过程保存模型Checkpoint的策略。按Step保存需要配置保存Checkpoint的间隔,按Epoch保存则在每个Epoch训练完成后自动保存模型Checkpoint。 |
| Checkpoint保存个数 | Checkpoint保存个数(Number of Checkpoint),训练过程最终要保存的Checkpoint个数。Checkpoint保存可以在系统故障时从最近的Checkpoint中恢复训练,但保存Checkpoint会增加训练时长。 |
| Checkpoint保存间隔数 | Checkpoint保存间隔数(Checkpoint Interval),训练过程中保存Checkpoint的间隔Step数。间隔太短可能导致频繁的Checkpoint操作增加训练时长,间隔太长则可能在故障时丢失更多的数据。注意:Checkpoint保存策略为按Step时使用 |
| 随机种子 | 随机种子(Random Seed),是在随机数生成算法中设定的一个初始值,用于确保随机数生成的可重复性。通过设置随机种子,可以在相同的算法和参数下,生成相同的随机数序列。 |
| 学习率调整计划 | 学习率调整计划(schedulerType),用于在训练过程中动态调整学习率,以优化模型的收敛速度和性能。根据模型的训练情况和任务需求,选择合适的学习率调整方式。 |
| cosine 策略的波数 | cosine 策略的波数(Period of Cosine),波数定义了余弦函数周期的长短。减少波数可以使模型训练过程稳定,增加波数可以避免陷入局部最优。 |
| polynomial 策略的末端 LR | polynomial 策略的末端 LR(Polynomial Decay End Learning Rate),指的是在多项式衰减策略中,学习率下降到最后所达到的最小值。这个值通常设置得较低,该值若生效需要比学习率小,保证在模型训练后期实现细致的优化。 |
| polynomial 策略的幂数 | polynomial 策略的幂数(Polynomial Decay Power),是指在多项式衰减学习率调整策略中,用于控制学习率下降曲线陡峭程度的指数。幂数越大,可以避免陷入局部最优;幂数越小,可以使模型训练过程稳定。 |
| 验证步数 | 验证步数(Validation Steps),计算验证集Loss的间隔步数;为0时不开启验证,没有相关指标。 |
| LoRA 策略中的秩 | LoRA 策略中的秩(LoRA Rank),决定了微调过程中引入的低秩矩阵的复杂度。较小的秩可以减少参数数量,降低过拟合风险,但可能不足以捕捉任务所需的所有特征;较大的秩可能增强模型的表示能力,但会增加计算和存储负担。 |
| DPO偏好损失类型 | DPO中偏好损失类型(Loss Type),可选择的类型包括sigmoid、ipo、kto_pair。sigmoid适用于一般情况,提供稳定训练过程,ipo可以纠正模型过度自信的问题,kto可以使模型更符合用户偏好。 |
| 早停策略 | 早停策略(Early Stopping),监控精调任务的指标变化情况,指标连续不变则提前终止训练。 |
| 早停指标 | 早停策略选择ture时,显示此指标。早停指标(Early Stopping Metric),根据该监控指标决定任务是否早停。 |
| 早停指标变化量 | 早停策略选择ture时,显示此指标。早停指标变化量(Early Stopping Metric Change),当精调任务指标的变化量超过早停指标变化量时才认为发生变化。根据实际损失曲线进行决定。 |
| 早停指标稳定次数 | 早停策略选择ture时,显示此指标。早停指标稳定次数(Early Stopping Patience),早停指标连续不变化的次数。如果设置的稳定次数较小,早停策略会更敏感,可能在模型尚未充分训练时就停止训练;如果设置的稳定次数较大,早停策略会更宽松,允许模型有更多的训练周期来改善性能。 |
DeepSeek
DeepSeek是杭州深度求索人工智能基础技术研究有限公司研发的通用AI模型。在知识问答、代码生成、数学计算等方面具备优秀的能力。
DeepSeek-R1
单条数据支持8k tokens。DeepSeek-R1在后训练阶段大规模使用了强化学习技术,在仅有极少标注数据的情况下,极大提升了模型推理能力。在数学、代码、自然语言推理等任务上,性能比肩 OpenAI o1 正式版。
| 训练方法 | 简单描述 |
|---|---|
| LoRA | 训练过程中只更新低秩部分的参数,需要的计算资源更少,训练过程更快,可以减少过拟合的风险。 |
- 参数配置
| 超参数 | 简单描述 |
|---|---|
| 迭代轮次 | 迭代轮次(Epoch),控制模型训练过程中遍历整个数据集的次数。建议设置在1-5之间,小数据集可增大Epoch以促进模型收敛。 |
| 学习率 | 学习率(Learning Rate),控制模型参数更新步长的速度。过高会导致模型难以收敛,过低则会导致模型收敛速度过慢,平台已给出默认推荐值,可根据经验调整。 |
| 序列长度 | 序列长度(Sequence Length),单条数据的最大长度,包括输入和输出。该长度在模型的训练和推理过程中全部适用,超过该长度的部分将在推理时自动截断,单位为token。如果数据集中的文本普遍较短,建议选择较短的序列长度以提高计算效率。 |
| 全局批大小 | 全局批大小(GlobalBatchsize),每次训练迭代使用的样本数,为了加快训练效率,多条样本会使用Packing尽可能拼接到一个序列长度内。 |
| 预热比例 | 预热比例(Learning Rate Warmup),训练初期学习率预热步数占用总的训练步数的比例。学习率预热可以提高模型稳定性和收敛速度。 |
| 正则化系数 | 正则化系数(Weight Decay),控制正则化项对模型参数的影响强度。适当增大系数可以增强正则化效果,防止过拟合,但过高的系数可能导致模型欠拟合。 |
| beta | 温度超参(beta),温度超参beta用于控制模型输出分布的集中程度。较高的beta值会使输出更具确定性,而较低的beta值则使输出更具多样性。 |
| 学习率调整计划 | 学习率调整计划(schedulerType),用于在训练过程中动态调整学习率,以优化模型的收敛速度和性能。根据模型的训练情况和任务需求,选择合适的学习率调整方式。 |
| LoRA 策略中的秩 | LoRA 策略中的秩(LoRA Rank),决定了微调过程中引入的低秩矩阵的复杂度。较小的秩可以减少参数数量,降低过拟合风险,但可能不足以捕捉任务所需的所有特征;较大的秩可能增强模型的表示能力,但会增加计算和存储负担。 |
| loraAlpha | LoRA微调中的缩放系数(LoRA Alpha),定义了LoRA适应的学习率缩放因子。该参数过高,可能会导致模型的微调过度,失去原始模型的能力;改参数过低,可能达不到预期的微调效果。 |
| loraDropout | LoRA微调中的Dropout系数(LoRA Dropout),用于防止lora训练中的过拟合。 |
| DPO偏好损失类型 | DPO中偏好损失类型(Loss Type),可选择的类型包括sigmoid、ipo、kto_pair。sigmoid适用于一般情况,提供稳定训练过程,ipo可以纠正模型过度自信的问题,kto可以使模型更符合用户偏好。 |
DeepSeek-R1-Distill-Qwen-14B
单条数据支持32k tokens。DeepSeek-R1-Distill-Qwen-14B是DeepSeek基于Qwen2.5-14B蒸馏得到的。
| 训练方法 | 简单描述 |
|---|---|
| 全量更新 | 在训练过程中对大模型的全部参数进行更新,可以充分利用训练数据,有潜力在新任务上达到更好的性能。 |
| LoRA | 训练过程中只更新低秩部分的参数,需要的计算资源更少,训练过程更快,可以减少过拟合的风险。 |
- 参数配置
| 超参数 | 简单描述 |
|---|---|
| 迭代轮次 | 迭代轮次(Epoch),控制模型训练过程中遍历整个数据集的次数。建议设置在1-5之间,小数据集可增大Epoch以促进模型收敛。 |
| 学习率 | 学习率(Learning Rate),控制模型参数更新步长的速度。过高会导致模型难以收敛,过低则会导致模型收敛速度过慢,平台已给出默认推荐值,可根据经验调整。 |
| 序列长度 | 序列长度(Sequence Length),单条数据的最大长度,包括输入和输出。该长度在模型的训练和推理过程中全部适用,超过该长度的部分将在推理时自动截断,单位为token。如果数据集中的文本普遍较短,建议选择较短的序列长度以提高计算效率。 |
| 全局批大小 | 全局批大小(GlobalBatchsize),每次训练迭代使用的样本数,为了加快训练效率,多条样本会使用Packing尽可能拼接到一个序列长度内。 |
| 保存日志间隔 | 保存日志间隔(Logging Interval),设定模型训练过程中记录日志的间隔步数。合理设置可以平衡日志记录的详细程度和存储、处理资源的消耗。 |
| 预热比例 | 预热比例(Learning Rate Warmup),训练初期学习率预热步数占用总的训练步数的比例。学习率预热可以提高模型稳定性和收敛速度。 |
| 正则化系数 | 正则化系数(Weight Decay),控制正则化项对模型参数的影响强度。适当增大系数可以增强正则化效果,防止过拟合,但过高的系数可能导致模型欠拟合。 |
| beta | 温度超参(beta),温度超参beta用于控制模型输出分布的集中程度。较高的beta值会使输出更具确定性,而较低的beta值则使输出更具多样性。 |
| Checkpoint保存策略 | Checkpoint保存策略(Checkpoint Save Strategy),训练过程保存模型Checkpoint的策略。按Step保存需要配置保存Checkpoint的间隔,按Epoch保存则在每个Epoch训练完成后自动保存模型Checkpoint。 |
| Checkpoint保存个数 | Checkpoint保存个数(Number of Checkpoint),训练过程最终要保存的Checkpoint个数。Checkpoint保存可以在系统故障时从最近的Checkpoint中恢复训练,但保存Checkpoint会增加训练时长。 |
| Checkpoint保存间隔数 | Checkpoint保存间隔数(Checkpoint Interval),训练过程中保存Checkpoint的间隔Step数。间隔太短可能导致频繁的Checkpoint操作增加训练时长,间隔太长则可能在故障时丢失更多的数据。注意:Checkpoint保存策略为按Step时使用 |
| 随机种子 | 随机种子(Random Seed),是在随机数生成算法中设定的一个初始值,用于确保随机数生成的可重复性。通过设置随机种子,可以在相同的算法和参数下,生成相同的随机数序列。 |
| 学习率调整计划 | 学习率调整计划(schedulerType),用于在训练过程中动态调整学习率,以优化模型的收敛速度和性能。根据模型的训练情况和任务需求,选择合适的学习率调整方式。 |
| cosine 策略的波数 | cosine 策略的波数(Period of Cosine),波数定义了余弦函数周期的长短。减少波数可以使模型训练过程稳定,增加波数可以避免陷入局部最优。 |
| polynomial 策略的末端 LR | polynomial 策略的末端 LR(Polynomial Decay End Learning Rate),指的是在多项式衰减策略中,学习率下降到最后所达到的最小值。这个值通常设置得较低,该值若生效需要比学习率小,保证在模型训练后期实现细致的优化。 |
| polynomial 策略的幂数 | polynomial 策略的幂数(Polynomial Decay Power),是指在多项式衰减学习率调整策略中,用于控制学习率下降曲线陡峭程度的指数。幂数越大,可以避免陷入局部最优;幂数越小,可以使模型训练过程稳定。 |
| 验证步数 | 验证步数(Validation Steps),计算验证集Loss的间隔步数;为0时不开启验证,没有相关指标。 |
| LoRA 策略中的秩 | LoRA 策略中的秩(LoRA Rank),决定了微调过程中引入的低秩矩阵的复杂度。较小的秩可以减少参数数量,降低过拟合风险,但可能不足以捕捉任务所需的所有特征;较大的秩可能增强模型的表示能力,但会增加计算和存储负担。 |
| DPO偏好损失类型 | DPO中偏好损失类型(Loss Type),可选择的类型包括sigmoid、ipo、kto_pair。sigmoid适用于一般情况,提供稳定训练过程,ipo可以纠正模型过度自信的问题,kto可以使模型更符合用户偏好。 |
Qianfan
Qianfan是千帆大模型平台推出的大模型,在通用和垂类场景中进一步增强。
Qianfan-Sug
单条数据支持8192 tokens。Qianfan-Sug是千帆大模型平台下的一款对话预测模型,能够基于对话上下文精准识别用户意图,并智能推测用户接下来的可能提问。
| 训练方法 | 简单描述 |
|---|---|
| 全量更新 | 在训练过程中对大模型的全部参数进行更新,可以充分利用训练数据,有潜力在新任务上达到更好的性能。 |
| LoRA | 训练过程中只更新低秩部分的参数,需要的计算资源更少,训练过程更快,可以减少过拟合的风险。 |
- 参数配置
| 超参数 | 简单描述 |
|---|---|
| 迭代轮次 | 迭代轮次(Epoch),控制模型训练过程中遍历整个数据集的次数。建议设置在1-5之间,小数据集可增大Epoch以促进模型收敛。 |
| 学习率 | 学习率(Learning Rate),控制模型参数更新步长的速度。过高会导致模型难以收敛,过低则会导致模型收敛速度过慢,平台已给出默认推荐值,可根据经验调整。 |
| 序列长度 | 序列长度(Sequence Length),单条数据的最大长度,包括输入和输出。该长度在模型的训练和推理过程中全部适用,超过该长度的部分将在推理时自动截断,单位为token。如果数据集中的文本普遍较短,建议选择较短的序列长度以提高计算效率。 |
| 全局批大小 | 全局批大小(GlobalBatchsize),每次训练迭代使用的样本数,为了加快训练效率,多条样本会使用Packing尽可能拼接到一个序列长度内。 |
| 保存日志间隔 | 保存日志间隔(Logging Interval),设定模型训练过程中记录日志的间隔步数。合理设置可以平衡日志记录的详细程度和存储、处理资源的消耗。 |
| 预热比例 | 预热比例(Learning Rate Warmup),训练初期学习率预热步数占用总的训练步数的比例。学习率预热可以提高模型稳定性和收敛速度。 |
| 正则化系数 | 正则化系数(Weight Decay),控制正则化项对模型参数的影响强度。适当增大系数可以增强正则化效果,防止过拟合,但过高的系数可能导致模型欠拟合。 |
| beta | 温度超参(beta),温度超参beta用于控制模型输出分布的集中程度。较高的beta值会使输出更具确定性,而较低的beta值则使输出更具多样性。 |
| Checkpoint保存策略 | Checkpoint保存策略(Checkpoint Save Strategy),训练过程保存模型Checkpoint的策略。按Step保存需要配置保存Checkpoint的间隔,按Epoch保存则在每个Epoch训练完成后自动保存模型Checkpoint。 |
| Checkpoint保存个数 | Checkpoint保存个数(Number of Checkpoint),训练过程最终要保存的Checkpoint个数。Checkpoint保存可以在系统故障时从最近的Checkpoint中恢复训练,但保存Checkpoint会增加训练时长。 |
| Checkpoint保存间隔数 | Checkpoint保存间隔数(Checkpoint Interval),训练过程中保存Checkpoint的间隔Step数。间隔太短可能导致频繁的Checkpoint操作增加训练时长,间隔太长则可能在故障时丢失更多的数据。注意:Checkpoint保存策略为按Step时使用 |
| 随机种子 | 随机种子(Random Seed),是在随机数生成算法中设定的一个初始值,用于确保随机数生成的可重复性。通过设置随机种子,可以在相同的算法和参数下,生成相同的随机数序列。 |
| 学习率调整计划 | 学习率调整计划(schedulerType),用于在训练过程中动态调整学习率,以优化模型的收敛速度和性能。根据模型的训练情况和任务需求,选择合适的学习率调整方式。 |
| cosine 策略的波数 | cosine 策略的波数(Period of Cosine),波数定义了余弦函数周期的长短。减少波数可以使模型训练过程稳定,增加波数可以避免陷入局部最优。 |
| polynomial 策略的末端 LR | polynomial 策略的末端 LR(Polynomial Decay End Learning Rate),指的是在多项式衰减策略中,学习率下降到最后所达到的最小值。这个值通常设置得较低,该值若生效需要比学习率小,保证在模型训练后期实现细致的优化。 |
| polynomial 策略的幂数 | polynomial 策略的幂数(Polynomial Decay Power),是指在多项式衰减学习率调整策略中,用于控制学习率下降曲线陡峭程度的指数。幂数越大,可以避免陷入局部最优;幂数越小,可以使模型训练过程稳定。 |
| 验证步数 | 验证步数(Validation Steps),计算验证集Loss的间隔步数;为0时不开启验证,没有相关指标。 |
| LoRA 策略中的秩 | LoRA 策略中的秩(LoRA Rank),决定了微调过程中引入的低秩矩阵的复杂度。较小的秩可以减少参数数量,降低过拟合风险,但可能不足以捕捉任务所需的所有特征;较大的秩可能增强模型的表示能力,但会增加计算和存储负担。 |
| DPO偏好损失类型 | DPO中偏好损失类型(Loss Type),可选择的类型包括sigmoid、ipo、kto_pair。sigmoid适用于一般情况,提供稳定训练过程,ipo可以纠正模型过度自信的问题,kto可以使模型更符合用户偏好。 |
·Llama
Llama 是Meta AI推出的开源大语言模型。
Meta-Llama-3.1-8B
单条数据支持8192tokens。Meta-Llama-3.1-8B是在15T+tokens上训练的80亿参数预训练大语言模型,推理效果整体优于同参数量级开源模型。
| 训练方法 | 简单描述 |
|---|---|
| 全量更新 | 在训练过程中对大模型的全部参数进行更新,可以充分利用训练数据,有潜力在新任务上达到更好的性能。 |
| LoRA | 训练过程中只更新低秩部分的参数,需要的计算资源更少,训练过程更快,可以减少过拟合的风险。 |
- 参数配置
| 超参数 | 简单描述 |
|---|---|
| 迭代轮次 | 迭代轮次(Epoch),控制模型训练过程中遍历整个数据集的次数。建议设置在1-5之间,小数据集可增大Epoch以促进模型收敛。 |
| 学习率 | 学习率(Learning Rate),控制模型参数更新步长的速度。过高会导致模型难以收敛,过低则会导致模型收敛速度过慢,平台已给出默认推荐值,可根据经验调整。 |
| 序列长度 | 序列长度(Sequence Length),单条数据的最大长度,包括输入和输出。该长度在模型的训练和推理过程中全部适用,超过该长度的部分将在推理时自动截断,单位为token。如果数据集中的文本普遍较短,建议选择较短的序列长度以提高计算效率。 |
| 全局批大小 | 全局批大小(GlobalBatchsize),每次训练迭代使用的样本数,为了加快训练效率,多条样本会使用Packing尽可能拼接到一个序列长度内。 |
| 保存日志间隔 | 保存日志间隔(Logging Interval),设定模型训练过程中记录日志的间隔步数。合理设置可以平衡日志记录的详细程度和存储、处理资源的消耗。 |
| 预热比例 | 预热比例(Learning Rate Warmup),训练初期学习率预热步数占用总的训练步数的比例。学习率预热可以提高模型稳定性和收敛速度。 |
| 正则化系数 | 正则化系数(Weight Decay),控制正则化项对模型参数的影响强度。适当增大系数可以增强正则化效果,防止过拟合,但过高的系数可能导致模型欠拟合。 |
| beta | 温度超参(beta),温度超参beta用于控制模型输出分布的集中程度。较高的beta值会使输出更具确定性,而较低的beta值则使输出更具多样性。 |
| Checkpoint保存策略 | Checkpoint保存策略(Checkpoint Save Strategy),训练过程保存模型Checkpoint的策略。按Step保存需要配置保存Checkpoint的间隔,按Epoch保存则在每个Epoch训练完成后自动保存模型Checkpoint。 |
| Checkpoint保存个数 | Checkpoint保存个数(Number of Checkpoint),训练过程最终要保存的Checkpoint个数。Checkpoint保存可以在系统故障时从最近的Checkpoint中恢复训练,但保存Checkpoint会增加训练时长。 |
| Checkpoint保存间隔数 | Checkpoint保存间隔数(Checkpoint Interval),训练过程中保存Checkpoint的间隔Step数。间隔太短可能导致频繁的Checkpoint操作增加训练时长,间隔太长则可能在故障时丢失更多的数据。注意:Checkpoint保存策略为按Step时使用 |
| 随机种子 | 随机种子(Random Seed),是在随机数生成算法中设定的一个初始值,用于确保随机数生成的可重复性。通过设置随机种子,可以在相同的算法和参数下,生成相同的随机数序列。 |
| 学习率调整计划 | 学习率调整计划(schedulerType),用于在训练过程中动态调整学习率,以优化模型的收敛速度和性能。根据模型的训练情况和任务需求,选择合适的学习率调整方式。 |
| cosine 策略的波数 | cosine 策略的波数(Period of Cosine),波数定义了余弦函数周期的长短。减少波数可以使模型训练过程稳定,增加波数可以避免陷入局部最优。 |
| polynomial 策略的末端 LR | polynomial 策略的末端 LR(Polynomial Decay End Learning Rate),指的是在多项式衰减策略中,学习率下降到最后所达到的最小值。这个值通常设置得较低,该值若生效需要比学习率小,保证在模型训练后期实现细致的优化。 |
| polynomial 策略的幂数 | polynomial 策略的幂数(Polynomial Decay Power),是指在多项式衰减学习率调整策略中,用于控制学习率下降曲线陡峭程度的指数。幂数越大,可以避免陷入局部最优;幂数越小,可以使模型训练过程稳定。 |
| 验证步数 | 验证步数(Validation Steps),计算验证集Loss的间隔步数;为0时不开启验证,没有相关指标。 |
| LoRA 策略中的秩 | LoRA 策略中的秩(LoRA Rank),决定了微调过程中引入的低秩矩阵的复杂度。较小的秩可以减少参数数量,降低过拟合风险,但可能不足以捕捉任务所需的所有特征;较大的秩可能增强模型的表示能力,但会增加计算和存储负担。 |
| DPO偏好损失类型 | DPO中偏好损失类型(Loss Type),可选择的类型包括sigmoid、ipo、kto_pair。sigmoid适用于一般情况,提供稳定训练过程,ipo可以纠正模型过度自信的问题,kto可以使模型更符合用户偏好。 |
| 早停策略 | 早停策略(Early Stopping),监控精调任务的指标变化情况,指标连续不变则提前终止训练。 |
| 早停指标 | 早停策略选择ture时,显示此指标。早停指标(Early Stopping Metric),根据该监控指标决定任务是否早停。 |
| 早停指标变化量 | 早停策略选择ture时,显示此指标。早停指标变化量(Early Stopping Metric Change),当精调任务指标的变化量超过早停指标变化量时才认为发生变化。根据实际损失曲线进行决定。 |
| 早停指标稳定次数 | 早停策略选择ture时,显示此指标。早停指标稳定次数(Early Stopping Patience),早停指标连续不变化的次数。如果设置的稳定次数较小,早停策略会更敏感,可能在模型尚未充分训练时就停止训练;如果设置的稳定次数较大,早停策略会更宽松,允许模型有更多的训练周期来改善性能。 |
·Baichuan2
Baichuan2是百川智能推出的新一代开源大语言模型。
Baichuan2-7B-Chat
单条数据支持4096 token。Baichuan2-7B-Chat 是在大约 1.2 万亿 tokens 上训练的 70 亿参数模型。
| 训练方法 | 简单描述 |
|---|---|
| 全量更新 | 在训练过程中对大模型的全部参数进行更新,可以充分利用训练数据,有潜力在新任务上达到更好的性能。 |
| LoRA | 训练过程中只更新低秩部分的参数,需要的计算资源更少,训练过程更快,可以减少过拟合的风险。 |
- 参数配置
| 超参数 | 简单描述 |
|---|---|
| 迭代轮次 | 迭代轮次(Epoch),控制模型训练过程中遍历整个数据集的次数。建议设置在1-5之间,小数据集可增大Epoch以促进模型收敛。 |
| 学习率 | 学习率(Learning Rate),控制模型参数更新步长的速度。过高会导致模型难以收敛,过低则会导致模型收敛速度过慢,平台已给出默认推荐值,可根据经验调整。 |
| 序列长度 | 序列长度(Sequence Length),单条数据的最大长度,包括输入和输出。该长度在模型的训练和推理过程中全部适用,超过该长度的部分将在推理时自动截断,单位为token。如果数据集中的文本普遍较短,建议选择较短的序列长度以提高计算效率。 |
| 全局批大小 | 全局批大小(GlobalBatchsize),每次训练迭代使用的样本数,为了加快训练效率,多条样本会使用Packing尽可能拼接到一个序列长度内。 |
| 预热比例 | 预热比例(Learning Rate Warmup),训练初期学习率预热步数占用总的训练步数的比例。学习率预热可以提高模型稳定性和收敛速度。 |
| 正则化系数 | 正则化系数(Weight Decay),控制正则化项对模型参数的影响强度。适当增大系数可以增强正则化效果,防止过拟合,但过高的系数可能导致模型欠拟合。 |
| beta | 温度超参(beta),温度超参beta用于控制模型输出分布的集中程度。较高的beta值会使输出更具确定性,而较低的beta值则使输出更具多样性。 |
| Checkpoint保存个数 | Checkpoint保存个数(Number of Checkpoint),训练过程最终要保存的Checkpoint个数。Checkpoint保存可以在系统故障时从最近的Checkpoint中恢复训练,但保存Checkpoint会增加训练时长。 |
| Checkpoint保存间隔数 | Checkpoint保存间隔数(Checkpoint Interval),训练过程中保存Checkpoint的间隔Step数。间隔太短可能导致频繁的Checkpoint操作增加训练时长,间隔太长则可能在故障时丢失更多的数据。注意:Checkpoint保存策略为按Step时使用 |
| 随机种子 | 随机种子(Random Seed),是在随机数生成算法中设定的一个初始值,用于确保随机数生成的可重复性。通过设置随机种子,可以在相同的算法和参数下,生成相同的随机数序列。 |
| 学习率调整计划 | 学习率调整计划(schedulerType),用于在训练过程中动态调整学习率,以优化模型的收敛速度和性能。根据模型的训练情况和任务需求,选择合适的学习率调整方式。 |
| 验证步数 | 验证步数(Validation Steps),计算验证集Loss的间隔步数;为0时不开启验证,没有相关指标。 |
| LoRA 策略中的秩 | LoRA 策略中的秩(LoRA Rank),决定了微调过程中引入的低秩矩阵的复杂度。较小的秩可以减少参数数量,降低过拟合风险,但可能不足以捕捉任务所需的所有特征;较大的秩可能增强模型的表示能力,但会增加计算和存储负担。 |
| DPO偏好损失类型 | DPO中偏好损失类型(Loss Type),可选择的类型包括sigmoid、ipo、kto_pair。sigmoid适用于一般情况,提供稳定训练过程,ipo可以纠正模型过度自信的问题,kto可以使模型更符合用户偏好。 |
数据配置
训练任务的选择数据及相关配置,大模型调优任务需要匹配Prompt+Chosen+Rejected类型的数据集。至少需要100条数据才可发起训练。
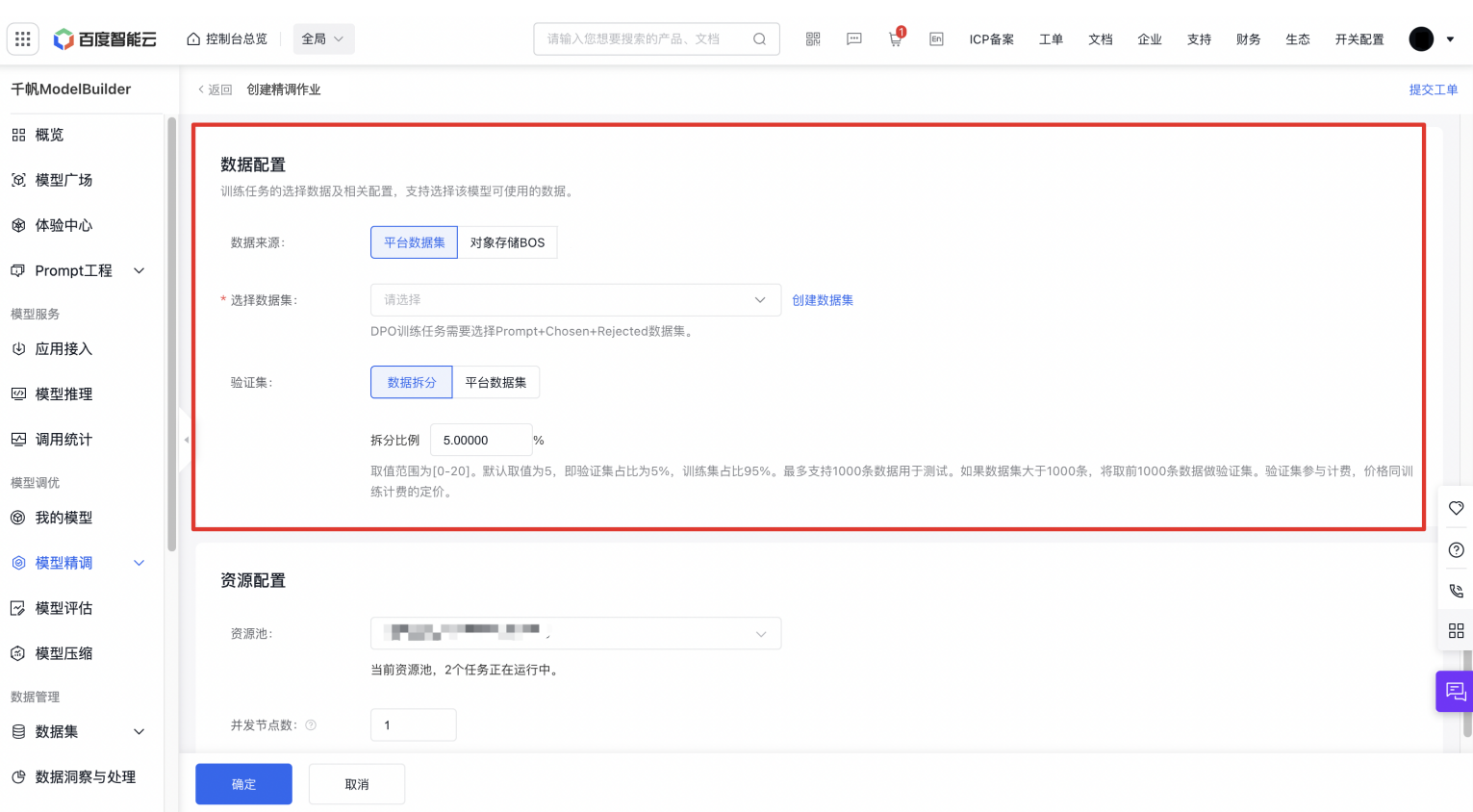
数据集来源可以为千帆平台已发布的数据集版本或BOS,如果选择两个及以上的数据集,支持数据配比,数据占比总和等于100%。如果当前平台没有您已准备好的训练数据,您可以按下图所示创建数据集并发布。
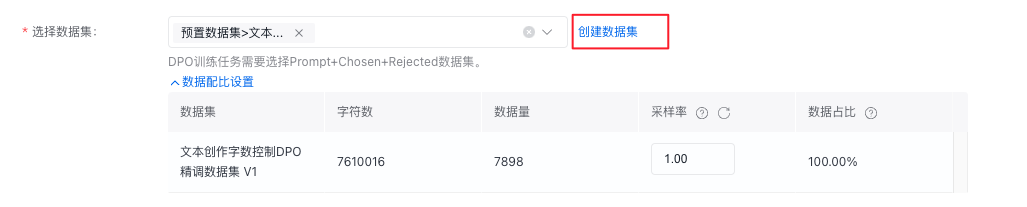
您可以通过提高采样率,来提升数据集的占比。
采样率:对数据集进⾏随机采样,取值范围为[0.01-10]。当数据集过⼤或质量不⾼,可以利⽤⽋采样(采样率⼩于1)来缩减训练数据的⼤⼩;当数据集过⼩或质量较⾼,可以利⽤过采样(采样率⼤于1)来增加训练数据的⼤⼩,数值越⼤训练时对该部分数据的关注度越⾼,但训练时⻓及费⽤越⾼,推荐过采样率范围为[1-5]。
数据拆分比例:您可以选择对上面已选择的数据集进行拆分作为测试集,或者指定数据作为测试集。
- 数据拆分比例:比如设置20,则表示选定数据集版本总数的80%作为训练集,20%作为验证集。
- 平台数据集:需要选择Prompt+Chosen+Rejected类的数据集。最多支持1000条数据用于测试。如果数据集大于1000条,将取前1000条数据做测试集。
- DPO支持选择Prompt+Chosen+Rejected数据,Prompt中支持单轮对话和多轮对话。
若数据集保存在BOS中,请勿在提交任务后修改BOS数据。修改后可能会导致任务失败!
关于训练费用可查看价格文档。
另外本训练任务支持您选择开启闲时训练,任务提交后,等待平台资源空闲时进行调度。不保证资源的独占,训练过程中可能会被抢占。适合对时效性要求不高的任务。其支持范围和价格可查看闲时训练计费明细
以上所有操作完成后,点击“确定”,则发起模型训练的任务。